
背景需求:
【教学类-160-01】20260408 AI视频培训-练习1"豆包AI视频"![]() https://mp.csdn.net/mp_blog/creation/editor/159965108
https://mp.csdn.net/mp_blog/creation/editor/159965108
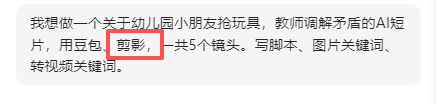

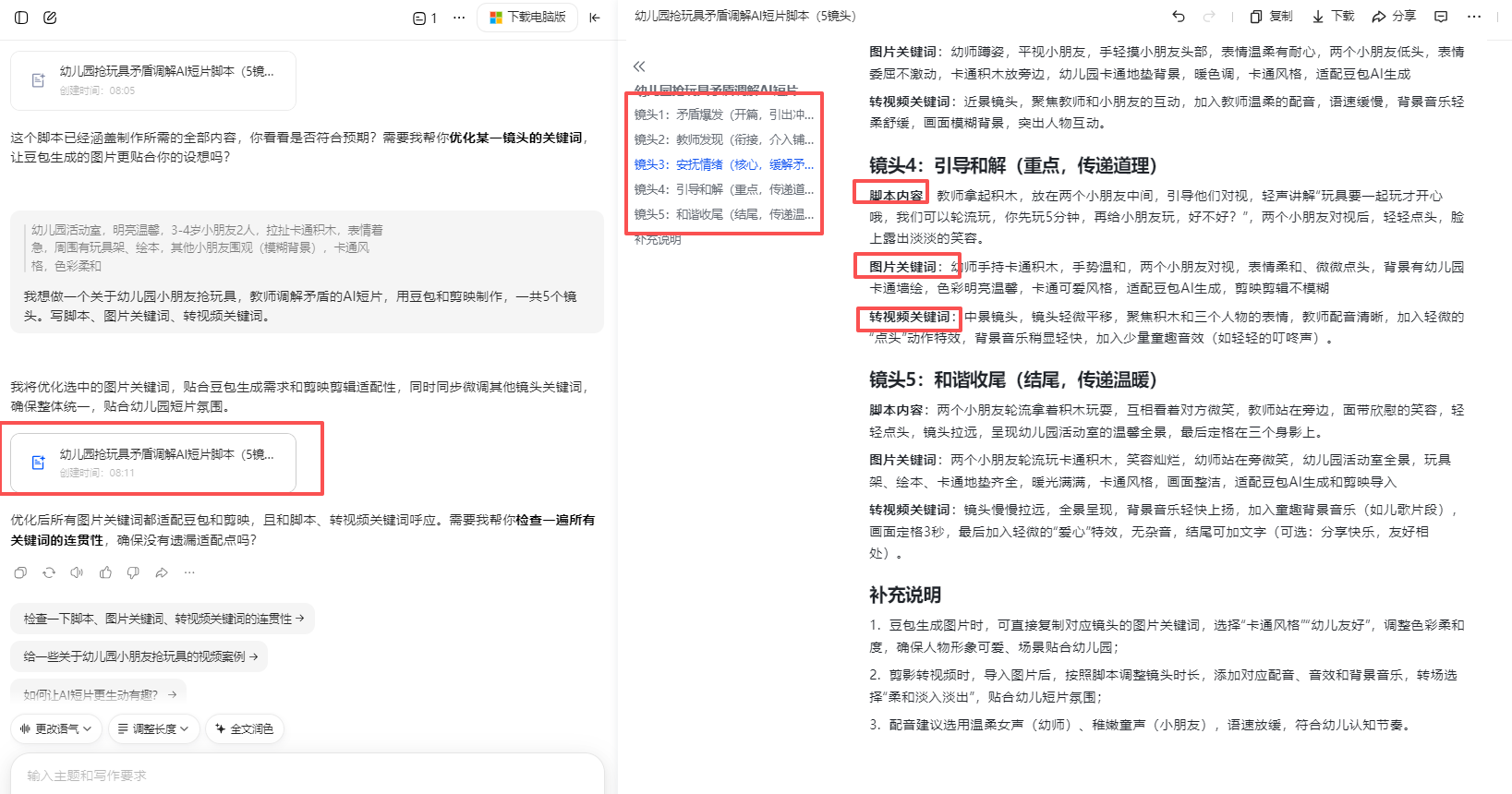

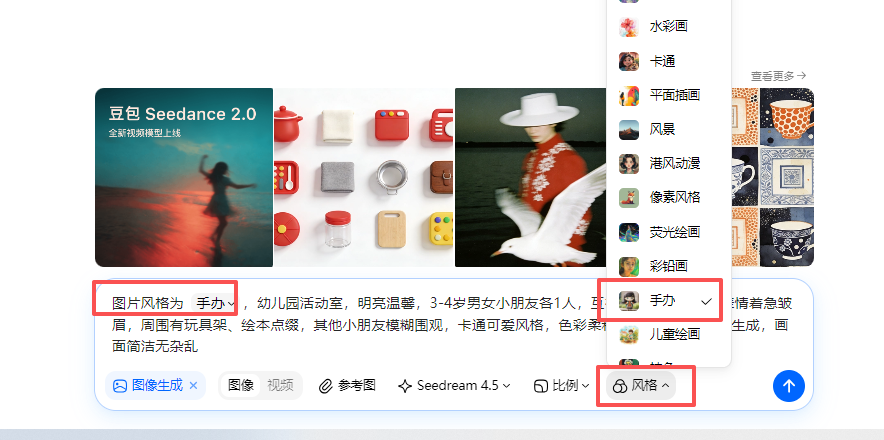
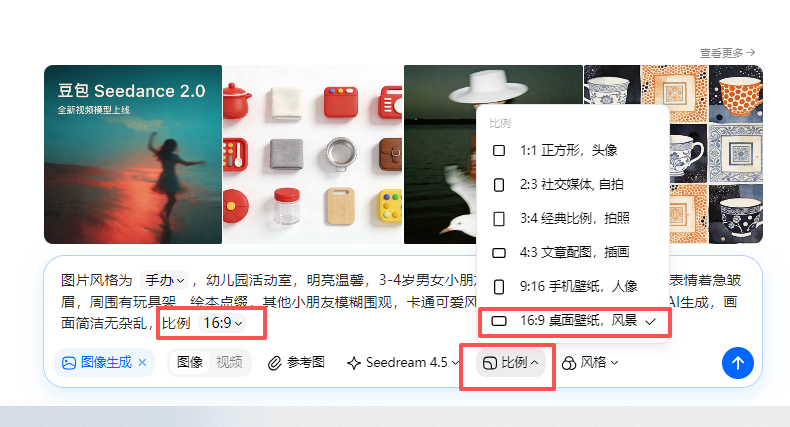

