欢迎来到我的频道【点击跳转专栏】
作者说:我想说 基础 不等于 简单 ;算法能力不是一蹴而就的,而是来自日积月累的积累和练习!积小流终成江海,诸君 加油!!
文章目录
- [1. 倍增思想](#1. 倍增思想)
- [1.1 快速幂(模版题)](#1.1 快速幂(模版题))
- [1.2 ⼤整数乘法](#1.2 ⼤整数乘法)
- [2. 离散化](#2. 离散化)
- [2.0 unique(加餐)](#2.0 unique(加餐))
- [2.1 离散化原理和模版](#2.1 离散化原理和模版)
- [2.2 火烧赤壁(模版的灵活使用)](#2.2 火烧赤壁(模版的灵活使用))
- [2.3 贴海报(离散化导致的区间缩小问题)](#2.3 贴海报(离散化导致的区间缩小问题))
1. 倍增思想
1.1 快速幂(模版题)
https://www.luogu.com.cn/problem/P1226
题目简单翻译一下就是2^10%9=7解法1:
- 直接暴力循环 但是会超时并且算出来的数据会存不下!
解法2: 倍增思想
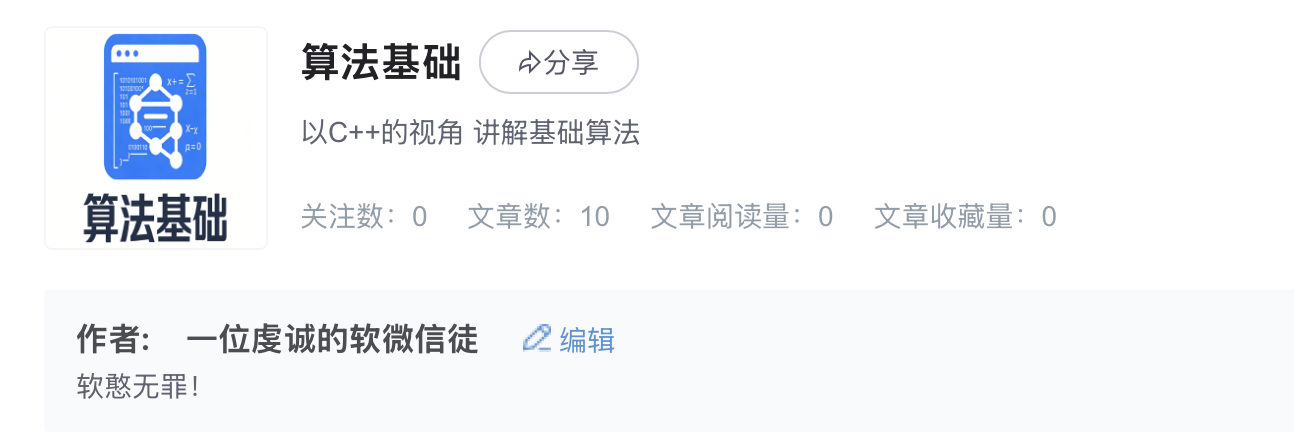
假如说
a^32正常求需要 跳32次(利用循环不断a*a*a*a.....*a)!但利用倍增只需要5次!
但是此时有个问题 因为你此时正好求的是 32次方 所以这么做比较爽 如果是让你求11次方呢?
利用
「二进制」以及「倍增」的思想,通过一个具体的例子说明,比如 3 11 3^{11} 311:
- 幂运算的运算法则: a b + c = a b × a c a^{b+c} = a^b \times a^c ab+c=ab×ac;
- 通过一个数的二进制表示,可以写成若干数相加: 11 = ( 1011 ) 2 = 1 × 2 3 + 0 × 2 2 + 1 × 2 1 + 1 × 2 0 11 = (1011)_2 = 1 \times 2^3 + 0 \times 2^2 + 1 \times 2^1 + 1 \times 2^0 11=(1011)2=1×23+0×22+1×21+1×20
- 两者结合: 3 11 = 3 ( 1011 ) 2 = 3 1 × 2 3 + 0 × 2 2 + 1 × 2 1 + 1 × 2 0 = 3 8 × 3 0 × 3 2 × 3 1 3^{11} = 3^{(1011)_2} = 3^{1 \times 2^3 + 0 \times 2^2 + 1 \times 2^1 + 1 \times 2^0} = 3^8 \times 3^0 \times 3^2 \times 3^1 311=3(1011)2=31×23+0×22+1×21+1×20=38×30×32×31
因此,当我们知道 3 1 , 3 2 , 3 4 , 3 8 , . . . , 3 log 2 n 3^1, 3^2, 3^4, 3^8, ..., 3^{\log_2 n} 31,32,34,38,...,3log2n 之后,只用做几次乘法就能计算出 3 11 3^{11} 311。
如何快速算出 3 1 , 3 2 , 3 3 , . . . , 3 log 2 n 3^1, 3^2, 3^3, ..., 3^{\log_2 n} 31,32,33,...,3log2n。其实很简单,从前往后看,后一个数是前一个数的平方:
3 1 = 3 3^1 = 3 31=3
3 2 = 3 1 × 3 1 = 9 3^2 = 3^1 \times 3^1 = 9 32=31×31=9
3 4 = 3 2 × 3 2 = 81 3^4 = 3^2 \times 3^2 = 81 34=32×32=81
3 8 = 3 4 × 3 4 = 6561 3^8 = 3^4 \times 3^4 = 6561 38=34×34=6561因此,计算 3 11 3^{11} 311,我们只需将 11 的二进制表示中 1 所对应的幂乘起来即可。
通过这种方案 就能把时间复杂度优化成
log2n!
