
摘要
大型语言模型(LLM)经常出现**幻觉现象**,生成**错误或过时的知识**。因此,模型编辑方法应运而生,以实现**针对性的知识更新**。为达到这一目标,主流范式采用**先定位再编辑**的思路:首先定位具有影响力的参数,再通过引入扰动对其进行编辑。尽管该类方法效果显著,但现有研究表明,这种扰动不可避免地会破坏大语言模型中原本保存的知识,尤其在**连续编辑**场景下问题更为突出。 针对上述问题,我们提出 **AlphaEdit** 这一全新解决方案:在对参数施加扰动之前,先将扰动**投影到保留知识的零空间**中。我们从理论上证明,该投影操作能够保证编辑后的模型在被查询保留知识时输出保持不变,从而缓解知识被破坏的问题。 在多种大语言模型上开展的大量实验表明(包括 LLaMA3、GPT2-XL 和 GPT-J),仅需增加一行用于投影的代码,AlphaEdit 即可将大多数"先定位再编辑"方法的性能平均提升 **36.7%**。 代码开源地址:https://github.com/jianghoucheng/AlphaEdit
1 引言
大型语言模型(LLM)已被证明能够在预训练阶段存储海量知识,并在推理阶段对知识进行调用(Brown 等,2020;Petroni 等,2019;Roberts 等,2020;Liu 等,2024)。尽管具备这一能力,这类模型仍频繁出现幻觉问题,生成错误或过时的信息(Cao 等,2021;Mitchell 等,2022a)。虽然基于更新后知识的微调提供了一种直接解决方案,但该方法通常耗时过长,成本难以承受(Mitchell 等,2022b)。有鉴于此,模型编辑方法应运而生,能够在更新目标知识的同时保留模型中的其他知识(Yao 等,2023;Gupta 等,2024)。总体而言,模型编辑方法主要分为两类:
(1)参数修改方法,直接对一小部分参数进行调整(Meng 等,2023;Jiang 等,2025);
(2)参数保留方法,在不改动原始参数的前提下集成额外模块(Huang 等,2023;Yu 等,2024;Hartvigsen 等,2023;Zheng 等,2023)。
本文重点研究用于模型编辑的参数修改方法。具体来说,现有参数修改方法普遍遵循**先定位再编辑**的范式(Meng 等,2022)。其核心思路是:先通过因果追踪定位具有影响力的参数 W,再引入扰动 完成编辑(Li 等,2024b)。求解
的常规目标是最小化待更新知识上的输出误差,记为
。此外,待保留知识上的输出误差
通常也会被加入目标函数,作为约束项以保证模型在保留知识上的准确性。 这类方法虽取得了良好效果,但现有范式存在一个关键局限:难以在知识更新误差
与知识保留误差
之间保持平衡。具体而言,为优先保证更新成功,已有研究通常通过赋予更大权重更侧重最小化
,而对
的控制不足。这会导致编辑后的大型语言模型(即编辑后模型)对待更新知识产生过拟合。这种过拟合会引发模型内部隐层表示的分布偏移。图 1(b)展示了这一偏移现象:
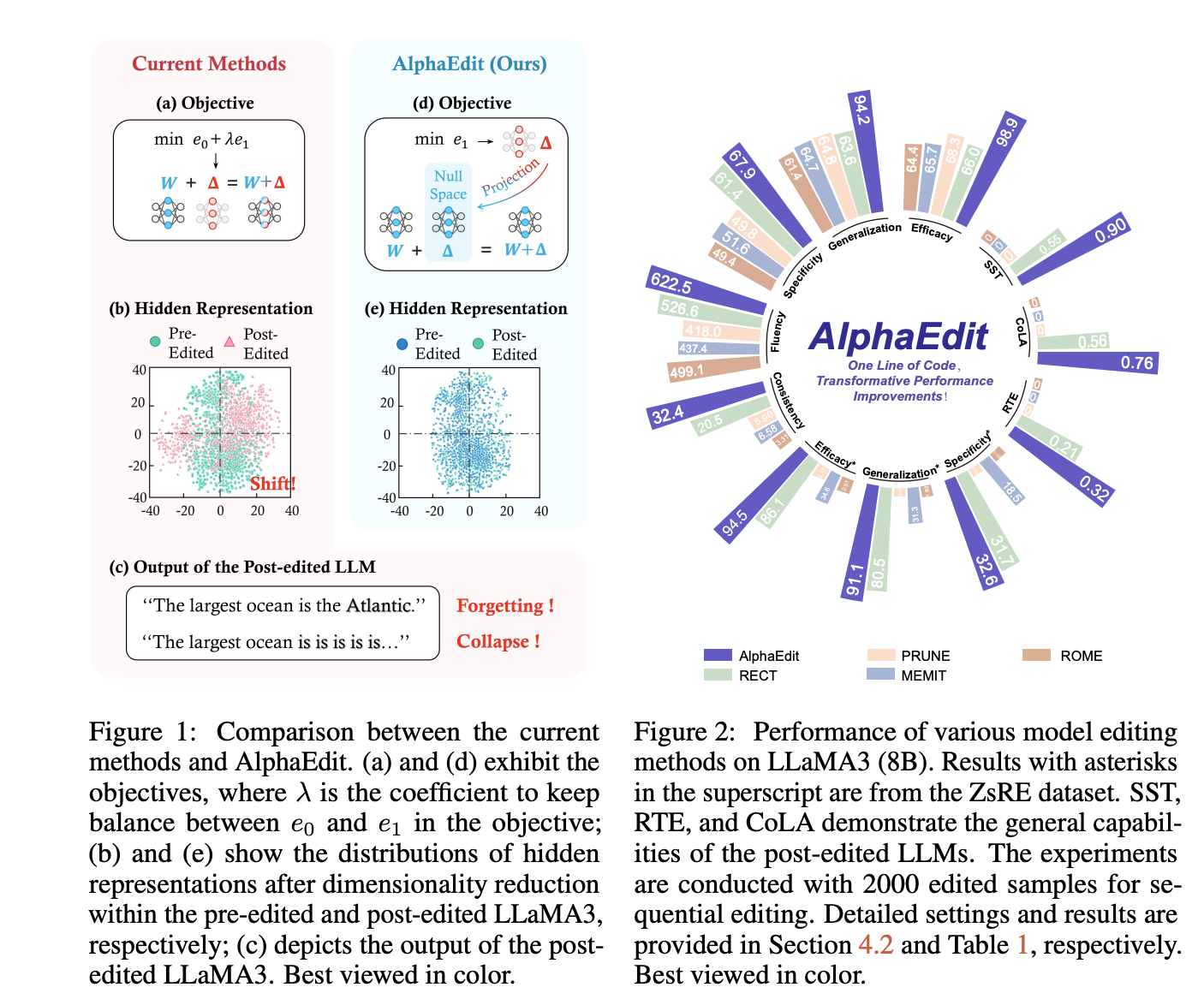
编辑后的 LLaMA-3(8B)(Meta,2024)的隐层表示分布与原始模型(即编辑前模型)出现明显偏离。更严重的是,在模型需要连续执行多次编辑的序列编辑场景中(Gupta & Anumanchipalli,2024),过拟合的累积效应会逐步侵蚀模型的知识保留能力与语句生成连贯性,最终导致模型遗忘与模型崩溃,如图 1(c)所示。 为解决上述问题,我们将 从现有目标函数中移除,使模型能够专注于最小化
