在处理复杂的工程回归或时间序列预测任务时,传统的机器学习模型往往只能提供单一的"点预测"结果(Point Prediction)。然而,在实际应用(如风电功率预测、负荷预测、金融风险评估)中,系统往往受到多种随机噪声的干扰,单一的值难以反映未来的不确定性。
为了解决这一问题,本文结合具体代码,详细解析一种既能保证极高非线性拟合精度,又能量化预测不确定性 的混合模型:基于最小二乘支持向量机(LSSVM)与自适应带宽核密度估计(ABKDE)的区间预测模型。
1. 核心模型架构概述
本模型的运行逻辑可分为两大核心阶段:
- 点预测阶段 (LSSVM): 挖掘多维输入特征与单一输出之间的非线性映射关系,输出高精度的确定性预测值,并提取预测误差。
- 区间预测阶段 (ABKDE): 摒弃传统的误差服从正态分布的假设,利用自适应带宽核密度估计,对 LSSVM 的预测误差进行非参数拟合,进而叠加到点预测结果上,生成具有特定置信水平(如 95%)的预测区间。
2. 数据处理与特征工程
高质量的数据是模型成功的前提。在代码中,数据处理流程非常标准:
-
缺失值清理与划分: 使用
rmmissing剔除异常空值,保证数据纯洁性。代码将数据集按 70% 训练集、30% 测试集 的比例划分,符合常规机器学习的验证逻辑。 -
输入输出定义: 取前 f_f\f 列为多维输入特征,最后一列为单输出,明确了"多输入单输出"的结构。
-
归一化处理 (mapminmax): 由于特征往往具有不同的量纲(例如温度、湿度、风速等),直接输入计算会导致模型偏向数值大的特征。代码将输入和输出严格映射到了 0,10, 10,1 区间:
matlab[p_train, ps_input] = mapminmax(P_train, 0, 1); p_test = mapminmax('apply', P_test, ps_input);注:这里使用了
apply保证测试集严格使用训练集的归一化参数,防止了"数据泄露",是非常严谨的学术操作。
3. LSSVM 点预测模型构建
标准的 SVM 解决回归问题(SVR)时需要求解复杂的二次规划问题。而 最小二乘支持向量机 (LSSVM) 将不等式约束替换为等式约束,将求解过程转化为求解线性方程组,极大提升了运算速度,同时保留了优秀的泛化能力。
在参数设置中,代码定义了以下关键属性:
type = 'f':指定为回归任务(Function estimation)。kernel = 'RBF_kernel':径向基核函数。RBF 核能够将数据映射到无限维空间,是处理非线性回归的首选。- 超参数设定: * 正则化参数 γ\gammaγ (
gam = 750):控制模型的复杂度与拟合误差之间的平衡。值越大,模型越倾向于拟合训练数据(容易过拟合)。- 核函数宽度 σ2\sigma^2σ2 (
sig = 25):决定了 RBF 核函数的作用范围。
- 核函数宽度 σ2\sigma^2σ2 (
模型训练完成后,输出测试集的点预测结果 T_sim2,并通过 mapminmax('reverse', ...) 进行反归一化,恢复真实物理量纲。
4. 基于 ABKDE 的预测不确定性量化
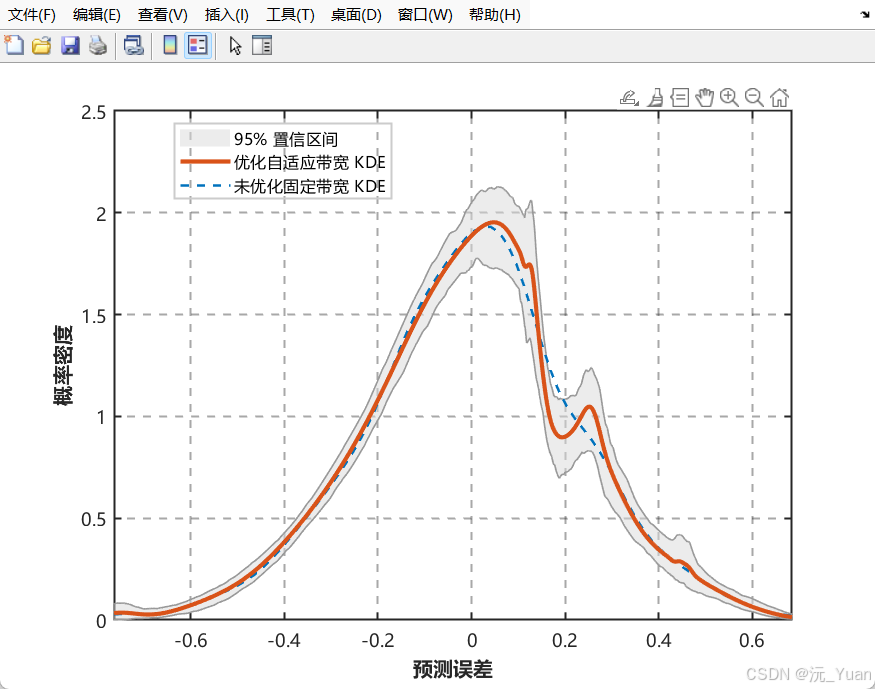
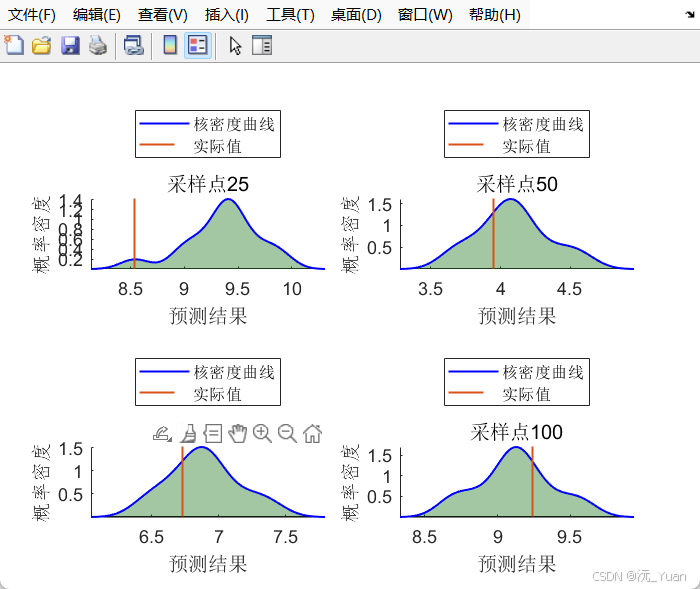
这是本模型的最大亮点。传统的区间预测常假设误差服从正态分布,这在现实中极其脆弱(真实误差往往呈现"长尾"或"偏态")。核密度估计 (KDE) 是一种非参数估计方法,完全由数据自身驱动来拟合概率密度函数(PDF)。
固定带宽 vs 自适应带宽 (ABKDE)
标准 KDE 的公式如下:
f^(x)=1nh∑i=1nK(x−Xih)\hat{f}(x) = \frac{1}{nh} \sum_{i=1}^{n} K \left( \frac{x - X_i}{h} \right)f^(x)=nh1i=1∑nK(hx−Xi)
其中 hhh 为带宽。固定带宽在数据密集区可能过于平滑,在稀疏区可能震荡。
代码中引入了 ABKDE(Error)(自适应带宽),它能够根据局部数据密度自动调节 hhh:数据密集处带宽小(保留细节),稀疏处带宽大(降低噪点)。
求解预测区间
代码设定了多组分位数 z=0.975;0.95;0.875;... z = 0.975; 0.95; 0.875; \\dotsz=0.975;0.95;0.875;...。以 95% 置信区间为例(对应单侧 z=0.975z=0.975z=0.975):
- 根据 ABKDE 拟合出的概率密度分布,通过
QuantSol_FUN积分求解出误差的上下分位点 Q1Q1Q1 和 Q2Q2Q2。 - 将误差分位点叠加到点预测结果上,生成最终的上下界:
c
Lower(:,m) = T_sim2 + Q1(m);
