认识RNN模型
什么是RNN模型
RNN(Recurrent Neural Network), 中文称作循环神经网络, 它一般以序列数据为输入, 通过网络内部的结构设计有效捕捉序列之间的关系特征, 一般也是以序列形式进行输出.
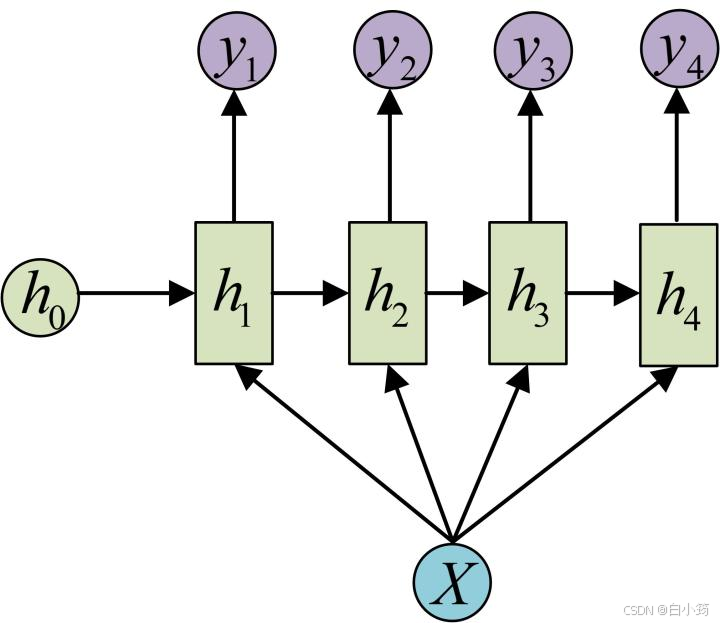
一般单层神经网络结构:
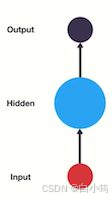
RNN单层网络结构:
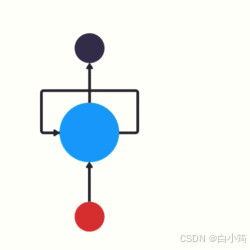
以时间步对RNN进行展开后的单层网络结构:

RNN的循环机制使模型隐层上一时间步产生的结果, 能够作为当下时间步输入的一部分(当下时间步的输入除了正常的输入外还包括上一步的隐层输出)对当下时间步的输出产生影响.
RNN模型的作用
因为RNN结构能够很好利用序列之间的关系, 因此针对自然界具有连续性的输入序列, 如人类的语言, 语音等进行很好的处理, 广泛应用于NLP领域的各项任务, 如文本分类, 情感分析, 意图识别, 机器翻译等.
RNN模型的分类
这里我们将从两个角度对RNN模型进行分类. 第一个角度是输入和输出的结构, 第二个角度是RNN的内部构造.
按照输入和输出的结构进行分类:
- N vs N - RNN * N vs 1 - RNN * 1 vs N - RNN * N vs M - RNN
按照RNN的内部构造进行分类:
- 传统RNN * LSTM * Bi-LSTM * GRU * Bi-GRU
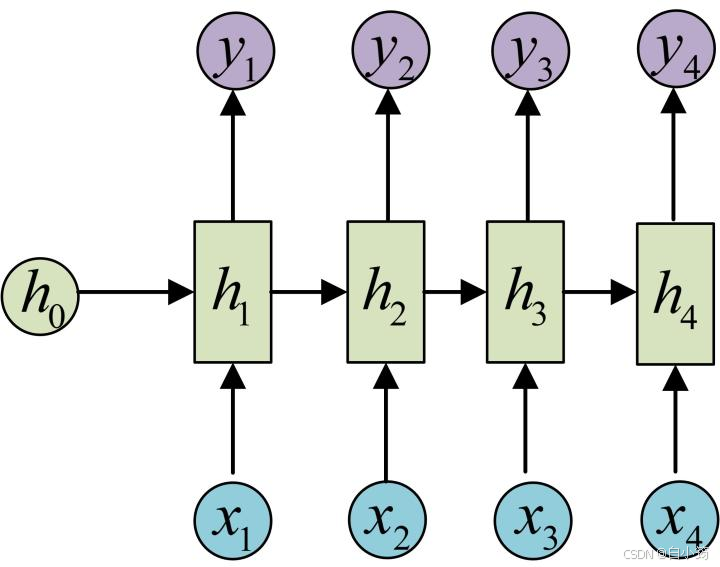
N vs N - RNN: * 它是RNN最基础的结构形式, 最大的特点就是: 输入和输出序列是等长的. 由于这个限制的存在, 使其适用范围比较小, 可用于生成等长度的合辙诗句.
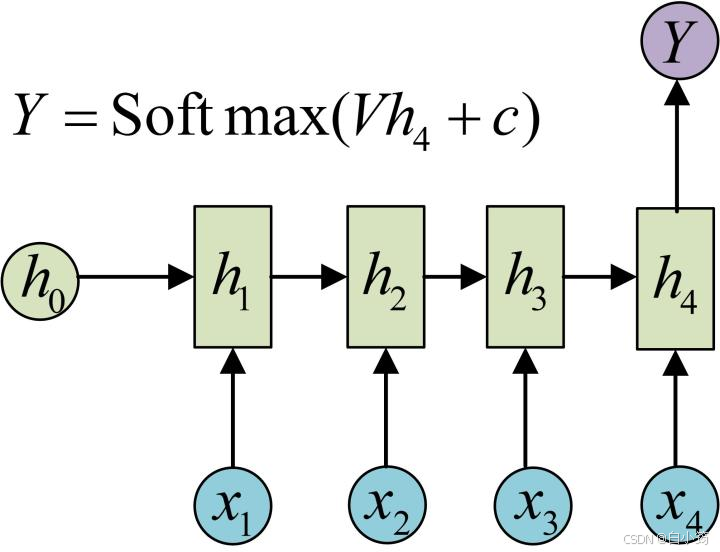
N vs 1 - RNN: * 有时候我们要处理的问题输入是一个序列,而要求输出是一个单独的值而不是序列,应该怎样建模呢?我们只要在最后一个隐层输出h上进行线性变换就可以了,大部分情况下,为了更好的明确结果, 还要使用sigmoid或者softmax进行处理. 这种结构经常被应用在文本分类问题上.
1 vs N - RNN: * 如果输入不是序列而输出为序列的情况怎么处理呢?我们最常采用的一种方式就是使该输入作用于每次的输出之上. 这种结构可用于将图片生成文字任务等.
N vs M - RNN: * 这是一种不限输入输出长度的RNN结构, 它由编码器和解码器两部分组成, 两者的内部结构都是某类RNN, 它也被称为seq2seq架构. 输入数据首先通过编码器, 最终输出一个隐含变量c, 之后最常用的做法是使用这个隐含变量c作用在解码器进行解码的每一步上, 以保证输入信息被有效利用.
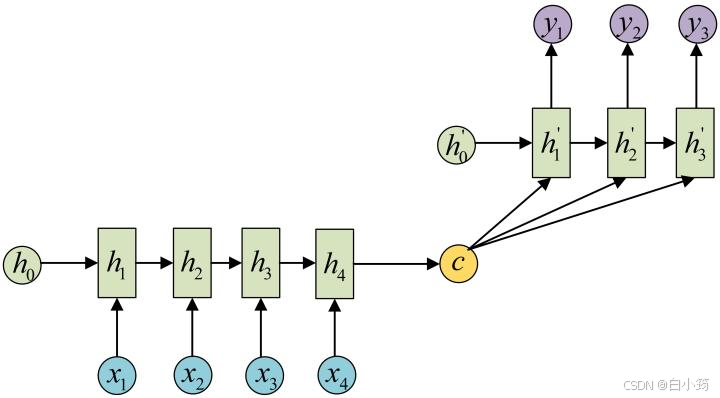
seq2seq架构最早被提出应用于机器翻译, 因为其输入输出不受限制,如今也是应用最广的RNN模型结构. 在机器翻译, 阅读理解, 文本摘要等众多领域都进行了非常多的应用实践.
传统RNN模型
传统RNN的内部结构图
RNN结构分析
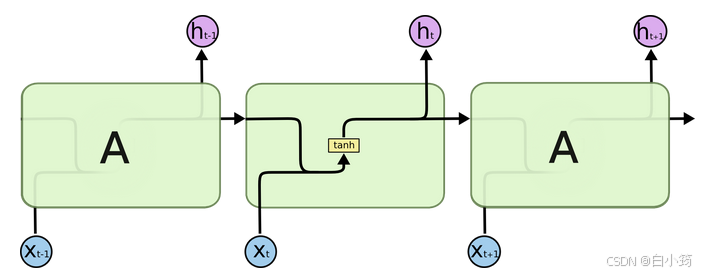
内部结构分析: * 我们把目光集中在中间的方块部分, 它的输入有两部分, 分别是h(t-1)以及x(t), 代表上一时间步的隐层输出, 以及此时间步的输入, 它们进入RNN结构体后, 会"融合"到一起, 这种融合我们根据结构解释可知, 是将二者进行拼接, 形成新的张量x(t), h(t-1), 之后这个新的张量将通过一个全连接层(线性层), 该层使用tanh作为激活函数, 最终得到该时间步的输出h(t), 它将作为下一个时间步的输入和x(t+1)一起进入结构体. 以此类推
内部结构过程演示: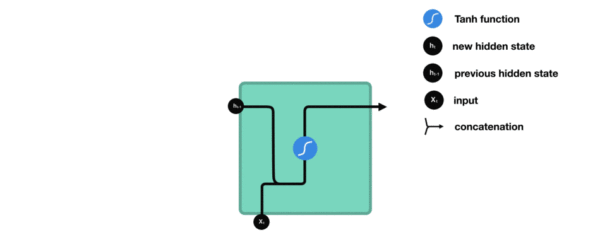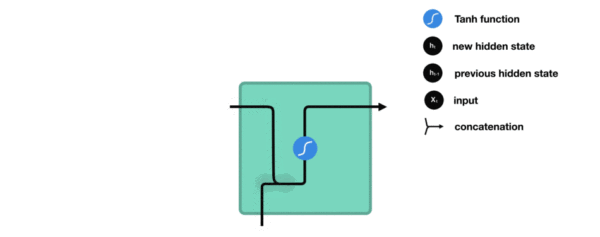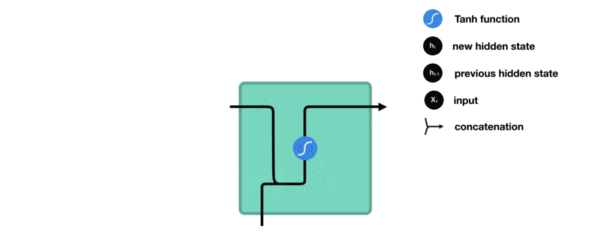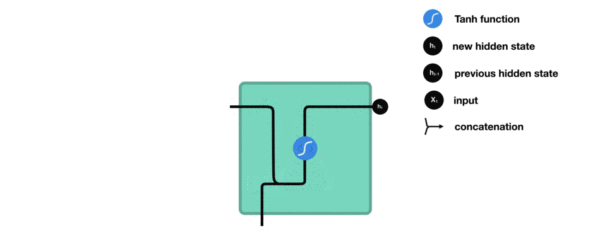
根据结构分析得出内部计算公式:
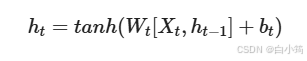
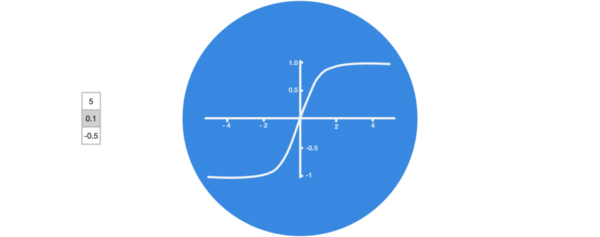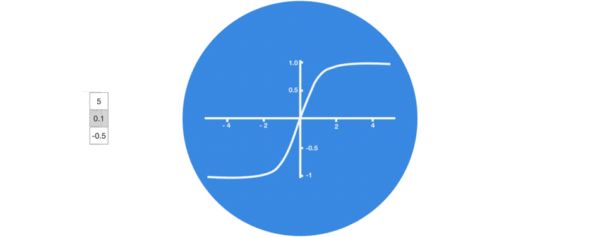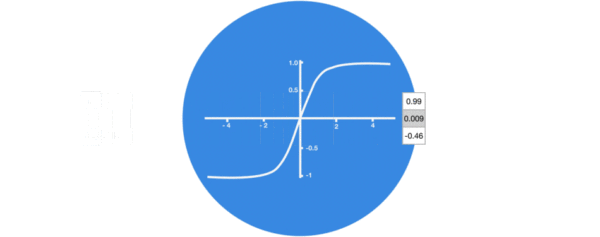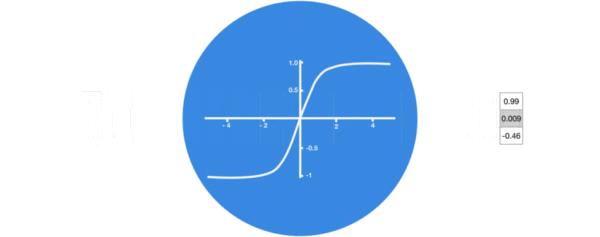
激活函数tanh的作用:
用于帮助调节流经网络的值, tanh函数将值压缩在-1和1之间.
