让数据教会模型如何思考------神经网络学习的核心就是自动从数据中找到最优的权重参数。
前言:什么是神经网络学习?
与传统机器学习方法需要人工设计特征量(如SIFT、HOG等)不同,神经网络可以直接从原始数据中"学习"出最优的权重参数。这意味着,无论处理图像、语音还是文本数据,我们都可以用同样的流程直接解决问题。那么,神经网络是如何进行学习的呢?核心就在于:找一个能衡量模型好坏的标准,然后不断调整参数让这个标准变得最小。这个标准,就是我们今天要重点讨论的------损失函数。
一、损失函数:衡量模型优劣的标尺
损失函数(Loss Function)就像一把"刻度尺",用来衡量神经网络的预测结果与真实答案之间的差距。损失函数的值越小,说明模型预测得越准确;反之,值越大,说明模型还需要继续努力。
我们来看三种最常见的损失函数。
1.1 均方误差(MSE / L2 Loss)
均方误差是回归任务中最常用的损失函数之一,它的计算公式如下:
L = (1/n) * Σ(y_i - t_i)^2其中,y_i 是神经网络的输出,t_i 是真实标签(正确的解),n 是数据的维度。有些教材为了方便求导,还会在前面加一个 1/2 的系数。
import numpy as np
def mean_squared_error(y, t):
"""
均方误差损失函数(MSE/L2 Loss)
参数:
y: 神经网络的预测输出(numpy数组)
t: 真实标签(one-hot编码,numpy数组)
返回:
loss: 均方误差值
"""
# 加1/2是为了求导后形式更简洁,不影响优化方向
return 0.5 * np.sum((y - t) ** 2)
# 示例:假设有3个类别,真实标签是类别1(one-hot编码为[0,1,0])
t = np.array([0, 1, 0]) # 正确解标签
y1 = np.array([0.1, 0.8, 0.1]) # 预测正确概率较高
y2 = np.array([0.6, 0.2, 0.2]) # 预测错误
print("预测正确的损失:", mean_squared_error(y1, t))
print("预测错误的损失:", mean_squared_error(y2, t))MSE的特点与注意事项:
MSE对预测值和真实值之间的差异进行平方计算,这意味着误差越大,损失值会以指数级增长。这种特性既是优点也是缺点:优点 是能让模型更快地关注那些预测偏差较大的样本;缺点是当数据中存在异常值时,平方操作会放大异常值的影响,导致梯度爆炸,模型难以收敛。
1.2 交叉熵误差(Cross Entropy Error)
交叉熵误差是分类任务中最常用的损失函数,特别适合多分类场景。其公式如下:
L = - (1/n) * Σ t_i * log(y_i)这里 t_i 是one-hot编码的正确标签(只有正确类别对应的位置为1,其余为0),log是自然对数。
def cross_entropy_error(y, t):
"""
交叉熵损失函数
参数:
y: 神经网络的输出(预测概率)
t: 监督数据(可以是one-hot向量,也可以是类别索引)
返回:
loss: 交叉熵误差值
"""
# 如果输入是一维数据(单个样本),将其reshape成二维
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 如果监督数据是one-hot向量,转换为正确解标签的索引
# argmax(axis=1) 返回每行最大值的索引
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
# 用1e-7防止log(0)出现负无穷大
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
# 示例:手写数字识别,有10个类别
y = np.array([0.01, 0.02, 0.05, 0.80, 0.01, 0.01, 0.02, 0.03, 0.02, 0.03]) # 模型预测
t = np.array([0, 0, 0, 1, 0, 0, 0, 0, 0, 0]) # one-hot标签(数字3)
print("交叉熵损失:", cross_entropy_error(y, t))为什么选择交叉熵?
