### 文章目录
- [@toc](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [论文基本信息](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [一句话总结](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [0. 论文概述(Executive Summary)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [1. 问题背景与动机](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [1.1 研究的重要性](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [1.2 现有方法的演进](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [1.3 现存的主要问题](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [2. 相关工作与创新关联](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [2.1 前人工作综述](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**聚合型立体匹配方法**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**迭代型立体匹配方法**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**频率信息应用**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [2.2 存在的问题与不足](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [2.3 本论文与前人工作的关系](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [3. 贡献与核心创新点](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [3.1 核心创新点一:Selective Recurrent Unit (SRU)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [3.2 核心创新点二:Contextual Spatial Attention (CSA)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**子模块1:通道注意力增强(Channel Attention Enhancement, CAE)**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**子模块2:空间注意力提取器(Spatial Attention Extractor, SAE)**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [4. 方法与网络设计](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [4.1 整体网络架构概览](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**4.1.1 网络的多级结构**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**4.1.2 多级结构示意**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**4.1.3 各模块功能概述**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [4.2 网络详细分析](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**4.2.1 特征提取模块详解**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**4.2.2 成本体积构建模块详解**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**4.2.3 Contextual Spatial Attention (CSA) 详解**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**4.2.4 Selective Recurrent Unit (SRU) 详解**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**4.2.5 损失函数与训练策略**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [4.3 核心创新的技术支撑](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [5. 实验结果](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [5.1 数据集与评估指标](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**数据集描述**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**评估指标**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [5.2 消融研究](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**5.2.1 模块有效性验证**(表1:Scene Flow测试集)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**5.2.2 通用性验证**(表2)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**5.2.3 迭代次数的影响**(表3)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**5.2.4 核大小选择**(表4)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [5.3 性能对比](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**5.3.1 Scene Flow 基准(表5)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**5.3.2 边缘 vs 非边缘区域分析**(表7)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**5.3.3 KITTI 基准排名**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**5.3.4 ETH3D 和 Middlebury**(表8)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [5.4 定性可视化分析](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**5.4.1 KITTI 上的视觉对比(图5)**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**5.4.2 Middlebury 上的定性结果和注意力图**(图7)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [**5.4.3 不同网络的注意力图差异(图6)**](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [5.5 反射区域(病态区域)的性能(表9:补充材料)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [6. 不足之处与未来工作](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [6.1 现有限制](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [6.2 未来研究方向](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [7. 