使用Pytorch构建RNN模型
python
import torch
import torch.nn as nn
def dm_rnn_for_base():
'''
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
'''
rnn = nn.RNN(5, 6, 1) #A
'''
第一个参数:sequence_length(输入序列的长度)
第二个参数:batch_size(批次的样本数量)
第三个参数:input_size(输入张量的维度)
'''
input = torch.randn(1, 3, 5) #B
'''
第一个参数:num_layer * num_directions(层数*网络方向)
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
'''
h0 = torch.randn(1, 3, 6) #C
# [1,3,5],[1,3,6] ---> [1,3,6],[1,3,6]
output, hn = rnn(input, h0)
print('output--->',output.shape, output)
print('hn--->',hn.shape, hn)
print('rnn模型--->', rnn)
# 程序运行效果如下:
output---> torch.Size([1, 3, 6]) tensor([[[ 0.8947, -0.6040, 0.9878, -0.1070, -0.7071, -0.1434],
[ 0.0955, -0.8216, 0.9475, -0.7593, -0.8068, -0.5549],
[-0.1524, 0.7519, -0.1985, 0.0937, 0.2009, -0.0244]]],
grad_fn=<StackBackward0>)
hn---> torch.Size([1, 3, 6]) tensor([[[ 0.8947, -0.6040, 0.9878, -0.1070, -0.7071, -0.1434],
[ 0.0955, -0.8216, 0.9475, -0.7593, -0.8068, -0.5549],
[-0.1524, 0.7519, -0.1985, 0.0937, 0.2009, -0.0244]]],
grad_fn=<StackBackward0>)
rnn模型---> RNN(5, 6)
python
# 输入数据长度发生变化
def dm_rnn_for_sequencelen():
'''
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
'''
rnn = nn.RNN(5, 6, 1) #A
'''
第一个参数:sequence_length(输入序列的长度)
第二个参数:batch_size(批次的样本数量)
第三个参数:input_size(输入张量的维度)
'''
input = torch.randn(20, 3, 5) #B
'''
第一个参数:num_layer * num_directions(层数*网络方向)
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
'''
h0 = torch.randn(1, 3, 6) #C
# [20,3,5],[1,3,6] --->[20,3,6],[1,3,6]
output, hn = rnn(input, h0) #
print('output--->', output.shape)
print('hn--->', hn.shape)
print('rnn模型--->', rnn)
# 程序运行效果如下:
output---> torch.Size([20, 3, 6])
hn---> torch.Size([1, 3, 6])
rnn模型---> RNN(5, 6)
python
def dm_run_for_hiddennum():
'''
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
'''
rnn = nn.RNN(5, 6, 2) # A 隐藏层个数从1-->2 下面程序需要修改的地方?
'''
第一个参数:sequence_length(输入序列的长度)
第二个参数:batch_size(批次的样本数量)
第三个参数:input_size(输入张量的维度)
'''
input = torch.randn(1, 3, 5) # B
'''
第一个参数:num_layer * num_directions(层数*网络方向)
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
'''
h0 = torch.randn(2, 3, 6) # C
output, hn = rnn(input, h0) #
print('output-->', output.shape, output)
print('hn-->', hn.shape, hn)
print('rnn模型--->', rnn) # nn模型---> RNN(5, 6, num_layers=11)
# 结论:若只有一个隐藏次 output输出结果等于hn
# 结论:如果有2个隐藏层,output的输出结果有2个,hn等于最后一个隐藏层
# 程序运行效果如下:
output--> torch.Size([1, 3, 6]) tensor([[[ 0.4987, -0.5756, 0.1934, 0.7284, 0.4478, -0.1244],
[ 0.6753, 0.5011, -0.7141, 0.4480, 0.7186, 0.5437],
[ 0.6260, 0.7600, -0.7384, -0.5080, 0.9054, 0.6011]]],
grad_fn=<StackBackward0>)
hn--> torch.Size([2, 3, 6]) tensor([[[ 0.4862, 0.6872, -0.0437, -0.7826, -0.7136, -0.5715],
[ 0.8942, 0.4524, -0.1695, -0.5536, -0.4367, -0.3353],
[ 0.5592, 0.0444, -0.8384, -0.5193, 0.7049, -0.0453]],
[[ 0.4987, -0.5756, 0.1934, 0.7284, 0.4478, -0.1244],
[ 0.6753, 0.5011, -0.7141, 0.4480, 0.7186, 0.5437],
[ 0.6260, 0.7600, -0.7384, -0.5080, 0.9054, 0.6011]]],
grad_fn=<StackBackward0>)
rnn模型---> RNN(5, 6, num_layers=2)传统RNN优缺点
传统RNN的优势
由于内部结构简单, 对计算资源要求低, 相比之后我们要学习的RNN变体:LSTM和GRU模型参数总量少了很多, 在短序列任务上性能和效果都表现优异.
传统RNN的缺点
传统RNN在解决长序列之间的关联时, 通过实践,证明经典RNN表现很差, 原因是在进行反向传播的时候, 过长的序列导致梯度的计算异常, 发生梯度消失或爆炸.
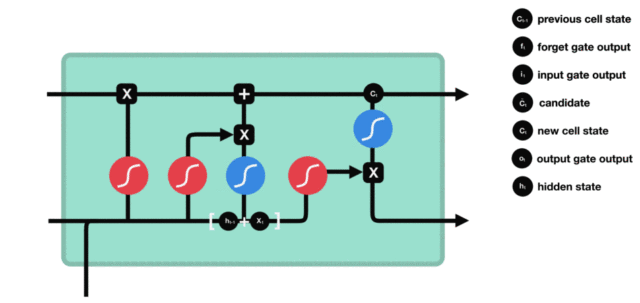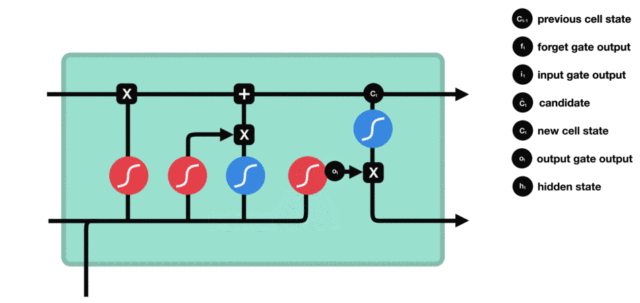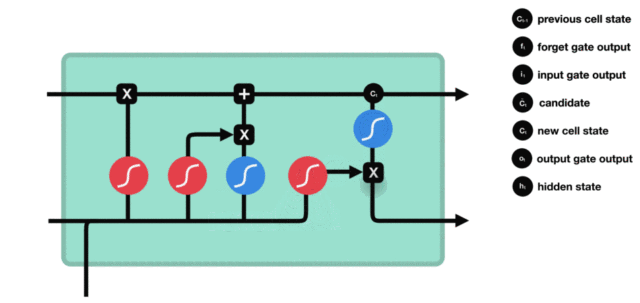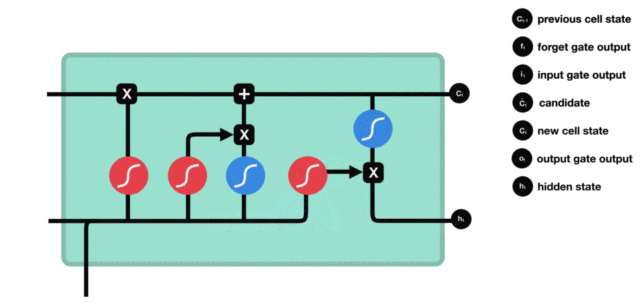
LSTM模型
LSTM介绍
LSTM(Long Short-Term Memory)也称长短时记忆结构, 它是传统RNN的变体, 与经典RNN相比能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时LSTM的结构更复杂, 它的核心结构可以分为四个部分去解析:
- 遗忘门
- 输入门
- 细胞状态
- 输出门
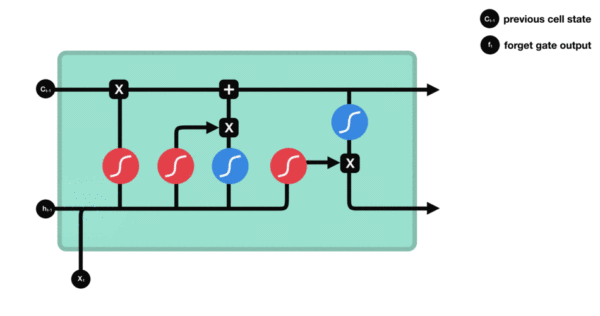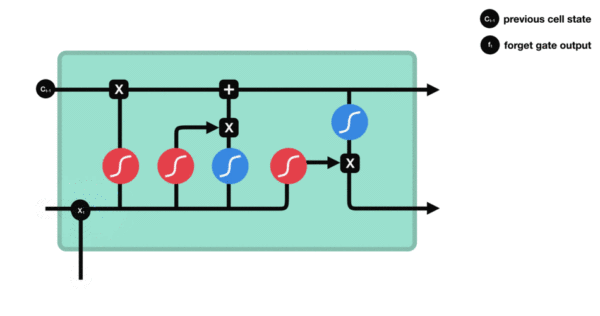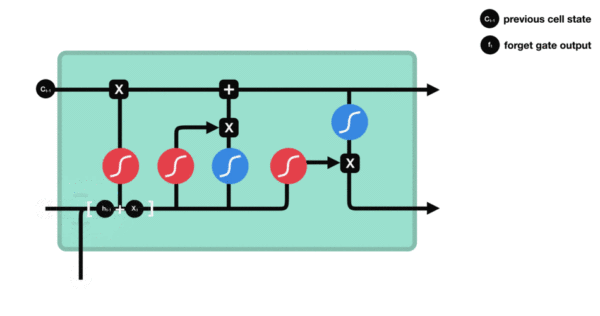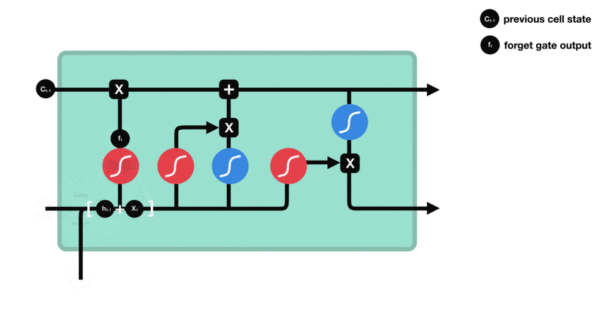
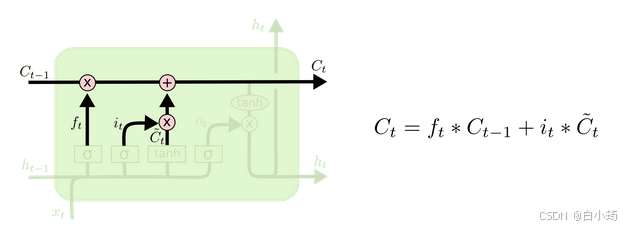
LSTM的内部结构图
LSTM结构分析
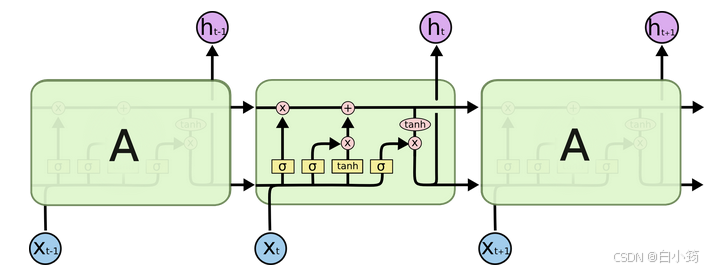
遗忘门部分结构图与计算公式:
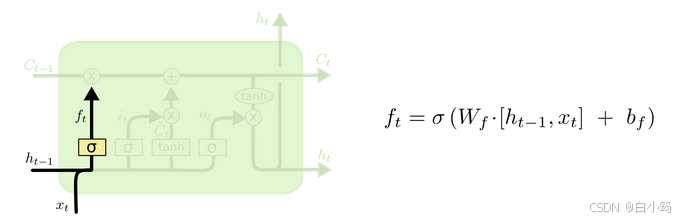
遗忘门结构分析: * 与传统RNN的内部结构计算非常相似, 首先将当前时间步输入x(t)与上一个时间步隐含状态h(t-1)拼接, 得到x(t), h(t-1), 然后通过一个全连接层做变换, 最后通过sigmoid函数进行激活得到f(t), 我们可以将f(t)看作是门值, 好比一扇门开合的大小程度, 门值都将作用在通过该扇门的张量, 遗忘门门值将作用的上一层的细胞状态上, 代表遗忘过去的多少信息, 又因为遗忘门门值是由x(t), h(t-1)计算得来的, 因此整个公式意味着根据当前时间步输入和上一个时间步隐含状态h(t-1)来决定遗忘多少上一层的细胞状态所携带的过往信息.
