目录
前言
一、系统整体架构设计
[1.1 设计目标与性能指标](#1.1 设计目标与性能指标)
[1.2 平台选型与资源分析](#1.2 平台选型与资源分析)
[1.3 软硬件协同架构(PS + PL)](#1.3 软硬件协同架构(PS + PL))
FPGA(PL)负责数据面
ARM(PS)负责控制面
两者通信方式
二、模块层级关系与数据流设计
[2.1 模块划分与职责分层](#2.1 模块划分与职责分层)
[2.2 模块层级关系说明(重点)](#2.2 模块层级关系说明(重点))
[2.3 数据流路径(核心流水线)](#2.3 数据流路径(核心流水线))
1、全流水线处理
2、单向数据流
3、基于流的处理机制
[2.4 异常路径与 CPU 交互](#2.4 异常路径与 CPU 交互)
三、关键设计注意事项
[3.1 时钟域与跨域处理](#3.1 时钟域与跨域处理)
[3.2 数据一致性与流水线稳定性](#3.2 数据一致性与流水线稳定性)
[3.3 流表设计与资源权衡](#3.3 流表设计与资源权衡)
四、结合方向
[4.1 模块化思想一致](#4.1 模块化思想一致)
[4.2 数据流驱动模型](#4.2 数据流驱动模型)
[4.3 控制与执行分离](#4.3 控制与执行分离)
[4.4 接口通信类比](#4.4 接口通信类比)
五、本文总结
六、更多操作
[📌 FPGA 与系统级开发延伸](#📌 FPGA 与系统级开发延伸)
[📌 前端工程化与系统可视化方向](#📌 前端工程化与系统可视化方向)

前言
在家庭和小型办公使用光猫或路由器 构建的网络环境中,"千兆带宽 "并不等于"千兆性能"。
当网络中同时存在多路 4K 视频流、NAS 数据传输、P2P 下载以及大量智能设备接入时,传统网络设备的性能瓶颈会迅速暴露:
CPU 占用率持续飙升
网络延迟明显增加
丢包与抖动频繁出现
问题的根本原因在于:
所有数据包都由路由设备的 CPU 完成处理,数据面完全依赖软件实现。
NAT、ACL、流量分类等功能本身并不复杂,但在高并发场景下,"每个数据包都必须经过 CPU 处理"这一机制,会将计算压力快速放大,最终形成瓶颈。
为了解决这一问题,本文基于 Xilinx ZYNQ-MINI 7Z010 CLG400 -1 设计了一套 FPGA 高速路由转发加速系统,通过将高频数据处理逻辑从 CPU 卸载到 FPGA,实现:
千兆线速转发能力
NAT 硬件加速
数据面与控制面分离
显著降低 CPU 占用率
在进一步说明系统架构之前,需要先明确一个关键概念:
普通路由器内部本身就包含 CPU(通常为 ARM 或 MIPS 架构) ,并运行类似 OpenWrt 的嵌入式系统。在传统架构中,所有数据包(转发、NAT、过滤)都必须经过该 CPU 处理 ,这也是网络性能瓶颈的核心来源。
而在本文使用的 Xilinx ZYNQ-7000 SoC(7Z010)中,芯片本身是一个典型的"CPU + FPGA "异构结构:
PS(ARM)≈ CPU,负责控制面(配置、管理、流表下发)
PL(FPGA)负责数据面(高速转发、包处理流水线)
因此本文中提到的"CPU压力降低",本质含义是:
将数据转发从"路由器CPU / ZYNQ-PS"迁移到 FPGA(PL)中完成
在实际部署中,本系统主要有两种使用形态:
(1)中间加速层模式(推荐)
光猫 → FPGA加速板 → 路由器 → 终端设备
此时 FPGA 负责主要数据转发逻辑,路由器仅承担 WiFi、终端接入与管理功能,从而显著降低路由器 CPU 负载。
(2)简化路由核心模式(进阶)
光猫 → FPGA → 终端设备
此时 ZYNQ 内部的 PS(ARM)承担路由器 CPU 职责,PL 负责高速转发,但需要自行实现更多网络协议与控制逻辑。
👉 总体可以这样理解:
传统网络:所有数据必须经过路由器 CPU
本系统:数据优先在 FPGA 中完成处理,仅少量控制流量交由 CPU 处理
这套软硬件分离 的架构,从根源上避开了传统软路由 CPU 算力不足 的短板。这里的软硬件 ,是针对 ZYNQ 芯片内部的 PS(ARM 软件)+ PL(FPGA 硬件逻辑) 来说的:
- 软件 :指 PS 端 ARM 处理器上运行的软件程序,负责路由控制、协议处理、流表配置等控制面逻辑。
- 硬件 :指 PL 端 FPGA 可编程逻辑电路,通过硬件电路直接实现数据包解析、NAT、线速转发等数据面处理。
通过将核心转发任务硬件化 ,系统可稳定实现千兆线速转发 ,在多设备并发、大流量传输场景下,有效降低网络延迟与丢包率 ,同时大幅减轻处理器负载 ,最终实现网络传输提速、运行更稳定 的加速效果,全面提升整体网络体验。
本文将从 系统架构设计、模块层级关系、数据流路径以及工程实现注意事项 四个方面展开,适合具备一定数字电路或嵌入式基础的开发者参考与实践。

一、系统整体架构设计
1.1 设计目标与性能指标
本系统定位为透明加速网关,部署在光猫与主路由之间,不改变原有网络结构。
核心设计指标如下:
支持双千兆接口(WAN / LAN),全双工线速转发
单包处理延迟控制在微秒级(< 1μs)
支持 500~1000 条硬件流表(基于 BRAM)
支持 IPv4 NAT(源 IP / 端口转换)
ARM 侧仅处理控制与异常流量
设计的核心思想可以概括为一句话:
高频操作交给 FPGA,低频逻辑交给 CPU。
1.2 平台选型与资源分析
系统基于 Xilinx ZYNQ-MINI 7Z010 CLG400 -1 平台构建,该器件将 ARM 与 FPGA 集成在同一芯片中,具备良好的软硬件协同能力。
主要资源包括:
ARM Cortex-A9(PS 端)
FPGA 可编程逻辑(PL 端)
约 28K 逻辑单元
片上 BRAM(用于流表和缓存)
千兆以太网 MAC
资源使用策略:
-
BRAM:流表、FIFO 缓冲
-
LUT / FF:数据处理流水线
-
DSP:基本不参与关键路径
在合理设计下,该平台完全可以支撑千兆级网络转发任务。
1.3 软硬件协同架构(PS + PL)
系统采用典型的控制面与数据面分离架构:
FPGA(PL)负责数据面
数据包解析(以太网/IP/传输层)
流表查找
NAT 地址转换
TTL 递减
校验和更新
转发 / 丢弃决策
ARM(PS)负责控制面
ARP / DHCP / ICMP 等协议处理
路由信息维护
流表管理与下发
异常包处理
两者通信方式
AXI-Lite:寄存器配置、状态读取
AXI-Stream + DMA:数据包交互