而无需权衡。为避免对待更新知识过拟合,我们将这一新目标的解**投影到保留知识的零空间**(Wang 等,2021),再将其应用于模型参数,如图 1(d)所示。借助矩阵投影与零空间的数学性质,我们的新目标能够保证编辑后模型的隐层表示分布保持不变,如图 1(e)所示。这一不变性使得编辑后模型在降低
的同时,可将
维持在接近零的水平,从而缓解模型遗忘与模型崩溃问题。我们在第 3 节给出了详细的理论证明。简而言之,我们将该方法命名为 **AlphaEdit**,一种简洁高效、面向大型语言模型的零空间约束编辑方案。 为验证方法有效性,我们在多个具有代表性的大型语言模型上开展了大量实验,包括 GPT-2 XL(Radford 等,2019)与 LLaMA-3(8B)。结果表明,相较于表现最优的基线方法,仅需在经典模型编辑方法 MEMIT(Meng 等,2023)中增加一行代码,AlphaEdit 即可实现平均 **36.7% 以上**的性能提升,如图 2 所示。此外,实验验证表明,这一简洁的优化策略可轻松集成到大多数现有模型编辑方法中(Ma 等,2024;Gu 等,2024),作为即插即用的增强模块显著提升其性能。这体现了 AlphaEdit 在大型语言模型高效知识更新中的重要价值,可为该领域的更广泛应用与未来发展提供支撑。
2 预备知识
2.1 自回归语言模型
自回归大型语言模型(LLM)根据序列中已有的 token 预测下一个 token \(x\)。具体而言,模型中第 \(l\) 层对应 \(x\) 的隐状态记为 \(h_l\),其计算方式为:,其中 \(a_l\) 和 \(m_l\) 分别表示注意力模块与前馈网络(FFN)层的输出;
和
为前馈层的权重矩阵;
为非线性激活函数,
表示层归一化。参照 Meng 等人(2022)的设置,本文将注意力模块与前馈模块并行表示。 值得注意的是,前馈网络中的 \(W_{\text{out}}^l\) 通常被解释为线性关联存储器,承担键值对形式的信息存储与检索功能(Geva et al., 2021)。具体来说,如果将大语言模型中存储的知识形式化为三元组
------分别表示主体 \(s\)、关系 \(r\) 和客体 \(o\)(例如 \(s=\text{"最近一届奥运会"}\),\(r=\text{"举办地是"}\),\(o=\text{"巴黎"}\))------那么 \(W_{\text{out}}^l\) 将一组编码 \((s,r)\) 的输入键 \(k\) 与对应编码 \(o\) 的值 \(v\) 相关联,即:
这一解释启发了大多数模型编辑方法通过修改前馈网络层实现知识更新(Hase et al., 2023; Li et al., 2024a; Hu et al., 2024)。为简化表述,后续章节统一用 \(W\) 代指 。
2.2 大语言模型中的模型编辑
模型编辑旨在通过单次或多次编辑(即连续编辑)更新大语言模型中存储的知识。在"先定位再编辑"范式下,每次编辑通过添加一个扰动 \(\Delta\) 来修改模型参数 \(W\)。具体而言,假设每次编辑需要更新 u 条 \((s,r,o)\) 形式的知识,施加扰动后的 \(W\) 应能关联 \(u\) 组新的键值对,其中键 \(k\) 与值 \(v\) 分别编码新知识的 \((s,r)\) 与 \(o\)。设 ,其中 \(d_0\) 和 \(d_1\) 分别为前馈网络中间层与输出层的维度。将这些键与值按列拼接为矩阵:
其中 \(k,v\) 的下标对应待更新知识的编号。
据此,优化目标可写为:
其中 表示矩阵所有元素的平方和。 此外,令 \(K_0,V_0\) 为由待保留知识的键值对拼接而成的矩阵。现有方法(Meng et al., 2023; Gu et al., 2024)通常引入包含 \(K_0,V_0\) 的误差项以实现知识保留,形式如下:
(5)
由于 编码模型中需要保留的知识,因此满足
(参见式 (2))。利用正规方程(Lang, 2012),若式 (5) 存在闭式解,则可写为:
(6)
尽管难以直接获取 \(K_0\)(因为我们几乎无法获得模型存储的全部知识),但可通过大量文本输入进行估计(Meng et al., 2023)。在实际应用中,通常从维基百科随机抽取 100,000 个 \((s,r,o)\) 三元组来编码 \(K_0\)(Meng et al., 2023),使得 \(K_0\) 成为一个具有 100,000 列的高维矩阵(即 。具体实现步骤见附录 B.1。
3 方法
在本节中,我们首先介绍**零空间**的概念及其与模型编辑的关系(第 3.1 节)。以此为基础,我们给出将给定扰动 ∆ 投影到编码保留知识的矩阵 \(K_0\) 之零空间的方法(第 3.2 节)。随后,在第 3.3 节中提出一种融合了上述投影操作的全新编辑优化目标。
3.1 零空间
零空间是本文工作的核心。我们首先给出**左零空间**(下文简称为零空间)的定义:给定两个矩阵 \(A\) 和 \(B\),当且仅当满足 \(BA=0\) 时,称 \(B\) 位于 \(A\) 的零空间中。更多细节可参见 Adam-NSCL(Wang 等,2021)。 在模型编辑场景下,如果将扰动 ∆ 投影到 \(K_0\) 的零空间(即 ,其中
表示投影后的扰动),再将其加入参数 \(W\),可得:
这表明经过投影的扰动不会破坏需要保留的知识所对应的键值对关联 \(\{K_0,V_0\}\),从而保证模型中原有知识的存储不受影响。 因此,本文在将扰动 ∆ 加入模型参数 \(W\) 之前,先将其投影到 \(K_0\) 的零空间以保护保留知识。这一保护机制使我们可以将式 (5) 目标函数中用于约束保留知识的第一项移除。
3.2 零空间投影
在 3.1 节中,我们简要说明了为何需要将 ∆ 投影到 \(K_0\) 的零空间。本节重点介绍该投影的具体实现方式。 如第 2.2 节末尾所述,矩阵 具有高维度,包含 100,000 列。因此,直接将扰动 ∆ 投影到 \(K_0\) 的零空间会面临巨大的计算与存储开销。为此,我们采用非中心化协方差矩阵
的零空间作为替代,以降低计算复杂度,因为 \(d_0\) 通常远小于 100,000。该矩阵与 \(K_0\) 的零空间完全等价(详细证明见附录 B.2)。 借鉴现有零空间投影方法(Wang 等,2021),我们首先对 \(K_0K_0^\top\) 进行**奇异值分解(SVD)**:
其中 \(U\) 的每一列均为 \(K_0K_0^\top\) 的特征向量。随后,移除 \(U\) 中对应非零特征值的特征向量,并将剩余部分记为子矩阵 \(\hat{U}\)。据此,投影矩阵 \(P\) 可定义为: \ P = \\hat{U}\\hat{U}\^\\top. \\tag{9} \\ 该投影矩阵可将 ∆ 的列向量映射到 \(K_0K_0^\top\) 的零空间,因其满足 \(\Delta P \cdot K_0K_0^\top = 0\)。详细推导见附录 B.3。由于 \(K_0\) 与 \(K_0K_0^\top\) 共享同一零空间,可得 \(\Delta P \cdot K_0 = 0\)。因此: \ (W+\\Delta P)K_0 = WK_0 = V_0. \\tag{10} \\ 这表明投影矩阵 \(P\) 能够保证模型编辑不会干扰大语言模型中已保留的知识。
3.3 基于零空间约束的模型编辑