遗忘门内部结构过程演示:
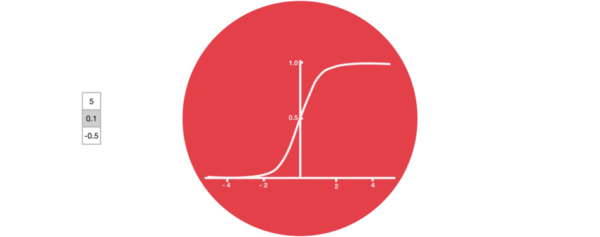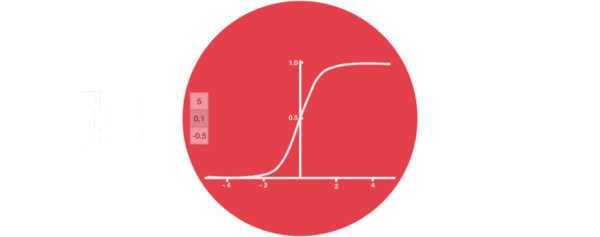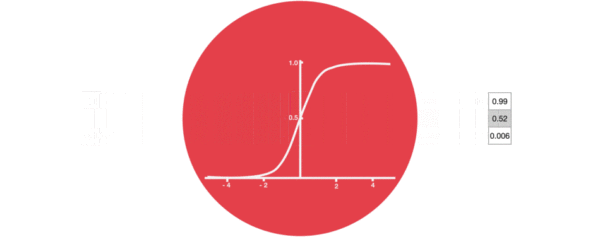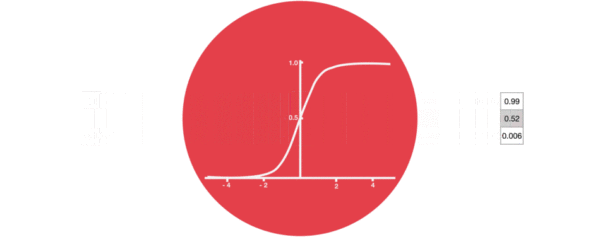
激活函数sigmiod的作用: * 用于帮助调节流经网络的值, sigmoid函数将值压缩在0和1之间
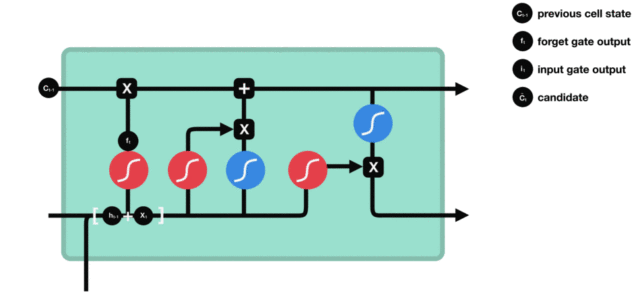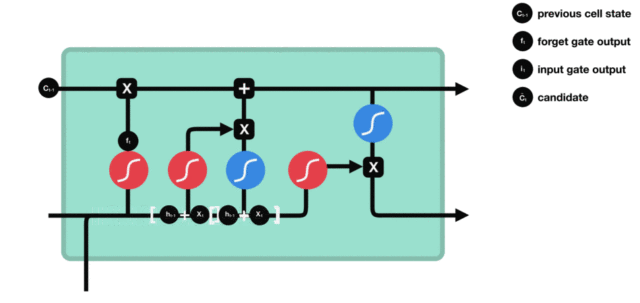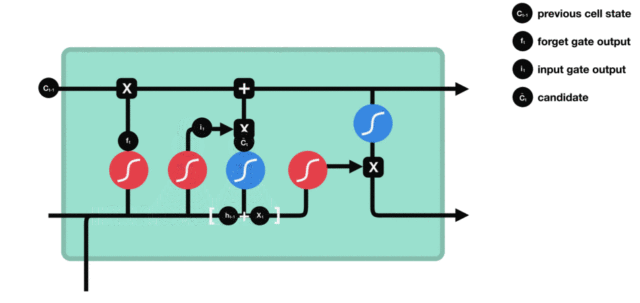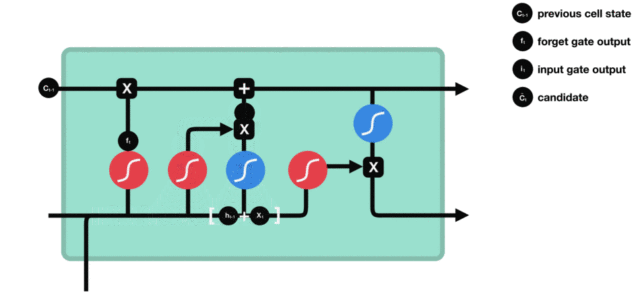
输入门部分结构图与计算公式:
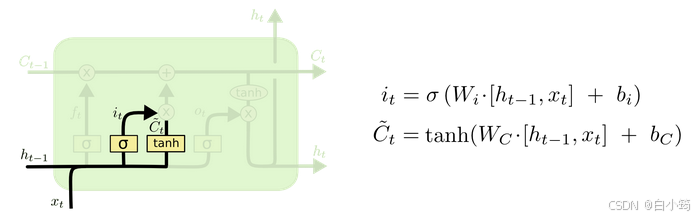
输入门结构分析: * 我们看到输入门的计算公式有两个, 第一个就是产生输入门门值的公式, 它和遗忘门公式几乎相同, 区别只是在于它们之后要作用的目标上. 这个公式意味着输入信息有多少需要进行过滤. 输入门的第二个公式是与传统RNN的内部结构计算相同. 对于LSTM来讲, 它得到的是当前的细胞状态, 而不是像经典RNN一样得到的是隐含状态.
输入门内部结构过程演示:
细胞状态更新图与计算公式:
细胞状态更新分析: * 细胞更新的结构与计算公式非常容易理解, 这里没有全连接层, 只是将刚刚得到的遗忘门门值与上一个时间步得到的C(t-1)相乘, 再加上输入门门值与当前时间步得到的未更新C(t)相乘的结果. 最终得到更新后的C(t)作为下一个时间步输入的一部分. 整个细胞状态更新过程就是对遗忘门和输入门的应用.
细胞状态更新过程演示: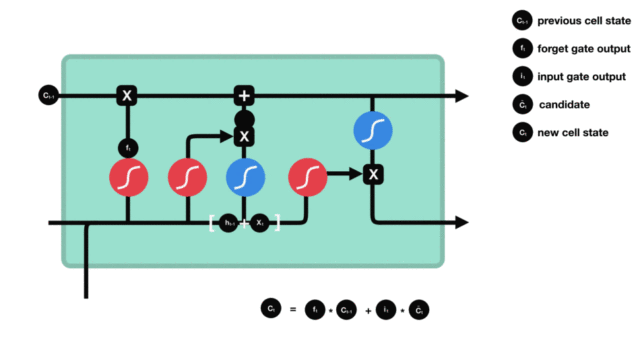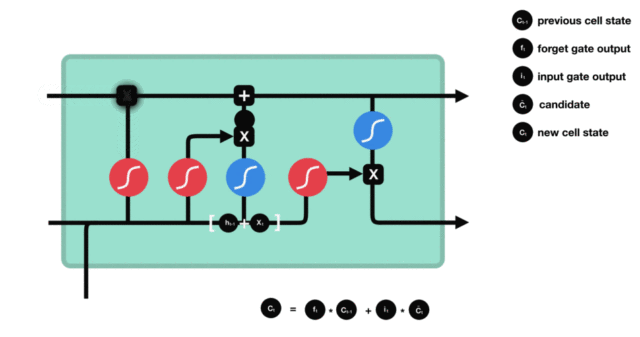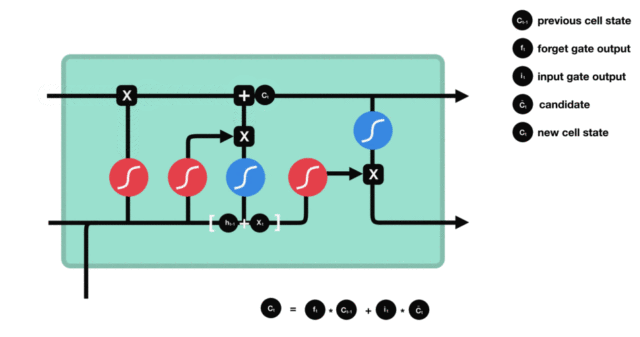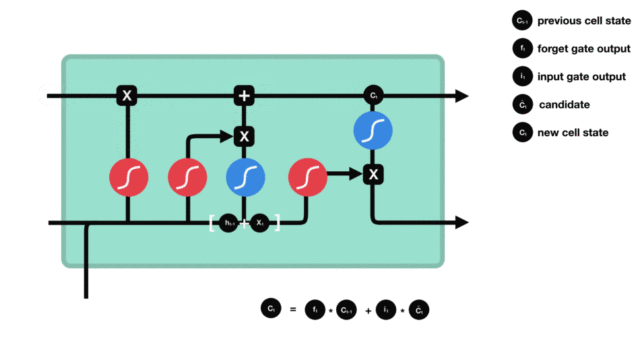
输出门部分结构图与计算公式:
输出门结构分析: * 输出门部分的公式也是两个, 第一个即是计算输出门的门值, 它和遗忘门,输入门计算方式相同. 第二个即是使用这个门值产生隐含状态h(t), 他将作用在更新后的细胞状态C(t)上, 并做tanh激活, 最终得到h(t)作为下一时间步输入的一部分. 整个输出门的过程, 就是为了产生隐含状态h(t).
Bi-LSTM介绍
Bi-LSTM即双向LSTM, 它没有改变LSTM本身任何的内部结构, 只是将LSTM应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出
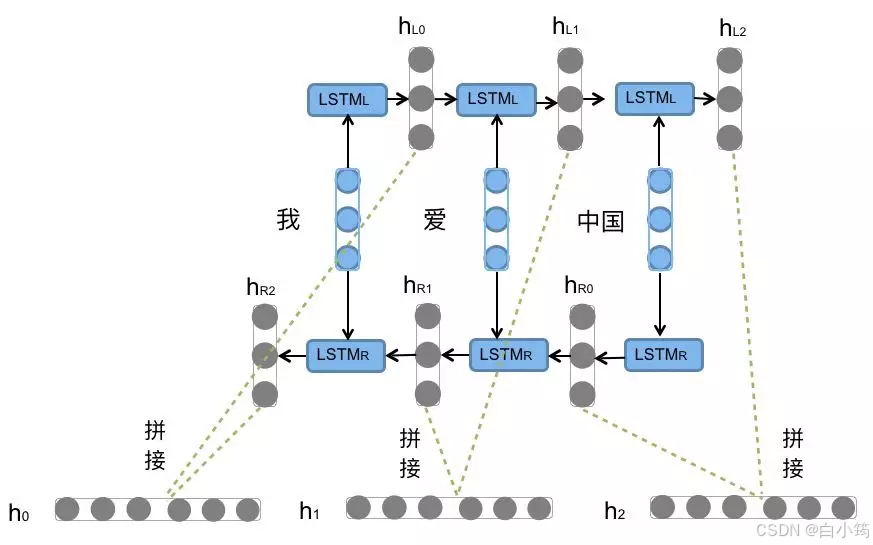 Bi-LSTM结构分析: * 我们看到图中对"我爱中国"这句话或者叫这个输入序列, 进行了从左到右和从右到左两次LSTM处理, 将得到的结果张量进行了拼接作为最终输出. 这种结构能够捕捉语言语法中一些特定的前置或后置特征, 增强语义关联,但是模型参数和计算复杂度也随之增加了一倍, 一般需要对语料和计算资源进行评估后决定是否使用该结构.
