在移动端自动化(如挂机、任务执行、数据采集)中,一个核心难题是:
👉 脚本如何识别屏幕上的文字?
答案就是:OCR(文字识别)+ API接口调用
本篇文章将带你完整实现:
-
懒人精灵调用 OCR 接口全过程
-
截图 → 上传 → 识别 → 获取文字
-
可直接参考的脚本示例
-
常见问题与优化方案
一、OCR 在懒人精灵中的作用
OCR(Optical Character Recognition)是将图片中的文字转为文本的技术。
在懒人精灵中的应用场景:
-
自动识别游戏任务文字
-
自动读取APP界面内容
-
自动判断按钮/状态
-
电商信息采集
👉 如果你是新手,建议先阅读:
👉 《文字识别通用OCR接口调用与功能说明》(第6篇)
二、实现思路(核心流程)
懒人精灵实现 OCR 的步骤如下:
👉 标准流程:
1️⃣ 截图当前屏幕
2️⃣ 上传图片到 OCR API
3️⃣ 接收 JSON 返回结果
4️⃣ 提取文字内容
5️⃣ 根据结果执行操作
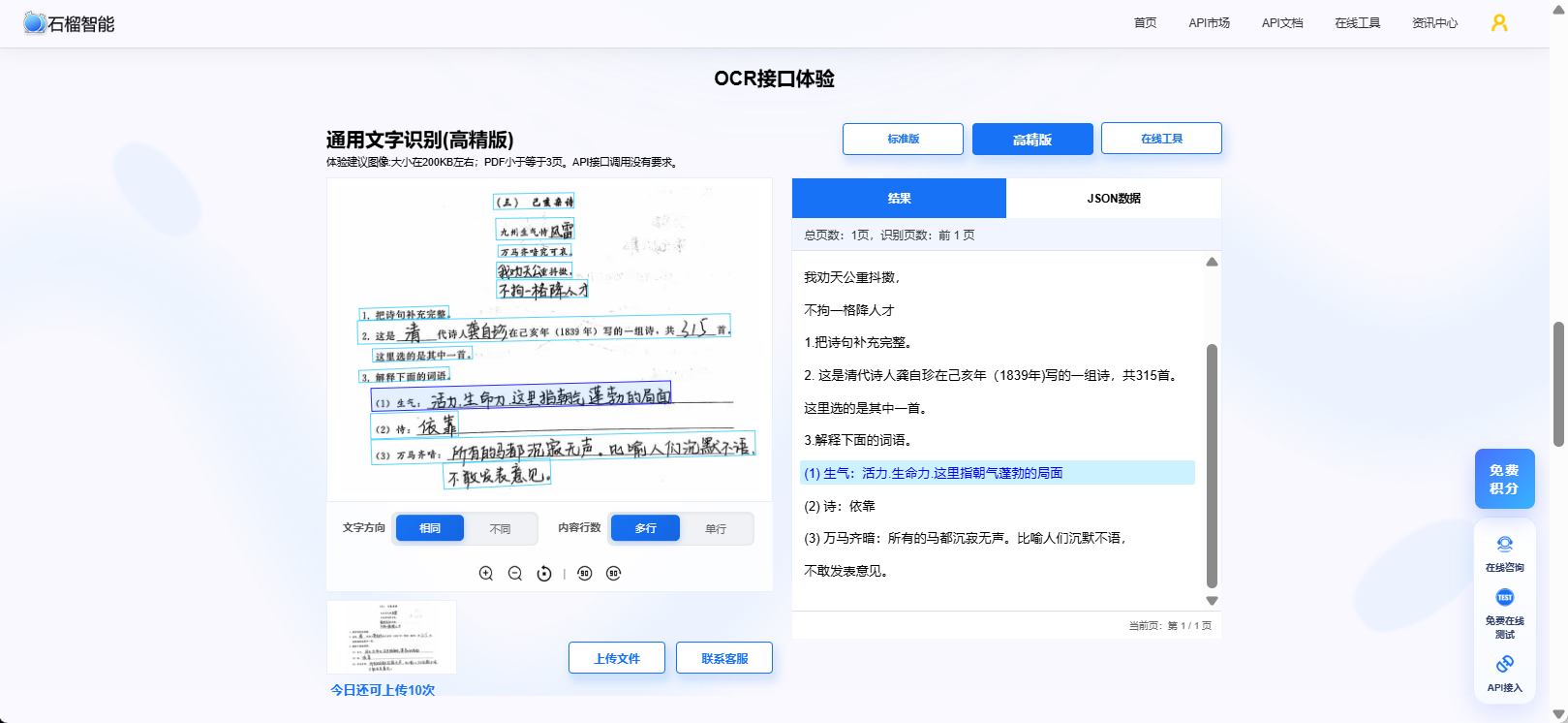
三、OCR API 接口说明
接口支持:
-
通用文字识别
-
多语言识别
-
自动纠偏
-
高精度模式
👉 支持免费在线体验,API文档齐全,有各语言的接入代码:http://test.market.shiliuai.com/general-ocr
四、懒人精灵 OCR 实战步骤
1️⃣ 截图保存
-- 截图保存
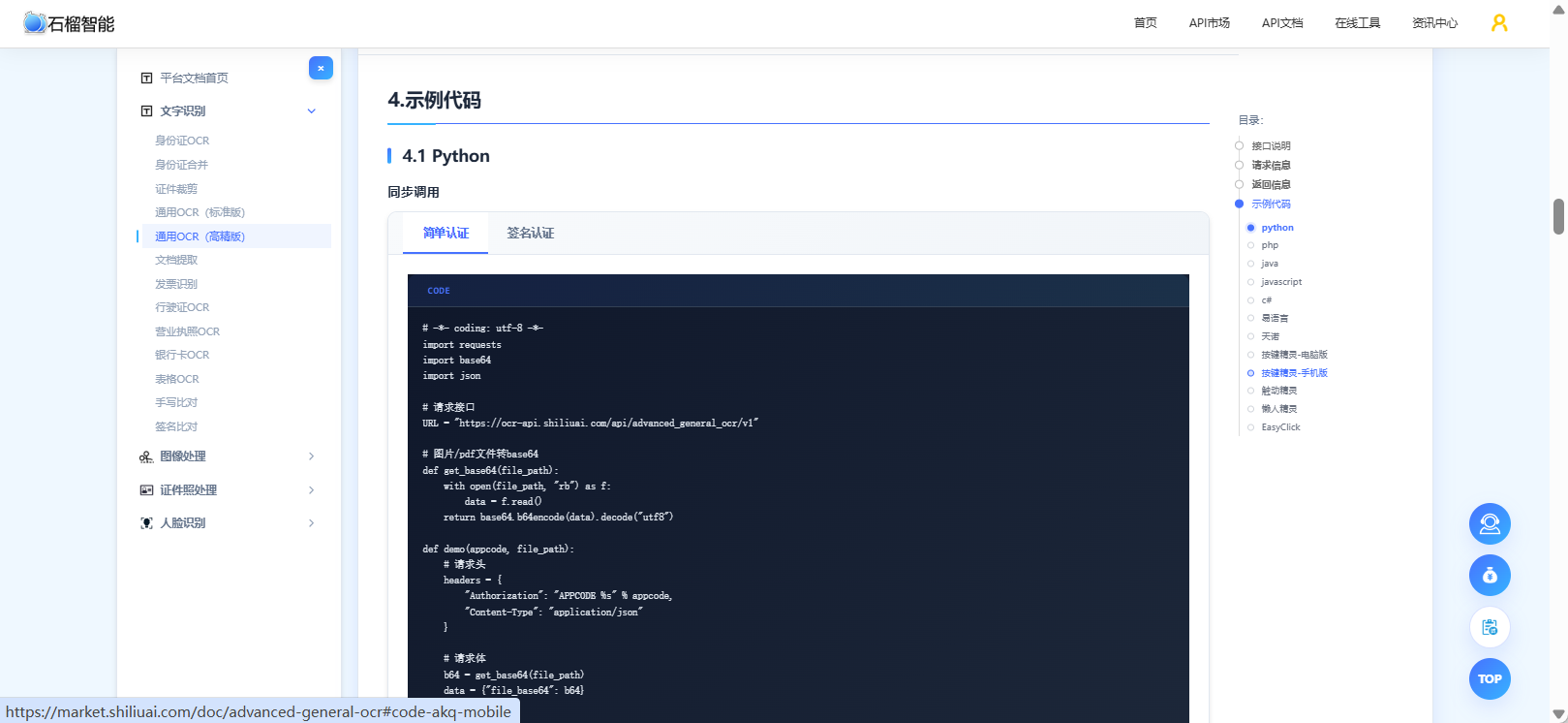
snapshot("/sdcard/ocr.png", 0, 0, 720, 1280)2️⃣ 调用 OCR API(上传图片)
-- ===========================
-- 接口API文档:https://market.shiliuai.com/doc/advanced-general-ocr
-- ===========================
local url = "POST http(s)://ocr-api.shiliuai.com/api/advanced_general_ocr/v1"
-- 发送POST请求(示意)
local result = http.post(url, {
file = "@/sdcard/ocr.png"
})3️⃣ 打印返回结果
log(result)4️⃣ 解析识别文字
local text = json.decode(result).data.text
