在大模型应用开发中,对话系统是最常见的场景之一。LangChain 作为大模型应用开发框架,在 v1.0 版本中进行了架构大重构,摒弃了旧版冗余组件,引入了更简洁、可扩展的 LCEL(LangChain 表达式语言),让开发者能更高效地构建对话应用。
本文将手把手教你,使用 Streamlit(前端交互)+ LangChain v1.0+(大模型调用与流程管理)+ 通义千问(大模型),实现一个功能完整、架构规范的多会话AI聊天页面,支持会话新建、切换、删除、清空,以及本地会话持久化、流式输出等核心功能,全程采用 LangChain v1.0+ 新版写法,彻底抛弃旧版 Chain 和 Memory 组件。
一、技术选型与核心优势
在开始编码前,先明确各技术栈的选型原因和核心优势,确保整个技术架构简洁、高效、可维护。
1. 前端:Streamlit
Streamlit 是一款专为数据科学和机器学习开发者设计的 Web 应用框架,无需前端开发经验,用 Python 代码即可快速构建交互式页面。选择它的核心原因:
- 开发效率极高:几行代码就能实现聊天输入框、会话列表、消息展示等核心组件,无需编写 HTML/CSS/JS。
- 原生支持聊天组件:
st.chat_message、st.chat_input可直接实现聊天界面,无需额外封装。 - 会话状态管理:
st.session_state可轻松保存会话数据、当前选中会话等状态,刷新页面不丢失(配合本地文件持久化,实现长期保存)。 - 流式输出支持:通过
st.empty()占位符,可轻松实现 AI 回复的"打字机效果",提升用户体验。
2. 大模型框架:LangChain v1.0+
LangChain v1.0+ 相比旧版(v0.x)有了根本性的架构优化,核心优势的是引入了 LCEL,让大模型调用流程更简洁、更灵活。本文全程采用新版写法,核心特点:
- 摒弃旧版冗余组件:不再使用
ConversationChain、ConversationBufferMemory等旧版组件,改用更轻量的ChatPromptTemplate+MessagesPlaceholder实现对话记忆。 - LCEL 管道式调用:通过
|符号将提示词模板、大模型串联成管道,调用逻辑一目了然,可灵活扩展(如添加输出解析、过滤等中间环节)。 - 新版模型封装:使用
ChatTongyi(而非旧版Tongyi),更贴合大模型的聊天交互场景,支持流式输出、温度调节等核心参数。 - 可扩展性强:支持异步调用、多模型切换、RAG(检索增强生成)等高级功能,为后续功能升级预留空间。
3. 大模型:通义千问(qwen-turbo)
选择通义千问(阿里云出品)的核心原因:
- 免费额度高:
qwen-turbo模型免费额度充足,适合开发者调试和小型应用部署,无需担心成本。 - 中文支持优秀:针对中文场景优化,对话流畅、理解准确,适合中文用户交互。
- LangChain 原生支持:通过
langchain-community包中的ChatTongyi可直接调用,无需额外封装 API 请求。
4. 会话持久化:本地 JSON 文件
采用本地 JSON 文件保存会话数据,优势是无需依赖数据库,部署简单、轻量,适合小型应用;后续可轻松扩展为 MySQL、Redis 等数据库,兼容性强。
二、环境准备与依赖安装
在开始编码前,先完成环境配置和依赖安装,确保所有组件能正常运行。
1. 环境要求
- Python 版本:3.8+(推荐 3.10+,兼容性更好)
- 依赖包:streamlit、langchain、langchain-community、dashscope
2. 依赖安装命令
打开终端,执行以下命令安装所有依赖:
pip install streamlit langchain langchain-community dashscope说明:
- streamlit:构建前端交互页面
- langchain:LangChain 核心框架(v1.0+)
- langchain-community:社区提供的第三方组件(包含
ChatTongyi) - dashscope:阿里云通义千问的 Python SDK,用于调用大模型 API
3. 通义千问 API Key 获取
调用通义千问需要 API Key,获取步骤如下:
- 访问 阿里云百炼平台,使用阿里云账号登录。
- 登录后,点击右上角头像 → 「API-KEY管理」。
- 点击「创建API-KEY」,生成后复制保存(后续代码中需要使用)。
注意:API Key 属于敏感信息,请勿泄露,后续可通过环境变量配置,避免硬编码。
三、核心功能设计与架构解析
本文实现的 AI 聊天页面,核心功能如下:
- 会话管理:新建会话、切换会话、删除会话、清空当前会话
- 对话功能:用户输入、AI 流式回复(打字机效果)、上下文连续对话
- 持久化:会话数据保存到本地 JSON 文件,关闭页面、重启应用不丢失
- 交互体验:简洁美观的 UI、会话状态提示、操作反馈
整体架构流程图
暂时无法在豆包文档外展示此内容
核心模块拆解
- 前端交互模块:负责页面渲染、用户操作接收(会话管理、消息输入)、消息展示。
- 会话管理模块:负责会话的新建、切换、删除、清空,以及会话数据的加载和保存。
- LangChain 对话模块:基于 LCEL 构建对话流程,负责提示词模板构造、历史消息拼接、大模型调用、流式输出处理。
- 持久化模块:负责将会话数据(聊天记录)保存到本地 JSON 文件,确保数据不丢失。
四、完整代码实现与详细解析
下面是完整的代码实现,每一部分都添加了详细注释,同时结合前文的架构解析,帮你理解每一行代码的作用。代码可直接复制运行,只需替换自己的通义千问 API Key 即可。
完整代码(streamlit_qwen_chat_v1.py)