Bi-LSTM结构分析: * 我们看到图中对"我爱中国"这句话或者叫这个输入序列, 进行了从左到右和从右到左两次LSTM处理, 将得到的结果张量进行了拼接作为最终输出. 这种结构能够捕捉语言语法中一些特定的前置或后置特征, 增强语义关联,但是模型参数和计算复杂度也随之增加了一倍, 一般需要对语料和计算资源进行评估后决定是否使用该结构.
使用Pytorch构建LSTM模型
python
# 定义LSTM的参数含义: (input_size, hidden_size, num_layers)
# 定义输入张量的参数含义: (sequence_length, batch_size, input_size)
# 定义隐藏层初始张量和细胞初始状态张量的参数含义:
# (num_layers * num_directions, batch_size, hidden_size)
python
# 定义LSTM的参数含义: (input_size, hidden_size, num_layers)
# 定义输入张量的参数含义: (sequence_length, batch_size, input_size)
# 定义隐藏层初始张量和细胞初始状态张量的参数含义:
# (num_layers * num_directions, batch_size, hidden_size)
>>> import torch.nn as nn
>>> import torch
>>> rnn = nn.LSTM(5, 6, 2)
>>> input = torch.randn(1, 3, 5)
>>> h0 = torch.randn(2, 3, 6)
>>> c0 = torch.randn(2, 3, 6)
>>> output, (hn, cn) = rnn(input, (h0, c0))
>>> output
tensor([[[ 0.0447, -0.0335, 0.1454, 0.0438, 0.0865, 0.0416],
[ 0.0105, 0.1923, 0.5507, -0.1742, 0.1569, -0.0548],
[-0.1186, 0.1835, -0.0022, -0.1388, -0.0877, -0.4007]]],
grad_fn=<StackBackward>)
>>> hn
tensor([[[ 0.4647, -0.2364, 0.0645, -0.3996, -0.0500, -0.0152],
[ 0.3852, 0.0704, 0.2103, -0.2524, 0.0243, 0.0477],
[ 0.2571, 0.0608, 0.2322, 0.1815, -0.0513, -0.0291]],
[[ 0.0447, -0.0335, 0.1454, 0.0438, 0.0865, 0.0416],
[ 0.0105, 0.1923, 0.5507, -0.1742, 0.1569, -0.0548],
[-0.1186, 0.1835, -0.0022, -0.1388, -0.0877, -0.4007]]],
grad_fn=<StackBackward>)
>>> cn
tensor([[[ 0.8083, -0.5500, 0.1009, -0.5806, -0.0668, -0.1161],
[ 0.7438, 0.0957, 0.5509, -0.7725, 0.0824, 0.0626],
[ 0.3131, 0.0920, 0.8359, 0.9187, -0.4826, -0.0717]],
[[ 0.1240, -0.0526, 0.3035, 0.1099, 0.5915, 0.0828],
[ 0.0203, 0.8367, 0.9832, -0.4454, 0.3917, -0.1983],
[-0.2976, 0.7764, -0.0074, -0.1965, -0.1343, -0.6683]]],
grad_fn=<StackBackward>)LSTM优缺点
LSTM优势:
LSTM的门结构能够有效减缓长序列问题中可能出现的梯度消失或爆炸, 虽然并不能杜绝这种现象, 但在更长的序列问题上表现优于传统RNN.
LSTM缺点:
由于内部结构相对较复杂, 因此训练效率在同等算力下较传统RNN低很多.
GRU模型
GRU介绍
GRU(Gated Recurrent Unit)也称门控循环单元结构, 它也是传统RNN的变体, 同LSTM一样能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时它的结构和计算要比LSTM更简单, 它的核心结构可以分为两个部分去解析:
- 更新门
- 重置门
GRU的内部结构图
GRU结构分析
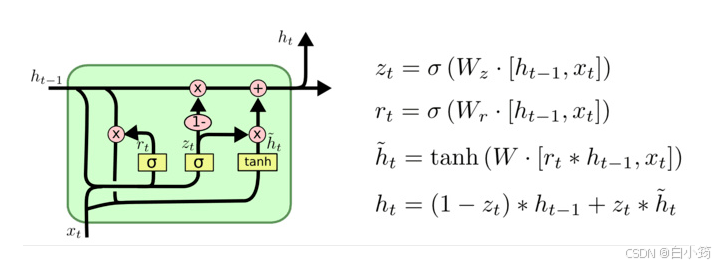 GRU的更新门和重置门结构图:
GRU的更新门和重置门结构图:
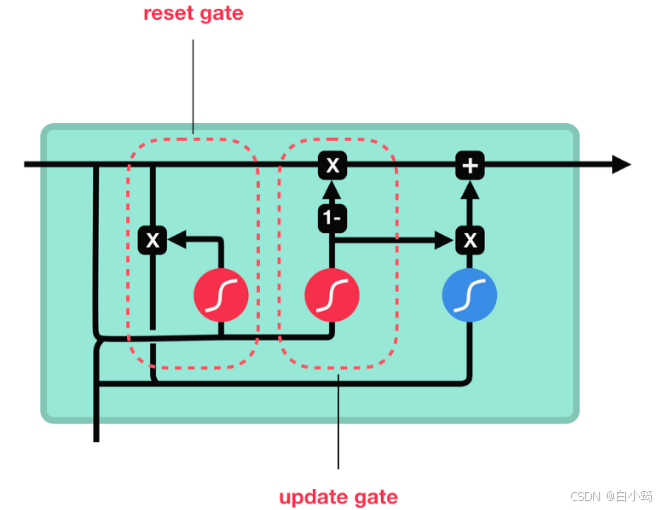
和之前分析过的LSTM中的门控一样, 首先计算更新门和重置门的门值, 分别是z(t)和r(t), 计算方法就是使用X(t)与h(t-1)拼接进行线性变换, 再经过sigmoid激活. 之后重置门门值作用在了h(t-1)上, 代表控制上一时间步传来的信息有多少可以被利用. 接着就是使用这个重置后的h(t-1)进行基本的RNN计算, 即与x(t)拼接进行线性变化, 经过tanh激活, 得到新的h(t). 最后更新门的门值会作用在新的h(t),而1-门值会作用在h(t-1)上, 随后将两者的结果相加, 得到最终的隐含状态输出h(t), 这个过程意味着更新门有能力保留之前的结果, 当门值趋于1时, 输出就是新的h(t), 而当门值趋于0时, 输出就是上一时间步的h(t-1).
Bi-GRU介绍
Bi-GRU与Bi-LSTM的逻辑相同, 都是不改变其内部结构, 而是将模型应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出.
使用Pytorch构建GRU模型
nn.GRU类实例化对象主要参数解释: * input: 输入张量x. * h0: 初始化的隐层张量h.
python
>>> import torch
>>> import torch.nn as nn
>>> rnn = nn.GRU(5, 6, 2)
>>> input = torch.randn(1, 3, 5)
>>> h0 = torch.randn(2, 3, 6)
>>> output, hn = rnn(input, h0)
>>> output
tensor([[[-0.2097, -2.2225, 0.6204, -0.1745, -0.1749, -0.0460],
[-0.3820, 0.0465, -0.4798, 0.6837, -0.7894, 0.5173],
[-0.0184, -0.2758, 1.2482, 0.5514, -0.9165, -0.6667]]],
grad_fn=<StackBackward>)
>>> hn
tensor([[[ 0.6578, -0.4226, -0.2129, -0.3785, 0.5070, 0.4338],
[-0.5072, 0.5948, 0.8083, 0.4618, 0.1629, -0.1591],
[ 0.2430, -0.4981, 0.3846, -0.4252, 0.7191, 0.5420]],
[[-0.2097, -2.2225, 0.6204, -0.1745, -0.1749, -0.0460],
[-0.3820, 0.0465, -0.4798, 0.6837, -0.7894, 0.5173],
[-0.0184, -0.2758, 1.2482, 0.5514, -0.9165, -0.6667]]],
grad_fn=<StackBackward>)GRU优缺点
GRU的优势: * GRU和LSTM作用相同, 在捕捉长序列语义关联时, 能有效抑制梯度消失或爆炸, 效果都优于传统RNN且计算复杂度相比LSTM要小.
GRU的缺点: * GRU仍然不能完全解决梯度消失问题, 同时其作用RNN的变体, 有着RNN结构本身的一大弊端, 即不可并行计算, 这在数据量和模型体量逐步增大的未来, 是RNN发展的关键瓶颈
注意力机制介绍
注意力机制的由来,解决了什么问题?