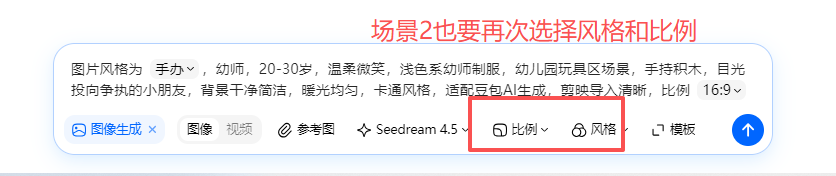

不是前面孩子的衣服了,从两女变成一男一女了

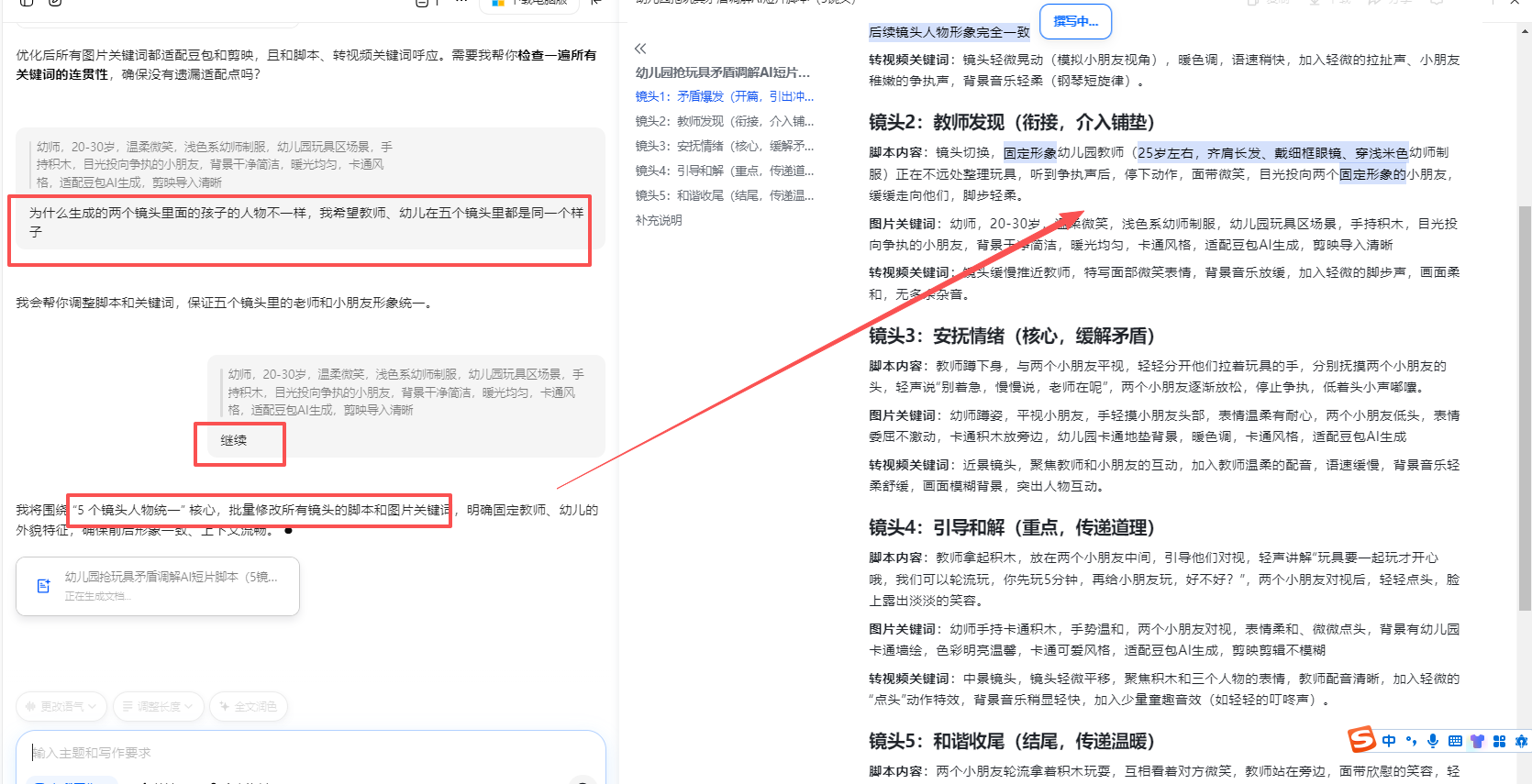

详细的人物特征描述(衣服颜色等)控制人物尽量相似。



显示了男女正确服饰和发型,但是背景变了(我需要建构积木的背景)
考虑增加图片的参考图,控制人物、背景相似性

用第4张做参考图首帧

结果就是在原图上增加了一位老师(只有一张照片)
测试不用参考图,果然生成四张

继续用参考图


下载五张图片
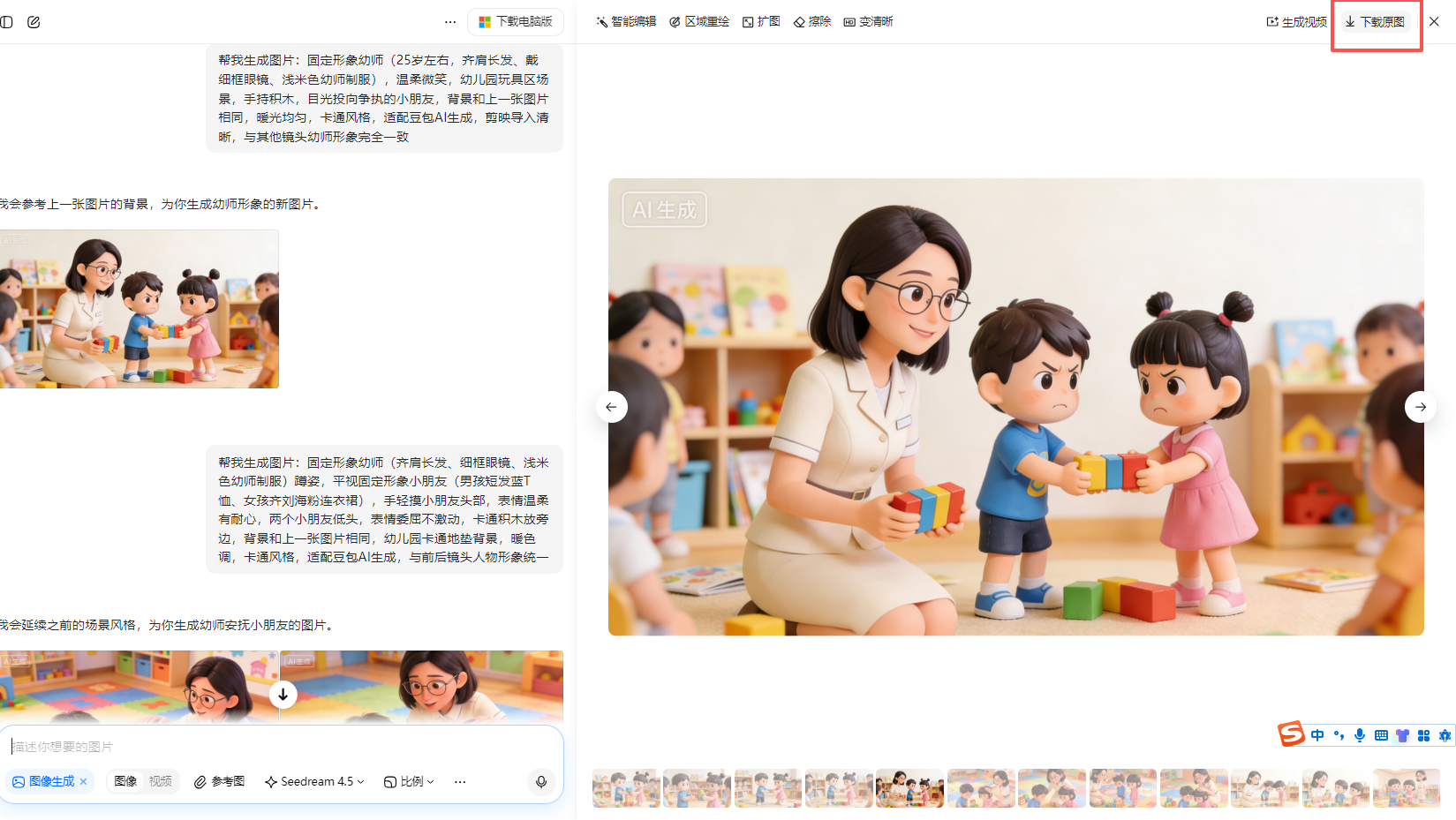
女孩没有小揪揪,重新制作





下载5张图,风格相近
感觉,转视频的关键词比较简单




太神奇了,两个孩子的配音,太符合实际情况了!

