I/O 多路复用:从 select 到 epoll
前言
在上一篇文章中,我们用 BSD Socket API 实现了一个基础的 TCP 服务器。那个服务器的核心逻辑很简单------为每个客户端连接创建一个线程去处理读写。当连接数只有几个的时候,这套方案工作得很好。但想象一下流媒体服务器的真实场景:一个 RTMP 推流服务可能同时承载数百路推流和数千路拉流,一个 WebRTC SFU 需要维持成千上万的 PeerConnection。如果每个连接都占用一个线程,操作系统光线程调度和上下文切换就已经不堪重负了。
这就是 I/O 多路复用 (I/O Multiplexing)要解决的问题:让一个线程同时监听多个文件描述符的 I/O 事件,哪个就绪了就处理哪个。
本文将从最古老的 select 出发,经过 poll,重点讲解 Linux 下的 epoll,最后简要介绍 io_uring。在 epoll 部分,我们会给出一个完整的、使用 ET 模式 + 非阻塞 I/O 的高并发 TCP 服务器实现。
1. 为什么需要 I/O 多路复用
传统阻塞 I/O 的瓶颈
当我们对一个 socket 调用 recv() 时,如果内核接收缓冲区没有数据,当前线程就会被挂起,直到数据到达。这意味着一个线程在同一时刻只能等待一个 socket。
thread-per-connection 模型的问题
为了同时处理多个连接,最直觉的做法是为每个连接创建一个线程:
cpp
while (true) {
int connfd = accept(listenfd, nullptr, nullptr);
std::thread([connfd] {
char buf[4096];
while (true) {
ssize_t n = recv(connfd, buf, sizeof(buf), 0);
if (n <= 0) break;
send(connfd, buf, n, 0);
}
close(connfd);
}).detach();
}这种模型在连接数增大时问题非常明显:
- 内存开销:Linux 默认线程栈大小为 8MB,1000 个连接就需要约 8GB 仅用于栈空间。
- 上下文切换:线程数远超 CPU 核心数时,大量 CPU 时间浪费在线程切换上。
- 创建销毁成本:频繁创建/销毁线程本身就是昂贵操作(即使用线程池也无法根本解决并发上限问题)。
I/O 多路复用的思路完全不同:不再让每个线程死等一个 fd,而是让一个线程同时监听所有 fd,内核告诉我们哪些 fd 就绪了,我们只处理那些就绪的。
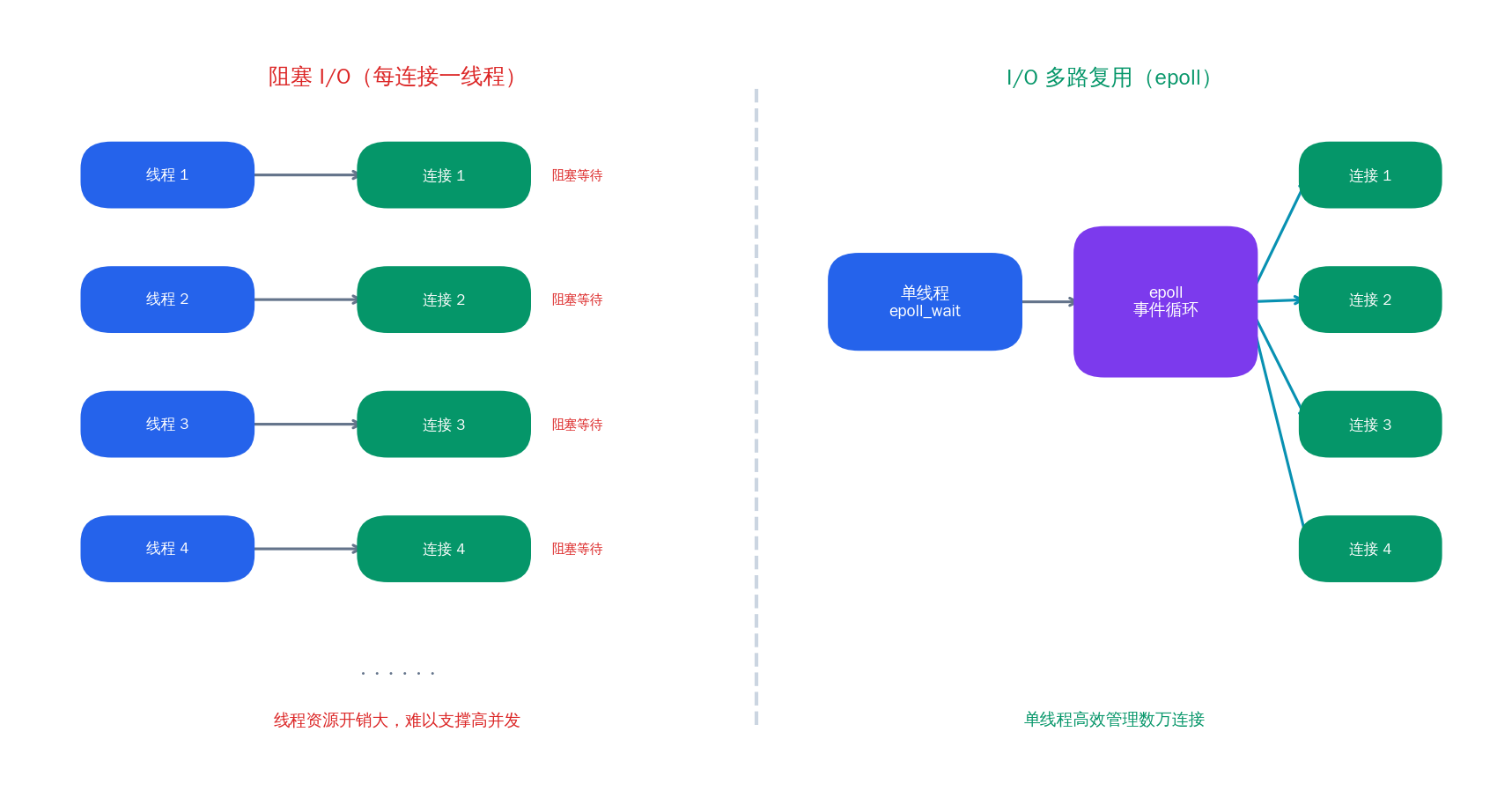
2. select:最古老的多路复用
select 是 POSIX 标准定义的第一个 I/O 多路复用接口,几乎所有类 Unix 系统都支持。