在认识注意力之前,我们先简单了解下机器翻译任务:
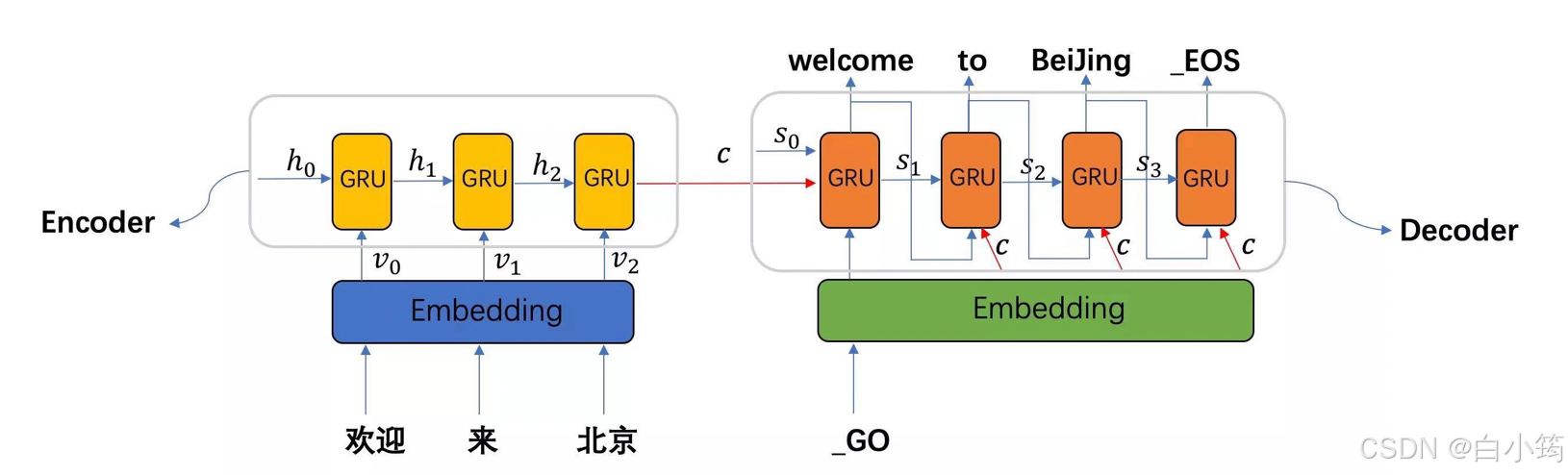
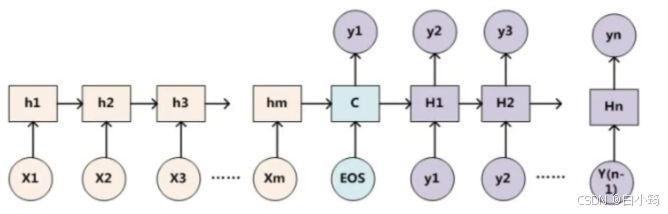
- seq2seq模型架构包括三部分,分别是encoder(编码器)、decoder(解码器)、中间语义张量c。
- 图中表示的是一个中文到英文的翻译:欢迎 来 北京 → welcome to BeiJing。编码器首先处理中文输入"欢迎 来 北京",通过GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c;接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量, 逐个生成对应的翻译语言
- 早期在解决机器翻译这一类seq2seq问题时,通常采用的做法是利用一个编码器(Encoder)和一个解码器(Decoder)构建端到端的神经网络模型,但是基于编码解码的神经网络存在两个问题
-问题1:如果翻译的句子很长很复杂,比如直接一篇文章输进去,模型的计算量很大,并且模型的准确率下降严重。
-问题2:在翻译时,可能在不同的语境下,同一个词具有不同的含义,但是网络对这些词向量并没有区分度,没有考虑词与词之间的相关性,导致翻译效果比较差。 - 针对这样的问题,注意力机制被提出
注意力机制分类以及如何实现
通俗来讲就是对于模型的每一个输入项,可能是图片中的不同部分,或者是语句中的某个单词分配一个权重,这个权重的大小就代表了我们希望模型对该部分一个关注程度。
深度学习中的注意力机制通常可分为三类: 软注意(全局注意)、硬注意(局部注意)和自注意(内注意)
-
软注意机制(Soft/Global Attention:
对每个输入项的分配的权重为0-1之间,也就是某些部分关注的多一点,某些部分关注的少一点,因为对大部分信息都有考虑,但考虑程度不一样,所以相对来说计算量比较大。
-
硬注意机制(Hard/Local Attention,了解即可):
对每个输入项分配的权重非0即1,和软注意不同,硬注意机制只考虑那部分需要关注,哪部分不关注,也就是直接舍弃掉一些不相关项。优势在于可以减少一定的时间和计算成本,但有可能丢失掉一些本应该注意的信息。
-
自注意力机制( Self/Intra Attention): 对每个输入项分配的权重取决于输入项之间的相互作用,即通过输入项内部的"表决"来决定应该关注哪些输入项。和前两种相比,在处理很长的输入时,具有并行计算的优势。
Soft Attention (最常见)
需要注意:注意力机制是一种通用的思想和技术,不依赖于任何模型,换句话说,注意力机制可以用于任何模型。我们这里只是以文本处理领域的Encoder-Decoder框架为例进行理解。这里我们分别以普通Encoder-Decoder框架以及加Attention的Encoder-Decoder框架分别做对比。
普通Encoder-Decoder框架
下图1是Encoder-Decoder框架的一种抽象表示方式:
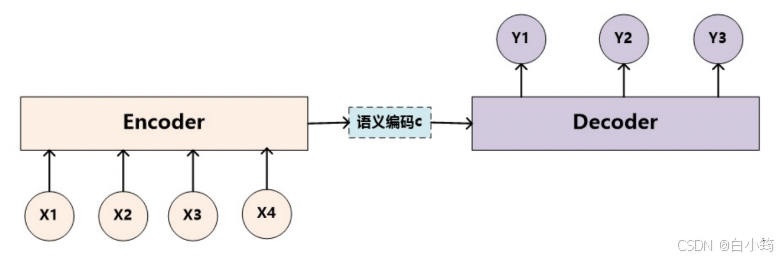
上图图例可以把它看作由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
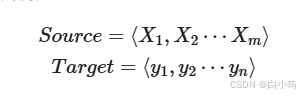
encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
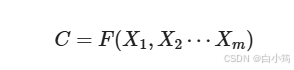
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息,y_1, y_2...y_i-1来生成i时刻要生成的单词y_i
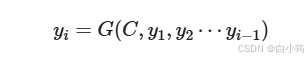
上述图中展示的Encoder-Decoder框架是没有体现出"注意力模型"的,所以可以把它看作是注意力不集中的分心模型。为什么说它注意力不集中呢?请观察下目标句子Target中每个单词的生成过程如下: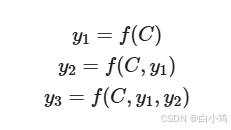
其中f是Decoder的非线性变换函数。从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子Source的语义编码C都是一样的,没有任何区别。而语义编码C又是通过对source经过Encoder编码产生的,因此对于target中的任何一个单词,source中任意单词对某个目标单词y_i来说影响力都是相同的,这就是为什么说图1中的模型没有体现注意力的原因。
加Attention的Encoder-Decoder框架
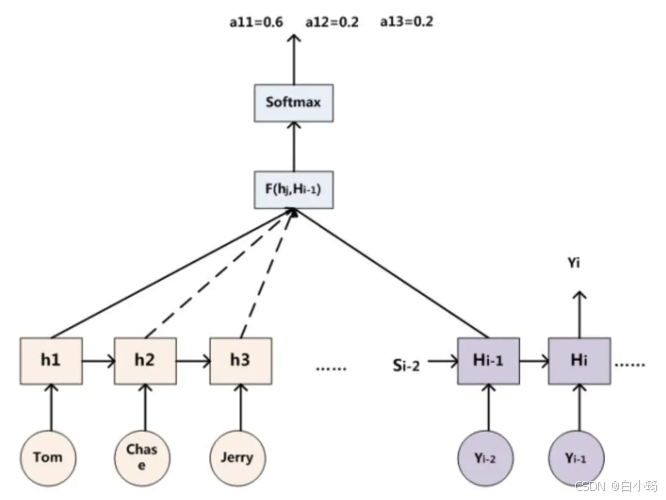
举例说明,为何添加Attention
- 比如机器翻译任务,输入source为:Tom chase Jerry,输出target为:"汤姆","追逐","杰瑞"。在翻译"Jerry"这个中文单词的时候,普通Encoder-Decoder框架中,source里的每个单词对翻译目标单词"杰瑞"贡献是相同的,很明显这里不太合理,显然"Jerry"对于翻译成"杰瑞"更重要。
- 如果引入Attention模型,在生成"杰瑞"的时候,应该体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:(Tom,0.3)(Chase,0.2) (Jerry,0.5).每个英文单词的概率代表了翻译当前单词"杰瑞"时,注意力分配模型分配给不同英文单词的注意力大小
因此,基于上述例子所示, 对于target中任意一个单词都应该有对应的source中的单词的注意力分配概率.而且,由于注意力模型的加入,原来在生成target单词时候的中间语义C就不再是固定的,而是会根据注意力概率变化的C,加入了注意力模型的Encoder-Decoder框架就变成了下图所示
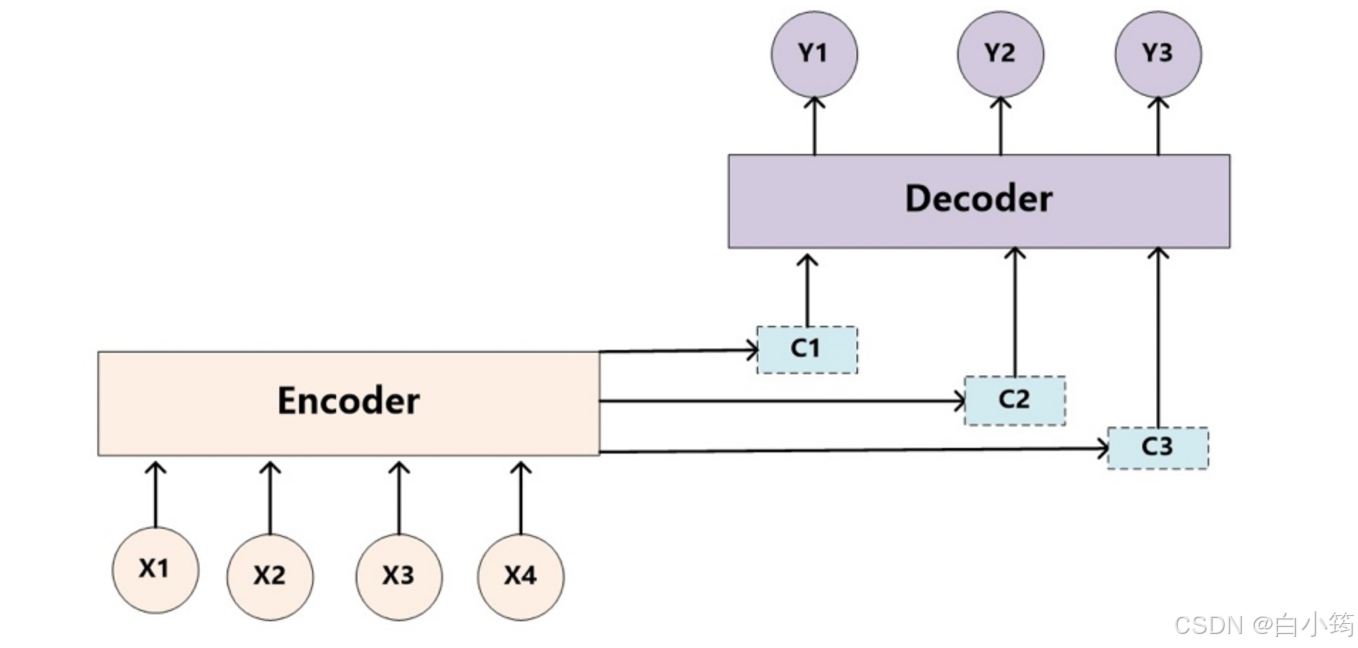
即生成目标句子单词的过程成了下面的形式:
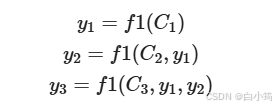
而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:
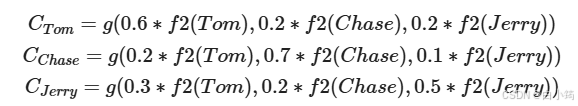
f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即下列公式
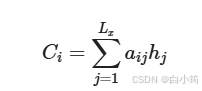
Lx代表输入句子source的长度, a_ij代表在Target输出第i个单词时source输入句子中的第j个单词的注意力分配系数, 而hj则是source输入句子中第j个单词的语义编码, 假设Ci下标i就是上面例子所说的'汤姆', 那么Lx就是3, h1=f('Tom'), h2=f('Chase'),h3=f('jerry')分别输入句子每个单词的语义编码, 对应的注意力模型权值则分别是0.6, 0.2, 0.2, 所以g函数本质上就是加权求和函数。
如何得到注意力概率分布
为了便于说明,我们假设Encoder-Decoder框架中,Encoder和Decoder都采用RNN模型,如下图4所示:
那么注意力分配概率分布值的通用计算过程如下:
上图中h_i表示Source中单词j对应的隐层节点状态h_j,H_i表示Target中单词i的隐层节点状态,注意力计算的是Target中单词i对Source中每个单词对齐可能性,即F(h_j,H_i-1),而函数F可以用不同的方法,然后函数F的输出经过softmax进行归一化就得到了注意力分配概率分布。
上面就是经典的Soft Attention模型的基本思想,区别只是函数F会有所不同
Attention机制的本质思想
其实Attention机制可以看作,Target中每个单词是对Source每个单词的加权求和,而权重是Source中每个单词对Target中每个单词的重要程度。
将Source中的构成元素看作是一系列的数据对,给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,即权重系数;然后对Value进行加权求和,并得到最终的Attention数值。将本质思想表示成公式如下:
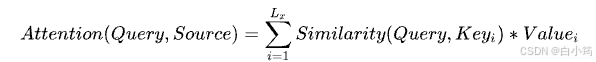 深度学习中的注意力机制中提到:Source 中的 Key 和 Value 合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。因此,Attention计算转换为下面3个阶段
深度学习中的注意力机制中提到:Source 中的 Key 和 Value 合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。因此,Attention计算转换为下面3个阶段
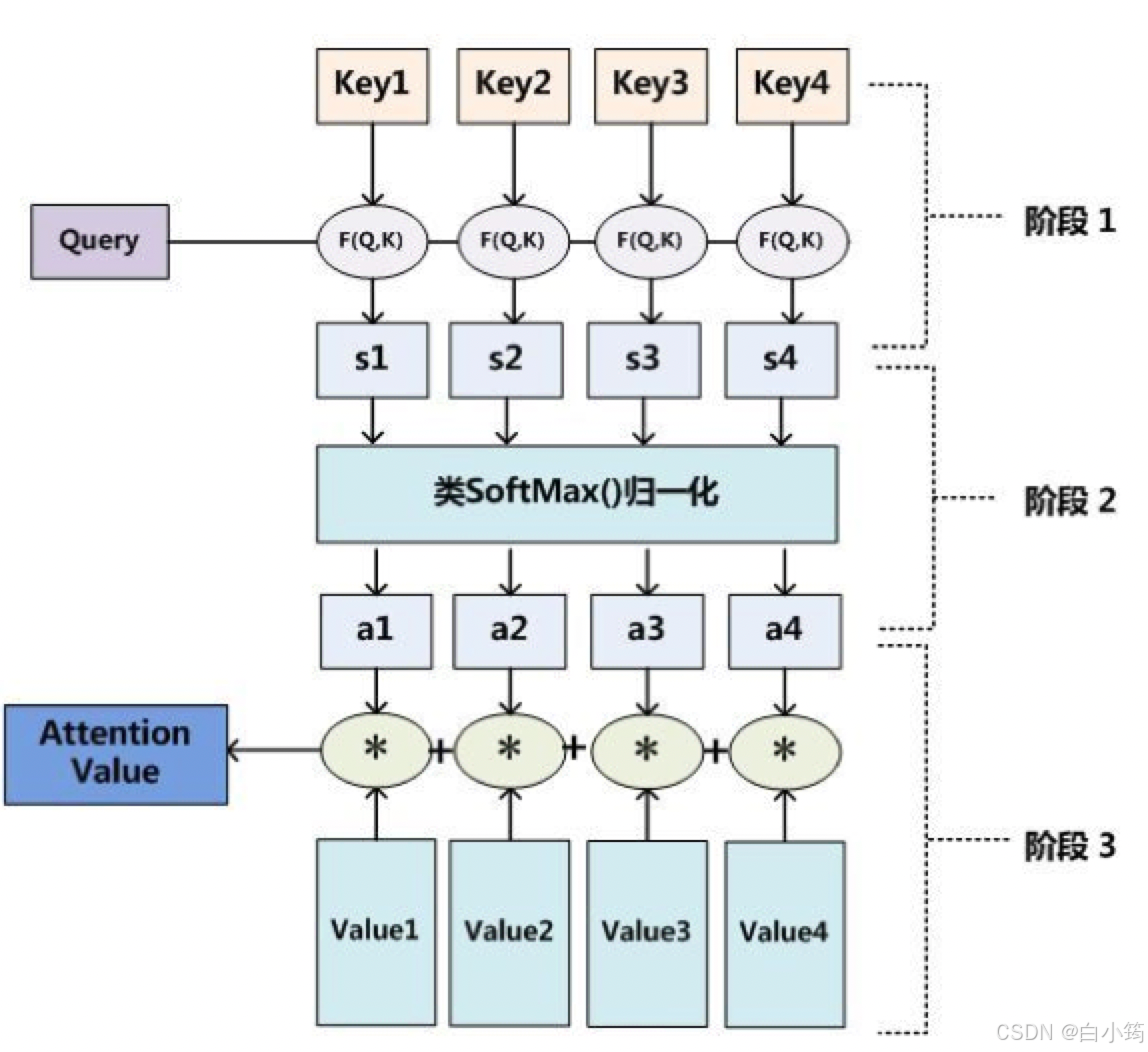
Attention 3步计算过程Attention3步计算过程:
- 第一步:Query和Key进行相似度计算,得到Attention Score;
- 第二步:对Attention Score进行Softmax归一化,得到权值矩阵;
- 第三步:权重矩阵与Value进行加权求和计算。
常见的注意力计算规则
将Q,K进行纵轴拼接, 做一次线性变化, 再使用softmax处理获得结果最后与V做张量乘法
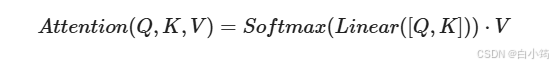
将Q,K进行纵轴拼接, 做一次线性变化后再使用tanh函数激活, 然后再进行内部求和, 最后使用softmax处理获得结果再与V做张量乘法.