关于如何解决存不下的问题!这里算是个取模运算的规则
死记就行!
当计算过程中,只有加法和乘法的时候,如果要对结果取模的时候 取模可以放在任何位置!加法取模
( A + B ) % M O D = ( ( A % M O D ) + ( B % M O D ) ) % M O D (A + B) \% MOD = ((A \% MOD) + (B \% MOD)) \% MOD (A+B)%MOD=((A%MOD)+(B%MOD))%MOD乘法取模
( A × B ) % M O D = ( ( A % M O D ) × ( B % M O D ) ) % M O D (A \times B) \% MOD = ((A \% MOD) \times (B \% MOD)) \% MOD (A×B)%MOD=((A%MOD)×(B%MOD))%MOD
补充加餐:
当计算结果出现减法,结果可能是负数,此时如果需要补正,就需要"模加模"的技巧来补正!
( A − B ) % M O D = ( ( A % M O D ) − ( B % M O D ) + M O D ) % M O D (A - B) \% MOD = ((A \% MOD) - (B \% MOD) + MOD) \% MOD (A−B)%MOD=((A%MOD)−(B%MOD)+MOD)%MOD
cppint res = (a - b + MOD) % MOD; // 计算过程: // 1. a - b = 3 - 5 = -2 // 2. -2 + MOD = -2 + 10 = 8 <-- 关键步骤:把负数"提"到正数范围 // 3. 8 % 10 = 8结果:
8。
结论: 与数学上的正确答案一致。💡 如果 a > b 会怎样?
你可能会问:"如果结果是正数,加了 MOD 会不会出错?" 假设我们要计算 8 − 3 8 - 3 8−3 (即
a = 8,b = 3),正确答案应该是 5。
cppint res = (a - b + MOD) % MOD; // 计算过程: // 1. a - b = 8 - 3 = 5 // 2. 5 + MOD = 5 + 10 = 15 // 3. 15 % 10 = 5结果:
5。
结论: 即使原本结果是正数,加上 MOD 后再取模,结果依然正确。📌 总结:
所以在写代码时,为了保险起见,凡是涉及模意义下的减法,无脑加上
+ MOD再% MOD即可。
当计算过程中 存在除法的时候,取模会造成结果错误 此时就要 求逆元 这个就不展开说了 感兴趣可以自己搜一下

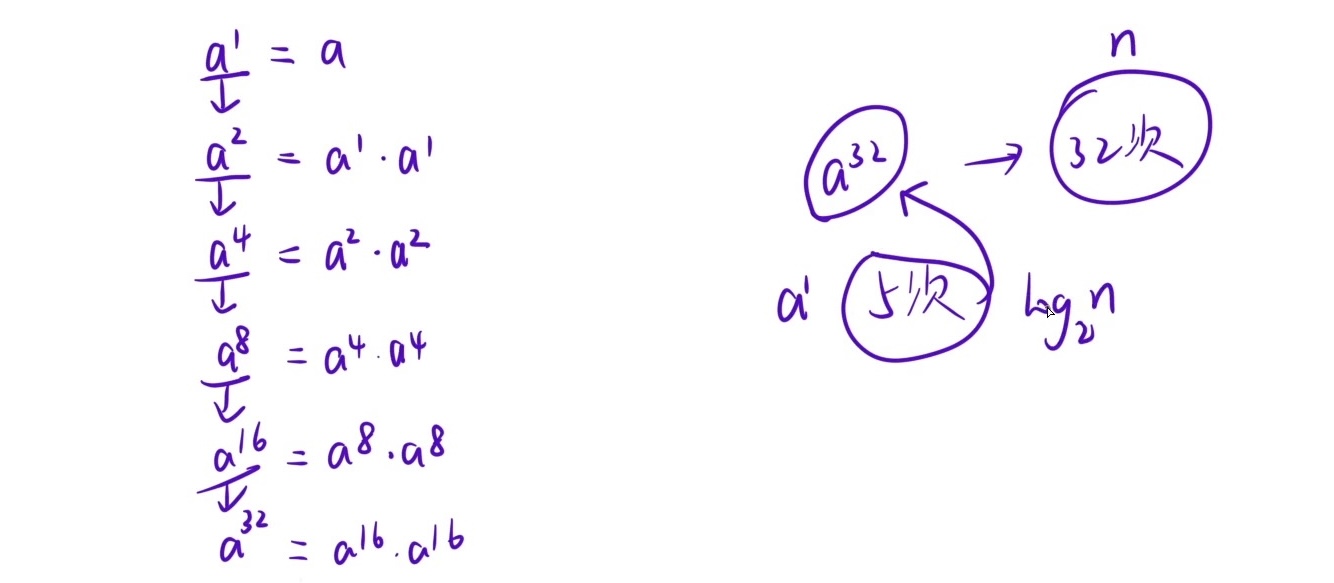
cpp
#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
// a^b % p 的值
LL quickpow(LL a, LL b, LL p)
{
LL ret = 1;
while(b)
{
if(b & 1) ret = ret * a % p;
a = a * a % p;
b >>= 1; // 提取 b 的⼆进制位
}
return ret;
}
int main()
{
LL a, b, p;
scanf("%lld%lld%lld", &a, &b, &p);
printf("%lld^%lld mod %lld=%lld\n", a, b, p, quickpow(a, b, p));
return 0;
}核心代码模版块:
cpp
LL ret = 1;
while(b)
{
if(b & 1) ret = ret * a % p;
a = a * a % p;
b >>= 1; // 提取 b 的⼆进制位
}我知道这个还是不好理解:我专门画了图还是a^11%p为例子:
你可以理解成每个
a的多少次方必须有个%p然后每两个(假设)a^1%p * a^2%p他相当于套了层括号得把他看成一个数[a^1%p * a^2%p]你想把他还原回(a^1 * a^2) %p. 必须再%个p[a^1%p * a^2%p] % p这个也就相当于为什么要ret = ret * a % p这么写的原因 因为代码其实更像是ret = (ret * a) % p就是每套层()把他看成一个数字 就要一个%p当然我说可能还是看不懂 可以自己试着结合例子 推推看!