API 原型
cpp
#include <sys/select.h>
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
void FD_ZERO(fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);fd_set 的本质是一个位图 (bitmap),每一位对应一个文件描述符。调用 select 时,我们把要监听的 fd 置位;select 返回后,内核会修改这个位图,只保留就绪的 fd。
使用示例
cpp
fd_set read_fds;
FD_ZERO(&read_fds);
FD_SET(listenfd, &read_fds);
int maxfd = listenfd;
std::vector<int> clients;
while (true) {
fd_set tmp = read_fds;
int ready = select(maxfd + 1, &tmp, nullptr, nullptr, nullptr);
if (ready < 0) break;
if (FD_ISSET(listenfd, &tmp)) {
int connfd = accept(listenfd, nullptr, nullptr);
FD_SET(connfd, &read_fds);
clients.push_back(connfd);
if (connfd > maxfd) maxfd = connfd;
}
for (int fd : clients) {
if (FD_ISSET(fd, &tmp)) {
char buf[4096];
ssize_t n = recv(fd, buf, sizeof(buf), 0);
if (n <= 0) {
close(fd);
FD_CLR(fd, &read_fds);
} else {
send(fd, buf, n, 0);
}
}
}
}select 的三大局限
- fd 数量限制 :
fd_set的大小由FD_SETSIZE决定,通常为 1024。这意味着 select 最多只能监听 1024 个文件描述符------对流媒体服务器来说远远不够。 - 每次调用需重新设置 :
select会修改传入的fd_set,所以每次调用前必须重新设置所有 fd,这带来额外的用户态开销。 - O(n) 遍历 :
select返回后只告诉你"有几个 fd 就绪了",但不告诉你是哪几个。你必须遍历所有被监听的 fd,逐个调用FD_ISSET检查。
3. poll:select 的改进
poll 用一个 pollfd 结构体数组替代了 fd_set 位图:
cpp
#include <poll.h>
struct pollfd {
int fd;
short events; // 关注的事件
short revents; // 实际发生的事件
};
int poll(struct pollfd *fds, nfds_t nfds, int timeout);相比 select 的改进
- 无 fd 数量硬限制 :
pollfd数组大小由用户自己管理,不受FD_SETSIZE约束。 - 输入输出分离 :
events是输入,revents是输出,不会破坏原始设置,无需每次重新填充。
仍然存在的问题
poll 的根本性能瓶颈与 select 一样:每次调用都需要将整个 pollfd 数组从用户态拷贝到内核态,返回后仍然需要 O(n) 遍历整个数组来找出就绪的 fd。当监听上万个连接但活跃的只有几十个时,绝大部分遍历都是浪费。
虽然 revents 标记了哪些 fd 就绪,但这些标记分散在整个数组中,poll 返回的只是就绪 fd 的数量 ,而不是它们的位置。你无法跳过未就绪的元素,只能从头到尾逐个检查 revents 是否非零------这正是 O(n) 开销的来源。后面会看到,epoll_wait 则直接返回一个紧凑的就绪事件列表,从根本上消除了这一问题。
4. epoll:Linux 下的终极方案
epoll 是 Linux 2.6 引入的 I/O 多路复用机制,也是目前 Linux 高性能网络编程的事实标准。Nginx、Redis、流媒体服务器 SRS 等知名项目都基于 epoll 构建。
三个核心 API
cpp
#include <sys/epoll.h>
// 创建 epoll 实例,返回 epoll 文件描述符
int epoll_create1(int flags);
// 添加/修改/删除监听的 fd
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 等待事件就绪
int epoll_wait(int epfd, struct epoll_event *events,
int maxevents, int timeout);与 select/poll 最根本的区别在于:epoll 在内核中维护了一个持久的数据结构 ,注册 fd 是一次性操作(epoll_ctl),而等待事件(epoll_wait)只返回就绪的 fd 列表,无需遍历所有被监听的 fd。
内核实现原理
epoll 在内核中使用两个核心数据结构:
- 红黑树:存储所有被监听的 fd,支持 O(log n) 的增删查。
- 就绪链表 :当某个 fd 上有事件就绪时,内核通过回调函数将其加入就绪链表。
epoll_wait只需要检查这个链表是否为空,非空则直接返回就绪的 fd。