Upper(:,m) = T_sim2 + Q2(m);5. 模型评估指标体系
一个优秀的区间预测模型,必须经过严苛的指标检验。代码中包含了两套完整的评估体系。
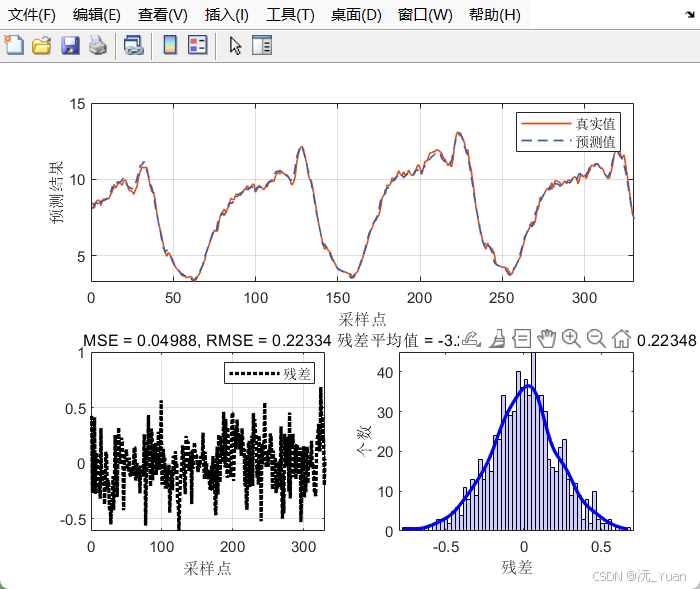
5.1 点预测精度评估
通过计算点预测值与真实值之间的误差:
- 决定系数 (R2R^2R2): 衡量模型对数据方差的解释程度,越接近 1 越好。
- 均方根误差 (RMSE) & 平均绝对误差 (MAE): 衡量预测值偏离真实值的绝对距离,越小越好。
- 平均绝对百分比误差 (MAPE): 衡量相对误差,直观反映预测精度的百分比。
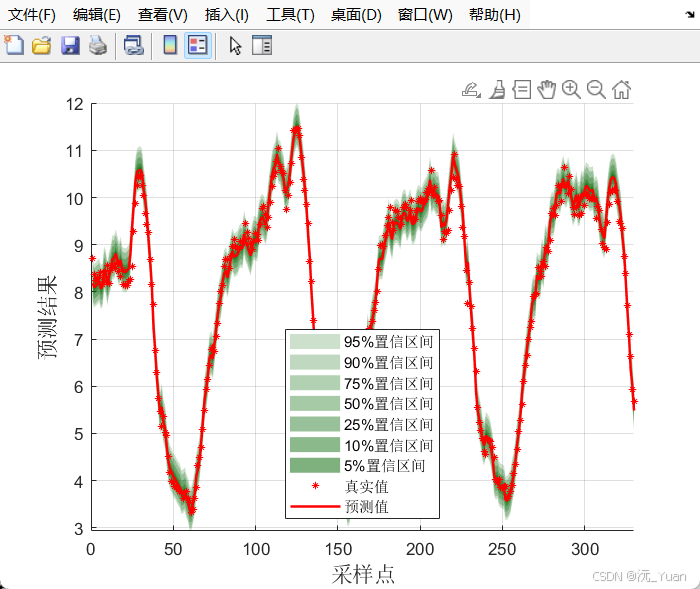
5.2 区间预测质量评估
区间预测不能仅看准确率(把区间设为无穷大,准确率必为100%,但这毫无意义)。代码使用了以下高级指标来综合评估:
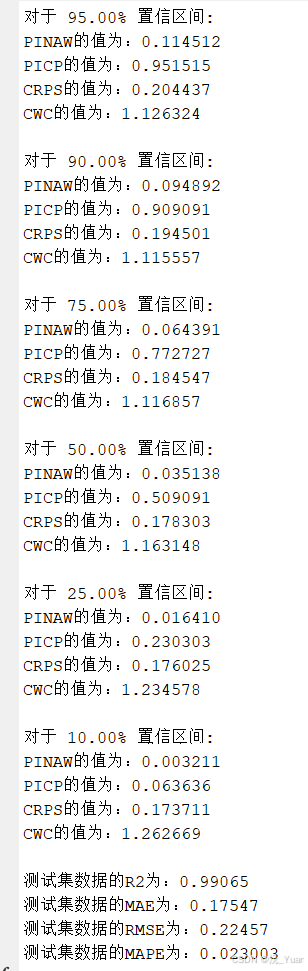
- 区间覆盖率 (PICP, Prediction Interval Coverage Probability): 真实值落在预测区间内的比例。对于 95% 置信区间,PICP 应尽量大于或等于 95%。
- 区间归一化平均宽度 (PINAW, Prediction Interval Normalized Average Width): 评估区间的宽度。在满足 PICP 的前提下,PINAW 越小越好(区间越窄,提供的信息越精确)。
- 连续分级概率评分 (CRPS): 衡量预测概率分布与真实观测值的整体偏差。
- 覆盖率宽度准则 (CWC, Coverage Width-based Criterion): 这是一个综合性惩罚函数。当 PICP 达标时,CWC 主要由 PINAW 决定;当 PICP 不达标时,CWC 会给予指数级惩罚。CWC 是评价区间预测模型优劣的最终指标。
6. 运行结果
6. 结语
基于 LSSVM-ABKDE 的模型架构,不仅发挥了 LSSVM 在小样本、非线性回归中的高效与精准,更通过引入自适应带宽核密度估计,突破了传统点预测的局限性。它所输出的不仅仅是一个冷冰冰的数字,而是一个包含概率置信度的区间,为工程决策(如电力系统调度、水库流量控制等)提供了极其重要的不确定性风险参考。配合全面且美观的可视化图窗,该模型具备极高的学术价值与工业落地潜力。