概述
一个机器学习项目从开始到结束大致分为 5 步,分别是定义问题、收集数据和预处理、选择算法和确定模型、训练拟合模型、评估并优化模型性能。当然这 5 步是一个循环迭代的过程:
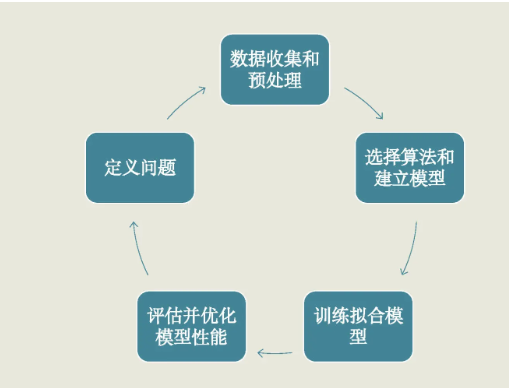
一、定义问题
(1)需求梳理
(2)分析
是监督学习还是无监督学习,属于哪种算法
二、收集数据和预处理
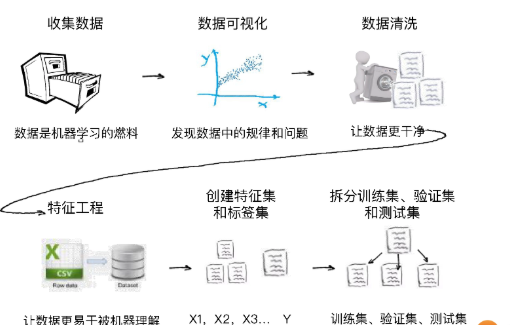
"数据的收集和预处理"在所有机器学习项目中都会出现,它的作用是为机器学习模型提供好的燃料。数据好,模型才跑得更带劲。这步骤看似只有一句话,其实里面包含了好几个小步骤,完整来讲有 6 步:收集数据;数据可视化;数据清洗;特征工程;构建特征集和标签集;拆分训练集、验证集和测试集。
1、收集数据
首先是收集数据,这一步又叫采集数据。不过,在现实中,收集数据通常很辛苦,要在运营环节做很多数据埋点、获取用户消费等行为信息和兴趣偏好信息,有时候还需要上网爬取数据。
2、数据可视化
(1)解析数据
在正式可视化之前,需要把收集到的数据导入运行环境。数据导入我们需要用到 Pandas 数据处理工具包。这个包可是操作数据的利器,DataFrame 是机器学习中常见的二维表格类型数据结构。
import pandas as pd # 导入Pandas数据处理工具包
df_ads = pd.read_csv('xxx.csv') # 读入数据
df_ads.head() # 显示前几行数据(2)可视化
有了数据集,接下来我们要做的是数据可视化的工作,也就是通过可视化去观察一下数据,为选择具体的机器学习模型找找感觉。
数据可视化是个万金油技能,能做的事非常多。比如说,可以看一看特征和标签之间可能存在的关系,也可以看看数据里有没有"脏数据"和"离群点"等。
3、数据清洗
很多人都把数据清洗比作"炒菜"前的"洗菜",也就是说数据越干净,模型的效果也就越好。清洗的数据一般分为 4 种情况:
(1)处理缺失的数据
如果备份系统里面有缺了的数据,那我们尽量补录;如果没有,我们可以剔除掉残缺的数据,也可以用其他数据记录的平均值、随机值或者 0 值来补值。这个补值的过程叫数据修复。
(2)处理重复的数据
如果是完全相同的重复数据处理,删掉就行了。可如果同一个主键出现两行不同的数据,比如同一个身份证号后面有两条不同的地址,我们就要看看有没有其他辅助的信息可以帮助我们判断(如时戳),要是无法判断的话,只能随机删除或者全部保留。
(3)处理错误的数据
比如商品的销售量、销售金额出现负值,这时候就需要删除或者转成有意义的正值。再比如表示百分比或概率的字段,如果值大于 1,也属于逻辑错误数据。
(4)处理不可用的数据
这指的是整理数据的格式,比如有些商品以人民币为单位,有些以美元为单位,就需要先统一。另一个常见例子是把"是"、"否"转换成"1"、"0"值再输入机器学习模型。
4、特征工程
特征工程是一个专门的机器学习子领域,而且我认为它是数据处理过程中最有创造力的环节,特征工程做得好不好,非常影响机器学习模型的效率。
举例:你知道什么是 BMI 指数吗?它等于体重除以身高的平方,这就是一个特征工程。就是说经过了这个过程,BMI 这一个指数就替代了原来的两个特征------体重和身高,而且完全能客观地描绘我们的身材情况。