python
import streamlit as st
import json
import os
from datetime import datetime
# -------------------- LangChain v1.0+ 新版导入(核心) --------------------
# 通义千问新版聊天模型(替代旧版 Tongyi)
from langchain_community.chat_models import ChatTongyi
# 聊天提示词模板(支持插入历史消息)
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 聊天消息相关(用于构造历史消息格式)
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.messages import BaseMessage
# -------------------------- 页面基础配置 --------------------------
# 设置页面标题、图标、布局,提升用户体验
st.set_page_config(
page_title="通义千问 AI 助手(LangChain v1.0+)",
page_icon="🤖",
layout="wide" # 宽布局,适配会话列表+聊天区域的双栏结构
)
# -------------------------- 敏感信息配置 --------------------------
# 替换为你自己的通义千问 API Key(建议后续用环境变量配置,避免硬编码)
DASHSCOPE_API_KEY = "你的通义千问 API KEY"
# -------------------------- 会话管理模块(本地持久化) --------------------------
# 会话数据保存的本地文件路径
CHAT_FILE = "sessions.json"
# 初始化 Streamlit 会话状态(保存所有会话、当前选中会话)
# sessions:字典,key=会话ID,value=聊天记录列表(每个元素是{"role": "user/assistant", "content": "消息内容"})
if "sessions" not in st.session_state:
st.session_state.sessions = {}
# current_session:当前选中的会话ID,初始为None(无选中会话)
if "current_session" not in st.session_state:
st.session_state.current_session = None
# 1. 加载本地会话数据(应用启动时执行,恢复之前的会话)
def load_sessions():
# 检查会话文件是否存在,存在则加载,不存在则初始化空字典
if os.path.exists(CHAT_FILE):
with open(CHAT_FILE, "r", encoding="utf-8") as f:
# 从JSON文件中读取会话数据,赋值给session_state.sessions
st.session_state.sessions = json.load(f)
# 2. 保存会话数据(每次会话变化时执行:新建、发送消息、删除、清空)
def save_sessions():
# 将session_state.sessions中的数据写入JSON文件,确保中文正常显示(ensure_ascii=False)
with open(CHAT_FILE, "w", encoding="utf-8") as f:
json.dump(st.session_state.sessions, f, ensure_ascii=False, indent=2)
# 3. 新建会话(点击"新建会话"按钮触发)
def new_session():
# 生成唯一会话ID(基于当前时间戳,避免重复)
session_id = f"会话_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
# 为新会话初始化空的聊天记录
st.session_state.sessions[session_id] = []
# 将当前会话切换到新建的会话
st.session_state.current_session = session_id
# 保存会话到本地文件
save_sessions()
# 4. 切换会话(点击历史会话列表中的会话触发)
def switch_session(session_id):
# 将当前会话ID切换为选中的会话ID
st.session_state.current_session = session_id
# 5. 清空当前会话(点击"清空当前会话"按钮触发)
def clear_session():
# 仅当有选中会话时,清空该会话的聊天记录
if st.session_state.current_session:
st.session_state.sessions[st.session_state.current_session] = []
# 保存清空后的会话数据
save_sessions()
# 6. 删除会话(点击会话右侧的删除按钮触发)
def del_session(session_id):
# 从会话字典中删除指定会话
del st.session_state.sessions[session_id]
# 如果删除的是当前选中的会话,将当前会话置为None
if st.session_state.current_session == session_id:
st.session_state.current_session = None
# 保存删除后的会话数据
save_sessions()
# -------------------- LangChain v1.0+ 对话模块(LCEL 核心) --------------------
def get_chain():
"""
构建 LangChain v1.0+ 对话链(LCEL 管道式写法)
返回:prompt | llm 的 LCEL 管道,可直接调用 stream 方法实现流式输出
"""
# 1. 初始化通义千问聊天模型
llm = ChatTongyi(
model_name="qwen-turbo", # 通义千问标准版,免费额度高,适合调试和小型应用
dashscope_api_key=DASHSCOPE_API_KEY, # 传入通义千问API Key
temperature=0.7, # 温度值(0=严谨,1=创意),根据需求调整
streaming=True # 开启流式输出,实现打字机效果
)
# 2. 构建聊天提示词模板(新版核心,替代旧版 ConversationChain)
# MessagesPlaceholder:用于插入历史对话消息,variable_name="history" 对应后续传入的历史参数
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个有用、友好的AI助手,能够清晰、准确地回答用户的各种问题,语气自然亲切。"), # 系统提示词,定义AI角色
MessagesPlaceholder(variable_name="history"), # 历史对话占位符,自动插入之前的聊天记录
("human", "{input}") # 用户输入占位符,对应用户的新问题
])
# 3. LCEL 管道式组合(新版标准写法,替代旧版 Chain)
# prompt | llm:将提示词模板和大模型串联,调用时传入 history 和 input 即可
return prompt | llm
# -------------------------- 前端界面渲染(Streamlit) --------------------------
# 加载本地会话数据(应用启动时执行)
load_sessions()
# 侧边栏:会话管理(新建、切换、删除会话)
with st.sidebar:
st.title("📂 会话管理") # 侧边栏标题
st.divider() # 分隔线,提升UI美观度
# 新建会话按钮(占满侧边栏宽度,使用use_container_width=True)
if st.button("➕ 新建会话", use_container_width=True):
new_session()
st.subheader("历史会话") # 历史会话标题
# 获取所有会话ID,遍历展示
session_list = list(st.session_state.sessions.keys())
if session_list:
# 为每个会话创建"会话名称+删除按钮"的双栏布局
for sid in session_list:
col1, col2 = st.columns([7, 3]) # 两列,比例7:3,左侧会话名称,右侧删除按钮
with col1:
# 点击会话名称,切换到该会话
if st.button(sid, key=f"btn_{sid}", use_container_width=True):
switch_session(sid)
with col2:
# 点击删除按钮,删除该会话(key需唯一,避免冲突)
if st.button("🗑", key=f"del_{sid}", use_container_width=True):
del_session(sid)
else:
# 无历史会话时,显示提示信息
st.info("暂无会话,点击「新建会话」开始聊天吧~")
# 主界面:聊天区域
st.title("🤖 通义千问 AI 助手")
st.markdown("### LangChain v1.0+ 实战 | LCEL 标准写法 | 多会话支持")
st.divider()
# 无选中会话时,显示提示,阻止继续操作
if not st.session_state.current_session:
st.warning("👈 请先在左侧「会话管理」中新建或选择一个会话,再开始聊天~")
st.stop() # 停止后续代码执行
# 获取当前选中会话的ID和聊天记录
current_sid = st.session_state.current_session
current_messages = st.session_state.sessions[current_sid]
# 清空当前会话按钮(主界面顶部)
if st.button("🗑 清空当前会话", type="primary"): # primary类型按钮,突出显示
clear_session()
st.rerun() # 刷新页面,立即显示清空后的效果
# 渲染当前会话的聊天记录
st.markdown(f"#### 当前会话:{current_sid}")
for msg in current_messages:
# 根据消息角色(user/assistant),渲染对应的聊天气泡
with st.chat_message(msg["role"]):
st.markdown(msg["content"]) # 渲染消息内容
# 聊天输入框(页面底部,支持回车发送)
user_input = st.chat_input("请输入你的问题...")