总体评价](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [7.1 研究价值](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [7.2 核心贡献总结](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [7.3 方法的优势](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [7.4 方法的劣势](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [7.5 研究的深远意义](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [附录:关键公式速查表](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [参考资源](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [讨论](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [一、CSA(上下文空间注意力模块)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [🔷 子模块 1:通道注意力增强(CAE)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [🔷 子模块 2:空间注意力提取器(SAE)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [二、SRU(选择性循环单元)](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [🔶 标准 GRU 回顾](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [🔶 SRU 的核心改造](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [🔶 多级 SRU 结构](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [三、整体数据流总结](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [四、关键设计洞见](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [你的质疑是对的:Pool 本身不能判断频率](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [真正的推理链:从上下文特征到频率判断](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [第一步:上下文特征(Context Feature)天然编码了频率信息](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [第二步:CAE 做的是通道级别的"筛选放大"](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [第三步:SAE 做的是空间级别的"位置定位"](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [用一个直觉类比来理解](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [论文的直接原话印证](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [消融实验的间接证明](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [总结](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [SRU vs CREStereo RUM:基于原文的精准对比](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [先厘清"多个GRU"在各自框架里的真实含义](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [一、RUM 的"多GRU":级联粗到精](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [二、SRU 的"多GRU":单级内部的频率并行](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [三、成本体积的计算方式:另一个核心差异](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [四、设计动机的根本不同](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
- [五、一句话总结](#文章目录 @[toc] Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结 论文基本信息 一句话总结 0. 论文概述(Executive Summary) 1. 问题背景与动机 1.1 研究的重要性 1.2 现有方法的演进 1.3 现存的主要问题 2. 相关工作与创新关联 2.1 前人工作综述 聚合型立体匹配方法 迭代型立体匹配方法 频率信息应用 2.2 存在的问题与不足 2.3 本论文与前人工作的关系 3. 贡献与核心创新点 3.1 核心创新点一:Selective Recurrent Unit (SRU) 3.2 核心创新点二:Contextual Spatial Attention (CSA) 子模块1:通道注意力增强(Channel Attention Enhancement, CAE) 子模块2:空间注意力提取器(Spatial Attention Extractor, SAE) 4. 方法与网络设计 4.1 整体网络架构概览 4.1.1 网络的多级结构 4.1.2 多级结构示意 4.1.3 各模块功能概述 4.2 网络详细分析 4.2.1 特征提取模块详解 4.2.2 成本体积构建模块详解 4.2.3 Contextual Spatial Attention (CSA) 详解 4.2.4 Selective Recurrent Unit (SRU) 详解 4.2.5 损失函数与训练策略 4.3 核心创新的技术支撑 5. 实验结果 5.1 数据集与评估指标 数据集描述 评估指标 5.2 消融研究 5.2.1 模块有效性验证(表1:Scene Flow测试集) 5.2.2 通用性验证(表2) 5.2.3 迭代次数的影响(表3) 5.2.4 核大小选择(表4) 5.3 性能对比 **5.3.1 Scene Flow 基准(表5) 5.3.2 边缘 vs 非边缘区域分析(表7) 5.3.3 KITTI 基准排名 5.3.4 ETH3D 和 Middlebury(表8) 5.4 定性可视化分析 5.4.1 KITTI 上的视觉对比(图5) 5.4.2 Middlebury 上的定性结果和注意力图(图7) 5.4.3 不同网络的注意力图差异(图6) 5.5 反射区域(病态区域)的性能(表9:补充材料) 6. 不足之处与未来工作 6.1 现有限制 6.2 未来研究方向 7. 总体评价 7.1 研究价值 7.2 核心贡献总结 7.3 方法的优势 7.4 方法的劣势 7.5 研究的深远意义 附录:关键公式速查表 参考资源 讨论 一、CSA(上下文空间注意力模块) 🔷 子模块 1:通道注意力增强(CAE) 🔷 子模块 2:空间注意力提取器(SAE) 二、SRU(选择性循环单元) 🔶 标准 GRU 回顾 🔶 SRU 的核心改造 🔶 多级 SRU 结构 三、整体数据流总结 四、关键设计洞见 你的质疑是对的:Pool 本身不能判断频率 真正的推理链:从上下文特征到频率判断 第一步:上下文特征(Context Feature)天然编码了频率信息 第二步:CAE 做的是通道级别的"筛选放大" 第三步:SAE 做的是空间级别的"位置定位" 用一个直觉类比来理解 论文的直接原话印证 消融实验的间接证明 总结 SRU vs CREStereo RUM:基于原文的精准对比 先厘清"多个GRU"在各自框架里的真实含义 一、RUM 的"多GRU":级联粗到精 二、SRU 的"多GRU":单级内部的频率并行 三、成本体积的计算方式:另一个核心差异 四、设计动机的根本不同 五、一句话总结)