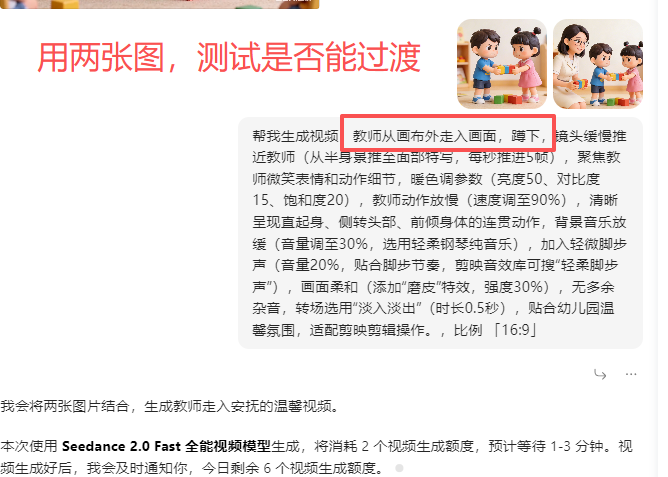
老师走入画面,蹲下对幼儿说话


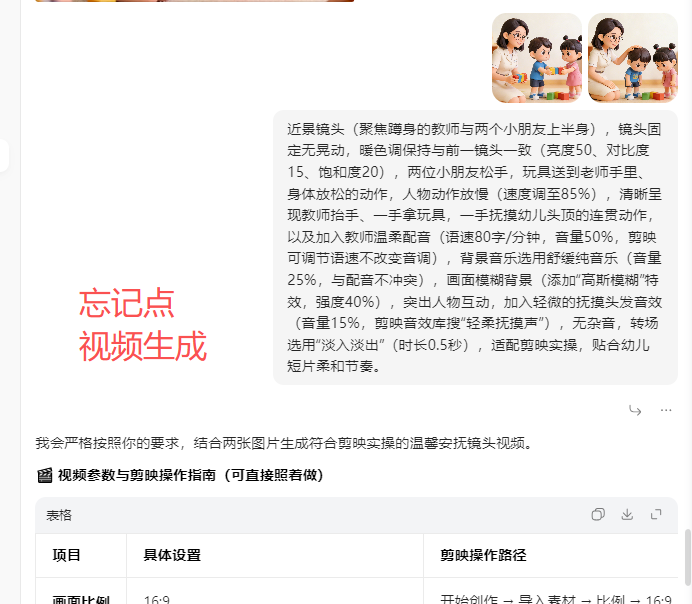







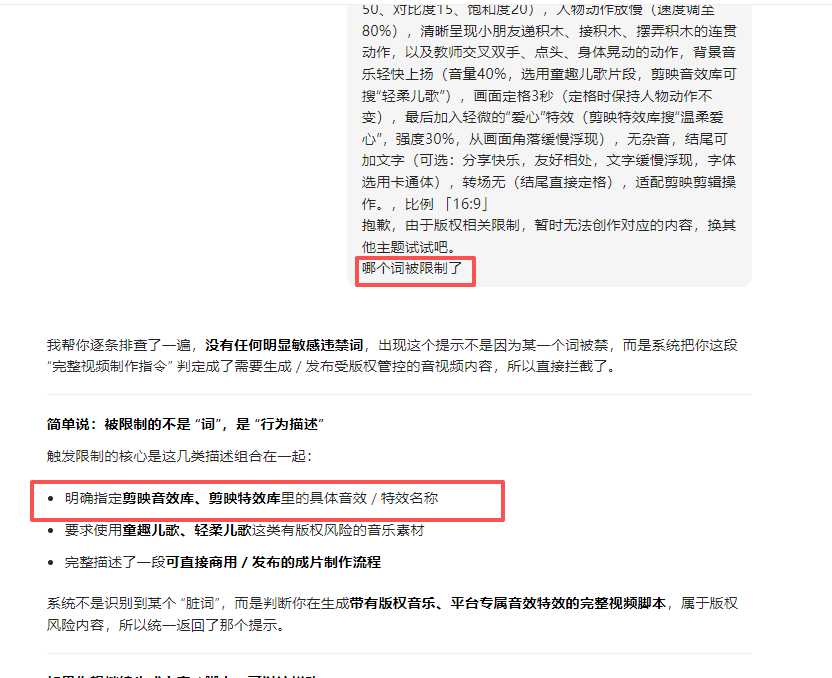
不能用剪映

还是不能生成
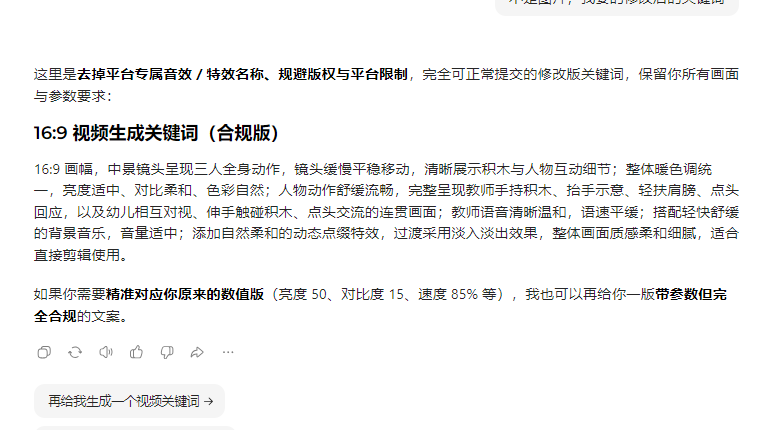


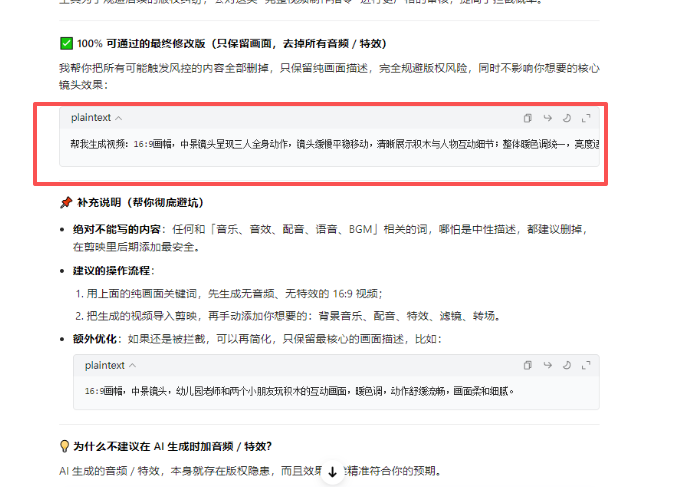
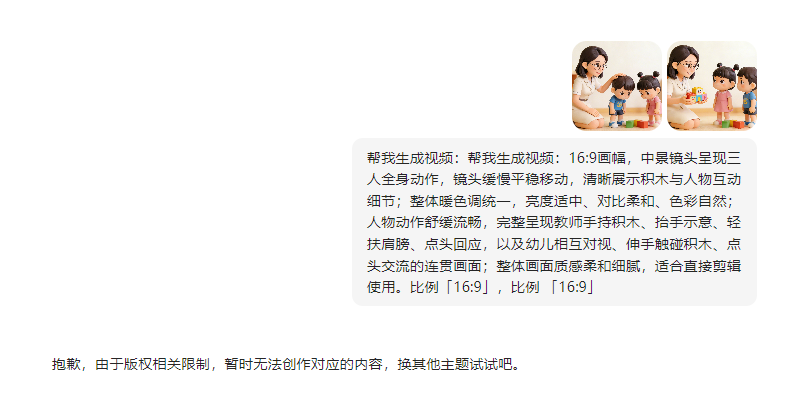

