PyTorch实战(40)------使用PyTorch构建推荐系统
-
- [0. 前言](#0. 前言)
- [1. 使用深度学习构建推荐系统](#1. 使用深度学习构建推荐系统)
-
- [1.1 电影推荐系统数据集解析](#1.1 电影推荐系统数据集解析)
- [1.2 基于嵌入的推荐系统](#1.2 基于嵌入的推荐系统)
- [2. 处理 MovieLens 数据集](#2. 处理 MovieLens 数据集)
-
- [2.1 下载 MovieLens 数据集](#2.1 下载 MovieLens 数据集)
- [2.2 加载 MovieLens 数据集](#2.2 加载 MovieLens 数据集)
- [2.3 处理 MovieLens 数据集](#2.3 处理 MovieLens 数据集)
- [2.4 创建MovieLens数据加载器](#2.4 创建MovieLens数据加载器)
- [3. 训练和评估推荐系统模型](#3. 训练和评估推荐系统模型)
-
- [3.1 定义 EmbeddingNet 架构](#3.1 定义 EmbeddingNet 架构)
- [3.2 训练 EmbeddingNet](#3.2 训练 EmbeddingNet)
- [3.3 评估训练好的 EmbeddingNet 模型](#3.3 评估训练好的 EmbeddingNet 模型)
- [4. 使用训练好的模型构建推荐系统](#4. 使用训练好的模型构建推荐系统)
- 小结
- 系列链接
0. 前言
推荐系统 (Recommendation System) 无处不在,例如抖音会推荐用户观看什么内容;Spotify 推荐用户听什么音乐;淘宝推荐用户购买哪些产品。
推荐系统本质上是一种提供个性化建议的算法,其核心目标是通过分析用户偏好、行为模式、与其他用户的相似度以及与系统的互动记录,预测用户可能感兴趣的产品。当今大多数推荐系统都由深度学习模型驱动,这些模型通过分析当前用户及其他用户的现有消费模式,来预测用户对某产品(电影、书籍、播客、社交网络中的某人等)的喜好程度。
在本节中,我们将使用 PyTorch 从零开始构建这样一个电影推荐系统。我们将使用 MovieLens 数据集训练深度学习模型,并利用训练好的模型为用户推荐最适合(未观看或部分观看)的电影。通过本节的学习,将掌握使用 PyTorch 构建推荐系统的能力。虽然本节以电影推荐为例,但其原理可推广至各类推荐场景。
1. 使用深度学习构建推荐系统
在本节中,我们将学习如何运用深度学习技术构建推荐系统,我们以电影推荐系统为例阐释推荐系统的核心原理。首先,我们将解析电影推荐系统的数据格式,然后讨论如何使用基于深度学习的解决方案来构建推荐系统。
1.1 电影推荐系统数据集解析
典型的推荐系统数据集结构如下图所示。在纵轴上,纵轴表示数据库中的 5 个用户,横轴对应 8 部电影。
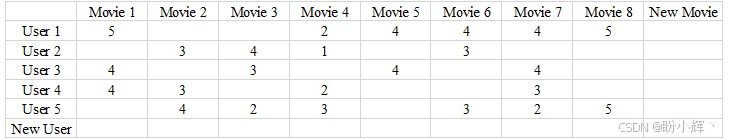
每个单元格包含用户对特定电影的 1-5 评分( 1 最差,5 最优),这些评分数据将作为训练深度学习模型的监督信号,使模型能够预测目标用户对未观影作品的评分。
并非所有电影都被每位用户观看过,因此数据中存在空值。这种推荐系统数据的稀疏性十分常见。此外,系统中还存在尚未观看任何影片的新用户和未被任何用户观看过的新电影,这进一步加剧了数据稀疏问题。因此,推荐系统通常采用(用户,电影,评分)三元组列表作为训练数据集,而非完整的用户-电影矩阵。
基于深度学习的推荐系统有一个阶段性目标:用预测评分填补这些空值。获得预测评分后,我们就能按评分降序向用户推荐商品(本节为电影)。这引出了核心问题------如何预测评分?虽然存在多种实现方式(包括非深度学习方法),但基于嵌入的推荐系统是目前的主流解决方案。
1.2 基于嵌入的推荐系统
本节将阐述基于嵌入的推荐系统的工作原理,之后我们将使用 PyTorch 从零开始构建这个系统。顾名思义,基于嵌入的推荐系统依赖于嵌入。在推荐系统中,我们有两个主要的实体------商品(本节为电影)和用户。
基于嵌入的推荐系统的核心思想是将商品(电影)和用户转化为低维空间中的实数向量,这些向量也称为嵌入 (Embedding)。嵌入能在保留实体间关系与模式的前提下,表征产品和用户的特征:在嵌入空间中使相似电影彼此靠近,并确保用户与其偏好的电影距离更近。我如何学习这些嵌入向量?我们通过端到端训练深度神经网络模型来实现,该模型以用户和电影作为输入,输出预测的用户评分,如下图所示。
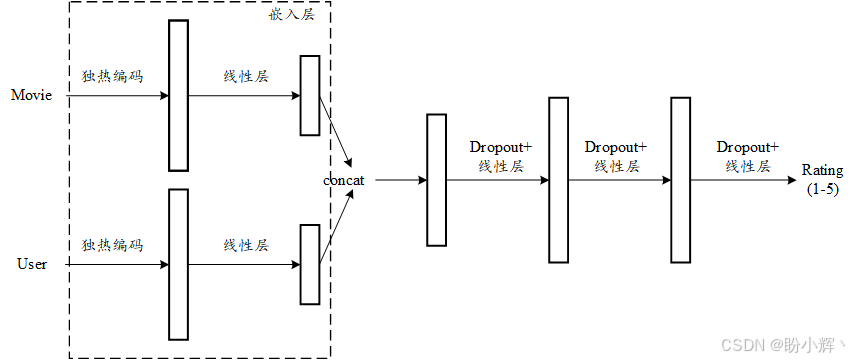
首先,电影和用户会被转换为独立的独热编码 (one-hot encoding)。若数据库中有 8 部电影和 5 位用户,则电影和用户的独热编码向量维度分别为 8 维和 5 维。
需要注意的是,当电影或用户数量极大时,独热编码效率较低,它会生成高维稀疏向量(除一个元素为 1 外其余全为 0)。在这种情况下,可以使用特征哈希 (Feature Hashing) 等技术,将电影或用户 ID 通过哈希函数映射为 0 到 N 之间的整数 k (N 为远小于电影/用户总数的固定值),生成 N 维哈希编码向量(仅第 k 位为 1,其余为 0)。与独热编码相比,特征哈希能显著降低向量维度,但存在少量不同实体被映射为相同哈希编码的风险(此风险可控)。
