HumDex 是一个面向人形机器人 全身灵巧操作 的便携式遥操作系统。
- 采用
基于IMU的全身追踪方案,15个节点,纯惯性追踪不受视觉遮挡限制 基于学习的灵巧手重定向方法,实现20自由度灵巧手的实时控制,替代传统的基于优化的IK求解- 构建
两阶段模仿学习框架,使用人类数据提升泛化,再用真是机器人数据微调
论文地址:HumDex: Humanoid Dexterous Manipulation Made Easy
代码地址:https://github.com/physical-superintelligence-lab/humdex
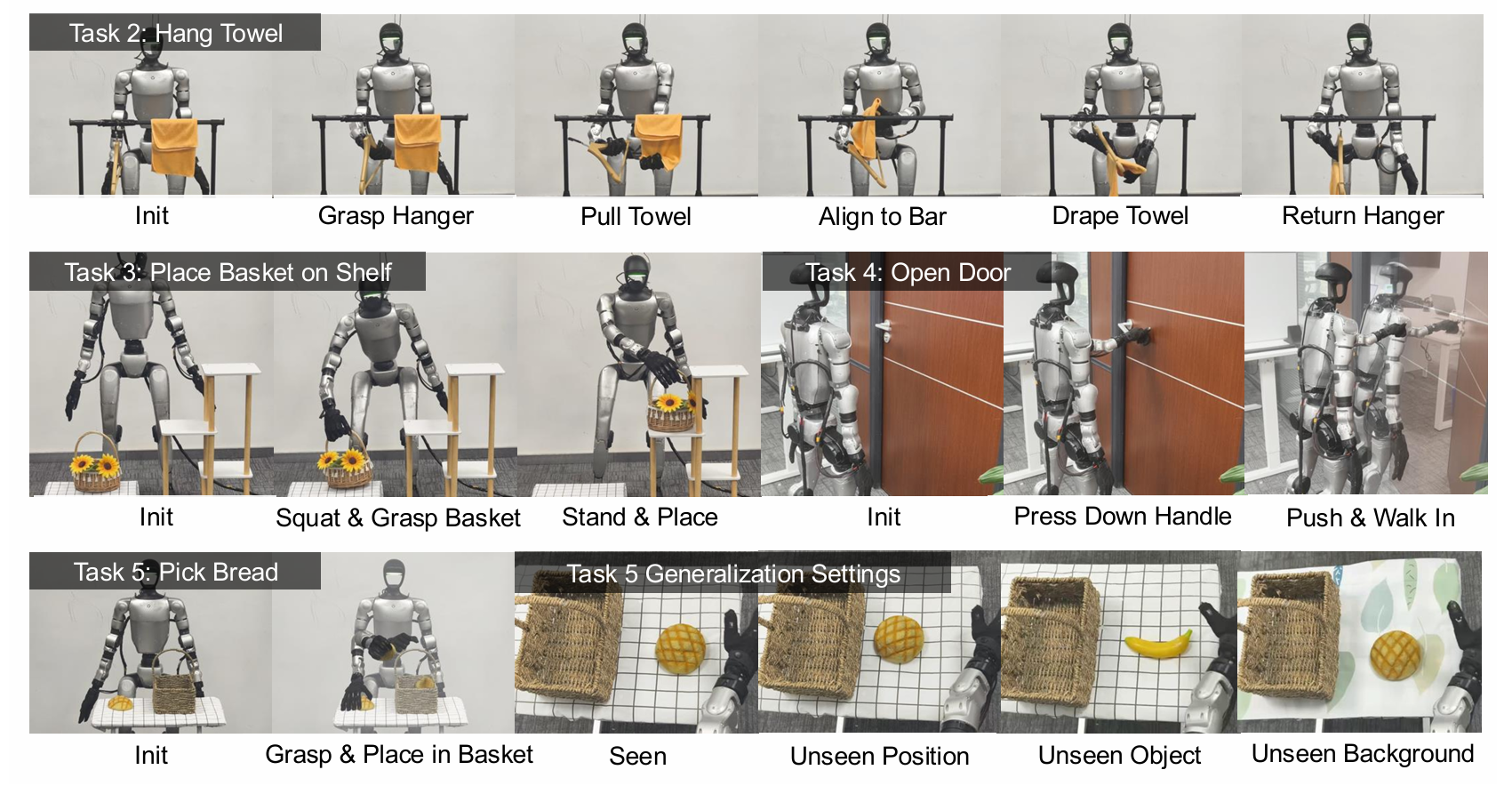
解决人形机器人灵巧操作数据采集的效率、精度、泛化性瓶颈问题。
一、方法架构
如下图所示,HumDex采用分层架构

-
异构计算策略:
- 身体 :采用模型驱动(基于优化),利用精确的机器人运动学模型处理浮基动力学
- 手部 :采用数据驱动(基于学习),通过数据学习人类到机器人的非线性映射,避免手工设计复杂的接触约束
-
精度与速度的权衡:
- 全身控制允许较高延迟(~10ms优化求解),因为人体运动惯性大
- 手部控制要求极低延迟(<5ms),MLP前向传播满足100Hz实时性要求
如下图所示,进一步展示了 HumDex 的架构思路。
1. 上层通道:全身运动重定向(Body Teleoperation)
目标:将人体大尺度运动映射到人形机器人全身姿态,解决平衡与 locomotion 问题。
| 环节 | 技术细节 | 设计 rationale |
|---|---|---|
| 输入 p t R p_t^R ptR | IMU 追踪器捕获的全身骨骼姿态(15节点) | 纯惯性方案,抗遮挡,支持大范围移动 |
| 重定向算法 | Humanoid Retargeting (GMR框架) | 采用基于优化的 General Motion Retargeting,求解非线性最小二乘问题,最小化方向误差和相对位置误差 |
| 输出 q t R q_t^R qtR | 35维低层控制目标(身体关节角度) | 输入 TWIST2 等预训练的低层控制器,负责动态平衡与力矩控制 |
| 执行体 | Unitree G1 人形机器人本体 | 接收目标关节角,实现全身跟踪 |
关键技术点 :使用骨盆中心坐标系(Pelvis-centric)处理 IMU 全局漂移问题,通过相对位置约束而非绝对世界坐标,确保重定向精度。
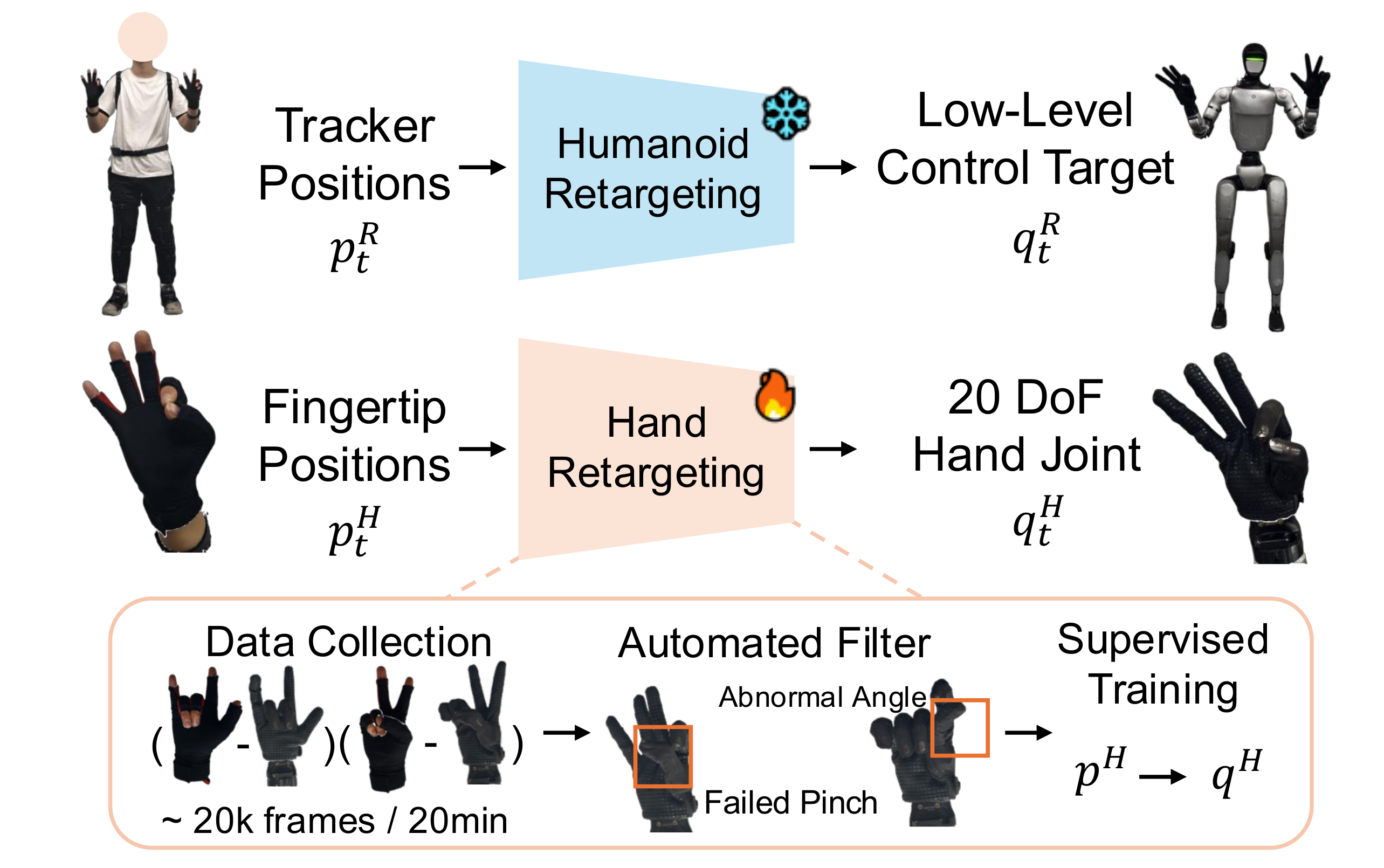
2. 中层通道:灵巧手重定向(Dexterous Hand Control)
目标:实现20自由度(20-DoF)的精细手指控制,支持工具使用等灵巧操作。
| 环节 | 技术细节 | 设计 rationale |
|---|---|---|
| 输入 p t H p_t^H ptH | 惯性手套捕获的5个指尖3D位置(拇指+四指) | 低维紧凑表示(15维),避免直接映射高维关节角导致的歧义 |
| 重定向算法 | Hand Retargeting (基于学习的MLP) | 与身体通道分离:身体用优化(精度高但慢),手部用学习(速度快且平滑),满足实时性(100Hz) |
| 输出 q t H q_t^H qtH | 20维手部关节角度(WUJI手) | 直接通过位置控制器执行,绕过强化学习策略,确保精度 |
| 执行体 | WUJI 灵巧手 | 每指4自由度,支持精细抓取与操作 |
关键技术点 :采用监督学习替代在线优化 。传统方法需每帧求解 IK(计算昂贵且不稳定),而 HumDex 通过预训练轻量级 MLP 实现常数时间推理(constant-time inference)。
3. 底层:手部重定向模型的数据 Pipeline(虚线框)
这部分展示了学习式手部重定向的训练数据生成流程,是整个系统能够"即插即用"的关键:
阶段一:Data Collection(数据采集)
- 同步采集 :操作员佩戴惯性手套执行随机手势,同时通过离线优化 IK 求解器 计算对应的机器人关节配置 q H q^H qH
- 数据量 :约 20,000 帧(20分钟) 的配对数据 { ( p H , q H ) } \{(p^H, q^H)\} {(pH,qH)}
- 双模态记录:同时记录人手(输入)和机器人手(标签)
阶段二:Automated Filter(自动过滤)
- 异常角度过滤:检测超出机器人关节极限的姿态
- 失败捏合过滤:剔除指尖穿透或无法闭合的抓取配置(如图中红色框标记的 "Failed Pinch")
- 目的:确保训练数据质量,避免不稳定抓取模式
阶段三:Supervised Training(监督训练)
