文章目录
-
- [一、 引言:计算机如何"理解"人类语言?](#一、 引言:计算机如何“理解”人类语言?)
-
- [1.1 从传统搜索到语义搜索的进化](#1.1 从传统搜索到语义搜索的进化)
- [1.2 什么是向量化 (Embedding)?万物皆可坐标化](#1.2 什么是向量化 (Embedding)?万物皆可坐标化)
- [二、 核心原理解析:如何在茫茫人海中找到那个"它"?](#二、 核心原理解析:如何在茫茫人海中找到那个“它”?)
-
- [2.1 距离的度量:余弦相似度 (Cosine)](#2.1 距离的度量:余弦相似度 (Cosine))
- [2.2 经典概念:什么是 Top-K 召回?](#2.2 经典概念:什么是 Top-K 召回?)
- [三、 为什么选择 PostgreSQL + pgvector?](#三、 为什么选择 PostgreSQL + pgvector?)
-
- [3.1 关系型数据库的复兴](#3.1 关系型数据库的复兴)
- [3.2 pgvector 简介及核心优势](#3.2 pgvector 简介及核心优势)
- [3.3 扒开底层看 SQL:pgvector 究竟怎么存和查?](#3.3 扒开底层看 SQL:pgvector 究竟怎么存和查?)
