核心技术栈:Obsidian + opencode/claudecode + Obsidian Web Clip + notebookLM
核心理念:让 LLM 一次性消化信息,然后永远记住、维护、更新这个结构化知识库。
蹭热点:把旧知识库迁进结构化 Wiki
主要是 Karpathy 的知识库概念太火了,我想蹭蹭。原本我就有一套知识库,可以迁移过去试试。
以前维护知识库成本太高:一个人除了写文档,还得写索引;每次提问都得重新搜文档,知识难以积累,知识库反而成了负担。

迁移之后最大的体会就是确实减负了。以前需要我自己复制粘贴,AI 只能帮我总结、提炼元信息;文档之间的关联也不强。每次向知识库提问,往往是针对单个/多个文档先检索,再拼出答案。用过类似 ima、notebookLM 的朋友应该也有同感。
这套知识库的结构简化了管理,也让维护文章之间的关联关系更方便。也可以基于它给出的方案做调整。

方案:构建由 LLM 维护的结构化 Wiki
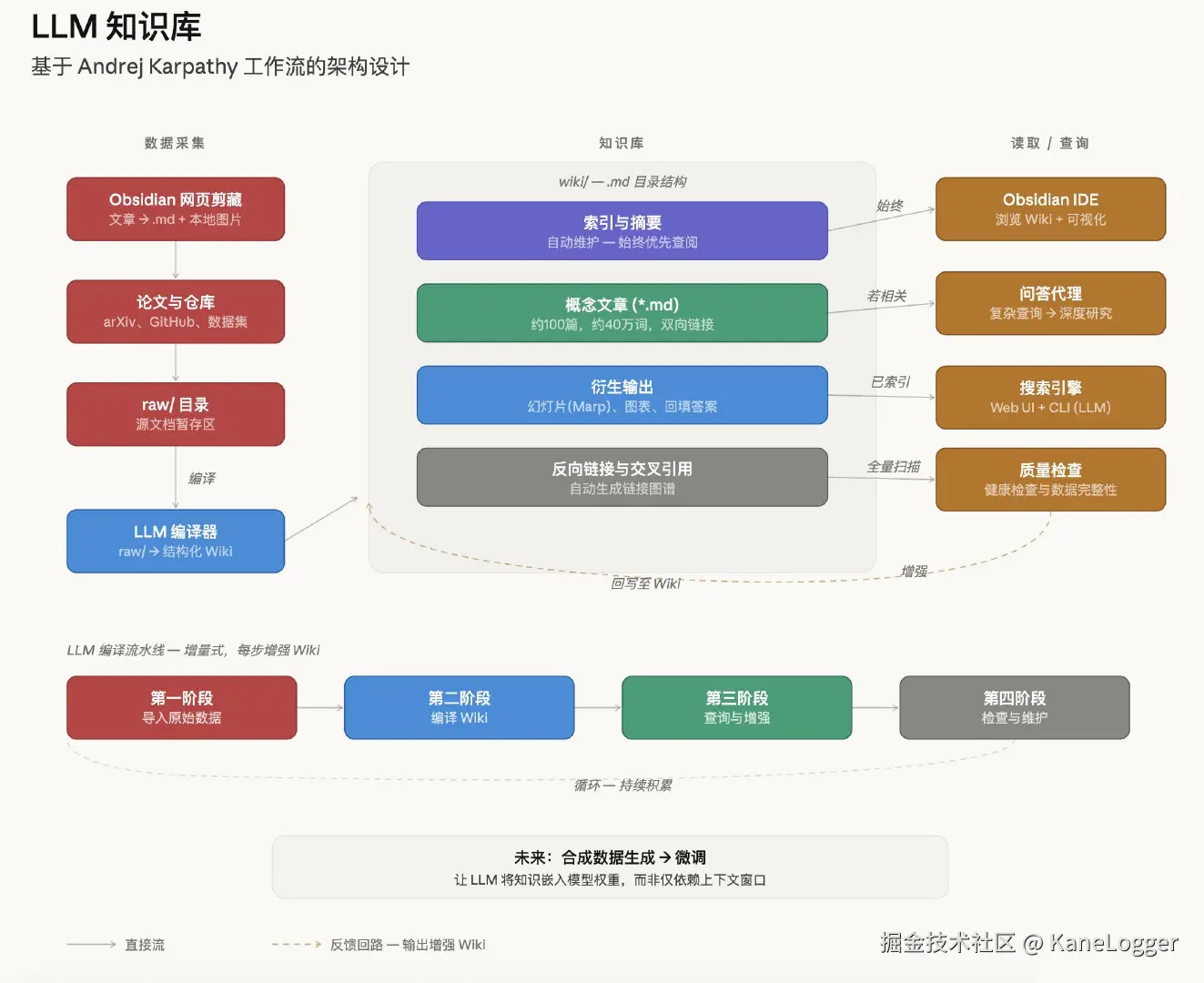
通过这个方案,每次新增一篇文档,AI 就会把文档信息写入 Wiki 的知识网络中。