交叉熵的核心优势在于它与softmax函数配合使用时的梯度特性------梯度形式简洁,训练稳定。对数运算使得概率接近0时损失趋于无穷大,会迫使模型快速纠正错误。而log运算的平滑性又能让模型在已经预测正确的情况下保持稳定。
1.3 分类任务与回归任务的损失函数选择
在动手写代码之前,我们需要明确一点:不同任务类型要选择不同的损失函数。
二分类任务(如判断邮件是否为垃圾邮件)推荐使用二元交叉熵损失(Binary Cross-Entropy Loss):
L = - (1/n) * Σ [ y_i * log(ŷ_i) + (1 - y_i) * log(1 - ŷ_i) ]其中 ŷ_i 是模型预测样本为正类的概率(通常在0到1之间)。这个公式巧妙地处理了正负两类样本:当真实标签为1时,只看第一项;当真实标签为0时,只看第二项。
多分类任务(如手写数字识别0-9)则使用多类交叉熵损失(Categorical Cross-Entropy Loss):
L = - (1/n) * Σ Σ y_i,c * log(ŷ_i,c)其中 C 是类别总数,y_i,c 表示样本 i 是否属于类别 c(0或1),ŷ_i,c 是模型预测样本 i 属于类别 c 的概率。
回归任务(如预测房价)最常用的三种损失函数:
-
MAE(L1 Loss)
:L = (1/n) * Σ |y_i - ŷ_i|,对异常值鲁棒性强,但在0点处不可导
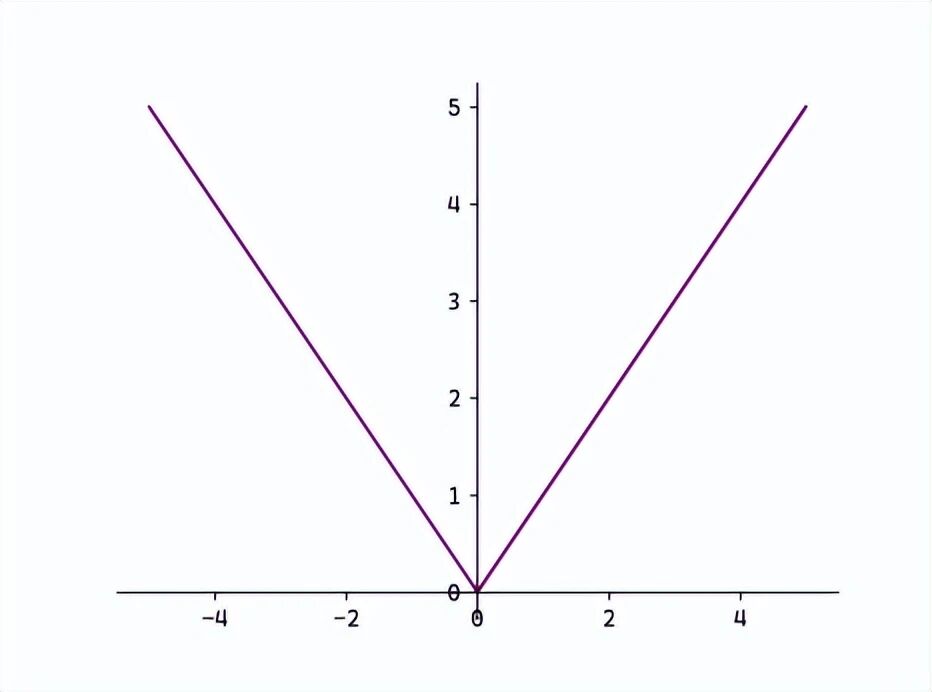
-
MSE(L2 Loss)
:L = (1/n) * Σ (y_i - ŷ_i)^2,收敛速度快,但对异常值敏感
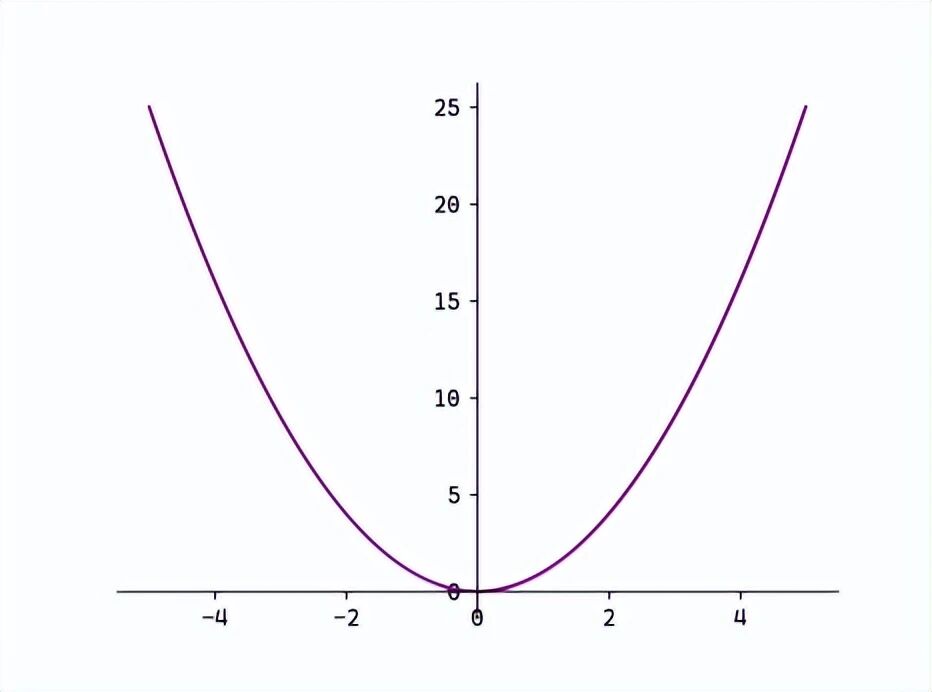
-
Smooth L1
:结合两者优点,在误差较小时用L2保证平滑可导,误差较大时用L1抵抗异常值影响
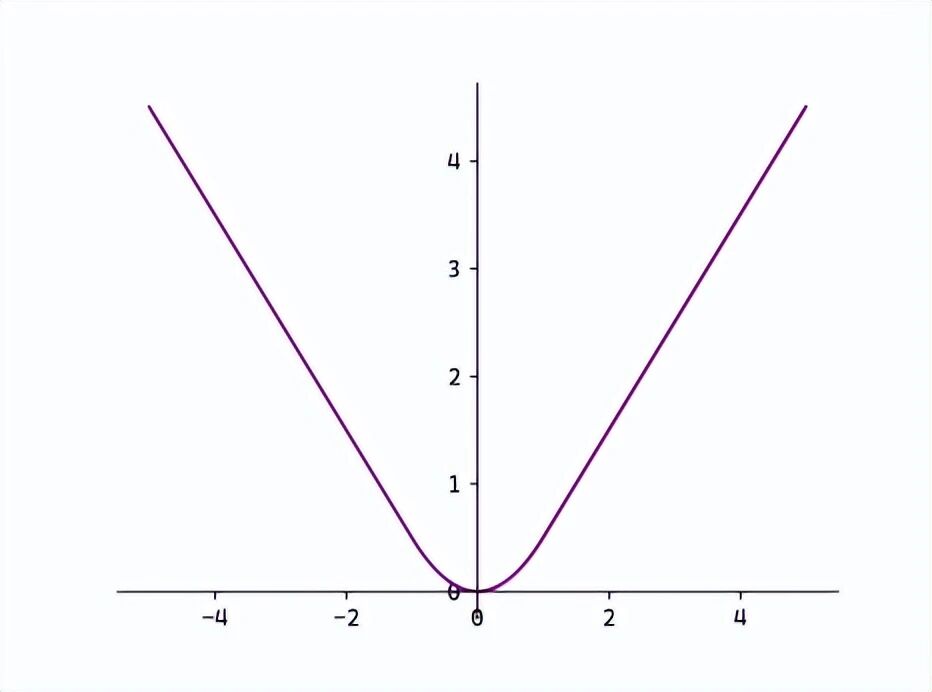
def smooth_l1_loss(y, t, beta=1.0):
"""
Smooth L1 损失函数
当误差 < beta 时使用 L2 损失(平方项),当误差 >= beta 时使用 L1 损失(线性项)
参数:
y: 预测值
t: 真实值
beta: 阈值,通常设为1
"""
diff = np.abs(y - t)
loss = np.where(diff < beta, 0.5 * diff ** 2 / beta, diff - 0.5 * beta)
return np.mean(loss)二、数值微分:让计算机学会求导
理解了损失函数,下一步就是想办法让它最小化。在数学上,我们会对损失函数求导,然后解出导数为0的点。但在神经网络中,损失函数极其复杂(可能包含数百万个参数),根本找不到解析解。
这时候,数值微分就派上了用场------它是一种近似求导的方法,在工程应用中非常广泛。
2.1 导数与中心差分
根据导数的数学定义:
f'(x) = lim(h→0) [f(x+h) - f(x)] / h我们可以用很小的h来近似计算导数值:
def numerical_diff(f, x):
"""
数值微分(中心差分法)
参数:
f: 目标函数
x: 求导点
返回:
该点的导数值
"""
# 选择微小值h,不能太小(避免舍入误差),也不能太大(降低精度)
h = 1e-4 # 0.0001