这意味着 epoll_wait 的时间复杂度与就绪的 fd 数量成正比(O(k),k 为就绪数),而非监听的总 fd 数量。这在"大量连接但少量活跃"的流媒体场景下优势极为突出。
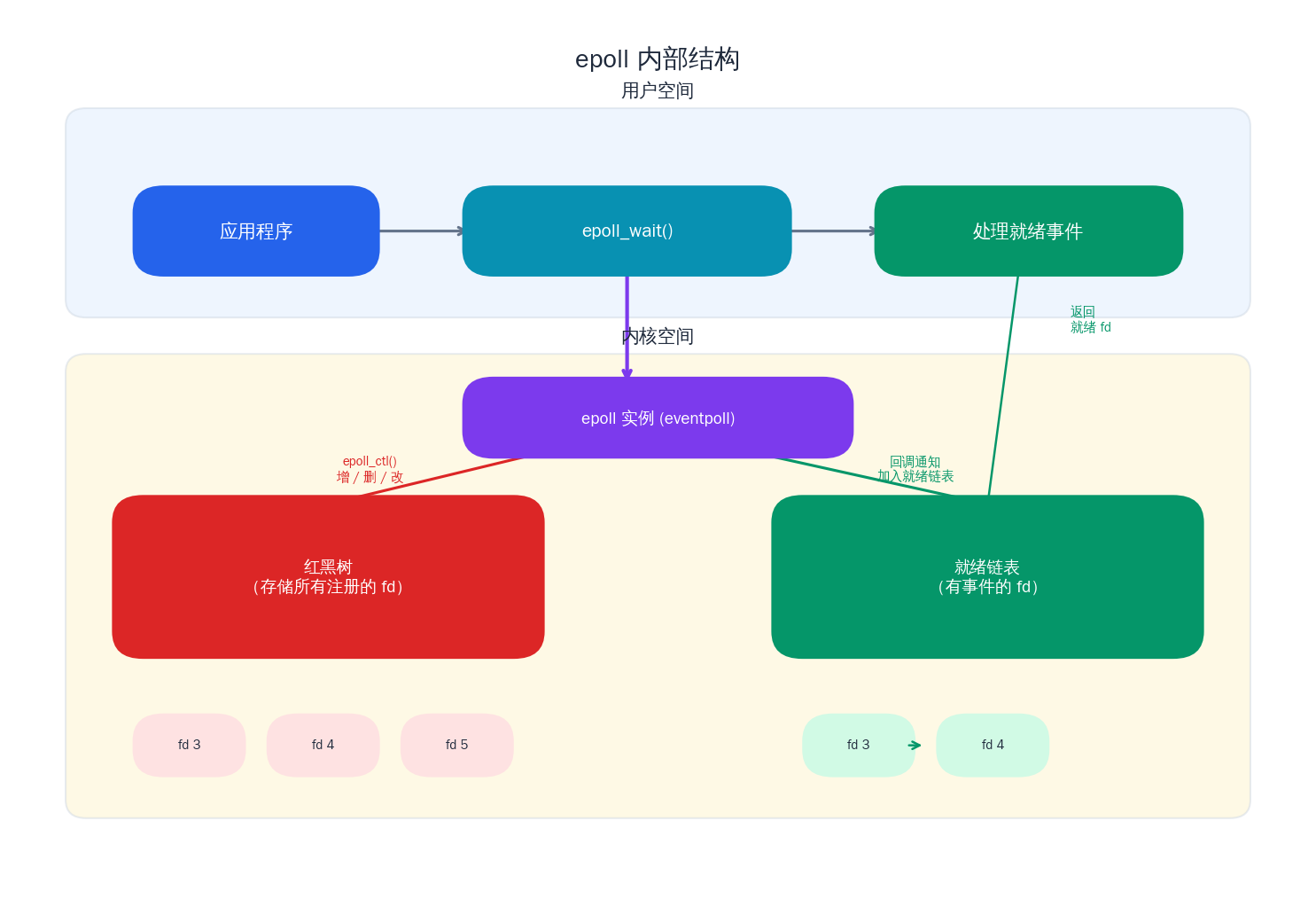
LT vs ET
epoll 支持两种触发模式:
LT(Level Triggered,水平触发) ------默认模式。只要 fd 的缓冲区还有数据可读(或可写),每次 epoll_wait 都会返回该 fd。行为与 select/poll 一致,编程简单,不容易出错。
ET(Edge Triggered,边缘触发) ------只在状态变化 时通知一次。例如新数据到达时通知一次,如果你没读完,epoll_wait 不会再次返回该 fd,直到下一次新数据到达。
ET 模式的优势是减少了 epoll_wait 的返回次数,在高吞吐场景下性能更好。但它有一个硬性要求:必须配合非阻塞 I/O,且必须循环读/写直到返回 EAGAIN。否则数据会残留在缓冲区得不到处理。
在流媒体服务器中,ET + 非阻塞 I/O 是最常见的选择。
实战:用 epoll 构建高并发 TCP 服务器
下面是一个完整可编译的 echo 服务器,使用 ET 模式 + 非阻塞 I/O,可以轻松处理上万并发连接:
cpp
#include <sys/epoll.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <unistd.h>
#include <fcntl.h>
#include <cerrno>
#include <cstring>
#include <cstdio>
#include <vector>
constexpr int kPort = 8080;
constexpr int kMaxEvents = 1024;
void set_nonblocking(int fd) {
int flags = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
}
void add_to_epoll(int epfd, int fd, uint32_t events) {
epoll_event ev{};
ev.events = events;
ev.data.fd = fd;
epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &ev);
}
int create_listen_socket() {
int fd = socket(AF_INET, SOCK_STREAM, 0);
int opt = 1;