# 处理用户输入,调用AI回复
if user_input:
# 1. 显示用户输入的消息
with st.chat_message("user"):
st.markdown(user_input)
# 2. 将用户消息添加到当前会话的聊天记录中
current_messages.append({"role": "user", "content": user_input})
# 3. 保存会话数据(更新聊天记录)
save_sessions()
# 4. 获取 LangChain 对话链(LCEL 管道)
chain = get_chain()
# 5. 构造历史消息格式(适配 LangChain 的 MessagesPlaceholder)
# 排除刚发送的用户消息(因为用户消息已作为 input 传入,历史消息只需之前的对话)
history_messages = [
{"role": msg["role"], "content": msg["content"]}
for msg in current_messages[:-1]
]
# 6. 调用AI模型,实现流式输出(打字机效果)
with st.chat_message("assistant"):
# 创建占位符,用于动态更新AI回复内容
placeholder = st.empty()
full_answer = "" # 存储完整的AI回复
# LCEL 流式调用(新版核心,stream方法返回生成器,逐块获取AI回复)
for chunk in chain.stream({
"history": history_messages, # 历史对话消息
"input": user_input # 用户新输入的问题
}):
# 逐字符拼接AI回复(实现打字机效果)
full_answer += chunk.content
# 实时更新占位符内容,添加"▌"模拟打字光标
placeholder.markdown(full_answer + "▌")
# 打字机效果结束,显示完整回复(移除光标)
placeholder.markdown(full_answer)
# 7. 将AI回复添加到当前会话的聊天记录中
current_messages.append({"role": "assistant", "content": full_answer})
# 8. 保存会话数据(更新AI回复)
save_sessions()代码核心部分详细解析
下面针对代码中最关键的 3 个模块,进行更细致的解析,帮助你理解 LangChain v1.0+ 的新版写法核心。
1. LangChain v1.0+ 对话链(LCEL 核心)
这是本文的重点,也是 LangChain v1.0+ 与旧版的核心区别。代码中 get_chain() 函数实现了 LCEL 管道的构建,核心逻辑如下:
- ChatTongyi :新版通义千问聊天模型封装,替代了旧版的
