在计算机视觉领域,人体姿态检测和脸部关键点检测是应用广泛的技术方向,无论是直播美颜、运动分析还是人机交互,都能看到它们的身影。MediaPipe作为Google开源的多媒体处理框架,提供了开箱即用的姿态和人脸检测解决方案,极大降低了开发门槛。本文将详细介绍如何使用MediaPipe结合OpenCV实现人体姿态检测和脸部关键点检测。
一、环境准备
在开始编码前,需要先安装相关依赖库:
bash
pip install opencv-python mediapipe• opencv-python:用于图像/视频的读取、处理和显示;
• mediapipe:提供预训练的姿态检测和人脸关键点检测模型。
二、人体姿态检测实现
1. 核心原理
MediaPipe的Pose模型可以检测人体33个关键节点(如鼻子、肩膀、手肘、膝盖等),返回每个节点的三维坐标(x/y/z),并支持关键点平滑、人体抠图等功能。
2. 完整代码实现
python
import cv2
import mediapipe as mp
if __name__ == '__main__':
# 初始化MediaPipe Pose模块
mp_pose = mp.solutions.pose
# 配置Pose模型参数
pose = mp_pose.Pose(
static_image_mode=True, # 静态图像模式(处理单张图片)
model_complexity=1, # 模型复杂度:0(快/精度低)、1(平衡)、2(慢/精度高)
smooth_landmarks=True, # 平滑关键点,减少抖动
min_detection_confidence=0.5, # 检测置信度阈值
min_tracking_confidence=0.5 # 跟踪置信度阈值
)
# 初始化绘图工具
drawing = mp.solutions.drawing_utils
# 读取图像并转换颜色空间(OpenCV默认BGR,MediaPipe需要RGB)
img = cv2.imread("1111.png")
cv2.imshow("input", img)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 处理图像,获取姿态关键点
results = pose.process(img_rgb)
# 将图像转回BGR格式,用于OpenCV显示
img_bgr = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2BGR)
# 输出关键点数量并打印每个关键点的三维坐标
if results.pose_landmarks:
print(f"人体姿态关键点数量:{len(results.pose_landmarks.landmark)}")
for i in range(len(results.pose_landmarks.landmark)):
x = results.pose_landmarks.landmark[i].x # 归一化x坐标(0-1)
y = results.pose_landmarks.landmark[i].y # 归一化y坐标(0-1)
z = results.pose_landmarks.landmark[i].z # 归一化z坐标(深度)
print(f"关键点{i}:x={x:.4f}, y={y:.4f}, z={z:.4f}")
# 绘制关键点和连接线条
drawing.draw_landmarks(img_bgr, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
# 显示结果图像
cv2.imshow("keypoint", img_bgr)
# 绘制3D姿态关键点(单独窗口)
drawing.plot_landmarks(results.pose_world_landmarks, mp_pose.POSE_CONNECTIONS)
# 等待按键后释放资源
cv2.waitKey(0)
cv2.destroyAllWindows()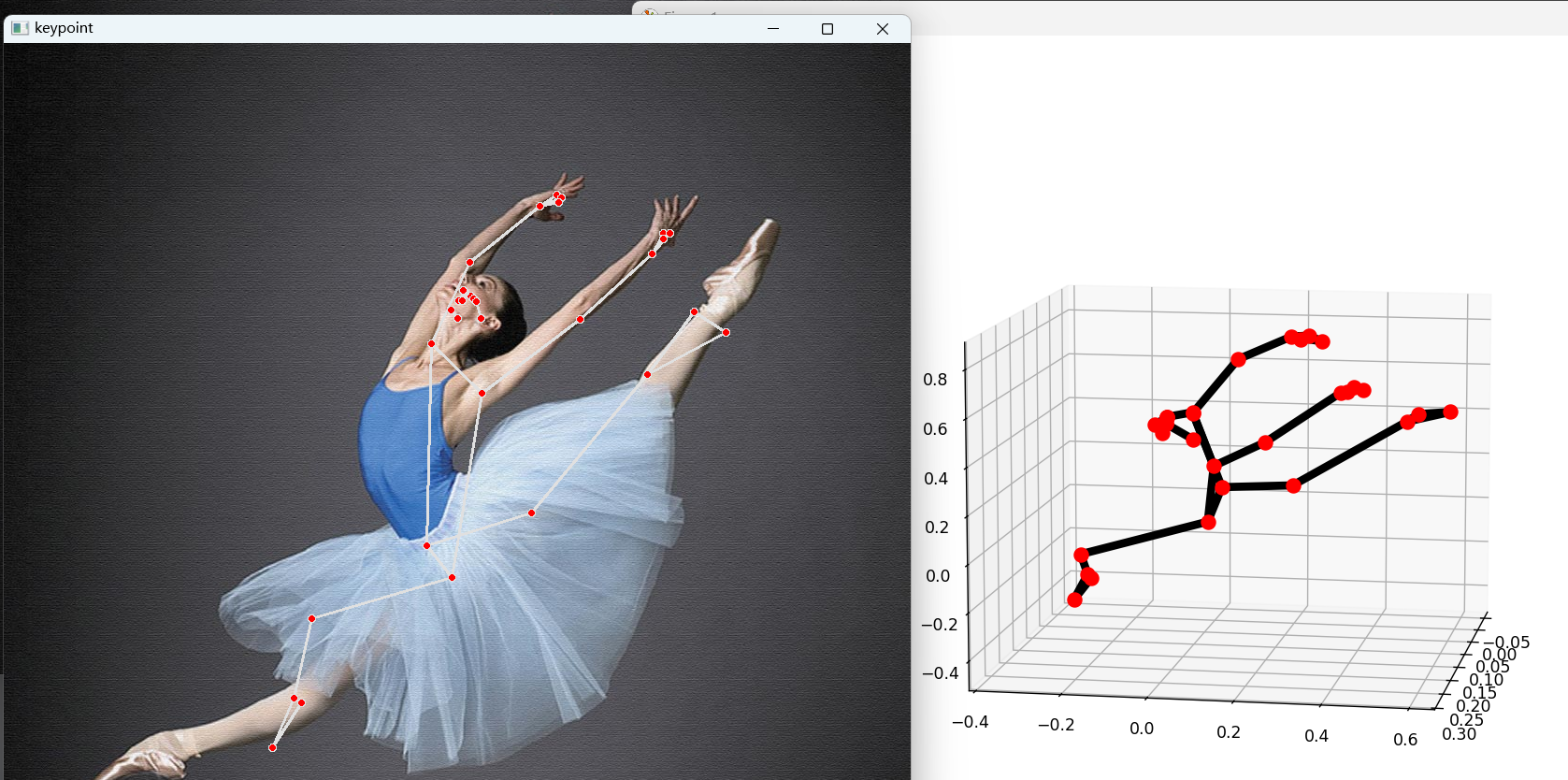
3. 关键参数说明
• static_image_mode:是否为静态图像模式,处理单张图片时设为True,处理视频流时设为False;
• model_complexity:模型复杂度,取值0/1/2,数值越大精度越高但速度越慢;
• smooth_landmarks:是否平滑关键点,减少检测结果的抖动;
• min_detection_confidence:检测置信度阈值,低于该值的检测结果会被忽略;
• min_tracking_confidence:视频流跟踪置信度阈值,低于该值会重新触发检测。
三、脸部关键点检测(实时摄像头版)
1. 核心原理