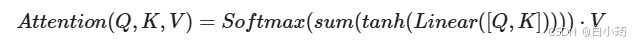
将Q与K的转置做点积运算, 然后除以一个缩放系数, 再使用softmax处理获得结果最后与V做张量乘法.
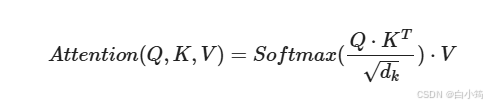
Hard Attention
硬注意力机制是根据注意力分布选择输入向量中的一个作为输出。这里有两种选择方式:
- 选择注意力分布中,分数最大的那一项对应的输入向量作为Attention机制的输出。
- 根据注意力分布进行随机采样,采样结果作为Attention机制的输出。
硬性注意力通过以上两种方式选择Attention的输出,这会使得最终的损失函数与注意力分布之间的函数关系不可导,导致无法使用反向传播算法训练模型,硬性注意力通常需要使用强化学习来进行训练。因此,一般深度学习算法会使用软性注意力的方式进行计算。
Self Attention
Self Attention是Google在transformer模型中提出的,上面介绍的都是一般情况下Attention发生在Target元素Query和Source中所有元素之间。而Self Attention,指的是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力机制。当然,具体的计算过程仍然是一样的,只是计算对象发生了变化而已。
上面内容也有说到,一般情况下Attention本质上是Target和Source之间的一种单词对齐机制。那么如果是Self Attention机制,到底学的是哪些规律或者抽取了哪些特征呢?或者说引入Self Attention有什么增益或者好处呢?仍然以机器翻译为例来说明, 如下图所示
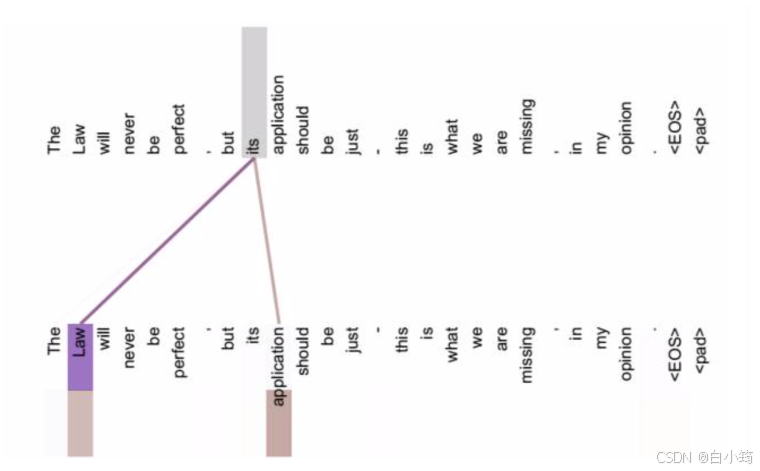
Attention的发展主要经历了两个阶段:
- 从上图中可以看到, self Attention可以远距离的捕捉到语义层面的特征(its的指代对象是Law).
- 应用传统的RNN, LSTM, 在获取长距离语义特征和结构特征的时候, 需要按照序列顺序依次计算, 距离越远的联系信息的损耗越大,
有效提取和捕获的可能性越小. - 但是应用self-attention时, 计算过程中会直接将句子中任意两个token的联系通过一个计算步骤直接联系起来
注意力机制实现步骤
第一步: 根据注意力计算规则, 对Q,K,V进行相应的计算.
第二步: 根据第一步采用的计算方法, 如果是拼接方法,则需要将Q与第二步的计算结果再进行拼接, 如果是转置点积, 一般是自注意力, Q与V相同, 则不需要进行与Q的拼接.
第三步: 最后为了使整个attention机制按照指定尺寸输出, 使用线性层作用在第二步的结果上做一个线性变换, 得到最终对Q的注意力表示.
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# 按照第一种规则实现注意力的计算
class MyAttention(nn.Module):
def __init__(self, query_size, key_size, value_size1, value_size2, output_size):
super().__init__()
self.query_size = query_size
self.key_size = key_size
self.value_size1 = value_size1 # V张量的中间维度
self.value_size2 = value_size2 # V张量的最后一个维度
self.output_size = output_size
self.attweight = nn.Linear(self.query_size + self.key_size, self.value_size1)
self.out = nn.Linear(self.query_size+self.value_size2, self.output_size)
def forward(self, Q, K ,V):
# Q: [1, 1, 32] -> Q[0]=[1, 32]
# K: [1, 1, 32] -> K[0]=[1, 32]
# V: [1, 32, 64]
attn_weights= F.softmax(self.attweight(torch.cat((Q[0], K[0]), dim=-1)), dim=-1) # [1,32]
attn_applied = torch.bmm(attn_weights.unsqueeze(0), V) # [1,1,32] * [1,32,64] = [1,1,64]
# 因为是cat计算的注意力,所以要将查询张量q和注意力加权求和结果进行cat计算,才能得到最终的输出结果
output = self.out(torch.cat((Q[0], attn_applied[0]), dim=-1)) # [1,32] * [1,64] = [1,96] -> [1,32]
return output, attn_weights
# 不进行任何维度变换,直接按照第一种规则实现注意力的计算
class OrMyAttention(nn.Module):
def __init__(self, query_size, key_size, value_size1, value_size2, output_size):
super().__init__()
self.query_size = query_size
self.key_size = key_size
self.value_size1 = value_size1 # V张量的中间维度
self.value_size2 = value_size2 # V张量的最后一个维度
self.output_size = output_size
self.attweight = nn.Linear(self.query_size + self.key_size, self.value_size1)
self.out = nn.Linear(self.query_size+self.value_size2, self.output_size)
def forward(self, Q, K, V):
attn_weights= F.softmax(self.attweight(torch.cat((Q, K), dim=-1)), dim=-1) # [1,1,32]
attn_applied = torch.bmm(attn_weights, V) # [1,1,32] * [1,32,64] = [1,1,64]
# 因为是cat计算的注意力,所以要将查询张量q和注意力加权求和结果进行cat计算,才能得到最终的输出结果
output = self.out(torch.cat((Q, attn_applied), dim=-1)) # [1,1,32] * [1,1,64] = [1,1,96] -> [1,1,32]
return output, attn_weights
if __name__ == '__main__':
query_size = 32
key_size = 32
value_size1 = 32 # 32个单词
value_size2 = 64 # 64个特征
output_size = 32
# 假设了序列长度为1,输入的查询张量q和键张量k的维度都是[1, 1, 32],输入的值张量v的维度是[1, 32, 64]
Q = torch.randn(1, 1, 32)
K = torch.randn(1, 1, 32)
V = torch.randn(1, 32, 64)
# V = torch.randn(1, value_size1, value_size2)
# 1 实例化注意力类 对象
myattobj = MyAttention(query_size, key_size, value_size1, value_size2, output_size)
myattobj2 = OrMyAttention(query_size, key_size, value_size1, value_size2, output_size)
# 2 把QKV数据扔给注意机制,求查询张量q的注意力结果表示、注意力权重分布
output, attn_weights = myattobj(Q, K, V)
print('查询张量q的注意力结果表示output--->', output.shape, output)
print('查询张量q的注意力权重分布attn_weights--->', attn_weights.shape, attn_weights)
output2, attn_weights2 = myattobj2(Q, K, V)
print('查询张量q的注意力结果表示output2--->', output2.shape, output2)
print('查询张量q的注意力权重分布attn_weights2--->', attn_weights2.shape, attn_weights2)RNN案例 seq2seq英译法
seq2seq模型架构
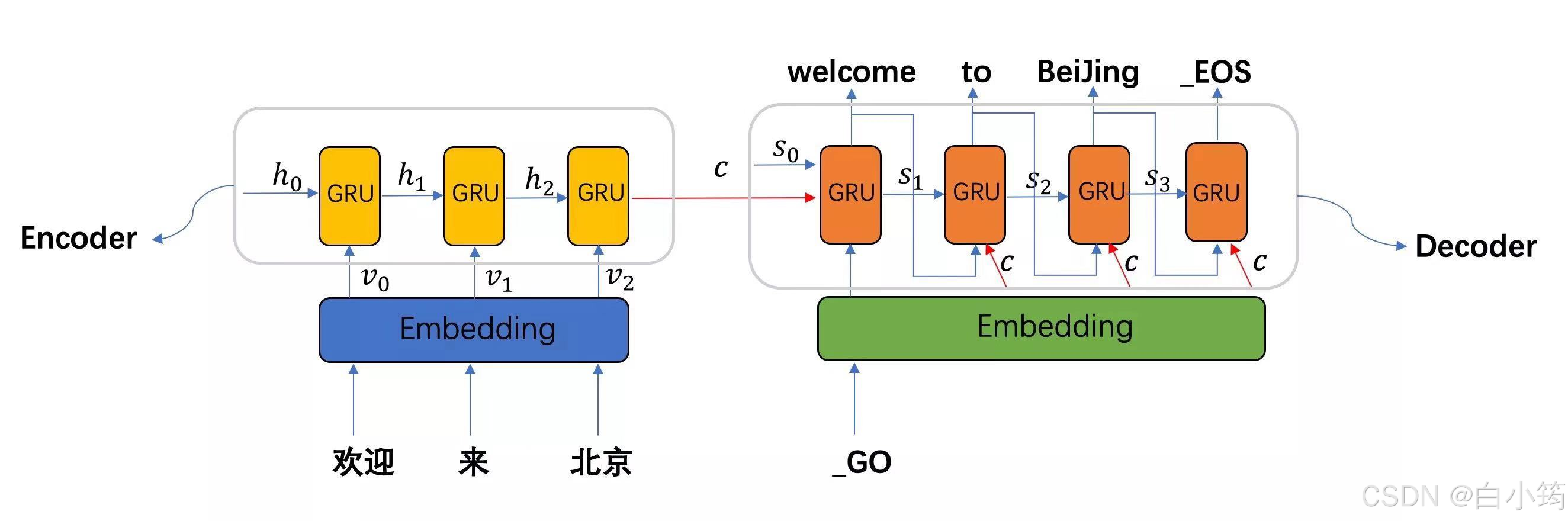
seq2seq模型架构分析:
- seq2seq模型架构包括三部分,分别是encoder(编码器)、decoder(解码器)、中间语义张量c。其中编码器和解码器的内部实现都使用了GRU模型
- 图中表示的是一个中文到英文的翻译:欢迎 来 北京 → welcome to BeiJing。编码器首先处理中文输入"欢迎 来
北京",通过GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c;接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量, - 逐个生成对应的翻译语言
我们的案例通过英译法来讲解seq2seq设计与实现。
导入工具包和工具函数
python
# 用于正则表达式
import re
# 用于构建网络结构和函数的torch工具包
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
# torch中预定义的优化方法工具包
import torch.optim as optim
import time
# 用于随机生成数据
import random
import matplotlib.pyplot as plt
# 设备选择, 我们可以选择在cuda或者cpu上运行你的代码
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 起始标志
SOS_token = 0
# 结束标志
EOS_token = 1
# 最大句子长度不能超过10个 (包含标点)
MAX_LENGTH = 10
# 数据文件路径
data_path = './data/eng-fra-v2.txt'
# 文本清洗工具函数
def normalizeString(s):
"""字符串规范化函数, 参数s代表传入的字符串"""
s = s.lower().strip()
# 在.!?前加一个空格 这里的\1表示第一个分组 正则中的\num
s = re.sub(r"([.!?])", r" \1", s)
# s = re.sub(r"([.!?])", r" ", s)
# 使用正则表达式将字符串中 不是 大小写字母和正常标点的都替换成空格
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s数据预处理
清洗文本和构建文本字典
python
def my_getdata():
# 1 按行读文件 open().read().strip().split(\n)
my_lines = open(data_path, encoding='utf-8').read().strip().split('\n')
print('my_lines--->', len(my_lines))
# 2 按行清洗文本 构建语言对 my_pairs
# 格式 [['英文句子', '法文句子'], ['英文句子', '法文句子'], ['英文句子', '法文句子'], ... ]
# tmp_pair, my_pairs = [], []
# for l in my_lines:
# for s in l.split('\t'):
# tmp_pair.append(normalizeString(s))
# my_pairs.append(tmp_pair)
# tmp_pair = []
my_pairs = [[normalizeString(s) for s in l.split('\t')] for l in my_lines]
print('len(pairs)--->', len(my_pairs))
# 打印前4条数据
print(my_pairs[:4])
# 打印第8000条的英文 法文数据
print('my_pairs[8000][0]--->', my_pairs[8000][0])
print('my_pairs[8000][1]--->', my_pairs[8000][1])
# 3 遍历语言对 构建英语单词字典 法语单词字典
# 3-1 english_word2index english_word_n french_word2index french_word_n
english_word2index = {"SOS": 0, "EOS": 1}
english_word_n = 2
french_word2index = {"SOS": 0, "EOS": 1}
french_word_n = 2
# 遍历语言对 获取英语单词字典 法语单词字典
for pair in my_pairs:
for word in pair[0].split(' '):
if word not in english_word2index:
english_word2index[word] = english_word_n
english_word_n += 1
for word in pair[1].split(' '):
if word not in french_word2index:
french_word2index[word] = french_word_n
french_word_n += 1
# 3-2 english_index2word french_index2word
english_index2word = {v:k for k, v in english_word2index.items()}
