前言
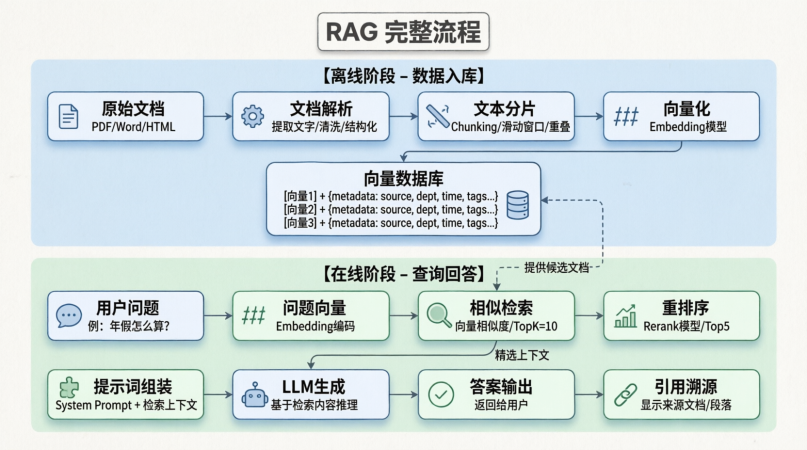
在前面的学习中,我们研究了RAG在离线阶段进行的工作----文档解析、文本分片与向量化,那么接下来就来研究一下在线阶段如何使用我们已经准备好的数据吧
也就是我们的检索、重排序与生成
实际上生产环境中还要考虑非常多的优化问题,但是今天只讲一些流程,对于项目、深度和优化,我后面一定会讲,也是我4月的主攻方向!
一、用户提问(User Query) & 查询预处理
虽然流程图上只是一个简单的输入框,但在工程上,这里往往是优化的第一步。
- 核心概念 :
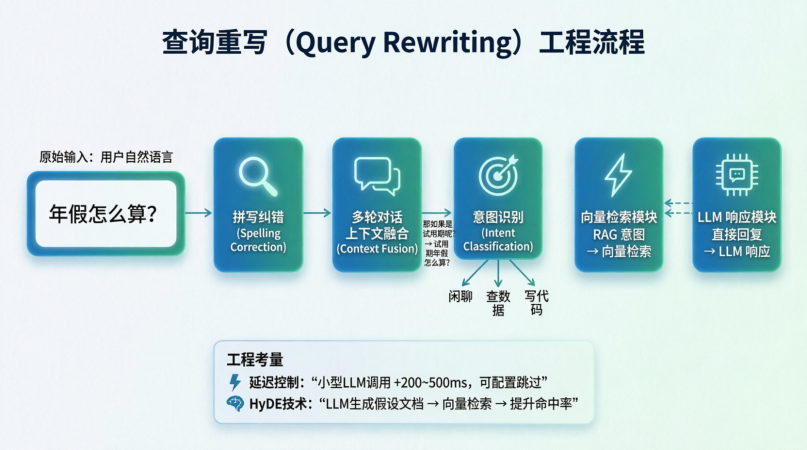
- 原始输入:用户自然语言输入,例如"年假怎么算?"。
- 查询重写 (Query Rewriting):用户的问题往往是不完整的、有歧义的,或者包含口语化表达。
- 详细流程 :
- 接收用户输入。
- 拼写纠错:如果是英文或特定术语,先纠错。
- 多轮对话上下文融合:如果用户接着问"那如果是试用期呢?",系统需要结合上一轮对话,将其重写为"试用期年假怎么算?"。
- 意图识别:判断用户是想闲聊、查数据还是写代码,从而决定走 RAG 流程还是直接回复。
- 工程化考量 :
- 延迟控制:重写通常需要一个小型的 LLM 调用,会增加几百毫秒的延迟。如果系统对速度要求极高,可以跳过此步。
- HyDE (Hypothetical Document Embeddings):这是一种高级技巧。让 LLM 先根据问题"瞎编"一个完美的答案文档,然后用这个"假文档"去向量库检索。因为假文档的向量分布往往比问题本身更接近真实文档,能显著提高检索命中率。
二. 问题向量 (Query Embedding)
- 核心概念 :
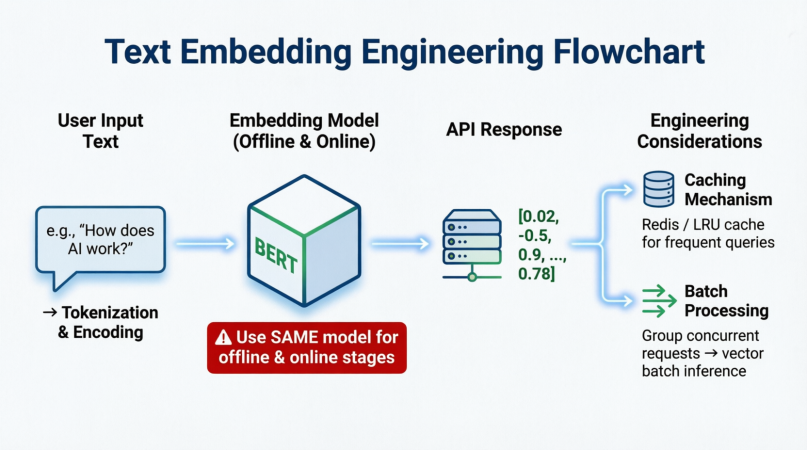
- 将处理后的文本问题转化为高维向量(Vector)。
- 关键原则 :必须使用与离线阶段完全相同的 Embedding 模型 。如果离线用了
text-embedding-3-small,在线也必须用它,否则向量空间不一致,检索结果为空或错误。
- 详细流程 :