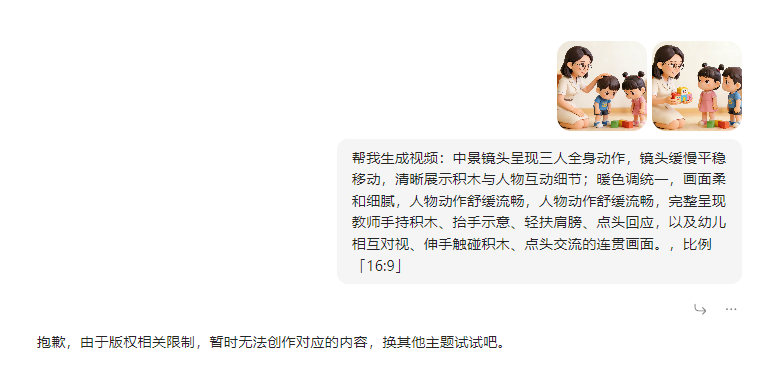



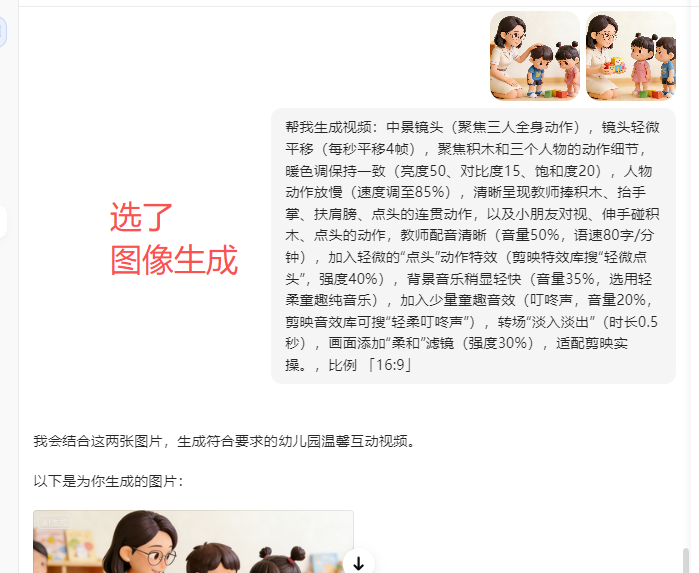
反复测试还是不能生成,AI图片试试,没有问题

换成通义万相

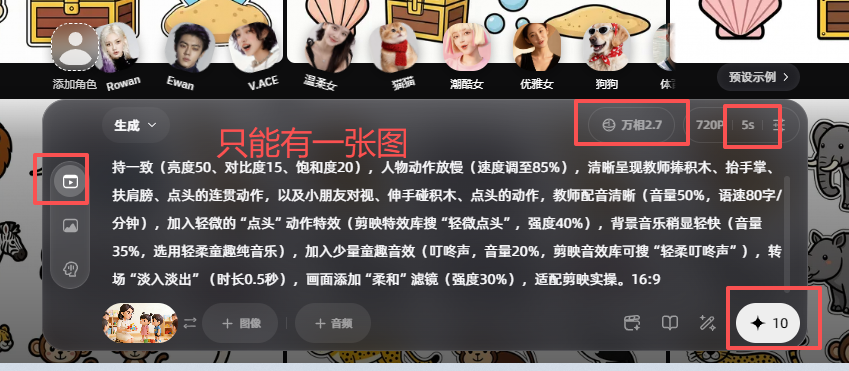


效果不错,用了积分是5分钟左右时长生成
再做一张,正好用完今天的10分积分
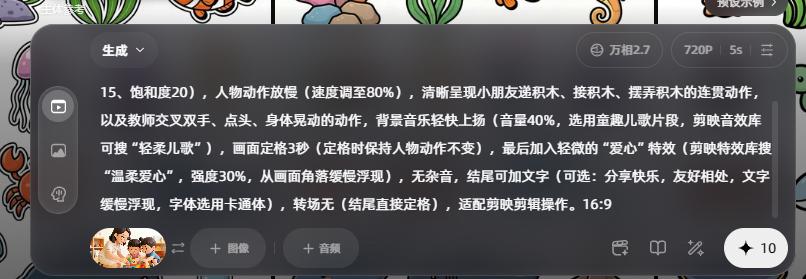

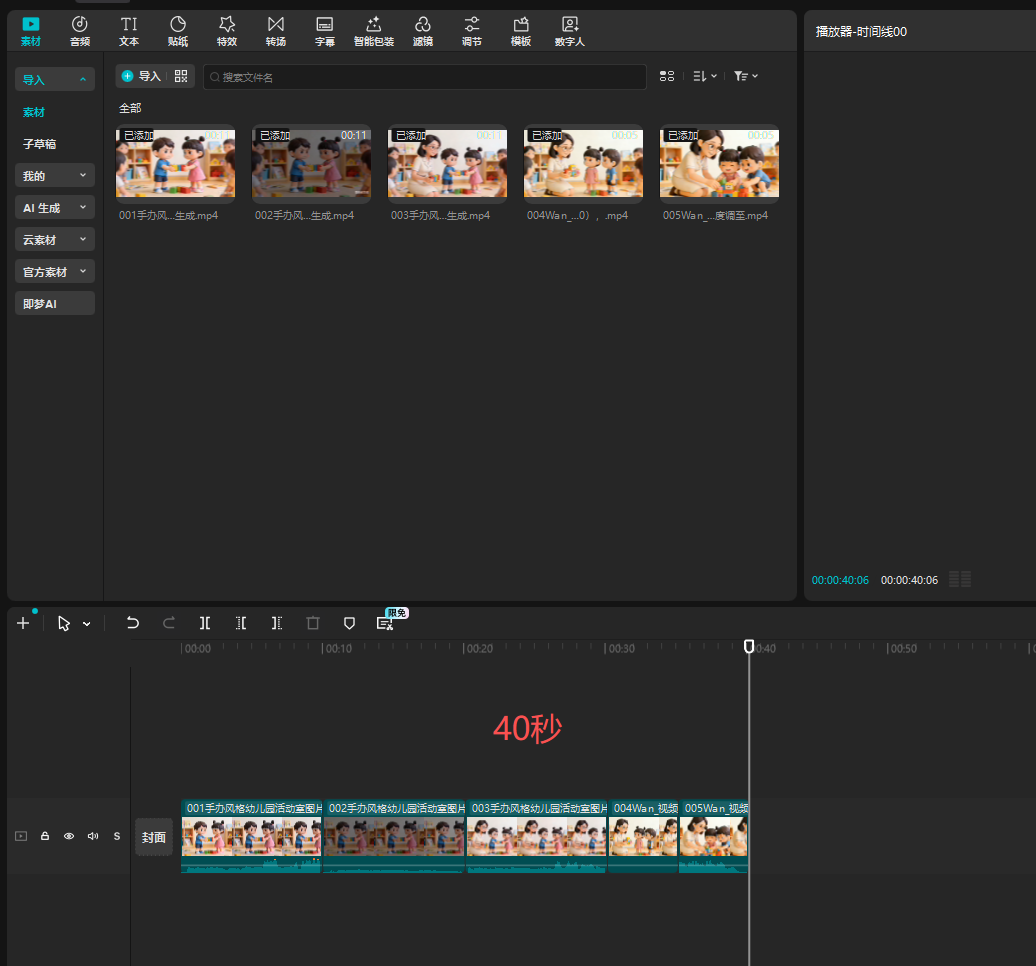
下载视频
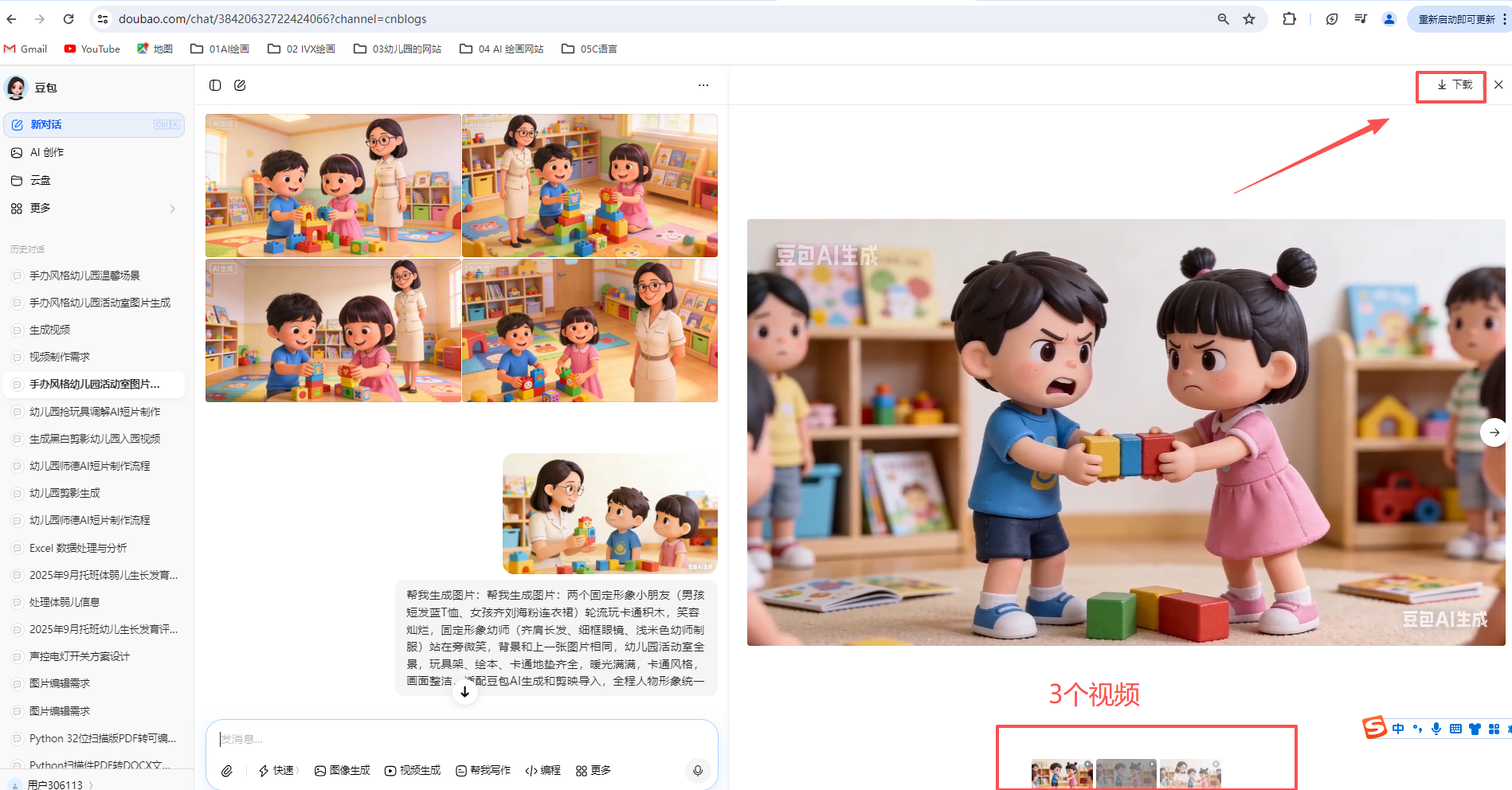

