第七章 指令微调学习(四)
7.6基于指令数据对大语言模型进行微调
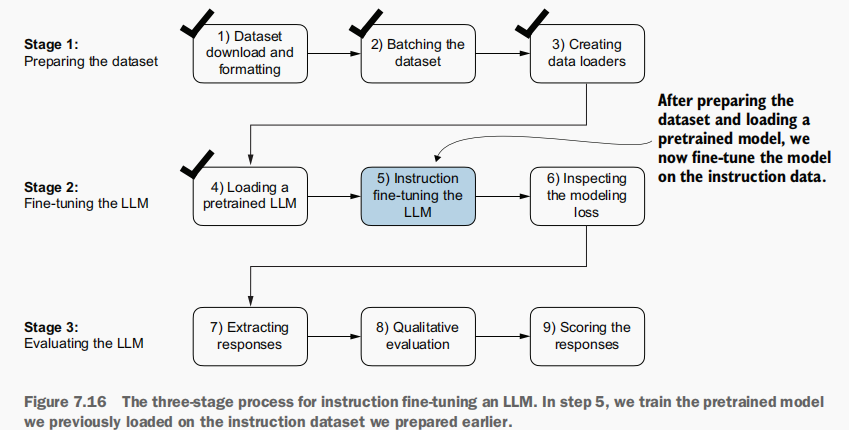
- 现在使用指令数据集在已加载的预训练模型上进行微调 ,需要使用到之前所用的损失计算和训练函数:
from pre_training import calc_loss_loader from Training_an_LLM_3_16 import train_model_simple - 计算初始训练和验证集的损失:
python
import torch
from pre_training import calc_loss_loader
from Download_instruction_dataset5_9 import train_loader, val_loader
from Training_an_LLM_3_16 import train_model_simple
from load_pretrained_model5_20 import val_data
from load_pretrained_model5_20 import model
import tiktoken
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
torch.manual_seed(123)
with torch.no_grad():
train_loss = calc_loss_loader(
train_loader, model, device, num_batches=5
)
val_loss = calc_loss_loader(val_loader, model, device,num_batches=5)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)
- 训练模型:初始化优化器、设置训练轮数,根据第7.5节中讨论的第一个验证集指令(val_data0)来定义评估频率及初始上下文,以便在训练过程中评估生成的LLM响应。
python
import torch
from pre_training import calc_loss_loader
from Download_instruction_dataset5_9 import train_loader, val_loader
from Training_an_LLM_3_16 import train_model_simple
from load_pretrained_model5_20 import val_data
from load_pretrained_model5_20 import model
import tiktoken
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
torch.manual_seed(123)
with torch.no_grad():
train_loss = calc_loss_loader(
train_loader, model, device, num_batches=5
)
val_loss = calc_loss_loader(val_loader, model, device,num_batches=5)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)
def format_input(entry):
instruction_text = (
f"Below is an instruction that describes a task. "
f"Write a response that appropriately completes the request."
f"\n\n### Instruction:\n{entry['instruction']}"
)
input_text = (
f"\n\n### Input:\n{entry['input']}" if entry["input"] else ""
)
return instruction_text + input_text
import time
start_time = time.time()
torch.manual_seed(123)
optimizer = torch.optim.AdamW(
model.parameters(), lr=0.00005, weight_decay=0.1
)
num_epochs = 2
tokenizer = tiktoken.get_encoding("gpt2")
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context=format_input(val_data[0]), tokenizer=tokenizer
)
end_time = time.time()
execution_time_minutes = (end_time - start_time) / 60
print(f"Training completed in {execution_time_minutes:.2f} minutes.")结果:
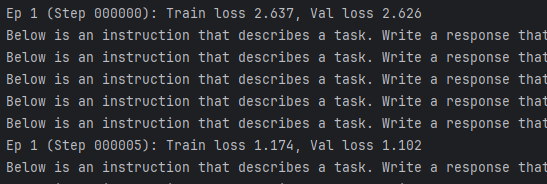
损失值的持续下降表明模型遵循指令并生成适当响应的能力正在提升;
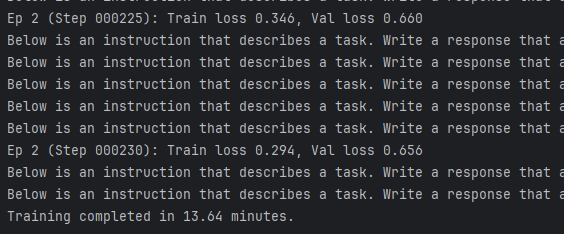
最终结果:

powershell
Ep 2 (Step 000230): Train loss 0.294, Val loss 0.656
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: 'The chef cooks the meal every day.' ### Response: The meal is cooked every day by the chef.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: What is the capital of the United Kingdom
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: 'The chef cooks the meal every day.' ### Response: The meal is cooked every day by the chef.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: What is the capital of the United Kingdom
Training completed in 13.64 minutes.训练结果表明 :模型学习效果显著 ------从两个训练周期中持续下降的训练损失和验证损失值即可看出这一点。说明模型逐渐提升了理解并遵循给定指令的能力。(不需要延长至第三个或更多训练周期,可能导致过拟合加剧。)我们将在后续章节更详细地重新评估模型的响应质量。