setsockopt(fd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
sockaddr_in addr{};
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = INADDR_ANY;
addr.sin_port = htons(kPort);
bind(fd, reinterpret_cast<sockaddr*>(&addr), sizeof(addr));
listen(fd, SOMAXCONN);
set_nonblocking(fd);
return fd;
}
void handle_accept(int listenfd, int epfd) {
while (true) {
int connfd = accept(listenfd, nullptr, nullptr);
if (connfd < 0) {
if (errno == EAGAIN || errno == EWOULDBLOCK) break;
break;
}
set_nonblocking(connfd);
add_to_epoll(epfd, connfd, EPOLLIN | EPOLLET);
}
}
void handle_read(int fd) {
char buf[4096];
while (true) {
ssize_t n = recv(fd, buf, sizeof(buf), 0);
if (n > 0) {
send(fd, buf, n, 0);
} else if (n == 0) {
close(fd);
return;
} else {
if (errno == EAGAIN || errno == EWOULDBLOCK) return;
close(fd);
return;
}
}
}
int main() {
int listenfd = create_listen_socket();
int epfd = epoll_create1(0);
add_to_epoll(epfd, listenfd, EPOLLIN | EPOLLET);
std::vector<epoll_event> events(kMaxEvents);
std::printf("epoll echo server listening on port %d\n", kPort);
while (true) {
int nready = epoll_wait(epfd, events.data(), kMaxEvents, -1);
for (int i = 0; i < nready; ++i) {
int fd = events[i].data.fd;
if (fd == listenfd) {