Tongyi(旧版属于 LLM,新版ChatTongyi属于 ChatModel,更贴合聊天场景,支持流式输出)。 - ChatPromptTemplate.from_messages :新版提示词模板,支持传入多轮消息(系统提示词、历史消息、用户输入),
MessagesPlaceholder是关键,用于动态插入历史对话,实现上下文连续聊天(替代旧版ConversationBufferMemory的记忆功能)。 - LCEL 管道(prompt | llm) :这是新版的核心写法,通过
|符号将提示词模板和大模型串联,形成一个可调用的管道。调用时,只需传入history(历史消息)和input(用户新输入),管道会自动完成"拼接提示词 → 调用大模型 → 返回结果"的流程,无需像旧版那样手动管理 Chain 和 Memory。
2. 会话管理与持久化
会话管理模块的核心是 st.session_state + 本地 JSON 文件,实现会话的"临时存储+长期保存":
- st.session_state:Streamlit 提供的会话状态管理工具,用于保存当前应用的所有会话数据和当前选中会话,刷新页面时不会丢失(但重启应用会丢失,因此需要配合本地文件持久化)。
- load_sessions() / save_sessions():这两个函数负责将会话数据读写到本地 JSON 文件,确保重启应用后,之前的会话记录依然存在。
- 会话操作函数 (new_session/switch_session/clear_session/del_session):封装了会话的所有操作,每个操作后都会调用
save_sessions(),确保数据同步保存到本地。
3. 流式输出(打字机效果)
流式输出是提升用户体验的关键,实现逻辑如下:
- 初始化
ChatTongyi时,设置streaming=True,开启流式输出。 - 调用 LCEL 管道的
stream()方法,返回一个生成器,逐块获取 AI 回复的内容。 - 使用
st.empty()创建占位符,逐字符拼接 AI 回复,并实时更新占位符内容,添加"▌"模拟打字光标,实现打字机效果。 - 当 AI 回复全部生成后,移除光标,显示完整回复。
五、应用运行与效果演示
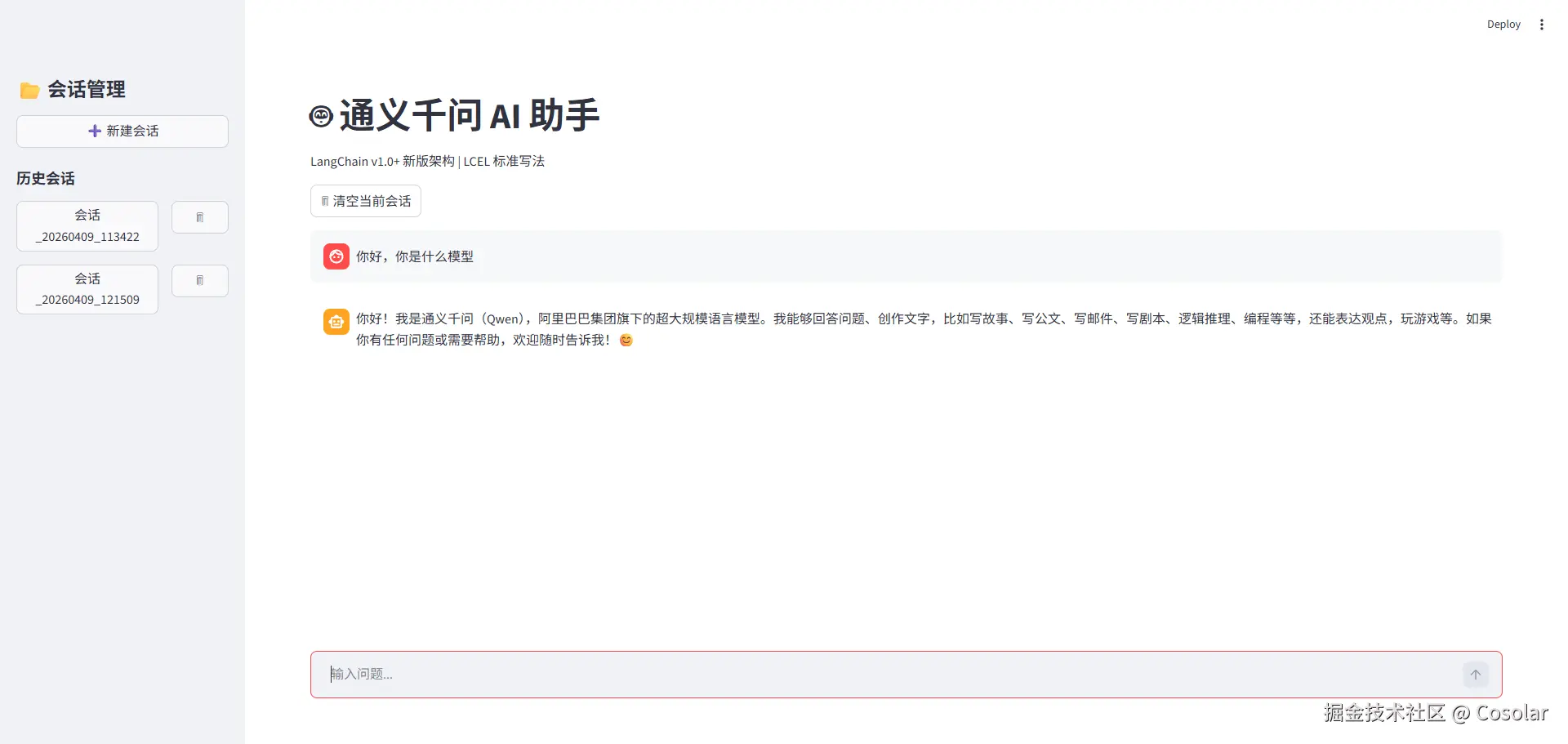
1. 运行步骤
- 将上述代码保存为
streamlit_qwen_chat_v1.py。 - 替换代码中的
DASHSCOPE_API_KEY为你自己的通义千问 API Key。 - 打开终端,执行以下命令运行应用:
streamlit run streamlit_qwen_chat_v1.py - 应用启动后,会自动打开浏览器,访问地址:
http://localhost:8501。
2. 效果演示
- 新建会话:点击左侧"新建会话",生成带有时间戳的会话,切换到该会话即可开始聊天。
