【大模型Prompt-Tuning方法进阶+提示词】-基础学习篇
文章目录
- 【大模型Prompt-Tuning方法进阶+提示词】-基础学习篇
- 前言
- 一、Prompt-Tuning方法入门
- 二、02-大模型prompt-Tuning方法进阶
-
- 1.引入库
- [说人话就是:# 🤖 大白话版:大模型的「Prompt-Tuning prompt调优」到底是啥?](# 🤖 大白话版:大模型的「Prompt-Tuning prompt调优」到底是啥?)
- 一、先搞懂核心概念
-
- [1. 什么是 Prompt-Tuning?](#1. 什么是 Prompt-Tuning?)
- [2. 为什么大模型能做到?](#2. 为什么大模型能做到?)
- 二、3种常用的「写提示词」方法,人话拆解
-
- [01 上下文学习(In-Context Learning)](#01 上下文学习(In-Context Learning))
- [02 指令学习(Instruction-Tuning)](#02 指令学习(Instruction-Tuning))
- [03 思维链(Chain-of-Thought, CoT)](#03 思维链(Chain-of-Thought, CoT))
- 三、一句话总结
- [🧠 思维链(CoT):一句话说透](#🧠 思维链(CoT):一句话说透)
-
- 一、人话拆解核心
-
- [1. 它是干嘛的?](#1. 它是干嘛的?)
- [2. 它和普通提示词的区别?](#2. 它和普通提示词的区别?)
- [3. 它的本质是什么?](#3. 它的本质是什么?)
- 二、一句话总结
- 2.PEFT大模型参数高效微调方法原理
- [🧩 Prefix-Tuning 大白话解释](#🧩 Prefix-Tuning 大白话解释)
-
- 一、核心一句话
- 二、人话拆解原理
-
- [1. 先搞懂它解决了什么问题](#1. 先搞懂它解决了什么问题)
- [2. 结合图里的例子更直观](#2. 结合图里的例子更直观)
- [3. 它的本质是什么?](#3. 它的本质是什么?)
- 三、核心优势(对比全量微调)
- 四、一句话总结
- [🧩 超简短版 Prefix-Tuning 任务形式解释](#🧩 超简短版 Prefix-Tuning 任务形式解释)
-
-
- [1. 核心用法](#1. 核心用法)
- [2. 输入结构](#2. 输入结构)
- [3. 关键优化](#3. 关键优化)
-
- [第二部分 大模型提示工程指南](#第二部分 大模型提示工程指南)
- 金融行业动态方向评估项目
- LLM实现金融文本分类
- LLM实现金融文本信息抽取
- LLM实现金融文本匹配
- 笔记
-
- [1 金融行业动态方向评估任务介绍](#1 金融行业动态方向评估任务介绍)
- [2 金融文本分类](#2 金融文本分类)
- [3 金融文本信息抽取](#3 金融文本信息抽取)
- [4 金融文本匹配](#4 金融文本匹配)
- 总结
- 全文极简通俗总结
- 机器学习概述
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了AI中的prompt提示词学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、Prompt-Tuning方法入门




Prompt-Tuning主要方法



二、02-大模型prompt-Tuning方法进阶
1.引入库

说人话就是:# 🤖 大白话版:大模型的「Prompt-Tuning prompt调优」到底是啥?
一、先搞懂核心概念
1. 什么是 Prompt-Tuning?
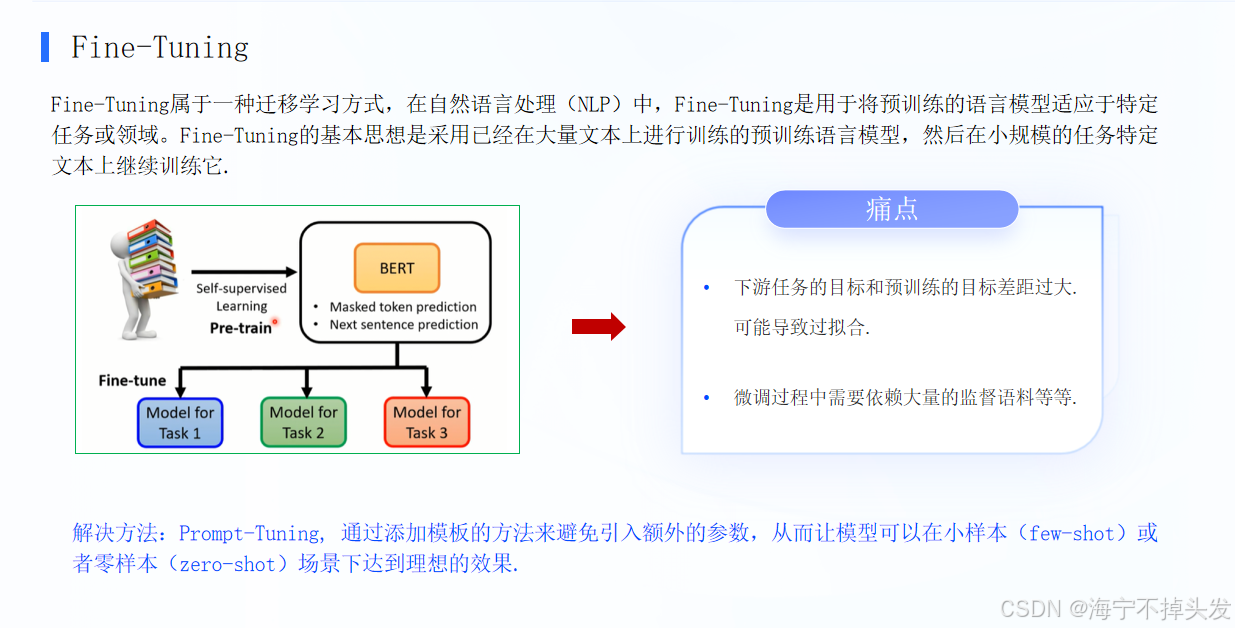
简单说,就是不用改模型本身的参数,只靠「写提示词(prompt)」,就让大模型学会新任务的方法。
- 对比传统的「Fine-tuning(全参数微调)」:以前要给模型喂大量数据、改它的内部参数,成本高、门槛高;
- 现在大模型(比如GPT-3这种参数超10亿的)足够大、训练数据足够多,只要给对提示词,就能直接用,不用重新训练,效果甚至比全微调还好。
2. 为什么大模型能做到?
核心就3点:
- 模型参数够多(相当于脑子够大)
- 训练用的语料够多(见多识广)
- 预训练任务设计得够好(学的东西够扎实)
二、3种常用的「写提示词」方法,人话拆解
01 上下文学习(In-Context Learning)
人话:给模型举几个例子,它就会做了
- 操作:不用给模型喂成千上万条数据,只需要在提示词里放3-5个「问题+答案」的小样本,模型就能自己学会这个任务的规律,直接输出正确结果。
- 举个例子:你要让模型做「把中文翻译成英文」,不用重新训练,只需要在prompt里写: 你好 → Hello
谢谢 → Thank you
再见 → Goodbye
早上好 → ?
