1.环境搭建
这个项目使用的是字节旗下的trae开发环境
项目开始前首先得连接远程终端,要么是虚拟机要么是云服务器
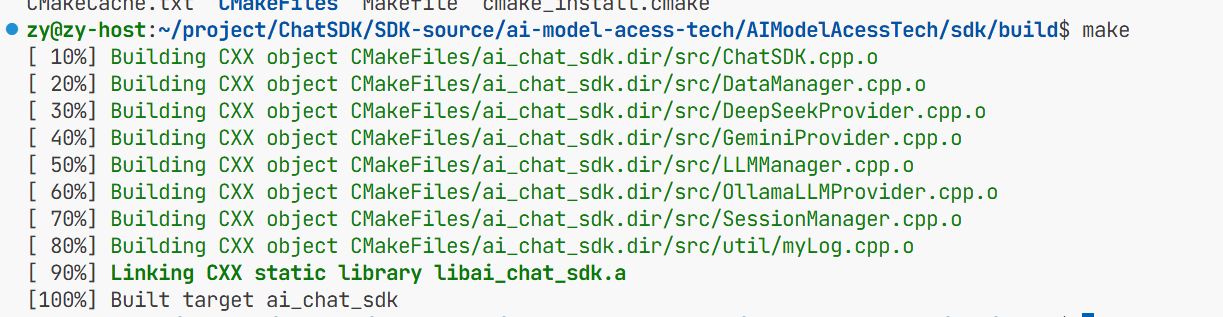
从远端克隆完头文件后再到本地来编译
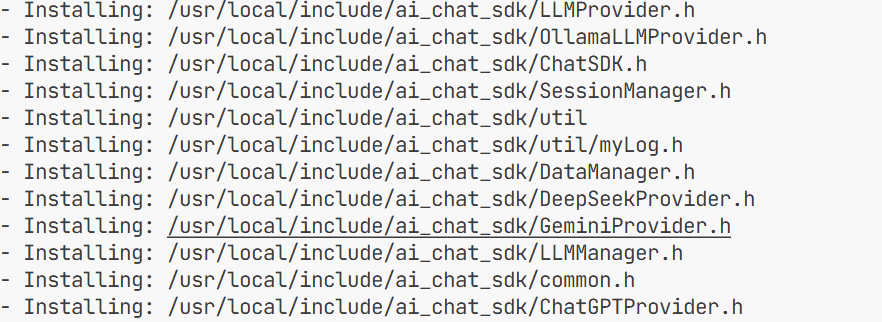
编译完成后要将编译好的库文件以及头文件进行安装 安装到系统的根目录 这样以后用可以找到

这样用到的头文件就拷贝到系统的头文件之中了


这样可以看到我们要的头文件就拷贝到了include文件下了 这就是我们需要的头文件
2.项目的初步使用
现在环境搭建好了 现在就可以来简单使用一下ChatSDK了 此时我们要在这个目录下创建一个chatDemo.cpp的文件进行与模型的对话
此时就在这个路径下显示的创建了这个cpp
#include<ai_chat_sdk/ChatSDK.h>//包含聊天SDK头文件
#include<ai_chat_sdk/util/myLog.h>//包含日志头文件
#include<ai_chat_sdk/common.h>//包含公共头文件
#include <cstdio>
#include<iostream>//包含iostream头文件
#include <spdlog/common.h>
void sendMessageStream(ai_chat_sdk::ChatSDK& chat_sdk, std::string& session_id)
{
std::cout<<"-------------------------发送消息-------------------------"<<std::endl;
std::string message;//创建字符串对象 ,用于存储用户输入的消息
std::cout<<"user消息:>"<<std::endl;//输出提示信息 ,提示用户输入消息
std::getline(std::cin, message);//获取用户输入的消息 ,获取用户输入的消息 ,将用户输入的消息赋值给message
chat_sdk.sendMessageStream(session_id, message,[](const std::string& response, bool done){//创建lambda表达式 ,用于处理模型的响应
std::cout<<"assistant消息:"<<response<<std::endl;//输出模型的响应 ,输出模型的响应 ,将模型的响应赋值给response
if(done){//如果done为true,表示模型的响应完成
std::cout<<"-------------------------消息接收完成-------------------------"<<std::endl;//输出消息接收完成信息 ,输出消息接收完成信息 ,将消息接收完成信息赋值给response
}
});
}
int main()
{
bite::Logger::initLogger("aiChatDemo","stdout",spdlog::level::info);//初始化日志 第二个参数指的是把日志输出到控制台
ai_chat_sdk::ChatSDK chat_sdk;//创建聊天SDK对象 初始化
//配置deepseek模型
ai_chat_sdk::APIConfig deepseek;//创建API配置对象 deepseek进行配置
deepseek._apiKey=std::getenv("deepseek_api_key");//获取环境变量中的API密钥 ,获取环境变量中设置deepseek_api_key的API密钥
deepseek._temperature=0.7;//设置温度参数 ,设置温度参数为0.7,控制模型的输出随机性
deepseek._maxTokens=2048;//设置最大令牌数 ,设置最大令牌数为2048,控制模型的输出长度
deepseek._modelName="deepseek-chat";//设置模型名称 ,设置模型名称为deepseek-chat
std::vector<std::shared_ptr<ai_chat_sdk::Config>> configs;//智能指针向量 ,用于存储API配置对象的智能指针
configs.push_back(std::make_shared<ai_chat_sdk::APIConfig>(deepseek));//将deepseek配置对象添加到向量中 ,添加deepseek配置对象的智能指针
chat_sdk.initModels(configs);//初始化模型
std::cout<<"-------------------------创建对话-------------------------"<<std::endl;
std::string session_id=chat_sdk.createSession("deepseek-chat");//创建对话 ,创建对话 ,返回对话ID
int userop=1;
while(true){
std::cout<<"-------------------------1.send_message 0.exit-------------------------"<<std::endl;
std::cin>>userop;//获取用户操作 ,获取用户输入的用户操作 ,将用户操作赋值给userop
if(userop==0){//如果用户操作为0,表示用户输入结束会话
break;//跳出循环 ,结束用户操作
}
getchar();//获取用户输入的换行符 ,获得缓冲区里的回车符
sendMessageStream(chat_sdk, session_id);
}
return 0;
}
这就是整个与deepseek交谈的互动界面内容
上面做好之后还要创建一个CMakeLists.txt这是一个配置文件进行编译和连接的
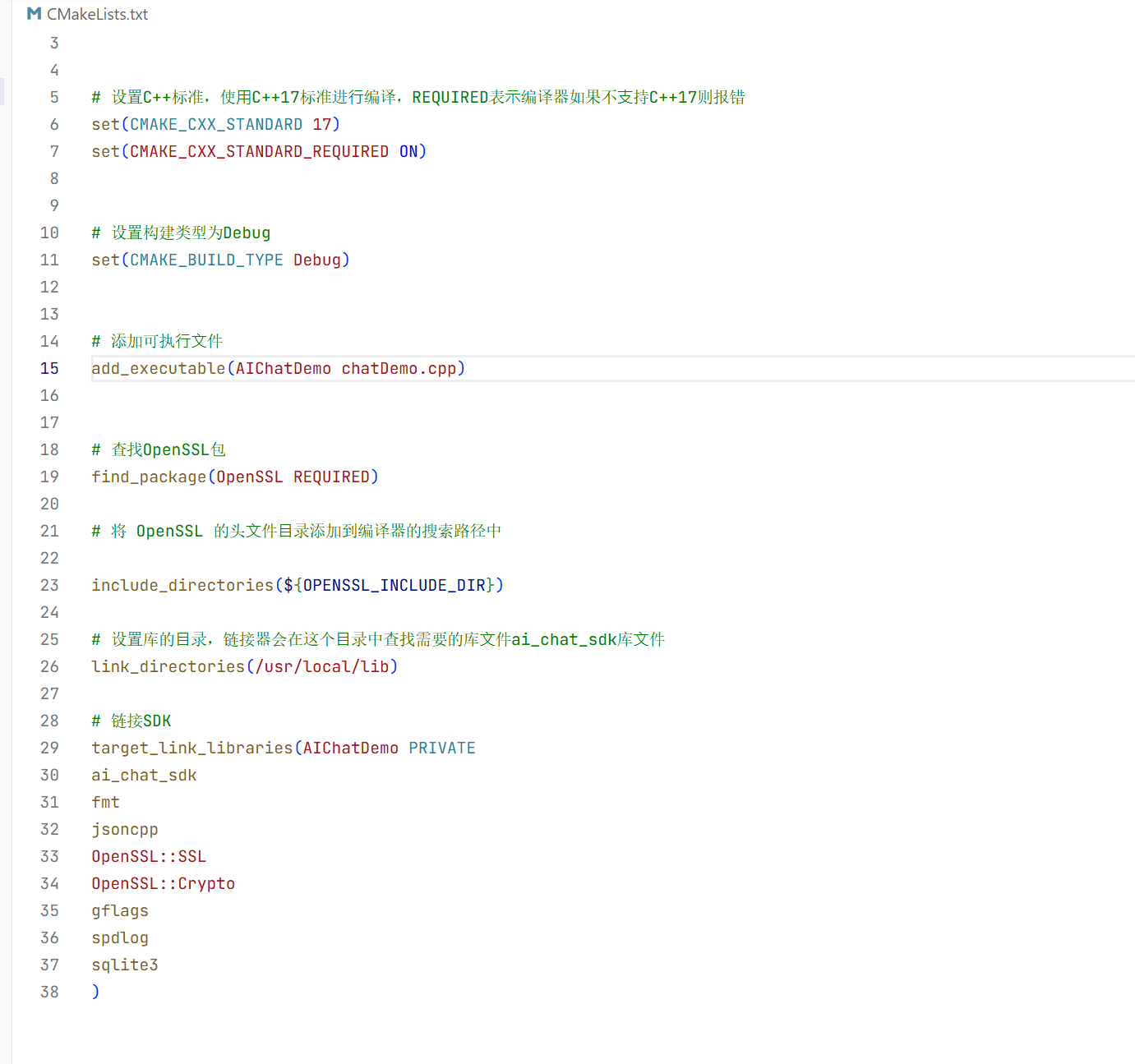
此时就在这个目录下创建了 build用来包含创建生成文件

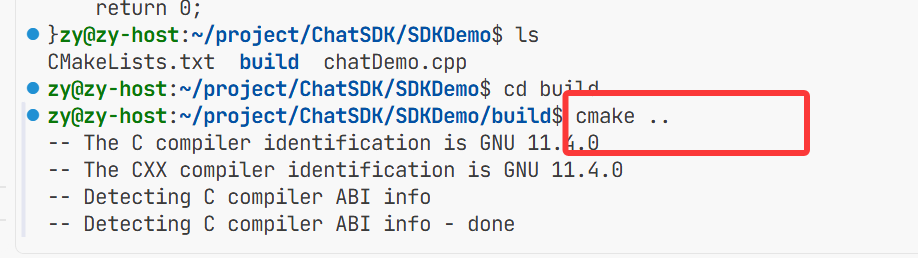
在这个路径下cmake ..去找这个刚写的CMakeLists.txt然后进行编译
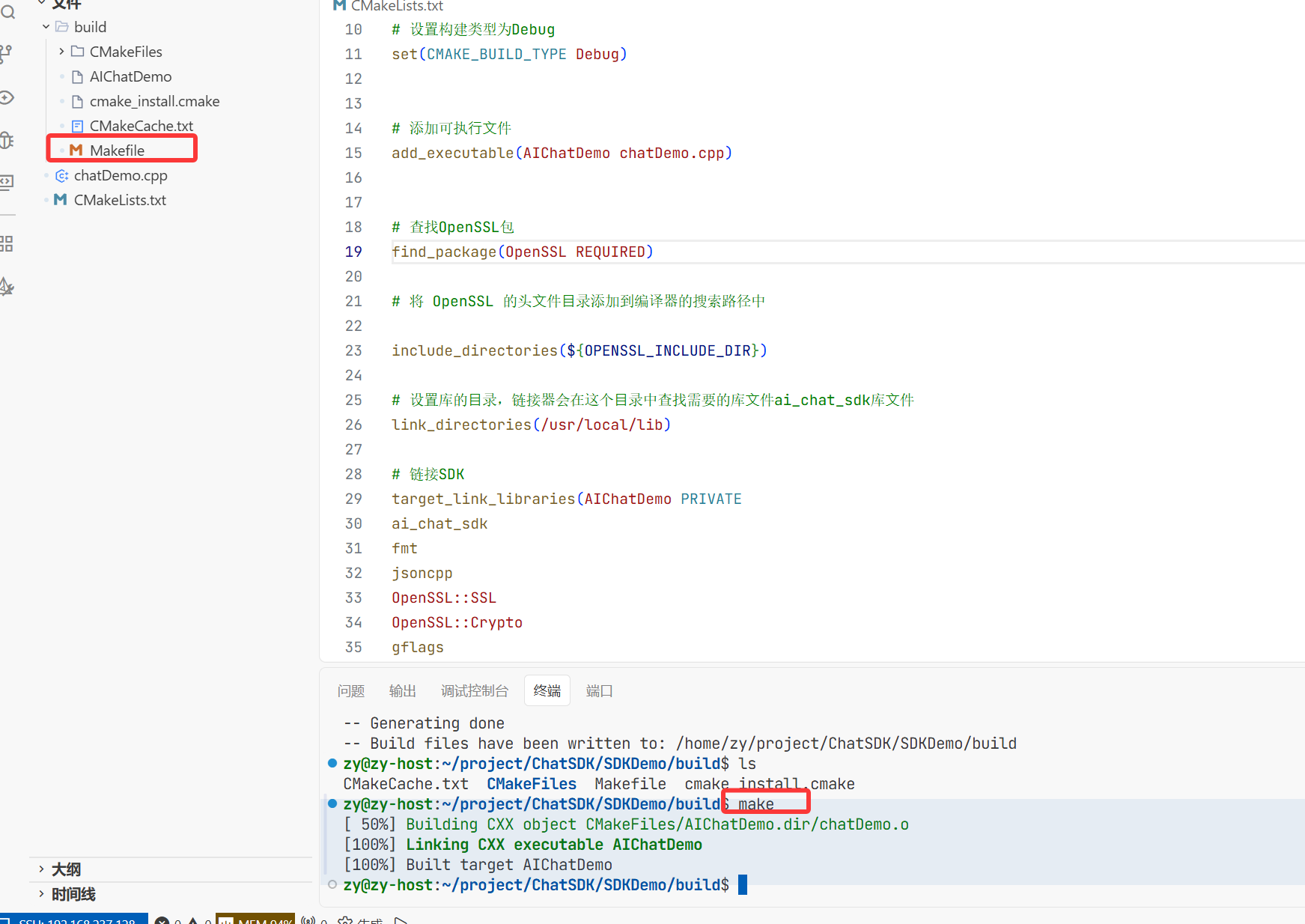
然后make一下就去找工程下面的Makefile下面的目录 Makefile下面就包含了去编译的步骤
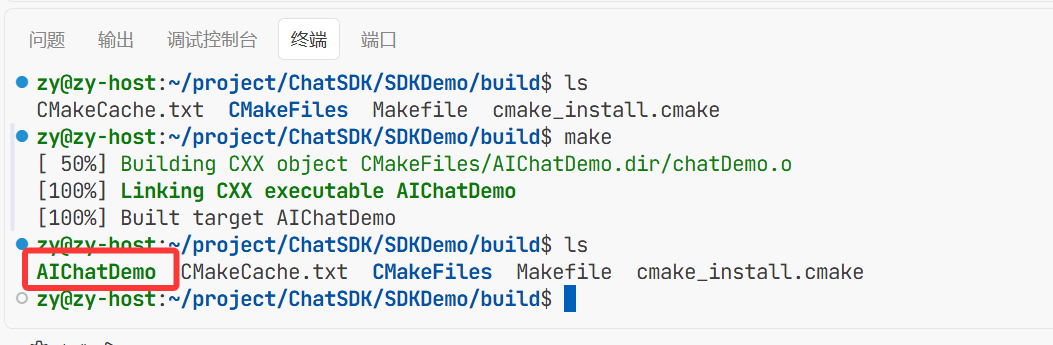
make编译一下后生成可执行文件 这个AIChatDemo就是可执行文件

执行完遇到数据库野指针的问题了
首先通过gbd调试发现是原文第36deepseek_api_key是野指针原因就是我没有配置环境变量导致连
接不上deepseek 所以要去deepseek的官网创建dpi然后将环境变量导入进去

导入完成后即可连接成功

此时chatDemo的入手就到这里
3. deep seek API介绍


通过api接入的话输入这个指令
deepseek接口测试
了解完deepseek的API后接下来我们要用AIPFOX这个软件测试这个API接口
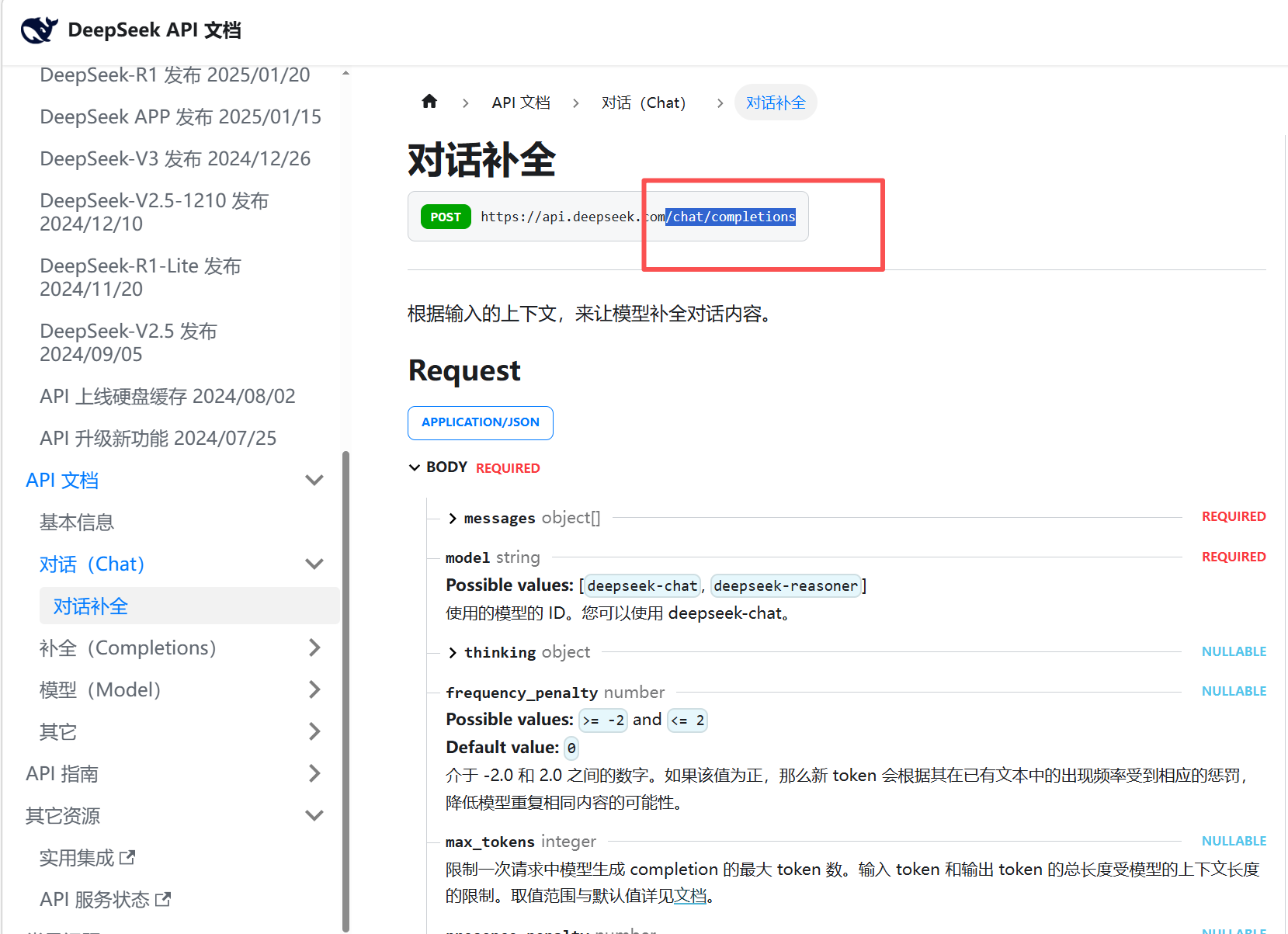
从使用目录找到这个对话补全找到接口的路径来进行测试
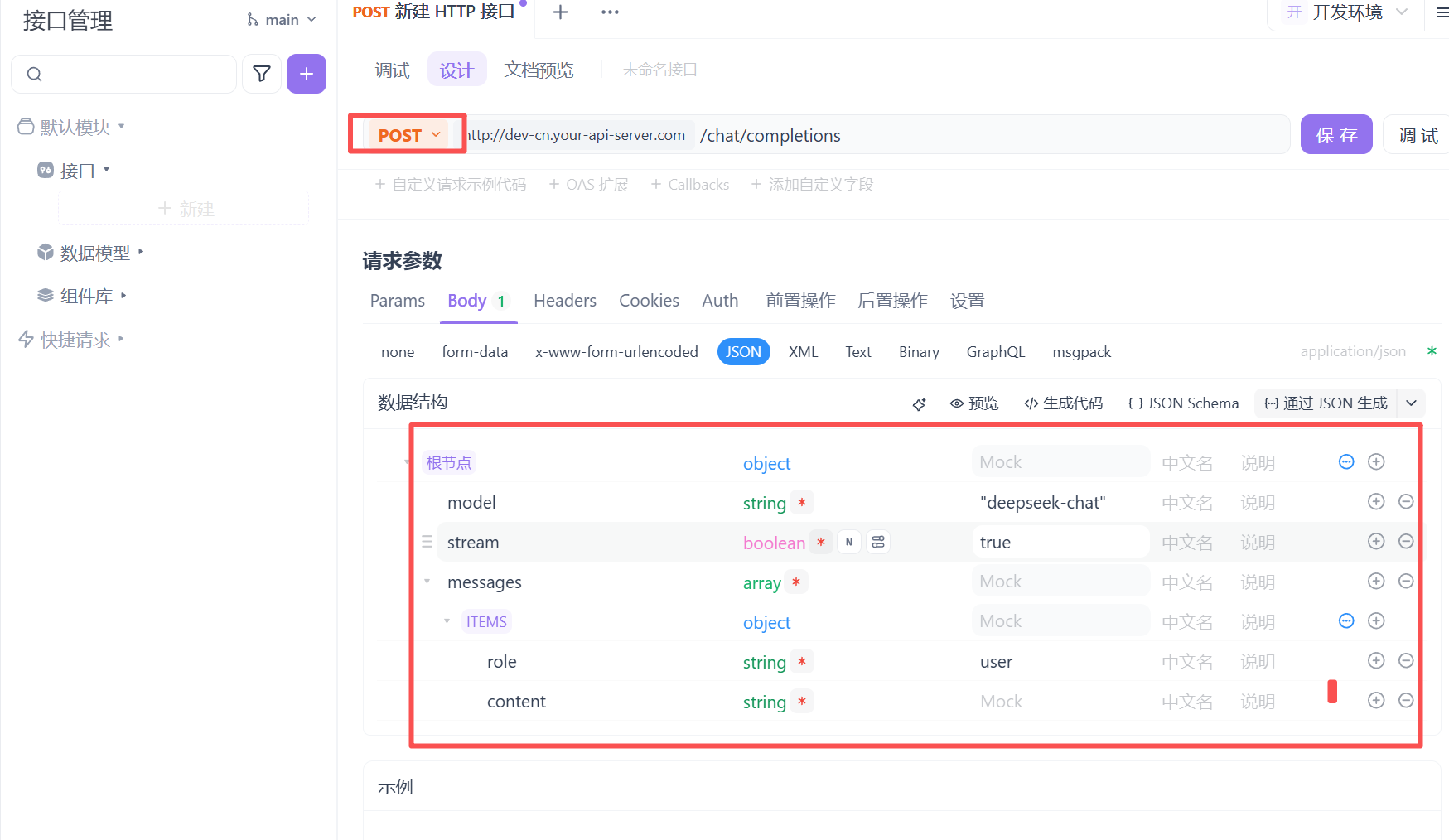
这就是接口调用 这是接口调用的请求参数
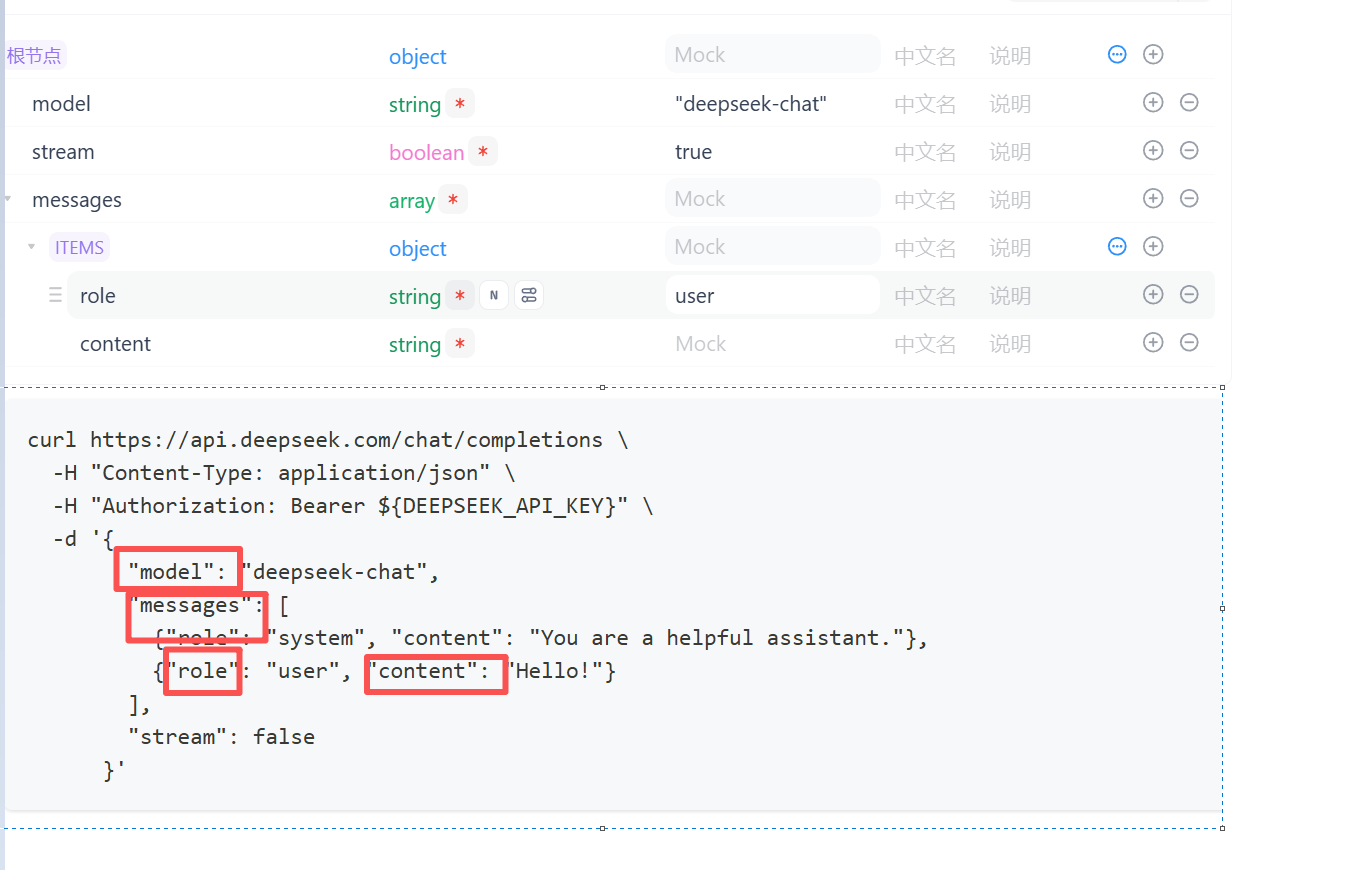
就是按照deepseek手册来进行接口的测试
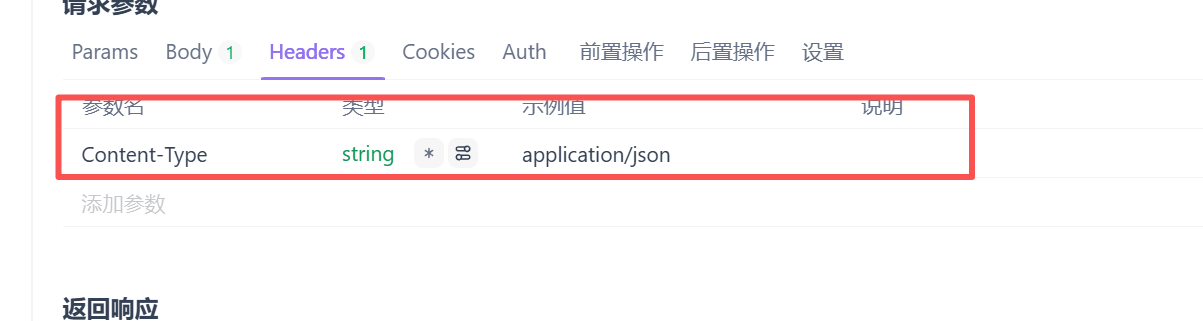
还要调整传递给服务器以什么格式来组织的以json上面设置的参数来传递的
还要设置认证参数
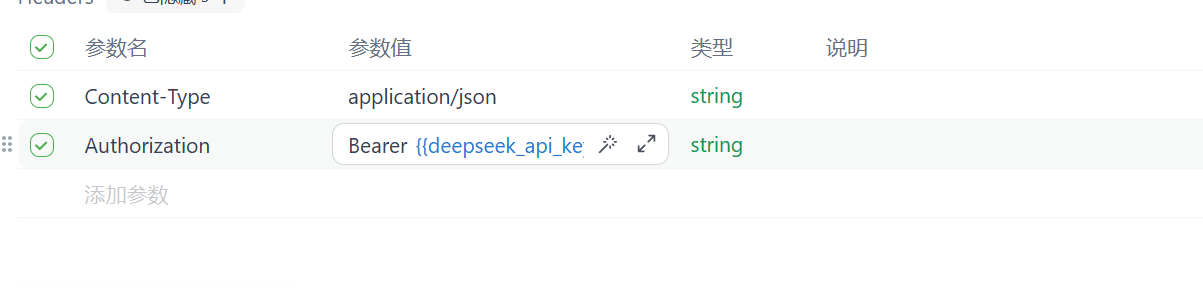
这个deepseek_api_key就是在测试环境下设置的本地变量 就相当于你的api key
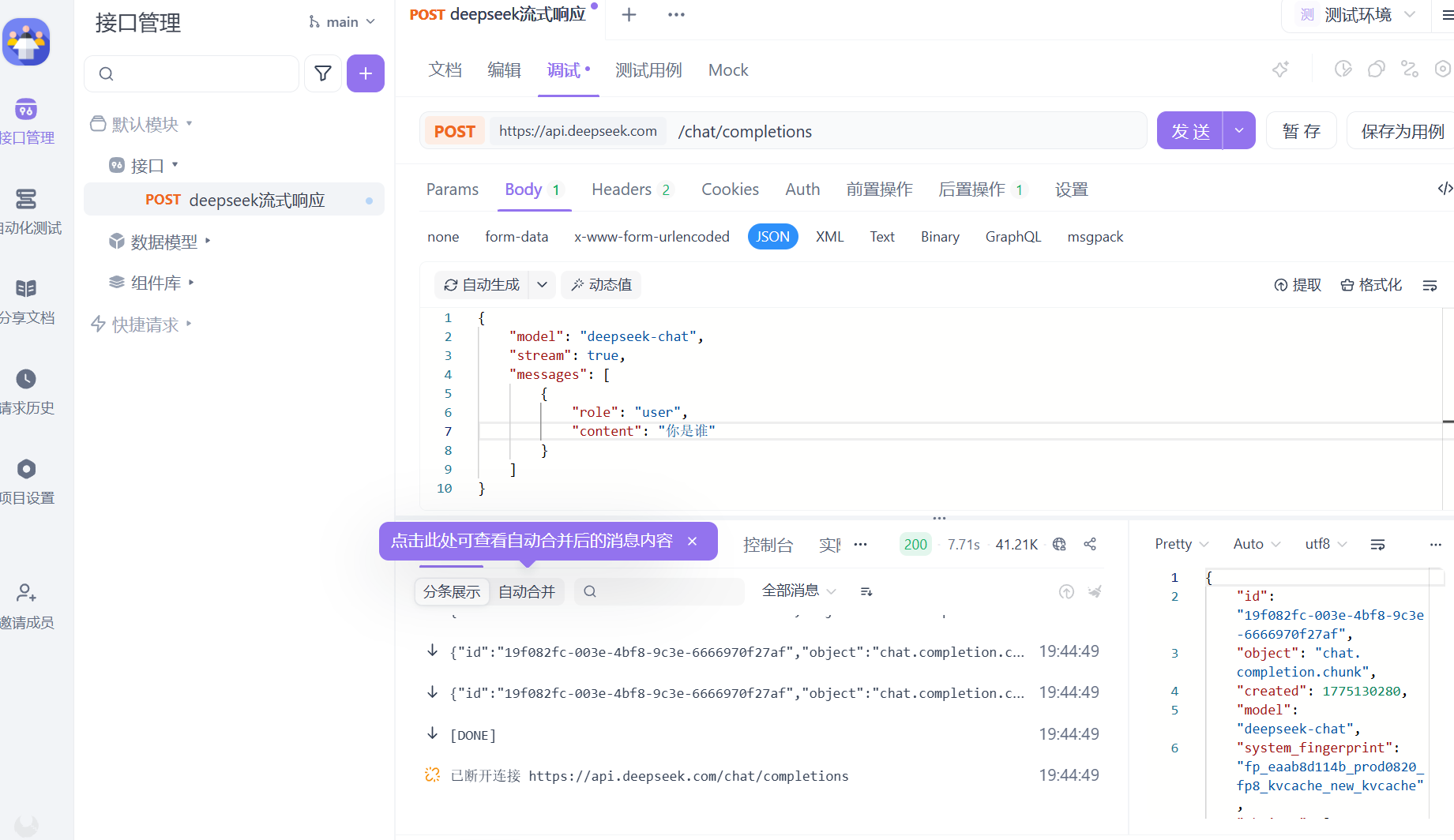
此时测试发送你是谁这样就会有响应了 这样的是流式发送 大模型会一点点的发送他所获取的信息
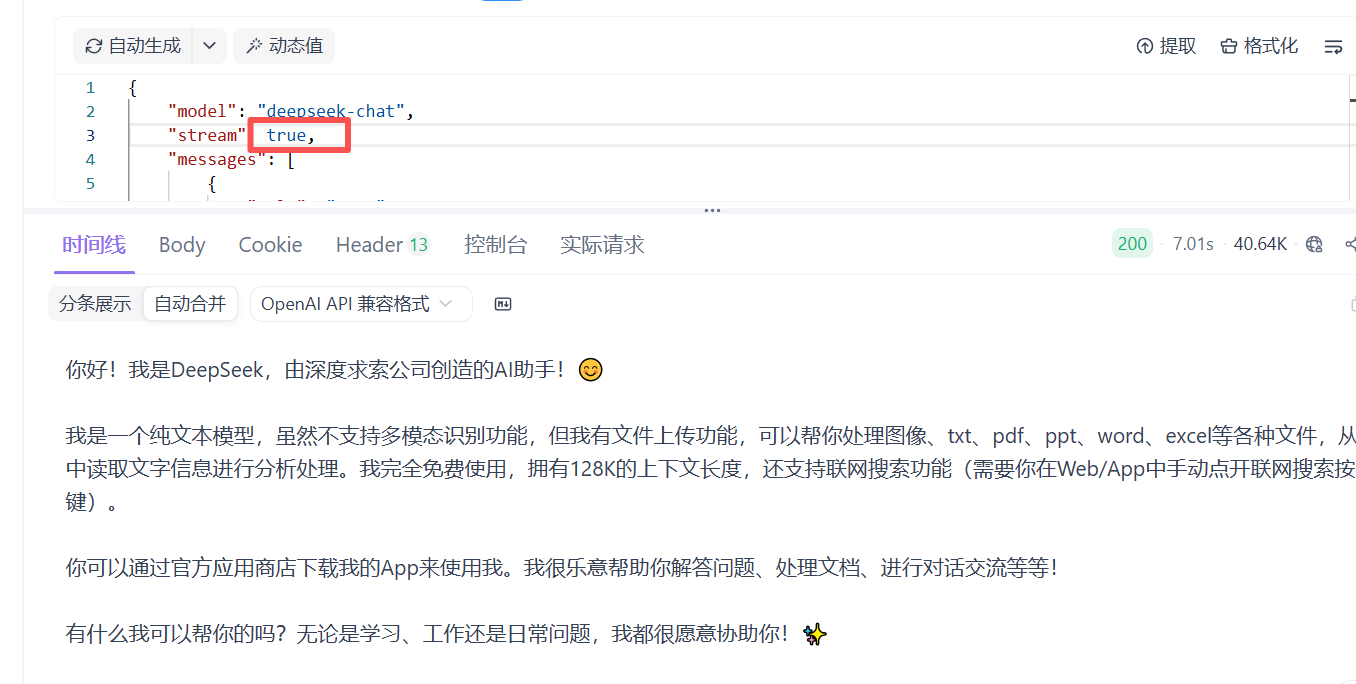
这就是非流式反馈 是直接反馈的的 这样就测试完成了 也就是接入成功。
4.项目的编写:
1.准备工作
上面的都是在进行测试和普及 现在就要开始编写基本的数据结构了
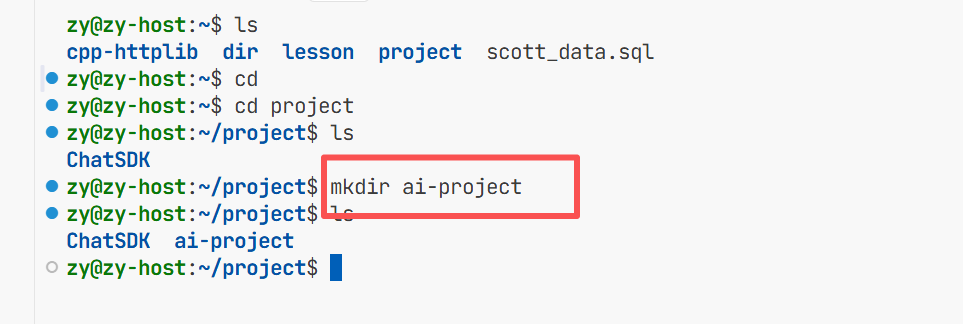
首先在项目路径下创建一个ai-project的目录用来存储这个项目
然后进入到这个目录 再从远端创建一个这个项目的仓库 然后git clone本地相当于在这个仓库里面存放我们编写的代码
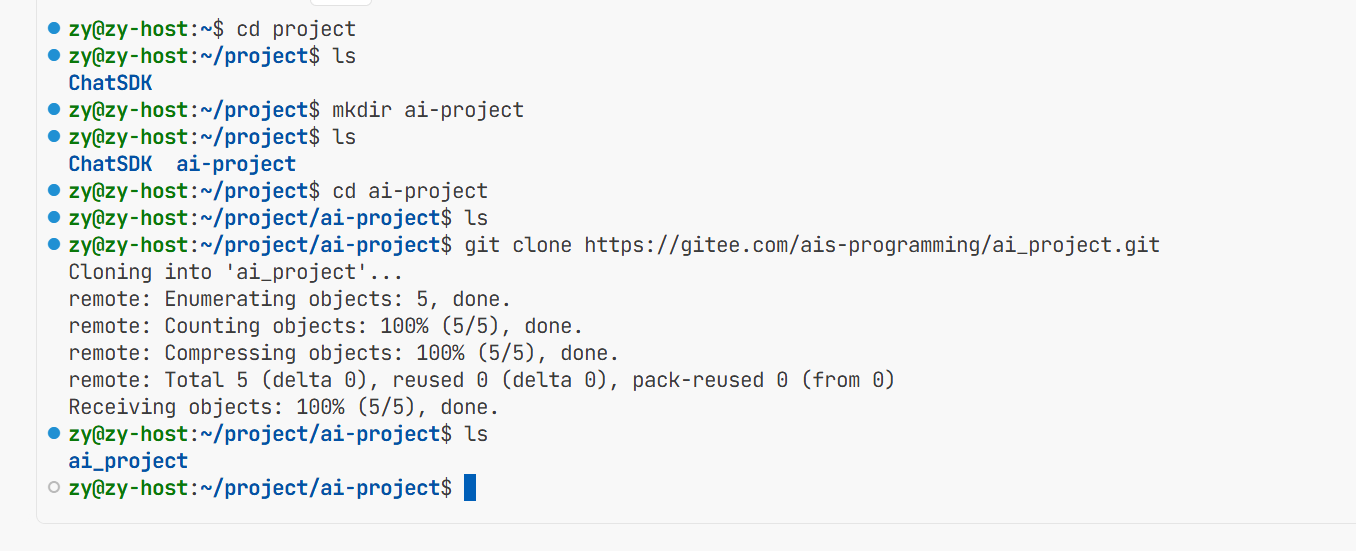
此时就从远端仓库拉取下来了 然后我们之后就在ai_project这个目录下编写我们的代码 注意我在创建的时候犯了小失误 两个名字是差不多的只是-和_的区别 所以要注意一下
此时我们再进入这个远程仓库这个目录 可以发现 有git这个目录 但是我们不想让他在trae出现 所以我们再创建一个目录
注意以后我们就在此目录下写我们接入模型的代码了

2.基本数据结构的编写
在这个目录下创建一个sdk文件夹用来放置我们的源文件和头文件 我们做到头文件与源文件的分离
方便我们开发完编译成静态库 当我们运行安装时只需要拷贝我们的静态的头文件和源文件即可
1.在include下创建一个common.h的头文件用来放我们所需要的数据库
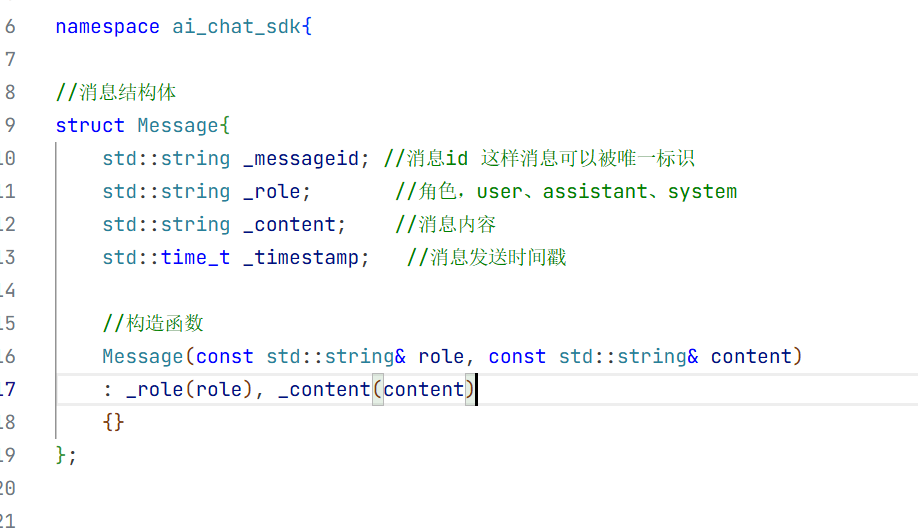
此时我们构造函数只需要初始化角色和用户输入内容即可。
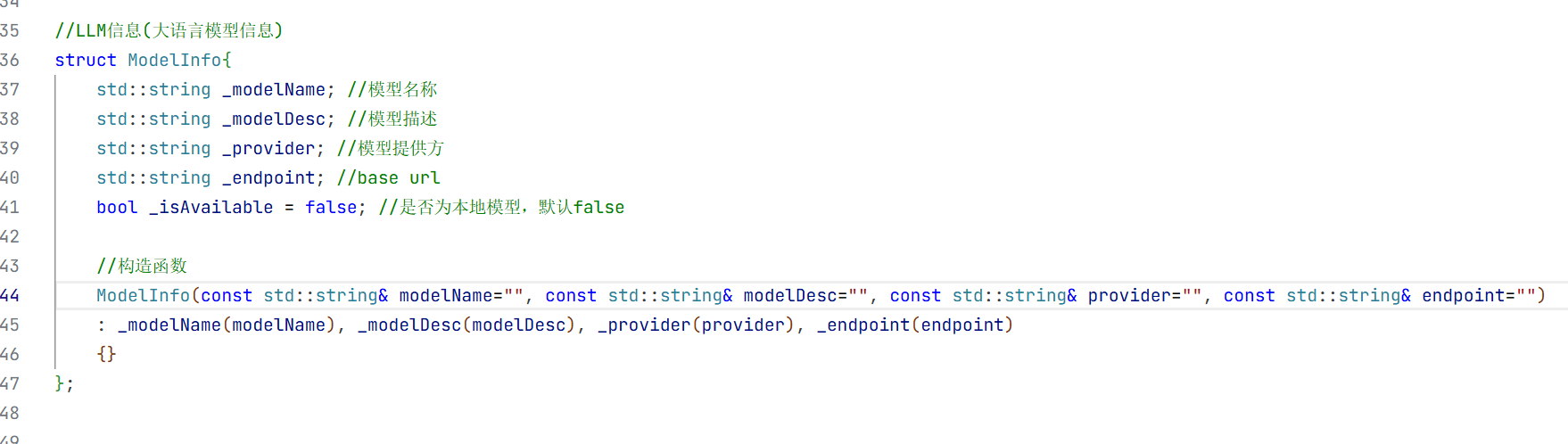
2.大模型的公共配置参数的结构体


3.通过API方式接入的云端大模型

4.最后完成页面中大模型的基本信息介绍
5.会话消息结构体
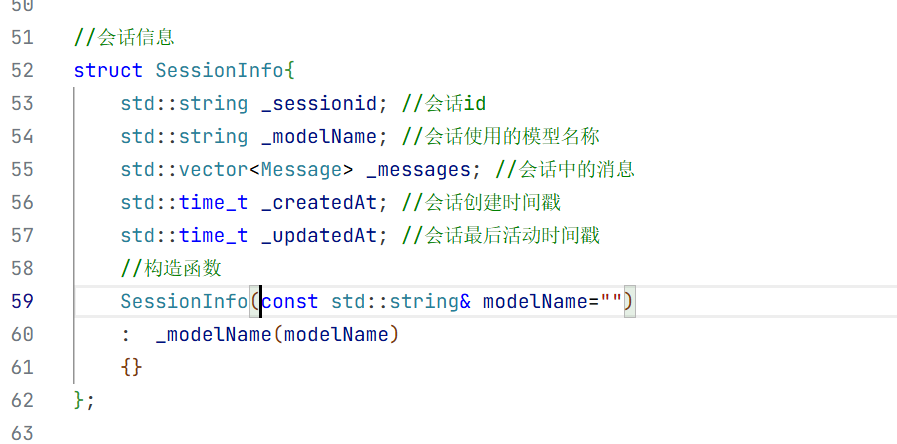
在构造方法中我们只需要初始化大模型名称即可 因为其他的只有这个对话开始的时候你才知道是什么时候开始的
#pragma once
#include <string>
#include <ctime>
#include <vector>
namespace ai_chat_sdk{
//消息结构体
struct Message{
std::string _messageid; //消息id 这样消息可以被唯一标识
std::string _role; //角色,user、assistant、system
std::string _content; //消息内容
std::time_t _timestamp; //消息发送时间戳
//构造函数
Message(const std::string& role, const std::string& content)
: _role(role), _content(content)
{}
};
//大模型公共配置参数
struct Config{
std::string _modelid; //模型id
double _temperature = 0.7; //温度参数
int _max_tokens = 2048; //最大token数
};
//通过API方式调用云端大模型
struct APIConfig: public Config{
std::string _apikey; //api key
};
//通过ollama方式调用本地大模型
//LLM信息(大语言模型信息)
struct ModelInfo{
std::string _modelName; //模型名称
std::string _modelDesc; //模型描述
std::string _provider; //模型提供方
std::string _endpoint; //base url
bool _isAvailable = false; //是否为本地模型,默认false
//构造函数
ModelInfo(const std::string& modelName="", const std::string& modelDesc="", const std::string& provider="", const std::string& endpoint="")
: _modelName(modelName), _modelDesc(modelDesc), _provider(provider), _endpoint(endpoint)
{}
};
//会话信息
struct SessionInfo{
std::string _sessionid; //会话id
std::string _modelName; //会话使用的模型名称
std::vector<Message> _messages; //会话中的消息
std::time_t _createdAt; //会话创建时间戳
std::time_t _updatedAt; //会话最后活动时间戳
//构造函数
SessionInfo(const std::string& modelName="")
: _modelName(modelName)
{}
};
}//end namespace ai_chat_sdk这就是我们接入大模型所需要的最基本的结构体 这样就创建好了。
3.日志
1.日志的概念:
当我们运行执行的时候 不管是报错还是成功运行 都将这些信息存储在日志中 不管是后续的调试还是测试 这样都可以了解程序运行时发生了什么 ,通常将日志信息写入控制台或者文件中或者远程服务器中。
2.日志的级别:
1.TRACE:
日志的级别分为TRACE:最详细的跟踪信息 用于追踪程序的执行的流程 比如函数的进入和退出。
2.DEBUG:
调试信息 ,帮助开发人员理解程序运行的状态比如监控执行的关键节点,重要的变量状态。
3 .INFO:
重要的运行信息 反映程序的正常状态比如系统启动成功,配置文件加载成功
4.WARN:
潜在的问题信息 但是不影响程序的执行 比如非关键性错误
5.ERRO:
表示程序运行出错,影响特定功能,但程序仍正常执行 比如 文件打开失败 比如数据库连接失败
6.CRITICAL:
严重错误导致系统崩溃无法运行 比如内存耗尽,数据损坏,导致一些致命错误。
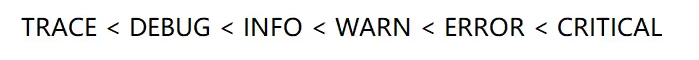
3.日志存储管理:
⽇志库可以将⽇志信息输出到多种⽬标,如控制台、⽂件、远程服务器等。同时,⽇志库通常⽀持
⽇志⽂件的轮转、压缩和归档,⽅便⻓期存储和管理。
⽐如设置⽇志⽂件每天⾃动轮转,并在⽂件⼤⼩超过⼀定阈值时进⾏压缩归档。这有助于避免⽇志
⽂件过⼤导致磁盘空间不⾜。 ⽽ std::cout 只能将信息输出到控制台,⽆法直接⽀持⽇志⽂件的存
储和管理功能。
4.线程安全:
在多线程程序中,⽇志库通常提供了线程安全的机制,确保⽇志输出不会出现冲突或数据错乱。在
多线程环境下,多个线程可能同时尝试写⼊⽇志。⽇志库通过锁或其他同步机制确保⽇志输出的线
程安全。 std::cout 在多线程环境下可能会出现⽇志输出混乱的问题,需要开发者⼿动实现线程安全机制。
5.日志库的封装:
本项⽬采⽤google的spdlog⽇志库进⾏⽇志管理,为了使⽤⽅便,对spdlog库采⽤单例模式进
⾏简单封装。
首先在这两个文件下创建两个util的工具使用的文件夹 当后续有什么工具需要封装的时候 往这个文件夹下面放就行了。
1.日志库头文件的封装:
封装这个myLog.h时我们要用单例类去封装



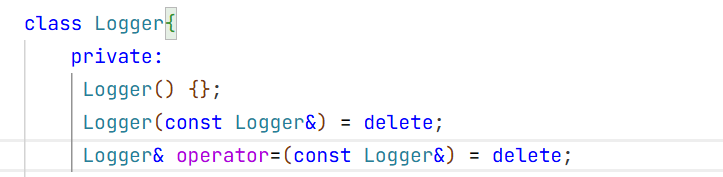
构造函数私有化并且 赋值重载和拷贝构造要被禁用掉。
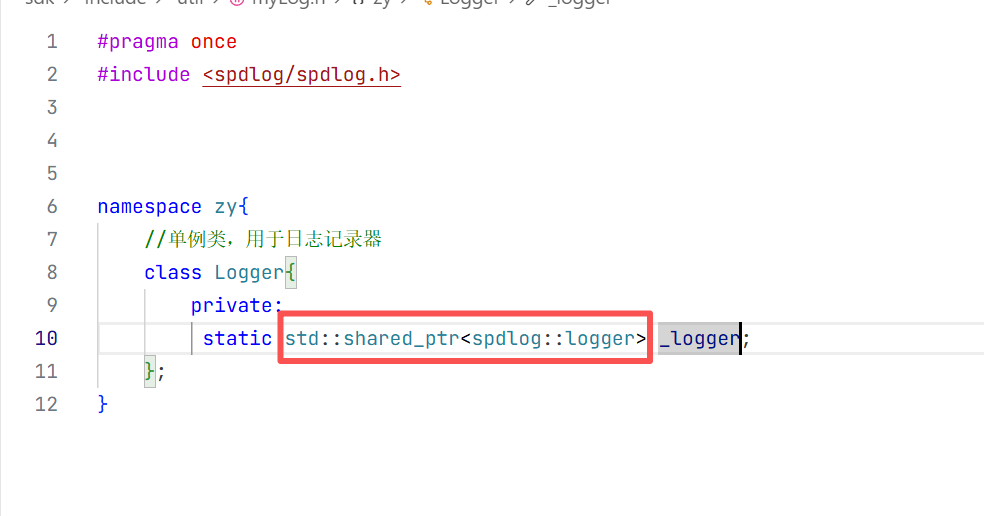
这里 智能指针去管理spdlog去实现的日志器

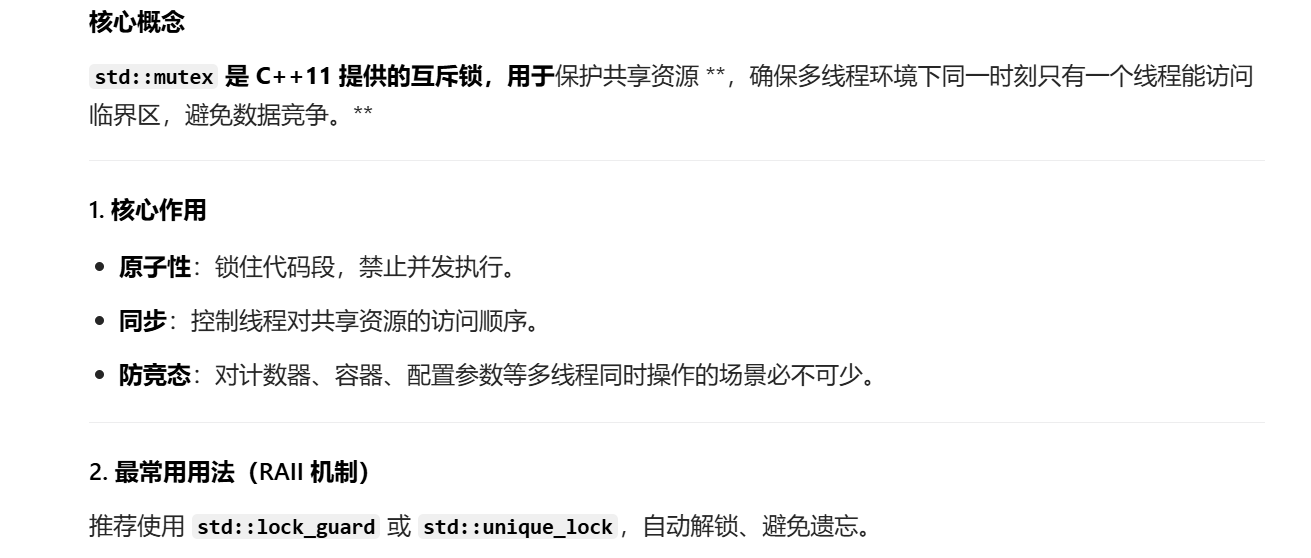

还要去封装日志的初始化 第一个参数是日志名称 第二个参数是到达什么级别输入到哪个文件中,第三个参数是日志的级别。

这样我们日志库的头文件就封装好了
接下来就要去封装源文件了:
2.日志库源文件的封装:
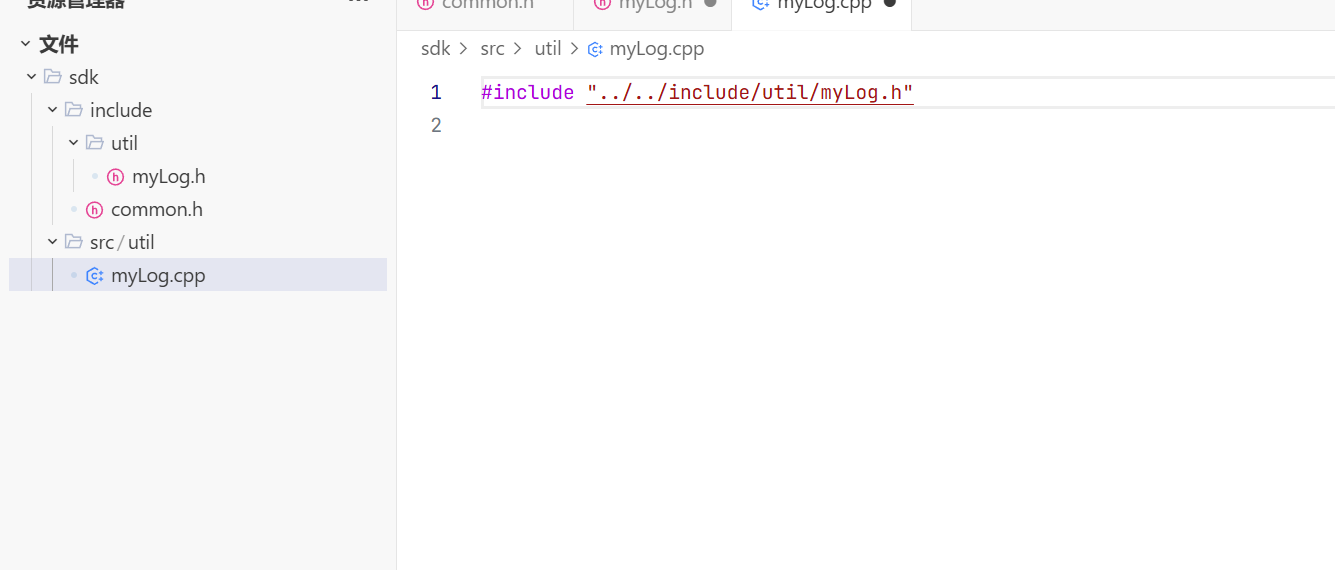
因为头文件和源文件我们要分开封装所以我们这里还要让他去指定路径找这个头文件
日志格式的设置:

调用fmt的库 这样你打印的

花括号就是占位符 这就是对应日志格式设置里对应的行号+名称
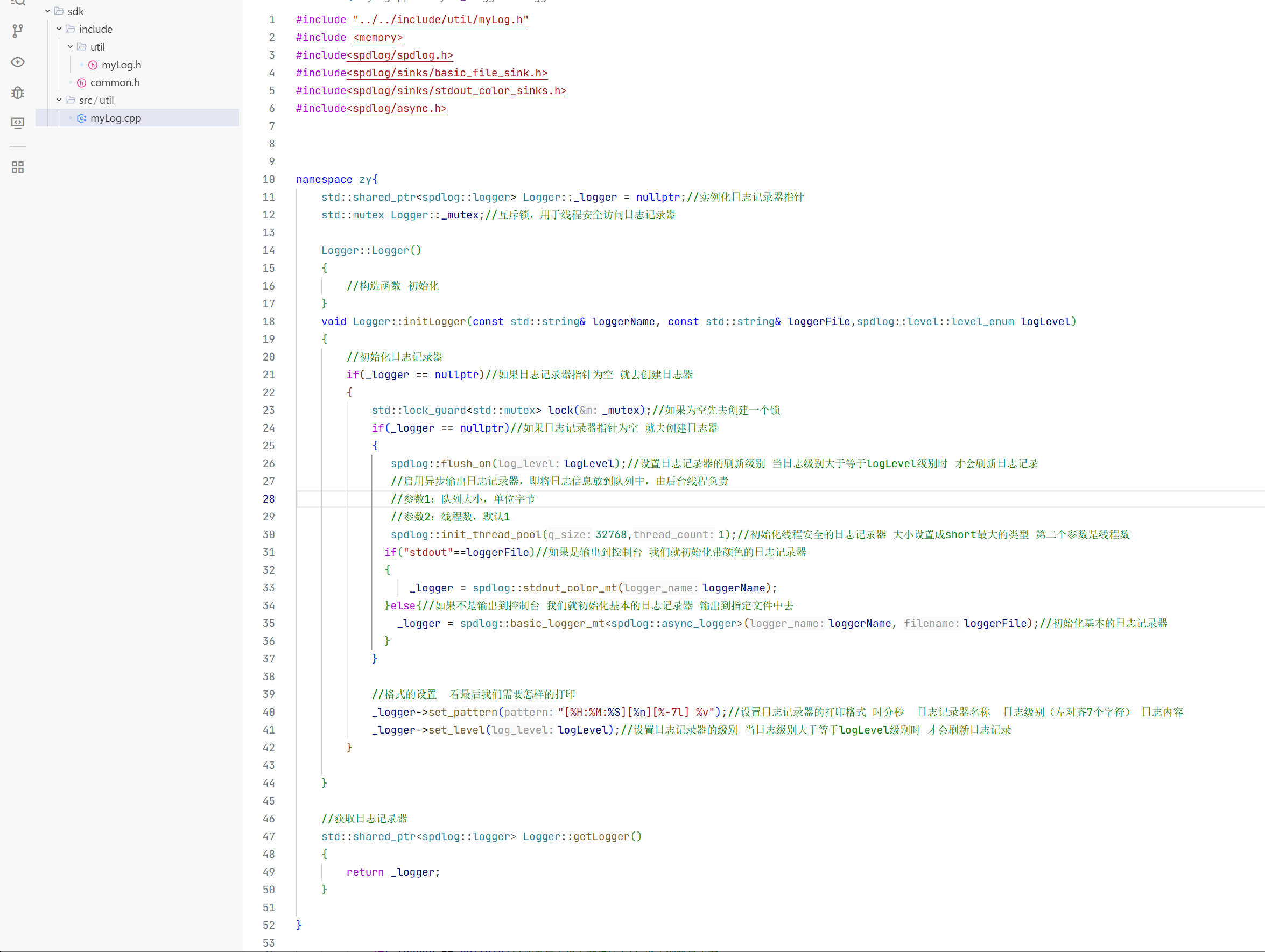
#include "../../include/util/myLog.h"
#include <memory>
#include<spdlog/spdlog.h>
#include<spdlog/sinks/basic_file_sink.h>
#include<spdlog/sinks/stdout_color_sinks.h>
#include<spdlog/async.h>
namespace zy{
std::shared_ptr<spdlog::logger> Logger::_logger = nullptr;//实例化日志记录器指针
std::mutex Logger::_mutex;//互斥锁,用于线程安全访问日志记录器
Logger::Logger()
{
//构造函数 初始化
}
void Logger::initLogger(const std::string& loggerName, const std::string& loggerFile,spdlog::level::level_enum logLevel)
{
//初始化日志记录器
if(_logger == nullptr)//如果日志记录器指针为空 就去创建日志器
{
std::lock_guard<std::mutex> lock(_mutex);//如果为空先去创建一个锁
if(_logger == nullptr)//如果日志记录器指针为空 就去创建日志器
{
spdlog::flush_on(logLevel);//设置日志记录器的刷新级别 当日志级别大于等于logLevel级别时 才会刷新日志记录
//启用异步输出日志记录器,即将日志信息放到队列中,由后台线程负责
//参数1:队列大小,单位字节
//参数2:线程数,默认1
spdlog::init_thread_pool(32768,1);//初始化线程安全的日志记录器 大小设置成short最大的类型 第二个参数是线程数
if("stdout"==loggerFile)//如果是输出到控制台 我们就初始化带颜色的日志记录器
{
_logger = spdlog::stdout_color_mt(loggerName);
}else{//如果不是输出到控制台 我们就初始化基本的日志记录器 输出到指定文件中去
_logger = spdlog::basic_logger_mt<spdlog::async_logger>(loggerName, loggerFile);//初始化基本的日志记录器
}
}
//格式的设置 看最后我们需要怎样的打印
_logger->set_pattern("[%H:%M:%S][%n][%-7l] %v");//设置日志记录器的打印格式 时分秒 日志记录器名称 日志级别(左对齐7个字符) 日志内容
_logger->set_level(logLevel);//设置日志记录器的级别 当日志级别大于等于logLevel级别时 才会刷新日志记录
}
}
//获取日志记录器
std::shared_ptr<spdlog::logger> Logger::getLogger()
{
return _logger;
}
}这样日志库源文件的封装就结束了。
6.Provider的介绍和引入
1.LLMProvider的实现思路
这里我们的实现就采用了策略模式

举个例子
假设你现在要从宿舍去学校图书馆,但宿舍到图书馆之间有⼀段距离,你可以采⽤下属三⽅ 式去:
•
⾛路(最节省钱,但慢)
•
骑⾃⾏⻋(中等速度,中等花销)
•
坐校内公交⻋(最快,但贵)

//去机房方式策略的封装
class TransportStrategy {
public:
virtual void go() = 0;
};
class WalkStrategy : public TransportStrategy {
public:
virtual void go() override { cout << "⾛路去机房🚶"; }
};
class BikeStrategy : public TransportStrategy {
public:
virtual void go() override { cout << "骑⻋去机房🚴"; }
};
class BusStrategy : public TransportStrategy {
public:
virtual void go() override { cout << "打⻋去机房🚕"; }
};
};
class Student {
private:
TransportStrategy* strategy;
public:
void setStrategy(TransportStrategy* s) { strategy = s; }
void goToLab() { strategy->go(); }
};
int main(){
Student me;
me.setStrategy(new WalkStrategy());
me.goToLab(); // 输出: ⾛路去机房🚶
me.setStrategy(new BusStrategy());
me.goToLab(); // 输出: 打⻋去机房🚕
return 0;
}程序⾮常美观且灵活,在使⽤时只需和TransportStrategy 打交道,不需要知道背后到底是
WalkStrategy、BikeStrategy或BusStrategy。如果想更换模式,只需要更换⼀个具体的策略对象即
可,程序基本不需要改动。
策略模式是设计模式的⼀种,它的核⼼思想是它定义了⼀些列算法,将每⼀个算法(或⾏为)封装起来, 使它们可以相互替换,⽽不⽤再代码中写⼀堆if-else/switch来决定⽤哪个算法。即把"做事的⽅ 式"抽象出来,运⾏时根据需要选择哪种⽅式去执⾏。
但当我们要在自己程序上去聊天时 我们需要具备的:大模型提供者 所以接下来我们要封装一个父类LLM提供者 提供这些功能 然后这些派生类去继承然后完成各自的功能即可。

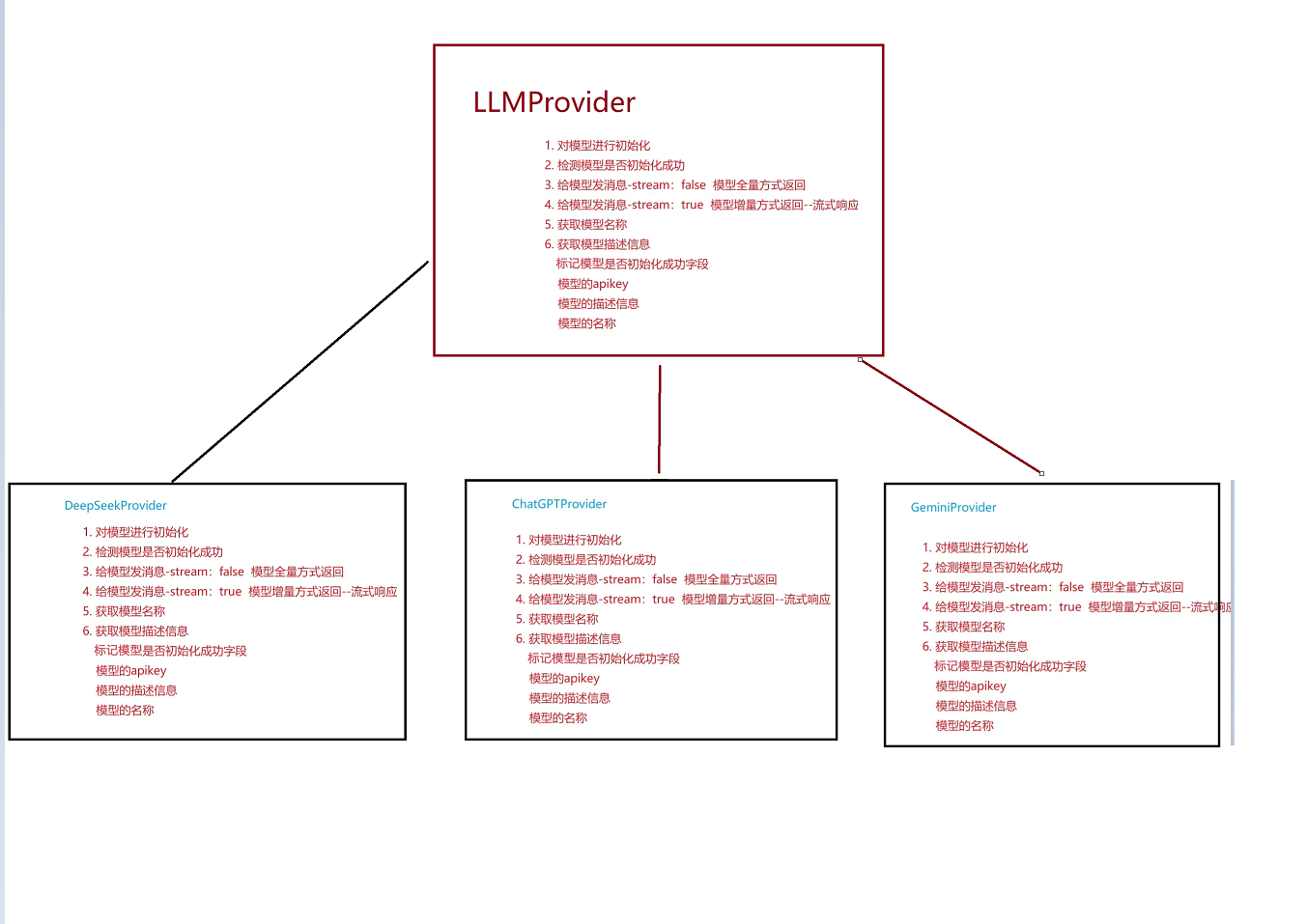
这样去继承我们就可以实习一个整体的功能然后局部的功能局部去实现 就避免了代码的重复
c++中基类的指针可以指向子类对象(运用了多态的机制) 然后我们发消息时用哪个看你传的是哪个大模型即可 然后将一些公共部分实现成虚函数即可

我们在实现LLMProvider时将其变为 抽象类 也就是将其方法都变成=0 然后变为抽象类也就是接口类 规范了子类是实现的方法
这样当我们只需要去调用LLMProvider即可然后再由编译器自己去调用不同模型的Provider
这样就完成了实现

我们将这个LLMProvider这个类封装到include文件夹下面 因为他只是一个抽象类 并没有去实现什么
php
#include <string>
#include <map>
#include <vector>
#include "common.h"
#include <functional>
namespace ai_chat_sdk{
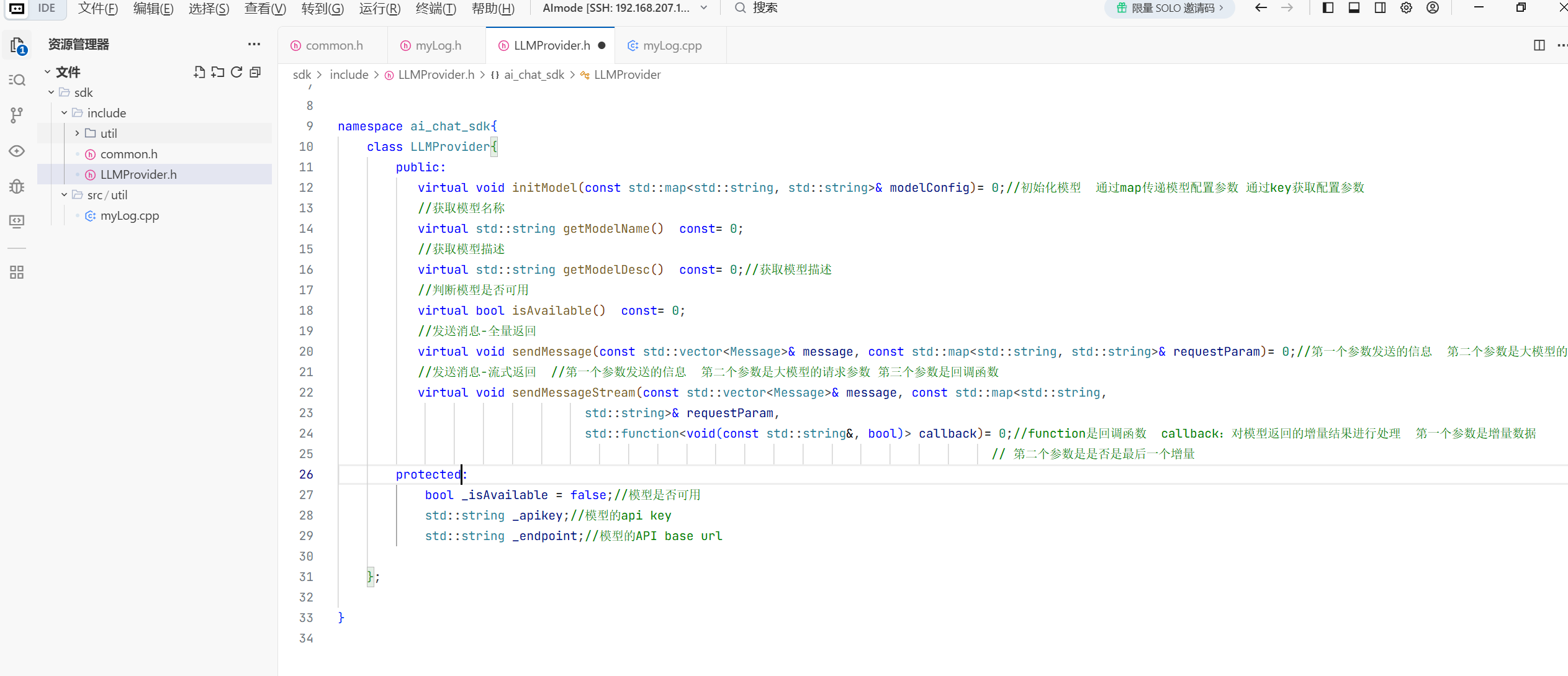
class LLMProvider{
public:
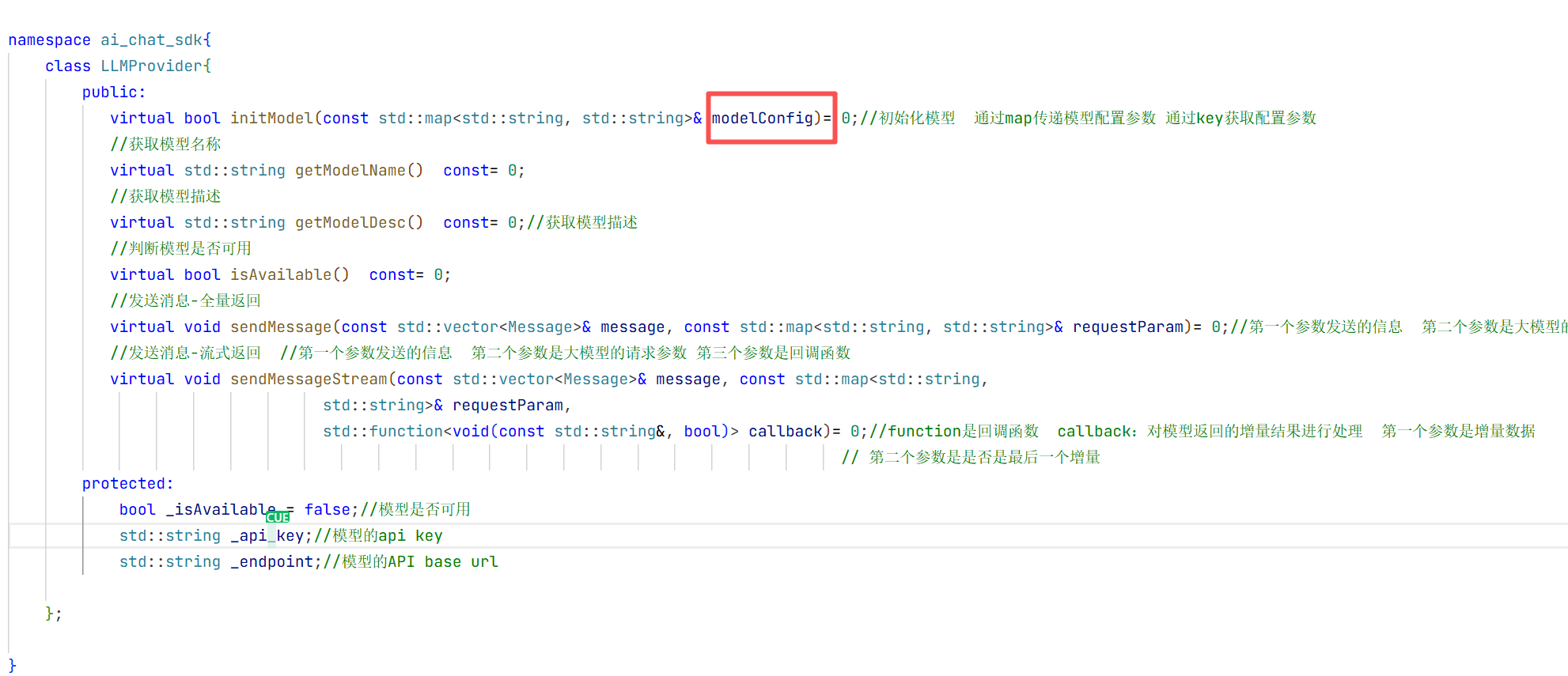
virtual bool initModel(const std::map<std::string, std::string>& modelConfig)= 0;//初始化模型 通过map传递模型配置参数 通过key获取配置参数
//获取模型名称
virtual std::string getModelName() const= 0;
//获取模型描述
virtual std::string getModelDesc() const= 0;//获取模型描述
//判断模型是否可用
virtual bool isAvailable() const= 0;
//发送消息-全量返回
virtual void sendMessage(const std::vector<Message>& message, const std::map<std::string, std::string>& requestParam)= 0;//第一个参数发送的信息 第二个参数是大模型的请求参数
//发送消息-流式返回 //第一个参数发送的信息 第二个参数是大模型的请求参数 第三个参数是回调函数
virtual void sendMessageStream(const std::vector<Message>& message, const std::map<std::string,
std::string>& requestParam,
std::function<void(const std::string&, bool)> callback)= 0;//function是回调函数 callback:对模型返回的增量结果进行处理 第一个参数是增量数据
// 第二个参数是是否是最后一个增量
protected:
bool _isAvailable = false;//模型是否可用
std::string _apikey;//模型的api key
std::string _endpoint;//模型的API base url
};
}这样 顶层抽象类就实现好了 这样以后你用哪个大模型 底层弄好了 你就可以去封装自己大模型的类 再去调用这个顶层类 这样就避免的代码的冗余。
7.deepseek的接入封装:
1.deepseek的API介绍:

top_p的含义也就是控制动态选词的质量高低
如果我们去看deepseek对话需求文档我们可以看到调用要传很多的参数 但是我们实际在实现时可以不用传递这么多 只需要传递重要的就行
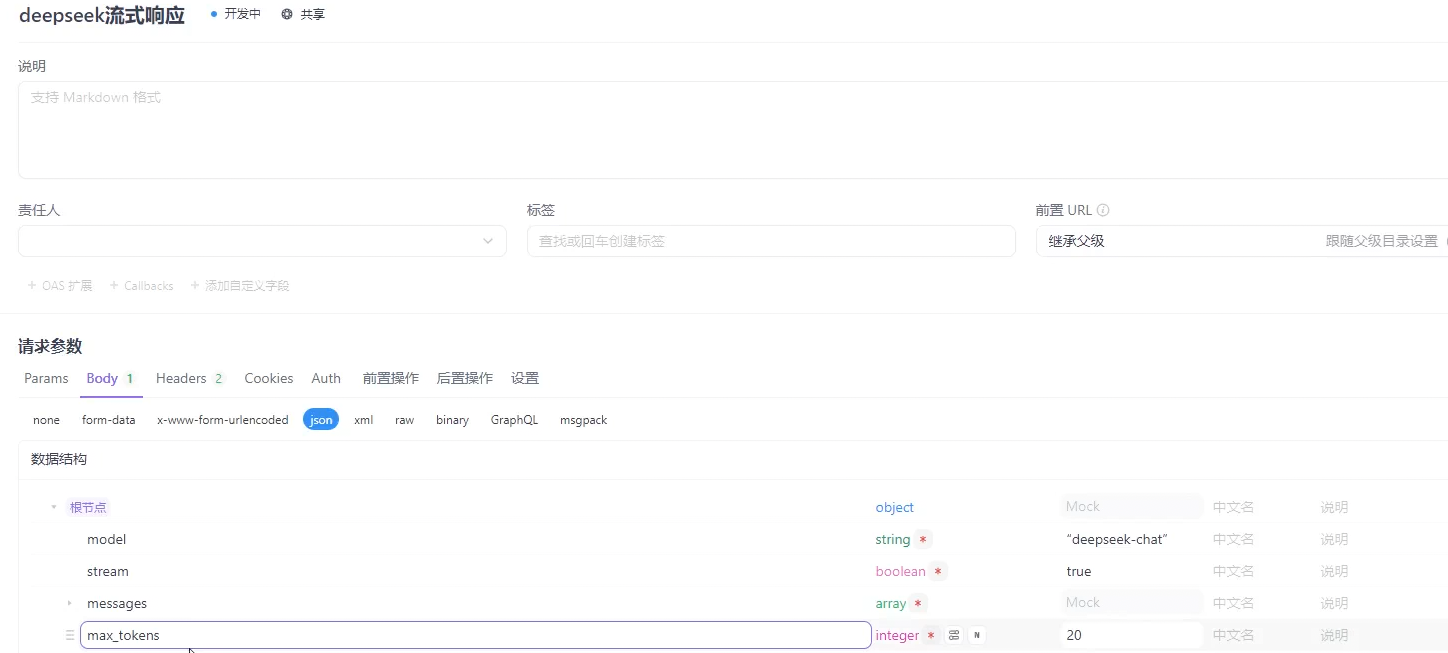
像我们在APIfox做的小验证我们只穿了 模型名称 输出流 消息 最大token数 也能完成调用
通过API调用的时候
注意:
•
⽆状态服务原则: DeepSeek的API基于⽆状态设计,每次请求视为独⽴会话。若需维护对话连续
性,必须由客⼾端主动管理并传递完整上下⽂ 。这与HTTP协议的⽆状态特性⼀致。
•
系统提⽰:若需保持⻆⾊设定,如始终以专家⾝份回答,每次请求必须包含系统级指令
•
对话历史:模型仅处理当前请求中的上下⽂,⽆法关联前序对话
这里需要注意的是假如你在APIfox第一次调用告诉了你的名字给大模型 第二发送我是谁的问题后 他会不记得 因为每次HTTP协议是独立的,就相当于你现在的这个调用 每一次对话都是独立的,
他不记得上下文。
但是当年在网页端去问deep seek同样的问题时 他会记得 因为deepseek官网后台 维护了与用户的聊天记录。
因为在APIfox调用时 没有维护与用户聊天记录 导致不知道与用户的聊天记录 所以每段对话是独立的 所以用API调用的时需要带上之前的聊天记录 才能根据上下文回答用户的问题。

我们根据回复的内容通过循环解析 找到这个content这个内容
2.deepseek的初始化:
1.deepseek头文件的实现
先在include下面创建支持deepseek初始化的头文件 做到头文件与源文件分离 直接继承父类 然后父类是保护成员但子类可以访问就不用写成员变量了
2.deepseek源文件的实现
再继续在src创建一个初始化deepseek的源文件即可 然后来进行初始化的实现
1.初始化模型的实现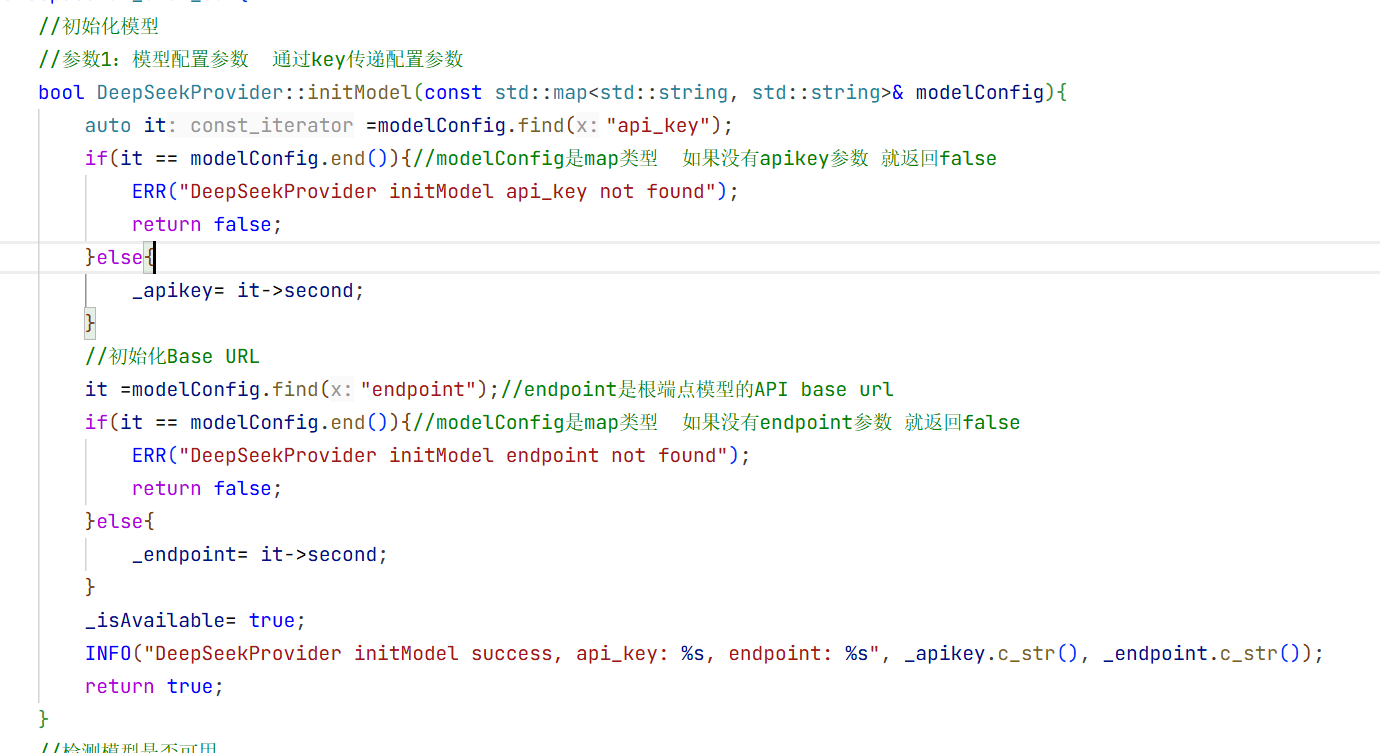
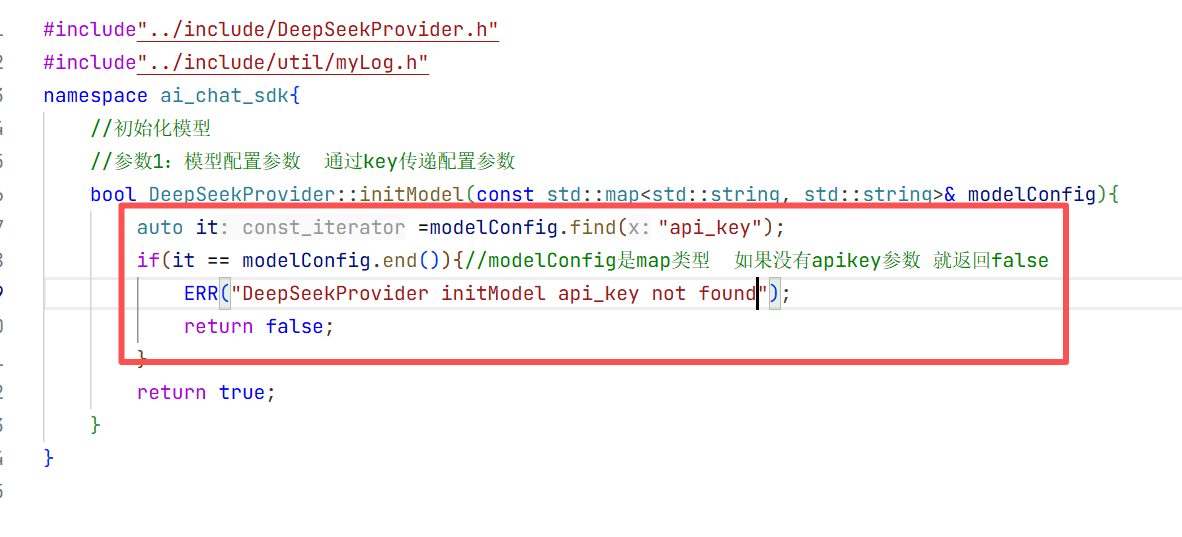
在cpp实现中我们去找这个map类型中的key值没找到说明你的api_key不存在 如果找到了就用map的value值去初始化api_key
2.检测模型和获取模型名称和描述模型信息
3.发送消息的实现(全量返回)

前面这个部分就相当于根端点 相当于endpoint 就初始化这个Base url 相当于就是一个网址
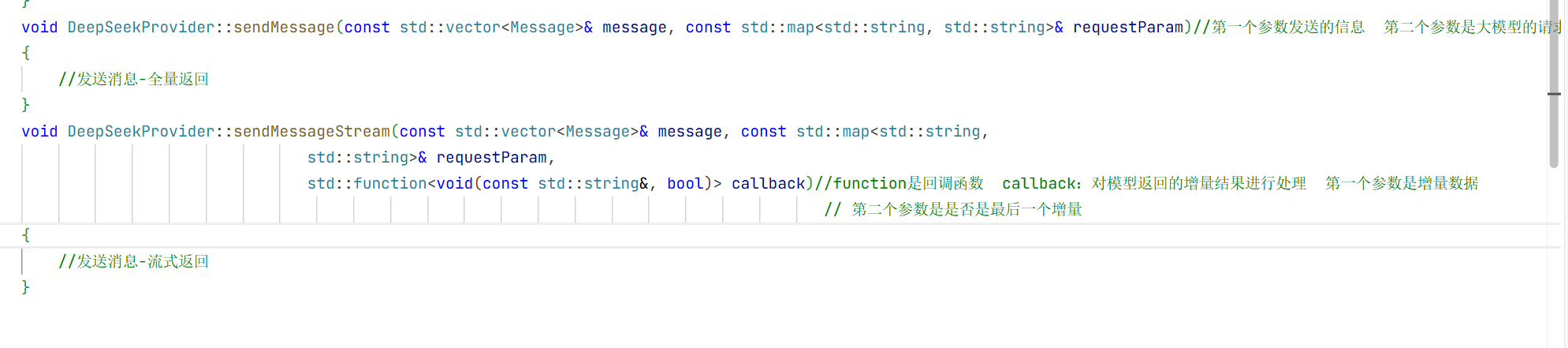
现在最重要的部分就是发送消息时 给模型发送的消息列表要构造好 我们之前介绍了如果用API调用的话 不发送历史消息模型是不知道我们上面的聊天内容的,所以我们要发送历史消息 第一个参数message就是消息列表,第二个参数就是请求参数 比如模型名称 消息列表 温度 token值 是否开启流式响应
相对于deepseek的服务器来说,sdk实际上就是一个http客户端

这里http客户端不需要我们手搓只需要调用第三方库 cpp-httplib的使用 包含这个头文件即可
这时候就跟我们在APIfox演示的一样要设置请求头 请求体


接下来就要设置请求头:
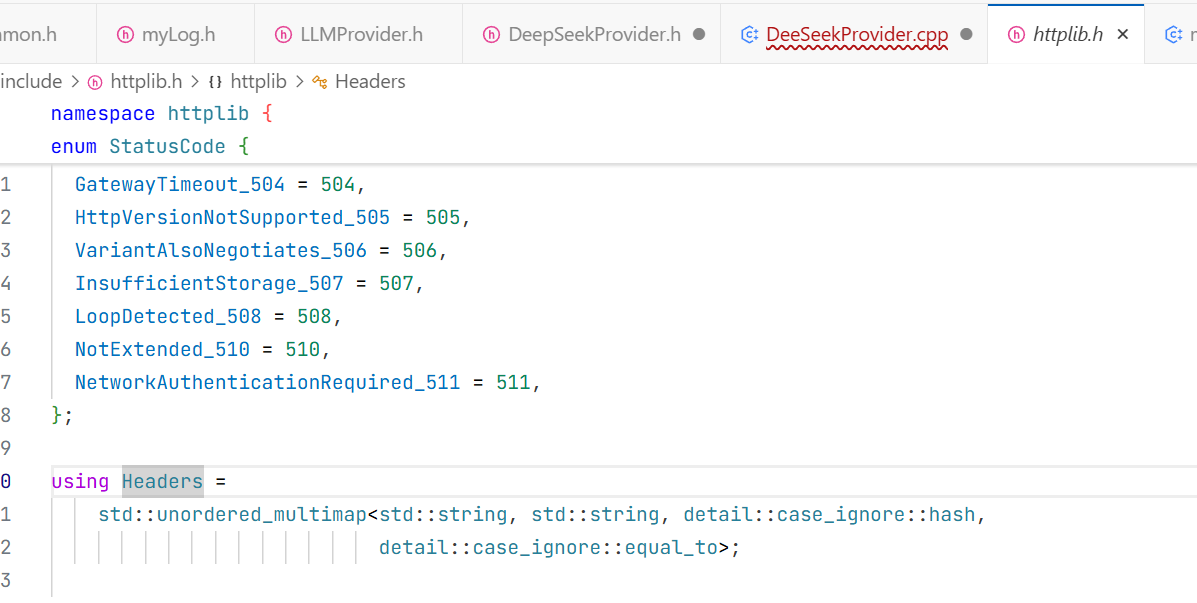
可以看到请求头封装的时候是一个哈希桶来实现的。

都是与接口测试时使用的参数类型是一样的。
解析响应体的实现


这个函数用来解析响应体的。
解析完响应体之后 我们要把返回来的答案解析出来 拿到关键的内容 所以这时候我们就要通过循环解析来拿到这个content。 接下来就要检测响应的json对象是否有content的内容