# 中心差分:同时计算x+h和x-h两边的值
# 相比前向差分(只用x+h),中心差分的精度更高
return (f(x + h) - f(x - h)) / (2 * h)
# 测试:对 f(x) = x^2 求导,在 x=2 处应为 4
f = lambda x: x ** 2
print("数值微分结果:", numerical_diff(f, 2)) # 约等于4
print("解析解结果: ", 4)这里我们使用了 中心差分法,即同时取x点左右两侧的增量来计算差分,这比只计算单侧的前向差分法(f(x+h) - f(x))/h 的精度要高得多。
一个重要的工程细节:h不能选得太小。当h小到1e-10甚至更小时,由于计算机浮点数精度的限制,会出现舍入误差。通常选择1e-4是比较合适的折中值。
2.2 偏导数
当函数有多个自变量时,我们需要计算偏导数------即固定其他变量,只改变其中一个,观察函数值的变化。
例如,对于二元函数 f(x, y) = x² + xy + y²:
-
关于x的偏导数:∂f/∂x = 2x + y
-
关于y的偏导数:∂f/∂y = x + 2y
偏导数的数值计算同样可以用数值微分来实现------只改变目标自变量,其他自变量保持不变。
2.3 梯度
多元函数的偏导数构成一个向量,这就是梯度:
∇f(a) = [∂f/∂x₁(a), ∂f/∂x₂(a), ..., ∂f/∂xₙ(a)]梯度的一个重要性质:梯度指向的是函数值增大最快的方向。
这意味着,如果我们想找到函数的最小值,应该沿着梯度的反方向(即负梯度方向)前进。
def numerical_gradient(f, x):
"""
计算函数 f 在点 x 处的梯度(数值微分法)
参数:
f: 目标函数
x: 自变量数组(numpy数组)
返回:
grad: 与x同形状的梯度数组
"""
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # 创建一个与x形状相同的零数组
# 对x的每一个维度逐一计算偏导数
for idx in range(x.size):
tmp_val = x[idx] # 保存原始值
# 计算 f(x+h)
x[idx] = float(tmp_val) + h
fxh1 = f(x)
# 计算 f(x-h)
x[idx] = tmp_val - h
fxh2 = f(x)
# 中心差分计算该维度的偏导数值
grad[idx] = (fxh1 - fxh2) / (2 * h)
# 还原x[idx]的值
x[idx] = tmp_val
return grad
# 示例:计算 f(x,y) = x^2 + xy + y^2 在点(1,1)处的梯度
def func(x):
return x[0]**2 + x[0]*x[1] + x[1]**2
x = np.array([1.0, 1.0])
grad = numerical_gradient(func, x)
print("梯度结果:", grad) # 输出约为[3, 3]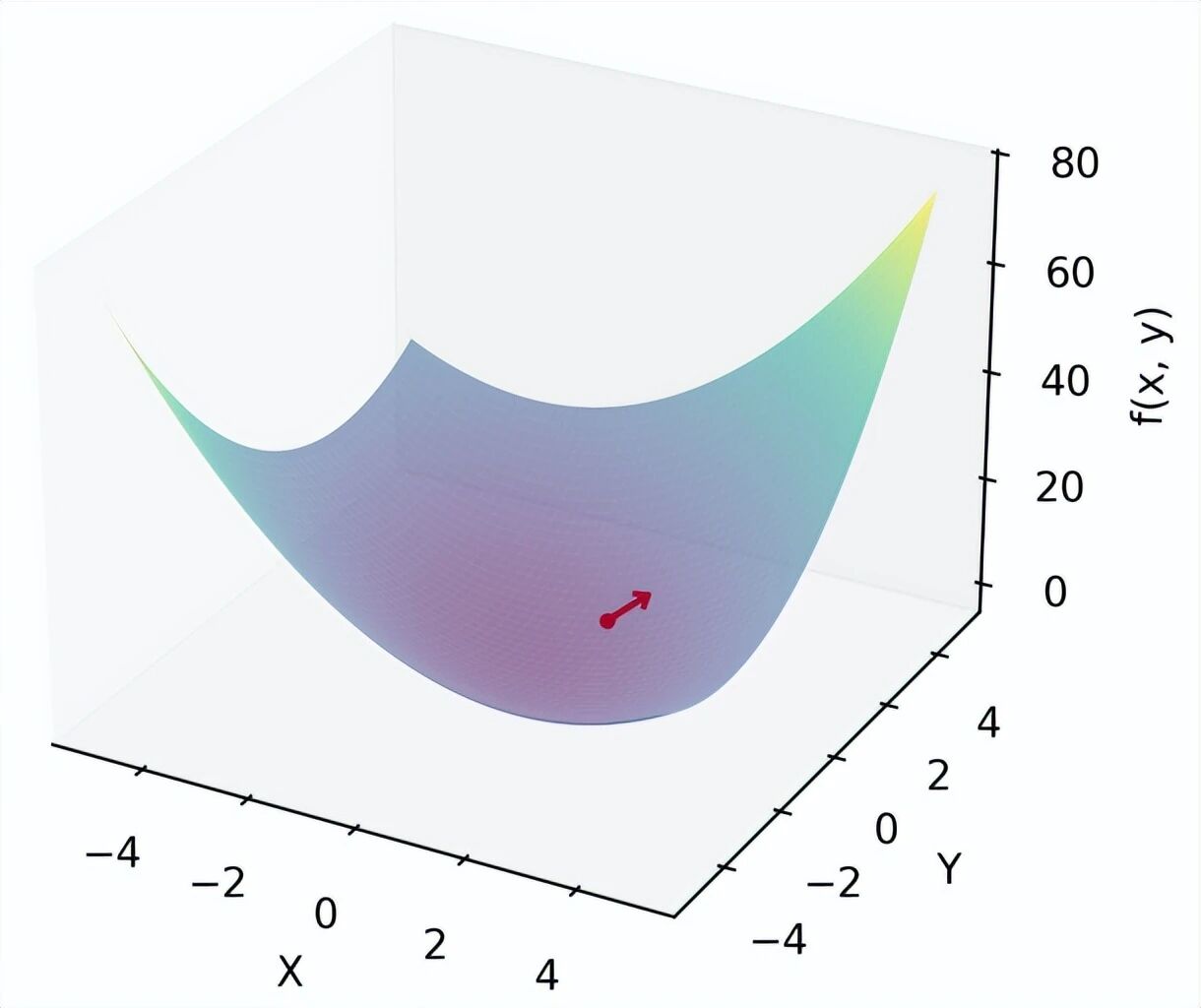
三、神经网络的梯度计算
在神经网络中,我们需要计算的是 损失函数关于权重参数的梯度。这个梯度告诉我们:每个权重应该朝哪个方向调整,才能让损失函数下降得最快。
以一个简单的一层网络为例,假设输入是2维,输出是3维,权重矩阵 W 的形状为 2×3:
W = [w₁₁ w₁₂ w₁₃]
[w₂₁ w₂₂ w₂₃]
