Ubuntu datasophon1.2.1 二开之九:验证离线数据入湖
- 背景
- 环境准备
- 遇到坑及填平方法
-
- [1.现象: 经典的 NoClassDefFoundError,例如 org/apache/spark/kafka010/KafkaConfigUpdater 和 org/apache/spark/sql/connector/write/Write。](#1.现象: 经典的 NoClassDefFoundError,例如 org/apache/spark/kafka010/KafkaConfigUpdater 和 org/apache/spark/sql/connector/write/Write。)
- [2. Spark与Paimon版本不兼容](#2. Spark与Paimon版本不兼容)
- [3. HDFS权限问题](#3. HDFS权限问题)
- [4. 元数据存储方式选择](#4. 元数据存储方式选择)
- [5. 环境与组件升级](#5. 环境与组件升级)
- [6.Spark 找不到 Kafka 数据源](#6.Spark 找不到 Kafka 数据源)
- [下载匹配版本的 Kafka 依赖](#下载匹配版本的 Kafka 依赖)
- [在 DS Spark 任务的"选项参数"中添加 --jars](#在 DS Spark 任务的"选项参数"中添加 --jars)
-
- [7.Paimon 表创建失败(Derby 权限问题)](#7.Paimon 表创建失败(Derby 权限问题))
- [8.Kafka Topic 不存在](#8.Kafka Topic 不存在)
- [查看所有 topic](#查看所有 topic)
- [使用正确的 topic 名称](#使用正确的 topic 名称)
-
- [9.Spark 版本不匹配导致类找不到](#9.Spark 版本不匹配导致类找不到)
- [10.DolphinScheduler 参数换行问题](#10.DolphinScheduler 参数换行问题)
- [11.Shell 脚本换行符问题](#11.Shell 脚本换行符问题)
- 转换换行符
- [或直接在 DS 的脚本框中编写,不上传文件](#或直接在 DS 的脚本框中编写,不上传文件)
-
- [12.Shell 脚本中 Spark 命令缺少配置](#12.Shell 脚本中 Spark 命令缺少配置)
- [13.CSV 导入 ClickHouse 格式错误](#13.CSV 导入 ClickHouse 格式错误)
- [将 CSV 转换为 TSV(逗号 → 制表符)](#将 CSV 转换为 TSV(逗号 → 制表符))
-
- [14.Shell 脚本 while 循环只执行一次](#14.Shell 脚本 while 循环只执行一次)
- [不推荐:while 循环逐行插入](#不推荐:while 循环逐行插入)
- 推荐:管道批量导入
-
- [15. Paimon 表写入失败(表不存在)](#15. Paimon 表写入失败(表不存在))
- 最后
背景
前面一篇已经验证在线数据入湖了,最后一步就是验证离线数据入湖。虽然已经做好坑坑洼洼的准备。但是困难比预想要多得多。花时间要多得多。为了最后一哆嗦,坚持坚持坚持,终于胜利!
环境准备
1. 在datasophon安装好dolphinscheduler 3.1.8