log("识别结果:" .. text)五、完整示例脚本
-- ===========================
-- 懒人精灵 OCR 自动识别示例
-- API接口文档:https://market.shiliuai.com/doc/advanced-general-ocr
-- ===========================
function ocr_easy(appcode, imagePath)
local url = "https://ocr-api.shiliuai.com/api/advanced_general_ocr/v1"
local body = jsonLib.encode({ file_base64 = getFileBase64(imagePath) })
local headers = {}
headers["Authorization"] = "APPCODE " .. appcode
headers["Content-Type"] = "application/json"
local resp = httpPost(url, body, { headers = headers })
return jsonLib.decode(resp)
end六、常见问题(避坑指南)
❌ 1. 识别不准确?
常见原因:
-
截图模糊
-
分辨率过低
-
图片有遮挡
👉 优化方案:
结合:《图片变清晰 API 实战》
❌ 2. 返回为空?
可能原因:
-
图片未成功上传
-
API地址错误
-
参数格式问题
❌ 3. 中文乱码?
👉 检查:
-
JSON解析是否正确
-
返回编码是否为 UTF-8
七、进阶玩法(非常重要)
你可以把 OCR 和其他 API 组合👇
🚀 玩法1:OCR + 去水印
👉 先清理图片 → 再识别
参考:《图片去水印 API 实战》
🚀 玩法2:OCR + 高清化
👉 模糊截图 → 提升清晰度 → 再识别
参考: 《图片变清晰 API》
🚀 玩法3:自动化任务执行
👉 实现:
-
自动识别
-
自动点击
-
自动流程执行
八、总结
通过本文你已经掌握:
✅ 懒人精灵调用 OCR API 的完整流程
✅ 移动端截图识别实现方法
✅ 可直接参考的脚本示例
📚 延伸阅读
🎯 最后
👉 在移动端自动化领域(懒人精灵 / 脚本工具)中,OCR 是实现"智能识别"的核心能力。
👉 建议直接体验石榴智能的文字识别API接口,支持免费测试,几分钟即可完成接入。