- 映射学习 :训练 MLP f θ : R 15 → R 20 f_\theta: \mathbb{R}^{15} \to \mathbb{R}^{20} fθ:R15→R20,即 p H ↦ q H p^H \mapsto q^H pH↦qH
- 损失函数 :均方误差(MSE) min θ E ∥ f θ ( p ) − q ∥ 2 2 \min_\theta \mathbb{E}\\\|f_\\theta(p) - q\\\|_2\^2 minθE∥fθ(p)−q∥22
- 推理:运行时直接前向传播,无需迭代优化
二、当前问题 与 解决方案(可选观看)
1.1、遥操作硬件追踪方案
对比分析遥操作硬件追踪方案,"现有遥操作硬件存在便携性-精度非此即彼权衡"的痛点。
A、现有研究分类:按追踪硬件划分为三类,各有显著缺陷
现有人形全身遥操作系统按核心追踪硬件分为三类:
动捕基系统:以光学动捕为代表,优势是跟踪精度高 ,能满足全身运动的精细控制;但缺陷是依赖专用固定基础设施(需专门的动捕房间),便携性为0,完全无法实现多样化场景的数采。外骨骼基系统:优势同样是精度高,能实现人类动作的精准映射;但缺陷是硬件笨重、需坐姿操作,对操作者的动作限制大,无法完成全身移动、站姿操作等复杂任务,适配性极差。视觉/VR基系统:是现有研究中尝试解决便携性的主流方案,优势是部署灵活、便携性好 ;但核心缺陷是存在严重的遮挡问题 ------操作者手部必须始终处于传感器视野内,否则跟踪丢失,同时还存在精度偏低的问题;此外,该类系统的操作范围受传感器视野限制,进一步压缩了可完成的任务类型。
B、解决思路
针对上述问题,HumDex明确了硬件层的创新方向:
- 采用
IMU基的运动追踪方案:由15个轻量化追踪器组成,佩戴于人体关键部位,实现无约束的运动捕捉------既摆脱了固定基础设施的限制(解决便携性问题),又无视觉遮挡问题(解决跟踪稳定性问题),同时保证了高跟踪精度,打破了传统硬件的便携性-精度权衡; - 适配
20DoF的全灵巧手:支持全维度的精细手指控制,而非简单的二进制开/关,能完成工具操作、双手协调等需要精细灵巧运动的任务,突破了现有执行器的操作限制。

1.2、灵巧手重定向
当前,存在"灵巧手控制多依赖优化式重定向,精度低、泛化差、需手动调参"的痛点
核心是人类手部动作,到机器人手部动作的映射方法 ,连接遥操作硬件和机器人执行的关键桥梁。
灵巧手重定向方法分为传统优化式 和新兴学习式两类。
A、优化式和学习式分析
1)优化式重定向:现有主流方案,存在固有缺陷
这是目前灵巧手重定向的主流方法 ,核心思路是将人类手部动作到机器人手部动作的映射,转化为带约束的优化问题(如约束逆运动学IK、非线性最小二乘):
- 核心设计:通过目标项 保留任务相关的几何关系(如指尖位置、手部姿态),通过约束项 保证机器人的运动学可执行性;为提升稳定性,还会加入时间一致性正则化 、接触一致性/互穿惩罚项,避免手部与物体的穿模、动作抖动。
- 核心缺陷:高度依赖人工设计的目标项和约束项 ,需要大量的手动参数调优 ,且每帧都需要求解优化问题,计算成本高、实时性差;同时,优化结果的泛化性有限,面对未见过的手部姿态易出现动作失准。
2)学习式重定向:新兴技术路线,解决优化式核心痛点
这是该领域的最新研究趋势 ,核心思路是直接从人类观测中预测机器人手部配置,而非逐帧求解优化问题:
- 核心优势:减少对人工设计目标的依赖,推理速度快(恒时推理),实时性好,更适配遥操作的实时控制需求;典型代表为GeoRT,提出了基于几何准则的超快神经重定向方法,实现了实时性能,支持可扩展的遥操作流水线。
- 现有不足:部分学习式方法(如GeoRT)仍依赖复杂的几何准则设计 ,模型复杂度较高,尚未实现轻量化、极简式的设计,难以适配便携遥操作系统的部署需求。
B、问题解决
采用学习式的灵巧手重定向方法 ,并做了轻量化、实用化改进,形成了更适配便携遥操作的手重定向方案:
- 采用极简的输入表征 :仅以人类五指尖的3D位置作为输入,无需复杂的手部姿态特征提取,降低了感知层的复杂度;
- 设计轻量的模型结构 :用小型MLP回归器替代复杂的神经网络,实现从15D指尖位置(5指尖×3D)到20D机器人手关节角的直接映射,模型推理速度快、部署成本低;
- 采用监督学习的简单范式:基于配对的指尖-关节样本训练,无需复杂的几何准则或强化学习奖励设计,训练过程简单、可复现性高。
三、全身灵巧遥操作系统
3.1、问题表述与系统分层架构
将全身灵巧遥操作定义为分层控制问题:
- 高层策略 π h i g h \pi_{high} πhigh:由人类操作员与重定向算法组成,负责生成运动目标
- 低层控制器 π l o w \pi_{low} πlow:任务无关的运动跟踪策略,负责稳定执行与平衡控制
关键创新在于解耦控制 :将全身关节目标 q r e f q_{ref} qref 显式分解为:
q r e f = q b o d y , q h a n d q_{ref} = q_{body}, q_{hand} qref=qbody,qhand
- 身体部分 q b o d y q_{body} qbody:输入TWIST2预训练策略,生成动态平衡与
运动所需的扭矩 - 手部部分 q h a n d q_{hand} qhand:绕过策略网络,直接通过关节位置控制器执行,确保灵巧操作的精确性(避免强化学习策略的平滑处理损失精度)
3.2、低层控制接口设计
(a) 身体控制器接口
- 指令向量 p c m d p_{cmd} pcmd 包含:根部线速度 v r o o t v_{root} vroot、根部高度 z r e f z_{ref} zref、根部姿态 Θ r o o t \Theta_{root} Θroot、偏航角速度 ψ ˙ r e f \dot{\psi}{ref} ψ˙ref、全身关节目标 q r e f q{ref} qref
- 兼容性:通过ZMQ消息骨干网支持多种低层控制器(如TWIST2或SONIC),实现低延迟同步(100Hz控制频率)
(b) 灵巧手控制(核心差异化设计)
- 突破TWIST2限制 :TWIST2使用VR手柄触发器控制二元开闭,而HumDex支持20-DoF全灵巧控制
- 学习式重定向 :轻量级MLP将操作员五个指尖的3D位置(IMU手套捕获)映射到机器人20维关节角度
- 优势:生成平滑自然的运动轨迹,无需手工调参,且推理时间为常数(适合实时控制)
3.3、高层遥操作:基于IMU的重定向
技术方案对比
| 方案类型 | 代表系统 | 局限性 | HumDex解决方案 |
|---|---|---|---|
| 光学动捕 | VICON | 需专用房间,固定基础设施 | 15个轻量级IMU传感器,完全便携 |
| VR视觉追踪 | PICO/Quest | 遮挡敏感,手必须在视野内 | 纯惯性追踪,无视遮挡 |
| 外骨骼 | Xsens/ others | 笨重,通常需坐着操作 | 总重<300g,支持全身自由活动 |
HumDex采用的方案:
- IMU硬件的无约束设计 :采用轻量化、无绳的IMU穿戴设备,支持连续10小时以上操作 、50米+通信距离,摆脱房间/传感器视野限制,实现"野外"数采;
- 骨盆中心优化:解决IMU全局漂移 (最核心的技术细节):IMU的固有缺陷是无绝对位置参考,易产生全局漂移 ,本研究通过骨盆中心的相对位置优化 替代绝对位置跟踪,求解机器人最优配置 q ∗ q^* q∗,
重定向算法(GMR框架)
采用以骨盆为中心的优化公式解决IMU固有的全局位置漂移问题:
- 优化目标 :最小化连杆方向误差 + 关键末端执行器的相对位置误差(相对于骨盆坐标系,而非绝对世界坐标)
- 数学表达 :
q ∗ ( t ) = arg min q ( ∑ i ∈ L R w i R ∥ R i H ( t ) − R i R ( q ) ∥ 2 + ∑ j ∈ L P w j P ∥ p j H , r e l ( t ) − p j R , r e l ( q ) ∥ 2 ) q^*(t) = \arg\min_q \left( \sum_{i\in\mathcal{L}R} w_i^R \|R_i^H(t) - R_i^R(q)\|^2 + \sum{j\in\mathcal{L}_P} w_j^P \|p_j^{H,rel}(t) - p_j^{R,rel}(q)\|^2 \right) q∗(t)=argqmin i∈LR∑wiR∥RiH(t)−RiR(q)∥2+j∈LP∑wjP∥pjH,rel(t)−pjR,rel(q)∥2
该数学表达是 General Motion Retargeting (GMR) 框架的核心优化问题,用于将人体动作实时映射到人形机器人。
1. 优化目标与变量
q ∗ ( t ) = arg min q ⋯ q^*(t) = \arg\min_q \Big \\cdots \\Big q∗(t)=argqmin⋯
- 优化变量 q q q:机器人在时刻 t t t 的关节配置(Unitree G1为35维:身体15维 + 每只手10维)
- 输出 q ∗ ( t ) q^*(t) q∗(t):使目标函数最小化的最优关节角度,作为低层控制器的跟踪目标
2. 目标函数的双项结构
公式包含两个互补的误差项,分别处理不同类型的运动映射:
(a) 方向/旋转误差项(第一项)
∑ i ∈ L R w i R ∥ R i H ( t ) − R i R ( q ) ∥ 2 \sum_{i\in\mathcal{L}_R} w_i^R \|R_i^H(t) - R_i^R(q)\|^2 i∈LR∑wiR∥RiH(t)−RiR(q)∥2
| 符号 | 含义 | 技术细节 |