因此,经过了这个特征工程,我们可以把 BMI 指数作为新特征,输入用于评估健康情况的机器学习模型。
这样做的好处是什么?以 BMI 特征工程为例,它降低了特征数据集的维度。维度就是数据集特征的个数。要知道,在数据集中,每多一个特征,模型拟合时的特征空间就更大,运算量也就更大。所以,摒弃掉冗余的特征、降低特征的维度,能使机器学习模型训练得更快。
当然,如果问题相对简单,对特征工程的要求并不高。
5、构建特征集和标签集
无监督学习算法需要这个步骤吗?答案是不需要。因为无监督算法根本就没有标签。
特征就是所收集的各个数据点,是要输入机器学习模型的变量。而标签是要预测、判断或者分类的内容。对于所有监督学习算法,我们都需要向模型中输入"特征集"和"标签集"这两组数据。因此,在开始机器学习的模型搭建之前,我们需要先构建一个特征数据集和一个标签数据集。
不过,从原数据集从列的维度纵向地拆分成了特征集和标签集后,还需要进一步从行的维度横向拆分。为啥还要拆分呀?因为机器学习并不是通过训练数据集找出一个模型就结束了,我们需要用验证数据集看看这个模型好不好,然后用测试数据集看看模型在新数据上能不能用。
6、拆分训练集、验证集和测试集
说明:对于学习型项目来说,为了简化流程,经常会省略验证的环节。这个例子比较简单,所以我们也省略了验证,只拆分训练集和测试集,而此时的测试集就肩负着验证和测试双重功能了。
拆分的时候,留作测试的数据比例一般是 20% 或 30%。不过如果你的数据量非常庞大,比如超过 1 百万的时候,那你也不一定非要留这么多。一般来说有上万条的测试数据就足够了。这里我会按照 80/20 的比例来拆分数据。具体的拆分,我们会用机器学习工具包 scikit-learn 里的数据集拆分工具 train_test_split 来完成:
#将数据集进行80%(训练集)和20%(验证集)的分割
from sklearn.model_selection import train_test_split #导入train_test_split工具
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=0)虽然是随机分割,但我们要指定一个 random_state 值,这样就保证程序每次运行都分割一样的训练集和测试集。训练集和测试集每次拆分都不一样的话,那比较模型调参前后的优劣就失去了固定的标准。现在,训练集和测试集拆分也完成了:
特征训练集(X_train)、特征测试集(X_test)、标签训练集(y_train)、标签测试集(y_test)
三、选择算法并建立模型
1、确定算法
在这一步中,我们需要先根据特征和标签之间的关系,选出一个合适的算法,并找到与之对应的合适的算法包,然后通过调用这个算法包来建立模型,选算法的过程很考验数据科学家们的经验。
一般来说,我们在解决具体问题的时候,会选择多种算法进行建模,相互比较之后,再确定比较适合的模型。
2、建立模型
确定好算法后,我们接着来看一下调用什么样的算法包建立模型比较合适。比如我们已经选定使用线性回归算法,但是在 sklearn 中又有很多线性回归算法包,比如说基本的线性回归算法 LinearRegression,以及在它的基础上衍生出来的 Lasso 回归和 Ridge 回归等。
那哪一个才是适合的算法包呢?其实,我们一般选算法包的方法是从能够解决该问题的最简单的算法开始尝试,直到得到满意的结果为止。其中LinearRegression,它也是机器学习中最常见、最基础的回归算法包。
