内容比较多,水平有限,有问题请评论
一、什么是CPU绑核
CPU 绑核 是将 Pod 中的容器绑定到特定的 CPU 核心上执行,避免 CPU 调度切换带来的性能开销,适用于延迟敏感、高性能计算场景。尤其是游戏服务器。
具体如下:
| 收益 | 说明 | 典型提升 |
|---|---|---|
| 减少上下文切换 | 避免进程在 CPU 间迁移 | 降低 20-40% 开销 |
| 提高缓存命中率 | L1/L2/L3 缓存持续有效 | 提升 30-50% 性能 |
| 降低延迟抖动 | 消除调度不确定性 | P99 延迟降低 50% |
| NUMA 本地访问 | CPU 和内存同节点 | 内存延迟降低 50% |
| 资源隔离 | 避免 Pod 间 CPU 竞争 | 性能更稳定 |
绑核收益:
- 减少上下文切换
- 提高 CPU 缓存命中率
- 降低延迟抖动
- 提升性能稳定性
二、K8S 绑核核心组件
1. 组件架构
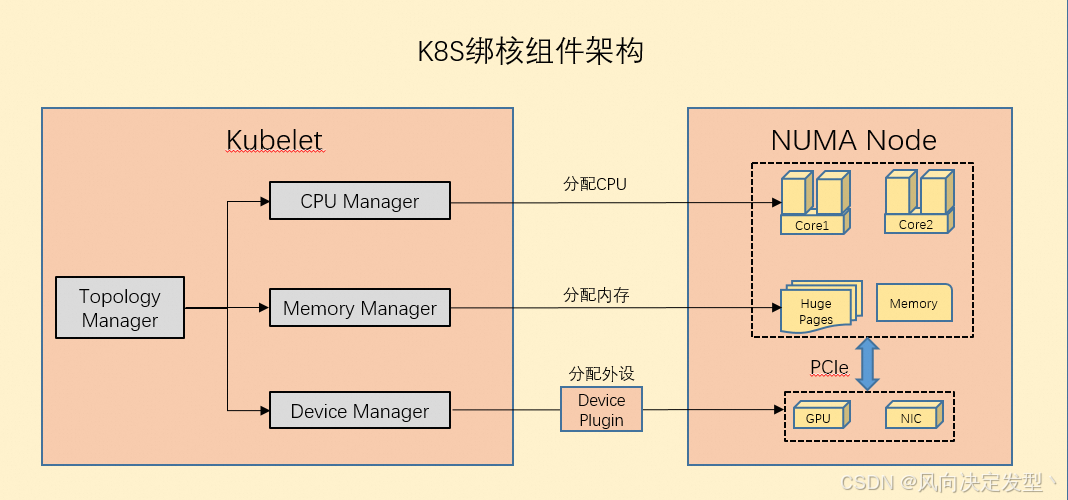
图 1
CPUManager是独立运行的组件,在kubelet配置CPU Manager+QoS为guaranteed的pod+整数CPU请求,即可实现绑核。架构图包含了NUMA架构的拓扑感知场景,NUMA及TopologyManager会作为拓展知识点在下文介绍。
2. 组件功能
| 组件 | 作用 | 必要性 | 配置参数 |
|---|---|---|---|
| CPU Manager | 分配独占 CPU 核心 | 必需 | cpuManagerPolicy |
| Memory Manager | 分配内存 | 可选 | memoryManagerPolicy |
| Topology Manager | NUMA 拓扑感知 | 推荐 | topologyManagerPolicy |
| Device Plugin | 特殊设备支持 | 可选 | - |
三、NUMA架构带来的挑战
在学习资源分配机制的时候这一块内容绝对是重中之重。这里简单介绍一下NUMA架构,关于NUMA的内容可以在网上详细学习。
推荐一篇NUMA的文档: https://developer.aliyun.com/article/1282880
1.什么是NUMA
NUMA:非同一内存访问是一种用于多处理器的电脑内存体设计,内存访问时间取决于处理器的内存位置。 在NUMA下,处理器访问它自己的本地存储器的速度比非本地存储器(存储器的地方到另一个处理器之间共享的处理器或存储器)快一些。
多处理器也被称为多路服务器、多U服务器
2.NUMA的核心原理
NUMA 节点的内存大小由物理硬件决定(内存条插在哪个 CPU 对应的插槽)。不能通过软件直接"设置"大小,但可以通过均衡插内存条、BIOS 配置、numactl 绑定、cgroups 限制等方式影响内存的使用和分配。最佳实践是均衡配置各 NUMA 节点的内存容量,减少远程访问。
NUMA架构的关键术语:
- CPU Socket:对应主板上的CPU插槽,即一个单独的物理CPU芯片。
- CPU Core:指的是CPU Socket中的一个核心(运算单元)或者Pysical Processor,即物理CPU。我们所说的8核、16核CPU指的是一个CPU Socket中封装8、16个不同的独立的CPU运算单元。
- Logical Processor:通过Hyper-Threading超线程技术将一个CPU Core变成两个Core,这是逻辑上的概念,所以也称为逻辑CPU。
- NUMA Node:可以理解为CPU Core的分组,包括一个或者多个CPU Core及对应的内存和I/O独立区块,有服务器主板上的一组线路和相关芯片、CPU、内存等硬件组成
3.主板示意图
既然是由硬件决定,那我们找一个双u服务器主板来看看

图 2
上图中能看到两个银色边框的位置就是2个CPU Socket插槽,分别对应4个内存条的卡槽,默认情况下这个系统应该是2个numa node