french_index2word = {v:k for k, v in french_word2index.items()}
print('len(english_word2index)-->', len(english_word2index))
print('len(french_word2index)-->', len(french_word2index))
print('english_word_n--->', english_word_n, 'french_word_n-->', french_word_n)
return english_word2index, english_index2word, english_word_n, french_word2index, french_index2word, french_word_n, my_pairs构建数据源对象
python
# 原始数据 -> 数据源MyPairsDataset --> 数据迭代器DataLoader
# 构造数据源 MyPairsDataset,把语料xy 文本数值化 再转成tensor_x tensor_y
# 1 __init__(self, my_pairs)函数 设置self.my_pairs 条目数self.sample_len
# 2 __len__(self)函数 获取样本条数
# 3 __getitem__(self, index)函数 获取第几条样本数据
# 按索引 获取数据样本 x y
# 样本x 文本数值化 word2id x.append(EOS_token)
# 样本y 文本数值化 word2id y.append(EOS_token)
# 返回tensor_x, tensor_y
class MyPairsDataset(Dataset):
def __init__(self, my_pairs):
# 样本x
self.my_pairs = my_pairs
# 样本条目数
self.sample_len = len(my_pairs)
# 获取样本条数
def __len__(self):
return self.sample_len
# 获取第几条 样本数据
def __getitem__(self, index):
# 对index异常值进行修正 [0, self.sample_len-1]
index = min(max(index, 0), self.sample_len-1)
# 按索引获取 数据样本 x y
x = self.my_pairs[index][0]
y = self.my_pairs[index][1]
# 样本x 文本数值化
x = [english_word2index[word] for word in x.split(' ')]
x.append(EOS_token)
tensor_x = torch.tensor(x, dtype=torch.long, device=device)
# 样本y 文本数值化
y = [french_word2index[word] for word in y.split(' ')]
y.append(EOS_token)
tensor_y = torch.tensor(y, dtype=torch.long, device=device)
# 注意 tensor_x tensor_y都是一维数组,通过DataLoader拿出数据是二维数据
# print('tensor_y.shape===>', tensor_y.shape, tensor_y)
# 返回结果
return tensor_x, tensor_y构建数据迭代器
python
def dm_test_MyPairsDataset():
# 1 实例化dataset对象
mypairsdataset = MyPairsDataset(my_pairs)
# 2 实例化dataloader
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
for i, (x, y) in enumerate (mydataloader):
print('x.shape', x.shape, x)
print('y.shape', y.shape, y)
if i == 1:
break输出结果:
python
x.shape torch.Size([1, 8]) tensor([[ 2, 16, 33, 518, 589, 1460, 4, 1]])
y.shape torch.Size([1, 8]) tensor([[ 6, 11, 52, 101, 1358, 964, 5, 1]])
x.shape torch.Size([1, 6]) tensor([[129, 78, 677, 429, 4, 1]])
y.shape torch.Size([1, 7]) tensor([[ 118, 214, 1073, 194, 778, 5, 1]])构建基于GRU的编码器和解码器:
构建基于GRU的编码器
python
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
# input_size 编码器 词嵌入层单词数 eg:2803
# hidden_size 编码器 词嵌入层每个单词的特征数 eg 256
super(EncoderRNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 实例化nn.Embedding层
self.embedding = nn.Embedding(input_size, hidden_size)
# 实例化nn.GRU层 注意参数batch_first=True
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
def forward(self, input, hidden):
# 数据经过词嵌入层 数据形状 [1,6] --> [1,6,256]
output = self.embedding(input)
# 数据经过gru层 数据形状 gru([1,6,256],[1,1,256]) --> [1,6,256] [1,1,256]
output, hidden = self.gru(output, hidden)
return output, hidden
def inithidden(self):
# 将隐层张量初始化成为1x1xself.hidden_size大小的张量
return torch.zeros(1, 1, self.hidden_size, device=device)构建基于GRU的解码器
python
class DecoderRNN(nn.Module):
def __init__(self, output_size, hidden_size):
# output_size 编码器 词嵌入层单词数 eg:4345
# hidden_size 编码器 词嵌入层每个单词的特征数 eg 256
super(DecoderRNN, self).__init__()
self.output_size = output_size
self.hidden_size = hidden_size
# 实例化词嵌入层
self.embedding = nn.Embedding(output_size, hidden_size)
# 实例化gru层,输入尺寸256 输出尺寸256
# 因解码器一个字符一个字符的解码 batch_first=True 意义不大
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
# 实例化线性输出层out 输入尺寸256 输出尺寸4345
self.out = nn.Linear(hidden_size, output_size)
# 实例化softomax层 数值归一化 以便分类
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden):
# 数据经过词嵌入层
# 数据形状 [1,1] --> [1,1,256] or [1,6]--->[1,6,256]
output = self.embedding(input)
# 数据结果relu层使Embedding矩阵更稀疏,以防止过拟合
output = F.relu(output)
# 数据经过gru层
# 数据形状 gru([1,1,256],[1,1,256]) --> [1,1,256] [1,1,256]
output, hidden = self.gru(output, hidden)
# 数据经过softmax层 归一化
# 数据形状变化 [1,1,256]->[1,256] ---> [1,4345]
output = self.softmax(self.out(output[0]))
return output, hidden
def inithidden(self):
# 将隐层张量初始化成为1x1xself.hidden_size大小的张量
return torch.zeros(1, 1, self.hidden_size, device=device)构建基于GRU和Attention的解码器
python
class AttnDecoderRNN(nn.Module):
def __init__(self, output_size, hidden_size, dropout_p=0.1, max_length=MAX_LENGTH):
# output_size 编码器 词嵌入层单词数 eg:4345
# hidden_size 编码器 词嵌入层每个单词的特征数 eg 256
# dropout_p 置零比率,默认0.1,
# max_length 最大长度10
super(AttnDecoderRNN, self).__init__()
self.output_size = output_size
self.hidden_size = hidden_size
self.dropout_p = dropout_p
self.max_length = max_length
# 定义nn.Embedding层 nn.Embedding(4345,256)
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
# 定义线性层1:求q的注意力权重分布
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
# 定义线性层2:q+注意力结果表示融合后,在按照指定维度输出
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
# 定义dropout层
self.dropout = nn.Dropout(self.dropout_p)
# 定义gru层
self.gru = nn.GRU(self.hidden_size, self.hidden_size, batch_first=True)
# 定义out层 解码器按照类别进行输出(256,4345)
self.out = nn.Linear(self.hidden_size, self.output_size)
# 实例化softomax层 数值归一化 以便分类
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden, encoder_outputs):
# input代表q [1,1] 二维数据 hidden代表k [1,1,256] encoder_outputs代表v [10,256]
# 数据经过词嵌入层
# 数据形状 [1,1] --> [1,1,256]
embedded = self.embedding(input)
# 使用dropout进行随机丢弃,防止过拟合
embedded = self.dropout(embedded)
# 1 求查询张量q的注意力权重分布, attn_weights[1,10]
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
# 2 求查询张量q的注意力结果表示 bmm运算, attn_applied[1,1,256]
# [1,1,10],[1,10,256] ---> [1,1,256]
attn_applied = torch.bmm(attn_weights.unsqueeze(0), encoder_outputs.unsqueeze(0))
# 3 q 与 attn_applied 融合,再按照指定维度输出 output[1,1,256]
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
# 查询张量q的注意力结果表示 使用relu激活
output = F.relu(output)
# 查询张量经过gru、softmax进行分类结果输出
# 数据形状[1,1,256],[1,1,256] --> [1,1,256], [1,1,256]
output, hidden = self.gru(output, hidden)
# 数据形状[1,1,256]->[1,256]->[1,4345]
output = self.softmax(self.out(output[0]))
# 返回解码器分类output[1,4345],最后隐层张量hidden[1,1,256] 注意力权重张量attn_weights[1,10]
return output, hidden, attn_weights
def inithidden(self):
# 将隐层张量初始化成为1x1xself.hidden_size大小的张量
return torch.zeros(1, 1, self.hidden_size, device=device)构建模型训练函数, 并进行训练
teacher_forcing介绍:
它是一种用于序列生成任务的训练技巧, 在seq2seq架构中, 根据循环神经网络理论,解码器每次应该使用上一步的结果作为输入的一部分, 但是训练过程中,一旦上一步的结果是错误的,就会导致这种错误被累积,无法达到训练效果, 因此,我们需要一种机制改变上一步出错的情况,因为训练时我们是已知正确的输出应该是什么,因此可以强制将上一步结果设置成正确的输出, 这种方式就叫做teacher_forcing.
teacher_forcing的作用:
能够在训练的时候矫正模型的预测,避免在序列生成的过程中误差进一步放大.
teacher_forcing能够极大的加快模型的收敛速度,令模型训练过程更快更平稳.