配置租户
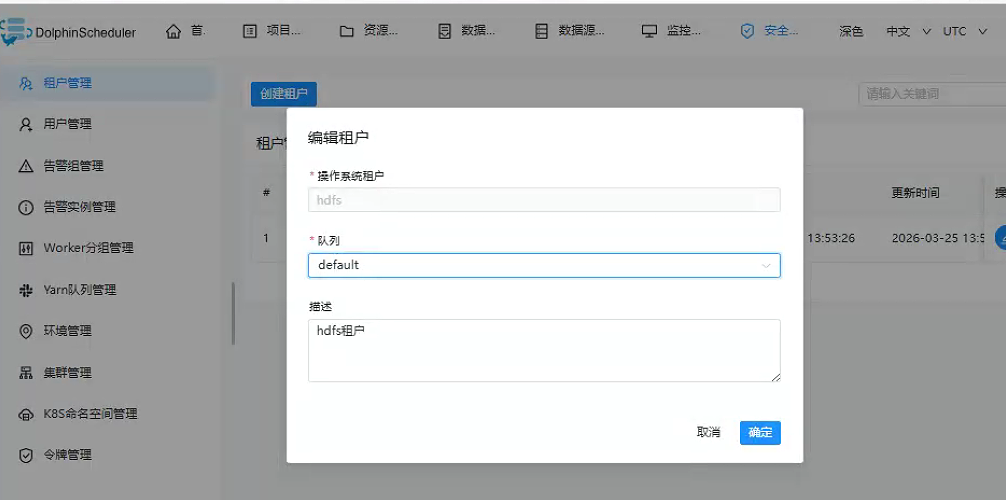
hdfs就是linux用户
创建环境
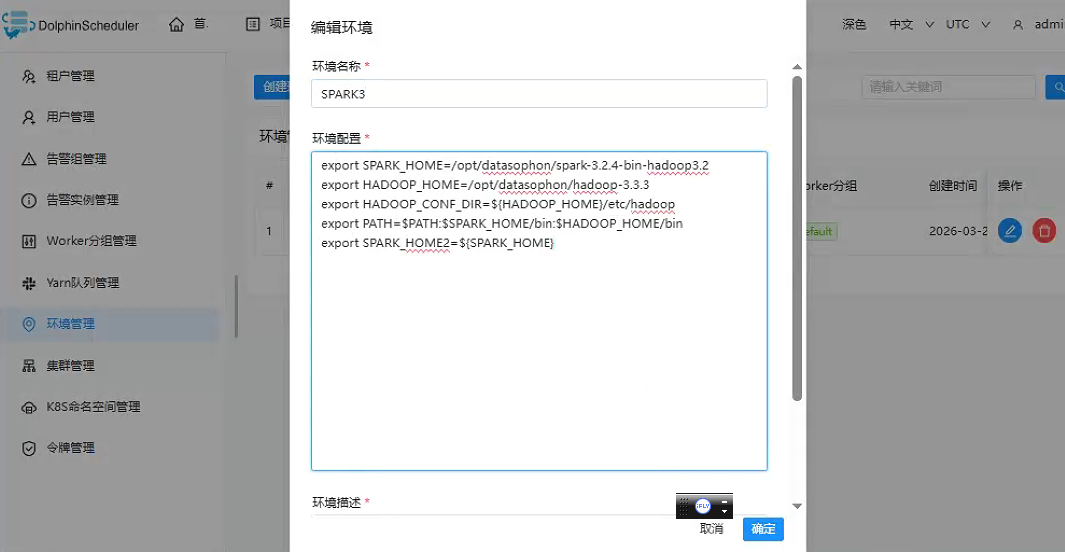
告诉ds spark3位置,hdfs位置
修改配置文件
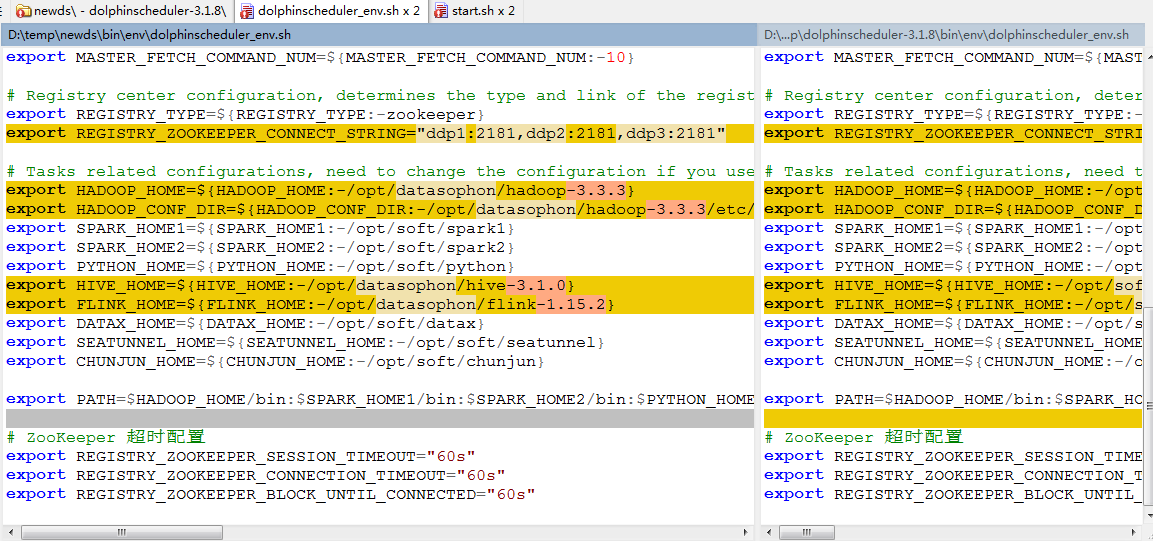
修改bin\env\dolphinscheduler_env.sh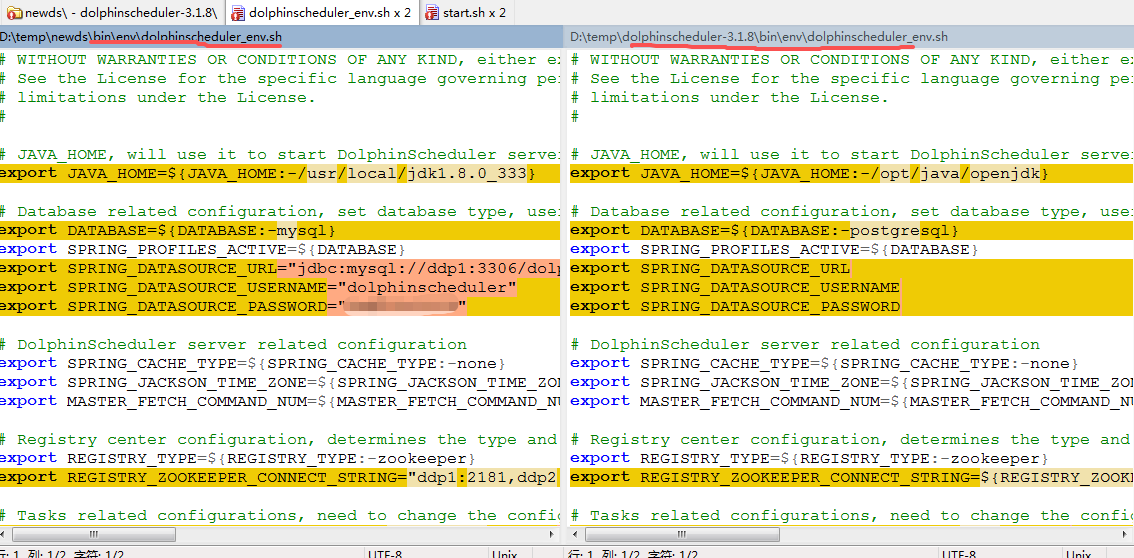
总结一下:
1.修改数据库类型为mysql,指定数据库url,用户名及密码
2.修改zk地址
3.修改hadoop位置及它配置目录
4.jdk位置
5.hive及flink位置
修改 work-server\bin\start.sh
就修改一行:
原来:
javascript
$JAVA_HOME/bin/java $JAVA_OPTS \
-cp "$DOLPHINSCHEDULER_HOME/conf":"$DOLPHINSCHEDULER_HOME/libs/*" \
org.apache.dolphinscheduler.server.worker.WorkerServer改成:
javascript
$JAVA_HOME/bin/java $JAVA_OPTS \
-cp "$DOLPHINSCHEDULER_HOME/conf":"$DOLPHINSCHEDULER_HOME/libs/*":${HADOOP_CONF_DIR}:${HADOOP_HOME}/share/hadoop/common/*:${HADOOP_HOME}/share/hadoop/hdfs/* \
org.apache.dolphinscheduler.server.worker.WorkerServer启动时传入hdfs配置目录及home目录
2. 升级spark3版本
datasophon 自带spark3.1.3 ,不支持paimon,换句话paimon,支持spark 从3.2版本开始。必须升级,否则报类找不到,这个问题耽搁我好长时间,paimon从0.7-0.9都试,还试了kafka-connect方式。
遇到坑及填平方法
1.现象: 经典的 NoClassDefFoundError,例如 org/apache/spark/kafka010/KafkaConfigUpdater 和 org/apache/spark/sql/connector/write/Write。
填平方案:
依赖分析: 通过错误栈和GitHub issue确认,KafkaConfigUpdater 类属于 Spark 而非 Paimon,且需要额外的 spark-token-provider-kafka 等JAR包。
版本匹配: 最终放弃在Spark 3.1.3上挣扎,将Spark升级到与Paimon 0.9.0兼容的3.2.4版本,从根本上解决了 Write 类找不到的API不兼容问题。
依赖管理: 明确需要通过 --jars 参数或DataSophon资源中心,将 paimon-spark-3.2-0.9.0.jar 等所有依赖JAR包完整地提供给Spark任务。
2. Spark与Paimon版本不兼容
现象: 使用Paimon 0.8.2或0.9.0时,均报告 Write 类找不到。