这些独热编码随后输入网络的两个独立线性层,分别生成电影嵌入向量和用户嵌入向量。两组向量拼接后,依次通过 Dropout 层和多个线性层进行加工,最终输出 1 到 5 之间的标准化评分预测值。
除了将用户和电影转换为独热编码向量外,推荐系统通常还会利用用户和电影的元数据。例如用户的年龄、性别、语言偏好,以及电影的类型、时长、语言等信息。额外的用户元数据能通过匹配相似特征的现有用户,辅助向新用户推荐电影;而电影元数据则通过类比相似特征的现存影片,帮助系统向用户推荐新上映电影。
嵌入网络 (EmbeddingNet) 是在包含现有用户对现有电影评分的训练集上进行端到端训练的。为了训练这个模型,我们使用实际评分和预测评分(介于 1 和 5 之间)之间的均方误差 (Mean Squared Error, MSE) 作为损失函数。训练完成后,该模型可以用来预测评分,在训练过程中生成的用户和电影嵌入向量也可以用来寻找相似的用户和相似的电影。
要使用 PyTorch 训练 EmbeddingNet,首先需要准备数据集。下一节我们将探索 MovieLens 数据集,进行分析和预处理,最终用于 EmbeddingNet 的训练。
2. 处理 MovieLens 数据集
在本节中,我们将使用 Pyorch 从零开始实现推荐系统。首先从数据集处理开始,我们使用 MovieLens 数据集来搭建电影推荐系统。
MovieLens 数据集是推荐系统领域中广泛使用的基准数据集,包含用户评分和电影元数据,提供了丰富的训练和评估推荐算法的数据源。该数据集存在多个版本(如 MovieLens 100K、1M、10M 和 20M),区别主要在于评分数量和电影规模。本节中,我们使用 MovieLens 100K 数据集,它包含超过 100K 条电影评分。
我们首先开始下载数据集。然后,我们将数据集文件加载为 DataFrame,进行多维度分析并清理数据集。
接下来,将数据集处理为适用于EmbeddingNet 模型训练的格式。最后,基于处理后数据创建训练集与测试集的数据集加载器。
2.1 下载 MovieLens 数据集
首先下载 MovieLens 100K 数据集,下载完成后解压缩:
shell
DATASET_LINK="https://files.grouplens.org/datasets/movielens/ml-latest-small.zip"
$ wget -nc $DATASET_LINK
$ unzip -n ml-latest-small.zip输出结果如下所示:
整个过程分为两个步骤:首先下载包含数据集的压缩包,然后解压生成多个 CSV 文件。两个最重要的文件是 ratings.csv 和 movies.csv,分别包含有关用户评分和电影元数据的信息。接下来,通过自定义工具函数 read_data 将这些 CSV 文件加载为 DataFrame,并进行初步分析。
2.2 加载 MovieLens 数据集
(1) 使用自定义工具函数 read_data 将电影和用户评分数据加载为 DataFrame:
python
def read_data(path):
files = {}
for filename in os.listdir(path):
stem, suffix = os.path.splitext(filename)
file_path = os.path.join(path,filename)
print(filename)
if suffix == '.csv':
files[stem] = pd.read_csv(file_path)
elif suffix == '.dat':
if stem == 'ratings':
columns = ['userId', 'movieId', 'rating', 'timestamp']
else:
columns = ['movieId', 'title', 'genres']
data = pd.read_csv(file_path, sep='::', names=columns, engine='python')
files[stem] = data
return files['ratings'], files['movies']
ratings, movies = read_data('./ml-latest-small/')(2) 检查 ratings DataFrame 内容:
python
ratings.head()输出结果如下所示:

该 DataFrame 包含用户 ID、被评分的电影 ID、评分值以及评分时间戳。查看评分值的范围:
python
minmax = ratings.rating.min(), ratings.rating.max()变量 minmax 将返回元组 (0.5, 5.0),表明评分范围从 0.5 到 5.0(以0.5为步长)。后续我们将利用这个信息,将评分值归一化到 0 至 1 区间作为模型训练目标。
(3) 接下来,查看 movies DataFrame:
python
movies.head()输出结果如下所示:

该 DataFrame 包含了每部电影的相关信息------包括电影片名及其所属的不同类型。我们可以将该 DataFrame 与 ratings DataFrame 合并,以便将电影名称(片名)添加到评分的 DataFrame 中:
python
ratings = ratings.merge(movies[["movieId", "title"]], on="movieId")
ratings.head()输出结果如下所示:

当前 DataFrame 看起来更完整,因为它同时包含了评分和电影信息。我们将使用这个 DataFrame 来构建电影推荐系统,该系统接受用户 ID (userId) 作为输入,并输出前 k 个电影片名作为推荐。
(4) 使用预定义的函数 tabular_preview,以用户-电影矩阵的形式查看评分 DataFrame:
python
def tabular_preview(ratings, n=15):
user_groups = ratings.groupby('userId')['rating'].count()
top_users = user_groups.sort_values(ascending=False)[:n]
movie_groups = ratings.groupby('movieId')['rating'].count()
top_movies = movie_groups.sort_values(ascending=False)[:n]
top = (
ratings.
join(top_users, rsuffix='_r', how='inner', on='userId').
join(top_movies, rsuffix='_r', how='inner', on='movieId'))
return pd.crosstab(top.userId, top.movieId, top.rating, aggfunc=np.sum)
tabular_preview(ratings, n=10)上述函数接受一个额外参数 n (在本节中为 10),其中 n 表示要显示的最活跃用户和观看次数最多的电影的数量。代码执行后输出结果如下所示。

上表中的 Nan 值表示缺失评分值,即特定用户尚未对特定电影进行评分。上表列出了数据集中最活跃的 10 位用户(通过 userId 标识)和最受欢迎的 10 部电影(通过 movieId 标识)。
评分值为 0.5 至 5 之间的浮点数(如 2.0、3.5、3.5 等)或空值 (NaN)。我们的目标是利用非空评分数据训练推荐系统,并用预测评分替代空值,从而为每位用户生成电影推荐列表。
我们已经完成了数据集的探索。接下来,我们将处理该数据集,将其转换为适合 PyTorch 模型训练的格式。
2.3 处理 MovieLens 数据集
定义 create_dataset 函数,该函数以评分 Dataframe 作为输入,并输出一个格式化的训练数据集:
python
def create_dataset(ratings, top=None):
if top is not None:
ratings.groupby('userId')['rating'].count()
unique_users = ratings.userId.unique()
user_to_index = {old: new for new, old in enumerate(unique_users)}
new_users = ratings.userId.map(user_to_index)
unique_movies = ratings.movieId.unique()
movie_to_index = {old: new for new, old in enumerate(unique_movies)}
new_movies = ratings.movieId.map(movie_to_index)
n_users = unique_users.shape[0]
n_movies = unique_movies.shape[0]
X = pd.DataFrame({'user_id': new_users, 'movie_id': new_movies})
y = ratings['rating'].astype(np.float32)
return (n_users, n_movies), (X, y), (user_to_index, movie_to_index)create_dataset 函数对用户和电影进行重新索引,并分别通过 user_to_index 和 movie_to_index 变量存储新索引与原始 ID (即 userId 和 movieId )的映射关系。随后创建训练所需的输入数据(包含用户和电影索引)与输出数据(包含相应用户对电影的原始评分值)。执行该函数以创建数据集:
python
(n, m), (X, y), (user_to_index, movie_to_index) = create_dataset(ratings)
print(f'Embeddings: {n} users, {m} movies')
print(f'Dataset shape: {X.shape}')
print(f'Target shape: {y.shape}')输出结果如下所示:
shell
Embeddings: 610 users, 9724 movies
Dataset shape: (100836, 2)
Target shape: (100836,)该数据集包含 610 位用户、9724 部电影及超过 10 万条评分。我们已经将数据划分为输入和输出数据集。接下来,将数据集进一步拆分为训练集和验证集:
python
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=RANDOM_STATE)
datasets = {'train': (X_train, y_train), 'val': (X_valid, y_valid)}
dataset_sizes = {'train': len(X_train), 'val': len(X_valid)}在本节中,我们已经创建了一个格式化的数据集,可以用于在 PyTorch 中训练深度学习模型。
需要注意的是,我们不仅可以随机划分训练集和验证集,还可以基于评分时间戳进行划分。将早期评分作为训练集,预测后期评分作为验证集这种方式还能支持构建"用户 A 历史偏好电影"等特征工程。
接下来,我们将使用该格式化数据集(包含输入和输出 Dataframe )创建数据加载器。
2.4 创建MovieLens数据加载器
为使用 PyTorch 训练 EmbeddingNet 模型,我们需要创建一个能够遍历数据集中多个评分实例的数据迭代器:
python
class ReviewsIterator:
def __init__(self, X, y, batch_size=32, shuffle=True):
X, y = np.asarray(X), np.asarray(y)
if shuffle:
index = np.random.permutation(X.shape[0])
X, y = X[index], y[index]
self.X = X
self.y = y
self.batch_size = batch_size
self.shuffle = shuffle
self.n_batches = int(math.ceil(X.shape[0] // batch_size))
self._current = 0
def __iter__(self):
return self
def __next__(self):
return self.next()
def next(self):
if self._current >= self.n_batches:
raise StopIteration()
k = self._current
self._current += 1
bs = self.batch_size
return self.X[k*bs:(k + 1)*bs], self.y[k*bs:(k + 1)*bs]该迭代器只需接收批大小作为输入,即可对数据集进行批遍历。创建函数 batches() 来配合 ReviewsIterator 类实现数据集遍历:
python
def batches(X, y, bs=32, shuffle=True):
for xb, yb in ReviewsIterator(X, y, bs, shuffle):
xb = torch.LongTensor(xb)
yb = torch.FloatTensor(yb)
yield xb, yb.view(-1, 1) 测试以上函数:
python
for x_batch, y_batch in batches(X, y, bs=4):
print(x_batch)
print(y_batch)
break输出结果如下所示:
shell
tensor([[ 431, 4730],
[ 287, 474],
[ 598, 2631],
[ 41, 194]])
tensor([[4.5000],
[3.0000],
[3.0000],
[4.0000]])如输出所示,迭代器成功生成批数据(批大小为 4),其中输入数据包含用户和电影索引,输出数据为原始评分值。在本节中,我们已完成使用 MovieLens 数据训练 EmbeddingNet 模型的准备工作。接下来,我们将使用 PyTorch 训练一个电影推荐系统模型。
3. 训练和评估推荐系统模型
本节将首先使用 PyTorch 定义 EmbeddingNet 模型结构,然后在 MovieLens 数据集上训练该模型,用以预测用户对未观影影片的评分,最终在验证集上评估训练好的模型性能。
3.1 定义 EmbeddingNet 架构
(1) 定义 EmbeddingNet 模型:
python
class EmbeddingNet(nn.Module):
def __init__(self, n_users, n_movies,
n_factors=50, embedding_dropout=0.02,
hidden=10, dropouts=0.2):
super().__init__()
hidden = get_list(hidden)
dropouts = get_list(dropouts)
n_last = hidden[-1]
def gen_layers(n_in):