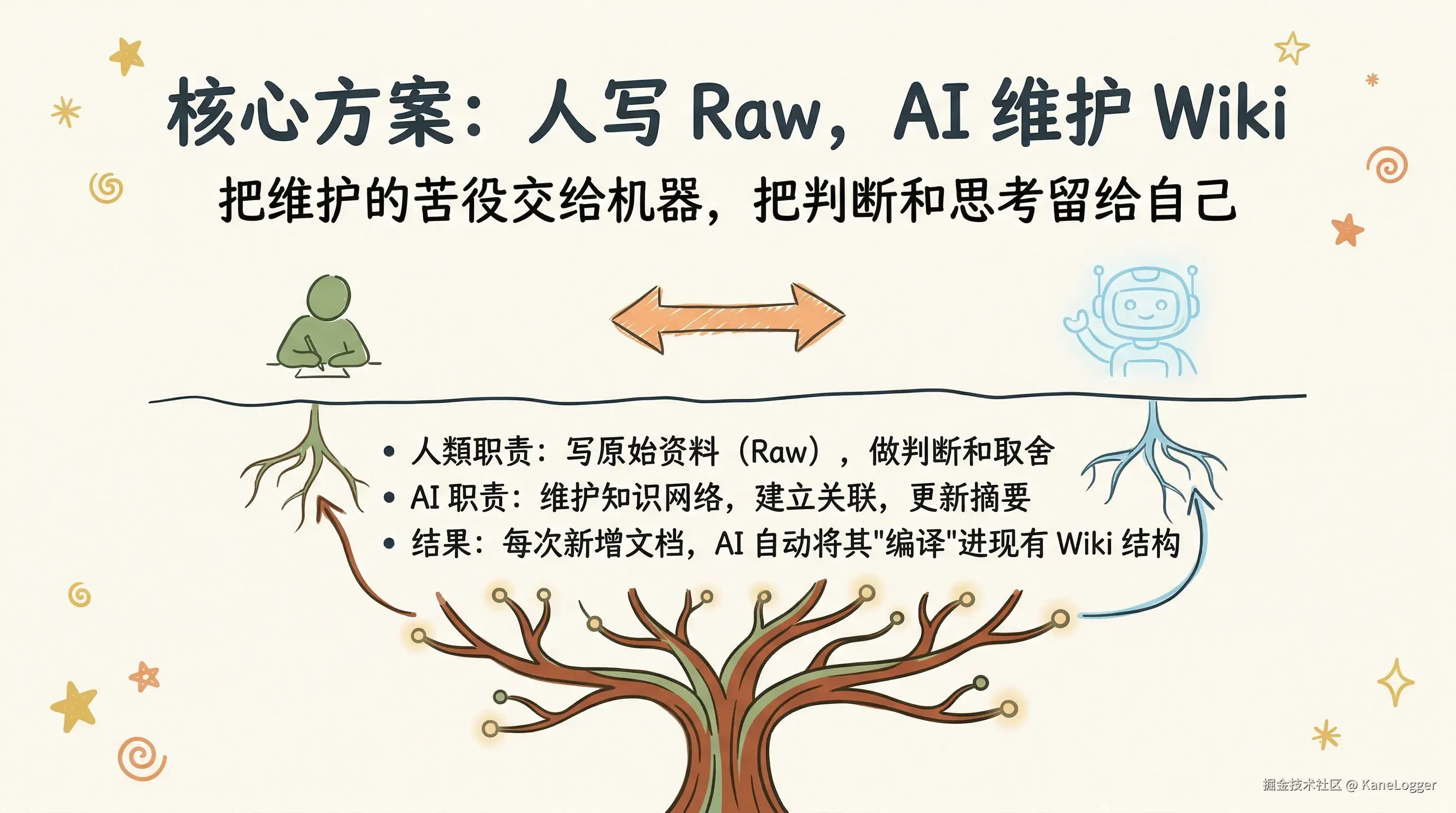
人负责写 Raw,AI 负责维护 Wiki。
通过三层结构实现:
- Raw sources (raw/目录) 原始资料
- The wiki (wiki/目录)
- The schema (AGENTS.md) 用于详细规定 wiki 的结构、formatter、filename normalization、ingest/query/lint 规则等。
- 核心操作:Ingest, Query, Lint

核心工作流
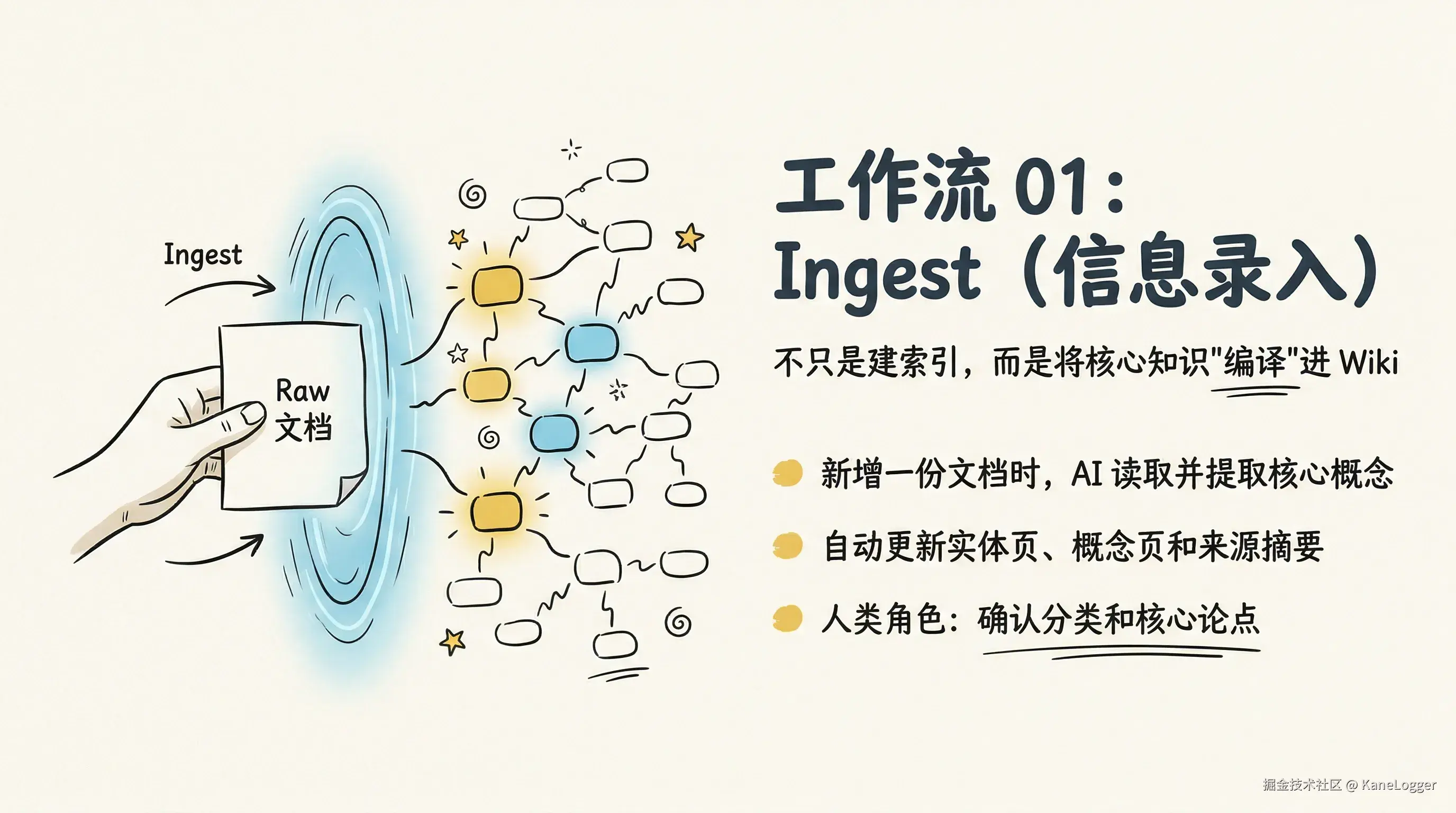
- 信息录入(Ingest):新增一份文档时,LLM 不仅仅是建立索引,而是将其核心知识"编译"进现有的 Wiki 结构中。
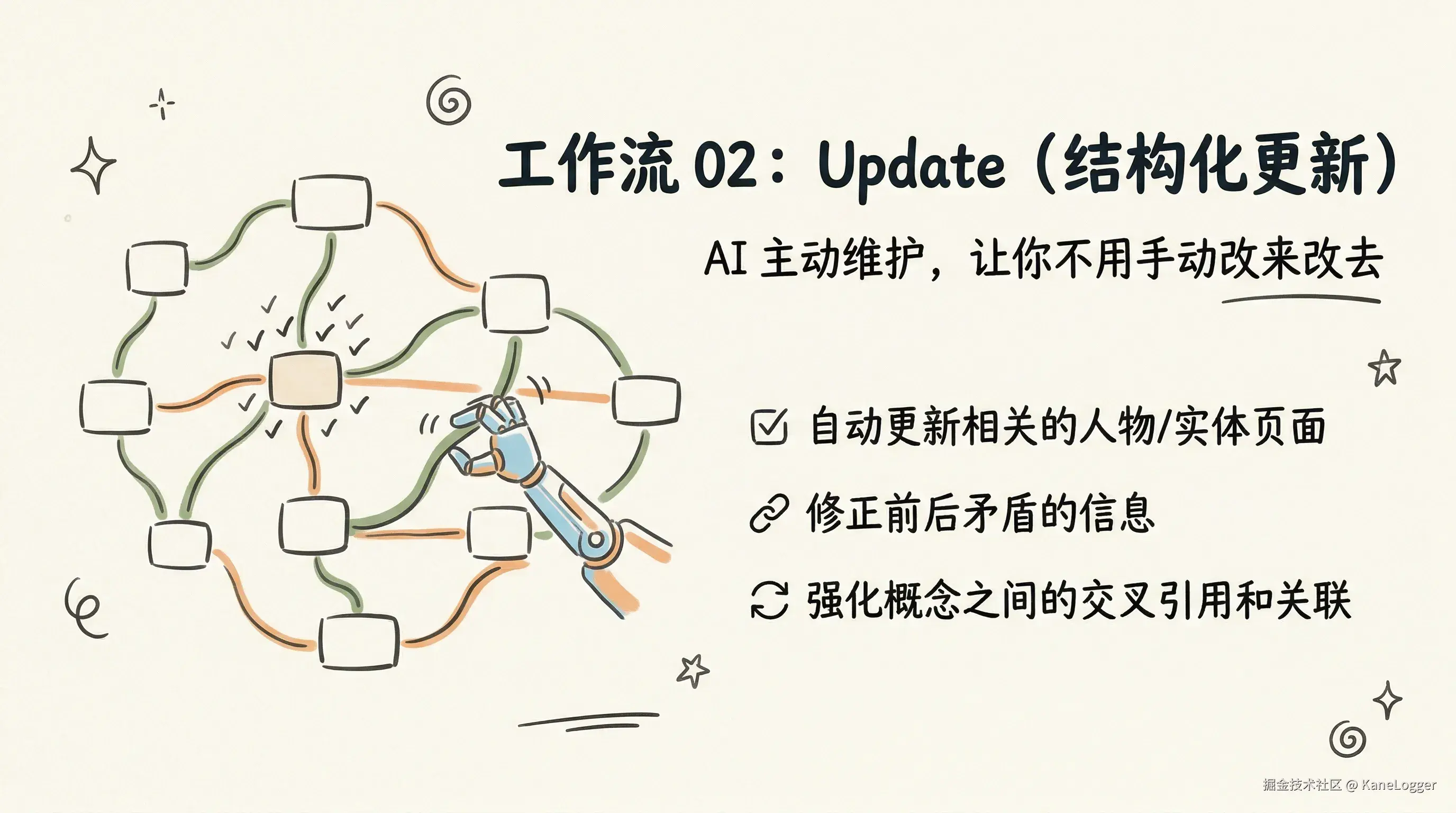
- 结构化更新(Update):自动更新相关的人物页面、修正前后矛盾的信息、强化概念之间的关联。
