目录
[5.1 环境建模与状态空间构建](#5.1 环境建模与状态空间构建)
[5.2 动作空间与奖励函数设计](#5.2 动作空间与奖励函数设计)
[5.3 Q表初始化](#5.3 Q表初始化)
[5.4 迭代训练与Q表更新](#5.4 迭代训练与Q表更新)
[5.5 策略提取与性能评估](#5.5 策略提取与性能评估)
1.前言
多Agent系统(Multi-Agent System, MAS)的理论和应用研究是当前人工智能领域的研究热点。RoboCup(Robot World Cup)机器人足球比赛是一种典型的多Agent系统,该系统具有动态环境、多个Agent之间合作与竞争并存、受限的通信带宽和随机噪音等特点。通过RoboCup这个标准的测试平台,可以深入研究和评价多Agent系统中的各种理论和算法,并将结果应用到其他领域。强化学习(Reinforcement Learning, RL)是一种无监督的机器学习技术,能够利用不确定的环境奖赏发现最优的行为序列,实现动态环境下的在线学习,因此被公认为是构成智能Agent的理想技术之一。本文以简化RoboCup足球场景为测试平台,采用Q学习算法实现进攻Agent的智能决策,包括路径规划、避障和射门策略的自主学习。
2.算法测试效果图预览
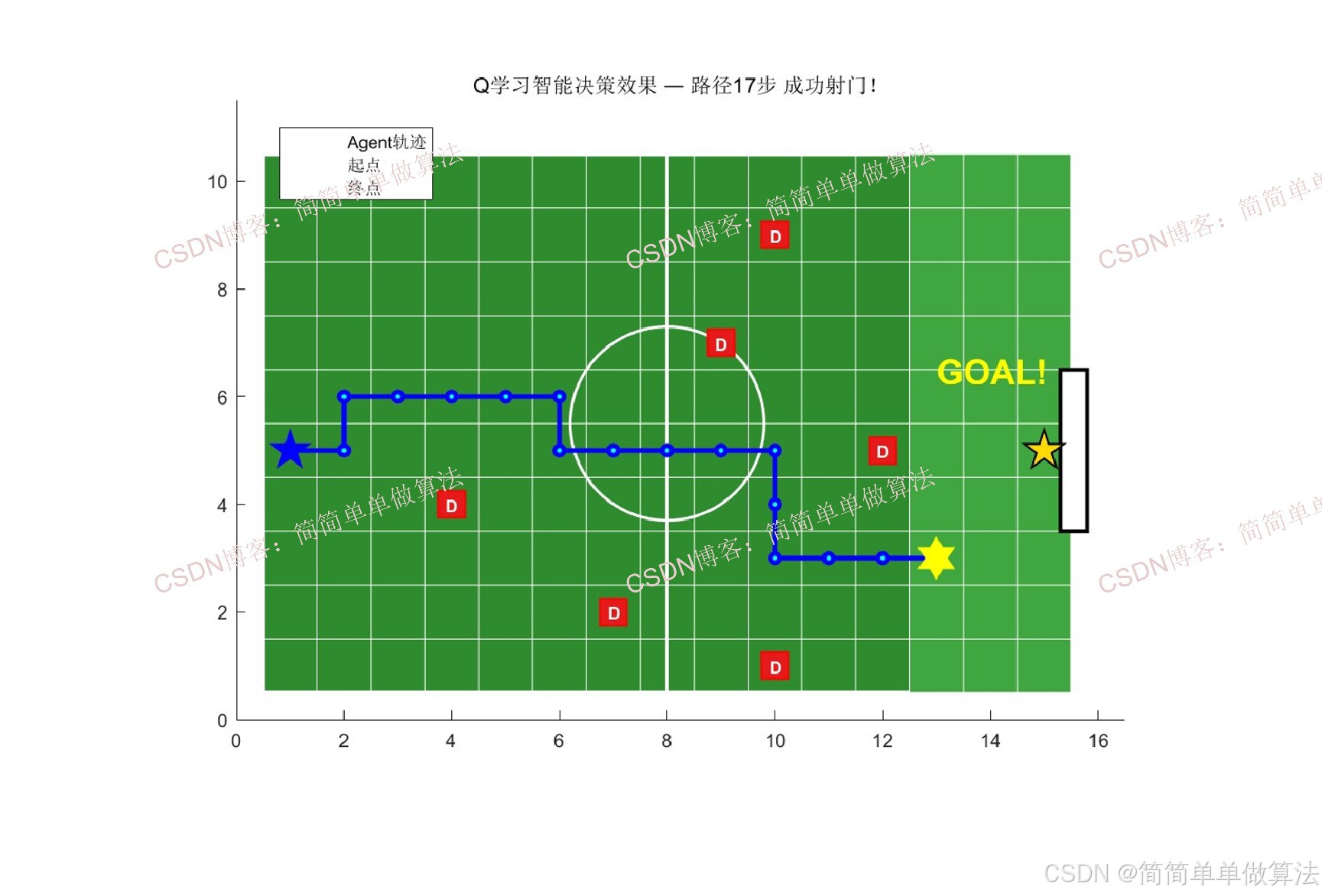
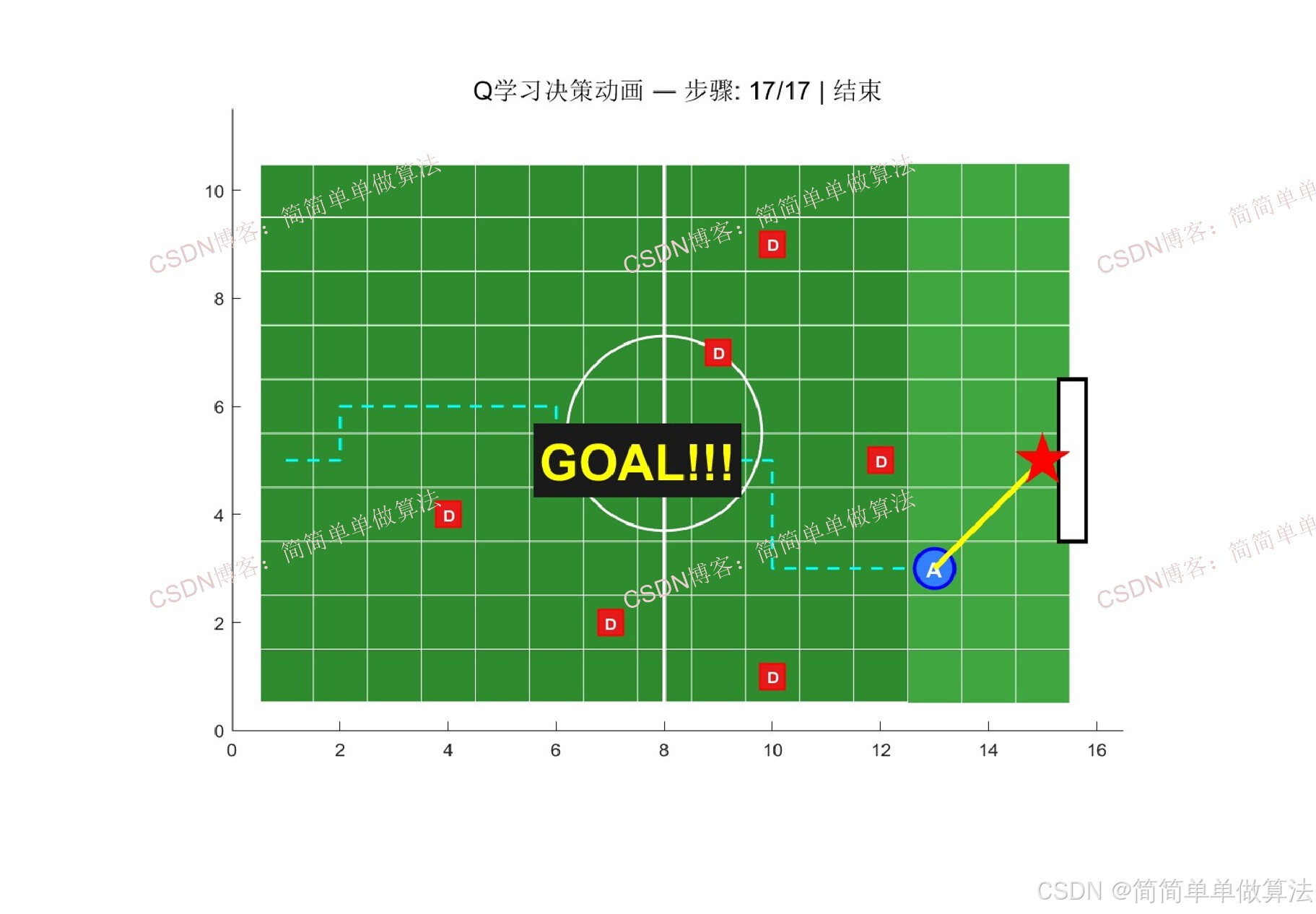
3.算法运行软件版本
matlab2024b
4.部分核心程序
actionNames = {'上移','下移','左移','右移','射门'};
for f = 1:nFrames
clf;
