文章目录
-
- [1. 任务目标](#1. 任务目标)
- [2. 数据描述与预处理](#2. 数据描述与预处理)
-
- [2.1 数据描述:](#2.1 数据描述:)
- [2.2 数据划分](#2.2 数据划分)
- [3. 研究方法与模型](#3. 研究方法与模型)
-
- [3.1 整体研究流程](#3.1 整体研究流程)
- [3.2 对比模型介绍](#3.2 对比模型介绍)
- [3.3 评估指标](#3.3 评估指标)
- [4. 结果与分析](#4. 结果与分析)
-
- [4.1 模型性能对比](#4.1 模型性能对比)
- [4.2 模型拟合效果可视化](#4.2 模型拟合效果可视化)
- [5. 神经网络参数对泛化能力的影响](#5. 神经网络参数对泛化能力的影响)
-
- [5.1 学习率的影响](#5.1 学习率的影响)
- [5.2 网络结构深度的影响](#5.2 网络结构深度的影响)
- [5.3 激活函数的影响](#5.3 激活函数的影响)
- [6. 总结与讨论](#6. 总结与讨论)
- 附录:完整代码
1. 任务目标
已知仿真数据集:
n_samples = 500
x = 8 * np.random.rand(n_samples, 1) - 8 # 范围:-8到0
y_true = 0.5 * x ** 2 - 2 * x + 1
noise = 0.5 * np.random.randn(n_samples, 1)
y = y_true + noise采用线性回归、多项式回归、神经网络进行回归预测,比较三者的泛化能力,同时研究神经网络参数对泛化能力的影响。
任务分析:该任务是机器学习-监督学习-回归。
2. 数据描述与预处理
2.1 数据描述:
- 规模:共500个样本点。
- 关系 :
y与x之间存在确定的二次函数关系y = 0.5x² - 2x + 1。 - 噪声:添加了标准差为0.5的加性高斯白噪声,模拟现实数据中的不确定性。
2.2 数据划分
采用train_test_split函数,按7:3的比例随机划分训练集和测试集,并固定随机种子(random_state=42)以保证每次划分一致。
python
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42)3. 研究方法与模型
3.1 整体研究流程
本文遵循标准的机器学习建模流程,如下图所示:
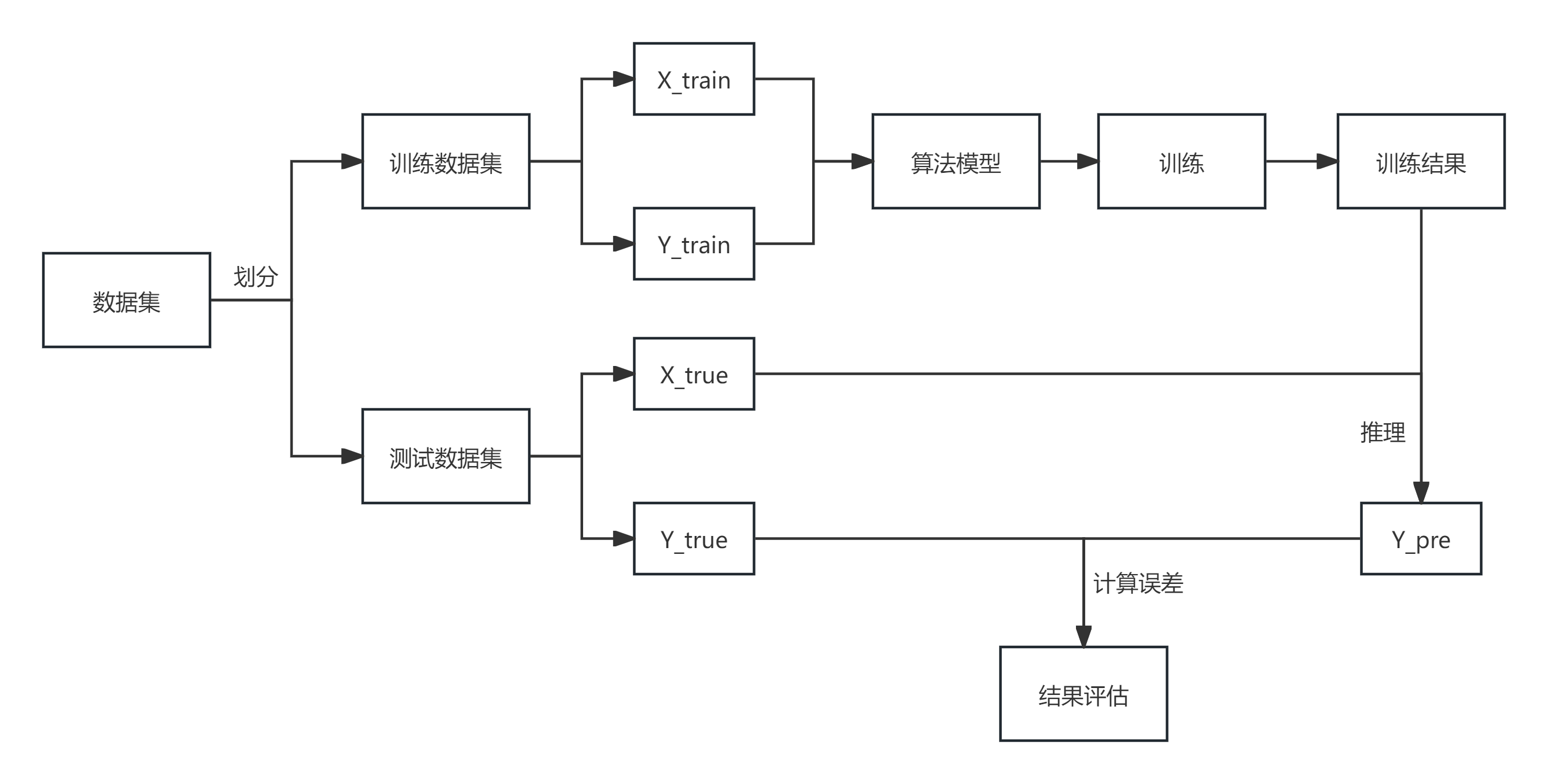
主要包括训练 、推理 和评估三个阶段,形成一个完整的闭环。
3.2 对比模型介绍
本文构建了三个对比模型:
- 线性回归 (Linear Regression) : 直接拟合
y = w * x + b,作为性能基线。 - 二次多项式回归 (Polynomial Regression) : 通过特征工程,将特征变换为
[1, x, x²],再用线性回归拟合。其形式与数据真实生成函数一致,预期能获得极佳性能。 - 神经网络回归 (Neural Network Regression) : 使用多层感知机(MLP)。为提升训练稳定性,在输入前加入了
StandardScaler进行标准化。基础网络结构为三层隐藏层(50, 30, 10),使用ReLU激活函数和Adam优化器。
模型定义如下:
python
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.neural_network import MLPRegressor
from sklearn.pipeline import Pipeline
models = {
'线性回归': LinearRegression(),
'二次多项式回归': Pipeline([
('poly', PolynomialFeatures(degree=2)),