- 知识固化(Solidify):知识被深度处理一次后,复杂问题的相关结论便在维基页面间的交叉引用中固化,后续查询无需重新检索大量原始文档。

4. 实践:基于 Obsidian 的落地指南
本章节将详细介绍如何利用 Obsidian 及相关插件,搭建上述 LLM 驱动的知识库底层环境。
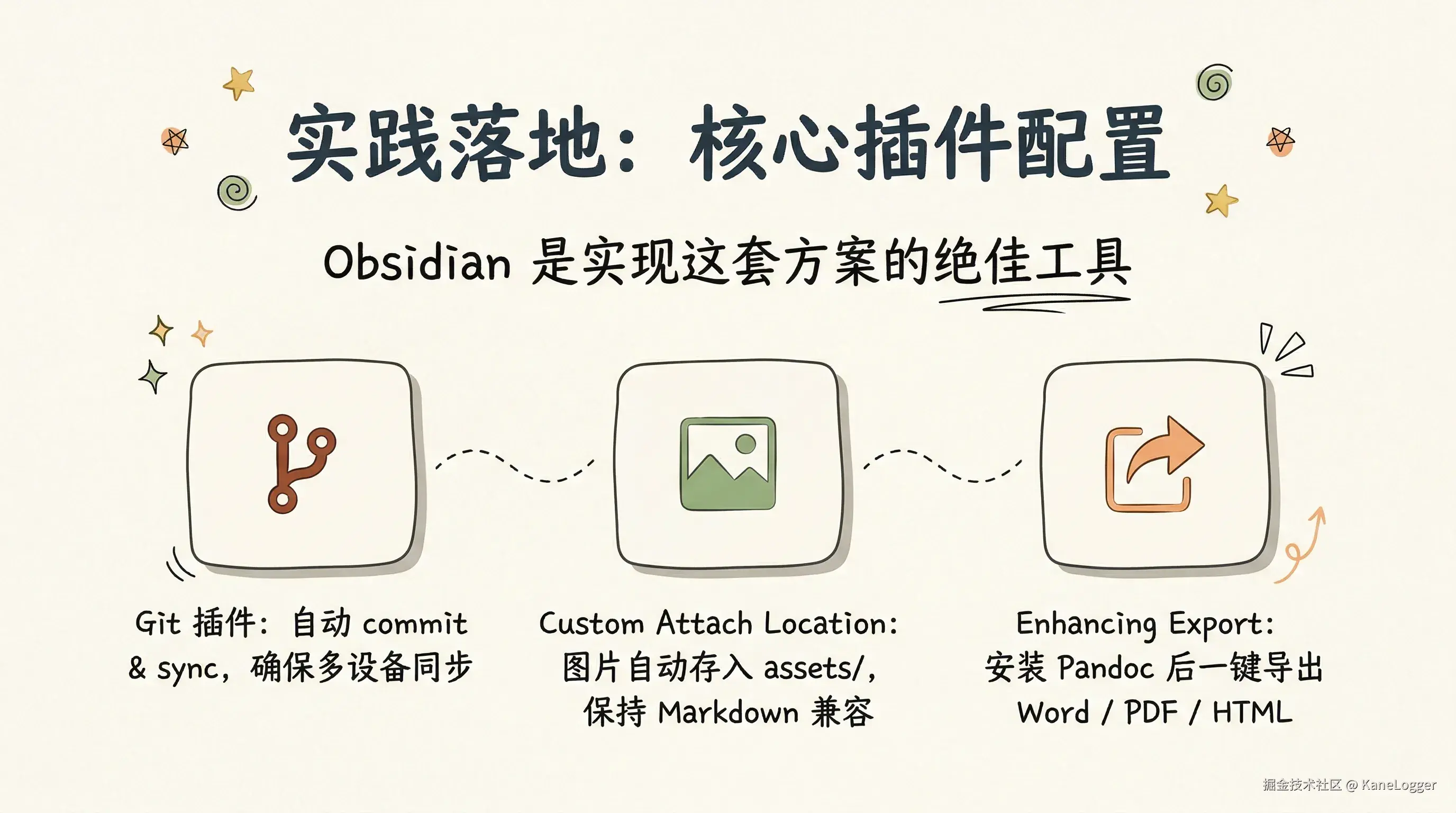
4.1 核心插件配置
以下是实现自动化与格式兼容性的三大关键插件:
| 插件名称 | 核心功能描述 | 关键配置项与注意事项 |
|---|---|---|
| Git | 自动化版本管理,实现与 GitHub 的无缝同步 | • Auto commit-and-sync interval: 1 分钟 • Auto commit-and-sync after stopping file edits: 开启 • Pull on start: 开启 |
| Custom Attach Location | 自定义附件(如图片)的存储位置与命名规则,确保标准 Markdown 兼容性 | • Markdown URL 格式: assets/${noteName}/${filename} • 附件重命名模式: 全部 • 是否重命名附件文件: 开启 |