drawField(gridRows, gridCols, shootZoneCol, goalPos, defenderBase, nDefenders);
% 已走轨迹
if f > 1
plot(trajectory(1:f,2), trajectory(1:f,1), 'c--','LineWidth',1.5);
end
% Agent当前位置
plot(trajectory(f,2), trajectory(f,1), 'bo','MarkerSize',22,...
'MarkerFaceColor',0.2 0.5 1,'LineWidth',2);
text(trajectory(f,2), trajectory(f,1), 'A','Color','w',...
'FontSize',12,'FontWeight','bold','HorizontalAlignment','center');
% 运动方向箭头
if f < nFrames
dr = trajectory(f+1,1)-trajectory(f,1);
dc = trajectory(f+1,2)-trajectory(f,2);
quiver(trajectory(f,2), trajectory(f,1), dc*0.6, dr*0.6, 0,...
'Color','y','LineWidth',2.5,'MaxHeadSize',2);
end
% 射门特效
if f == nFrames && goalReached
plot(trajectory(f,2), goalPos(2), trajectory(f,1), goalPos(1),...
'y-','LineWidth',3);
plot(goalPos(2),goalPos(1),'rp','MarkerSize',30,...
'MarkerFaceColor','r');
text(gridCols/2, gridRows/2, 'GOAL!!!','Color','y',...
'FontSize',28,'FontWeight','bold','HorizontalAlignment','center',...
'BackgroundColor',0.1 0.1 0.1 );
end
% 信息标注
if f <= length(actionSeq)
infoStr = sprintf('步骤: %d/%d | 动作: %s', f, nFrames-1, actionNames{actionSeq(f)});
else
infoStr = sprintf('步骤: %d/%d | 结束', f-1, nFrames-1);
end