模型就能自己输出「Good morning」。
- 本质:靠模型的「上下文理解能力」,从少量例子里举一反三。
02 指令学习(Instruction-Tuning)
人话:给模型说清楚「你要做什么」,它就会做了
- 操作:不用给例子,直接用清晰的指令告诉模型任务要求,比如「请把下面的句子总结成100字以内的摘要」「请用Python写一个冒泡排序的代码」。
- 进阶玩法:给模型喂一堆「指令+对应答案」的数据集做预训练,让模型学会「听懂人类指令」,之后就能适配各种不同的任务。
- 本质:让模型学会「遵循指令」,不管什么任务,只要说清楚要求,就能执行。
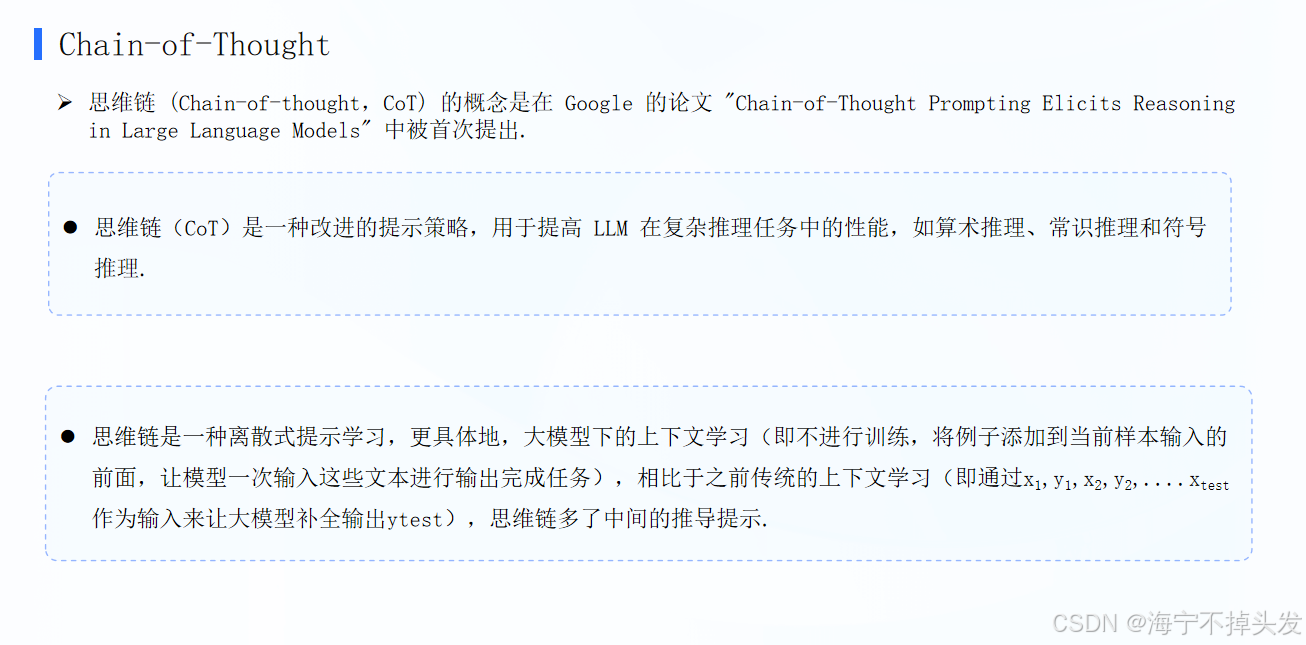
03 思维链(Chain-of-Thought, CoT)
人话:让模型「一步一步想」,别直接给答案
- 操作:在提示词里加一句「请一步一步思考,写出你的推理过程,再给出最终答案」,或者直接给一个「分步推理」的例子。
- 举个例子:做数学题「小明有5个苹果,吃了2个,又买了3个,现在有几个?」
普通prompt:直接问答案,模型可能瞎算;
CoT prompt:「请一步一步计算:小明原本有5个,吃了2个后剩5-2=3个,又买了3个,3+3=6个,所以答案是6」,模型就会跟着这个逻辑一步步推理,正确率大幅提升。 - 本质:激发模型的推理能力,让它把「思考过程」说出来,而不是直接蹦结果,解决复杂问题更靠谱。
三、一句话总结
Prompt-Tuning 就是大模型时代的「零成本/低成本用模型」方法:
- 小任务:给几个例子(上下文学习)
- 通用任务:说清楚要求(指令学习)
- 复杂推理任务:让它一步步想(思维链)
不用改模型、不用训模型,靠「写好提示词」就能让大模型干活,是现在AI应用最核心的技术之一。
要不要我再给你补一份这3种方法的实战prompt模板,你可以直接复制用?


🧠 思维链(CoT):一句话说透
就是让大模型「把思考过程说出来,再给答案」,别直接蹦结果,大幅提升复杂问题的正确率。
一、人话拆解核心
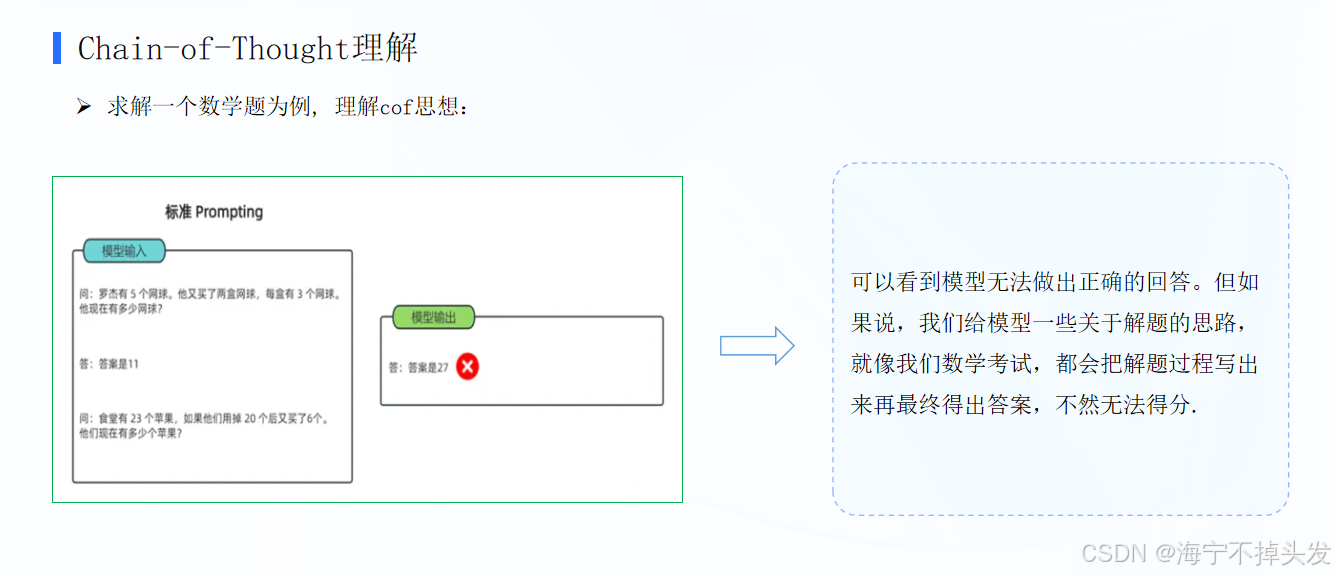
1. 它是干嘛的?
专门解决大模型「做数学题、逻辑题、推理题容易瞎蒙」的问题。
- 以前:你问「小明有5个苹果,吃了2个,又买了3个,现在有几个?」,模型直接给「6」,但你不知道它是算对的还是蒙对的;
- 用了思维链:你让它「一步一步想,写出计算过程再给答案」,模型会输出: 第一步:原本有5个,吃了2个,5-2=3个
第二步:又买了3个,3+3=6个
最终答案:6
不仅结果对,还能保证逻辑是通的,不会瞎算。
2. 它和普通提示词的区别?
- 传统上下文学习 :只给「问题+答案」的例子,比如: 问题1:5-2=? 答案:3
问题2:3+3=? 答案:6
问题3:5-2+3=? 答案:?
模型只学「输入→输出」的映射,中间逻辑是黑盒,复杂题容易错。
- 思维链(CoT) :给「问题+推导过程+答案」的例子,多了中间的思考步骤,让模型学会「先推理,再给结果」。
3. 它的本质是什么?
- 是一种不用改模型、不用训练,只靠改提示词就能提升大模型推理能力的技巧;
- 核心是「把人类的分步思考逻辑,教给大模型」,让它模仿人类的思考方式解题,而不是靠概率瞎猜。
二、一句话总结
思维链 = 「让大模型写解题步骤」,专治大模型做复杂题「脑子一热瞎给答案」的毛病,零成本提升推理正确率。
要不要我给你几个直接复制就能用的思维链prompt模板,不管是数学题、逻辑题还是代码题都能用?