| Enhancing Export | 增强导出功能,支持 Word、HTML、PDF 等多格式输出 | • 需前置安装 Pandoc • 需在插件设置中指定 Pandoc 可执行文件的绝对路径 |
4.2 环境搭建操作手册
请按照以下步骤完成本地环境的初始化:
- 准备环境:在 Obsidian 设置中关闭"安全模式",以允许安装社区插件。
- 优化链接:在"文件与链接"设置中,将"内部链接类型"改为基于当前笔记的相对路径,并取消"使用 Wiki 链接",以获得最广泛的 Markdown 兼容性。
- 版本控制初始化:
- 在 GitHub 创建私有(Private)仓库,并克隆到本地。
- 用 Obsidian 打开该本地仓库文件夹。
- 在根目录创建
.gitignore,添加.obsidian/workspace.json以排除工作区缓存。
- 插件安装与联调:
- 配置 Git 插件,确保笔记修改停止 1 分钟后自动推送至 GitHub。
- 配置 Custom Attach Location 插件。粘贴图片时,系统将在
assets下自动创建同名的子文件夹用于存放图片,并生成标准 Markdown 链接,确保在 VS Code、GitHub 等多端完美渲染。 - 安装 Pandoc 并配置 Enhancing Export 插件,实现右键一键导出。
4.3 知识库目录结构规范
一个标准的、由 LLM 维护的知识库(kb/),应遵循严格的目录层级约束:
sh
kb/
├── schema.md # 元规则:LLM操作手册,定义页面格式、命名约定、更新流程
├── index.md # 知识地图:所有页面的目录+一句话摘要,LLM查询时的入口
├── log.md # 黑匣子:append-only 操作日志,用于追踪和回滚
├── raw/ # 原料库:用户放入的原始文档(PDF、文章、笔记)
│ └── assets/ # 附件目录:图片、数据文件,本地存储防止死链
├── wiki/ # 知识网络:LLM生成的全部内容(人类只读,通过对话修改)
│ ├── meta/ # 元页面:关于知识库自身的页面(待办、清单、统计)