系统在运行时,绝大多数数据包仅在FPGA 可编程逻辑(PL 端)内完成处理,实现 网络加速 功能,只有少量异常流量会进入 FPGA 芯片内置的 ARM 处理器(PS 端)处理,无需占用传统软路由的独立 CPU 资源。
这样设计能让FPGA 内置 ARM 处理器 不会因大量数据包处理出现卡顿,网络转发无延迟、不丢包 ,相比传统软路由,千兆带宽下可实现线速满速转发 ,高并发场景下网速吞吐能力提升数倍,网络传输速度与稳定性 大幅提升。
二、模块层级关系与数据流设计
2.1 模块划分与职责分层
FPGA 逻辑划分为 10 个核心模块:
| 模块名称 | 功能说明 |
|---|---|
| top_router_accelerator | 顶层模块,负责例化与连接 |
| rx_control | 数据接收控制 |
| packet_parser | 数据包解析 |
| flow_table_lookup | 流表查找 |
| action_engine | 动作执行 |
| output_queues | 队列与调度 |
| tx_control | 数据发送 |
| csr_interface | 控制寄存器接口 |
| axi_dma_controller | DMA 数据交互 |
| tb_router_accelerator | 仿真测试平台 |
这些模块按照"输入 → 处理 → 输出"的路径组织,形成清晰的数据处理链路。
2.2 模块层级关系说明(重点)
在 FPGA 设计中,一个非常关键但容易被忽略的点是:
模块层级由代码中的"例化关系"决定,而不是文件夹结构。
也就是说:
.v 文件放在哪个目录 → 不影响硬件结构
模块之间的父子关系 → 完全由 instantiation 决定
实际层级结构如下:
top_router_accelerator
├── rx_control(WAN)
├── rx_control(LAN)
├── packet_parser
├── flow_table_lookup
├── action_engine
├── output_queues
├── tx_control(WAN)
├── tx_control(LAN)
├── csr_interface
└── axi_dma_controller结论很明确:
谁例化谁,谁就是父模块。
工程实践中建议:
文件夹仅用于代码分类(如 rx / tx / core / ctrl)
不要试图通过目录结构表达硬件层级
2.3 数据流路径(核心流水线)
系统的数据流路径如下:
PHY → rx_control → packet_parser → flow_table_lookup
→ action_engine → output_queues → tx_control → PHY该路径具有以下特点:
1、全流水线处理
各模块独立工作,多个数据包可同时在不同阶段处理,提高吞吐能力。
2、单向数据流
数据只向前流动,没有回环路径,降低设计复杂度。
3、基于流的处理机制
每个数据包独立解析、查表、执行动作,实现高效处理。
2.4 异常路径与 CPU 交互
当出现以下情况时:
流表未命中
ARP / ICMP 报文
异常或特殊数据包
系统会进入"慢路径":
bash
action_engine → DMA → DDR → ARM → DMA → FPGA设计原则:
快路径(FPGA):处理绝大多数流量