2.PEFT大模型参数高效微调方法原理
🧩 Prefix-Tuning 大白话解释
一、核心一句话
Prefix-Tuning 是一种「只改一点点,不碰大模型本体」的低成本微调方法:给大模型加一段专属的「任务前缀」,只训练这段前缀的参数,大模型本身完全不动,就能适配不同任务。
二、人话拆解原理
1. 先搞懂它解决了什么问题
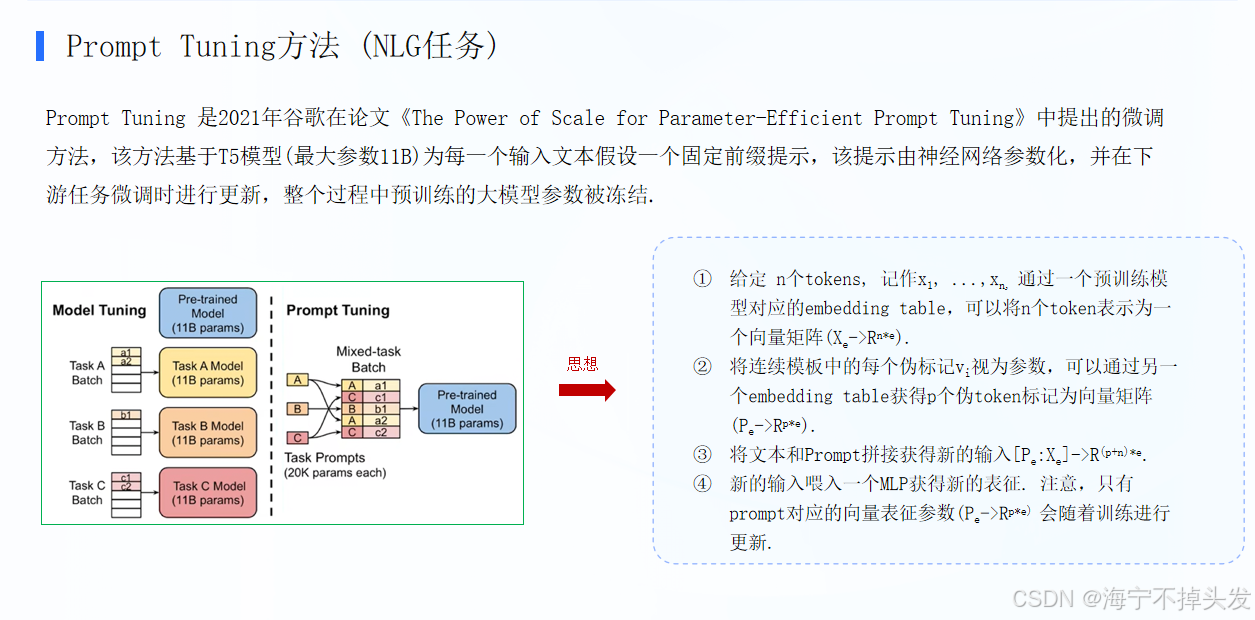
传统全量微调(Fine-tuning):
- 要给大模型做新任务(比如翻译、摘要、表格转文本),就得把整个大模型的所有参数都重新训练一遍
- 缺点:成本极高(大模型参数动辄几十亿上百亿)、每个任务都要存一整套完整模型、容易把大模型原本的能力训坏(灾难性遗忘)
Prefix-Tuning 就是来解决这个问题的:
- 不用改大模型本体,只在输入内容的最前面,加一段「虚拟前缀(virtual tokens)」
- 训练时,只更新这段前缀的参数,大模型的所有参数完全冻结不动
- 不同任务,只需要训练不同的前缀,大模型本体共用一套,成本直接砍到地板
2. 结合图里的例子更直观
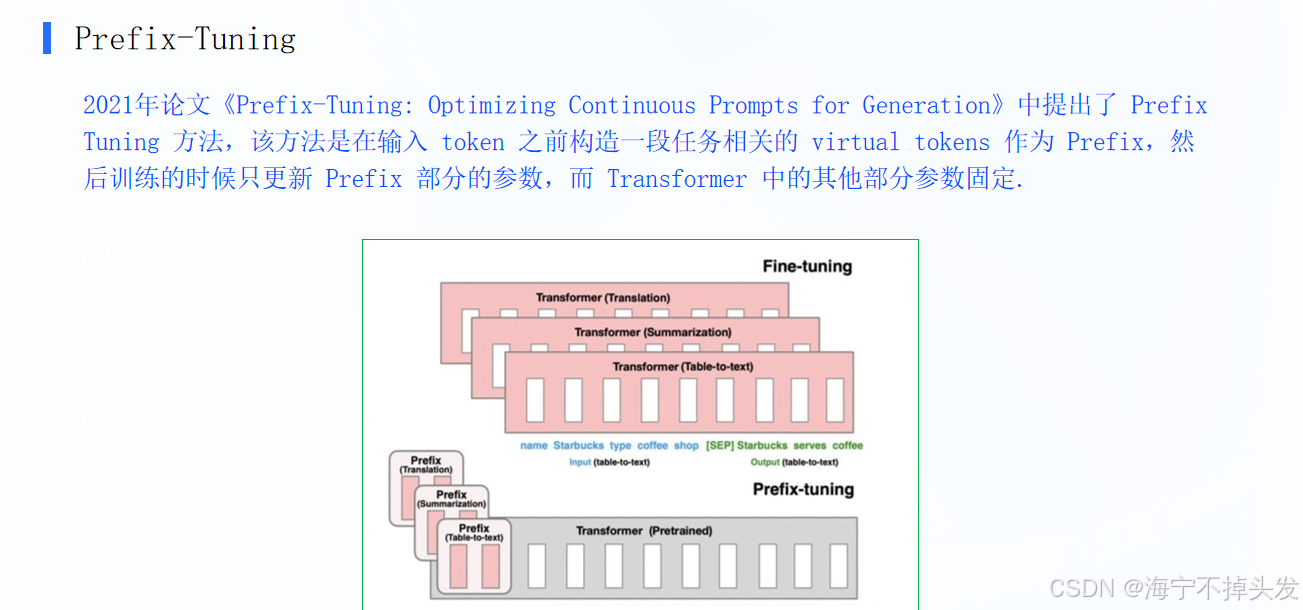
- 上方「Fine-tuning」:翻译、摘要、表格转文本3个任务,每个任务都要单独训一整个Transformer模型,3个任务3套完整模型,红色部分全是要训的参数
- 下方「Prefix-tuning」:3个任务共用同一个预训练好的Transformer大模型(灰色部分完全不动),只给每个任务加一段专属的「Prefix(粉色小方块)」,只训这一点点参数,3个任务只需要存3个小前缀,不用存3个大模型
3. 它的本质是什么?
相当于给大模型装了「任务插件」:
- 大模型是电脑主机(完全不动)
- 不同任务是不同的软件(只需要装对应的插件/驱动,也就是Prefix)
- 不用换主机,只换插件,就能让主机跑不同的任务,成本极低、效率极高
三、核心优势(对比全量微调)
| 特性 | 全量Fine-tuning | Prefix-Tuning |
|---|---|---|
| 训练成本 | 极高(训整个大模型) | 极低(只训前缀) |
| 模型存储 | 每个任务存一整套大模型 | 只存小前缀,共用一个大模型 |
| 大模型能力 | 容易训坏、遗忘 | 完全保留预训练能力,无遗忘 |
| 多任务适配 | 麻烦,每个任务单独训 | 简单,只训不同前缀,快速切换 |
四、一句话总结
Prefix-Tuning = 给大模型加「任务专属前缀」,只训前缀、不动本体,用极低的成本让大模型适配各种任务,是大模型时代的「轻量微调神器」。
要不要我再给你补一份Prefix-Tuning和LoRA、Prompt-Tuning的对比表,帮你彻底分清这几种轻量微调方法的区别?