在模运算中,多个数相乘再取模,等于每个数先分别取模,乘起来之后,最后再取一次模。
(a×b×c×d)%p=((a%p)×(b%p)×(c%p)×(d%p))%p这么写都是对的!


1.2 ⼤整数乘法
https://www.luogu.com.cn/problem/P10446#ide
跟快速幂的思想一致,我们通过一个具体的例子模拟一下算法的流程,比如 3 × 11:
- 乘法的分配率: a × ( b + c ) = a × b + a × c a \times (b + c) = a \times b + a \times c a×(b+c)=a×b+a×c;
- 通过一个数的二进制表示,可以写成若干数相加:
11 = ( 1011 ) 2 = 1 × 2 3 + 0 × 2 2 + 1 × 2 1 + 1 × 2 0 11 = (1011)_2 = 1 \times 2^3 + 0 \times 2^2 + 1 \times 2^1 + 1 \times 2^0 11=(1011)2=1×23+0×22+1×21+1×20 - 两者结合:
3 × 11 = 3 × ( 1 × 2 3 + 0 × 2 2 + 1 × 2 1 + 1 × 2 0 ) = 3 × 8 + 3 × 0 + 3 × 2 + 3 × 1 3 \times 11 = 3 \times (1 \times 2^3 + 0 \times 2^2 + 1 \times 2^1 + 1 \times 2^0) = 3 \times 8 + 3 \times 0 + 3 \times 2 + 3 \times 1 3×11=3×(1×23+0×22+1×21+1×20)=3×8+3×0+3×2+3×1
因此,当我们知道 3 × 1 , 3 × 2 , 3 × 4 , 3 × 8 , . . . , 3 × log 2 n 3 \times 1, 3 \times 2, 3 \times 4, 3 \times 8, ..., 3 \times \log_2^n 3×1,3×2,3×4,3×8,...,3×log2n 之后,只用做几次加法就能计算出 3 × 11。
如何实现这个算法呢,以 a × b a \times b a×b 为例:
- 一边提取 b b b 的二进制表示中的每一位;
- 一边让 a = a + a a = a + a a=a+a,不断变成之前的两倍(倍增的思想);
- 在提取 b b b 的二进制表示时,如果这一位是 1,就加上对应位置的权值。
cpp
#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
LL a,b,p,ret;
void qadd()
{
while(b)
{
if(b&1)
ret=(ret+a)%p;
a=(a+a)%p;
b>>=1;
}
}
int main()
{
cin>>a>>b>>p;
qadd();
cout<<ret;
}核心机制:取模运算锁死了范围
代码中最关键的两行是:
ret = (ret + a) % p;a = (a + a) % p;
这意味着,无论 a 和 ret 怎么变化,它们的值永远被限制在 0 0 0 到 p − 1 p-1 p−1 之间。
只要题目给定的模数 p p p 在 long long 的范围内(即 p < 9.22 × 10 18 p < 9.22 \times 10^{18} p<9.22×1018),那么变量 a 和 ret 本身永远不会溢出。
-
对于
a = (a + a) % p- 因为
a始终小于 p p p,所以a + a的最大值接近 2 p 2p 2p。 - 只要 2 p 2p 2p 不超过
long long的上限( 9.22 × 10 18 9.22 \times 10^{18} 9.22×1018),这一步就是安全的。
- 因为
-
对于
ret = (ret + a) % p- 同理,
ret和a都小于 p p p,它们的和小于 2 p 2p 2p。只要 2 p 2p 2p 不溢出,这一步也是安全的。
- 同理,
2. 离散化
2.0 unique(加餐)
std::unique 是 C++ STL 中一个非常实用的算法,但它常常因为名字而被误解。简单来说,它的核心作用是去除"相邻"的重复元素,而不是去除容器中所有的重复项。
理解它的关键在于明白它并不是真正地删除元素 ,而是移动元素。