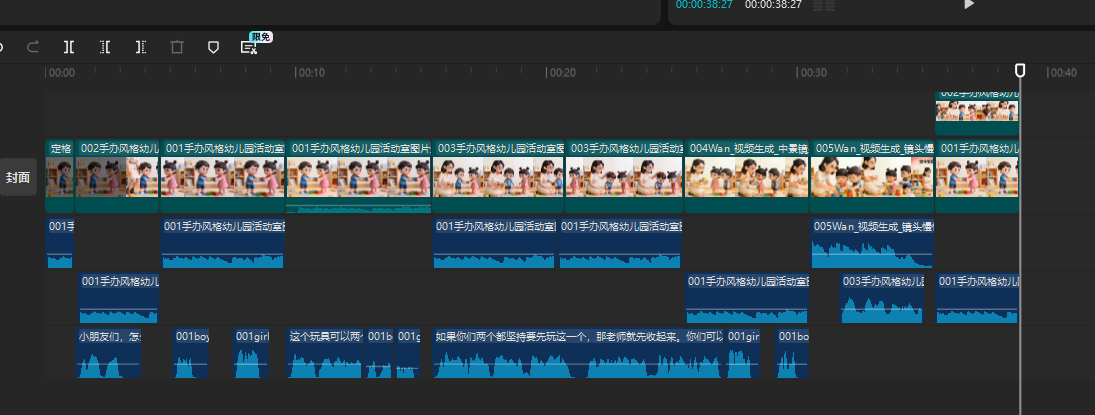
豆包每段10秒
万相每段5秒
一共40秒
统一背景音乐
需要模拟小男孩、小女孩、老师的声音
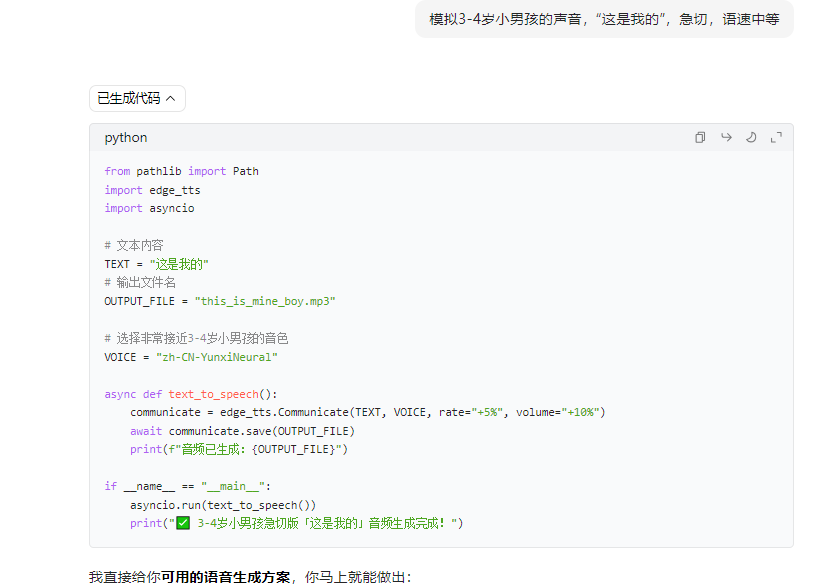
是Python模拟声音
python
from pathlib import Path
import edge_tts
import asyncio
# 文本内容
TEXT = "这是我的"
# 输出文件名
path=r'C:\Users\jg2yXRZ\OneDrive\桌面\20260409豆包AI幼儿吵架'
OUTPUT_FILE = path+r"\001boy.mp3"
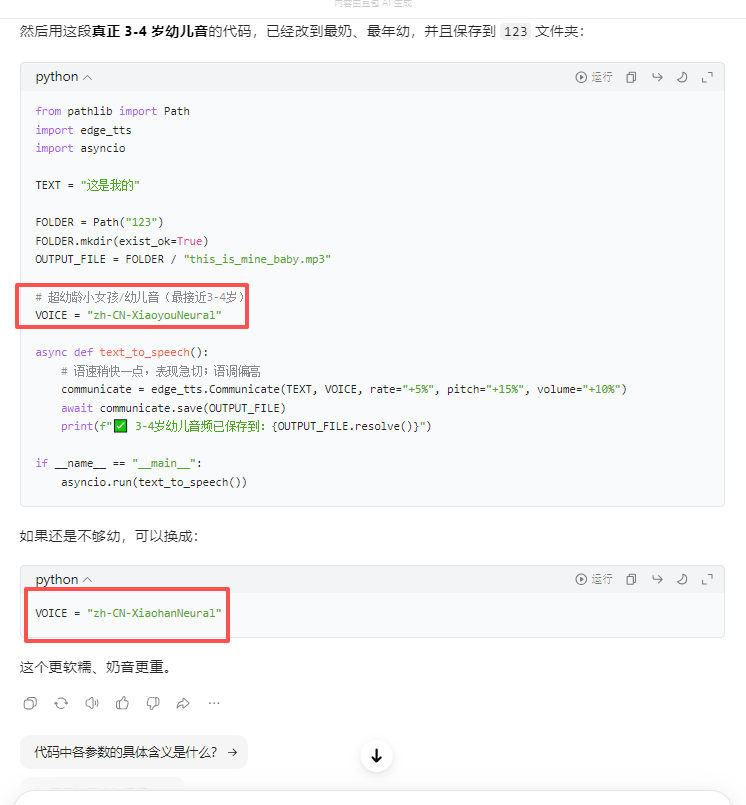
# 选择非常接近3-4岁小男孩的音色
VOICE = "zh-CN-YunxiNeural"
async def text_to_speech():
communicate = edge_tts.Communicate(TEXT, VOICE, rate="+5%", volume="+10%")
await communicate.save(OUTPUT_FILE)
print(f"音频已生成:{OUTPUT_FILE}")
if __name__ == "__main__":
asyncio.run(text_to_speech())
print("✅ 3-4岁小男孩急切版「这是我的」音频生成完成!")
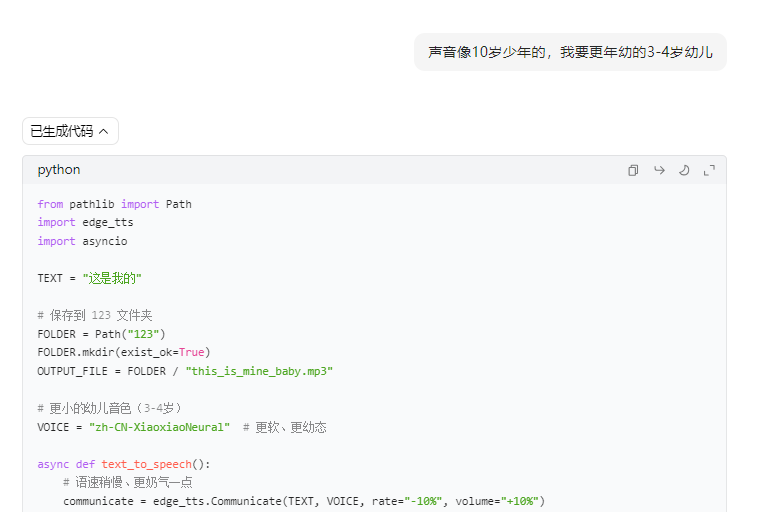

