文章目录
-
-
- [Vision Transformer学习笔记:从 Attention 核心理论到 PyTorch 源码实战](#Vision Transformer学习笔记:从 Attention 核心理论到 PyTorch 源码实战)
- [一、写在前面:为什么要把 Transformer 用在视觉上?](#一、写在前面:为什么要把 Transformer 用在视觉上?)
-
- [1.1 Transformer 的辉煌成就](#1.1 Transformer 的辉煌成就)
- [1.2 CNN 的局限性](#1.2 CNN 的局限性)
- [1.3 ViT 的大胆尝试](#1.3 ViT 的大胆尝试)
- [二、理论根基:Transformer 核心机制回顾](#二、理论根基:Transformer 核心机制回顾)
-
- [2.1 什么是注意力(Attention)?](#2.1 什么是注意力(Attention)?)
- [2.2 什么是自注意力(Self-Attention)的核心?](#2.2 什么是自注意力(Self-Attention)的核心?)
- [2.3 Q、K、V 到底是什么?](#2.3 Q、K、V 到底是什么?)
- [2.4 缩放点积注意力(Scaled Dot-Product Attention)](#2.4 缩放点积注意力(Scaled Dot-Product Attention))
- [2.5 多头注意力(Multi-Head Attention)](#2.5 多头注意力(Multi-Head Attention))
- [2.6 网络稳定器:Add & Norm](#2.6 网络稳定器:Add & Norm)
- [2.7 Pre-LN vs Post-LN](#2.7 Pre-LN vs Post-LN)
- [2.8 前馈神经网络(FFN)](#2.8 前馈神经网络(FFN))
- [2.9 位置编码(Positional Encoding)](#2.9 位置编码(Positional Encoding))
- [三、Vision Transformer (ViT) 完整架构解析](#三、Vision Transformer (ViT) 完整架构解析)
-
- [3.1 核心思想:图片 = Patch 序列](#3.1 核心思想:图片 = Patch 序列)
- [3.2 ViT 整体架构图](#3.2 ViT 整体架构图)
- [3.3 各模块深度解析](#3.3 各模块深度解析)
-
- [模块一:图像分块(Patch Partition)](#模块一:图像分块(Patch Partition))
- 为什么用卷积不用全连接?
- 卷积的好处:
- 卷积核到底怎么算的?
- 什么是数据增强?
-
- [模块二:Patch Embedding(线性投影层)](#模块二:Patch Embedding(线性投影层))
- [模块三:CLS Token 与位置编码](#模块三:[CLS] Token 与位置编码)
- 为什么官方实现都用CLS直接分类?
- 为什么用CLS不用平均Token进行分类?
- MLP(多层感知机)的作用
-
- [模块四:Transformer Encoder(核心计算模块)](#模块四:Transformer Encoder(核心计算模块))
- [模块五:分类头(Classification Head)](#模块五:分类头(Classification Head))
- [四、ViT 完整 PyTorch 实现](#四、ViT 完整 PyTorch 实现)
- [五、ViT 的数据流全程追踪](#五、ViT 的数据流全程追踪)
-
- 第一阶段:图像"数字化"
- [第二阶段:Transformer Encoder 深度理解](#第二阶段:Transformer Encoder 深度理解)
- 第三阶段:输出预测
- [六、ViT 家族成员](#六、ViT 家族成员)
- [七、ViT 与 NLP Transformer 的关键差异](#七、ViT 与 NLP Transformer 的关键差异)
-
- [为什么 ViT 不需要 Decoder?](#为什么 ViT 不需要 Decoder?)
- [为什么 ViT 不需要 Padding Mask?](#为什么 ViT 不需要 Padding Mask?)
- [八、ViT 的训练策略](#八、ViT 的训练策略)
-
- [8.1 学习率策略](#8.1 学习率策略)
- [8.2 数据增强与正则化](#8.2 数据增强与正则化)
- [8.3 预训练的重要性](#8.3 预训练的重要性)
- [1. 图像分块与嵌入 (Patch Embedding)](#1. 图像分块与嵌入 (Patch Embedding))
- [2. 多头自注意力机制 (Multi-Head Attention)](#2. 多头自注意力机制 (Multi-Head Attention))
- [3. 前馈神经网络 (MLP)](#3. 前馈神经网络 (MLP))
- [4. Transformer 编码器块 (Encoder Block)](#4. Transformer 编码器块 (Encoder Block))
- [5. ViT 主模型 (VisionTransformer)](#5. ViT 主模型 (VisionTransformer))
- [九、ViT 位置编码的可视化解读](#九、ViT 位置编码的可视化解读)
- [十、ViT 的注意力可视化](#十、ViT 的注意力可视化)
- [十一、ViT 与 CNN 的全面对比](#十一、ViT 与 CNN 的全面对比)
-
- [👁️ 十、ViT 的注意力可视化解析](#👁️ 十、ViT 的注意力可视化解析)
- [十二、ViT 的后续发展与重要变体](#十二、ViT 的后续发展与重要变体)
-
- [12.1 训练效率优化](#12.1 训练效率优化)
- [12.2 架构改进](#12.2 架构改进)
- [12.3 多模态统一](#12.3 多模态统一)
- 十三、实践建议
-
- [13.1 显卡配置建议](#13.1 显卡配置建议)
- [13.2 调优策略总结](#13.2 调优策略总结)
- [ViT 项目实战](#ViT 项目实战)
-
- [一、 图像的"词汇化":Patch Embedding 源码解析](#一、 图像的“词汇化”:Patch Embedding 源码解析)
- [二、 给瞎子指路:CLS Token 与 位置编码](#二、 给瞎子指路:[CLS] Token 与 位置编码)
- [三、 灵魂引擎:多头自注意力 (MSA) 的高效实现](#三、 灵魂引擎:多头自注意力 (MSA) 的高效实现)
- [四、 模型训练部分](#四、 模型训练部分)
- 十五、总结
-
- [ViT 的核心贡献](#ViT 的核心贡献)
- [ViT 的设计哲学](#ViT 的设计哲学)
-
Vision Transformer学习笔记:从 Attention 核心理论到 PyTorch 源码实战
"An Image is Worth 16x16 Words" ------ 一张图片等价于 16×16 的"单词"
本文基于 Transformer 的核心理论,从 Attention 机制出发,系统且深入地讲解 Vision Transformer (ViT) 的工作原理、架构设计与代码实现。
一、写在前面:为什么要把 Transformer 用在视觉上?
1.1 Transformer 的辉煌成就
前一篇:Transformer学习笔记:从 Attention 核心理论到机器翻译代码项目学习实战

Transformer 凭借其极其大胆的创新------"彻底抛弃循环(RNN)和卷积(CNN),仅仅依赖注意力机制(Attention Mechanism)",在 NLP 领域大放异彩。从 BERT 到 GPT,从机器翻译到文本生成,Transformer 已经统治了自然语言处理的每一个角落。
那么一个自然的问题是:既然 Transformer 在序列建模上如此强大,能不能把图像也看作某种"序列",直接用 Transformer 来处理呢?
1.2 CNN 的局限性
传统 CNN 在计算机视觉中已经统治了很多年,但它天生有一些"归纳偏置"(Inductive Bias):
- 局部性(Locality):卷积核只关注局部区域,感受野需要逐层扩大
- 平移不变性(Translation Invariance):卷积核在图像上滑动共享权重
- 层级结构:必须通过多层堆叠才能获得全局信息
这些特性在小数据集上是优势(帮助模型更快学习),但在大数据时代,它们反而成了性能天花板。

1.3 ViT 的大胆尝试
2020 年,Google 提出了 Vision Transformer (ViT),核心思想极其简洁:
把图像切成一个个小块(Patch),每个 Patch 就像 NLP 中的一个"单词",然后直接用标准的 Transformer Encoder 来处理这个"Patch 序列"。
vision transformer正式把transformer带入视觉主干,带动了"大规模预训练---下游任务" 微调方式成为视觉主流路线之一
几乎不做任何针对视觉的特殊修改,就这样"暴力"地把 NLP 的 Transformer 搬到了视觉领域------而且效果惊艳!

二、理论根基:Transformer 核心机制回顾
在深入 ViT 之前,我们必须先牢牢掌握 Transformer 的核心组件。以下内容基于原论文《Attention Is All You Need》进行梳理。
2.1 什么是注意力(Attention)?
当我们看一句话的时候,每一个字会重点关注与之相关联的字。
例如 "我是一只鸟 ",当我们理解"鸟"这个字时,会自动关注"一只"(量词修饰)和"我"(主语),而对"是"的关注度可能较低。注意力机制就是让模型自动学会这种"关注程度"的分配。
2.2 什么是自注意力(Self-Attention)的核心?
