**Apache Kafka** 是一款由 Apache 软件基金会维护的**开源分布式事件流平台(Distributed Event Streaming Platform)**,核心定位是**高吞吐、低延迟、持久化、可扩展**的消息中间件与实时数据处理引擎,广泛用于大数据、微服务、实时计算等场景。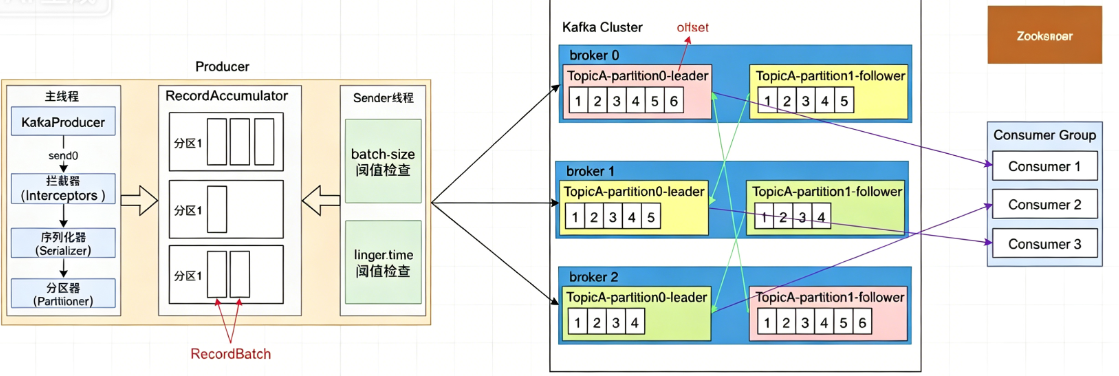
一、核心概念和架构组件
- 集群角色
①Producer(生产者)
消息发送方,负责将业务事件(如订单、日志、用户行为)发送到指定 Topic。
特性:批量发送、消息压缩、分区路由、幂等性、事务。
②Broker(服务代理)
Kafka 服务器节点,负责存储消息、处理读写请求、管理副本 。
一个集群由多个 Broker 组成,无中心节点。
③Consumer(消费者)
消息接收方,订阅 Topic 并拉取(Pull)消息处理。
特性:自主控制消费速度、按 Offset 断点续传、支持重放。
④Consumer Group(消费者组)
多个 Consumer 组成的逻辑组,同一组内负载均衡、不同组间广播 。
1 个分区只能被组内 1 个 Consumer 消费(保证顺序)。
分区数 ≥ 组内 Consumer 数(否则 Consumer 空闲)。
⑤Controller(控制器)
集群 "大脑",由某 Broker 兼任:管理元数据、分区 Leader 选举、副本同步、故障转移。 - 存储核心(Topic-Partition-Replica)
①Topic(主题)
消息的逻辑分类(如 order-topic、log-topic),类似数据库表。
②Partition(分区)
Topic 的物理分片,一个 Topic 可分多个 Partition,分布在不同 Broker。
有序、不可变、追加写入的日志文件(只进不出)。
每条消息有唯一 Offset(偏移量) ,标识消费位置。
分区是并行与扩展 的最小单位。
③Replica(副本)
每个分区可配置 N 个副本(如 3 副本),分布在不同 Broker。
Leader :唯一读写节点,处理所有生产 / 消费请求。
Follower :只同步、不读写,故障时从 ISR(同步副本集) 选新 Leader。 - 元数据管理(ZK/KRaft)
①ZooKeeper 模式
存储集群元数据、Controller 选举、Broker 心跳、分区状态。
②KRaft 模式
Kafka 内置 Raft 协议,去掉 ZooKeeper 依赖,元数据自管理,更轻量、更稳定。 - 持久化与复制
消息以顺序写入磁盘的日志文件形式持久存储,此设计结合操作系统的页缓存实现了极高的吞吐性能。
每个分区可以配置多个副本,分布在不同的Broker上,其中一个为领导者负责读写,其他为追随者用于故障转移,从而提供高可用性。
二、Kafka的定位和核心特性
- 主要定位
Kafka 本质是基于发布 - 订阅(Pub/Sub )模式的分布式日志系统,消息以 "事件流" 形式存储与流转。而Kafka是一个以高吞吐、可扩展、分布式 为主要优势的流处理平台,核心设计用于实时处理海量数据流。在实际项目中广泛应用于构建实时数据管道和流式应用。 - 核心特性
高吞吐与低延迟 :即使处理TB级数据,也能保持毫秒级延迟。
可扩展性 :通过增加Broker和分区,可轻松扩展至数百台节点。
持久性与可靠性 :消息持久化到磁盘并支持多副本,防止数据丢失。
高并发 :支持数千个客户端同时读写。
高可用 :多副本(Replica)机制,节点故障不丢数据、不中断服务。
实时 + 离线 :同时支持实时流处理与离线数据加载(如 Hadoop)。
丰富的生态:与Spark、Flink、Storm等主流流处理框架无缝集成。
三、Kafka的工作流程
- 消息生产(Producer → Broker)
1)Producer 指定 Topic,按分区策略(Key 哈希 / 轮询 / 自定义)路由到 Partition。
2)直接发送到该 Partition 的 Leader Broker(无中转)。
3)Leader 写入磁盘(顺序写,性能极高),Follower 异步同步。
4)按 ACK 级别确认:
acks=0:发完即返回(性能最高、可能丢数据)。
acks=1:Leader 写入成功即返回(默认)。
acks=all:ISR 全部同步成功才返回(最高可靠)。 - 消息存储(Broker)