- 调用 Embedding 模型 API 或本地模型。
- 输出一个固定长度的浮点数数组(例如
[0.02, -0.5, 0.9...])。
- 工程化考量 :
- 缓存机制 (Caching):对于高频问题(如"公司wifi密码"),直接缓存其向量结果,避免重复调用模型,节省成本和时间。
- 批量处理 :如果有并发请求,尽量合并 Embedding 请求以提高吞吐量。
三、相似检索 (Retrieval)
这是 RAG 的"心脏",负责从向量数据库中捞数据。
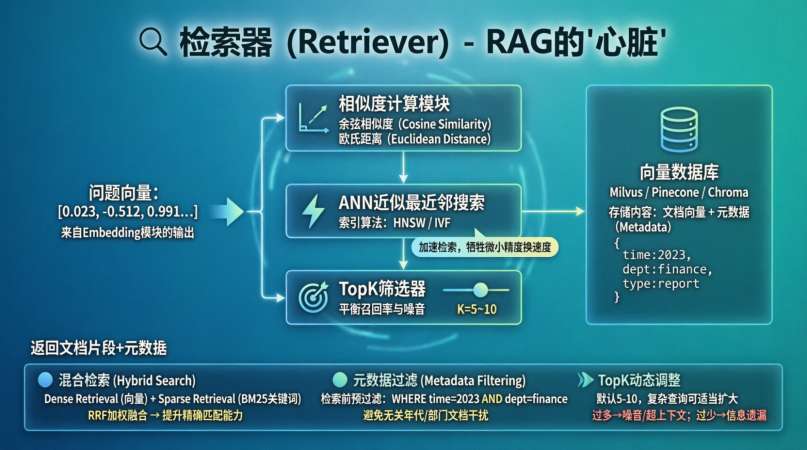
- 核心概念 :
- 向量相似度计算:通常使用余弦相似度 (Cosine Similarity) 或 欧氏距离 (Euclidean Distance)。
- ANN (Approximate Nearest Neighbors):近似最近邻搜索。因为精确搜索太慢,工程上通常用 HNSW 或 IVF 等索引算法来加速。
- TopK:设定返回多少条最相关的文档片段(Chunk)。
- 详细流程 :
- 拿着"问题向量"去向量数据库(如 Milvus, Pinecone, Elasticsearch, Chroma)中比对。
- 计算问题向量与库中所有向量的距离。
- 返回距离最近(相似度最高)的 TopK 个文档片段及其元数据(Metadata)。
- 工程化考量 (重中之重) :
- 混合检索 (Hybrid Search) :单纯靠向量检索有时候不准(比如搜特定的产品型号 "X-200",向量可能抓不住精确匹配)。最佳实践是:向量检索 (Dense Retrieval) + 关键词检索 (Sparse Retrieval / BM25)。最后通过加权算法(如 RRF)合并结果。
- 元数据过滤 (Metadata Filtering) :在检索前加过滤条件。例如用户问"2023年的财报",可以在检索时直接过滤
time=2023的文档,避免检索到 2022 年的干扰项。 - TopK 的选择:通常设为 5-10。太少可能漏掉关键信息,太多会引入噪音且超出 LLM 上下文窗口。