填平方案:
放弃低版本组合: 确认Paimon从某个版本开始强依赖Spark 3.2的DataSource V2 API,与你的Spark 3.1.3环境不兼容。
升级Spark: 决定将Spark从 3.1.3 升级到 3.2.4。这一步是解决问题的关键转折点,虽然需要升级组件,但一劳永逸地解决了兼容性问题。
3. HDFS权限问题
现象: 建表或写入时报 Permission denied,用户 root123 无法在 /user/paimon/warehouse 或 /user/hive/warehouse 下创建目录。
填平方案:
使用 sudo -u hdfs: 切换到HDFS超级用户执行权限修复命令。
递归授权: 执行 hdfs dfs -chown -R root123:supergroup /user/paimon 和 hdfs dfs -chmod -R 755 /user/paimon,将目录所有者改为当前用户并赋予写权限。
调整Hive仓库权限: 类似地,对 /user/hive/warehouse 目录也进行了权限调整,确保了元数据操作顺畅。
4. 元数据存储方式选择
现象: 使用Paimon默认的文件系统Catalog时,元数据直接存在HDFS上,导致并发问题和权限困扰。
填平方案:
切换为Hive Metastore: 最终决定使用 Hive Metastore 作为Paimon的Catalog。配置如下:
text
--conf spark.sql.catalog.paimon.metastore=hive
--conf spark.sql.catalog.paimon.uri=thrift://ddp1:9083
明确数据存储路径: 同时指定 spark.sql.catalog.paimon.warehouse,实现元数据(在MySQL/Hive)与数据文件(在HDFS)的分离,使整个架构更清晰、更稳定。
5. 环境与组件升级
现象: 旧版Spark 3.1.3成为兼容性瓶颈,且DataSophon管理着多个组件,升级有顾虑。
填平方案:
确认兼容性: 检查并确认Hadoop 3.3.3、Hive 3.1.3、Kafka 2.4.1等核心组件与Spark 3.2.4和JDK 11兼容。
分步升级: 选择保持JDK 8不变,仅升级Spark到3.2.4,将影响面降到最低,成功绕过JDK升级的风险。
6.Spark 找不到 Kafka 数据源
错误信息:
text
Failed to find data source: kafka
原因: Spark 默认不包含 Kafka 集成包。
解决方案:
bash
下载匹配版本的 Kafka 依赖
spark-sql-kafka-0-10_2.12-3.2.0.jar
kafka-clients-2.8.0.jar
commons-pool2-2.11.1.jar
在 DS Spark 任务的"选项参数"中添加 --jars
--jars /path/to/spark-sql-kafka-0-10_2.12-3.2.0.jar,/path/to/kafka-clients-2.8.0.jar,/path/to/commons-pool2-2.11.1.jar
关键点:
版本必须与 Spark 版本匹配
commons-pool2 是 Kafka 消费者的传递依赖,容易遗漏