检测响应的json对象是否包含choices字段 如果包含再检测choices是否为数组,如果为数组检测是否为空 取choices0实际也是一个json对象replyconten然后再去当中找message中的content即可。
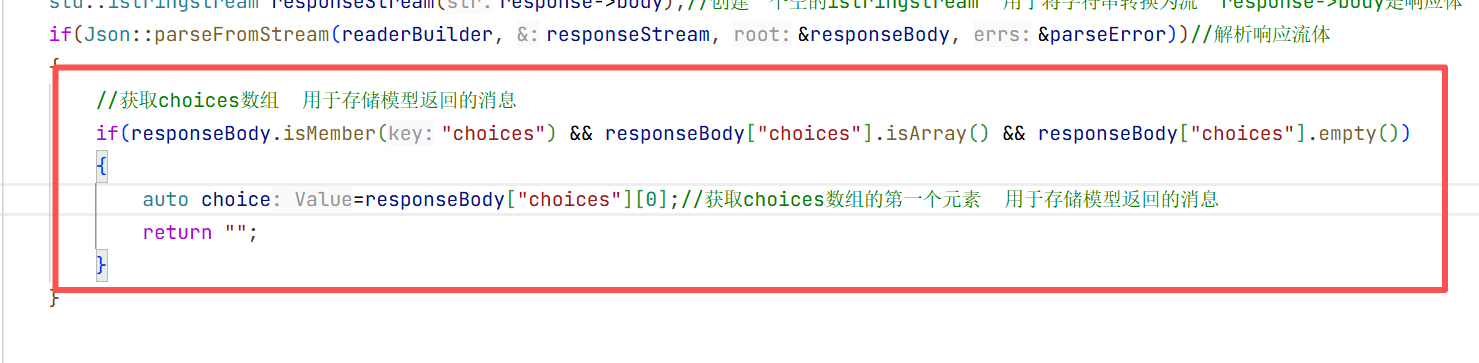
这一层只是获取到choice这部分 后面还要获取message里面的content

此时这一层再去寻找这一部分的主要内容
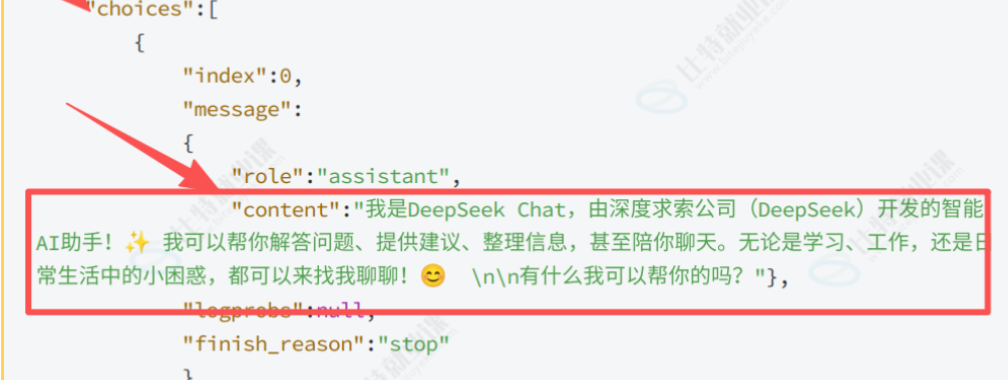

这就是整个解析的过程。
4.发送消息全量返回的测试:
1.测试代码的编写
为了保证代码的整洁 我们把测试代码和sdk文件夹分离开来 重新建立一个文件夹用来测试:
这个文件用来调用和测试大模型的方法 这里我们用gtest框架来进行调试
2.配置环境变量apikey


这里我们不在代码中展示接入大模型的apikey这是很私密的东西 所以我们要测试的话我们把获得到的apikey配置到环境变量中去执行上面的 把环境变量配置到文件中 这样就可以去调用了

这个名字要与你在配置环境变量中的名字要一样
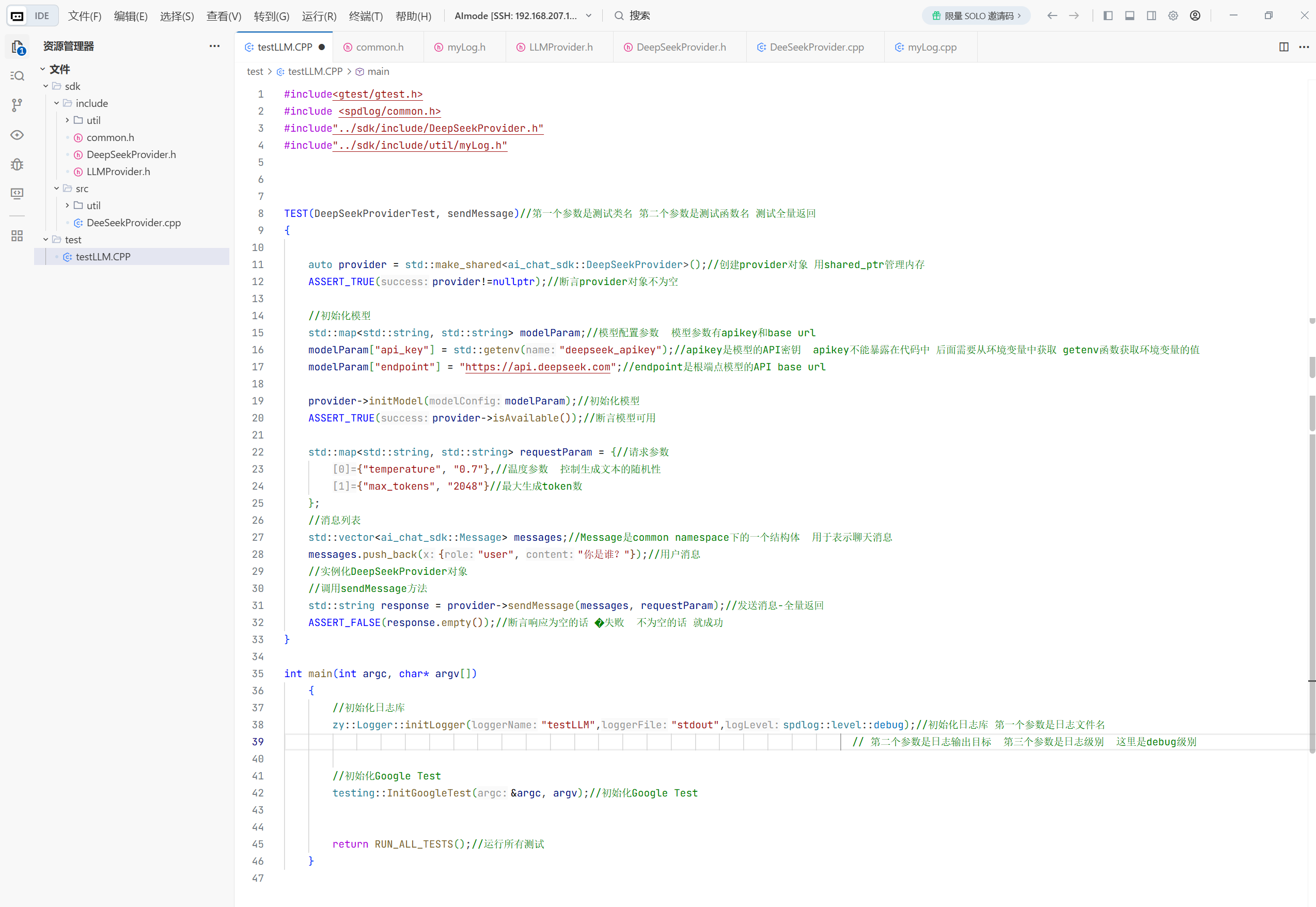
这就是测试发送消息全量返回的测试代码
写完这个代码我们还要去编写CMakeList 这样就可以直接编译然后运行
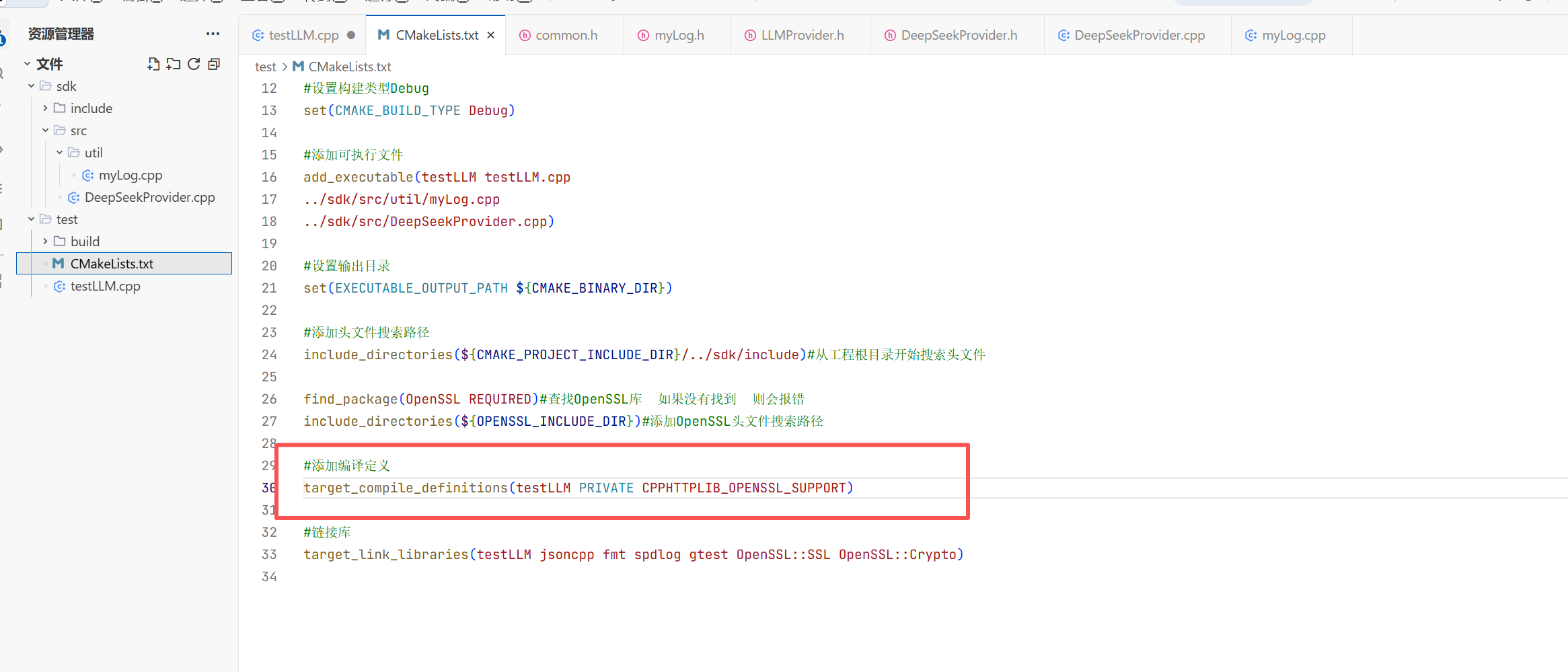
3.CMakeLists.txt文件的编写:
4.测试的问题:
首先进入到test的目录中


再在test目录下创建一个build目录 用来存放我们的测试用例

然后cmake一下去让他找上一个路径的CMakeLists.txt
遇到的错误1 把testLLM.cpp拼成了大写的CPP导致编译不出来
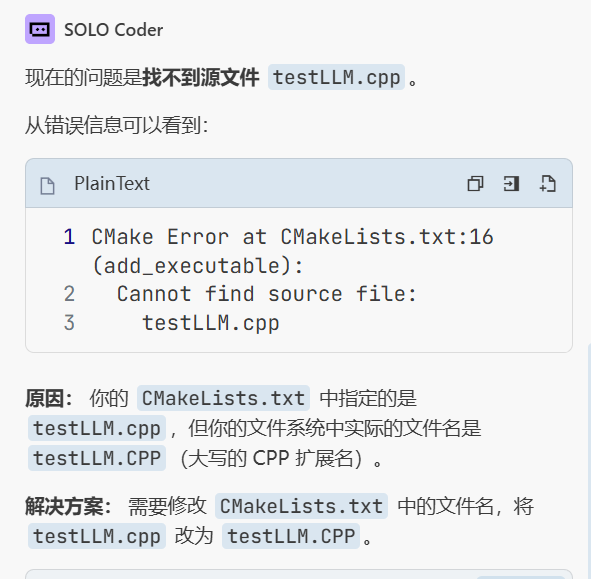
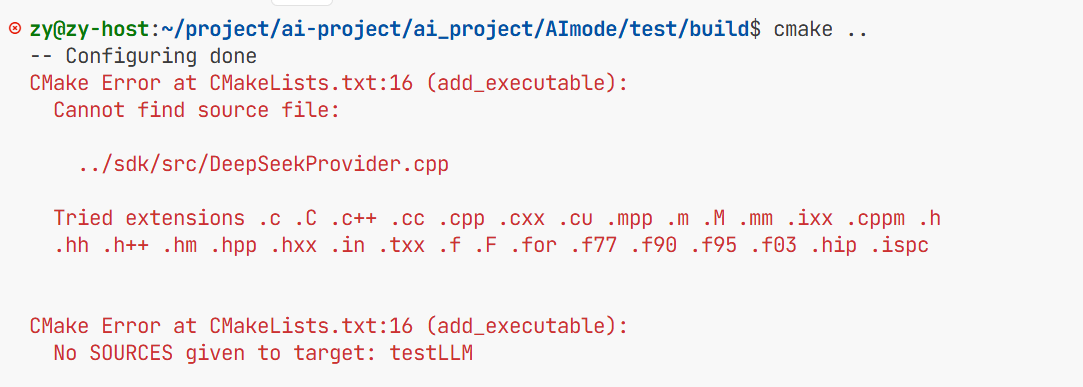
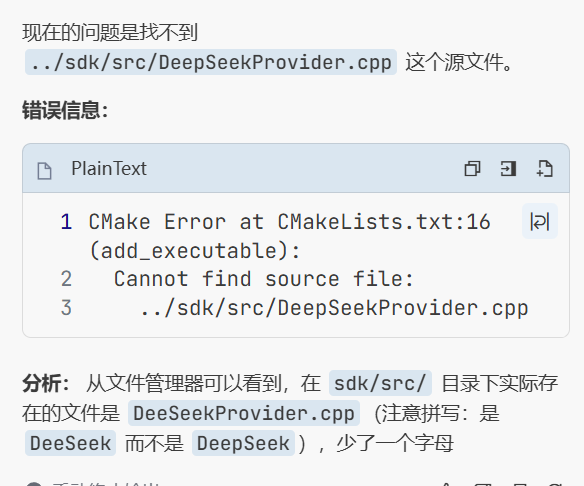
遇到的错误2 把Deepseekprovider.cpp少写了一个p
还要httplib这个默认是不支持http协议的 所以这里我们要将其改一下 让其支持
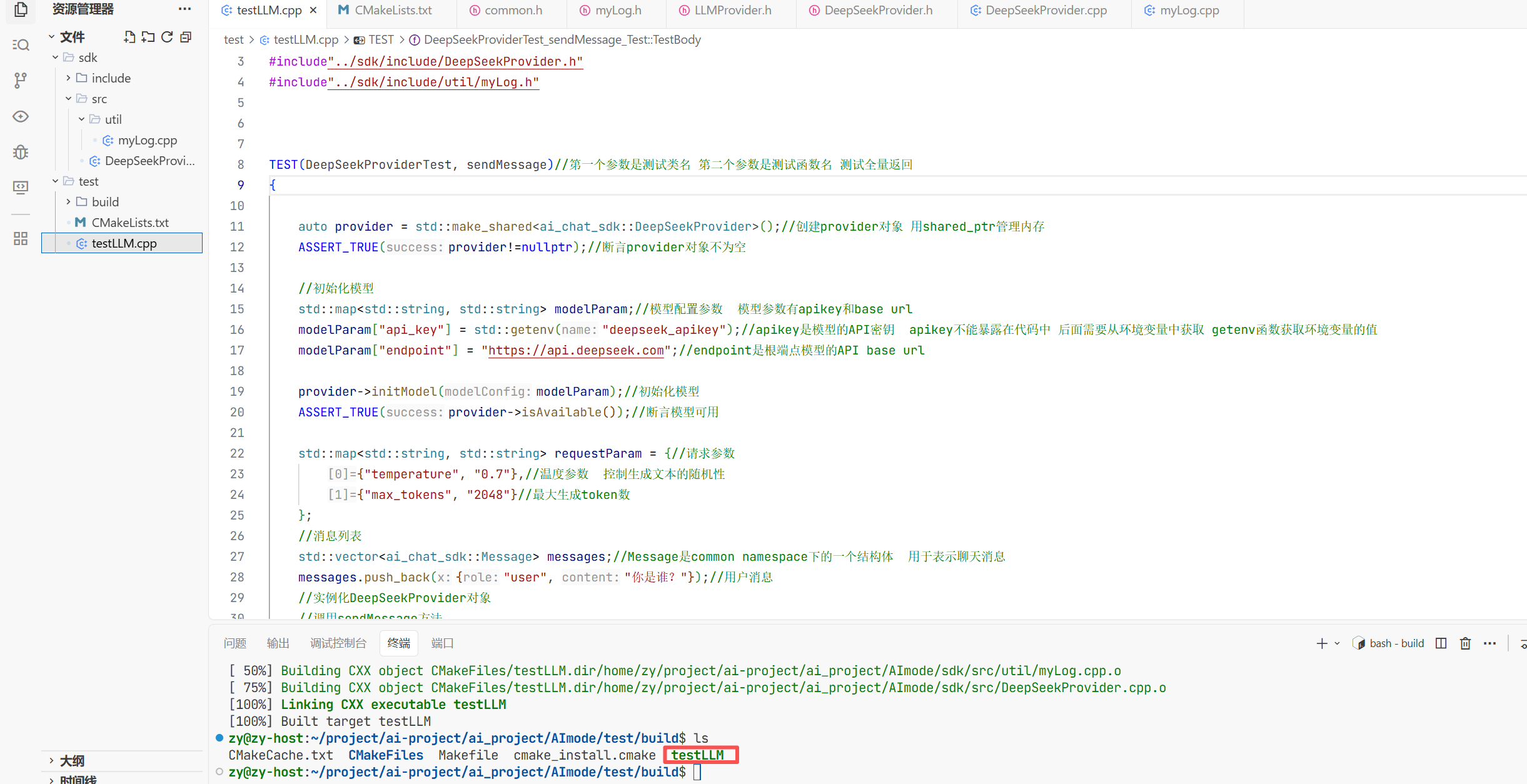
现在我们就成功编译出来了

但当我去./tetsLLM时虽然运行成功了但是报告了段错误根本原因是我没有更改环境变量 而我是直接把这个apikey传进去了
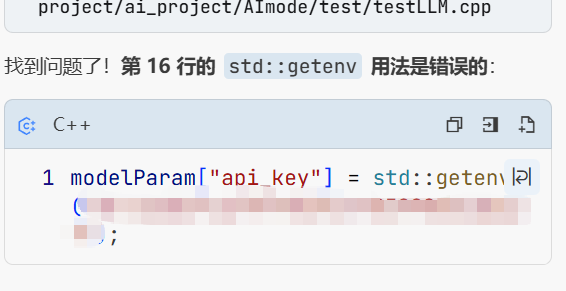
而这个gentenv这个函数是用来获取环境变量中的东西的而我这里环境变量找不到这个玩意 所以报错了
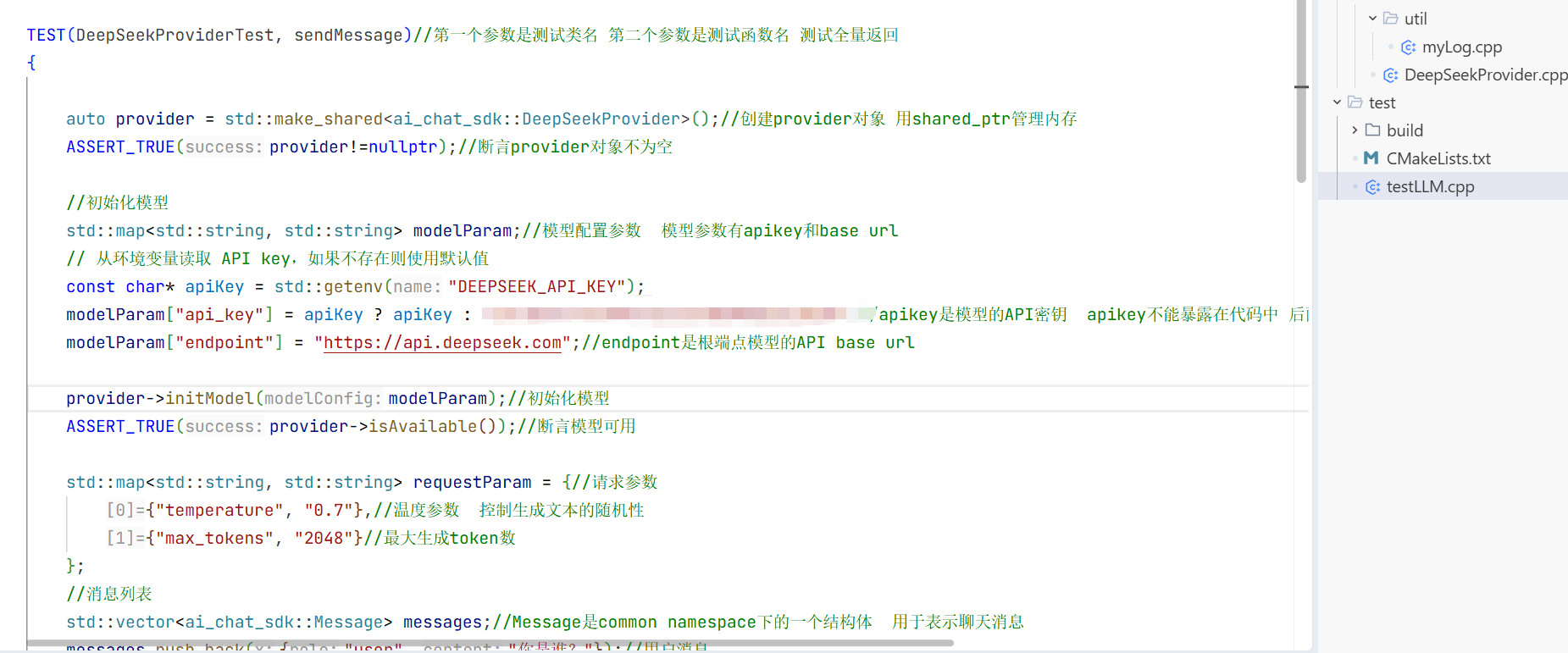
所以这里我直接用三目运算符看看是否存在不存在就显示的传我这个 在我后面把gat和genimi的apikey拿到之后再去把环境变量改掉 用getenv这个函数去隐匿的调用apikey。
这样完成后就能成功调用了
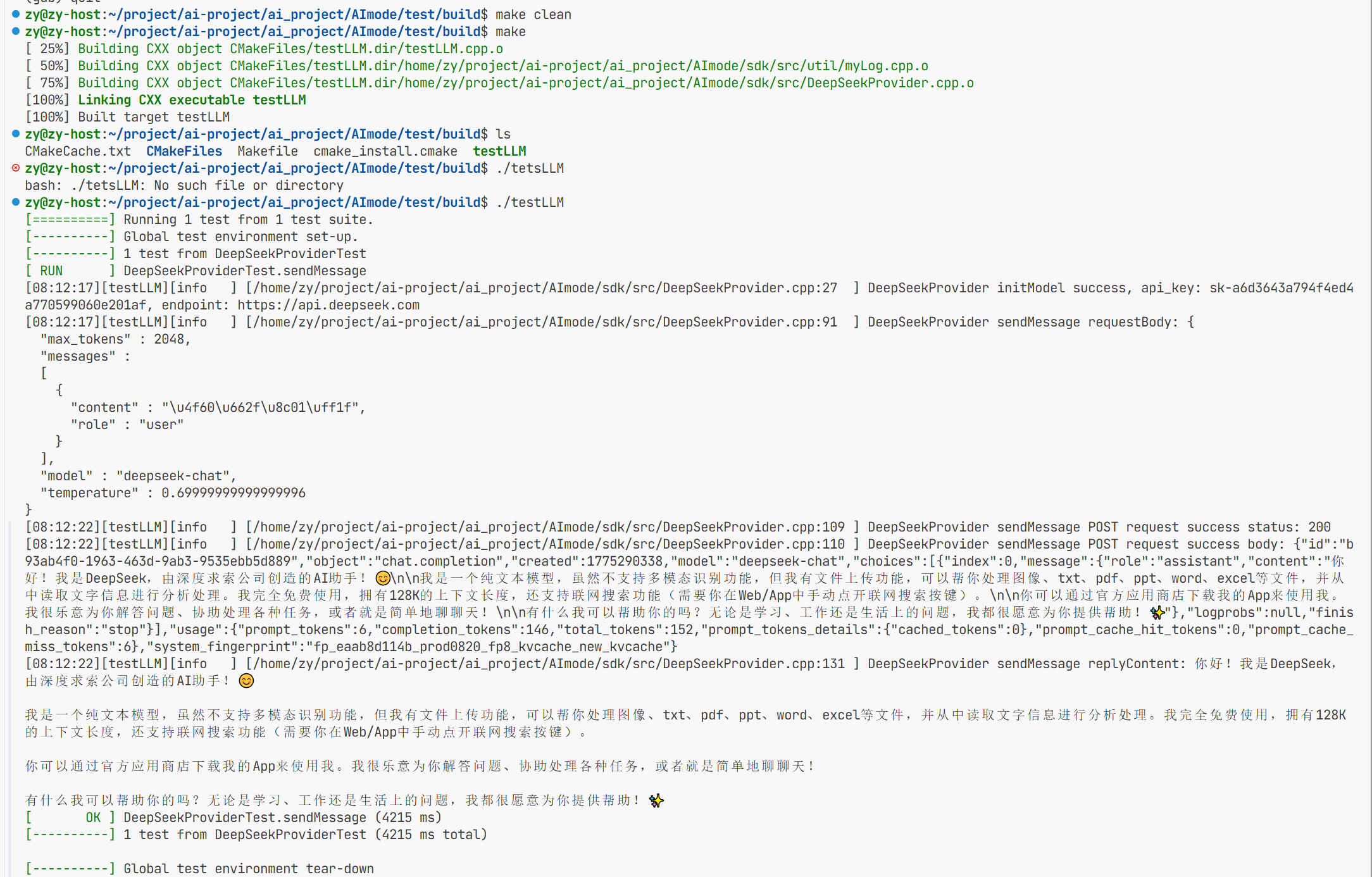

在这个文件目录下的第131行进行返回来的答案进行了解析并打印
这样全量返回的测试就结束了。聊天助手采用全量返回效果不怎么好 如果聊天时要求过多响应时间过长会不好 所以需要流式返回。
cpp
#include<gtest/gtest.h>
#include <spdlog/common.h>
#include <unistd.h>
#include"../sdk/include/DeepSeekProvider.h"
#include"../sdk/include/util/myLog.h"
TEST(DeepSeekProviderTest, sendMessage)//第一个参数是测试类名 第二个参数是测试函数名 测试全量返回
{
auto provider = std::make_shared<ai_chat_sdk::DeepSeekProvider>();//创建provider对象 用shared_ptr管理内存
ASSERT_TRUE(provider!=nullptr);//断言provider对象不为空
//初始化模型
std::map<std::string, std::string> modelParam;//模型配置参数 模型参数有apikey和base url
// 从环境变量读取 API key,如果不存在则使用默认值
const char* apiKey = std::getenv("DEEPSEEK_API_KEY");
modelParam["api_key"] = apiKey ? apiKey : "你的apikey";//apikey是模型的API密钥 apikey不能暴露在代码中 后面需要从环境变量中获取 getenv函数获取环境变量的值
modelParam["endpoint"] = "https://api.deepseek.com";//endpoint是根端点模型的API base url
provider->initModel(modelParam);//初始化模型
ASSERT_TRUE(provider->isAvailable());//断言模型可用
std::map<std::string, std::string> requestParam = {//请求参数
{"temperature", "0.7"},//温度参数 控制生成文本的随机性
{"max_tokens", "2048"}//最大生成token数
};
//消息列表
std::vector<ai_chat_sdk::Message> messages;//Message是common namespace下的一个结构体 用于表示聊天消息
messages.push_back({"user", "你是谁?"});//用户消息
//实例化DeepSeekProvider对象
//调用sendMessage方法
std::string response = provider->sendMessage(messages, requestParam);//发送消息-全量返回
ASSERT_FALSE(response.empty());//断言响应为空的话 �失败 不为空的话 就成功
}
int main(int argc, char* argv[])
{
//初始化日志库
zy::Logger::initLogger("testLLM","stdout",spdlog::level::debug);//初始化日志库 第一个参数是日志文件名
// 第二个参数是日志输出目标 第三个参数是日志级别 这里是debug级别
//初始化Google Test
testing::InitGoogleTest(&argc, argv);//初始化Google Test
return RUN_ALL_TESTS();//运行所有测试
}5.发送消息的实现(流式返回)
流式响应:
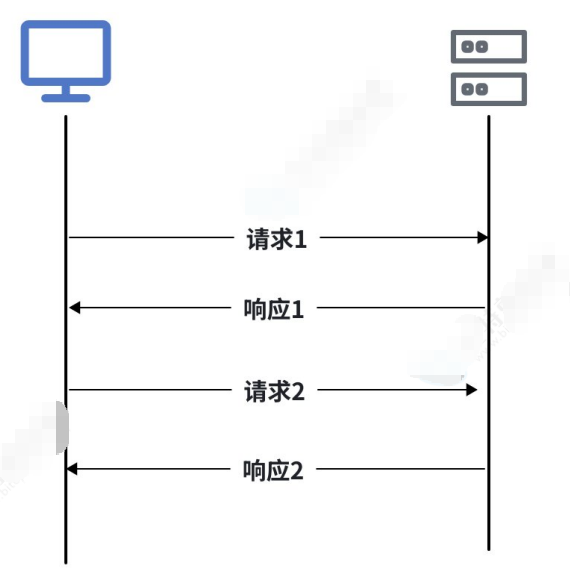
1.http协议:
两次请求与响应之间是没有任何交集的
HTTP协议是严格的"请求-响应"模型,永远是客⼾端发起请求,服务器才能响应,服务器就像个"哑
巴",它知道更多内容,但是它⽆法主动告诉你。这种⼀问⼀答的模式对于⼤部分⽹⻚浏览器、数据提 交等场景已经⾜够了。
但是有些场景下,服务器需要主动向客⼾端推送⼀些实时数据,⽐如,在看体育直播时,服务器要及 时将⽐赛分数、⾦球球员等信息推送给客⼾端;在多⼈在线游戏中,服务器需要实时同步玩家的操作 和游戏状态;在使⽤导航类应⽤时,服务器需要实时推动导航信息等。
⼤佬们也发现这个问题了,在2004年的时候Ian Hickson就提出了SSE概念,Opera浏览器是第⼀个⽀ 持SSE的,2011年开始,⼀些主流浏览器(Chrome、Firefox、Safari)开始逐步⽀持SSE,2015年时 SSE规范才正式成为W3C的标准。
说白了我们需要实时更新时 不需要与客户端交互 只要发生变化就需要发送给我 所以我们这里就可以才用轮询的方式 其实也不是客户端主动发数据给我们 只是我们循环要求他不断输出数据
这样的话可能会导致很多无效的访问且可能都不是时时的消息。
2.SSE协议:
SSE是Server Send Event的缩写,即服务器发送事件,是建⽴在HTTP协议之上的开发标准,允许服务器主动向客⼾端(如浏览器)推送实时数据。

所以这种协议非常适合大模型这种实时推送数据
SSE通过单⼀的持久连接实现数据的实时传输,客⼾端⽆需频繁发起请求。
SSE协议特点
•
单向通信:服务器可以主动推送数据到客⼾端,但客⼾端⽆法直接通过SSE向服务器发送数据
•
基于HTTP协议:SSE使⽤标准的HTTP协议,⽆需额外的协议或端⼝配置,兼容性好易于实现
•
轻量级:SSE的实现更简单,代码量少,适合简单的实时数据推送场景
•
⾃动重连:如果连接断开,浏览器会⾃动尝试重新连接,⽆需开发者⼿动处理重连逻辑
•
⽀持事件类型:服务器可以发送不同类型事件,客⼾端可以根据事件类型执⾏不同的操作
•
⽀持消息ID:每条消息可以包含⼀个唯⼀的ID,⽤于断线重连后恢复消息流
数据格式:
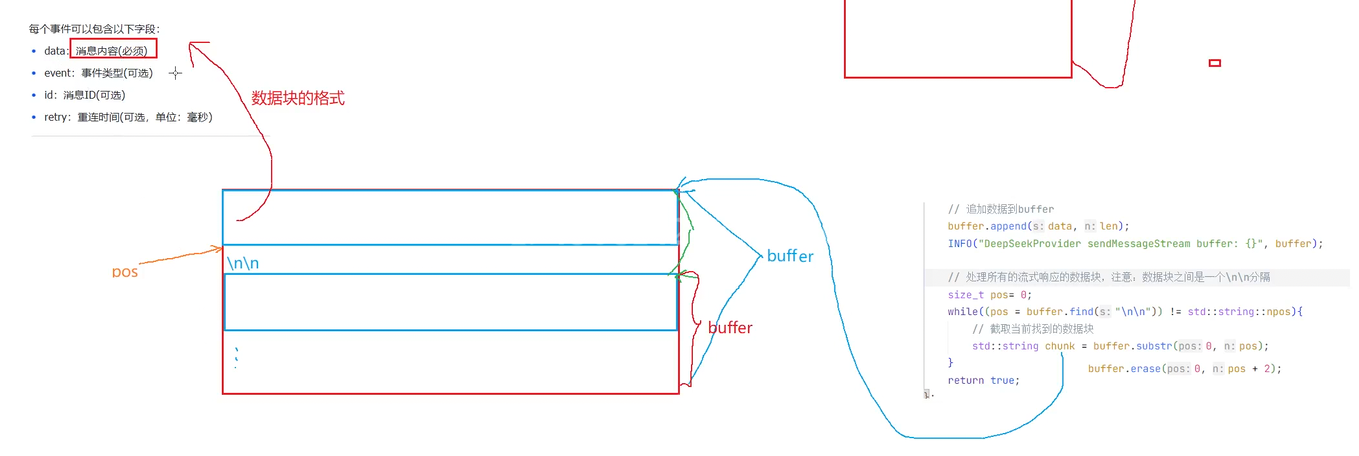
每个事件可以包含以下字段:
•
data:消息内容(必须) •
event:事件类型(可选)
•
id:消息ID(可选)
•
retry:重连时间(可选,单位:毫秒)
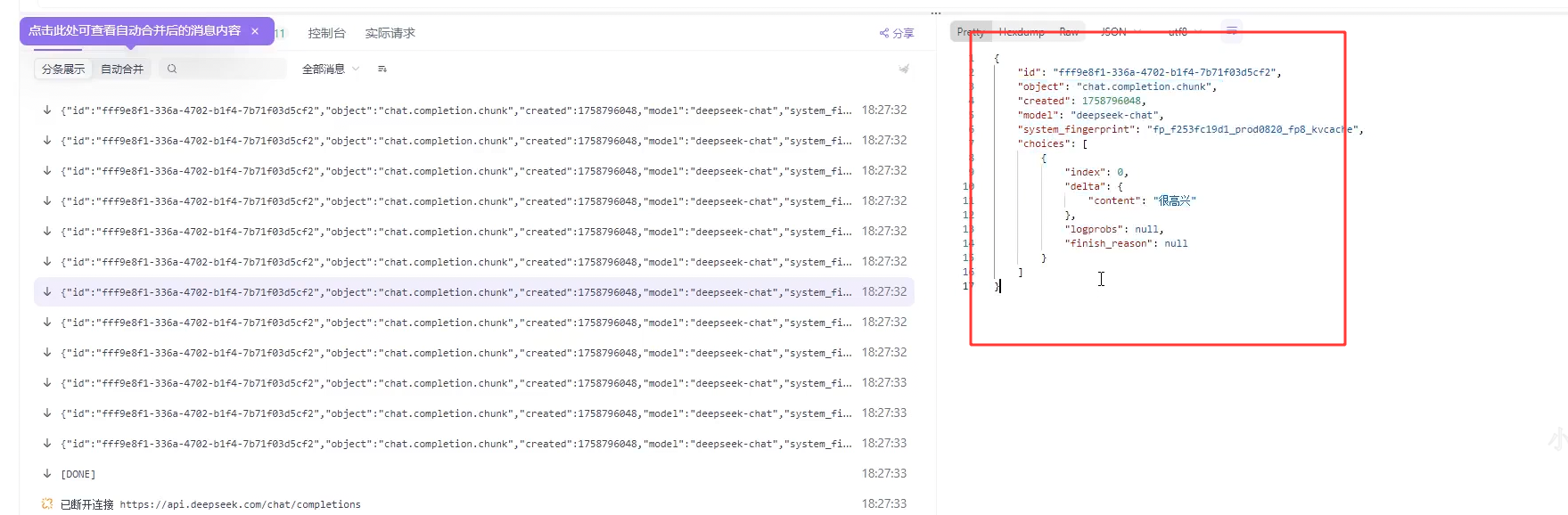
代码块
data: Hello, world!
event: message
id: 123
retry: 10000
data: Another message
每条消息以两个换⾏符 (\n\n) 结束,消息流传输完毕后会有专⻔的结束标记,不同实现结束标记不
同,⽐如data: DONE。
前⾯我们演⽰向DeepSeek、ChatGPT、Gemini等⼤模型提问时,这些⼤模型并不是⼀次性将完整回 答丢给⽤⼾,⽽是服务器边思考,边主动将思考结果吐(推送)给⽤⼾的,就和打字⼀样⼀点点输出,⽤⼾不需要⻓时间的等待,能及时看到服务器响应的结果,体验⽐较好,这种⽅式称为流式响应。SSE推 出后实际不温不⽕,⼤模型爆⽕后,正式⼤模型场景的需要,SSE协议就爆⽕了
SSE协议你客户端不发送请求 服务器不会主动给客户端发送协议
3.WebSocket协议
SSE协议有⼀个缺陷就是单向传输,即数据只能由服务器给客⼾端推送,在新闻推送、股票⾏情、体育⽐分等场景是⽐较合适的,因为这些场景客⼾端⽆需给服务器发数据。
但有些场景SSE就束⼿⽆策了。⽐如:你在你们宿舍的微信群⾥发了⼀个消息"谁去⻝堂帮我捎个饭", 服务器收到后需要"谁去⻝堂帮我捎个个饭"这条消息主动推送给群中其他⼈,其他⼈收到消息后,就 需要发消息回应你⽽不是不闻不问。此处由舍友回复"滚犊⼦",那服务器收到后⼜要推送给其他⼈... 该场景中,不仅需要服务器主动给客⼾端推送消息,也需要客⼾端给服务器发送消息。这种场景下 WebSocket协议就派上⽤场了。

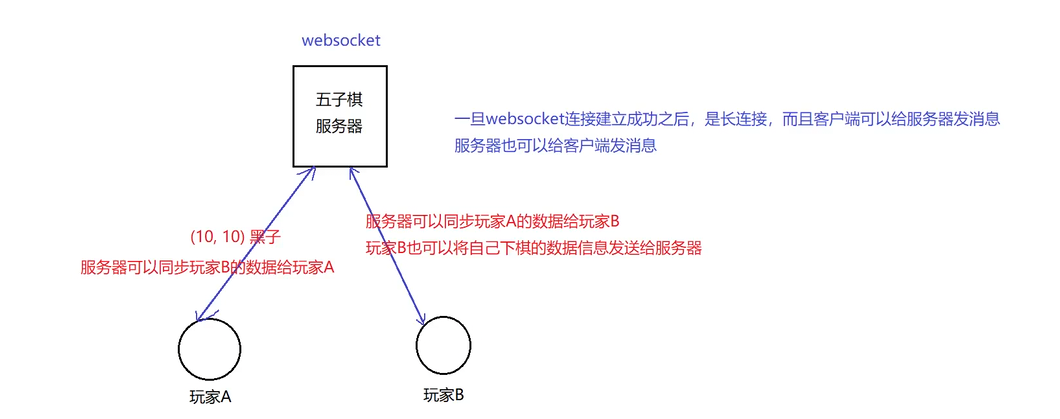
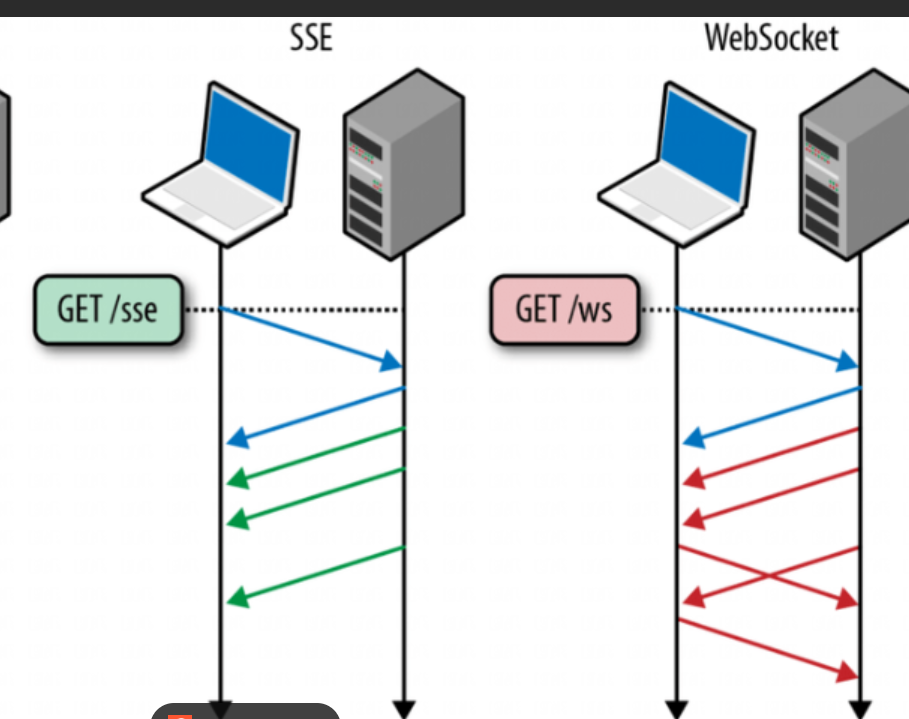
为什么DeepSeek的助⼿消息使⽤SSE,不使⽤websocket?
答:⼤模型的回复是服务器向客⼾端推送数据的单项数据流,在此期间客⼾端不需要给⼤模型服务器 发送消息,⽽SSE刚好是服务器主动单项给客⼾端推送数据,并且实现简单⾼效,因此⼤模型回复通常都使⽤SSE协议。而HTTP协议不记得上次问的内容所以也不用HTTP协议
4.了解HTTP的请求参数
HTTP普通响应体和流式响应体
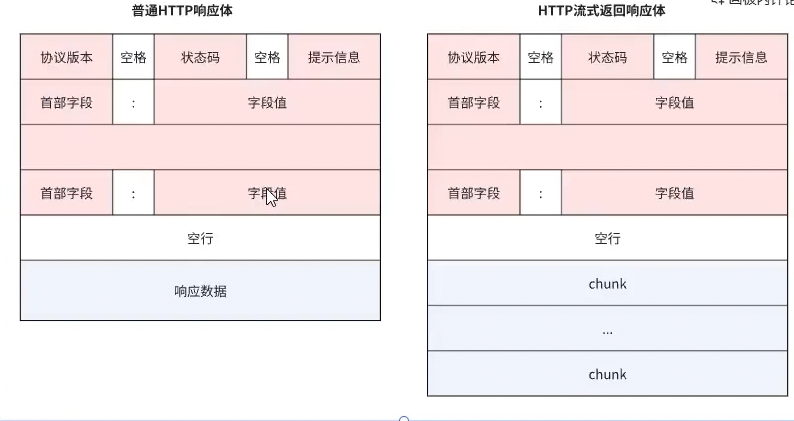
普通HTTP响应体中,⼀个响应包含⼀个响应头和⼀个响应体,
在HTTP流式返回响应体中,⼀个响应包含⼀个响应头和多个响应块。在流式返回时,会先返回响应 头,然后在逐个返回各个响应体,因此在发送流式响应时,需要在请求参数中告知HTTP服务器,响应 头和chunk该如何处理。

按住ctrl然后点击httplib调用的函数就能进入转到他定义的地方了

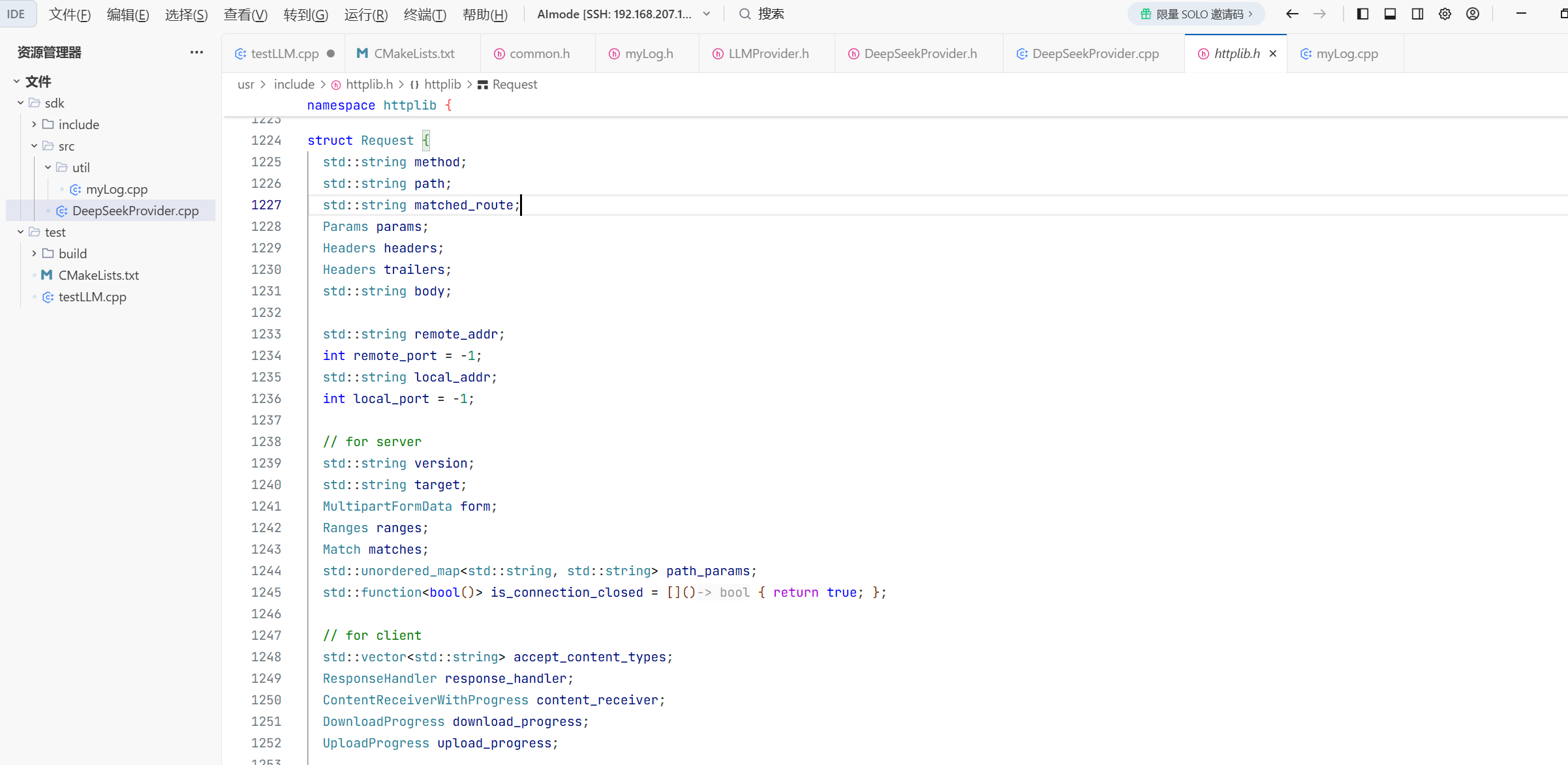
这就是所需要的参数
cpp
struct Request {
// 通⽤参数
std::string method; // 请求⽅法,GET、POST等
std::string path; // 资源路径,URL中域名之后的部分,⽐如:/api/users
Headers headers; // HTTP请求头,类型为 multimap<string, string>
std::string body; // HTTP请求体 存放服务器请求参数
// 查询参数:
Params params; // 查询参数,类型为 multimap<string, string>
//一般附加在URL的末尾 用于向服务器传输一些额外的数据
//比如查询商品的价格降序排序 这些都是查询参数 而不是路径
// 路径参数或路由参数, 类型为 unordered_map<string, string>
std::unordered_map<std::string, std::string> path_params;//是URL的变量部分,用于动态获取URL中特定的段落值 功能:比如获取指定用户的谋篇文章 GET/api/users_id/posts/post_id
// for client
ResponseHandler response_handler;//响应处理器 是一个函数包装器 对应满足条件的函数进行包装
ContentReceiverWithProgress content_receiver;//内容接收器 类型也是一个函数包装器
//content type 请求方式
};

response_handler 为响应处理回调函数,实际类型为 std::function<void(const
Response&)> , 如果发起请求时设置该函数,当客⼾端收到完整的HTTP响应头和⼀些体(如果存在) 后,会调⽤该函数,并传⼊构造好的Response对象。
content_recevier 内容接收回调函数,是处理流式处理响应的关键,类型为:
function<bool(const char* data, size_t len, uint64_t offset, uint64_t total)>
◦
data:指向当前接收到的数据块的指针
◦
len: 当前数据块的⻓度
◦
offset: 当前数据块在请求体中的偏移量
◦
total: 请求体的总⻓度
◦
返回值:true表⽰继续接收数据,false表⽰停⽌接收数据
设置该回调函数后,客⼾端不会等待整个响应体传输完再存到response.body中,⽽是每收到⼀⼩块
数据就⽴刻调⽤该回调函数,处理实时数据,
5.基本的实现
总的来说流式返回比全量返回多的是传一个stream,还有解析请求体的返回不一样 ,还要服务器返回一块数据后要定义一个数据处理的方式也就要解析传过来的内容

这就是基本设置这七个设置跟全量返回是差不多的只是改动了画方括号的地方
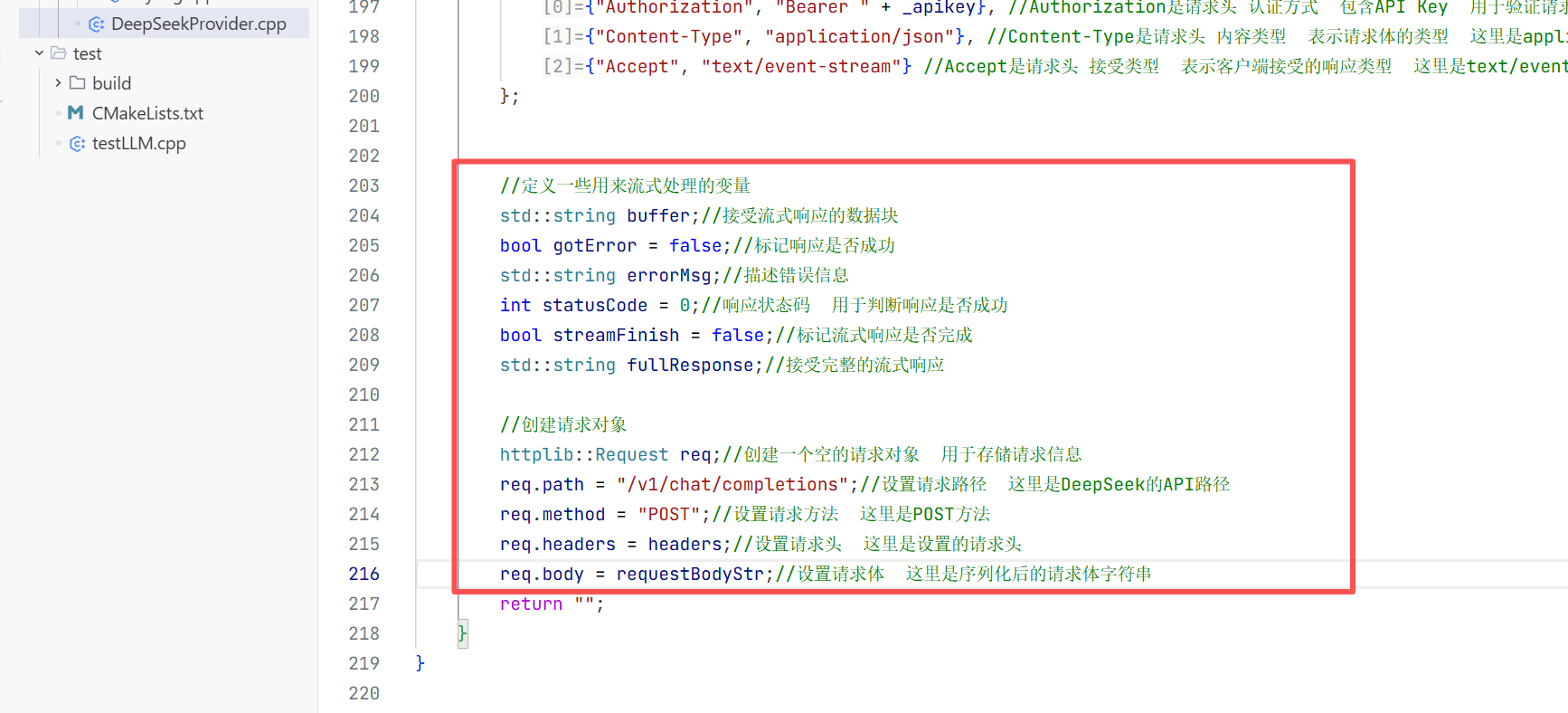
发送请求时与全量返回不一样的是这里需要在外边创建变量和对象 这样方便
6.响应处理器的实现

7.数据接受处理器的实现

因为是首个字段再加两个\n\n才到下一个字段 所以当我们截取第一个字段后 再加上两个字符从这个位置再去截取我们需要的内容

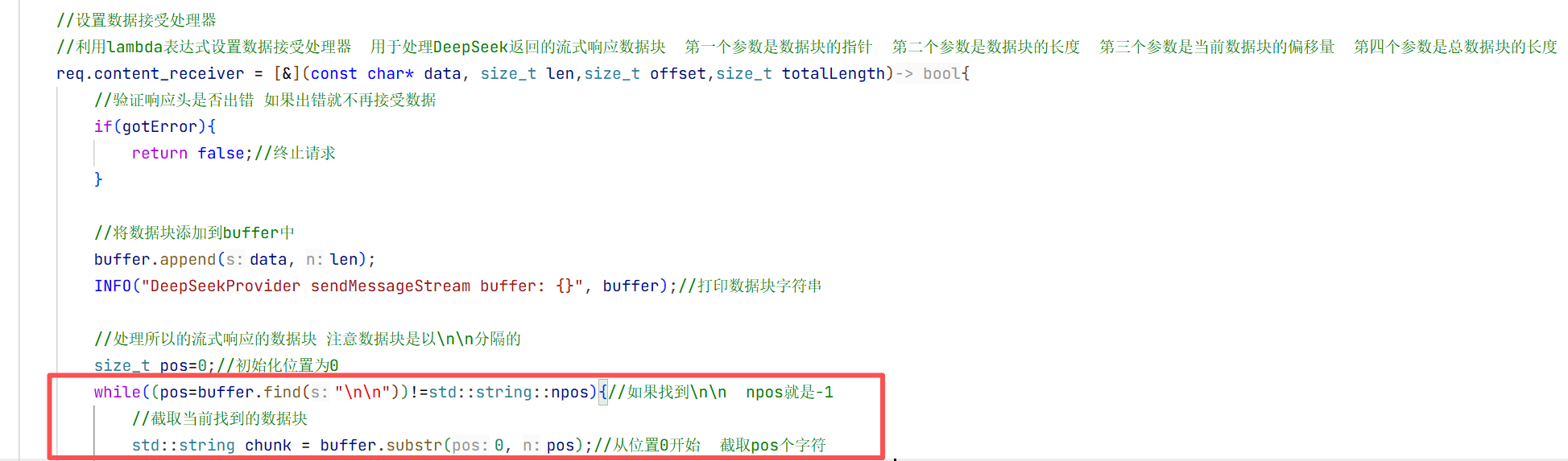
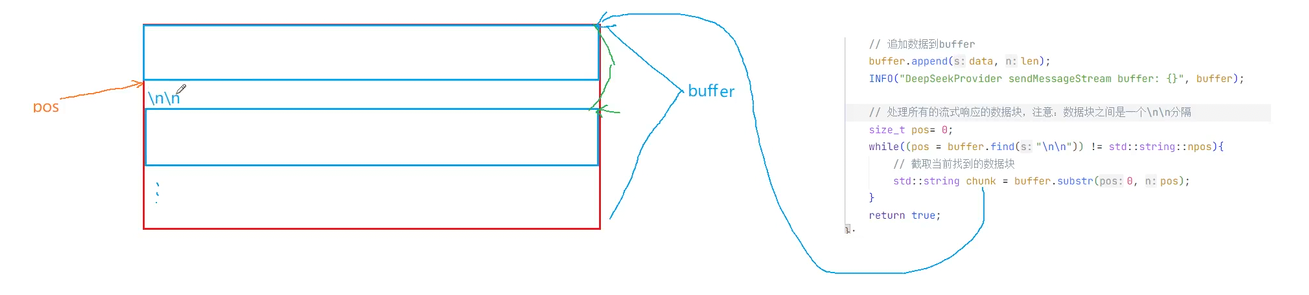
块和块之间用了两个\n去做分割 所以我们截取我们要的信息时要去把那两个\n\n给去掉

删除之后新buffer就是这个
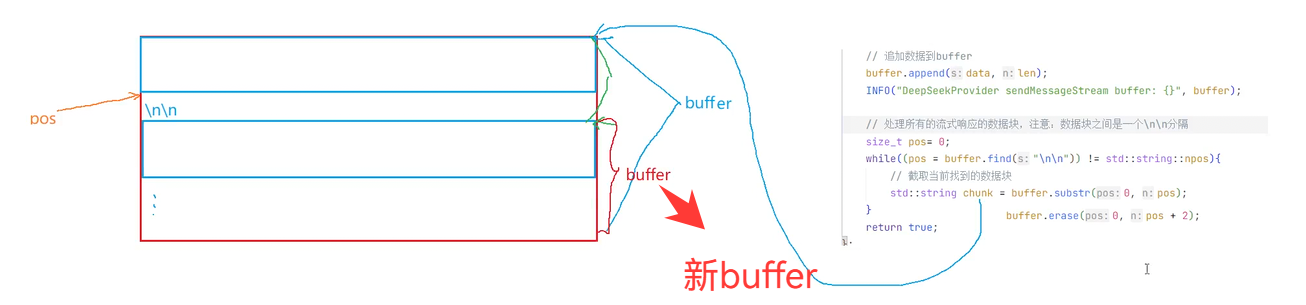
再去处理掉空行和注释

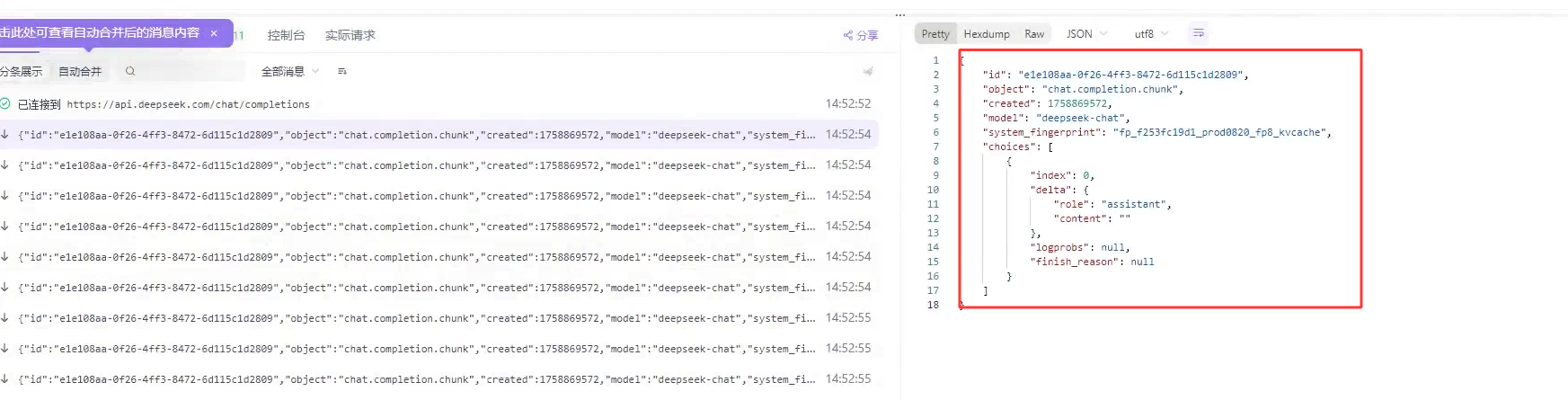
我们模型返回的消息存储在数据块中data : 的后面 所以我们要去拿取这个有效数据

如果前六个字符是data冒号空格 说明后面的就是我们需要的有效数据

光光到这还没有结束
我们还要去反序列化 才能拿到这样的结果

此时我们就拿到反序列化的数据了
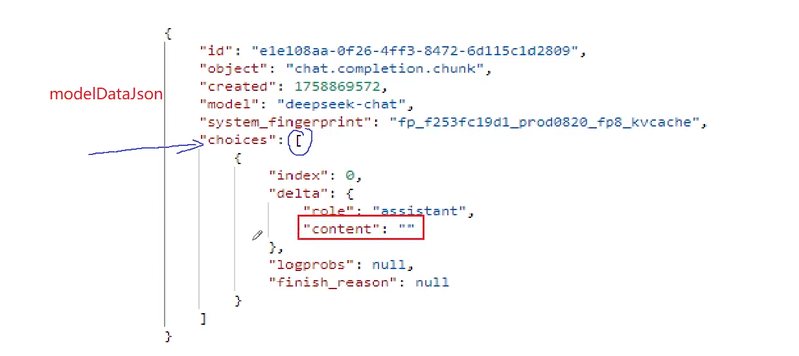
整个数据存储在modelDateJson中所以现在我们要去验证是否有choices这个数组 然后choices是否有元素 如果不为空就返回了内容就去拿第0个位置的元素
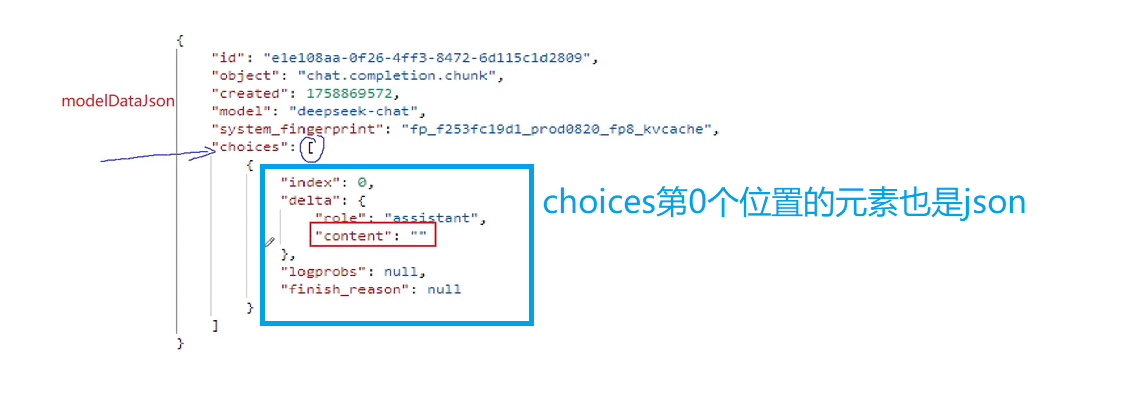
再去看这个json对象是否有delta这个字段 这个字段也是一个json对象 在这个delta看看是否包含conten 如果有就拿出来 这样就是我们想要的内容 就是一层套娃再套娃
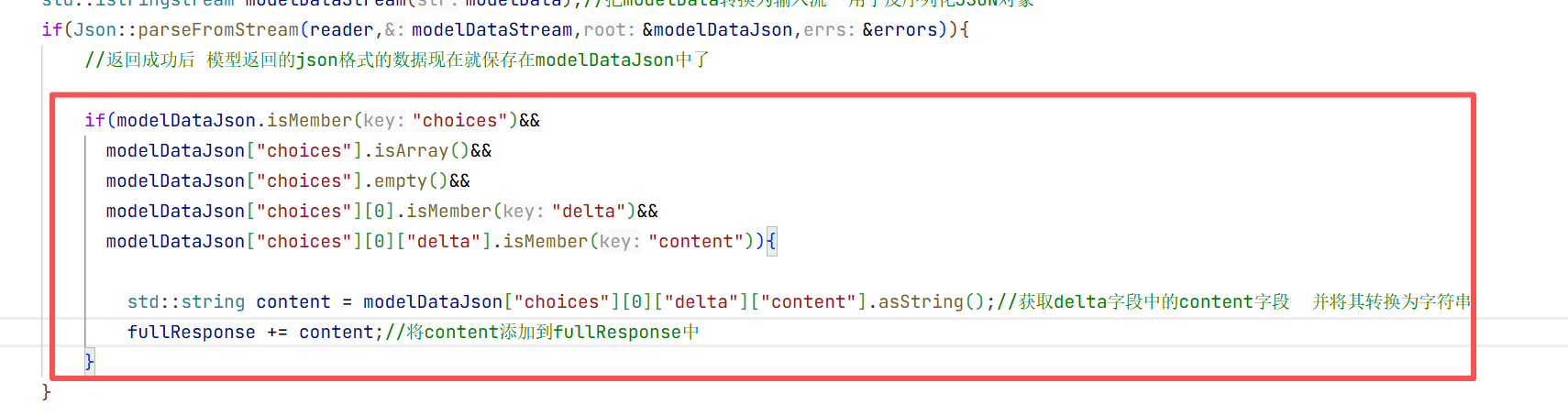
这个就是整个套娃的过程
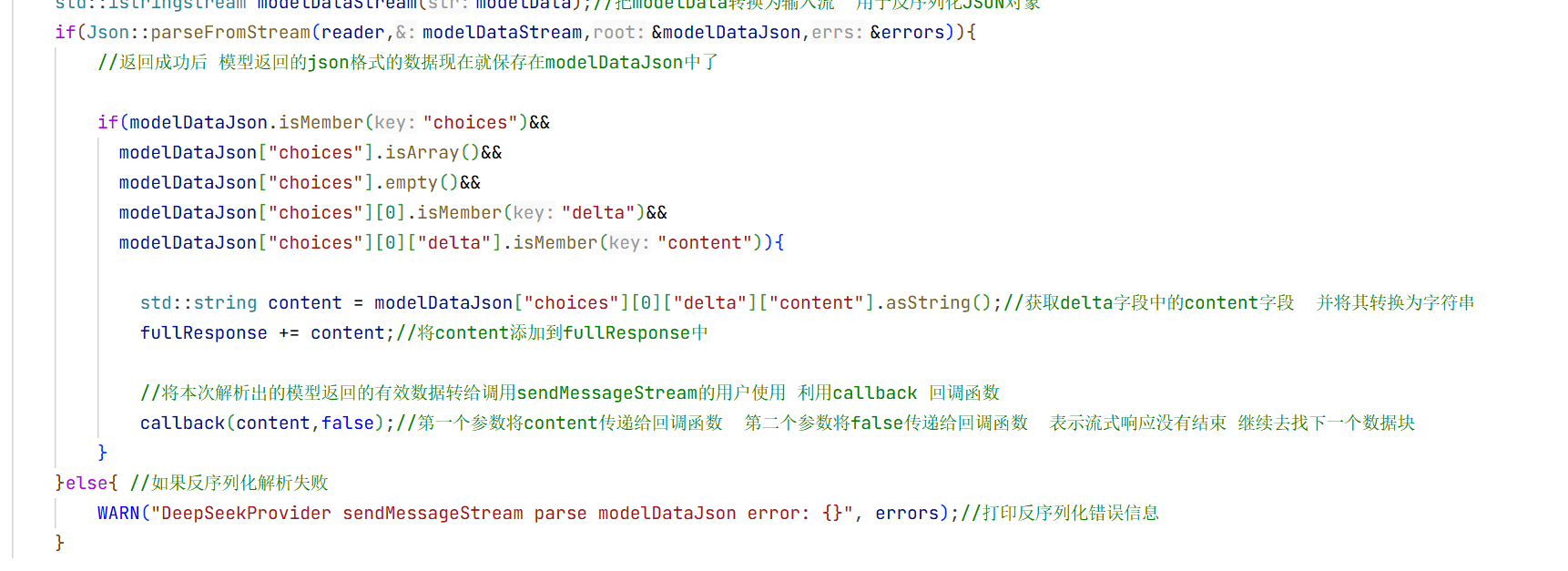

这就是整个数据接受处理器的实现
8.给模型发送请求:


明明我们上面设置了响应处理器的时候已经对结果进行了检测 那这里是在检测什么呢?
这两个检测是不一样的 在使用send这个方法时 send函数默认情况下是阻塞的,阻塞的机制适合小文件处理 简单API请求,一旦在Request中的content_receiver中设置之后send就是非阻塞的
一般适合流式响应和大文件的下载



所以在这里我们也要去检查返回值看看send目前是阻塞状态还是非阻塞状态
响应处理器只会响应一次 后后续由接收器去响应
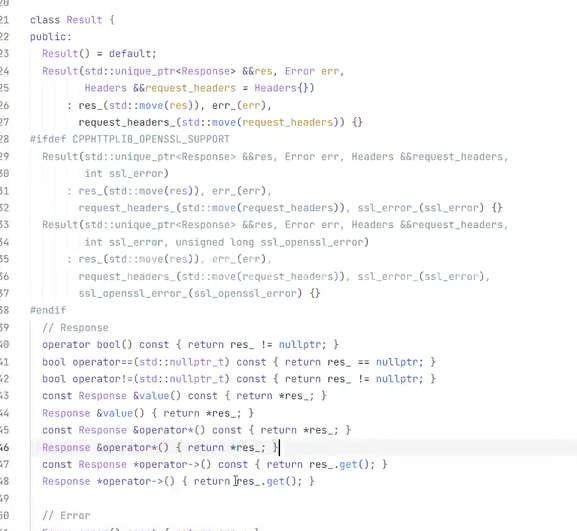
client的返回值是返回的是一个result对象

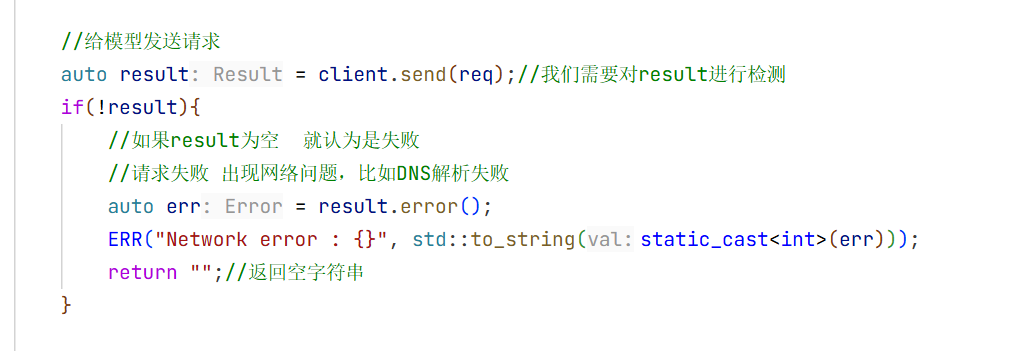
这就是整个流式返回的实现
cpp
//发送消息-流式返回
std::string DeepSeekProvider::sendMessageStream(const std::vector<Message>& messages,
const std::map<std::string,std::string>& requestParam,
std::function<void(const std::string&, bool)> callback)//function是回调函数 callback:对模型返回的增量结果进行处理 第一个参数是增量数据
// 第二个参数是是否是最后一个增量
{
//发送消息-流式返回
//1.检测模型是否可用
if(!isAvailable())//如果模型不可用 就返回空字符串
{
ERR("DeepSeekProvider sendMessageStream model not available");//打印模型不可用错误信息
return "";
}
//2.构造请求参数
double temperature = 0.7;
int maxTokens = 2048;
//去找requestParam中是否有temperature和max_tokens参数 有就使用用户提供的参数值 没找到就使用默认值
if(requestParam.find("temperature") != requestParam.end()){
temperature = std::stod(requestParam.at("temperature"));//stod是将字符串转换为double类型
}
if(requestParam.find("max_tokens") != requestParam.end()){
maxTokens = std::stoi(requestParam.at("max_tokens"));//stoi是将字符串转换为int类型
}
//3.构造历史消息
Json::Value messagesArray(Json::arrayValue);//创建一个空的数组 用于存储历史消息
for(const auto& message : messages){//遍历messages向量 每个消息都添加到数组中
Json::Value messageObject;//创建一个空的对象
messageObject["role"] = message._role;//role是消息的角色 有user、assistant、system三种角色
messageObject["content"] = message._content;//content是消息的内容
messagesArray.append(messageObject);//将消息对象添加到数组中
}
//4.构造请求体
Json::Value requestBody;//创建一个空的对象 用于存储请求体
requestBody["model"] = getModelName();//获取模型的名称
requestBody["messages"] = messagesArray;//messages是历史消息数组 用于存储历史消息
requestBody["temperature"] = temperature;//temperature是温度参数 用于控制模型的随机性
requestBody["max_tokens"] = maxTokens;//max_tokens是最大token数 用于控制模型的输出长度
requestBody["stream"] = true;//stream是流式参数 用于控制是否返回流式结果
//5.序列化
Json::StreamWriterBuilder writeBuilder;//创建一个空的构建器 用于将Json::Value转换为字符串
writeBuilder["indentation"] = " ";//设置缩进为2个空格
std::string requestBodyStr = Json::writeString(writeBuilder, requestBody);//将Json::Value转换为字符串builder
INFO("DeepSeekProvider sendMessageStream requestBody: {}", requestBodyStr);//打印请求体字符串
//6。使用HTTPlib创建客户端
httplib::Client client(_endpoint.c_str());//创建一个HTTP客户端 用于发送HTTP请求 把根端点告诉客户端 客户端会根据根端点去发送请求
client.set_connection_timeout(30,0);//设置连接超时时间为30秒 0表示不设置超时时间
client.set_read_timeout(300,0);//设置读取超时时间为300秒(流式返回时需要设置为较大值) 0表示不设置超时时间
//7.设置请求头
httplib::Headers headers={
{"Authorization", "Bearer " + _apikey}, //Authorization是请求头 认证方式 包含API Key 用于验证请求
{"Content-Type", "application/json"}, //Content-Type是请求头 内容类型 表示请求体的类型 这里是application/json
{"Accept", "text/event-stream"} //Accept是请求头 接受类型 表示客户端接受的响应类型 这里是text/event-stream
};
//定义一些用来流式处理的变量
std::string buffer;//接受流式响应的数据块
bool gotError = false;//标记响应是否成功
std::string errorMsg;//描述错误信息
int statusCode = 0;//响应状态码 用于判断响应是否成功
bool streamFinish = false;//标记流式响应是否完成
std::string fullResponse;//接受完整的流式响应
//创建请求对象
httplib::Request req;//创建一个空的请求对象 用于存储请求信息
req.path = "/v1/chat/completions";//设置请求路径 这里是DeepSeek的API路径
req.method = "POST";//设置请求方法 这里是POST方法
req.headers = headers;//设置请求头 这里是设置的请求头
req.body = requestBodyStr;//设置请求体 这里是序列化后的请求体字符串
//设置响应处理器
//利用lambda表达式设置响应处理器 用于处理DeepSeek返回的流式响应
req.response_handler = [&](const httplib::Response& res){
if(res.status != 200){ //如果响应状态码不是200 就认为是失败
gotError = true;
errorMsg = "HTTP status code: " + std::to_string(res.status);
return false;//终止请求
}
return true; //继续接受流式响应数据块
};
//设置数据接受处理器
//利用lambda表达式设置数据接受处理器 用于处理DeepSeek返回的流式响应数据块 第一个参数是数据块的指针 第二个参数是数据块的长度 第三个参数是当前数据块的偏移量 第四个参数是总数据块的长度
req.content_receiver = [&](const char* data, size_t len,size_t offset,size_t totalLength){
//验证响应头是否出错 如果出错就不再接受数据
if(gotError){
return false;//终止请求
}
//将数据块添加到buffer中
buffer.append(data, len);
INFO("DeepSeekProvider sendMessageStream buffer: {}", buffer);//打印数据块字符串
//处理所以的流式响应的数据块 注意数据块是以\n\n分隔的
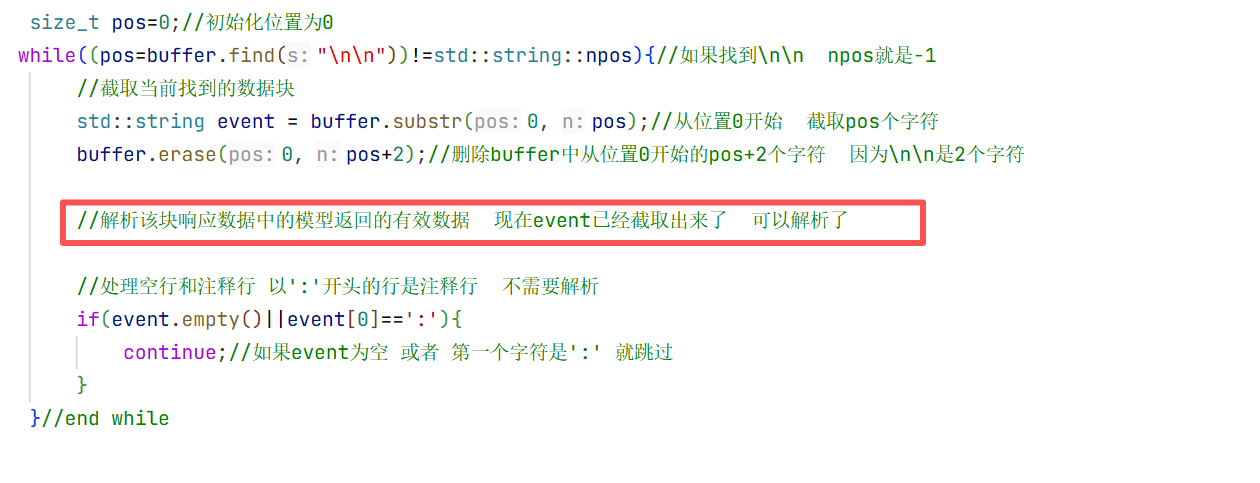
size_t pos=0;//初始化位置为0
while((pos=buffer.find("\n\n"))!=std::string::npos){//如果找到\n\n npos就是-1
//截取当前找到的数据块
std::string chunk = buffer.substr(0, pos);//从位置0开始 截取pos个字符
buffer.erase(0, pos+2);//删除buffer中从位置0开始的pos+2个字符 因为\n\n是2个字符
//解析该块响应数据中的模型返回的有效数据 现在chunk已经截取出来了 可以解析了
//处理空行和注释行 以':'开头的行是注释行 不需要解析
if(chunk.empty()||chunk[0]==':'){
continue;//如果chunk为空 或者 第一个字符是':' 就跳过
}
//获取模型返回的有效数据
if(chunk.compare(0,6,"data: ")==0){//如果chunk中没有data字段 就跳过
std::string modelData = chunk.substr(6);//从data: 后面开始截取 截取到chunk的结束
//检测是否为结束标记
if(modelData=="[DONE]"){
streamFinish = true;//设置流式响应完成标记为true
return true;//返回true 流式响应完成
}
//反序列化
Json::Value modelDataJson;//保存反序列化后的JSON对象
Json::CharReaderBuilder reader;
std::string errors;//保存反序列化错误信息
std::istringstream modelDataStream(modelData);//把modelData转换为输入流 用于反序列化JSON对象
if(Json::parseFromStream(reader,modelDataStream,&modelDataJson,&errors)){
//返回成功后 模型返回的json格式的数据现在就保存在modelDataJson中了
if(modelDataJson.isMember("choices")&&
modelDataJson["choices"].isArray()&&
modelDataJson["choices"].empty()&&
modelDataJson["choices"][0].isMember("delta")&&
modelDataJson["choices"][0]["delta"].isMember("content")){
std::string content = modelDataJson["choices"][0]["delta"]["content"].asString();//获取delta字段中的content字段 并将其转换为字符串
fullResponse += content;//将content添加到fullResponse中
//将本次解析出的模型返回的有效数据转给调用sendMessageStream的用户使用 利用callback 回调函数
callback(content,false);//第一个参数将content传递给回调函数 第二个参数将false传递给回调函数 表示流式响应没有结束 继续去找下一个数据块
}
}else{ //如果反序列化解析失败
WARN("DeepSeekProvider sendMessageStream parse modelDataJson error: {}", errors);//打印反序列化错误信息
}
}
}
return true;
};
//给模型发送请求
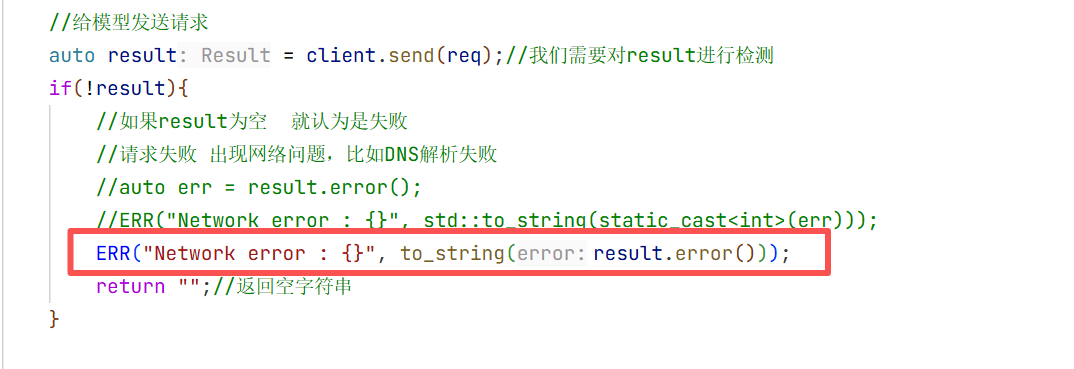
auto result = client.send(req);//我们需要对result进行检测
if(!result){
//如果result为空 就认为是失败
//请求失败 出现网络问题,比如DNS解析失败
auto err = result.error();
ERR("Network error : {}", std::to_string(static_cast<int>(err)));
return "";//返回空字符串
}
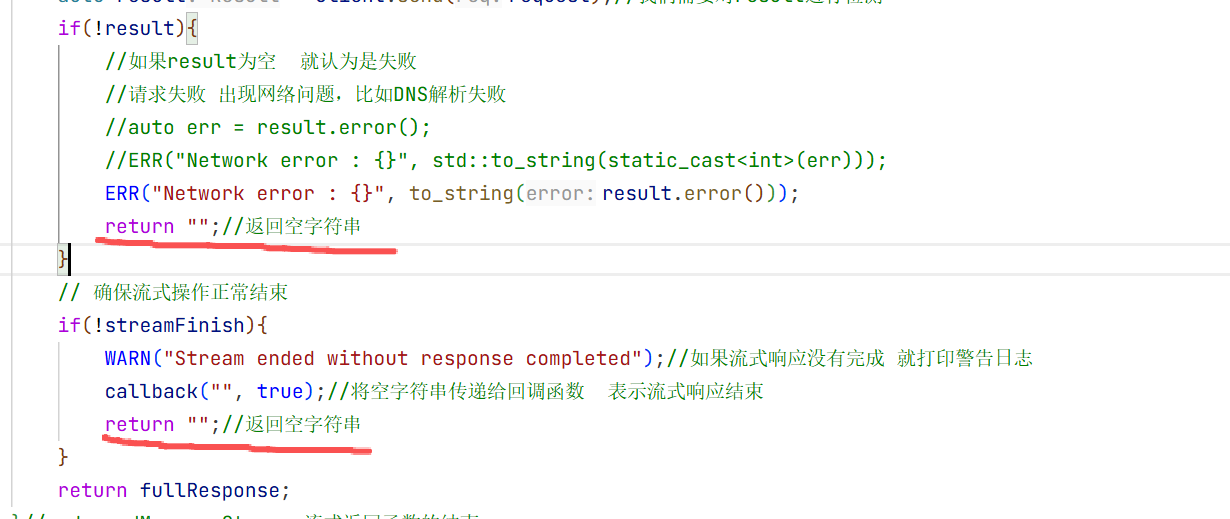
// 确保流式操作正常结束
if(!streamFinish){
WARN("Stream ended without [DONE] marker");//如果流式响应没有结束标记 就打印警告日志
callback("", true);//将空字符串传递给回调函数 表示流式响应结束
}
return fullResponse;
}//end sendMessageStream 流式返回函数的结束6.发送消息流式返回的实现:
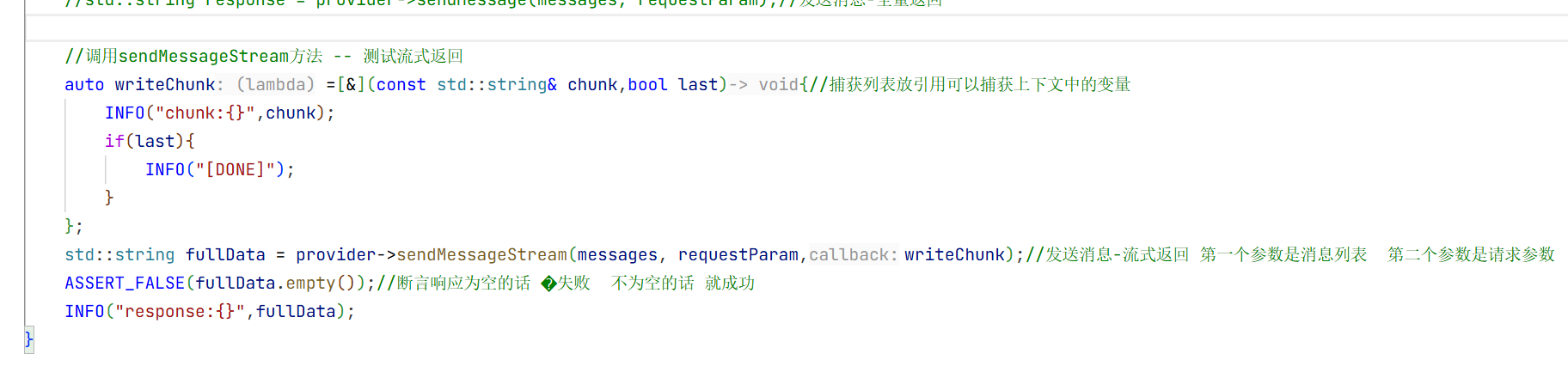
1.测试代码:


只需要改变一下调用方法即可 但这里流式返回需要三个参数 还需要一个回调函数
cpp
//调用sendMessageStream方法 -- 测试流式返回
auto writeChunk =[&](const std::string& chunk,bool last){//捕获列表放引用可以捕获上下文中的变量
INFO("chunk:{}",chunk);
if(last){
INFO("[DONE]");
}
};
std::string fullData = provider->sendMessageStream(messages, requestParam,writeChunk);//发送消息-流式返回 第一个参数是消息列表 第二个参数是请求参数
ASSERT_FALSE(fullData.empty());//断言响应为空的话 �失败 不为空的话 就成功
INFO("response:{}",fullData);这就是调用流式返回的代码。 CMakeLists不需要修改因为我们没有添加新的方法
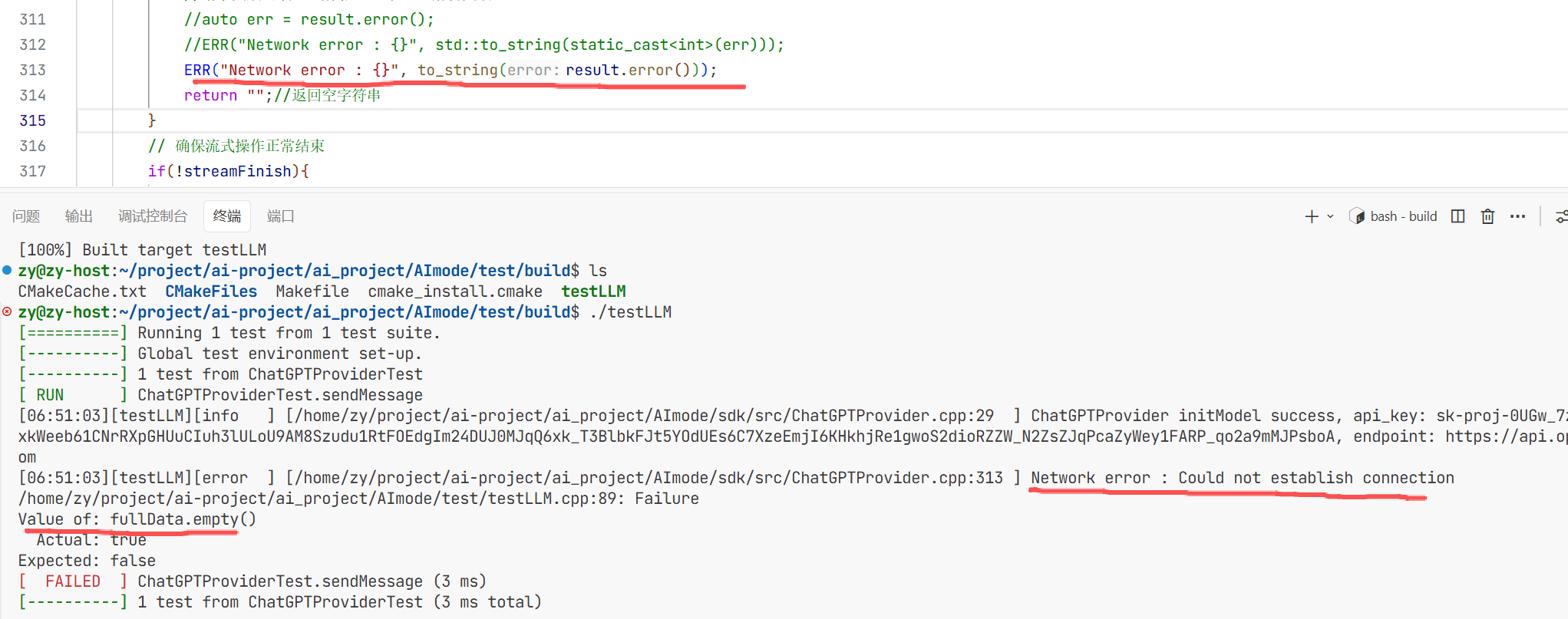
2.测试的问题:
1


这个错误就是我们在调用日志库时发生了报错 也就是源代码这块erro发现了错误
错误产生的原因是我们借助httplib创建的客户端 然后如果不对 就打印报错的日志 spdlog库是没问题的 是因为我们使用不当spdlog打印时支持我们的常见类型 但是这个result不支持 是因为result是一个enum class 类型 通过类来定义枚举类型 这与传统定义enum类型是不同的

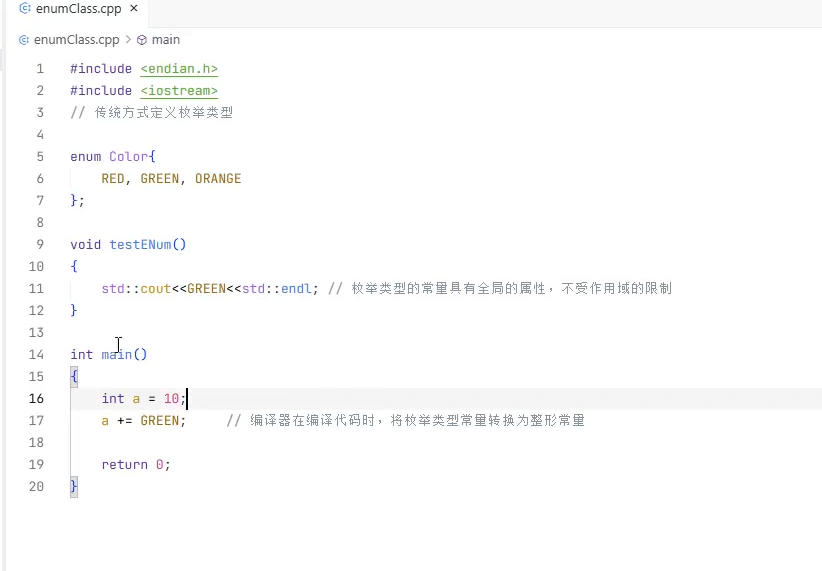
而c++11新语法enum class将枚举常量变成受作用域的限制 所以你要调用必须要有作用域限定符
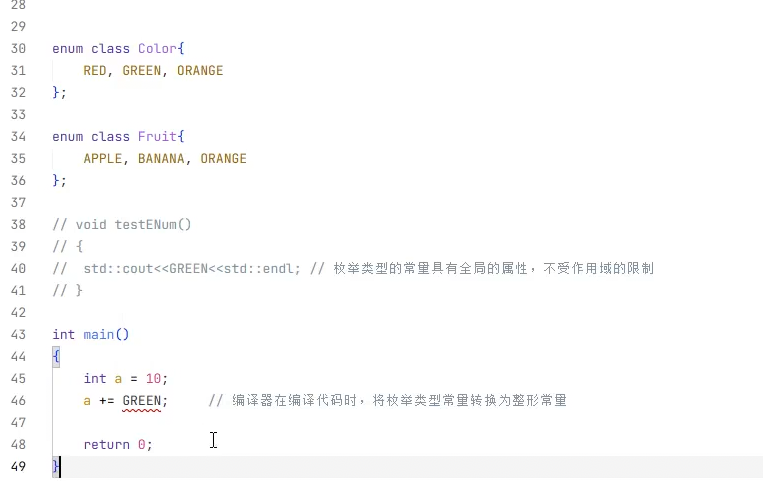