- [四、 Spring AI 代码实战:打通 Embeding 与 pgvector 检索](#四、 Spring AI 代码实战:打通 Embeding 与 pgvector 检索)
-
- [4.1 环境准备](#4.1 环境准备)
- [4.2 Embedding 模型的调用 (把文字变数组)](#4.2 Embedding 模型的调用 (把文字变数组))
- [4.3 数据入库与相似度检索 (Top-K)](#4.3 数据入库与相似度检索 (Top-K))
- [五、 总结](#五、 总结)
给大模型装上真正的"外接硬盘":从语义检索原理到 Spring Boot 工程落地
在 RAG(检索增强生成)系列的前两篇文章中,我们聊了为什么需要 RAG,也详细讲解了如何通过 Chunking 策略把长文档"切碎"。今天,我们要啃下一块不可或缺的硬骨头:这些切碎的文本,系统到底是怎么理解并检索出来的?
这其中的核心魔法,就是向量化(Embedding)与向量检索 。本文将带你从底层原理出发,结合业界当红炸子鸡 PostgreSQL + pgvector,在 Spring AI 语境下完成一次完美的"语义搜索"实战。
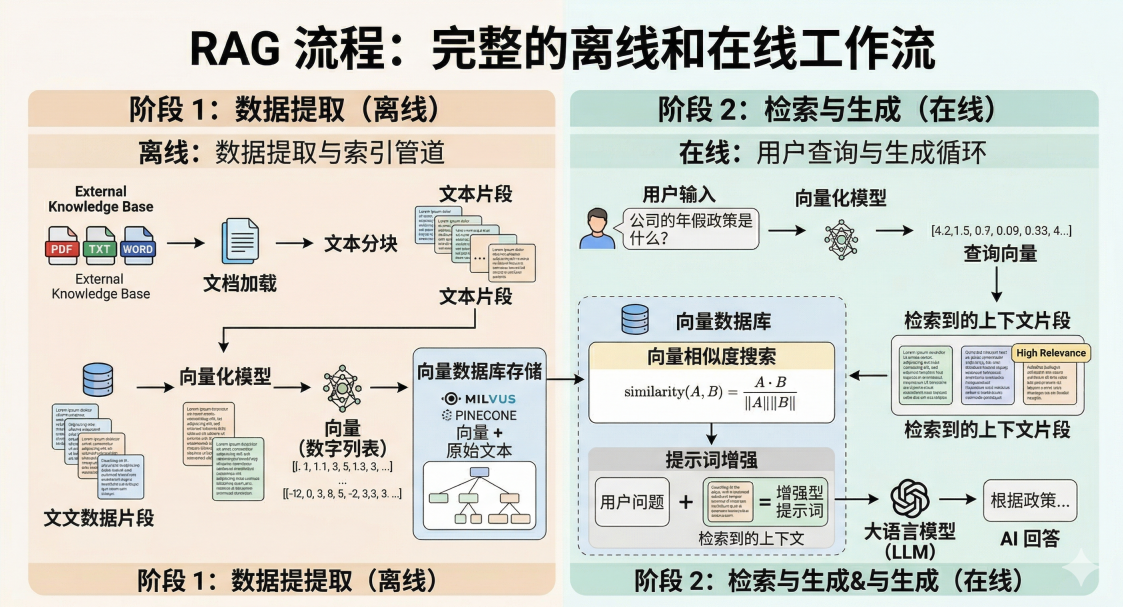
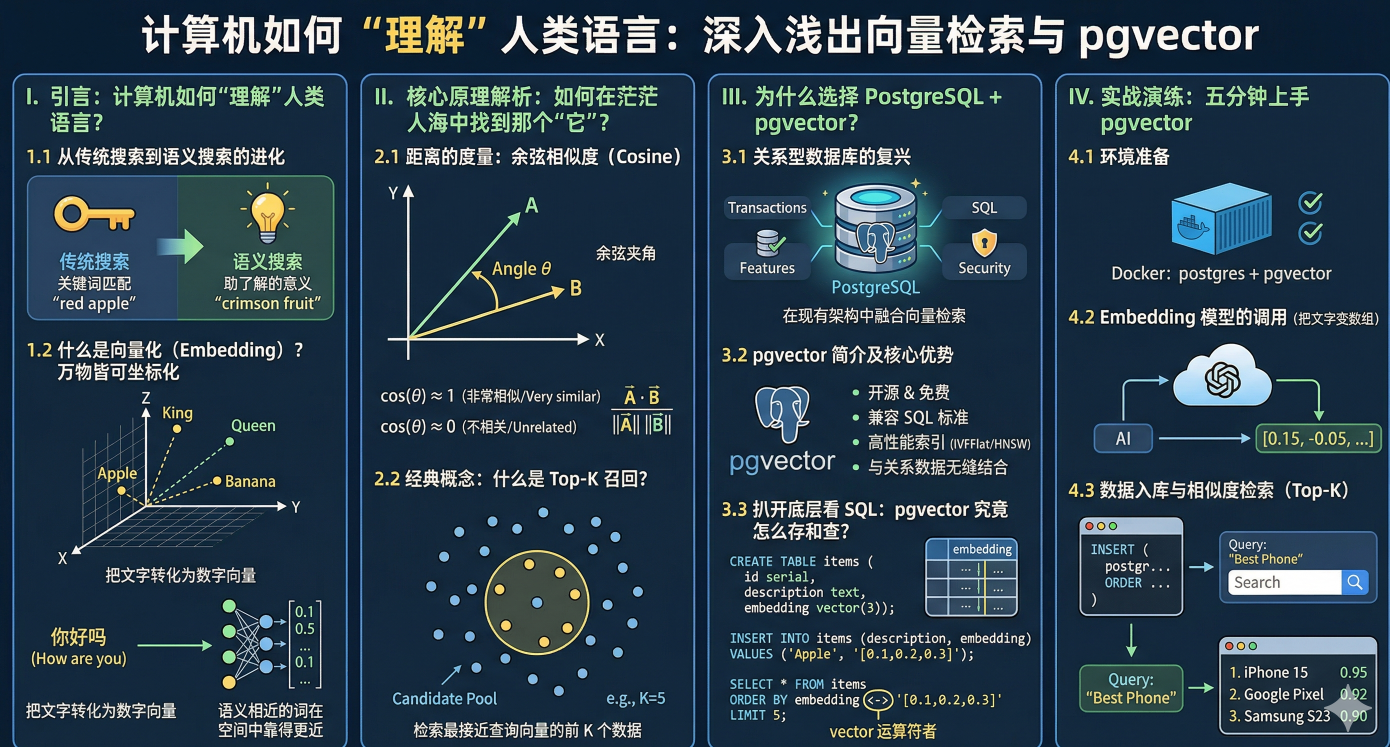
一、 引言:计算机如何"理解"人类语言?