|---|---|---|
| L R \mathcal{L}_R LR | 需跟踪方向的连杆集合 | 通常包括:头部、躯干、四肢(大腿、小腿、上臂、前臂) |
| R i H ( t ) R_i^H(t) RiH(t) | 时刻 t t t 人体第 i i i 个连杆的旋转矩阵(IMU直接测量) | IMU的核心优势:直接输出高精度方向(四元数/旋转矩阵),无漂移积累 |
| R i R ( q ) R_i^R(q) RiR(q) | 机器人第 i i i 个连杆在配置 q q q 下的前向运动学计算值 | 通过URDF模型和当前关节角 q q q 实时计算 |
| w i R w_i^R wiR | 方向跟踪权重 | 对关键连杆(如躯干、手臂)分配更高权重,确保姿态保真 |
| ∣ ⋅ ∣ |\cdot| ∣⋅∣ | 旋转距离度量 | 通常采用Frobenius范数或测地线距离(geodesic distance) |
物理意义:确保机器人各身体部位的方向与操作员一致,维持全身姿态的自然性。
(b) 相对位置误差项(第二项)------ 关键创新
∑ j ∈ L P w j P ∥ p j H , r e l ( t ) − p j R , r e l ( q ) ∥ 2 \sum_{j\in\mathcal{L}_P} w_j^P \|p_j^{H,rel}(t) - p_j^{R,rel}(q)\|^2 j∈LP∑wjP∥pjH,rel(t)−pjR,rel(q)∥2
| 符号 | 含义 | 关键设计 |
|---|---|---|
| L P \mathcal{L}_P LP | 需跟踪位置的末端执行器集合 | 通常包括:双手、双脚、头部 |
| p j H , r e l ( t ) p_j^{H,rel}(t) pjH,rel(t) | 相对于人体骨盆(pelvis)的相对位置 | p j H , r e l = p j H , w o r l d − p p e l v i s H , w o r l d \mathbf{p}_j^{H,rel} = \mathbf{p}j^{H,world} - \mathbf{p}{pelvis}^{H,world} pjH,rel=pjH,world−ppelvisH,world |
| p j R , r e l ( q ) p_j^{R,rel}(q) pjR,rel(q) | 机器人第 j j j 个末端执行器相对于机器人根部的位置 | 同理计算相对坐标 |
关键创新:Pelvis-Centric 坐标系
- 问题 :IMU系统存在全局位置漂移 (double integration of acceleration),无法提供可靠的绝对世界坐标 p H , w o r l d \mathbf{p}^{H,world} pH,world
- 解决方案 :采用相对位置而非绝对位置,将参考系原点固定在骨盆(pelvis)上
- 优势 :
- 消除全局漂移影响(漂移对所有IMU同步,相对差分后抵消)
- 保留关键运动学关系(手相对于躯干的位置决定操作可达性)
- 兼容GMR求解器(General Motion Retargeting标准框架)
该公式是GMR(General Motion Retargeting)框架的IMU适配版本:
- 标准GMR:通常使用绝对位置(需要无漂移的全局定位,如光学动捕)
- HumDex改进 :通过将绝对位置 p j H , w o r l d p_j^{H,world} pjH,world 替换为相对位置 p j H , r e l p_j^{H,rel} pjH,rel,使GMR兼容IMU数据
权重 w i R w_i^R wiR 和 w j P w_j^P wjP 体现任务优先级:
python
# 典型权重分配策略(推测)
weights = {
# 方向权重 w_i^R
'torso_orientation': 1.0, # 躯干方向最重要(平衡)
'arm_orientation': 0.8, # 手臂方向影响操作
'leg_orientation': 0.9, # 腿部方向影响 locomotion
# 位置权重 w_j^P
'hand_position': 1.0, # 手部位置对操作至关重要
'foot_position': 0.9, # 脚部位置影响步态稳定性
'head_position': 0.5 # 头部位置相对次要
}- 实时性 :虽然是非线性最小二乘问题,但由于:
- 维度适中(35维)
- 使用上一时刻的解作为热启动(warm start)
- 可采用Gauss-Newton或LM算法
- 实际可在100Hz下实时求解
- 约束处理 :隐式包含关节极限约束(通过 q q q 的定义域)和自碰撞约束(通过权重调节)