让模型自动算出每个字与所有字的关联程度(注意力分数),再用这个分数给每个字生成一个融合上下文信息的新表示(新的向量矩阵)。
关键词:"自"注意力 ------ 因为 Q、K、V 都来自同一个输入序列本身。通俗地说,就是自己和自己做注意力计算,整个过程都是"我"自己参与。
2.3 Q、K、V 到底是什么?
用一个生动的比喻来理解:
| 概念 | 含义 | 比喻 |
|---|---|---|
| Q (Query / 查询) | 我要找什么 | 用来发起匹配的"需求" |
| K (Key / 键) | 我是什么 | 用来被别人匹配的"自我介绍" |
| V (Value / 值) | 我有什么 | 匹配成功后,用来最终提取的"实际内容" |
2.4 缩放点积注意力(Scaled Dot-Product Attention)
这是整个注意力机制的计算核心,公式为:
Attention ( Q , K , V ) = Softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=Softmax(dk QKT)V
计算过程分四步走:
-
匹配打分 :拿着自己的需求 Q 和每个字的自我介绍 K 的转置做矩阵相乘。点积结果越大,匹配度越高,两个字越相关。
-
缩放(Scale) :为了防止点积结果过大导致 Softmax 梯度消失,除以缩放因子 d k \sqrt{d_k} dk 。
-
归一化(Softmax) :通过 Softmax 函数将原始分数变成加起来等于 1 的概率权重。这样就把原始注意力分数转变为注意力权重,方便后面进行加权求和。
-
加权求和 :最后将注意力权重与 V(值向量)矩阵加权相乘求和,提取出融合后的上下文特征。
python
def attention(query, key, value, mask=None, dropout=None):
d_k = query.size(-1)
# 1&2. Q和K的转置做点积,再除以缩放因子
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 处理掩码
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 3. Softmax 归一化为概率权重
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
# 4. 加权求和,得到融合上下文的特征
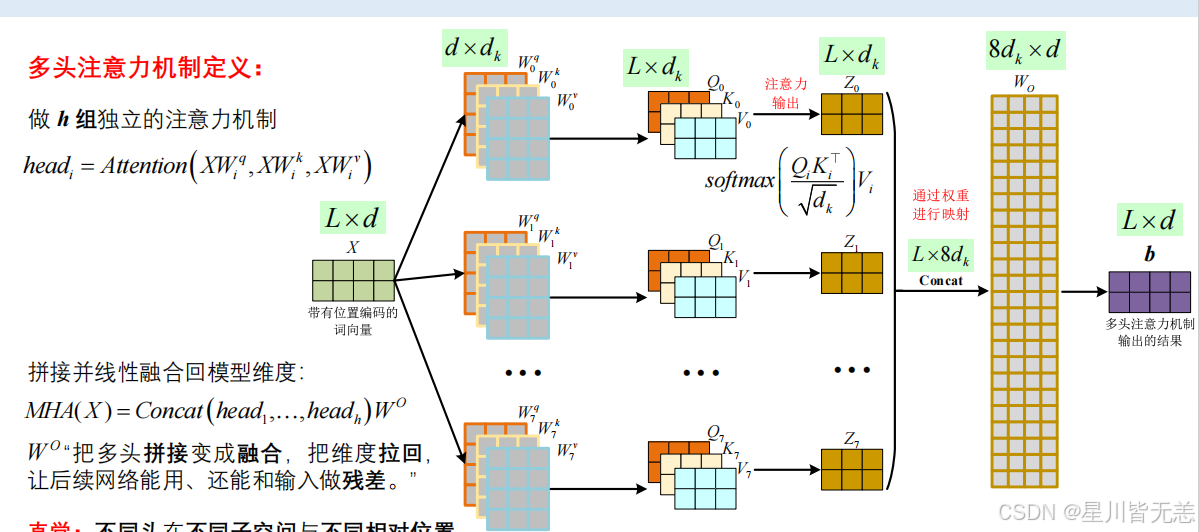
return torch.matmul(p_attn, value), p_attn2.5 多头注意力(Multi-Head Attention)
为什么用多头? 单头就像从一个角度看世界,容易看不全。多头则是从多个角度同时观察,信息更丰富、更精准。
模型会将 Q、K、V 分成几个头(比如 8 头),不同的头去学习不同的注意力模式 (有的学主谓关系,有的学代词指代)。每个头的权重矩阵( W Q W_Q WQ、 W K W_K WK、 W V W_V WV)都不一样,最后再把所有头的输出**拼接(Concat)**起来,通过线性层 W O W_O WO 恢复模型维度。
W O W_O WO 将多头拼接变为多头融合,将维度拉回,让后续网络能用,还能和输入做残差。假如你输入的是 L × d L \times d L×d 维度的数据,那么最终融合输出的也是 L × d L \times d L×d。
python
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super().__init__()
self.d_k = d_model // h # 单头维度 (e.g., 768 / 12 = 64)
self.h = h
# 4个线性层: Q, K, V 的投影 + 最后的输出融合 W_O
self.linears = clones(nn.Linear(d_model, d_model), 4)
def forward(self, query, key, value, mask=None):
nbatches = query.size(0)
# 1. 线性映射并切分成 h 个头
query, key, value = [
l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))
]
# 2. 调用 attention 计算分数
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 3. 将多头拼接起来 (Concat)
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
# 4. 最后做一次线性变换恢复维度
return self.linears[-1](x)2.6 网络稳定器:Add & Norm
这部分由**残差连接(Residual Connection)和层归一化(Layer Normalization)**组成。
残差连接 (Add):
深层神经网络在反向传播时容易产生梯度消失,导致前面的层学不动。残差结构 X o u t = x + Sublayer ( x ) X_{out} = x + \text{Sublayer}(x) Xout=x+Sublayer(x) 提供了一条直通路径,保住了梯度的流动。即使注意力层学废了,原汁原味的信息还在!
层归一化 (Norm):
与 CNN 常用的 Batch Norm 不同,这里是对**每个样本的特征维度(每层)**进行归一化,使得数据分布更加稳定,加速收敛。
| 特性 | LayerNorm | BatchNorm |
|---|---|---|
| 统计范围 | 单个样本内部 | 一个 batch |
| 是否依赖 batch size | ❌ 不依赖 | ✔ 依赖 |
| 推理阶段 | 不需要额外统计 | 需要 running mean/var |
层归一化中,缩放参数 γ 和平移参数 β 是可学习的,通过反向传播更新;而均值和方差是基于当前输入动态计算的统计量,不参与参数学习。
python
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super().__init__()
self.a_2 = nn.Parameter(torch.ones(features)) # 可学习的缩放参数 γ
self.b_2 = nn.Parameter(torch.zeros(features)) # 可学习的平移参数 β
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
# Layer Norm: y = γ * (x - mean) / sqrt(std² + eps) + β
return self.a_2 * (x - mean) / torch.sqrt(std ** 2 + self.eps) + self.b_2为什么要加 γ 和 β? 如果不加,数据就被强行变成均值为 0、方差为 1 的标准正态分布。这虽然好训练,但会破坏网络前面好不容易提取到的特征表达。模型会在反向传播时,自己学会如何把归一化后的数据"缩放"和"平移"到一个最合适的分布上。
2.7 Pre-LN vs Post-LN
原论文是先残差连接再做归一化(Post-LN) ,但后来学术界和工业界发现,Post-LN 在模型层数很深时容易出现训练梯度不稳定的情况。目前业界更流行的是 Pre-LN 结构:先进行层归一化,再进行残差连接,梯度流动更加顺畅,训练更稳定。
python
# Pre-LN 结构(GPT、LLaMA、ViT 等主流模型采用)
return x + self.dropout(sublayer(self.norm(x)))这也是为什么后来的主流大模型(如 GPT 系列、LLaMA、ViT 等)基本都悄悄换成了 Pre-LN 的原因。
2.8 前馈神经网络(FFN)
前馈神经网络是一种无循环的多层神经网络,数据从输入到输出单向流动。在 Transformer 中,FFN 由两个线性层和一个激活函数组成:
FFN ( x ) = Linear 2 ( Activation ( Linear 1 ( x ) ) ) \text{FFN}(x) = \text{Linear}_2(\text{Activation}(\text{Linear}_1(x))) FFN(x)=Linear2(Activation(Linear1(x)))
- 线性层也叫全连接层,前一层的每一个神经元都和后一层的每一个神经元全部连上线
- 如果后面加了 ReLU/GELU 激活函数,那么整体就不再是纯线性
2.9 位置编码(Positional Encoding)
Transformer 模型不包含卷积也不包含递归!正因为模型没有 RNN 循环结构,输入是并行的,它天生是个"脸盲"------如果没有位置编码向量,就无法感知词语的先后顺序。
pos指当前词在句子中的位置i指词嵌入矩阵的维度索引- 偶数维度用 sin,奇数维度用 cos
- 位置编码向量的每一维都对应一个正弦波
关键点 :词嵌入向量的维度 d 和位置编码的维度 d 必须一样,否则维度不同无法相加!
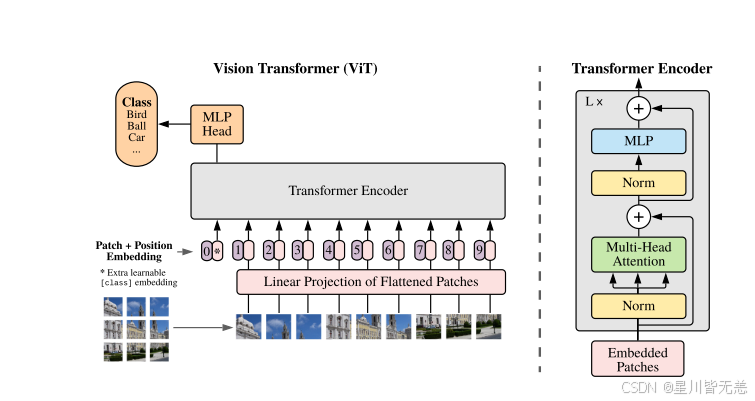
三、Vision Transformer (ViT) 完整架构解析
有了上面的 Transformer 理论基础,现在我们正式进入 ViT 的世界!