核心原理:移动而非删除
std::unique 会遍历一个范围 [first, last),将重复的元素"压缩"掉。它的工作方式是:
- 保留第一个元素。
- 检查后续元素,如果与前面保留的元素相同,就跳过它;如果不同,就把它移动到当前"新"序列的末尾。
- 最终,所有不重复的元素会被移动到容器的前部,形成一个"新"的有效范围。
函数会返回一个迭代器,这个迭代器指向这个"新"有效范围的末尾之后 的位置。原容器中,这个新末尾之后的元素则处于一个未定义的、但可被覆盖的状态。
重要提示 :
std::unique只作用于相邻 的重复元素。如果想去除容器中所有重复项,必须先对容器进行排序(std::sort),让所有相同的元素都聚集在一起。
这是使用 std::unique 的标准流程,通常与 std::sort 和容器的 erase 方法结合使用。
cpp
#include <iostream>
#include <vector>
#include <algorithm> // 包含 std::sort 和 std::unique
int main() {
std::vector<int> vec = {5, 2, 8, 2, 1, 5, 5, 9};
// 1. 排序:让相同的元素相邻
std::sort(vec.begin(), vec.end());
// vec 现在是: {1, 2, 2, 5, 5, 5, 8, 9}
// 2. 使用 unique:移动重复元素到末尾
// 返回的迭代器指向第一个"多余"的元素
auto new_end = std::unique(vec.begin(), vec.end());
// vec 现在是: {1, 2, 5, 8, 9, ?, ?, ?}
// new_end 指向索引为 5 的位置(第一个 ?)
// 3. 使用 erase:真正删除多余的元素
vec.erase(new_end, vec.end());
// vec 现在是: {1, 2, 5, 8, 9}
// 打印结果
for (int n : vec) {
std::cout << n << " ";
}
std::cout << std::endl;
return 0;
}总结
- 作用 :移除相邻的重复元素。
- 前提:要实现完全去重,必须先排序。
- 行为:移动元素,而非删除。容器大小不变。
- 返回值:一个迭代器,指向去重后新逻辑结尾的下一个位置。
- 最佳实践 :配合
erase方法使用,形成著名的 "erase-remove 惯用法" 的变体:container.erase(std::unique(...), container.end());。
2.1 离散化原理和模版
当题目中数据范围很大,但是数据的总量不是很大,并且我们需要用数据的值来映射数组的下标时,我们就可以用离散化的思想先预处理一下所有的数据,使的每一个数据都映射成一个范围较小的值。
离散化 本质上是一种 "数据压缩" 技术,专门用来解决数据范围过大(比如 10 9 10^9 109)但实际数量很少(比如 10 5 10^5 105)的矛盾。
它的核心思想是:保序映射 。即把数值很大、分布很稀疏的原始数据,映射成数值很小、分布紧凑的整数(通常是 1 , 2 , 3... 1, 2, 3... 1,2,3...),同时保持它们之间的大小关系不变。
想象一下这个场景:
- 问题:你要统计 5 个人的年龄。
- 数据 :他们的年龄分别是
1000000000(10亿),2000000000,1500000000,1000000000,500。 - 困境 :如果你想用一个数组
count[年龄]++来统计,你需要开辟一个大小为 20亿 的数组!这直接导致内存溢出 (Memory Limit Exceeded)。 - 观察 :虽然年龄数值很大,但实际上只有 4 个不同的值(500, 10亿, 15亿, 20亿)。
离散化的作用 :
我们将这 4 个数分别重新编号:
- 500 → \rightarrow → 1
- 1000000000 → \rightarrow → 2
- 1500000000 → \rightarrow → 3
- 2000000000 → \rightarrow → 4
这样,我们只需要一个大小为 5 的数组就能解决问题了。
具体例子
