一、环境说明
- 系统:Ubuntu 22.04 LTS
- 内存:16GB
- 安装方式:手动二进制部署(非官方脚本、非 Docker)
- 适用场景:本地大模型推理、RAG 向量知识库、个人 DevOps 平台底层环境
二、前置准备
安装包:ollama-linux-amd64.tar.zst采用离线包部署,避开官方 curl 脚本下载慢、HTTP2 framing error 等网络问题。
三、安装步骤
1. 安装 zst 解压工具
bash
运行
sudo apt update && sudo apt install zstd -y2. 解压安装包
bash
运行
# 解压 zst 为 tar
zstd -d ollama-linux-amd64.tar.zst
# 解压 tar 包
tar -xf ollama-linux-amd64.tar3. 移动到系统目录并赋权
bash
运行
sudo mv bin/ollama /usr/local/bin/
sudo chmod +x /usr/local/bin/ollama4. 验证安装版本
bash
运行
ollama --version图 1:
ollama --version版本验证成功截图,显示客户端版本 0.20.4 即为安装完成。
5. 启动 Ollama 服务
bash
运行
ollama serve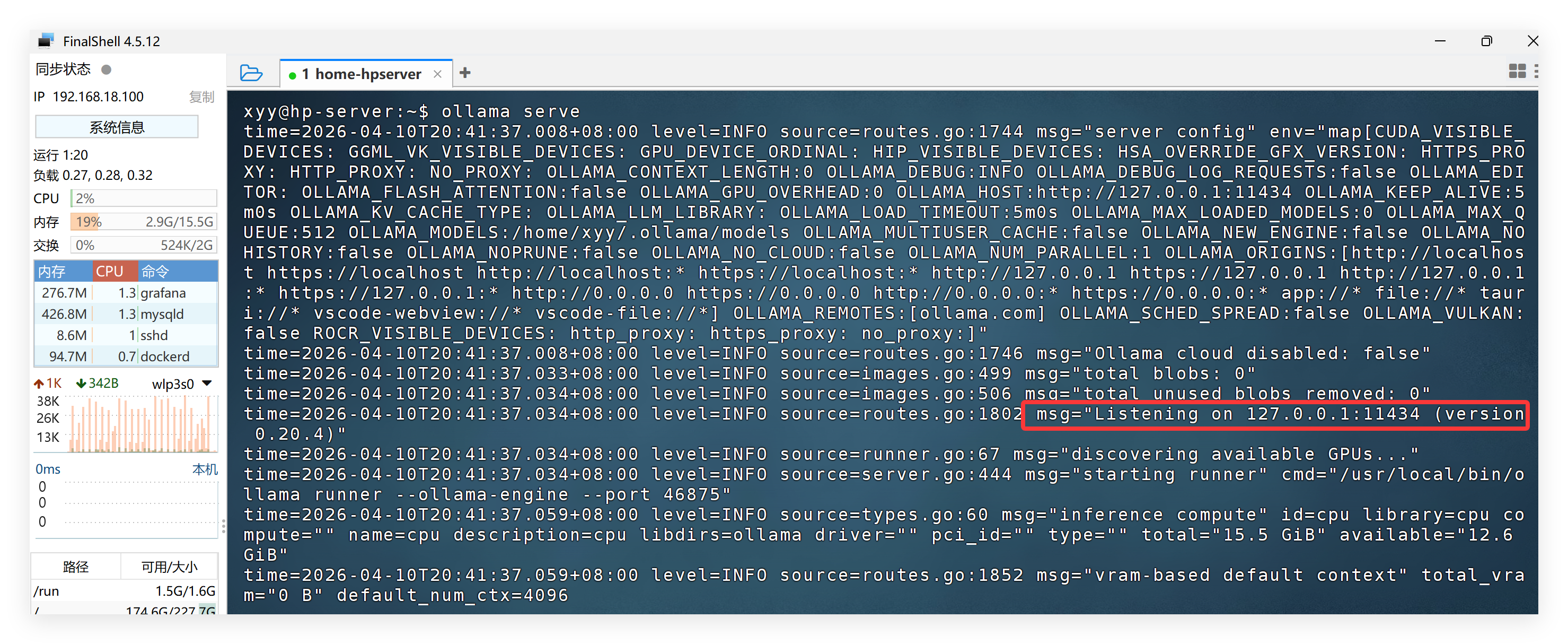
图 2:
ollama serve启动成功界面,出现Listening on 127.0.0.1:11434代表服务正常运行。
6. 拉取向量模型(RAG 专用)
bash
运行
ollama pull nomic-embed-text
图 3:
nomic-embed-text向量模型下载中,受网络环境影响,下载速度较慢,可通过配置国内镜像、手动离线导入等方式优化。
7. 查看已安装模型
bash
运行
ollama list四、常见问题
-
官方脚本下载失败使用二进制离线包,彻底规避 HTTP2 网络错误、连接超时。
-
模型下载速度慢可配置国内镜像加速,或多次断点续传。
-
服务后台常驻
bash
运行
nohup ollama serve &
五、实战说明
本次使用二进制手动部署,相比 Docker 更轻量、相比官方脚本更稳定,16GB 内存服务器可稳定运行向量模型与轻量大模型,作为后续 AI 知识库、RAG 系统的底层推理环境
六、后续规划
下一步部署 Milvus 向量数据库,打通 Ollama + Milvus 本地 RAG 知识库完整链路。
关注我
持续更新《人生底稿》成长史 &《技术底稿》&《产品底稿》实战干货一起踏实成长,不焦虑、不内卷。
📚 系列导航:
【技术底稿】01:37岁老码农,用4台机器搭了套个人DevOps平台
【产品底稿01】37 岁 Java 老码农,用 Java 搭了个 AI 写作助手,把自己 14 年技术文章全喂给了 AI!