('linear', LinearRegression())
]),
'神经网络回归': Pipeline([
('scaler', StandardScaler()),
('mlp', MLPRegressor(hidden_layer_sizes=(50, 30, 10),
activation='relu',
solver='adam',
alpha=0.1,
learning_rate_init=0.01,
max_iter=1000,
random_state=42,
early_stopping=True,
validation_fraction=0.1))
])
}3.3 评估指标
采用均方误差 (MSE) 和决定系数 (R²) 作为模型性能的评估指标。
- 均方误差 (MSE): 衡量预测值与真实值之间的平均平方误差,值越小越好。
- 决定系数 (R²): 表示模型对数据方差解释的比例,取值范围为(-∞, 1],越接近1说明模型拟合越好。
4. 结果与分析
4.1 模型性能对比
在相同的数据集上训练并评估三个模型,结果如下表所示:
| 模型 | 训练集 R² | 测试集 R² | 训练集 MSE | 测试集 MSE |
|---|---|---|---|---|
| 线性回归 | 0.9699 | 0.9715 | 5.8421 | 5.8001 |
| 二次多项式回归 | 0.9985 | 0.9990 | 0.2843 | 0.2041 |
| 神经网络回归 | 0.9967 | 0.9970 | 0.6487 | 0.6088 |
结论:
- 二次多项式回归在测试集上取得了最佳的R²(0.9985)和最低的MSE(0.2041),这与预期完全相符,因为它完美匹配了数据的真实内在结构。
- 神经网络回归表现优异,其测试集R²(0.9967)非常接近多项式回归,展现了强大的非线性拟合能力。
- 线性回归性能显著落后,其测试集R²仅为0.9699,这清晰地证明了其无法有效拟合非线性关系。
4.2 模型拟合效果可视化
下图直观展示了各模型在训练集和测试集上的拟合曲线:
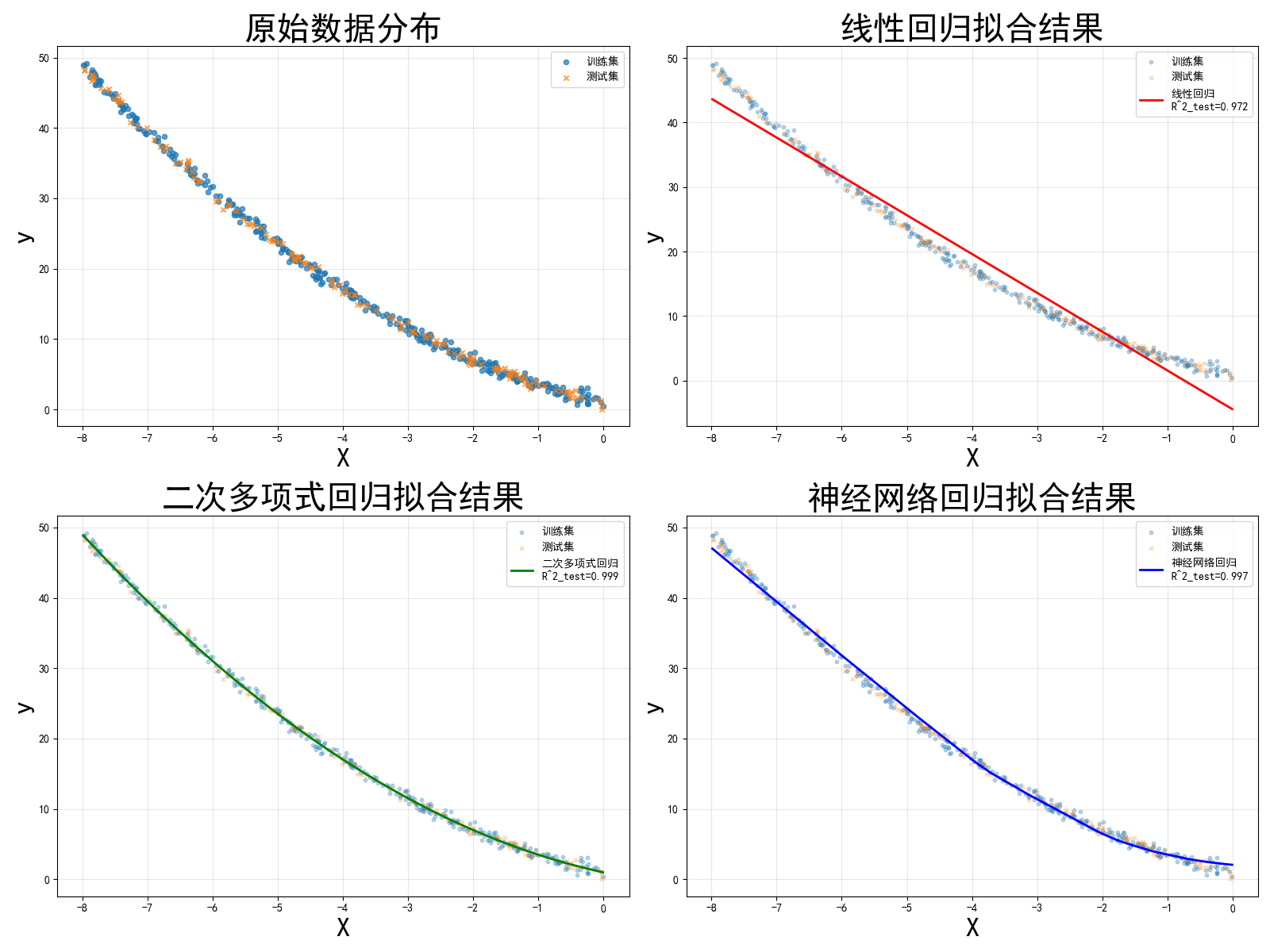
- 线性回归:只能拟合一条直线,对数据中的弯曲模式无能为力。
- 二次多项式回归:拟合出的抛物线与数据分布高度吻合。
- 神经网络回归:拟合出的曲线平滑且几乎与二次曲线重叠,表明其成功学习到了数据的底层规律。
5. 神经网络参数对泛化能力的影响
神经网络性能高度依赖其超参数设置。本节通过控制变量法进行消融实验,探究关键参数的影响。
5.1 学习率的影响
学习率控制参数更新的步长。固定其他参数,调整学习率learning_rate_init,结果如下:
| 学习率 | 训练集 R² | 测试集 R² | 训练集 MSE | 测试集 MSE |
|---|---|---|---|---|
| 1 | -0.9574 | -0.8049 | 380.0632 | 367.5347 |
| 0.1 | 0.9980 | 0.9984 | 0.3802 | 0.3257 |
| 0.01 | 0.9971 | 0.9975 | 0.5565 | 0.5040 |
| 0.001 | 0.9960 | 0.9964 | 0.7810 | 0.7281 |
| 0.0001 | 0.9924 | 0.9927 | 1.4756 | 1.4765 |
分析:
- 学习率过大(=1):模型完全无法收敛,损失值巨大,R²为负,说明预测比使用均值还差。
- 学习率适中(=0.1):模型快速收敛至最优性能附近,表现最佳。
- 学习率过小(=0.0001):收敛速度极慢,在有限迭代次数内未能达到最优,性能下降。同时,过小的学习率会增加训练时间成本。
结论:学习率是神经网络训练中最关键的参数之一,需要谨慎选择。