1.1 从传统搜索到语义搜索的进化
传统的搜索(如 Elasticsearch 早期的纯文本匹配或 MySQL 的 LIKE)是基于关键字的。你搜"苹果",它只会返回包含"苹果"这两个字的内容。如果你搜"研发 iPhone 的公司",传统搜索可能会傻眼,因为字面上毫无重合。
为了让计算机真正"理解"语义,而不是机械地比对字符,Embedding 技术诞生了。
1.2 什么是向量化 (Embedding)?万物皆可坐标化
简单来说,Embedding 就是把人类的文字(词语、句子、甚至图像),翻译成计算机能懂的一长串数字(数组)。这串数字,在数学上就叫作"向量"。
我们可以把向量在这个多维空间里想象成一个具体的"坐标"。
- 语义相近的词(比如"高兴"和"开心"),它们在空间中的坐标离得非常近。
- 语义无关的词(比如"高兴"和"水杯"),它们在空间中的坐标离得很远。
这就实现了极其降维打击的能力:我们不再匹配字面,而是匹配"意思"。
二、 核心原理解析:如何在茫茫人海中找到那个"它"?
当所有切碎的文档块,和用户的"问题"都被转换成高维空间里的"坐标点"后,检索的过程就变成了纯粹的几何题。
2.1 距离的度量:余弦相似度 (Cosine)
在几十上百维的空间里,我们怎么判断两个点离得近不近?最常用的数学工具是余弦相似度(Cosine Similarity) 。
它不去量两个点之间的绝对直线距离,而是看这两个点连线所在的"夹角"。
- 夹角越小(趋近于0度),余弦值越接近 1,代表在语义方向上极其相似。
- 夹角越大,代表语义方向偏离,毫无关联。
2.2 经典概念:什么是 Top-K 召回?
这就是我们在 RAG 架构图中经常看到的词。
假设你的知识库被切分成了 100 万个文档块(得到了 100 万个向量)。当用户问了一个问题(转换为 1 个向量),系统的任务就是在空间里算出和这个问题夹角最小余弦相似度最高 的前 K 个文档块。
这挑选出来的前 K 个最相关的段落,就叫做 Top-K 召回。它们将被作为 Prompt 的参考资料,喂给大模型。
三、 为什么选择 PostgreSQL + pgvector?
理解了原理,我们要用什么"数据库"来存这些坐标,并且能飞快地算出余弦相似度呢?
3.1 关系型数据库的复兴
早几年,独立向量数据库(如 Pinecone、Milvus)大行其道。但随着技术发展,大家发现:专门维护一个只有向量的数据库运维成本太高了。业务系统里原有的关系型数据怎么办?
于是,最强大的开源关系型数据库 PostgreSQL 站了出来。
3.2 pgvector 简介及核心优势
pgvector 是 PG 的一个开源扩展插件,让 PG 原生支持了向量数据类型以及各种向量相似度计算(余弦、欧氏距离、内积等)。
- 统一技术栈:你可以把业务数据(如用户的年龄、订单号)和向量数据存放在同一个库甚至同一张表里。
- 无缝 Metadata 过滤 :结合我们上一篇讲的元数据,在 SQL 里加一句
WHERE department = 'HR'就能直接缩小向量计算的范围,性能无敌。
3.3 扒开底层看 SQL:pgvector 究竟怎么存和查?