│ ├── entities/ # 实体页:人物、组织、产品、作品(名词为主)
│ ├── concepts/ # 概念页:理论、模型、方法、原则(抽象类别)
│ ├── sources/ # 源文件摘要:每份 raw 文档的结构化摘要
│ └── synthesis/ # 综合产物:对比分析、年度总结、决策记录(高阶洞察)
└── archive/ # 坟场:过时/废弃的 wiki 页面,定期由 LLM 迁移至此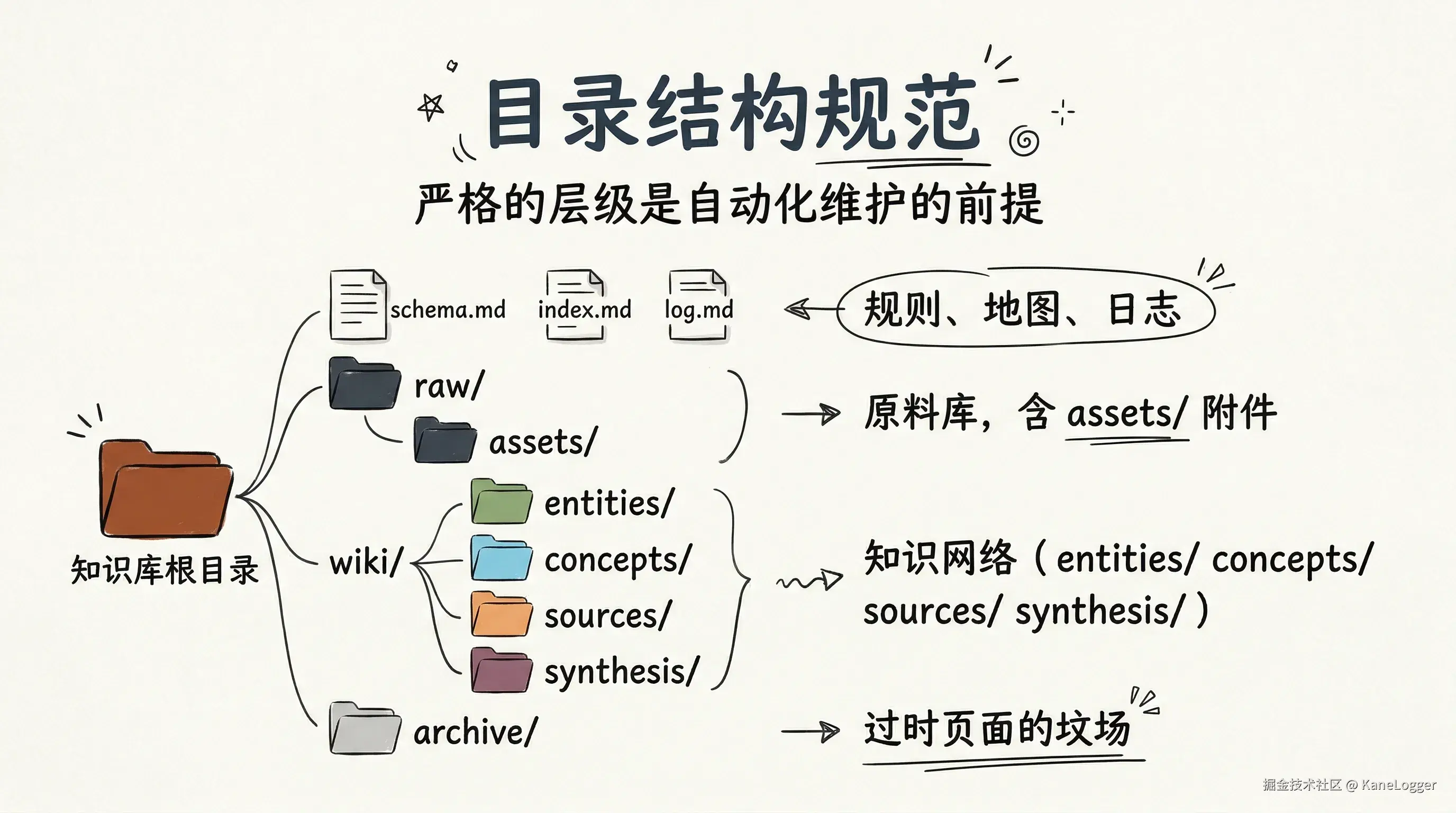
也可以把 文档 复制下来让AI去操作。
text
1. 参考 wiki.md 给出将本项目迁移成知识库的方案,要求给出三个方案以及每个方案的设计思路。
2. 当前项目是否符合 wiki.md 描述的知识库。5. 使用场景
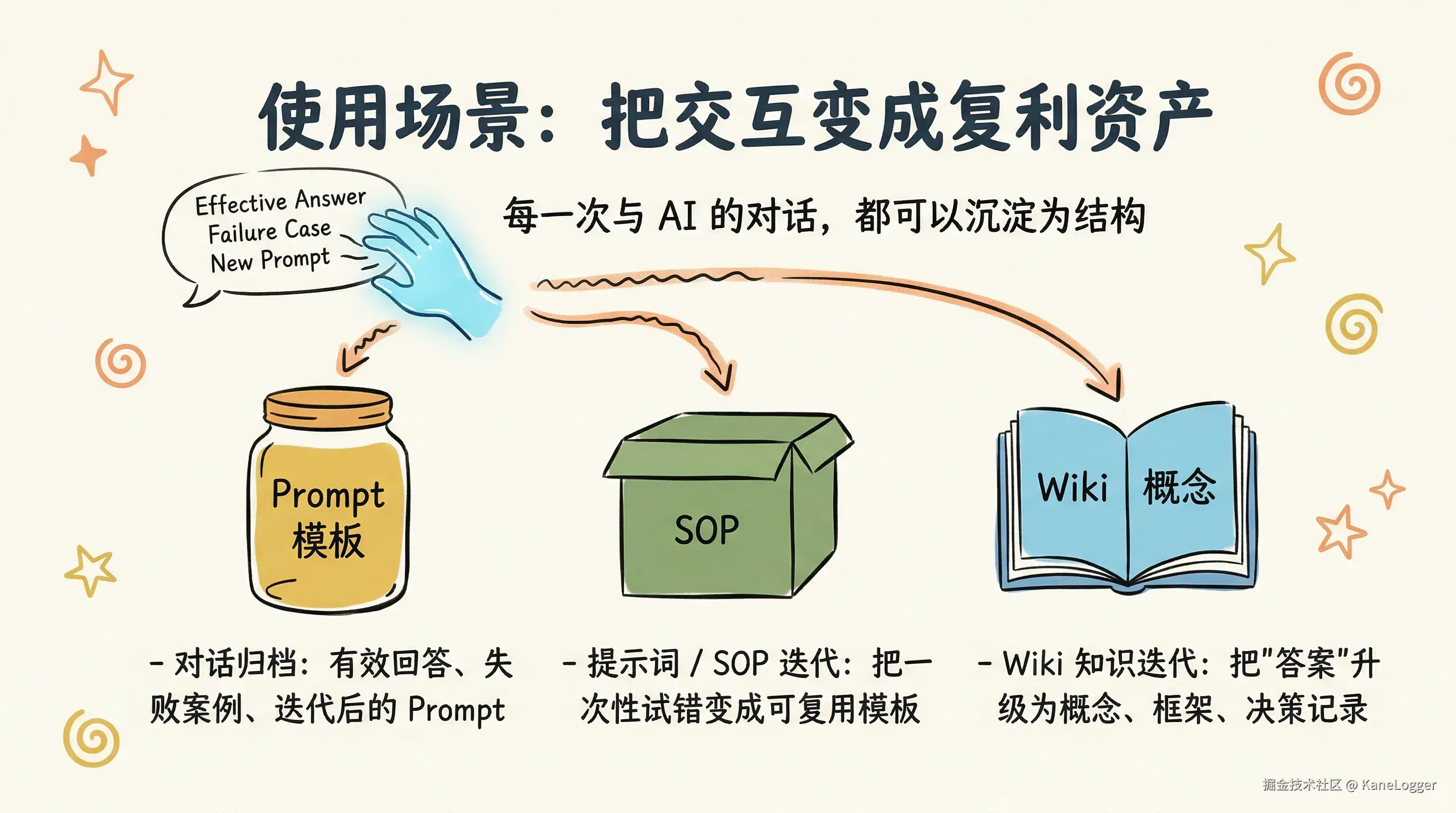
把每一次与 AI 的交互,从"消耗品"变成"复利资产"。你独有的经历与判断,才是护城河。
理论依据参考:
核心思想不是"会用更多工具",而是建立一个模型/工具可替换的闭环:对话产生数据,数据沉淀为结构,结构再反过来提升下一次对话质量。