Selective-Stereo: 自适应频率信息选择用于立体匹配 论文总结
论文基本信息
论文标题
Selective-Stereo: Adaptive Frequency Information Selection for Stereo Matching
(选择性立体匹配:自适应频率信息选择用于立体匹配)
作者信息
| 作者 | 角色 | 机构 |
|---|---|---|
| Xianqi Wang* | 第一作者 | Huazhong University of Science and Technology (HUST) |
| Gangwei Xu* | 第一作者 | Huazhong University of Science and Technology (HUST) |
| Hao Jia | 作者 | Huazhong University of Science and Technology (HUST) |
| Xin Yang† | 通讯作者 | Huazhong University of Science and Technology (HUST) |
发表信息
- 提交平台:arXiv
- 论文ID:2403.00486v1
- 提交日期:2024年3月1日
- 预印本发布日期:March 1, 2024
代码开源
📌 GitHub仓库:https://github.com/Windsrain/Selective-Stereo
一句话总结
本论文提出了一个新颖的选择性循环单元(SRU)和上下文空间注意力模块(CSA),通过自适应融合多频率的隐藏视差信息来改进迭代立体匹配方法,在多个基准测试中排名第一。
0. 论文概述(Executive Summary)
本论文针对现有迭代优化立体匹配方法(如RAFT-Stereo和IGEV-Stereo)的核心问题提出解决方案。这些方法因固定感受野而难以同时捕获高频信息(边缘)和低频信息(纹理区域),导致细节丧失、边缘模糊和弱纹理区域匹配错误。论文提出的Selective-Stereo(选择性立体匹配)框架包含两个关键创新:Selective Recurrent Unit (SRU) 和 Contextual Spatial Attention (CSA)。SRU通过多个不同核大小的GRU分支融合多频率信息,CSA则生成注意力图来自适应地加权这些信息。该方法具有良好的通用性,可应用于不同的迭代立体匹配方法,在KITTI 2012、KITTI 2015、ETH3D和Middlebury四个基准上均排名第一,验证了其有效性。
1. 问题背景与动机
1.1 研究的重要性
立体匹配是计算机视觉的基础研究领域,探索对位于一对校正图像中的匹配点之间的位移(视差)的计算,在3D重建和自动驾驶等应用中具有重要作用。
1.2 现有方法的演进
- 聚合型方法:早期的方法通过构建4D成本体积并使用3D CNN过滤,能有效聚合几何信息,但需要大量卷积,计算成本高,难以应用于高分辨率图像。
- 迭代优化方法:近年来RAFT-Stereo和IGEV-Stereo等基于迭代优化的方法成为主流,能处理高分辨率图像,但存在两个关键问题:
1.3 现存的主要问题
| 问题 | 具体表现 | 影响 |
|---|---|---|
| 固定感受野 | 传统循环单元具有固定的感受野,仅关注当前频率信息 | 无法同时捕获边缘的高频信息和光滑区域的低频信息 |
| 信息丧失 | 迭代过程中隐藏信息逐渐融入全局低频信息而丧失局部高频信息 | 细节模糊、边缘模糊、弱纹理区域匹配错误 |
| 噪声问题 | 全对成本体积包含大量噪声信息 | 迭代过程中关键信息的丧失风险 |
2. 相关工作与创新关联
2.1 前人工作综述
聚合型立体匹配方法
- DispNet:建立后续网络架构的基础
- GC-Net:提出4D级联成本体积和软argmin函数
- PSMNet:堆叠沙漏3D CNN改进成本聚合
- GwcNet:提出分组相关体积(Group-wise Correlation Volume)
- GA-Net:设计半全局引导聚合层和局部引导聚合层
- ACVNet:使用注意力权重抑制冗余信息
迭代型立体匹配方法
- RAFT-Stereo:基于光流方法RAFT,引入全对成本体积金字塔和GRU循环更新
- IGEV-Stereo:在迭代前使用轻量级成本聚合网络
- CREStereo:分层网络和堆叠级联架构
- DLNR:用LSTM替代GRU,解耦隐状态更新和视差预测
频率信息应用
- Octave Convolution:按频率分解混合特征图
- 频域学习:发现CNN模型对低频通道比高频通道更敏感
- DSGAN/LITv2:在超分辨率和注意力层中引入频率分离
2.2 存在的问题与不足
现有迭代方法的根本局限性在于:
- 固定感受野设计:传统GRU单元虽然设计简洁,但无法根据图像区域的不同频率特性进行自适应调整
- 全局信息与局部信息的平衡失衡:网络在迭代过程中逐渐偏向全局低频信息,丧失细节
- 缺乏空间自适应机制:不能根据图像中不同区域的特性(边缘vs纹理)选择合适的信息融合策略
2.3 本论文与前人工作的关系
| 方面 | 前人工作 | 本论文的改进 |
|---|---|---|
| 频率处理 | 被动识别频率特性 | 主动设计多分支GRU以主动捕获多频率信息 |
| 融合策略 | 简单的加权平均或求和 | Contextual Spatial Attention 的自适应加权融合 |
| 感受野 | 固定3个感受野 | 动态感受野,通过注意力融合产生6个以上的有效感受野 |
| 通用性 | 方法特定于某个网络 | 高度通用,可应用于RAFT-Stereo、IGEV-Stereo、DLNR等 |
3. 贡献与核心创新点
3.1 核心创新点一:Selective Recurrent Unit (SRU)
创新概述:提出一个新的迭代更新算子,用多个不同核大小的GRU分支替代传统的单一GRU。
核心思想:
- 多分支设计:使用小核大小的GRU(如1×1或3×3)捕获高频信息(边缘、细节)
- 多频率融合:使用大核大小的GRU(如1×5或更大)捕获低频信息(平滑区域、全局结构)
- 动态感受野:通过多分支与注意力融合,从原本的3个固定感受野扩展到6个及以上的有效感受野
数学表达:
感受野计算公式: r 0 = ∑ l = 1 L ( ( k l − 1 ) ∏ i = 1 l − 1 s i ) + 1 r_0 = \sum_{l=1}^{L} \left((k_l - 1) \prod_{i=1}^{l-1} s_i\right) + 1 r0=l=1∑L((kl−1)i=1∏l−1si)+1
其中 k l k_l kl 表示核大小, s i s_i si 表示步长。
单个GRU的定义(传统): z k = σ ( Conv ( h k − 1 , x k , W z ) ) z_k = \sigma(\text{Conv}(h_{k-1}, x_k, W_z)) zk=σ(Conv(hk−1,xk,Wz)) r k = σ ( Conv ( h k − 1 , x k , W r ) ) r_k = \sigma(\text{Conv}(h_{k-1}, x_k, W_r)) rk=σ(Conv(hk−1,xk,Wr)) h ~ ∗ k = tanh ( Conv ( r k ⊙ h ∗ k − 1 , x k , W h ) ) \tilde{h}*k = \tanh(\text{Conv}(r_k \\odot h\*{k-1}, x_k, W_h)) h~∗k=tanh(Conv(rk⊙h∗k−1,xk,Wh)) h k = ( 1 − z k ) ⊙ h k − 1 + z k ⊙ h ~ k ( 3 ) h_k = (1 - z_k) \odot h_{k-1} + z_k \odot \tilde{h}_k \quad \quad (3) hk=(1−zk)⊙hk−1+zk⊙h~k(3)
其中 x k x_k xk 为视差、相关性、隐藏信息和上下文信息的级联。
SRU融合方程 : h k = A ⊙ h k s + ( 1 − A ) ⊙ h k l ( 4 ) h_k = A \odot h_k^s + (1 - A) \odot h_k^l \quad \quad (4) hk=A⊙hks+(1−A)⊙hkl(4)
其中:
- A A A 为CSA模块生成的注意力图
- h k s h_k^s hks 为小核GRU的隐信息(捕获高频)
- h k l h_k^l hkl 为大核GRU的隐信息(捕获低频)
3.2 核心创新点二:Contextual Spatial Attention (CSA)
创新概述:从上下文信息中提取多级注意力图,用于指导SRU中的自适应融合。
设计组成:
子模块1:通道注意力增强(Channel Attention Enhancement, CAE)