handle_accept(listenfd, epfd);
} else if (events[i].events & EPOLLIN) {
handle_read(fd);
}
}
}
close(listenfd);
close(epfd);
return 0;
}编译运行:
bash
g++ -std=c++17 -O2 -o epoll_echo epoll_echo.cpp
./epoll_echo可以用 telnet 127.0.0.1 8080 或 nc 测试,也可以用压测工具模拟成百上千的并发连接。
这段代码有几个值得注意的设计要点:
- listen socket 也用 ET 模式 :
accept在循环中调用,直到返回EAGAIN,确保一次事件通知能接受所有排队的连接。 - recv 循环读直到 EAGAIN:ET 模式的核心约定。
- epoll_wait 只返回就绪的 fd:无需遍历所有连接,事件驱动效率极高。
在实际的流媒体服务器中,handle_read 内部会进行协议解析(如 RTMP chunk 解包、RTP 包解析),然后将数据分发到对应的流处理流水线中。
5. io_uring 简介
io_uring 是 Linux 5.1(2019)引入的新一代异步 I/O 框架,由 Jens Axboe 设计。如果说 epoll 是"通知你 fd 就绪,你自己去读写",那 io_uring 就是"你提交读写请求,内核帮你完成后通知你"------这才是真正的异步 I/O。
核心设计
io_uring 通过两个环形缓冲区(ring buffer)实现用户态与内核态的高效通信:
- 提交队列(Submission Queue, SQ):应用程序将 I/O 请求(SQE)放入 SQ。
- 完成队列(Completion Queue, CQ):内核完成 I/O 后将结果(CQE)放入 CQ。
这两个队列通过 mmap 在用户态和内核态之间共享,提交和收割 I/O 操作可以完全不需要系统调用(配合 SQPOLL 模式),极大减少了用户态/内核态切换开销。
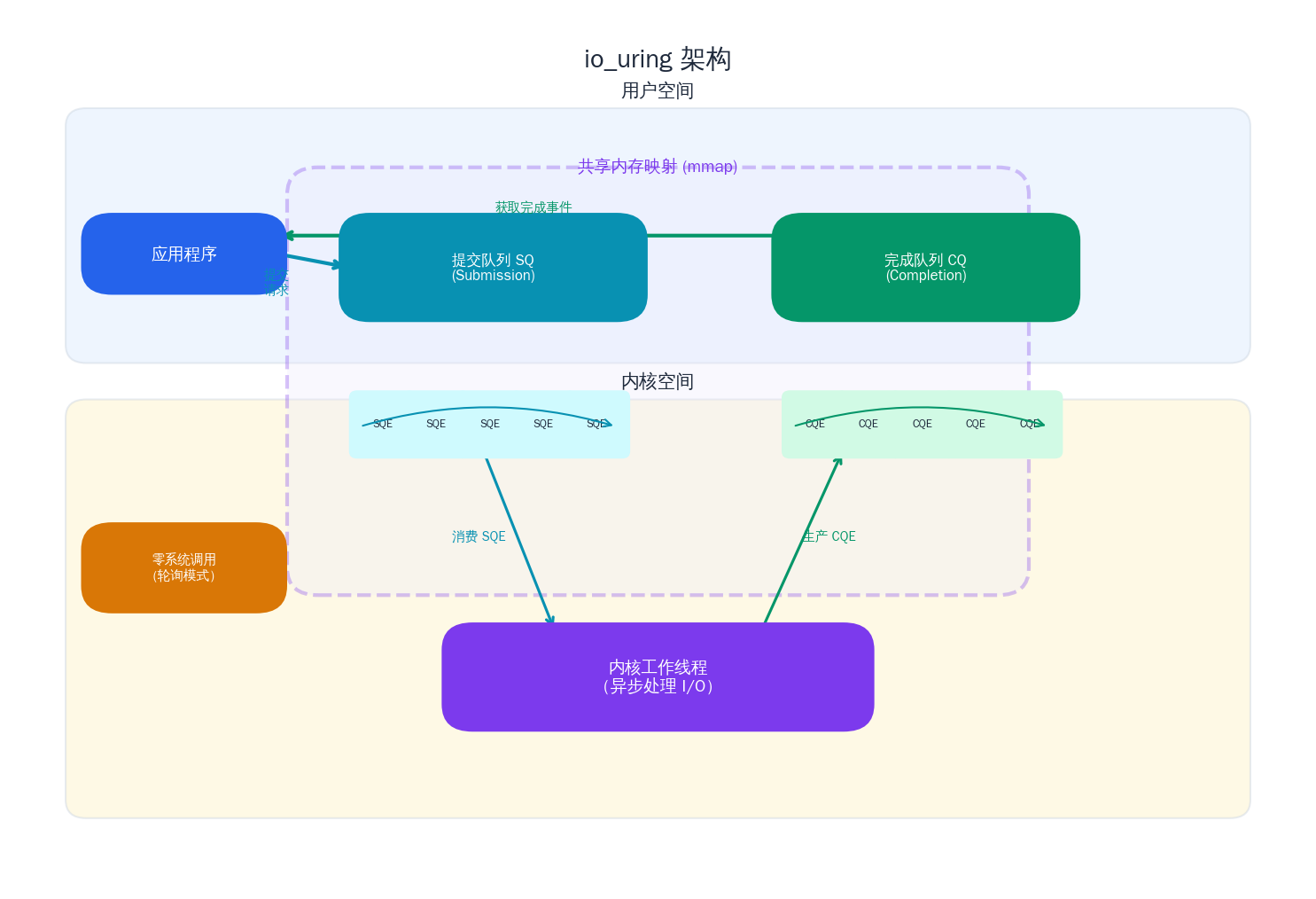
在流媒体服务器中的潜力
io_uring 对流媒体服务器有很强的吸引力:
- 零系统调用开销 :SQPOLL 模式下内核线程持续轮询 SQ,应用提交 I/O 无需
syscall。 - 批量提交 :一次
io_uring_enter可以提交多个 I/O 操作,适合流媒体场景下需要同时向多路客户端发送数据的模式。 - 支持 fixed buffers:注册固定缓冲区后内核直接使用,避免了每次 I/O 的内存拷贝注册开销。