构建内部迭代训练函数:
python
def Train_Iters(x, y, my_encoderrnn, my_attndecoderrnn, myadam_encode, myadam_decode, mycrossentropyloss):
# 1 编码 encode_output, encode_hidden = my_encoderrnn(x, encode_hidden)
encode_hidden = my_encoderrnn.inithidden()
encode_output, encode_hidden = my_encoderrnn(x, encode_hidden) # 一次性送数据
# [1,6],[1,1,256] --> [1,6,256],[1,1,256]
# 2 解码参数准备和解码
# 解码参数1 encode_output_c [10,256]
encode_output_c = torch.zeros(MAX_LENGTH, my_encoderrnn.hidden_size, device=device)
for idx in range(x.shape[1]):
encode_output_c[idx] = encode_output[0, idx]
# 解码参数2
decode_hidden = encode_hidden
# 解码参数3
input_y = torch.tensor([[SOS_token]], device=device)
myloss = 0.0
y_len = y.shape[1]
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
if use_teacher_forcing:
for idx in range(y_len):
# 数据形状数据形状 [1,1],[1,1,256],[10,256] ---> [1,4345],[1,1,256],[1,10]
output_y, decode_hidden, attn_weight = my_attndecoderrnn(input_y, decode_hidden, encode_output_c)
target_y = y[0][idx].view(1)
myloss = myloss + mycrossentropyloss(output_y, target_y)
input_y = y[0][idx].view(1, -1)
else:
for idx in range(y_len):
# 数据形状数据形状 [1,1],[1,1,256],[10,256] ---> [1,4345],[1,1,256],[1,10]
output_y, decode_hidden, attn_weight = my_attndecoderrnn(input_y, decode_hidden, encode_output_c)
target_y = y[0][idx].view(1)
myloss = myloss + mycrossentropyloss(output_y, target_y)
topv, topi = output_y.topk(1)
if topi.squeeze().item() == EOS_token:
break
input_y = topi.detach()
# 梯度清零
myadam_encode.zero_grad()
myadam_decode.zero_grad()
# 反向传播
myloss.backward()
# 梯度更新
myadam_encode.step()
myadam_decode.step()
# 返回 损失列表myloss.item()/y_len
return myloss.item() / y_len构建模型训练函数
python
def Train_seq2seq():
# 实例化 mypairsdataset对象 实例化 mydataloader
mypairsdataset = MyPairsDataset(my_pairs)
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 实例化编码器 my_encoderrnn 实例化解码器 my_attndecoderrnn
my_encoderrnn = EncoderRNN(2803, 256)
my_attndecoderrnn = AttnDecoderRNN(output_size=4345, hidden_size=256, dropout_p=0.1, max_length=10)
# 实例化编码器优化器 myadam_encode 实例化解码器优化器 myadam_decode
myadam_encode = optim.Adam(my_encoderrnn.parameters(), lr=mylr)
myadam_decode = optim.Adam(my_attndecoderrnn.parameters(), lr=mylr)
# 实例化损失函数 mycrossentropyloss = nn.NLLLoss()
mycrossentropyloss = nn.NLLLoss()
# 定义模型训练的参数
plot_loss_list = []
# 外层for循环 控制轮数 for epoch_idx in range(1, 1+epochs):
for epoch_idx in range(1, 1+epochs):
print_loss_total, plot_loss_total = 0.0, 0.0
starttime = time.time()
# 内层for循环 控制迭代次数
for item, (x, y) in enumerate(mydataloader, start=1):
# 调用内部训练函数
myloss = Train_Iters(x, y, my_encoderrnn, my_attndecoderrnn, myadam_encode, myadam_decode, mycrossentropyloss)
print_loss_total += myloss
plot_loss_total += myloss
# 计算打印屏幕间隔损失-每隔1000次
if item % print_interval_num ==0 :
print_loss_avg = print_loss_total / print_interval_num
# 将总损失归0
print_loss_total = 0
# 打印日志,日志内容分别是:训练耗时,当前迭代步,当前进度百分比,当前平均损失
print('轮次%d 损失%.6f 时间:%d' % (epoch_idx, print_loss_avg, time.time() - starttime))
# 计算画图间隔损失-每隔100次
if item % plot_interval_num == 0:
# 通过总损失除以间隔得到平均损失
plot_loss_avg = plot_loss_total / plot_interval_num
# 将平均损失添加plot_loss_list列表中
plot_loss_list.append(plot_loss_avg)
# 总损失归0
plot_loss_total = 0
# 每个轮次保存模型
torch.save(my_encoderrnn.state_dict(), './my_encoderrnn_%d.pth' % epoch_idx)
torch.save(my_attndecoderrnn.state_dict(), './my_attndecoderrnn_%d.pth' % epoch_idx)
# 所有轮次训练完毕 画损失图
plt.figure()
plt.plot(plot_loss_list)
plt.savefig('./s2sq_loss.png')
plt.show()
return plot_loss_list构建模型评估函数
python
# 模型评估代码与模型预测代码类似,需要注意使用with torch.no_grad()
# 模型预测时,第一个时间步使用SOS_token作为输入 后续时间步采用预测值作为输入,也就是自回归机制
def Seq2Seq_Evaluate(x, my_encoderrnn, my_attndecoderrnn):
with torch.no_grad():
# 1 编码:一次性的送数据
encode_hidden = my_encoderrnn.inithidden()
encode_output, encode_hidden = my_encoderrnn(x, encode_hidden)
# 2 解码参数准备
# 解码参数1 固定长度中间语义张量c
encoder_outputs_c = torch.zeros(MAX_LENGTH, my_encoderrnn.hidden_size, device=device)
x_len = x.shape[1]
for idx in range(x_len):
encoder_outputs_c[idx] = encode_output[0, idx]
# 解码参数2 最后1个隐藏层的输出 作为 解码器的第1个时间步隐藏层输入
decode_hidden = encode_hidden
# 解码参数3 解码器第一个时间步起始符
input_y = torch.tensor([[SOS_token]], device=device)
# 3 自回归方式解码
# 初始化预测的词汇列表
decoded_words = []
# 初始化attention张量
decoder_attentions = torch.zeros(MAX_LENGTH, MAX_LENGTH)
for idx in range(MAX_LENGTH): # note:MAX_LENGTH=10
output_y, decode_hidden, attn_weights = my_attndecoderrnn(input_y, decode_hidden, encoder_outputs_c)
# 预测值作为为下一次时间步的输入值
topv, topi = output_y.topk(1)
decoder_attentions[idx] = attn_weights
# 如果输出值是终止符,则循环停止
if topi.squeeze().item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(french_index2word[topi.item()])
# 将本次预测的索引赋值给 input_y,进行下一个时间步预测
input_y = topi.detach()
# 返回结果decoded_words, 注意力张量权重分布表(把没有用到的部分切掉)
return decoded_words, decoder_attentions[:idx + 1]模型评估函数调用
python
# 加载模型
PATH1 = './gpumodel/my_encoderrnn.pth'
PATH2 = './gpumodel/my_attndecoderrnn.pth'
def dm_test_Seq2Seq_Evaluate():
# 实例化dataset对象
mypairsdataset = MyPairsDataset(my_pairs)
# 实例化dataloader
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 实例化模型
input_size = english_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_encoderrnn = EncoderRNN(input_size, hidden_size)
# my_encoderrnn.load_state_dict(torch.load(PATH1))
my_encoderrnn.load_state_dict(torch.load(PATH1, map_location=lambda storage, loc: storage), False)
print('my_encoderrnn模型结构--->', my_encoderrnn)
# 实例化模型
input_size = french_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_attndecoderrnn = AttnDecoderRNN(input_size, hidden_size)
# my_attndecoderrnn.load_state_dict(torch.load(PATH2))
my_attndecoderrnn.load_state_dict(torch.load(PATH2, map_location=lambda storage, loc: storage), False)
print('my_decoderrnn模型结构--->', my_attndecoderrnn)
my_samplepairs =
[
['i m impressed with your french .', 'je suis impressionne par votre francais .'],
['i m more than a friend .', 'je suis plus qu une amie .'],
['she is beautiful like her mother .', 'elle est belle comme sa mere .']
]
print('my_samplepairs--->', len(my_samplepairs))
for index, pair in enumerate(my_samplepairs):
x = pair[0]
y = pair[1]
# 样本x 文本数值化
tmpx = [english_word2index[word] for word in x.split(' ')]
tmpx.append(EOS_token)
tensor_x = torch.tensor(tmpx, dtype=torch.long, device=device).view(1, -1)
# 模型预测
decoded_words, attentions = Seq2Seq_Evaluate(tensor_x, my_encoderrnn, my_attndecoderrnn)
# print('decoded_words->', decoded_words)
output_sentence = ' '.join(decoded_words)
print('\n')
print('>', x)
print('=', y)
print('<', output_sentence)Attention张量制图:
python
def dm_test_Attention():
# 实例化dataset对象
mypairsdataset = MyPairsDataset(my_pairs)
# 实例化dataloader
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 实例化模型
input_size = english_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_encoderrnn = EncoderRNN(input_size, hidden_size)
# my_encoderrnn.load_state_dict(torch.load(PATH1))
my_encoderrnn.load_state_dict(torch.load(PATH1, map_location=lambda storage, loc: storage), False)
# 实例化模型
input_size = french_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_attndecoderrnn = AttnDecoderRNN(input_size, hidden_size)
# my_attndecoderrnn.load_state_dict(torch.load(PATH2))
my_attndecoderrnn.load_state_dict(torch.load(PATH2, map_location=lambda storage, loc: storage), False)
sentence = "we re both teachers ."
# 样本x 文本数值化
tmpx = [english_word2index[word] for word in sentence.split(' ')]
tmpx.append(EOS_token)
tensor_x = torch.tensor(tmpx, dtype=torch.long, device=device).view(1, -1)
# 模型预测
decoded_words, attentions = Seq2Seq_Evaluate(tensor_x, my_encoderrnn, my_attndecoderrnn)
print('decoded_words->', decoded_words)
# print('\n')
# print('英文', sentence)
# print('法文', output_sentence)
plt.matshow(attentions.numpy()) # 以矩阵列表的形式 显示
# 保存图像
plt.savefig("./s2s_attn.png")
plt.show()
print('attentions.numpy()--->\n', attentions.numpy())
print('attentions.size--->', attentions.size())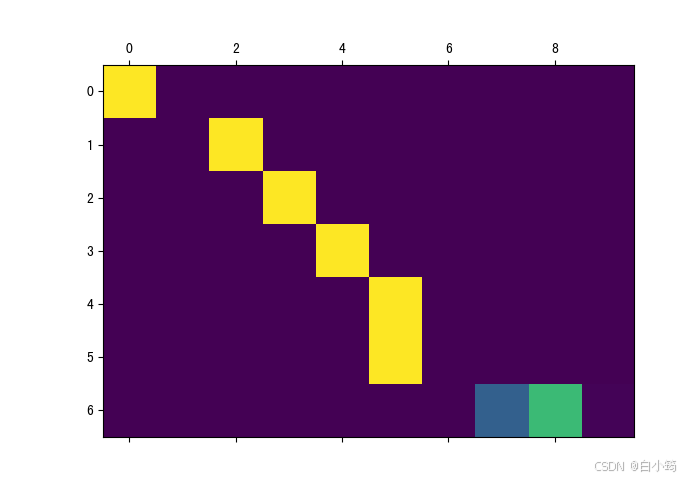
Attention图像的纵坐标代表输入的源语言各个词汇对应的索引, 0-6分别对应"we", "re", "both", "teachers", ".", "", 纵坐标代表生成的目标语言各个词汇对应的索引, 0-7代表'nous', 'sommes', 'toutes', 'deux', 'enseignantes', '.', '', 图中浅色小方块(颜色越浅说明影响越大)代表词汇之间的影响关系, 比如源语言的第1个词汇对生成目标语言的第1个词汇影响最大, 源语言的第4,5个词对生成目标语言的第5个词会影响最大, 通过这样的可视化图像, 我们可以知道Attention的效果好坏, 与我们人为去判定到底还有多大的差距. 进而衡量我们训练模型的可用性.