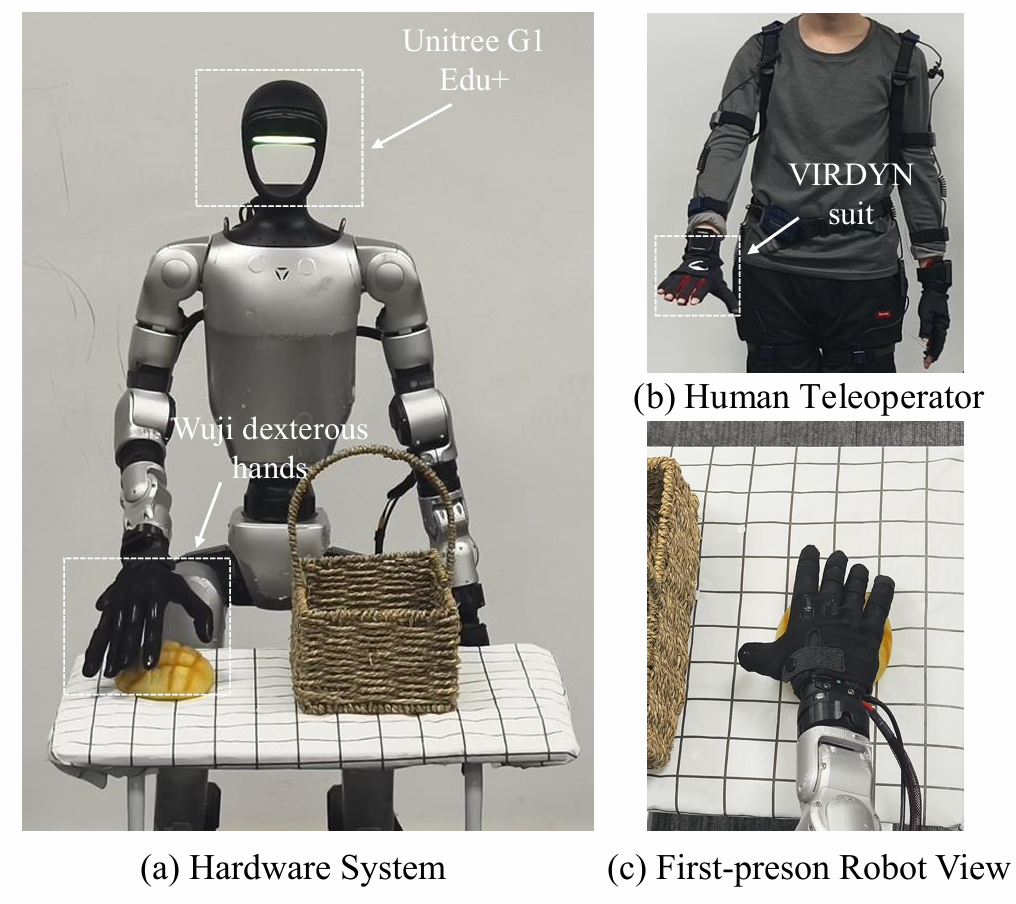
3.4、硬件实现细节
身体追踪系统(双配置)
| 参数 | 商业方案(Vdmocap) | 低成本开源方案(SlimeVR) |
|---|---|---|
| 成本 | ~$数千 | <$200 |
| 节点数 | 15节点 | 6-16节点(灵活配置) |
| 传感器 | 专用IMU阵列 | ICM-45686 6轴IMU(低陀螺仪漂移) |
| 通信 | 标准WiFi/专有协议 | nRF52840 SoC + ESB协议(抗WiFi干扰) |
| 续航 | 数小时 | >20小时 |
| 单节点重量 | - | <20g(3D打印外壳) |
灵巧手追踪系统
- 硬件选项:支持Vdhand和Manus两种商业惯性手套
- 传感器布局:IMU分布于手背(dorsum)和各手指段
- 关键优势 :纯惯性方案 确保在以下场景仍能准确捕捉:
- 手部被物体严重遮挡(如握持扫描器时)
- 手部位于机器人身体后方(视觉盲区)
四、基于学习的灵巧手重定向
这部分连接 人类手部操作 和 机器人灵巧手执行 的关键桥梁 ,解决了 「如何将IMU捕捉的人类指尖位置,实时映射为机器人20DoF灵巧手的可执行关节角」 的问题。
核心设计是:轻量化MLP回归模型 ,替代传统的优化式重定向 ,实现无手动调参、实时推理、平滑运动的手部控制,是实现灵巧操作的核心模块。
4.1、核心问题:人类-机器人手部的映射抽象
将手重定向抽象为端到端的回归问题
核心目标:从人类五指尖的3D位置,直接预测机器人20DoF灵巧手的关节角 ,且满足实时性 (遥操作要求)、无手动调参 (工程实用性)、运动平滑(避免机器人关节抖动)。
- 关键预处理:将IMU捕捉的指尖3D位置转换为手套腕部坐标系,而非世界坐标系,进一步避免IMU的全局漂移影响,提升映射精度。
4.2、核心设计1:端到端的回归模型定义
(1)输入与输出(极简表征,降低复杂度)
- 输入 p t ∈ R 15 p_t \in \mathbb{R}^{15} pt∈R15:人类五指尖的3D位置拼接(5指尖×3个维度=15维),无复杂的手部姿态特征提取,感知层极简,降低计算成本;
- 输出 q t ∈ R 20 q_t \in \mathbb{R}^{20} qt∈R20:机器人Wuji灵巧手的20DoF关节角(4DoF/手指×5手指=20维),直接作为低阶控制器的 q h a n d q_{hand} qhand输入,无需中间转换;
- 映射函数:学习一个重定向函数 f θ : R 15 → R 20 f_\theta: \mathbb{R}^{15} \to \mathbb{R}^{20} fθ:R15→R20, θ \theta θ为模型参数,实现端到端的输入-输出映射。
(2)模型结构:轻量化MLP(多层感知机)
采用小型MLP 作为模型骨干,而非复杂的深度学习网络,核心原因是遥操作的实时性要求 (需恒时推理)和部署的轻量化要求,MLP的设计遵循**"极简、高效"**原则,无复杂的注意力/卷积模块,保证推理速度。
手指模块化MLP:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
class FingerSubnet(nn.Module):
"""
单手指子网络 (Finger-wise Modular Design)
输入: 单个指尖的3D位置 (3,)
输出: 该手指的4个关节角度 (4,)
"""
def __init__(self):
super(FingerSubnet, self).__init__()
self.network = nn.Sequential(
nn.Linear(3, 128), # Input(3) → FC(128)
nn.LeakyReLU(), # LeakyReLU
nn.BatchNorm1d(128), # BN
nn.Linear(128, 128), # FC(128)
nn.LeakyReLU(), # LeakyReLU
nn.BatchNorm1d(128), # BN
nn.Linear(128, 4), # FC(4)
nn.Tanh() # Tanh 输出范围 [-1, 1]
)
def forward(self, x):
return self.network(x)
class HandRetargetingNetwork(nn.Module):
"""
完整的手部重定向网络
输入: 5个指尖的3D位置 (15,) [拇指, 食指, 中指, 无名指, 小指]
输出: 20个手部关节角度 (20,) [每个手指4个DoF]
"""
def __init__(self):
super(HandRetargetingNetwork, self).__init__()