第 3.2 节已经给出如何通过投影操作保证保留知识不被破坏。本节介绍如何利用该投影优化现有的模型编辑目标函数。从式 (5) 中的单次编辑目标出发,优化过程分为三步:
(1) 将扰动 \(\Delta\) 替换为经过投影的扰动 ,以保证扰动不会破坏需要保留的知识;
(2) 移除目标中与 \(K_0\) 相关的项,因为步骤 (1) 已经确保保留知识不被破坏;
(3) 加入正则项 \(\|\Delta P\|_2\) 以保证收敛稳定。 经过上述优化,式 (5) 变为:
其中 \(K_1\) 和 \(V_1\) 为式 (3) 所定义的待更新知识的键矩阵与值矩阵。 在连续编辑任务中,执行当前编辑时,需要在目标函数(参见式 (11))中额外加入一项,以避免扰动破坏此前编辑所更新的知识。设 \(K_p\) 和 \(V_p\) 为历史更新知识对应的键矩阵与值矩阵,定义方式与前文 \(K_1\)、\(V_1\) 一致。该项应最小化 以保护对应的键值关联。由于相关知识已在历史编辑中完成更新,满足 \(WK_p=V_p\),因此该项可简化为
。将其加入式 (11) 后得到新的优化目标: \ \\Delta = \\mathop{\\arg\\min}_{\\tilde{\\Delta}} \\Big( \\big\\\|(W+\\tilde{\\Delta}P)K_1-V_1\\big\\\|_2 + \\big\\\|\\tilde{\\Delta}P\\big\\\|_2 + \\big\\\|\\tilde{\\Delta}PK_p\\big\\\|_2 \\Big). \\tag{12} \\ 为便于表达,我们将当前编辑的残差向量定义为 \(R=V_1-WK_1\)。在此基础上,可通过正规方程(Lang, 2012)求解式 (12): \ (\\Delta PK_1-R)K_1\^\\top P + \\Delta P + \\Delta PK_pK_p\^\\top P = 0. \\tag{13} \\ 求解式 (13) 即可得到最终扰动 \(\Delta_{\text{AlphaEdit}}=\Delta P\),并将其加入模型参数 \(W\): \ \\Delta_{\\text{AlphaEdit}} = RK_1\^\\top P \\big(K_pK_p\^\\top P + K_1K_1\^\\top P + I\\big)\^{-1}. \\tag{14} \\ 详细推导过程及括号内矩阵的可逆性证明分别见附录 B.4 与 B.5。该解 \(\Delta_{\text{AlphaEdit}}\) 不仅能让模型存储当前编辑的待更新知识,还能保证原有保留知识与历史更新知识均不受影响。 此外,为便于对比,我们给出 MEMIT(Meng et al., 2023)等现有方法的常用解形式如下: \ \\Delta_{\\text{MEMIT}} = RK_1\^\\top \\big(K_pK_p\^\\top + K_1K_1\^\\top + K_0K_0\^\\top\\big)\^{-1}. \\tag{15} \\ 对比式 (14) 与 (15) 可以明显看出,本方法仅在标准解的基础上加入投影矩阵 \(P\) 做微小改动,因此可以轻松集成到现有模型编辑算法中。图 3 从收敛目标的角度总结了这一改动。我们强调:仅需增加一行代码实现该修改,即可显著提升多数编辑方法的效果,如图 2 所示。更详细的实验结果见第 4 节。 不仅如此,由于投影矩阵 \(P\) 完全独立于待更新知识,只需计算一次,便可直接用于任意下游编辑任务。因此,与基线方法相比,AlphaEdit 带来的额外时间开销几乎可以忽略,兼具高效性与有效性。