输入:上下文信息 c ∈ R^(C×H×W)
↓
平均池化 & 最大池化 → f_avg, f_max ∈ R^(C×1×1)
↓
两层卷积变换 → 元素求和 → Sigmoid函数
↓
输出:通道权重 M_c ∈ R^(C×1×1) [0,1]子模块2:空间注意力提取器(Spatial Attention Extractor, SAE)
输入:CAE处理后的信息
↓
在通道维度进行池化 → 拼接形成 R^(2×H×W)
↓
一层卷积 + Sigmoid函数
↓
输出:注意力图 A ∈ R^(H×W) [0,1]注意力图的语义含义:
- 高权重区域 :需要高频信息的区域(边缘、细节、薄物体)
- 对应于上下文中特征值较高的位置
- 与小核GRU结果相乘(强调高频)
- 低权重区域 :需要低频信息的区域(平滑纹理、低纹理)
- 对应于上下文中特征值较低的位置
- 与大核GRU结果相乘(强调低频)
关键特性:
- 动态生成:注意力图随不同图像内容动态变化
- 多级结构:在1/4、1/8、1/16三个分辨率都生成注意力图
- 网络自适应:不同网络中的注意力图呈现不同倾向性(见图6)
4. 方法与网络设计
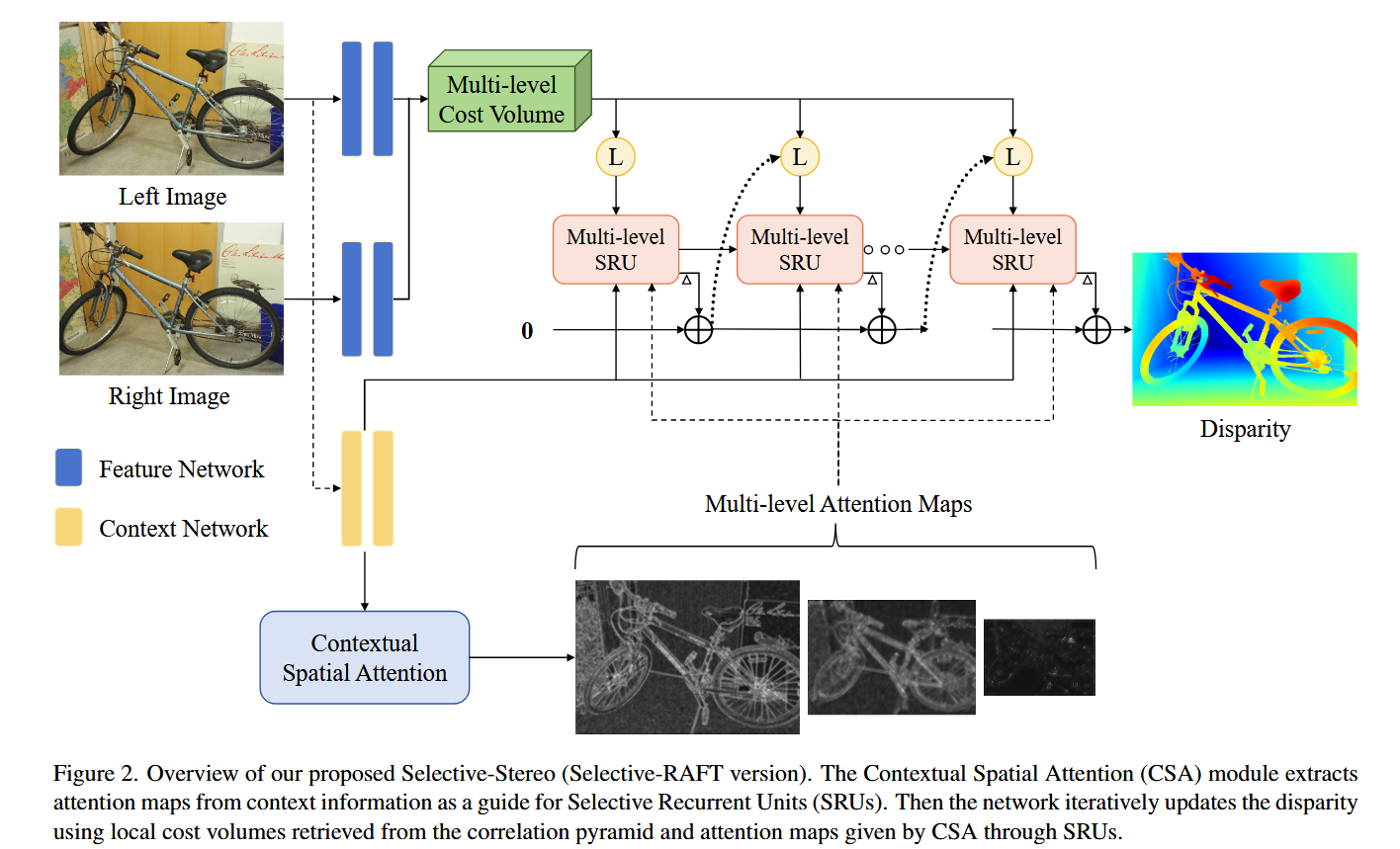
4.1 整体网络架构概览
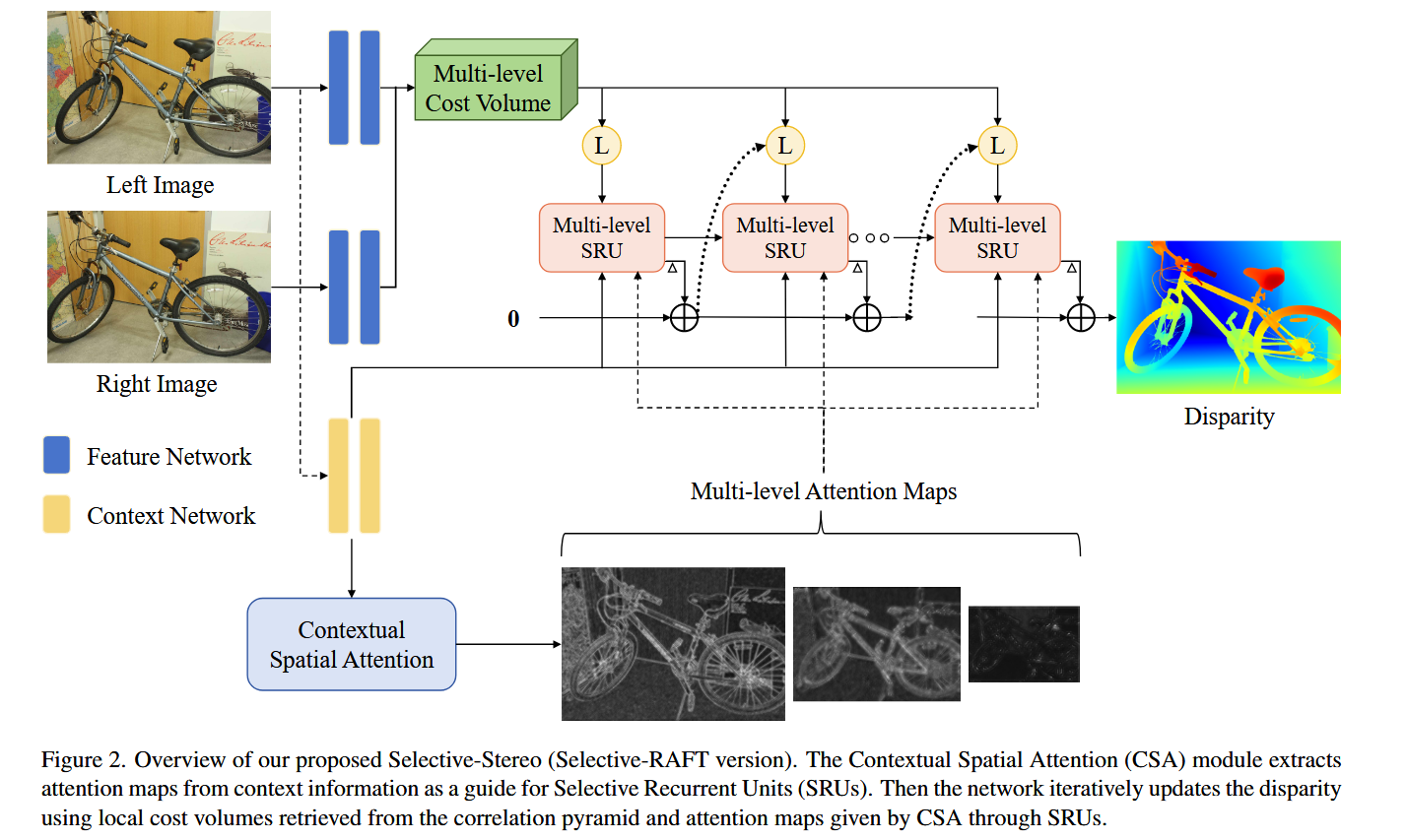
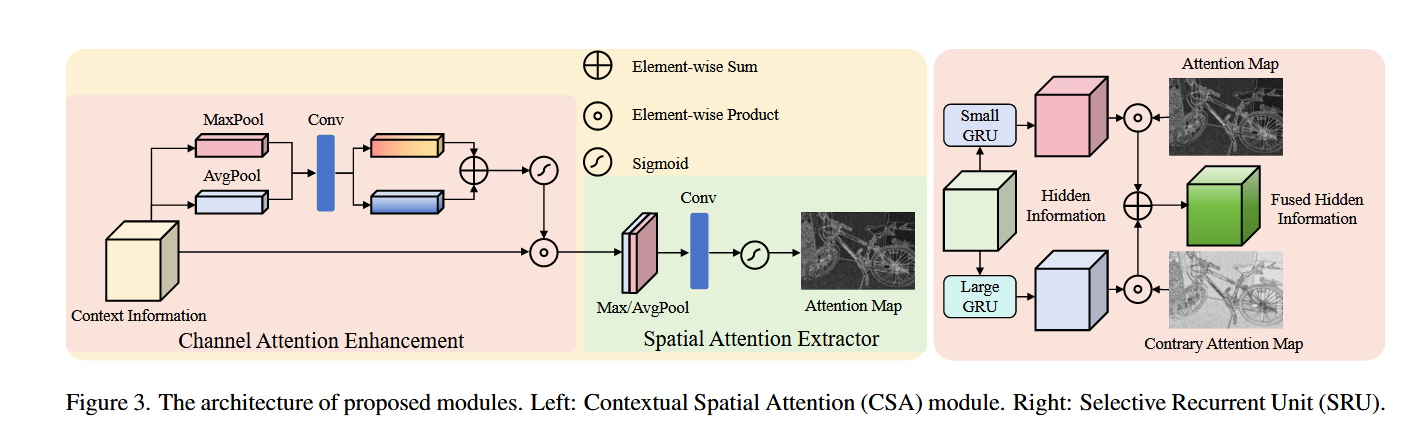
4.1.1 网络的多级结构
左右图像对 I_l, I_r ∈ R^(3×H×W)
↓
[特征提取]
↓
┌─ 特征网络 → 左右特征 f, g ∈ R^(C×H/4×W/4)
└─ 上下文网络 → 多级上下文特征 f^c_i (i=1,2,3)
↓
[成本体积构建]
↓
全对相关性 C ∈ R^(H/4 × W/4 × W/4)
↓
4级相关性金字塔 {C_i} (i=1,2,3,4)
↓
┌─ 上下文空间注意力 (CSA)
│ → 多级注意力图
│
└─ 多级选择性循环单元 (SRU)
循环迭代更新
↓
[上采样]
↓
最终视差图4.1.2 多级结构示意
1/4分辨率
d
↓
[SRU @ 1/4]
↗ ↓ ↘
上采 隐信息 下采
/ | \
1/8分辨率 1/4分辨率 1/4分辨率
↓ ↓ ↓
[SRU] 融合 [SRU]
@ 1/8 输出 @ 1/8
↓ ↑ ↓
1/16分辨率 1/8分辨率 1/16分辨率
↓ ↓ ↓
[SRU] [SRU] [SRU]
@ 1/16 @ 1/16 @ 1/164.1.3 各模块功能概述
| 模块 | 输入 | 输出 | 功能 |
|---|---|---|---|
| 特征网络 | 左右图像 | 多级特征图 | 提取初始特征表示 |
| 上下文网络 | 左右特征 | 多级上下文特征 | 为注意力模块提供信息 |
| CSA | 上下文特征 | 多级注意力图 | 识别图像区域的频率特性 |
| SRU | 隐信息、相关性、视差 | 融合后的隐信息 | 自适应融合多频率信息 |
4.2 网络详细分析
4.2.1 特征提取模块详解
特征网络(Feature Network):
- 初始下采样 :输入图像 I l , I r ∈ R 3 × H × W I_l, I_r \in \mathbb{R}^{3 \times H \times W} Il,Ir∈R3×H×W
- 使用7×7卷积层下采样到1/2分辨率
- 中间处理 :
- 残差块提取特征
- 下采样到1/4分辨率
- 最终输出 :
- 1×1卷积得到 f , g ∈ R C × H / 4 × W / 4 f, g \in \mathbb{R}^{C \times H/4 \times W/4} f,g∈RC×H/4×W/4
上下文网络(Context Network):
- 架构一致性:与特征网络相同的初始结构
- 额外深度:添加额外的残差块和下采样层
- 多级特征 :得到三级上下文特征 f i c f^c_i fic (i=1,2,3) 在1/4、1/8、1/16分辨率
隐状态与上下文初始化 : h i = tanh ( f i c ) h_i = \tanh(f^c_i) hi=tanh(fic) c i = ReLU ( f i c ) ( 1 ) c_i = \text{ReLU}(f^c_i) \quad \quad (1) ci=ReLU(fic)(1)
4.2.2 成本体积构建模块详解
全对相关性计算 : C i j k = ∑ h f h i j ⋅ g h i k , C ∈ R H / 4 × W / 4 × W / 4 ( 2 ) C_{ijk} = \sum_h f_{hij} \cdot g_{hik}, \quad C \in \mathbb{R}^{H/4 \times W/4 \times W/4} \quad \quad (2) Cijk=h∑fhij⋅ghik,C∈RH/4×W/4×W/4(2)
其中:
- f h i j f_{hij} fhij:左特征图在空间位置(i,j)处的特征向量
- g h i k g_{hik} ghik:右特征图在空间位置(i,k)处的特征向量
- ∑ h \sum_h ∑h 为通道维度求和
相关性金字塔构建:
- 基础成本体积 C C C 作为第一级
- 使用1D平均池化(核大小2,步长2)在最后维度进行4次池化
- 得到 { C 1 , C 2 , C 3 , C 4 C_1, C_2, C_3, C_4 C1,C2,C3,C4} 四个金字塔层级
- 每层代表不同的视差范围和分辨率
4.2.3 Contextual Spatial Attention (CSA) 详解
完整流程图示:
上下文信息 c ∈ R^(C×H×W)
│
├─→ [平均池化] → f_avg ∈ R^(C×1×1)
│
└─→ [最大池化] → f_max ∈ R^(C×1×1)
│
├─→ [Conv] → [Conv] → [Add]
└─→ [Conv] → [Conv] → [Sigmoid] → M_c ∈ R^(C×1×1)
│
└─→ [元素乘积] → 通道加权特征
│
├─→ [平均池化] → 2×H×W
├─→ [最大池化] → 2×H×W
└─→ [拼接] → 2×H×W
│
└─→ [Conv + Sigmoid] → A ∈ R^(H×W)
输出:注意力图 A
含义:
- A_{ij} ≈ 1:位置(i,j)需要高频信息(边缘、细节)
- A_{ij} ≈ 0:位置(i,j)需要低频信息(纹理、平滑)空间注意力的物理意义:
| 上下文特征值 | 对应区域特征 | 推荐GRU | 原因 |
|---|---|---|---|
| 高特征值 | 边缘、纹理变化剧烈 | 小核(1×1, 3×3) | 能捕获快速变化的高频信息 |
| 低特征值 | 平滑、低纹理区域 | 大核(1×5, 3×5) | 需要更大感受野来推断匹配 |
4.2.4 Selective Recurrent Unit (SRU) 详解
多级更新结构:
在1/8和1/16分辨率:
输入:
- 注意力图 A
- 上下文信息 c
- 同分辨率隐信息 h
- 相邻分辨率隐信息
↓
[SRU]
↓
输出:融合隐信息 → 传递给相邻分辨率或下一迭代
在1/4分辨率:
输入:
- 上述所有输入
- + 视差 d
- + 局部成本体积
↓
[SRU]
↓
通过两层卷积生成视差残差 → 更新视差
↓
通过凸组合上采样到全分辨率SRU的关键设计要素:
-
双分支GRU结构:
小核GRU分支(捕获高频):
核大小:1×1 或 3×3(感受野小) 适用:边缘、细节区域 特点:局部感受性强,细节保留好大核GRU分支(捕获低频):
核大小:1×5 或 3×5(感受野大) 适用:平滑、纹理均一区域 特点:全局感受性强,鲁棒性好 -
自适应融合方程:
h k = A ⊙ h k s + ( 1 − A ) ⊙ h k l h_k = A \odot h_k^s + (1-A) \odot h_k^l hk=A⊙hks+(1−A)⊙hkl
其中:
- A A A 来自CSA模块,值域0,1
- h k s h_k^s hks 来自小核GRU
- h k l h_k^l hkl 来自大核GRU
- 高权重区域( A ≈ 1 A \approx 1 A≈1):强调 h k s h_k^s hks(高频)
- 低权重区域( A ≈ 0 A \approx 0 A≈0):强调 h k l h_k^l hkl(低频)
-
传统GRU与本方法的对比:
传统方法 : z k = σ ( Conv ( h k − 1 , x k , W z ) ) z_k = \sigma(\text{Conv}(h_{k-1}, x_k, W_z)) zk=σ(Conv(hk−1,xk,Wz)) r k = σ ( Conv ( h k − 1 , x k , W r ) ) r_k = \sigma(\text{Conv}(h_{k-1}, x_k, W_r)) rk=σ(Conv(hk−1,xk,Wr)) h ~ ∗ k = tanh ( Conv ( r k ⊙ h ∗ k − 1 , x k , W h ) ) \tilde{h}*k = \tanh(\text{Conv}(r_k \\odot h\*{k-1}, x_k, W_h)) h~∗k=tanh(Conv(rk⊙h∗k−1,xk,Wh)) h k = ( 1 − z k ) ⊙ h k − 1 + z k ⊙ h ~ k h_k = (1-z_k) \odot h_{k-1} + z_k \odot \tilde{h}_k hk=(1−zk)⊙hk−1+zk⊙h~k
本方法的改进:
- 上下文信息直接加入 x k x_k xk(而非分离成 c z , c r , c h c_z, c_r, c_h cz,cr,ch)
- 使用不同核大小的卷积充分利用上下文
- 通过CSA生成的注意力加权融合多分支
4.2.5 损失函数与训练策略
损失函数 : L = ∑ i = 1 N γ N − i ∣ ∣ d i − d g t ∣ ∣ 1 ( 6 ) L = \sum_{i=1}^{N} \gamma^{N-i} ||d_i - d^{gt}||_1 \quad \quad (6) L=i=1∑NγN−i∣∣di−dgt∣∣1(6)
其中:
- d i d_i di:第i次迭代的预测视差
- d g t d^{gt} dgt:真值视差
- γ = 0.9 \gamma = 0.9 γ=0.9:衰减系数
- N N N:总迭代次数
损失的特点:
- 递增权重策略 :早期迭代的损失权重较小( γ N − 1 , γ N − 2 , . . . \gamma^{N-1}, \gamma^{N-2}, ... γN−1,γN−2,...),最后迭代权重为1
- 物理意义:强调最终迭代结果的精度,同时让网络学习逐步优化的过程
- 收敛性:这种加权方式有利于快速收敛
训练策略:
- 数据集:Scene Flow (35,454训练对,4,370测试对)
- 预训练 :
- 优化器:AdamW
- 学习率策略:one-cycle学习率,初值2e-4
- 批大小:8
- 迭代次数:200k步
- 裁剪大小:320×720
- 训练迭代次数:22步
- 微调策略 (针对不同数据集):
- KITTI:50k步,批大小8
- ETH3D:390k步(两阶段,180k+210k)
- Middlebury:300k步(两阶段,200k+100k)
4.3 核心创新的技术支撑
动态感受野分析:
多级SRU结构的有效感受野:
- 传统GRU的感受野:只有3个固定值( k , 2 k + 3 , 3 k + 6 k, 2k+3, 3k+6 k,2k+3,3k+6)
- SRU的感受野:6个及以上
- 融合时的动态性:注意力图使不同像素被不同感受野加权影响
噪声过滤机制:
- 初始成本体积包含大量噪声
- 多分支GRU相当于进行二次滤波
- 大核GRU对噪声的平滑作用
- CSA的自适应加权进一步控制信息质量
5. 实验结果
5.1 数据集与评估指标
数据集描述
| 数据集 | 类型 | 特点 | 训练集 | 测试集 |
|---|---|---|---|---|
| Scene Flow | 合成 | 高保真,最终通道,密集标注 | 35,454对 | 4,370对 |
| KITTI 2012 | 真实驾驶 | 室外,真实环境 | 194对 | 195对 |
| KITTI 2015 | 真实驾驶 | 室外,高分辨率 | 200对 | 200对 |
| ETH3D | 真实 | 灰度对,室内/室外 | 27对 | 20对 |
| Middlebury | 真实 | 高分辨率,室内 | 15对 | 15对 |
评估指标
- EPE (End Point Error):预测视差与真值视差的平均绝对误差(像素)
- D1-all:视差误差>1像素的百分比(KITTI)
- >1px 或 >2px:错误像素的百分比
- Bad 0.5/1.0/2.0/4.0:ETH3D/Middlebury特定指标
5.2 消融研究
5.2.1 模块有效性验证(表1:Scene Flow测试集)
模型配置 EPE(px) >1px(%) 参数(M) 改进
─────────────────────────────────────────────────────────────────
基线 (RAFT-Stereo) 0.53 6.08 11.12 -
+ SRU (无CSA) 0.50 5.38 11.65 ↓5.7%
+ SRU + CSA (反向权重) 0.50 5.58 11.65 ↑3.7%
完整模型 (Selective-RAFT) 0.47 5.32 11.65 ↓11.3%关键发现:
- SRU单独的贡献 :即使不加CSA,仅通过多分支融合也能改进5.7%
- 验证了多频率信息融合的必要性
- 说明简单求和多个分支也有意义
- CSA的关键作用 :反向权重反而降低性能
- 证明CSA生成的权重确实反映了频率信息的实际分布
- 正确的权重对性能至关重要
- 完整模型 :总改进11.3%,参数仅增加4%
- 高效率的改进
5.2.2 通用性验证(表2)
模型 EPE(px) >1px(%) 参数(M) 改进幅度
────────────────────────────────────────────────────────
RAFT-Stereo 0.53 6.08 11.12
Selective-RAFT 0.47 5.32 11.65 ↓11.3%
IGEV-Stereo 0.47 5.21 12.60
Selective-IGEV 0.44 4.98 13.14 ↓6.4%
DLNR 0.49 5.06 57.37
Selective-DLNR 0.46 4.73 58.09 ↓6.1%重要结论:
- 所有方法都获得显著改进
- 参数增加量(0.5-1.0M)相对较小
- 通用性强:即使对LSTM的DLNR也能适用
5.2.3 迭代次数的影响(表3)
迭代次数 1 2 3 4 8 32
──────────────────────────────────────────────────
RAFT 2.08 1.13 0.87 0.75 0.58 0.53
Sel-RAFT 1.95 1.06 0.81 0.69 0.53 0.47
改进 ↓6% ↓6% ↓7% ↓8% ↓9% ↓11%
IGEV 0.66 0.62 0.58 0.55 0.50 0.47
Sel-IGEV 0.65 0.60 0.56 0.53 0.48 0.44
改进 ↓2% ↓3% ↓3% ↓4% ↓4% ↓6%关键发现:
- 本方法在少量迭代时优势更明显
- Selective-RAFT 用8次迭代达到RAFT-Stereo 32次的性能(EPE 0.53)
- 说明SRU的信息融合能更高效地优化视差
- 对实时应用有重要意义(减少计算量)
5.2.4 核大小选择(表4)
核大小配置 EPE(px) >1px(%)
────────────────────────────────────────
1×1 + 1×5 0.48 5.41
3×3 + 1×5 0.48 5.30
1×1 + 3×3 0.47 5.32 ← 选中设计决策 :选择 1×1 + 3×3
- 性能相当(EPE 0.47)
- 计算成本更低
- 更好的计算效率和精度平衡
5.3 性能对比
**5.3.1 Scene Flow 基准(表5)
方法 EPE(px) 相对改进
─────────────────────────────────────
CSPN 0.78 -
LEAStereo 0.78 -
LaC + GANet 0.72 ↓11%
ACVNet 0.48 ↓37%
IGEV-Stereo 0.47 ↓38%
Selective-RAFT 0.47 ↓38%
Selective-IGEV 0.44 ↓42% ★ 第一性能特点:
- Selective-IGEV达到SOTA
- 相对于LaC+GANet改进38.89%
5.3.2 边缘 vs 非边缘区域分析(表7)
方法 边缘区域 非边缘区域
EPE(px) >1px(%) EPE(px) >1px(%)
───────────────────────────────────────────────────
RAFT 3.21 29.16 0.53 6.53
Sel-RAFT 2.40 21.63 0.40 4.65
改进 ↓25% ↓26% ↓25% ↓29%
IGEV 2.23 20.42 0.41 4.58
Sel-IGEV 2.18 20.01 0.38 4.35
改进 ↓2% ↓2% ↓7% ↓5%重要发现:
- Selective-RAFT 在边缘区域改进明显:EPE下降25%
- IGEV的成本体积已聚合,边缘区域改进有限但仍有提升
- 证明了本方法对高频信息的有效捕获
5.3.3 KITTI 基准排名
KITTI 2012:
