在无监督学习中,聚类和降维是两种最常见的算法,不过它们应用场景很不一样。聚类我们说过了,主要可以用来做分组;而降维,则是通过数学变换,将原始高维属性空间转变为一个低维"子空间",它本质上是通过最主要的几个特征维度实现对数据的描述。
聚类算法可以让机器把数据集中的样本按照特征的性质分组,不过它只是帮我们把数据特征彼此邻近的用户聚成一组(这里的组称为聚类的簇)。而这里说的"特征彼此邻近",指的这些用户的数据特征在坐标系中有更短的向量空间距离。也就是说,聚类算法是把空间位置相近的特征数据归为同一组。
聚类算法本身并不知道哪一组用户是高价值,哪一组用户是低价值。分完组之后,我们还要根据机器聚类的结果,人为地给这些用户组贴标签,看看哪一组价值高,哪一组价值低。我这里把这种人为贴标签的过程称为"聚类后概念化"。
一、聚类算法------K-Means(K- 均值)算法
这个算法不仅简洁,而且效率也高,是我们最常用的聚类算法。像文档归类、欺诈行为检测、用户分组等等这些场景,我们往往都能用到。
在 K-Means 算法中,"K"是一个关键。K 代表聚类的簇(也就是组)的个数。比如说,我们想把 M 值作为特征,将用户分成 3 个簇(即高、中、低三个用户组),那这里的 K 值就是 3,并且需要我们人工指定。
指定 K 的数值后,K-Means 算法会在数据中随机挑选出 K 个数据点,作为簇的质心(centroid),这些质心就是未来每一个簇的中心点,算法会根据其它数据点和它的距离来进行聚类。
挑选出质心后,K-Means 算法会遍历每一个数据点,计算它们与每一个质心的距离(比如欧式距离)。数据点离哪个质心近,就跟哪个质心属于一类。
遍历结束后,每一个质心周围就都聚集了很多数据点,这时候啊,算法会在数据簇中选择更靠近中心的质心,如果原来随机选择的质心不合适,就会让它下岗。
在整个聚类过程中,为了选择出更好的质心,"挑选质心"和"遍历数据点与质心的距离"会不断重复,直到质心的移动变化很小了,或者说固定不变了,那 K-Means 算法就可以停止了。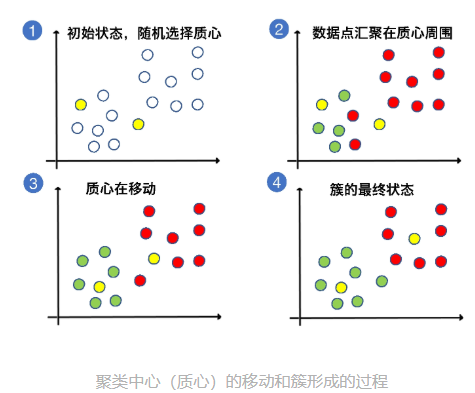
我们前面说 K 值需要人工指定,那怎么在算法的辅助下确定 K 值呢?
手肘法选取 K 值
其实,在事先并不是很确定分成多少组比较合适的情况下,"手肘法"(elbow method)可以帮我们决定,在某一批数据点中,数据分为多少组比较合适。
手肘法是通过聚类算法的损失值曲线来直观确定簇的数量。损失值曲线,就是以图像的方法绘出,取每一个 K 值时,各个数据点距离质心的平均距离。如下图所示,当 K 取值很小的时候,整体损失很大,也就是说各个数据点距离质心的距离特别大。而随着 K 的增大,损失函数的值会在逐渐收敛之前出现一个拐点。此时的 K 值就是一个比较好的值。
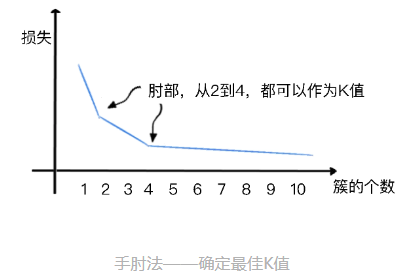
你看图中,损失随着簇的个数而收敛的曲线大概像个手臂,最佳 K 值的点像是一个手肘,这就是为什么我们会叫它"手肘法"的原因。