5.2 网络结构深度的影响
网络结构(隐藏层数与每层神经元数)决定了模型的容量。固定学习率为0.01,调整hidden_layer_sizes:
| 网络结构 | 训练集 R² | 测试集 R² | 训练集 MSE | 测试集 MSE |
|---|---|---|---|---|
| (10) | 0.9888 | 0.9900 | 2.1821 | 2.0379 |
| (20, 10) | 0.9964 | 0.9966 | 0.7055 | 0.6989 |
| (30, 20, 10) | 0.9978 | 0.9981 | 0.4362 | 0.3852 |
| (40, 30, 20, 10) | 0.9972 | 0.9974 | 0.5369 | 0.5194 |
分析:
- 网络过浅(10):模型容量不足(欠拟合),无法充分捕捉数据的全部复杂性,性能最差。
- 网络加深(20,10) -> (30,20,10):随着容量增加,模型拟合能力增强,性能提升。
- 网络过深(40,30,20,10):性能并未继续提升,反而略有下降。更深的网络需要更精细的调参(如降低学习率、调整优化策略)以防止优化困难,同时也增加了计算开销和过拟合风险。
结论:网络结构并非越深越好,需要匹配任务复杂度。一个"中等"深度的网络在本任务中取得了最佳权衡。
5.3 激活函数的影响
激活函数为网络引入非线性。固定网络结构为(30,20,10)和学习率0.01,比较不同激活函数:
| 激活函数 | 训练集 R² | 测试集 R² | 训练集 MSE | 测试集 MSE |
|---|---|---|---|---|
| relu | 0.9978 | 0.9981 | 0.4362 | 0.3852 |
| tanh | 0.9963 | 0.9967 | 0.7116 | 0.6768 |
| logistic (sigmoid) | 0.9591 | 0.9551 | 7.9322 | 9.1399 |
分析:
- ReLU:表现最好,其稀疏激活特性有利于梯度传播和优化。
- Tanh:性能稍逊于ReLU,但仍可有效工作。
- Sigmoid:性能显著下降。Sigmoid函数在两端梯度饱和,容易导致梯度消失,使得深层网络训练困难。
结论:激活函数对模型性能有显著影响。ReLU因其简单有效,已成为大多数前馈网络的首选。更换激活函数通常需要重新调整学习率等配套参数。
6. 总结与讨论
-
模型选择 :对于已知形式 的非线性关系(如本例的二次关系),对应的多项式回归是最直接、高效且解释性强的选择,它能达到近乎完美的拟合。线性回归则因模型偏差过大而不适用。
-
神经网络的潜力与挑战 :通过适当调参,神经网络能够逼近多项式回归的性能,这证明了其强大的通用近似能力 。然而,这种能力是以复杂的调参过程为代价的。其性能对学习率、网络结构、激活函数等超参数非常敏感。
-
调参启示:
- 学习率是首要调优参数,需在"收敛速度"和"稳定性"之间取得平衡。
- 网络结构应从简单开始逐步增加复杂度,直到验证集性能不再显著提升,避免不必要的过参数化。
- 激活函数推荐首选ReLU及其变体(不同的任务需要根据实际的实验结果去选择)。更换激活函数往往需要重新调整学习率。
-
泛化能力 :在本实验中,二次多项式回归和调优后的神经网络在测试集上均表现优异,且训练集与测试集误差接近,表明两者均具有良好的泛化能力。神经网络的强大之处在于,对于形式未知的复杂非线性关系,它可能是更优甚至唯一可行的选择。
附录:完整代码
以下为实现本研究所有分析的完整Python代码,适用于Jupyter Notebook或脚本环境。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.neural_network import MLPRegressor