3.1 核心思想:图片 = Patch 序列
ViT 的核心洞察非常简洁优雅:
NLP Transformer: 一句话 → 切分成单词序列 → Transformer Encoder → 理解语义
Vision Transformer: 一张图 → 切分成 Patch 序列 → Transformer Encoder → 理解图像"An Image is Worth 16×16 Words" ------ 一张图片可以被看作由 16×16 大小的"单词"组成的"句子"。
3.2 ViT 整体架构图
┌────────────────────────────────────────────────────────────────────┐
│ Vision Transformer (ViT) │
│ │
│ 输入图像 (224 × 224 × 3) │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ ① 图像分块 │ 切成 196 个 16×16 的 Patch │
│ │ (Patch Split) │ │
│ └─────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ ② Patch 嵌入 │ 每个 Patch 展平后线性映射到 D 维 │
│ │ (Linear Proj.) │ 等价于一次卷积操作 │
│ └─────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ ③ 拼接 [CLS] │ 在序列最前面加入可学习的分类 Token │
│ │ + 位置编码 │ 加入可学习的位置编码保留空间信息 │
│ └─────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────┐ │
│ │ ④ Transformer Encoder × L 层 │ │
│ │ ┌───────────────────────────────────────┐ │ │
│ │ │ Layer Norm │ │ │
│ │ │ ↓ │ │ │
│ │ │ Multi-Head Self-Attention │ │ │
│ │ │ ↓ (+ Residual) │ │ │
│ │ │ Layer Norm │ │ │
│ │ │ ↓ │ │ │
│ │ │ MLP (FFN): Linear → GELU → Linear │ │ │
│ │ │ ↓ (+ Residual) │ │ │
│ │ └───────────────────────────────────────┘ │ │
│ │ × L 层重复 │ │
│ └─────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ ⑤ 取 [CLS] 输出 │ 经过 Layer Norm │
│ │ → MLP Head │ 通过分类头输出预测结果 │
│ └─────────────────┘ │
│ │ │
│ ▼ │
│ 分类结果 (num_classes) │
└────────────────────────────────────────────────────────────────────┘3.3 各模块深度解析
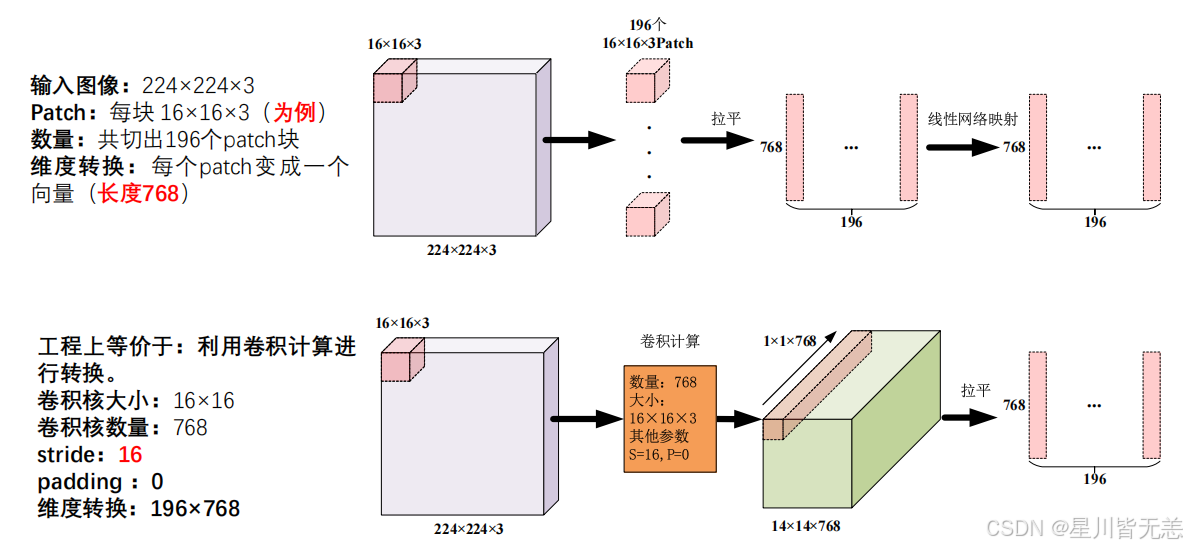
模块一:图像分块(Patch Partition)
就像 NLP 中把一句话切分成一个个单词一样,ViT 把图像切分成一个个固定大小的"图片块"(Patch):
python
输入图像尺寸: H × W × C = 224 × 224 × 3
Patch 大小: P × P = 16 × 16
Patch 数量: N = (H/P) × (W/P) = 14 × 14 = 196
每个 Patch: P × P × C = 16 × 16 × 3 = 768 维(展平后)类比 NLP:如果 Transformer 处理的句子有 196 个"单词",那么 ViT 处理的图像就有 196 个"Patch"。每个 Patch 就是图像中的一个局部区域。
卷积核:
一个小窗口,用来在图片上"扫一遍"提取特征。
最常见的是3x3卷积核,里面是一堆数字。
卷积:用核在图上滑动计算的过程。
通道:彩色图有RGB3个通道。
步长:每次滑几格。
低级核:找线条,找边缘
高级核:找形状,找物体。
CNN实际上就是一层层的卷积核堆叠起来的。每一层负责看"更高级的东西"。
从像素------线条------形状------部件------整体 一层层往上抽象起来的。
为什么用卷积不用全连接?
1.防止梯度爆炸
2.全连接容易看不清局部特征
3.平移一点就认不出来、
卷积的好处:
1.只看局部
2.权重共享
3.平移不变性
卷积核到底怎么算的?
1...盖在图片一小块上
2.对应位置相乘,再相加
3.结果作为新图片上的一个像素
Hidden Size D:隐藏层维度/特征维度
隐藏层维度=特征维度
目的:把原始特征加工成更高级的特征,神经网络中干活的层。
什么是数据增强?
在保证模型标签不变的情况下对训练数据进行可控变换,让模型见过足够多的"变种",缓解过拟合和数据稀缺问题。
模块二:Patch Embedding(线性投影层)
Patch Embedding的作用:
把2D图像转换成Transformer能处理的一维Token序列(196*768),而且卷积等价实现。
Transformer的输入格式:Batch,序列长度,特征维度
每个 Patch 展平后是一个 768 维的向量,通过一个线性投影层将其映射到模型的隐藏维度 D:
python
class PatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.num_patches = (img_size // patch_size) ** 2 # 196
# 巧妙地用一个卷积操作同时完成"分块"和"线性投影"!
# kernel_size = patch_size, stride = patch_size → 不重叠地切割图像
# 输出通道数 = embed_dim → 完成线性投影
self.proj = nn.Conv2d(
in_channels, # 输入通道 3 (RGB)
embed_dim, # 输出维度 768
kernel_size=patch_size, # 卷积核大小 = Patch 大小 = 16
stride=patch_size # 步长 = Patch 大小 = 16(不重叠)
)
def forward(self, x):
# x: (B, 3, 224, 224)
x = self.proj(x) # (B, 768, 14, 14) --- 卷积完成分块+投影
x = x.flatten(2) # (B, 768, 196) --- 展平空间维度
x = x.transpose(1, 2) # (B, 196, 768) --- 调整为序列格式
return x为什么用 Conv2d 而不是手动切分? 因为
kernel_size=stride=patch_size的卷积操作在数学上完全等价于"将图像切分成不重叠的 Patch,展平后乘以权重矩阵",但实现更高效、更优雅。
类比 NLP :这一步等价于 NLP 中的 词嵌入(Word Embedding) ------把离散的"单词 ID"映射为连续的稠密向量。只不过这里的"单词"是一个个图像块。正如文档中所说:"使用词嵌入矩阵将 ID 映射为具有连续维度的向量,从而实现语义相近的词向量距离近,差异大的词距离远。" 在 ViT 中,视觉上相似的 Patch 在嵌入空间中也会彼此接近。
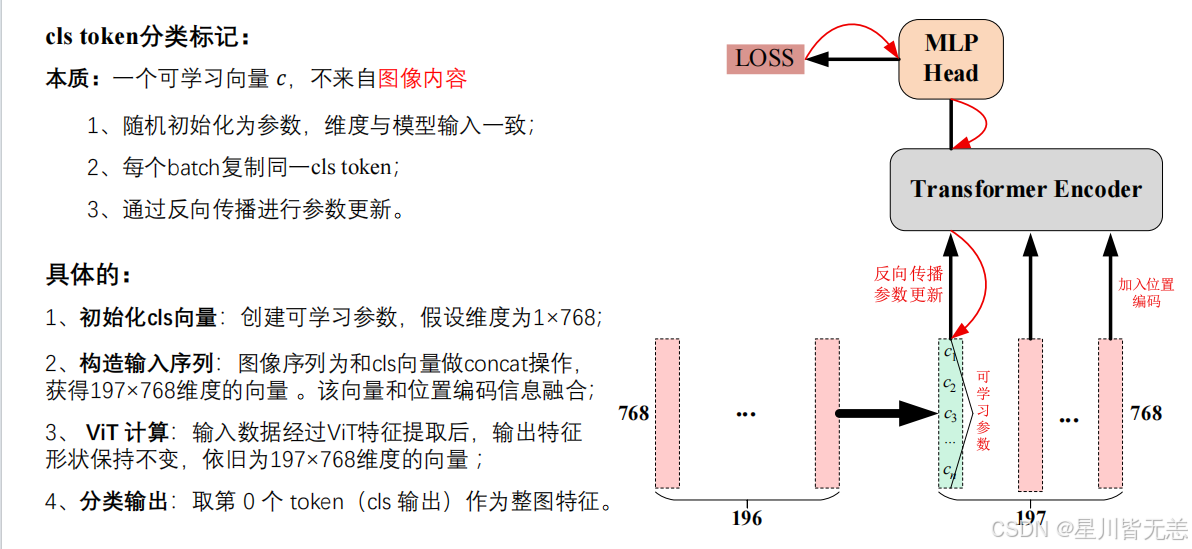
模块三:CLS Token 与位置编码
CLS Token(类别 Token):
借鉴 BERT 的做法,在 Patch 序列的最前面添加一个可学习的特殊 Token ,称为 CLS Token。它不对应图像中的任何区域,但经过 Transformer Encoder 的层层自注意力计算后,它会融合整个图像的全局信息,最终用于分类。
本质:是可学习向量,参数,不来自于图像内容。
维度与,模型输入一致。
每个batch都要复制同一个CLS Token
依旧反向传播进行参数更新。
为什么官方实现都用CLS直接分类?
因为CLS Token就像一个"总汇报员",经过Transformer Encoder层层计算之后,它里面汇总了整张图的全局信息,最后用CLS做分类。CLS不来自于图像内容,只负责"占位"和"汇总",经过训练,会自动变成整幅图的特征摘要。
CLS是整个注意力网络"最受关注的向量"。最后只取第0个CLS送进MLP head做分类,其它的1-196个只是局部的图像特征。
CNN用卷积,有局部感受野和平移不变性,最后用全局平均池化(GAP)------>得到整图的特征。
为什么用CLS不用平均Token进行分类?
CLS Token:可学习的嵌入向量
Token:模型处理的最小基本单位。对于语音识别处理,对音频波拆成一个时间帧,每一帧都是1Token Embedding(嵌入向量)。
首先平均会丢失关键信息,因为平均的话是线性融合的,表达信息的能力有限。
而非线性融合能捕捉更复杂的全局特征。即使模型规模很大,CLS Token依然是最优选择。
位置编码(Position Embedding):
正如文档中强调的:
"Transformer 天生是个'脸盲',如果没有位置编码向量,就无法感知词语的先后顺序。"
对于 ViT 来说也是一样------如果不加位置编码,模型就不知道每个 Patch 在图像中的空间位置(左上角还是右下角)。
采用标准可学习1D位置编码
每一个Token对应一个位置位置向量,都要加上它自己对应位置的位置编码。
为什么要直接相加?而不是直接拼接?