这里可以直观理解:"内存访问取决于处理器的内存位置"
4.NUMA架构示意图
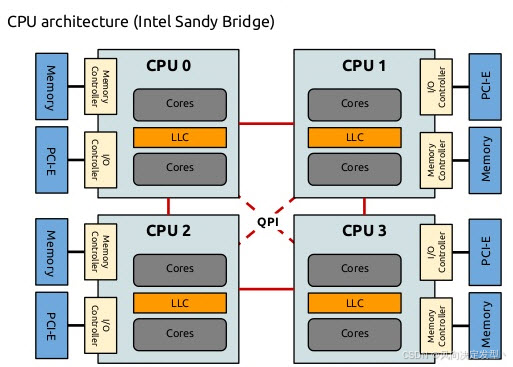
图 3
在系统里面查看(测试机,环境有限,这里主要介绍几个命令)
bash
[root@test ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2 # 逻辑CPU
On-line CPU(s) list: 0,1
Thread(s) per core: 2 # 超线程技术
Core(s) per socket: 1 # socket有几个物理核心
Socket(s): 1 # 1个socket对应1个CPU卡槽
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum
Stepping: 4
CPU MHz: 2500.002
BogoMIPS: 5000.00
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 33792K
NUMA node0 CPU(s): 0,1
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 arat
[root@test ~]# numactl -H # 这里也能看出逻辑CPU对应的内存大小
available: 1 nodes (0)
node 0 cpus: 0 1 # NUMA node0 有几个逻辑cpu
node 0 size: 1966 MB # NUMA Node0的内存大小
node 0 free: 81 MB
node distances:
node 0
0: 10
[root@test ~]# numastat # 这个命令可以查看跨numaNode访问的情况
node0
numa_hit 767343825
numa_miss 0
numa_foreign 0
interleave_hit 12721
local_node 767343825
other_node 0运行在NUMA架构中的某个进程如果被分配了位于不同NUMA Node中的CPU和内存,则可能会导致性能下降。所以Kubernetes针对NUMA架构的特性,定制专门的资源分配策略以发挥NUMA架构的优势。
四、CPU Manager 详解
Kubernetesv1.26版本中成为stable版本
1. 策略类型
| 策略 | 说明 | 适用场景 |
|---|---|---|
| none | 默认策略,无绑核 | 通用场景 |
| static | 独占 CPU 绑核 | 高性能场景 |
static策略下的独占策略:
- full-fcpus-only:必须为一个pod分配完整的CPU Core(物理核心)
- distribute-cpus-across-numa:跨NUMA Node均匀分配CPU
- align-by-socket:将pod所使用的CPU扩展到整个CPU Socket上
2. 工作原理
CPU Manager 工作流程
① Kubelet 启动时
└─► 根据 reservedSystemCPUs 预留系统 CPU
└─► 剩余 CPU 加入可分配池
② Pod 创建时
└─► 检查 limits.cpu 是否为整数
└─► 是:从可分配池分配独占 CPU
└─► 否:使用共享 CPU(CFS 调度)
③ 容器启动时
└─► 写入 cgroup cpuset 文件
└─► 进程只能运行在绑定的 CPU 上
④ Pod 删除时
└─► 释放 CPU 回可分配池
3. 配置示例
bash
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
# 启用 CPU Manager
cpuManagerPolicy: "static"
cpuManagerReconcilePeriod: "10s"