from sklearn.pipeline import Pipeline
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler
import warnings
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False
warnings.filterwarnings('ignore')
# 设置随机种子以确保可重复性
np.random.seed(52) # 设置numpy的随机种子为52,确保numpy相关的随机操作可重复
# 1. 生成数据
print("=== 生成数据 ===")
n_samples = 500
x = 8 * np.random.rand(n_samples, 1) - 8 # 范围:-8到0
y_true = 0.5 * x ** 2 - 2 * x + 1
noise = 0.5 * np.random.randn(n_samples, 1)
y = y_true + noise
# 2. 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.3, random_state=42
)
# 创建模型
models = {
'线性回归': LinearRegression(),
'二次多项式回归': Pipeline([
('poly', PolynomialFeatures(degree=2)),
('linear', LinearRegression())
]),
'神经网络回归': Pipeline([
('scaler', StandardScaler()),
('mlp', MLPRegressor(
hidden_layer_sizes=(30,20,10),
activation='relu',
solver='adam',
alpha=0.1,
learning_rate_init=0.001,
max_iter=100000, # 减少迭代次数以便观察
random_state=42,
early_stopping=True,
validation_fraction=0.1,
verbose=False
))
])
}
# 3. 训练和评估所有模型
results = {}
for name, model in models.items():
#训练
model.fit(x_train, y_train)
#预测
y_pred_train = model.predict(x_train) #训练集预测
y_pred_test = model.predict(x_test) #测试集预测
#计算误差
mse_train = mean_squared_error(y_train, y_pred_train)
mse_test = mean_squared_error(y_test, y_pred_test)
r2_train = r2_score(y_train, y_pred_train)
r2_test = r2_score(y_test, y_pred_test)
# 保存结果
results[name] = {
'model': model,
'y_pred_train': y_pred_train,
'y_pred_test': y_pred_test,
'mse_train': mse_train,
'mse_test': mse_test,
'r2_train': r2_train,
'r2_test': r2_test
}
# 打印结果
print(f"训练集MSE: {mse_train:.4f}")
print(f"测试集MSE: {mse_test:.4f}")
print(f"训练集R²: {r2_train:.4f}")