为了让你不仅知其然,还知其所以然。在接入框架之前,我们先看看原生的 PostgreSQL (安装了 pgvector 后) 是怎么写 SQL 的:
1. 创建带有向量字段的表
sql
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE document_chunks (
id bigserial PRIMARY KEY,
content text, -- 存文本内容
metadata jsonb, -- 存元数据 (如部门、时间等)
embedding vector(1536) -- 存 1536 维的向量坐标
);2. 插入向量数据
sql
-- 实际开发中,[0.1, 0.2...] 这串数组是大模型 API 算出来后返回给你的
INSERT INTO document_chunks (content, metadata, embedding)
VALUES ('苹果不仅仅是水果...', '{"department": "HR"}', '[0.11, 0.22, 0.33...]');3. 核心:余弦相似度检索 (Top-K)!
sql
-- 在 pgvector 中, `<=>` 操作符就代表计算"余弦距离 / 余弦相似度"
-- ORDER BY 距离 ASC,就是找出"夹角最小、最相似"的数据
SELECT content, metadata
FROM document_chunks
WHERE metadata->>'department' = 'HR' -- 绝赞的业务 Metadata 过滤
ORDER BY embedding <=> '[0.14, 0.55, 0.43...]' -- 这串数字是你"问题"的向量
LIMIT 4; -- 这就是大名鼎鼎的 Top-K (K=4)看到这里是不是有一种豁然开朗的感觉?所谓高大上的向量数据库,在 SQL 层面其实就是多了一个 <=> 排序。
四、 Spring AI 代码实战:打通 Embeding 与 pgvector 检索
让我们回到熟悉的 Spring Boot 工程中,看看 Spring AI 是如何把上述原理优雅封装的。
4.1 环境准备
在 pom.xml 中引入 Spring AI 核心包以及 pgvector 启动器(以 PostgreSQL 为例):
xml
<dependencies>
<!-- 其他 Spring Boot 依赖... -->
<!-- Spring AI pgvector store 启动器 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId>
</dependency>
</dependencies>配置 application.yml 连接到装了 pgvector 插件的 PG 数据库:
yaml
spring:
datasource:
url: jdbc:postgresql://localhost:5432/rag_db
username: myuser
password: mypassword
ai:
vectorstore:
pgvector:
index-type: HNSW
distance-type: COSINE_DISTANCE # 指定使用余弦相似度
dimensions: 1536 # 根据你使用的 Embedding 模型维度决定4.2 Embedding 模型的调用 (把文字变数组)
在 Spring AI 中,负责处理向量化的接口是 EmbeddingModel。它可以无缝对接 OpenAI、通义千问、Ollama 等各家大厂的 Embedding API。
java
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingResponse;
import java.util.List;
@RestController
public class EmbeddingController {
private final EmbeddingModel embeddingModel;
public EmbeddingController(EmbeddingModel embeddingModel) {
this.embeddingModel = embeddingModel;
}
@GetMapping("/embed")
public List<Double> embedMyText() {
// 调用底层大厂模型,一键将文字转为 Float/Double 数组
return this.embeddingModel.embed("苹果不仅仅是水果,还是一家科技公司。");
}
}4.3 数据入库与相似度检索 (Top-K)
在实际开发中,我们不需要手动去算余弦夹角,Spring AI 的 VectorStore 接口直接帮我们办妥了一切。配合上篇讲过的 Chunking:
java
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.SearchRequest;
@Service
public class RagService {
private final VectorStore vectorStore; // 这里由于引入了 Starter,底层实现已经是 PgVectorStore
public RagService(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
// 1. 存入经过 Chunking 处理的文档块
public void ingestData(List<Document> chunks) {
// 底层会自动调用 EmbeddingModel 将 content 变成向量,并以原生 SQL 方式存入 PostgreSQL
vectorStore.add(chunks);
}
// 2. 根据用户问题,进行 Top-K 召回检索
public List<Document> searchTopK(String userQuestion) {
// SearchRequest 就是在做余弦相似度计算!
return vectorStore.similaritySearch(
SearchRequest.query(userQuestion)
.withTopK(4) // 我们只要夹角最小(最相似)的前 4 个段落
);
}
}五、 总结
今天我们拔掉了 RAG 中最硬核的钉子:
- 我们明白了计算机是通过向量 (Embedding)和余弦相似度 (Cosine Similarity) 来真正理解语义并"大海捞针"的。
- 我们学习了 Top-K 召回 的概念本质。
- 结合 Spring AI 与极具性价比的 PostgreSQL (pgvector),我们仅仅用了几行代码就搭建起了一个工业级的向量知识检索底层。