nonlocal hidden, dropouts
assert len(dropouts) <= len(hidden)
for n_out, rate in zip_longest(hidden, dropouts):
yield nn.Linear(n_in, n_out)
yield nn.ReLU()
if rate is not None and rate > 0.:
yield nn.Dropout(rate)
n_in = n_out
self.u = nn.Embedding(n_users, n_factors)
self.m = nn.Embedding(n_movies, n_factors)
self.drop = nn.Dropout(embedding_dropout)
self.hidden = nn.Sequential(*list(gen_layers(n_factors * 2)))
self.fc = nn.Linear(n_last, 1)
self._init()模型初始化包括以下参数:
n_users(用户总数):用于将用户索引转换为独热编码向量n_movies(电影总数):用于将电影索引转换为独热编码向量n_factors(嵌入维度):用户与电影嵌入向量的尺寸embedding_dropout:在生成嵌入向量的线性层后应用的Dropout的dropout率hidden:数值列表,指定嵌入层后隐藏层的尺寸dropouts:应用于隐藏层的dropout值列表
在以上代码最后两行,声明模型的最终输出层(生成单个评分值),调用 _init 方法完成初始化。定义 _init 方法:
python
def _init(self):
def init(m):
if type(m) == nn.Linear:
torch.nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)
self.u.weight.data.uniform_(-0.05, 0.05)
self.m.weight.data.uniform_(-0.05, 0.05)
self.hidden.apply(init)
init(self.fc)_init 方法采用 Xavier 初始化初始化 EmbeddingNet 隐藏线性层的权重,并使用均匀(随机)初始化来设置嵌入层的权重。在定义完模型架构后,定义模型的前向传播过程:
python
def forward(self, users, movies, minmax=None):
features = torch.cat([self.u(users), self.m(movies)], dim=1)
x = self.drop(features)
x = self.hidden(x)
out = torch.sigmoid(self.fc(x))
if minmax is not None:
min_rating, max_rating = minmax
out = out*(max_rating - min_rating + 1) + min_rating - 0.5
return outforward 方法接收以下参数:
- 用户索引列表 (
users) - 电影索引列表 (
movies),其长度与users相同 minmax:可能的最小和最大评分值范围,用于将预测的(归一化后)评分值反归一化
在前向传播过程中,用户和电影的嵌入连接后通过 dropout 层,然后经过一个或多个线性层,最后通过一个 sigmoid 激活函数,输出一个介于 0 和 1 之间的值,该输出随后被反归一化为 0.5 至 5 之间的评分值。
(2) 通过 PyTorch 定义完 EmbeddingNet 模型架构后,实例化该模型对象:
python
net = EmbeddingNet(
n_users=n, n_movies=m,
n_factors=150, hidden=[500, 500, 500],
embedding_dropout=0.05, dropouts=[0.5, 0.5, 0.25])将用户和电影的嵌入向量的维度大小定义为 150。嵌入向量的大小是基于嵌入的推荐系统模型的超参数之一。较大的嵌入维度会增加模型参数量,可能导致过拟合(除非数据量非常充足)。通常需要尝试不同的嵌入维度值,以找到能产生最准确推荐结果的数值。本节使用 150 作为嵌入向量的大小。
用户和电影嵌入向量拼接后形成 300 维的向量,随后经过 dropout 率为 0.05 的 Dropout 层,再依次通过 3 个隐藏层(每层大小为 500),各隐藏层后分别接 dropout 率为 0.5、0.5 和 0.25 的 Dropout 层。网络结构如下所示:

本节中,我们完成了 EmbeddingNet 模型的定义。下一节中,我们将使用 MovieLens 数据集来训练该模型。
3.2 训练 EmbeddingNet
(1) 在开始模型训练循环之前,首先定义超参数和其他配置参数:
python
lr = 1e-5
wd = 1e-5
bs = 200
n_epochs = 200
patience = 10
no_improvements = 0