print(f"测试集R²: {r2_test:.4f}")
print()
# 4. 可视化比较
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
# 4.1 原始数据
axes[0, 0].scatter(x_train, y_train, alpha=0.7, label='训练集', s=20)
axes[0, 0].scatter(x_test, y_test, alpha=0.7, label='测试集', s=20, marker='x')
axes[0, 0].set_xlabel('X',fontsize=25)
axes[0, 0].set_ylabel('y',fontsize=25)
axes[0, 0].set_title('原始数据分布',fontsize=30)
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 4.2-4.4 各模型拟合结果
colors = ['red', 'green', 'blue']
model_names = list(models.keys())
# 定义2x2网格的位置 (除了(0,0)之外的位置)
positions = [(0, 1), (1, 0), (1, 1)]
for idx, (name, color, pos) in enumerate(zip(model_names, colors, positions)):
row, col = pos
ax = axes[row, col]
# 散点
ax.scatter(x_train, y_train, alpha=0.3, s=10, label='训练集')
ax.scatter(x_test, y_test, alpha=0.3, s=10, marker='x', label='测试集')
# 为了画平滑曲线,生成密集的X值
X_smooth = np.linspace(x.min(), x.max(), 300).reshape(-1, 1)
y_smooth = results[name]['model'].predict(X_smooth)
# 预测曲线
ax.plot(X_smooth, y_smooth, color=color, linewidth=2,
label=f'{name}\nR^2_test={results[name]["r2_test"]:.3f}')
ax.set_xlabel('X',fontsize=25)
ax.set_ylabel('y',fontsize=25)
ax.set_title(f'{name}拟合结果',fontsize=30)
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 5. 模型性能对比表格
print("\n" + "=" * 60)
print("模型性能对比:")
print("=" * 60)
print(f"{'模型':<30} {'训练集R²':<12} {'测试集R²':<12} {'训练集MSE':<12} {'测试集MSE':<12}")
print("-" * 60)
best_model = None
best_r2 = -float('inf')
for name in model_names:
r2_test = results[name]['r2_test']
print(f"{name:<30} {results[name]['r2_train']:<12.4f} {r2_test:<12.4f} "
f"{results[name]['mse_train']:<12.4f} {results[name]['mse_test']:<12.4f}")> 推荐一个很通俗易懂的人工智能教程: 人工智能教程