什么是LLM做推荐的三种范式?Prompt-based、Embedding-based、Fine-tuning深度解析
🚀 本文收录于Github:AI-From-Zero 项目 ------ 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
by @Laizhuocheng
一、简介
想象你去一家新开的餐厅,服务员有三种方式为你推荐菜品:
- 第一种:服务员直接问你"想吃什么",然后根据你的描述现场思考推荐(像Prompt-based)
- 第二种:餐厅已经把所有菜品的特色标签化,快速匹配你的口味偏好(像Embedding-based)
- 第三种:服务员跟你相处久了,记住了你每次来点的菜,越来越懂你的口味(像Fine-tuning)
这就是大语言模型(LLM)做推荐的三种核心范式。随着ChatGPT的爆火,越来越多人开始探索:能不能让"懂一切"的LLM来帮我们做推荐?本文将深入解析这三种技术路线,帮你理解它们各自的优势和适用场景。
二、什么是LLM推荐的三种范式
简单来说,这三种范式代表了我们对LLM能力利用深度的不同选择:
| 范式 | 核心思路 | 类比 | 技术深度 |
|---|---|---|---|
| Prompt-based | 把LLM当黑盒推理引擎,用自然语言描述推荐任务 | 现场问服务员 | 浅层利用 |
| Embedding-based | 只用LLM的语义编码能力生成特征向量 | 菜品标签系统 | 中层利用 |
| Fine-tuning | 让LLM专门学习推荐任务,深度适配业务 | 专属私人管家 | 深度利用 |
三种范式的投入成本和效果预期是递增的。实际应用中它们经常组合使用,比如用Embedding做召回、Fine-tuned模型做排序、Prompt处理特殊case。
三、三种范式如何工作
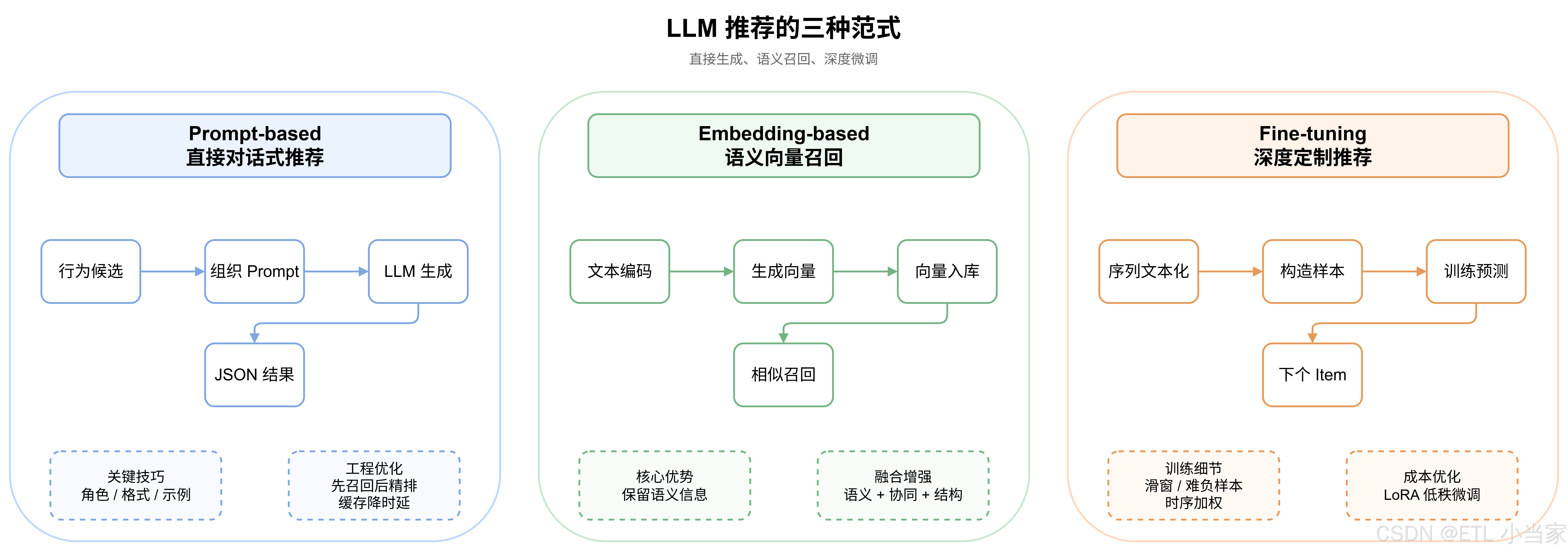
3.1 Prompt-based:直接对话式推荐
这是最直接的方式。你把用户历史行为、候选物品信息通过自然语言组织成prompt,让LLM直接生成推荐结果。
举个例子:
用户最近观看了《人类简史》《时间简史》这两个纪录片,
请从以下列表中推荐三个最相关的视频:
1.《宇宙探秘》 2.《美食之旅》 3.《量子物理入门》...
请按照JSON格式返回结果,包含视频名、推荐理由、相关度评分。关键技巧:
- 角色设定:在prompt开头加上"你是一个资深的图书推荐专家..."