cpuManagerPolicyOptions:
full-pcups-only: "true"
distribute-cpus-across-numa: "false" # 根据实际情况开启
# 预留系统 CPU(防止系统进程被抢占)
reservedSystemCPUs: "0-3"
# 可选:预留特定 CPU 给系统
# reservedCPUs: "0-3"启动参数方式:
bash
kubelet \
--cpu-manager-policy=static \
--cpu-manager-reconcile-period=10s \
--reserved-cpus=0-34.使用限制
- Pod QoS级别必须是guaranteed级别,也就是spec.containers.resources.limits.cpu=spec.containers.resources.requests.cpu,并且是不小于1的整数
五、Memory Manager 详解
Kubernetesv1.29版本中成为stable版本
1. 策略类型
| 策略 | 说明 | 适用场景 |
|---|---|---|
| none | 默认策略,不影响内存分配 | 通用场景 |
| static | 分配内存和HugePage | 高性能场景 |
2. 配置示例
bash
memoryManagerPolicy: Static
reservedMemory:
numaNode: 0
limits:
memory: 2148Mi3.使用限制
- Pod QoS级别必须是guaranteed级别,也就是spec.containers.resources.limits.memory=spec.containers.resources.requests.memory
- 仅能用于linux系统
六、Device Manager详解
Kubernetesv1.26版本中成为stable版本
Device Manager 是 Kubelet 中的设备管理组件,负责管理节点上的特殊硬件设备(如 GPU、FPGA、RDMA 网卡、TPU 等),并为 Pod 提供设备分配和隔离能力。
Device Maneger没有策略类型,主要是注册本地设备,并由kubelet发布到API Server。这就是注册和上报的过程。接下来就可以直接给pod分配了
配置示例
以nvidia GPU为例,以下内容来自官方文档:
bash
# Daemonset类型部署 Device Plugin
kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.1/deployments/static/nvidia-device-plugin.yml
# 查看节点设备资源
kubectl describe node <node-name> | grep -A 5 "Allocatable"
# 输出示例
Allocatable:
cpu: 16
memory: 32Gi
nvidia.com/gpu: 4 # GPU 资源已注册
# Pod 配置
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda12.5.0
resources:
requests:
nvidia.com/gpu: 1 # 请求设备
limits:
nvidia.com/gpu: 1 # 限制设备
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
$ kubectl logs gpu-pod
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
DoneNVIDIA插件官方文档:https://github.com/NVIDIA/k8s-device-plugin
七、Topology Manager 详解
1. 为什么需要 Topology Manager?