排名 方法 2-noc 2-all D1-bg D1-fg D1-all
────────────────────────────────────────────────────────
1 Selective-IGEV 1.59 2.05 1.33 2.61 1.55 ★
2 IGEV-Stereo 1.71 2.17 1.38 2.67 1.59
3 Selective-RAFT 1.64 2.09 1.41 2.71 1.63KITTI 2015:
排名 方法 D1-noc D1-all EPE(noc) EPE(all)
──────────────────────────────────────────────────────────
1 Selective-IGEV 1.07 1.38 0.4 0.4 ★
2 IGEV-Stereo 1.12 1.44 0.4 0.4
3 Selective-RAFT 1.10 1.43 0.4 0.55.3.4 ETH3D 和 Middlebury(表8)
ETH3D:
方法 Bad 1.0 Bad 0.5 Bad 4.0 AvgErr
──────────────────────────────────────────────────
Selective-IGEV 1.23 3.06 0.05 0.12 ★ 第一
IGEV-Stereo 1.12 3.52 0.11 0.14
CREStereo 0.98 3.58 0.10 0.13Middlebury:
方法 Bad 2.0 Bad 1.0 Bad 4.0 AvgErr
──────────────────────────────────────────────────
Selective-IGEV 2.51 1.36 0.91 6.53 ★ 第一
DLNR 3.20 1.89 1.06 6.82
EAI-Stereo 3.68 2.14 1.09 7.81排名总结:
- ✓ KITTI 2012:第一
- ✓ KITTI 2015:第一
- ✓ ETH3D:第一
- ✓ Middlebury:第一
5.4 定性可视化分析
5.4.1 KITTI 上的视觉对比(图5)
左图 | IGEV-Stereo | Selective-IGEV | 分析
───────────────────────────────────────
| 模糊边缘 | 清晰边缘 | ✓ 高频改进
| 纹理过平滑 | 纹理保留 | ✓ 低频保持
| 弱纹理错误 | 弱纹理准确 | ✓ 容错能力5.4.2 Middlebury 上的定性结果和注意力图(图7)
三列显示:
1. 原始左图
2. IGEV-Stereo视差图
3. 本方法的注意力图
4. Selective-IGEV视差图
关键观察:
- 注意力图在边缘/纹理变化处值大(≈1)
- 在平滑/低纹理处值小(≈0)
- 对应于CSA的自适应能力
- 视差精度提升:特别是无纹理和薄物体区域改进幅度:
- 大无纹理区域:9.20% → 3.79%(错误率下降59%)
- 薄物体:1.17% → (准确改进)
5.4.3 不同网络的注意力图差异(图6)
Selective-RAFT 的注意力图:
- 大量大核权重
- 原因:成本体积含噪声,需要大核平滑
- 特点:更关注降噪
Selective-IGEV 的注意力图:
- 小核权重突出
- 原因:成本体积已聚合,保持细节重要
- 特点:更关注细节,但大核权重在边缘重要启示:
- CSA体现网络自适应性
- 同一模块在不同网络中呈现不同策略
- 反映了不同网络的内在需求差异
5.5 反射区域(病态区域)的性能(表9:补充材料)
方法 2-noc 2-all 3-noc 3-all
────────────────────────────────────────────
IGEV-Stereo 7.29 8.48 4.11 4.76
Selective-RAFT 7.19 7.96 4.35 4.68 ↓
Selective-IGEV 6.73 7.84 3.79 4.38 ↓
改进相对IGEV ↓8% ↓8% ↓8% ↓8%意义:
- 反射区域属于病态匹配区域(多解问题)
- 大核能捕获全局信息来解决歧义
- CSA在这些难区域自动提高大核权重
- 体现了多频率融合的鲁棒性
6. 不足之处与未来工作
6.1 现有限制
- 感受野仍受预定义限制
- 虽然通过注意力融合实现了动态感受野
- 但分支的核大小仍需预先设定
- 不能根据全局内容完全自适应选择
- 计算和内存成本
- 多分支结构增加计算开销
- 大核卷积消耗较多内存
- 实时应用受限
- 参数效率
- DLNR类方法参数基数大(57M+)
- 添加SRU/CSA后进一步增加
6.2 未来研究方向
- 轻量化卷积的结合
- 深度可分离卷积
- 分组卷积
- 动态卷积
- 目标:降低内存和时间成本
- Self-Attention 的融合
- 传统卷积的感受野受限
- Self-Attention具有全局感受野
- 结合两者的优势:局部精度+全局一致性
- 频率域研究
- 显式频率分解(如小波变换)
- 频域-空域联合优化
- 动态频率选择机制
- 跨网络泛化性
- 目前验证了RAFT/IGEV/DLNR
- 可探索新兴迭代方法
- 提高方法的通用适配性
7. 总体评价
7.1 研究价值
| 维度 | 评价 | 论据 |
|---|---|---|
| 问题重要性 | ★★★★★ | 固定感受野是迭代方法的核心瓶颈 |
| 方案创新性 | ★★★★☆ | 多分支+注意力融合方式简洁有效 |
| 理论深度 | ★★★☆☆ | 缺乏深层理论分析,多为经验设计 |
| 实验充分性 | ★★★★★ | 消融、通用性、多数据集验证完整 |
| 实际影响力 | ★★★★☆ | 四个SOTA榜单,但计算成本仍需改进 |
7.2 核心贡献总结
问题识别
↓
"多频率信息难以同时捕获"
↓
解决方案设计
├─ 多分支GRU(不同核大小)
└─ CSA自适应加权(基于上下文)
↓
理论验证
├─ 动态感受野分析
├─ 频率语义对应
└─ 注意力可视化
↓
实验验证
├─ 4个基准第一名 ✓
├─ 高通用性验证 ✓
├─ 详细消融研究 ✓
└─ 定性分析充分 ✓7.3 方法的优势
✓ 问题诊断精准 :准确指出固定感受野的害处 ✓ 解决方案简洁 :不引入复杂设计,便于集成 ✓ 通用性强 :可应用于多种迭代框架 ✓ 效果显著 :排名多个SOTA,改进明显 ✓ 可解释性好:注意力图可视化理解清晰
7.4 方法的劣势
✗ 计算成本 :相对基线增加计算和内存 ✗ 理论分析 :缺乏深层数学/信息论分析
✗ 参数约束 :核大小等超参需手工设定 ✗ 实时性 :虽改进迭代效率,但绝对时间仍较长 ✗ 启发有限:主要思路为工程优化而非根本创新
7.5 研究的深远意义
- 频率视角的新认知 :
- 展示了频率信息在视觉任务中的重要性
- 为后续工作提供新的思路
- 自适应融合的范式 :
- 多分支+注意力的框架可推广到其他任务
- 立体匹配 → 光流 → 深度估计等
- 迭代优化的进展 :
- 验证了迭代型方法的继续优化空间
- 可能激发更多改进方向的探索
附录:关键公式速查表
| 公式 | 用途 | 序号 |
|---|---|---|
| h i = tanh ( f i c ) , c i = ReLU ( f i c ) h_i = \tanh(f^c_i), c_i = \text{ReLU}(f^c_i) hi=tanh(fic),ci=ReLU(fic) | 隐状态初始化 | (1) |
| C i j k = ∑ h f h i j ⋅ g h i k C_{ijk} = \sum_h f_{hij} \cdot g_{hik} Cijk=∑hfhij⋅ghik | 全对相关性 | (2) |
| GRU单元方程 | 循环更新 | (3) |
| h k = A ⊙ h k s + ( 1 − A ) ⊙ h k l h_k = A \odot h_k^s + (1-A) \odot h_k^l hk=A⊙hks+(1−A)⊙hkl | 自适应融合 | (4) |
| r 0 = ∑ l ( ( k l − 1 ) ∏ i = 1 l − 1 s i ) + 1 r_0 = \sum_l ((k_l-1)\prod_{i=1}^{l-1}s_i) + 1 r0=∑l((kl−1)∏i=1l−1si)+1 | 感受野计算 | (5) |
| $L = \sum_{i=1}^N \gamma^{N-i} | d_i - d^{gt} | _1$ |
参考资源
- 代码链接:https://github.com/Windsrain/Selective-Stereo
- 论文链接:arXiv:2403.00486v1
- 发表日期:2024年3月
- 会议/期刊:待查(预印本)
讨论
一、CSA(上下文空间注意力模块)
CSA 的职责是生成注意力图,告诉 SRU:"这个位置应该用高频信息(小核),还是低频信息(大核)?"