- 发送消息:在底部输入框输入问题,回车发送,AI 会以打字机效果返回回复,同时保存对话记录。
- 会话管理:可切换历史会话(自动恢复该会话的聊天记录)、删除不需要的会话、清空当前会话的聊天记录。
- 持久化效果:关闭浏览器、重启应用后,之前的会话记录依然存在,无需重新开始。
六、常见问题与优化方向
1. 常见问题解决
- API Key 错误 :如果出现
Invalid API Key错误,请检查 API Key 是否正确,是否有拼写错误,或是否在阿里云平台激活了通义千问服务。 - 流式输出不生效 :确保
ChatTongyi初始化时设置了streaming=True,且 LangChain 版本为 v1.0+。 - 会话数据丢失 :检查
save_sessions()函数是否在每次会话操作后都被调用,确保 JSON 文件路径正确(默认保存在当前运行目录)。 - 依赖版本冲突 :如果出现导入错误,可尝试指定依赖版本(如
pip install langchain==1.0.0 streamlit==1.32.0)。
2. 优化方向(可扩展功能)
本文实现的是基础版本,可根据需求扩展以下功能,提升应用的实用性和体验:
- 敏感信息优化 :将 API Key 配置到环境变量,避免硬编码(使用
os.getenv("DASHSCOPE_API_KEY")获取)。 - UI 美化:添加暗黑模式、微信风格聊天气泡、会话重命名功能。
- 多模型切换:支持切换通义千问不同模型(qwen-turbo、qwen-plus),或添加其他大模型(如文心一言、DeepSeek)。
- 聊天记录导出:支持将当前会话的聊天记录导出为 TXT、Markdown 文件。
- RAG 检索增强:添加文档上传功能,实现基于文档的问答(LangChain v1.0+ 原生支持 RAG 流程)。
- 异步调用 :使用 LangChain 的异步 API(
ainvoke、astream),提升应用响应速度。 - 错误处理:添加异常捕获(如 API 调用失败、网络错误),显示友好的错误提示,提升应用稳定性。
七、最后
本文基于 LangChain v1.0+ 新版架构,结合 Streamlit 和通义千问,实现了一个功能完整、架构规范的多会话 AI 聊天页面。核心亮点在于:
- 完全采用 LangChain v1.0+ 新版写法,摒弃旧版冗余组件,使用 LCEL 管道式调用,代码更简洁、可扩展。
- 功能完整,涵盖会话管理、流式输出、本地持久化等核心需求,可直接用于生产环境或二次开发。
- 入门门槛低,无需前端开发经验,Python 开发者可快速上手,同时详细的代码解析帮助理解 LangChain v1.0+ 的核心变化。
通过本文的实战,你不仅能掌握 Streamlit 构建前端交互页面的方法,还能深入理解 LangChain v1.0+ 的 LCEL 架构,为后续构建更复杂的大模型应用(如智能体、RAG 系统)打下基础。