慢路径(CPU):处理少量复杂情况
这种快慢路径分离 的分层机制,让系统在保障超高转发性能 的同时,仍具备灵活的协议扩展与异常处理能力。
三、关键设计注意事项
3.1 时钟域与跨域处理
系统中存在多个时钟域,例如:
PHY 接收时钟
系统主时钟
跨时钟域是 FPGA 设计中最容易出问题的部分之一。
推荐方案:
使用异步 FIFO 进行数据缓冲
使用双寄存器同步控制信号
禁止做法:
直接跨时钟读取信号
在组合逻辑中跨域
否则极易出现亚稳态问题,导致系统不稳定。
3.2 数据一致性与流水线稳定性
在高速数据通路中,必须保证控制信号与数据严格对齐:
valid(数据有效)
ready(下游可接收)
last(包结束标志)
常见问题:
last 信号丢失 → 帧错乱
ready 处理错误 → 数据阻塞
建议统一采用 AXI-Stream 风格接口规范,以保证系统稳定运行。
3.3 流表设计与资源权衡
流表是系统性能的核心。
推荐实现方式:
Hash + BRAM
线性探测解决冲突
不推荐:
-
全 CAM 实现(资源消耗过大)
设计建议:
使用 CRC32 作为 Hash 函数
控制冲突深度
保证查找延迟可控
经验结论:
稳定、可预测的性能,比极限性能更重要。
综上,在高速网络转发设计中,稳定、可预测的性能,远比盲目追求极限峰值性能更为重要 。
只有保证转发延迟固定、流表查询时序可控、数据通路无异常抖动,才能在千兆线速场景下始终做到不丢包、不卡顿,让系统在长时间高并发运行时依旧可靠。
四、结合方向
与前端开发方向的结合
从工程视角来看,这类 FPGA 系统与前端开发其实有很多相通之处。
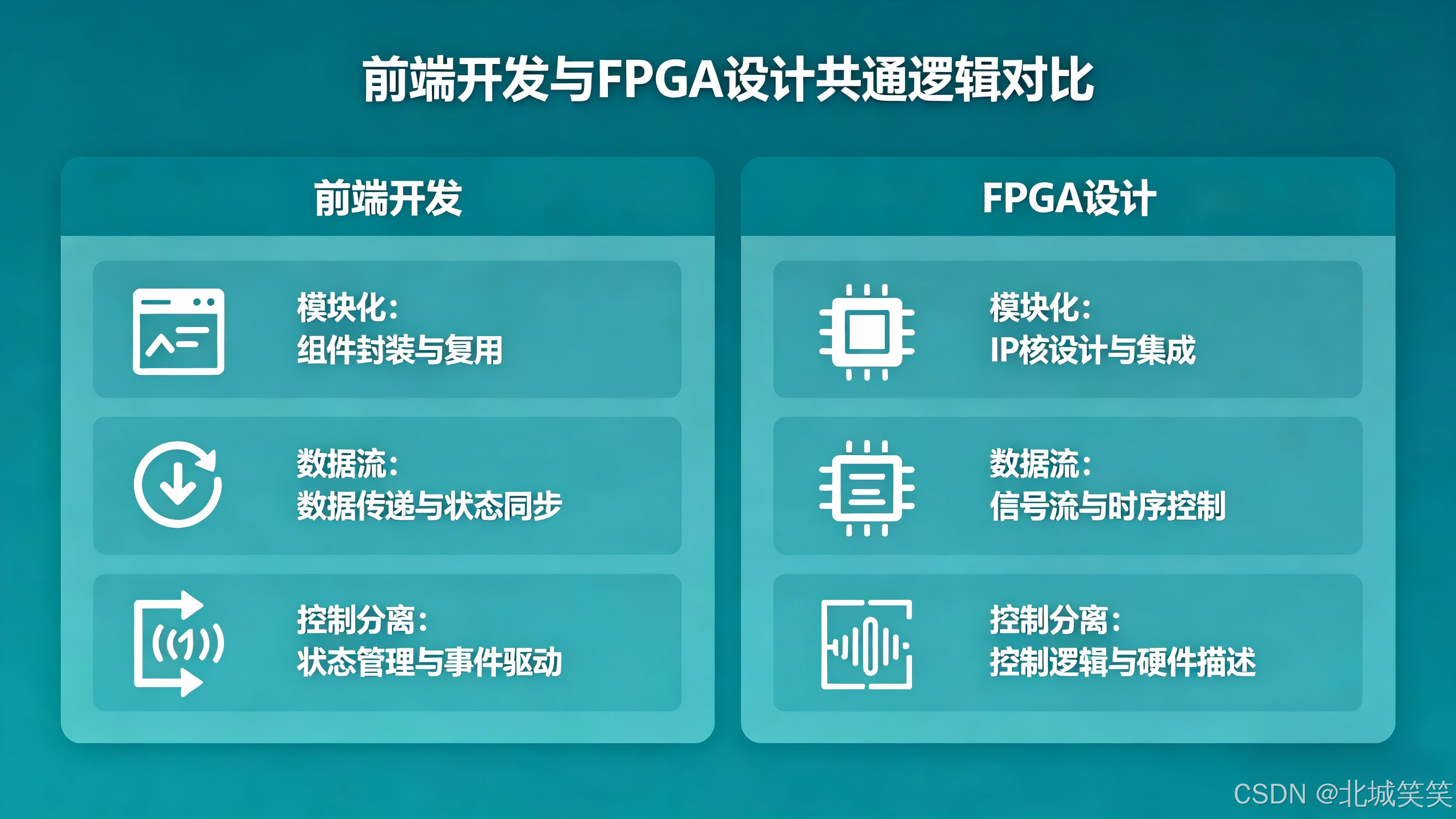
4.1 模块化思想一致
FPGA:模块(module)
前端:组件(component)
两者本质都是:
通过拆分复杂系统,降低耦合度,提高可维护性
4.2 数据流驱动模型
FPGA:数据流(stream)驱动处理
前端:状态驱动 UI 更新
本质都是:
数据变化 → 触发处理 → 输出结果
4.3 控制与执行分离
FPGA:控制面(ARM) + 数据面(FPGA)
前端:业务逻辑层 + 渲染层
这是一种非常典型的系统设计模式。
4.4 接口通信类比
AXI-Lite ≈ 接口请求(API)
DMA ≈ 流式数据(WebSocket)
👉 对于前端开发者来说:
如果你理解了组件化、状态管理、数据流,那么理解 FPGA 系统架构并不困难。
二者在设计思想上高度同源 ,这种共通的工程化思维 ,能够有效打破软件前端与硬件底层 的开发壁垒,降低跨领域学习 的门槛。
这不仅是工程开发能力 的共通复用,更是上层软件与底层硬件 在设计逻辑上的深度契合,二者还可形成两大核心结合方向:
- 一是软硬协同可视化管控 ,由前端搭建路由加速的配置、监控与管理界面,FPGA 硬件层提供实时转发数据,实现高速网络系统的可视化运维 ;
- 二是全栈网络产品一体化开发 ,前端负责用户交互与业务逻辑,FPGA 完成底层硬件转发加速 ,联合打造高性能软硬一体 的网关设备。
未来可以依托这种跨领域设计思路 ,将前端的模块化、规范化开发 思路延伸到 FPGA 硬件加速设计中,进一步探索软硬协同开发 在网络加速、边缘网关等场景的落地,打通软件应用层与硬件加速层 的壁垒,实现从上层应用到底层硬件转发的全链路技术拓展 。