假设有一组数组 A = 100 , 30000 , 200 , 100 , 500000 A = 100, 30000, 200, 100, 500000 A=100,30000,200,100,500000。
- 去重 :找出所有出现过的数 { 100 , 200 , 30000 , 500000 } \{100, 200, 30000, 500000\} {100,200,30000,500000}。
- 排序:从小到大排列(其实上面已经排好了)。
- 映射(编号) :
- 100 → 1 100 \rightarrow 1 100→1
- 200 → 2 200 \rightarrow 2 200→2
- 30000 → 3 30000 \rightarrow 3 30000→3
- 500000 → 4 500000 \rightarrow 4 500000→4
原数组 A A A 就变成了离散化后的数组 A ′ = 1 , 3 , 2 , 1 , 4 A' = 1, 3, 2, 1, 4 A′=1,3,2,1,4。
关键点:
- 原数组中 100 < 30000 100 < 30000 100<30000,新数组中 1 < 3 1 < 3 1<3。大小关系没变。
- 原数组中 100 = = 100 100 == 100 100==100,新数组中 1 = = 1 1 == 1 1==1。相等关系没变。
cpp
//离散化模版一:排序+去重+二分查找离散之后的结果
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+10;
int n;
int a[N];
int pos;//标记去重之后的元素个数
int disc[N];//帮助离散化 存储映射关系 比如说 999 对应 1
//二分x的位置
int find(int x)
{
int l=1,r=pos;
while(l<r)
{
int mid=(l+r)/2;
if(disc[mid]>=x) r=mid;
else l = mid + 1;
}
return l;
}
int main()
{
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>a[i];
disc[++pos]=a[i];
}
//离散化
//1. 先排序
sort(disc+1,disc+1+pos);
//2.去重
pos=unique(disc+1,disc+1+pos)-(disc+1);
//查看离散化的对应关系!
for(int i=1;i<=n;i++)
{
cout<<a[i]<<"离散化之后:"<<find(a[i])<<endl;
}
}
cpp
//【离散化模版⼆】
// 离散化⽅式⼆:排序 + STL
// 本质是和⽅式⼀ 样的,只不过借助了 STL,去重以及查找更⽅便
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+10;
int n;
int a[N];
int pos;//标记去重后的元素个数
int disc[N];//帮助离散化
unordered_map<int,int> id;//<原始的值,离散之后的值>
int main()
{
cin>>n;
for(int i=1;i<=n;i++)]
{
cin>>a[i];
disc[++pos]=a[i];
}
int cnt=1;//标记当前这个值是第几号元素
//离散化
sort(disc+1,disc+1+pos);//排序
int cnt=0;//当前这个值是第几号元素
//用STL辅助去重
for(int i=1;i<=pos;i++)
{
int x = disc[i];
//如果哈希表里面有这个元素
if(id.count(x))
{
continue;
}
//如果没有
cnt++;//离散化的值++ 0->1
id[x]=cnt;//将值绑定进入哈希表 cnt为元素个数!
}
//这样就不需要二分了 直接利用哈希表特性 将查找的时间复杂度从O(logn) 直接降低到 O(1)
for(int i=1;i<=n;i++)
{
cout<<a[i]<<"离散化之后:"<<id[a[i]]<<endl;
}
return 0;
}⚠️:离散化的主要时间复杂度其实主要还是消耗在排序上面 所以都是 O(n*logn)级别的!