目前已有一些项目开始用 io_uring 构建网络框架,但在生产环境中还不如 epoll 成熟。对于新项目,可以作为性能优化的备选方案持续关注。
6. 性能对比与选型建议
| 特性 | select | poll | epoll | io_uring |
|---|---|---|---|---|
| fd 数量限制 | 1024(FD_SETSIZE) | 无硬限制 | 无硬限制 | 无硬限制 |
| 数据结构 | 位图 | 数组 | 红黑树 + 就绪链表 | 环形缓冲区 |
| 每次调用开销 | O(n) 拷贝 + 遍历 | O(n) 拷贝 + 遍历 | O(k) 仅返回就绪 | 接近零(共享内存) |
| 触发模式 | LT | LT | LT / ET | 异步完成 |
| 内核版本要求 | 所有 Unix | 所有 Unix | Linux 2.6+ | Linux 5.1+ |
| 跨平台 | 是 | 是 | 仅 Linux | 仅 Linux |
n = 监听的 fd 总数,k = 就绪的 fd 数量
流媒体服务器如何选择
绝大多数情况下选 epoll。原因很实际:
- 流媒体服务器几乎都部署在 Linux 上,跨平台不是主要考量。
- 典型场景是"大量连接、少量同时活跃",正好是 epoll 的最佳适用场景。
- 生态成熟,无论是直接使用还是通过 libevent/libev/libuv 等事件库间接使用,epoll 都是首选后端。
如果你开发跨平台的客户端库(比如需要同时支持 macOS 的 kqueue),可以考虑使用 libevent 或 libuv 做抽象层。
io_uring 目前更适合对延迟和吞吐有极致要求的场景,且团队愿意承担较新内核版本的依赖风险。
总结
本文从传统阻塞 I/O 的瓶颈出发,依次介绍了 Linux 下四种 I/O 多路复用机制:
- select:最古老、最通用,但 1024 fd 限制和 O(n) 遍历使其不适合高并发。
- poll:去掉了 fd 数量限制,但 O(n) 开销依旧。
- epoll:红黑树 + 就绪链表设计,O(k) 复杂度,支持 ET 模式,是当前 Linux 高性能网络编程的标准方案。
- io_uring:真正的异步 I/O,通过共享环形缓冲区实现接近零系统调用的 I/O 提交,代表着 Linux I/O 的未来方向。
我们还给出了一个完整的 epoll ET 模式 echo 服务器。但你可能已经发现,这个服务器的代码虽然比 thread-per-connection 高效得多,结构上仍然比较原始------事件分发、协议处理、业务逻辑全部耦合在一起。
在下一篇文章《Reactor 模式与事件驱动网络框架》中,我们将在 epoll 之上构建 Reactor 模式,把事件循环、连接管理、协议解析分层解耦,搭建出一个真正可以用于流媒体服务的网络框架。