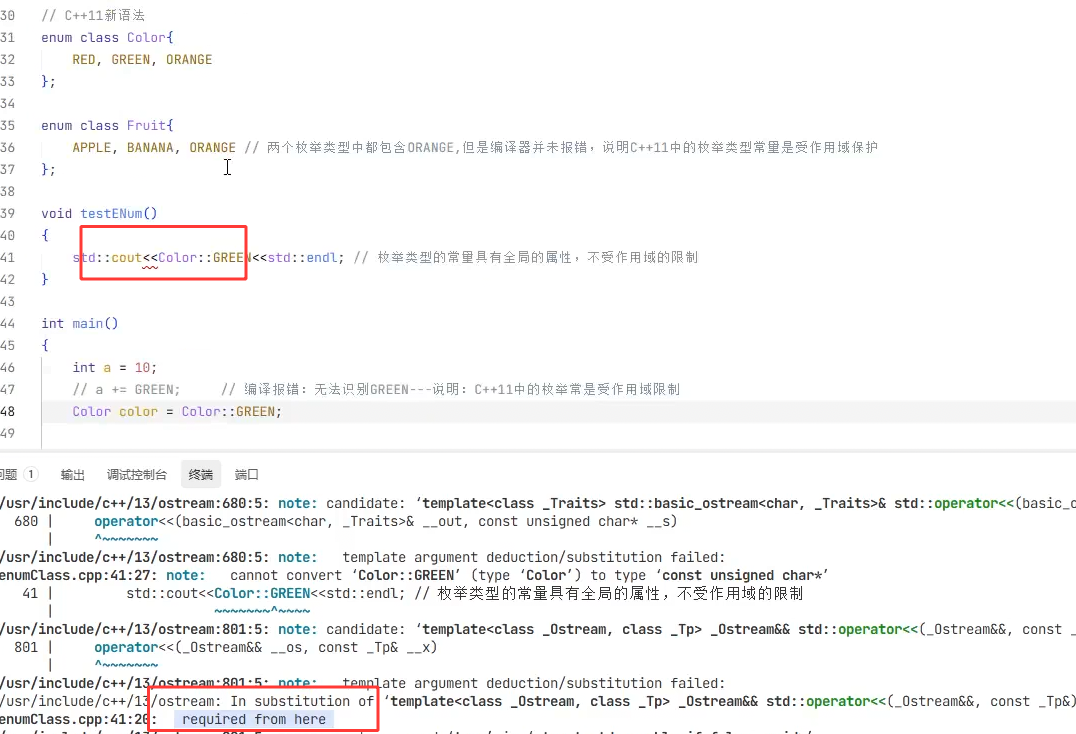
此处如果要调用的话 这个新语法不会隐士转换成int类型 所以这里要打印的话 这里需要封装重载输出运算符 或者 封装一个函数可以转换 然后外面调用也行
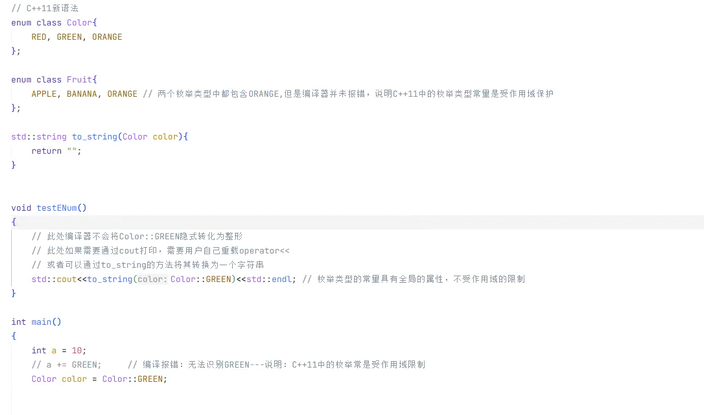
所以上面的报错也是这样 所以我们要加上转换方法 不然spdlog识别不了
2
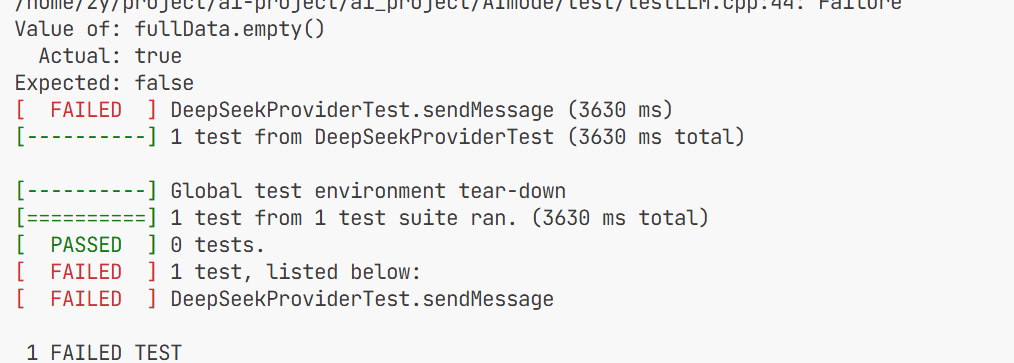
这是导致一直返回空数据 导致返回失败 然后我去检查了一下代码发现
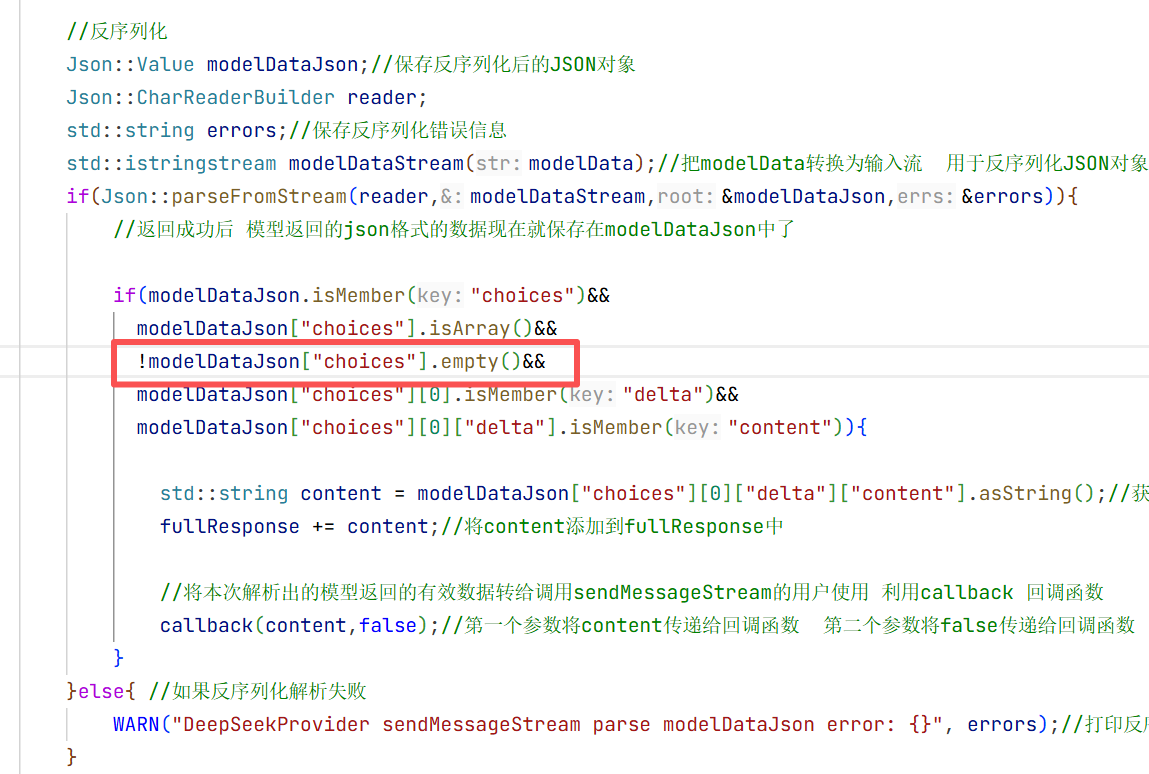
我在之前忘记加!要不然这个循环进不去无法拿到解析出来的数据导致流式响应返回的fullresponse一直为空 所以测试代码的fulldate一直为空所以会报错 修改之后:
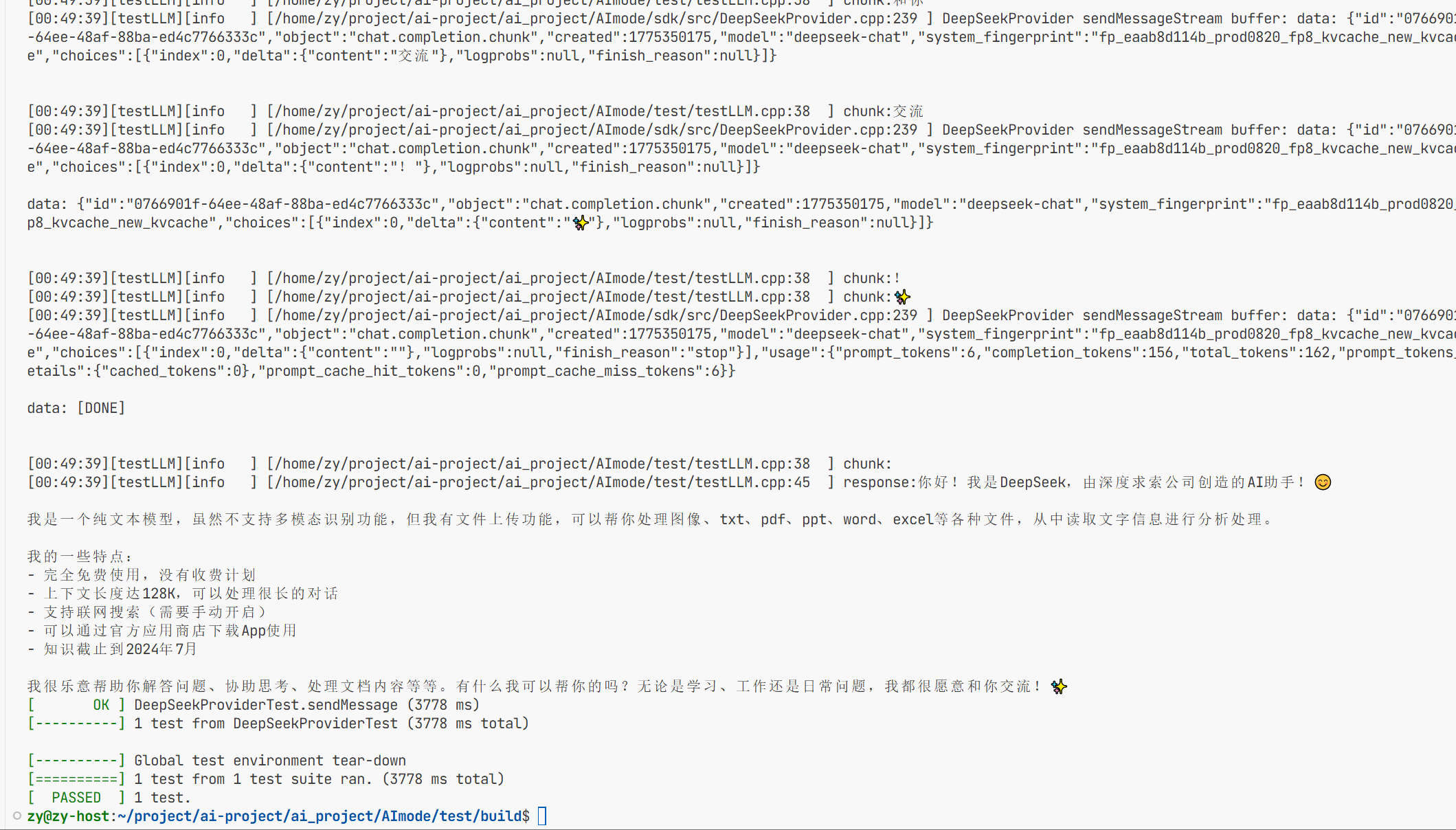
也是可以正确的响应了。
所以deepseek的接入已经实现完成了。
8.chatgpt的接入和封装:
1.头文件的编写
实际上就是把deepseek接入的头文件拷贝过来 然后改名字和一些细节即可:
此时头文件就封装好了
cpp
#include <string>
#include <map>
#include <vector>
#include "common.h"
#include <functional>
#include "LLMProvider.h"
namespace ai_chat_sdk{
class ChatGPTProvider:public LLMProvider{
public:
virtual bool initModel(const std::map<std::string, std::string>& modelConfig);//初始化模型 通过map传递模型配置参数 通过key获取配置参数
//获取模型名称
virtual std::string getModelName() const;
//获取模型描述
virtual std::string getModelDesc() const;//获取模型描述
//判断模型是否可用
virtual bool isAvailable() const;
//发送消息-全量返回
virtual std::string sendMessage(const std::vector<Message>& messages, const std::map<std::string, std::string>& requestParam);//第一个参数发送的信息 第二个参数是大模型的请求参数
//发送消息-流式返回 //第一个参数发送的信息 第二个参数是大模型的请求参数 第三个参数是回调函数
virtual std::string sendMessageStream(const std::vector<Message>& messages, const std::map<std::string,
std::string>& requestParam,
std::function<void(const std::string&, bool)> callback);//function是回调函数 callback:对模型返回的增量结果进行处理 第一个参数是增量数据
// 第二个参数是是否是最后一个增量
};
}2.源文件的编写:
整个格局跟deepseek的接入一样 只是API的调用方式与deepseek有区别
所以现在我们要去了解一下chatgpt的API
3.API的介绍:
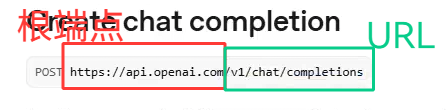
其实差不多跟deep seek的API介绍差不多
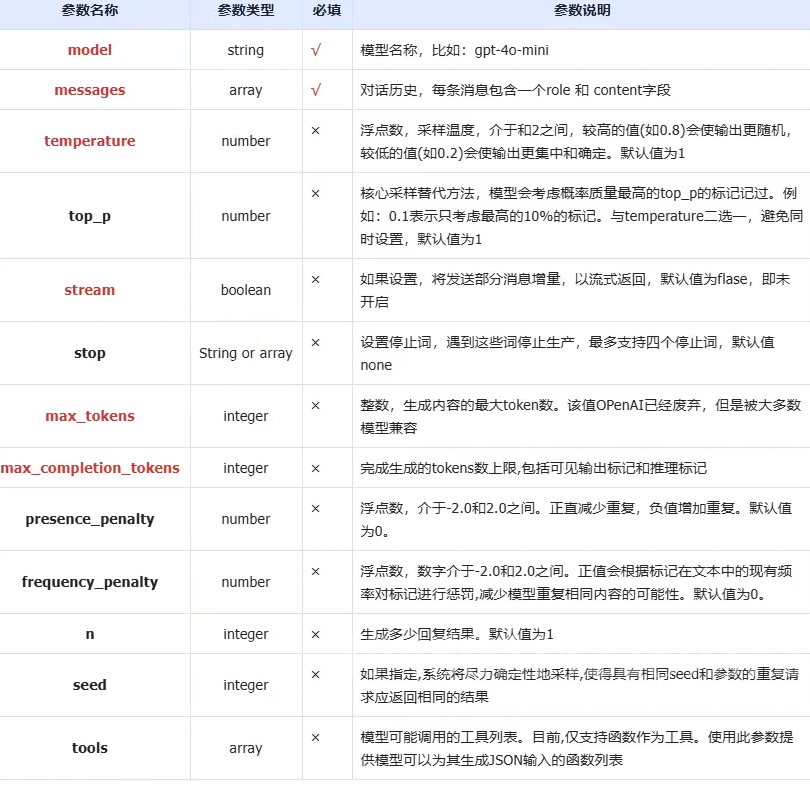

4.API的测试:
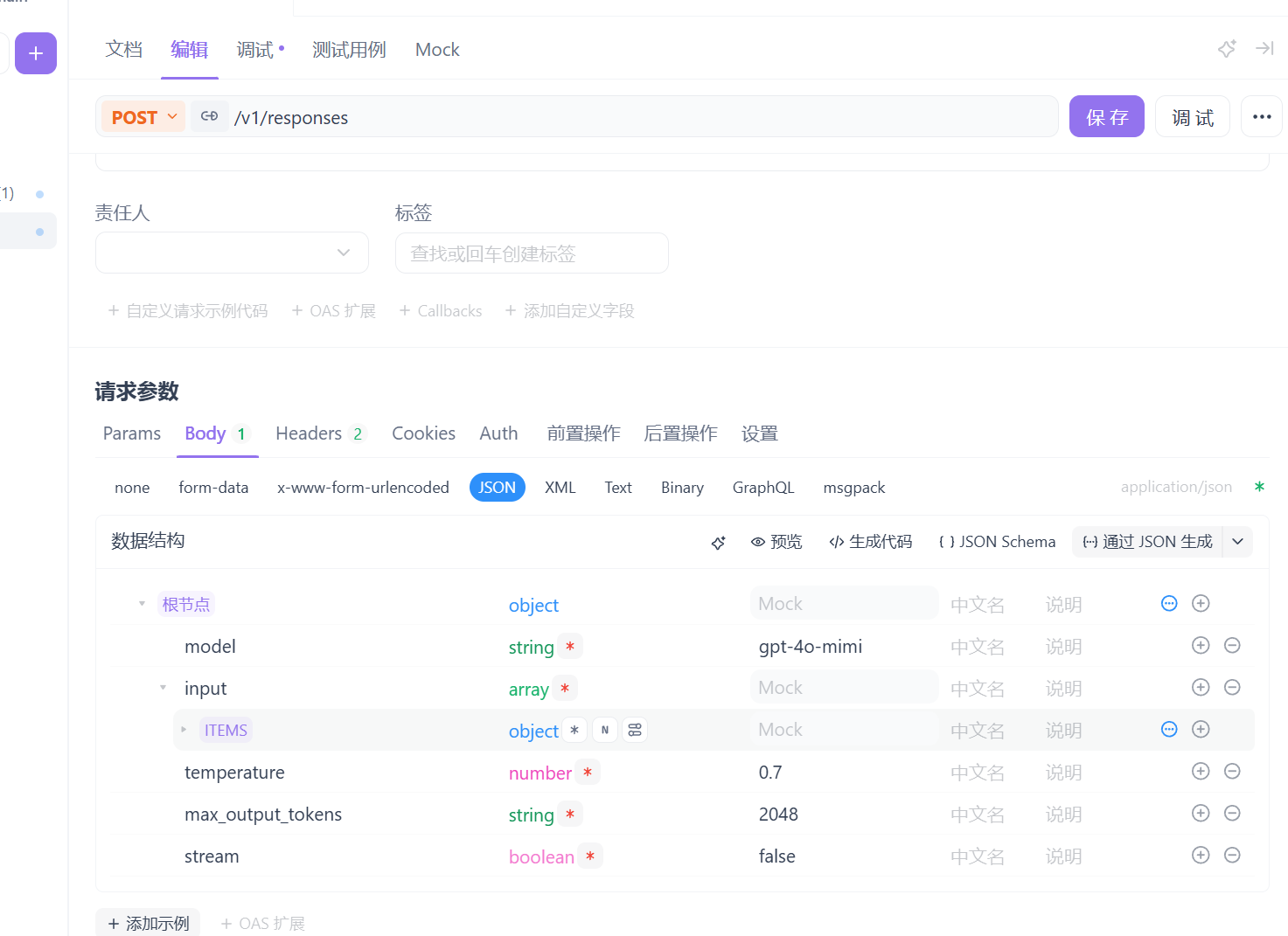
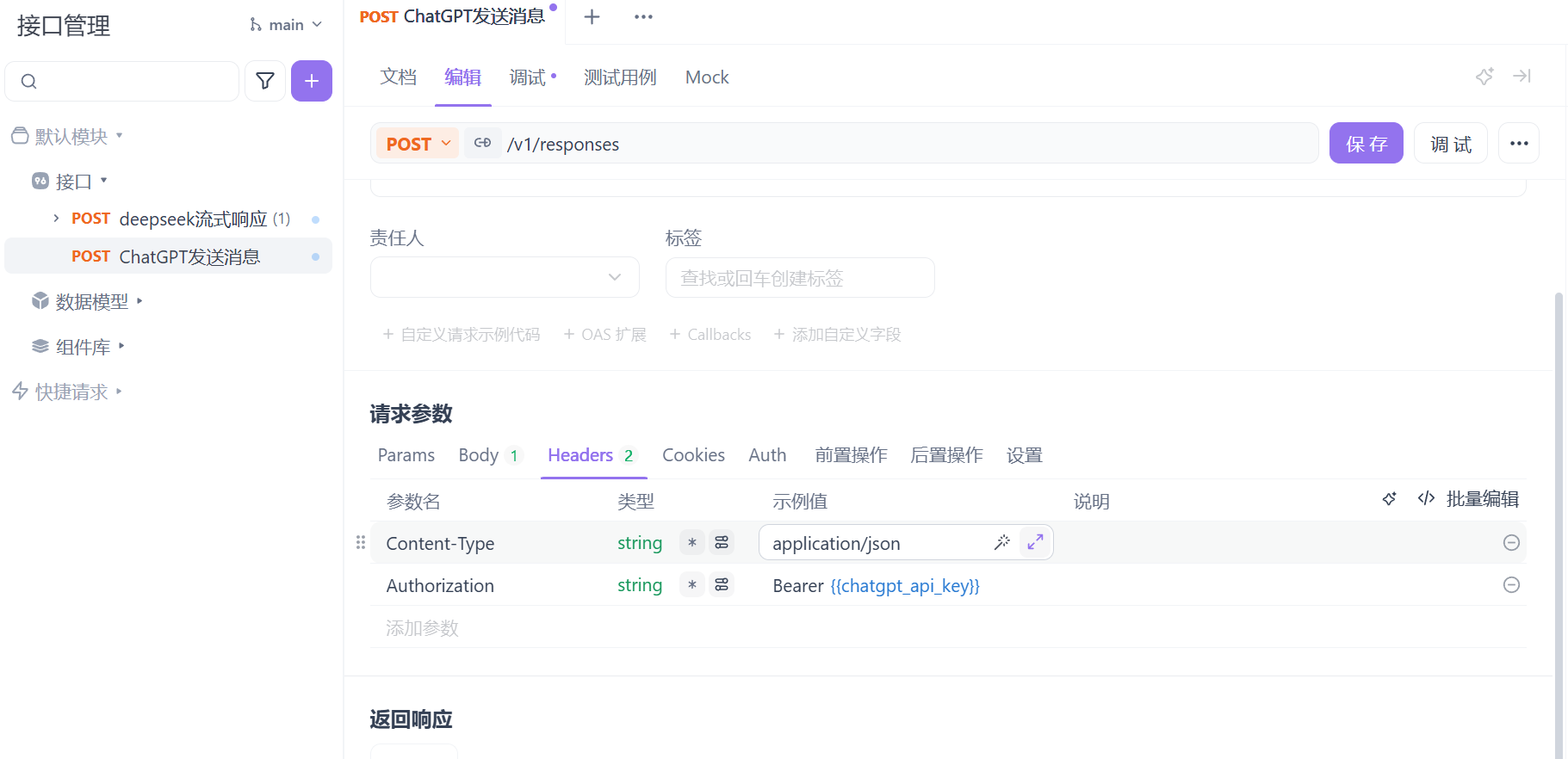
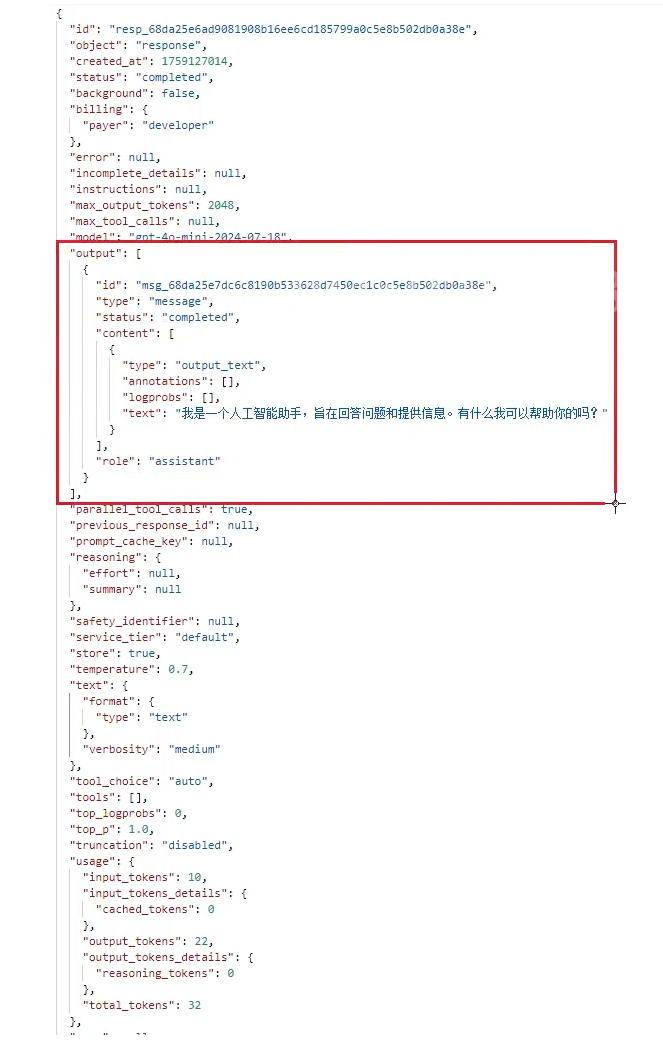
到后面就要解析这一段。
5.发送消息的实现(全量返回)
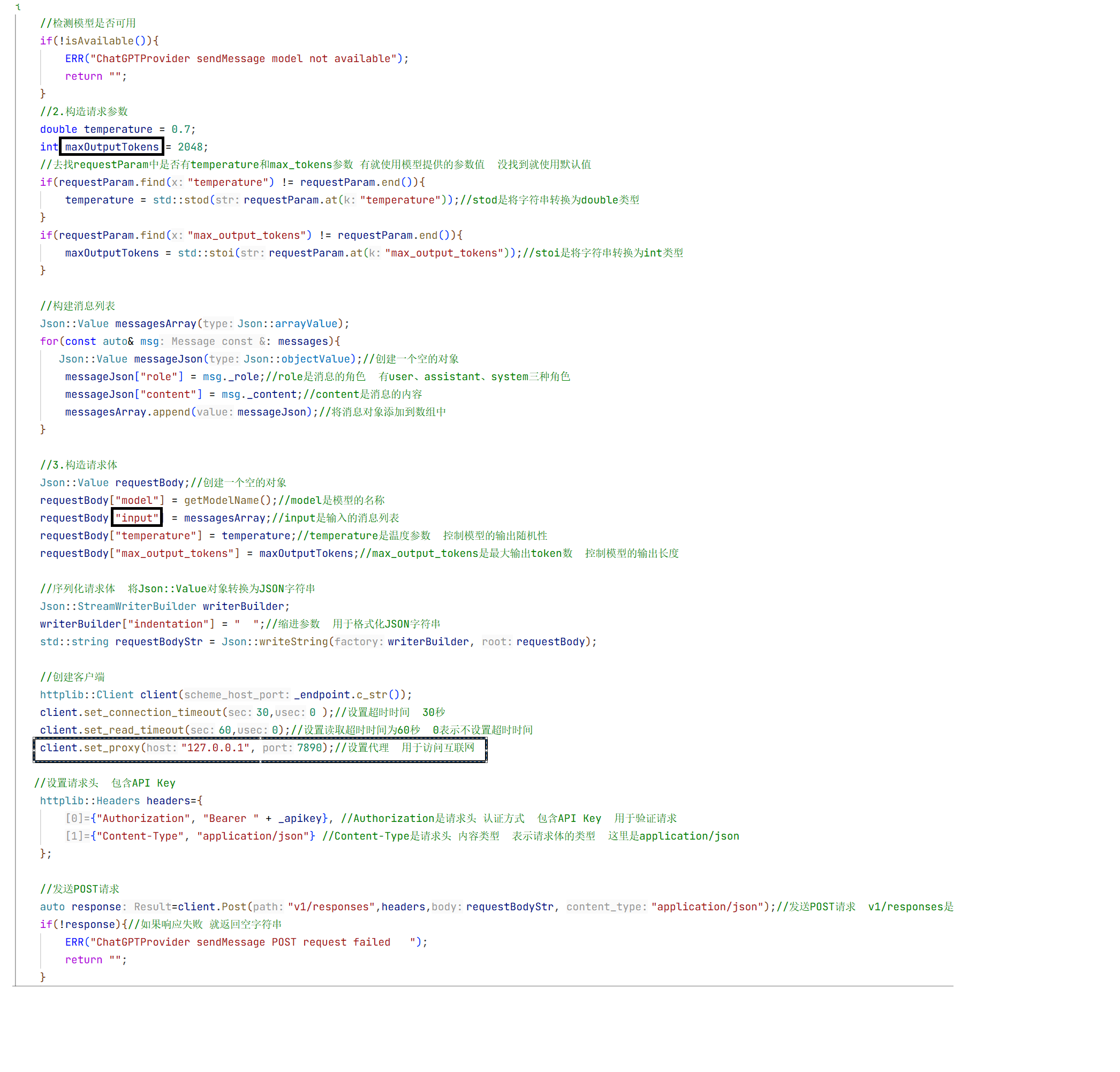
这些画框的字段和deepseek的实现不一样
最大的不一样就是将响应体序列化完后存储在responesJson中 我们要如何把他从中解析出来拿到我们想要的文本内容:
转化解析的思路:

deepseek中的choice就是这里的output 所以这里有改变

这里解析时就按照上面所提供的思路来进行判断即可。
cpp
//发送消息-全量返回
std::string ChatGPTProvider::sendMessage(const std::vector<Message>& messages, const std::map<std::string, std::string>& requestParam)
{
//检测模型是否可用
if(!isAvailable()){
ERR("ChatGPTProvider sendMessage model not available");
return "";
}
//2.构造请求参数
double temperature = 0.7;
int maxOutputTokens = 2048;
//去找requestParam中是否有temperature和max_tokens参数 有就使用模型提供的参数值 没找到就使用默认值
if(requestParam.find("temperature") != requestParam.end()){
temperature = std::stod(requestParam.at("temperature"));//stod是将字符串转换为double类型
}
if(requestParam.find("max_output_tokens") != requestParam.end()){
maxOutputTokens = std::stoi(requestParam.at("max_output_tokens"));//stoi是将字符串转换为int类型
}
//构建消息列表
Json::Value messagesArray(Json::arrayValue);
for(const auto& msg: messages){
Json::Value messageJson(Json::objectValue);//创建一个空的对象
messageJson["role"] = msg._role;//role是消息的角色 有user、assistant、system三种角色
messageJson["content"] = msg._content;//content是消息的内容
messagesArray.append(messageJson);//将消息对象添加到数组中
}
//3.构造请求体
Json::Value requestBody;//创建一个空的对象
requestBody["model"] = getModelName();//model是模型的名称
requestBody["input"] = messagesArray;//input是输入的消息列表
requestBody["temperature"] = temperature;//temperature是温度参数 控制模型的输出随机性
requestBody["max_output_tokens"] = maxOutputTokens;//max_output_tokens是最大输出token数 控制模型的输出长度
//序列化请求体 将Json::Value对象转换为JSON字符串
Json::StreamWriterBuilder writerBuilder;
writerBuilder["indentation"] = " ";//缩进参数 用于格式化JSON字符串
std::string requestBodyStr = Json::writeString(writerBuilder, requestBody);
//创建客户端
httplib::Client client(_endpoint.c_str());
client.set_connection_timeout(30,0 );//设置超时时间 30秒
client.set_read_timeout(60,0);//设置读取超时时间为60秒 0表示不设置超时时间
client.set_proxy("127.0.0.1", 7890);//设置代理 用于访问互联网
//设置请求头 包含API Key
httplib::Headers headers={
{"Authorization", "Bearer " + _apikey}, //Authorization是请求头 认证方式 包含API Key 用于验证请求
{"Content-Type", "application/json"} //Content-Type是请求头 内容类型 表示请求体的类型 这里是application/json
};
//发送POST请求
auto response=client.Post("v1/responses",headers,requestBodyStr, "application/json");//发送POST请求 v1/responses是模型的API路径 requestBodyStr是请求体 headers是请求头 "application/json"是请求体的类型
if(!response){//如果响应失败 就返回空字符串
ERR("ChatGPTProvider sendMessage POST request failed ");
return "";
}
//检测响应状态码是否为200 是否成功
if(response->status != 200){
ERR("ChatGPTProvider sendMessage POST request failed, status: {}", response->status);
return "";
}
INFO("ChatGPTProvider sendMessage POST request success body: {}", response->body);//打印响应体
//对模型返回的结构进行序列化 上面我们拿到的是字符流 这里我们使用Json::parseFromStream函数将字符流转换为Json::Value对象
Json::CharReaderBuilder reader;
std::string errorJson;//用于存储解析错误信息
Json::Value responseJson;//用于存储解析后的JSON对象
std::istringstream responseStream(response->body);//将响应体转换为字符流
if(!Json::parseFromStream(reader,responseStream, &responseJson,&errorJson)){
ERR("ChatGPTProvider sendMessage POST request failed, response body parse failed");
return "";
}
//从响应体中提取模型返回的内容 序列化的结果保存在responseJson对象中
if(responseJson.isMember("output") && responseJson["output"].isArray() && !responseJson["output"].empty()){
auto outPut = responseJson["output"][0];//获取第一个元素 即模型返回的内容
if(outPut.isMember("content") && outPut["content"].isArray() && !outPut["content"].empty() && outPut["content"][0].isMember("text")){
//判断content字段是否为字符串数组 如果不为空且第一个元素包含了text字段 就返回text字段的值
std::string replyString = outPut["content"][0]["text"].asString();
INFO("ChatGPTProvider sendMessage POST request success, reply: {}", replyString);
return replyString;
}
}
ERR("ChatGPTProvider sendMessage POST request failed, response body parse failed,errorJson: {}", errorJson);//打印解析错误信息
return "";
}6.测试全量返回:
1.测试遇到的问题:
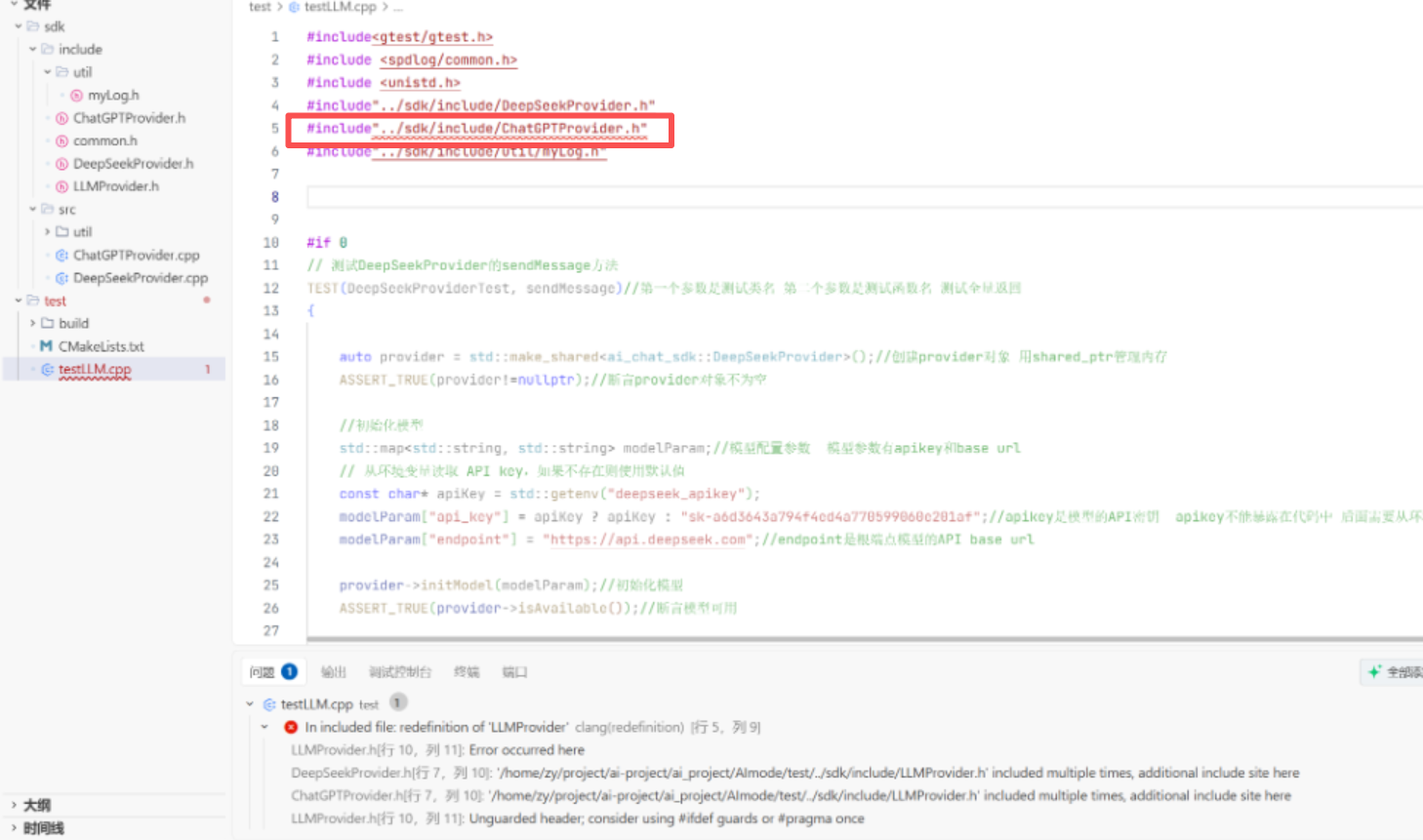
一开始我不能同时包含这两个头文件是因为这两个头文件中都包含了LLMProvider.h 而且我没有加#pragma once 所以不能被同时调用两次 所以要加上这个。
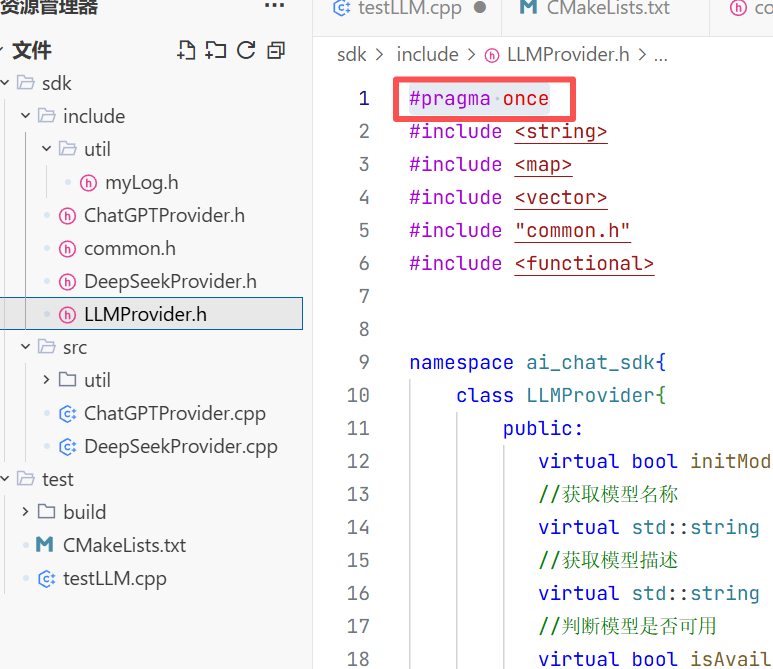
这样就可以了。
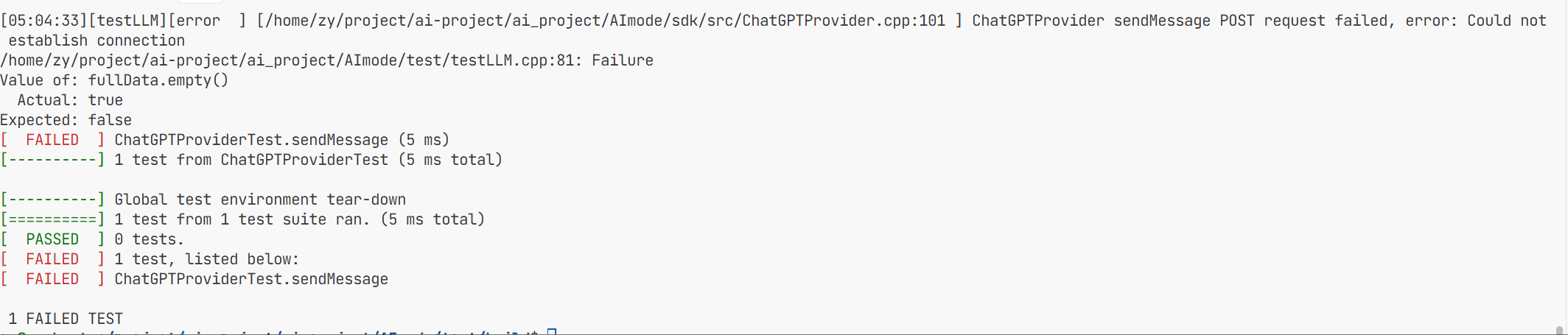
测试一下代码成功运行 但是因为我的APIkey没有了 所以这里显示连接错误 服务器端禁止我们访问。
7.发送消息的实现(流式返回)
1.主要实现

这些的实现跟deepseek的实现是一样的
2.数据接收器的实现
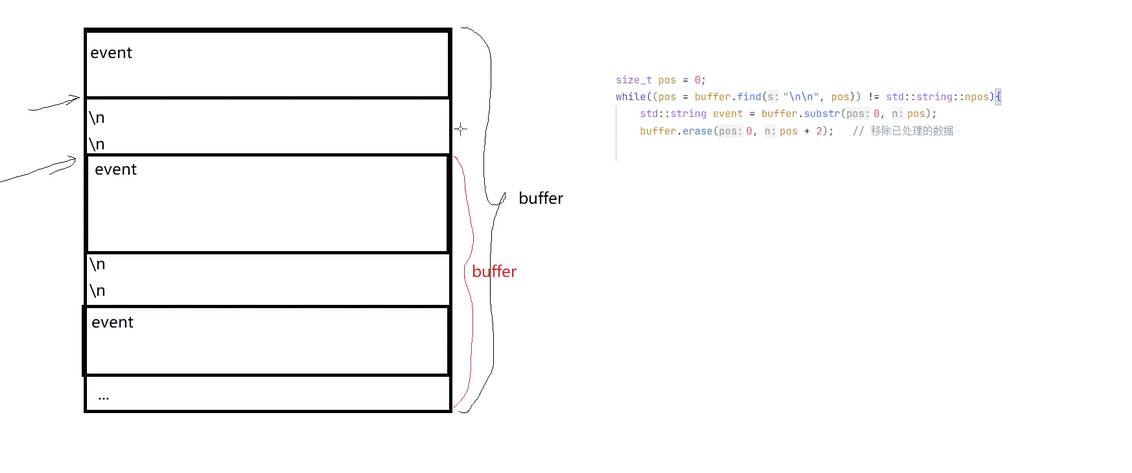
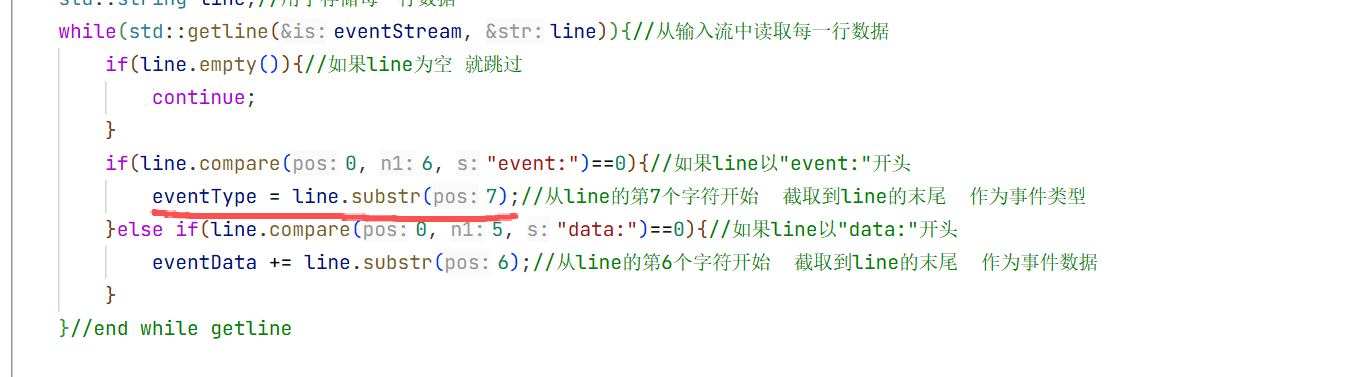
这一小部分的判断是先找到\n\n这个地方 然后从上面截取到这个\n\n然后获得event 这就是我们要的内容 然后再去解析。

这个跟deepseek不一样这个不是代码块而是事件流。

我们要去捕获这个响应的数据

还需要去检测这两个事件

这里我们不直接去写代码 因为我们先看不解析时打印的结果是什么 再根据打印的结果 再根据机制再去解析
这里我们先去实现剩下的东西再去根据结果实现数据接收器的解析

然后直接测试看看返回来的是什么样的

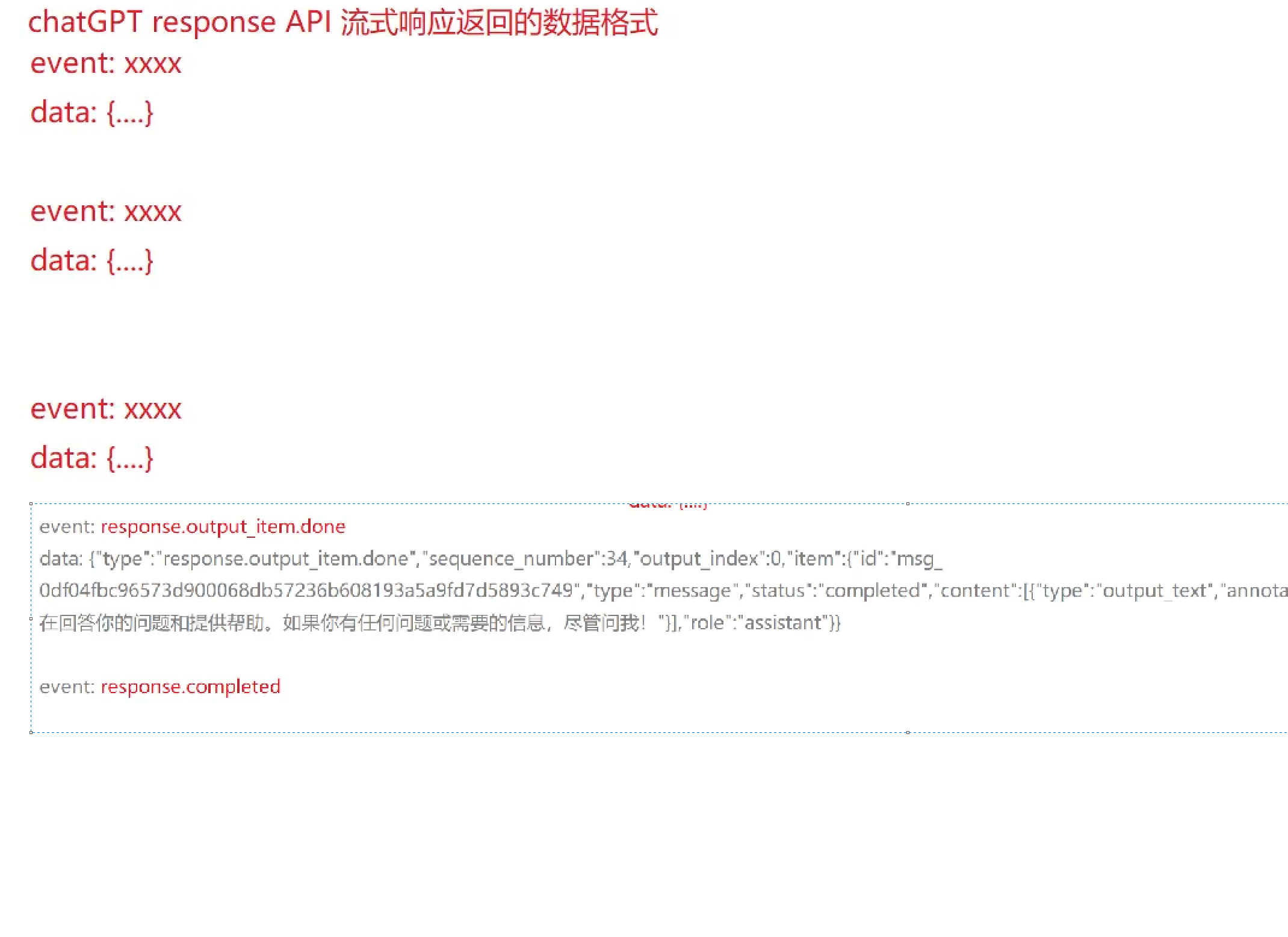
chatgpt返回的格式就像这样的
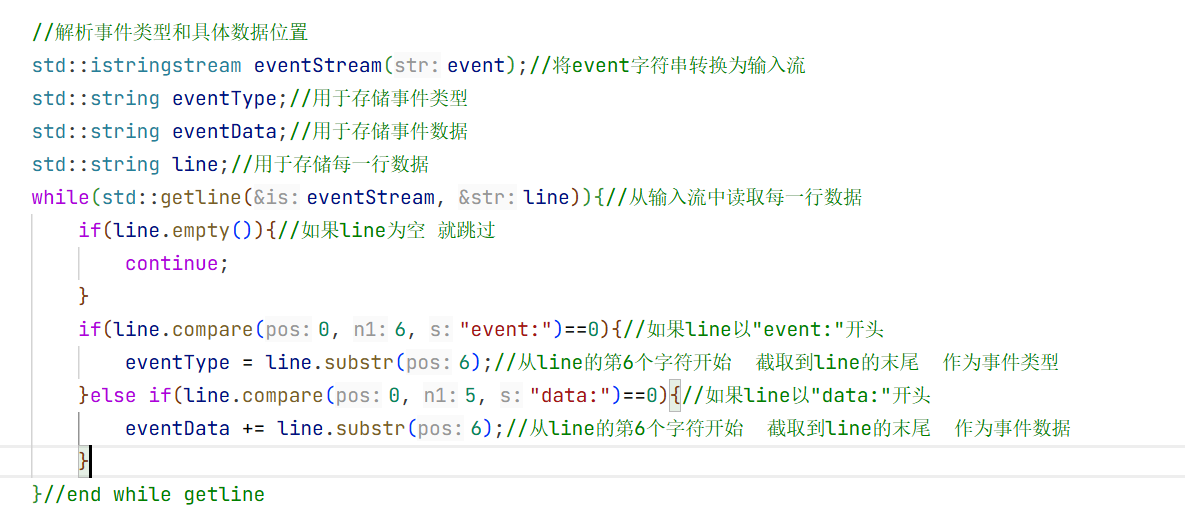
去比较一下前六个字符是不是"event:"是的话后面的那一行内容就是事件类型

再去比较一下前五个字符是不是"data:"是的话直接从第六个位置截取到末尾就是事件数据
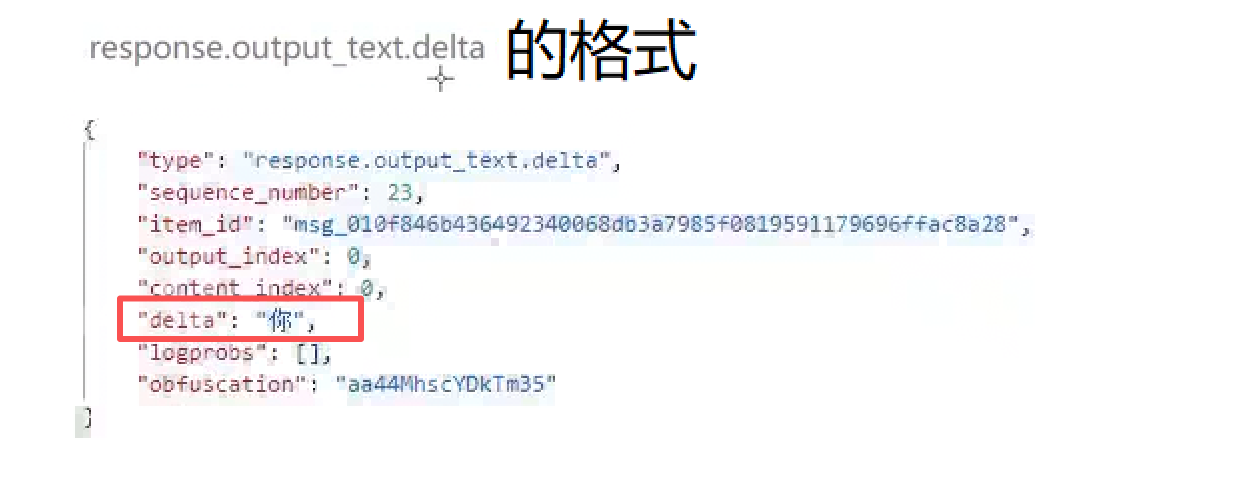



把我们想要的文本内容给取出来
这样整个的数据接收器就实现好了。
数据接收器的代码:
cpp
//处理所有的流式响应的数据块 注意数据块是以\n\n分隔的
size_t pos=0;//初始化位置为0
while((pos=buffer.find("\n\n"))!=std::string::npos){//如果找到\n\n npos就是-1
//截取当前找到的数据块
std::string event = buffer.substr(0, pos);//从位置0开始 截取pos个字符
buffer.erase(0, pos+2);//删除buffer中从位置0开始的pos+2个字符 因为\n\n是2个字符
//解析事件类型和具体数据位置
std::istringstream eventStream(event);//将event字符串转换为输入流
std::string eventType;//用于存储事件类型
std::string eventData;//用于存储事件数据
std::string line;//用于存储每一行数据
while(std::getline(eventStream, line)){//从输入流中读取每一行数据
if(line.empty()){//如果line为空 就跳过
continue;
}
if(line.compare(0, 6, "event:")==0){//如果line以"event:"开头
eventType = line.substr(6);//从line的第6个字符开始 截取到line的末尾 作为事件类型
}else if(line.compare(0, 5, "data:")==0){//如果line以"data:"开头
eventData += line.substr(6);//从line的第6个字符开始 截取到line的末尾 作为事件数据
}
}//end while getline
//对模型返回的结果序列化
Json::Value chunk;//保存序列化后的JSON对象
Json::CharReaderBuilder reader;
std::string errs;//保存序列化错误信息
std::istringstream eventDateStream(eventData);//把eventData转换为输入流 用于反序列化JSON对象
if(!Json::parseFromStream(reader, eventDateStream, &chunk, &errs)){//如果序列化失败 就打印错误日志
ERR("ChatGPTProvider sendMessageStream parse body failed,error : {}", errs);//打印错误日志
continue;//跳过当前数据块
}
//按照事件类型进行数据分析
if(eventType == "response.output_text.delta"){
//如果是response.output_text.delta事件
if(chunk.isMember("delta") && chunk["delta"].isString()){//如果delta是chunk的成员 且是字符串类型
std::string delta = chunk["delta"].asString();//将delta添加到fullResponse中
callback(delta, false);//将delta传递给回调函数 表示不是最后一个增量
}
}else if(eventType == "response.output_item.done"){
//如果是response.output_item.done事件
// 表⽰该块输出结束
if(chunk.isMember("item") && chunk["item"].isObject()){
Json::Value item = chunk["item"];
if(item.isMember("content") &&
item["content"].isArray() &&
!item["content"].empty() &&
item["content"][0].isMember("text") &&
item["content"][0]["text"].isString())
{
fullResponse += item["content"][0]["text"].asString();//将text添加到fullResponse中
}
}
}else if(eventType == "response.completed"){
//如果是response.completed事件
streamFinish = true;//设置流式响应完成标志
callback("", true);//将空字符串传递给回调函数 表示流式响应结束
return true;
}
}//end while pos!=std::string::npos
return true;//继续接受数据块
};//end lambda3.整个流式返回的代码实现
cpp
//发送消息-流式返回
std::string ChatGPTProvider::sendMessageStream(const std::vector<Message>& messages,
const std::map<std::string, std::string>& requestParam,
std::function<void(const std::string&, bool)> callback)
{
//检测模型是否可用
if(!isAvailable()){
ERR("ChatGPTProvider sendMessageStream model not available");
return "";
}
//构造请求参数
double temperature = 0.7;
int maxOutputTokens = 2048;
//去找requestParam中是否有temperature和max_output_tokens参数 有就使用用户提供的参数值 没找到就使用默认值
if(requestParam.find("temperature") != requestParam.end()){
temperature = std::stod(requestParam.at("temperature"));//stod是将字符串转换为double类型
}
if(requestParam.find("max_output_tokens") != requestParam.end()){
maxOutputTokens = std::stoi(requestParam.at("max_output_tokens"));//stoi是将字符串转换为int类型
}
//构造历史消息
Json::Value messagesArray(Json::arrayValue);
for(const auto& msg: messages){
Json::Value messageJson(Json::objectValue);//创建一个空的对象
messageJson["role"] = msg._role;//role是消息的角色 有user、assistant、system三种角色
messageJson["content"] = msg._content;//content是消息的内容
messagesArray.append(messageJson);//将消息对象添加到数组中
}
//构造请求体
Json::Value requestBody;//创建一个空的对象
requestBody["model"] = getModelName();//model是模型的名称
requestBody["input"] = messagesArray;//input是输入的消息列表
requestBody["temperature"] = temperature;//temperature是温度参数 控制模型的输出随机性
requestBody["max_output_tokens"] = maxOutputTokens;//max_output_tokens是最大输出token数 控制模型的输出长度
requestBody["stream"] = true;//stream是是否开启流式返回 true开启 false关闭
//序列化请求体 将Json::Value对象转换为JSON字符串
Json::StreamWriterBuilder writerBuilder;
writerBuilder["indentation"] = " ";//缩进参数 用于格式化JSON字符串
std::string requestBodyStr = Json::writeString(writerBuilder, requestBody);
//创建客户端
httplib::Client client(_endpoint.c_str());
client.set_connection_timeout(60,0 );//设置超时时间 60秒
client.set_read_timeout(300,0);//设置读取超时时间为300秒 0表示不设置超时时间
client.set_proxy("127.0.0.1", 7890);//设置代理 用于访问互联网
//设置请求头 包含API Key
httplib::Headers headers={
{"Authorization", "Bearer " + _apikey}, //Authorization是请求头 认证方式 包含API Key 用于验证请求
{"Content-Type", "application/json"}, //Content-Type是请求头 内容类型 表示请求体的类型 这里是application/json
{"Accept", "text/event-stream"} //Accept是请求头 接受的响应类型 这里是text/event-stream
};
//流式处理的相关变量
std::string buffer;//用于存储模型返回的内容
bool gotError = false;//用于判断是否获取到错误信息
std::string errorMsg;//用于存储解析错误信息
int statusCode = 0;//用于存储响应状态码
bool streamFinish = false;//用于判断是否流式返回完成
std::string fullResponse;//存储完整的流式响应内容
//创建请求对象
httplib::Request request;
request.method = "POST";
request.path = "/v1/responses";
request.body = requestBodyStr;
request.headers = headers;
//设置响应处理器
//利用lambda表达式设置响应处理器 用于处理DeepSeek返回的流式响应
request.response_handler = [&](const httplib::Response& res){
statusCode = res.status;
if(statusCode != 200){ //如果响应状态码不是200 就认为是失败
gotError = true;
errorMsg = "ChatGPTProvider sendMessageStream POST request failed, status " +std::to_string(statusCode);
return false;//终止请求
}
return true; //继续接受流式响应数据块
};
//设置数据接收处理器
//利用lambda表达式设置数据接受处理器 用于处理ChatGPT返回的流式响应数据块 第一个参数是数据块的指针 第二个参数是数据块的长度 第三个参数是当前数据块的偏移量 第四个参数是总数据块的长度
request.content_receiver = [&](const char* data, size_t dataLenth,size_t offset,size_t totalLength){
//验证响应头是否出错 如果出错就不再接受数据
if(gotError){
return false;//终止请求
}
//将数据块添加到buffer中
buffer.append(data, dataLenth);
INFO("ChatGPTProvider sendMessageStream received data: {}", buffer);//打印数据块字符串
//处理所有的流式响应的数据块 注意数据块是以\n\n分隔的
size_t pos=0;//初始化位置为0
while((pos=buffer.find("\n\n"))!=std::string::npos){//如果找到\n\n npos就是-1
//截取当前找到的数据块
std::string event = buffer.substr(0, pos);//从位置0开始 截取pos个字符
buffer.erase(0, pos+2);//删除buffer中从位置0开始的pos+2个字符 因为\n\n是2个字符
//解析事件类型和具体数据位置
std::istringstream eventStream(event);//将event字符串转换为输入流
std::string eventType;//用于存储事件类型
std::string eventData;//用于存储事件数据
std::string line;//用于存储每一行数据
while(std::getline(eventStream, line)){//从输入流中读取每一行数据
if(line.empty()){//如果line为空 就跳过
continue;
}
if(line.compare(0, 6, "event:")==0){//如果line以"event:"开头
eventType = line.substr(6);//从line的第6个字符开始 截取到line的末尾 作为事件类型
}else if(line.compare(0, 5, "data:")==0){//如果line以"data:"开头
eventData += line.substr(6);//从line的第6个字符开始 截取到line的末尾 作为事件数据
}
}//end while getline
//对模型返回的结果序列化
Json::Value chunk;//保存序列化后的JSON对象
Json::CharReaderBuilder reader;
std::string errs;//保存序列化错误信息
std::istringstream eventDateStream(eventData);//把eventData转换为输入流 用于反序列化JSON对象
if(!Json::parseFromStream(reader, eventDateStream, &chunk, &errs)){//如果序列化失败 就打印错误日志
ERR("ChatGPTProvider sendMessageStream parse body failed,error : {}", errs);//打印错误日志
continue;//跳过当前数据块
}
//按照事件类型进行数据分析
if(eventType == "response.output_text.delta"){
//如果是response.output_text.delta事件
if(chunk.isMember("delta") && chunk["delta"].isString()){//如果delta是chunk的成员 且是字符串类型
std::string delta = chunk["delta"].asString();//将delta添加到fullResponse中
callback(delta, false);//将delta传递给回调函数 表示不是最后一个增量
}
}else if(eventType == "response.output_item.done"){
//如果是response.output_item.done事件
// 表⽰该块输出结束
if(chunk.isMember("item") && chunk["item"].isObject()){
Json::Value item = chunk["item"];
if(item.isMember("content") &&
item["content"].isArray() &&
!item["content"].empty() &&
item["content"][0].isMember("text") &&
item["content"][0]["text"].isString())
{
fullResponse += item["content"][0]["text"].asString();//将text添加到fullResponse中
}
}
}else if(eventType == "response.completed"){
//如果是response.completed事件
streamFinish = true;//设置流式响应完成标志
callback("", true);//将空字符串传递给回调函数 表示流式响应结束
return true;
}
}//end while pos!=std::string::npos
return true;//继续接受数据块
};//end lambda
//给模型发送请求
auto result = client.send(request);//我们需要对result进行检测
if(!result){
//如果result为空 就认为是失败
//请求失败 出现网络问题,比如DNS解析失败
//auto err = result.error();
//ERR("Network error : {}", std::to_string(static_cast<int>(err)));
ERR("Network error : {}", to_string(result.error()));
return "";//返回空字符串
}
// 确保流式操作正常结束
if(!streamFinish){
WARN("Stream ended without response completed");//如果流式响应没有完成 就打印警告日志
callback("", true);//将空字符串传递给回调函数 表示流式响应结束
}
return fullResponse;
}//end sendMessageStream 流式返回函数的结束4.测试流式返回:
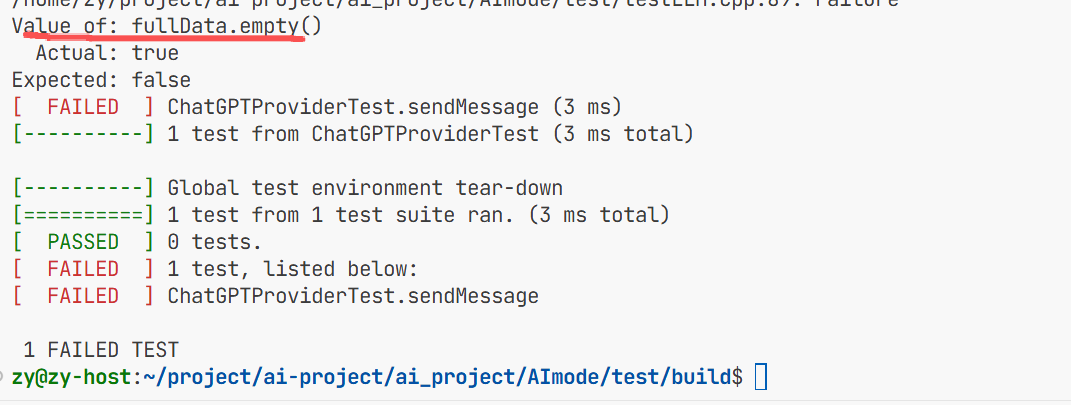
这里告诉我们返回了空的数据 所以代码写的还是有问题
那么返回时就没有走我们的fullresponse返回返回的是这两个空字符串
这个是网络问题
还有个问题之前我们是从第6个字符来截取的

而这里还有个空格如果从第六个字符截取的话把空格也截取进去了 也会报错。
9.Gemini的接入和封装:
1.初步的实现:
头文件的实现
源文件的实现
2.API的介绍
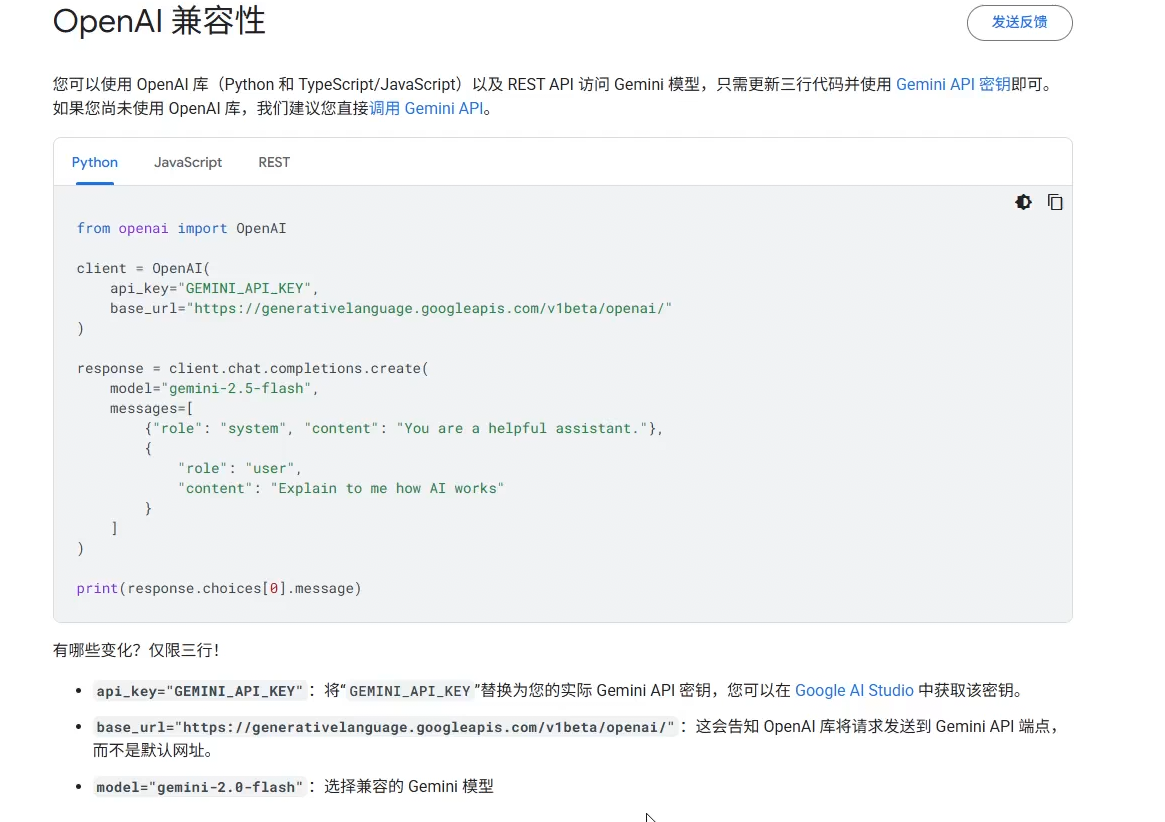
这里我们接入的是和opean ai 兼容的API
3.发送消息的实现(全量返回)

这里跟deepseek的实现都差不多的就不过多赘述了
cpp
//发送消息-全量返回
std::string GeminiProvider::sendMessage(const std::vector<Message>& messages, const std::map<std::string, std::string>& requestParam){
//检测模型是否可用
if(!isAvailable()){
ERR("GeminiProvider sendMessage model not available");
return "";
}
//2.构造请求参数
double temperature = 0.7;
int max_tokens = 2048;
//去找requestParam中是否有temperature和max_tokens参数 有就使用模型提供的参数值 没找到就使用默认值
if(requestParam.find("temperature") != requestParam.end()){
temperature = std::stod(requestParam.at("temperature"));//stod是将字符串转换为double类型
}
if(requestParam.find("max_tokens") != requestParam.end()){
max_tokens = std::stoi(requestParam.at("max_tokens"));//stoi是将字符串转换为int类型
}
//3.构造历史消息
Json::Value messagesArray(Json::arrayValue);//创建一个空的数组 用于存储历史消息
for(const auto& message : messages){//遍历messages向量 每个消息都添加到数组中
Json::Value messageObject;//创建一个空的对象
messageObject["role"] = message._role;//role是消息的角色 有user、assistant、system三种角色
messageObject["content"] = message._content;//content是消息的内容
messagesArray.append(messageObject);//将消息对象添加到数组中
}
//4.构造请求体
Json::Value requestBody;//创建一个空的对象 用于存储请求体
//方括号里要使用正确的字段 这样模型才会去解析
requestBody["model"] = getModelName();//model是模型名称 这里是gemini-2.0-flash
requestBody["messages"] = messagesArray;//messages是历史消息数组
requestBody["temperature"] = temperature;//temperature是温度参数 控制生成文本的随机性
requestBody["max_tokens"] = max_tokens;//max_tokens是最大生成token数 控制生成文本的长度
//5.请求序列化
Json::StreamWriterBuilder writeBuilder;//创建一个空的构建器 用于将Json::Value转换为字符串
writeBuilder["indentation"] = " ";//设置缩进为2个空格
std::string requestBodyStr = Json::writeString(writeBuilder, requestBody);//将Json::Value转换为字符串builder
INFO("GeminiProvider sendMessage requestBody: {}", requestBodyStr);//打印请求体
//6.使用cpp-httplib库构造HTTP客户端
httplib::Client client(_endpoint.c_str());//创建一个HTTP客户端 用于发送HTTP请求 把根端点告诉客户端 客户端会根据根端点去发送请求
client.set_connection_timeout(30,0);//设置连接超时时间为30秒 0表示不设置超时时间
client.set_read_timeout(60,0);//设置读取超时时间为60秒 0表示不设置超时时间
client.set_proxy("127.0.0.1", 7890);//设置代理 用于访问互联网
//7.设置请求头 包含API Key
httplib::Headers headers={
{"Authorization", "Bearer " + _apikey}, //Authorization是请求头 认证方式 包含API Key 用于验证请求
//{"Content-Type", "application/json"} //Content-Type是请求头 内容类型 表示请求体的类型 这里是application/json
};
//8.发送POST请求
auto response=client.Post("/v1beta/openai/chat/completions",headers,requestBodyStr, "application/json");//发送POST请求 /v1beta/openai/chat/completions是模型的API路径 requestBodyStr是请求体 headers是请求头 "application/json"是请求体的类型
if(!response){//如果响应失败 就返回空字符串
ERR("GeminiProvider sendMessage POST request failed, error: {}", to_string(response.error()));
return "";
}
INFO("GeminiProvider sendMessage POST request success status: {}", response->status);//打印响应状态码
INFO("GeminiProvider sendMessage POST request success body: {}", response->body);//打印响应体
//检测响应是否成功
if(response->status != 200){//如果响应状态码不是200 就返回
return "";
}
//9.解析响应体
//对模型返回的结构进行序列化 上面我们拿到的是字符流 这里我们使用Json::parseFromStream函数将字符流转换为Json::Value对象
Json::CharReaderBuilder readerBuilder;
std::string errorJson;//用于存储解析错误信息
Json::Value responseBody;//用于存储解析后的JSON对象
std::istringstream responseStream(response->body);//将响应体转换为字符流
if(!Json::parseFromStream(readerBuilder,responseStream, &responseBody,&errorJson)){
ERR("GeminiProvider sendMessage POST request failed, response body parse failed");
return "";
}
//获取choices数组 用于存储模型返回的消息
if(responseBody.isMember("choices") && responseBody["choices"].isArray() && !responseBody["choices"].empty())
{
auto choice=responseBody["choices"][0];//获取choices数组的第一个元素 用于存储模型返回的消息
if(choice.isMember("message") && choice["message"].isMember("content"))//如果choices数组的第一个元素有message成员 且message成员有content成员
{
std::string replyContent=choice["message"]["content"].asString();//获取message成员的content成员 用于存储模型返回的消息内容
INFO("GeminiProvider sendMessage replyContent: {}", replyContent);//打印模型返回的消息内容
return replyContent;//返回模型返回的消息内容
}
return "";
}
//解析失败
ERR("GeminiProvider response body parse failed");
return "";
}4.全量返回的测试:
测试代码 测试不光要改这个还需要去更改CMakeLists.txt 让他多去生成一个Gemini.cpp
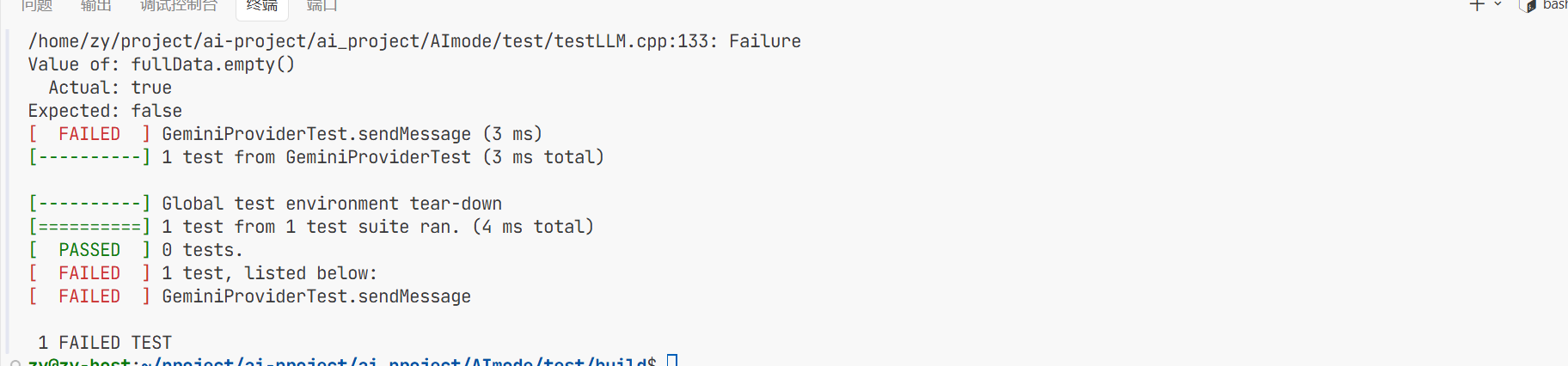
还是代理有错误 是因为apikey错误了 无法连接。
5.发送消息的实现(流式返回)
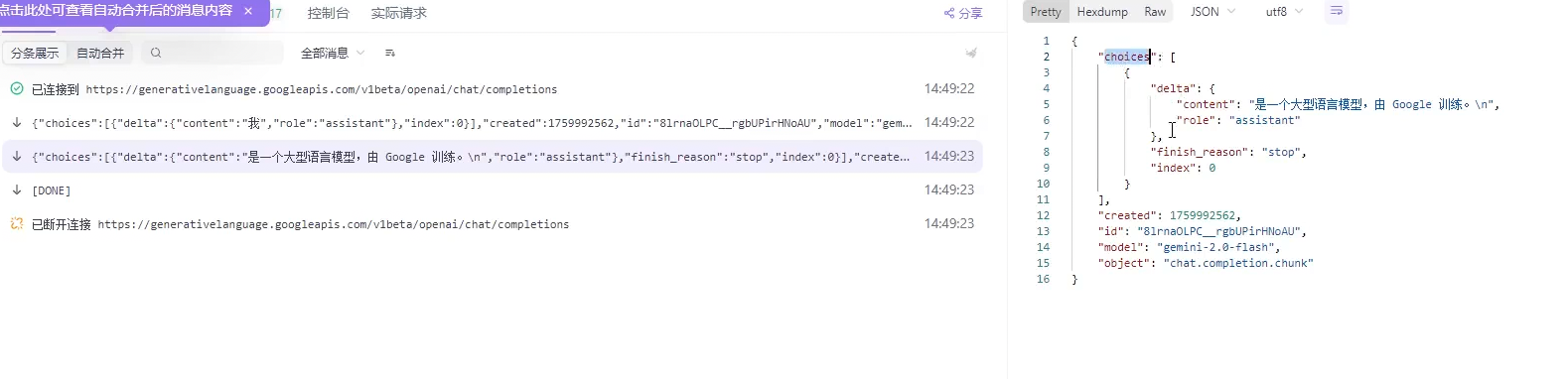
我们还是老样子去测试一下流式返回有哪些参数 可以看出这个参数跟deepseek很相似
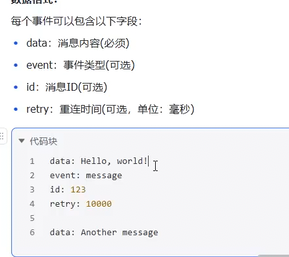
就是这种数据格式也就是SSH协议的数据 所以接下来的流式返回实现跟deepseek是差不多的。
这就是整个的实现因为Gemini和deepseek的返回格式都是SSH协议这样返回的不像chatgpt一样还要单独去处理 所以上基本一致
cpp
//发送消息-流式返回
std::string GeminiProvider::sendMessageStream(const std::vector<Message>& messages, const std::map<std::string, std::string>& requestParam,
std::function<void(const std::string&, bool)> callback)
{
//1.检测模型是否可用
if(!isAvailable())//如果模型不可用 就返回空字符串
{
ERR("GeminiProvider sendMessageStream model not available");//打印模型不可用错误信息
return "";
}
//2.构造请求参数
double temperature = 0.7;
int max_tokens = 2048;
//去找requestParam中是否有temperature和max_tokens参数 有就使用用户提供的参数值 没找到就使用默认值
if(requestParam.find("temperature") != requestParam.end()){
temperature = std::stod(requestParam.at("temperature"));//stod是将字符串转换为double类型
}
if(requestParam.find("max_tokens") != requestParam.end()){
max_tokens = std::stoi(requestParam.at("max_tokens"));//stoi是将字符串转换为int类型
}
//3.构造历史消息
Json::Value messagesArray(Json::arrayValue);//创建一个空的数组 用于存储历史消息
for(const auto& message : messages){//遍历messages向量 每个消息都添加到数组中
Json::Value messageObject;//创建一个空的对象
messageObject["role"] = message._role;//role是消息的角色 有user、assistant、system三种角色
messageObject["content"] = message._content;//content是消息的内容
messagesArray.append(messageObject);//将消息对象添加到数组中
}
//4.构造请求体
Json::Value requestBody;//创建一个空的对象 用于存储请求体
requestBody["model"] = getModelName();//获取模型的名称
requestBody["messages"] = messagesArray;//messages是历史消息数组 用于存储历史消息
requestBody["temperature"] = temperature;//temperature是温度参数 用于控制模型的随机性
requestBody["max_tokens"] = max_tokens;//max_tokens是最大token数 用于控制模型的输出长度
requestBody["stream"] = true;//stream是流式参数 用于控制是否返回流式结果
//5.序列化
Json::StreamWriterBuilder writeBuilder;//创建一个空的构建器 用于将Json::Value转换为字符串
writeBuilder["indentation"] = " ";//设置缩进为2个空格
std::string requestBodyStr = Json::writeString(writeBuilder, requestBody);//将Json::Value转换为字符串builder
INFO("GeminiProvider sendMessageStream requestBody: {}", requestBodyStr);//打印请求体字符串
//6。使用HTTPlib创建客户端
httplib::Client client(_endpoint.c_str());//创建一个HTTP客户端 用于发送HTTP请求 把根端点告诉客户端 客户端会根据根端点去发送请求
client.set_connection_timeout(60,0);//设置连接超时时间为60秒 0表示不设置超时时间
client.set_read_timeout(300,0);//设置读取超时时间为300秒(流式返回时需要设置为较大值) 0表示不设置超时时间
client.set_proxy("127.0.0.1", 7890);//设置代理 用于访问互联网
//7.设置请求头
httplib::Headers headers={
{"Authorization", "Bearer " + _apikey}, //Authorization是请求头 认证方式 包含API Key 用于验证请求
};
//定义一些用来流式处理的变量
std::string buffer;//接受流式响应的数据块
bool gotError = false;//标记响应是否成功
std::string errorMsg;//描述错误信息
int statusCode = 0;//响应状态码 用于判断响应是否成功
bool streamFinish = false;//标记流式响应是否完成
std::string fullResponse;//接受完整的流式响应
//创建请求对象
httplib::Request request;//创建一个空的请求对象 用于存储请求信息
request.path = "/v1beta/openai/chat/completions";//设置请求路径 这里是Gemini模型的API路径
request.method = "POST";//设置请求方法 这里是POST方法
request.headers = headers;//设置请求头 这里是设置的请求头
request.body = requestBodyStr;//设置请求体 这里是序列化后的请求体字符串
//设置响应处理器
//利用lambda表达式设置响应处理器 用于处理DeepSeek返回的流式响应
request.response_handler = [&](const httplib::Response& res){
statusCode = res.status;//获取响应状态码
if(statusCode != 200){ //如果响应状态码不是200 就认为是失败
gotError = true;
errorMsg = "HTTP status code: " + std::to_string(statusCode);
return false;//终止请求
}
return true; //继续接受流式响应数据块
};
//设置数据接受处理器
//利用lambda表达式设置数据接受处理器 用于处理DeepSeek返回的流式响应数据块
request.content_receiver = [&](const char* data, size_t dataLenth,size_t offset,size_t totalLength){
//验证响应头是否出错 如果出错就不再接受数据
if(gotError){
return false;//终止请求
}
//将数据块添加到buffer中
buffer.append(data, dataLenth);
INFO("GeminiProvider sendMessageStream received data: {}", buffer);//打印数据块字符串
//处理所以的流式响应的数据块 注意数据块是以\n\n分隔的
size_t pos=0;//初始化位置为0
while((pos=buffer.find("\n\n"))!=std::string::npos){//如果找到\n\n npos就是-1
//截取当前找到的数据块
std::string chunk = buffer.substr(0, pos);//从位置0开始 截取pos个字符
buffer.erase(0, pos+2);//删除buffer中从位置0开始的pos+2个字符 因为\n\n是2个字符
//解析该块响应数据中的模型返回的有效数据 现在chunk已经截取出来了 可以解析了
//处理空行和注释行 以':'开头的行是注释行 不需要解析
if(chunk.empty()||chunk[0]==':'){
continue;//如果chunk为空 或者 第一个字符是':' 就跳过
}
//获取模型返回的有效数据
if(chunk.compare(0,6,"data: ")==0){//如果chunk中没有data字段 就跳过
std::string modelData = chunk.substr(6);//从data: 后面开始截取 截取到chunk的结束
//检测是否为结束标记
if(modelData=="[DONE]"){
streamFinish = true;//设置流式响应完成标记为true
return true;//返回true 流式响应完成
}
//反序列化
Json::Value modelDataJson;//保存反序列化后的JSON对象
Json::CharReaderBuilder reader;
std::string errors;//保存反序列化错误信息
std::istringstream modelDataStream(modelData);//把modelData转换为输入流 用于反序列化JSON对象
if(Json::parseFromStream(reader,modelDataStream,&modelDataJson,&errors)){
//返回成功后 模型返回的json格式的数据现在就保存在modelDataJson中了
if(modelDataJson.isMember("choices")&&
modelDataJson["choices"].isArray()&&
!modelDataJson["choices"].empty()&&
modelDataJson["choices"][0].isMember("delta")&&
modelDataJson["choices"][0]["delta"].isMember("content")){
std::string content = modelDataJson["choices"][0]["delta"]["content"].asString();//获取delta字段中的content字段 并将其转换为字符串
fullResponse += content;//将content添加到fullResponse中
//将本次解析出的模型返回的有效数据转给调用sendMessageStream的用户使用 利用callback 回调函数
callback(content,false);//第一个参数将content传递给回调函数 第二个参数将false传递给回调函数 表示流式响应没有结束 继续去找下一个数据块
}
}else{ //如果反序列化解析失败
WARN("GeminiProvider sendMessageStream parse modelDataJson error: {}", errors);//打印反序列化错误信息
}
}
}//end while
return true;
};//end content_receiver lambda函数结束6.整个代码的实现:
cpp
#include"../include/GeminiProvider.h"
#include"../include/util/myLog.h"
#include<jsoncpp/json/json.h>
#include<httplib.h>
#include <jsoncpp/json/reader.h>
#include <jsoncpp/json/value.h>
namespace ai_chat_sdk{
//初始化模型 通过map传递模型配置参数 通过key获取配置参数
bool GeminiProvider::initModel(const std::map<std::string, std::string>& modelConfig){
auto it =modelConfig.find("api_key");
if(it == modelConfig.end()){//modelConfig是map类型 如果没有apikey参数 就返回false
ERR("GeminiProvider initModel api_key not found");
return false;
}else{
_apikey= it->second;
}
//初始化Base URL
it =modelConfig.find("endpoint");//endpoint是根端点模型的API base url
if(it == modelConfig.end()){//modelConfig是map类型 如果没有endpoint参数 就返回false
ERR("ChatGPTProvider initModel endpoint not found");
return false;
}else{
_endpoint= it->second;
}
_isAvailable= true;
INFO("GeminiProvider initModel success, endpoint: {}", _endpoint);
return true;
}
//检测模型是否可用
bool GeminiProvider::isAvailable() const
{
return _isAvailable;
}
//获取模型名称
std::string GeminiProvider::getModelName() const{
return "gemini-2.0-flash";
}
//获取模型描述
std::string GeminiProvider::getModelDesc() const
{
return "Google推出的Gemini-2.0-flash模型,支持中文对话和任务完成 高性能 高效率";
}
//发送消息-全量返回
std::string GeminiProvider::sendMessage(const std::vector<Message>& messages, const std::map<std::string, std::string>& requestParam){
//检测模型是否可用
if(!isAvailable()){
ERR("GeminiProvider sendMessage model not available");
return "";
}
//2.构造请求参数
double temperature = 0.7;
int max_tokens = 2048;
//去找requestParam中是否有temperature和max_tokens参数 有就使用模型提供的参数值 没找到就使用默认值
if(requestParam.find("temperature") != requestParam.end()){
temperature = std::stod(requestParam.at("temperature"));//stod是将字符串转换为double类型
}
if(requestParam.find("max_tokens") != requestParam.end()){
max_tokens = std::stoi(requestParam.at("max_tokens"));//stoi是将字符串转换为int类型
}
//3.构造历史消息
Json::Value messagesArray(Json::arrayValue);//创建一个空的数组 用于存储历史消息
for(const auto& message : messages){//遍历messages向量 每个消息都添加到数组中
Json::Value messageObject;//创建一个空的对象
messageObject["role"] = message._role;//role是消息的角色 有user、assistant、system三种角色
messageObject["content"] = message._content;//content是消息的内容
messagesArray.append(messageObject);//将消息对象添加到数组中
}
//4.构造请求体
Json::Value requestBody;//创建一个空的对象 用于存储请求体
//方括号里要使用正确的字段 这样模型才会去解析
requestBody["model"] = getModelName();//model是模型名称 这里是gemini-2.0-flash
requestBody["messages"] = messagesArray;//messages是历史消息数组
requestBody["temperature"] = temperature;//temperature是温度参数 控制生成文本的随机性
requestBody["max_tokens"] = max_tokens;//max_tokens是最大生成token数 控制生成文本的长度
//5.请求序列化
Json::StreamWriterBuilder writeBuilder;//创建一个空的构建器 用于将Json::Value转换为字符串
writeBuilder["indentation"] = " ";//设置缩进为2个空格
std::string requestBodyStr = Json::writeString(writeBuilder, requestBody);//将Json::Value转换为字符串builder
INFO("GeminiProvider sendMessage requestBody: {}", requestBodyStr);//打印请求体
//6.使用cpp-httplib库构造HTTP客户端
httplib::Client client(_endpoint.c_str());//创建一个HTTP客户端 用于发送HTTP请求 把根端点告诉客户端 客户端会根据根端点去发送请求
client.set_connection_timeout(30,0);//设置连接超时时间为30秒 0表示不设置超时时间
client.set_read_timeout(60,0);//设置读取超时时间为60秒 0表示不设置超时时间
client.set_proxy("127.0.0.1", 7890);//设置代理 用于访问互联网
//7.设置请求头 包含API Key
httplib::Headers headers={
{"Authorization", "Bearer " + _apikey}, //Authorization是请求头 认证方式 包含API Key 用于验证请求
//{"Content-Type", "application/json"} //Content-Type是请求头 内容类型 表示请求体的类型 这里是application/json
};
//8.发送POST请求
auto response=client.Post("/v1beta/openai/chat/completions",headers,requestBodyStr, "application/json");//发送POST请求 /v1beta/openai/chat/completions是模型的API路径 requestBodyStr是请求体 headers是请求头 "application/json"是请求体的类型
if(!response){//如果响应失败 就返回空字符串
ERR("GeminiProvider sendMessage POST request failed, error: {}", to_string(response.error()));
return "";
}
INFO("GeminiProvider sendMessage POST request success status: {}", response->status);//打印响应状态码
INFO("GeminiProvider sendMessage POST request success body: {}", response->body);//打印响应体
//检测响应是否成功
if(response->status != 200){//如果响应状态码不是200 就返回
return "";
}
//9.解析响应体
//对模型返回的结构进行序列化 上面我们拿到的是字符流 这里我们使用Json::parseFromStream函数将字符流转换为Json::Value对象
Json::CharReaderBuilder readerBuilder;
std::string errorJson;//用于存储解析错误信息
Json::Value responseBody;//用于存储解析后的JSON对象
std::istringstream responseStream(response->body);//将响应体转换为字符流
if(!Json::parseFromStream(readerBuilder,responseStream, &responseBody,&errorJson)){
ERR("GeminiProvider sendMessage POST request failed, response body parse failed");
return "";
}
//获取choices数组 用于存储模型返回的消息
if(responseBody.isMember("choices") && responseBody["choices"].isArray() && !responseBody["choices"].empty())
{
auto choice=responseBody["choices"][0];//获取choices数组的第一个元素 用于存储模型返回的消息
if(choice.isMember("message") && choice["message"].isMember("content"))//如果choices数组的第一个元素有message成员 且message成员有content成员
{
std::string replyContent=choice["message"]["content"].asString();//获取message成员的content成员 用于存储模型返回的消息内容
INFO("GeminiProvider sendMessage replyContent: {}", replyContent);//打印模型返回的消息内容
return replyContent;//返回模型返回的消息内容
}
return "";
}
//解析失败
ERR("GeminiProvider response body parse failed");
return "";
}
//发送消息-流式返回
std::string GeminiProvider::sendMessageStream(const std::vector<Message>& messages, const std::map<std::string, std::string>& requestParam,
std::function<void(const std::string&, bool)> callback)
{
//1.检测模型是否可用
if(!isAvailable())//如果模型不可用 就返回空字符串
{
ERR("GeminiProvider sendMessageStream model not available");//打印模型不可用错误信息
return "";
}
//2.构造请求参数
double temperature = 0.7;
int max_tokens = 2048;
//去找requestParam中是否有temperature和max_tokens参数 有就使用用户提供的参数值 没找到就使用默认值
if(requestParam.find("temperature") != requestParam.end()){
temperature = std::stod(requestParam.at("temperature"));//stod是将字符串转换为double类型
}
if(requestParam.find("max_tokens") != requestParam.end()){
max_tokens = std::stoi(requestParam.at("max_tokens"));//stoi是将字符串转换为int类型
}
//3.构造历史消息
Json::Value messagesArray(Json::arrayValue);//创建一个空的数组 用于存储历史消息
for(const auto& message : messages){//遍历messages向量 每个消息都添加到数组中
Json::Value messageObject;//创建一个空的对象
messageObject["role"] = message._role;//role是消息的角色 有user、assistant、system三种角色
messageObject["content"] = message._content;//content是消息的内容
messagesArray.append(messageObject);//将消息对象添加到数组中
}
//4.构造请求体
Json::Value requestBody;//创建一个空的对象 用于存储请求体
requestBody["model"] = getModelName();//获取模型的名称
requestBody["messages"] = messagesArray;//messages是历史消息数组 用于存储历史消息
requestBody["temperature"] = temperature;//temperature是温度参数 用于控制模型的随机性
requestBody["max_tokens"] = max_tokens;//max_tokens是最大token数 用于控制模型的输出长度
requestBody["stream"] = true;//stream是流式参数 用于控制是否返回流式结果
//5.序列化
Json::StreamWriterBuilder writeBuilder;//创建一个空的构建器 用于将Json::Value转换为字符串
writeBuilder["indentation"] = " ";//设置缩进为2个空格
std::string requestBodyStr = Json::writeString(writeBuilder, requestBody);//将Json::Value转换为字符串builder
INFO("GeminiProvider sendMessageStream requestBody: {}", requestBodyStr);//打印请求体字符串
//6。使用HTTPlib创建客户端
httplib::Client client(_endpoint.c_str());//创建一个HTTP客户端 用于发送HTTP请求 把根端点告诉客户端 客户端会根据根端点去发送请求
client.set_connection_timeout(60,0);//设置连接超时时间为60秒 0表示不设置超时时间
client.set_read_timeout(300,0);//设置读取超时时间为300秒(流式返回时需要设置为较大值) 0表示不设置超时时间
client.set_proxy("127.0.0.1", 7890);//设置代理 用于访问互联网
//7.设置请求头
httplib::Headers headers={
{"Authorization", "Bearer " + _apikey}, //Authorization是请求头 认证方式 包含API Key 用于验证请求
};
//定义一些用来流式处理的变量
std::string buffer;//接受流式响应的数据块
bool gotError = false;//标记响应是否成功
std::string errorMsg;//描述错误信息
int statusCode = 0;//响应状态码 用于判断响应是否成功
bool streamFinish = false;//标记流式响应是否完成
std::string fullResponse;//接受完整的流式响应
//创建请求对象
httplib::Request request;//创建一个空的请求对象 用于存储请求信息
request.path = "/v1beta/openai/chat/completions";//设置请求路径 这里是Gemini模型的API路径
request.method = "POST";//设置请求方法 这里是POST方法
request.headers = headers;//设置请求头 这里是设置的请求头
request.body = requestBodyStr;//设置请求体 这里是序列化后的请求体字符串
//设置响应处理器
//利用lambda表达式设置响应处理器 用于处理DeepSeek返回的流式响应
request.response_handler = [&](const httplib::Response& res){
statusCode = res.status;//获取响应状态码
if(statusCode != 200){ //如果响应状态码不是200 就认为是失败
gotError = true;
errorMsg = "HTTP status code: " + std::to_string(statusCode);
return false;//终止请求
}
return true; //继续接受流式响应数据块
};
//设置数据接受处理器
//利用lambda表达式设置数据接受处理器 用于处理DeepSeek返回的流式响应数据块
request.content_receiver = [&](const char* data, size_t dataLenth,size_t offset,size_t totalLength){
//验证响应头是否出错 如果出错就不再接受数据
if(gotError){
return false;//终止请求
}
//将数据块添加到buffer中
buffer.append(data, dataLenth);
INFO("GeminiProvider sendMessageStream received data: {}", buffer);//打印数据块字符串
//处理所以的流式响应的数据块 注意数据块是以\n\n分隔的
size_t pos=0;//初始化位置为0
while((pos=buffer.find("\n\n"))!=std::string::npos){//如果找到\n\n npos就是-1
//截取当前找到的数据块
std::string chunk = buffer.substr(0, pos);//从位置0开始 截取pos个字符
buffer.erase(0, pos+2);//删除buffer中从位置0开始的pos+2个字符 因为\n\n是2个字符
//解析该块响应数据中的模型返回的有效数据 现在chunk已经截取出来了 可以解析了
//处理空行和注释行 以':'开头的行是注释行 不需要解析
if(chunk.empty()||chunk[0]==':'){
continue;//如果chunk为空 或者 第一个字符是':' 就跳过
}
//获取模型返回的有效数据
if(chunk.compare(0,6,"data: ")==0){//如果chunk中没有data字段 就跳过
std::string modelData = chunk.substr(6);//从data: 后面开始截取 截取到chunk的结束
//检测是否为结束标记
if(modelData=="[DONE]"){
callback("", true);//将空字符串传递给回调函数 表示流式响应结束
streamFinish = true;//设置流式响应完成标记为true
return true;//返回true 流式响应完成
}
//反序列化
Json::Value modelDataJson;//保存反序列化后的JSON对象
Json::CharReaderBuilder reader;
std::string errors;//保存反序列化错误信息
std::istringstream modelDataStream(modelData);//把modelData转换为输入流 用于反序列化JSON对象
if(Json::parseFromStream(reader,modelDataStream,&modelDataJson,&errors)){
//返回成功后 模型返回的json格式的数据现在就保存在modelDataJson中了
if(modelDataJson.isMember("choices")&&
modelDataJson["choices"].isArray()&&
!modelDataJson["choices"].empty()&&
modelDataJson["choices"][0].isMember("delta")&&
modelDataJson["choices"][0]["delta"].isMember("content")){
std::string content = modelDataJson["choices"][0]["delta"]["content"].asString();//获取delta字段中的content字段 并将其转换为字符串
fullResponse += content;//将content添加到fullResponse中
//将本次解析出的模型返回的有效数据转给调用sendMessageStream的用户使用 利用callback 回调函数
callback(content,false);//第一个参数将content传递给回调函数 第二个参数将false传递给回调函数 表示流式响应没有结束 继续去找下一个数据块
}
}else{ //如果反序列化解析失败
WARN("GeminiProvider sendMessageStream parse modelDataJson error: {}", errors);//打印反序列化错误信息
}
}
}//end while
return true;
};//end content_receiver lambda函数结束
//给模型发送请求
auto result = client.send(request);//我们需要对result进行检测
if(!result){
//如果result为空 就认为是失败
//请求失败 出现网络问题,比如DNS解析失败
//auto err = result.error();
//ERR("Network error : {}", std::to_string(static_cast<int>(err)));
ERR("Network error : {}", to_string(result.error()));
return "";//返回空字符串
}
// 确保流式操作正常结束
if(!streamFinish){
WARN("Stream ended without [DONE] marker");//如果流式响应没有结束标记 就打印警告日志
callback("", true);//将空字符串传递给回调函数 表示流式响应结束
}
return fullResponse;
}//end sendMessageStream流式返回
}//end namespace ai_chat_sdk7.测试:

这里也就测试成功了
10.云端模型和本地模型的区别
为什么需要本地接⼊⼤模型
各⼤模型⼚商已经提供了⽹⻚版的⼤模型使⽤服务,⽐如DeepSeek、ChatGPT等,⽤⼾直接在⽹⻚上提问,就能得到需要的答案,为什么还要本地接⼊⼤模型呢?
使⽤云端⼤模型的优点
•
效果强:云端算⼒⾜、模型⼤,输出质量通过⾼于本地模型
•
即开即⽤:⽆需下载和配置,注册后即可使⽤
•
⾃动升级:官⽅会不断更新和优化模型
•
插件⽣态:ChatGPT plus、Gemini Advanced等往往⾃带额外功能
使⽤云端⼤模型的缺陷
•
隐私⻛险:输⼊的数据会传送到云端,虽然⼤⼚承诺,但仍有顾虑。许多⾏业(如医疗、⾦融、法
律、政府)的数据⾼度敏感,法律禁⽌将数据上传到第三⽅。⽽且企业内部的战略⽂档、代码库、设 计图等核⼼资产,如果通过API发送给第三⽅,存在泄露的⻛险
•
费⽤问题:⼤规模调⽤API需要付费,费⽤可能很⾼。虽然官⽹按token收费看起来单价不⾼,但对
于⾼频使⽤的企业或个⼈开发者来说,⻓期积累的成本⾮常巨⼤
⽹络依赖:需要⽹络,有时访问受限,延迟⾼。在⽆⽹络请求下⽆法使⽤,⽐如保密单位、偏远地
区等,⽽且⽹络⾼峰期可能还会遇到⽆法响应情况
•
可控性差:⽆法选择模型版本的内部细节,⽐如调整参数、控制模型输出格式、集成⾃定义函数等
本地部署⼤模型优点
•
隐私保护:数据完全在本地处理,不会上传云端
•
零调⽤费⽤:模型下载后随便⽤,不会产⽣API调⽤费⽤
•
离线可⽤:没有⽹络也能⽤,⾮常适合边缘场景
•
灵活可控:可以随时切换模型,甚⾄加载⾃⼰的训练模型
本地部署⼤模型的缺陷
•
硬件要求⾼:对显卡、内容要求⽐较⾼
•
效果有限:在低成本下效果有限
•
初始成本⾼:模型下载很⼤,运⾏时占⽤资源多
因此对于普通⽤⼾和⾮敏感任务,直接使⽤官⽹的云端服务是最简单、最经济的选择。
但对于企业、有隐私或特殊需求的⽤⼾,就需要本地部署⼤模型。
本地接⼊⼤模型步骤:

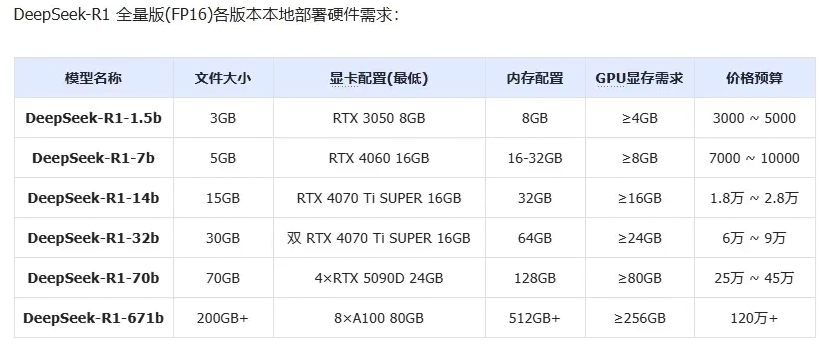
所以本地接入的成本也很大
11.ollama本地接入deepseek
1.ollama的介绍:
如果不用第三方工具的话会很麻烦:

"快速启动并运⾏⼤语⾔模型",官⽅的宣传语简洁地概括了Ollama的核⼼功能和价值主张。
Ollama 是⼀个开源的⼤型语⾔模型服务⼯具,旨在帮助⽤⼾快速在本地运⾏⼤模型。通过简单的安装 指令,⽤⼾可以通过⼀条命令轻松启动和运⾏开源的⼤型语⾔模型。 它提供了⼀个简洁易⽤的命令⾏界⾯和服务器,专为构建⼤型语⾔模型应⽤⽽设计。⽤⼾可以轻松下载、运⾏和管理各种开源 LLM。
与传统 LLM 需要复杂配置和强⼤硬件不同,Ollama 能够让⽤⼾在消费级的 PC 上体验 LLM 的强⼤功
能。
Ollama 会⾃动监测本地计算资源,如有 GPU 的条件,会优先使⽤ GPU 的资源,同时模型的推理速度 也更快。如果没有 GPU 条件,直接使⽤ CPU 资源。
Ollama特点:
•
开源免费:Ollama 及其⽀持的模型完全开源且免费,⽤⼾可以随时访问和使⽤这些资源,⽽⽆需
⽀付任何费⽤。
•
简单易⽤:Ollama ⽆需复杂的配置和安装过程,只需⼏条简单的命令即可启动和运⾏,为⽤⼾节
省了⼤量时间和精⼒。
•
⽀持多平台:Ollama 提供了多种安装⽅式,⽀持 Mac、Linux 和 Windows 平台,并提供 Docker
镜像,满⾜不同⽤⼾的需求。
•
模型丰富:Ollama ⽀持包括 DeepSeek-R1、 Llama3.3、Gemma2、Qwen2 在内的众多热⻔开
源 LLM,⽤⼾可以轻松⼀键下载和切换模型,享受丰富的选择。
•
功能⻬全:Ollama 将模型权重、配置和数据捆绑成⼀个包,定义为 Modelfile,使得模型管理更加
简便和⾼效。
•
⽀持⼯具调⽤:Ollama ⽀持使⽤ Llama 3.1 等模型进⾏⼯具调⽤。这使模型能够使⽤它所知道的
⼯具来响应给定的提⽰,从⽽使模型能够执⾏更复杂的任务。
•
资源占⽤低:Ollama 优化了设置和配置细节,包括 GPU 使⽤情况,从⽽提⾼了模型运⾏的效率,确保在资源有限的环境下也能顺畅运⾏。
•
隐私保护:Ollama 所有数据处理都在本地机器上完成,可以保护⽤⼾的隐私。
•
社区活跃:Ollama 拥有⼀个庞⼤且活跃的社区,⽤⼾可以轻松获取帮助、分享经验,并积极参与
到模型的开发和改进中,共同推动项⽬的发展。
有一堆的模型可供我们选择
这就是到时候我们API调用的时候需要的参考文档。
2.ollama的手动安装:
因为github是外网 我们服务器在下载的时候会很慢 所以这里手动下载会很快
先去github官网搜ollama然后把linux环境下的安装包先下载到windows上 再手动拖拽到家目录下面
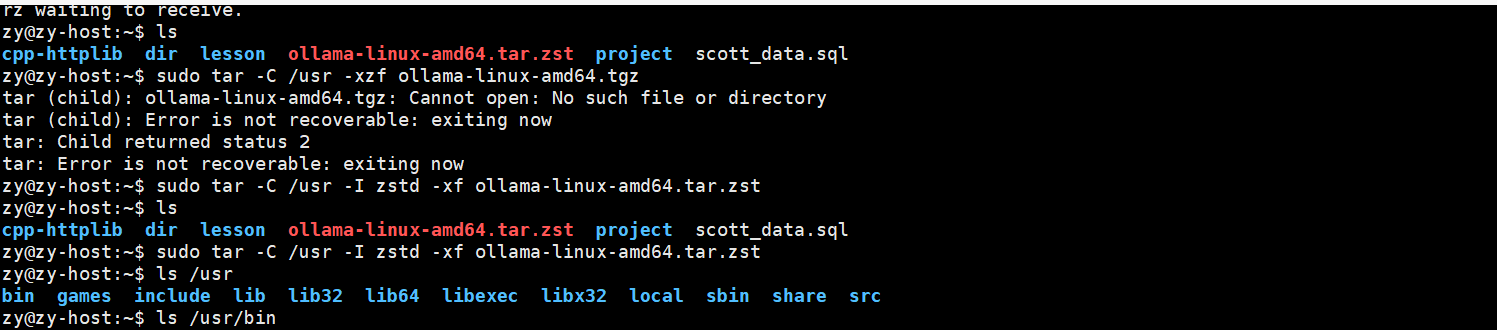
再根据解压指令解压到/usr目录下
详细过程移步到:【保姆级教程】手把手教你离线安装Ollama - 知乎
这样ollama就安装完成了
3.ollama的常见指令:

ollama的运行状态


这就是我下载的模型

这是我ollama的端口号 这里只有我本机能够使用。

这样就可以运行大模型了


这样才能退出ollama不然会识别成文字

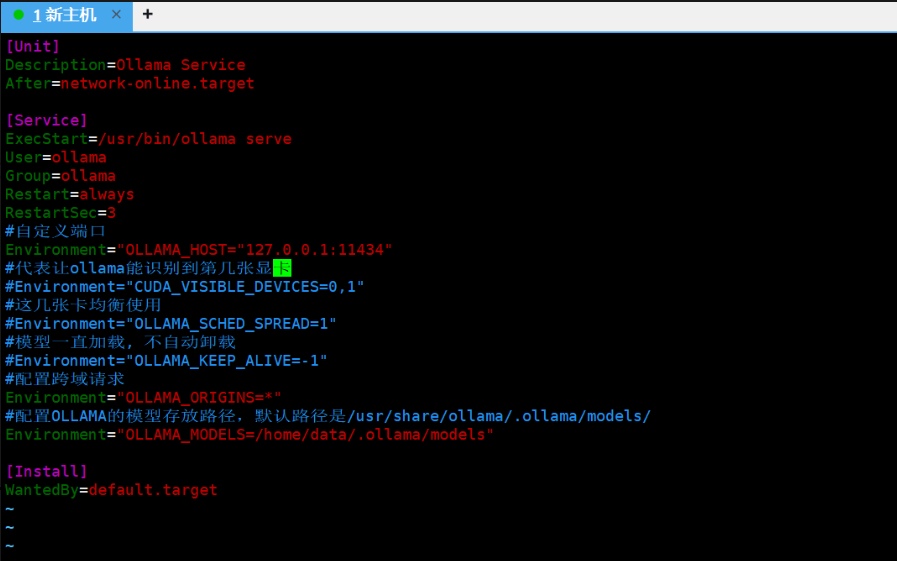
这是我配置的环境变量
4.通过ollama初始化模型:

这里跟初始化上面三个大模型不一样 因为那里有官方提供的服务器 远程接入:
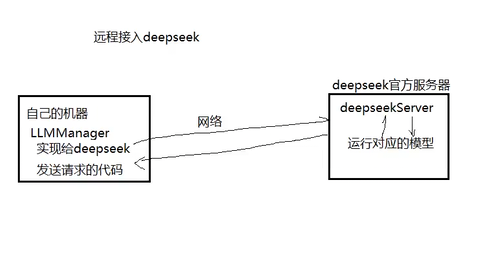
那通过ollama接入本地模型的话:
0llamaLLMProvider
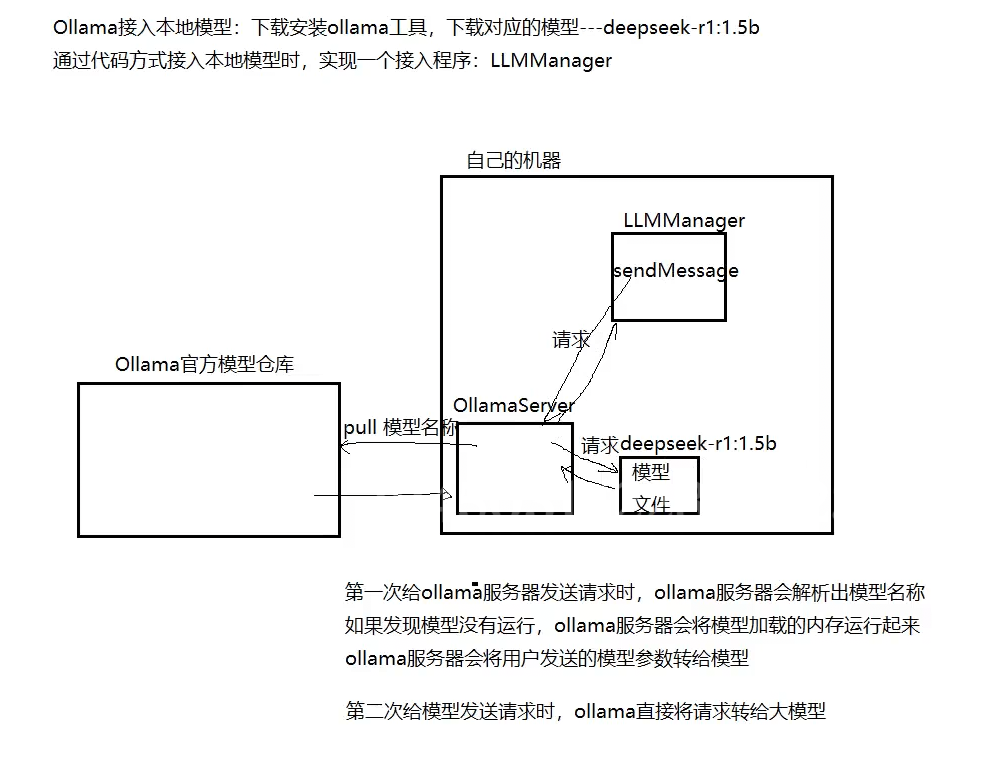
这里我们需要自己实现0llamaLLMProvider 而不是用LLMProvider 因为我们还要增加几个变量 比如模型名称啥的 这样用户就能知道你使用的是什么模型了。
头文件
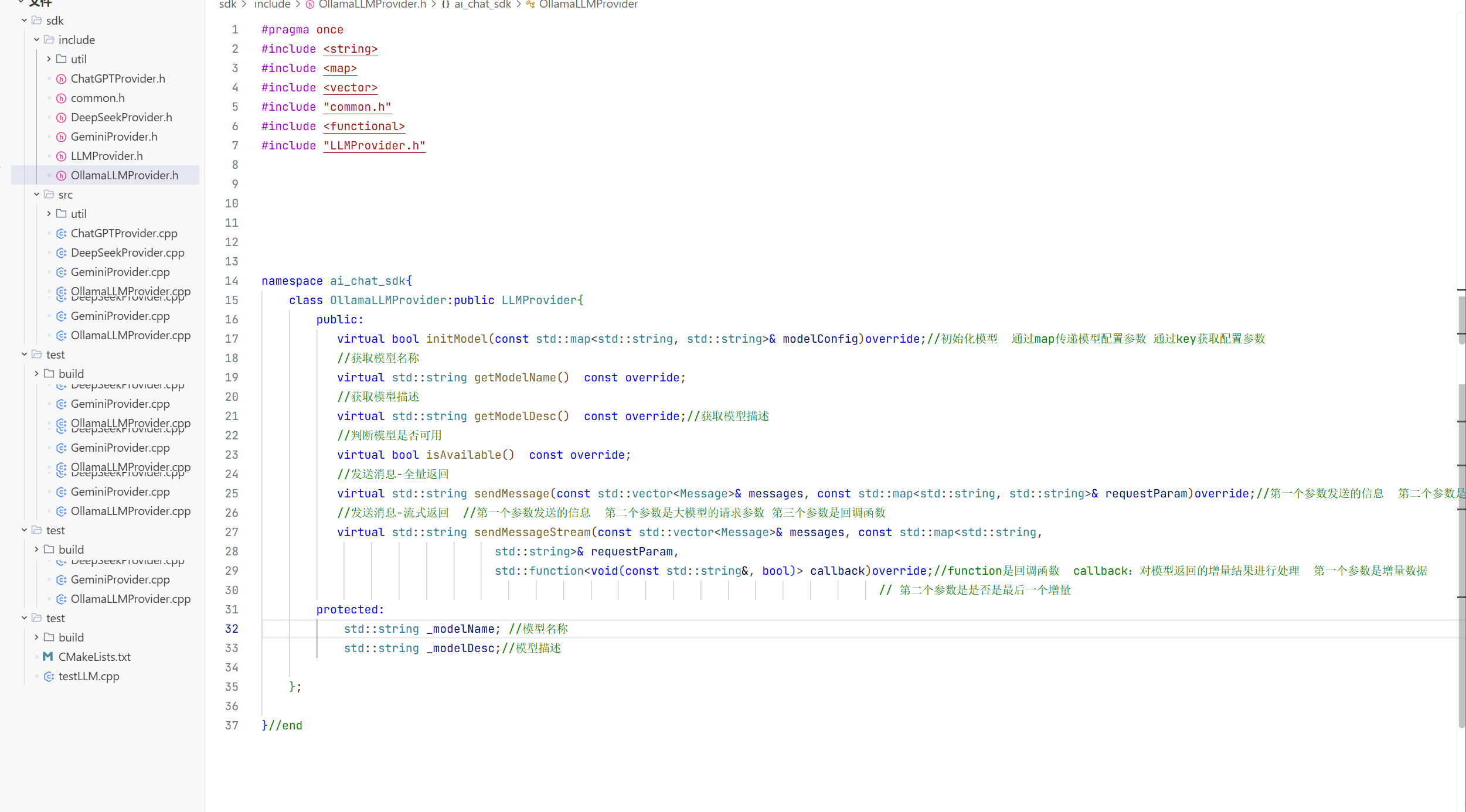
模型的初始化的基础步骤:
5.全量返回:

这里的格式还和上面实现的模型小小不一样的点就在这
cpp
// 发送消息给模型
std::string OllamaLLMProvider::sendMessage(
const std::vector<Message>& messages,
const std::map<std::string, std::string>& request_param) {
// 检查模型是否有效
if(!_isAvailable) {
ERR("OllamaLLMProvider: model is not init!");
return "";
}
// 获取采样温度和 max_tokens
double temperature = 0.7;
int max_tokens = 2048;
if(request_param.find("temperature") != request_param.end()) {
temperature = std::stof(request_param.at("temperature"));
}
if(request_param.find("max_tokens") != request_param.end()) {
max_tokens = std::stoi(request_param.at("max_tokens"));
}
// 构建历史消息
Json::Value messages_array(Json::arrayValue);
for(const auto& message : messages) {
Json::Value msg;
msg["role"] = message._role;
msg["content"] = message._content;
messages_array.append(msg);
}
// 构建请求体
Json::Value options;
options["temperature"] = temperature;
options["num_ctx"] = max_tokens;
Json::Value request_body;
request_body["model"] = _modelName;
request_body["messages"] = messages_array;
request_body["stream"] = false;
request_body["options"] = options;
// 序列化
Json::StreamWriterBuilder writer;
std::string json_string = Json::writeString(writer, request_body);
DBG("OllamaLLMProvider: request_body:{}", json_string);
// 创建HTTP Client
httplib::Client client(_endpoint);
client.set_connection_timeout(30, 0); // 30秒超时
client.set_read_timeout(60, 0); // 60秒读取超时
// 设置请求头
httplib::Headers headers = {
{"Content-Type", "application/json"}
};
// 发送POST请求
auto response = client.Post("/api/chat", headers, json_string, "application/json");
if(!response) {
ERR("Failed to connect to OllamaLLMProviderAPI - check network and SSL!");
return "";
}
DBG("OllamaLLMProviderAPI response status: {}", response->status);
DBG("OllamaLLMProviderAPI response body: {}", response->body);
// 检查响应是否成功
if(response->status != 200) {
ERR("OllamaLLMProviderAPI returned non-200 status: {} - {}", response->status, response->body);
return "";
}
// 解析响应体
Json::Value response_json;
Json::CharReaderBuilder reader_builder;
std::string parse_errors;
std::istringstream response_stream(response->body);
if(!Json::parseFromStream(reader_builder, response_stream, &response_json, &parse_errors)) {
ERR("Failed to parse OllamaLLMProviderAPI response: {}", parse_errors);
return "";
}
// 解析大模型回复内容
// 大模型回复包含在message的json对象中
if(response_json.isMember("message") && response_json["message"].isMember("content")) {
std::string reply_content = response_json["message"]["content"].asString();
INFO("Received Ollama response: {}", reply_content);
return reply_content;
}
// 解析失败,返回错误信息
ERR("Invalid response format from Ollama API");
return "Invalid response format from Ollama API";
}

全量返回的测试就结束了
6.流式返回:
cpp
// 发送消息-流式返回
std::string OllamaLLMProvider::sendMessageStream(
const std::vector<Message>& messages,
const std::map<std::string, std::string>& request_param,
std::function<void(const std::string&, bool)> callback){
// 检测模型是否可用
if(!isAvailable()){
ERR("OllamaLLMProvider::sendMessageStream: model is not available");
return "";
}
// 构造请求参数
// 构造温度值和最大tokens数
float temperature = 0.7f;
int maxTokens = 1024;
if(request_param.find("temperature") != request_param.end()){
temperature = std::stof(request_param.at("temperature"));
}
if(request_param.find("max_tokens") != request_param.end()){
maxTokens = std::stoi(request_param.at("max_tokens"));
}
// 构建历史消息
Json::Value messageArray(Json::arrayValue);
for(const auto& message : messages){
Json::Value messageObject(Json::objectValue);
messageObject["role"] = message._role;
messageObject["content"] = message._content;
messageArray.append(messageObject);
}
// 构建请求体
Json::Value options(Json::objectValue);
options["temperature"] = temperature;
options["num_ctx"] = maxTokens;
Json::Value requestBody(Json::objectValue);
requestBody["model"] = _modelName;
requestBody["messages"] = messageArray;
requestBody["options"] = options;
requestBody["stream"] = true;
// 序列化请求体
Json::StreamWriterBuilder writerBuilder;
std::string requestBodyStr = Json::writeString(writerBuilder, requestBody);
// 创建http客户端
httplib::Client client(_endpoint.c_str());
client.set_connection_timeout(30, 0); // 30秒连接超时
client.set_read_timeout(300, 0); // 300秒读取超时
// 设置请求头
httplib::Headers headers = {
{"Content-Type", "application/json"}
};
// 流式处理变量
std::string buffer;
bool gotError = false;
std::string errorMsg;
int statusCode = 0;
bool streamFinish = false;
std::string fullData;
// 创建请求对象
httplib::Request request;
request.method = "POST";
request.path = "/api/chat";
request.headers = headers;
request.body = requestBodyStr;
// 响应头处理器
request.response_handler = [&](const httplib::Response& response) -> bool {
statusCode = response.status;
if(statusCode != 200){
gotError = true;
errorMsg = "OllamaLLMProvider::sendMessageStream: failed to send request, status: " + std::to_string(statusCode);
return false; // 终止请求
}
return true;
};
// 内容接收器
request.content_receiver = [&](const char* data, size_t dataLen, uint64_t offset,uint64_t totalLength)->bool{
// 如果http响应头出错,就不需要接收后续数据
if(gotError){
return false; // 终止接收
}
buffer.append(data, dataLen);
// 处理每个数据块,数据块之间是以\n间隔的
// 注意:此处接收到的数据块并不是模型返回的SSE格式的数据,而是经过Ollama服务器处理之后的数据
size_t pos = 0;
while((pos = buffer.find("\n", pos)) != std::string::npos){
std::string chunk = buffer.substr( 0, pos);
buffer.erase(0, pos + 1);
if(chunk.empty()){
continue;
}
// 反序列化
Json::Value chunkJson;
Json::CharReaderBuilder readerBuilder;
std::string errors;
std::istringstream chunkStream(chunk);
if(!Json::parseFromStream(readerBuilder, chunkStream, &chunkJson, &errors)){
ERR("OllamaLLMProvider::sendMessageStream: failed to parse chunk json, errors: {}", errors);
continue;
}
// 处理结束标记
if(chunkJson.get("done", false).asBool()){
streamFinish = true;
callback("", true);
return true;
}
// 提取增量数据
if(chunkJson.isMember("message") && chunkJson["message"].isMember("content")){
std::string delta = chunkJson["message"]["content"].asString();
fullData += delta;
callback(delta, false);
}
}
return true;
};
// 给Ollama服务器发请求
auto response = client.send(request);
if(!response){
ERR("OllamaLLMProvider::sendMessageStream: failed to send request, error: {}", to_string(response.error()));
return "";
}
// 确保流式响应正常结束
if(!streamFinish){
ERR("OllamaLLMProvider::sendMessageStream: stream not finish, fullData: {}", fullData);
callback("", true);
}
return fullData;
}
这样就测试成功了。
12.LLMManager的实现:
可以看到我们测试的时候要调用大模型的时候会很麻烦 所以现在我们实现一个管理模型的方法
1.头文件的实现:
cpp
#pragma once
#include <map>
#include <memory>
#include <string>
#include <functional>
#include "LLMProvider.h"
namespace ai_chat_sdk{
// LLM 管理
class LLMManager{
public:
// 注册 LLM 提供者
bool registerProvider(const std::string& name,std::unique_ptr<LLMProvider> provider);
// 初始化指定模型
bool initModel(const std::string& modelName, const std::map<std::string,std::string>& modelParam);
// 获取可⽤模型列表
std::vector<ModelInfo> getAvailableModels()const;
// 检查模型是否可⽤
bool isModelAvailable(const std::string& modelName)const;
// 发送消息到指定模型
std::string sendMessage(const std::string& modelName,const std::vector<Message>& messages,const std::map<std::string, std::string>&requestParam);
// 发送消息到指定模型,流式响应
std::string sendMessageStream(const std::string& modelName,const std::vector<Message>& messages,const std::map<std::string, std::string>& requestParam,std::function<void(const std::string&, bool)> callback);
private:
//key 模型的名称 value 模型提供器
std::map<std::string, std::unique_ptr<LLMProvider>> _providers;
//key 模型的名称 value 模型信息
std::map<std::string, ModelInfo> _modelInfos;
};
} // end ai_chat_sdk2.源文件的实现:
cpp
#include "../include/LLMManger.h"
#include"../include/util/myLog.h"
namespace ai_chat_sdk{
// 注册 LLM 提供者
bool LLMManager::registerProvider(const std::string& modelName,std::unique_ptr<LLMProvider> provider)
{
// 参数检测
if(!provider){
ERR("Cannot register null provider,modelName={}",modelName);
return false;
}
// 注意,unique_ptr是防拷⻉的,此处只能通过move的⽅式将资源转移给当前对象
// 因此,provider在设置的时候,设置成⼀个临时变量
_providers[modelName] = std::move(provider);
// 添加模型信息
_modelInfos[modelName] = ModelInfo(modelName);
// 模型注册成功
INFO("Register LLM Provider,modelName : {}", modelName);
return true;
}
// 初始化指定模型
bool LLMManager::initModel(const std::string& modelName, const std::map<std::string, std::string>& modelParam)
{
// 检测模型是否注册
auto it = _providers.find(modelName);
if(it == _providers.end()){
ERR("Model {} is not registered!!!", modelName);
return false;
}
// 模型已经注册过了,可以进⾏初始化
bool isSuccess = it->second->initModel(modelParam);
if(isSuccess){
INFO("Model {} init success!!!", modelName);
_modelInfos[modelName]._modelDesc = it->second->getModelDesc();
_modelInfos[modelName]._isAvailable = true;
}else{
INFO("Model {} init Failed!!!", modelName);
_modelInfos[modelName]._isAvailable = false;
}
return isSuccess;
}
// 获取可⽤模型列表
std::vector<ModelInfo> LLMManager::getAvailableModels()const
{
// 从注册的模型列表中筛选出所有可⽤的模型
std::vector<ModelInfo> models;
for(const auto& pair : _modelInfos){
if(pair.second._isAvailable){
models.push_back(pair.second);
}
}
return models;
}
// 检查模型是否可⽤
bool LLMManager::isModelAvailable(const std::string& modelName)const
{
auto it= _modelInfos.find(modelName);//
return it != _modelInfos.end() && it->second._isAvailable;//返回模型是否可⽤的结果
}
//发送消息给指定模型 全量返回模型回复
//第一个参数:模型名称
//第二个参数:消息列表
//第三个参数:请求参数,如api key、max_tokens等
std::string LLMManager::sendMessage(const std::string& modelName,const std::vector<Message>& messages, const std::map<std::string, std::string>& requestParam)
{
// 检测模型是否注册
auto it = _providers.find(modelName);
if(it == _providers.end()){
ERR("Model {} is not registered!!!", modelName);
return "";
}
// 检测模型是否可⽤
if(!isModelAvailable(modelName)){
ERR("Model {} is not available!!!", modelName);
return "";
}
// 模型已注册,调⽤模型提供方发送消息
return it->second->sendMessage(messages,requestParam);
}
// 发送消息到指定模型,流式响应
//第一个参数:模型名称
//第二个参数:消息列表
//第三个参数:请求参数,如api key、max_tokens等
//第四个参数:回调函数,用于处理流式响应
std::string LLMManager::sendMessageStream(const std::string& modelName,
const std::vector<Message>& messages,
const std::map<std::string, std::string>& requestParam,
std::function<void(const std::string&, bool)> callback)
{
// 检测模型是否注册
auto it = _providers.find(modelName);
if(it == _providers.end()){
ERR("Model {} is not registered!!!", modelName);
return "";
}
// 检测模型是否可⽤
if(!isModelAvailable(modelName)){
ERR("Model {} is not available!!!", modelName);
return "";
}
return it->second->sendMessageStream(messages,requestParam,callback);//调⽤模型提供方发送消息
}
}//end namespace其实这些实现就是封装一个大的类 如果你想调用其他的大模型 就指定调用哪个类就行了 没必要像测试那样一个个去调用。
13.会话管理:
1.介绍会话:
因为我们要封装一个智能聊天助手 但是现在仅仅只靠这个大模型管理是远远不行的:

我们在最开始的common文件中就封装了这个会话结构
2.会话管理的实现:
下面就是我们需要实现会话的方法内容:

1.头文件的实现:
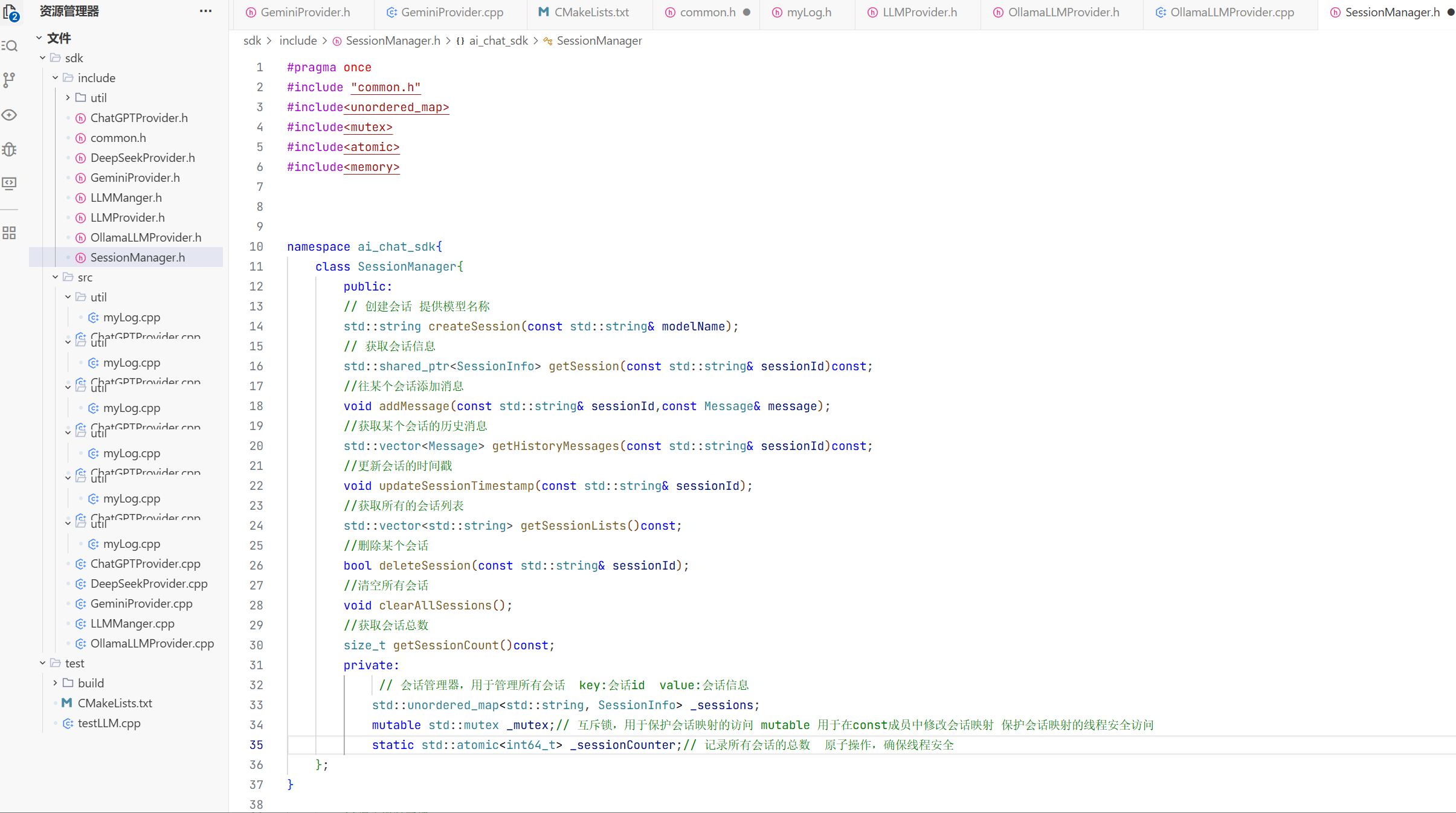
cpp
#pragma once
#include "common.h"
#include<unordered_map>
#include<mutex>
#include<atomic>
#include<memory>
namespace ai_chat_sdk{
class SessionManager{
public:
// 创建会话 提供模型名称
std::string createSession(const std::string& modelName);
// 获取会话信息
std::shared_ptr<SessionInfo> getSession(const std::string& sessionId)const;
//往某个会话添加消息
void addMessage(const std::string& sessionId,const Message& message);
//获取某个会话的历史消息
std::vector<Message> getHistoryMessages(const std::string& sessionId)const;
//更新会话的时间戳
void updateSessionTimestamp(const std::string& sessionId);
//获取所有的会话列表
std::vector<std::string> getSessionLists()const;
//删除某个会话
bool deleteSession(const std::string& sessionId);
//清空所有会话
void clearAllSessions();
//获取会话总数
size_t getSessionCount()const;
private:
std::string generateSessionId();//生成会话id
std::string generateMessageId(size_t messageCounter);//生成消息id 当前会话的消息计数
private:
// 会话管理器,用于管理所有会话 key:会话id value:会话信息
std::unordered_map<std::string, std::shared_ptr<SessionInfo>> _sessions;
mutable std::mutex _mutex;// 互斥锁,用于保护会话映射的访问 mutable 用于在const成员中修改会话映射 保护会话映射的线程安全访问
std::atomic<int64_t> _sessionCounter={0};// 记录所有会话的总数 原子操作,确保线程安全
};
}2.源文件的实现:
1.消息id和会话id的实现:

2.创建会话:

根据这个结构来创建会话

因为考虑到会话可能比较大 我们用智能指针封装 让他在堆上:
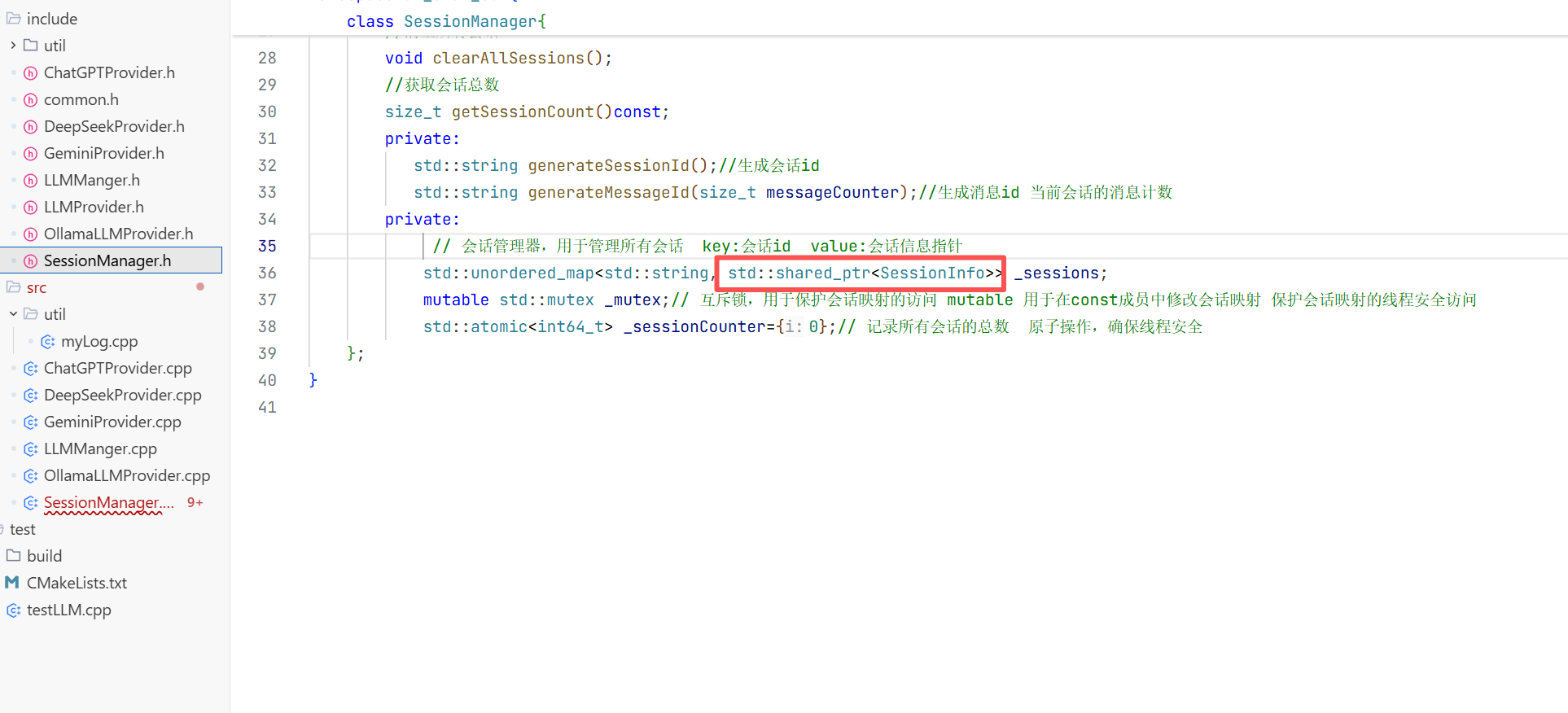
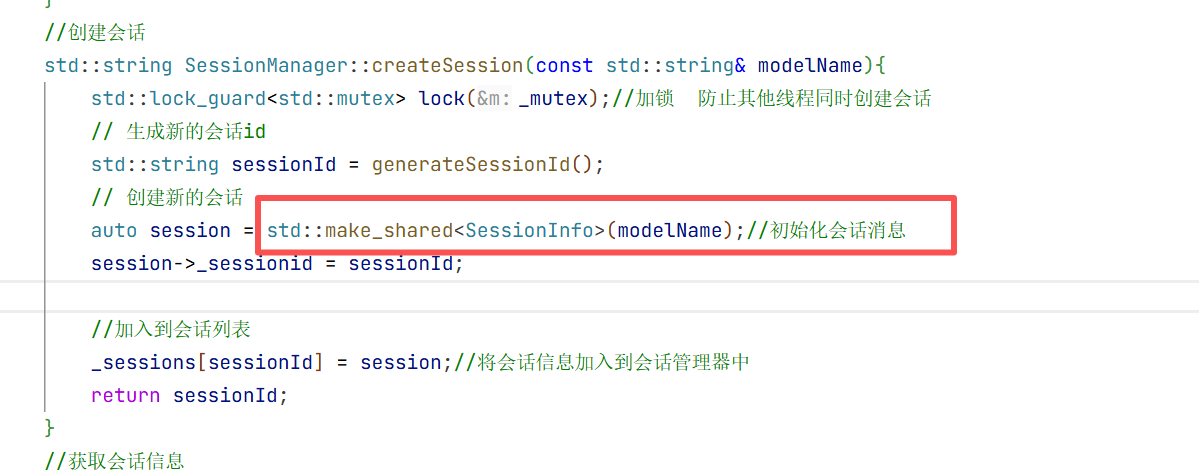
3.往某个会话添加消息:
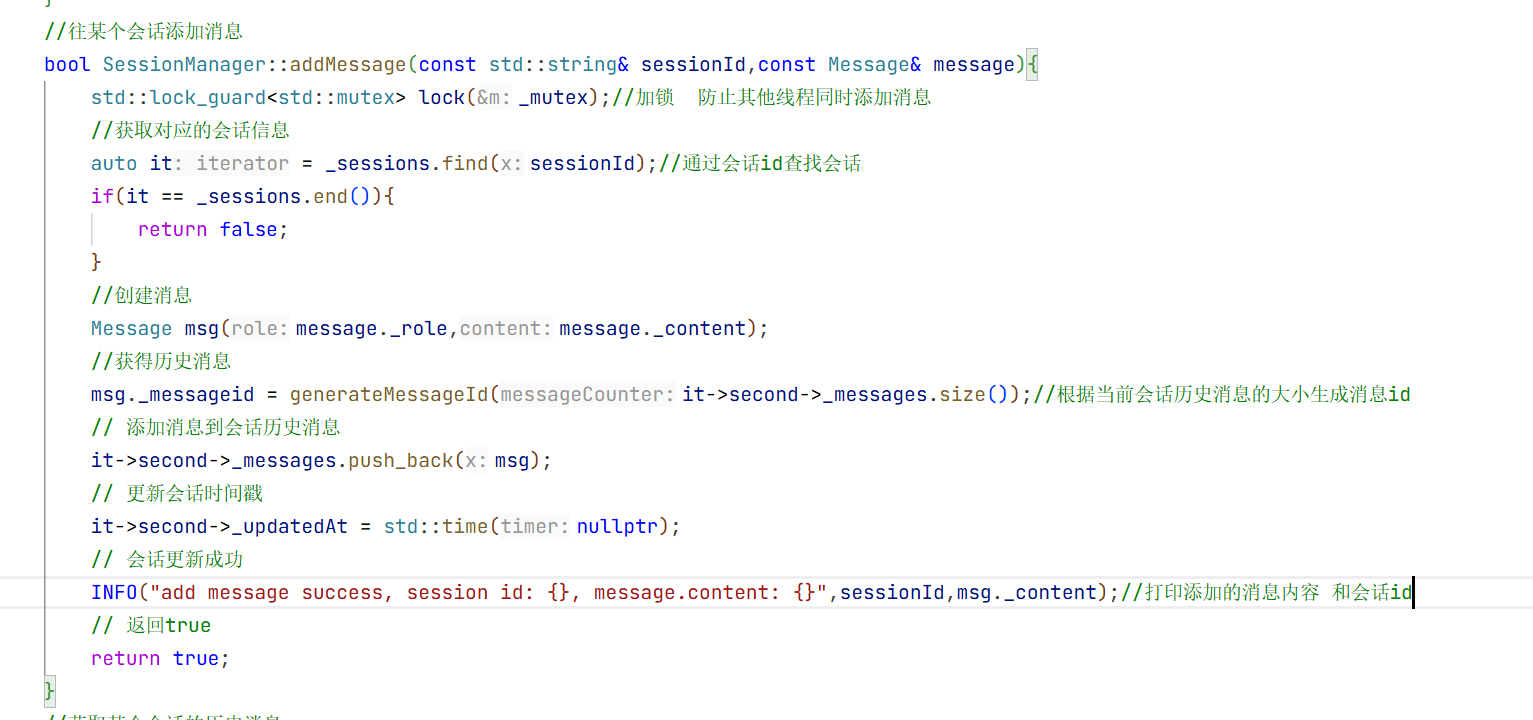
cpp
//往某个会话添加消息
bool SessionManager::addMessage(const std::string& sessionId,const Message& message){
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时添加消息
//获取对应的会话信息
auto it = _sessions.find(sessionId);//通过会话id查找会话
if(it == _sessions.end()){
return false;
}
//创建消息
Message msg(message._role,message._content);
//获得历史消息
msg._messageid = generateMessageId(it->second->_messages.size());//根据当前会话历史消息的大小生成消息id
// 添加消息到会话历史消息
it->second->_messages.push_back(msg);
// 更新会话时间戳
it->second->_updatedAt = std::time(nullptr);
// 会话更新成功
INFO("add message success, session id: {}, message.content: {}",sessionId,msg._content);//打印添加的消息内容 和会话id
// 返回true
return true;
}4.获取某个会话的历史消息:
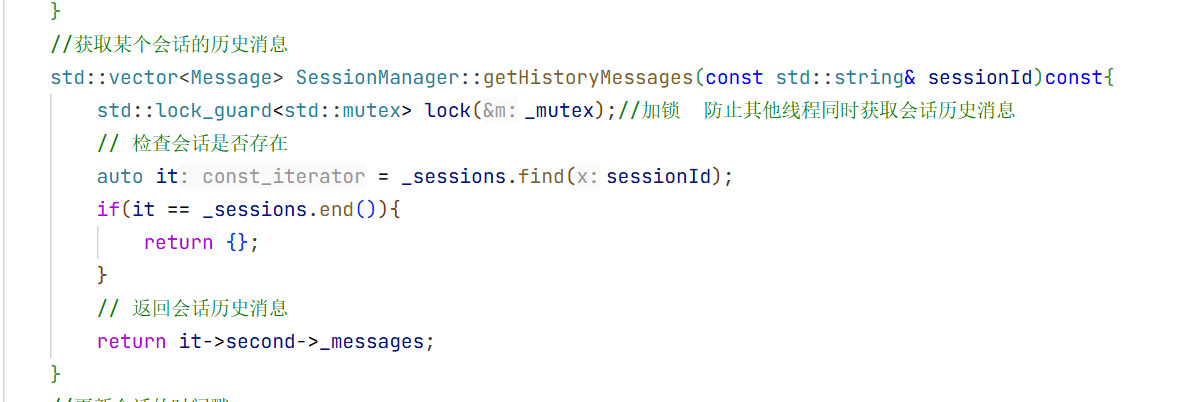
cpp
//获取某个会话的历史消息
std::vector<Message> SessionManager::getHistoryMessages(const std::string& sessionId)const{
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时获取会话历史消息
// 检查会话是否存在
auto it = _sessions.find(sessionId);
if(it == _sessions.end()){
return {};
}
// 返回会话历史消息
return it->second->_messages;
}5.更新会话的时间戳:
cpp
//更新会话的时间戳
void SessionManager::updateSessionTimestamp(const std::string& sessionId){
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时更新会话时间戳
// 检查会话是否存在
auto it = _sessions.find(sessionId);
if(it == _sessions.end()){
ERR("Session {} not found!!!",sessionId);
return;
}
// 更新会话时间戳
it->second->_updatedAt = std::time(nullptr);
// 会话更新成功
INFO("update session timestamp success, session id: {}",sessionId);//打印会话id
}6.获取所有会话的列表:
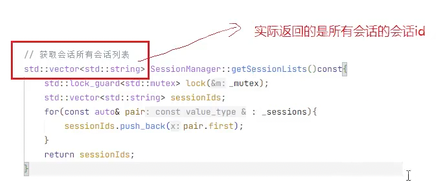
我们用string存储的原因是 其实实际返回的是所有会话的会话id

其实返回指针地址没有用 你返回id 如果不是在同一台电脑使用的话 返回地址没有用
那能否直接把这个会话对象返回呢?

还要注意返回的这些会话id中,最好按照时间戳进行降序排序 拿到最新的会话

cpp
//获取所有的会话列表
std::vector<std::string> SessionManager::getSessionLists()const{
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时获取会话列表
//构建一个临时对话列表,将其内容的会话按照更新的时间降序排序
std::vector<std::pair<std::time_t,std::shared_ptr<SessionInfo>>> temp;//临时会话列表中存储会话时间戳和会话对象
temp.reserve(_sessions.size());//分配内存 避免重复分配内存
//将会话添加到临时会话列表中
for(const auto& pair : _sessions){
temp.emplace_back(pair.second->_updatedAt,pair.second);//将会话时间戳和会话对象添加到临时会话列表中
}
// 对临时会话列表进行排序 auto转化前的类std::pair<std::time_t,std::shared_ptr<SessionInfo>>
std::sort(temp.begin(),temp.end(),[](const auto& a,const auto& b){//利用lambda表达式对临时会话列表进行排序
return a.first > b.first;//按照会话时间戳降序排序
});
std::vector<std::string> sessionIds;//存储排序后的会话id
sessionIds.reserve(_sessions.size());//分配内存 避免重复分配内存
// 提取排序后的会话id
for(const auto& pair : temp){
sessionIds.push_back(pair.second->_sessionid);
}
// 返回排序后的会话id
return sessionIds;
}7.其他功能的实现:
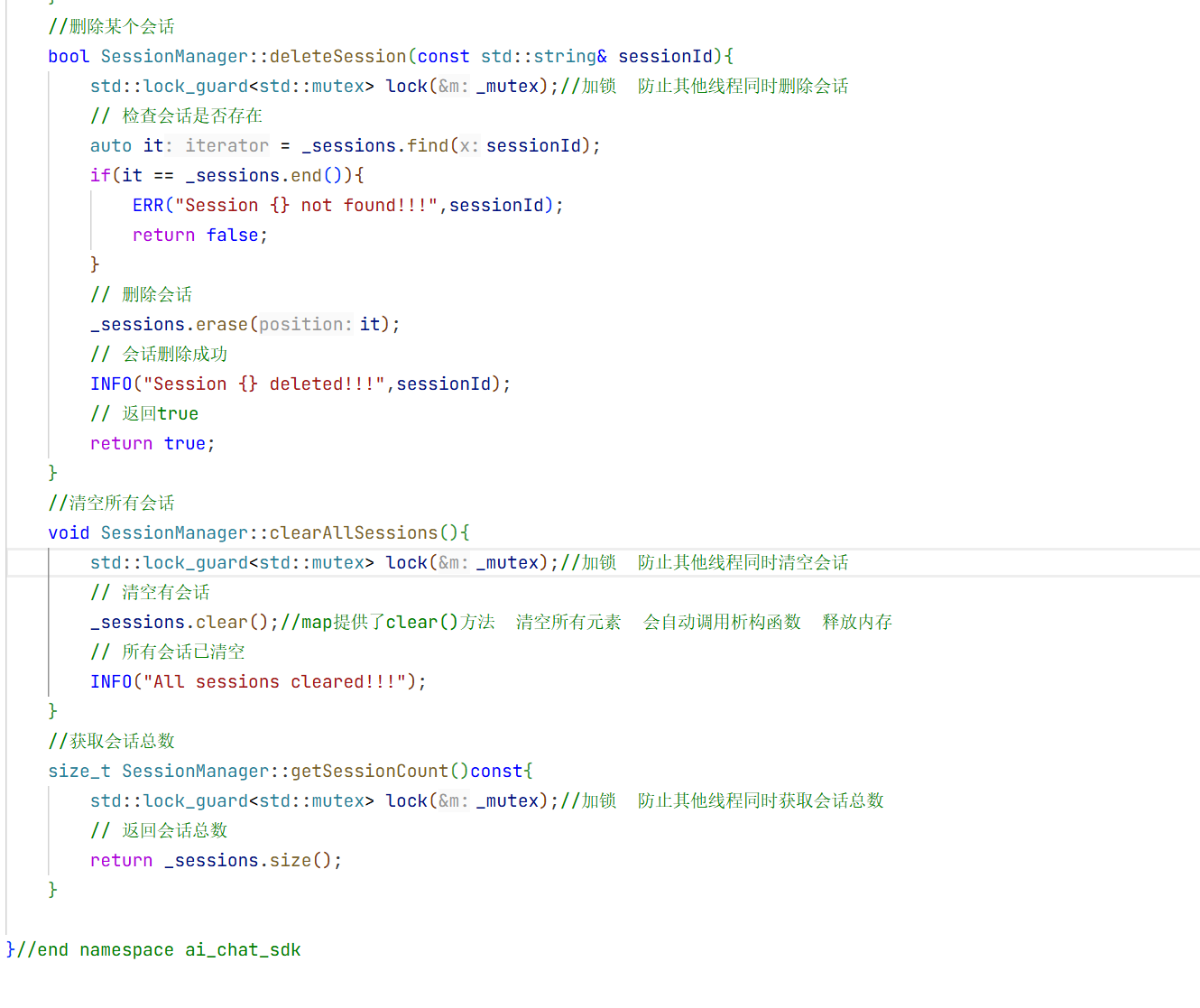
8.整个代码预览:
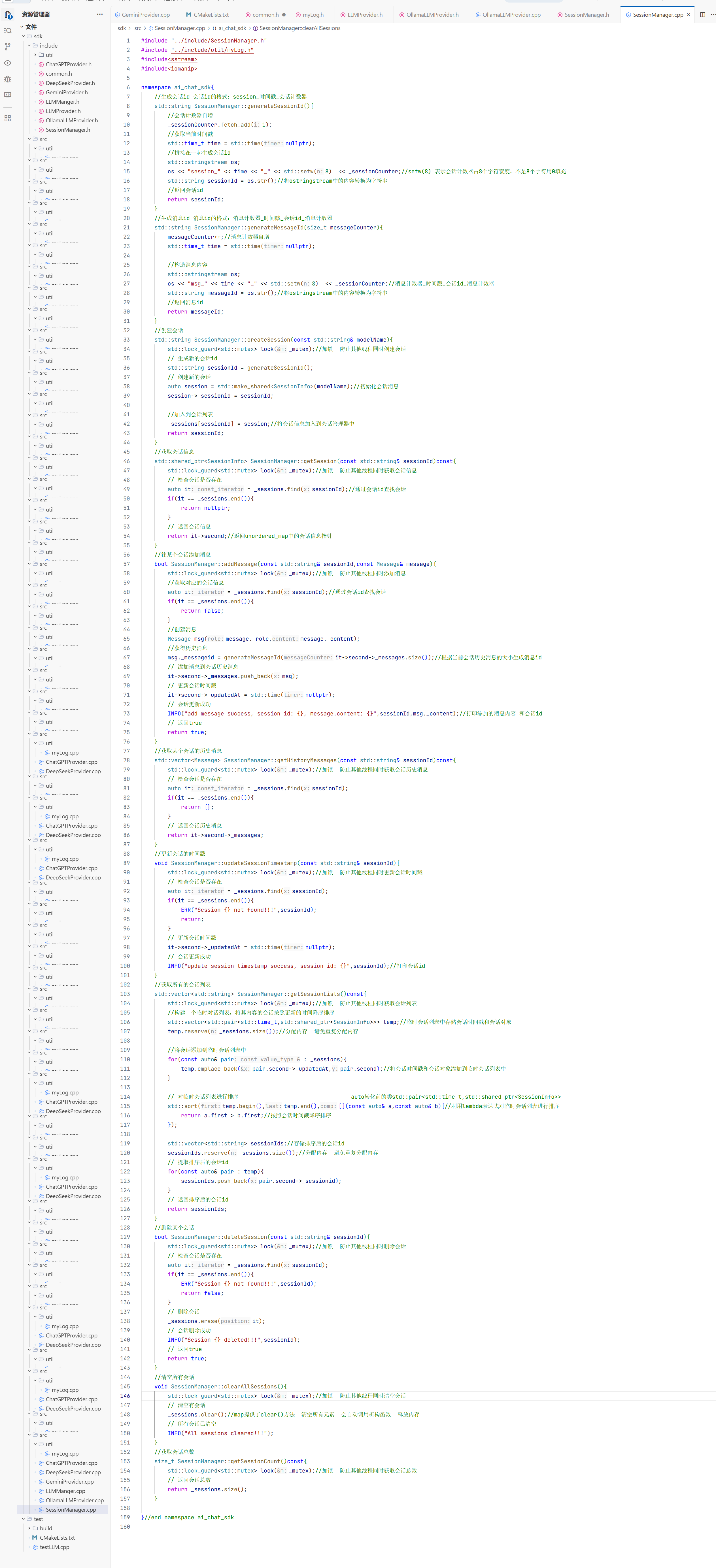
cpp
#include "../include/SessionManager.h"
#include "../include/util/myLog.h"
#include<sstream>
#include<iomanip>
namespace ai_chat_sdk{
//生成会话id 会话id的格式:session_时间戳_会话计数器
std::string SessionManager::generateSessionId(){
//会话计数器自增
_sessionCounter.fetch_add(1);
//获取当前时间戳
std::time_t time = std::time(nullptr);
//拼接在一起生成会话id
std::ostringstream os;
os << "session_" << time << "_" << std::setw(8) << _sessionCounter;//setw(8) 表示会话计数器占8个字符宽度,不足8个字符用0填充
std::string sessionId = os.str();//将ostringstream中的内容转换为字符串
//返回会话id
return sessionId;
}
//生成消息id 消息id的格式:消息计数器_时间戳_会话id_消息计数器
std::string SessionManager::generateMessageId(size_t messageCounter){
messageCounter++;//消息计数器自增
std::time_t time = std::time(nullptr);
//构造消息内容
std::ostringstream os;
os << "msg_" << time << "_" << std::setw(8) << _sessionCounter;//消息计数器_时间戳_会话id_消息计数器
std::string messageId = os.str();//将ostringstream中的内容转换为字符串
//返回消息id
return messageId;
}
//创建会话
std::string SessionManager::createSession(const std::string& modelName){
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时创建会话
// 生成新的会话id
std::string sessionId = generateSessionId();
// 创建新的会话
auto session = std::make_shared<SessionInfo>(modelName);//初始化会话消息
session->_sessionid = sessionId;
//加入到会话列表
_sessions[sessionId] = session;//将会话信息加入到会话管理器中
return sessionId;
}
//获取会话信息
std::shared_ptr<SessionInfo> SessionManager::getSession(const std::string& sessionId)const{
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时获取会话信息
// 检查会话是否存在
auto it = _sessions.find(sessionId);//通过会话id查找会话
if(it == _sessions.end()){
return nullptr;
}
// 返回会话信息
return it->second;//返回unordered_map中的会话信息指针
}
//往某个会话添加消息
bool SessionManager::addMessage(const std::string& sessionId,const Message& message){
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时添加消息
//获取对应的会话信息
auto it = _sessions.find(sessionId);//通过会话id查找会话
if(it == _sessions.end()){
return false;
}
//创建消息
Message msg(message._role,message._content);
//获得历史消息
msg._messageid = generateMessageId(it->second->_messages.size());//根据当前会话历史消息的大小生成消息id
// 添加消息到会话历史消息
it->second->_messages.push_back(msg);
// 更新会话时间戳
it->second->_updatedAt = std::time(nullptr);
// 会话更新成功
INFO("add message success, session id: {}, message.content: {}",sessionId,msg._content);//打印添加的消息内容 和会话id
// 返回true
return true;
}
//获取某个会话的历史消息
std::vector<Message> SessionManager::getHistoryMessages(const std::string& sessionId)const{
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时获取会话历史消息
// 检查会话是否存在
auto it = _sessions.find(sessionId);
if(it == _sessions.end()){
return {};
}
// 返回会话历史消息
return it->second->_messages;
}
//更新会话的时间戳
void SessionManager::updateSessionTimestamp(const std::string& sessionId){
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时更新会话时间戳
// 检查会话是否存在
auto it = _sessions.find(sessionId);
if(it == _sessions.end()){
ERR("Session {} not found!!!",sessionId);
return;
}
// 更新会话时间戳
it->second->_updatedAt = std::time(nullptr);
// 会话更新成功
INFO("update session timestamp success, session id: {}",sessionId);//打印会话id
}
//获取所有的会话列表
std::vector<std::string> SessionManager::getSessionLists()const{
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时获取会话列表
//构建一个临时对话列表,将其内容的会话按照更新的时间降序排序
std::vector<std::pair<std::time_t,std::shared_ptr<SessionInfo>>> temp;//临时会话列表中存储会话时间戳和会话对象
temp.reserve(_sessions.size());//分配内存 避免重复分配内存
//将会话添加到临时会话列表中
for(const auto& pair : _sessions){
temp.emplace_back(pair.second->_updatedAt,pair.second);//将会话时间戳和会话对象添加到临时会话列表中
}
// 对临时会话列表进行排序 auto转化前的类std::pair<std::time_t,std::shared_ptr<SessionInfo>>
std::sort(temp.begin(),temp.end(),[](const auto& a,const auto& b){//利用lambda表达式对临时会话列表进行排序
return a.first > b.first;//按照会话时间戳降序排序
});
std::vector<std::string> sessionIds;//存储排序后的会话id
sessionIds.reserve(_sessions.size());//分配内存 避免重复分配内存
// 提取排序后的会话id
for(const auto& pair : temp){
sessionIds.push_back(pair.second->_sessionid);
}
// 返回排序后的会话id
return sessionIds;
}
//删除某个会话
bool SessionManager::deleteSession(const std::string& sessionId){
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时删除会话
// 检查会话是否存在
auto it = _sessions.find(sessionId);
if(it == _sessions.end()){
ERR("Session {} not found!!!",sessionId);
return false;
}
// 删除会话
_sessions.erase(it);
// 会话删除成功
INFO("Session {} deleted!!!",sessionId);
// 返回true
return true;
}
//清空所有会话
void SessionManager::clearAllSessions(){
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时清空会话
// 清空有会话
_sessions.clear();//map提供了clear()方法 清空所有元素 会自动调用析构函数 释放内存
// 所有会话已清空
INFO("All sessions cleared!!!");
}
//获取会话总数
size_t SessionManager::getSessionCount()const{
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时获取会话总数
// 返回会话总数
return _sessions.size();
}
}//end namespace ai_chat_sdk14 sqlite:
上面封装好了模型管理文件后 如果不封装数据库 这些信息就存储在内存当中 而当年一旦关机重启 这些会话信息就找不到了 所以我们要将这些会话信息放入到数据库中。

我们这里使用sqlite即可 不需要mysql这种支持高并发的库 这个项目没有这么大的项目逻辑,只需要一个轻量化的数据库即可。
保姆级使用教程:SQLite 数据类型 | 菜鸟教程


安装完成后 就可以在终端执行了 这个跟mysql是差不多的支持标准的sql语句
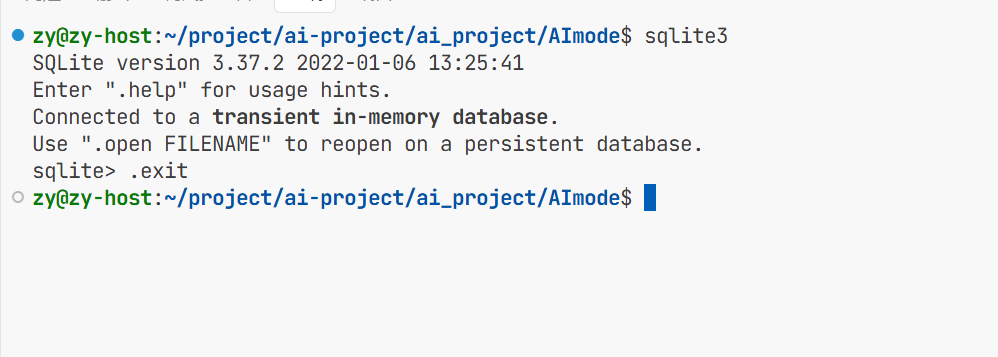
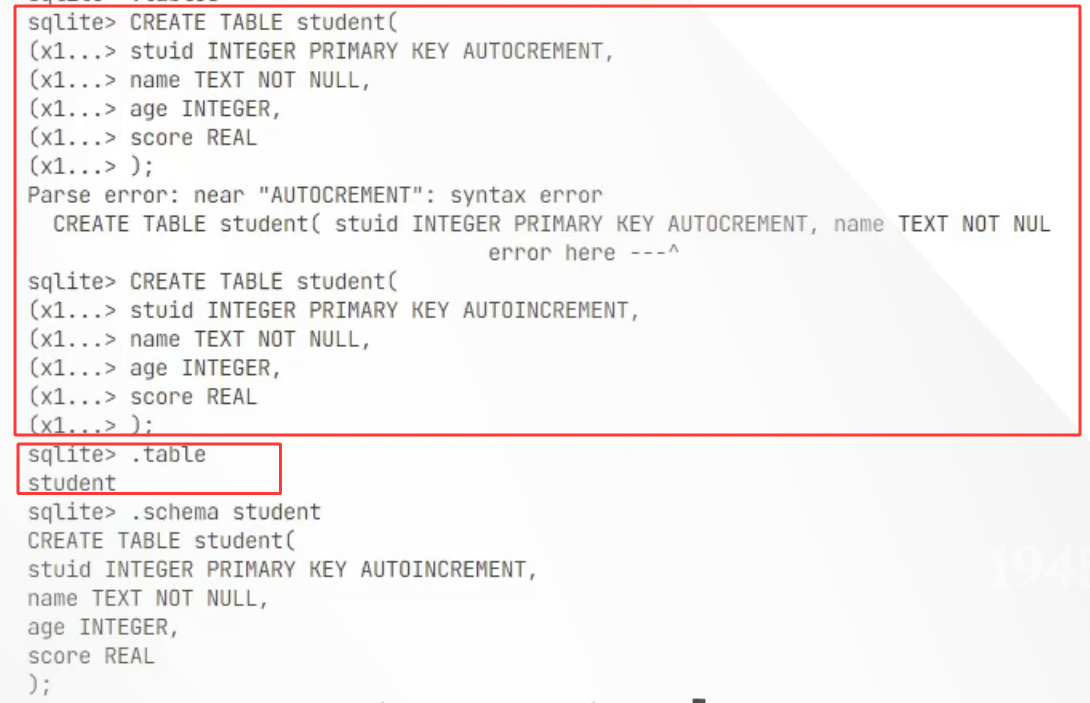
上面是命令行的操作方式

代码连接库的方式 上面是编译时连接静态库 第二个通过修改CMake文件来添加连接方式
详细介绍 可转到菜鸟教程
15.数据管理的实现:
我们要创建两个表来存储会话和消息的信息
1.头文件的编写:
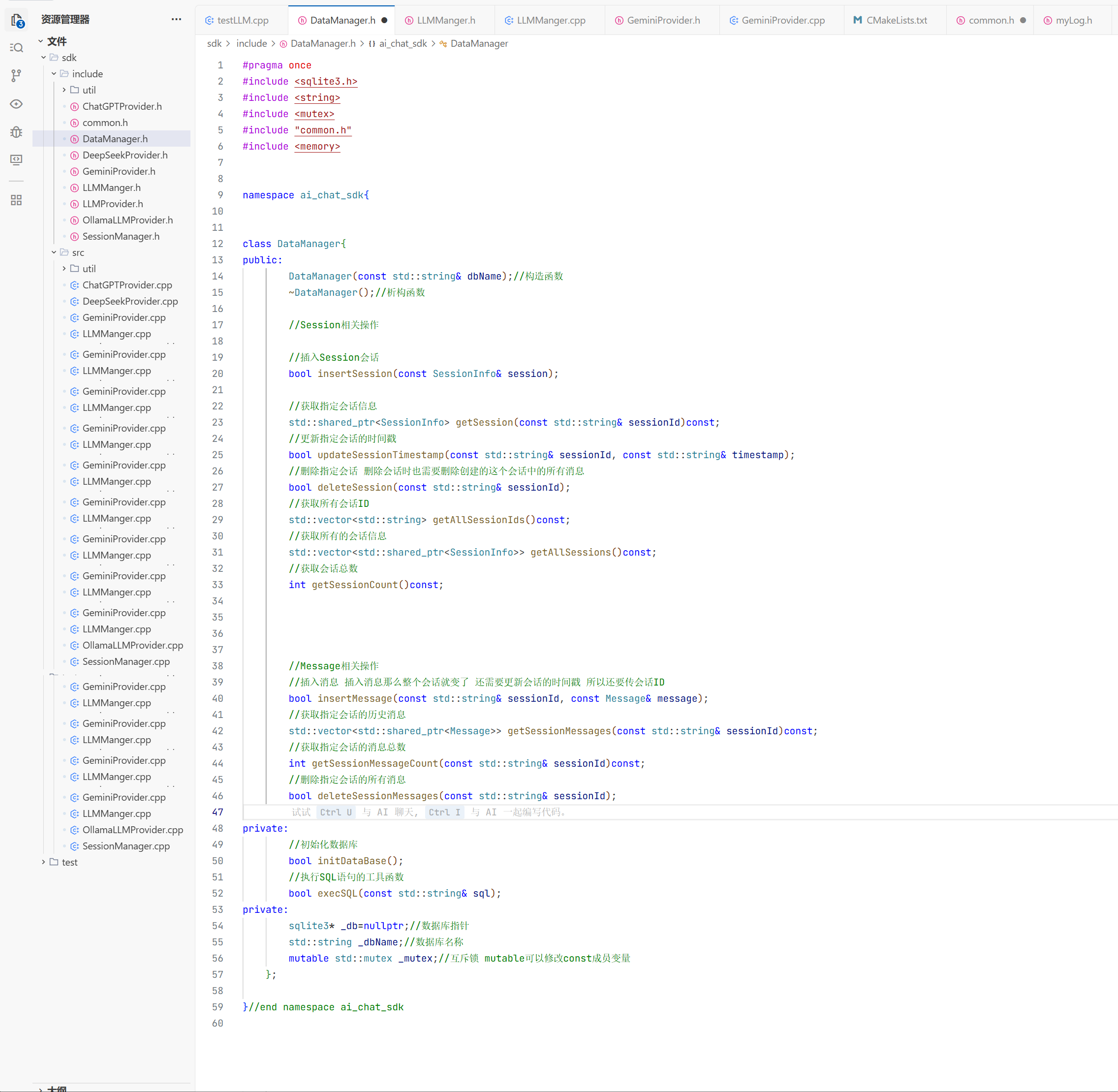
cpp
#pragma once
#include <sqlite3.h>
#include <string>
#include <mutex>
#include "common.h"
#include <memory>
namespace ai_chat_sdk{
class DataManager{
public:
DataManager(const std::string& dbName);//构造函数
~DataManager();//析构函数
//Session相关操作
//插入Session会话
bool insertSession(const SessionInfo& session);
//获取指定会话信息
std::shared_ptr<SessionInfo> getSession(const std::string& sessionId)const;
//更新指定会话的时间戳
bool updateSessionTimestamp(const std::string& sessionId, const std::string& timestamp);
//删除指定会话 删除会话时也需要删除创建的这个会话中的所有消息
bool deleteSession(const std::string& sessionId);
//获取所有会话ID
std::vector<std::string> getAllSessionIds()const;
//获取所有的会话信息
std::vector<std::shared_ptr<SessionInfo>> getAllSessions()const;
//获取会话总数
int getSessionCount()const;
//Message相关操作
//插入消息 插入消息那么整个会话就变了 还需要更新会话的时间戳 所以还要传会话ID
bool insertMessage(const std::string& sessionId, const Message& message);
//获取指定会话的历史消息
std::vector<std::shared_ptr<Message>> getSessionMessages(const std::string& sessionId)const;
//获取指定会话的消息总数
int getSessionMessageCount(const std::string& sessionId)const;
//删除指定会话的所有消息
bool deleteSessionMessages(const std::string& sessionId);
private:
//初始化数据库
bool initDataBase();
//执行SQL语句的工具函数
bool execSQL(const std::string& sql);
private:
sqlite3* _db=nullptr;//数据库指针
std::string _dbName;//数据库名称
mutable std::mutex _mutex;//互斥锁 mutable可以修改const成员变量
};
}//end namespace ai_chat_sdk2.源文件的编写:
1.构造函数和析构函数:
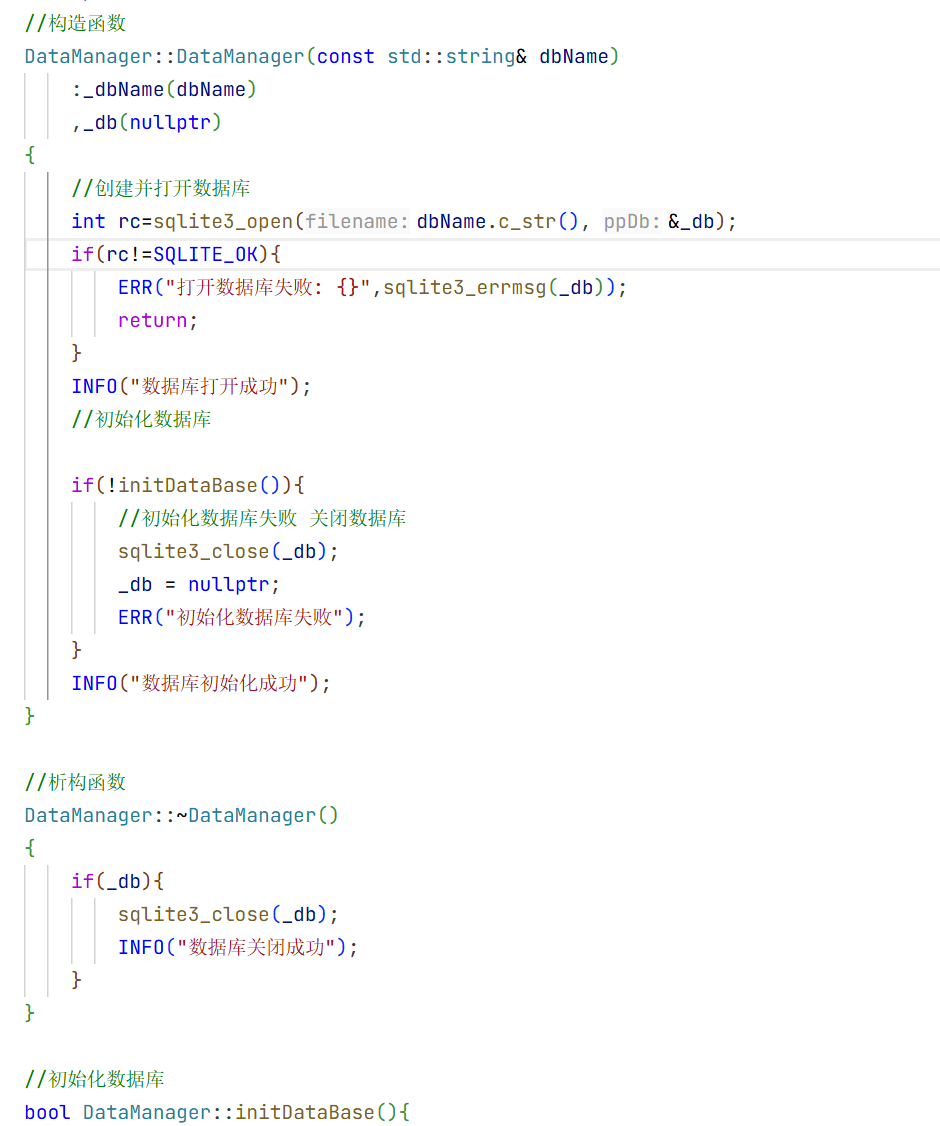
2.初始化数据库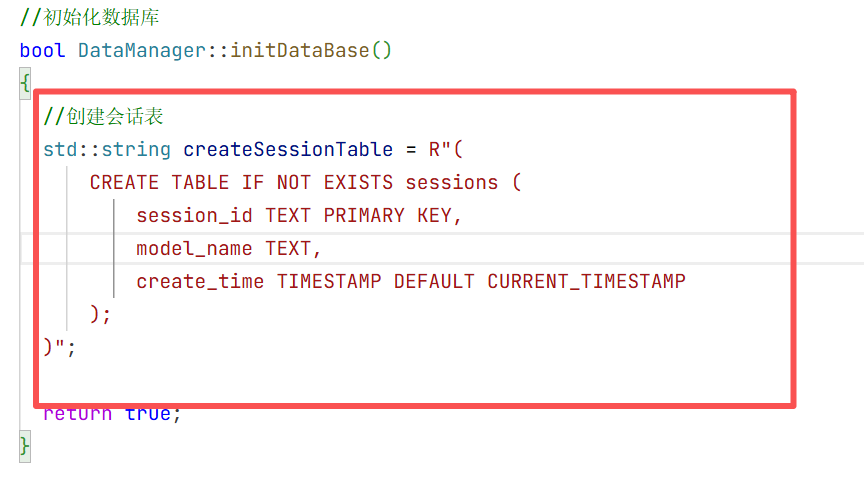
创建会话表时要根据定义的会话格式来进行创建
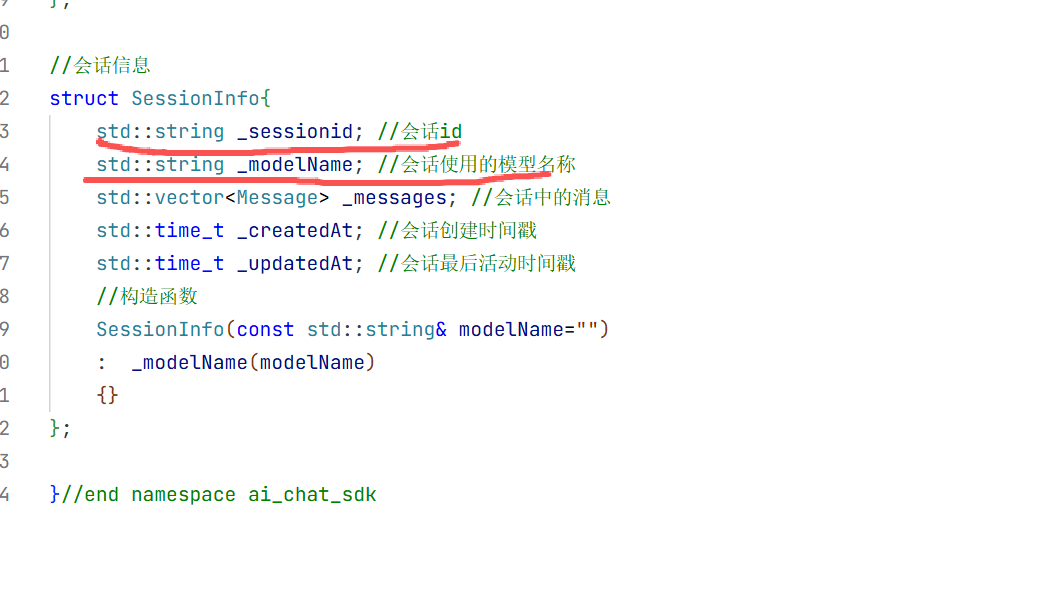
消息列表我们要单独存放另一张表上的。
会话列表的创建
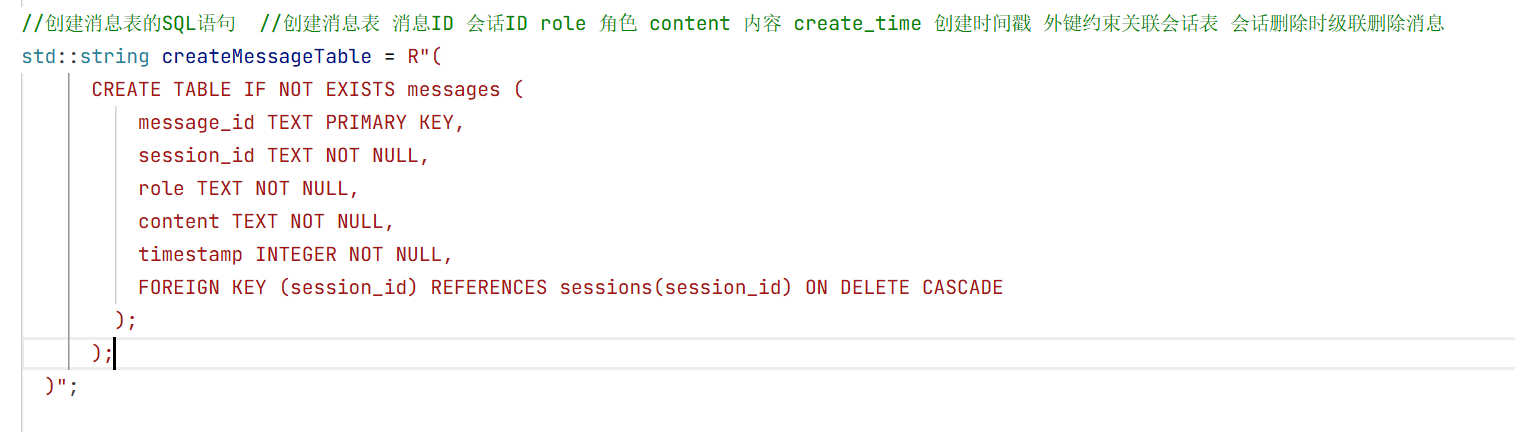

根据创建的结构体来进行建表只是多了以一个会话id这样好和会话列表连接在一起
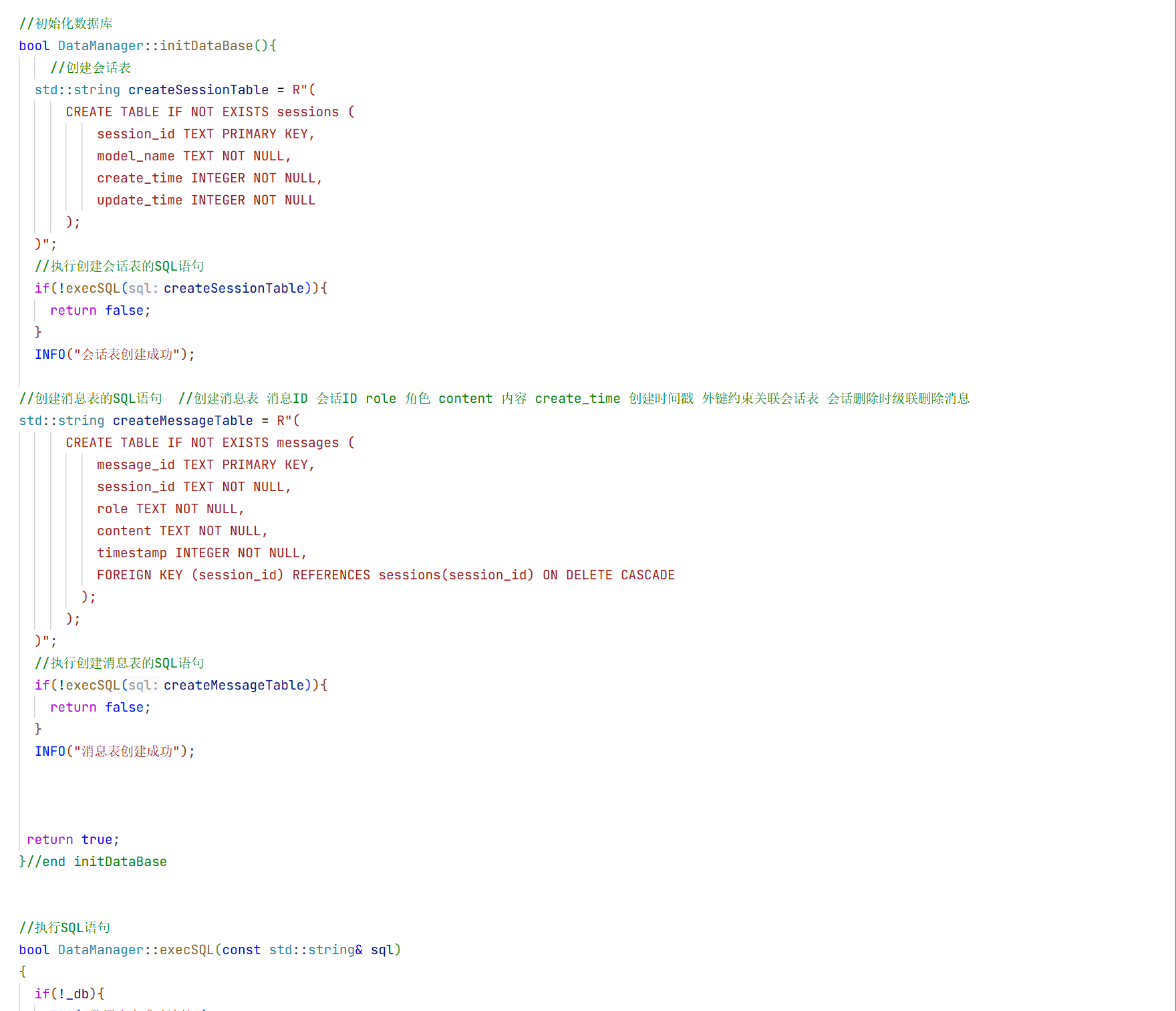
3.执行sql语句的函数编写:
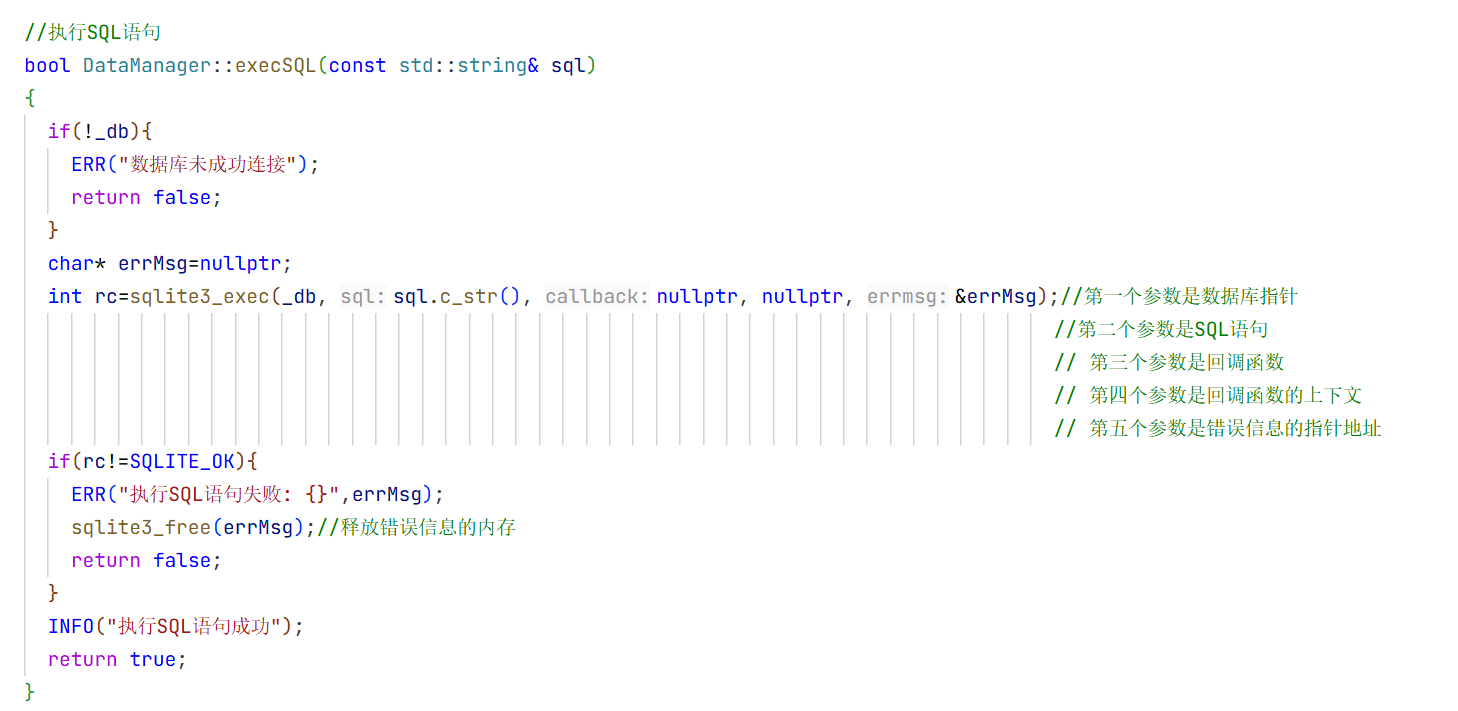
3.会话部分的函数功能实现
1.插入会话的实现:

这????就是占位符的意思填的时候就根据上面的格式来的
2.获取指定会话信息的实现:

reinterpret_cast将sqlite3_column_text返回的const char*转换为std::string的构造函数
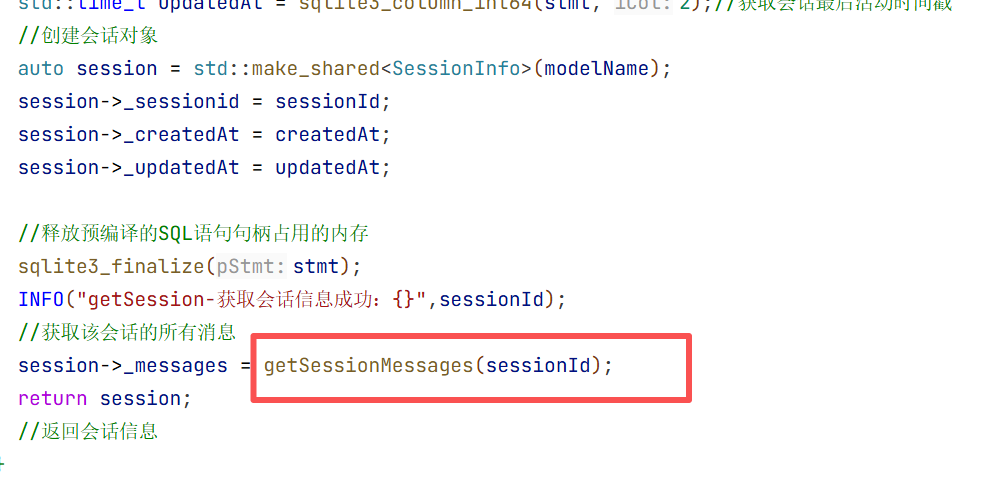
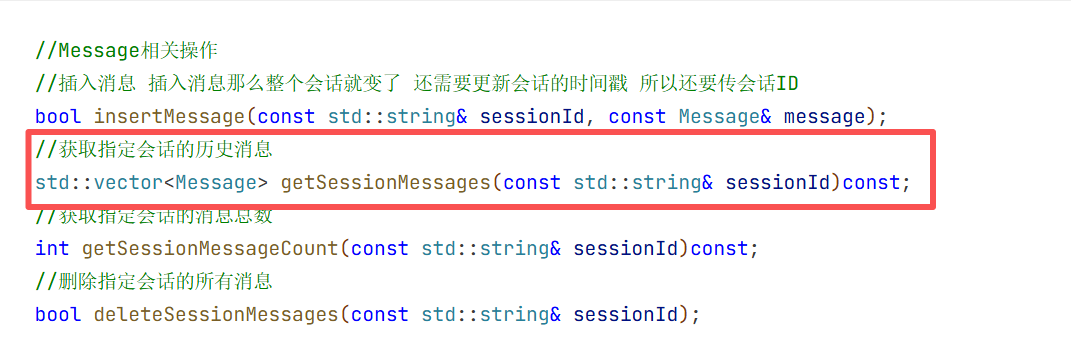
这里取去调用了消息相关操作的获取指定会话的历史消息的这个函数 因为本函数一开始已经加锁了所有要注意在是实现这个getSessionMessages时不能加锁 不然就死锁了。
3.更新会话的时间戳的实现:

4.删除指定会话:
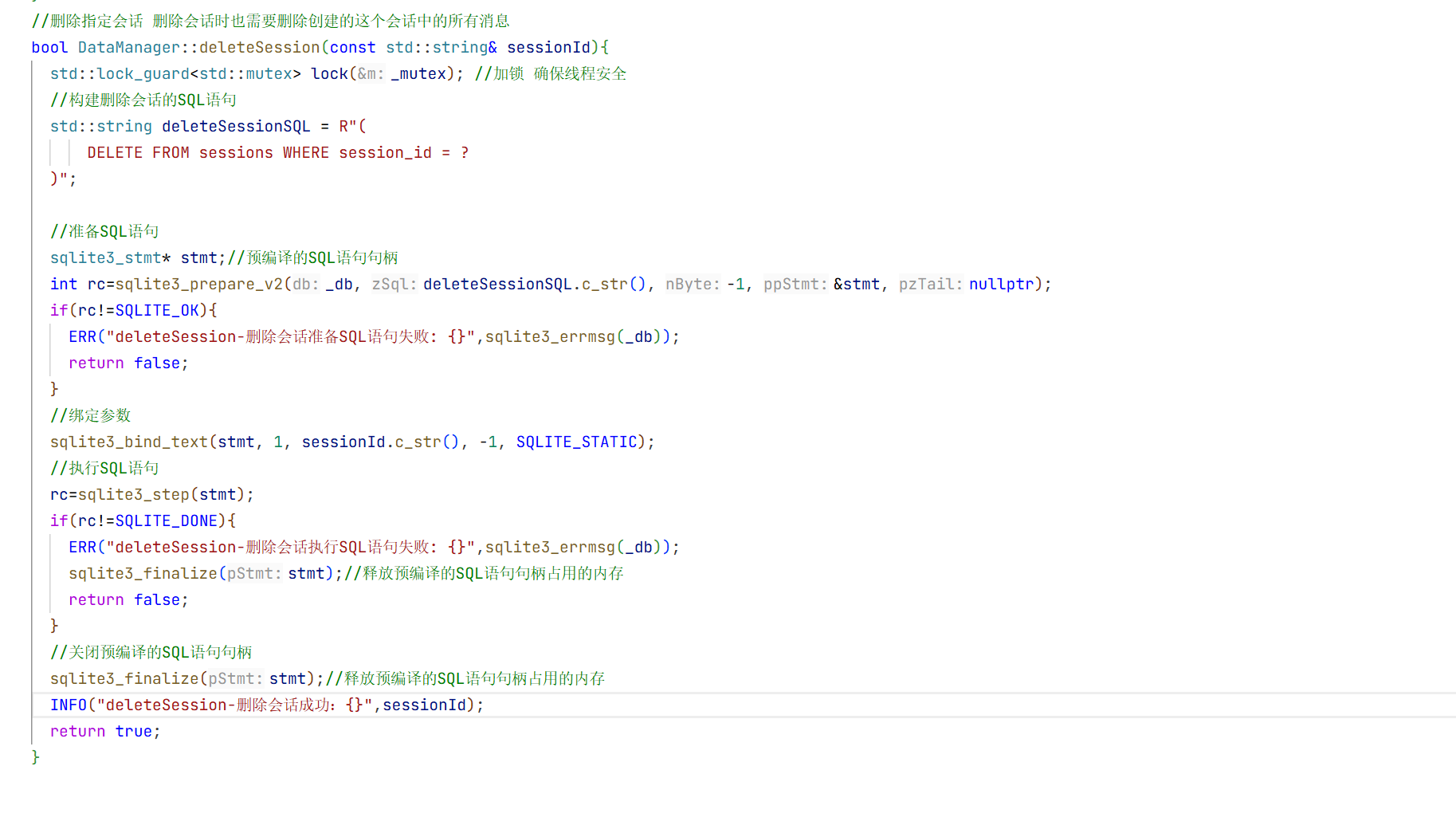
5.获取所有会话ID
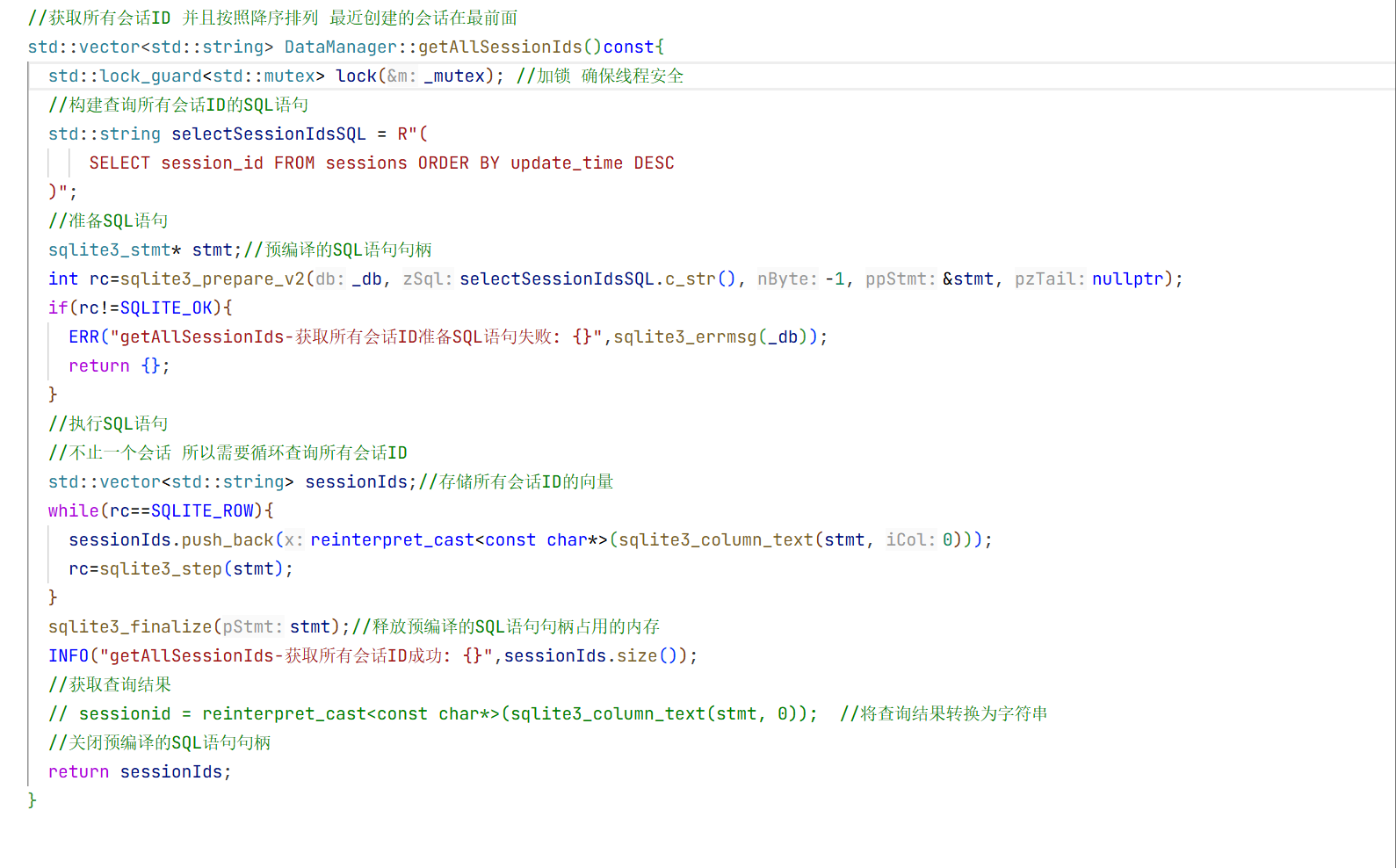
6.获取所有会话信息:
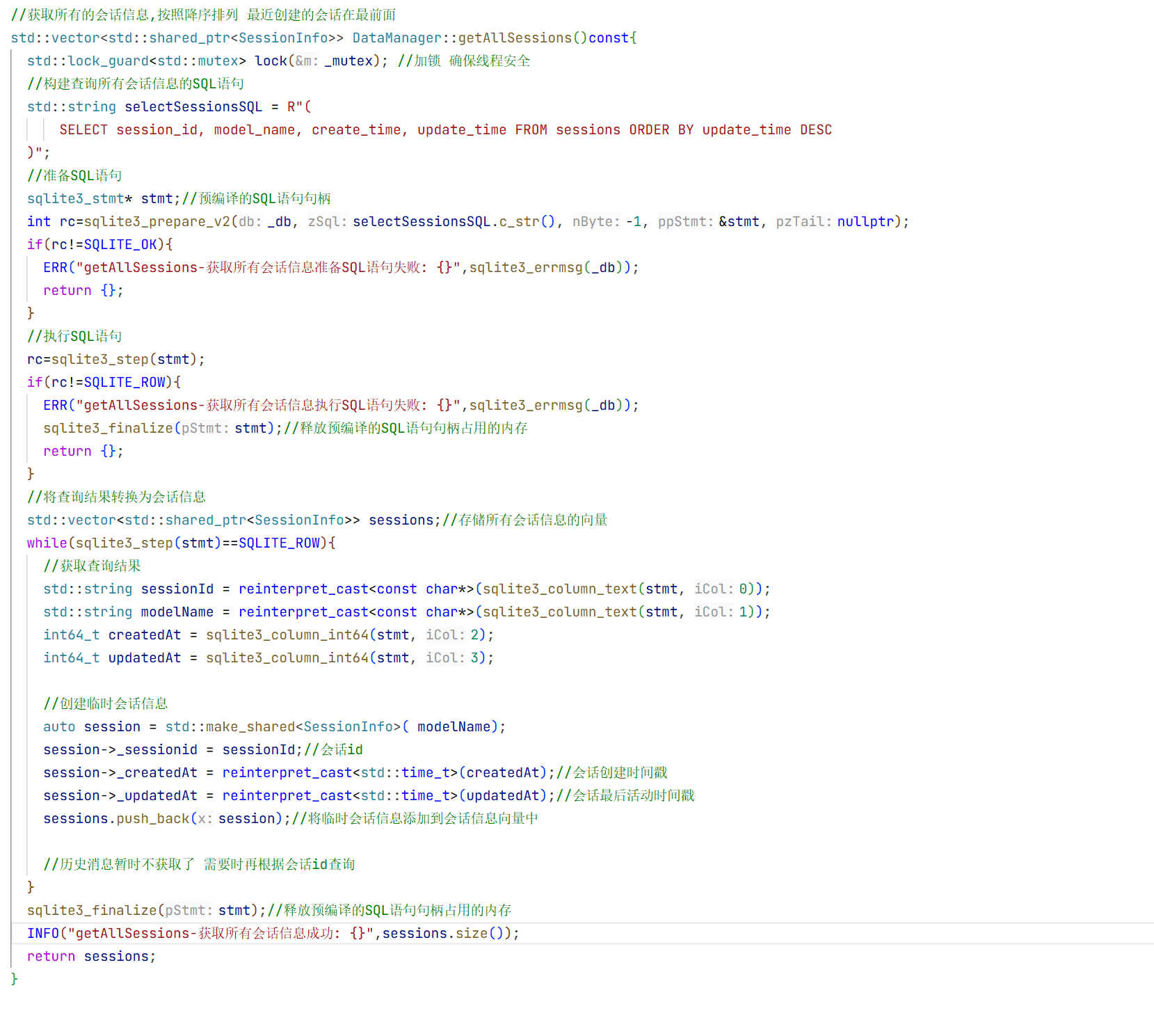
7.获取会话总数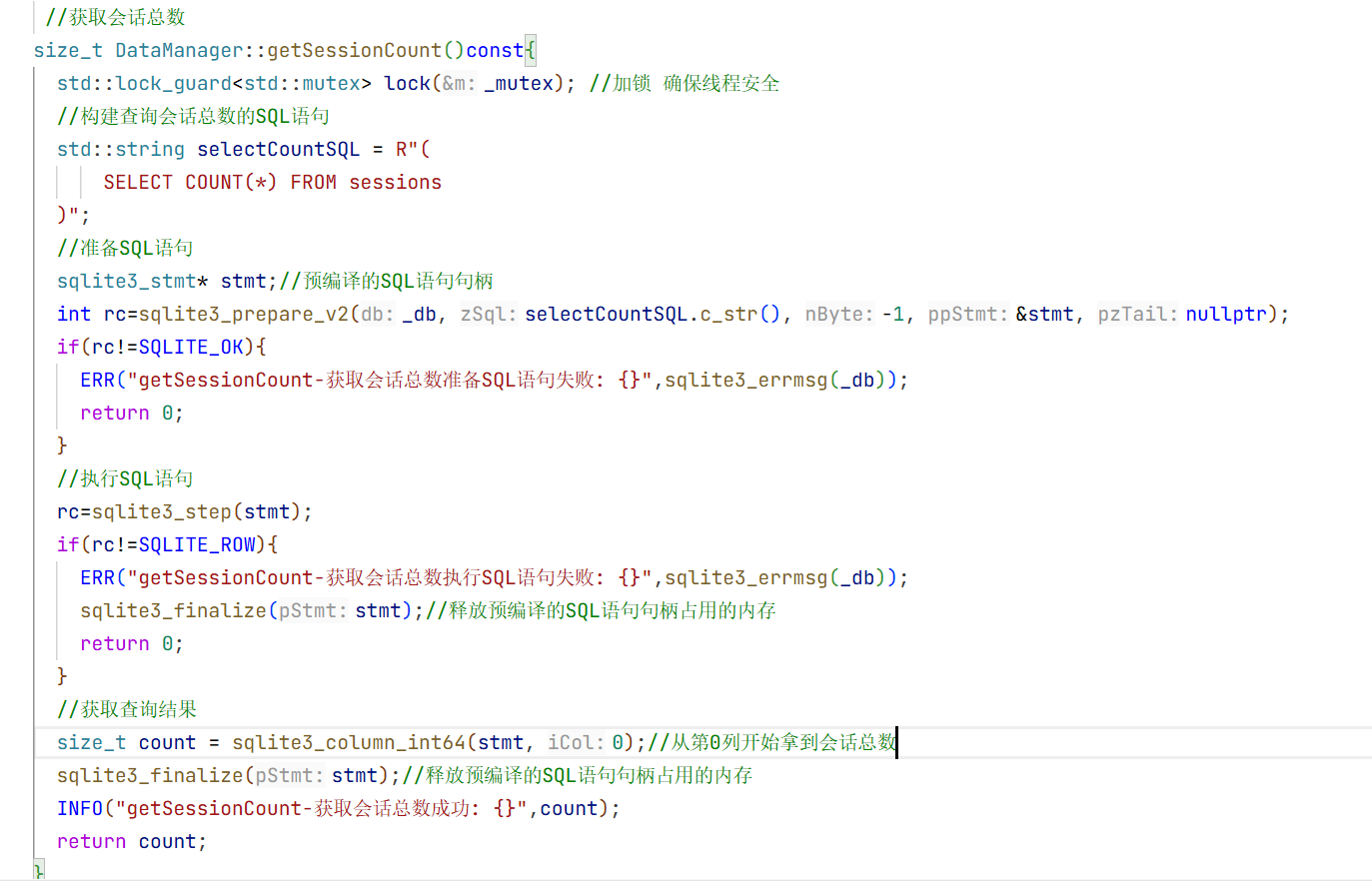
4.消息部分的函数功能实现:
1.插入新消息的实现:
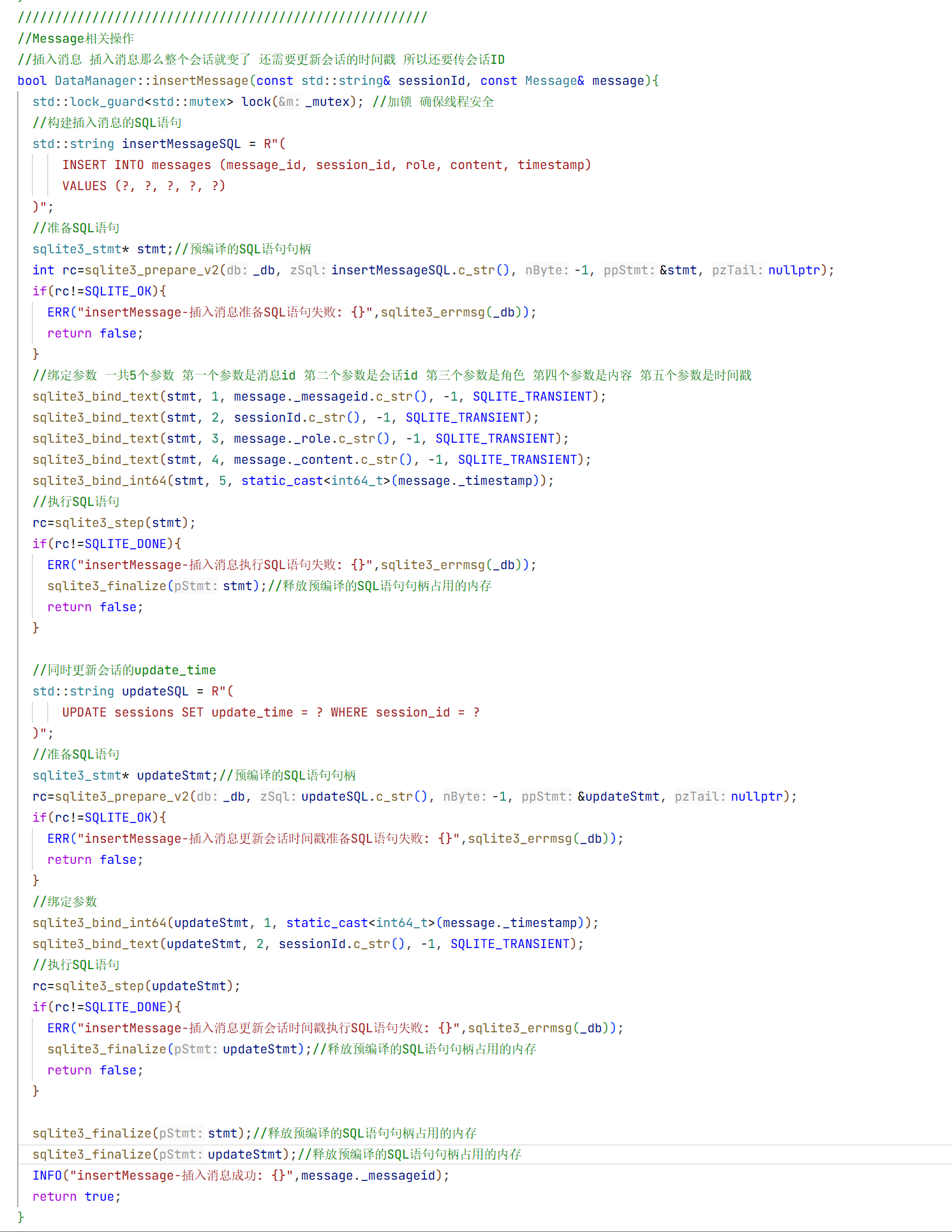
2.获取指定会话的历史消息
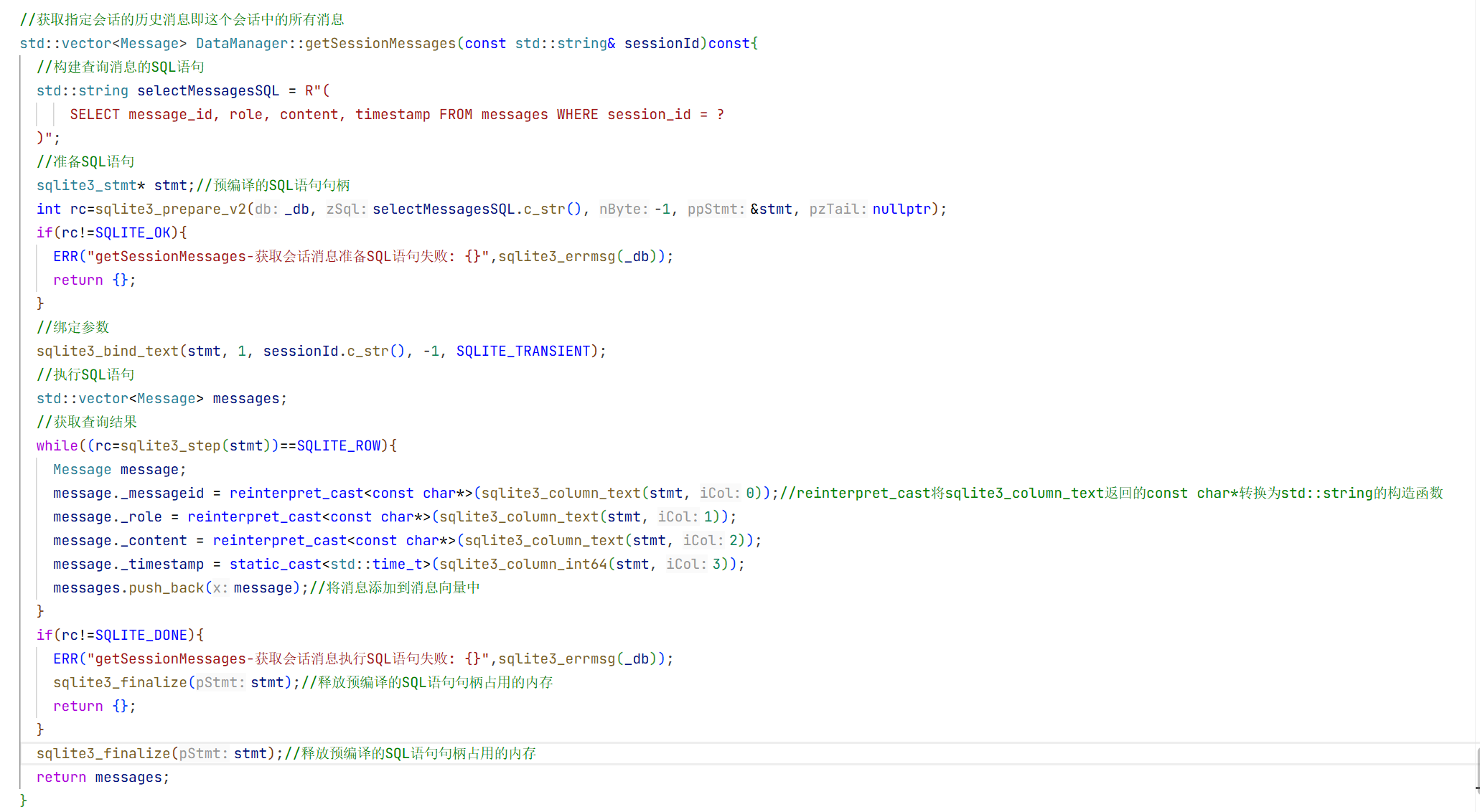
3.删除指定会话的所有消息的实现:
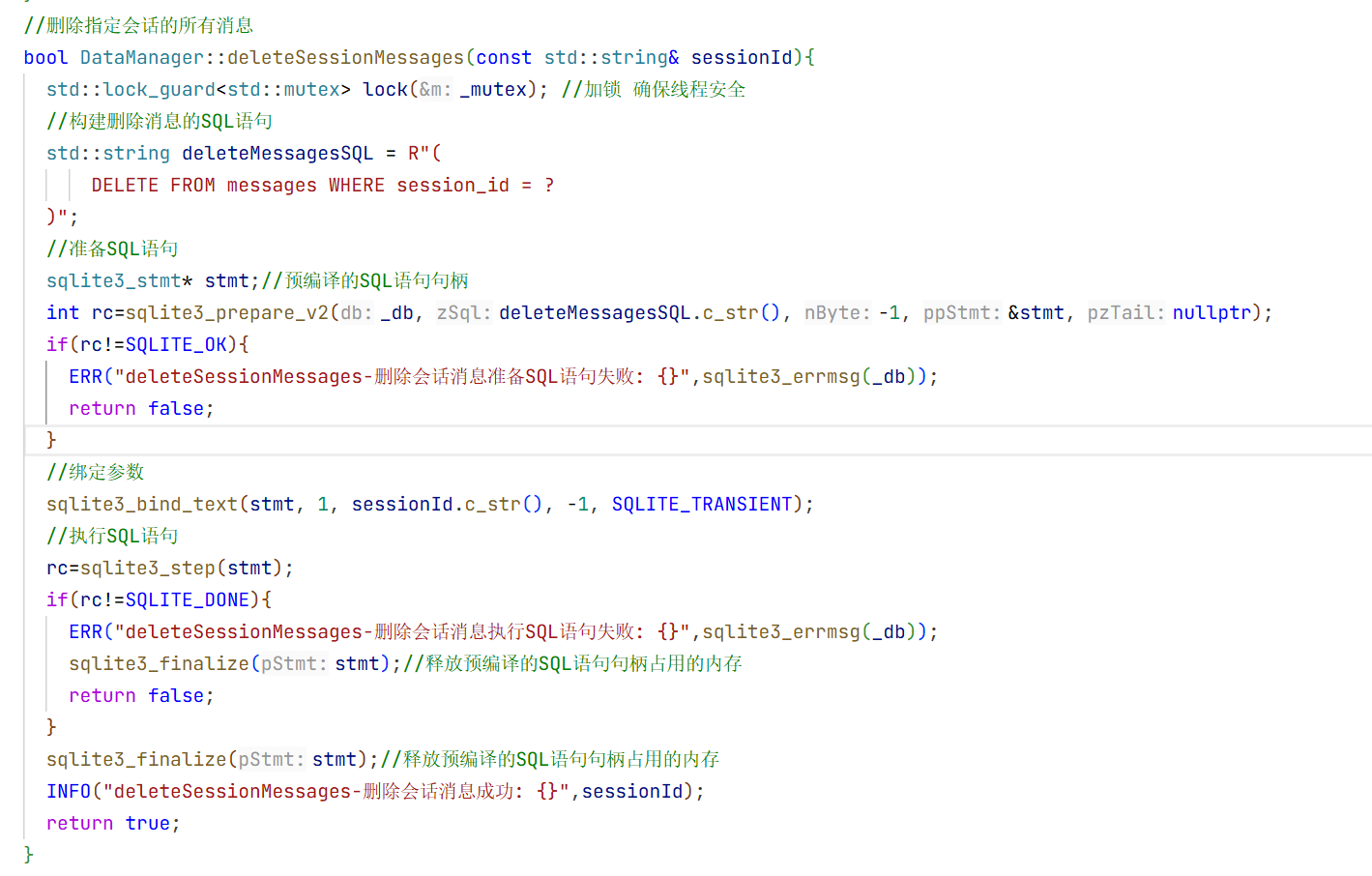
16.会话管理和数据管理相结合:
接着往下走的话还需要把会话管理和数据管理结合起来 我们需要把会话管理的数据放到数据去。
这样的话我们就可以跟大模型开启多轮聊天了,每次聊天就相当于会话的开始。
这里数据管理和会话管理是分开的,我们需要把他关联起来。当你的会话一更新你的数据库就得更新。
我们需要把会话管理中加上一个数据管理的对象
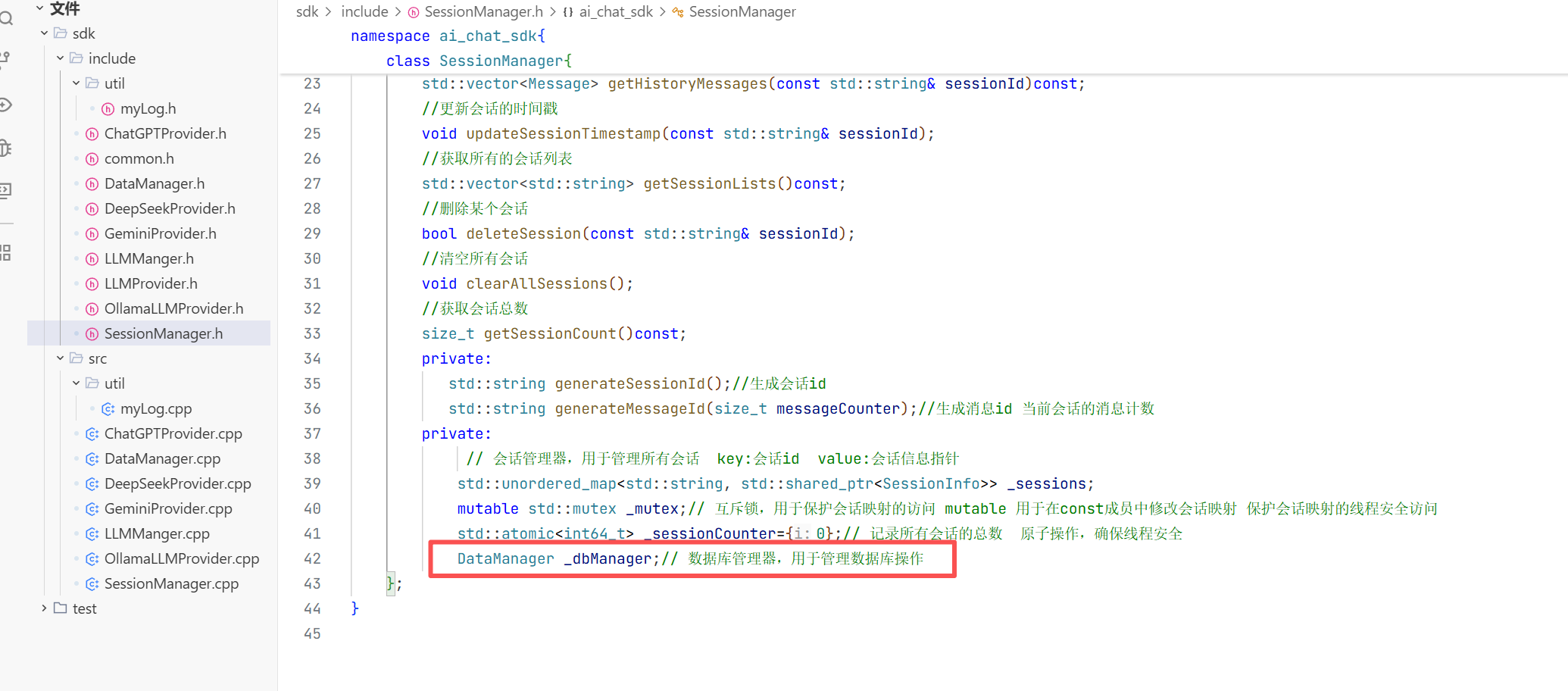
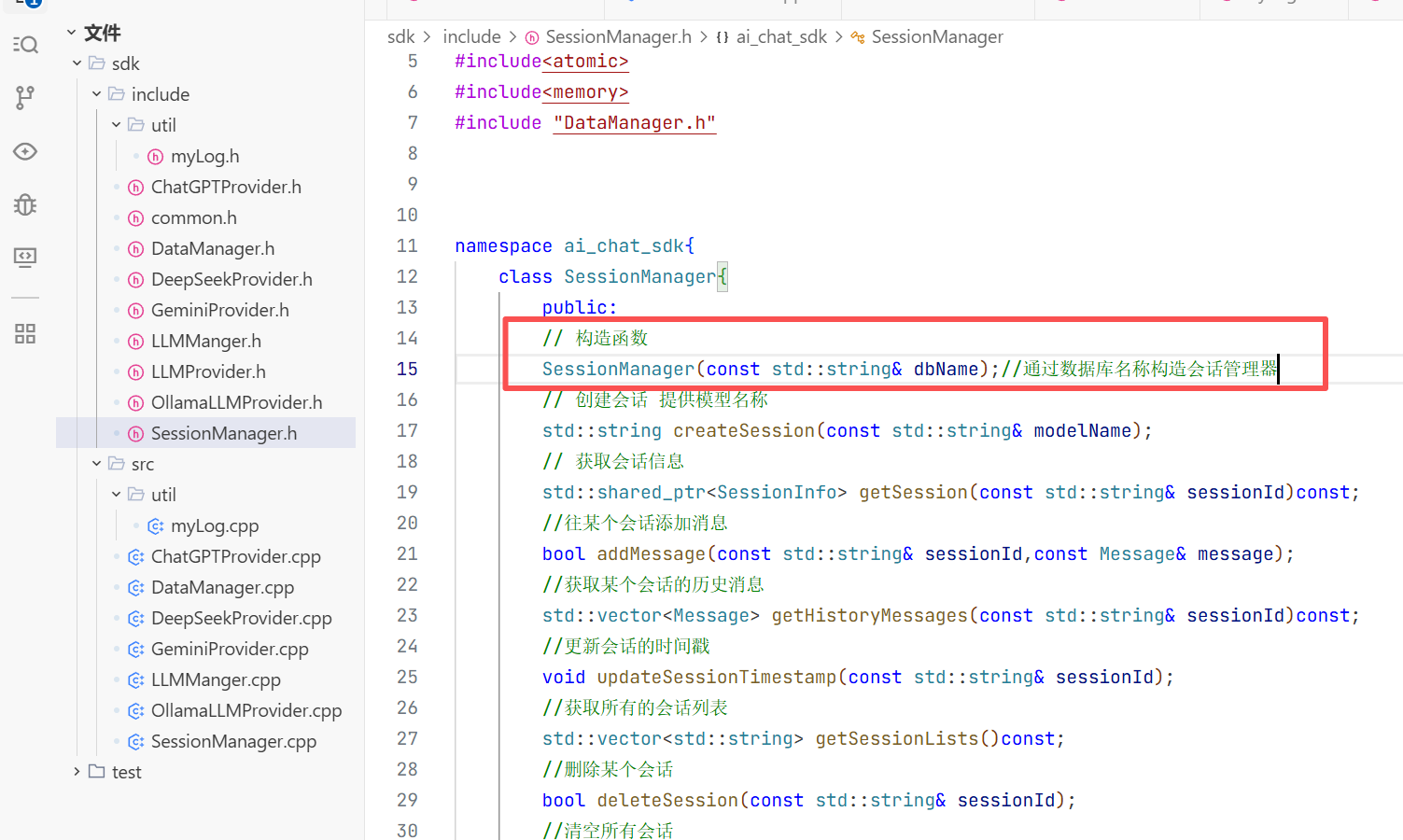
再加上用数据库名称构造会话管理器。
这里析构我们让编译器调用自己的析构函数。
1.构造函数的实现:
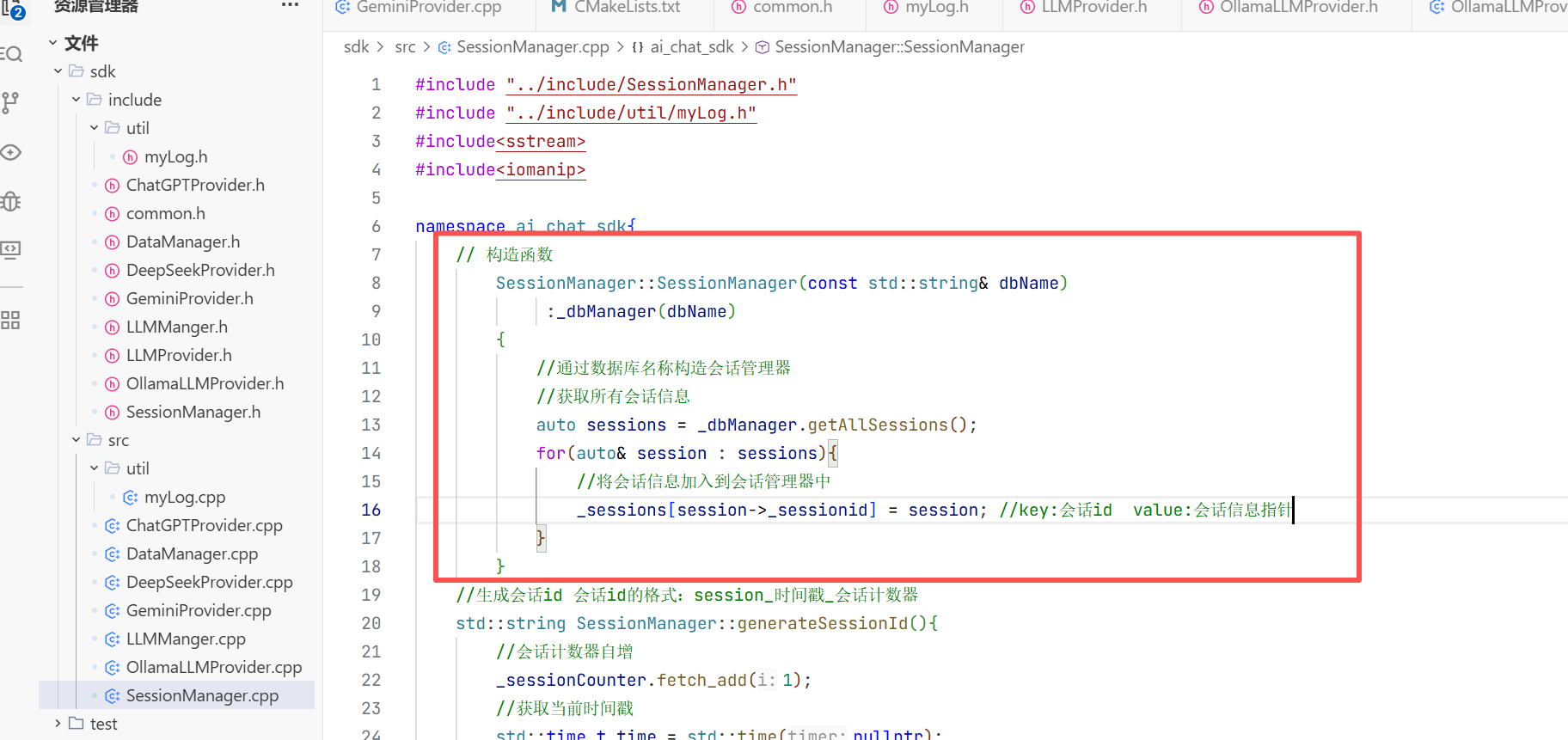
生成会话id和消息id不需要修改:

2.创建会话的重写:
我们要在创建会话时把数据插入到数据库中去
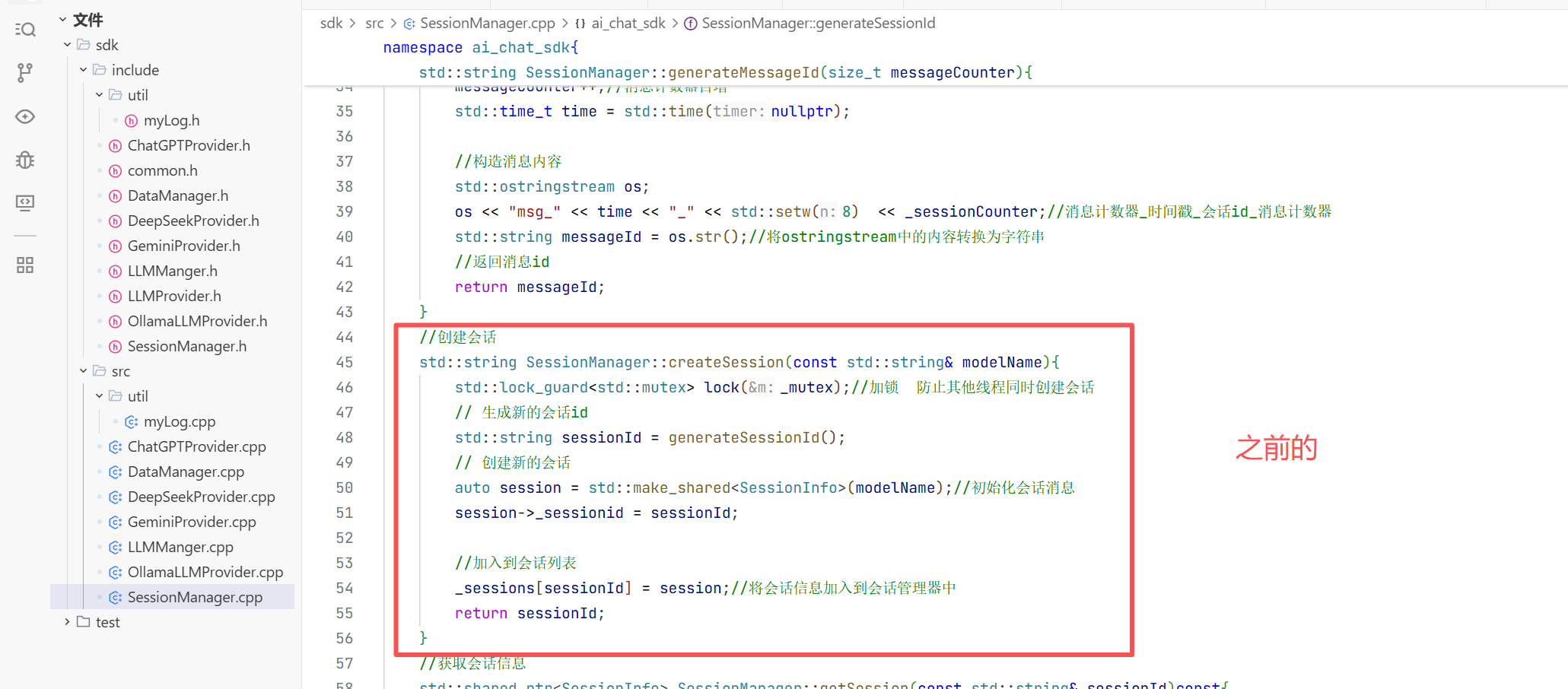
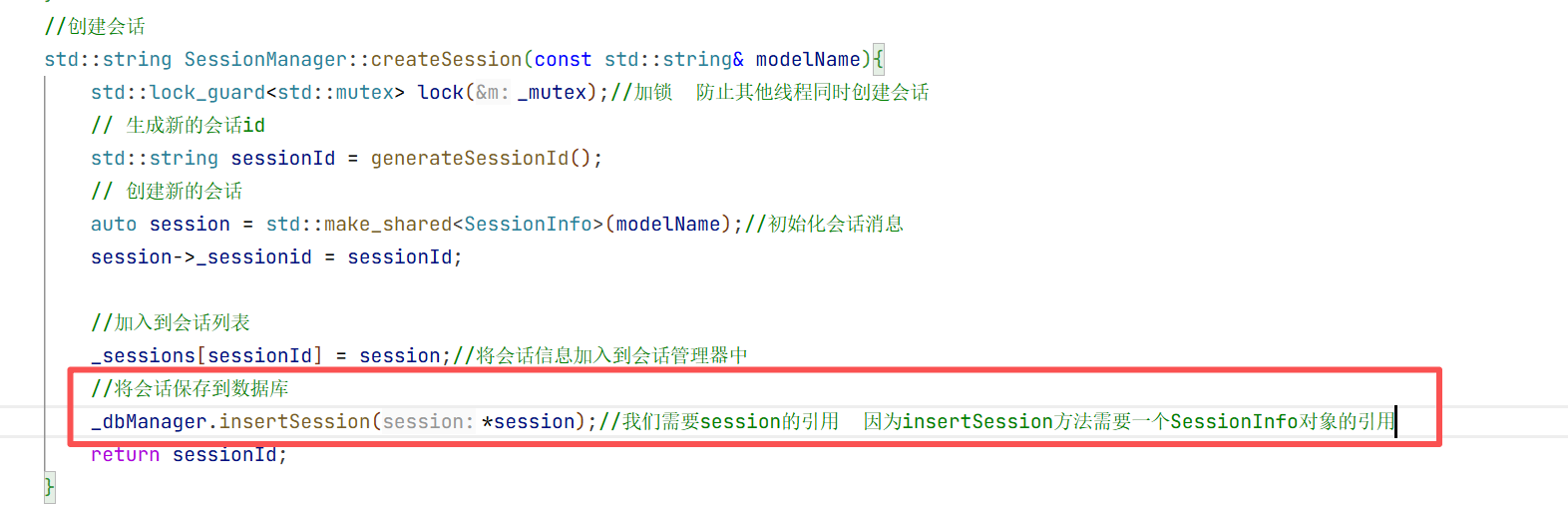
这里insertSession插入的时候也有锁,而这里创建会话的时候也有锁
我们这里手动加锁和解锁

3.获取会话的重写:
没有数据库的实现时 我们先在内存中去查找。
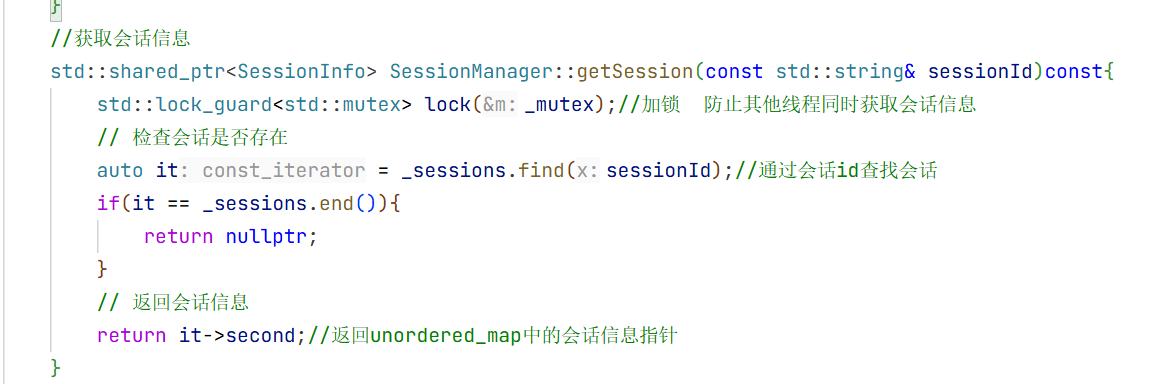
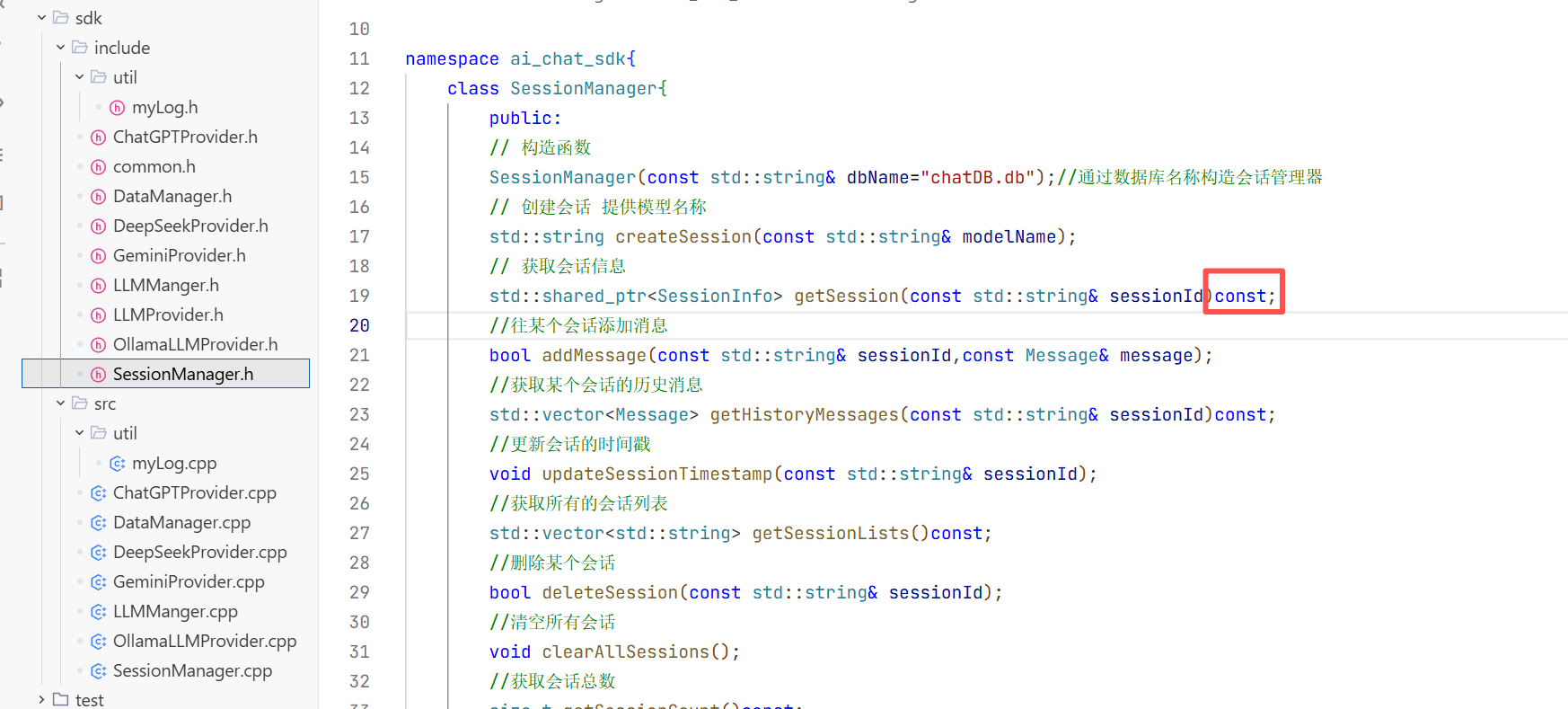
我们获取会话的实现是const类型 但是这里我们要添加查找到的会话到会话列表 所以我们要把const去掉

4.往某个会话添加消息的重写:
以前的
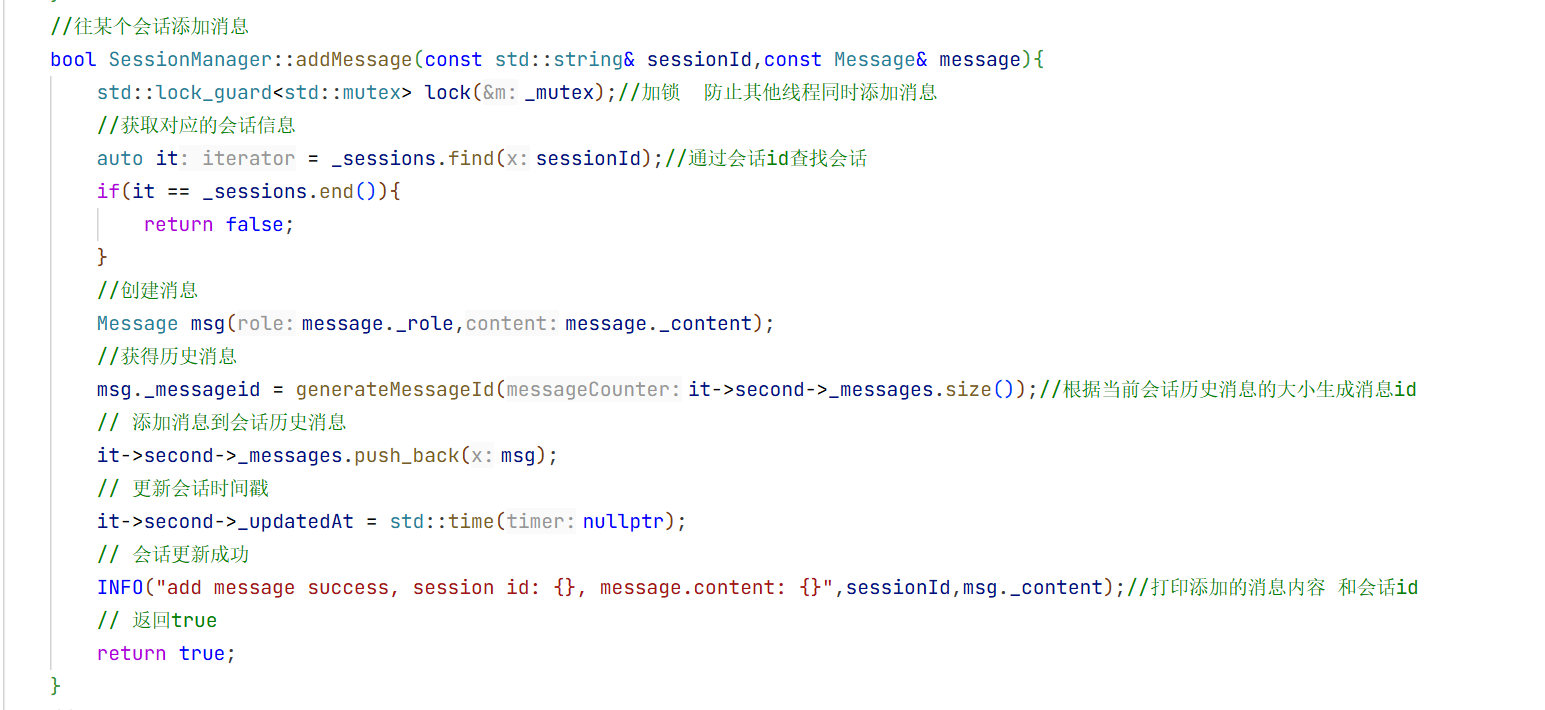
获取会话已经写好了 所以不管你这个会话存不存在 他都拿到我们的内存上了。
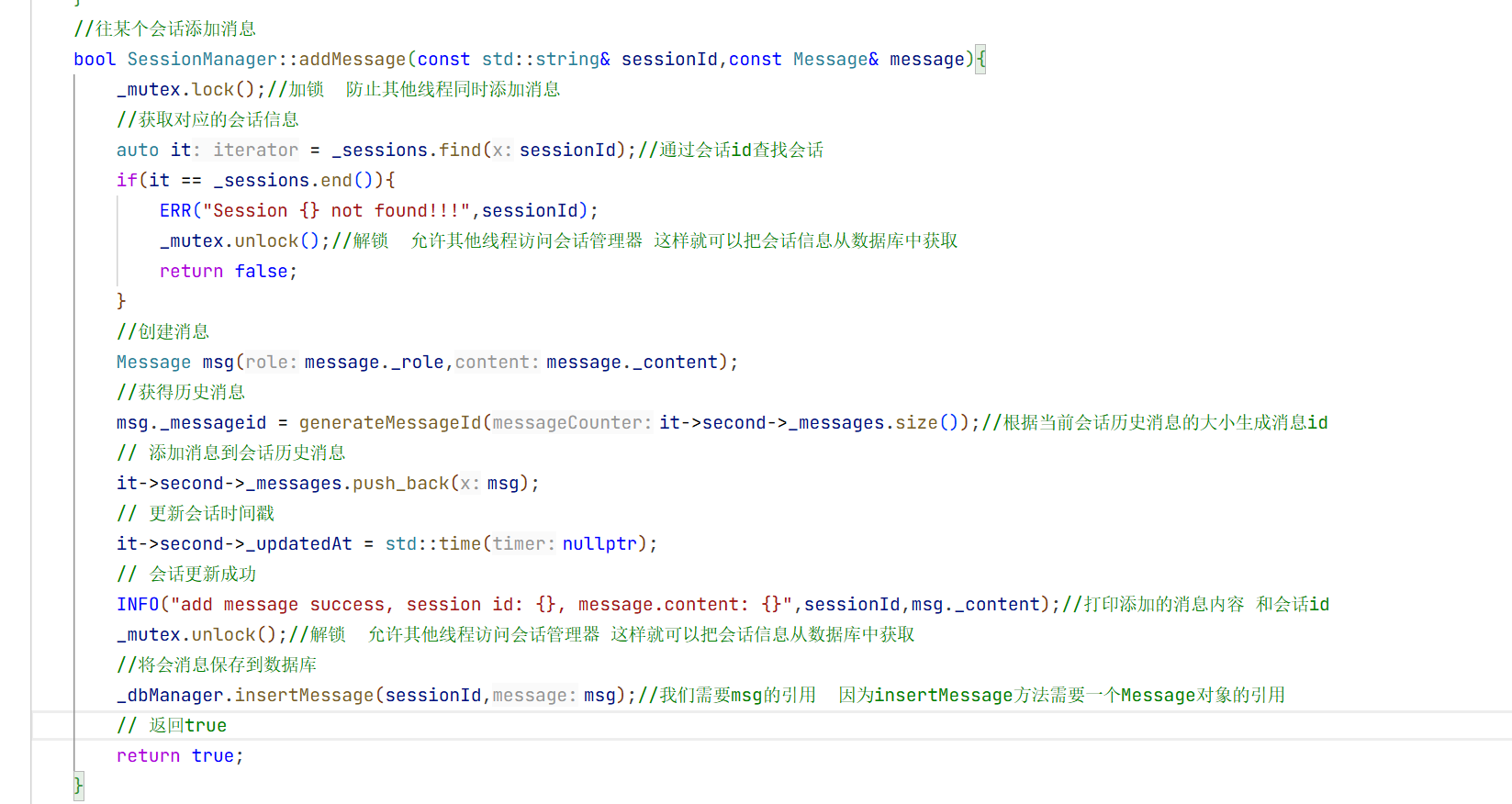
5.获取某个会话的历史消息:

6.更新会话的时间戳重写:
因为会话的时间戳重写了 所以数据库中的数据库也要进行重写
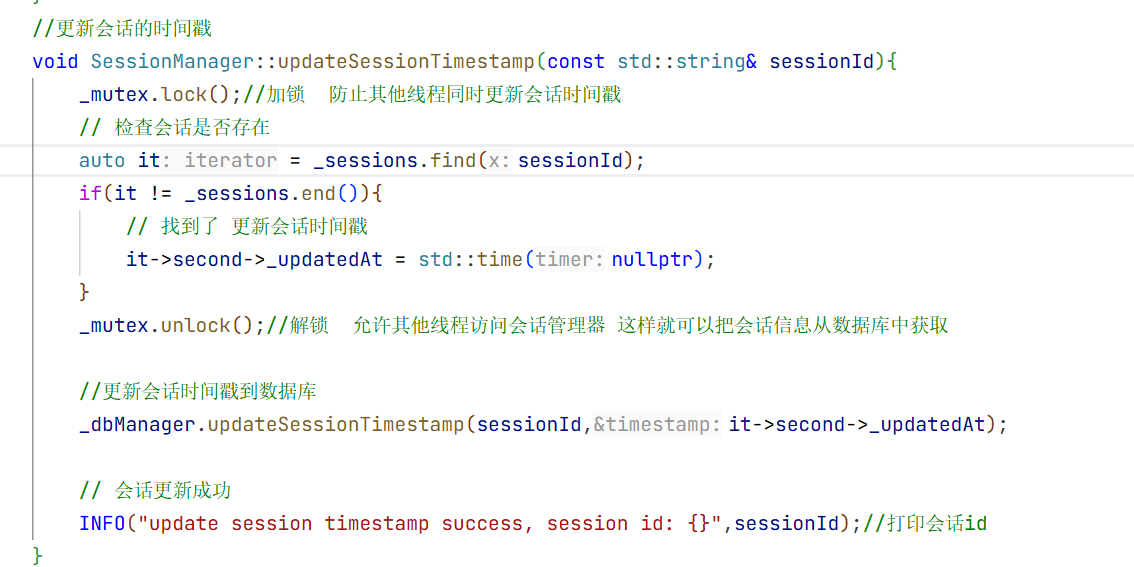
7.获取所有的会话列表的重写:

获取所有会话时如果数据库的会话不在内存中 就把数据库的会话列表也添加进来。
8.删除某个会话的重写:
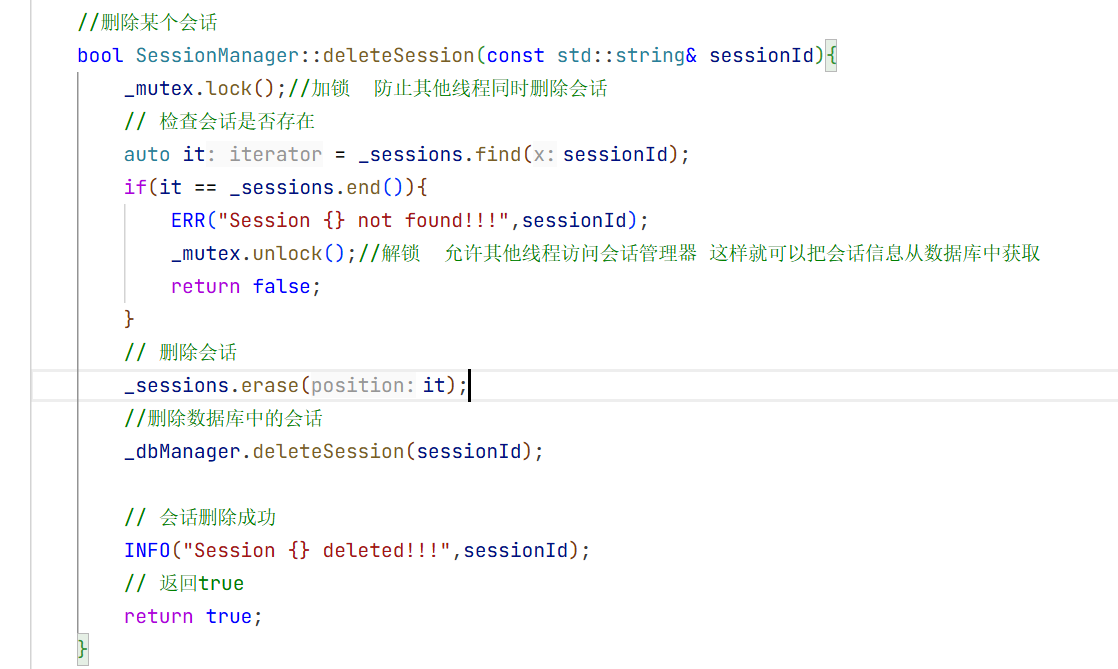
这里我们还需要加上一个方法删除数据库会话的方法

这里我们只需要去删会话即可,不需要去删除消息 因为构建消息列表时加了外键约束和级联
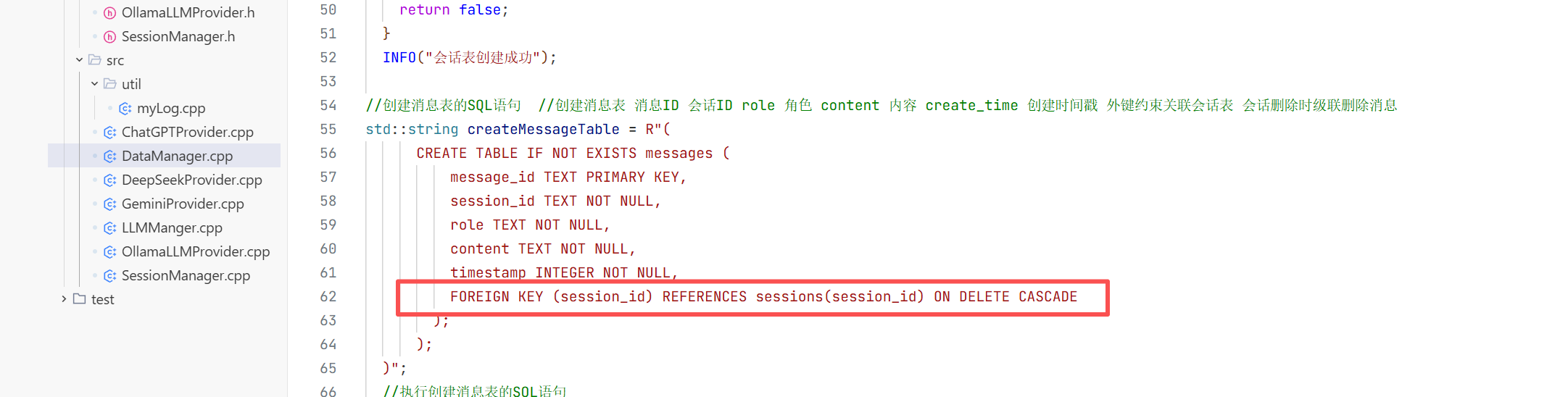
一旦你会话列表删除了,消息列表也要被删除。
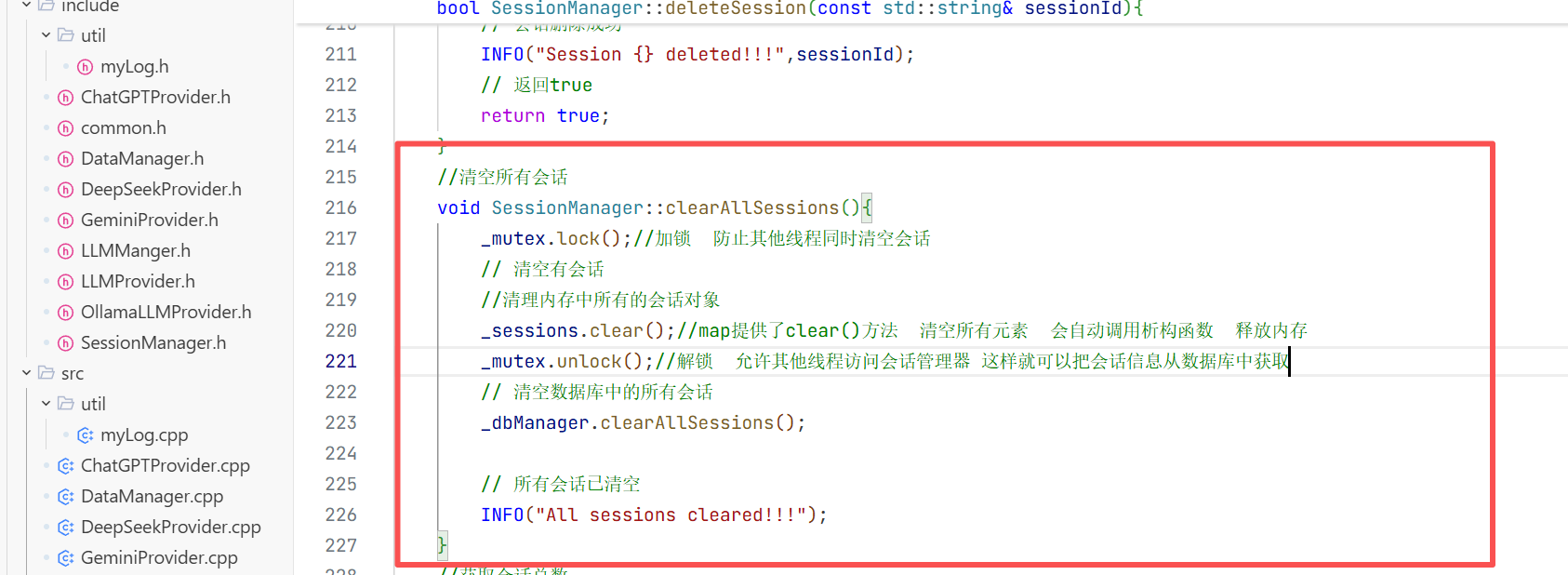
9.获取会话总数
这个不用重写当我们服务器启动我们一开始就拿到了所有会话
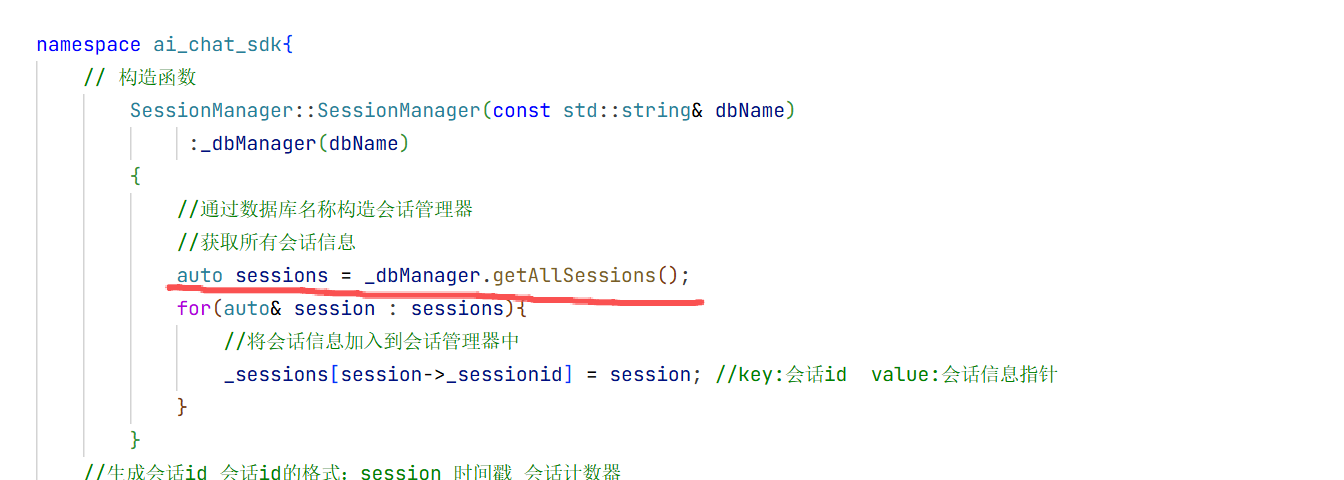
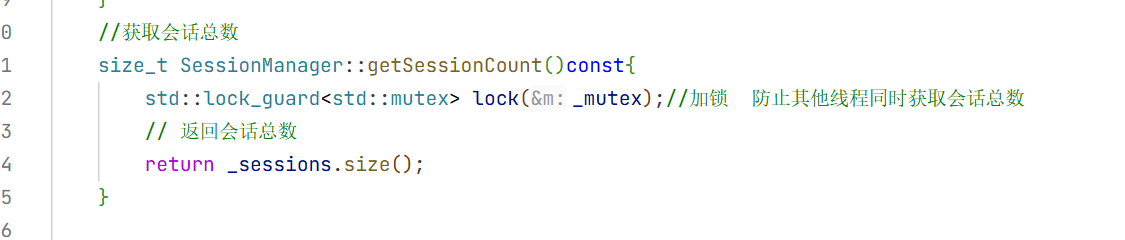
10.重写后的代码:
cpp
#include "../include/SessionManager.h"
#include "../include/util/myLog.h"
#include<sstream>
#include<iomanip>
namespace ai_chat_sdk{
// 构造函数
SessionManager::SessionManager(const std::string& dbName)
:_dbManager(dbName)
{
//通过数据库名称构造会话管理器
//获取所有会话信息
auto sessions = _dbManager.getAllSessions();
for(auto& session : sessions){
//将会话信息加入到会话管理器中
_sessions[session->_sessionid] = session; //key:会话id value:会话信息指针
}
}
//生成会话id 会话id的格式:session_时间戳_会话计数器
std::string SessionManager::generateSessionId(){
//会话计数器自增
_sessionCounter.fetch_add(1);
//获取当前时间戳
std::time_t time = std::time(nullptr);
//拼接在一起生成会话id
std::ostringstream os;
os << "session_" << time << "_" << std::setw(8) << _sessionCounter;//setw(8) 表示会话计数器占8个字符宽度,不足8个字符用0填充
std::string sessionId = os.str();//将ostringstream中的内容转换为字符串
//返回会话id
return sessionId;
}
//生成消息id 消息id的格式:消息计数器_时间戳_会话id_消息计数器
std::string SessionManager::generateMessageId(size_t messageCounter){
messageCounter++;//消息计数器自增
std::time_t time = std::time(nullptr);
//构造消息内容
std::ostringstream os;
os << "msg_" << time << "_" << std::setw(8) << _sessionCounter;//消息计数器_时间戳_会话id_消息计数器
std::string messageId = os.str();//将ostringstream中的内容转换为字符串
//返回消息id
return messageId;
}
//创建会话
std::string SessionManager::createSession(const std::string& modelName){
_mutex.lock();//加锁 防止其他线程同时创建会话
// 生成新的会话id
std::string sessionId = generateSessionId();
// 创建新的会话
auto session = std::make_shared<SessionInfo>(modelName);//初始化会话消息
session->_sessionid = sessionId;
session->_createdAt = session->_updatedAt=std::time(nullptr);//创建会话时创建时间与更新时间相同 当前时间戳
//加入到会话列表
_sessions[sessionId] = session;//将会话信息加入到会话管理器中
_mutex.unlock();//解锁 允许其他线程访问会话管理器 这样就可以把会话信息加入到数据库中
//将会话保存到数据库
_dbManager.insertSession(*session);//我们需要session的引用 因为insertSession方法需要一个SessionInfo对象的引用
return sessionId;
}
//获取会话信息
std::shared_ptr<SessionInfo> SessionManager::getSession(const std::string& sessionId){
//先在内存中查找会话信息
_mutex.lock();//加锁 防止其他线程同时获取会话信息
// 检查会话是否存在
auto it = _sessions.find(sessionId);//通过会话id查找会话
if(it != _sessions.end()){
//如果会话存在
//解锁 允许其他线程访问会话管理器 这样就可以把会话信息从数据库中获取
_mutex.unlock();
//将这个会话的历史消息从数据库中获取
it->second->_messages = _dbManager.getSessionMessages(sessionId);
//返回会话信息
return it->second;
}
//内存中没找到就要去数据库中查找
_mutex.unlock();//解锁 允许其他线程访问会话管理器 这样就可以把会话信息从数据库中获取
auto session = _dbManager.getSession(sessionId);//通过会话id查找会话
//如果数据库中存在会话
//将会话信息加入到内存中
if(session){
_mutex.lock();//加锁 防止其他线程同时获取会话信息
auto it = _sessions.find(sessionId);//通过会话id查找会话
if(it == _sessions.end()){
//内存中没有找到 说明会话不存在
//将会话信息加入到会话管理器中
_sessions[sessionId] = session;//key:会话id value:会话信息指针
}
_mutex.unlock();//解锁 允许其他线程访问会话管理器 这样就可以把会话信息从数据库中获取
//如果会话不在内存中 我们就要从数据库中获取会话信息并加入到内存中的话管理器中
//将这个会话的历史消息从数据库中获取
session->_messages = _dbManager.getSessionMessages(sessionId);//将数据库中的消息赋值给会话信息
//返回会话信息
return session;
}
WARN("Session {} not found!!!", sessionId);
return nullptr;//返回nullptr表示会话不存在
}
//往某个会话添加消息
bool SessionManager::addMessage(const std::string& sessionId,const Message& message){
_mutex.lock();//加锁 防止其他线程同时添加消息
//获取对应的会话信息
auto it = _sessions.find(sessionId);//通过会话id查找会话
if(it == _sessions.end()){
ERR("Session {} not found!!!",sessionId);
_mutex.unlock();//解锁 允许其他线程访问会话管理器 这样就可以把会话信息从数据库中获取
return false;
}
//创建消息
Message msg(message._role,message._content);
//获得历史消息
msg._messageid = generateMessageId(it->second->_messages.size());//根据当前会话历史消息的大小生成消息id
// 添加消息到会话历史消息
it->second->_messages.push_back(msg);
// 更新会话时间戳
it->second->_updatedAt = std::time(nullptr);
// 会话更新成功
INFO("add message success, session id: {}, message.content: {}",sessionId,msg._content);//打印添加的消息内容 和会话id
_mutex.unlock();//解锁 允许其他线程访问会话管理器 这样就可以把会话信息从数据库中获取
//将会消息保存到数据库
_dbManager.insertMessage(sessionId,msg);//我们需要msg的引用 因为insertMessage方法需要一个Message对象的引用
// 返回true
return true;
}
//获取某个会话的历史消息
std::vector<Message> SessionManager::getHistoryMessages(const std::string& sessionId)const{
_mutex.lock();//加锁 防止其他线程同时获取会话历史消息
// 检查会话是否存在
//先在内存中查找会话信息 如果内存中获取不到就去数据库中查找
auto it = _sessions.find(sessionId);
if(it != _sessions.end()){
//如果会话存在
//解锁 允许其他线程访问会话管理器 这样就可以把会话信息从数据库中获取
_mutex.unlock();
//返回会话历史消息
return it->second->_messages;
}
//解锁 允许其他线程访问会话管理器 这样就可以把会话信息从数据库中获取
_mutex.unlock();
//内存中没有找到 去数据库中查找会话信息
return _dbManager.getSessionMessages(sessionId);
}
//更新会话的时间戳
void SessionManager::updateSessionTimestamp(const std::string& sessionId){
_mutex.lock();//加锁 防止其他线程同时更新会话时间戳
// 检查会话是否存在
auto it = _sessions.find(sessionId);
if(it != _sessions.end()){
// 找到了 更新会话时间戳
it->second->_updatedAt = std::time(nullptr);
}
_mutex.unlock();//解锁 允许其他线程访问会话管理器 这样就可以把会话信息从数据库中获取
//更新会话时间戳到数据库
_dbManager.updateSessionTimestamp(sessionId,it->second->_updatedAt);
// 会话更新成功
INFO("update session timestamp success, session id: {}",sessionId);//打印会话id
}
//获取所有的会话列表
std::vector<std::string> SessionManager::getSessionLists()const{
auto sessions = _dbManager.getAllSessions();//从数据库中获取所有的会话信息
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时获取会话列表
//构建一个临时对话列表,将其内容的会话按照更新的时间降序排序
std::vector<std::pair<std::time_t,std::shared_ptr<SessionInfo>>> temp;//临时会话列表中存储会话时间戳和会话对象
temp.reserve(_sessions.size());//分配内存 避免重复分配内存
//将会话添加到临时会话列表中
for(const auto& pair : _sessions){
temp.emplace_back(pair.second->_updatedAt,pair.second);//将会话时间戳和会话对象添加到临时会话列表中
}
// 将数据库中获取到的会话添加到临时会话列表中
for(const auto& session : sessions){
if(_sessions.find(session->_sessionid) == _sessions.end()){
// 如果内存中没有找到 则添加到临时会话列表中
temp.emplace_back(session->_updatedAt,session);//将会话时间戳和会话对象添加到临时会话列表中
}
}
// 对临时会话列表进行排序 auto转化前的类std::pair<std::time_t,std::shared_ptr<SessionInfo>>
std::sort(temp.begin(),temp.end(),[](const auto& a,const auto& b){//利用lambda表达式对临时会话列表进行排序
return a.first > b.first;//按照会话时间戳降序排序
});
std::vector<std::string> sessionIds;//存储排序后的会话id
sessionIds.reserve(_sessions.size());//分配内存 避免重复分配内存
// 提取排序后的会话id
for(const auto& pair : temp){
sessionIds.push_back(pair.second->_sessionid);
}
// 返回排序后的会话id
return sessionIds;
}
//删除某个会话
bool SessionManager::deleteSession(const std::string& sessionId){
_mutex.lock();//加锁 防止其他线程同时删除会话
// 检查会话是否存在
auto it = _sessions.find(sessionId);
if(it == _sessions.end()){
ERR("Session {} not found!!!",sessionId);
_mutex.unlock();//解锁 允许其他线程访问会话管理器 这样就可以把会话信息从数据库中获取
return false;
}
// 删除会话
_sessions.erase(it);
_mutex.unlock();//解锁 允许其他线程访问会话管理器 这样就可以把会话信息从数据库中获取
//删除数据库中的会话
_dbManager.deleteSession(sessionId);
// 会话删除成功
INFO("Session {} deleted!!!",sessionId);
// 返回true
return true;
}
//清空所有会话
void SessionManager::clearAllSessions(){
_mutex.lock();//加锁 防止其他线程同时清空会话
// 清空有会话
//清理内存中所有的会话对象
_sessions.clear();//map提供了clear()方法 清空所有元素 会自动调用析构函数 释放内存
_mutex.unlock();//解锁 允许其他线程访问会话管理器 这样就可以把会话信息从数据库中获取
// 清空数据库中的所有会话
_dbManager.clearAllSessions();
// 所有会话已清空
INFO("All sessions cleared!!!");
}
//获取会话总数
size_t SessionManager::getSessionCount()const{
std::lock_guard<std::mutex> lock(_mutex);//加锁 防止其他线程同时获取会话总数
// 返回会话总数
return _sessions.size();
}
}//end namespace ai_chat_sdk17.ChatSDK:
1.SDK的介绍:
SDK就是程序员的⼯具箱,Software Develop Kit的缩写,⼀套帮开发者⽅便开发特定功能的⼯具包。
⽐如:
•
微信⽀付SDK:你只要接⼊SDK,就能在程序中⽀持微信⽀付,不⽤⾃⼰研究⽀付安全、加密、银
⾏对接等。
•
相机SDK:使⽤⼚商提供的SDK,就能让APP调⽤收集摄像头拍照、录像
SDK中通常包含:
•
库⽂件:被⼈已经写好的功能,需要实现什么功能直接调⽤即可。
•
API接⼝:告诉你该怎么和平台打交道。
•
⽂档:说明书,告诉你怎么⽤
•
⽰例代码:相当于菜谱,照这些就能跑通
•
调试⼯具:出错时能帮你查问题
也就是说:SDK就是⼚商打包好的⼀套"现成⼯具+说明书",让开发者可以更快、更安全、更省⼼地在 ⾃⼰的软件中实现特定功能。
2.ChatSDK的封装:
相当于再提供一个接口把会话管理和数据管理连接在一起。
1.头文件的实现:
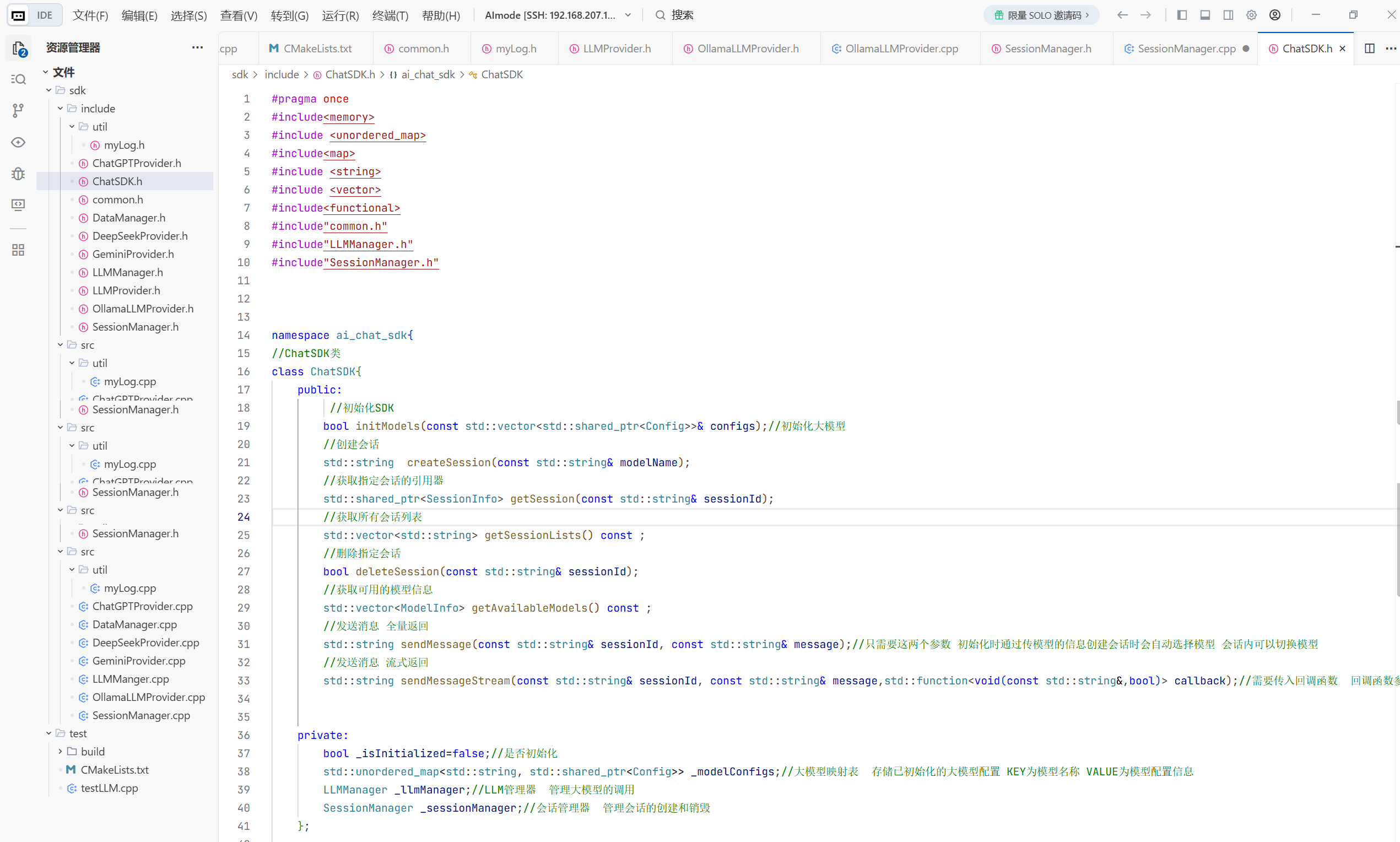
cpp
#pragma once
#include<memory>
#include <unordered_map>
#include<map>
#include <string>
#include <vector>
#include<functional>
#include"common.h"
#include"LLMManager.h"
#include"SessionManager.h"
namespace ai_chat_sdk{
//ChatSDK类
class ChatSDK{
public:
//初始化大模型
bool initModels(const std::vector<std::shared_ptr<Config>>& configs);//初始化大模型
//创建会话
std::string createSession(const std::string& modelName);
//获取指定会话的引用器
std::shared_ptr<SessionInfo> getSession(const std::string& sessionId);
//获取所有会话列表
std::vector<std::string> getSessionLists() const ;
//删除指定会话
bool deleteSession(const std::string& sessionId);
//获取可用的模型信息
std::vector<ModelInfo> getAvailableModels() const ;
//发送消息 全量返回
std::string sendMessage(const std::string& sessionId, const std::string& message);//只需要这两个参数 初始化时通过传模型的信息创建会话时会自动选择模型 会话内可以切换模型
//发送消息 流式返回
std::string sendMessageStream(const std::string& sessionId, const std::string& message,std::function<void(const std::string&,bool)> callback);//需要传入回调函数 回调函数参数为 消息内容 是否是最后一条消息
private:
bool _isInitialized=false;//是否初始化
std::unordered_map<std::string, std::shared_ptr<Config>> _modelConfigs;//大模型映射表 存储已初始化的大模型配置 KEY为模型名称 VALUE为模型配置信息
LLMManager _llmManager;//LLM管理器 管理大模型的调用
SessionManager _sessionManager;//会话管理器 管理会话的创建和销毁
};
}//end namespace ai_chat_sdk2.源文件的实现:
1.大模型的初始化:
这里初始化可以去直接调用LLMManager实现的初始化模型的方法:
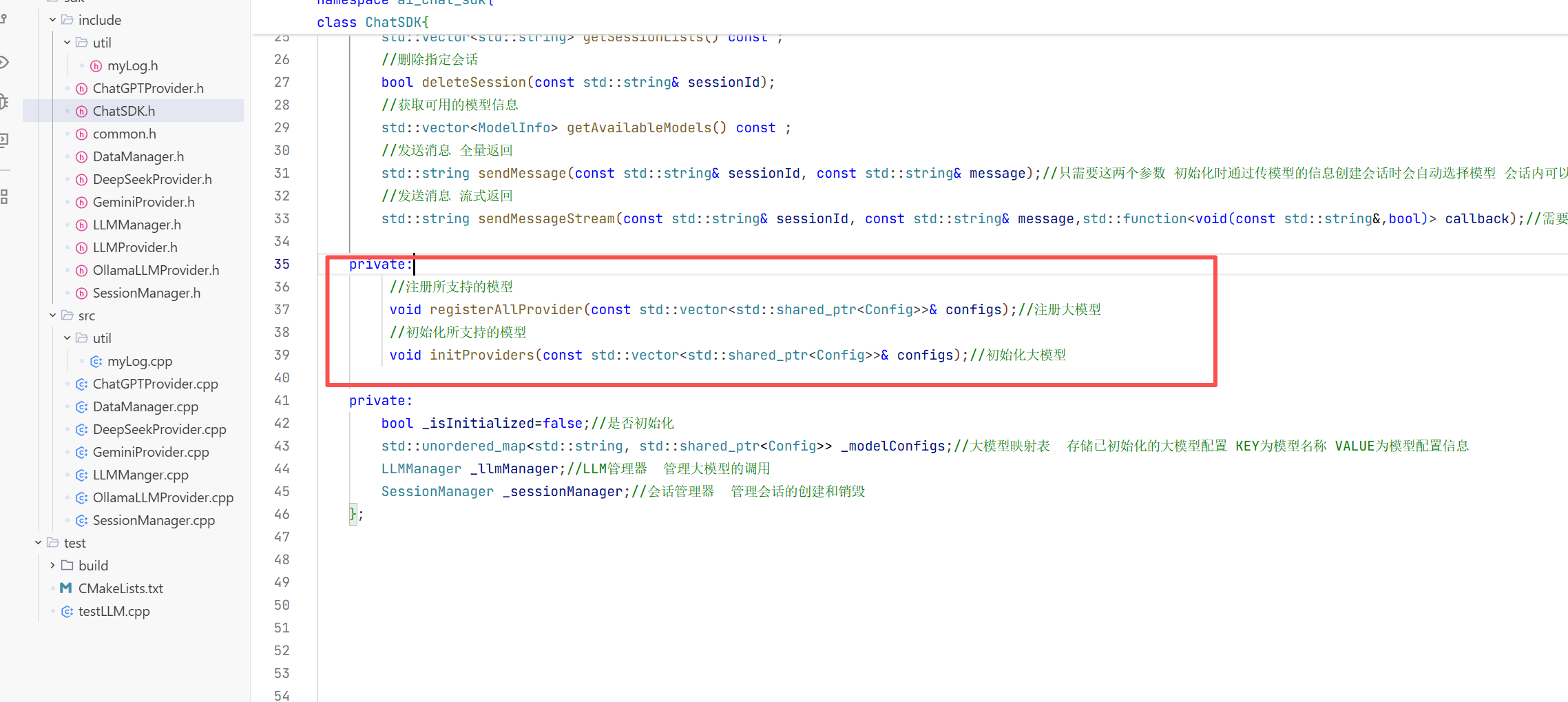
这里跟LLMManager保持一致一个注册一个初始化 所以这里头文件还要加上这两个私有方法