测试后用了三种声音
python
# 男孩的声音
from pathlib import Path
import edge_tts
import asyncio
import os
# TEXT = "这是我的!"
# TEXT = "不行,是我的!"
TEXT = "我要刚才的!"
# 你要的保存路径
SAVE_DIR = r"C:\Users\jg2yXRZ\OneDrive\桌面\20260409豆包AI幼儿吵架"
os.makedirs(SAVE_DIR,exist_ok=True)
OUTPUT_FILE = SAVE_DIR +fr"\001boy{TEXT}.mp3"
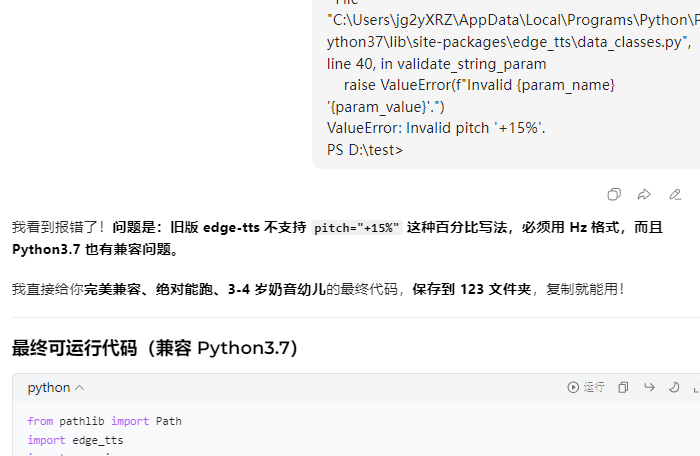
# ✅ 全世界通用、永远不报错、最像3-4岁小男孩
# VOICE = "zh-CN-YunxiNeural"
VOICE = "zh-CN-YunxiaNeural" # 最小男孩
async def text_to_speech():
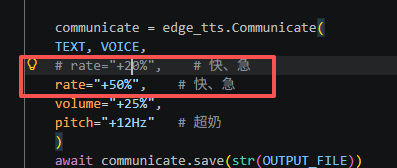
communicate = edge_tts.Communicate(
TEXT, VOICE,
rate="+50%", # 快、急
volume="+25%",
pitch="+12Hz" # 超奶
)
await communicate.save(str(OUTPUT_FILE))
print("✅ 生成成功!")
print("音频位置:", OUTPUT_FILE)
if __name__ == "__main__":
asyncio.run(text_to_speech())
# # 版本 2:经典正太(7~9 岁)------ Yunxi(最稳、不报错)
# python
# 运行
# VOICE = "zh-CN-YunxiNeural"
# communicate = edge_tts.Communicate(
# TEXT, VOICE,
# rate="+18%",
# volume="+20%",
# pitch="+9Hz"
# )
# 版本 3:清亮少年男孩(9~12 岁)------ Yunhao
# python
# 运行
# VOICE = "zh-CN-YunhaoNeural"
# communicate = edge_tts.Communicate(
# TEXT, VOICE,
# rate="+15%",
# volume="+20%",
# pitch="+6Hz"
# )
# 版本 4:大男孩 / 哥哥(10~14 岁)------ Yunjian
# python
# 运行
# VOICE = "zh-CN-YunjianNeural"
# communicate = edge_tts.Communicate(
# TEXT, VOICE,
# rate="+12%",
# volume="+18%",
# pitch="+4Hz"
# )
# 三、查看所有可用音色(命令)
python
# 女孩的声音
from pathlib import Path
import edge_tts
import asyncio
import os
TEXT = "我要这个玩具"
# TEXT = "是我先拿到的"
# TEXT = "是我先拿到的"
# 你要的保存路径
SAVE_DIR = r"C:\Users\jg2yXRZ\OneDrive\桌面\20260409豆包AI幼儿吵架"
os.makedirs(SAVE_DIR,exist_ok=True)
OUTPUT_FILE = SAVE_DIR +fr"\001girl{TEXT}.mp3"
# ✅ 全世界通用、永远不报错、最像3-4岁小男孩
# VOICE = "zh-CN-YunxiNeural"
VOICE = "zh-CN-XiaoxiaoNeural" # 最尖最小女孩
async def text_to_speech():
# communicate = edge_tts.Communicate(
# TEXT,
# VOICE,
# rate="+15%", # 急切
# pitch="+8Hz" # 变幼、变奶
communicate = edge_tts.Communicate(
TEXT,
VOICE,
rate="+25%", # 超快,急切