2.2 火烧赤壁(模版的灵活使用)
离散化是一种思想,模板其实不用背,根据算法思想就可以实现。而且实现离散化的方式也可以在上述模板的基础上修改,千万不要生搬硬套(大家也会看到有些题解里面是借助结构体离散化的,但是核心的思想都是不变的);
https://www.luogu.com.cn/problem/P1496
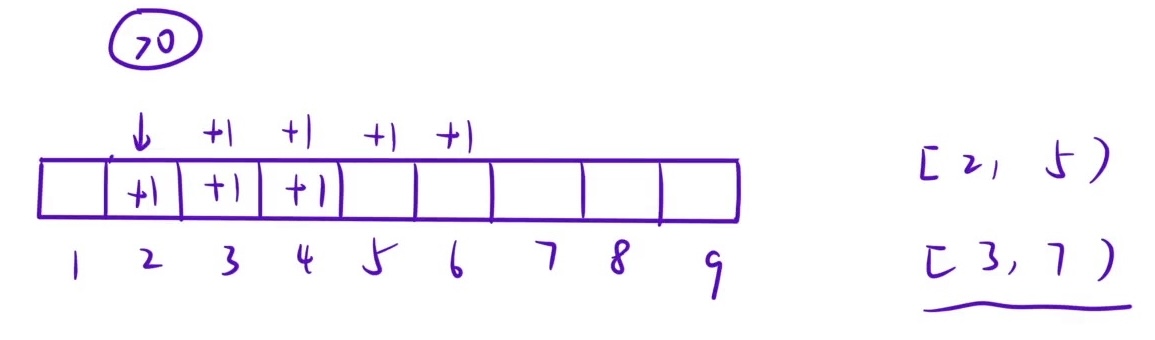
分析题目:区间是左闭右开 即[5,11)实际着火点是[5,10]
其实抛开 这篇文章主旨不谈 这题本质是
差分问题! 当格子数量>0我是不是就能表示该格子着火了捏~因此可以创建⼀个原数组的
差分数组,然后执⾏完区间修改操作之后,还原原数组,统计⼤于 0的区间⻓度。如果 差分有点遗忘 可以看我之前写的博客 点击转跳
好了 问题来了 根据题目的范围 其实我们是创建不出来差分数组的。这道题的范围逆天到
-2的31次方~2的31次方但我们看题目给出的范围其实一共最多就 4e4的数据那么我们是不是可以考虑使用离散化来解决这道题目呢!
然后通过前缀和还原差分数组!但是!!!
千万不要在还原的差分数组里面求长度啊 比如此时的 1 对应的其实是-1记得拿离散化之前的数来相加!
这道题建议自己边画边写 尤其差分和对应关系 必须好好画!不然你题解看了一样写不出来!

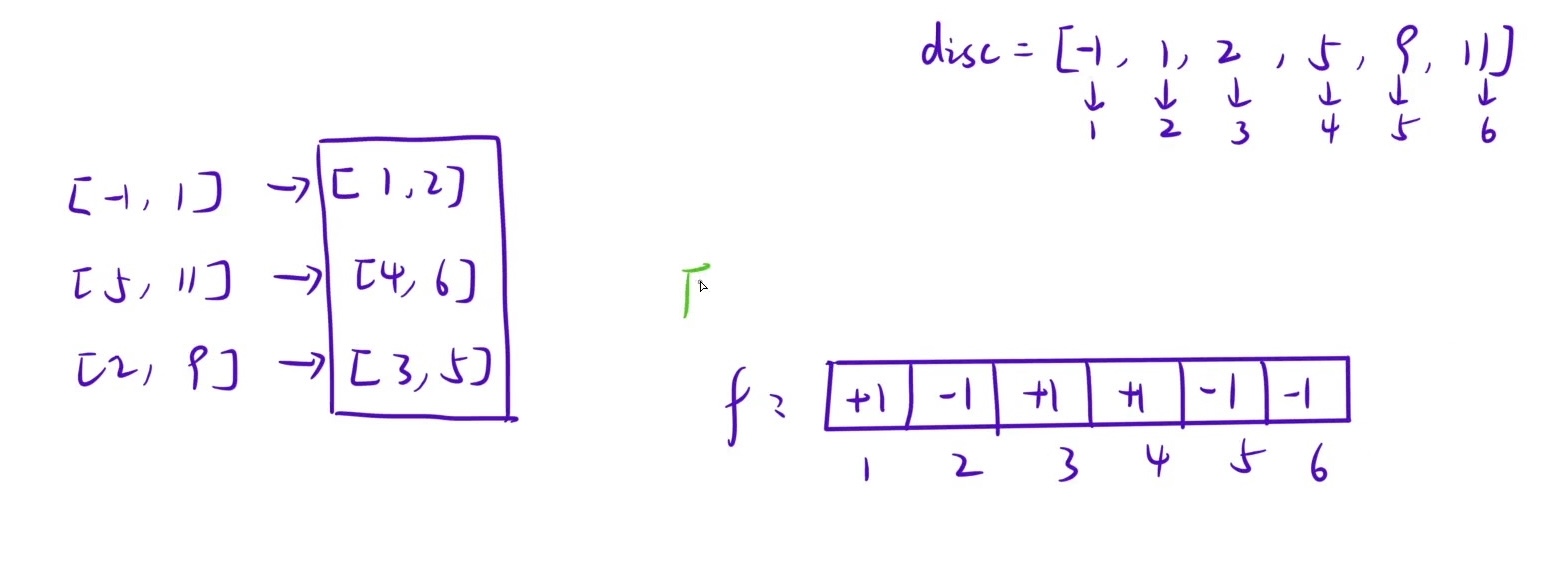
cpp
#include<bits/stdc++.h>
using namespace std;
const int N=2e4+10;
int a[N],b[N];
int disc[2*N];
int pos;
unordered_map<int,int> id;
int f[N*2];
int main()
{
int n;
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>a[i]>>b[i];
disc[++pos]=a[i];
disc[++pos]=b[i];
}
sort(disc+1,disc+1+pos);
//关键步骤!必须必须去重!不然还原的时候会出事
pos=unique(disc+1,disc+1+pos)-(disc+1);
for(int i=1;i<=pos;i++)
{
int x=disc[i];
id[x]=i;
}
//在离散化的基础上做差分
for(int i=1;i<=n;i++)
{
int l=a[i],r=b[i];
f[id[l]]++;
f[id[r]]--;
}
//还原差分数组
for(int i=1;i<=pos;i++)
{
f[i]=f[i-1]+f[i];
}
//统计结果
int ret=0;
//这段代码不好写的 必须要试着画一画!