模型已经创建出来了,我们可以开始训练它了。不过,有一点需要指出,建立模型时,你通常还需要了解它有哪些外部参数,同时指定好它的外部参数的值。
from sklearn.linear_model import LinearRegression # 导入线性回归算法模型
linereg_model = LinearRegression() # 使用线性回归算法创建模型模型的参数有两种:内部参数和外部参数。内部参数是属于算法本身的一部分,不用我们人工来确定,刚才提到的权重 w 和截距 b,都是线性回归模型的内部参数;而外部参数也叫做超参数,它们的值是在创建模型时由我们自己设定的。对于 LinearRegression 模型来讲,它的外部参数主要包括两个布尔值:
fit_intercept ,默认值为 True,代表是否计算模型的截距。
normalize,默认值为 False,代表是否对特征 X 在回归之前做规范化。
不过呢,对于比较简单的模型来说,默认的外部参数设置也都是不错的选择,所以,我们不显式指定外部参数而直接调用模型,也是可以的。在上面的代码中,我就是在创建模型时直接使用了外部参数的默认值。
四、训练模型
训练模型就是用训练集中的特征变量和已知标签,根据当前样本的损失大小来逐渐拟合函数,确定最优的内部参数,最后完成模型。虽然看起来挺复杂,但这些步骤,我们都通过调用 fit 方法来完成。
linereg_model.fit(X_train, y_train) # 用训练集数据,训练机器,拟合函数,确定内部参数这样,我们就完成了对模型的训练。既然训练模型是机器学习的核心环节,怎么只有一句代码?由于优秀的机器学习库的存在,我们可以用一两行语句实现很强大的功能。所以,不要小看上面那个简单的 fit 语句,这是模型进行自我学习的关键过程。
fit 方法是机器学习的核心环节,里面封装了很多具体的机器学习核心算法,我们只需要把特征训练数据集和标签训练数据集,同时作为参数传进 fit 方法就行了。在这个过程里,fit 的核心就是减少损失,使函数对特征到标签的模拟越来越贴切。这个拟合的过程,同时也是机器学习算法优化其内部参数的过程。而优化参数的关键就是减小损失。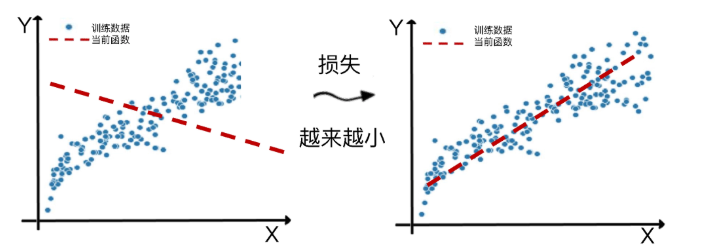
那什么是损失呢?它其实是对糟糕预测的惩罚,同时也是对模型好坏的度量。损失也就是模型的误差,也称为成本或代价。名字虽多,但都是一个意思,就是当前预测值和真实值之间的差距的体现。它是一个数值,表示对于单个样本而言模型预测的准确程度。如果模型的预测完全准确,则损失为 0;如果不准确,就有损失。在机器学习中,我们追求的当然是比较小的损失。不过,模型好不好,还不能仅看单个样本,还要针对所有数据样本,找到一组平均损失"较小"的函数模型。样本的损失大小,从几何意义上基本可以理解为预测值和真值之间的几何距离。平均距离越大,说明误差越大,模型越离谱。在下面这个图中,左边是平均损失较大的模型,右边是平均损失较小的模型,模型所有数据点的平均损失很明显大过右边模型。
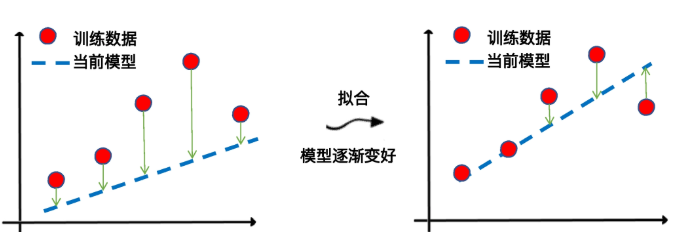