🧩 超简短版 Prefix-Tuning 任务形式解释
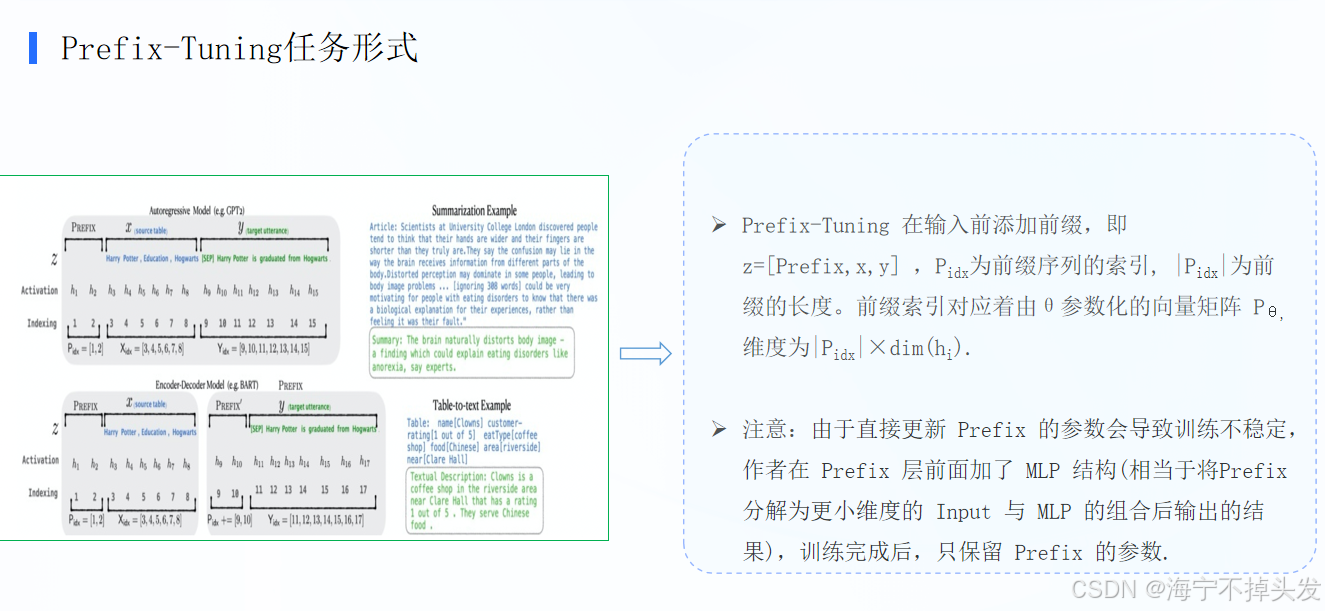
1. 核心用法
给大模型输入加一段专属前缀(Prefix),只训前缀参数,模型本体完全不动,适配不同任务。
- GPT类自回归模型:前缀加在整个输入最前面
- BART类编解码模型:编码器、解码器两侧都加专属前缀
2. 输入结构
z = [Prefix, x, y]
Prefix:任务专属前缀(只训这部分)x:源数据、y:目标输出(全程冻结不动)- 前缀是一个小参数矩阵,维度为「前缀长度 × 模型隐藏层维度」
3. 关键优化
直接训前缀易不稳定,加MLP辅助训练(把前缀拆成小输入+MLP映射),训练完只保留最终前缀参数,MLP可丢弃。
一句话总结:给模型加任务专属前缀,只训前缀、不动本体,用MLP稳训练,低成本适配多任务。

第二部分 大模型提示工程指南











5.迭代优化

文本转换

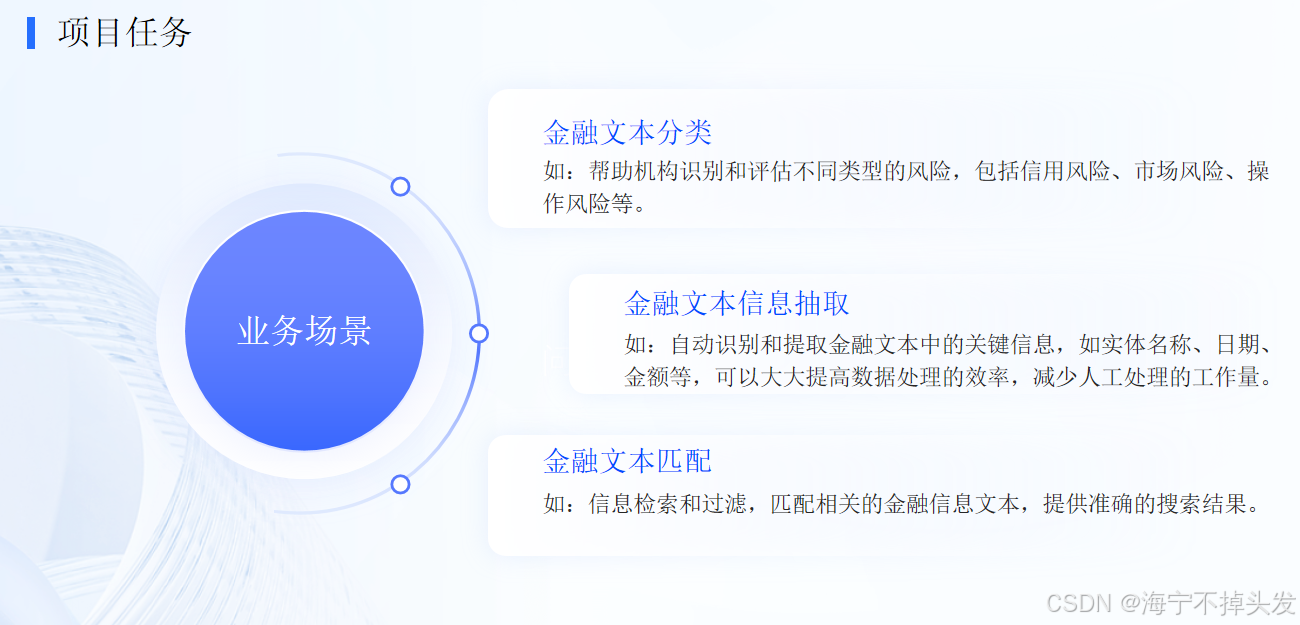
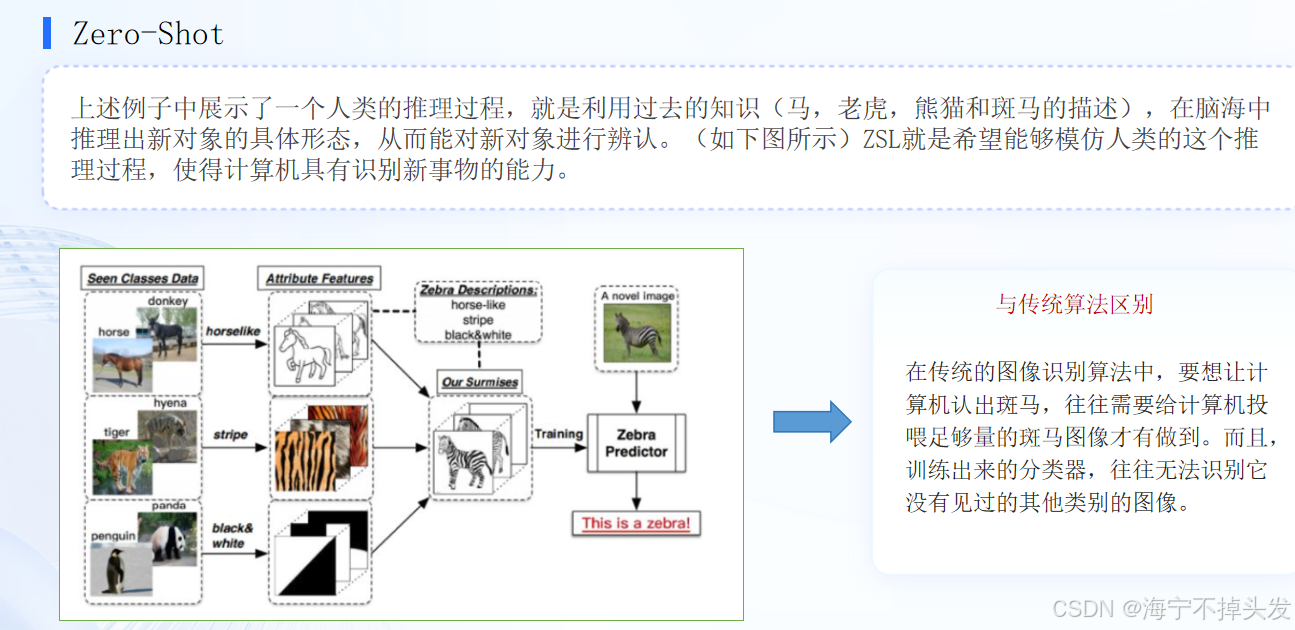
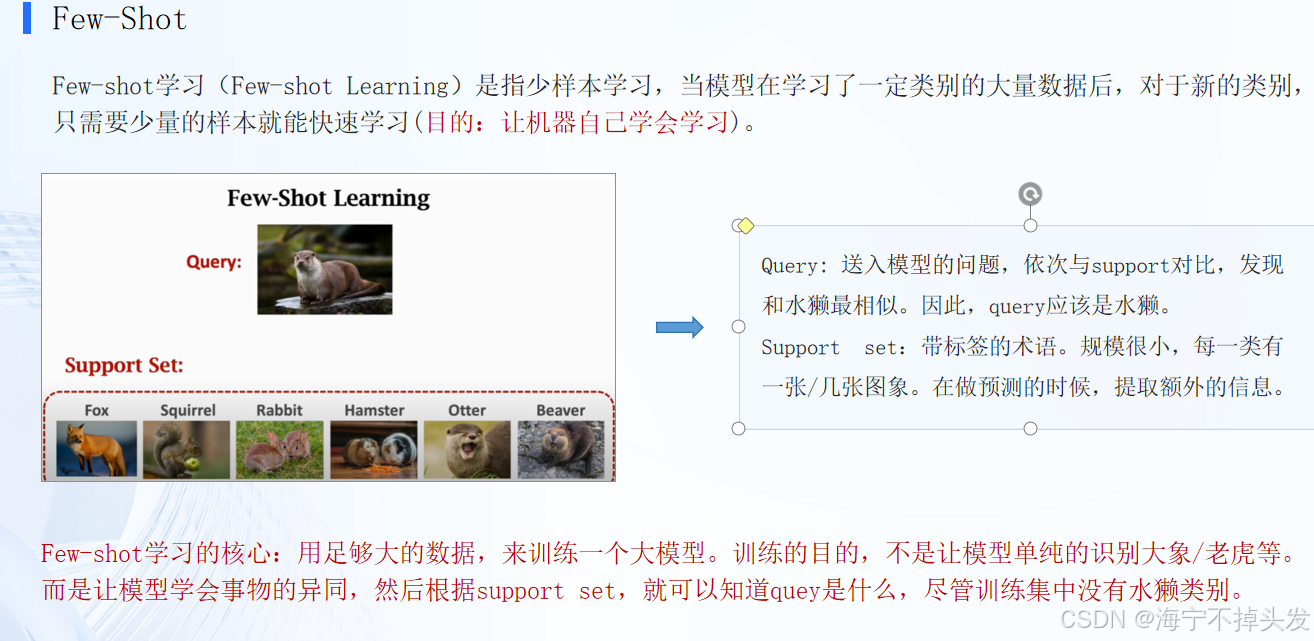
金融行业动态方向评估项目




项目任务与方法介绍


LLM实现金融文本分类
LLM实现金融文本信息抽取

LLM实现金融文本匹配


笔记
1 金融行业动态方向评估任务介绍
-
背景介绍:
properties当前金融领域数据大量激增, 如何从繁杂的数据中获取有效的信息, 进而帮助投资者或者研究者减少决策失误带来的损失,成为金融数据分析方法研究的热门话题。 随着科技的进步,人工智能技术在各行业中的应用越来越广泛,而金融领域也不例外。人工智能技术的应用可以为金融企业提供更高效、精准的服务,也可以帮助投资者更好的地进行投资决策。 -
大模型应用三种场景:
- 金融文本分类
- 金融信息抽取
- 金融文本匹配
-
任务目的:基于金融领域数据,实现LLM的直接应用,重点是掌握Prompt的书写方式
2 金融文本分类
-
目的
properties举例说明: "公司资产负债表显示,公司偿债能力强劲,现金流充足,为未来投资和扩张提供了坚实的财务基础。" 判断上述这句话描述的是['新闻报道', '公司公告', '财务公告', '分析师报告']中哪一种类型的报告。 -
prompt设计
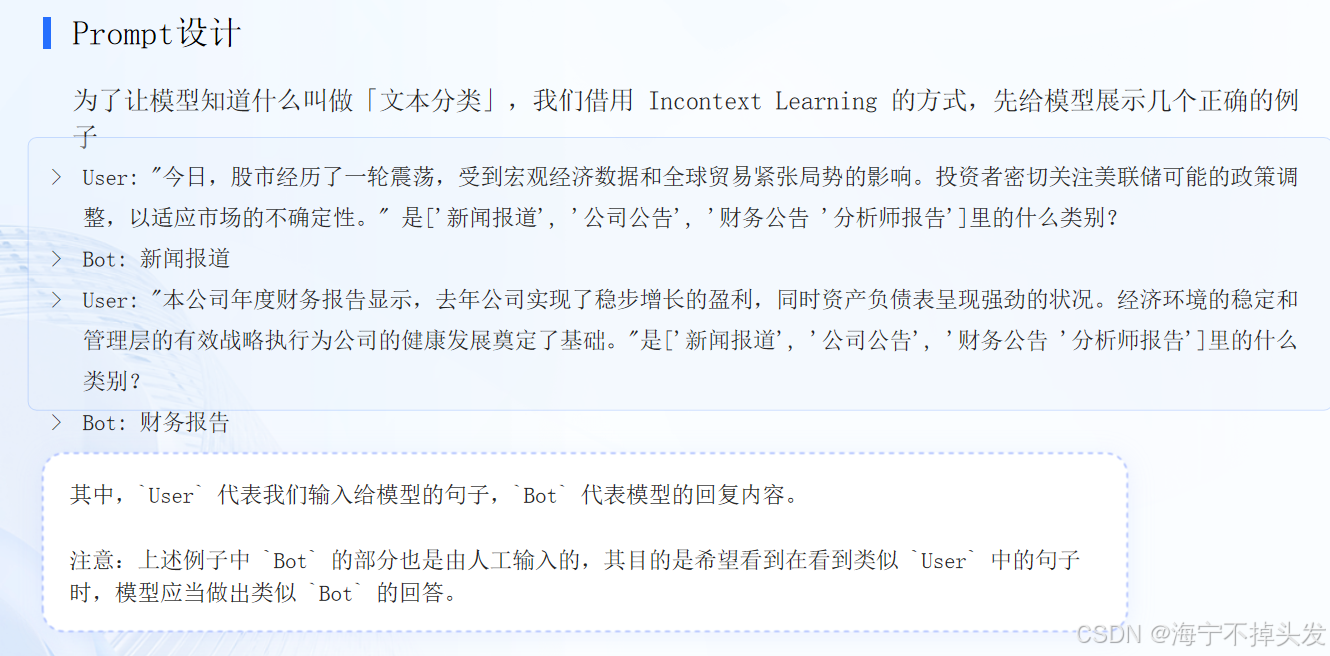
properties要点: 向模型解释什么叫作「文本分类任务」; 需要让模型按照我们指定的格式输出为了让模型知道什么叫做「文本分类」,我们借用 Incontext Learning 的方式,先给模型展示几个正确的例子
User: "今日,股市经历了一轮震荡,受到宏观经济数据和全球贸易紧张局势的影响。投资者密切关注美联储可能的政策调整,以适应市场的不确定性。" 是'新闻报道', '公司公告', '财务公告 '分析师报告'里的什么类别?