因为Transformer里面所有Token维度必须一样,直接逐元素相加·,维度不变,这样模型既能看到内容信息,又能看到位置信息。
不同于原始 Transformer 使用固定的正余弦位置编码,ViT 使用可学习的位置编码:
python
# [CLS] Token: 可学习参数,维度 (1, 1, D)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# 位置编码: 可学习参数,维度 (1, N+1, D)
# N+1 = 196 个 Patch + 1 个 [CLS] Token = 197
self.pos_embed = nn.Parameter(torch.zeros(1, 197, embed_dim))
# 拼接过程
def prepare_tokens(self, x):
B = x.shape[0]
# Patch Embedding
patch_tokens = self.patch_embed(x) # (B, 196, 768)
# 将 [CLS] Token 扩展到 batch 维度并拼接
cls_tokens = self.cls_token.expand(B, -1, -1) # (1,1,768) → (B,1,768)
tokens = torch.cat([cls_tokens, patch_tokens], dim=1) # (B, 197, 768)
# 加上位置编码(维度必须一致才能相加!)
tokens = tokens + self.pos_embed # (B, 197, 768) + (1, 197, 768)
return self.dropout(tokens)为什么 ViT 用可学习位置编码而非正余弦编码? 实验表明,对于 ViT,可学习的位置编码和正余弦编码效果差异不大 。但可学习编码更灵活------模型可以自己学出最适合视觉任务的空间位置关系。有趣的是,可视化学到的位置编码后会发现,空间上相邻的 Patch 确实学到了相似的位置编码。
MLP(多层感知机)的作用
目的是对每一个Patch的特征做非线性变换,提取更深层更复杂的语义。
模块四:Transformer Encoder(核心计算模块)
ViT 使用的是标准的 Transformer Encoder(只有 Encoder,没有 Decoder),堆叠 L 层。每一层包含:
┌──────────────────────────────────────────────────┐
│ Transformer Encoder Block │
│ │
│ Input │
│ │ │
│ ├──────────────────────────┐ │
│ │ │ │
│ ▼ │ (残差连接) │
│ Layer Norm │ │
│ │ │ │
│ ▼ │ │
│ Multi-Head Self-Attention │ │
│ │ │ │
│ ▼ │ │
│ + ◄──────────────────────────┘ │
│ │ │
│ ├──────────────────────────┐ │
│ │ │ │
│ ▼ │ (残差连接) │
│ Layer Norm │ │
│ │ │ │
│ ▼ │ │
│ MLP (FFN) │ │
│ [Linear → GELU → Dropout │ │
│ → Linear → Dropout] │ │
│ │ │ │
│ ▼ │ │
│ + ◄──────────────────────────┘ │
│ │ │
│ Output │
└──────────────────────────────────────────────────┘注意:ViT 采用的是 Pre-LN 结构!:
"目前业界更流行的是 Pre-LN 结构,先进行层归一化,再进行残差连接,梯度流动更加顺畅,训练更稳定。"
python
class TransformerBlock(nn.Module):
def __init__(self, embed_dim=768, num_heads=12, mlp_ratio=4.0, dropout=0.1):
super().__init__()
# Pre-LN: 先 Norm 再计算
self.norm1 = nn.LayerNorm(embed_dim)
self.attn = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout)
self.norm2 = nn.LayerNorm(embed_dim)
mlp_hidden_dim = int(embed_dim * mlp_ratio)
self.mlp = nn.Sequential(
nn.Linear(embed_dim, mlp_hidden_dim), # 第一个线性层: D → 4D
nn.GELU(), # GELU 激活函数(比 ReLU 更平滑)
nn.Dropout(dropout),
nn.Linear(mlp_hidden_dim, embed_dim), # 第二个线性层: 4D → D
nn.Dropout(dropout),
)
def forward(self, x):
# ===== 子层 1: Multi-Head Self-Attention =====
# Pre-LN: 先归一化
h = self.norm1(x)
# 自注意力: Q=K=V 都来自同一个输入("自"注意力)
h, _ = self.attn(h, h, h)
# 残差连接: 即使注意力层学废了,原汁原味的信息还在
x = x + h
# ===== 子层 2: Feed Forward Network =====
# Pre-LN: 先归一化
h = self.norm2(x)
# FFN: 不发生 token 之间的交互,逐个进行非线性空间映射
h = self.mlp(h)
# 残差连接
x = x + h
return xViT 中的自注意力过程(以图像理解为例):
想象一张猫的图片被切成 196 个 Patch:
-
生成 Q、K、V:每个 Patch 都通过三个权重矩阵生成自己的 Q(我要找什么上下文)、K(我能提供什么上下文)、V(我实际的语义内容)
-
打分计算:当计算"猫耳朵"所在 Patch 的注意力时,它的 Q 会去和所有 196 个 Patch 的 K 分别做点积。模型可能发现:
- 与"猫眼睛" Patch 的匹配分数非常高(空间相邻且语义相关)
- 与"猫尾巴" Patch 也有一定分数(都属于猫的身体部位)
- 与"背景天空" Patch 的分数很低(语义无关)
-
加权融合:用 Softmax 归一化分数后,乘以每个 Patch 的 V 矩阵
-
结果 :经过这一步,"猫耳朵" Patch 的向量被彻底改变了------它不再是孤立的一小块像素,而是融合了整个猫的全局上下文信息的特征
这就是 ViT 相比 CNN 最大的优势:从第一层开始就拥有全局感受野! CNN 需要堆叠很多层才能让一个像素"看到"远处的像素,而 ViT 的自注意力机制天生就是全局的。
关于 GELU vs ReLU:
ViT 中的 FFN 使用 GELU 激活函数而非 ReLU。GELU 可以看作 ReLU 的平滑版本,在接近 0 的区域不会像 ReLU 那样"硬截断",有助于梯度的平滑流动。
模块五:分类头(Classification Head)
经过 L 层 Transformer Encoder 的锤炼后,我们取 CLS Token 的输出进行分类:
python
# 最终的 Layer Norm
x = self.norm(x) # (B, 197, 768)
# 取 [CLS] Token 的输出(第 0 个位置)
cls_output = x[:, 0] # (B, 768)
# 通过分类头映射到类别数
logits = self.mlp_head(cls_output) # (B, num_classes)为什么用 CLS Token 而不是所有 Patch 的平均? CLS Token 在自注意力过程中会主动去关注所有 Patch 的信息,经过多层交互后,它自然成为了整个图像的全局表示。当然,实验表明使用**全局平均池化(GAP)**替代 CLS Token 也能达到类似的效果。
四、ViT 完整 PyTorch 实现
python
import torch
import torch.nn as nn
import math
class PatchEmbedding(nn.Module):
"""将图像切分为 Patch 并进行线性投影"""
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) ** 2 # 196
# 用卷积同时完成分块和线性投影
self.proj = nn.Conv2d(in_channels, embed_dim,
kernel_size=patch_size, stride=patch_size)
def forward(self, x):
# (B, 3, 224, 224) → (B, 768, 14, 14) → (B, 768, 196) → (B, 196, 768)
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class MultiHeadSelfAttention(nn.Module):
"""多头自注意力机制"""
def __init__(self, embed_dim=768, num_heads=12, dropout=0.1):
super().__init__()
self.num_heads = num_heads
self.d_k = embed_dim // num_heads # 每个头的维度: 768/12=64
self.scale = self.d_k ** -0.5 # 缩放因子: 1/√d_k
# Q、K、V 的线性投影(合并为一个大矩阵,效率更高)
self.qkv = nn.Linear(embed_dim, embed_dim * 3)
self.proj = nn.Linear(embed_dim, embed_dim) # 输出融合层 W_O
self.attn_drop = nn.Dropout(dropout)
self.proj_drop = nn.Dropout(dropout)
def forward(self, x):
B, N, C = x.shape
# 一次性生成 Q、K、V 并切分多头
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.d_k).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0) # 每个: (B, num_heads, N, d_k)
# 缩放点积注意力: Attention(Q,K,V) = Softmax(QK^T / √d_k) V
attn = (q @ k.transpose(-2, -1)) * self.scale # (B, heads, N, N)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# 加权求和
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # (B, N, C)
# 输出投影 W_O: 多头拼接 → 多头融合
x = self.proj(x)
x = self.proj_drop(x)
return x
class MLP(nn.Module):
"""前馈神经网络 (FFN)"""
def __init__(self, embed_dim=768, mlp_ratio=4.0, dropout=0.1):
super().__init__()
hidden_dim = int(embed_dim * mlp_ratio)
self.fc1 = nn.Linear(embed_dim, hidden_dim) # 升维: D → 4D
self.act = nn.GELU() # GELU 激活
self.fc2 = nn.Linear(hidden_dim, embed_dim) # 降维: 4D → D
self.drop = nn.Dropout(dropout)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class TransformerEncoderBlock(nn.Module):
"""Transformer Encoder 的一个 Block(Pre-LN 结构)"""
def __init__(self, embed_dim=768, num_heads=12, mlp_ratio=4.0, dropout=0.1):
super().__init__()
self.norm1 = nn.LayerNorm(embed_dim)
self.attn = MultiHeadSelfAttention(embed_dim, num_heads, dropout)
self.norm2 = nn.LayerNorm(embed_dim)
self.mlp = MLP(embed_dim, mlp_ratio, dropout)
def forward(self, x):