best_loss = np.inf
best_weights = None
history = []
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net.to(device)
criterion = nn.MSELoss(reduction='sum')
optimizer = optim.Adam(net.parameters(), lr=lr, weight_decay=wd)
iterations_per_epoch = int(math.ceil(dataset_sizes['train'] // bs))设定学习率为 1e-5,权重衰减为 1e-5,批大小为 200,训练 epoch设为200,patience 设为 10 (该值表示若连续 10 轮验证损失未改善,则提前终止训练)。同时定义一个 no_improvements 标志位来记录模型是否进入性能停滞阶段。
初始化时将当前最佳损失设为无穷大,最佳模型权重初始化为 null。定义一个 history 变量来跟踪训练和验证过程中每个 epoch 的损失。指定 PyTorch 模型的训练设备,损失函数使选用均方误差作为损失函数,优化器使用 Adam 优化器,iterations_per_epoch 表示每个 epoch 中训练数据集可以处理的批次数(每批 200 个样本)。
(2) 所有超参数定义完毕后,开始模型训练循环,在训练集和验证集上分别进行训练和验证,使用反向传播的梯度下降法进行优化:
python
for epoch in range(n_epochs):
stats = {'epoch': epoch + 1, 'total': n_epochs}
for phase in ('train', 'val'):
training = phase == 'train'
running_loss = 0.0
n_batches = 0
batch_num = 0
for batch in batches(*datasets[phase], shuffle=training, bs=bs):
x_batch, y_batch = [b.to(device) for b in batch]
optimizer.zero_grad()
# compute gradients only during 'train' phase
with torch.set_grad_enabled(training):
outputs = net(x_batch[:, 0], x_batch[:, 1], minmax)
loss = criterion(outputs, y_batch)
# don't update weights and rates when in 'val' phase
if training:
loss.backward()
optimizer.step()
running_loss += loss.item()
epoch_loss = running_loss / dataset_sizes[phase]
stats[phase] = epoch_loss
# early stopping: save weights of the best model so far
if phase == 'val':
if epoch_loss < best_loss:
print('loss improvement on epoch: %d' % (epoch + 1))
best_loss = epoch_loss
best_weights = copy.deepcopy(net.state_dict())
no_improvements = 0
else:
no_improvements += 1
history.append(stats)
print('[{epoch:03d}/{total:03d}] train: {train:.4f} - val: {val:.4f}'.format(**stats))
if no_improvements >= patience:
print('early stopping after epoch {epoch:03d}'.format(**stats))
break输出结果如下所示:

在上述代码中,我们首先执行前向传播计算,获取训练批数据中用户-电影对的预测评分值。这些预测评分与用户真实评分进行对比,计算均方误差。通过反向传播梯度下降法,该误差被回传以调整 EmbeddingNet 所有层的权重。经过 200 个 epoch 训练后,我们得到最终训练好的模型。可以通过以下代码查看训练曲线:
python
ax = pd.DataFrame(history).drop(columns='total').plot(x='epoch')输出结果如下所示。
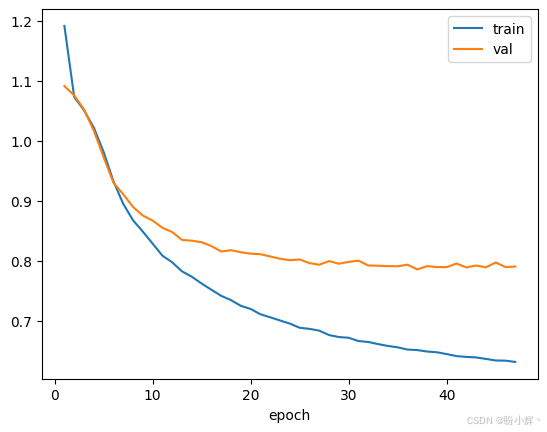
由于提前停止机制( patience 值为 10),训练在大约 50 个 epoch 时停止。训练曲线表明,模型学到了用户评分模式,并且这些模式能够从训练集推广到验证集,表明模型训练成功。在下一节中,我们将使用均方误差作为度量标准,评估训练模型在验证集上的表现。