title(sprintf('Q学习决策动画 --- %s', infoStr), 'FontSize',14);
drawnow;
pause(0.3);
end
5.算法理论概述
本算法以简化RoboCup足球场景为测试平台,采用Q学习算法实现进攻Agent的智能决策,包括路径规划、避障和射门策略的自主学习。具体实现步骤如下:
5.1 环境建模与状态空间构建
将RoboCup球场离散化为𝑁𝑟×𝑁𝑐的网格世界,状态空间大小为:

每个状态𝑠对应Agent在网格中的一个坐标位置(𝑟,𝑐),状态编码函数为:

5.2 动作空间与奖励函数设计
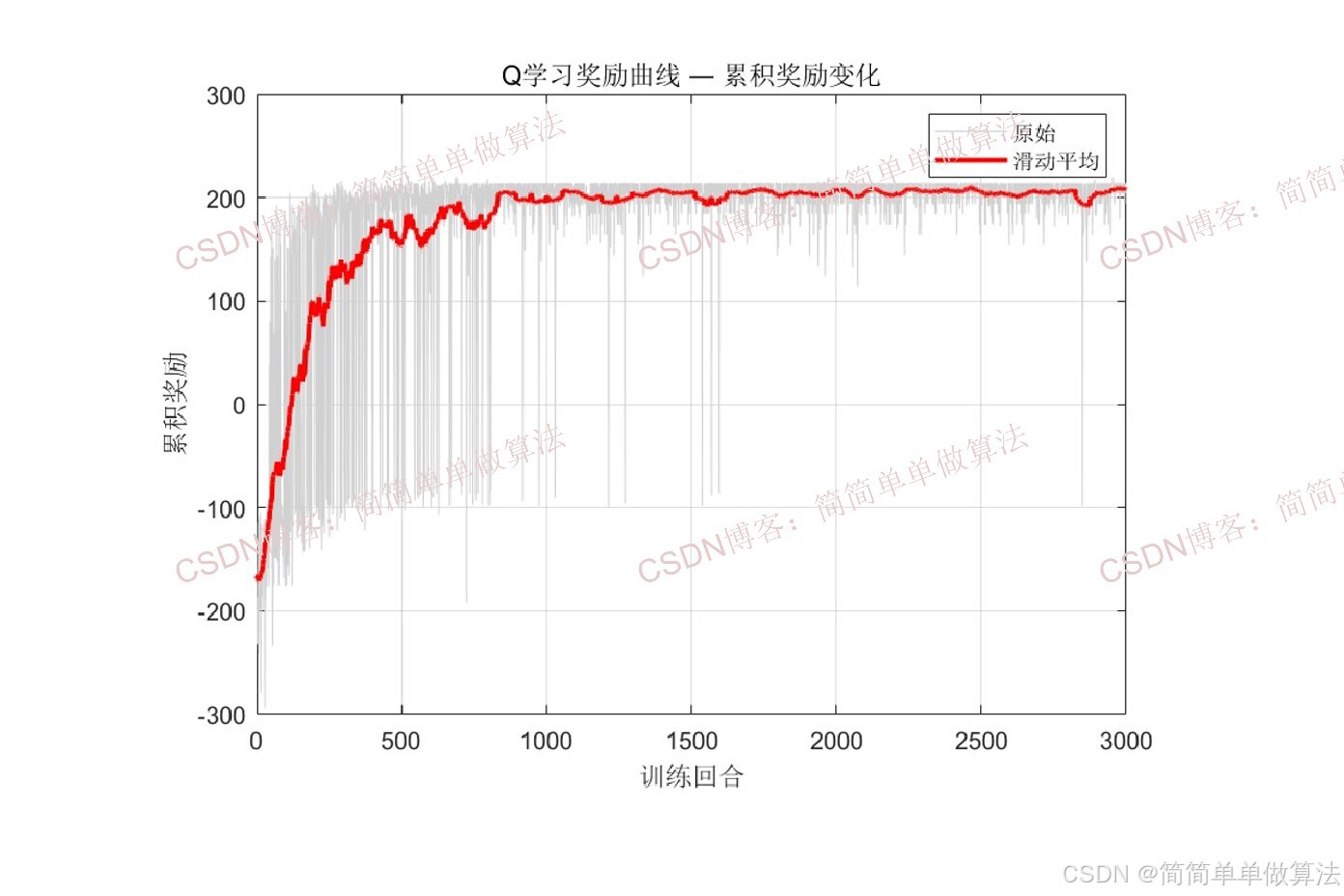
动作空间包含五种离散动作:上、下、左、右移动和射门,即∣𝐴∣=5。奖励函数设计为分层结构:

接近球门的引导奖励基于曼哈顿距离计算:
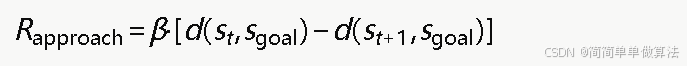