- 通过分析训练与验证损失曲线 来进一步了解模型的学习过程。
采用与预训练阶段相同的plot_losses函数:
python
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
def plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):
fig, ax1 = plt.subplots(figsize=(5, 3))
ax1.plot(epochs_seen, train_losses, label="Training loss")
ax1.plot(
epochs_seen, val_losses, linestyle="-.", label="Validation loss"
)
ax1.set_xlabel("Epochs")
ax1.set_ylabel("Loss")
ax1.legend(loc="upper right")
ax1.xaxis.set_major_locator(MaxNLocator(integer=True))
ax2 = ax1.twiny()
ax2.plot(tokens_seen, train_losses, alpha=0)
ax2.set_xlabel("Tokens seen")
fig.tight_layout()
plt.show()
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)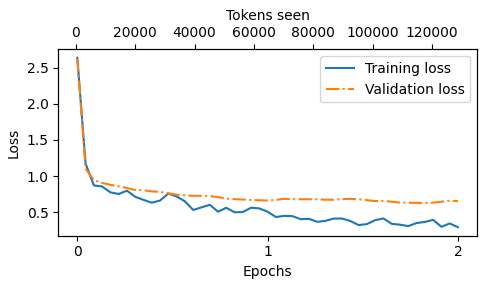
从损失曲线图可以看出,模型在训练集和验证集上的性能在整个训练过程中均显著提升。
初始阶段损失值的快速下降 表明模型能迅速从数据中学习到有意义的模式与特征表示;随后进入第二个训练周期后,损失值虽持续下降但增速放缓 ,这说明模型正在优化已学得的特征表示,并逐渐收敛 至稳定解。
虽然图中的损失曲线表明模型正在有效训练,但最关键的因素在于其响应质量与正确性的表现。因此,接下来我们需要提取这些响应,并将其存储在一种能够用于评估和量化响应质量的格式中。
总结 :已完成指令的微调,并进行了训练和验证损失的的可视化。
整体代码:
python
import torch
from pre_training import calc_loss_loader
from Download_instruction_dataset5_9 import train_loader, val_loader
from Training_an_LLM_3_16 import train_model_simple
from load_pretrained_model5_20 import val_data
from load_pretrained_model5_20 import model
import tiktoken
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
torch.manual_seed(123)
with torch.no_grad():
train_loss = calc_loss_loader(
train_loader, model, device, num_batches=5
)
val_loss = calc_loss_loader(val_loader, model, device,num_batches=5)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)
def format_input(entry):
instruction_text = (
f"Below is an instruction that describes a task. "
f"Write a response that appropriately completes the request."
f"\n\n### Instruction:\n{entry['instruction']}"
)
input_text = (
f"\n\n### Input:\n{entry['input']}" if entry["input"] else ""
)
return instruction_text + input_text
import time
start_time = time.time()
torch.manual_seed(123)
optimizer = torch.optim.AdamW(
model.parameters(), lr=0.00005, weight_decay=0.1
)
num_epochs = 2
tokenizer = tiktoken.get_encoding("gpt2")
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context=format_input(val_data[0]), tokenizer=tokenizer
)
end_time = time.time()
execution_time_minutes = (end_time - start_time) / 60
print(f"Training completed in {execution_time_minutes:.2f} minutes.")
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
def plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):
fig, ax1 = plt.subplots(figsize=(5, 3))
ax1.plot(epochs_seen, train_losses, label="Training loss")
ax1.plot(
epochs_seen, val_losses, linestyle="-.", label="Validation loss"
)
ax1.set_xlabel("Epochs")
ax1.set_ylabel("Loss")
ax1.legend(loc="upper right")
ax1.xaxis.set_major_locator(MaxNLocator(integer=True))
ax2 = ax1.twiny()
ax2.plot(tokens_seen, train_losses, alpha=0)
ax2.set_xlabel("Tokens seen")
fig.tight_layout()
plt.show()
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)写给自己:加油!再接再厉!相信自己!