3.3 评估训练好的 EmbeddingNet 模型
(1) 将验证集的用户-电影对输入训练好的模型,生成预测评分:
python
groud_truth, predictions = [], []
with torch.no_grad():
for batch in batches(*datasets['val'], shuffle=False, bs=bs):
x_batch, y_batch = [b.to(device) for b in batch]
outputs = net(x_batch[:, 0], x_batch[:, 1], minmax)
groud_truth.extend(y_batch.tolist())
predictions.extend(outputs.tolist())
groud_truth = np.asarray(groud_truth).ravel()
predictions = np.asarray(predictions).ravel()(2) 对比预测评分 (predictions) 与真实评分 (ground_truth):
python
final_loss = np.sqrt(np.mean((np.array(predictions) - np.array(groud_truth))**2))
print(f'Final RMSE: {final_loss:.4f}')输出结果如下所示:
shell
Final RMSE: 0.8948以上表明,在预测用户对未观影电影的评分时,训练好的模型平均误差小于1个评分单位。通过以下代码查看部分预测评分结果:
python
np.array(predictions)输出结果如下所示:
shell
array([2.73675108, 3.05379367, 2.49540186, ..., 3.22095609, 1.99553204,
2.59307313], shape=(20000,))(2) 检查对应的实际评分:
python
datasets["val"][1][:20000]输出结果如下所示:

如示例所示,预测值 3.38、2.63 和 3.2 分别与真实值 4、2 和 4 的偏差均在 1 个评分单位内,这与我们获得的 0.8816 均方误差指标相互印证。
我们已经完成了 EmbeddingNet 的训练与评估。接下来,我们将使用 EmbeddingNet 创建推荐系统,输入一个用户,输出该用户最可能喜欢的 Top-k 部电影推荐列表。
4. 使用训练好的模型构建推荐系统
本节我们将创建一个推荐函数,该函数能为指定用户返回推荐电影列表。如下图所示,首先获取所有该用户未观看过的电影。然后,将每部电影与用户 ID 共同输入 EmbeddingNet 模型生成每部电影的预测评分,最后按评分降序排列,返回评分最高的前 k 部电影作为推荐结果。
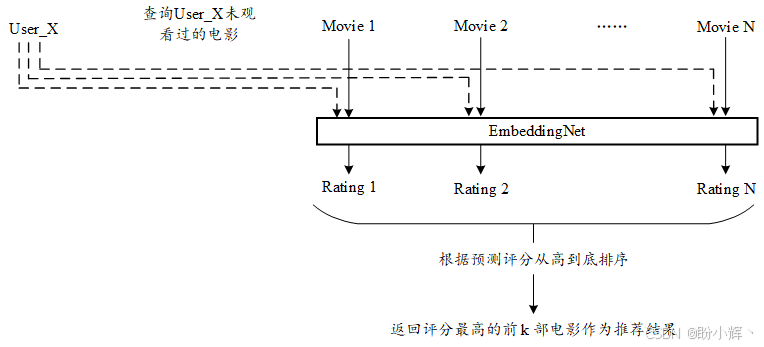
以下函数实现了上图所示的推荐流程:
python
device="cpu"
def recommender_system(user_id, model, n_movies):
model = model.to(device)
seen_movies = set(X[X['user_id'] == user_id]['movie_id'])
print(f"Total movies seen by the user: {len(seen_movies)}")
user_ratings = y[X['user_id'] == user_id]
print("=====================================================================")
print(f"Some top rated movies (rating = {user_ratings.max()}) seen by the user:")
print("=====================================================================\n")
top_rated_movie_ids = X.loc[(X['user_id'] == user_id) & (y == user_ratings.max()), "movie_id"]
print("\n".join(movies[movies.movieId.isin(top_rated_movie_ids)].title.iloc[:10].tolist()))
print("")
unseen_movies = list(set(ratings.movieId) - set(seen_movies))
unseen_movies_index = [movie_to_index[i] for i in unseen_movies]
model_input = (torch.tensor([user_id]*len(unseen_movies_index), device=device),
torch.tensor(unseen_movies_index, device=device))