它分为两个串联的子模块:
🔷 子模块 1:通道注意力增强(CAE)
输入: 上下文信息 c ∈ R C × H × W c \in \mathbb{R}^{C \times H \times W} c∈RC×H×W
步骤:
- 分别对空间维度做 AvgPool 和 MaxPool ,得到两个形状为 R C × 1 × 1 \mathbb{R}^{C \times 1 \times 1} RC×1×1 的向量 f a v g f_{avg} favg、 f m a x f_{max} fmax
- 两个向量各自独立地通过两层卷积进行特征变换
- 将两者相加 ,再经过 Sigmoid 得到通道权重 M c ∈ R C × 1 × 1 M_c \in \mathbb{R}^{C \times 1 \times 1} Mc∈RC×1×1
- 与输入做逐元素乘积:高特征值的通道被增强,低特征值的通道被抑制
c ′ = M c ⊙ c c' = M_c \odot c c′=Mc⊙c
直觉: CAE 先判断哪些通道包含有价值的频率信息,然后放大/压缩它们,为后续空间注意力提取做准备。
🔷 子模块 2:空间注意力提取器(SAE)
输入: CAE 输出后的特征图 c ′ c' c′
步骤:
- 对通道维度 做 AvgPool 和 MaxPool,各得到 R 1 × H × W \mathbb{R}^{1 \times H \times W} R1×H×W 的图
- 在通道维度拼接,得到 R 2 × H × W \mathbb{R}^{2 \times H \times W} R2×H×W
- 用一层卷积 + Sigmoid 生成最终注意力图 A ∈ R 1 × H × W A \in \mathbb{R}^{1 \times H \times W} A∈R1×H×W
关键性质: A i j 大 ⇔ 该位置需要高频信息(边缘、细节) A_{ij} \text{ 大} \Leftrightarrow \text{该位置需要高频信息(边缘、细节)} Aij 大⇔该位置需要高频信息(边缘、细节) A i j 小 ⇔ 该位置需要低频信息(平滑纹理区) A_{ij} \text{ 小} \Leftrightarrow \text{该位置需要低频信息(平滑纹理区)} Aij 小⇔该位置需要低频信息(平滑纹理区)
直觉: 因为高频区域(边缘)在上下文特征图中本身有更高的激活值,所以平均/最大池化后,这些区域自然会有更高的空间响应,从而注意力图能自动区分"边缘区域"和"平滑区域"。
二、SRU(选择性循环单元)
SRU 的职责是利用 CSA 给出的注意力图,融合来自不同感受野 GRU 的隐状态。
🔶 标准 GRU 回顾
传统 GRU 的更新过程如下(第 k k k 次迭代):
z k = σ ( Conv ( h k − 1 , x k , W z ) ) z_k = \sigma(\text{Conv}(h_{k-1}, x_k, W_z)) zk=σ(Conv(hk−1,xk,Wz)) r k = σ ( Conv ( h k − 1 , x k , W r ) ) r_k = \sigma(\text{Conv}(h_{k-1}, x_k, W_r)) rk=σ(Conv(hk−1,xk,Wr)) h ~ ∗ k = tanh ( Conv ( r k ⊙ h ∗ k − 1 , x k , W h ) ) \tilde{h}*k = \tanh(\text{Conv}(r_k \\odot h\*{k-1}, x_k, W_h)) h~∗k=tanh(Conv(rk⊙h∗k−1,xk,Wh)) h k = ( 1 − z k ) ⊙ h k − 1 + z k ⊙ h ~ k h_k = (1 - z_k) \odot h_{k-1} + z_k \odot \tilde{h}_k hk=(1−zk)⊙hk−1+zk⊙h~k
其中 x k x_k xk 是视差、代价体相关特征、隐状态和上下文信息的拼接。
⚠️ 问题在于:单个 GRU 的卷积核大小固定,感受野固定,只能捕捉单一频率信息。
🔶 SRU 的核心改造
SRU 将单个 GRU 换成两个并行的 GRU 分支,各自使用不同的卷积核大小:
| 分支 | 卷积核 | 捕捉的信息 |
|---|---|---|
| Small GRU → h k s h_k^s hks | 1×1(小核) | 高频信息:边缘、细节、薄物体 |
| Large GRU → h k l h_k^l hkl | 3×3(大核) | 低频信息:平滑区域、全局结构 |
融合公式(核心公式):
h k = A ⊙ h k s + ( 1 − A ) ⊙ h k l \boxed{h_k = A \odot h_k^s + (1 - A) \odot h_k^l} hk=A⊙hks+(1−A)⊙hkl
-
A A A:来自 CSA 的注意力图
-
在边缘区域 : A A A 大 → 大权重给小核分支 h k s h_k^s hks(保留高频细节)
-
在平滑区域 : A A A 小 → 大权重给大核分支 h k l h_k^l hkl(融合低频信息)
-
融合的妙处:
-
h k s h^s_k hks**(小核GRU)**:天生对局部变化敏感 → 自然捕获高频
-
h k l h^l_k hkl(大核GRU)**:天生对全局一致性敏感 → 自然捕获低频
-
A(CSA的注意力图)
:根据图像内容动态决定权重比例
- 边缘处:A≈1 → 强调小核(保留高频细节)
- 平滑处:A≈0 → 强调大核(保持低频平滑)
-
🔶 多级 SRU 结构
SRU 在 1/4、1/8、1/16 三个分辨率上同时运作,形成多级结构:
1/16分辨率 SRU ──────┐
↓(上采样/下采样传递隐状态)
1/8分辨率 SRU ──────┤
↓
1/4分辨率 SRU ──── 输出视差残差 → 更新视差- 低分辨率(1/16, 1/8):只处理注意力图、上下文信息、相邻分辨率传来的隐状态
- 高分辨率(1/4):额外接入视差 和局部代价体,输出视差残差
这种设计让感受野从原来 3 个固定值 扩展为 6 个动态值 (每个分辨率各有大、小核两种感受野),再经过注意力图加权后,实现真正意义上的动态感受野。
三、整体数据流总结
输入图像对
↓
特征网络 → 左右特征 f, g
上下文网络 → 多级上下文特征 f_c (1/4, 1/8, 1/16)
↓
构建相关代价体金字塔
↓
CSA 模块 ← 上下文特征
↓ 生成多级注意力图 A
↓
多级 SRU 迭代更新:
┌─ Small GRU (1×1) → h_k^s
├─ Large GRU (3×3) → h_k^l
└─ 融合: h_k = A⊙h_k^s + (1-A)⊙h_k^l
↓
视差残差 → 累加更新视差
↓
凸组合上采样 → 全分辨率视差图四、关键设计洞见
| 设计选择 | 原因 |
|---|---|
| 核大小选 1×1 + 3×3 | 实验验证(见论文 Table 4),性能与计算效率最优 |
| 注意力图来自上下文特征而非隐状态 | 上下文特征更稳定,且天然反映图像频率分布 |
| 融合用加权插值而非拼接 | 参数增加仅 ~4%,实现轻量化 |
| 反转注意力图的消融实验 | 证明 CSA 的权重方向真实有效,反转后性能下降 |
这两个模块的精妙之处在于:CSA 是"裁判",SRU 是"运动员" ------ 裁判按区域判断该谁上场,运动员负责在自己擅长的频段上执行。
这是个非常好的问题!让我先仔细读一下原文,再给你深入解答。 这是个直击核心的好问题!读完原文后,我可以给你一个更诚实、更深入的解答。
你的质疑是对的:Pool 本身不能判断频率
你的直觉非常准确。单纯的 AvgPool / MaxPool 操作本身并不能直接判断高频或低频信息,这里有一个被论文表述得比较隐晦的核心逻辑链,需要仔细拆解。
真正的推理链:从上下文特征到频率判断
第一步:上下文特征(Context Feature)天然编码了频率信息
CSA 的输入不是原始图像,而是经过上下文网络 深度处理过的特征图 c c c:
c = ReLU ( f c i ) , f c i 来自多层残差网络 c = \text{ReLU}(f_c^i), \quad f_c^i \text{ 来自多层残差网络} c=ReLU(fci),fci 来自多层残差网络
这个特征图经过卷积网络学习后,天然地在边缘/细节区域产生更高的激活值。这是因为:
- 卷积核在训练过程中会学习到对"变化大的区域"(即高频区域,如边缘)产生更高的响应
- 平滑区域的像素变化小,特征值相对较低
所以频率信息已经隐含在特征图的数值大小中了,Pool 只是在提取这种已存在的模式。
第二步:CAE 做的是通道级别的"筛选放大"
c (C×H×W)
↓ AvgPool + MaxPool (spatial)
favg, fmax (C×1×1)
↓ 两层Conv 分别变换
↓ Element-wise Sum
↓ Sigmoid → Mc (C×1×1)
↓ Element-wise Product
c' = Mc ⊙ cCAE 的作用是:找出哪些通道对频率判断更有价值,放大它们、压制噪声通道。
AvgPool捕捉通道的整体激活水平(平均信号强度)MaxPool捕捉通道中最显著的激活峰值- 两层 Conv 让网络学习哪种通道组合更能区分频率,这是有参数可训练的!