Bot: 新闻报道
User: "本公司年度财务报告显示,去年公司实现了稳步增长的盈利,同时资产负债表呈现强劲的状况。经济环境的稳定和管理层的有效战略执行为公司的健康发展奠定了基础。"是'新闻报道', '公司公告', '财务公告 '分析师报告'里的什么类别?
Bot: 财务报告
-
代码实现
python# ---*-coding:utf-8-*- """ 利用 LLM 进行文本分类任务。 """ # 注意:pip install rich from rich import print from rich.console import Console import ollama # 提供所有类别以及每个类别下的样例 class_examples = { '新闻报道': '今日,股市经历了一轮震荡,受到宏观经济数据和全球贸易紧张局势的影响。投资者密切关注美联储可能的政策调整,以适应市场的不确定性。', '财务报告': '本公司年度财务报告显示,去年公司实现了稳步增长的盈利,同时资产负债表呈现强劲的状况。经济环境的稳定和管理层的有效战略执行为公司的健康发展奠定了基础。', '公司公告': '本公司高兴地宣布成功完成最新一轮并购交易,收购了一家在人工智能领域领先的公司。这一战略举措将有助于扩大我们的业务领域,提高市场竞争力', '分析师报告': '最新的行业分析报告指出,科技公司的创新将成为未来增长的主要推动力。云计算、人工智能和数字化转型被认为是引领行业发展的关键因素,投资者应关注这些趋势'} def init_prompts(): """ 初始化前置prompt,便于模型做 incontext learning。 """ class_list = list(class_examples.keys()) pre_history = [{"role": "system", "content": f"现在你是一个文本分类器,你需要按照要求将我给你的句子分类到:{class_list}类别中。"}, ] for _type, exmpale in class_examples.items(): pre_history.append({"role": "user", "content": f'"{exmpale}"是 {class_list} 里的什么类别?'}) pre_history.append({"role": "assistant", "content": _type}) return {'class_list': class_list, 'pre_history': pre_history} def inference( sentences: list, custom_settings: dict ): """ 推理函数。 Args: sentences (List[str]): 待推理的句子。 custom_settings (dict): 初始设定,包含人为给定的 few-shot example。 """ for sentence in sentences: with console.status("[bold bright_green] Model Inference..."): sentence_with_prompt = f""{sentence}"是 {custom_settings['class_list']} 里的什么类别?" response = ollama.chat(model='qwen2.5:7b', messages=[*custom_settings['pre_history'], {"role": 'user', "content": sentence_with_prompt}]) response = response["message"]["content"] print(f'>>> [bold bright_red]sentence: {sentence}') print(f'>>> [bold bright_green]inference answer: {response}') # print(history) if __name__ == '__main__': console = Console() sentences = [ "今日,央行发布公告宣布降低利率,以刺激经济增长。这一降息举措将影响贷款利率,并在未来几个季度内对金融市场产生影响。", "本公司宣布成功收购一家在创新科技领域领先的公司,这一战略性收购将有助于公司拓展技术能力和加速产品研发。", "公司资产负债表显示,公司偿债能力强劲,现金流充足,为未来投资和扩张提供了坚实的财务基础。", "最新的分析报告指出,可再生能源行业预计将在未来几年经历持续增长,投资者应该关注这一领域的投资机会", ] custom_settings = init_prompts() print(custom_settings) inference( sentences, custom_settings )
3 金融文本信息抽取
-
目的
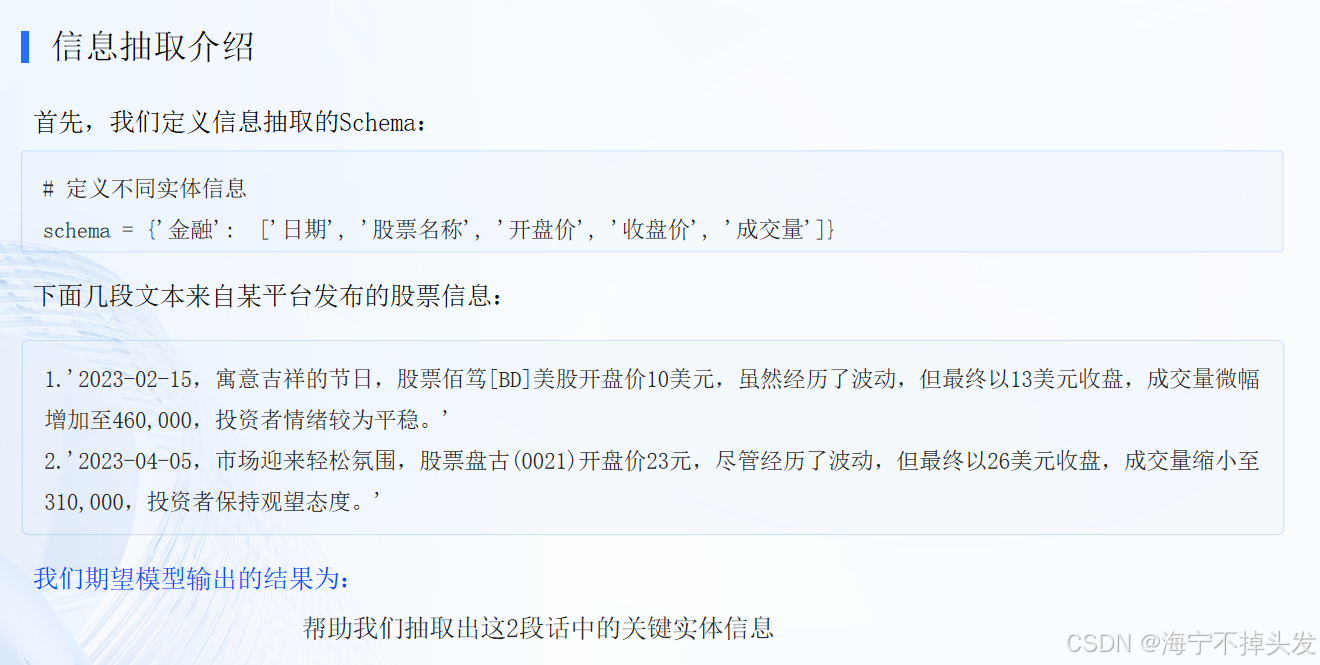
properties举例说明: "2023-02-15,寓意吉祥的节日,股票佰笃[BD]美股开盘价10美元,虽然经历了波动,但最终以13美元收盘,成交量微幅增加至460,000,投资者情绪较为平稳。" 抽取上述这句话中的 ['日期', '股票名称', '开盘价', '收盘价', '成交量']关键信息。 -
prompt设计
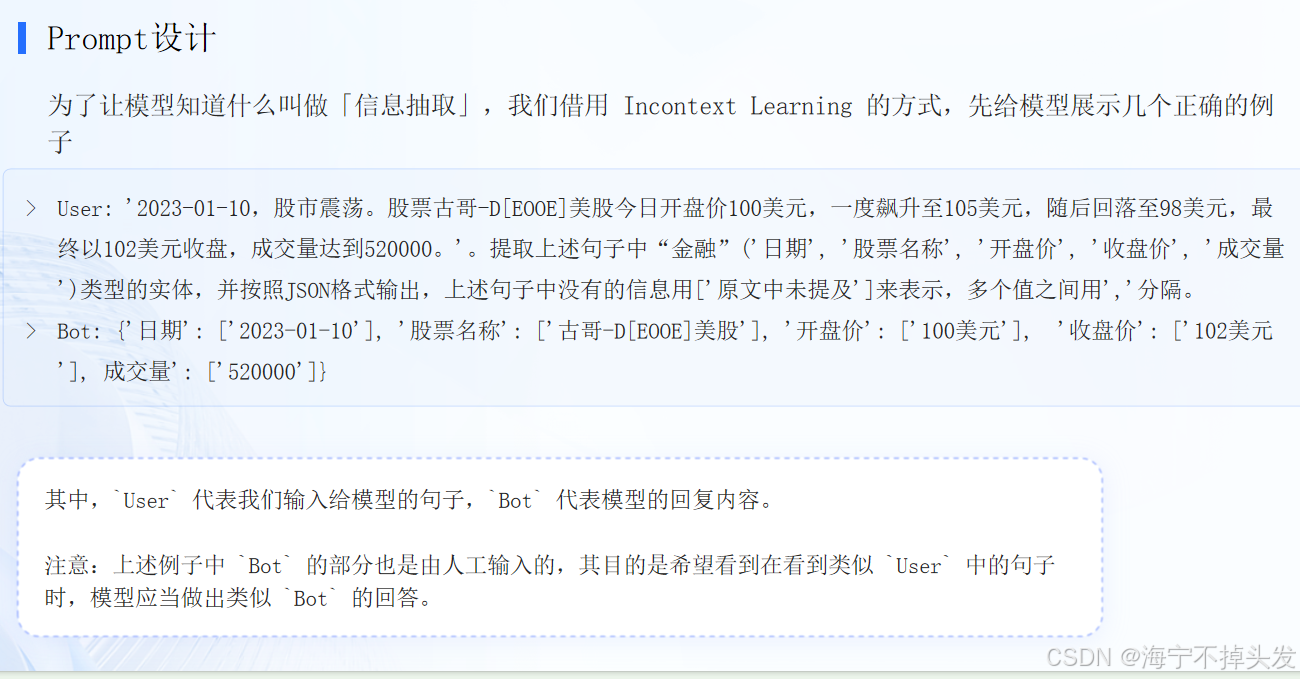
properties要点: 向模型解释什么叫作「信息抽取任务」; 让模型按照我们指定的格式(json)输出为了让模型知道什么叫做「信息抽取」,我们借用 Incontext Learning 的方式,先给模型展示几个正确的例子
User: '2023-01-10,股市震荡。股票古哥-DEOOE美股今日开盘价100美元,一度飙升至105美元,随后回落至98美元,最终以102美元收盘,成交量达到520000。'。提取上述句子中"金融"('日期', '股票名称', '开盘价', '收盘价', '成交量')类型的实体,并按照JSON格式输出,上述句子中没有的信息用'原文中未提及'来表示,多个值之间用','分隔。
Bot: {'日期': '2023-01-10', '股票名称': '古哥-D\[EOOE美股'], '开盘价': '100美元', '收盘价': '102美元', 成交量': '520000'}
-
代码实现