7.Paimon 表创建失败(Derby 权限问题)
错误信息:
text
ERROR XBM0H: Directory /.../metastore_db cannot be created.
java.io.FileNotFoundException: derby.log (Permission denied)
原因: Spark 默认使用嵌入式 Derby 作为 Hive Metastore,没有配置 Hive Metastore 时会尝试在临时目录创建 Derby 数据库。
解决方案: 配置使用外部的 Hive Metastore
bash
--conf spark.sql.catalog.paimon.metastore=hive
--conf spark.sql.catalog.paimon.uri=thrift://hive-metastore-host:9083
--conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions
8.Kafka Topic 不存在
错误信息:
text
UNKNOWN_TOPIC_OR_PARTITION
原因: 脚本中配置的 topic 名称与实际不符。
解决方案:
bash
查看所有 topic
kafka-topics.sh --bootstrap-server kafka-host:9092 --list
使用正确的 topic 名称
kafka_topic = "user_log_topic" # 而不是 "user_log"
9.Spark 版本不匹配导致类找不到
错误信息:
text
java.lang.NoClassDefFoundError: org/apache/spark/kafka010/KafkaConfigUpdater
java.lang.ClassNotFoundException: org.apache.commons.pool2.impl.GenericKeyedObjectPoolConfig
原因: Spark 版本与 Kafka 依赖版本不匹配。
解决方案:
Spark 3.2.0 → 使用 spark-sql-kafka-0-10_2.12-3.2.0.jar 和 kafka-clients-2.8.0.jar
不能混用 3.2.4 的包
10.DolphinScheduler 参数换行问题
错误信息:
text
--conf: command not found
原因: DS 的"选项参数"中换行导致命令被分割。
解决方案: 所有参数写在一行,不要换行
properties
--jars /path/to/jar1.jar,/path/to/jar2.jar --conf key1=value1 --conf key2=value2
11.Shell 脚本换行符问题
错误信息:
text
$'\r': command not found
原因: 在 Windows 上编辑的脚本上传后带有 \r\n 换行符。
解决方案:
bash
转换换行符
sed -i 's/\r$//' script.sh
或直接在 DS 的脚本框中编写,不上传文件
12.Shell 脚本中 Spark 命令缺少配置
错误信息:
text
ERROR XBM0H: Directory /.../metastore_db cannot be created.