⚠️ 关键点:这两层 Conv 是可学习参数,不是固定规则,网络在训练中会学会"哪些通道承载高频信息"。
第三步:SAE 做的是空间级别的"位置定位"
c' (C×H×W) ← 经过CAE增强后的特征
↓ AvgPool + MaxPool (channel dimension)
两张图 (1×H×W)
↓ Concat → (2×H×W)
↓ Conv + Sigmoid → A (1×H×W)SAE 做通道维度的 Pool,相当于在问:"这个位置 (i,j) 上,跨所有通道的平均/最大激活值是多少?"
- 边缘位置:多个通道在此处都有强烈响应 → Pool 后值大 → Sigmoid 后 A i j A_{ij} Aij 大
- 平滑区域:各通道在此处响应平淡 → Pool 后值小 → Sigmoid 后 A i j A_{ij} Aij 小
同样,这里的 Conv 也是可学习的,它进一步整合 AvgPool 和 MaxPool 的信息。
用一个直觉类比来理解
想象上下文特征图像一张"热力图":
原图: 上下文特征图(激活值):
┌──────────┐ ┌──────────┐
│ 平滑天空 │ │ 0.1 0.1 │ ← 低激活 = 低频区域
│──────────│ │──────────│
│ 树木边缘 │ │ 0.9 0.8 │ ← 高激活 = 高频区域
│ 平坦地面 │ │ 0.2 0.1 │ ← 低激活 = 低频区域
└──────────┘ └──────────┘SAE 对通道做 Pool,就是在问每个空间位置"你有多热",然后把这个热度图变成注意力权重。Pool 在这里是一个无参数的"汇总统计"工具,真正的频率判断能力来自前置的上下文网络和后置的 Conv 学习。
论文的直接原话印证
原文 Section 3.3 的关键句子:
"this attention map has high weights in regions needing high-frequency information because this information possesses high feature values in the context information."
这句话承认了一个假设前提:高频信息在上下文特征中确实有更高的特征值。这个假设的成立依赖于:
- 上下文网络的表达能力(已被深度学习验证)
- 网络端到端训练时,损失函数会驱动上下文特征朝这个方向优化
消融实验的间接证明
论文 Table 1 的一个关键实验:把注意力图反转(Contrary):
| 模型 | EPE |
|---|---|
| SRU(无CSA) | 0.50 |
| SRU + CSA(反转权重) | 0.50(变差!) |
| SRU + CSA(正常) | 0.47 |
反转权重后性能下降,说明 CSA 输出的注意力图方向确实是正确的------边缘区域确实得到了高权重,而不是随机的。这从实验上证明了 Pool + Conv 确实学到了频率敏感的注意力图。
总结
| 层次 | 操作 | 是否可学习 | 作用 |
|---|---|---|---|
| 上下文网络 | 多层残差卷积 | ✅ | 将频率信息编码进特征值大小 |
| CAE的Conv | 两层卷积 | ✅ | 学习哪些通道承载频率信息 |
| Pool操作 | AvgPool/MaxPool | ❌(固定) | 仅做统计汇总,提取整体趋势 |
| SAE的Conv | 一层卷积+Sigmoid | ✅ | 学习将汇总统计转化为空间注意力图 |
Pool 本身是"哑巴工具",频率判断的智能藏在前后的可学习卷积层和上下文网络里。Pool 的价值在于它能无参数地压缩空间/通道信息,给后续 Conv 提供一个干净的全局统计视角。
你说得对,让我重新仔细读一下两篇论文的原文,确保描述准确。 两篇论文的原文都读完了,现在可以给出一个完全基于原文的、精准的对比分析了。
SRU vs CREStereo RUM:基于原文的精准对比
你的纠正非常准确,我之前的表述确实有偏差。下面严格按照原文来梳理两者的差异。
先厘清"多个GRU"在各自框架里的真实含义
这两种方法里的"多GRU",描述的完全是不同层面的事情:
| CREStereo RUM | Selective-Stereo SRU | |
|---|---|---|
| 多GRU在哪个维度 | 空间分辨率维度(1/16 → 1/8 → 1/4,三个级联层级,每级有一个RUM) | 感受野频率维度(同一层级内部,一个小核GRU + 一个大核GRU) |
| 多GRU的关系 | 串行级联:前一级的输出视差作为后一级的初始化 | 并行互补:两个GRU同时运行,输出加权融合 |
| 核心思想 | 粗到精地逐级细化视差(coarse-to-fine) | 同时捕获高频与低频信息后自适应融合 |
一、RUM 的"多GRU":级联粗到精
根据CREStereo原文(Sec 3.2 & Fig.2),RUM 的多GRU结构是这样的:
第1级(1/16分辨率)
视差初始化为全零
RUM 迭代 n 次 → 输出视差 d₁
↓ 上采样作为初始化
第2级(1/8分辨率)
RUM 迭代 n 次 → 输出视差 d₂
↓ 上采样作为初始化
第3级(1/4分辨率)
RUM 迭代 n 次 → 输出最终视差 d₃关键点:
- 三个级别的RUM共享同一套权重(原文:"all RUMs share the same weights")
- 每级内部是单个GRU在迭代(每次迭代调用AGCL重新计算相关性)
- 级联的意义是:低分辨率提供鲁棒的粗估计,高分辨率负责细节细化
- 级联之间是串行的,信息单向从粗到细流动
二、SRU 的"多GRU":单级内部的频率并行
根据Selective-Stereo原文(Sec 3.4 & Fig.3/4),SRU 的多GRU结构是这样的:
同一分辨率层级(如1/4)内部:
↓
┌─────────────────────┐
│ Small GRU (1×1核) │ → h^s_k(捕获高频)
│ Large GRU (3×3核) │ → h^l_k(捕获低频)
└─────────────────────┘
↓
h_k = A ⊙ h^s_k + (1−A) ⊙ h^l_k
↓
融合后的隐信息关键点:
- 两个GRU权重不共享(核大小不同,参数独立)
- 两个GRU并行处理同一输入,区别只在卷积核大小(感受野不同)
- 融合由CSA生成的注意力图 A A A 来动态决定
三、成本体积的计算方式:另一个核心差异
这是两者在迭代机制上最深层的差异:
CREStereo RUM(原文 Sec 3.1):
- 每次迭代重新计算局部相关性,使用 AGCL(Adaptive Group Correlation Layer)
- AGCL 带有可学习的偏移量 d x , d y dx, dy dx,dy(可变形搜索窗口)
- 公式: Corr ( x , y , d ) = 1 C ∑ i F 1 ( i , x , y ) ⋅ F 2 ( i , x ′ ′ + d x , y ′ ′ + d y ) \text{Corr}(x,y,d) = \frac{1}{C}\sum_i F_1(i,x,y) \cdot F_2(i, x''+dx, y''+dy) Corr(x,y,d)=C1∑iF1(i,x,y)⋅F2(i,x′′+dx,y′′+dy)
- 意义:每步迭代都能动态调整搜索位置,专门为应对非理想标定设计
Selective-Stereo SRU(原文 Sec 3.2):
- 一次性预构建全对相关性金字塔(All-pairs Correlation Pyramid)
- 每次迭代只是从已有金字塔中查询局部相关性,不重新计算
- 相关性的计算方式沿用 RAFT-Stereo,SRU本身不改变这一部分
- 意义:SRU 的创新完全集中在隐信息如何更新,而非相关性如何计算
四、设计动机的根本不同
| CREStereo RUM | Selective-Stereo SRU | |
|---|---|---|
| 要解决的核心问题 | 高分辨率图像细节恢复困难;非理想标定导致的匹配偏差 | 固定感受野无法同时捕获高频(边缘)和低频(纹理)信息 |
| 创新的核心模块 | AGCL(自适应局部相关层)才是真正的核心创新;RUM只是封装它的迭代框架 | SRU + CSA 本身就是核心创新,专注于隐信息的频率自适应融合 |
| 多GRU的作用 | 通过粗到细的分辨率级联扩大有效感受野 | 通过不同核大小的并行分支捕获不同频率信息 |
五、一句话总结
CREStereo 的"多GRU" = 三个共享权重、串行级联的 RUM,从粗到细逐级细化视差,真正的创新在于每步迭代中的 AGCL 动态相关性计算;
Selective-Stereo 的"多GRU" = 同一层级内部两个独立、并行的 GRU(核大小不同),同时捕获高/低频隐信息后由 CSA 注意力自适应加权融合,创新就在这个融合机制本身。
两者表面上都叫"多GRU",但前者是时间/空间维度上的串行分工 ,后者是频率维度上的并行互补,这是本质差异。