pythonimport json import ollama import re # 定义不同实体下的具备属性 schema = { '金融': ['日期', '股票名称', '开盘价', '收盘价', '成交量'], } IE_PATTERN = "{}\n\n提取上述句子中{}的实体,并按照JSON格式输出,上述句子中不存在的信息用['原文中未提及']来表示,多个值之间用','分隔。" # 提供一些例子供模型参考 ie_examples = { '金融': [ { 'content': '2023-01-10,股市震荡。股票古哥-D[EOOE]美股今日开盘价100美元,一度飙升至105美元,随后回落至98美元,最终以102美元收盘,成交量达到520000。', 'answers': { '日期': ['2023-01-10'], '股票名称': ['古哥-D[EOOE]美股'], '开盘价': ['100美元'], '收盘价': ['102美元'], '成交量': ['520000'], } } ] } def init_prompts(): """ 初始化前置prompt,便于模型做 incontext learning。 """ ie_pre_history = [{"role": "system", "content": "你是一个信息抽取助手。"},] for _type, example_list in ie_examples.items(): for example in example_list: sentence = example['content'] properties_str = ', '.join(schema[_type]) schema_str_list = f'"{_type}"({properties_str})' sentence_with_prompt = IE_PATTERN.format(sentence, schema_str_list) ie_pre_history.append({"role": "user", "content": f'{sentence_with_prompt}'}) ie_pre_history.append({"role": "assistant", "content": f"{json.dumps(example['answers'], ensure_ascii=False)}"}) return {'ie_pre_history': ie_pre_history} def clean_response(response: str): """ 后处理模型输出。 Args: response (str): _description_ """ # response1='```json["name":lucy]```abc```json["name":lucy]```' if '```json' in response: res = re.findall(r'```json(.*?)```', response, re.DOTALL) if len(res) and res[0]: response = res[0] response.replace('、', ',') try: return json.loads(response) except: return response def inference( sentences: list, custom_settings: dict ): """ 推理函数。 Args: sentences (List[str]): 待抽取的句子。 custom_settings (dict): 初始设定,包含人为给定的 few-shot example。 """ for sentence in sentences: cls_res = "金融" if cls_res not in schema: print(f'The type model inferenced {cls_res} which is not in schema dict, exited.') exit() properties_str = ', '.join(schema[cls_res]) schema_str_list = f'"{cls_res}"({properties_str})' sentence_with_ie_prompt = IE_PATTERN.format(sentence, schema_str_list) # print(f'sentence_with_ie_prompt-->{sentence_with_ie_prompt}') # 使用 Ollama 调用 Qwen2.5:7b 模型 response = ollama.chat( model="qwen2.5:7b", messages=[ *custom_settings['ie_pre_history'], {"role": "user", "content": sentence_with_ie_prompt} ] ) res_content = response["message"]["content"] ie_res = clean_response(res_content) print(f'>>> [bold bright_red]sentence: {sentence}') print(f'>>> [bold bright_green]inference answer: {ie_res}') if __name__ == '__main__': # 初始化句子和自定义设置 sentences = [ '2023-02-15,寓意吉祥的节日,股票佰笃[BD]美股开盘价10美元,虽然经历了波动,但最终以13美元收盘,成交量微幅增加至460,000,投资者情绪较为平稳。', '2023-04-05,市场迎来轻松氛围,股票盘古(0021)开盘价23元,尽管经历了波动,但最终以26美元收盘,成交量缩小至310,000,投资者保持观望态度。', ] # 初始化自定义设置 custom_settings = init_prompts() # 开始推理 inference( sentences, custom_settings )
4 金融文本匹配
-
目的
properties举例说明: "股票市场今日大涨,投资者乐观。', '持续上涨的市场让投资者感到满意。" 判断上述这两句话属于['相似', '不相似', '相似']中哪一种类型。 -
prompt设计
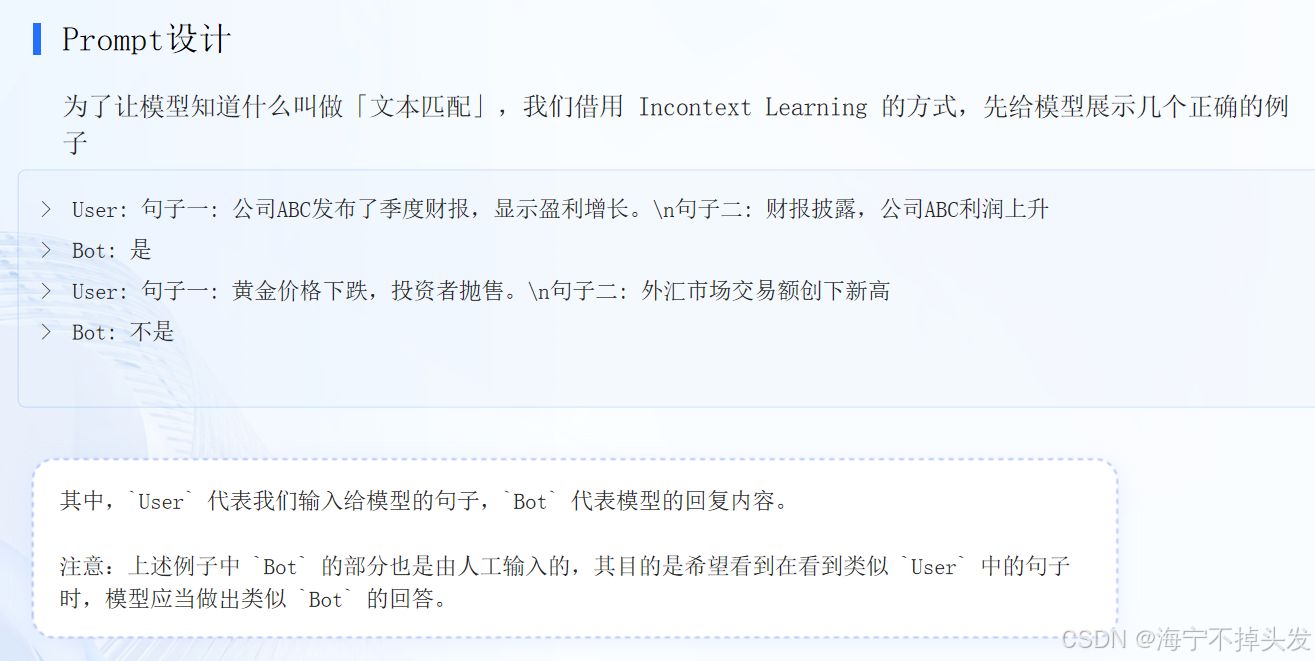
properties要点: 向模型解释什么叫作「文本匹配任务」; 需要让模型按照我们指定的格式输出为了让模型知道什么叫做「文本匹配」,我们借用 Incontext Learning 的方式,先给模型展示几个正确的例子
User: 句子一: 公司ABC发布了季度财报,显示盈利增长。\n句子二: 财报披露,公司ABC利润上升
Bot: 是
User: 句子一: 黄金价格下跌,投资者抛售。\n句子二: 外汇市场交易额创下新高
Bot: 不是
-
代码实现