五、本文总结
文章围绕 ZYNQ 7Z010(Xilinx ZYNQ-MINI 7Z010 CLG400 -1) ,系统性地介绍了一套 FPGA 高速路由转发加速系统的整体架构设计,核心内容包括:
明确了数据面硬件化的设计思路
构建了PS + PL 协同架构
梳理了模块划分与层级关系(由例化决定)
分析了完整数据流路径与慢路径机制
总结了跨时钟域、数据一致性、流表设计等关键注意事项
最终实现目标:
在不改变网络结构的前提下,实现千兆线速转发,并显著降低 CPU 负载。
如果从更高层次来看,这套系统不仅仅是一个网络加速方案,更是一种典型的:
高性能数据通路设计范式(High Performance Data Path Design)
后续可扩展方向包括:
IPv6 硬件转发
QoS 与流量调度
大规模流表扩展(DDR)
更复杂的数据处理(如 DPI)
如果你正在探索:
FPGA 网络加速
ZYNQ 系统设计
或从前端迈向底层系统开发
这类架构是一个非常值得深入实践的方向。
六、更多操作
如果你希望进一步深入 FPGA 网络加速 / ZYNQ 系统设计 / 数据面架构优化 方向,可以从以下内容继续扩展学习与实践:
📌 FPGA 与系统级开发延伸
👉 FPGA 专栏(持续更新)
https://blog.csdn.net/weixin_65793170/category_12665249.html![]() https://blog.csdn.net/weixin_65793170/category_12665249.html
https://blog.csdn.net/weixin_65793170/category_12665249.html
该系列内容主要包括:
高速网络接口设计(Ethernet / GMII / RGMII)
数据流流水线架构设计方法
PS + PL 协同系统实现思路
硬件转发与流表机制设计
复杂数据通路工程实践
👉 适合继续深入:
高性能网络设备设计
边缘计算与实时数据处理
FPGA工程化落地应用
📌 前端工程化与系统可视化方向
在本类系统中,前端不仅是展示层,也可以作为控制与调试入口,实现 FPGA 系统的可视化管理。
👉 Vue 工程化实战专栏
https://blog.csdn.net/weixin_65793170/category_12116741.html![]() https://blog.csdn.net/weixin_65793170/category_12116741.html
https://blog.csdn.net/weixin_65793170/category_12116741.html
主要内容包括:
Vue2 / Vue3 工程化实践
WebSocket 实时数据通信
ECharts 数据可视化
复杂系统前端架构设计
👉 在本系统中可扩展为:
流量实时监控面板
流表配置管理界面
FPGA运行状态可视化
网络数据实时分析大屏
实现:
FPGA 数据面 + 前端控制面的一体化系统架构
后续还可以继续深入:
万兆网络转发架构优化
大规模流表设计与扩展
FPGA + 前端 + 系统级融合实践
如果本文对你有帮助,欢迎:
👍 点赞 | ⭐ 收藏 | 💬 评论