检索出来就直接用吗? 肯定不是,我们还要优化,进一步提高准确性,那么就需要把检索出来的top-k进行一个重排序了。
四、重排序 (Rerank)
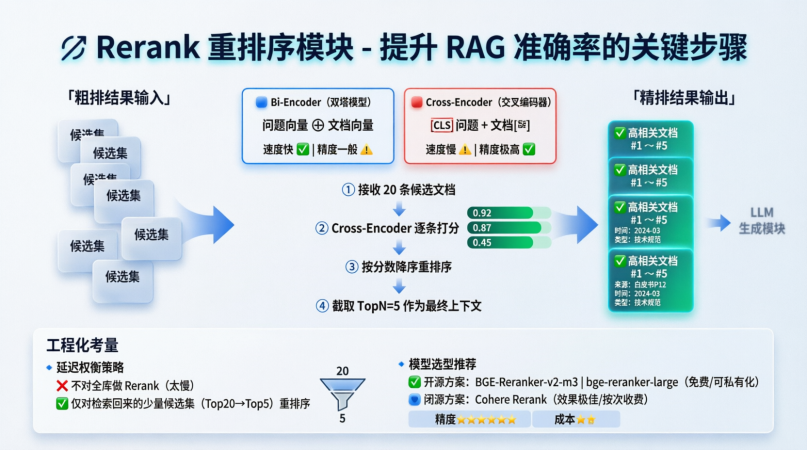
这是提升 RAG 准确率性价比最高的一步。
- 核心概念 :
- Bi-Encoder vs Cross-Encoder :
- 前面的 Embedding 是 Bi-Encoder(双塔模型),速度快但精度一般,它分别计算问题和文档的向量。
- Rerank 模型通常是 Cross-Encoder(交叉编码器),它将"问题"和"文档"拼接在一起输入模型,进行深度的语义交互匹配,精度极高,但速度慢。
- Bi-Encoder vs Cross-Encoder :
- 详细流程 :
- 接收上一步检索回来的 TopK(例如 20 条)粗排结果。
- 使用 Rerank 模型(如 BGE-Reranker, Cohere Rerank)对这 20 条逐一打分。
- 根据分数重新排序,截取分数最高的 TopN(例如 5 条)作为最终上下文。
- 工程化考量 :
- 延迟权衡:Rerank 模型通常比 Embedding 模型慢。不要对全库做 Rerank,只对检索回来的少量候选集做。
- 模型选择 :开源模型推荐
BGE-Reranker-v2-m3或bge-reranker-large,闭源推荐Cohere Rerank(效果极好但收费)。
五、提示词组装 (Prompt Construction)
这一步是将检索到的"食材"(文档)和"菜谱"(指令)打包给厨师(LLM)。
- 核心概念 :
- Context (上下文):检索到的文档片段。
- System Prompt (系统提示词):规定 LLM 的角色、回答风格、限制(如"不知道就说不知道,不要编造")。
- User Query (用户问题):原始问题。
- 详细流程 :
- 去重:检索回来的文档可能有重复内容,需要去重。
- 拼接:按照特定模板组装。
最终的提示词类似于:
你是一个助手。请根据以下参考信息回答问题。
如果参考信息里没有答案,请直接说"资料中未提及"。
参考信息:
1. [文档片段1内容]
2. [文档片段2内容]
...