# Pre-LN + 残差连接
x = x + self.attn(self.norm1(x)) # 自注意力子层
x = x + self.mlp(self.norm2(x)) # FFN 子层
return x
class VisionTransformer(nn.Module):
"""完整的 Vision Transformer 模型"""
def __init__(self, img_size=224, patch_size=16, in_channels=3,
num_classes=1000, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4.0, dropout=0.1):
super().__init__()
# ① Patch Embedding
self.patch_embed = PatchEmbedding(img_size, patch_size, in_channels, embed_dim)
num_patches = self.patch_embed.num_patches # 196
# ② CLS Token(可学习)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# ③ 位置编码(可学习)
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(dropout)
# ④ Transformer Encoder: L 层堆叠
self.blocks = nn.Sequential(*[
TransformerEncoderBlock(embed_dim, num_heads, mlp_ratio, dropout)
for _ in range(depth)
])
# ⑤ 最终 Layer Norm + 分类头
self.norm = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, num_classes)
# 权重初始化
self._init_weights()
def _init_weights(self):
nn.init.trunc_normal_(self.pos_embed, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
self.apply(self._init_module_weights)
def _init_module_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
def forward(self, x):
B = x.shape[0]
# ① Patch Embedding: (B, 3, 224, 224) → (B, 196, 768)
x = self.patch_embed(x)
# ② 拼接 [CLS] Token: (B, 196, 768) → (B, 197, 768)
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat([cls_tokens, x], dim=1)
# ③ 加位置编码
x = self.pos_drop(x + self.pos_embed)
# ④ Transformer Encoder
x = self.blocks(x)
# ⑤ 取 [CLS] 输出进行分类
x = self.norm(x)
cls_output = x[:, 0] # (B, 768)
logits = self.head(cls_output) # (B, num_classes)
return logits
# ========== 使用示例 ==========
if __name__ == "__main__":
model = VisionTransformer(
img_size=224,
patch_size=16,
num_classes=1000,
embed_dim=768,
depth=12,
num_heads=12,
)
# 模拟输入一张 224×224 的 RGB 图片
dummy_input = torch.randn(1, 3, 224, 224)
output = model(dummy_input)
print(f"输出形状: {output.shape}") # torch.Size([1, 1000])
print(f"模型参数量: {sum(p.numel() for p in model.parameters()) / 1e6:.1f}M")五、ViT 的数据流全程追踪
让我们用一张 224×224 的猫咪图片 完整追踪数据在 ViT 中的流动过程(类比文档中"我是一只鸟"的 Transformer 流程):
第一阶段:图像"数字化"
步骤 1:输入图像
bash
输入: 一张 224 × 224 × 3 的 RGB 猫咪照片步骤 2:Patch 分块 + 线性嵌入
bashs
动作: 将图片切成 14×14 = 196 个 16×16 的小块
每个小块展平为 768 维向量,再通过线性投影映射到嵌入空间
结果: (1, 196, 768) --- 196 个 768 维的 Patch 嵌入向量
类比: NLP 中把 5 个汉字各自映射为 512 维的词嵌入向量步骤 3:添加 CLS Token + 位置编码
bash
动作:
1. 在序列最前面拼接 [CLS] Token → (1, 197, 768)
2. 加上位置编码,让模型知道每个 Patch 在图像中的位置
结果: 197 个带有位置信息的 768 维向量
类比: NLP 中给 "我是一只鸟" 加上位置编码 Pos(0)~Pos(4)第二阶段:Transformer Encoder 深度理解
步骤 4.1:Multi-Head Self-Attention(多头自注意力)
bash
动作: 197 个 Token 互相"打分"
- [CLS] Token 的 Q 会去和所有 196 个 Patch 的 K 计算点积
- "猫耳朵" Patch 的 Q 和 "猫眼睛" Patch 的 K 匹配分数很高
- 用 Softmax 归一化后,加权提取 V 矩阵的特征
结果: 每个 Patch 不再是孤立的像素块,而是融合了全局上下文的特征
[CLS] Token 开始汇聚整张图片的信息
类比: NLP 中 "鸟" 融合了 "我"、"一只" 等上下文信息步骤 4.2:Add & Norm(残差连接 + 层归一化)
bash
动作:
- Add: 把原始输入直接加到注意力输出上,防止梯度消失
- Norm: 对特征维度做归一化,稳定数据分布
类比: "即使注意力层学废了,原汁原味的信息还在"步骤 4.3:Feed Forward(前馈神经网络)
bash
动作: 对每个 Token 独立进行非线性空间映射
768 → 3072 (升维) → GELU → 3072 → 768 (降维)
不发生 Token 之间的交互,而是逐个挖掘更深层的特征
类比: NLP 中对 "我"、"是"、"一"、"只"、"鸟" 逐个做非线性映射步骤 4.4:Add & Norm(再次残差连接 + 层归一化)
以上步骤重复 L 次(ViT-Base 为 12 次)
第三阶段:输出预测
步骤 5:分类输出
bash
动作:
1. 取出 [CLS] Token 的最终输出 → (1, 768)
2. 通过 Layer Norm 归一化
3. 通过线性分类头映射到 1000 个类别 → (1, 1000)
4. 查找概率最高的类别 → "猫"
类比: NLP Decoder 中取隐层向量通过 Linear+Softmax 输出概率分布六、ViT 家族成员
| 模型 | Encoder 层数 (L) | 隐藏维度 (D) | 注意力头数 (H) | MLP 维度 | 参数量 |
|---|---|---|---|---|---|
| ViT-Small | 12 | 384 | 6 | 1536 | 22M |
| ViT-Base | 12 | 768 | 12 | 3072 | 86M |
| ViT-Large | 24 | 1024 | 16 | 4096 | 307M |
| ViT-Huge | 32 | 1280 | 16 | 5120 | 632M |
类比文档中的参数配置:NLP Transformer 使用
d_model=512, n_heads=8, n_layers=6;ViT-Base 使用d_model=768, n_heads=12, n_layers=12------更宽更深。
七、ViT 与 NLP Transformer 的关键差异
| 对比维度 | NLP Transformer | Vision Transformer (ViT) |
|---|---|---|
| 输入 | 文本单词序列 | 图像 Patch 序列 |
| 嵌入方式 | 词嵌入 (Embedding) | Patch 嵌入 (Conv2d 投影) |
| 位置编码 | 固定正余弦编码 | 可学习的位置编码 |
| 架构 | Encoder + Decoder | 仅 Encoder |
| 归一化 | Post-LN (原论文) | Pre-LN |
| 激活函数 | ReLU | GELU |
| CLS Token | BERT 中使用 | ViT 中使用 |
| Mask 机制 | Padding Mask + Causal Mask | 无(不需要) |
| 输出 | 逐词生成 (自回归) | 一次性分类 |
为什么 ViT 不需要 Decoder?
文档中详细讲解了 Decoder 的作用:
"解码器和编码器不同,它是自回归的,也就是一个词一个词地往外蹦。"
"掩码机制强行把未来位置的分数变成了 -∞(Softmax 后变 0),杜绝了作弊!"
ViT 是做图像分类,不需要逐步生成序列,因此:
- 不需要 Decoder(不需要自回归生成)
- 不需要因果掩码(不存在"未来信息泄露"的问题)
- 不需要交叉注意力(没有源序列-目标序列的交互)
ViT 只需要 Encoder 把图像"嚼碎",提取出全局特征,然后一步到位输出分类结果即可。
为什么 ViT 不需要 Padding Mask?
在 NLP 中,由于同一批次的句子长度不同,需要 Padding 对齐,然后用 Mask 屏蔽无效位置。文档中解释道:
"Transformer 在处理批次样本数据的时候要求同一批次的所有句子长度要保持一致。"
但在 ViT 中,所有图像经过 resize 后大小完全一致 (都是 224×224),切出的 Patch 数量也完全一致(都是 196 个),因此不需要 Padding,也不需要 Padding Mask。
八、ViT 的训练策略
8.1 学习率策略
正如文档中强调的:
"深度 Transformer 非常娇贵,不能使用固定的学习率。需要采用 Warmup 策略:前期学习率呈线性增长,之后再随着步数平方根的倒数缓慢衰减。"
ViT 同样采用 Warmup + Cosine Decay 的学习率策略:
python
# Warmup + Cosine Annealing 学习率调度
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=0.1)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=300)8.2 数据增强与正则化
由于 ViT 缺乏 CNN 的归纳偏置,需要更强的数据增强和正则化:
- RandAugment / AutoAugment:随机数据增强
- Mixup / CutMix:样本混合增强
- Label Smoothing:标签平滑(文档中也提到这是调优策略之一)
- Dropout / DropPath:随机丢弃路径
- Weight Decay:权重衰减
8.3 预训练的重要性
ViT 的一个关键发现是:在中小数据集上,ViT 不如 CNN;但在大规模数据集上预训练后,ViT 反超 CNN!
| 预训练数据规模 | ViT vs CNN |
|---|---|
| ImageNet-1K (1.2M 张) | ViT < CNN |
| ImageNet-21K (14M 张) | ViT ≈ CNN |
| JFT-300M (300M 张) | ViT > CNN |
这是因为 ViT 几乎没有归纳偏置(不像 CNN 天生有局部性和平移不变性),所以它需要更多的数据来从零学习这些视觉特征。一旦数据量足够,它的灵活性反而成为优势。
1. 图像分块与嵌入 (Patch Embedding)
类名:PatchEmbed
这是 ViT 最核心的创新点之一:将 2D 图像转换为 1D 的 Token 序列。
-
巧妙的卷积实现: 代码并没有真的去写循环切图,而是使用了一个二维卷积层
nn.Conv2d。通过设置kernel_size=patch_size和stride=patch_size,卷积核正好能不重叠地滑过整张图片。 -
维度变化:
- 输入图像: B , 3 , H , W B, 3, H, W B,3,H,W
- 经过卷积: B , D , H / P , W / P B, D, H/P, W/P B,D,H/P,W/P (其中 D D D 是