pitch="+20Hz", # 尖锐
volume="+40%"
)
await communicate.save(str(OUTPUT_FILE))
print("✅ 生成成功!")
print("音频位置:", OUTPUT_FILE)
if __name__ == "__main__":
asyncio.run(text_to_speech())
# # 版本 2:经典正太(7~9 岁)------ Yunxi(最稳、不报错)
# python
# 运行
# VOICE = "zh-CN-YunxiNeural"
# communicate = edge_tts.Communicate(
# TEXT, VOICE,
# rate="+18%",
# volume="+20%",
# pitch="+9Hz"
# )
# 版本 3:清亮少年男孩(9~12 岁)------ Yunhao
# python
# 运行
# VOICE = "zh-CN-YunhaoNeural"
# communicate = edge_tts.Communicate(
# TEXT, VOICE,
# rate="+15%",
# volume="+20%",
# pitch="+6Hz"
# )
# 版本 4:大男孩 / 哥哥(10~14 岁)------ Yunjian
# python
# 运行
# VOICE = "zh-CN-YunjianNeural"
# communicate = edge_tts.Communicate(
# TEXT, VOICE,
# rate="+12%",
# volume="+18%",
# pitch="+4Hz"
# )
# 三、查看所有可用音色(命令)
python
# 老师的声音
from pathlib import Path
import edge_tts
import asyncio
# 教师常用台词(可改成你要的文本)
TEXT = "如果你们两个都坚持要先玩这一个,那老师就先收起来。你们可以一起选另一个玩具,或者各自玩一个不同的玩具。"
# 保存路径
SAVE_DIR = Path(r"C:\Users\jg2yXRZ\OneDrive\桌面\20260409豆包AI幼儿吵架\mp3")
SAVE_DIR.mkdir(parents=True, exist_ok=True)
# 温柔女教师音色(2种风格)
TEACHER_VOICES = [
("zh-CN-XiaoxiaoNeural", f"{TEXT}_晓晓.mp3"),
("zh-CN-XiaoyiNeural", f"{TEXT}_晓伊.mp3"),
]
async def generate_teacher_voice():
for voice, filename in TEACHER_VOICES:
out = SAVE_DIR / filename
tts = edge_tts.Communicate(
TEXT, voice,
rate="-20%", # 温柔慢一点
pitch="-5Hz", # 更温柔
volume="+15%" # 清晰
)
await tts.save(str(out))
print(f"✅ 已生成:{filename}")
await asyncio.sleep(0.5)
if __name__ == "__main__":
asyncio.run(generate_teacher_voice())
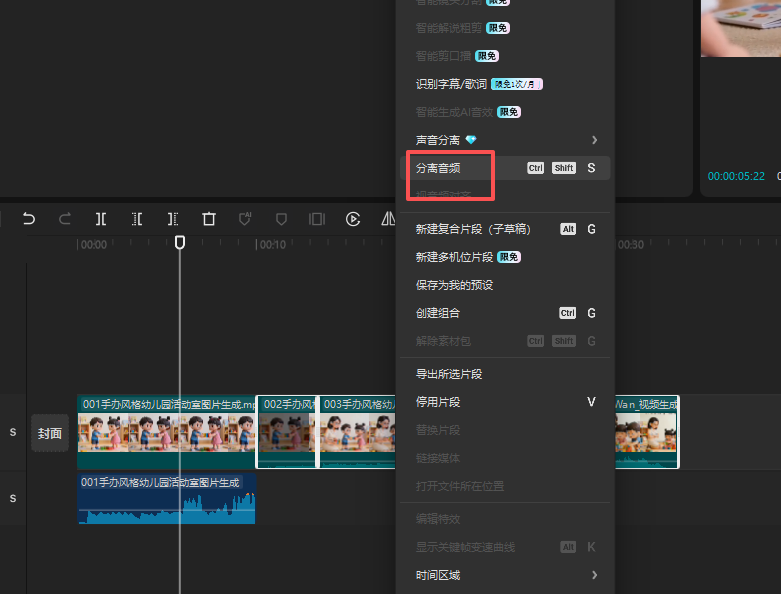
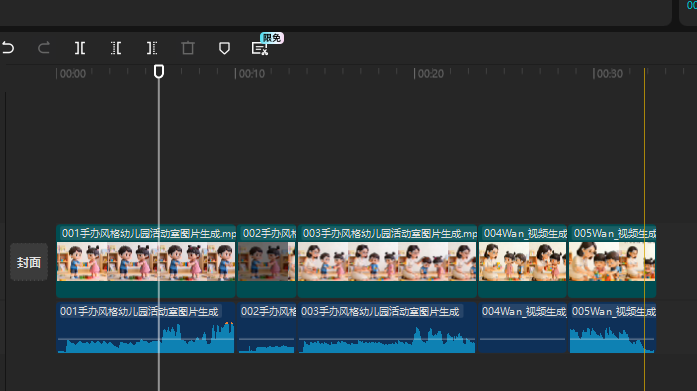
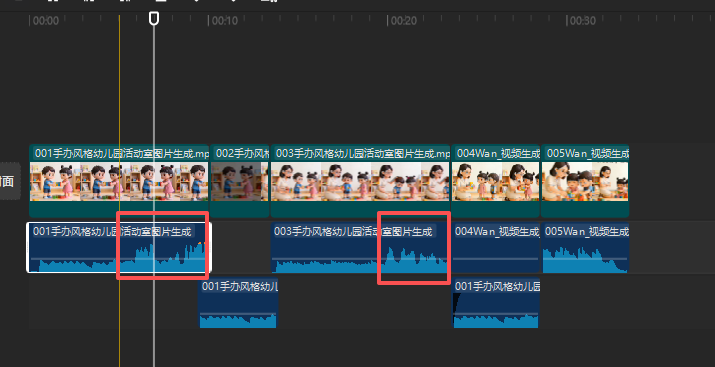
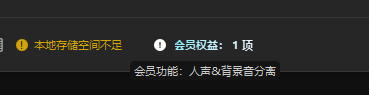
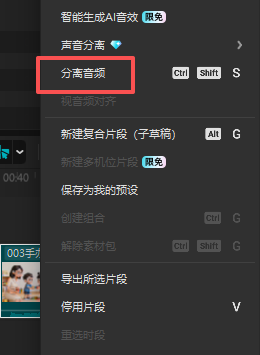
print("\n🎉 温柔女教师声音生成完成!")把豆包生成AI视频的音乐作为背景乐(最后发现不能用人声分里,要收费,但是分离音频是免费的)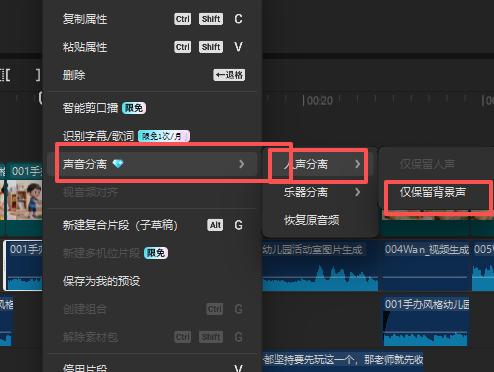
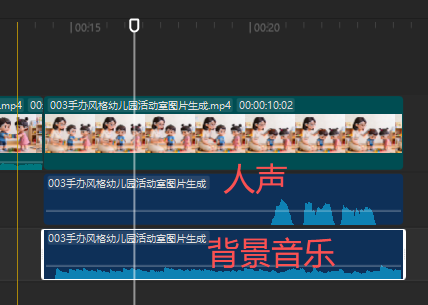
为了适应音频长度,补一段
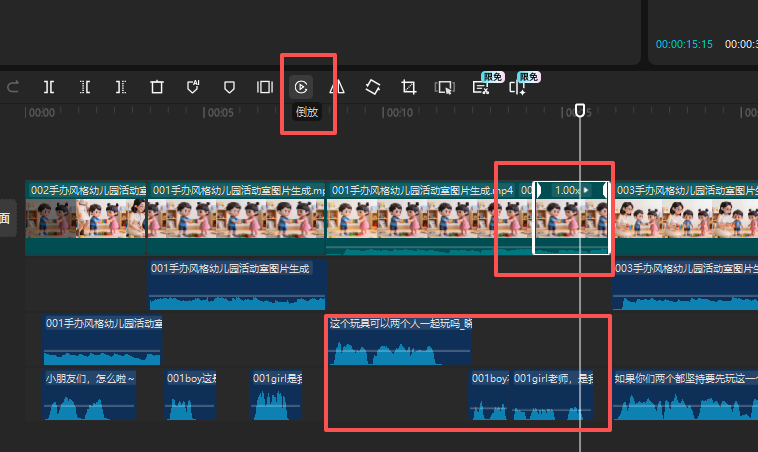
静态图片