# 为5个手指分别创建子网络
self.thumb_net = FingerSubnet() # 拇指
self.index_net = FingerSubnet() # 食指
self.middle_net = FingerSubnet() # 中指
self.ring_net = FingerSubnet() # 无名指
self.pinky_net = FingerSubnet() # 小指
def forward(self, fingertip_positions):
"""
Args:
fingertip_positions: (batch_size, 15)
- 每3维对应一个指尖的[x, y, z]
- 顺序: [thumb(0:3), index(3:6), middle(6:9), ring(9:12), pinky(12:15)]
Returns:
joint_angles: (batch_size, 20)
- 顺序: [thumb(0:4), index(4:8), middle(8:12), ring(12:16), pinky(16:20)]
"""
# 分离5个指尖的位置 (每个 tensor shape: [batch_size, 3])
thumb_pos = fingertip_positions[:, 0:3]
index_pos = fingertip_positions[:, 3:6]
middle_pos = fingertip_positions[:, 6:9]
ring_pos = fingertip_positions[:, 9:12]
pinky_pos = fingertip_positions[:, 12:15]
# 分别通过对应的子网络 (每个输出 shape: [batch_size, 4])
thumb_joints = self.thumb_net(thumb_pos)
index_joints = self.index_net(index_pos)
middle_joints = self.middle_net(middle_pos)
ring_joints = self.ring_net(ring_pos)
pinky_joints = self.pinky_net(pinky_pos)
# 拼接所有手指的关节角度 → (batch_size, 20)
joint_angles = torch.cat([
thumb_joints, index_joints, middle_joints, ring_joints, pinky_joints
], dim=1)
return joint_angles(3)训练目标与损失函数
将问题定义为监督回归问题 ,损失函数为均方误差(MSE) ,这是最经典的回归损失,保证预测的关节角与真实标签的误差最小,训练目标公式为:
m i n θ E ( p , q ) ∼ D ∣ f θ ( p ) − q ∣ 2 2 min {\theta} \mathbb{E}{(p, q) \sim \mathcal{D}}\left\|f_\\theta(p)-q\|_{2}\^{2}\\right minθE(p,q)∼D∣fθ(p)−q∣22
- 符号含义: D \mathcal{D} D为配对的训练数据集 (人类指尖位置 p p p + 机器人关节角 q q q); E \mathbb{E} E为数据集上的期望; ∣ ⋅ ∣ 2 2 |\cdot|_2^2 ∣⋅∣22为L2范数的平方(MSE核心)。
4.3、核心设计2:训练数据集 D \mathcal{D} D的构建(离线优化+少量数据)
训练数据采用离线优化式重定向生成,解决了**"如何获取高质量的配对标签"**的问题,核心步骤:
- 人类操作者佩戴惯性手套,完成多样化的手部姿态动作(包括任务相关姿态+经典灵巧姿态,如捏、抓、扣动等);
- 对每一个人类指尖位置 p p p,通过传统的优化式重定向算法 (约束逆运动学IK),求解机器人灵巧手的最优关节角 q q q(保证运动学可执行性);
- 收集上述配对数据,形成训练集 D \mathcal{D} D,仅需20k帧左右的配对数据 ,对应不到20分钟的录制时间,数据采集成本极低。
说明:
在HumDex论文的灵巧手重定向 场景中,约束逆运动学(IK)+非线性最小二乘 的离线求解,本质是为了从人类指尖3D位置这个「目标」,算出机器人灵巧手可执行的20DoF关节角,同时给机器人关节加「运动规则限制」,且这个计算过程只在训练MLP前做一次(离线),而非遥操作实时执行。
补充说明1:先明确两个核心概念的关系
论文里的约束逆运动学(IK)和非线性最小二乘 ,不是两个独立的方法,而是**「问题」和「求解这个问题的数学手段」**的关系:
- 逆运动学(IK) :是灵巧手重定向的核心问题
机器人领域分「正运动学」和「逆运动学」,对应灵巧手的逻辑极简单:- 正运动学:知道机器人灵巧手的关节角 (比如食指第1关节弯30°、第2关节弯60°),能通过数学模型算出指尖的3D位置(这是机器人的"本能",硬件自带运动学模型);
- 逆运动学:反过来,已知想要的指尖3D位置 (论文中是人类的五指尖位置 p t p_t pt),反推机器人需要的关节角 (论文中是真值 q t q_t qt)------这就是重定向的核心需求,也是逆运动学(IK)问题。
- 非线性最小二乘 :是求解灵巧手IK问题 的常用数学方法
灵巧手是多关节、非线性的复杂机械结构 (20DoF,5指各4DoF,手指间的运动相互关联),其逆运动学没有解析解 (不能用简单公式直接算),因此需要用数值优化方法 求解,非线性最小二乘就是这类方法中最成熟的一种(核心是"找一个最优解,让实际结果和目标结果的误差最小")。 - 「约束」 :给IK求解加机器人的物理规则限制
如果无约束求解IK,算出的关节角可能让机器人手"卡死"(比如关节转超物理极限)、"穿模"(手指互相撞),因此需要加约束条件 ,让求解出的关节角满足机器人的运动学可行性 ------这就是约束逆运动学。
补充说明2:灵巧手重定向中,「约束IK+非线性最小二乘」的离线求解步骤
贴合论文场景:输入是人类五指尖3D位置 p t p_t pt(15维),输出是WUJI 20DoF灵巧手关节角 q t q_t qt(20维),全程离线执行,只为生成MLP的训练真值,步骤共4步,每一步都通俗落地,无复杂公式:
步骤1:建立WUJI灵巧手的正运动学模型(基础前提)
首先要明确机器人灵巧手的"运动规则":给每个关节(20个)定义转动范围 (比如拇指基关节只能转090°,食指末关节只能转045°),并建立关节角→指尖3D位置 的数学映射模型(这是机器人厂商提供的基础模型,论文直接用)。
→ 有了这个模型,才能通过"逆推"求解IK问题。
步骤2:定义优化目标(用非线性最小二乘定"求解方向")
我们的核心需求是:让机器人灵巧手的指尖3D位置,尽量和人类的指尖3D位置重合 。
用非线性最小二乘的思路,就是把这个需求转化为**"误差最小化"的数学目标**:
最小化: E = ∑ i = 1 5 ∥ P 机器人 i ( q ) − P 人类 i ∥ 2 \text{最小化:} \quad E = \sum_{i=1}^5 \| P_{机器人i}(q) - P_{人类i} \|^2 最小化:E=i=1∑5∥P机器人i(q)−P人类i∥2
其中:
- P 人类 i P_{人类i} P人类i:论文中采集的人类第i根手指的指尖3D位置 (固定输入 p t p_t pt的一部分);
- P 机器人 i ( q ) P_{机器人i}(q) P机器人i(q):通过正运动学模型 ,由机器人关节角 q q q(20维,待求解)算出的机器人第i根手指的指尖3D位置;
- ∥ ⋅ ∥ 2 \| \cdot \|^2 ∥⋅∥2:计算位置误差的平方(最小二乘的核心,让误差更易优化);
- 求和:对5根手指的位置误差求和,保证所有指尖都尽量贴合人类。
→ 这个目标的意思是:找一组关节角q,让机器人5个指尖和人类的5个指尖的位置误差总和最小。
步骤3:加入运动学约束条件(让解"可执行",不卡死)
给上述优化目标加机器人的物理限制,排除掉那些机器人做不到的关节角,论文中主要加两类约束(贴合机器人实操):
- 关节限位约束 :每个关节的转动角度必须在硬件物理极限内(比如某关节最大只能转60°,求解结果就不能是70°);
- 时间一致性约束 (论文提及):相邻帧的关节角变化不能太大(比如上一帧关节角是30°,这一帧不能突然变到60°),避免机器人手出现剧烈抖动,保证动作平滑。
→ 加约束后,求解出的关节角 q t q_t qt才是机器人实际能执行的真值。
步骤4:离线数值求解,得到最优关节角 q t q_t qt
用非线性最小二乘优化算法 (比如Levenberg-Marquardt,机器人领域最常用),在步骤3的约束范围内 ,求解满足步骤2误差最小目标 的20DoF关节角q ------这个解就是论文中MLP训练所需的真值标签 q t q_t qt。
五、两阶段模仿学习
提出 使用人类视频数据,提升机器人策略泛化能力的两阶段训练框架。
5.1、思路流程

-
Stage 1(预训练) :仅在人类演示数据 上训练(约700条),通过重定向获得关节目标,利用动作历史近似本体状态。此阶段策略学习任务无关的泛化特征(如"物体→抓取点"映射、不同背景/位置的鲁棒性)。
-
Stage 2(微调) :仅在真实机器人遥操作数据上训练(约50条),冻结或微调策略,使动作输出适配G1机器人的具体动力学特性(关节摩擦、执行器延迟等)。
5.2、关键技术特点