for(int i=1;i<=pos;i++)
{
int j=i;
while(j<=pos&&f[j]>0) j++;
ret+=disc[j]-disc[i];
i=j;
}
cout<<ret;
}2.3 贴海报(离散化导致的区间缩小问题)
https://www.luogu.com.cn/problem/P3740
解法;可以给每张海报编个号,然后张贴完后看有几种数字就说明能看到多少张海报
方法很好想 但是:
如果按照上面的暴力模拟 那么时间复杂度就是
O(n*m)=1e10肯定超时了!所以这题需要先离散化,然后再去模拟!
注意:但是直接离散化会有个bug:
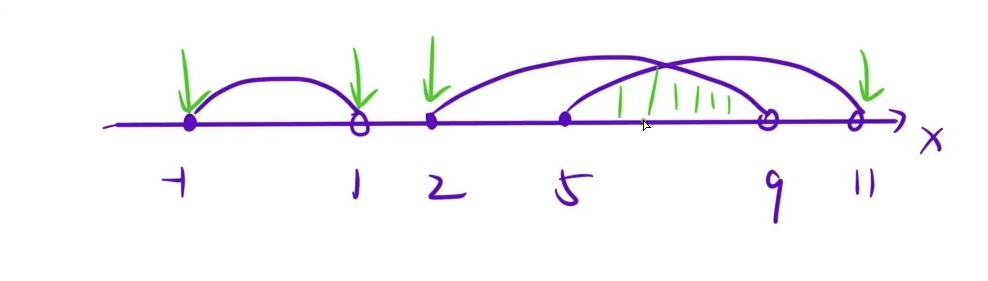
离散化在离散「区间问题」的时候一定要小心!因为我们
离散化操作会把区间缩短,从而导致丢失一些点。在涉及「区间覆盖」问题上,离散化会导致「结果出错」。比如我们这道题,如果有三个区间分别为:(2,5,2,3,5,6),离散化之后为:(1,3,1,2,3,4),区间覆盖如图所示:
实际是可以看到三张海报的,但是这么做就只能看到两张了!
bug的解决方式:在离散化
[x,y]的时候,会把x+1和y+1这两个数也离散化进去!比如说在离散化[2,5]的时候把[3,6]也加进去 那么我们在覆盖[2,5]的时候 就必定还有个3在中间!
本人画了张流程图(自己做一定要记得画图分析!!!)



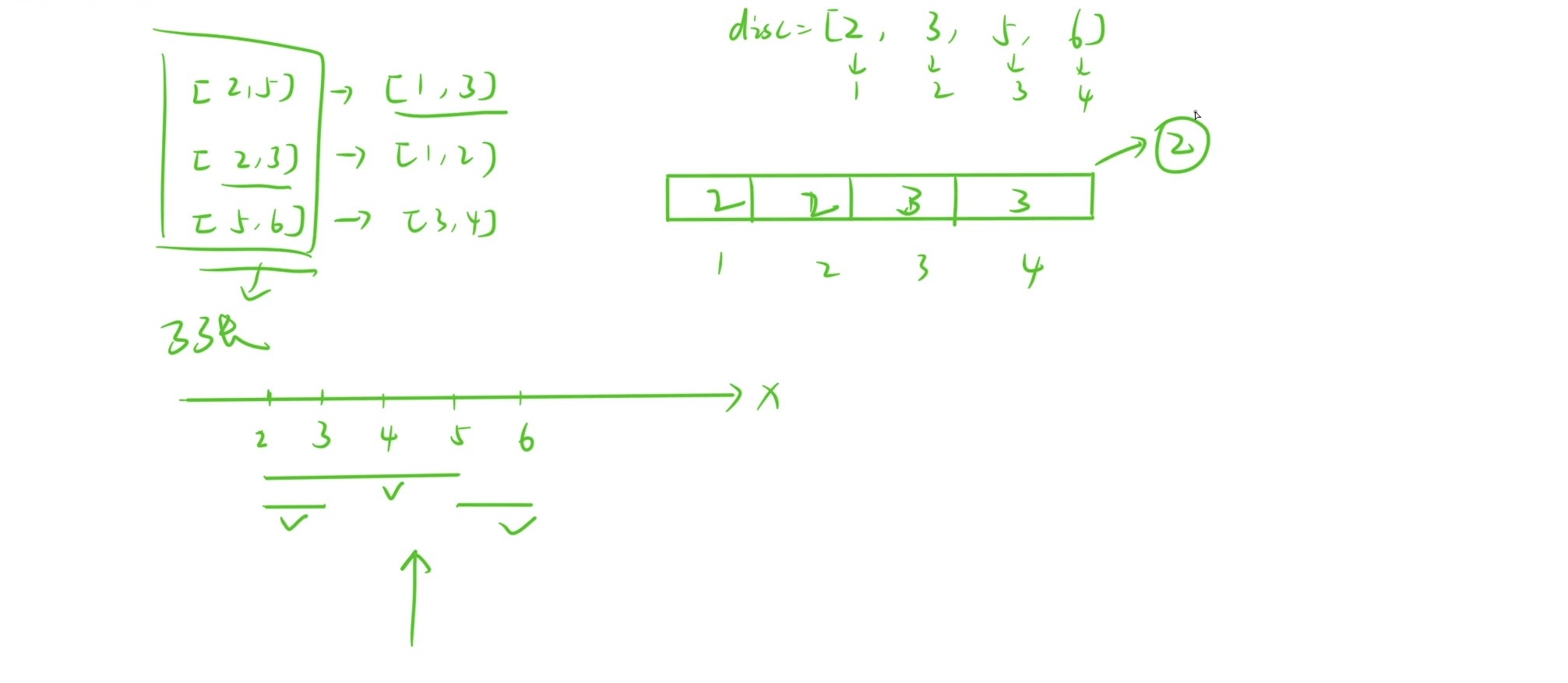

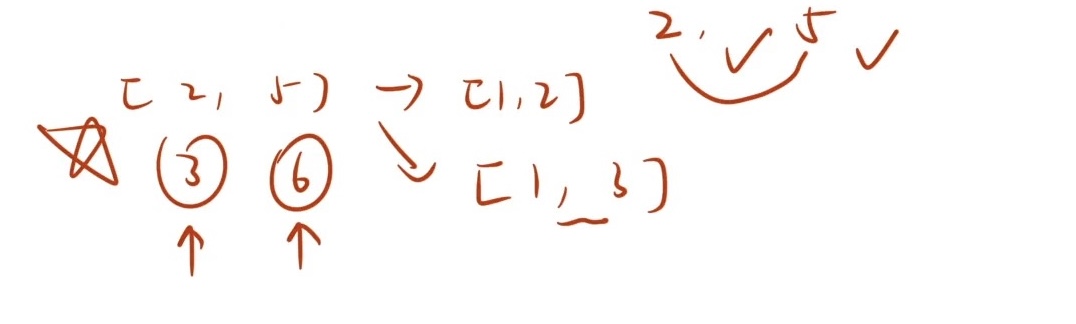

cpp
#include<bits/stdc++.h>
using namespace std;
const int N=1010;
int a[N],b[N];