MediaPipe的Face Mesh模型可以检测人脸478个关键点,覆盖眼睛、鼻子、嘴巴、脸颊等区域,支持多脸检测,适合实时处理摄像头画面。
2. 完整代码实现
python
import cv2
import mediapipe as mp
# 初始化MediaPipe Face Mesh模块
mp_face_mesh = mp.solutions.face_mesh
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
# 配置Face Mesh参数
face_mesh = mp_face_mesh.FaceMesh(
static_image_mode=False, # 视频流模式
max_num_faces=2, # 最多检测2张人脸
refine_landmarks=True, # 细化关键点(提升眼睛/嘴唇区域精度)
min_detection_confidence=0.5, # 检测置信度阈值
min_tracking_confidence=0.5 # 跟踪置信度阈值
)
# 打开摄像头(0表示默认摄像头)
cap = cv2.VideoCapture(0)
while cap.isOpened():
success, frame = cap.read()
if not success:
print("无法读取摄像头画面")
break
h, w = frame.shape[:2] # 获取画面宽高
# 转换颜色空间(BGR→RGB)
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 处理画面,获取人脸关键点
results = face_mesh.process(frame_rgb)
# 绘制人脸关键点
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
# 打印关键点数量(固定478个)
# print(f"人脸关键点数量:{len(face_landmarks.landmark)}")
# 绘制每个关键点的编号
for i in range(len(face_landmarks.landmark)):
x = face_landmarks.landmark[i].x
y = face_landmarks.landmark[i].y
# 将归一化坐标转换为像素坐标
px = int(x * w)
py = int(y * h)
# 在画面上绘制关键点编号
cv2.putText(frame, str(i), (px, py),
cv2.FONT_HERSHEY_SIMPLEX, 0.3, (0, 255, 0), 1)
# 绘制人脸网格(三角剖分)
mp_drawing.draw_landmarks(
image=frame,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_TESSELATION,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style()
)
# 显示结果画面
cv2.imshow('Face Mesh', frame)
# 按ESC键退出(27是ESC的ASCII码)
if cv2.waitKey(1) == 27:
break
# 释放摄像头资源并关闭窗口
cap.release()
cv2.destroyAllWindows()
3. 关键功能说明
• max_num_faces:设置最多检测的人脸数量,适合多人场景;
• refine_landmarks:开启后会细化眼睛和嘴唇区域的关键点,提升精度;
• FACEMESH_TESSELATION:绘制人脸三角网格,直观展示关键点连接关系;
• 关键点编号绘制:通过cv2.putText在每个关键点位置标注编号,便于后续针对性处理(如定位眼睛、嘴巴)。
四、扩展与优化
-
视频文件处理:将摄像头读取(cv2.VideoCapture(0))改为视频文件路径(cv2.VideoCapture("video.mp4")),即可处理本地视频;
-
关键点应用:
◦ 姿态检测:可提取特定关键点(如肩膀、膝盖)分析人体动作(如深蹲、俯卧撑计数);
◦ 人脸检测:可基于眼睛关键点实现眨眼检测,基于嘴巴关键点实现表情识别;
- 性能优化:
◦ 降低模型复杂度(如姿态检测设model_complexity=0)提升实时性;
◦ 缩小输入图像尺寸(如cv2.resize)减少计算量;
- 结果保存:使用cv2.imwrite保存检测后的图片,或cv2.VideoWriter保存视频流结果。
五、总结
MediaPipe结合OpenCV提供了简洁高效的姿态和人脸检测方案,无需手动训练模型,仅需几行代码即可实现高精度的关键点检测。无论是快速原型验证还是实际项目开发,这套组合都能大幅提升开发效率。希望本文能帮助大家快速上手MediaPipe,解锁更多计算机视觉应用场景。