原因: Shell 脚本中的 spark-sql 命令没有配置 Hive Metastore。
解决方案: 在 Shell 脚本中的每个 spark-sql 命令都要加上完整配置:
bash
${SPARK_HOME}/bin/spark-sql
--conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog
--conf spark.sql.catalog.paimon.metastore=hive
--conf spark.sql.catalog.paimon.uri=thrift://ddp1:9083
--conf spark.sql.catalog.paimon.warehouse=hdfs://.../warehouse
--conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions
13.CSV 导入 ClickHouse 格式错误
错误信息:
text
Code: 117. DB::Exception: Expected end of line: ... (INCORRECT_DATA)
原因:
CSV 中的 JSON 字段包含逗号和引号,干扰了 CSV 解析
时间格式 2026-03-29T10:00:00.000Z 不是 ClickHouse 默认格式
解决方案: 使用 TSV 格式替代 CSV
bash
将 CSV 转换为 TSV(逗号 → 制表符)
cat data.csv | sed 's/,/\t/g' | clickhouse client --query "INSERT INTO table FORMAT TSV"
14.Shell 脚本 while 循环只执行一次
错误信息: 循环内的命令导致循环提前退出。
原因: clickhouse-client 命令失败或 echo 干扰了循环变量。
解决方案: 放弃 while 循环,使用管道直接导入
bash
不推荐:while 循环逐行插入
while read line; do
clickhouse-client --query "INSERT ..."
done < file.csv
推荐:管道批量导入
cat file.csv | clickhouse-client --query "INSERT INTO table FORMAT TSV"
15. Paimon 表写入失败(表不存在)
错误信息:
text
Schema file not found in location paimon.default.ods_user_log. Please create table first.
解决方案: 先创建表,再写入数据
sql
CREATE TABLE IF NOT EXISTS paimon.default.ods_user_log (...) USING paimon;
或在 Python 脚本中自动创建:
python
if not spark.catalog.tableExists("paimon.default.ods_user_log"):
spark.sql("CREATE TABLE ...")
最后
成果截图:
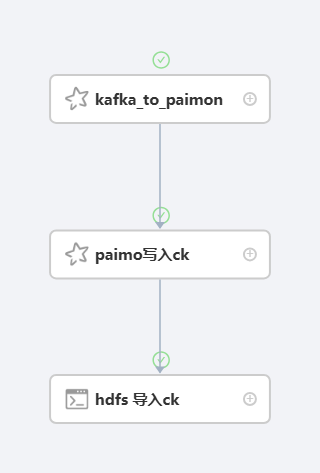
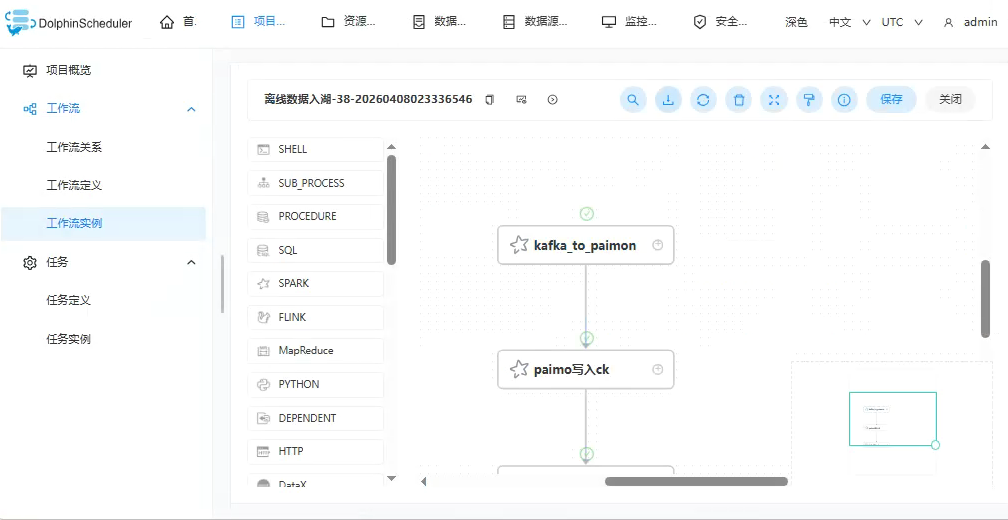
各个节点对应脚本
1.kafka_to_paimon
javascript
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit, from_json, to_timestamp
from pyspark.sql.types import StructType, StructField, StringType, TimestampType
import sys
import os
bizdate = sys.argv[1] if len(sys.argv) > 1 else os.environ.get("bizdate", "2026-03-29")
spark = SparkSession.builder \
.appName(f"KafkaToPaimon_Batch_{bizdate}") \
.config("spark.sql.catalog.paimon", "org.apache.paimon.spark.SparkCatalog") \
.config("spark.sql.catalog.paimon.warehouse", "hdfs://nameservice1/user/paimon/warehouse") \
.config("spark.sql.catalog.paimon.metastore", "hive") \
.config("spark.sql.catalog.paimon.uri", "thrift://ddp1:9083") \
.config("spark.sql.extensions", "org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions") \
.getOrCreate()
print(f"开始处理业务日期: {bizdate}")
# 定义 schema
json_schema = StructType([
StructField("user_id", StringType(), True),
StructField("event_time", StringType(), True),