2.注册所有的模型:
这里要注意一下 这个deepseekprovider是用唯一指针管理起来的


这里注册deep seek /chatgpt/Gemini 是差不多的因为都是云端大模型
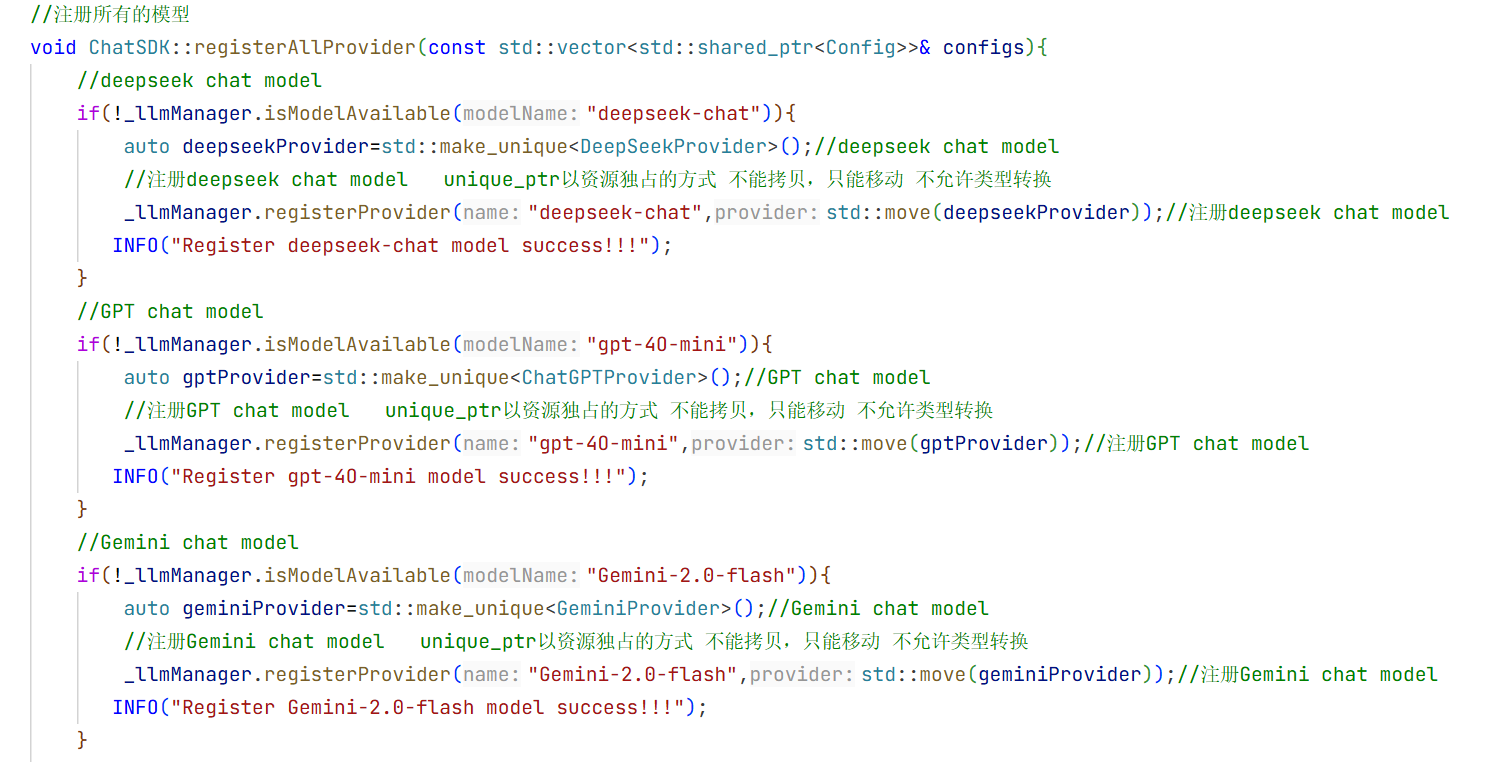
而通过Ollama接入本地大模型时有一些区别因为这些配置信息都是用户自己配置进来的 具体要接入什么模型由用户自己传进来就行 所以这里要循环看看到底调用的什么模型
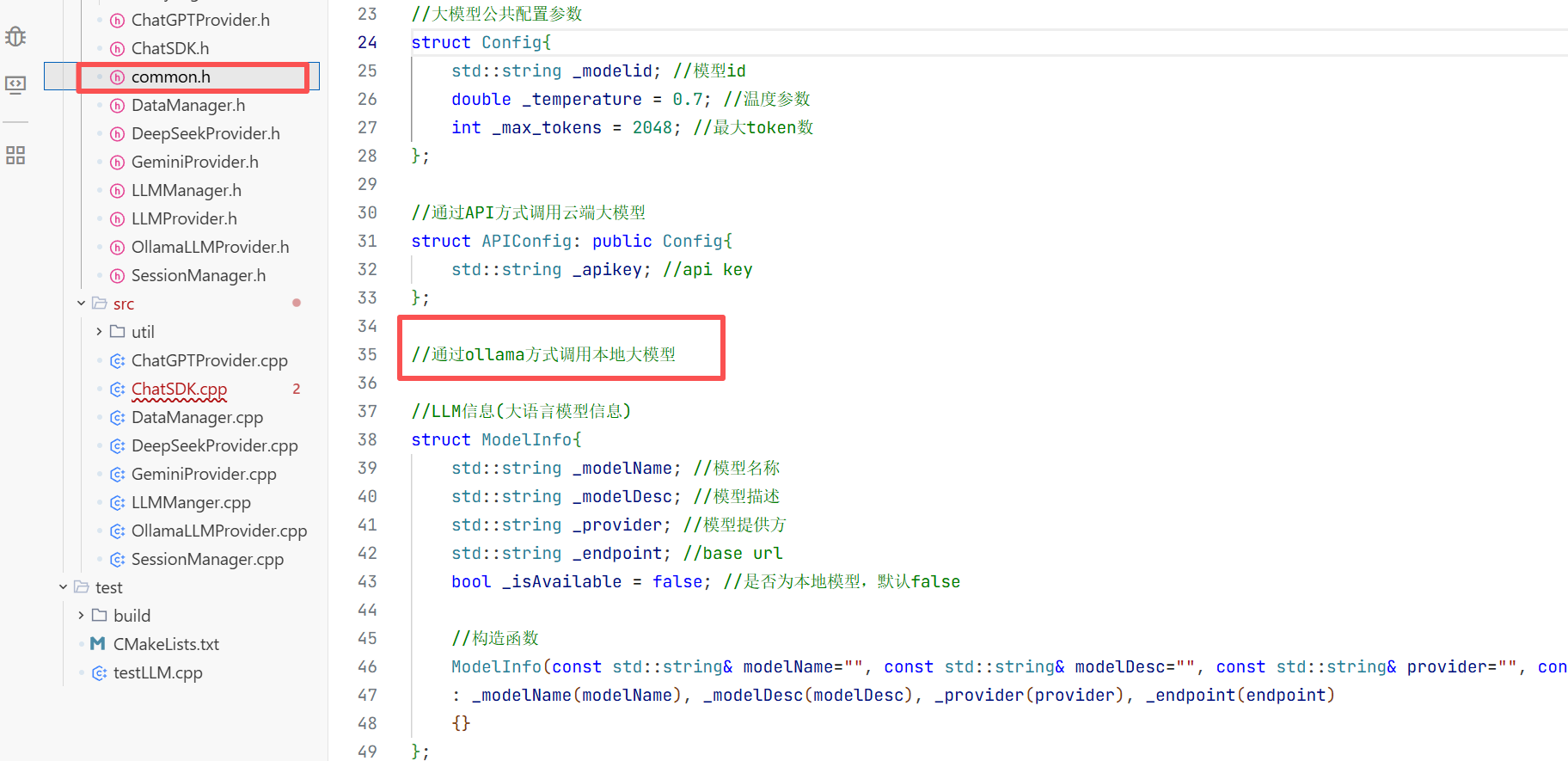
所以这里我们要去实现遗漏下来的common.h了 这里把接入Ollama的方式实现一下。
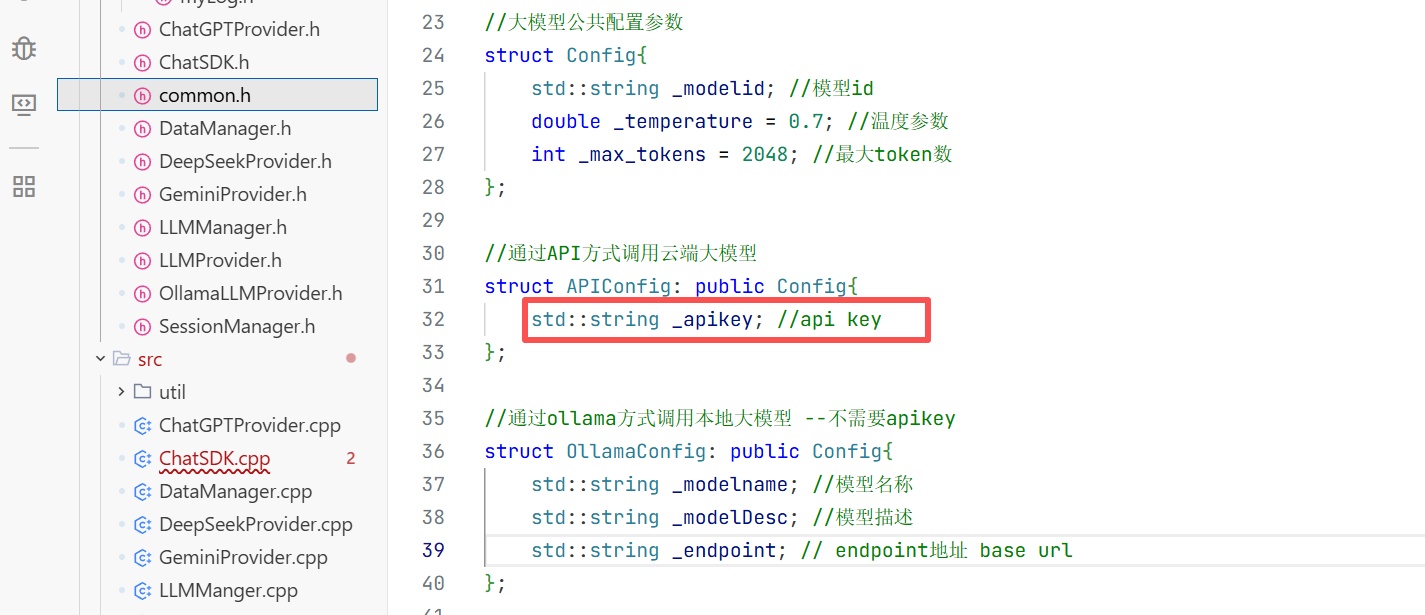
这里我们还要去修改一下 因为通过云端调用模型的话 我们只需要传api key所以这里我们可以将base url给写好 例如deepseek的: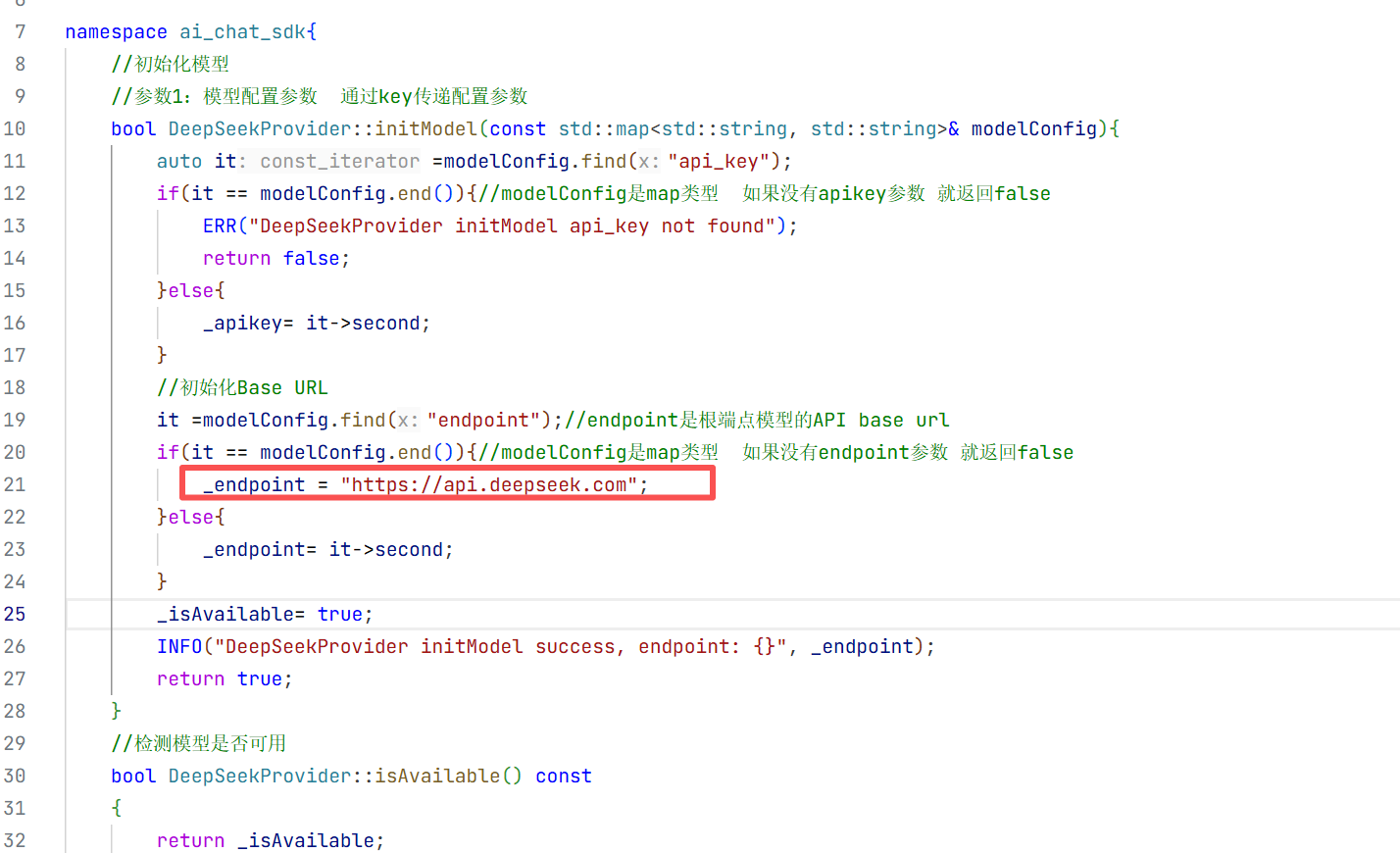
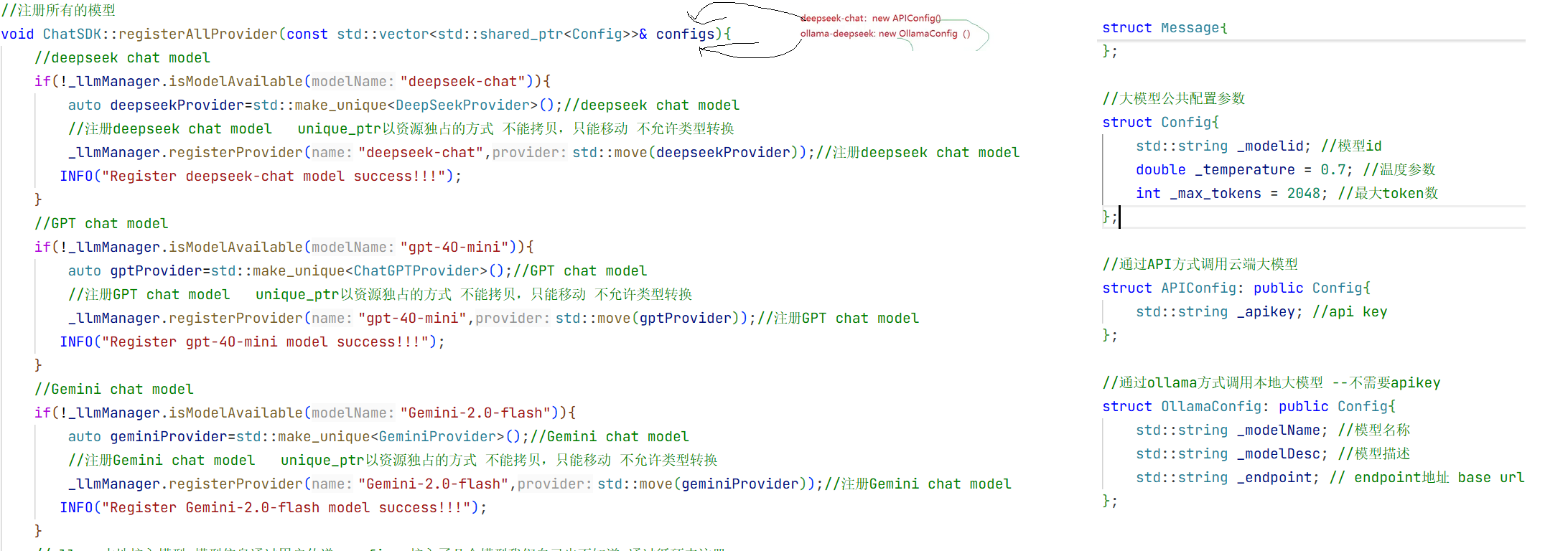
这里你调用不同的模型传过来不同的参数这些都继承为模型的信息只是你接入云端大模型多了一个
apikey的调用 而ollama需要你自己传模型的名字 而这里我们初始化ollama调用的模型时不需要传APIkey 所以我们要验证这个Config是不是ollama的Config

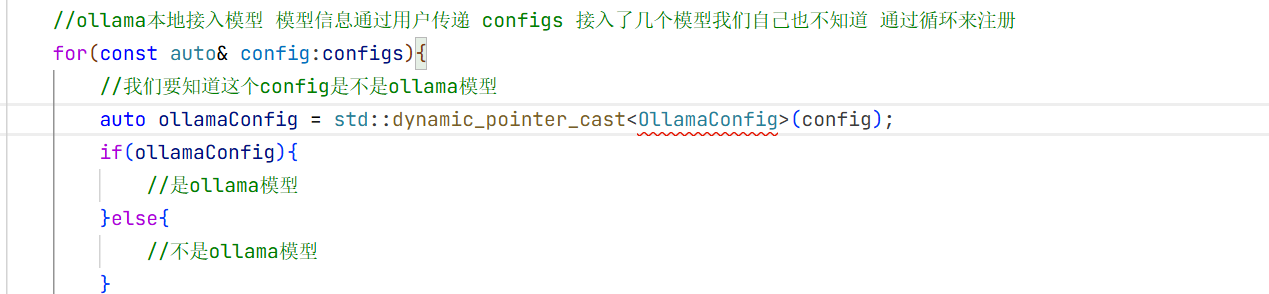
而dynamic_cast的使用需要你是虚函数而先在我们没有虚函数 所以还要在common中实现一个虚函数
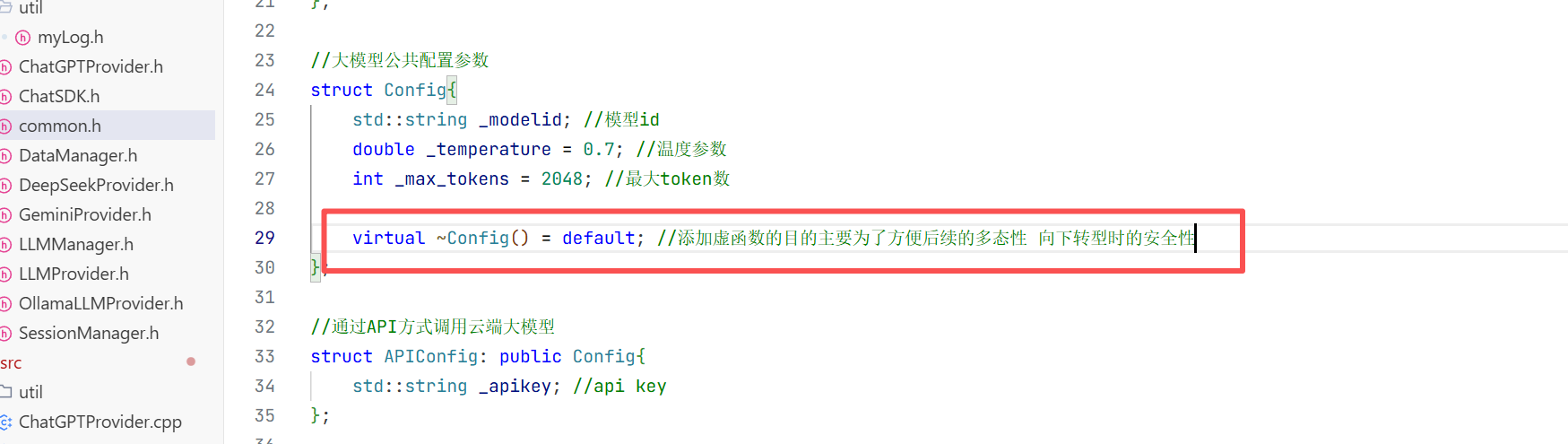
这样有虚函数 整个继承体系就有虚函数 这样我们代码的动态继承就正确了。
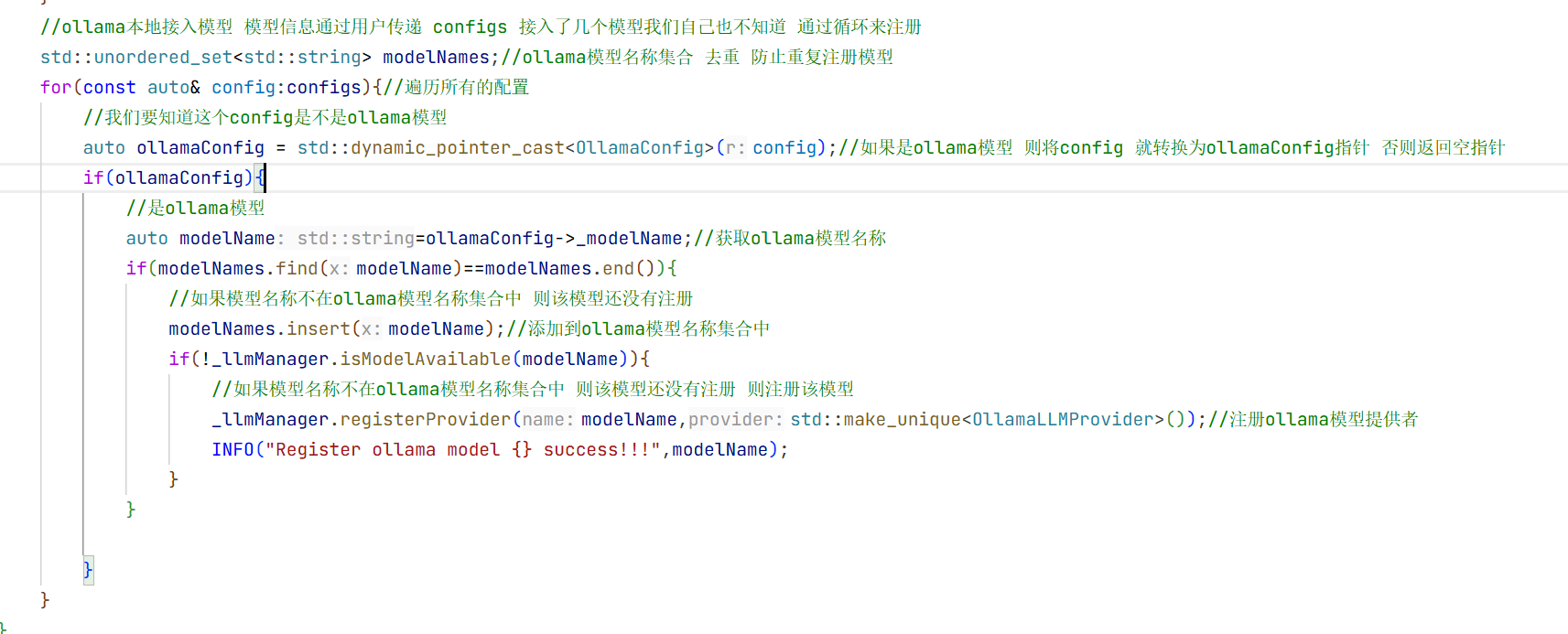
configs是模型的一些配置信息
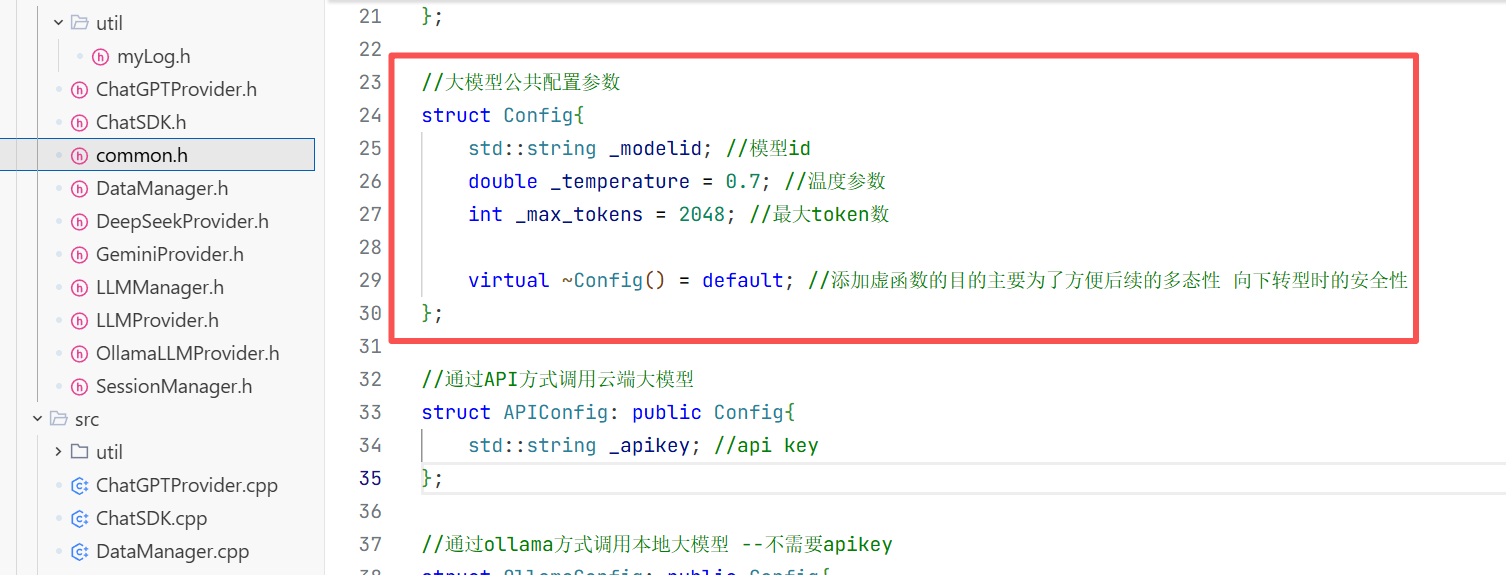
3.初始化所有的模型提供者:
首先先遍历我们现有的所有模型 然后判断是不是API模型或者是ollama模型 不同的模型来用不同的初始化方法 如果是API模型还要判断是不是我们所支持的模型
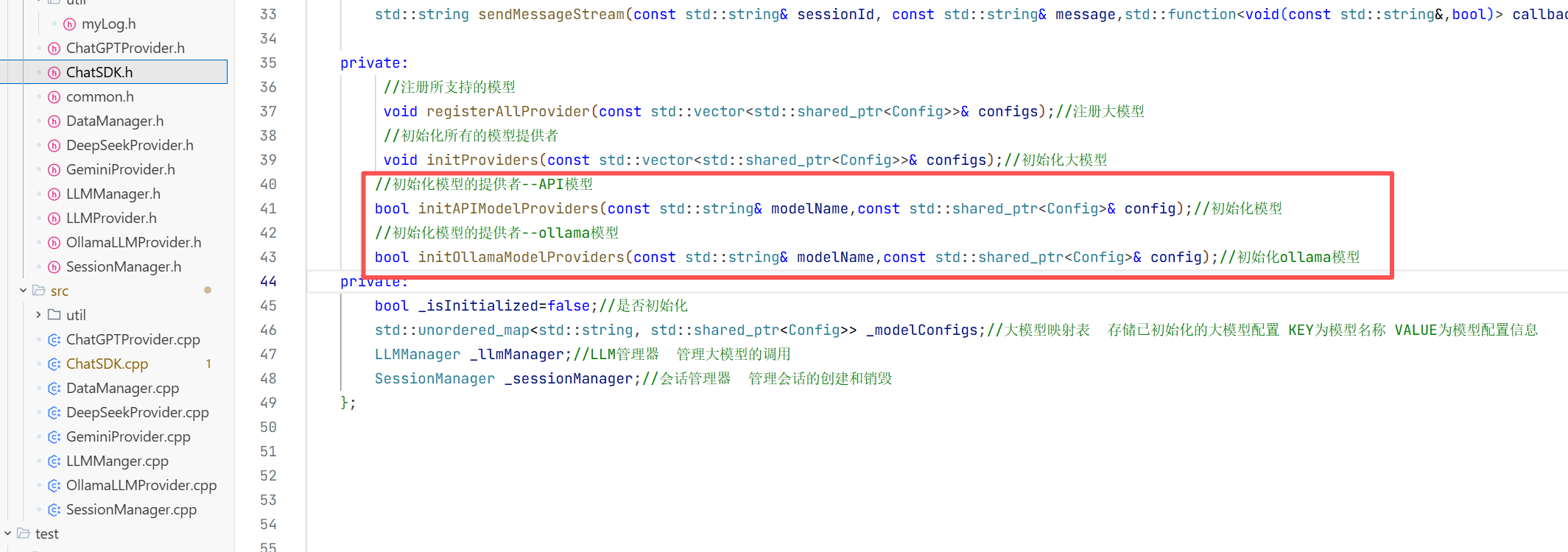
所以这里我们再加上两个发放用于初始化不同的模型 这里要传模型的名称 因为最后还是要通过LLM来初始化指定模型 所以要传模型名称
4.云端模型的初始化:

这里的配置参数也要和云端大模型的查找是一致的
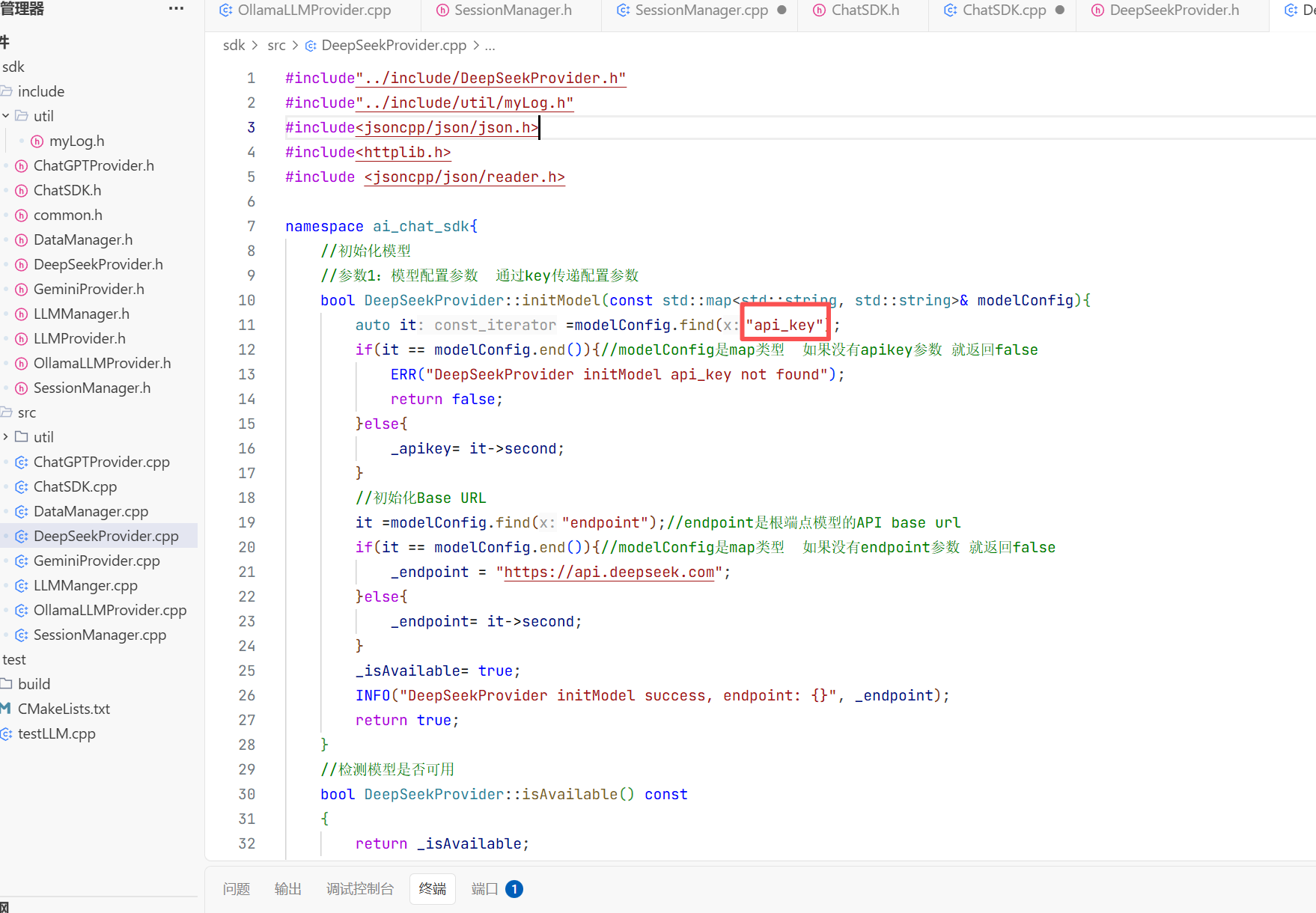
5.ollama模型的初始化:
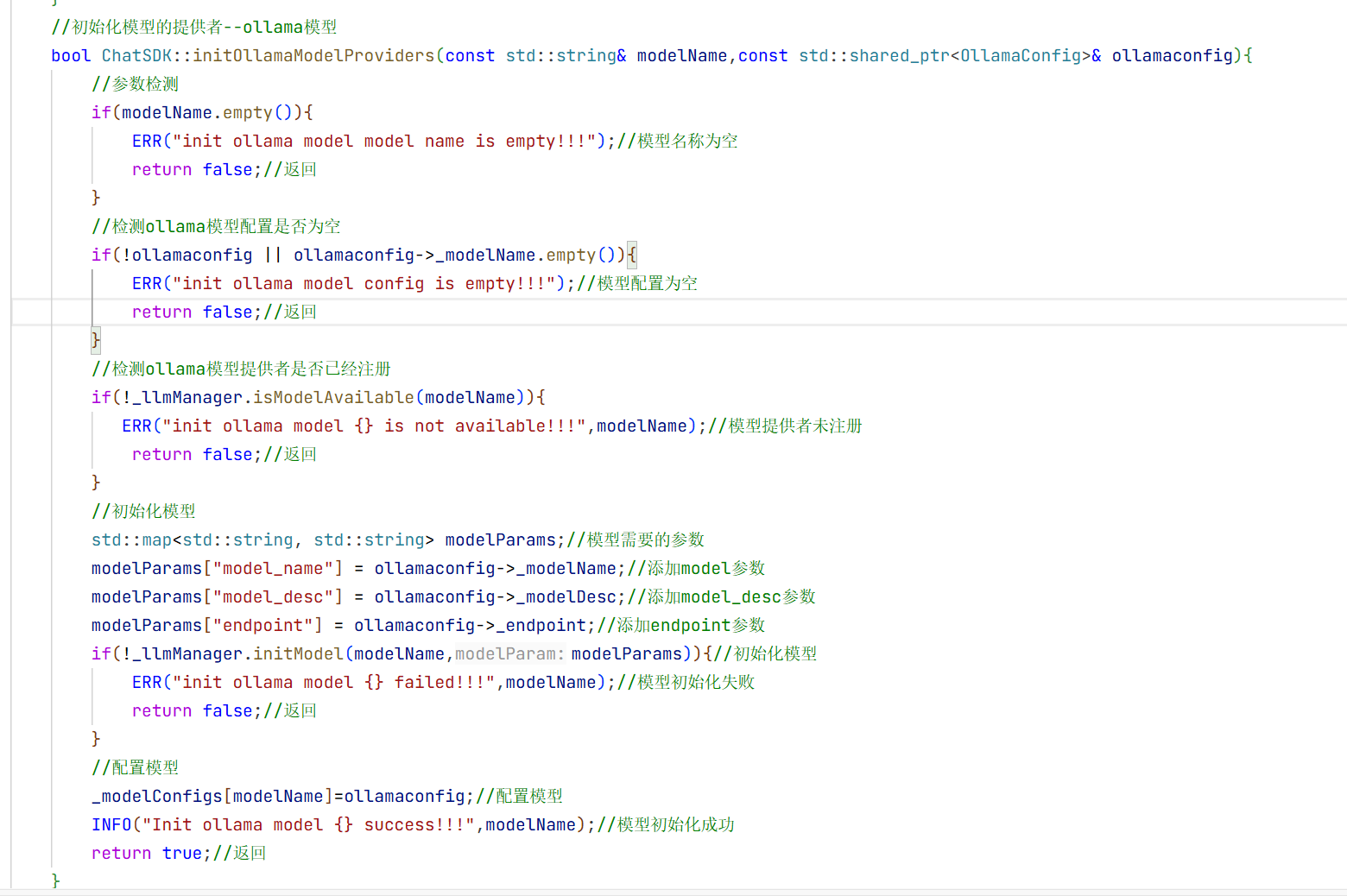
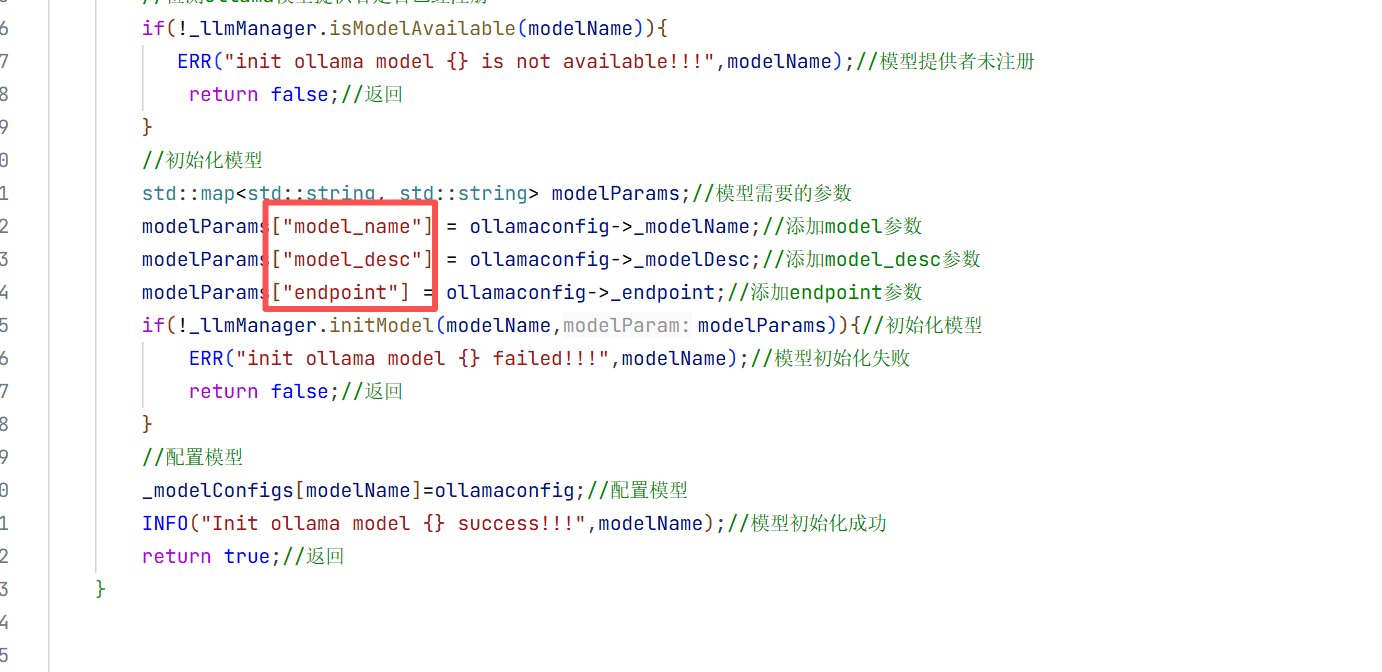
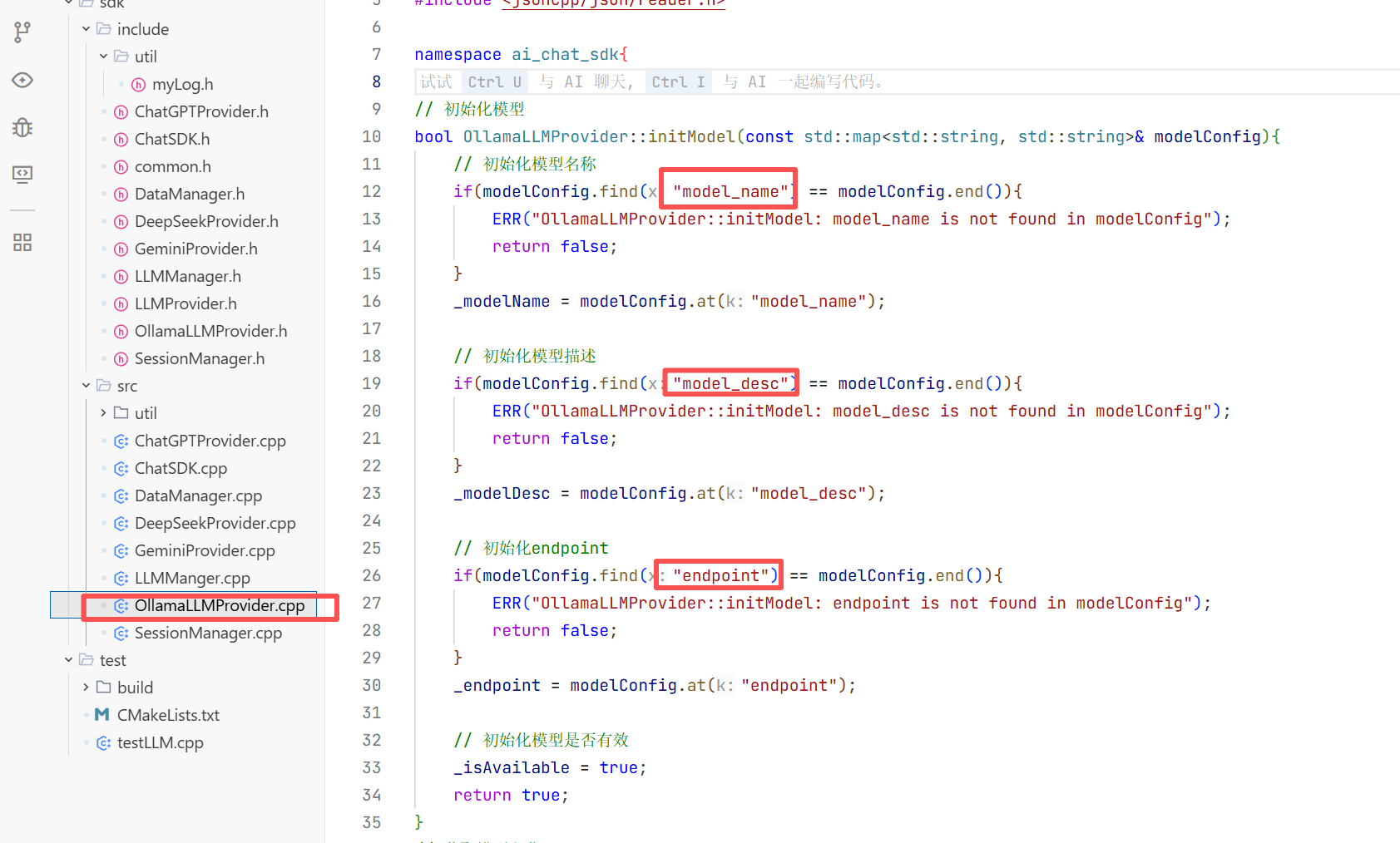
这个配置参数是和ollama模型的实现时查找是一致的要不然找不到
这两个方法实现完之后实现初始化所有的模型就可以去调用上面这两个方法了。
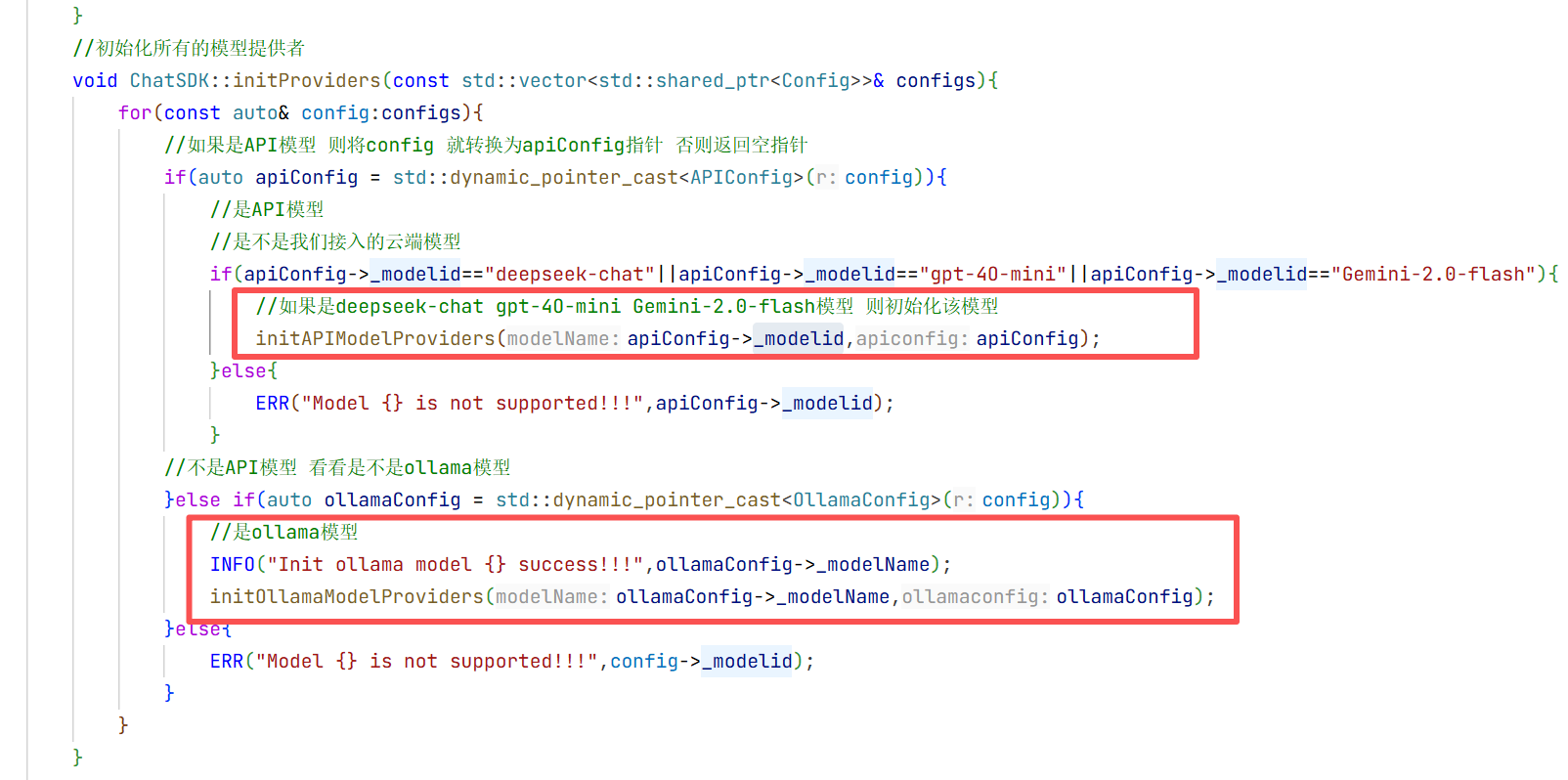
6.创建会话的实现:
7.获取指定会话:
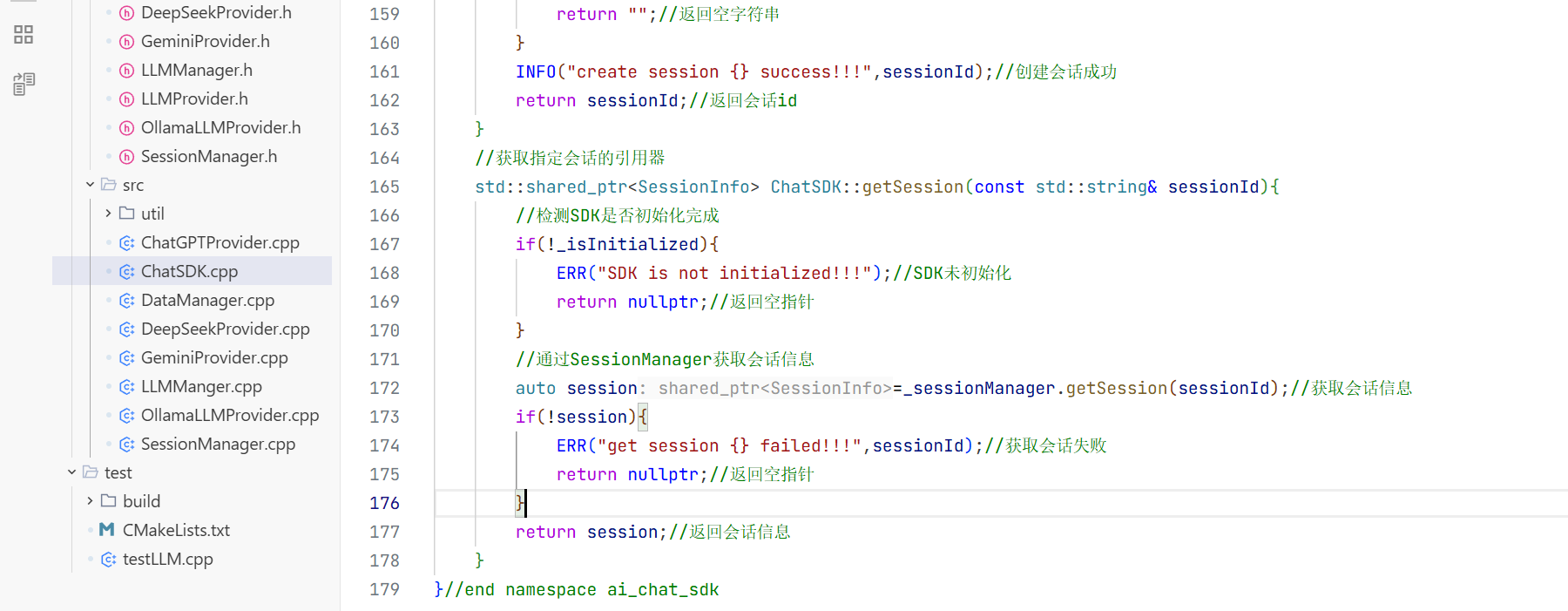
8.获取所有会话列表:
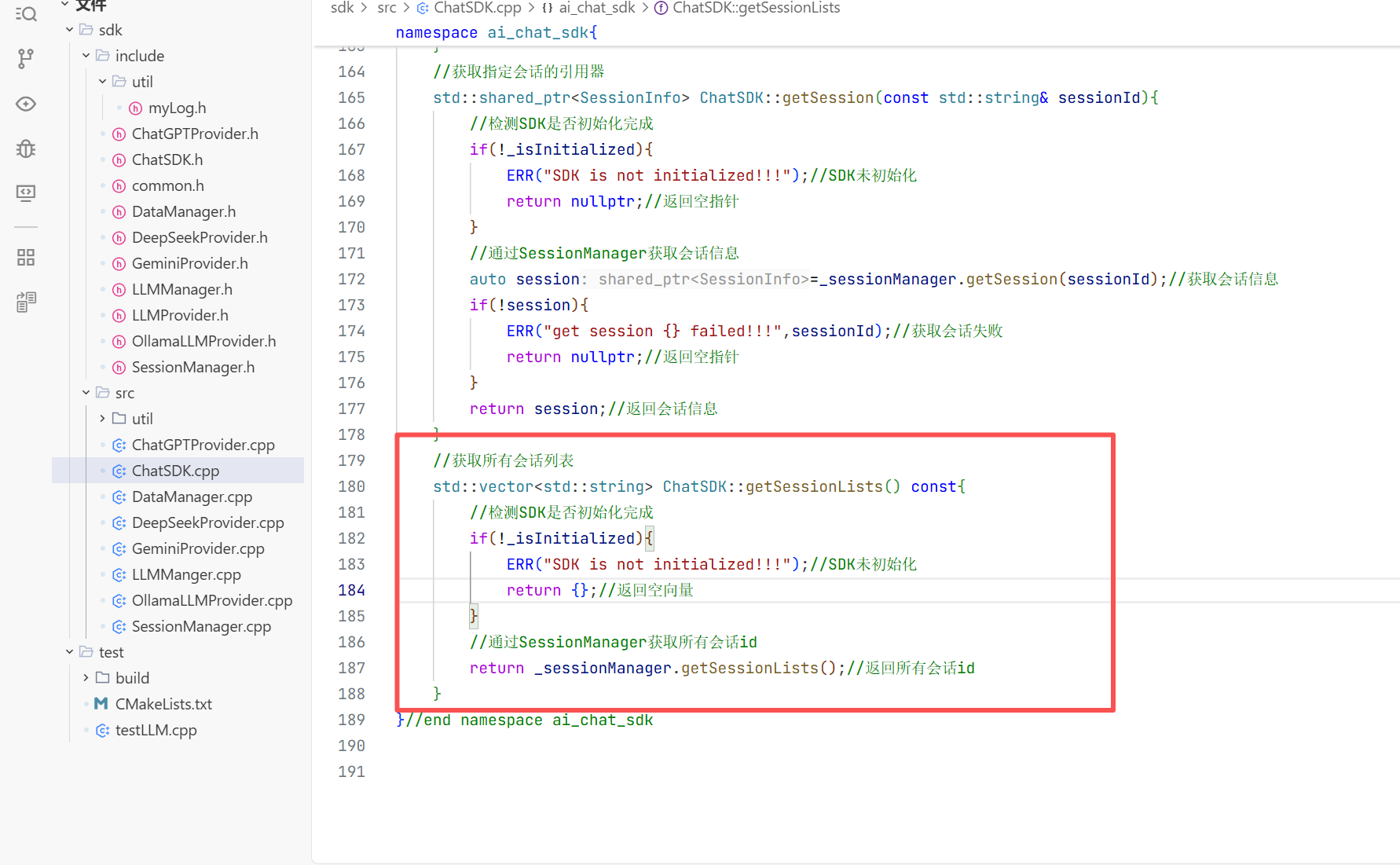
9.删除指定会话:
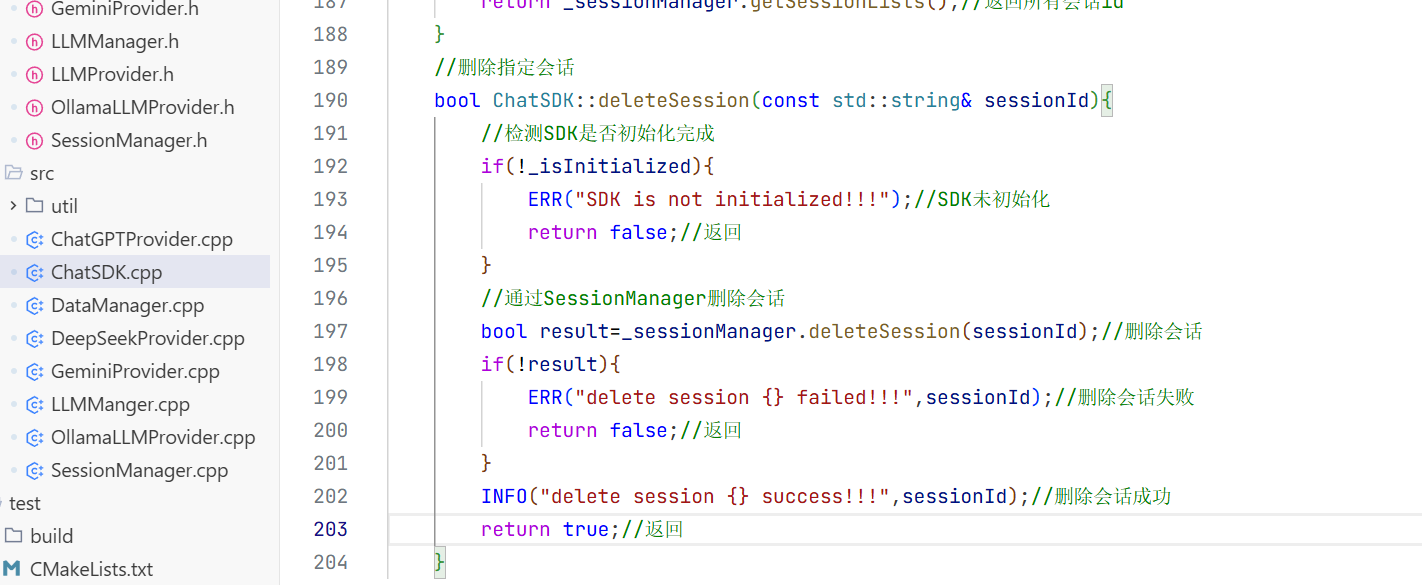
10.发送消息 全量返回的实现:

这里发送消息时我们还要把请求参数给构造好
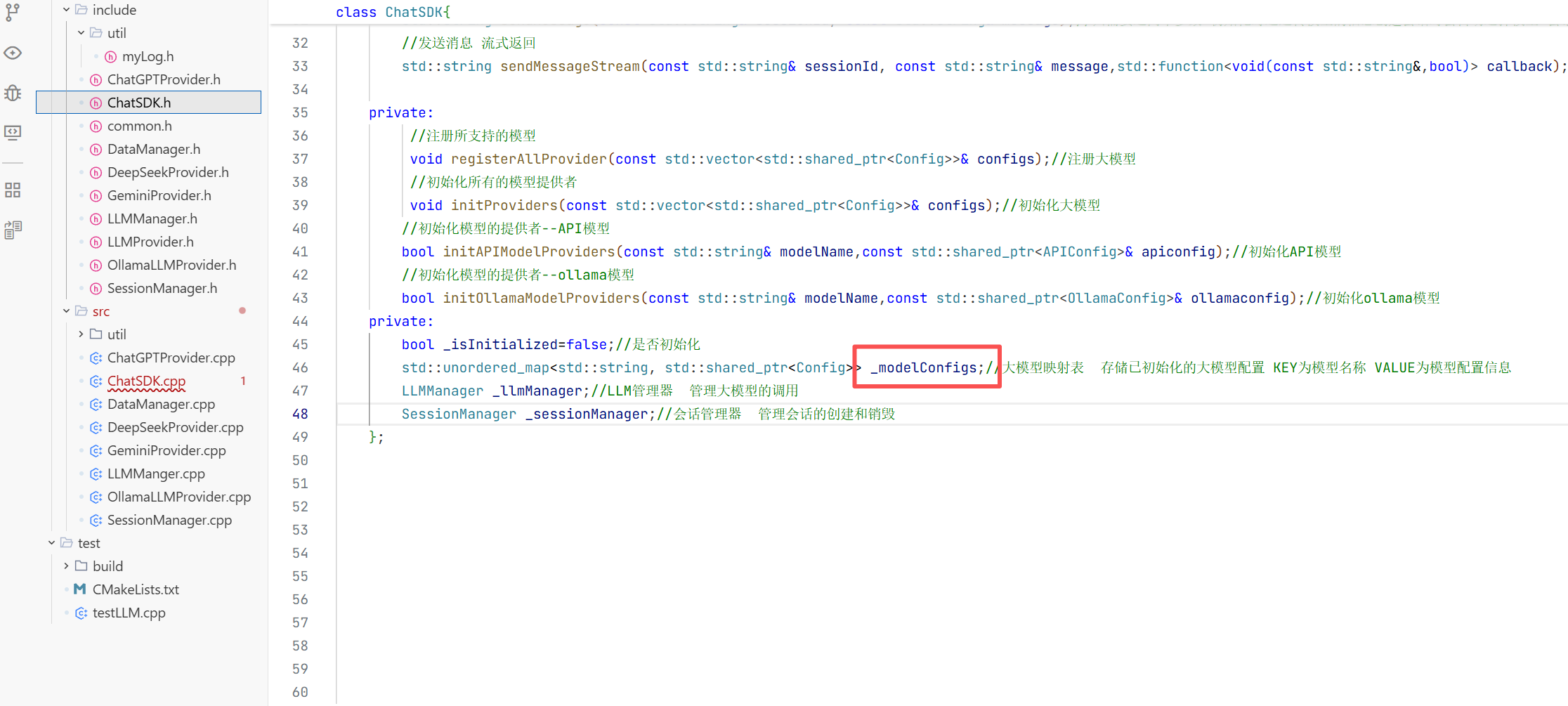
在头文件构造的时候我们就定义了一个变量用来存储 这个相关的配置信息

整体实现

11.发送消息 流式返回的实现:
跟前面的实现是一样的只是最后调用LLM提供的方法时调用的是流式返回的方法即可

3.ChatSDK的测试
这里测试SDK相当于测试了会话管理和数据管理
这里测试时需要创建ChatSDK的对象 Message对象
将配置好的参数放到一个vector容器中去 因为要创建ChatSDK时要传的参数就是vector类型的
这里我们先用deepseek做测试

这里我们还要去修改编译的文件因为这里使用到了数据库管理 所以我们要加上这个sqlit3库的链接
测试deepseek时
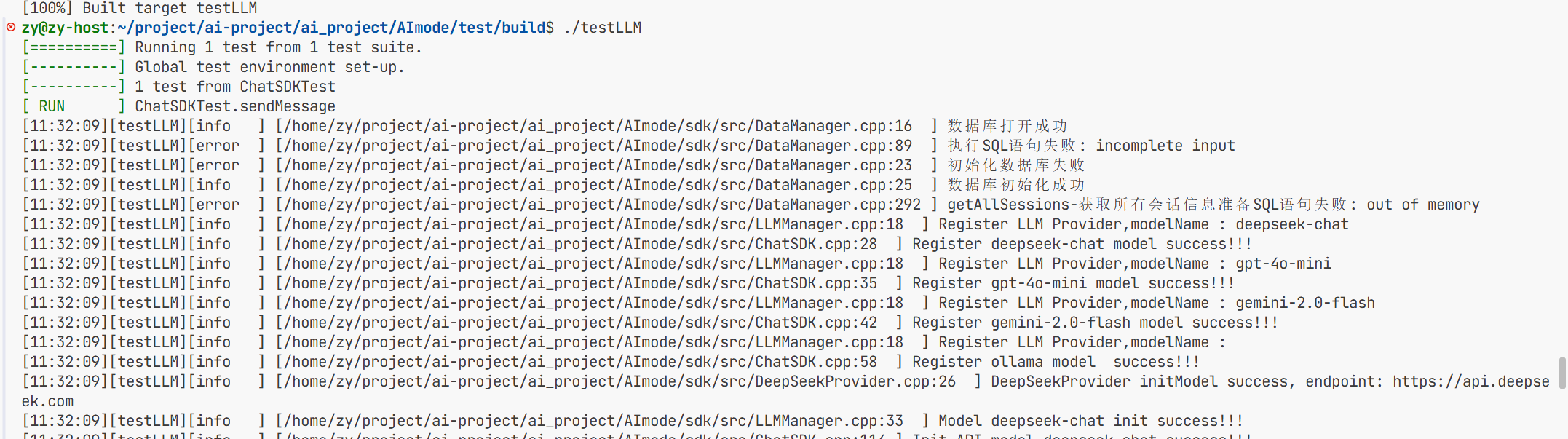
这里出现的问题是因为我的SQL语句出现了错误 通过AI修复后已经能正常使用了

测试通过ollama本地接入的deepseek模型:
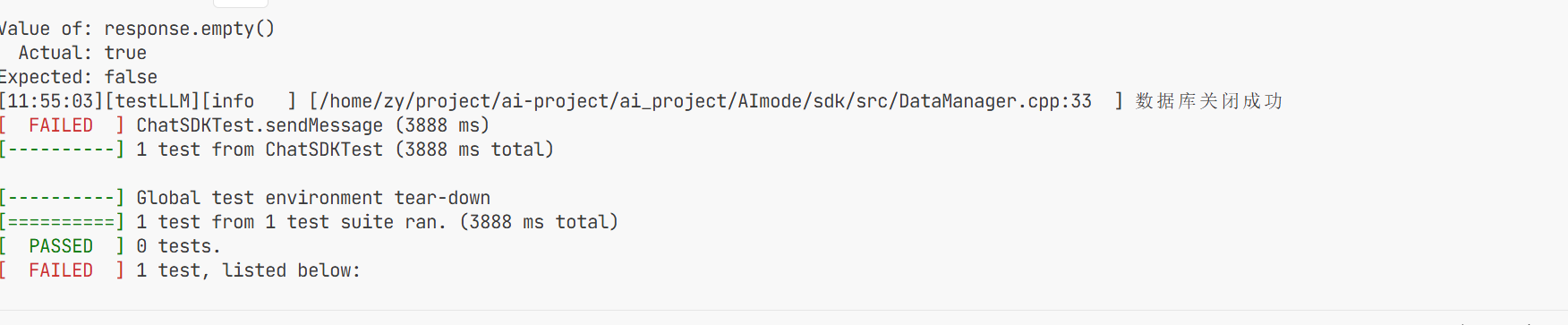
这个是因为我一开始把模型的名称赋值给了会话id导致找不到这字段导致错误。
4.ChatSDK的静态库生成:
编写完静态库这样别人在使用后 就之间包含这个头文件即可。不需要下载这么多执行文件。
实际上就是对整个sdk下的头文件进行编写 然后生成一个静态库
1.CMakeLists的编写
也就是包整个实现的文件打包。
因为是对include下的文件进行编写 所以这里必须和include下的文件持平。

实现的原理其实和测试的CMakeLists.txt的编写差不多
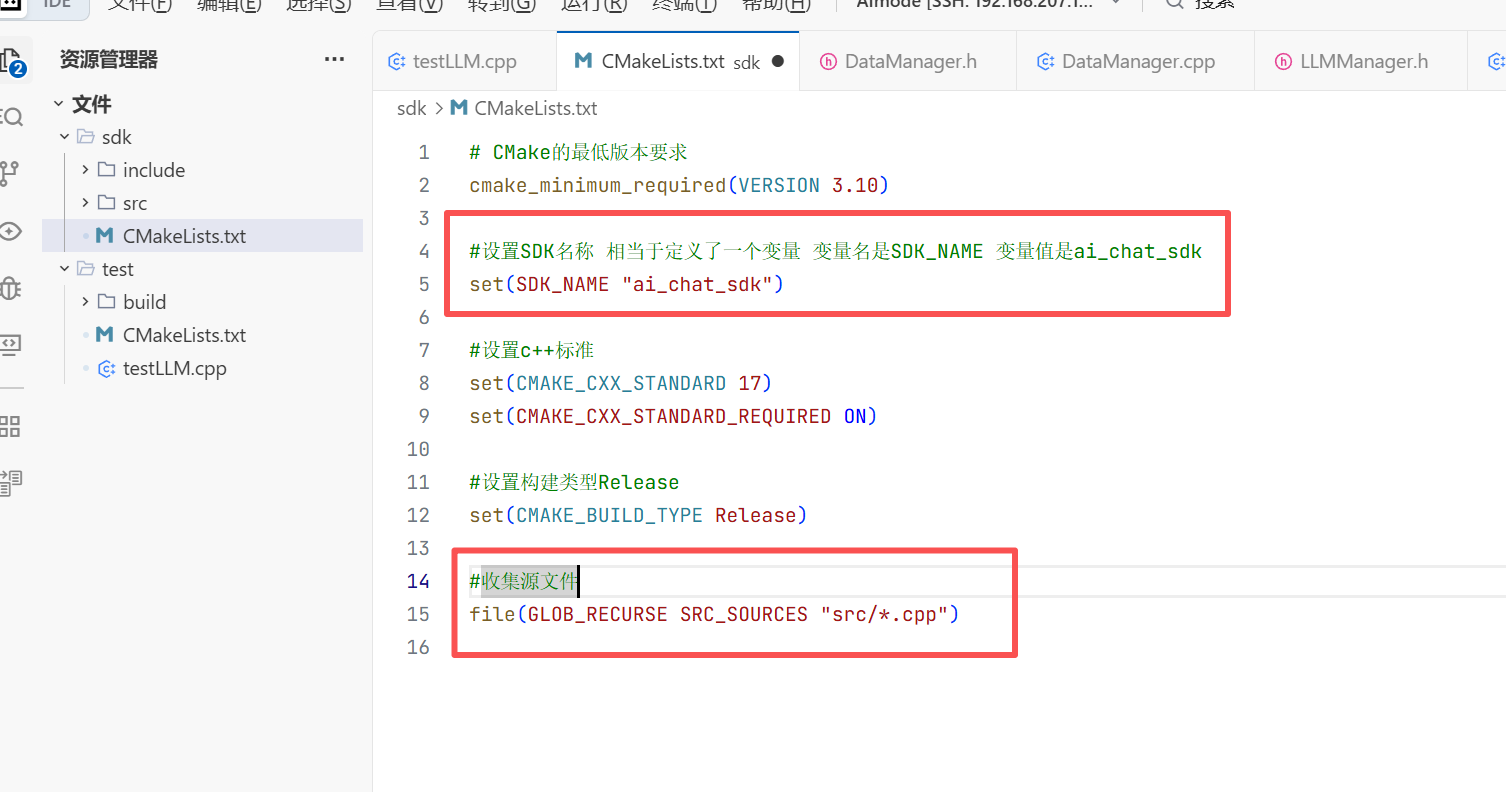
这里file是指获取SDK目录下后缀为cpp的所有文
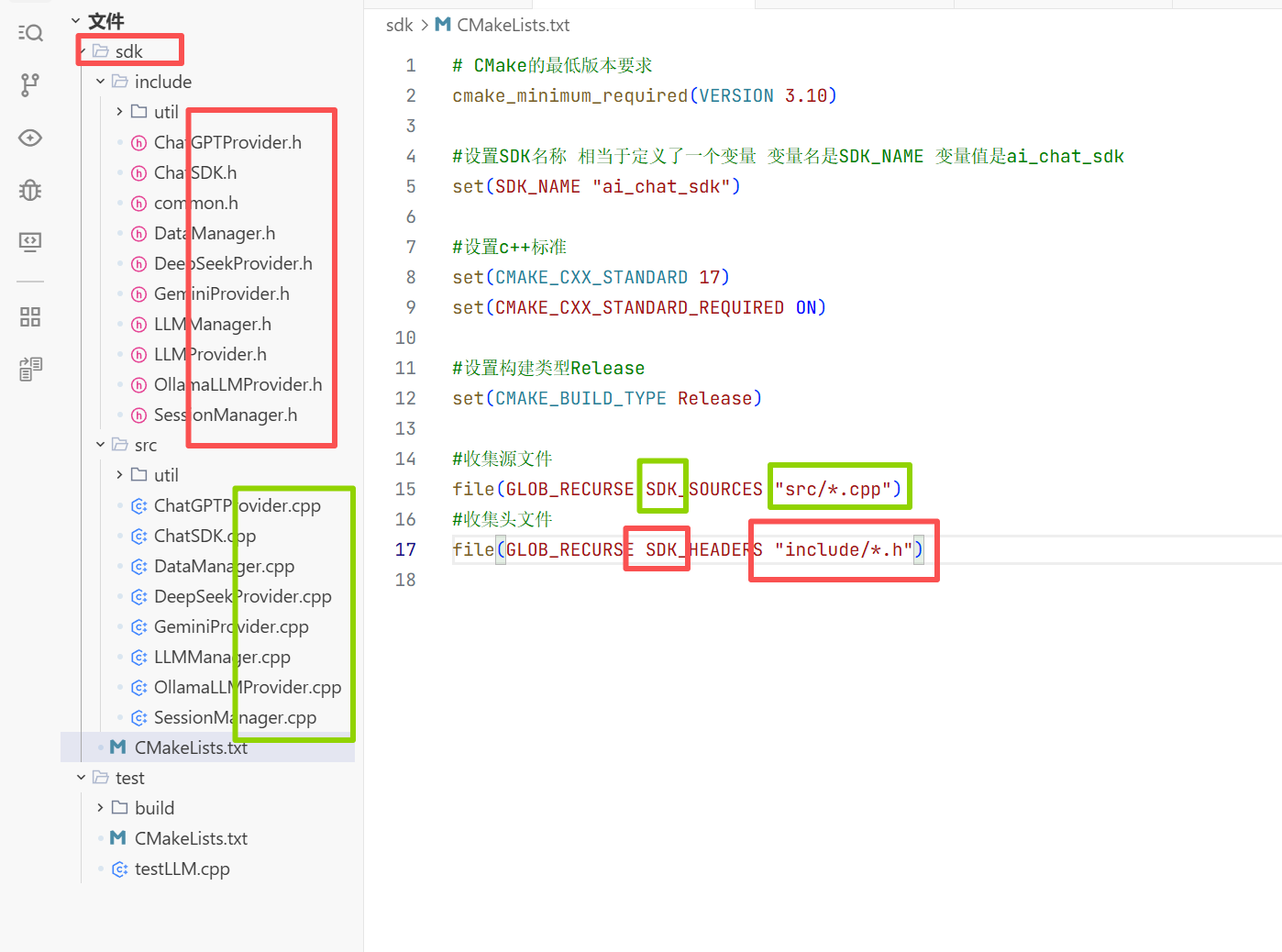

获取头文件与源文件生成静态库


这个的做法是使用那些库时像使用include的库一样不需要包含复杂的路径了 直接包就能使用
CMakeLists的代码:
cpp
# CMake的最低版本要求
cmake_minimum_required(VERSION 3.10)
#设置SDK名称 相当于定义了一个变量 变量名是SDK_NAME 变量值是ai_chat_sdk
set(SDK_NAME "ai_chat_sdk")
#设置c++标准
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
#设置构建类型Release
set(CMAKE_BUILD_TYPE Release)
#收集源文件
file(GLOB_RECURSE SDK_SOURCES "src/*.cpp")
#收集头文件
file(GLOB_RECURSE SDK_HEADERS "include/*.h")
#生成静态库 库名是ai_chat_sdk
add_library(${SDK_NAME} STATIC ${SDK_SOURCES} ${SDK_HEADERS})
#设置输出目录 输出到当前目录的build文件夹
set(EXECUTABLE_OUTPUT_PATH ${CMAKE_CURRENT_SOURCE_DIR}/build)
#定义httplib的CPPHTTPLIB_OPENSSL_SUPPORT宏 用于开启httplib的openssl支持
target_compile_definitions(${SDK_NAME} PUBLIC CPPHTTPLIB_OPENSSL_SUPPORT)
#设置头文件搜索路径 用于在编译时找到头文件
target_include_directories(${SDK_NAME} PUBLIC ${CMAKE_CURRENT_SOURCE_DIR}/include)
#设置静态库的链接目录
link_directories(/usr/local/lib)
find_package(OpenSSL REQUIRED)#查找OpenSSL库 如果没有找到 则会报错
include_directories(${OPENSSL_INCLUDE_DIR})#添加OpenSSL头文件搜索路径
#添加编译定义
target_compile_definitions(${SDK_NAME} PRIVATE CPPHTTPLIB_OPENSSL_SUPPORT)
#链接库 链接jsoncpp fmt spdlog OpenSSL::SSL OpenSSL::Crypto sqlite3
target_link_libraries(${SDK_NAME} jsoncpp fmt spdlog OpenSSL::SSL OpenSSL::Crypto sqlite3)
#安装规则 拷贝静态库到 /usr/local/lib 目录
install(TARGETS ${SDK_NAME}
ARCHIVE DESTINATION lib
)
#安装规则 拷贝头文件到系统目录下 /usr/local/include
install(DIRECTORY ${CMAKE_CURRENT_SOURCE_DIR}/include/
DESTINATION include/ai_chat_sdk
FILES_MATCHING PATTERN "*.h"
)2.静态库的生成:
在编译之前我们要把我之前测试安装的静态库代码给删除掉然后重新安装我直接写的静态库代码。
现在我们要编译sdk所以现在退出到sdk目录下
然后进入sdk目录创建一个build目录
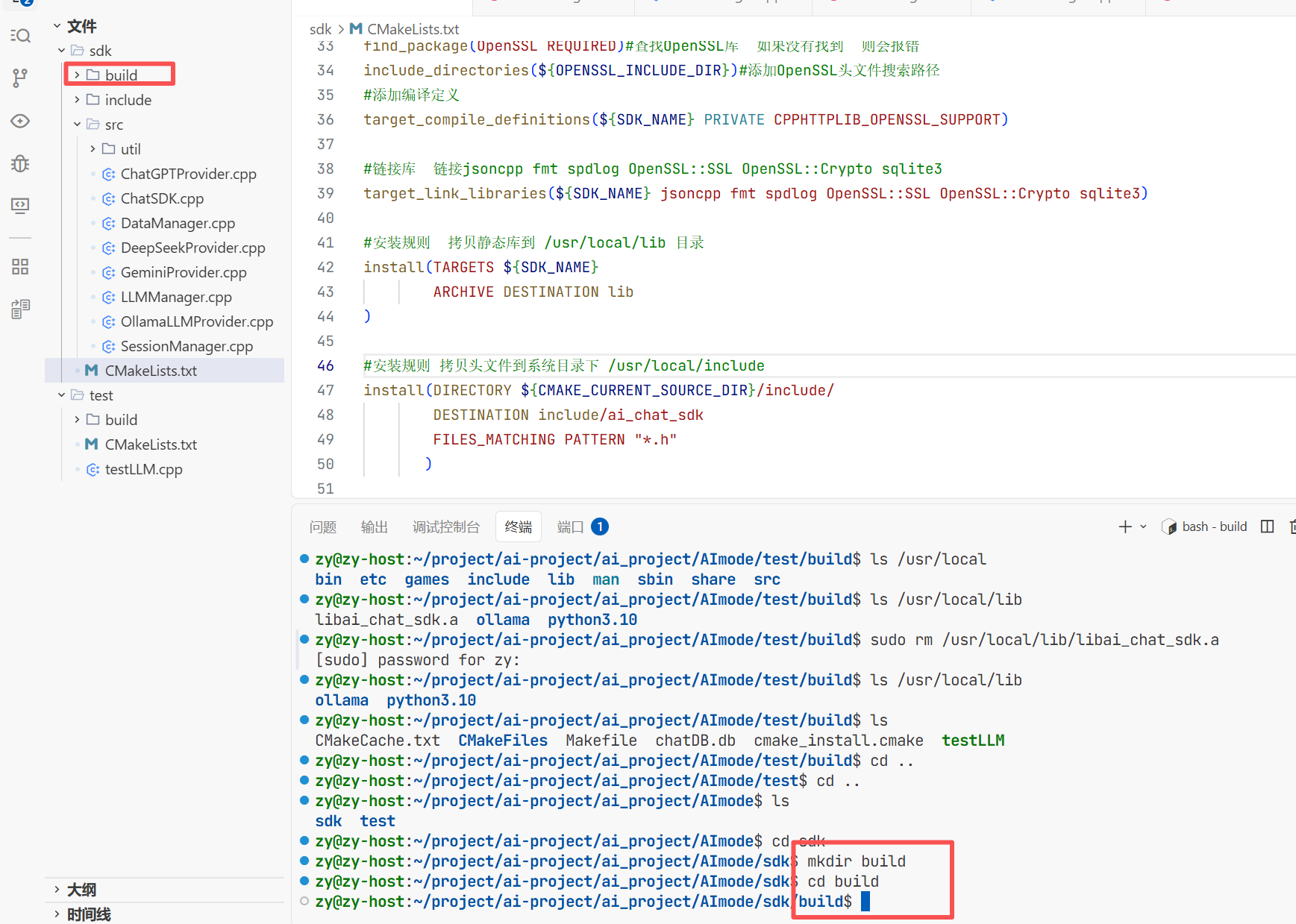
然后cd到build目录下 进行编译 对上一级整体目录进行编译
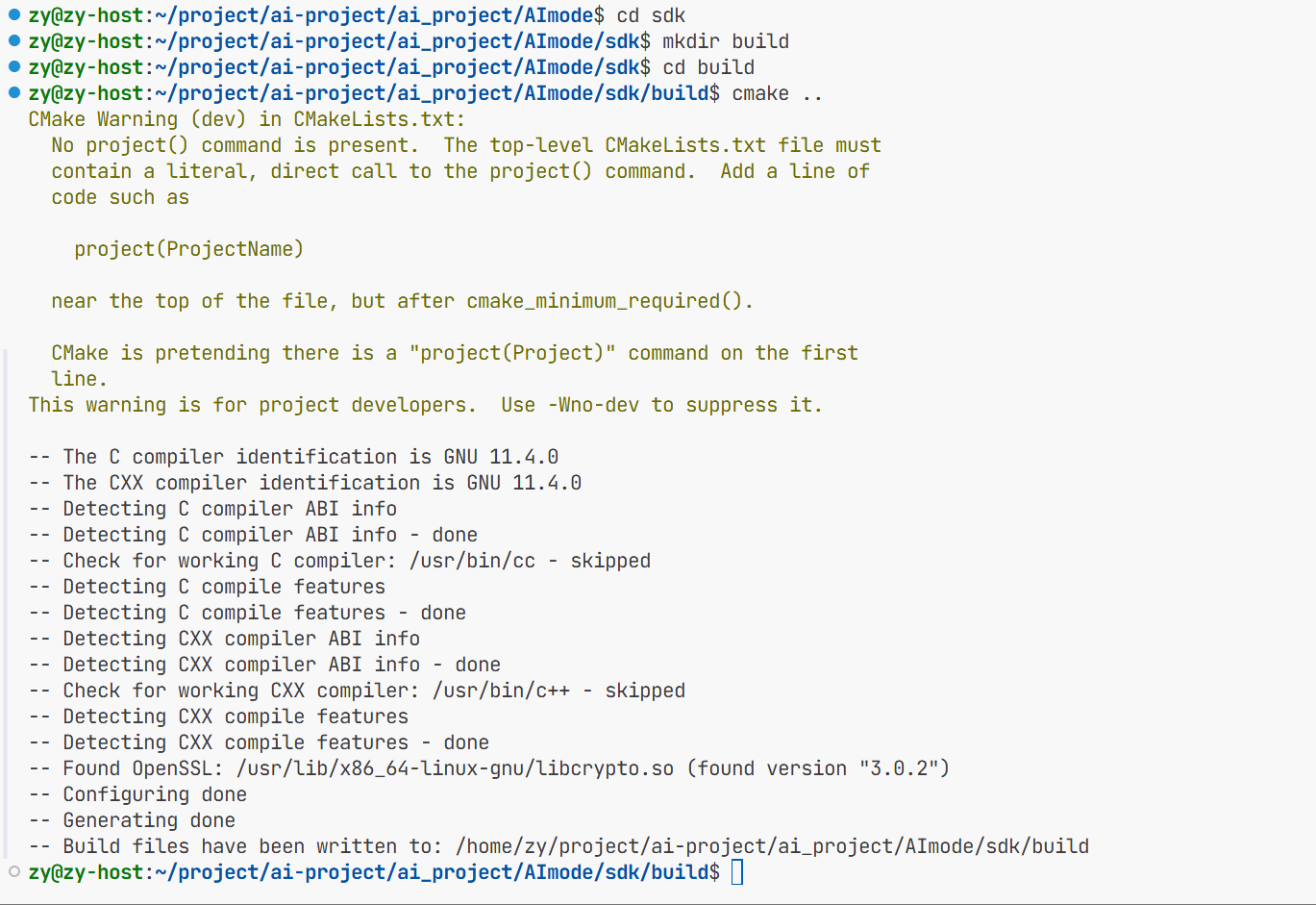
这样生成编译需要的文件就没问题了 然后现在对项目sdk进行编译
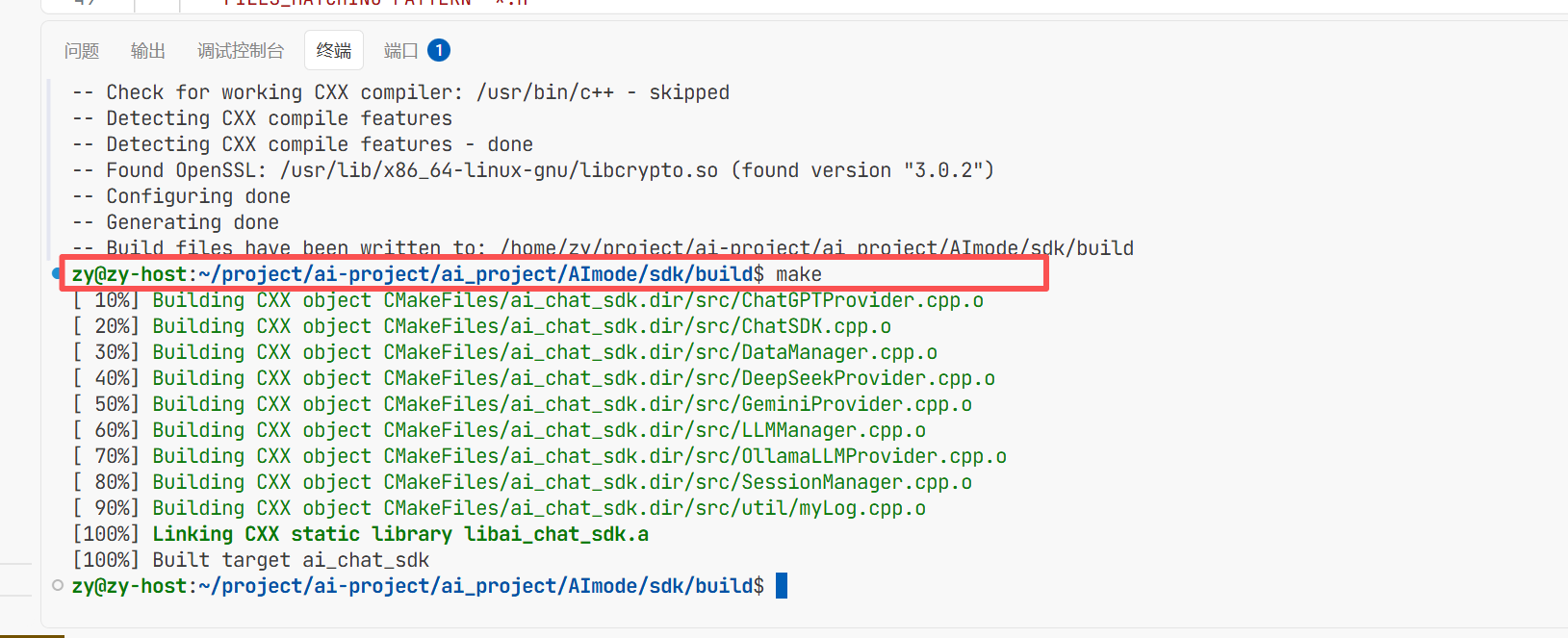
这样编译就完成了
这样我们的静态库就生成好了
3.静态库的安装:
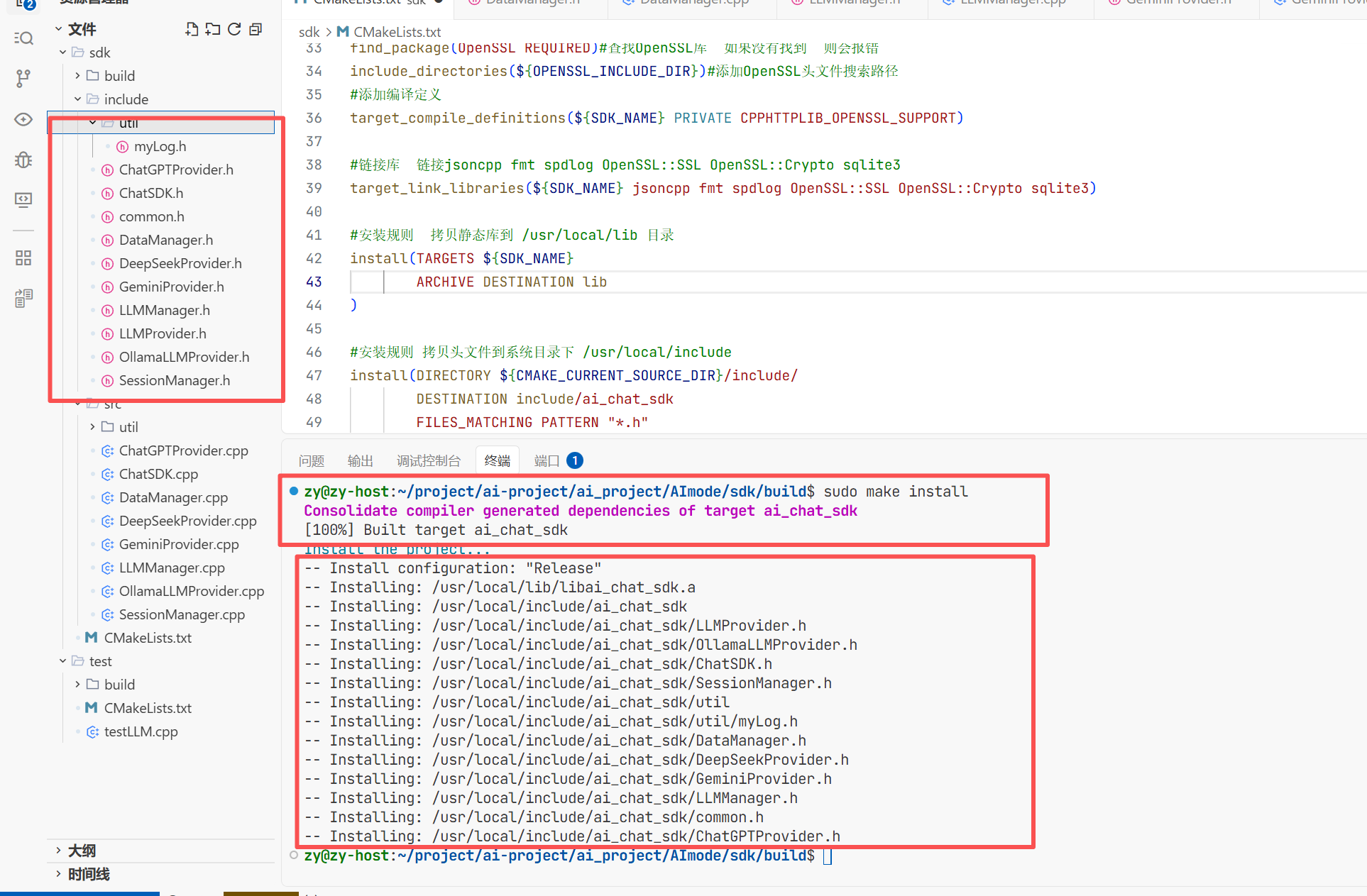
执行安装命令 这样就把我们所以的库全部安装完成了
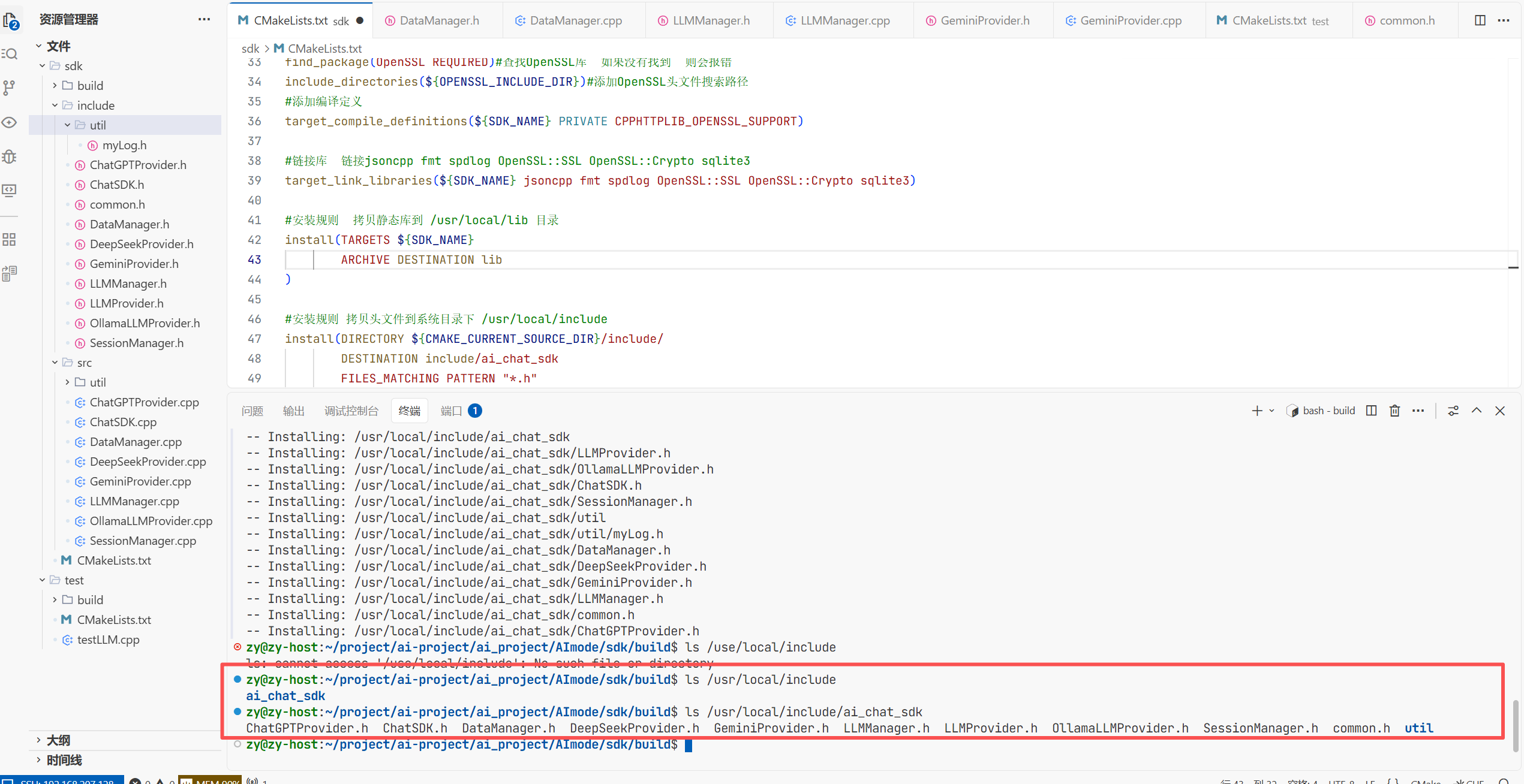
已经安装到指定目录下面了
这样以后我们使用的时候直接去gitee上把我们实现的静态库拉取下来就能使用了
4.ChatSDK的使用手册:
18.ChatServer:
1.基本功能介绍:
现在我们底层的代码已经实现好了 那么现在我们需要进行网页交互 那么我们需要实现一个前端页面,还需要实现一个聊天服务器。
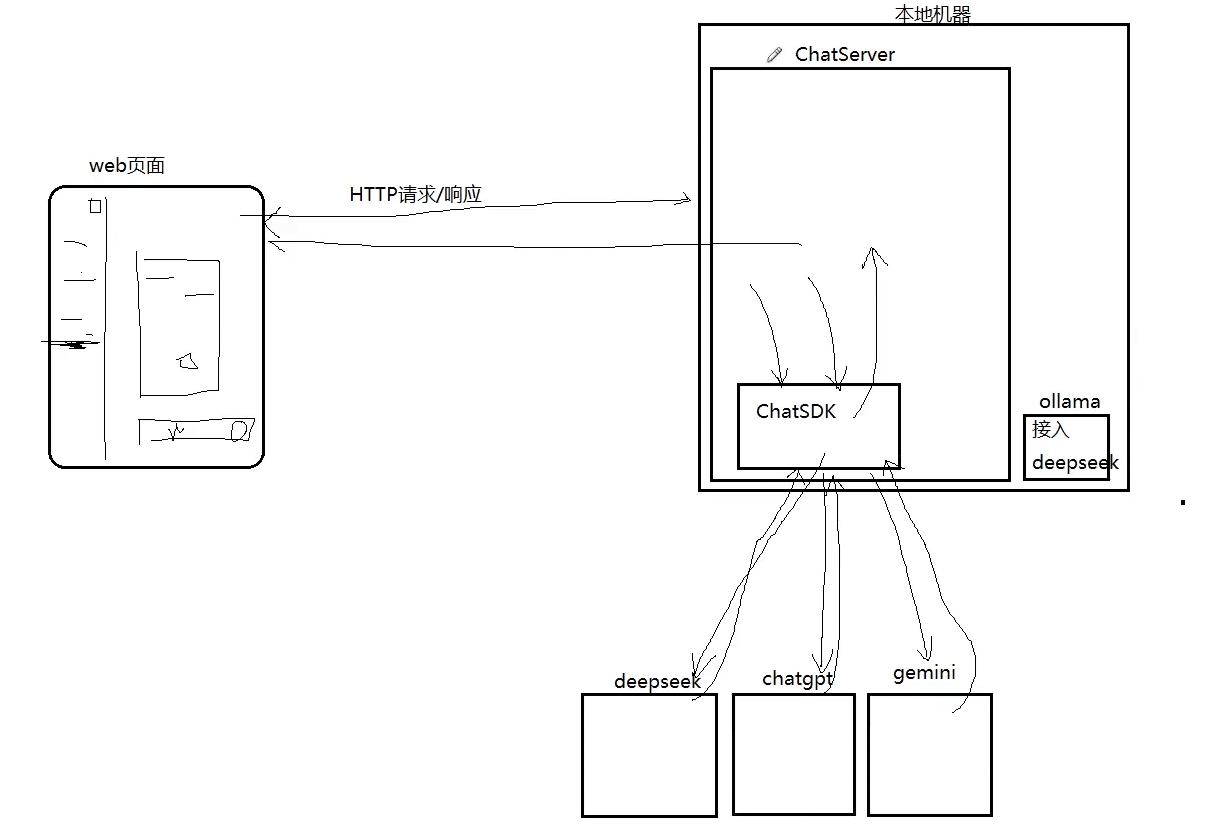
也就是现在我们要实现一个接口用于与前端页面进行交互,然后ChatSever发请求去给chatSDK然后再去云端服务器响应去返回消息,实现一个交互的功能。

2.接口的介绍
RESTful API
由于整个和⼤模型交互都是基于HTTP协议,聊天助⼿将来也是浏览器借助HTTP协议和服务器交互, 因此本项⽬接⼝采⽤RESTful API⻛格进⾏设计,它是基于HTTP协议的应⽤接⼝设计规划,提供了⼀ 种通过标准化操作和资源访问模式进⾏客⼾端和服务器通信的⽅式。
REST是 Representational State Transfer 的缩写,翻译过来就是表现层状态转移。
•
资源(Resource) RESTful API 中的每⼀个对象、实体或数据都被抽象为⼀个资源。例如,⽤⼾、⽂章 等都可以
作为资源。每个资源都通过⼀个唯⼀的 URI (统⼀资源标识符)标识。
•
URI(统⼀资源标识)
URI是⽤于标识资源的地址。 RESTful API 中,通常使⽤ URL (统⼀资源定位符)作为
URI 。例如:
▪
/users/123 表⽰ id 为 123 的⽤⼾资源
▪
/posts/456 表⽰ id 为 456 的⽂章资源
•
HTTP动作(HTTP Methods)
RESTful API 依赖于 HTTP 协议的常⻅⽅法来对资源进⾏操作,每个 HTTP ⽅法对应不同的
操作:
▪
GET : 获取资源
▪
POST :创建新的资源
▪
PUT :更新资源
▪
DELETE :删除资源
•
⽆状态
每个请求都是独⽴的,服务器不会保存客⼾端任何会话状态。客⼾端发来的每⼀个请求,都必须包
含服务器处理该请求所需的所有信息。
•
表现层状态转移( Representational State Transfer )
资源的表现形式可以是 JSON 、 XML 、 HTML 等格式,通常 RESTful API 使⽤ JSON 作
为数据交换格式,因为它轻量且易于解析。
请求URL: POST /api/user/id