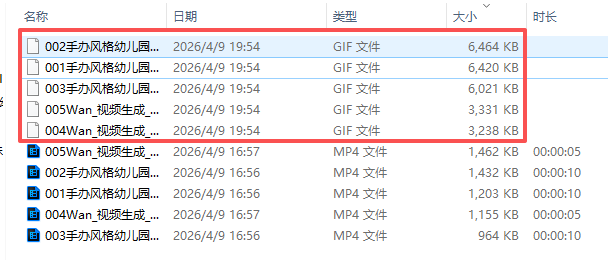
视频转GIF,必须用Python3.7.8才能运行成功
python
'''
结题报告WORD 插入 MP4转gif动画(降低帧率)
deepseek、阿夏
一定要用Python3.7.8
20250718
'''
import os
from moviepy.editor import VideoFileClip
def convert_mp4_to_gif(input_folder, output_folder=None, scale=0.5, fps=5, colors=128):
"""
修复版的MP4转GIF函数
"""
if output_folder is None:
output_folder = input_folder
os.makedirs(output_folder, exist_ok=True)
for filename in os.listdir(input_folder):
if filename.lower().endswith('.mp4'):
input_path = os.path.join(input_folder, filename)
output_path = os.path.join(output_folder, f"{os.path.splitext(filename)[0]}.gif")
print(f"正在转换: {filename}...")
try:
# 使用更稳定的方式读取视频
clip = VideoFileClip(input_path)
# 检查视频是否成功读取
if clip.duration == 0:
print(f"警告: {filename} 可能为空或损坏")
continue
# 调整尺寸(更保守的参数)
if scale is not None:
clip = clip.resize(scale)
# 限制GIF时长,避免文件过大
if clip.duration > 10: # 如果视频超过10秒,只取前10秒
clip = clip.subclip(0, 10)
# 使用更稳定的GIF输出参数
clip.write_gif(
output_path,
fps=min(fps, 8), # 限制最大帧率
program='ffmpeg',
verbose=False,
logger=None
)
# 检查输出文件
if os.path.exists(output_path) and os.path.getsize(output_path) > 0:
print(f"✓ 转换成功: {os.path.basename(output_path)}")
else:
print(f"✗ 转换失败: 输出文件为空")
except Exception as e:
print(f"✗ 转换 {filename} 时出错: {str(e)}")
finally:
if 'clip' in locals():
clip.close()
# 测试版本 - 更保守的参数
if __name__ == "__main__":
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20260409豆包AI幼儿吵架\视频'
# 首先检查文件夹是否存在
if not os.path.exists(path):
print(f"错误: 路径不存在 - {path}")
else:
print(f"找到文件夹,包含文件: {os.listdir(path)}")
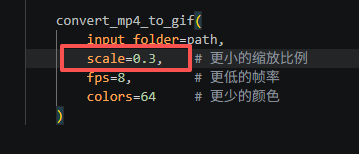
convert_mp4_to_gif(
input_folder=path,
scale=0.4, # 更小的缩放比例
fps=8, # 更低的帧率
colors=64 # 更少的颜色
)
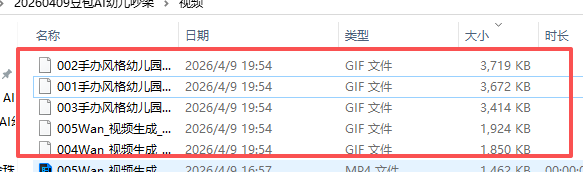




视频
20260409日豆包AI视频《小班抢玩具》(豆包+通义万相