embed_dim, P P P 是patch_size) flatten(2): 将高和宽两个空间维度展平,变成 B , D , N B, D, N B,D,N ( N N N 是 patch 的总数)transpose(1, 2): 交换维度,变成 Transformer 标准的序列格式 B , N , D B, N, D B,N,D。
2. 多头自注意力机制 (Multi-Head Attention)
类名:Attention
这是 Transformer 提取全局特征的核心引擎。
- 高效的 QKV 生成: 代码没有定义三个独立的线性层,而是用了一个
nn.Linear(dim, dim * 3)一次性生成 Query、Key 和 Value。之后通过reshape和permute将它们拆解并分配给不同的注意力头(Heads)。 - 注意力计算: A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d ) V Attention(Q, K, V) = Softmax(\frac{QK^T}{\sqrt{d}})V Attention(Q,K,V)=Softmax(d QKT)V。代码中
(q @ k.transpose(-2, -1)) * self.scale对应这部分数学计算,其中self.scale就是 1 d \frac{1}{\sqrt{d}} d 1,用于防止内积过大导致 Softmax 梯度消失。
3. 前馈神经网络 (MLP)
类名:Mlp
紧跟在 Attention 之后,对每个 Token 进行独立的特征变换。
- 结构: 经典的
Linear -> GELU -> Dropout -> Linear -> Dropout结构。 - 升维与降维: 中间隐藏层的维度通常是输入维度的 4 倍(由参数
mlp_ratio=4.决定)。它在这个过程中丰富了特征的表达空间,然后再次投影回原来的维度 D D D。
4. Transformer 编码器块 (Encoder Block)
类名:Block
将 Attention 和 MLP 组合在一起,构成一个完整的 Transformer 积木。
- Pre-LN 架构: 注意看
self.attn(self.norm1(x))和self.mlp(self.norm2(x))。ViT 采用的是 Pre-LayerNorm(在进入 Attention 或 MLP 之前进行归一化),这比早期的 Post-LN 训练起来更加稳定。 - 残差连接 (Residual Connection):
x = x + ...贯穿始终,保证了深层网络梯度能够有效回传。
5. ViT 主模型 (VisionTransformer)
类名:VisionTransformer
将上述组件像拼图一样拼凑起来。重点关注 forward_features 方法中的数据流:
- Patch 映射:
x = self.patch_embed(x)。 - 拼接 CLS Token: 初始化了一个可学习的分类向量
cls_token(形状为 1 , 1 , D 1, 1, D 1,1,D),在 Batch 维度扩展后,拼接到序列的头部。此时序列长度从 N N N 变成了 N + 1 N+1 N+1。 - 加上位置编码:
x = x + self.pos_embed。因为 Attention 本身没有位置概念,所以必须加上绝对位置编码(一个和序列一样长的可学习参数),告诉模型每个 patch 原来在图像的哪个位置。 - 通过编码器: 依次穿过
depth个Block。 - 提取分类特征:
self.pre_logits(x[:, 0])。整个序列跑完后,只提取第 0 个位置的特征(也就是 CLS Token 对应的输出),以此代表整张图像的全局信息。 - 输出: 最后输入到
self.head这个线性分类器中,输出每个类别的概率对数 (Logits)。
九、ViT 位置编码的可视化解读
ViT 学到的位置编码非常有趣。如果我们可视化 197 个位置编码向量之间的余弦相似度 ,会发现ViT 的可学习位置编码自动学会了二维空间结构------同一行/同一列的 Patch 位置编码相似度高,表明模型确实理解了图像的空间布局。
十、ViT 的注意力可视化
通过可视化不同层、不同头的注意力权重,可以发现 ViT 的"视觉理解方式":
浅层 (Layer 1-3): 深层 (Layer 10-12):
┌──────────┐ ┌──────────┐
│ ▓▓░░░░░░ │ 关注局部纹理 │ ░░▓▓▓░░░ │ 关注语义区域
│ ▓▓░░░░░░ │ (类似 CNN 浅层) │ ░░▓▓▓░░░ │ (关注整只猫)
│ ░░░░░░░░ │ │ ░░▓▓▓░░░ │
│ ░░░░░░░░ │ │ ░░░░░░░░ │
└──────────┘ └──────────┘
不同的注意力头关注不同的模式:
Head 1: 关注水平方向 Head 3: 关注对角方向 Head 7: 关注全局
Head 2: 关注垂直方向 Head 5: 关注局部细节 Head 11: 关注前景/背景这与多头注意力的设计理念完全一致------不同的头学习不同的注意力模式,多角度理解图像。
十一、ViT 与 CNN 的全面对比

| 维度 | CNN (卷积神经网络) | ViT (视觉 Transformer) |
|---|---|---|
| 归纳偏置 (Inductive Bias) | ✅ 强。具有局部性 (Locality) 和平移不变性 (Translation Invariance) | ❌ 弱。几乎无归纳偏置,完全靠数据驱动学习 |
| 感受野 (Receptive Field) | 局部------>全局(逐层扩大) | 全局(从第一层起就是全局感受野) |
| 数据需求 | 中小规模数据集即可训练收敛 | 需要大规模数据(如 ImageNet-21k 或 JFT-300M) |
| 可扩展性 (Scalability) | 有性能天花板(模型变大后收益递减) | 随规模持续提升(Scaling Law 表现极佳) |
| 计算模式 | 滑动窗口(局部密集计算) | 全局自注意力,计算复杂度 O ( N 2 ) O(N^2) O(N2) |
| 参数效率 | 共享卷积核,参数量相对较少 | 不共享权重,参数量通常较大 |
| 训练速度 | 较快(尤其是小模型) | 较慢(但矩阵运算非常适合 GPU/TPU 并行加速) |
| 特征交互 | 局部 ------>逐步聚合到全局 | 一步到位的全图全局特征交互 |
👁️ 十、ViT 的注意力可视化解析
图片上半部分展示了 ViT 强大的可解释性。与 CNN 难以理解的"黑盒"特征图不同,ViT 的注意力权重 (Attention Weights) 可以直接提取出来,告诉我们模型到底在"看"哪里:
- 层级差异 (Layers):
- 浅层 (Layer 1-3): 注意力分散,主要关注局部纹理、边缘(类似于 CNN 的浅层特征)。
- 深层 (Layer 10-12): 注意力高度集中,能够精准捕捉全局语义区域(例如准确覆盖一整只猫的轮廓)。
- 多头分工 (Heads): 多头注意力机制不是冗余的,不同的 Head 学到了不同的空间模式。
- 有的专门盯水平线 (Head 1),有的盯垂直线 (Head 2)。
- 有的专门剥离前景和背景 (Head 11)。
十二、ViT 的后续发展与重要变体
ViT 开启了视觉 Transformer 的时代,后续涌现出大量改进工作:
12.1 训练效率优化
| 模型 | 年份 | 核心贡献 |
|---|---|---|
| DeiT | 2021 | 知识蒸馏 + 强数据增强,首次在 ImageNet-1K 上高效训练 ViT |
| BEiT | 2021 | 借鉴 BERT 的 Masked Image Modeling 自监督预训练 |
| MAE | 2022 | Masked Autoencoder,遮住 75% 的 Patch 让模型重建 |
| DINOv2 | 2023 | 自监督 ViT,学习通用视觉特征 |
12.2 架构改进
| 模型 | 年份 | 核心贡献 |
|---|---|---|
| Swin Transformer | 2021 | 层级结构 + 窗口注意力,降低计算复杂度至 O(N) |
| PVT | 2021 | 金字塔结构 ViT,适用于密集预测任务 |
| CvT | 2021 | 在 ViT 中引入卷积,结合 CNN 和 Transformer 的优势 |
| ViT-G | 2022 | 扩展到 20 亿参数,持续提升性能 |
12.3 多模态统一
| 模型 | 年份 | 核心贡献 |
|---|---|---|
| CLIP | 2021 | 图文对比学习,ViT 作为视觉编码器 |
| DALL-E | 2021 | 图像生成中使用 ViT |
| GPT-4V | 2023 | 多模态大模型,视觉理解 + 语言生成 |
十三、实践建议
13.1 显卡配置建议
实际经验:
"显卡比较低的话,可以调整批次,降低维度,调整多头注意力机制中的头数和降低隐藏层层数,不然性能跑不起来..."
对于 ViT 训练同样适用:
python
# 低显存配置(8GB 显存)
config = {
'img_size': 224,
'patch_size': 16,
'embed_dim': 384, # 降低维度 (768 → 384)
'depth': 6, # 减少层数 (12 → 6)
'num_heads': 6, # 减少头数 (12 → 6)
'batch_size': 32, # 减小批次
}
# 高显存配置(24GB+ 显存)
config = {
'img_size': 224,
'patch_size': 16,
'embed_dim': 768, # 标准 ViT-Base
'depth': 12,
'num_heads': 12,
'batch_size': 256,
}13.2 调优策略总结
| 调优维度 | 具体策略 | 核心原理 |
|---|---|---|
| 学习率 | Warmup + Cosine Decay | Transformer 不能用固定学习率,需要预热后缓慢衰减 |
| 数据增强 | RandAugment + Mixup + CutMix | 弥补 ViT 缺乏归纳偏置的不足 |
| 正则化 | Label Smoothing + DropPath | 缓解过拟合,提升泛化能力 |
| 显存优化 | 梯度累加 (Gradient Accumulation) | 小 Batch 模拟大 Batch,稳定梯度更新 |
| 预训练 | 在大数据集上预训练,小数据集上微调 | ViT 在大数据上才能发挥真正实力 |
ViT 项目实战
数据集来源:著名的 PlantVillage 数据集。
这是计算机视觉和植物病理学领域最常用的基准数据集之一。这是由宾夕法尼亚州立大学(Penn State University)和 EPFL 的研究人员发起的一个开放获取项目。其核心目标是利用人工智能帮助农民识别农作物病害。
kaggle:https://www.kaggle.com/datasets/emmarex/plantdisease/data
一、 图像的"词汇化":Patch Embedding 源码解析
NLP 领域的 Transformer 只能处理一维序列(Token)。ViT 跨界 CV 的第一步,就是把 2D 图像变成 1D 的 Token 序列。论文中说要"切 Patch",但在代码中,我们绝不会写一个 for 循环去裁剪图片。
pythoN
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768):
super().__init__()
# 核心魔法:用二维卷积代替物理切图!
# kernel_size = stride = 16,意味着卷积核刚好不重叠地扫过整张图
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
# 假设输入 x 的形状: [Batch, 3通道, 224宽, 224高]
# 1. 卷积映射
# [B, 3, 224, 224] -> [B, 768, 14, 14]
# (此时14x14就是196个patch,每个patch被映射成了768维的向量)
x = self.proj(x)
# 2. 展平空间维度
# flatten(2) 表示从第2个维度(也就是高度14)开始展平
# [B, 768, 14, 14] -> [B, 768, 196]
x = x.flatten(2)
# 3. 维度置换,迎合 Transformer 的标准输入格式 [Batch, Sequence_Length, Embedding_Dim]
# [B, 768, 196] -> [B, 196, 768]
x = x.transpose(1, 2)
return x💡 核心感悟: 原来高深莫测的 Patch 划分,在工程上只需要一行 stride 和 kernel_size 相等的 Conv2d 就完美解决了。此时,一张图片已经变成了长度为 196 的"句子"。
二、 给瞎子指路:CLS Token 与 位置编码
把图片切碎后,Transformer 就像一个高度近视的人,它知道有哪些图块,但完全不知道这些图块原本在图片的左上角还是右下角。此外,处理完这 196 个 Token 后,我们用哪个输出来做分类呢?