因此,针对每一组不同的参数,机器都会基于样本数据集,用损失函数算一次平均损失。而机器学习的最优化过程,就是逐步减小训练集上损失的过程。具体到我们今天这个回归模型的拟合,它的关键环节就是通过梯度下降,逐步优化模型的参数,使训练集误差值达到最小。这也就是我们刚才讲的那个 fit 语句所要实现的最优化过程。
五、模型的评估和优化
1、预测
在几乎所有的机器学习项目中,你都可以用 predict 方法来进行预测,它就是用模型在任意的同类型数据集上去预测真值的,可以应用于验证集、测试集,当然也可以应用于训练集本身。
y_valid_preds_lr = model_lr.predict(X_valid) #用线性回归模型预测验证集
y_valid_preds_dtr = model_dtr.predict(X_valid) #用决策树模型预测验证集
y_valid_preds_rfr = model_rfr.predict(X_valid) #用随机森林模型预测验证集2、人为评估
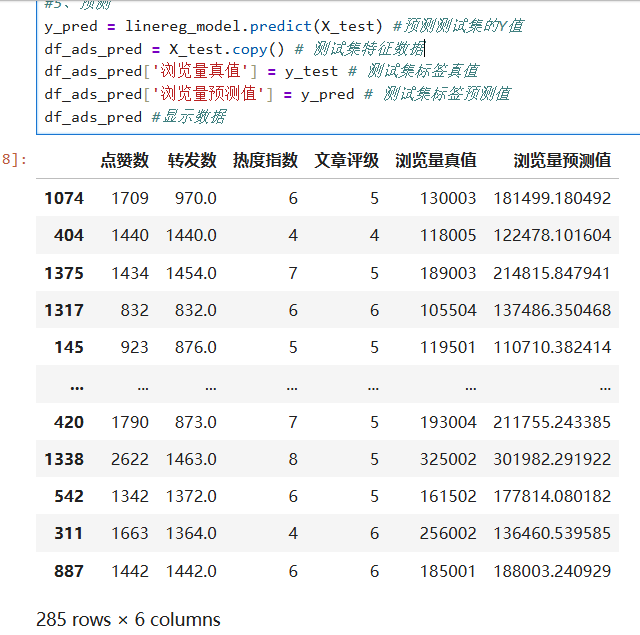
拿到预测结果后,我们可以再通过代码,把测试数据集的原始特征数据、原始标签真值,以及模型对标签的预测值组合在一起进行显示、比较。
df_ads_pred = X_test.copy() # 测试集特征数据
df_ads_pred['浏览量真值'] = y_test # 测试集标签真值
df_ads_pred['浏览量预测值'] = y_pred # 测试集标签预测值
df_ads_pred #显示数据输出:
3、模型自评分
当然,一个数据点接近真值完全不能说明问题,我们还是要用 R2、MSE 等评估指标在验证集上做整体的评估,比较模型的优劣。
from sklearn.metrics import r2_score, median_absolute_error #导入Sklearn评估模块
print('验证集上的R平方分数-线性回归: %0.4f' % r2_score(y_valid, model_lr.predict(X_valid)))
print('验证集上的R平方分数-决策树: %0.4f' % r2_score(y_valid, model_dtr.predict(X_valid)))
print('验证集上的R平方分数-随机森林: %0.4f' % r2_score(y_valid, model_rfr.predict(X_valid)))在机器学习中,常用于评估回归分析模型的指标有两种:R2 分数和 MSE 指标,并且大多数机器学习工具包中都会提供相关的工具。对此,你无需做过多了解,只需要知道我们这里的 score 这个 API 中,选用的是 R2 分数来评估模型的就可以了。
可以看到,R2 值约为 0.708。那这意味着什么呢?一般来说,R2 的取值在 0 到 1 之间,R2 越大,说明所拟合的回归模型越优。现在我们得到的 R2 值约为 0.708,在没有与其它模型进行比较之前,我们实际上也没法确定它是否能令人满意。
如果模型的评估分数不理想,我们就需要回到第 3 步,调整模型的外部参数,重新训练模型。要是得到的结果依旧不理想,那我们就要考虑选择其他算法,创建全新的模型了。如果很不幸,新模型的效果还是不好的话,我们就得回到第 2 步,看看是不是数据出了问题。
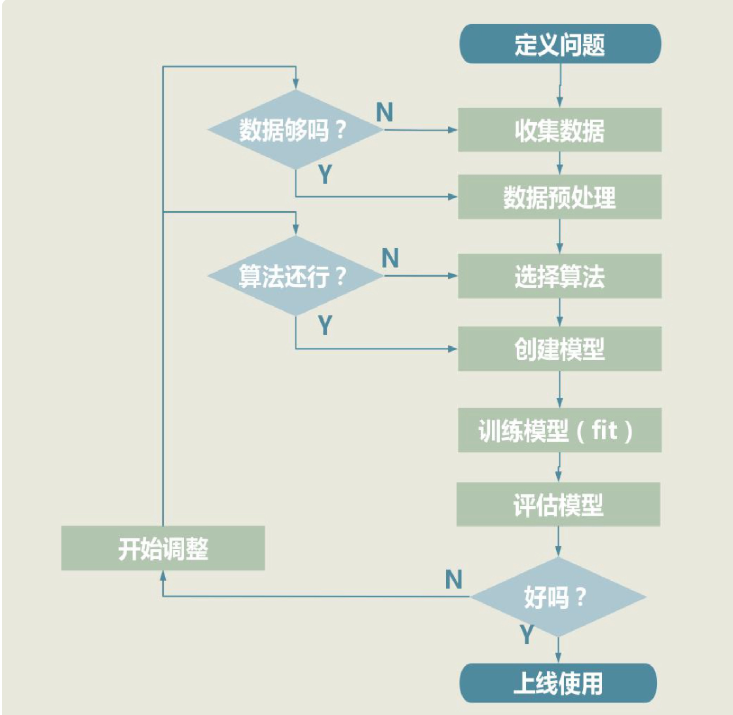
所以说机器学习项目是一个循环迭代的过程,优秀的模型都是一次次迭代的产物。