∂L/∂W = [∂L/∂w₁₁ ∂L/∂w₁₂ ∂L/∂w₁₃]
[∂L/∂w₂₁ ∂L/∂w₂₂ ∂L/∂w₂₃]以下是完整实现:
from common.functions import softmax, cross_entropy_error
from common.gradient import numerical_gradient
class SimpleNet:
"""
一个最简单的单层神经网络
用于演示神经网络梯度的计算方法
"""
def __init__(self):
# 随机初始化权重参数(2×3矩阵)
# 使用标准正态分布初始化的目的是打破对称性
self.W = np.random.randn(2, 3)
def predict(self, x):
"""
前向传播:计算预测值
x: 输入数据(形状为(2,)的向量)
输出: 预测值(形状为(3,)的向量)
"""
return np.dot(x, self.W)
def loss(self, x, t):
"""
计算损失函数值
x: 输入数据
t: 正确标签(one-hot编码)
"""
z = self.predict(x)
y = softmax(z) # softmax将输出转换为概率分布
loss = cross_entropy_error(y, t)
return loss
# 实例化网络
net = SimpleNet()
# 准备输入数据和标签
x = np.array([0.6, 0.9]) # 输入是一个2维向量
t = np.array([0, 0, 1]) # 正确解标签:第3个类别
# 定义损失函数关于权重参数的函数
f = lambda w: net.loss(x, t)
# 计算梯度
dW = numerical_gradient(f, net.W)
print("梯度矩阵 dW:\n", dW)梯度矩阵的意义:dW 的每个元素表示对应权重的更新方向和大小。如果某个位置的值是正数,说明增加这个权重会导致损失增大,因此需要减小它;反之,负值表示需要增加这个权重。
四、SGD:神经网络学习的核心算法
有了梯度的计算方法,接下来就是如何用梯度来更新参数了。
4.1 梯度下降法
梯度下降法的核心思想非常简单:沿着负梯度方向逐步调整参数,就能让损失函数值不断减小。
更新公式为:
x₁' = x₁ - η * ∂f/∂x₁
x₂' = x₂ - η * ∂f/x₂这里的 η(eta)被称为 学习率(learning rate) ,决定了每次参数更新的步长大小。
def gradient_descent(f, init_x, lr=0.01, step_num=100):
"""
梯度下降法
参数:
f: 目标函数(需要最小化的函数)
init_x: 初始参数值
lr: 学习率(learning rate)
step_num: 迭代次数
返回:
x: 优化后的参数值
x_history: 参数的历史记录(用于可视化)
"""
x = init_x
x_history = []
for i in range(step_num):
x_history.append(x.copy())
# 计算当前点的梯度
grad = numerical_gradient(f, x)
# 沿着负梯度方向更新参数
x -= lr * grad
return x, x_history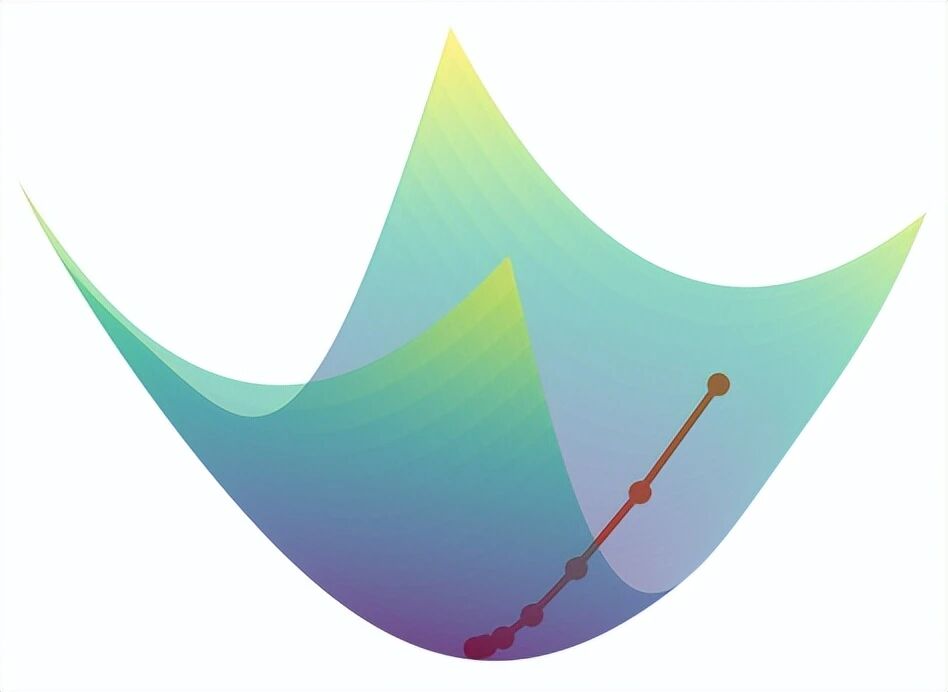