来看主类 VisionTransformer 的 __init__ 与 forward_features 方法:
python
# --- 在 __init__ 中定义 ---
# 1. 定义班长 [CLS] Token (全零初始化的可学习参数)
# 维度: [1, 1, 768]
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# 2. 定义绝对位置编码 (196个Patch + 1个CLS = 197)
# 维度: [1, 197, 768]
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
# --- 在 forward_features 中拼装 ---
def forward_features(self, x):
# x 此时经过 PatchEmbed 是 [B, 196, 768]
x = self.patch_embed(x)
# 把 [1, 1, 768] 的 cls_token 复制 Batch 份 -> [B, 1, 768]
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
# 将 CLS 拼接到序列的最前面:[B, 197, 768]
x = torch.cat((cls_token, x), dim=1)
# 加上位置编码,赋予空间信息! (利用了 PyTorch 的广播机制)
# [B, 197, 768] + [1, 197, 768] -> [B, 197, 768]
x = self.pos_drop(x + self.pos_embed)
# ...送入 Encoder Blocks...💡 核心感悟: [CLS] 就像一个班长,它游走在序列的最前面。经过多层 Attention 信息交互后,这个班长会吸收全图196 个图块的精华。最后我们只需要提取出这个班长的特征(即 x[:, 0]),送入线性层就能判断是哪种叶片病害了。
三、 灵魂引擎:多头自注意力 (MSA) 的高效实现
网上讲 的文章多如牛毛,但落实到 PyTorch 代码中,为了追求极致的 GPU 计算效率,我们通常不会写三个独立的 Linear 层。
翻开 vit_model.py 的 Attention 模块:
python
class Attention(nn.Module):
def __init__(self, dim, num_heads=8):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads # 例如 768 // 12 = 64
self.scale = head_dim ** -0.5 # 缩放因子 1/sqrt(d)
# 魔法:用一个全连接层一次性生成 Q, K, V!
# 输入维度 768,输出维度 768 * 3 = 2304
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
def forward(self, x):
B, N, C = x.shape # 例如 B, 197, 768
# 1. 一次性生成,然后切分
# x 经过 qkv 变成 [B, 197, 2304]
# reshape 后: [B, 197, 3, 12(头数), 64(每个头的维度)]
# permute 置换维度: [3(对应qkv), B, 12, 197, 64]
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# 优雅地拆包得到 q, k, v (各自形状均为 [B, 12, 197, 64])
q, k, v = qkv[0], qkv[1], qkv[2]
# 2. 矩阵乘法计算 Attention 权重分数 (注意 k.transpose 转置最后两维)
# [B, 12, 197, 64] @ [B, 12, 64, 197] -> [B, 12, 197, 197]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1) # 对序列长度维度做 Softmax
# 3. 将权重乘回 V 上
# [B, 12, 197, 197] @ [B, 12, 197, 64] -> [B, 12, 197, 64]
# transpose(1, 2) 把头数和序列长度换回来 -> [B, 197, 12, 64]
# reshape 把多头重新拼接回 768 维 -> [B, 197, 768]
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
return self.proj(x)这段代码堪称张量维度变换的艺术!正是这种全局的矩阵乘法,使得 ViT 从第一层开始就拥有了全局感受野,它能一步到位地建立图片左上角病斑与右下角枯萎叶片之间的联系,这是传统 CNN 需要堆叠极深网络才能做到的。
四、 模型训练部分
python
import os
import math
import argparse
import csv
import torch
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
from tools.my_dataset import build_vit_dataloaders
from model import vit_model as vit_models
from tools.utils import read_split_data, train_one_epoch, evaluate, ConsolePrinter # 数据划分、单epoch训练、验证评估函数
from tools.create_exp_folder import create_exp_folder
from tools.plot_metrics import plot_from_metrics_csv, plot_val_prf_curves, save_confusion_matrices
# 用于"权重-模型不匹配"时给出更明确的提示(按vit_model 里的工厂函数命名)
MODEL_SIGS = {
"vit_base_patch16_224_in21k": {"patch_size": 16, "embed_dim": 768, "depth": 12},
"vit_base_patch32_224_in21k": {"patch_size": 32, "embed_dim": 768, "depth": 12},
"vit_large_patch16_224_in21k": {"patch_size": 16, "embed_dim": 1024, "depth": 24},
"vit_large_patch32_224_in21k": {"patch_size": 32, "embed_dim": 1024, "depth": 24},
"vit_huge_patch14_224_in21k": {"patch_size": 14, "embed_dim": 1280, "depth": 32},
}
def _strip_module_prefix(state_dict):
# 兼容 DataParallel / DDP 保存的 "module.xxx"
if not isinstance(state_dict, dict):
return state_dict
if not state_dict:
return state_dict
has_module = any(k.startswith("module.") for k in state_dict.keys())
if not has_module:
return state_dict
return {k[len("module."):]: v for k, v in state_dict.items()}
def _infer_vit_sig_from_weights(state_dict):
"""
从权重里尽量推断出:patch_size / embed_dim / depth
用于当用户选错模型时给更友好的提示
"""
sig = {"patch_size": None, "embed_dim": None, "depth": None}
w = state_dict.get("patch_embed.proj.weight", None)
if w is not None and hasattr(w, "shape") and len(w.shape) == 4:
# [embed_dim, in_c, patch, patch]
sig["embed_dim"] = int(w.shape[0])
sig["patch_size"] = int(w.shape[2])
# depth:看 blocks.{i}.xxx 最大 i
max_idx = -1
for k in state_dict.keys():
if k.startswith("blocks."):
parts = k.split(".")
if len(parts) > 1 and parts[1].isdigit():
max_idx = max(max_idx, int(parts[1]))
if max_idx >= 0:
sig["depth"] = max_idx + 1
return sig
def _suggest_models_by_sig(sig):
"""
根据推断的 (patch_size, embed_dim, depth) 给出可能匹配的模型名
"""
ps, ed, dp = sig.get("patch_size"), sig.get("embed_dim"), sig.get("depth")
if ps is None or ed is None or dp is None:
return []
cands = []
for name, s in MODEL_SIGS.items():
if s["patch_size"] == ps and s["embed_dim"] == ed and s["depth"] == dp:
cands.append(name)
return cands
def _smart_load_weights(model, ckpt, args, device):
# 兼容两种格式:
# 1) 纯 state_dict(直接就是参数字典)
# 2) checkpoint(含 model_state/optimizer_state/...)
state_dict = ckpt["model_state"] if isinstance(ckpt, dict) and "model_state" in ckpt else ckpt
state_dict = _strip_module_prefix(state_dict)
# 如果是"训练保存的 checkpoint",可强校验 model 是否一致(避免你说的:B 权重配 L 模型)
if isinstance(ckpt, dict) and "args" in ckpt and isinstance(ckpt["args"], dict):
old_model = ckpt["args"].get("model", None)
if old_model is not None and hasattr(args, "model") and args.model != old_model:
raise RuntimeError(
f"Checkpoint was trained with model={old_model}, "
f"but now you selected --model={args.model}. Please make them一致。"
)
# 只删除分类头(类别数一定不匹配)
for k in ["head.weight", "head.bias"]:
state_dict.pop(k, None)
# 自动处理:过滤掉 shape 不匹配的 key,并统计匹配比例
model_sd = model.state_dict()
expected_keys = [k for k in model_sd.keys() if not k.startswith("head.")]
filtered = {}
shape_mismatch = []
unexpected = []
for k, v in state_dict.items():
if k in model_sd:
if model_sd[k].shape == v.shape:
filtered[k] = v
else:
shape_mismatch.append((k, tuple(v.shape), tuple(model_sd[k].shape)))
else:
unexpected.append(k)
matched = sum(1 for k in expected_keys if k in filtered)
keep_ratio = matched / max(1, len(expected_keys))
# 如果匹配比例过低,基本就是"模型选错了",直接报错并给提示
# (否则 strict=False 可能让你误以为加载成功,但其实没加载多少)
MIN_KEEP_RATIO = 0.85
if keep_ratio < MIN_KEEP_RATIO:
w_sig = _infer_vit_sig_from_weights(state_dict)
suggestions = _suggest_models_by_sig(w_sig)
msg = []
msg.append(f"权重与当前模型不匹配(keep_ratio={keep_ratio:.2%} < {MIN_KEEP_RATIO:.0%})")
msg.append(f"当前选择 --model={getattr(args, 'model', None)}")
msg.append(f"从权重推断到的结构特征:patch_size={w_sig.get('patch_size')}, embed_dim={w_sig.get('embed_dim')}, depth={w_sig.get('depth')}")
if suggestions:
msg.append("你更可能应该使用:")
for s in suggestions:
msg.append(f" --model {s}")
else:
msg.append("建议:确认你选择的 --model 是否与权重对应(Base/Large/Huge、patch_size、embed_dim、depth 必须一致)。")
# 额外给出几个最关键的 shape mismatch 例子,方便你定位
if shape_mismatch:
msg.append("部分 shape mismatch 示例(只显示前 5 个):")
for k, wsh, msh in shape_mismatch[:5]:
msg.append(f" - {k}: weight{wsh} vs model{msh}")
raise RuntimeError("\n".join(msg))
# 走到这里说明"基本匹配",允许 strict=False 加载(并把不匹配的部分留给随机初始化)
msg = model.load_state_dict(filtered, strict=False)
print(msg)
# 额外打印:哪些 key 因 shape 不匹配被跳过(少量时很正常,比如你改了分辨率/pos_embed 等)
if shape_mismatch:
print(f"skipped {len(shape_mismatch)} keys due to shape mismatch (showing first 10):")
for k, wsh, msh in shape_mismatch[:10]:
print(f" - {k}: weight{wsh} vs model{msh}")
return model
def build_model_and_prepare(args, device, num_classes: int):
create_model = getattr(vit_models, args.model, None)
if create_model is None or not callable(create_model):
# 给出可选项:只列出 vit_model 里"看起来像 ViT 工厂函数"的名字
candidates = [n for n in MODEL_SIGS.keys() if hasattr(vit_models, n)]
raise ValueError(
f"Unknown model: {args.model}\n"
f"Available candidates: {candidates}"
)
model = create_model(num_classes=num_classes).to(device)
if args.weights:
assert os.path.exists(args.weights), f"weights file: '{args.weights}' not exist."