5.3 Q表初始化
初始化Q表维度为∣𝑆∣×∣𝐴∣,所有元素置零:

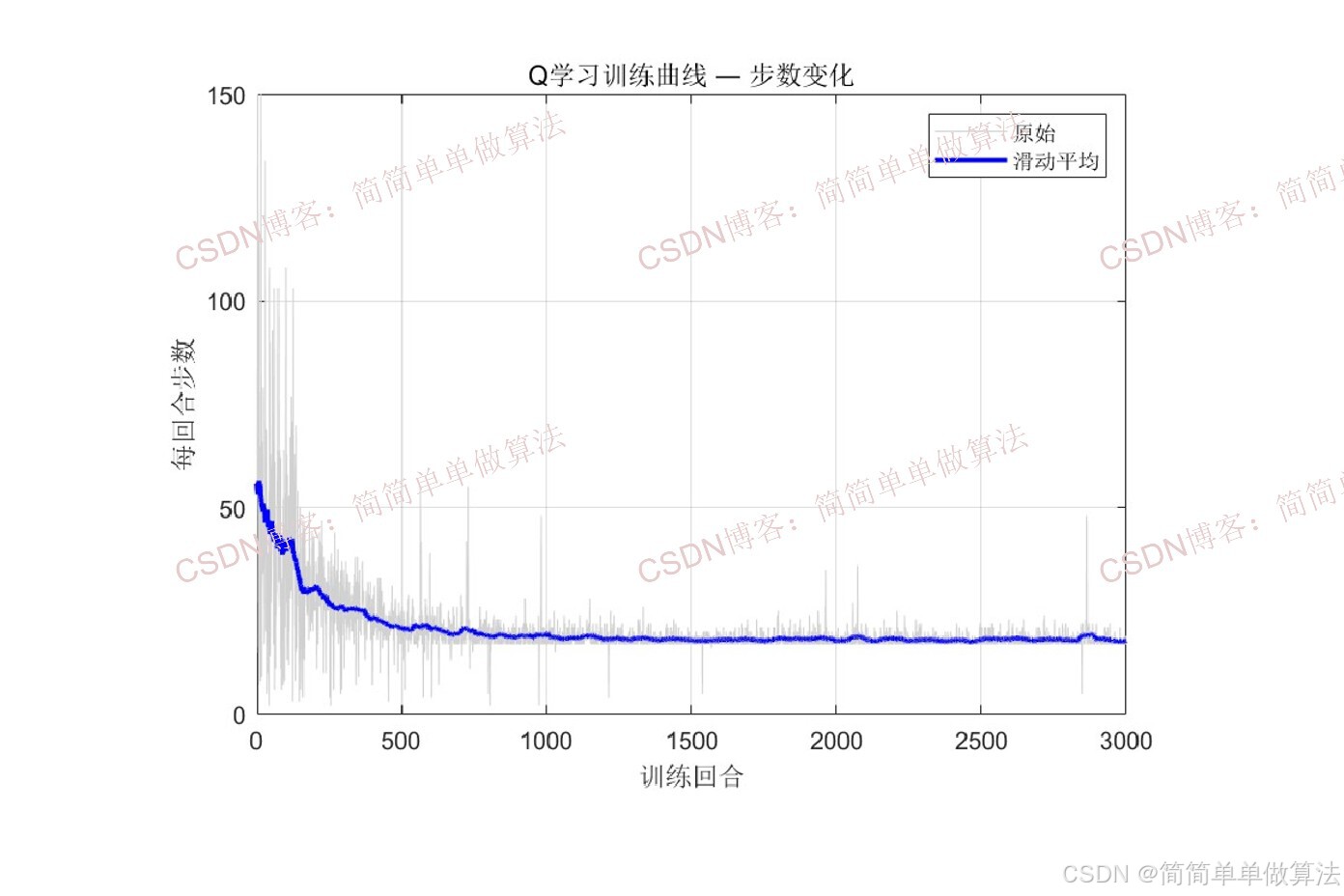
5.4 迭代训练与Q表更新
每个训练回合中重复执行:观测状态、选择动作、获取奖励、更新Q值:
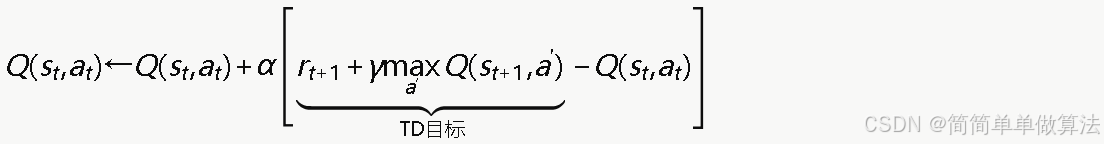
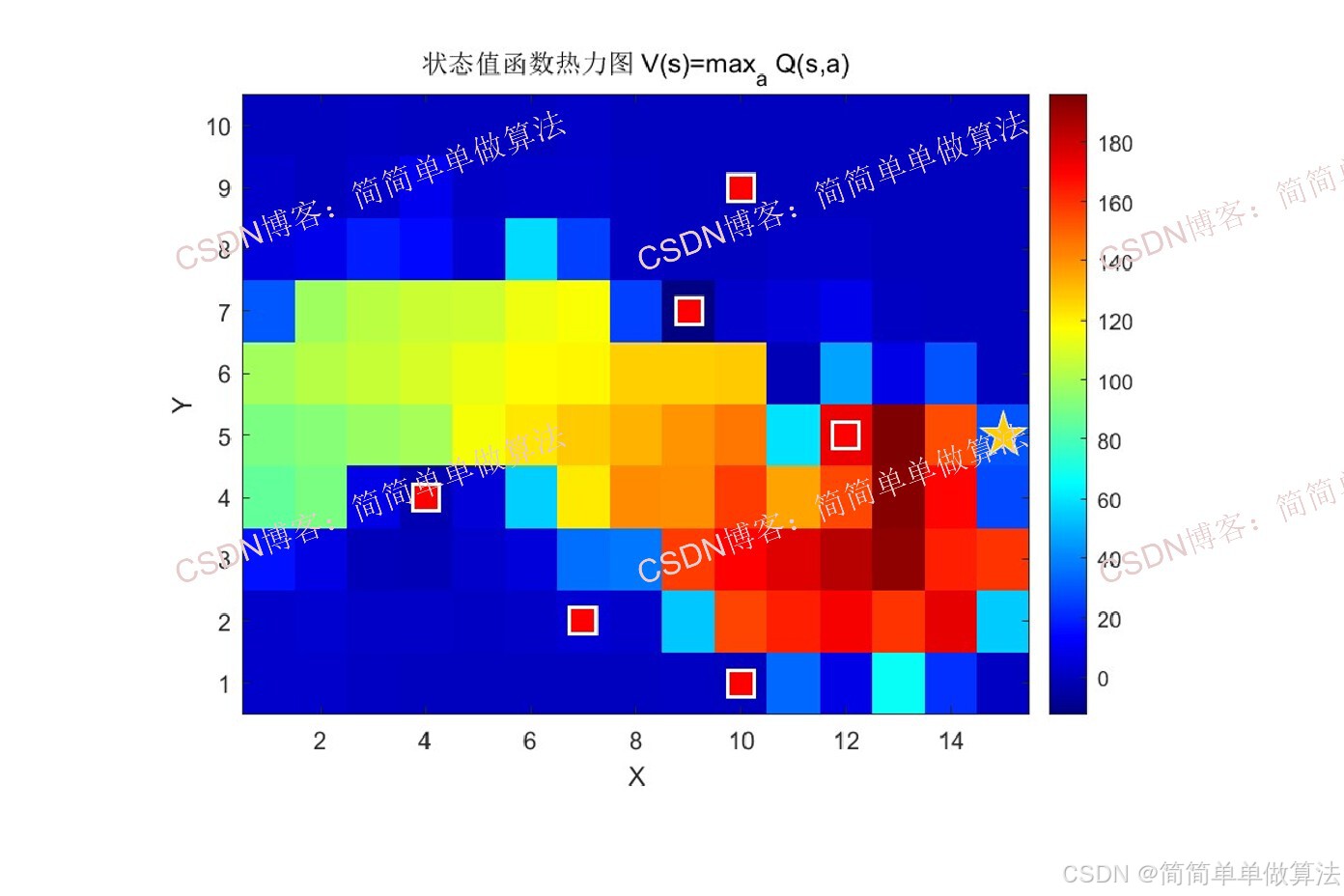
5.5 策略提取与性能评估
训练完成后提取贪心最优策略:
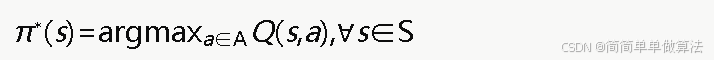
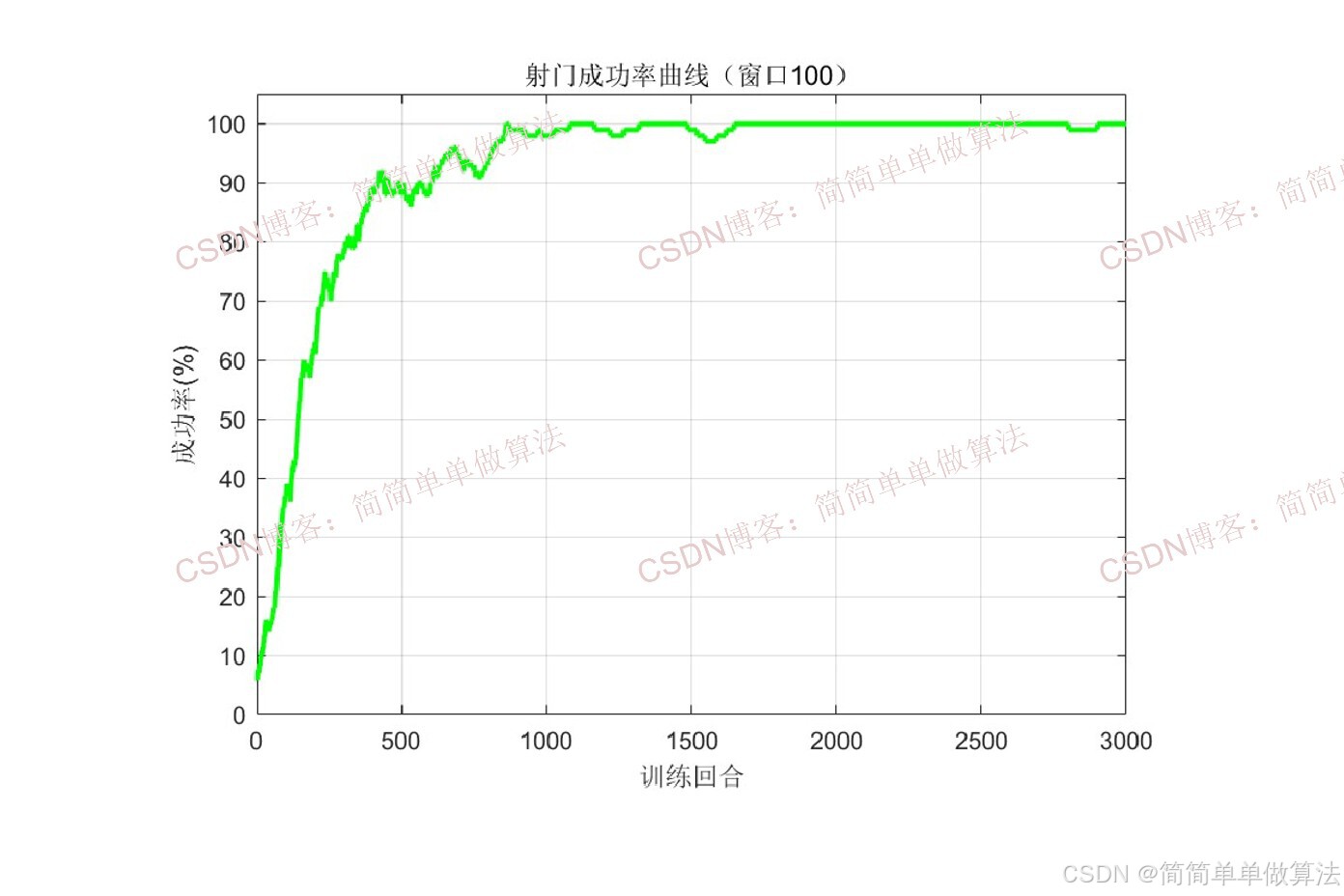
通过累积奖励、成功率和步数等指标评估决策效果。
6.算法完整程序工程
OOOOO
OOO
O
关注GZH后输入回复:0036