4.2 Epoch、Batch Size 和 Iteration
在动手写完整代码之前,有三个核心概念必须搞清楚:
-
Epoch
:模型完整遍历一次整个训练数据集的过程。训练10个Epoch意味着把全部数据反复学10遍。单次遍历通常不足以让模型收敛。
-
Batch Size
:每次训练时输入的样本数量。batch size=32表示每次用32个样本计算一次梯度并更新参数。小批量比单样本更稳定,比全批量更高效。
-
Iteration
:完成一个Batch数据的正向传播和反向传播的过程。当数据总数为2000、batch size=64时,一个Epoch需要2000/64≈32次Iteration。总迭代次数 = Epoch数 × 每Epoch的Iteration数。
超参数选择的实践建议:学习率是最敏感的超参数,过大或过小都会导致学习效果不佳。数据量较大时可以用较大的学习率和批量大小来提高效率,数据量较小时用小批量避免过拟合。
4.3 SGD算法详解
在实际应用中,我们使用的并不是原始的梯度下降法,而是 随机梯度下降法(Stochastic Gradient Descent,SGD) 。两者的区别在于:梯度下降法每次用全部数据计算梯度,计算量巨大;SGD每次只随机选择一小批数据(mini-batch)来计算梯度,大大提高了效率。
SGD的完整流程如下:
-
随机选择批数据
:从训练数据中随机选出一部分样本(mini-batch),目标是降低这批数据的损失函数值
-
计算梯度
:对当前的权重参数计算梯度值,负梯度表示损失函数下降最快的方向
-
更新参数
:按照更新公式沿负梯度方向调整权重参数
-
重复迭代
:重复上述步骤,直到完成预定的迭代次数
SGD之所以"随机",是因为每次选取的mini-batch都是随机采样的。这种随机性反而带来了好处:可以帮助模型跳出局部极小值,获得更好的泛化能力。
SGD的局限性:在复杂损失函数曲面上,SGD可能陷入局部极小值、鞍点或高原区域。因此在现代深度学习中,通常会采用更先进的优化器:
-
Momentum(动量法)
:引入物理中的惯性思想,积累历史梯度信息,加速收敛并减少震荡
-
AdaGrad
:自适应调整学习率,频繁更新的参数学习率变小,不常更新的参数学习率变大
-
RMSProp
:AdaGrad的改进版,引入指数衰减来避免学习率过早衰减
-
Adam
:结合了Momentum和RMSProp的优点,是目前应用最广泛的优化器,收敛快且稳定性好
在实际应用中,可以先用Adam快速搭建原型,如果对精度要求很高,再切换到SGD+Momentum进行精细调优。
五、完整实战:手写数字识别(MNIST)
理论讲完了,我们来搭建一个完整的神经网络,用手写数字数据集MNIST来验证学习效果。
5.1 MNIST数据集简介
MNIST(Modified National Institute of Standards and Technology)是机器学习领域最经典的数据集之一,常被作为深度学习的入门案例。
-
数据规模
:训练集60,000张,测试集10,000张
-
图像规格
:每张图片28×28像素,共784个像素
-
像素值
:0(白色)到255(黑色)之间的灰度值,通常归一化到0,1范围
-
标签
:0到9十个数字,使用one-hot编码表示
-
数据来源
:由250个不同职业的人手写绘制
5.2 TwoLayerNet 类实现
我们实现一个简单的两层神经网络(一个隐藏层 + 一个输出层):