ckpt = torch.load(args.weights, map_location=device)
model = _smart_load_weights(model, ckpt, args, device)
# freeze:只训练 pre_logits + head
if args.freeze_layers:
for name, p in model.named_parameters():
if ("head" not in name) and ("pre_logits" not in name):
p.requires_grad_(False)
else:
print(f"training {name}")
return model
def main(args):
# 设备选择:优先使用 args.device(例如 cuda:0),若无 GPU 则回退到 CPU
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
# 调用函数获取新的exp文件夹和weights文件夹路径
exp_folder, weights_folder = create_exp_folder()
# 在 main() 开头 exp_folder 创建之后,加:
metrics_path = os.path.join(exp_folder, "metrics.csv")
# 写表头(只写一次)
if not os.path.exists(metrics_path):
with open(metrics_path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["epoch", "train_loss", "train_acc", "val_loss", "val_acc", "val_p", "val_r", "val_f1", "lr"])
# 读取并划分数据集:返回训练/验证集图片路径与标签
train_images_path, train_images_label, val_images_path, val_images_label, num_classes = read_split_data(
args.data_path,
val_rate=0.2,
exp_folder=exp_folder,
seed=0)
# 构建训练/验证DataLoader
# 输入:训练/验证集的图片路径列表 + 标签列表
# 输出:两个可迭代对象 train_loader / val_loader,用于训练循环 for images, labels in loader
train_loader, val_loader = build_vit_dataloaders(
train_images_path, train_images_label, # 训练集:路径list + label list
val_images_path, val_images_label, # 验证集:路径list + label list
batch_size=args.batch_size # 每个 batch 样本数
)
# 构建并准备模型(迁移学习入口)
# - create_model(num_classes=K):创建ViT,并把分类头改成下游任务的K类
# - 若 args.weights非空:加载预训练权重(通常只加载backbone,删除head/pre_logits避免形状不匹配)
# - 若 args.freeze_layers=True:冻结除head/pre_logits外的参数,只微调分类头(适合小数据集)
model = build_model_and_prepare(args, device, num_classes)
# ===================== 优化器与学习率调度器 =====================
# 构建优化器:只优化requires_grad=True的参数
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=5E-5)
# 学习率调度器:余弦退火(Cosine LR)
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
# ===================== 权重保存相关 =====================
os.makedirs(weights_folder, exist_ok=True)
last_ckpt_path = os.path.join(weights_folder, "last.pth")
best_ckpt_path = os.path.join(weights_folder, "best.pth")
best_val_acc = -1.0
best_epoch = -1
# ===================== 训练 =====================
# 训练循环:按epoch迭代
printer = ConsolePrinter()
for epoch in range(args.epochs):
# ===== train header(蓝色)=====
print()
print(printer.train_header(colored=True))
train_loss, train_acc = train_one_epoch(
model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch,
epochs=args.epochs
)
scheduler.step()
# ===== val header(黄色)=====
print(printer.val_header(colored=True))
val_loss, val_acc, val_p, val_r, val_f1 = evaluate(
model=model,
data_loader=val_loader,
device=device,
epoch=epoch,
epochs=args.epochs,
num_classes=num_classes,
indent_spaces=16
)
# 读取当前学习率(scheduler.step() 之后 optimizer 里的 lr 已更新)
# param_groups 是 PyTorch 优化器的"参数组列表"
# 这里取第 0 组的学习率(常见情况只有一组)
lr_now = optimizer.param_groups[0]["lr"]
# 统一转成 Python float,方便后续:
# - 写入 metrics.csv
val_acc_value = float(val_acc.item()) if hasattr(val_acc, "item") else float(val_acc)
train_acc_value = float(train_acc.item()) if hasattr(train_acc, "item") else float(train_acc)
with open(metrics_path, "a", newline="") as f:
writer = csv.writer(f)
writer.writerow([epoch, train_loss, train_acc_value, val_loss, val_acc_value, val_p, val_r, val_f1, lr_now])
# ===================== 新增:保存 last / best =====================
# val_acc 兼容 float / tensor
val_acc_value = float(val_acc.item()) if hasattr(val_acc, "item") else float(val_acc)
# 保存 last:每个 epoch 覆盖写,最终得到最后一轮模型
torch.save({
"epoch": epoch,
"model_state": model.state_dict(),
"optimizer_state": optimizer.state_dict(),
"scheduler_state": scheduler.state_dict(),
"best_val_acc": best_val_acc,
"args": vars(args),
}, last_ckpt_path)
# 保存 best:若 val_acc 更好则更新
if val_acc_value > best_val_acc:
best_val_acc = val_acc_value
best_epoch = epoch
torch.save({
"epoch": epoch,
"model_state": model.state_dict(),
"optimizer_state": optimizer.state_dict(),
"scheduler_state": scheduler.state_dict(),
"best_val_acc": best_val_acc,
"args": vars(args),
}, best_ckpt_path)
# 训练结束后自动绘图
metrics_path = os.path.join(exp_folder, "metrics.csv")
plot_from_metrics_csv(metrics_path, out_dir=exp_folder, smooth=3)
# 训练全部结束后:画 PRF 曲线 + 混淆矩阵
plot_val_prf_curves(metrics_path, exp_folder) # 保存:exp_folder/val_prf_curve.png
# ===== 训练结束后:用 best 权重来画混淆矩阵 =====
# 训练结束后:加载 best 权重
best_path = os.path.join(weights_folder, "best.pth")
ckpt = torch.load(best_path, map_location=device)
model.load_state_dict(ckpt["model_state"], strict=True)
model.eval()
# 画混淆矩阵(best)
save_confusion_matrices(model, val_loader, device, num_classes, exp_folder)
print(f"curves saved to: {exp_folder} (loss_curve.*, acc_curve.*)")
print(f"Training done. Best val_acc={best_val_acc:.4f} at epoch={best_epoch}")
print(f"Last checkpoint: {last_ckpt_path}")
print(f"Best checkpoint: {best_ckpt_path}")
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# 训练与任务相关参数
parser.add_argument('--epochs', type=int, default=100) # 训练轮数
parser.add_argument('--batch-size', type=int, default=256) # batch size(注意属性名是 opt.batch_size)
parser.add_argument('--lr', type=float, default=0.001) # 初始学习率
parser.add_argument('--lrf', type=float, default=0.01) # 最终学习率比例(cosine schedule 末端比例)
# 数据路径
parser.add_argument('--data-path', type=str, default="Plant_Leaf_Disease") # 数据集根目录
parser.add_argument('--model', type=str, default="vit_base_patch16_224_in21k",
help='选择模型工厂函数名,例如 vit_base_patch16_224_in21k / vit_large_patch16_224_in21k')
# 迁移学习相关
# --weights:预训练权重路径,不想加载就传空字符串
parser.add_argument('--weights', type=str, default='weights/jx_vit_base_patch16_224_in21k-e5005f0a.pth',
help='initial weights path')
# 是否冻结 backbone(常用于小数据集微调:只训练 head / pre_logits)
parser.add_argument('--freeze-layers', type=bool, default=True)
# 设备选择
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
# 解析命令行参数
# 例如:python train.py --epochs 50 --batch-size 32 --device cpu
opt = parser.parse_args()
# 调用主训练函数 main(opt)
main(opt)思路:
迁移学习的思想,官方预训练权重👉 weights/jx_vit_base_patch16_224_in21k-e5005f0a.pth
权重名字大解密:
jx:代表 JAX。ViT 最初是由 Google 团队使用 JAX 框架(而不是 PyTorch)编写并训练的。这个前缀说明这个权重是由民间大神(通常是timm库的作者 rwightman)从 Google 官方的 JAX 格式转换成 PyTorch 支持的.pth格式的。vit_base:代表模型的体量是 Base 版本(基础版)。ViT 家族有 Base、Large、Huge 等不同体量,Base 版通常包含约 8600 万个参数(86M),是算力和效果平衡得最好的版本,最适合做个人项目。patch16:代表图像被切割的分块大小。模型在第一步(PatchEmbed)使用 16 × 16 16 \times 16 16×16 的网格来切分原图。224:代表模型训练时接受的标准输入图像分辨率是 224 × 224 224 \times 224 224×224。in21k:这是最核心的部分!代表它是在 ImageNet-21k 数据集上预训练的。普通的 ImageNet(通常叫 in1k)只有 1000 个类别、120 万张图;而 ImageNet-21k 包含了 21000 多个类别、1400 多万张图片!正是因为吃过这么海量的数据,这个权重才拥有了极其强大的特征提取能力。e5005f0a:这是文件内容的哈希码(Hash码)的前 8 位。主要用于校验文件下载是否完整,防止文件损坏导致加载失败。
让模型不用从头训练,站在巨人的肩膀上起步。
读取数据集 → 构建 ViT 模型 → 加载预训练权重(智能匹配)→ 冻结主干 → 训练 + 验证 → 记录指标 → 保存最优模型 → 自动绘制可视化图表
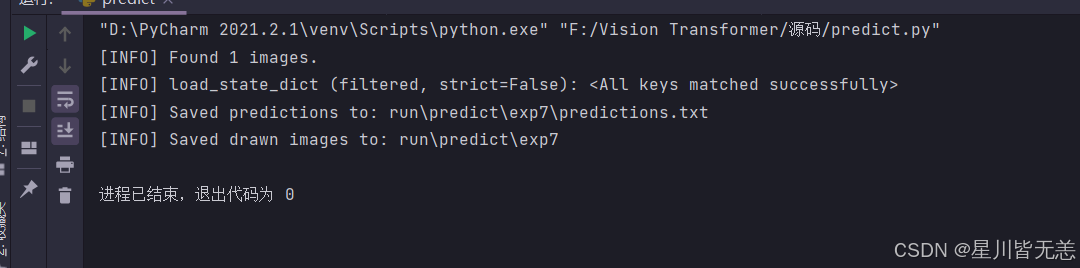
输入图片进行测试:


输出分类标签 和对应置信度 本机电脑环境有限 只训练了20轮 (显卡太垃圾...),训练100轮之后置信度在0.95-0.99,效果很好!

十五、总结
ViT 的核心贡献
- 证明了纯 Transformer 可以直接用于视觉任务,无需任何 CNN 组件
- 揭示了规模效应:随着数据和模型规模增大,ViT 的性能持续提升且超越 CNN
- 统一了视觉与语言的架构,为多模态模型(CLIP、GPT-4V)铺平了道路
ViT 的设计哲学
通过对比我们发现一个关键规律:
Large越多,网络越深,模型提取特征的能力就越强,但训练速度变慢,越容易过拟合。
MLP Size=D x4:VIT的标准设计,先升维更好的提取特征,再降维。
更大规模的训练数据训练效果更好。
Patch更小通常更强,但是更好算力,成本更高。
小数据阶段CNN占优。大数阶段ViT更强。
预训练计算量=模型大小x训练轮次
注意力机制距离:代表感受野大小
ViT 的成功再次印证了 Transformer 原论文的标题所蕴含的深意:
"Attention Is All You Need" ------ 注意力就是你所需要的一切
不仅在 NLP 领域,在计算机视觉领域,注意力机制同样是"你所需要的一切"。ViT 用最简洁的方式告诉我们:
只要数据足够多、模型足够大,最简单的方法往往就是最好的方法。
参考文献:
- Dosovitskiy et al. "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" (ICLR 2021)
- Vaswani et al. "Attention Is All You Need" (NeurIPS 2017)