用户问题:{query}- 上下文压缩 (Context Compression):如果检索回来的内容太长,超过了 LLM 的窗口限制,可以使用 LLM 或提取算法只保留与问题最相关的句子。
- 🛠️ 工程化考量 :
- Token 限制:必须计算组装后的 Prompt 总 Token 数,确保不超过模型上限(如 8k, 32k, 128k)。如果超长,需要截断或压缩。
- 防注入攻击:确保用户输入的问题不会覆盖掉 System Prompt 的指令(Prompt Injection)。
六. LLM 生成 (LLM Generation)
- 核心概念 :
- 基于组装好的 Prompt 进行推理生成。
- 详细流程 :
- 调用大模型 API(如 GPT-4, Claude, 或本地部署的 Llama 3)。
- 设置参数:
Temperature(通常设为 0 或很低,保证回答严谨、确定性强),Top_P等。
- 🛠️ 工程化考量 :
- 流式输出 (Streaming):为了用户体验,不要等生成完再返回,而是通过 SSE (Server-Sent Events) 一个字一个字地推送到前端,让用户感觉响应很快。
- 模型路由:简单问题用小模型(便宜、快),复杂推理用大模型(贵、慢)。
七、 答案输出 & 引用溯源 (Citation)
这是流程图的最后一步,也是建立用户信任的关键。
- 核心概念 :
- 引用溯源:告诉用户答案是根据哪份文件的哪一段生成的。
- 详细流程 :
- 解析回答:LLM 生成文本。
- 映射来源 :在 Prompt 组装阶段,我们给每个文档片段加了编号(如
[1],[2])。LLM 生成时如果能带上这些编号(如"根据规定1..."),后端就可以解析这些编号,找到对应的原始文档 URL 和段落。 - 前端渲染:在答案旁边显示小脚标,鼠标悬停显示原文,点击跳转原文。
- 🛠️ 工程化考量 :
- 强制引用:在 System Prompt 中明确要求 LLM:"回答必须在句尾标注来源编号,如 1"。
- 幻觉检测 :如果 LLM 生成了
[5]但实际只给了它 3 篇文档,说明产生了幻觉,需要后端进行校验和清洗。
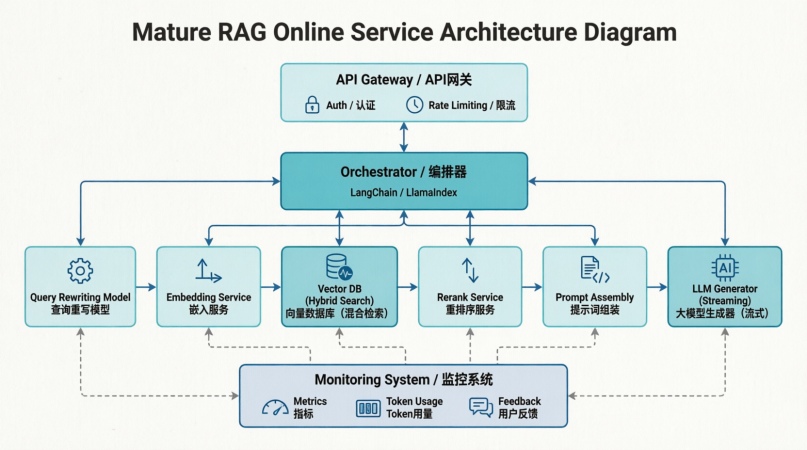
八、流程总结
从整理来说,RAG实际上很单纯,就是利用知识库,用特殊的方法:向量化、ANN等进行存储与检索,再对Prompt进行增强,来提高我们的LLM的回答效果。
那么实际开发的流程可以总结成以下图片:
但是实际企业级开发的流程更加的精密和严谨,接下来我会一一道来。