import numpy as np
from common.functions import sigmoid, softmax, cross_entropy_error
from common.gradient import numerical_gradient
class TwoLayerNet:
"""
两层神经网络
结构:输入层 → 隐藏层(sigmoid激活) → 输出层(softmax)
"""
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
"""
初始化网络参数
参数:
input_size: 输入层神经元数量(对于MNIST是784)
hidden_size: 隐藏层神经元数量
output_size: 输出层神经元数量(对于MNIST是10)
weight_init_std: 权重初始化的标准差(高斯分布)
"""
self.params = {}
# 第一层:输入层 → 隐藏层的权重和偏置
# 权重使用高斯分布随机初始化,目的是打破对称性
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
# 偏置初始化为0
self.params['b1'] = np.zeros(hidden_size)
# 第二层:隐藏层 → 输出层的权重和偏置
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
"""
前向传播(推理)
参数:
x: 输入数据(形状:[batch_size, input_size])
返回:
y: 预测结果(经过softmax的概率分布)
"""
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
# 第一层:线性变换 + sigmoid激活
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
# 第二层:线性变换 + softmax(输出概率)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
def loss(self, x, t):
"""
计算损失函数值
参数:
x: 输入数据
t: 监督数据(正确标签)
返回:
loss: 交叉熵损失值
"""
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
"""
计算识别准确率
参数:
x: 输入数据
t: 监督数据
返回:
accuracy: 准确率(0~1之间的浮点数)
"""
y = self.predict(x)
y = np.argmax(y, axis=1) # 取预测结果中概率最大的类别索引
# 确保 t 是一维数组(如果是one-hot则取argmax)
if t.ndim != 1:
t = np.argmax(t, axis=1)
# 计算正确预测的比例
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
"""
通过数值微分计算梯度
参数:
x: 输入数据
t: 监督数据
返回:
grads: 包含各参数梯度的字典
"""
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads5.3 使用SGD进行训练
以下是完整的训练流程代码,包含了数据加载、超参数配置、训练循环和可视化输出:
import numpy as np
import matplotlib.pyplot as plt
from two_layer_net import TwoLayerNet
# 加载MNIST数据(假设get_data()函数已经定义好)
x_train, x_test, t_train, t_test = get_data()
# 网络配置
network = TwoLayerNet(
input_size=784, # 输入层:28*28=784个像素
hidden_size=50, # 隐藏层:50个神经元(可根据需要调整)
output_size=10 # 输出层:10个类别(数字0~9)
)
# 超参数设置
iters_num = 10000 # 训练总迭代次数
train_size = x_train.shape[0] # 训练集大小(通常为60000)
batch_size = 100 # 每批数据量
learning_rate = 0.1 # 学习率
# 记录训练过程中的数据(用于分析和可视化)
train_loss_list = [] # 每个iteration的损失值
train_acc_list = [] # 每个epoch的训练集准确率
test_acc_list = [] # 每个epoch的测试集准确率
# 计算每个epoch包含的iteration数量
# 例如:60000个样本,batch_size=100,则每个epoch需要600次iteration
iter_per_epoch = max(train_size / batch_size, 1)
print("开始训练...")
print(f"训练样本数:{train_size}")
print(f"每个epoch包含的iteration数:{iter_per_epoch}")
print("=" * 50)
for i in range(iters_num):
# 步骤1:随机选择mini-batch
# np.random.choice:从0~train_size-1中随机选出batch_size个索引
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask] # 获取选中的图像数据
t_batch = t_train[batch_mask] # 获取对应的标签
# 步骤2:计算梯度
grad = network.numerical_gradient(x_batch, t_batch)
# 步骤3:更新参数(沿负梯度方向)
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 记录当前batch的损失值
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# 步骤4:每完成一个epoch,记录一次准确率
# 这样可以观察模型在训练集和测试集上的表现
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
epoch_num = i // iter_per_epoch
print(f"Epoch {epoch_num}: train_acc={train_acc:.4f}, test_acc={test_acc:.4f}")
print("=" * 50)
print("训练完成!")