- 格式控制:明确要求输出格式(JSON、列表等)
- Few-shot示例:加几个成功案例让LLM学习推荐模式
工程实践中的优化:
- 候选集太大怎么办?先用传统召回缩小到几十个,再用LLM精排
- 延迟太高怎么办?做多级缓存+异步预生成
3.2 Embedding-based:语义向量召回
这种方式不直接让LLM做决策,而是利用它强大的语义编码能力生成高质量的表征向量。
工作流程:
- 用LLM把商品标题、描述编码成768维向量
- 把向量存入Faiss等向量数据库
- 用户查询时,实时检索最相似的向量
为什么比传统方法好?
传统推荐可能只用到"类目、价格、销量"这些结构化特征。但LLM能把"有机手工阿克苏冰糖心苹果新鲜水果"编码成一个包含"健康""高品质""新鲜"等语义信息的向量。
进阶技巧------多路召回融合:
最终向量 = concat(语义向量, 协同向量, 结构化特征向量)把LLM生成的semantic embedding和传统协同过滤的behavior embedding拼接,既能捕捉语义关系,又能保留"喜欢周杰伦的人也喜欢林俊杰"这种协同信号。
3.3 Fine-tuning:深度定制推荐模型
这是最重的方案------让LLM彻底学习推荐任务本身。
核心思路 :
把用户行为序列化成文本,训练模型预测下一个item:
输入:"用户依次点击了商品A、B、C"
目标:预测下一个item D关键技术细节:
- 滑动窗口构造样本:"A"→"B","A,B"→"C",充分利用序列数据
- Hard Negative采样:选同类目但用户没点的商品做负样本
- 时序权重:最近行为给更高权重
训练成本优化------LoRA技术:
LLM动辄几十亿参数,全量fine-tune太贵。LoRA只在原模型旁加一个低秩矩阵:
- 原权重:4096×4096 = 1600万参数
- LoRA:两个4096×8矩阵 = 6万参数
- 效果损失很小,但成本大幅下降
四、三种范式的优缺点对比
| 维度 | Prompt-based | Embedding-based | Fine-tuning |
|---|---|---|---|
| 数据需求 | 几乎不需要标注数据 | 需要物品描述文本 | 强依赖大量用户行为日志 |
| 计算成本 | 每次推理调用LLM,延迟秒级 | 离线生成向量,在线毫秒级 | 训练成本高,推理可优化 |
| 效果上限 | 最不稳定,但冷启动有优势 | 中等,语义召回效果好 | 通常最好,深度适配业务 |
| 工程复杂度 | 中等,需要设计prompt | 最容易集成到现有系统 | 需要完整的训练pipeline |
| 可解释性 | 强,能生成推荐理由 | 弱,黑盒向量 | 中等 |
| 适用场景 | 冷启动、长尾query、对话推荐 | 大规模语义召回 | 核心推荐链路、追求效果上限 |
选型建议:
- 新上线内容(0曝光)→ Prompt-based
- 已有几千次曝光 → Embedding-based
- 核心场景(首页推荐)→ Fine-tuning
五、实际应用与发展趋势
5.1 实际应用场景
场景1:电商平台的冷启动
新上架的商品没有用户行为数据,直接用商品描述让LLM做语义匹配推荐,零成本上线。
场景2:新闻推荐的长尾query
用户搜索"适合3岁孩子的英语启蒙绘本",传统推荐很难处理这种复杂语义,但LLM能理解并直接给答案。
场景3:音乐平台的混合架构
- 主推荐流:Fine-tuned模型保证效果
- 新歌曲冷启动:Prompt-based做初始推荐
- 搜索功能:Embedding做语义召回
5.2 前沿发展趋势
-
交互式推荐:ICLR的Chat-Rec论文把推荐做成多轮对话,用户可以不断refine推荐结果
-
知识增强:把领域知识图谱注入LLM,增强推荐效果
-
多模态融合:结合文本、图像、视频等多模态信息做推荐
-
特征工程依然重要:单纯用商品标题效果一般,加入评论、问答等UGC内容,召回相关性会明显提升
六、总结与思考
LLM推荐相比传统推荐的本质优势 在于:传统系统做的是"模式识别",基于历史行为的统计规律做预测;而LLM引入了世界知识和推理能力,它不只是记住"买A的人也买B",而是理解A和B在语义上为什么相关。
一句话总结:Prompt-based是"现场问专家",Embedding-based是"建立语义索引",Fine-tuning是"培养专属专家"。成熟的推荐系统会根据不同子场景灵活组合这三种范式------核心链路追求效果上限,冷启动保证覆盖,对话式交互提升体验。
💡 深度思考:当LLM越来越强大,推荐系统的边界在哪里?也许未来的推荐不再是"猜你喜欢",而是"陪你发现"------从被动的信息推送,进化为主动的知识探索伙伴。这不仅是技术的升级,更是人机关系的重新定义。
参考资源:
- RecLLM:LLM推荐综述论文
- Chat-Rec:对话式推荐(ICLR)
- EasyRec:阿里推荐框架