主要场景:
- 对话 → 归档为可检索资产:有效回答、失败案例、边界线触碰、迭代后的提示词
- 提示词 / SOP / skill → 迭代:把一次性的试错变成可复用的模板与自动化能力
- Wiki 知识 → 迭代:把"答案"升级为"概念/框架/决策记录",形成跨主题复用
- 思维框架/工具 → 收集整理:从 AI 输出中提炼模型无关的逻辑结构,反哺人类判断
闭环示意:
text
对话/任务
↓ Capture(记录:目标/上下文/约束/结果/失败)
提示词 / SOP(可复用模板)
↓ Abstract(抽象:拆解出模型无关的逻辑结构与验证方式)
Wiki(concepts/entities/synthesis/sources)
↓ Embed(嵌入:skill/自动化工作流,把结构变成日常动作)
产出与决策
↺ Feedback(验证→修正→再沉淀)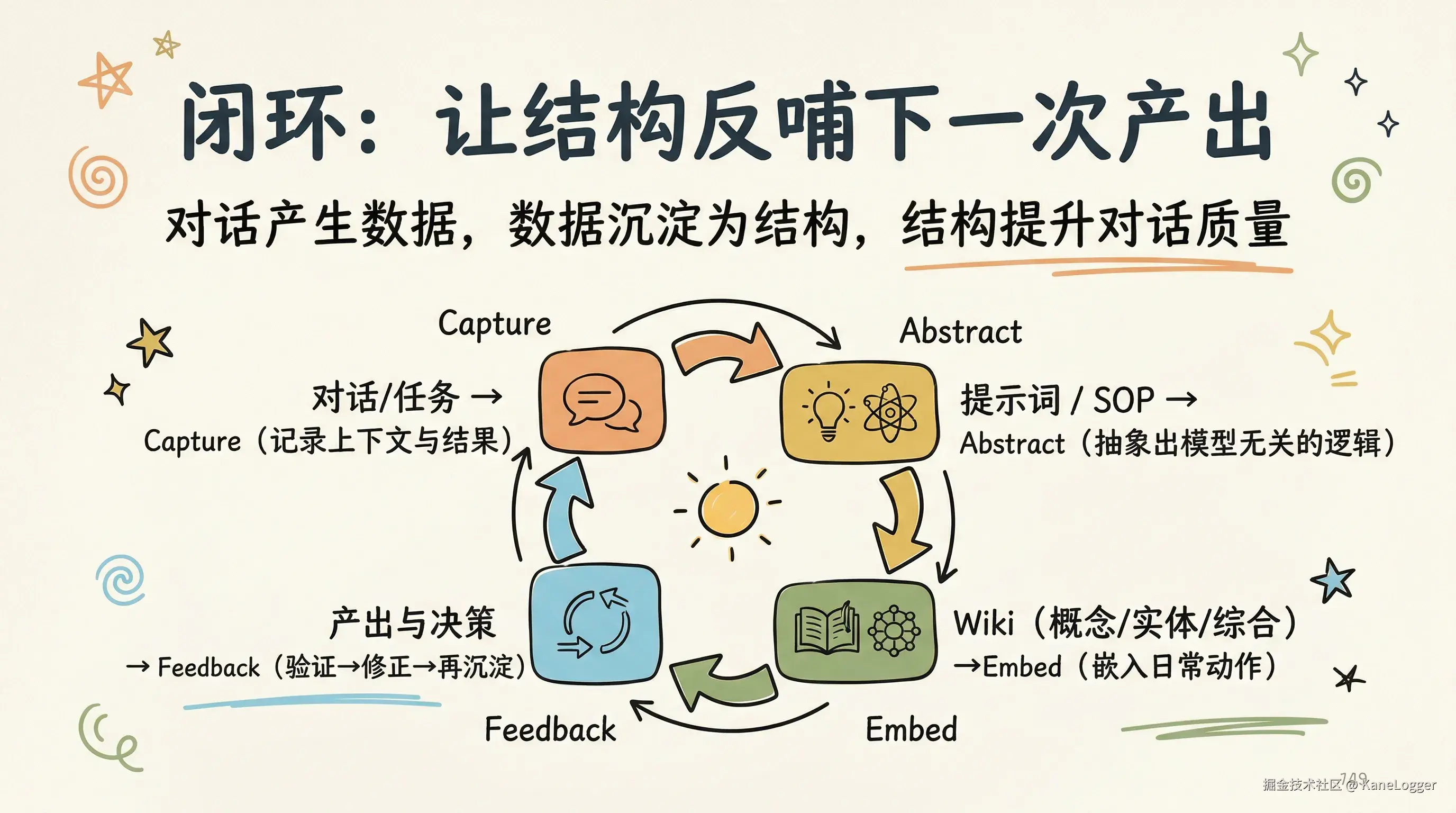
对话
- 对话结束立刻沉淀:记录有效回答、失败案例和高质量 Prompt;必要时让 AI 先总结,再由人类做取舍。本地可用自定义命令
/achieve。 - 复盘时只记录"可复用要素"(决策元数据),而不是堆"对话全文":
- 预期达到的效果是什么?
- 我用什么标准验证这次结果(正确性/可执行性/边界/成本)?
- 是否出现明显错误或幻觉?我是如何识别与修正的?
- 生成内容与预期不符时,我做了哪些调整(信息补全/约束收紧/输出格式/示例)?
- 这个提示词结构为什么有效(角色/背景/任务/限制/输出)?
- 抽象成模型无关的"通用逻辑描述":把对话中有效的步骤,固化为可迁移的模板(含输入字段、验证方式、失败兜底)。

6. 总结:知识工作价值链的重组
构建 LLM 维护的结构化知识库,本质上是一场知识工作价值链的重组:
- 人类的职责:策展人与提问者。你负责投喂优质源头数据、审视得出的结论、决定未来的研究与探索方向------人类做判断。
- 机器的职责:承担所有维护苦役。LLM 负责梳理逻辑、维护交叉链接、更新摘要、检查全库一致性------机器做整理。
当你读到这里,其实已经理解投资"记录"的重要性。因为这决定你是失去一天,还是积累一天。
所以现在开始就搭建自己的知识库吧。

