概念
是一种离线策略(off-policy) 的时序差分(TD)强化学习算法,用于学习最优动作价值函数 ,且不需要环境模型
核心思想
通过不断更新 Q 值,使 Q 函数逼近最优值。
更新时使用的目标值基于 贪婪选择 (取下一状态的最大 Q 值),但实际执行动作时可以遵循其他策略(如 ε-贪婪),因此是 离线策略 算法
更新公式
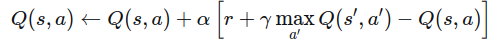
-
s:当前状态
-
a:当前执行的动作
-
r:获得的奖励
-
s′:下一状态
-
α:学习率(0~1,控制更新幅度)
-
γ:折扣因子(0~1,平衡即时与未来奖励)
-
maxa′Q(s′,a′):在下一状态所有动作中,选择最大的 Q 值
算法流程
初始化 Q(s,a) 为任意值(通常 0)
对每个 episode:
初始化状态 s
对 episode 中的每一步:
根据策略(如 ε-贪婪)从 Q 选择动作 a
执行动作 a,观察奖励 r 和下一状态 s'
Q(s,a) ← Q(s,a) + α [ r + γ * max_{a'} Q(s',a') - Q(s,a) ]
s ← s'
直到 s 为终止状态什么时候用 Q-learning?
-
状态和动作空间 离散且较小(可用表格存储)
-
想学习 确定性最优策略
-
环境没有模型,需要从交互中学习
如果状态空间很大(如图像),就需要 深度 Q 学习(DQN)