python# !/usr/bin/env python3 """ 利用 LLM 进行文本匹配任务。 """ from rich import print import ollama # 提供相似,不相似的语义匹配例子 examples = { '是': [ ('公司ABC发布了季度财报,显示盈利增长。', '财报披露,公司ABC利润上升。'), ], '不是': [ ('黄金价格下跌,投资者抛售。', '外汇市场交易额创下新高。'), ('央行降息,刺激经济增长。', '新能源技术的创新。') ] } def init_prompts(): """ 初始化前置prompt,便于模型做 incontext learning。 """ pre_history = [{"role": "system", "content": "现在你需要帮助我完成文本匹配任务,当我给你两个句子时,你需要回答我这两句话语义是否相似。只需要回答是否相似,不要做多余的回答。"}, ] for key, sentence_pairs in examples.items(): for sentence_pair in sentence_pairs: sentence1, sentence2 = sentence_pair pre_history.append({"role": "user", "content": f'句子一: {sentence1}\n句子二: {sentence2}\n上面两句话是相似的语义吗?'}) pre_history.append({"role": "assistant", "content": key}) return {'pre_history': pre_history} def inference( sentence_pairs: list, custom_settings: dict ): """ 推理函数。 Args: model (transformers.AutoModel): Language Model 模型。 sentence_pairs (List[str]): 待推理的句子对。 custom_settings (dict): 初始设定,包含人为给定的 few-shot example。 """ for sentence_pair in sentence_pairs: sentence1, sentence2 = sentence_pair sentence_with_prompt = f'句子一: {sentence1}\n句子二: {sentence2}\n上面两句话是相似的语义吗?' response = ollama.chat(model="qwen2.5:7b", messages=[*custom_settings["pre_history"], {"role":'user', "content":sentence_with_prompt}]) response = response["message"]["content"] print(f'>>> [bold bright_red]sentence: {sentence_pair}') print(f'>>> [bold bright_green]inference answer: {response}') if __name__ == '__main__': sentence_pairs = [ ('股票市场今日大涨,投资者乐观。', '持续上涨的市场让投资者感到满意。'), ('油价大幅下跌,能源公司面临挑战。', '未来智能城市的建设趋势愈发明显。'), ('利率上升,影响房地产市场。', '高利率对房地产有一定冲击。'), ] custom_settings = init_prompts() # print(f'custom_settings-->{custom_settings}') inference( sentence_pairs, custom_settings )
总结
全文极简通俗总结
机器学习概述
机器学习是人工智能的一个核心分支,它使计算机系统能够从数据中"学习"并改进性能,而无需显式编程。以下是关于机器学习的详细介绍:
基本概念
机器学习算法通过分析大量数据来识别模式并做出决策。与传统的硬编码程序不同,机器学习系统会随着处理更多数据而自动提高准确性。
主要类型
-
监督学习:
- 使用标记数据进行训练
- 示例:垃圾邮件分类、房价预测
- 常见算法:线性回归、决策树、支持向量机
-
无监督学习:
- 处理未标记数据
- 示例:客户细分、异常检测
- 常见算法:K-means聚类、主成分分析
-
强化学习:
- 通过奖励机制学习
- 示例:游戏AI、机器人控制
- 常见算法:Q-learning、深度Q网络
应用领域
- 计算机视觉:图像识别、目标检测
- 自然语言处理:机器翻译、情感分析
- 推荐系统:电商产品推荐、内容推送
- 医疗诊断:疾病预测、医学影像分析
- 金融科技:信用评分、欺诈检测
技术流程
典型机器学习项目包括以下步骤:
- 数据收集与清洗
- 特征工程
- 模型选择与训练
- 模型评估
- 部署与监控
发展趋势
当前机器学习领域的重要发展方向包括:
- 深度学习
- 自动化机器学习(AutoML)
- 可解释AI
- 联邦学习
- 边缘计算中的机器学习
随着计算能力的提升和数据量的增长,机器学习正在改变各行各业的运作方式,成为数字化转型的关键技术之一。
一、Prompt-Tuning核心知识(原理篇)
Prompt-Tuning的本质,是不用修改、重新训练大模型本体,仅靠优化提示词/轻量微调,就能让大模型低成本适配新任务 ,门槛和成本远低于传统的全量模型微调。
核心包含4个关键方法:
- 上下文学习(Few-shot):给模型3-5个「问题+标准答案」的例子,模型就能举一反三完成同类任务;
- 指令学习:用清晰的话给模型说清任务要求,模型就能直接按要求执行;
- 思维链(CoT):让模型分步写出推理过程再给答案,大幅提升数学、逻辑类复杂问题的正确率;
- Prefix-Tuning:进阶轻量微调方案,给大模型加一段任务专属的「前缀」,训练时只更新前缀参数、完全冻结模型本体,低成本适配多任务,还通过MLP结构解决了训练不稳定的问题。
二、金融场景实战项目(落地篇)
项目核心是用Prompt工程激活大模型能力,零门槛实现金融领域的3个核心NLP任务,无需专业算法训练,非技术人员也能快速上手。
- 金融文本分类:让模型给金融文本打标签,区分新闻报道、公司公告、财务报告、分析师报告等类别;
- 金融信息抽取:从股票相关文本里,精准提取日期、股票名称、开盘价、收盘价、成交量等关键信息,按指定JSON格式输出;
- 金融文本匹配:判断两段金融文本的语义是否相似,用于信息检索、内容过滤等场景。
所有任务均基于Qwen开源大模型,通过ollama本地调用实现,配套了完整可直接运行的Python代码,核心逻辑是用上下文学习写好提示词,让大模型直接完成任务。
一句话终极总结
这篇教程教你不用改大模型、不用重头训练,只靠写好提示词/轻量前缀微调,就能低成本让大模型干活,还手把手教你在金融文本场景落地实战。