int disc[4*N];
int t[4*N];//遍历用的
int mp[N];//统计数字出现个数
unordered_map<int,int> id;
int pos;
int n,m;
int main()
{
cin>>n>>m;
for(int i=1;i<=m;i++)
{
cin>>a[i]>>b[i];
disc[++pos]=a[i];
disc[++pos]=b[i];
disc[++pos]=a[i]+1;
disc[++pos]=b[i]+1;
}
//排序
sort(disc+1,disc+1+pos);
//去重
pos=unique(disc+1,disc+1+pos)-(disc+1);
//离散化
for(int i=1;i<=pos;i++)
{
int x=disc[i];
id[x]=i;
}
int ret=0;
//统计数量
for(int i=1;i<=m;i++)
{
int l=id[a[i]],r=id[b[i]];
while(l<=r)
{
int tmp=t[l];
if(mp[tmp]>0)
{
if(--mp[tmp]==0)
{
ret--;
}
}
t[l++]=i;
mp[i]++;
if(mp[i]==1)
{
ret++;
}
}
}
cout<<ret;
}
//当然 统计数字也可以创建成 bool mp 然后单独开一个for循环统计 不过时间复杂度会 +个m
// 统计整个数组中,⼀共有多少个不同的数
//int cnt = 0;
//for(int i = 1; i <= pos; i++)
//{
//int x = w[i];
//if(!x) continue; // 不要统计 0
//if(mp[x]) continue;
//cnt++;
//mp[x] = true;
}