3.接口的设计:
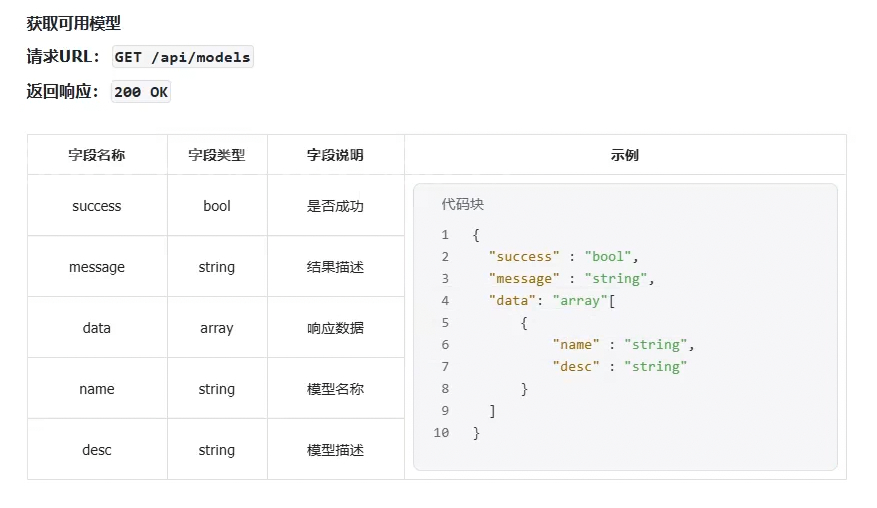
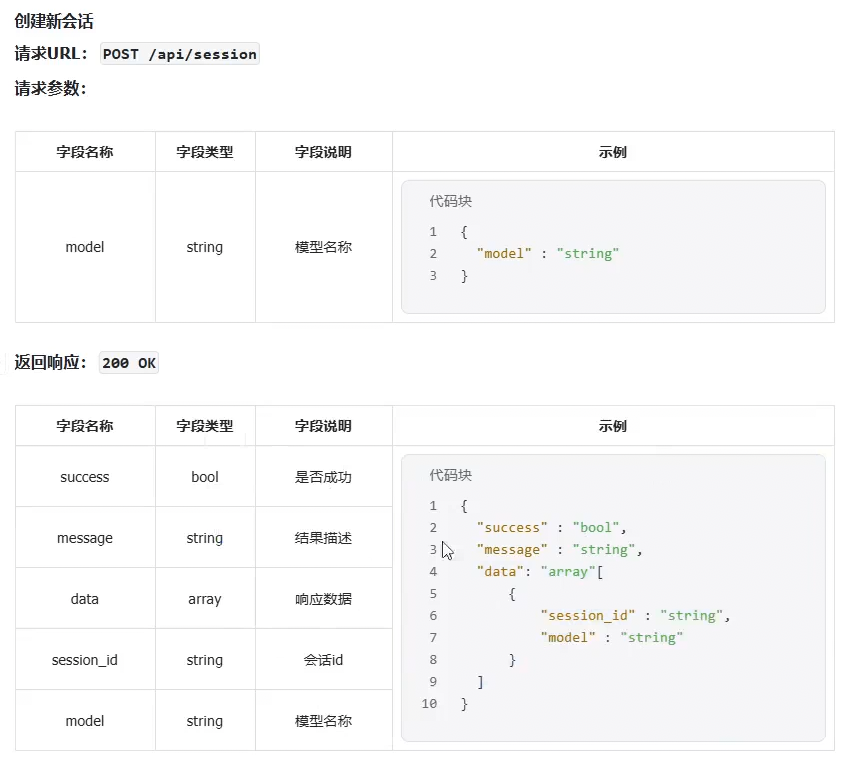
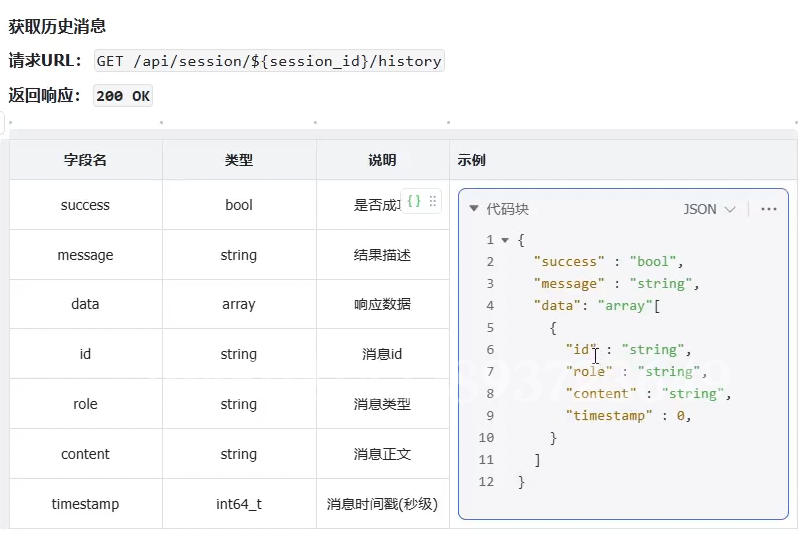
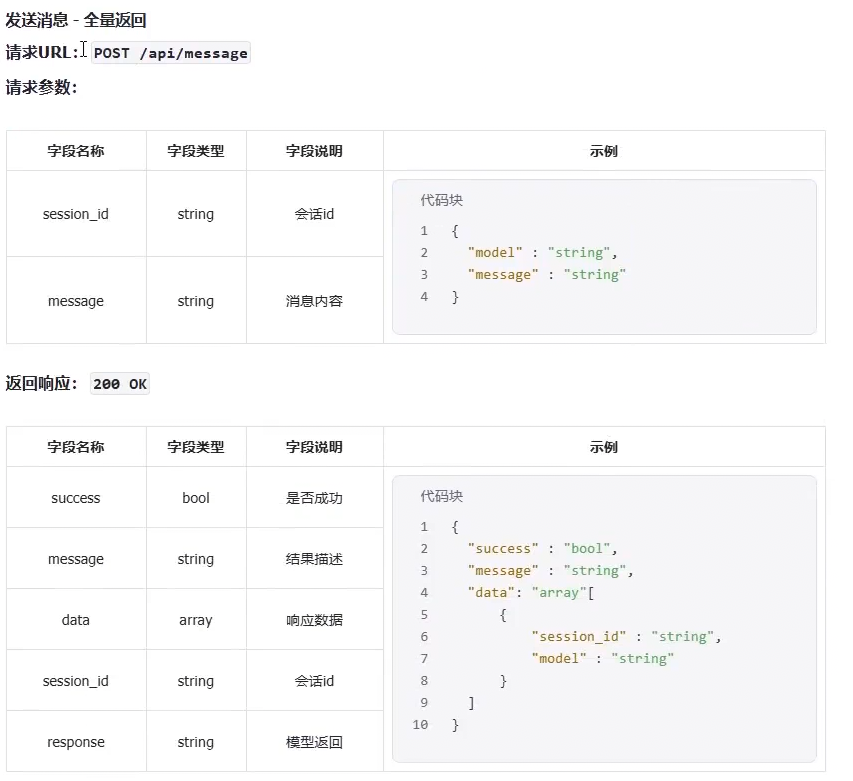
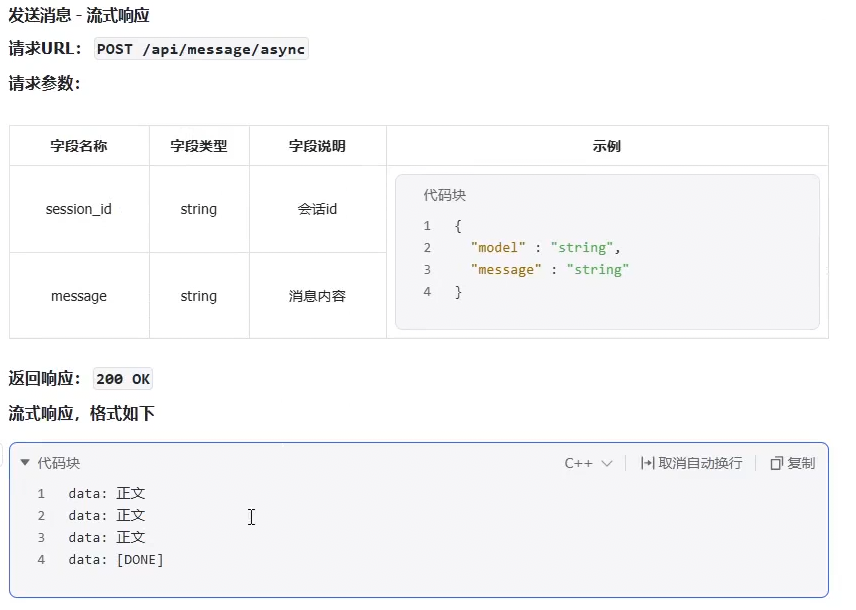

4.ChatServer的初始化:
我们在实现ChatServer时 我们要严格按照这个接口的设计来写他的格式。
我们设计的这个要和SDK级别是一致的
1.头文件:
这里我们能调用他的文件是因为我们上面已经执行安装成一个静态库了 直接include就直接包过来
这样就可以使用了
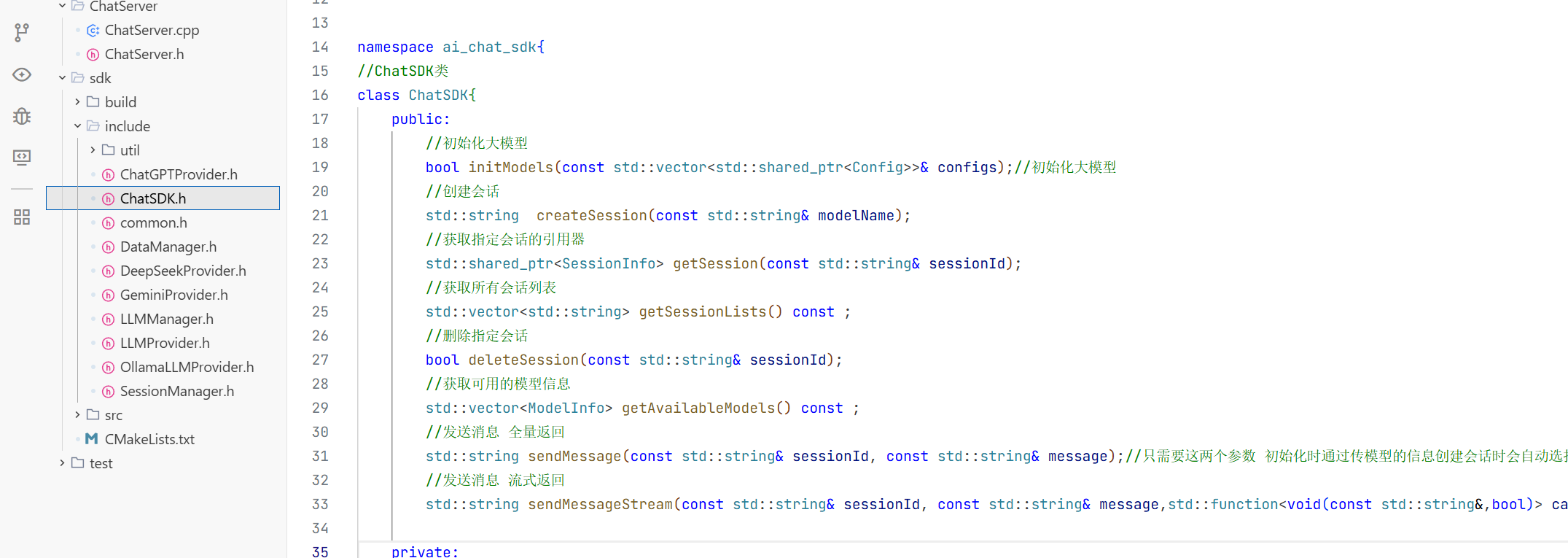
有了chatsdk后我们还要进行初始化 这里我们就要传一些模型的配置参数。
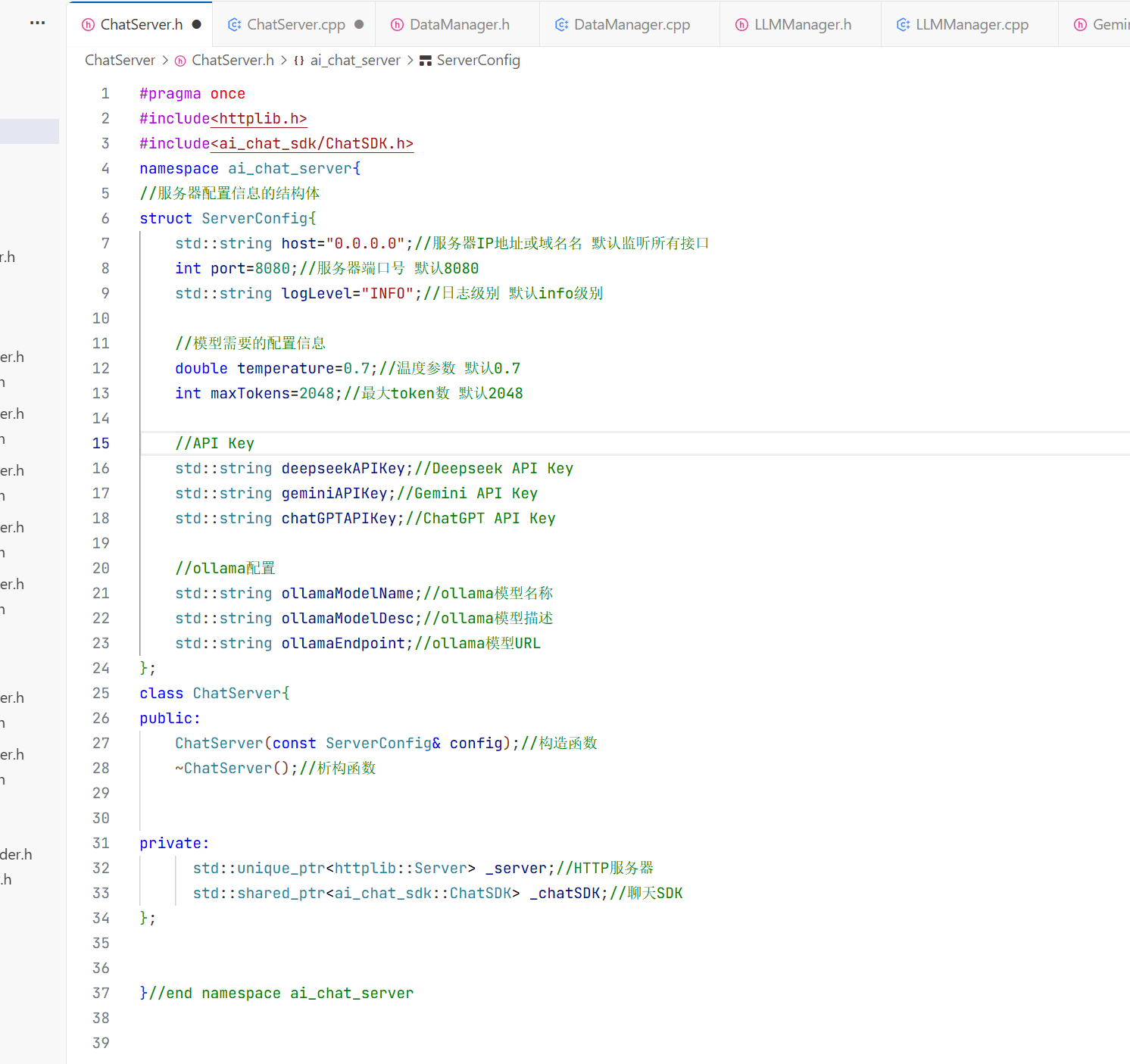
我们需要的基本的结构体和变量已经定义完成了
2.源文件:
这里我们要初始化模型 我们可以参考testLLM里的初始化方法:
这里复制过来即可
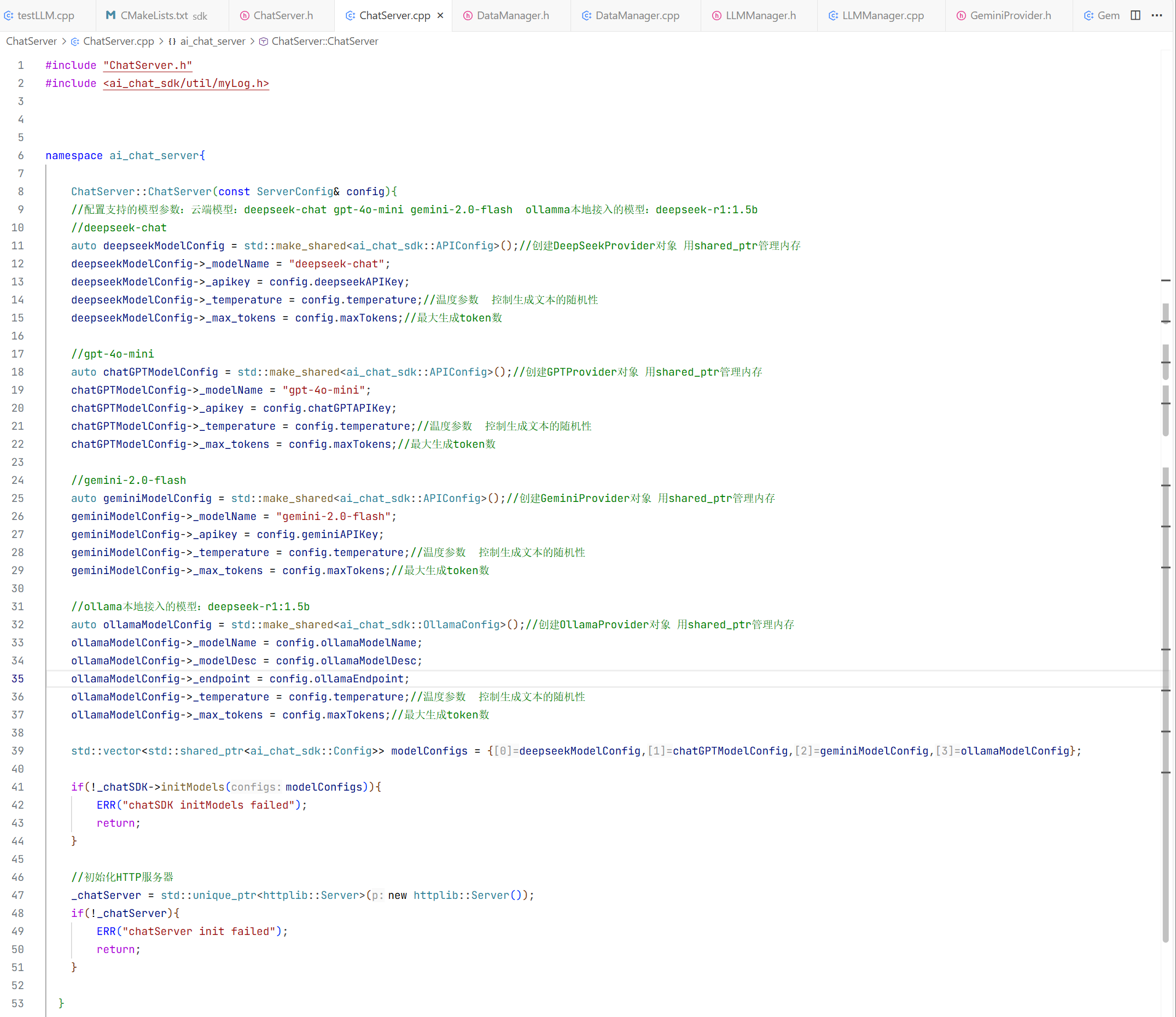
这里面模型的配置信息就不能写死了 测试的时候可以写死 现在要通过chat'sdk的配置参数来调用
ChatServer的初始化就好了 初始化模型 和初始化服务器。
5.ChatServer 服务器的启动:
头文件的更改
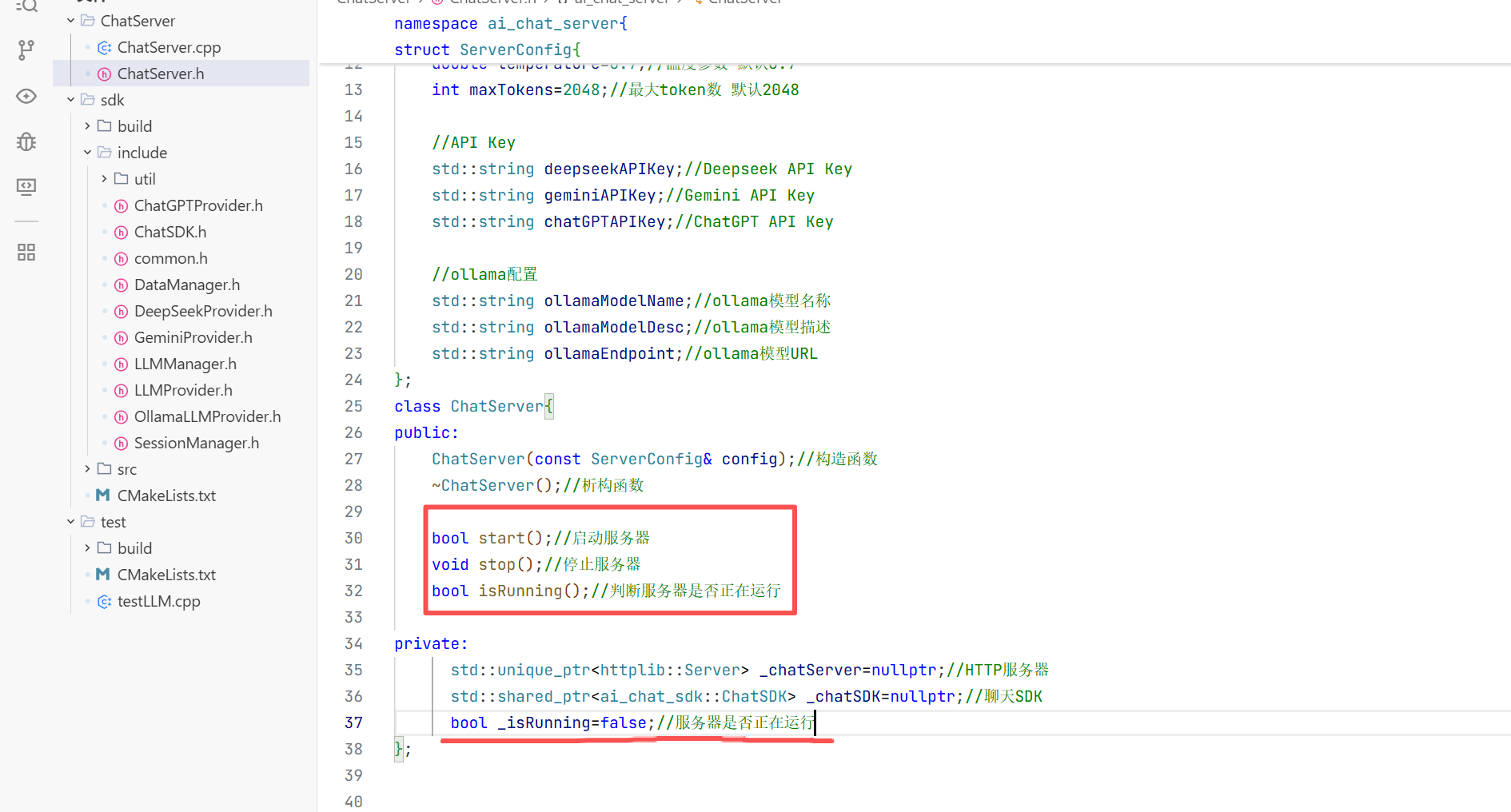
给一个成员变量用来标记服务器是否正在运行。
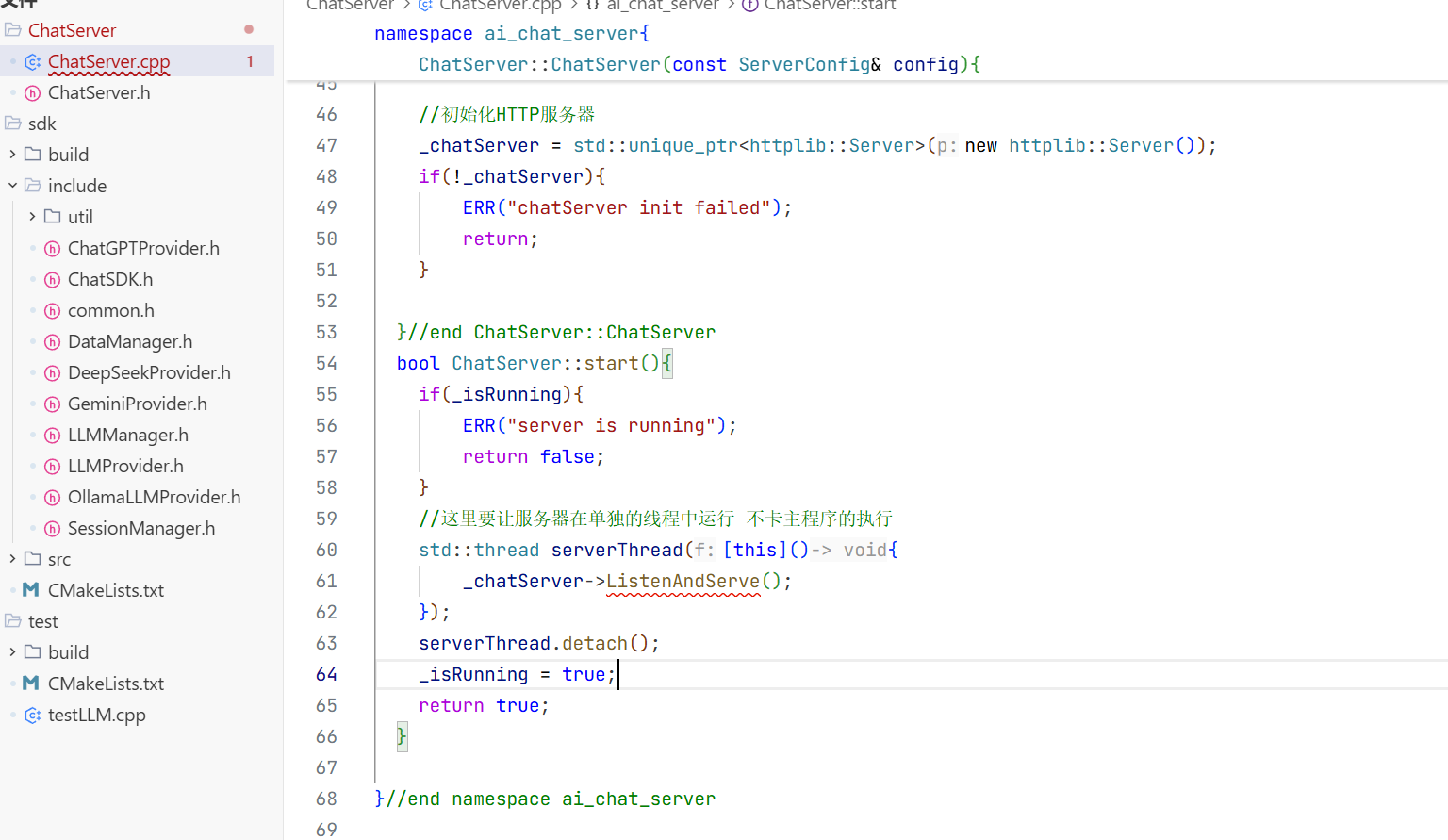
这里我们用库中的函数来提供一个线程 单独开一个线程 监听一下 但是这里我们需要服务器的ip地址和端口号 但是这里的配置信息只有在构造函数里面可见 所以这里我们还需要添加一个成员函数用来获取配置信息。这样就能获得用户传过来的配置信息了。
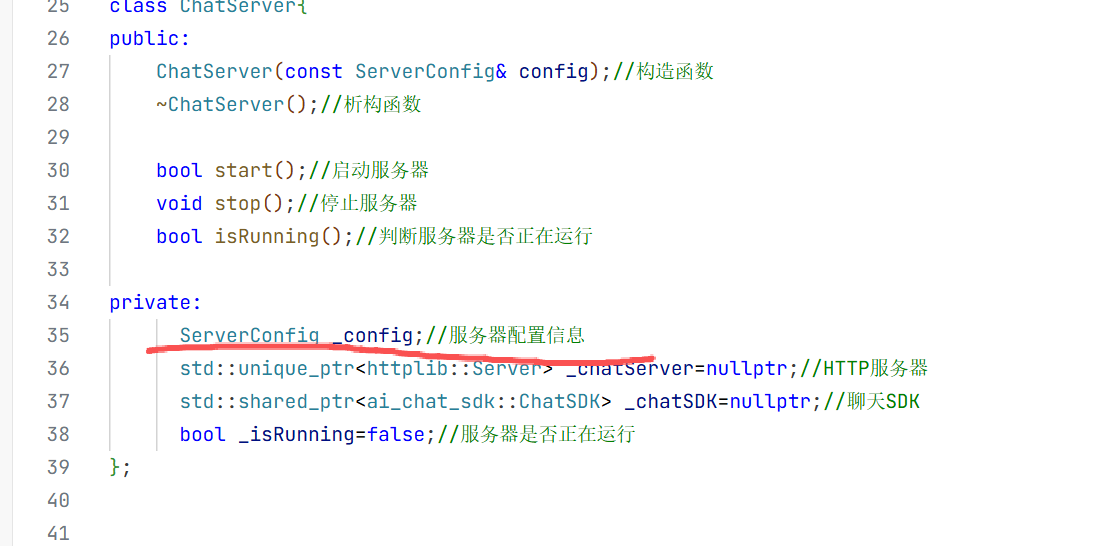
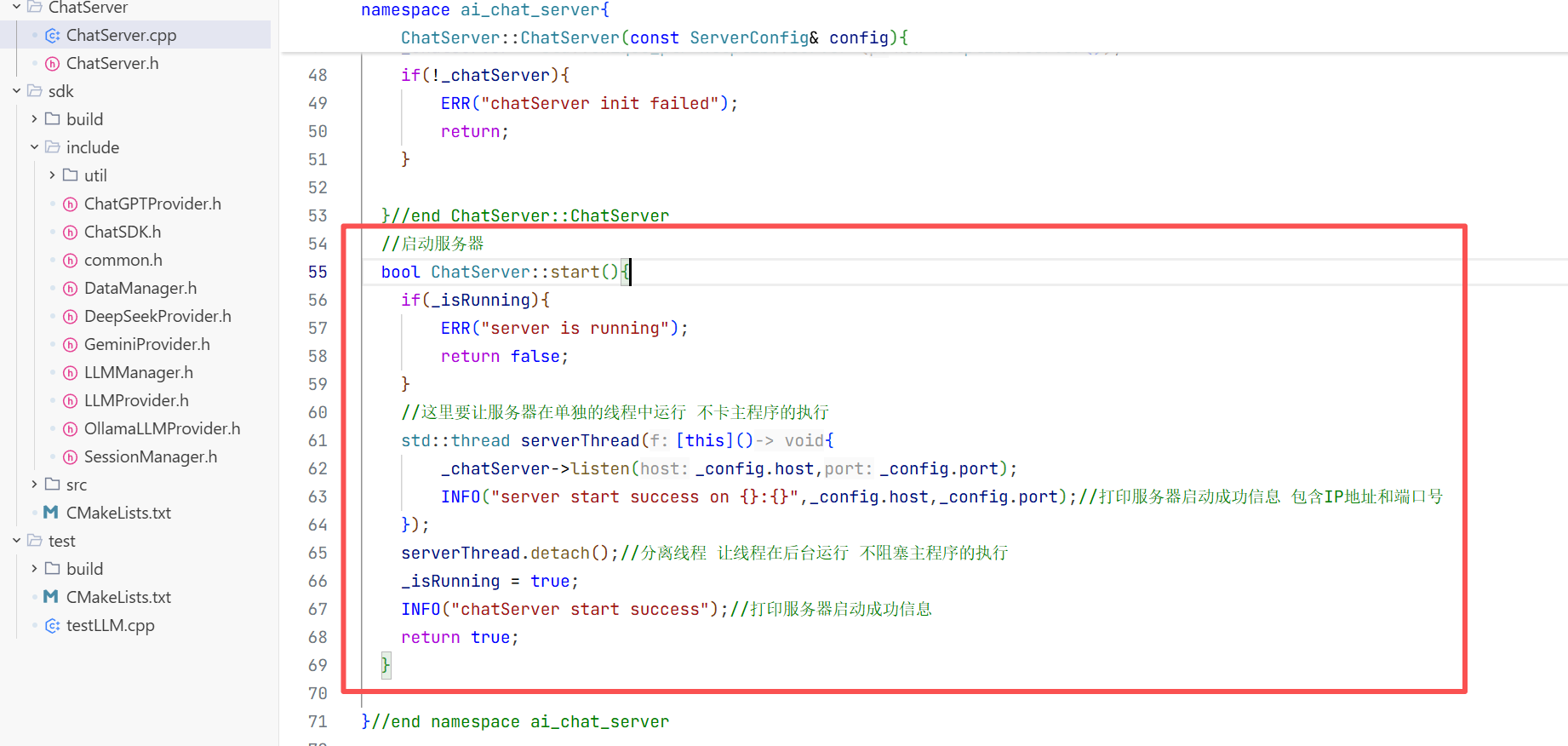
启动服务器这里就完成了
6..ChatServer 服务器的停止:
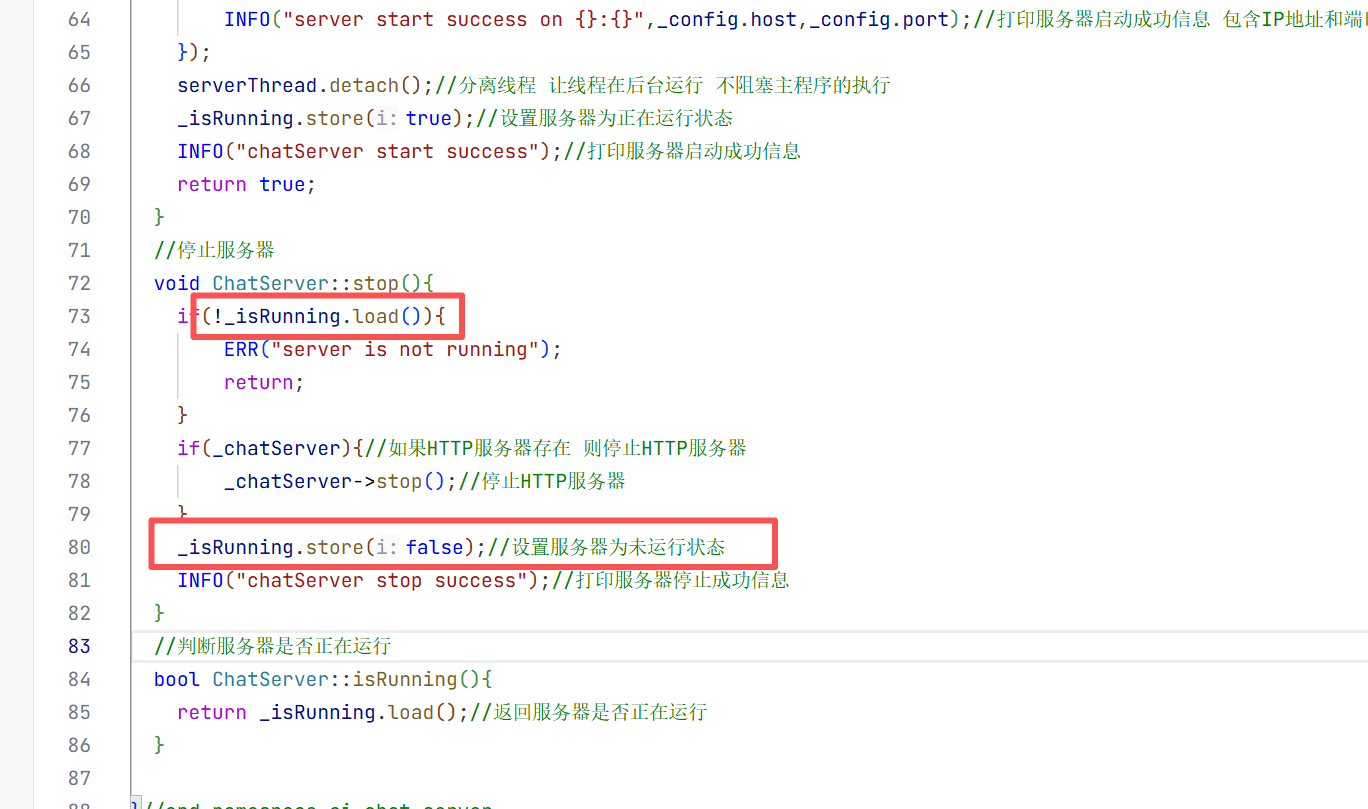
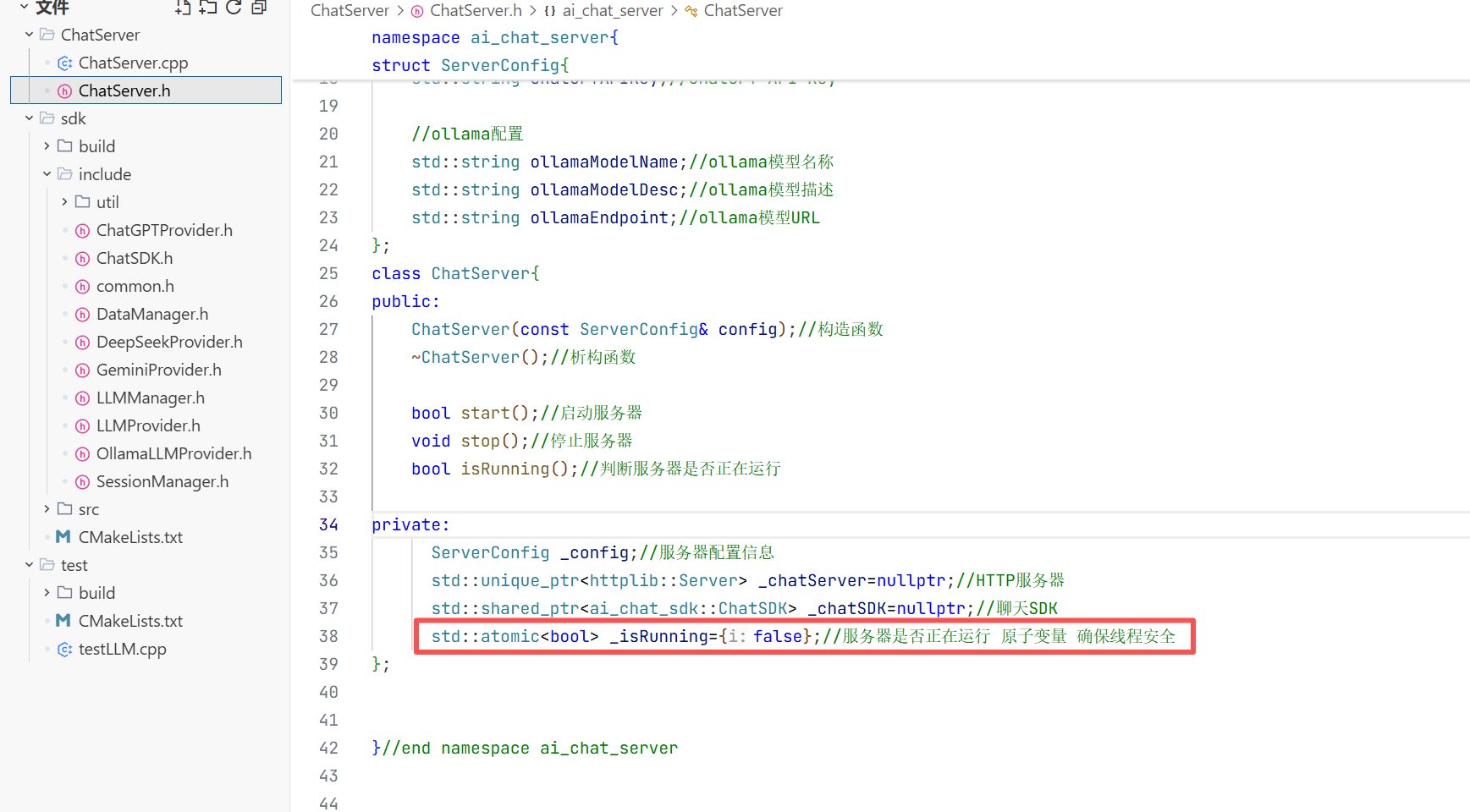
这里改变为用原子变量存储 来保证线程安全。
7.服务器接口的实现 :
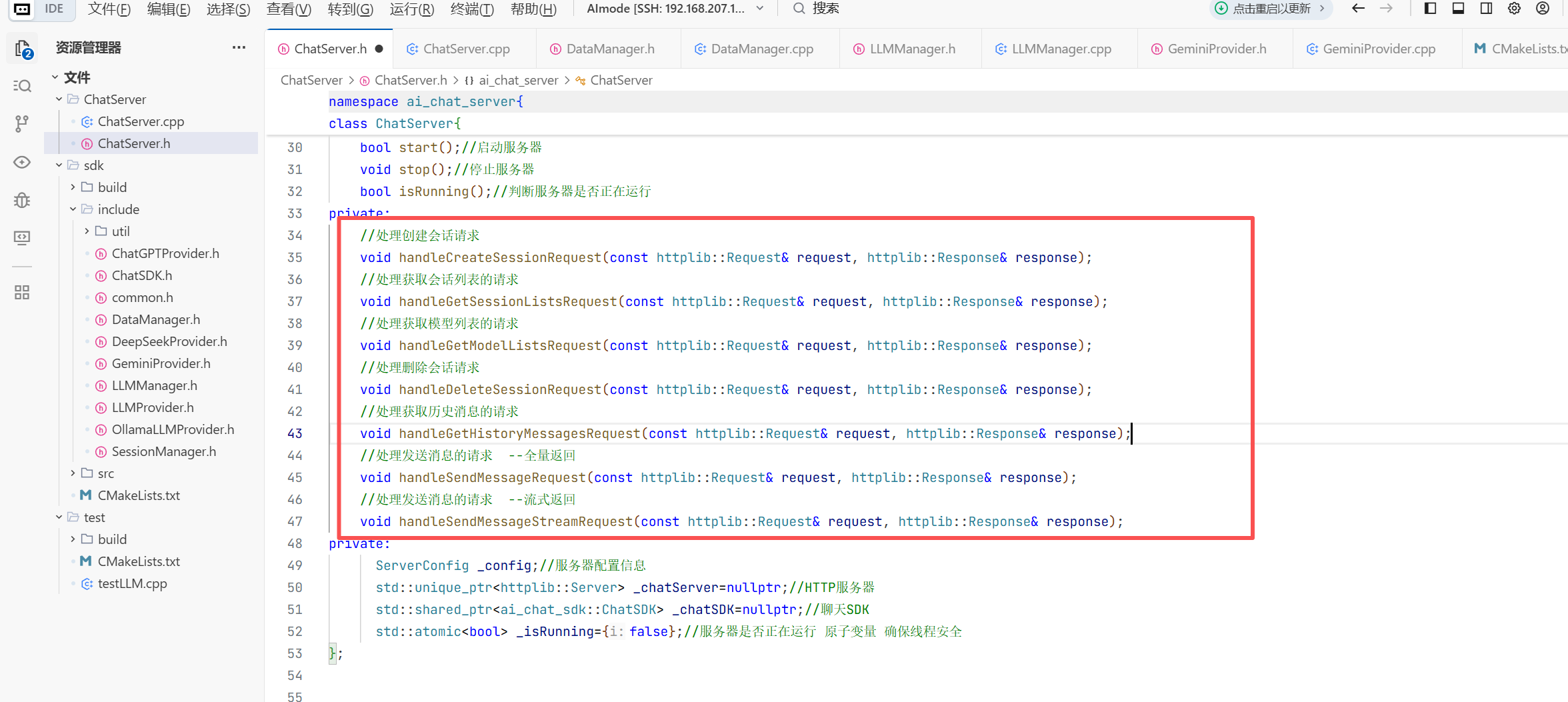
我们一共要处理这七个接口。
1.创建会话的接口:

要根据这个接口来实现,通过解析请求体 拿到请求参数
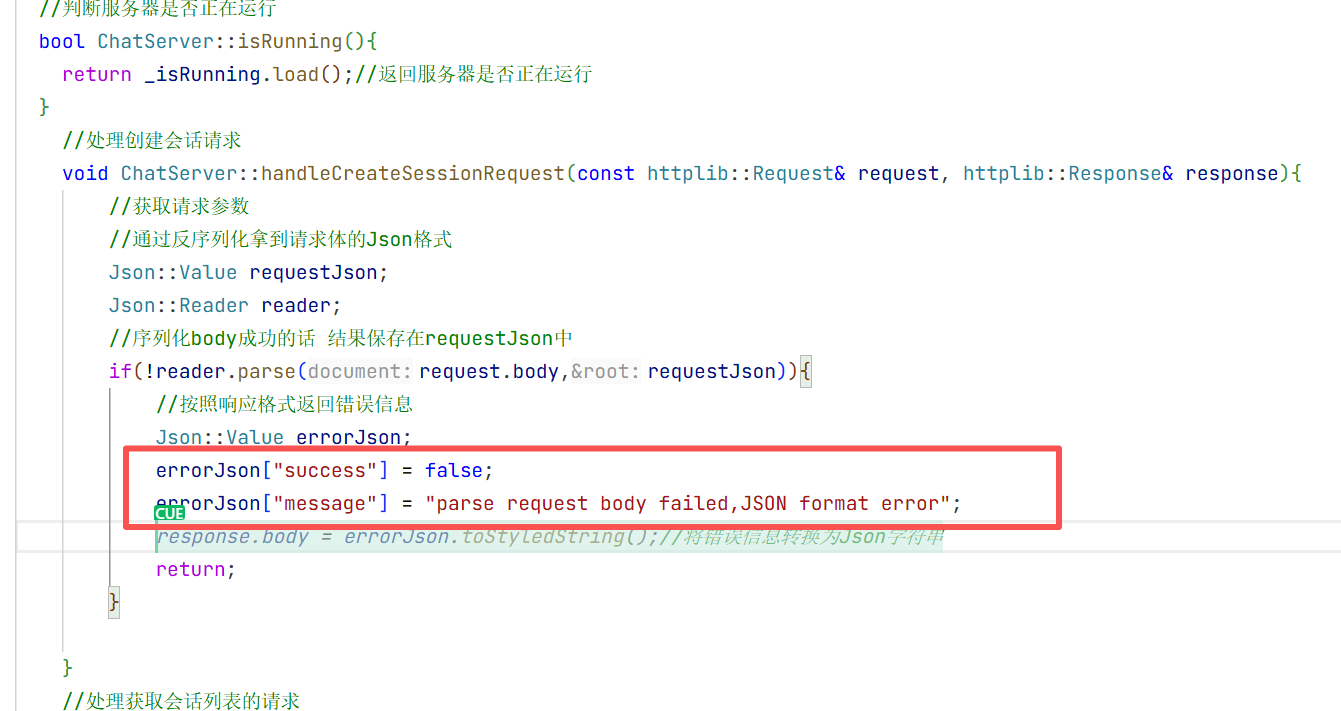

如果响应失败就没有这个数据信息就直接返回success的值和message的值即可。
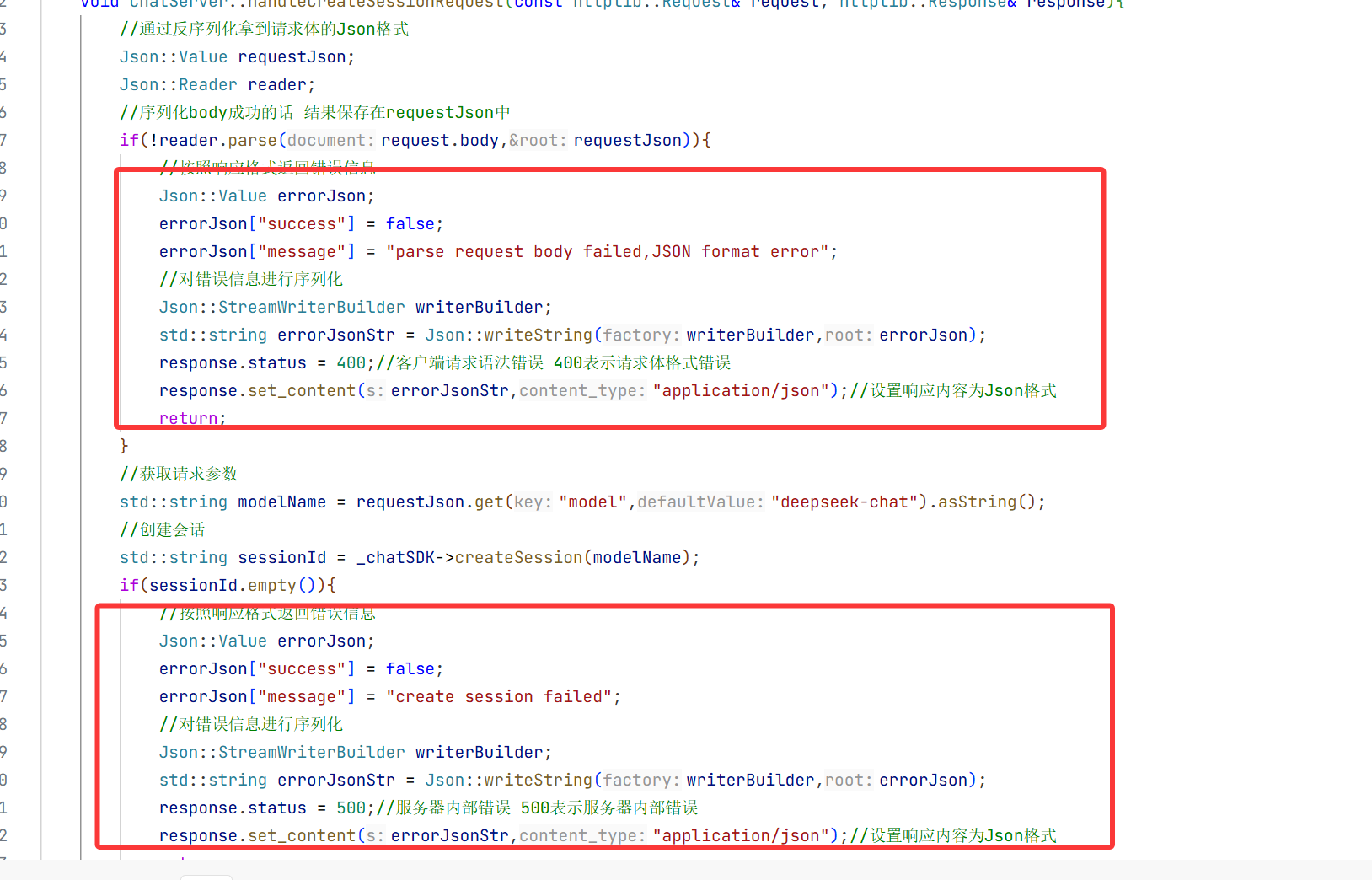
这样实现的话中间那段错误信息的解析就重复实现了 所以我们再单独实现一个函数 用来专门实现这个错误信息的。
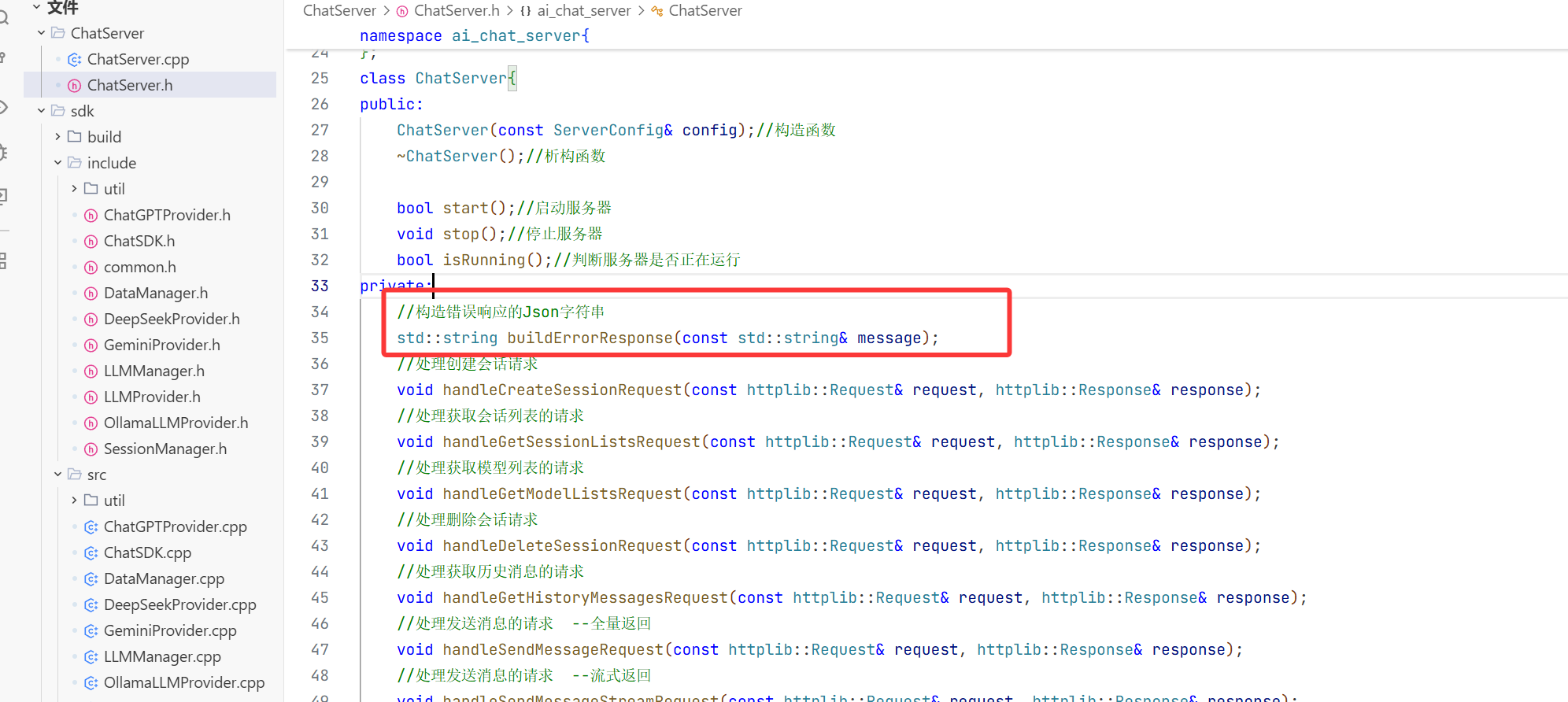

这样使用我们刚才所封装好的方法即可:
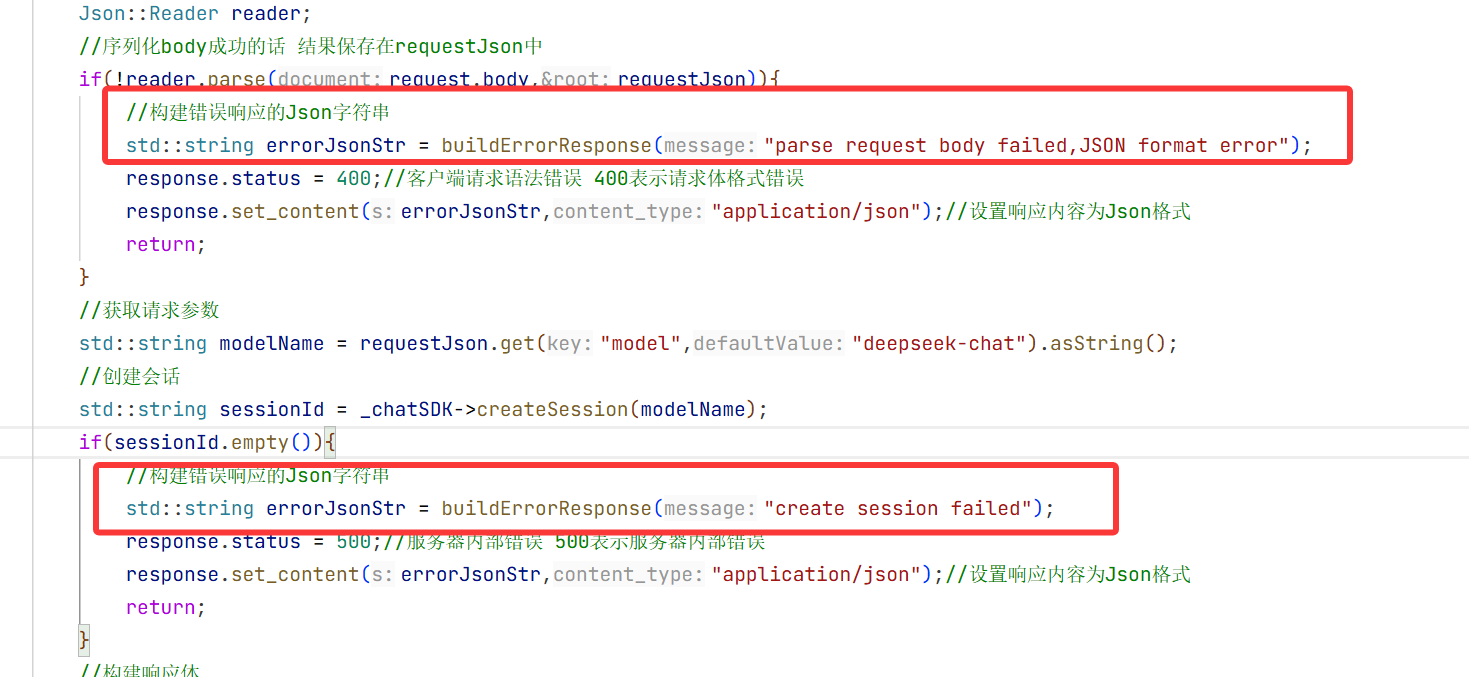

cpp
//处理创建会话请求
void ChatServer::handleCreateSessionRequest(const httplib::Request& request, httplib::Response& response){
//通过反序列化拿到请求体的Json格式
Json::Value requestJson;
Json::Reader reader;
//序列化body成功的话 结果保存在requestJson中
if(!reader.parse(request.body,requestJson)){
//构建错误响应的Json字符串
std::string errorJsonStr = buildErrorResponse("parse request body failed,JSON format error");
response.status = 400;//客户端请求语法错误 400表示请求体格式错误
response.set_content(errorJsonStr,"application/json");//设置响应内容为Json格式
return;
}
//获取请求参数
std::string modelName = requestJson.get("model","deepseek-chat").asString();
//创建会话
std::string sessionID = _chatSDK->createSession(modelName);
if(sessionID.empty()){
//构建错误响应的Json字符串
std::string errorJsonStr = buildErrorResponse("create session failed");
response.status = 500;//服务器内部错误 500表示服务器内部错误
response.set_content(errorJsonStr,"application/json");//设置响应内容为Json格式
return;
}
//构建响应体
Json::Value dataJson;//存储得到的响应数据
dataJson["session_id"] = sessionID;
dataJson["model"] = modelName;
Json::Value responseJson;
responseJson["success"] = true;
responseJson["message"]="create session success";
responseJson["data"] = dataJson;
//对成功信息进行序列化 序列化成字节流
Json::StreamWriterBuilder writerBuilder;
std::string responseJsonStr = Json::writeString(writerBuilder,responseJson);
response.status = 200;//成功 200表示请求成功
response.set_content(responseJsonStr,"application/json");//设置响应
return;
}//end handleCreateSessionRequest这就是整个创建会话接口的实现。
2.获取会话列表的请求接口:

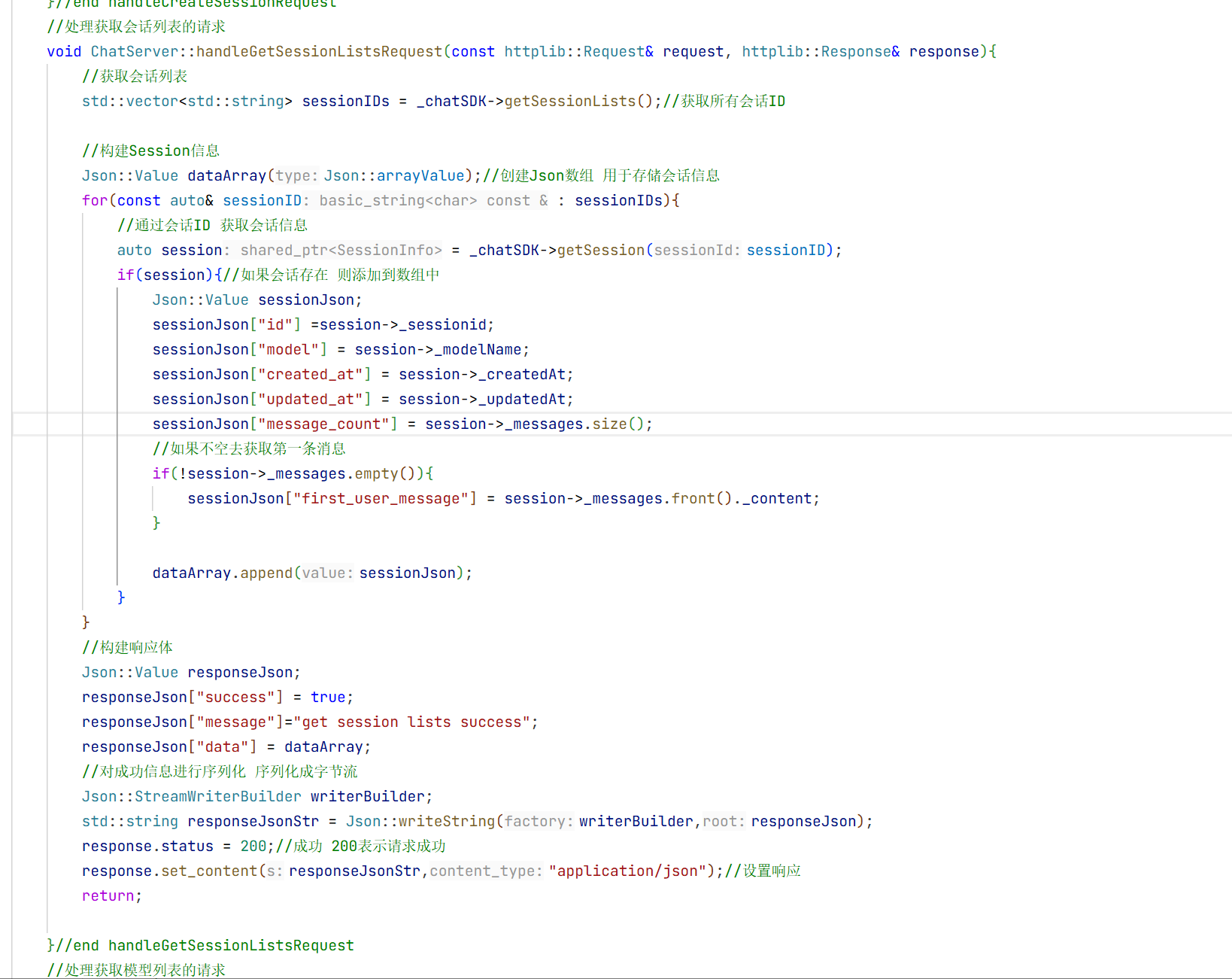
获取会话列表的请求接口就实现完成了
3.获取模型列表请求的接口:

这个接口是在用户新建对话时选择可用模型的时候弹出来的窗口
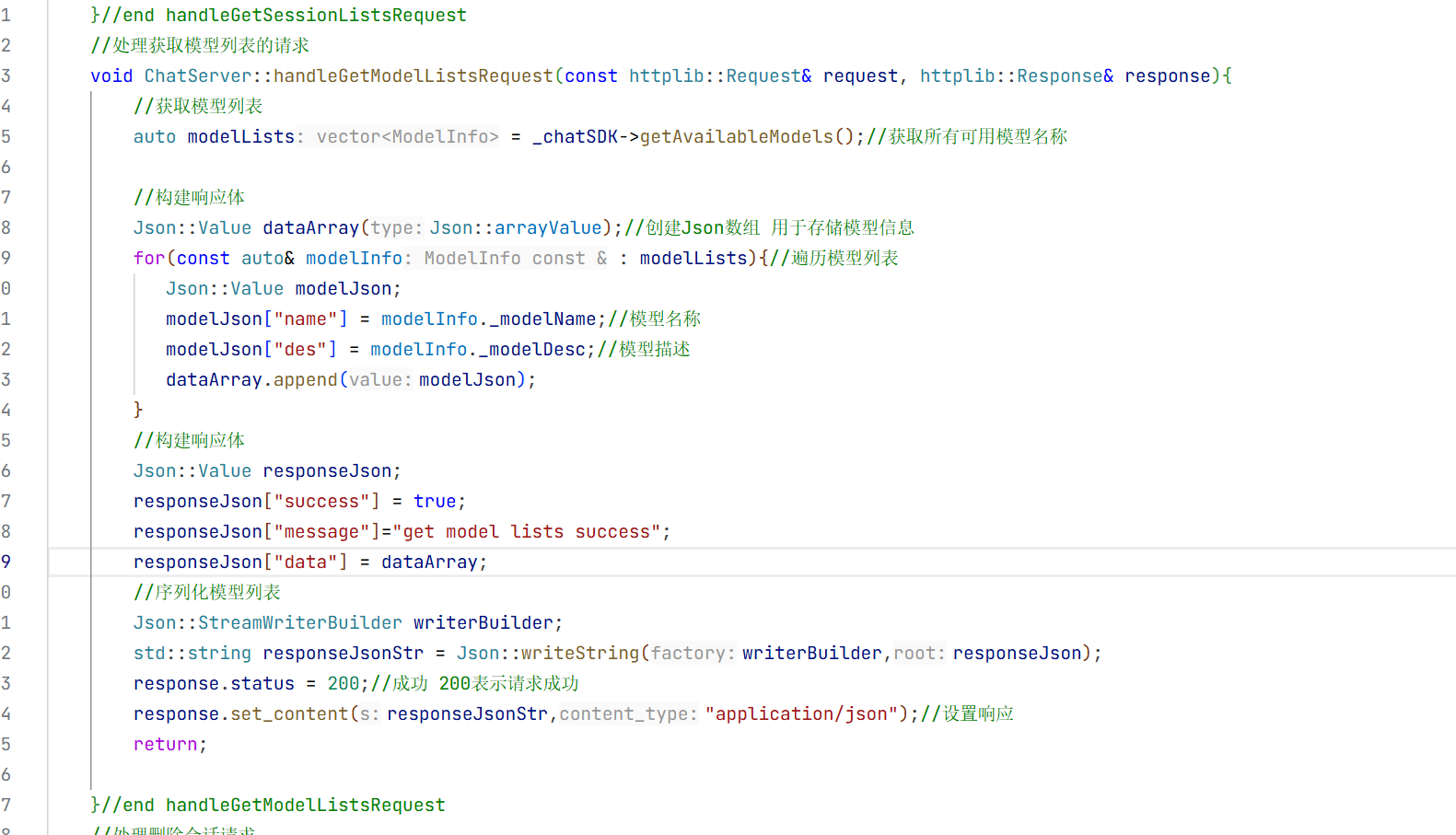
4.处理删除会话请求的接口:

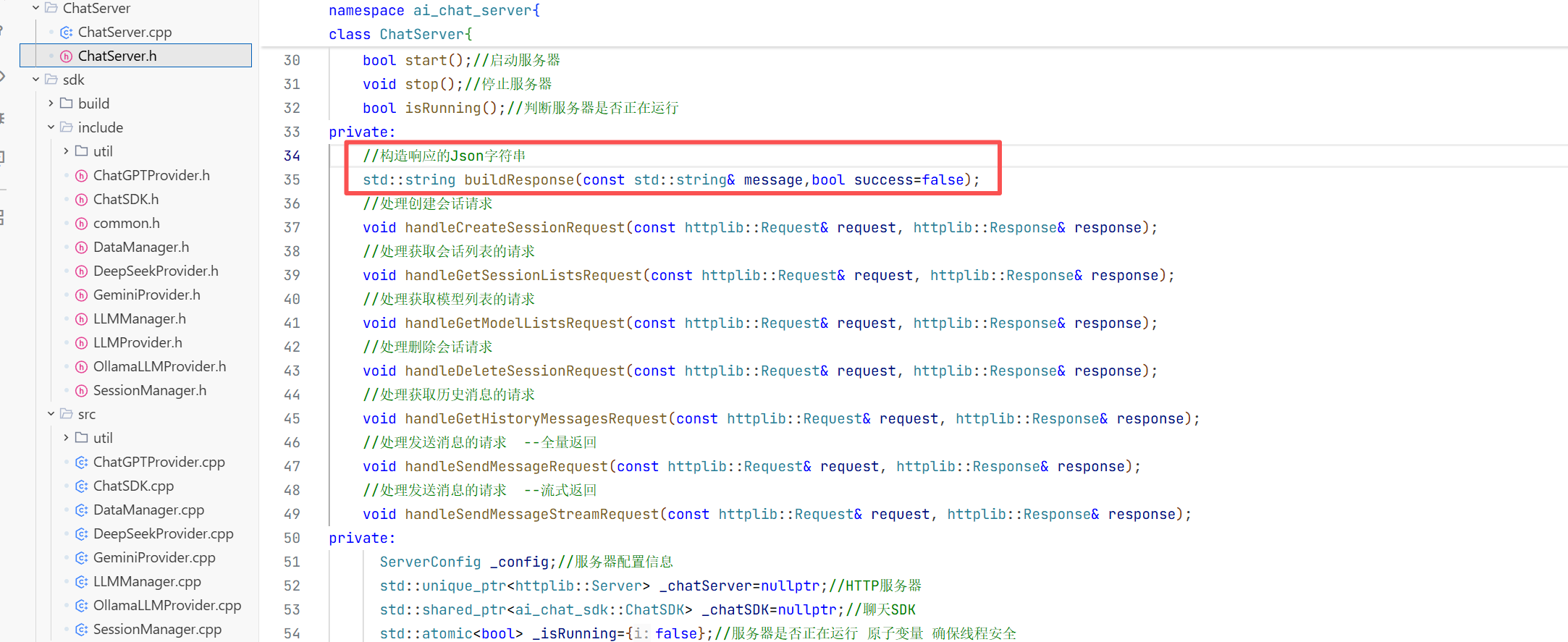
这里我们要更改一下上面实现的构建响应请求的函数 如果只能构造错误请求就有点鸡肋,所以这里实现成响应请求,如果成功就返回一个true
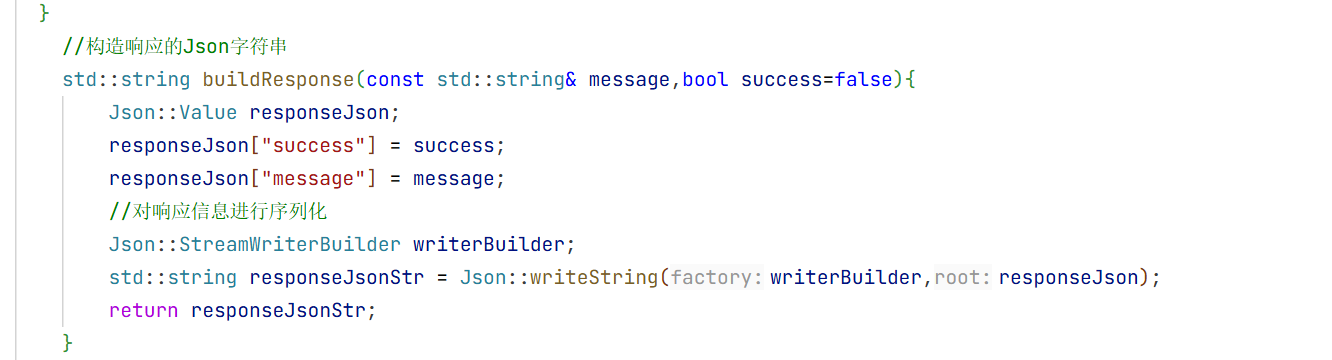
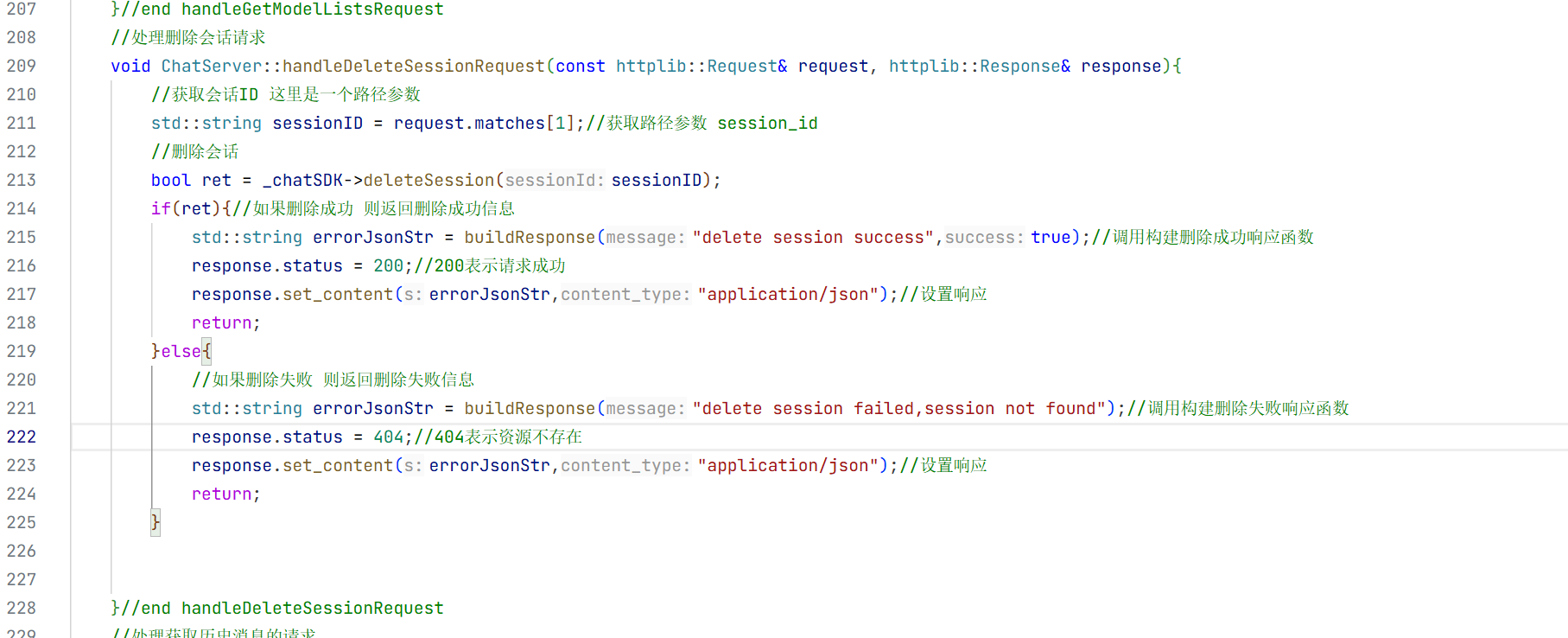
5.获取历史消息的请求接口:
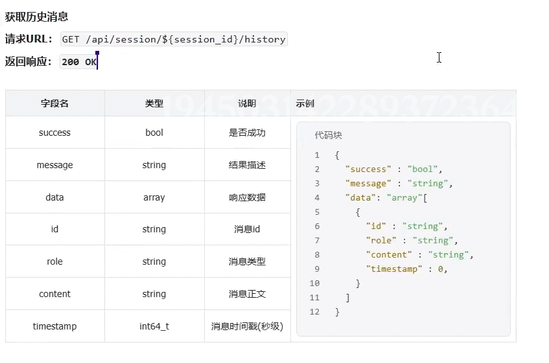

6.发送消息--全量返回 的接口实现:


这个基本上用不到因为基本默认都是流式返回
7.发送消息--流式返回 的接口实现:
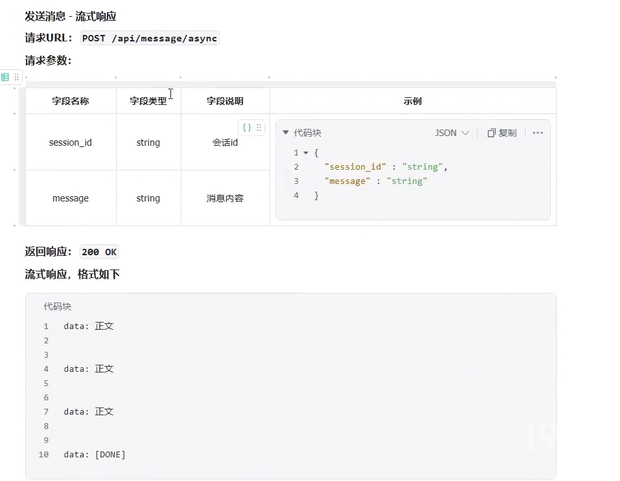
这里我们调用这个响应方法用到的参数 这个通常用于流式响应
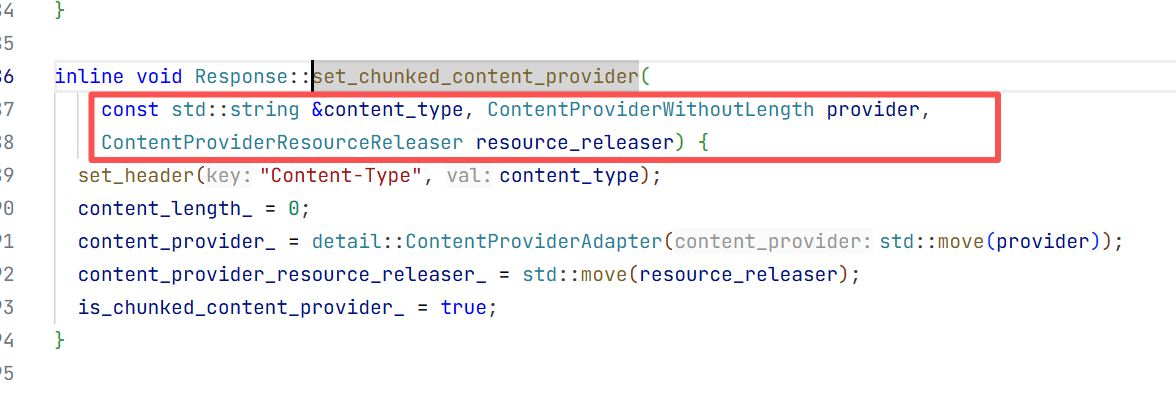
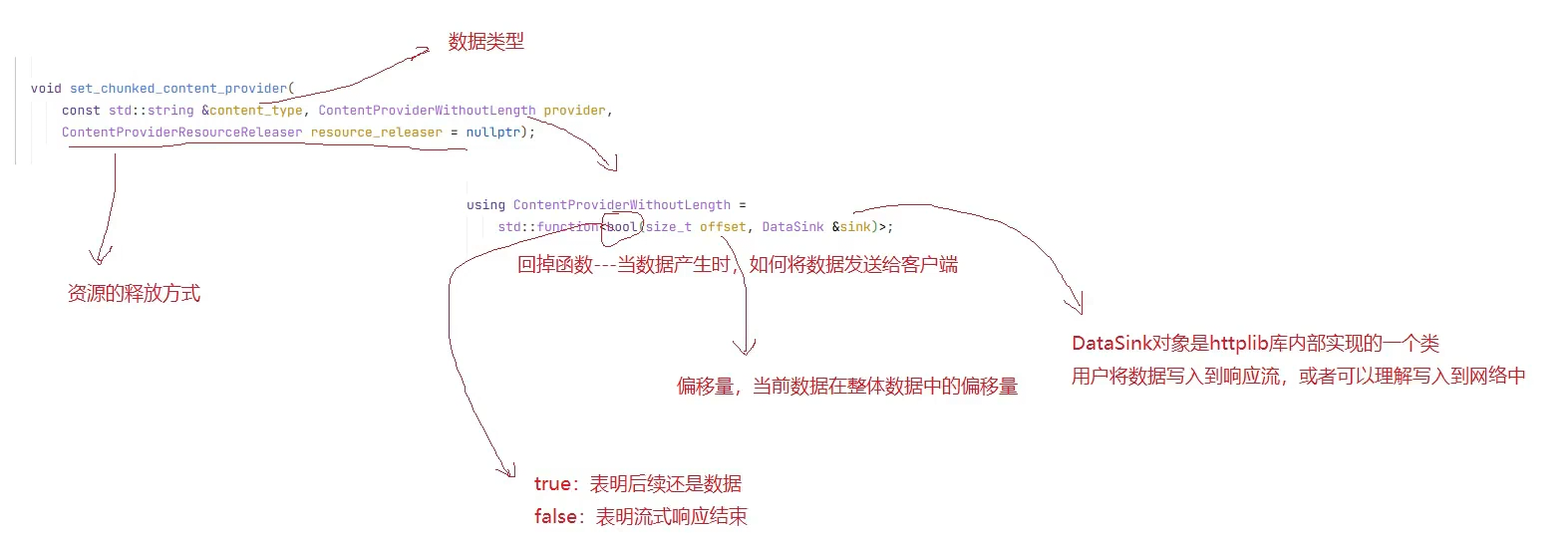

总体的实现:
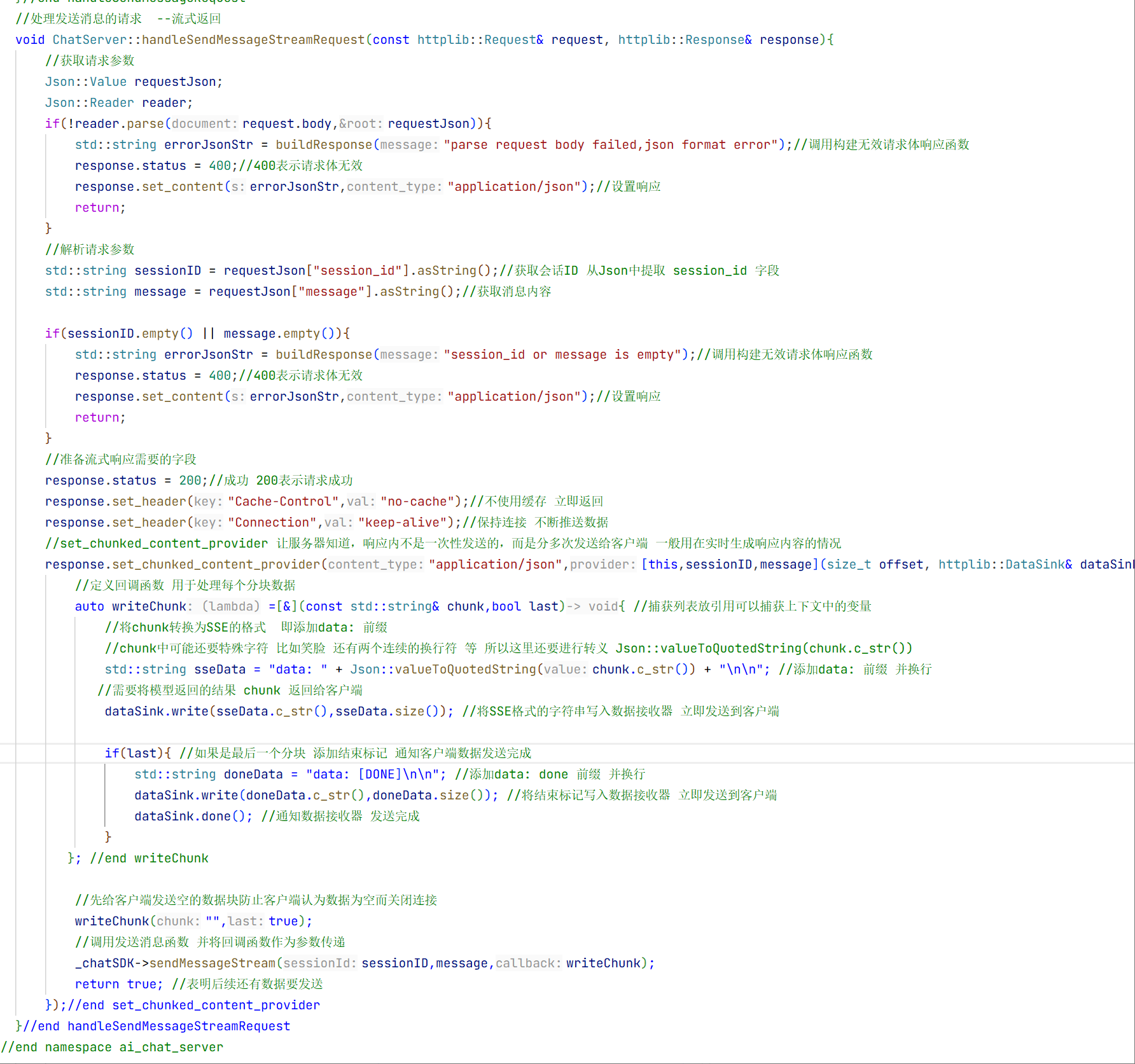
8.设置路由规则:
我们要将网页上的操作与服务器接口的操作实现一一对应,调用正确的函数。
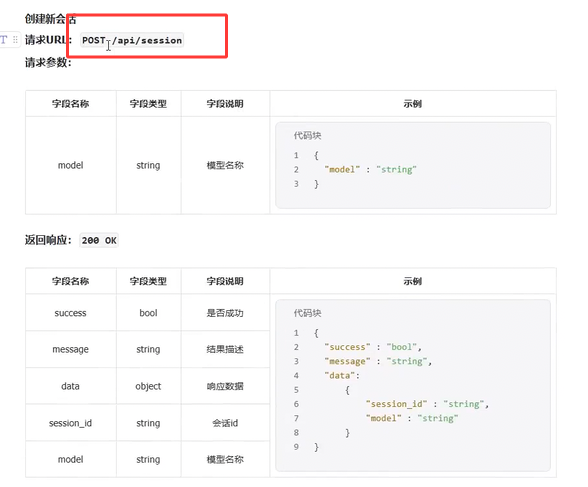
这个调用的路径就跟这个是一致的后面就不多赘述

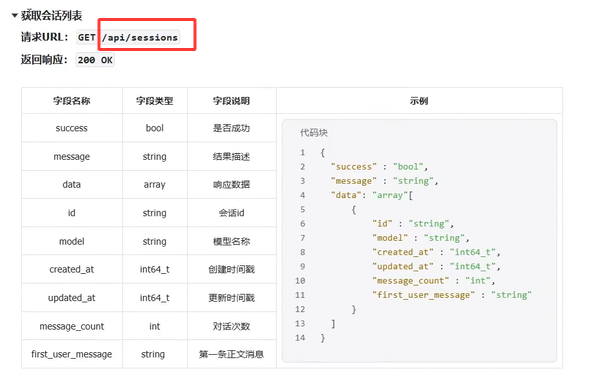

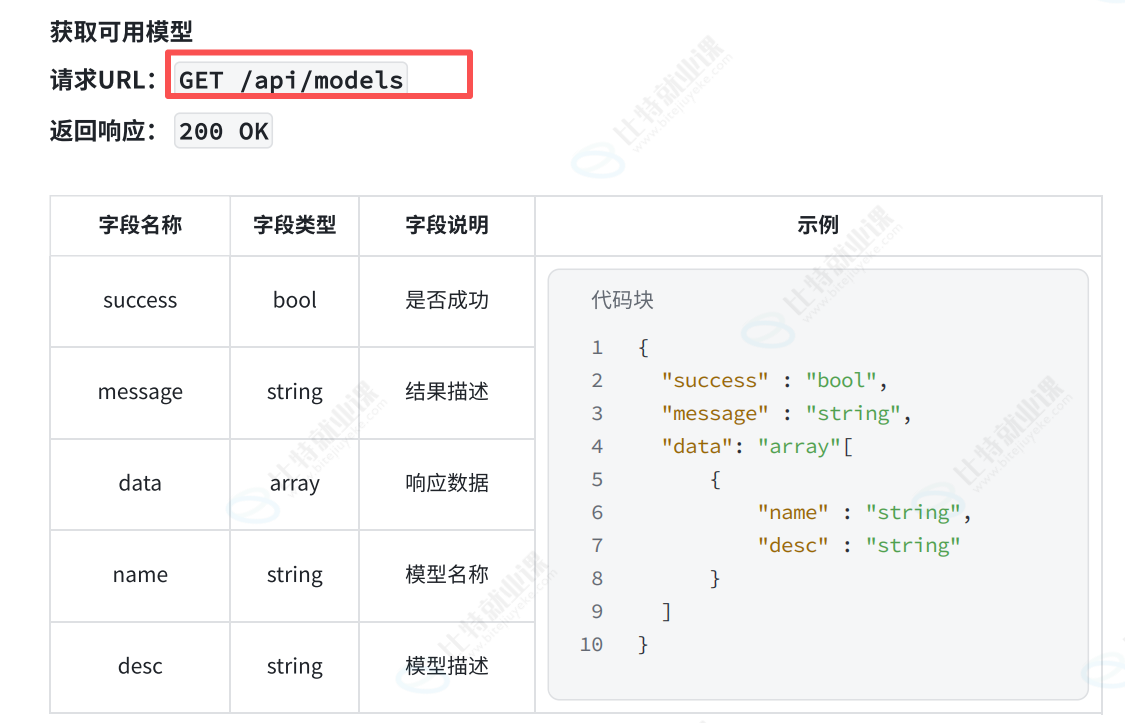

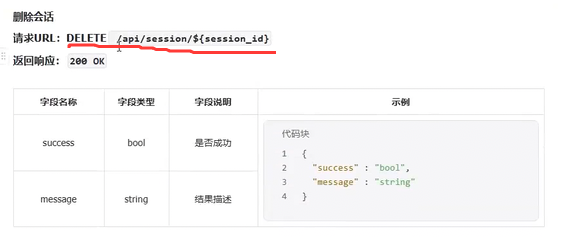

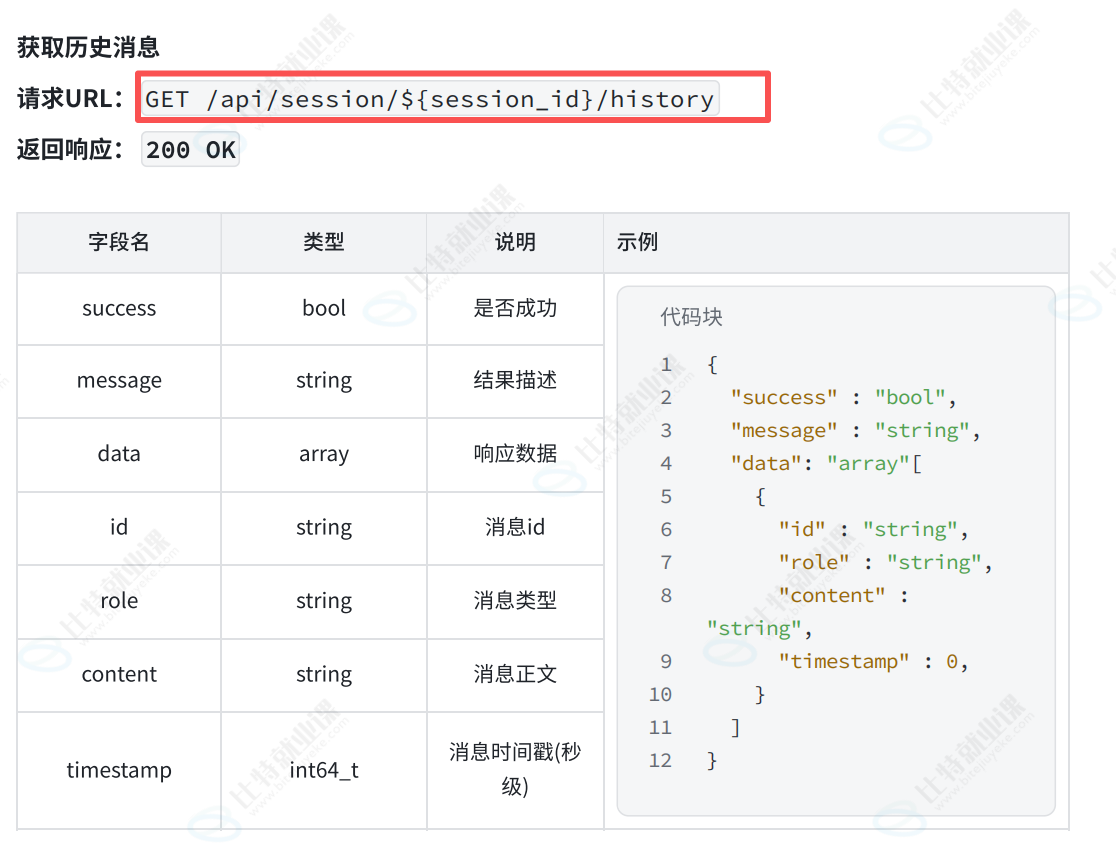

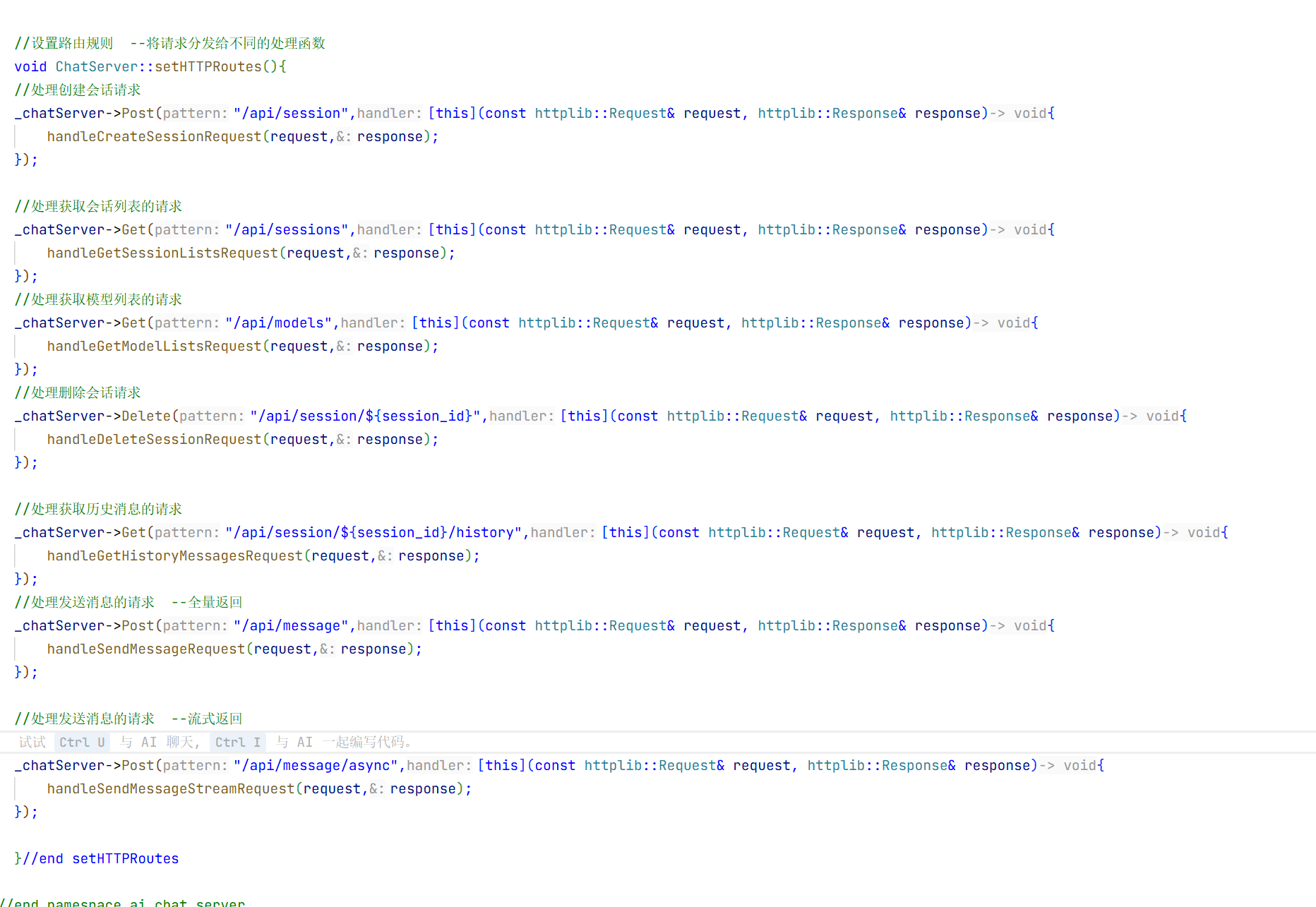
这就是全部接口的路由设置 但是什么时候去调用还没有搞定
我们要在服务器监听之前去调用这些函数 所以我们绑定路由规则时要放在服务器监听之前。
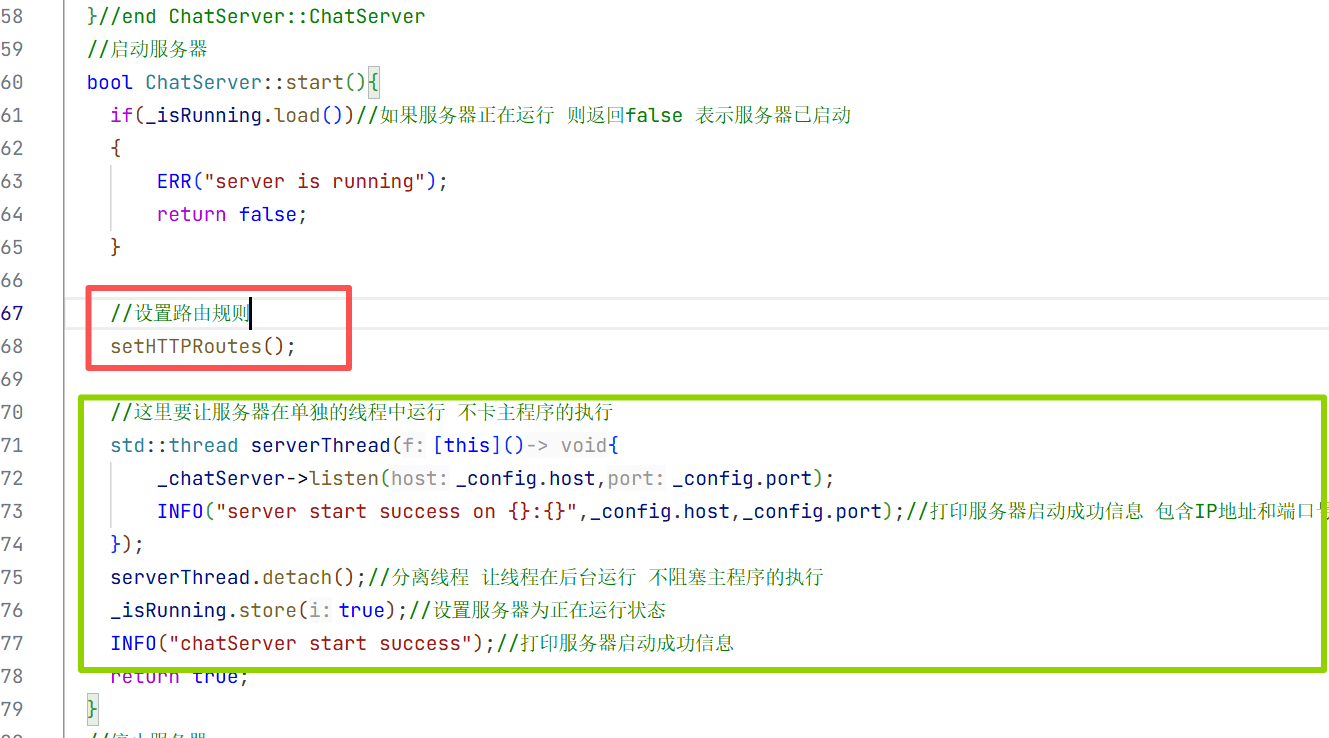
所以我们在启动服务器时而且在监听服务器之前完成调用。
还有一件事就是我们前端代码的生成路径