# 绘制准确率变化曲线
plt.figure(figsize=(10, 6))
epochs = np.arange(len(train_acc_list))
plt.plot(epochs, train_acc_list, 'o-', label='train acc', linewidth=2, markersize=6)
plt.plot(epochs, test_acc_list, 's--', label='test acc', linewidth=2, markersize=6)
plt.xlabel("epochs", fontsize=12)
plt.ylabel("accuracy", fontsize=12)
plt.ylim(0, 1.0)
plt.title("Training Progress: Accuracy vs Epochs", fontsize=14)
plt.legend(loc='lower right', fontsize=11)
plt.grid(True, alpha=0.3)
plt.show()
# 绘制损失值变化曲线(可选)
plt.figure(figsize=(10, 6))
plt.plot(train_loss_list, 'b-', linewidth=1)
plt.xlabel("iteration", fontsize=12)
plt.ylabel("loss", fontsize=12)
plt.title("Loss Decrease Over Training", fontsize=14)
plt.yscale('log') # 使用对数坐标便于观察
plt.grid(True, alpha=0.3)
plt.show()5.4 代码执行结果解读
执行上述代码后,我们会看到类似如下的输出:
开始训练...
训练样本数:60000
每个epoch包含的iteration数:600
==================================================
Epoch 0: train_acc=0.1021, test_acc=0.1018
Epoch 1: train_acc=0.4213, test_acc=0.4215
Epoch 2: train_acc=0.6212, test_acc=0.6208
Epoch 3: train_acc=0.7215, test_acc=0.7209
...
Epoch 16: train_acc=0.9421, test_acc=0.9365
==================================================
训练完成!结果分析:
-
初始状态(Epoch 0)
:准确率约10%,相当于随机猜测(10个类别盲猜正确率10%)。这很正常,因为权重是随机初始化的。
-
学习过程
:随着epoch增加,准确率快速提升。前几个epoch增长最快,之后增长速度逐渐放缓。
-
最终性能
:经过约16个epoch的训练后,测试集准确率可以达到93%以上。考虑到我们使用的网络结构非常简朴(只有一层隐藏层且没有使用任何正则化技巧),这个结果已经相当不错了。
-
过拟合观察
:训练集准确率通常会略高于测试集准确率,这是正常现象。如果训练集准确率远高于测试集,说明出现了过拟合,可以考虑增加正则化或减少网络复杂度。
为什么选择两层神经网络?
对于MNIST手写数字识别这种入门级任务,两层网络完全足够展示神经网络学习的核心流程------前向传播计算损失、反向传播计算梯度、SGD更新参数。输入层784个神经元对应28×28的像素图像,输出层10个神经元对应10个数字类别,中间隐藏层50个神经元提供了足够的表达能力。这个结构虽然简单,但已经可以完整地演示从数据加载到模型评估的全过程。
六、总结
回顾整个神经网络学习的过程,我们可以总结出以下核心要点:
1. 损失函数是学习的指挥棒
-
分类任务首选交叉熵损失 ,回归任务根据数据特点选择MSE(快速收敛但敏感) 、MAE(鲁棒性强) 或Smooth L1(兼顾两者)
-
损失函数的值越小,模型越准确
2. 数值微分是理解梯度的最佳切入点
-
通过中心差分法可以方便地计算数值梯度
-
数值梯度在工程调试中用于验证反向传播实现是否正确
-
实际训练中使用反向传播计算梯度,效率远高于数值微分
3. 梯度告诉我们应该往哪个方向走
-
梯度指向函数值增大最快的方向
-
沿着负梯度方向前进,可以逐步降低损失函数的值
-
梯度是零向量时对应极小值点、极大值点或鞍点
4. SGD是神经网络学习的主力算法
-
核心流程:选batch → 算梯度 → 更新参数 → 重复
-
随机性带来的好处:帮助跳出局部最优,提升泛化能力
-
现代深度学习在此基础上发展出了Momentum、Adam等更高效的优化器
5. 超参数调优是实践中的关键技能
-
学习率
:最敏感的超参数,过大容易震荡,过小收敛太慢
-
Batch Size
:需要平衡训练速度和收敛稳定性
-
Epoch数量
:过多会导致过拟合,过少会导致欠拟合
神经网络学习本质上是一个"试错 + 改进"的迭代过程。损失函数告诉模型错得有多严重,梯度告诉模型应该朝哪个方向改,SGD则负责实际执行这些改进。理解了这个闭环,你就掌握了神经网络学习的核心思想。