上文我们提到运行在NUMA架构中的某个进程如果被分配了位于不同NUMA Node中的CPU和内存,则可能会导致性能下降。
CPU Manager、Memory Manager及Device Manager都是独立运行的,在Static策略下都作为Topology Hint Provider的角色,为Topology Manager提供资源分配的NUMA拓扑提示,Topology Manager根据各Provider返回的TopologyHint来判断目标pod所需的各种资源是否满足。之后各Provider按照TopologyManager计算的最有TopologyHint分配资源。如图1所示
**简单一句话:**在NUMA架构中,Topology Manager综合各TopologyHint选择出一个合适NUMA Node。
2. 策略类型
| 策略 | 说明 | 调度行为 | 适用场景 |
|---|---|---|---|
| none | 不感知拓扑 | 无约束 | 默认 |
| best-effort | 尽力满足 | 不满足也调度 | 一般性能 |
| restricted | 必须满足 | 不满足则拒绝 | 高性能 |
| single-numa-node | 单 NUMA 节点 | 严格单节点 | 极致性能 |
3. 配置示例
bash
# Kubelet 配置
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
topologyManagerPolicy: "restricted"
# 默认是container,现在容器技术多用于微服务架构,所以也可根据实际情况改为pod
topologyManagerScope: "container" 推荐一篇关于Topology的文章:https://developer.aliyun.com/article/784148
4. 使用限制
- Topology Manager当前所能处理的最大NUMA Node数量是8
八、完整配置步骤(环境有限,步骤来自AI,可供参考)
1. 查看节点 CPU 拓扑
bash
# 查看 CPU 拓扑
lscpu
# 查看 NUMA 节点
numactl --hardware
# 输出示例
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7
node 0 size: 32000 MB
node 1 cpus: 8 9 10 11 12 13 14 15
node 1 size: 32000 MB2. 配置 Kubelet
假设这里是node-1节点
bash
# 备份原配置
cp /var/lib/kubelet/config.yaml /var/lib/kubelet/config.yaml.bak
# 编辑配置
vim /var/lib/kubelet/config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
# CPU Manager
cpuManagerPolicy: "static"
cpuManagerReconcilePeriod: "10s"
reservedSystemCPUs: "0-3"
cpuManagerPolicyOptions:
full-pcups-only: "true"
distribute-cpus-across-numa: "false" # 根据实际情况开启
# Memory Manager
memoryManagerPolicy: Static
reservedMemory:
numaNode: 0
limits:
memory: 2148Mi
# Topology Manager
topologyManagerPolicy: "restricted"
topologyManagerScope: "container"
# 其他必要配置
cgroupDriver: "systemd"
containerRuntimeEndpoint: "unix:///var/run/containerd/containerd.sock"3. 重启 Kubelet
bash
# 重载 systemd
systemctl daemon-reload
# 重启 Kubelet
systemctl restart kubelet
# 验证状态
systemctl status kubelet
# 查看 CPU Manager 状态
cat /var/lib/kubelet/cpu_manager_state4. 配置 Pod
bash
apiVersion: v1
kind: Pod
metadata:
name: cpu-pinned-pod
namespace: high-performance
annotations:
# Topology Manager 策略注解
topologymanager.kubernetes.io/policy: "restricted"
spec:
# 可选:指定节点
nodeName: node-1
containers:
- name: app
image: myapp:latest
# 关键:CPU 必须是整数
resources:
requests:
cpu: "4" # 必须是整数
memory: "8Gi"
limits:
cpu: "4" # 必须等于 requests
memory: "8Gi"
# 可选:CPU 亲和性
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cpu-pinning
operator: In
values:
- "enabled"5. 验证绑核
bash
# 1. 查看 Pod 调度
kubectl get pod cpu-pinned-pod -o wide
# 2. 查看 CPU 绑定
kubectl exec cpu-pinned-pod -- cat /sys/fs/cgroup/cpuset/cpuset.cpus
# 输出:4-7 (表示绑定到 CPU 4,5,6,7)
# 3. 查看进程 CPU 亲和性
kubectl exec cpu-pinned-pod -- taskset -cp $$
# 输出:4-7
# 4. 查看 NUMA 绑定
kubectl exec cpu-pinned-pod -- numactl --hardware
# 5. 查看内存分布
kubectl exec cpu-pinned-pod -- cat /proc/self/numa_maps
# 6. 查看 Kubelet 状态
cat /var/lib/kubelet/cpu_manager_state常用命令
| 检查项 | 命令 |
|---|---|
| Kubelet 配置 | `ps -ef |
| CPU Manager 状态 | cat /var/lib/kubelet/cpu_manager_state |
| Pod CPU 绑定 | kubectl exec <pod> -- cat /sys/fs/cgroup/cpuset/cpuset.cpus |
| 进程 CPU 亲和性 | kubectl exec <pod> -- taskset -cp $$ |
| NUMA 拓扑 | numactl --hardware、numactl --show |
| NUMA 内存分布 | kubectl exec <pod> -- cat /proc/self/numa_maps |
| 远程访问统计 | numastat |