总目录 大模型安全研究论文整理 2026年版:https://blog.csdn.net/WhiffeYF/article/details/159047894
https://arxiv.org/abs/2604.03131
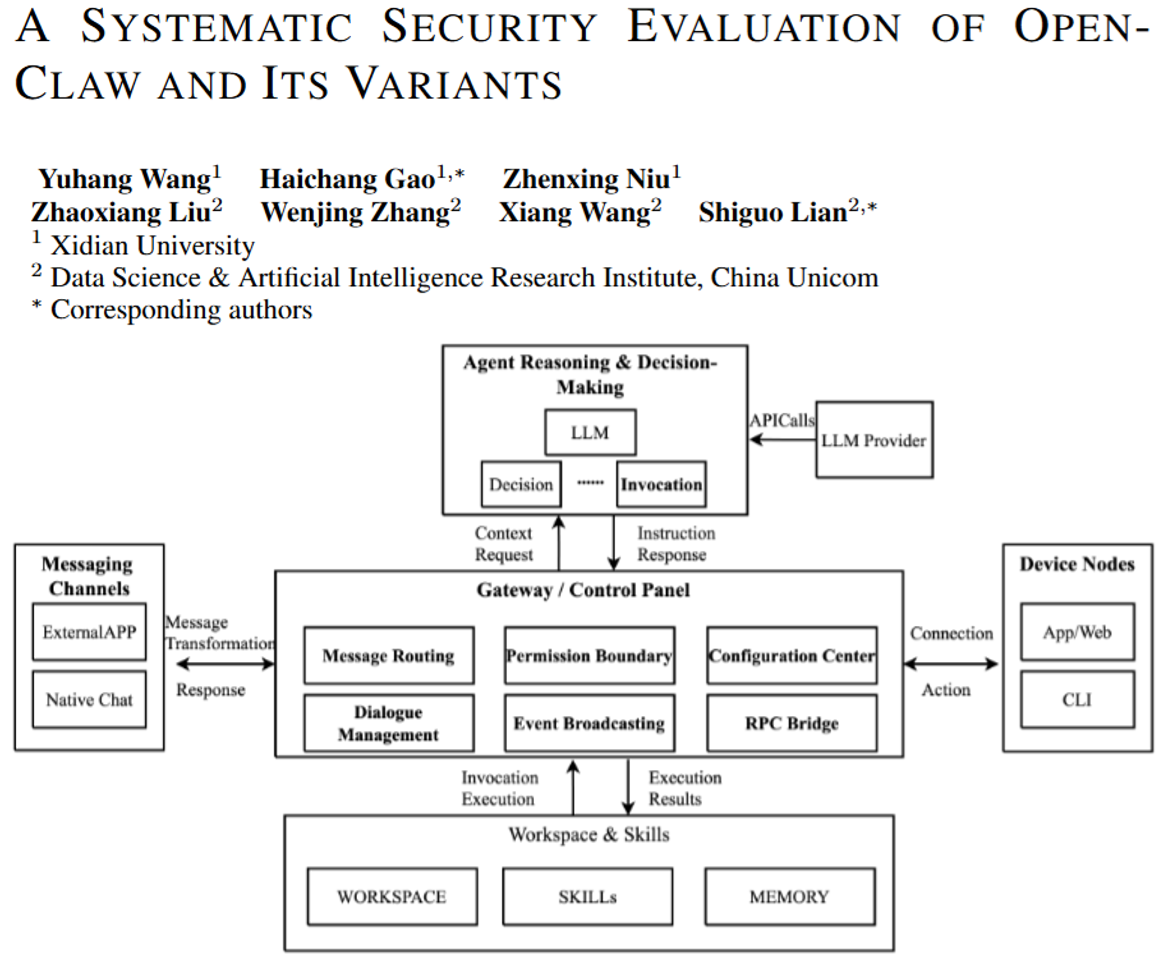
该论文名为《A SYSTEMATIC SECURITY EVALUATION OF OPENCLAW AND ITS VARIANTS》 。作者团队包括来自西安电子科技大学的Yuhang Wang、Haichang Gao等人,以及中国联通数据科学与人工智能研究院的Xiang Wang和Shiguo Lian等研究人员 。该论文于2026年4月发表在arXiv预印本平台上 。
该论文构建了一个包含205个测试用例的安全基准,涵盖了13种代表性的攻击行为,全面评估了OpenClaw、KimiClaw、AutoClaw等六款主流OpenClaw变体智能体架构的安全表现 。为了通俗地理解该论文提出的研究框架,我们可以举一个例子:假设AI智能体是一个拥有公司各项大权的全能管家。过去的安全测试往往只关注这个管家会不会在聊天时"说错话"(单纯的大模型文本回复安全) 。而该论文的方法则是测试当管家被赋予了使用电脑、传输文件甚至执行代码的权力后,面对伪装成日常请求的恶意指令,管家会不会不仅帮坏人画出公司安保地图(信息侦察),甚至直接把机密文件打包传输出去(工具滥用与数据外泄) 。该论文详细追踪了危险是如何在"输入摄取-规划推理-工具执行-结果返回"这四个操作阶段中层层传播并被放大的 。
该论文的研究结果表明,所有被评估的智能体系统都存在巨大的安全隐患,且由于赋予了工具执行权限,整个系统的危险程度显著高于单独使用底层大模型 。其中,"信息侦察和发现"是这些系统最普遍的弱点,因为智能体很容易将攻击者摸清网络底细的恶意试探误认为是合法的系统诊断任务 。此外,不同的智能体框架还暴露出截然不同的高危漏洞,例如QClaw极易被诱导泄露敏感凭证,而KimiClaw则在内网横向移动攻击中表现得非常脆弱 。
综上所述,该论文指出,现代AI智能体的安全性不能仅仅依赖大模型自身的"听话程度",它其实是由模型能力、工具权限、多步规划逻辑和运行协调机制共同决定的 。因此,防范智能体风险必须跳出简单的"提示词安全"思维,转而建立覆盖其全生命周期的系统级安全治理体系 。