1)每个 Partition 是日志分段(Segment):多个 .log + .index 文件。
2)消息持久化到磁盘,可配置保留策略(时间 / 大小 / 日志压缩)。
3)利用操作系统页缓存提升读性能。 - 消息消费(Broker → Consumer)
1)Consumer 属于某 Group,订阅 Topic。
2)组内协调:Coordinator 分配分区(Rebalance)。
3)Consumer 主动 Pull 消息(自主控速)。
4)手动 / 自动提交 Offset,记录消费进度(支持回溯)。
四、Kafka的应用场景
- 日志聚合与监控
1)流程:服务器 / 应用日志 → Kafka → ELK / 监控系统
2)说明:
分布式系统中,成百上千台机器会产生大量日志,直接收集困难、易丢失、压力大。
所有服务统一把日志发送到 Kafka,实现统一入口、削峰填谷、异步解耦 。
后端消费程序从 Kafka 读取日志,输出到:
①ELK(Elasticsearch + Logstash + Kibana) :日志检索、关键词搜索、异常排查。
②Prometheus + Grafana :监控指标、实时大盘、告警。
Kafka 起到缓冲队列作用,即使日志采集突增,也不会压垮后端存储。
3)优势:
高吞吐,扛得住海量日志。
异步解耦,不影响业务。
日志可持久化,支持回溯排查。 - 事件驱动微服务(EDA)
1)流程: 订单创建 → Kafka → 库存扣减、物流发货、通知推送
2)说明:
微服务之间不再直接调用(同步耦合),而是通过事件通信。
订单服务创建订单后,发送一条 order_created 事件到 Kafka 就结束。
其他服务订阅该主题,各自异步处理:
①库存服务:扣减库存
②物流服务:创建物流单
③消息服务:发短信 / App 推送
④会员服务:增加积分
服务之间完全解耦,新增业务只需新增消费者,不改动原有代码。
3)优势:
系统耦合度极低,易于扩展。
异步执行,接口响应极快。
一方故障不阻塞主流程。
便于灰度、降级、限流。 - 实时数据管道(CDC)
1)流程: DB 变更(Canal)→ Kafka → 数据仓库 / Redis / ES
2)说明:
CDC = 数据库变更捕获,实时同步 MySQL 等数据库的增删改。
使用 Canal / Debezium 监听 binlog,把数据变化发送到 Kafka。
下游系统消费 Kafka 数据,实现:
①同步到 数据仓库(Doris/ClickHouse/Hive) 做离线统计
②刷新 Redis 缓存,保证一致性
③写入 ES 实现商品实时搜索
④同步到其他业务库实现分库分表同步
形成统一实时数据总线,一份数据供全公司使用。
3)优势:
无侵入,不影响业务库。
低延迟,秒级同步。
解耦多端消费,互不影响。 - 用户行为分析
1)流程: 点击 / 浏览 / 加购 / 收藏 → Kafka → Flink 实时计算 → 推荐 / 大屏
2)说明:
APP / 网站埋点采集用户行为事件,高并发、海量、高频。
全部先写入 Kafka 做缓冲。
Flink 实时消费 Kafka,进行:
①实时用户画像
②实时商品推荐(猜你喜欢)
③实时热门榜单
④实时流量大盘、转化漏斗
数据还可落地到离线数仓做 T+1 报表。
3)优势:
扛得住亿级行为日志。
实时性强,体验更智能。
支持流批一体。 - 流式计算核心
1)场景: 实时风控、IoT 数据处理、实时指标计算
2)说明:
作为实时计算的中间枢纽,承接所有实时数据流。
典型业务:
①实时风控:交易流水→Kafka→Flink→异常检测(盗刷、羊毛党)
②IoT 物联网:设备上报数据→Kafka→实时监控、异常告警
③实时大屏:订单、支付、流量指标秒级更新
Kafka 提供:
①数据缓冲
②回溯重放
③多流合并
④高可用持久化
3)优势:
流式架构标准组件。
可对接 Flink/Spark/Storm 。
数据不丢、可重算。 - 替代传统 MQ
1)场景: 高吞吐、大数据量、需要持久化的场景替代 RabbitMQ/ActiveMQ
2)说明:
传统 MQ 适合业务消息、可靠投递、复杂路由,但吞吐有限、堆积能力弱。
Kafka 适合:
①超高吞吐(百万级 / 秒)
②长时间消息堆积
③多系统重复消费
④需要回溯重消费
例如:
①秒杀订单缓冲
②大量异步通知
③大批量离线任务调度
3)优势:
吞吐远超传统 MQ。
天然分布式、易扩容。
消息可持久保存、重复消费。