一、为什么 OCR 识别总是不准?
很多人在使用 OCR 接口时会遇到:
- ❌ 识别错误、乱码
- ❌ 关键字段识别不到
- ❌ 识别结果不完整
👉 但问题往往不在 OCR,而在图片质量。
最常见的 3 大问题:
- 模糊(低清晰度)
- 倾斜(拍摄角度问题)
- 反光(光照问题)
二、影响 OCR 识别率的核心因素
| 问题类型 | 影响 | 是否致命 |
|---|---|---|
| 模糊 | 字符边缘不清晰 | ⭐⭐⭐⭐ |
| 倾斜 | 行结构错乱 | ⭐⭐⭐ |
| 反光 | 字符被遮挡 | ⭐⭐⭐⭐ |
👉 结论:OCR 前必须做"图像预处理"(或API接口自动进行预处理)
三、整体解决方案(核心思路)
一套完整流程如下:
原始图片
↓
图片增强(变清晰)
(API接入,支持免费在线体验,参考网址:https://www.shiliuai.com/super_resolution/)
↓
几何校正(纠偏)
↓
去反光 / 去噪
↓
OCR识别
(API接入,支持免费在线体验,参考网址:https://market.shiliuai.com/general-ocr)四、问题一:模糊图片怎么处理?
解决方案:AI 超分辨率(图片变清晰 API)
模糊是最常见的问题。
👉 推荐做法:先用 图片变清晰 API 进行增强,再 OCR。
Python 示例
python
# API文档:https://www.shiliuai.com/api/tupianbiangaoqing
# -*- coding: utf-8 -*-
import requests
import base64
import cv2
import json
import numpy as np
api_key = '******' # 你的API KEY
file_path = '...' # 图片路径
with open(file_path, 'rb') as fp:
photo_base64 = base64.b64encode(fp.read()).decode('utf8')
url = 'https://api.shiliuai.com/api/super_resolution/v1'
headers = {'APIKEY': api_key, "Content-Type": "application/json"}
data = {
"image_base64": photo_base64,
"scale_factor": 2 # 放大2倍
}
response = requests.post(url=url, headers=headers, json=data)
response = json.loads(response.content)
"""
成功:{'code': 0, 'msg': 'OK', 'msg_cn': '成功', 'result_base64': result_base64}
or
失败:{'code': error_code, 'msg': error_msg, 'msg_cn': 错误信息}
"""
result_base64 = response['result_base64']
file_bytes = base64.b64decode(result_base64)
f = open('result.jpg', 'wb')
f.write(file_bytes)
f.close()
image = np.asarray(bytearray(file_bytes), dtype=np.uint8)
image = cv2.imdecode(image, cv2.IMREAD_UNCHANGED)
cv2.imshow('result', image)
cv2.waitKey(0)👉 该API接口支持免费在线体验:https://www.shiliuai.com/super_resolution/
五、问题二:图片倾斜怎么办?
解决方案:自动纠偏(旋转 + 透视矫正)
倾斜会导致:
- 行识别错乱
- 表格识别失败
👉 常见处理方式:
- 边缘检测 + 角度计算
- 自动旋转校正
👉 石榴智能 OCR 接口支持"自动纠偏"
六、问题三:反光 / 遮挡怎么处理?
解决方案:
1️⃣ 去反光(图像增强)
- 调整亮度 / 对比度
- 局部修复
2️⃣ 背景分离(抠图)
👉 使用 智能抠图 API 去掉复杂背景,支持免费在线体验:https://www.shiliuai.com/koutu/
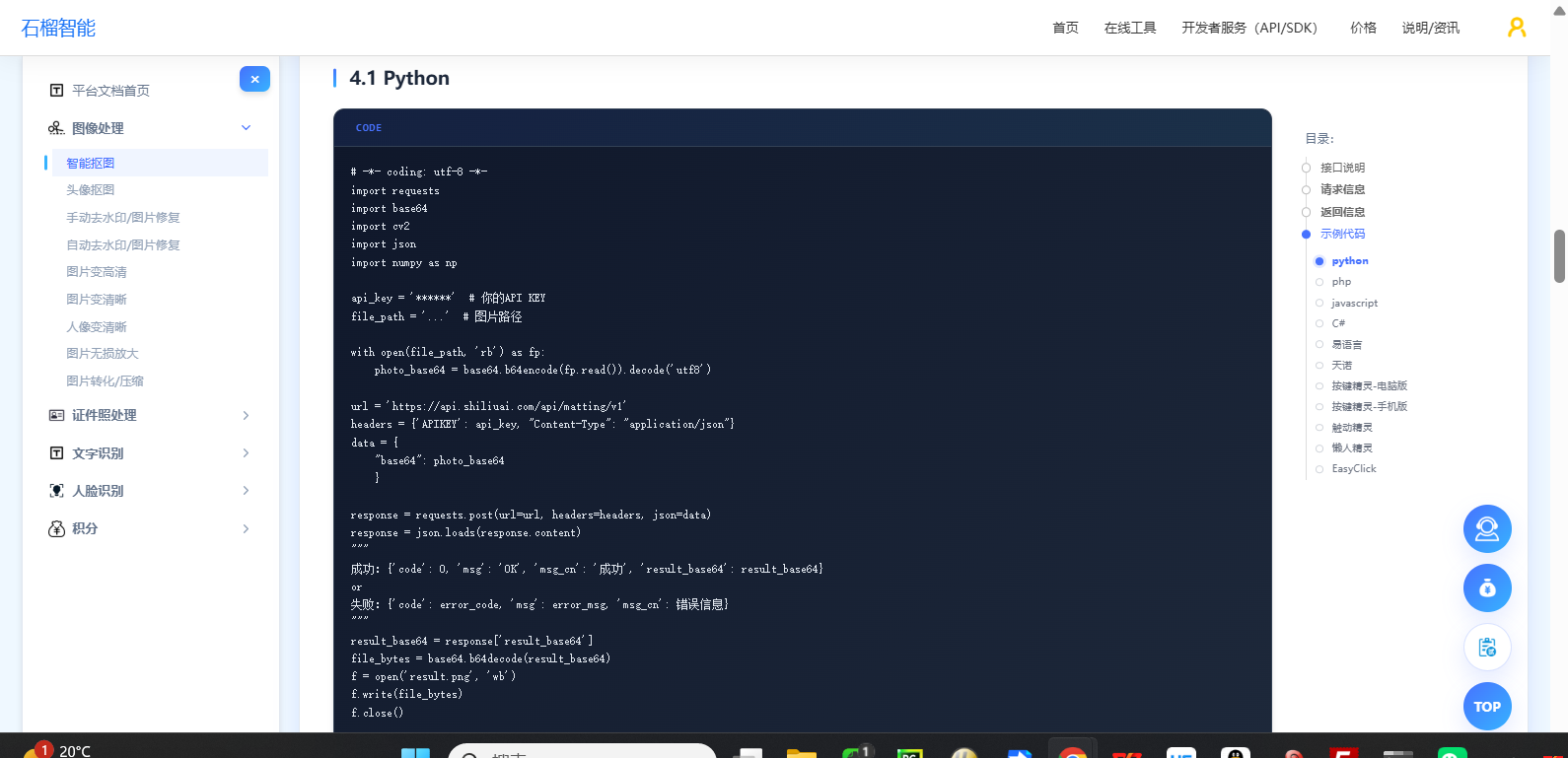
Python 示例
python
# API 文档: https://www.shiliuai.com/api/koutu
# -*- coding: utf-8 -*-
import requests
import base64
import cv2
import json
import numpy as np
api_key = '******' # 你的API KEY
file_path = '...' # 图片路径
with open(file_path, 'rb') as fp:
photo_base64 = base64.b64encode(fp.read()).decode('utf8')
url = 'https://api.shiliuai.com/api/matting/v1'
headers = {'APIKEY': api_key, "Content-Type": "application/json"}
data = {
"base64": photo_base64
}
response = requests.post(url=url, headers=headers, json=data)
response = json.loads(response.content)
"""
成功:{'code': 0, 'msg': 'OK', 'msg_cn': '成功', 'result_base64': result_base64}
or
失败:{'code': error_code, 'msg': error_msg, 'msg_cn': 错误信息}
"""
result_base64 = response['result_base64']
file_bytes = base64.b64decode(result_base64)
f = open('result.png', 'wb')
f.write(file_bytes)
f.close()
image = np.asarray(bytearray(file_bytes), dtype=np.uint8)
image = cv2.imdecode(image, cv2.IMREAD_UNCHANGED)
cv2.imshow('result', image)
cv2.waitKey(0)七、完整实战:OCR 前优化 + 识别
推荐流程
python
# 伪代码流程
image = 原始图片
# Step1:清晰化
image = 图片增强API(image)
# Step2:纠偏(如支持)
image = 自动纠偏(image)
# Step3:OCR识别
result = OCR_API(image)
print(result)
# OCR API网址:https://market.shiliuai.com/general-ocr
# 可以尝试下,支持免费在线体验,文档、示例代码齐全八、效果提高重点
- 原图 ---> 清晰化
- 倾斜 ---> 矫正
- 反光 ---> 优化
九、不同场景优化方案
📄 场景1:身份证 OCR
问题:
- 反光
- 倾斜
👉 推荐:
- 自动纠偏 + OCR专用接口
相关文章:
👉 《身份证 OCR 识别失败排查指南》
👉 《身份证正反面识别接口》
🧾 场景2:发票 OCR
问题:
- 模糊
- 折痕
👉 推荐:
- 图片增强 + 发票OCR
相关文章:
👉 《发票 OCR 识别实战》
🏥 场景3:医疗票据 OCR
问题:
- 字小 + 模糊
👉 推荐:
- 超分辨率 + OCR
十、常见问题
Q1:OCR 识别率能提升多少?
👉 一般可提升 20%~60%
Q2:一定要做预处理吗?
👉 是的,特别是模糊图片
Q3:可以批量处理吗?
👉 API 支持批量
十一、相关文章
十二、总结
如果你只是偶尔使用:
👉 推荐在线工具(无需开发)
如果你需要系统集成:
👉 建议直接接入 API,实现自动化处理