StructField("event_type", StringType(), True),
StructField("data", StringType(), True)
])
# Kafka 配置
kafka_bootstrap_servers = "ddp4:9092,ddp3:9092"
kafka_topic = "user_log_topic"
# 检查表是否存在,如果不存在则创建
print("检查表是否存在...")
try:
# 尝试查询表
spark.sql("SELECT 1 FROM paimon.default.ods_user_log LIMIT 1")
print("表已存在")
except Exception:
print("表不存在,正在创建...")
create_sql = """
CREATE TABLE paimon.default.ods_user_log (
user_id STRING,
event_time TIMESTAMP,
event_type STRING,
data STRING,
dt STRING
) USING paimon
PARTITIONED BY (dt)
TBLPROPERTIES (
'bucket' = '4',
'file.format' = 'parquet'
)
"""
spark.sql(create_sql)
print("表创建成功")
# 从 Kafka 读取数据
df = spark.read \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_bootstrap_servers) \
.option("subscribe", kafka_topic) \
.option("startingOffsets", "earliest") \
.option("endingOffsets", "latest") \
.load() \
.selectExpr("CAST(value AS STRING) as json_str")
# 解析 JSON
parsed_df = df.select(
from_json(col("json_str"), json_schema).alias("data")
).select(
col("data.user_id"),
to_timestamp(col("data.event_time")).alias("event_time"),
col("data.event_type"),
col("data.data"),
lit(bizdate).alias("dt")
).filter(col("user_id").isNotNull())
count = parsed_df.count()
print(f"从 Kafka 读取到 {count} 条有效数据")
if count > 0:
print("\n数据样例(前5条):")
parsed_df.show(5, truncate=False)
# 写入数据
parsed_df.write \
.format("paimon") \
.mode("append") \
.insertInto("paimon.default.ods_user_log")
print(f"✅ 写入完成,共 {count} 条记录")
else:
print("没有数据需要写入")
spark.stop()2.paimon写入ck(实际是写入hdfs,忘记改名称)
javascript
from pyspark.sql import SparkSession
bizdate = "2026-03-29"
spark = SparkSession.builder \
.appName(f"PaimonToClickHouse_{bizdate}") \
.config("spark.sql.catalog.paimon", "org.apache.paimon.spark.SparkCatalog") \
.config("spark.sql.catalog.paimon.metastore", "hive") \
.config("spark.sql.catalog.paimon.uri", "thrift://ddp1:9083") \
.config("spark.sql.catalog.paimon.warehouse", "hdfs://nameservice1/user/paimon/warehouse") \
.config("spark.sql.extensions", "org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions") \
.getOrCreate()
print("=" * 50)
print("Paimon → ClickHouse 导入")
print(f"业务日期: {bizdate}")
print("=" * 50)
# 读取数据
df = spark.sql(f"""
SELECT user_id, event_time, event_type, data
FROM paimon.default.ods_user_log
WHERE dt = '{bizdate}'
""")
count = df.count()
print(f"[1/2] Paimon 表中数据量: {count}")
if count > 0:
print("[2/2] 写入 ClickHouse...")