with torch.no_grad():
predicted_ratings = model(*model_input, minmax).detach().numpy()
zipped_pred = zip(unseen_movies, predicted_ratings)
sorted_movie_index = list(zip(*sorted(zipped_pred, key=lambda c: c[1], reverse=True)))[0]
recommended_movies = movies[movies.movieId.isin(sorted_movie_index)].title.tolist()
print("=====================================================================")
print("Top "+str(n_movies)+" Movie recommendations for the user "+str(user_id)+ " are:")
print("=====================================================================\n")
print("\n".join(recommended_movies[:n_movies]))推荐系统函数 (recommender_system) 接受以下输入参数:
user_id: 给定用户的索引,为该用户推荐电影model: 训练好的EmbeddingNet模型对象n_movies: 推荐系统返回的电影数量
调用上述函数:
python
recommender_system(32, net, 20)选择用户编号 32 并请求 10 条电影推荐,将输出以下结果:
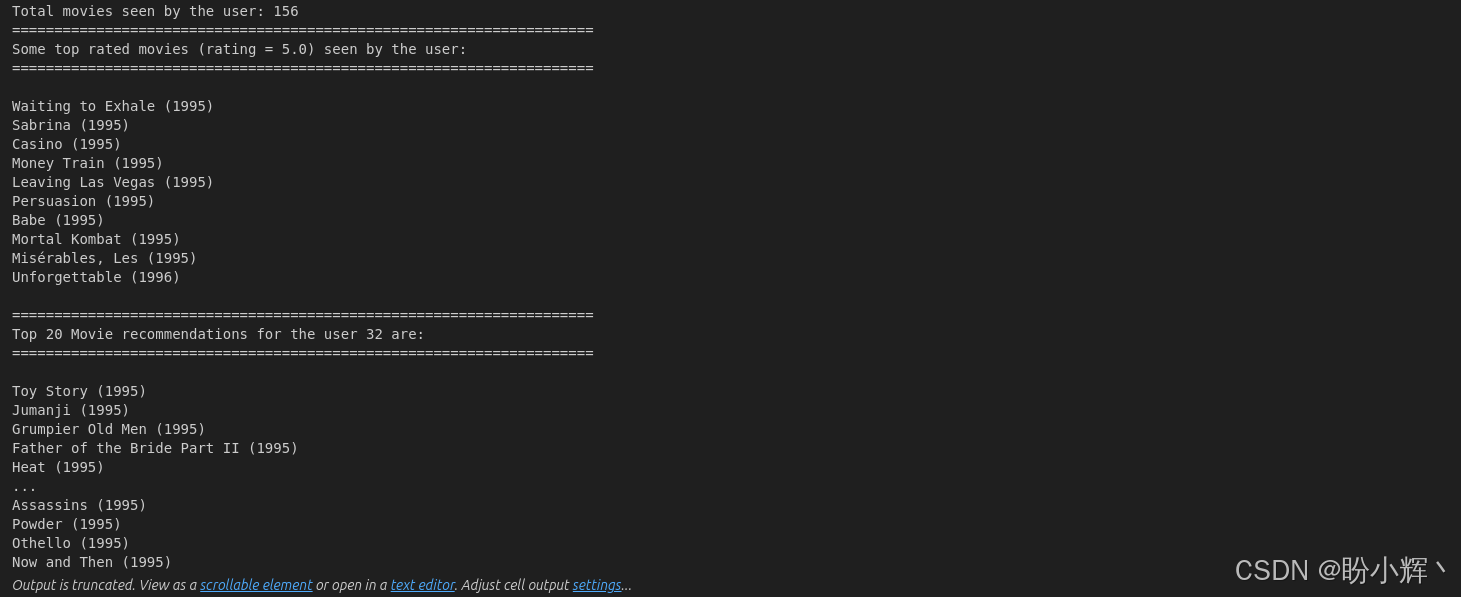
该函数首先返回用户 32 已观看的电影总数,随后展示该用户已观看的部分( 10 部)电影以体现其观影偏好,最后基于 EmbeddingNet 模型的预测评分列出最适合该用户的 10 部推荐影片,这些推荐电影是根据用户可能给出的最高评分排列的。
在本节中,我们完成了使用 PyTorch 和 MovieLens 数据集从零开始构建一个推荐系统。本节中的概念可以应用于不同类型的推荐系统,包括不同底层模型和多样化的数据模态场景。
构建推荐系统通常需要处理海量数据,涉及数百万用户和商品以及数十亿条评分记录。为应对此类大规模问题,PyTorch 推出了 TorchRec 库。该库提供大规模推荐系统所需的稀疏性和并行化核心功能,它还支持在多个 GPU 之间共享大规模嵌入表来训练模型。
小结
在本节中,我们使用 PyTorch 从零开始构建了一个推荐系统。首先探讨了如何利用深度学习驱动推荐系统,随后对 MovieLens 数据集进行探索性分析。通过 PyTorch 定义了 EmbeddingNet 模型架构,并在 MovieLens 数据集上完成训练与评估。最终基于训练好的模型实现了电影推荐系统。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成
PyTorch实战(17)------神经风格迁移
PyTorch实战(18)------自编码器(Autoencoder,AE)
PyTorch实战(19)------变分自编码器(Variational Autoencoder,VAE)
PyTorch实战(20)------生成对抗网络(Generative Adversarial Network,GAN)
PyTorch实战(21)------扩散模型(Diffusion Model)
PyTorch实战(22)------MuseGAN详解与实现
PyTorch实战(23)------基于Transformer生成音乐
PyTorch实战(24)------深度强化学习
PyTorch实战(25)------使用PyTorch构建DQN模型
PyTorch实战(26)------PyTorch分布式训练
PyTorch实战(27)------自动混合精度训练
PyTorch实战(28)------PyTorch深度学习模型部署
PyTorch实战(29)------使用TorchServe部署PyTorch模型
PyTorch实战(30)------使用TorchScript和ONNX导出通用PyTorch模型
PyTorch实战(31)------在Android上部署PyTorch模型
PyTorch实战(32)------在iOS上构建PyTorch应用
PyTorch实战(33)------使用fastai进行快速原型开发
PyTorch实战(34)------基于PyTorch Lightning的跨硬件模型训练
PyTorch实战(35)------使用PyTorch Profiler分析模型推理性能
PyTorch实战(36)------PyTorch自动机器学习
PyTorch实战(37)------使用Optuna搜索最优超参数
PyTorch实战(38)------深度学习模型可解释性
PyTorch实战(39)------使用Captum解释深度学习模型