1. 状态近似机制(解决缺失的本体感知)
- 问题 :人类操作时没有真实机器人,无法获取机器人本体状态 s t s_t st(关节位置、力矩等)。
- 解法 :利用动作-状态时间连续性 ,用前一时刻重定向动作 a t − 1 a_{t-1} at−1 近似当前状态 s t s_t st(验证表明30-100Hz控制频率下误差极小)。
2. 顺序训练策略(避免梯度冲突)
- 对比 :直接混合人类与机器人数据(Mix Baseline)成功率 0%,因相同视觉输入对应两种不同动作分布(人类肢体 vs 机器人关节),导致梯度信号冲突。
- 优势 :分阶段训练先固定视觉编码器 (学习泛化特征),再调整动作头(适配本体),有效解耦冲突。
3. 数据效率与泛化增益
| 指标 | Robot Only | HumDex(两阶段) | 提升 |
|---|---|---|---|
| 未见位置 | 40% | 70% | +75% |
| 未见物体 | 33% | 67% | +100% |
| 未见背景 | 30% | 83% | +178% |
- 成本优势 :仅需 50条机器人数据 (传统方法需数百条),通过 700条低成本人类数据(无需真实机器人,野外采集)实现强泛化。
4. 与现有方法的差异
- 不同于EgoMimic 7:无需硬件对齐(人类戴数据手套模拟机器人末端执行器),HumDex直接利用重定向结果。
- 不同于DexCap 20:无需人工在环修正,完全自动化训练流程。
该框架证明:无需昂贵的外部对齐或修正,仅通过顺序训练即可有效利用人类数据多样性。
人类数据提供视觉不变性 (忽略背景变化)和高层运动先验 (抓取策略),机器人数据提供精确执行能力(本体适应),两者通过分阶段结合实现"低成本+高泛化"的平衡。
5.3、补充说明:ACT
"ACT策略初始化 "指的是:在 Stage 1(人类数据预训练)阶段,先让 ACT 神经网络"学会"基本的视觉感知能力和运动规律,得到一个较好的初始权重;然后在 Stage 2(机器人数据微调)阶段,基于这个预训练好的权重继续训练,而不是从零开始。
1. ACT 是什么?
ACT(Action Chunking Transformer)是策略网络的架构,包含两个核心组件:
- 视觉编码器 :ResNet-18,把摄像头图像 I t I_t It 压缩成视觉特征向量
- Transformer 策略头 :根据视觉特征 + 本体状态 s t s_t st,预测未来一段动作序列 (Action Chunk) a t : t + h a_{t:t+h} at:t+h
2. "初始化"具体指什么?
在深度学习里,神经网络训练前需要先初始化权重(通常是随机初始化)。这里的"ACT策略初始化"特指:
| 阶段 | 权重来源 | 训练数据 | 学到的能力 |
|---|---|---|---|
| Stage 1 | 随机初始化 | 人类数据 (700条) | 视觉泛化能力 :忽略背景变化、识别不同位置/形状的物体 运动先验:"看到物体→伸手抓取"的粗粒度映射 |
| Stage 2 | 继承 Stage 1 的权重 (即"初始化") | 机器人数据 (50条) | 精调动作输出:适应 G1 机器人的关节摩擦、延迟等动力学特性 |
关键代码逻辑示意:
python
# Stage 1: 在人类数据上预训练
policy = ACT() # 随机初始化权重
policy.train(human_data, epochs=1000)
save_weights(policy, "human_pretrained.ckpt") # 保存学到的泛化特征
# Stage 2: 在机器人数据上微调
policy = ACT()
load_weights(policy, "human_pretrained.ckpt") # ← 这里!用Stage 1的权重初始化
policy.train(robot_data, epochs=4000) # 在此基础上继续训练相关文章推荐:
《VLA 系列》分析 Ψ₀ | Psi0 | 通用人形机器人 | 移动 + 操作
《VLA 系列》复现 Ψ₀ | Psi0 | 通用人形机器人 | 移动操作模型
《VLA 系列》Humanoid Everyday | 人形机器人 | 开源数据集
《VLA 系列》π0.5 | 流匹配 | 分层推理 | VLA
《VLA 系列》复现 π0.5 | 数据采集 | 模型微调 | DROID
《VLA 系列》复现 π0.5、π0-FAST、π0 | 环境搭建 | 模型推理
《VLA 系列》π0 | 流匹配 | 开山之作 | VLA
【VLA 系列】 πRL | 在线强化学习 | 流匹配 | VLA
《VLA 系列》SimpleVLA-RL | 端到端 在线强化学习 | VLA
分享完成~