# 保存为 CSV 到 HDFS
output_path = f"/tmp/paimon_export_{bizdate}"
df.coalesce(1).write.mode("overwrite").option("header", "false").csv(output_path)
print(f"✅ 数据已导出到 HDFS: {output_path}")
print(f" 请使用 clickhouse-client 导入数据")
else:
print("⚠️ 没有数据需要导入")
spark.stop()3.hdfs导入ck
javascript
#!/bin/bash
# 环境变量
CH_CLIENT=/opt/datasophon/clickhouse/bin/clickhouse
HOST=ddp3
PORT=9000
USER=default
BIZDATE="2026-03-29"
echo "=========================================="
echo "Paimon → ClickHouse 数据导入"
echo "业务日期: ${BIZDATE}"
echo "=========================================="
# 1. 下载 CSV 文件
echo "[1/5] 下载 CSV 文件..."
hdfs dfs -get -f /tmp/paimon_export_${BIZDATE}/part-*.csv /tmp/paimon_data_${BIZDATE}.csv 2>/dev/null
if [ ! -f /tmp/paimon_data_${BIZDATE}.csv ]; then
echo "❌ CSV 文件不存在"
exit 1
fi
TOTAL_LINES=$(wc -l < /tmp/paimon_data_${BIZDATE}.csv)
echo "CSV 文件行数: ${TOTAL_LINES}"
# 2. 创建 ClickHouse 表(如果不存在)
echo "[2/5] 创建 ClickHouse 表(如果不存在)..."
${CH_CLIENT} client --host ${HOST} --port ${PORT} --user ${USER} --query "
CREATE TABLE IF NOT EXISTS default.user_log (
user_id String,
event_time String,
event_type String,
data String
) ENGINE = MergeTree()
ORDER BY user_id
" 2>/dev/null
# 3. 删除当前日期的旧数据(避免重复)
echo "[3/5] 删除当前日期的旧数据..."
${CH_CLIENT} client --host ${HOST} --port ${PORT} --user ${USER} --query "
ALTER TABLE default.user_log DELETE WHERE event_time LIKE '${BIZDATE}%'
" 2>/dev/null
# 4. 导入数据(使用 TSV 格式)
echo "[4/5] 导入数据到 ClickHouse..."
# 将 CSV 转换为 TSV(用制表符分隔)后导入
cat /tmp/paimon_data_${BIZDATE}.csv | sed 's/,/\t/g' | ${CH_CLIENT} client --host ${HOST} --port ${PORT} --user ${USER} --query "INSERT INTO default.user_log FORMAT TSV"
# 5. 验证导入结果
echo "[5/5] 验证导入结果..."
COUNT=$(${CH_CLIENT} client --host ${HOST} --port ${PORT} --user ${USER} --query "SELECT COUNT(*) FROM default.user_log WHERE event_time LIKE '${BIZDATE}%'" 2>/dev/null)
TOTAL=$(${CH_CLIENT} client --host ${HOST} --port ${PORT} --user ${USER} --query "SELECT COUNT(*) FROM default.user_log" 2>/dev/null)
echo "=========================================="
echo "✅ 导入完成!"
echo " 本次导入行数: ${TOTAL_LINES}"
echo " 当前日期数据量: ${COUNT}"
echo " ClickHouse 总数据量: ${TOTAL}"
echo "=========================================="
# 显示数据样例
if [ "${TOTAL_LINES}" -gt 0 ]; then
echo ""
echo "新增数据样例:"
${CH_CLIENT} client --host ${HOST} --port ${PORT} --user ${USER} --query "SELECT * FROM default.user_log WHERE event_time LIKE '${BIZDATE}%' LIMIT 3" --format PrettyCompact
fi
# 清理临时文件
rm -f /tmp/paimon_data_${BIZDATE}.csv
echo ""
echo "=========================================="
echo "导入任务完成"
echo "=========================================="如需沟通:lita2lz