9.整个代码全览:
cpp
#include "ChatServer.h"
#include <ai_chat_sdk/common.h>
#include <ai_chat_sdk/util/myLog.h>
#include <jsoncpp/json/reader.h>
#include <jsoncpp/json/value.h>
#include <jsoncpp/json/forwards.h>
#include <jsoncpp/json/writer.h>
namespace ai_chat_server{
ChatServer::ChatServer(const ServerConfig& config){
//配置支持的模型参数:云端模型:deepseek-chat gpt-4o-mini gemini-2.0-flash ollamma本地接入的模型:deepseek-r1:1.5b
//deepseek-chat
auto deepseekModelConfig = std::make_shared<ai_chat_sdk::APIConfig>();//创建DeepSeekProvider对象 用shared_ptr管理内存
deepseekModelConfig->_modelName = "deepseek-chat";
deepseekModelConfig->_apikey = config.deepseekAPIKey;
deepseekModelConfig->_temperature = config.temperature;//温度参数 控制生成文本的随机性
deepseekModelConfig->_max_tokens = config.maxTokens;//最大生成token数
//gpt-4o-mini
auto chatGPTModelConfig = std::make_shared<ai_chat_sdk::APIConfig>();//创建GPTProvider对象 用shared_ptr管理内存
chatGPTModelConfig->_modelName = "gpt-4o-mini";
chatGPTModelConfig->_apikey = config.chatGPTAPIKey;
chatGPTModelConfig->_temperature = config.temperature;//温度参数 控制生成文本的随机性
chatGPTModelConfig->_max_tokens = config.maxTokens;//最大生成token数
//gemini-2.0-flash
auto geminiModelConfig = std::make_shared<ai_chat_sdk::APIConfig>();//创建GeminiProvider对象 用shared_ptr管理内存
geminiModelConfig->_modelName = "gemini-2.0-flash";
geminiModelConfig->_apikey = config.geminiAPIKey;
geminiModelConfig->_temperature = config.temperature;//温度参数 控制生成文本的随机性
geminiModelConfig->_max_tokens = config.maxTokens;//最大生成token数
//ollama本地接入的模型:deepseek-r1:1.5b
auto ollamaModelConfig = std::make_shared<ai_chat_sdk::OllamaConfig>();//创建OllamaProvider对象 用shared_ptr管理内存
ollamaModelConfig->_modelName = config.ollamaModelName;
ollamaModelConfig->_modelDesc = config.ollamaModelDesc;
ollamaModelConfig->_endpoint = config.ollamaEndpoint;
ollamaModelConfig->_temperature = config.temperature;//温度参数 控制生成文本的随机性
ollamaModelConfig->_max_tokens = config.maxTokens;//最大生成token数
std::vector<std::shared_ptr<ai_chat_sdk::Config>> modelConfigs = {deepseekModelConfig,chatGPTModelConfig,geminiModelConfig,ollamaModelConfig};
if(!_chatSDK->initModels(modelConfigs)){
ERR("chatSDK initModels failed");
return;
}
//初始化HTTP服务器
_chatServer = std::unique_ptr<httplib::Server>(new httplib::Server());
if(!_chatServer){
ERR("chatServer init failed");
return;
}
}//end ChatServer::ChatServer
//启动服务器
bool ChatServer::start(){
if(_isRunning.load())//如果服务器正在运行 则返回false 表示服务器已启动
{
ERR("server is running");
return false;
}
//设置路由规则
setHTTPRoutes();
//设置静态资源的路径
//前端页面相关的文件都放在www目录下 服务器启动时会自动将www目录下的文件挂载到服务器的根路径下
//注意 将来前端页面的名称会命名为index.html
//当用户在浏览器中输入:http://ip:port/index.html 会返回www目录下的index.html文件 http://ip:port/ 也能返回www目录下的index.html文件 ip:port 为服务器的IP地址和端口号
//在httblib中 默认情况下 如果请求只有ip和端口号 则httplib会默认使用index.html文件
_chatServer->set_mount_point("/","./www");//设置静态资源的路径 /www 表示静态资源的路径
//这里要让服务器在单独的线程中运行 不卡主程序的执行
std::thread serverThread([this](){
_chatServer->listen(_config.host,_config.port);
INFO("server start success on {}:{}",_config.host,_config.port);//打印服务器启动成功信息 包含IP地址和端口号
});
serverThread.detach();//分离线程 让线程在后台运行 不阻塞主程序的执行
_isRunning.store(true);//设置服务器为正在运行状态
INFO("chatServer start success");//打印服务器启动成功信息
return true;
}
//停止服务器
void ChatServer::stop(){
if(!_isRunning.load()){
ERR("server is not running");
return;
}
if(_chatServer){//如果HTTP服务器存在 则停止HTTP服务器
_chatServer->stop();//停止HTTP服务器
}
_isRunning.store(false);//设置服务器为未运行状态
INFO("chatServer stop success");//打印服务器停止成功信息
}
//判断服务器是否正在运行
bool ChatServer::isRunning(){
return _isRunning.load();//返回服务器是否正在运行
}
//构造响应的Json字符串
std::string buildResponse(const std::string& message,bool success){
Json::Value responseJson;
responseJson["success"] = success;
responseJson["message"] = message;
//对响应信息进行序列化
Json::StreamWriterBuilder writerBuilder;
std::string responseJsonStr = Json::writeString(writerBuilder,responseJson);
return responseJsonStr;
}
//处理创建会话请求
void ChatServer::handleCreateSessionRequest(const httplib::Request& request, httplib::Response& response){
//通过反序列化拿到请求体的Json格式
Json::Value requestJson;
Json::Reader reader;
//序列化body成功的话 结果保存在requestJson中
if(!reader.parse(request.body,requestJson)){
//构建错误响应的Json字符串
std::string errorJsonStr = buildResponse("parse request body failed,JSON format error");
response.status = 400;//客户端请求语法错误 400表示请求体格式错误
response.set_content(errorJsonStr,"application/json");//设置响应内容为Json格式
return;
}
//获取请求参数
std::string modelName = requestJson.get("model","deepseek-chat").asString();
//创建会话
std::string sessionID = _chatSDK->createSession(modelName);
if(sessionID.empty()){
//构建错误响应的Json字符串
std::string errorJsonStr = buildResponse("create session failed");
response.status = 500;//服务器内部错误 500表示服务器内部错误
response.set_content(errorJsonStr,"application/json");//设置响应内容为Json格式
return;
}
//构建响应体
Json::Value dataJson;//存储得到的响应数据
dataJson["session_id"] = sessionID;
dataJson["model"] = modelName;
Json::Value responseJson;
responseJson["success"] = true;
responseJson["message"]="create session success";
responseJson["data"] = dataJson;
//对成功信息进行序列化 序列化成字节流
Json::StreamWriterBuilder writerBuilder;
std::string responseJsonStr = Json::writeString(writerBuilder,responseJson);
response.status = 200;//成功 200表示请求成功
response.set_content(responseJsonStr,"application/json");//设置响应
return;
}//end handleCreateSessionRequest
//处理获取会话列表的请求
void ChatServer::handleGetSessionListsRequest(const httplib::Request& request, httplib::Response& response){
//获取会话列表
std::vector<std::string> sessionIDs = _chatSDK->getSessionLists();//获取所有会话ID
//构建Session信息
Json::Value dataArray(Json::arrayValue);//创建Json数组 用于存储会话信息
for(const auto& sessionID : sessionIDs){
//通过会话ID 获取会话信息
auto session = _chatSDK->getSession(sessionID);
if(session){//如果会话存在 则添加到数组中
Json::Value sessionJson;
sessionJson["id"] =session->_sessionid;
sessionJson["model"] = session->_modelName;
sessionJson["created_at"] = static_cast<int64_t>(session->_createdAt);
sessionJson["updated_at"] = static_cast<int64_t>(session->_updatedAt);
sessionJson["message_count"] = session->_messages.size();
//如果不空去获取第一条消息
if(!session->_messages.empty()){
sessionJson["first_user_message"] = session->_messages.front()._content;
}
dataArray.append(sessionJson);
}
}
//构建响应体
Json::Value responseJson;
responseJson["success"] = true;
responseJson["message"]="get session lists success";
responseJson["data"] = dataArray;
//对成功信息进行序列化 序列化成字节流
Json::StreamWriterBuilder writerBuilder;
std::string responseJsonStr = Json::writeString(writerBuilder,responseJson);
response.status = 200;//成功 200表示请求成功
response.set_content(responseJsonStr,"application/json");//设置响应
return;
}//end handleGetSessionListsRequest
//处理获取模型列表的请求
void ChatServer::handleGetModelListsRequest(const httplib::Request& request, httplib::Response& response){
//获取模型列表
auto modelLists = _chatSDK->getAvailableModels();//获取所有可用模型名称
//构建响应体
Json::Value dataArray(Json::arrayValue);//创建Json数组 用于存储模型信息
for(const auto& modelInfo : modelLists){//遍历模型列表
Json::Value modelJson;
modelJson["name"] = modelInfo._modelName;//模型名称
modelJson["des"] = modelInfo._modelDesc;//模型描述
dataArray.append(modelJson);
}
//构建响应体
Json::Value responseJson;
responseJson["success"] = true;
responseJson["message"]="get model lists success";
responseJson["data"] = dataArray;
//序列化模型列表
Json::StreamWriterBuilder writerBuilder;
std::string responseJsonStr = Json::writeString(writerBuilder,responseJson);
response.status = 200;//成功 200表示请求成功
response.set_content(responseJsonStr,"application/json");//设置响应
return;
}//end handleGetModelListsRequest
//处理删除会话请求
void ChatServer::handleDeleteSessionRequest(const httplib::Request& request, httplib::Response& response){
//获取会话ID 这里是一个路径参数
std::string sessionID = request.matches[1];//获取路径参数 session_id
//删除会话
bool ret = _chatSDK->deleteSession(sessionID);
if(ret){//如果删除成功 则返回删除成功信息
std::string errorJsonStr = buildResponse("delete session success",true);//调用构建删除成功响应函数
response.status = 200;//200表示请求成功
response.set_content(errorJsonStr,"application/json");//设置响应
return;
}else{
//如果删除失败 则返回删除失败信息
std::string errorJsonStr = buildResponse("delete session failed,session not found");//调用构建删除失败响应函数
response.status = 404;//404表示资源不存在
response.set_content(errorJsonStr,"application/json");//设置响应
return;
}
}//end handleDeleteSessionRequest
//处理获取历史消息的请求
void ChatServer::handleGetHistoryMessagesRequest(const httplib::Request& request, httplib::Response& response){
//获取会话id 这里是一个路径参数
std::string sessionID = request.matches[1];//获取路径参数 session_id
//获取会话信息
auto session = _chatSDK->getSession(sessionID);
if(!session){//如果会话不存在 则返回会不存在信息
std::string errorJsonStr = buildResponse("session not found");//调用构建会话不存在响应函数
response.status = 404;//404表示资源不存在
response.set_content(errorJsonStr,"application/json");//设置响应
return;
}
//会话存在 构建历史消息列表
Json::Value dataArray(Json::arrayValue);//创建Json数组 用于存储消息信息
for(const auto& message : session->_messages){//遍历消息列表
Json::Value messageJson;
messageJson["id"] = message._messageid;//消息ID
messageJson["role"] = message._role;//用户角色
messageJson["content"] = message._content;//消息内容
messageJson["timestamp"] = static_cast<int64_t>(message._timestamp);//消息时间戳
dataArray.append(messageJson);
}
//构建响应体
Json::Value responseJson;
responseJson["success"] = true;
responseJson["message"]="get history messages success";
responseJson["data"] = dataArray;
//对成功信息进行序列化 序列化成字节流
Json::StreamWriterBuilder writerBuilder;
std::string responseJsonStr = Json::writeString(writerBuilder,responseJson);
response.status = 200;//成功 200表示请求成功
response.set_content(responseJsonStr,"application/json");//设置响应
return;
}//end handleGetHistoryMessagesRequest
//处理发送消息的请求 --全量返回
void ChatServer::handleSendMessageRequest(const httplib::Request& request, httplib::Response& response){
//获取请求参数
Json::Value requestJson;
Json::Reader reader;
if(!reader.parse(request.body,requestJson)){
std::string errorJsonStr = buildResponse("parse request body failed,json format error");//调用构建无效请求体响应函数
response.status = 400;//400表示请求体无效
response.set_content(errorJsonStr,"application/json");//设置响应
return;
}
//解析请求参数
std::string sessionID = requestJson["session_id"].asString();//获取会话ID 从Json中提取 session_id 字段
std::string message = requestJson["message"].asString();//获取消息内容
if(sessionID.empty() || message.empty()){
std::string errorJsonStr = buildResponse("session_id or message is empty");//调用构建无效请求体响应函数
response.status = 400;//400表示请求体无效
response.set_content(errorJsonStr,"application/json");//设置响应
return;
}
//发送消息
std::string assistantMessage = _chatSDK->sendMessage(sessionID,message);//调用发送消息函数
//如果发送失败 则返回发送失败信息
if(assistantMessage.empty()){
std::string errorJsonStr = buildResponse("Failed to send AI response message");//调用构建无效请求体响应函数
response.status = 500;//500表示服务器内部错误
response.set_content(errorJsonStr,"application/json");//设置响应
return;
}
//构造响应参数
Json::Value dataJson;
dataJson["session_id"] = sessionID;
dataJson["response"] = assistantMessage;
//构建响应体
Json::Value responseJson;
responseJson["success"] = true;
responseJson["message"]="send message success";
responseJson["data"] = dataJson;
//对成功信息进行序列化 序列化成字节流
Json::StreamWriterBuilder writerBuilder;
std::string responseJsonStr = Json::writeString(writerBuilder,responseJson);
response.status = 200;//成功 200表示请求成功
response.set_content(responseJsonStr,"application/json");//设置响应
return;
}//end handleSendMessageRequest
//处理发送消息的请求 --流式返回
void ChatServer::handleSendMessageStreamRequest(const httplib::Request& request, httplib::Response& response){
//获取请求参数
Json::Value requestJson;
Json::Reader reader;
if(!reader.parse(request.body,requestJson)){
std::string errorJsonStr = buildResponse("parse request body failed,json format error");//调用构建无效请求体响应函数
response.status = 400;//400表示请求体无效
response.set_content(errorJsonStr,"application/json");//设置响应
return;
}
//解析请求参数
std::string sessionID = requestJson["session_id"].asString();//获取会话ID 从Json中提取 session_id 字段
std::string message = requestJson["message"].asString();//获取消息内容
if(sessionID.empty() || message.empty()){
std::string errorJsonStr = buildResponse("session_id or message is empty");//调用构建无效请求体响应函数
response.status = 400;//400表示请求体无效
response.set_content(errorJsonStr,"application/json");//设置响应
return;
}
//准备流式响应需要的字段
response.status = 200;//成功 200表示请求成功
response.set_header("Cache-Control","no-cache");//不使用缓存 立即返回
response.set_header("Connection","keep-alive");//保持连接 不断推送数据
//set_chunked_content_provider 让服务器知道,响应内不是一次性发送的,而是分多次发送给客户端 一般用在实时生成响应内容的情况
response.set_chunked_content_provider("application/json",[this,sessionID,message](size_t offset, httplib::DataSink& dataSink)->bool{
//定义回调函数 用于处理每个分块数据 给sendMessageStream函数调用
auto writeChunk =[&](const std::string& chunk,bool last){ //捕获列表放引用可以捕获上下文中的变量
//将chunk转换为SSE的格式 即添加data: 前缀
//chunk中可能还要特殊字符 比如笑脸 还有两个连续的换行符 等 所以这里还要进行转义 Json::valueToQuotedString(chunk.c_str())
std::string sseData = "data: " + Json::valueToQuotedString(chunk.c_str()) + "\n\n"; //添加data: 前缀 并换行
//需要将模型返回的结果 chunk 返回给客户端
dataSink.write(sseData.c_str(),sseData.size()); //将SSE格式的字符串写入数据接收器 立即发送到客户端
if(last){ //如果是最后一个分块 添加结束标记 通知客户端数据发送完成
std::string doneData = "data: [DONE]\n\n"; //添加data: done 前缀 并换行
dataSink.write(doneData.c_str(),doneData.size()); //将结束标记写入数据接收器 立即发送到客户端
dataSink.done(); //通知数据接收器 发送完成
}
}; //end writeChunk
//先给客户端发送空的数据块防止客户端认为数据为空而关闭连接
writeChunk("",true);
//调用发送消息函数 并将回调函数作为参数传递
_chatSDK->sendMessageStream(sessionID,message,writeChunk);
return true; //表明后续还有数据要发送
});//end set_chunked_content_provider
}//end handleSendMessageStreamRequest
//设置路由规则 --将请求分发给不同的处理函数
void ChatServer::setHTTPRoutes(){
//处理创建会话请求
_chatServer->Post("/api/session",[this](const httplib::Request& request, httplib::Response& response){
handleCreateSessionRequest(request,response);
});
//处理获取会话列表的请求
_chatServer->Get("/api/sessions",[this](const httplib::Request& request, httplib::Response& response){
handleGetSessionListsRequest(request,response);
});
//处理获取模型列表的请求
_chatServer->Get("/api/models",[this](const httplib::Request& request, httplib::Response& response){
handleGetModelListsRequest(request,response);
});
//处理删除会话请求
_chatServer->Delete("/api/session/${session_id}",[this](const httplib::Request& request, httplib::Response& response){
handleDeleteSessionRequest(request,response);
});
//处理获取历史消息的请求
_chatServer->Get("/api/session/${session_id}/history",[this](const httplib::Request& request, httplib::Response& response){
handleGetHistoryMessagesRequest(request,response);
});
//处理发送消息的请求 --全量返回
_chatServer->Post("/api/message",[this](const httplib::Request& request, httplib::Response& response){
handleSendMessageRequest(request,response);
});
//处理发送消息的请求 --流式返回
_chatServer->Post("/api/message/async",[this](const httplib::Request& request, httplib::Response& response){
handleSendMessageStreamRequest(request,response);
});
}//end setHTTPRoutes
} //end namespace ai_chat_server19.main方法的生成:
1.生成:
目前我们的服务器还运行不了 因为缺少了main方法
这里main方法我们需要提供ServerConfig的信息。
复杂的整体实现我们实现好了 接下来这些简单的代码我们交给trae来给我们生成。
这是trae生成的主函数的代码:
trae生成的CMake文件:
2.测试编译是否通过:
先cd到ChatServer目录下来 然后构建一个build目录来测试 编译结果放到build目录下
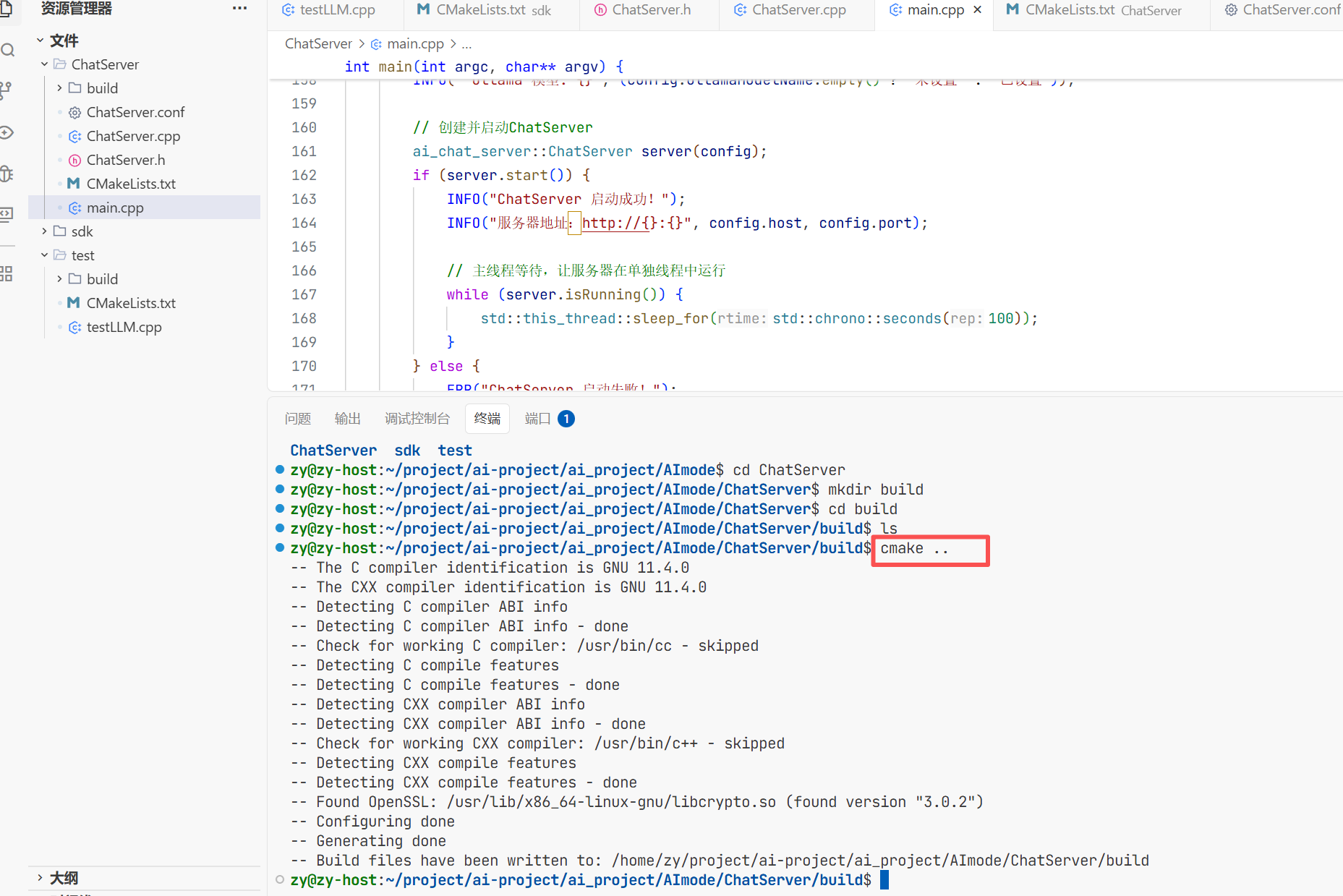
cmake ..让他去上一层目录去寻找编译的文件
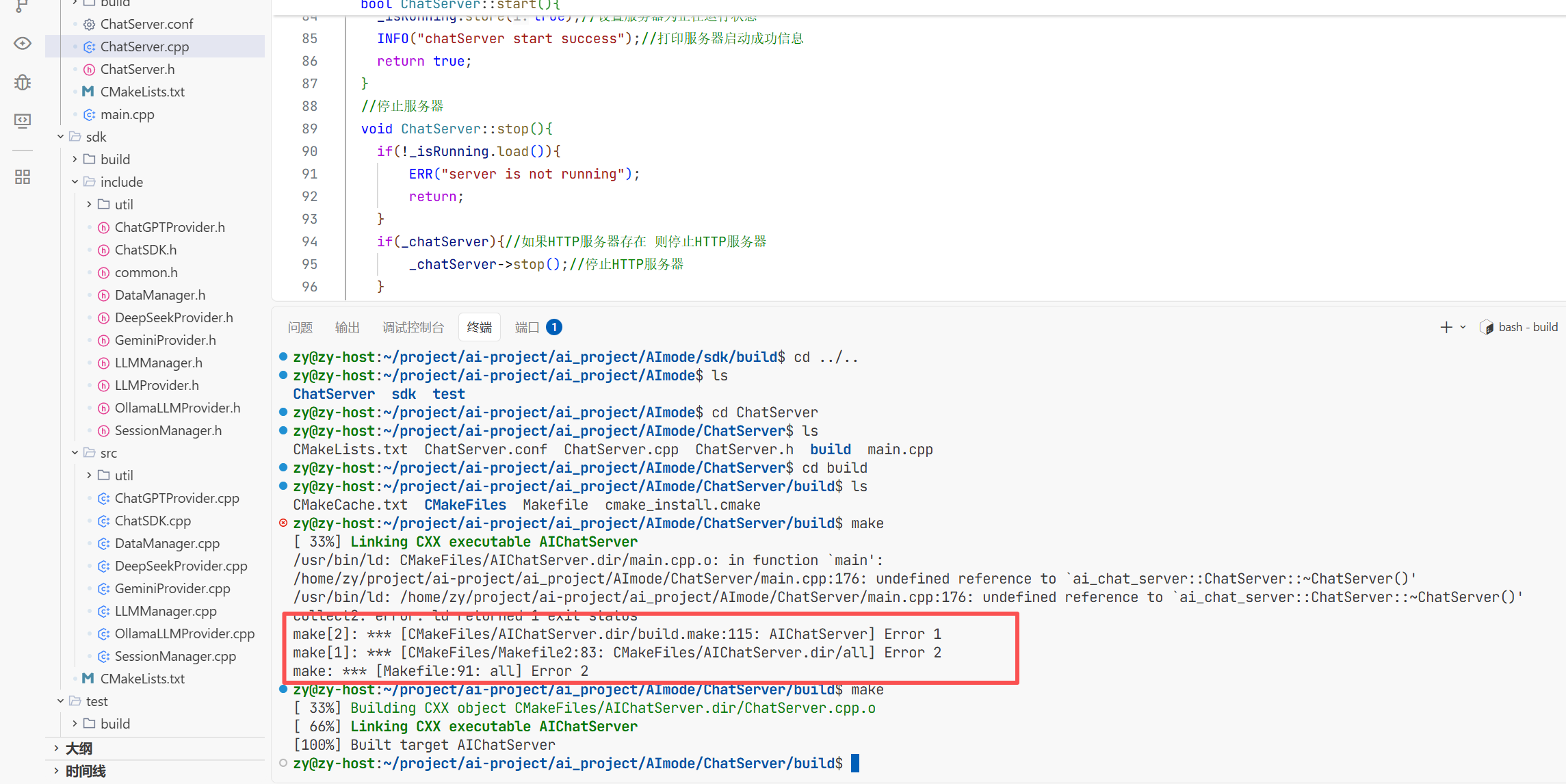
产生的问题是我忘记实现析构函数了,所以这里报错
加上析构函数就可以了
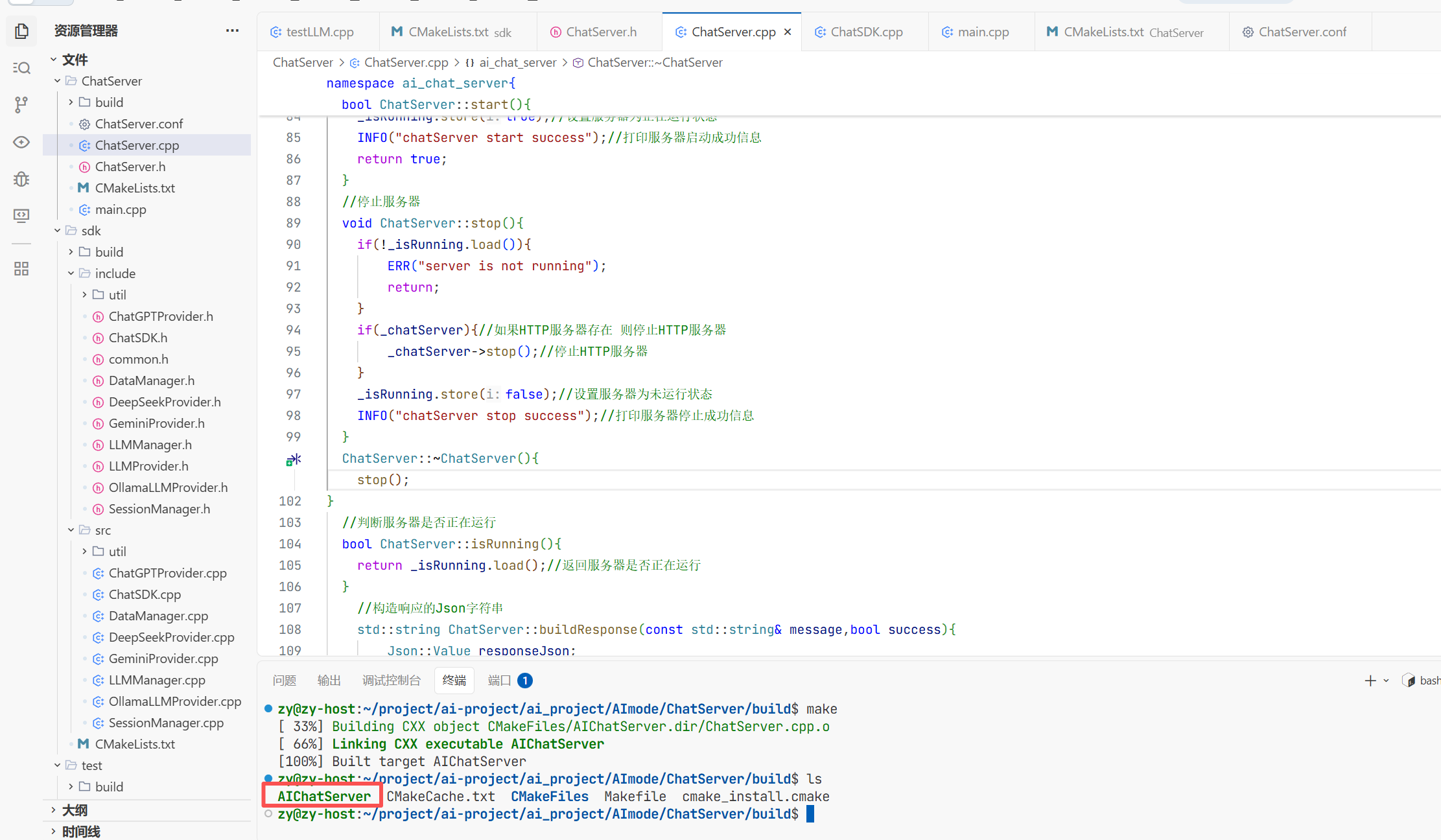
编译完成后在build目录下生成了一个AIChatServer的文件
3.测试服务器是否生成成功:
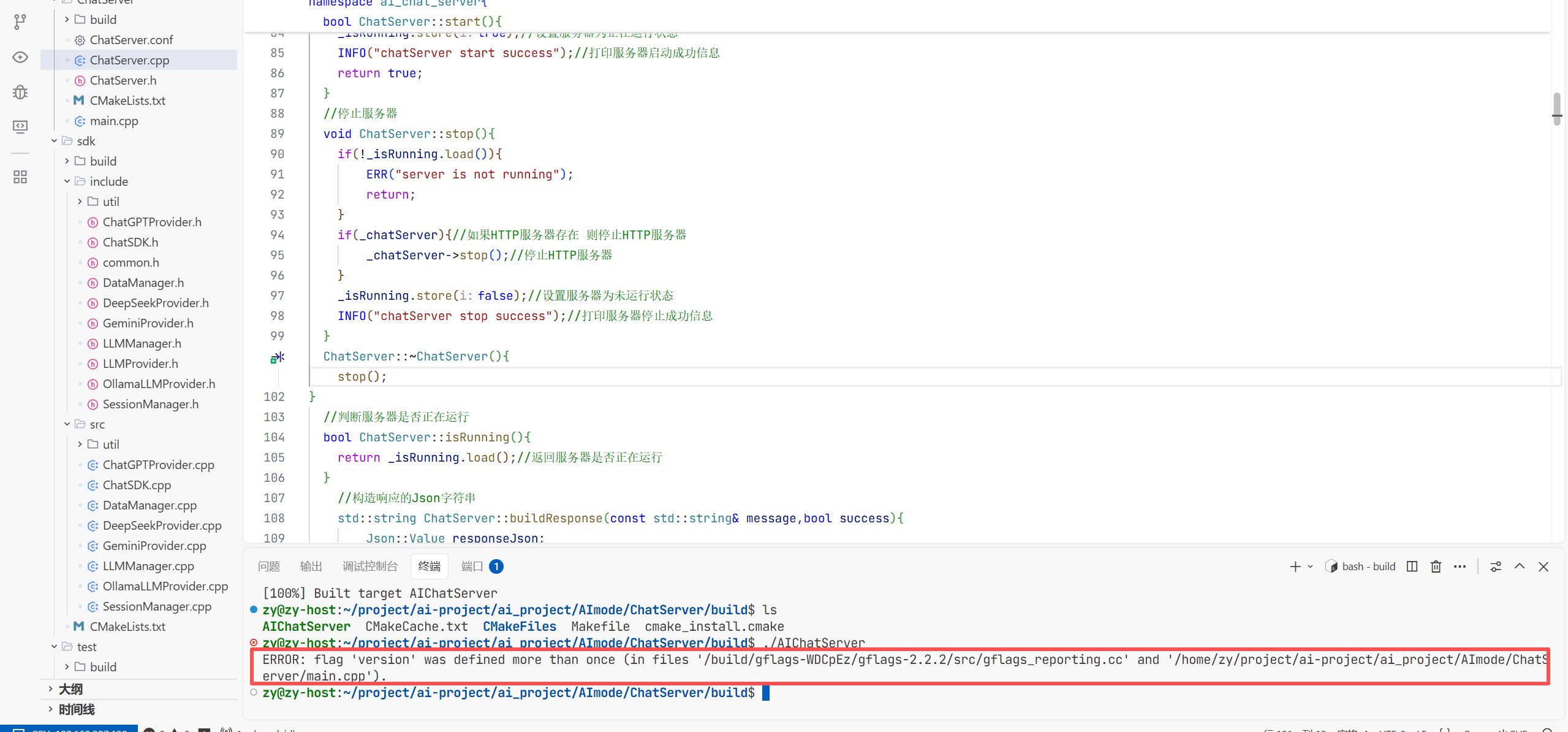
问题解释是这个flag version被定义了多次 那么就是mian函数出了问题
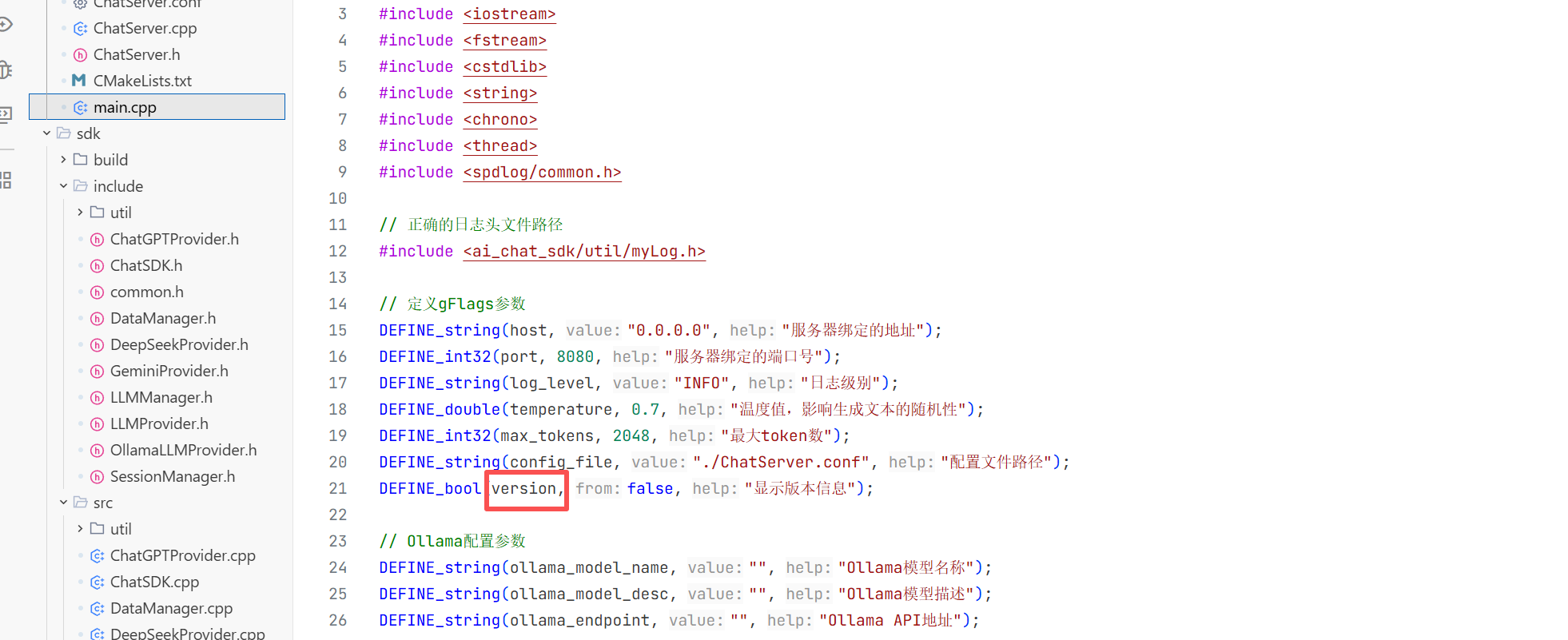
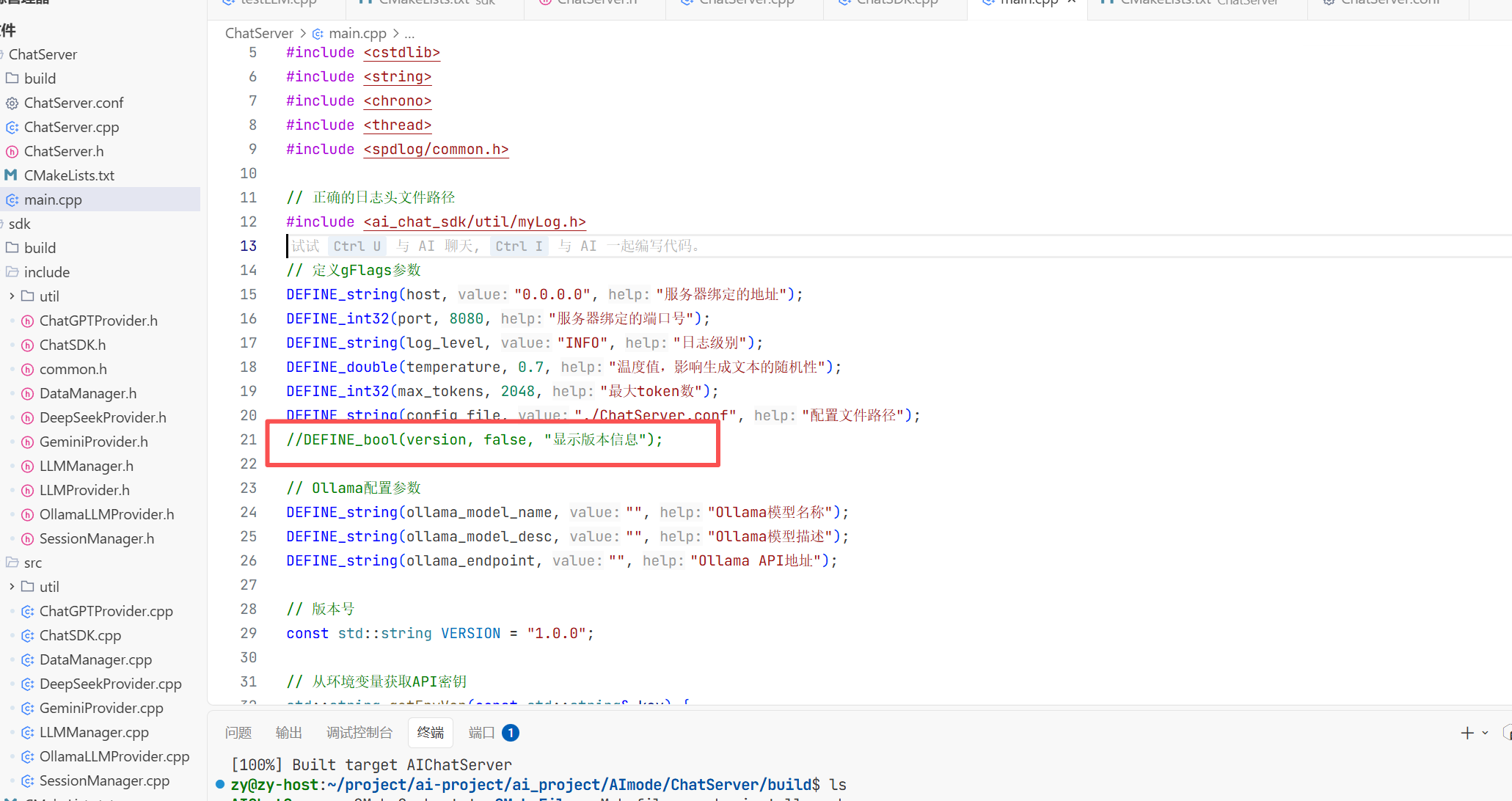
我们这里把注释掉重新编译再运行一下看看是否可行
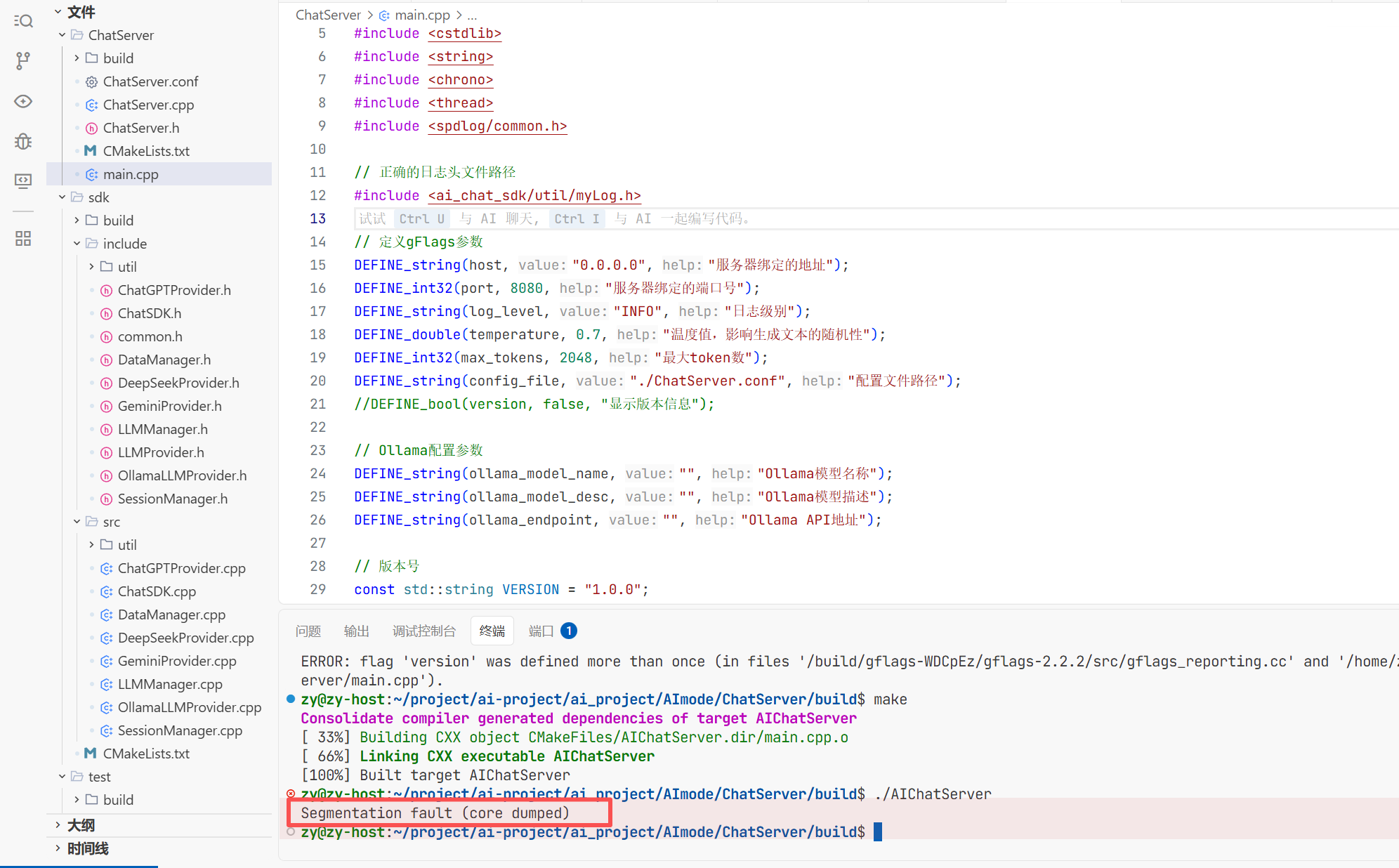
这里系统崩溃了并且没有任何的打印。
那么我们这里就要检查main函数里的实现方法了。

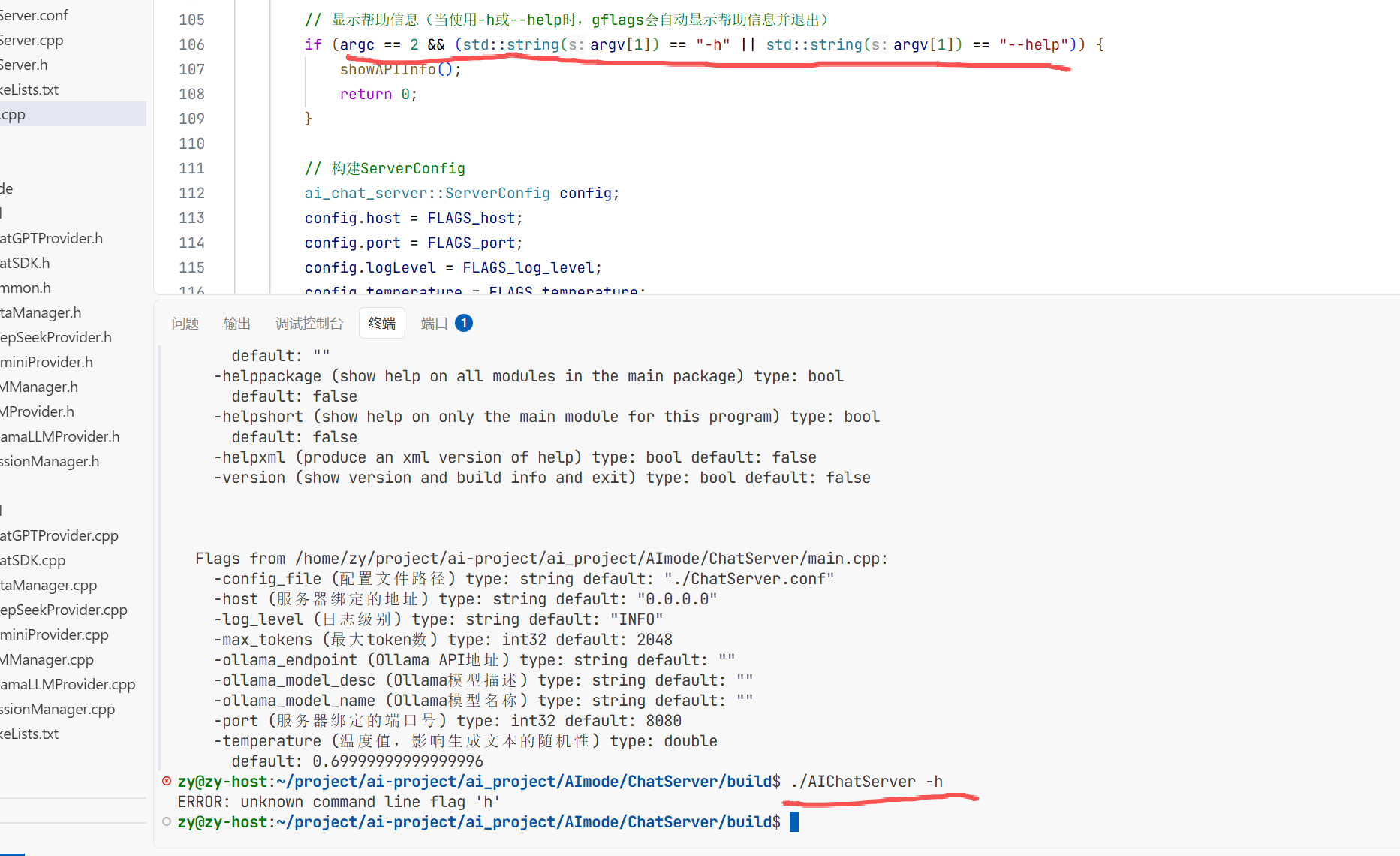
在main函数里面--help可以使用但是-h无法使用 这是因为我们没有定义-h的参数
那么在这里识别不出来 -h被gflags解析了但是没有定义-h的参数所以gflag无法识别进行报错
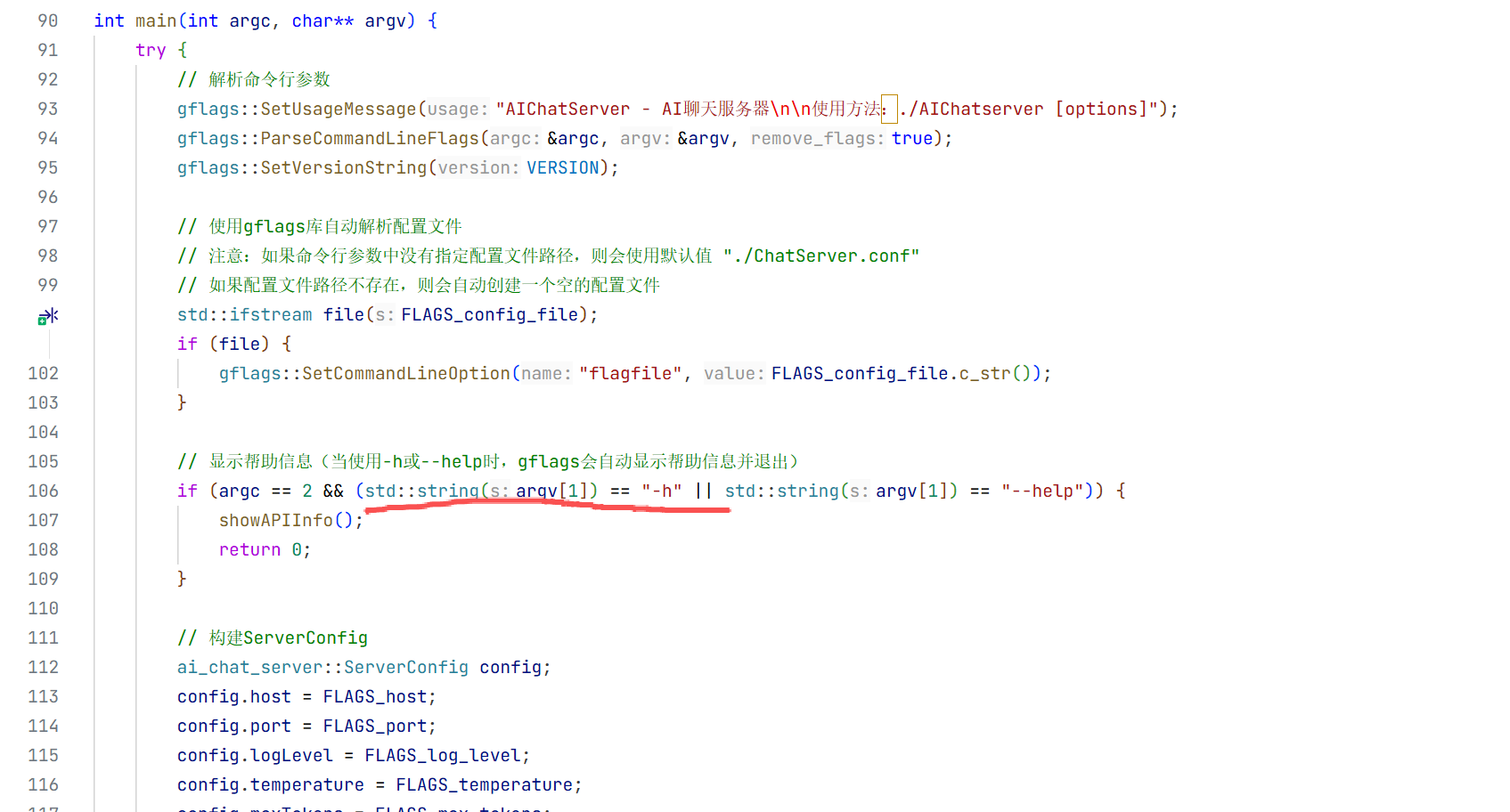
我们把这里的解析参数放到前面
这样gflags就去调用库里的-h去识别参数
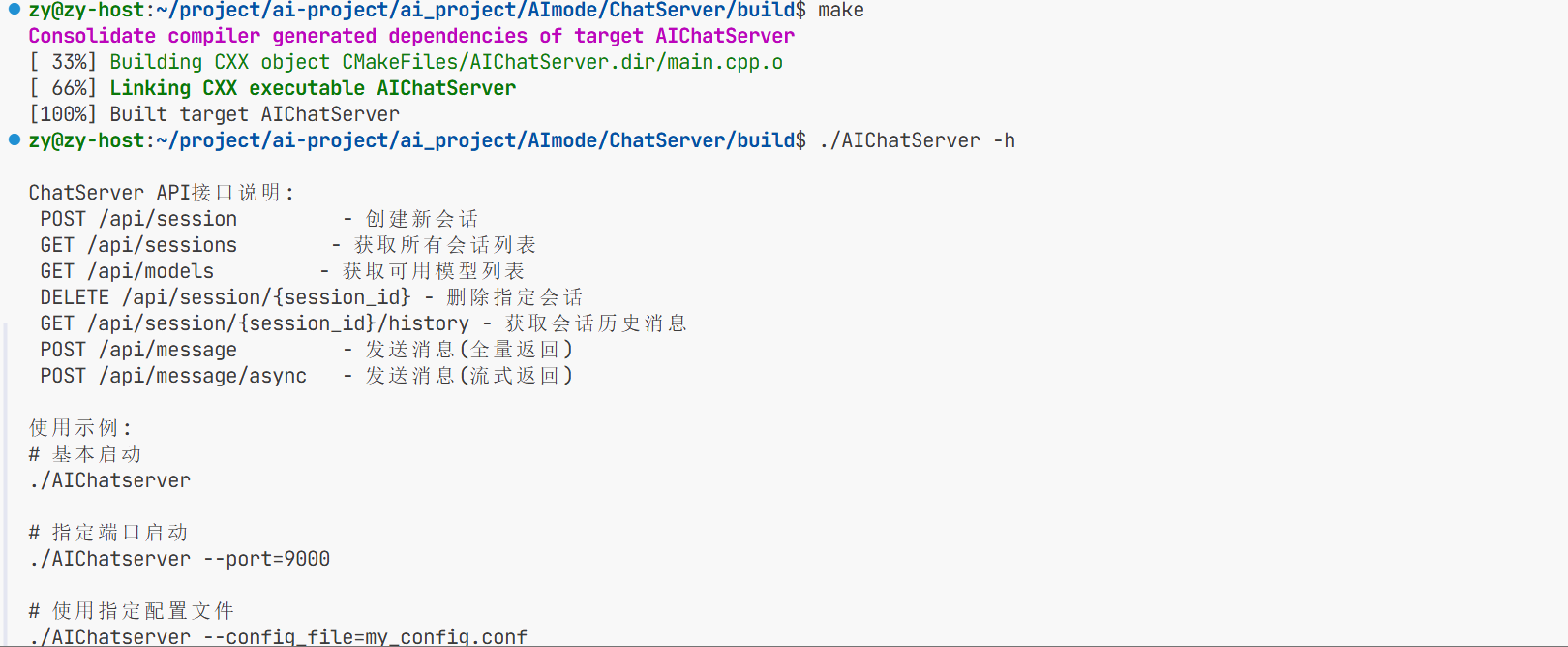
这样就可以正确识别出来了
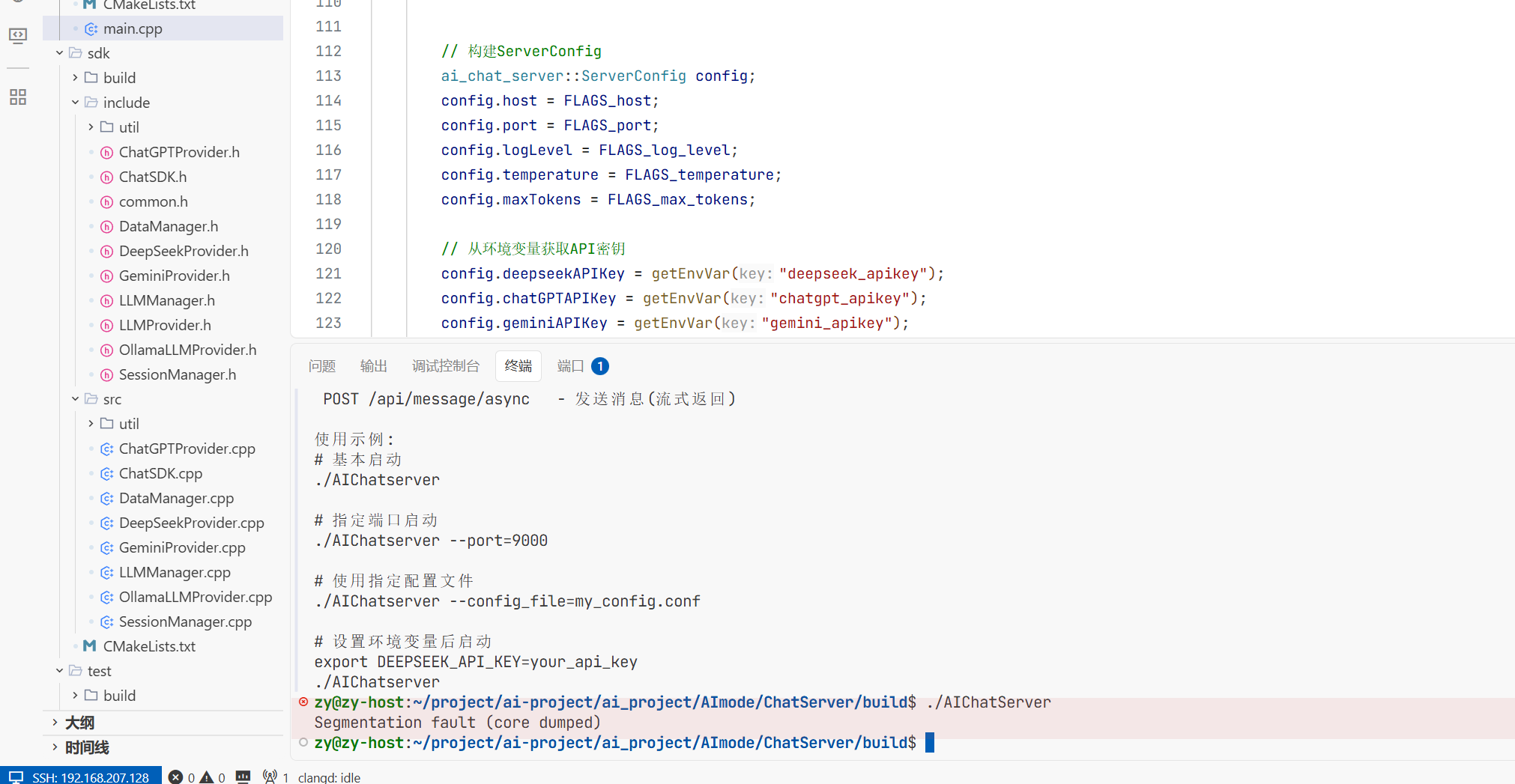
但是解决完这个程序还是报错了 而且很奇怪的是没有打印报错信息
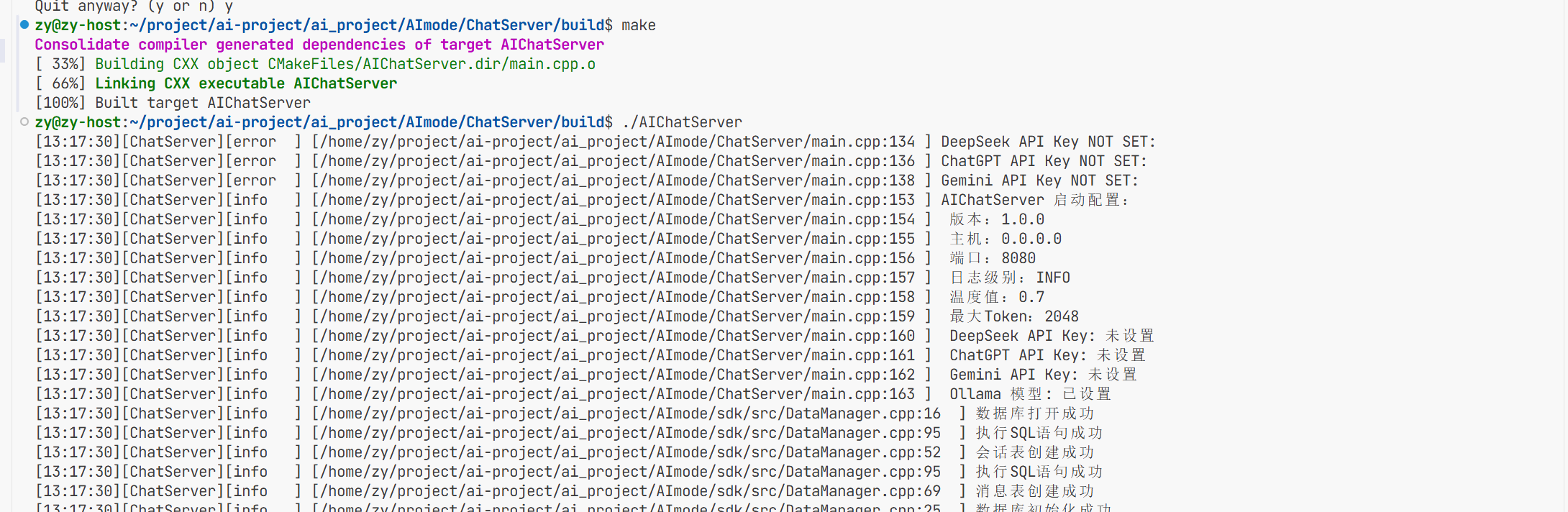
经过和ai的长时间拉扯终于找到了问题所在

是main函数生成的有问题
20.接口测试:
1.获取可用模型的接口测试:
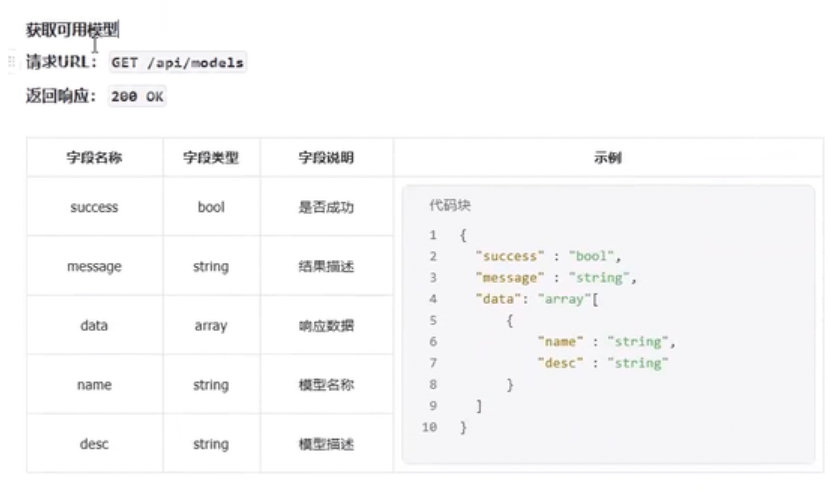
这个没有请求参数所以不用写请求参数
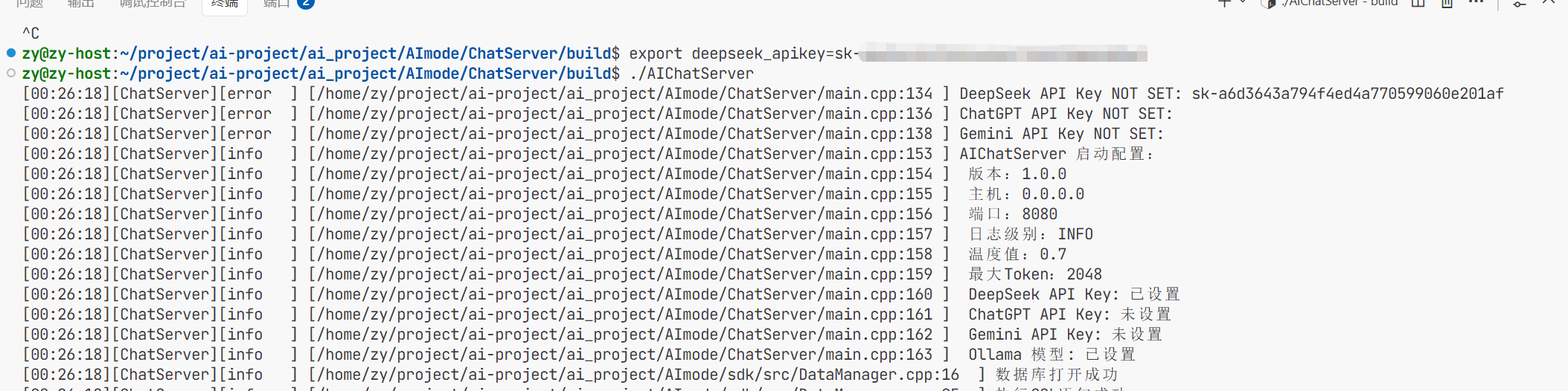
这里要事先导入环境变量要不然初始化不了模型
因为这里我chatgpt和gemini没有额度了所以我没导入apikey
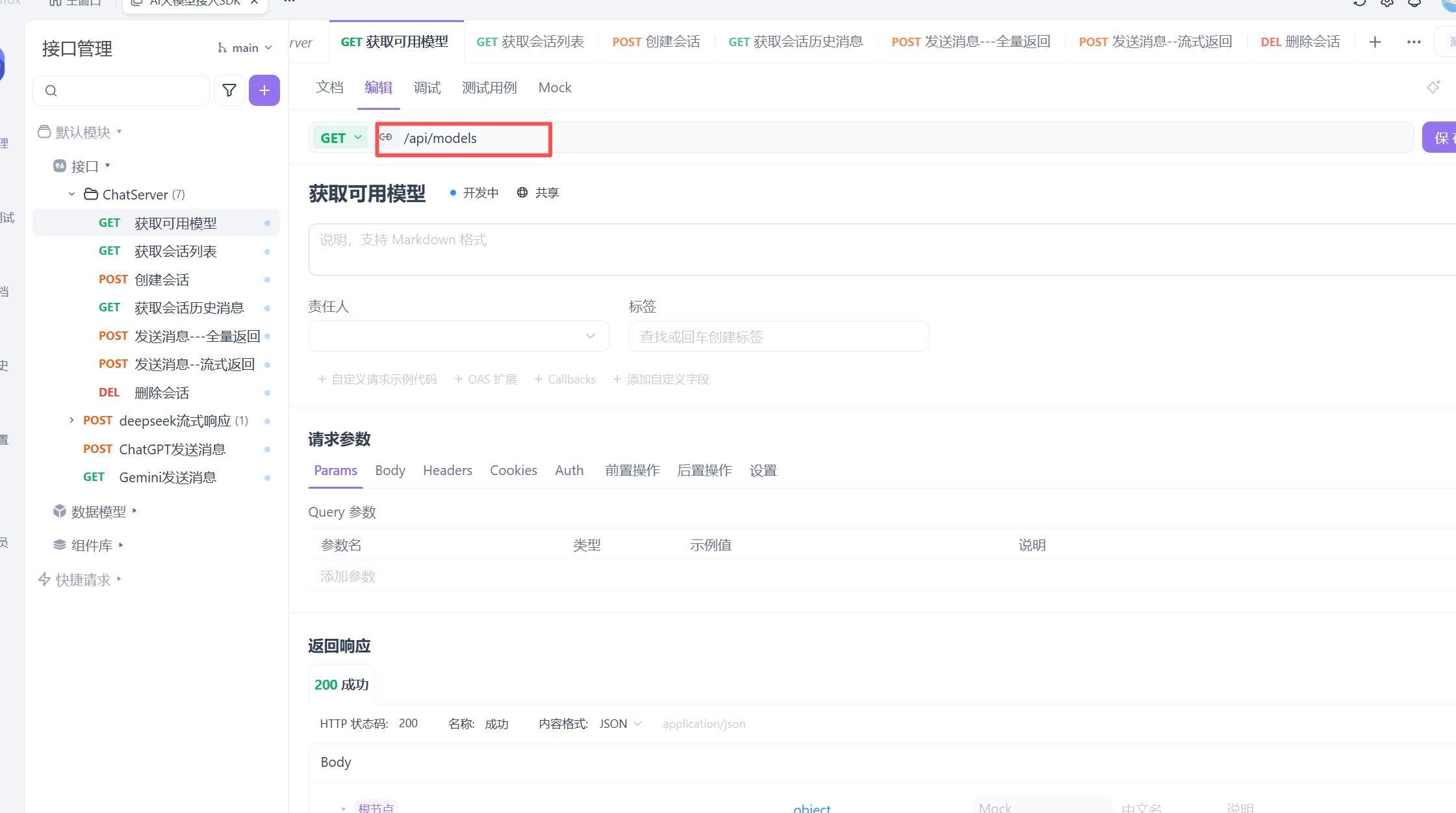
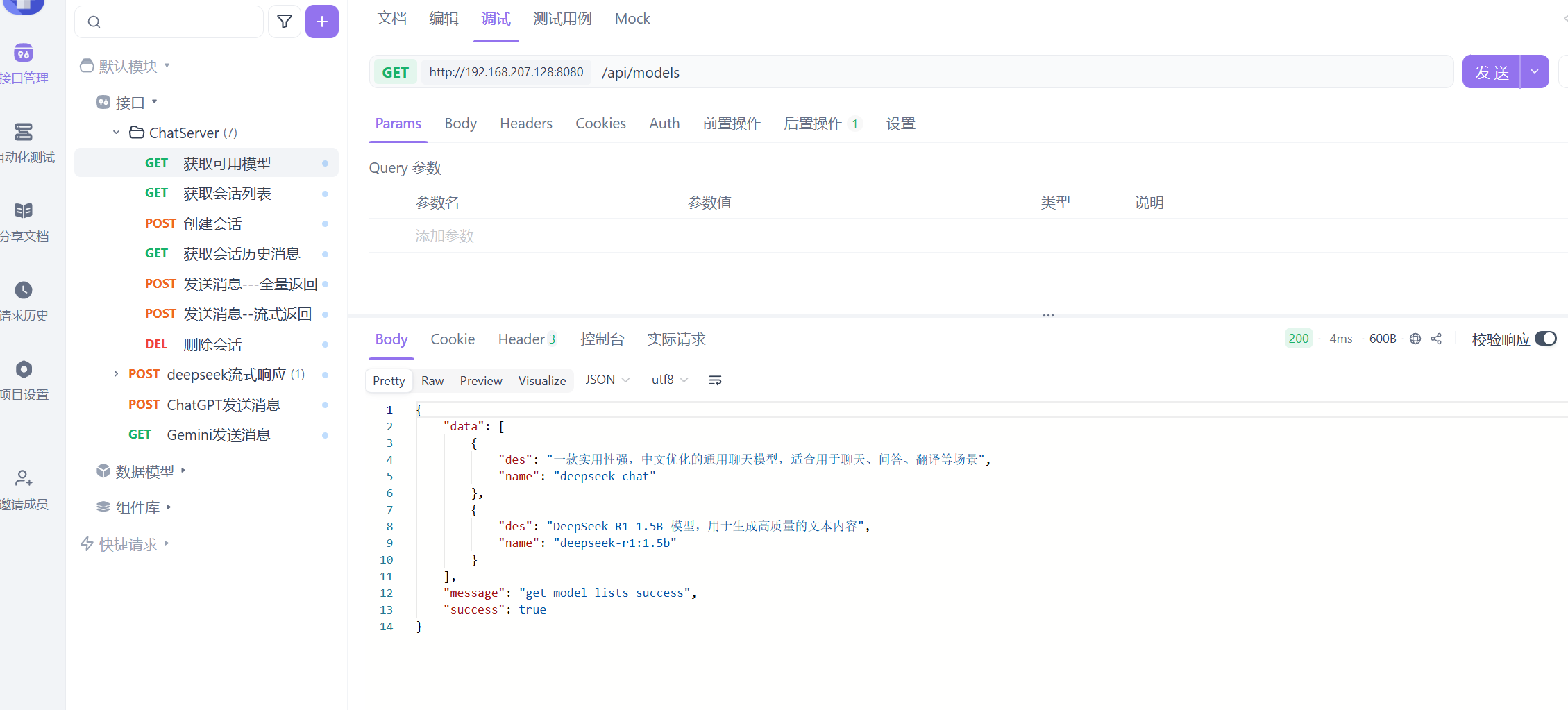
这样我们的接口就没问题了
2.创建会话的接口测试:
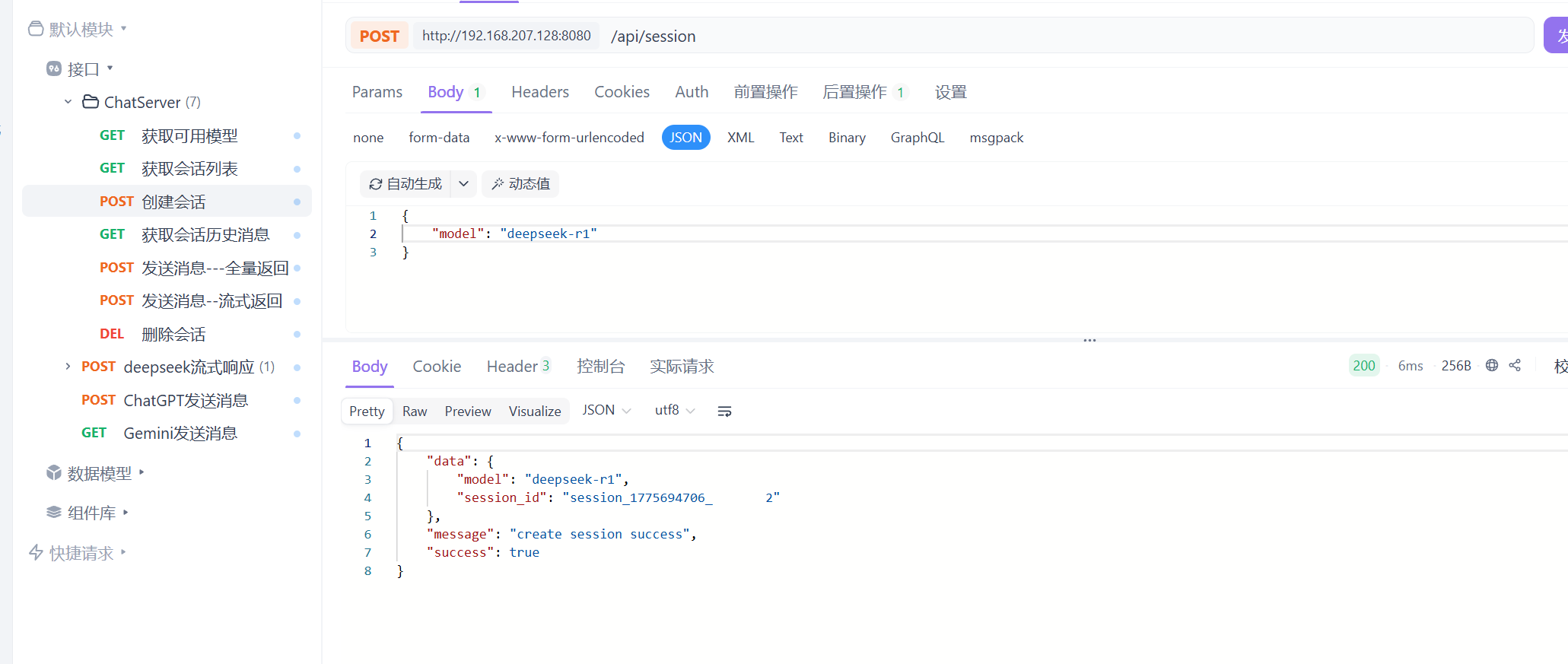
这里我分别用deepseek和deeepseek-1.5b创建了两个会话
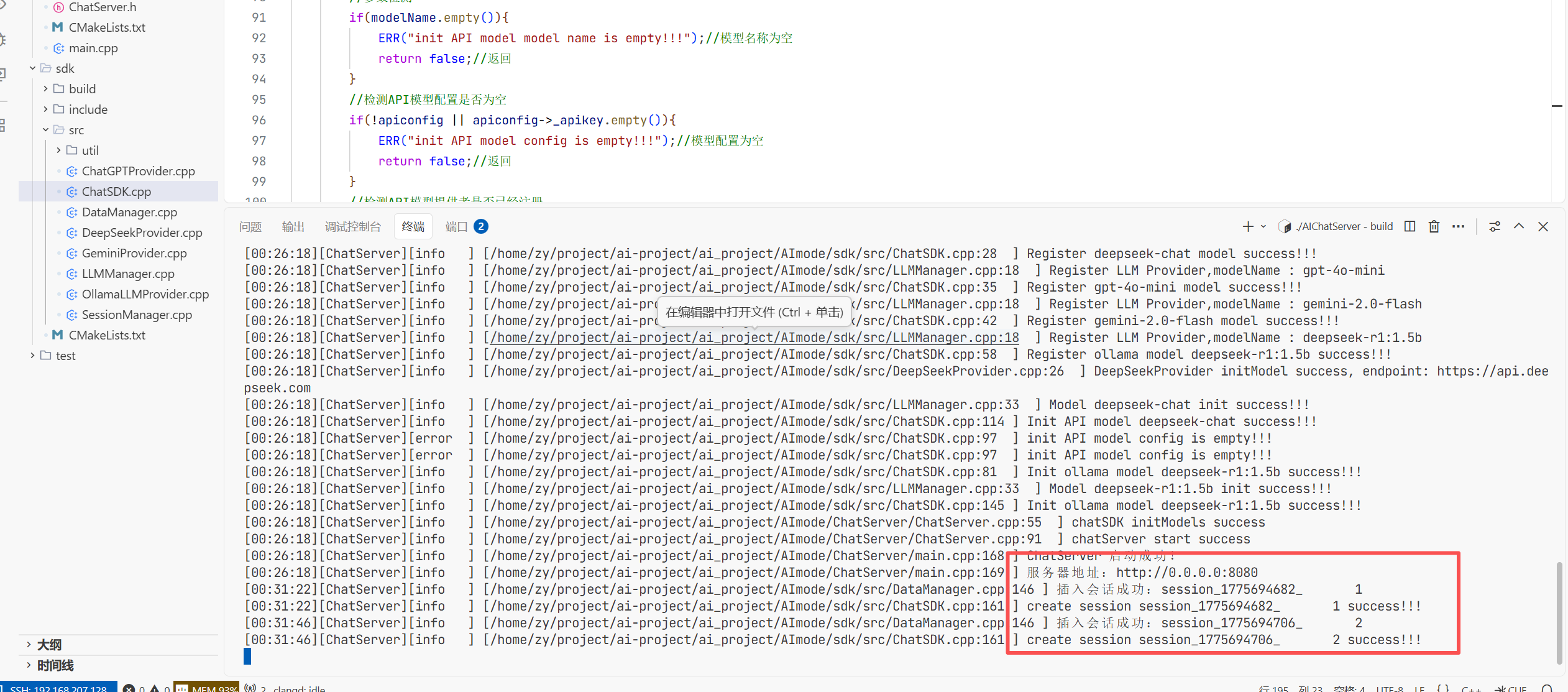
这里终端也创建成功了。
3.获取会话列表的接口测试:
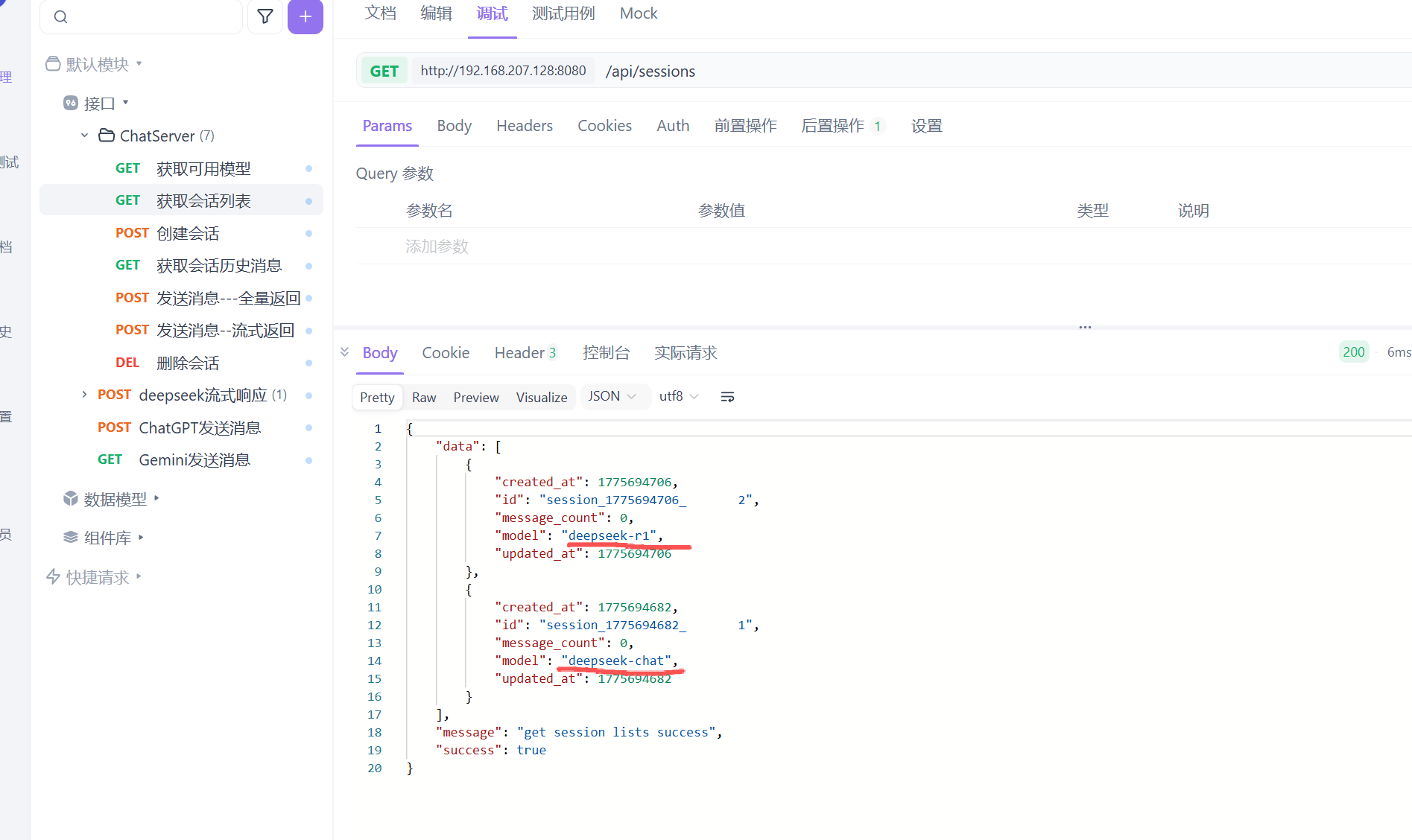
这样我们终端也运行成功了
4.删除会话的接口测试:
这个id就是我们刚才获取到会话列表里面的id
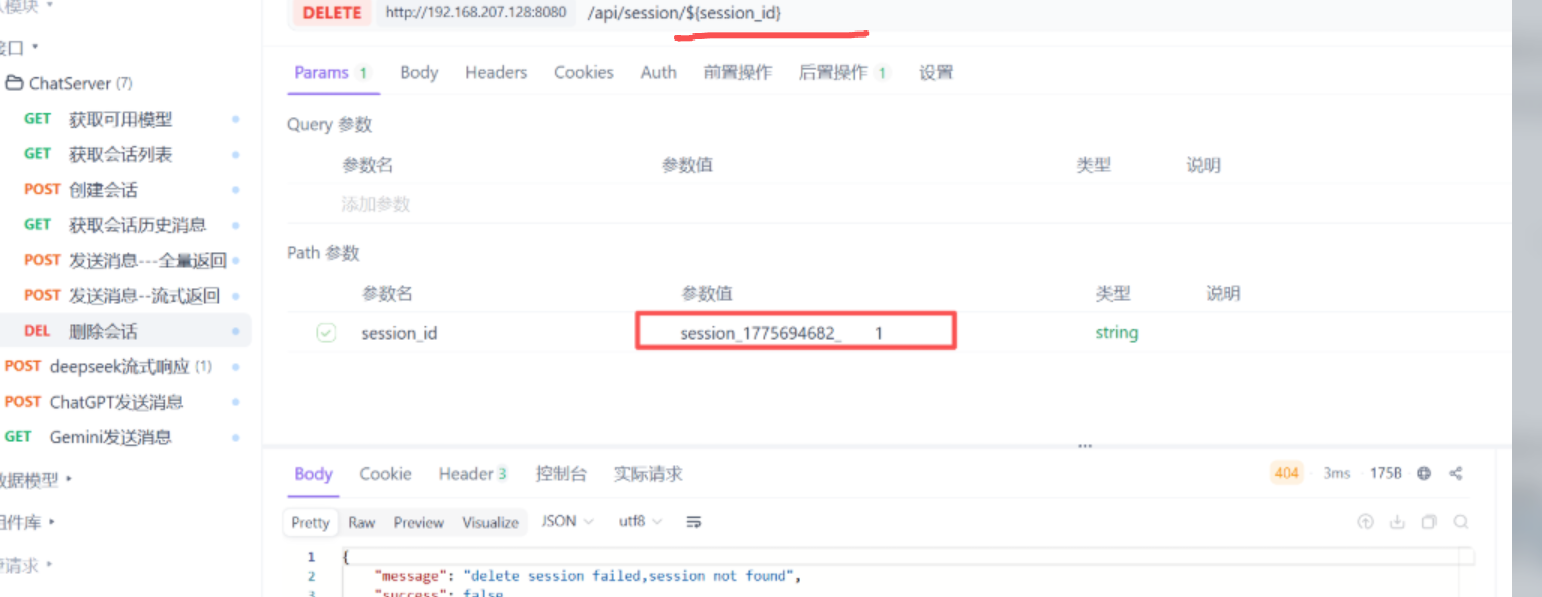
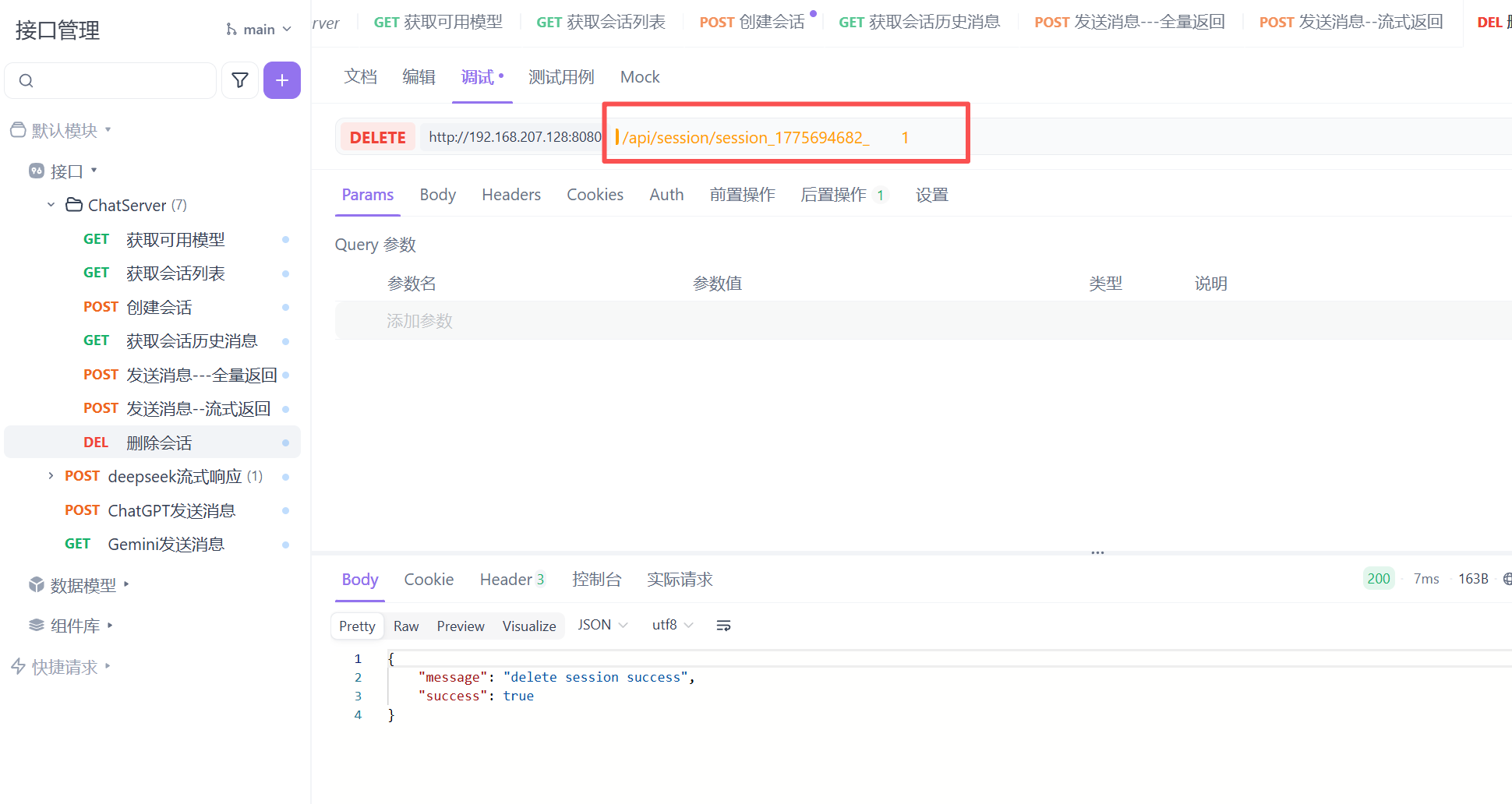
这里有语法请求错误他才会报错,这里正是我传递参数错误了,而不是我程序有错误。
5.发送消息--全量返回的接口测试:
这里我跟他打招呼
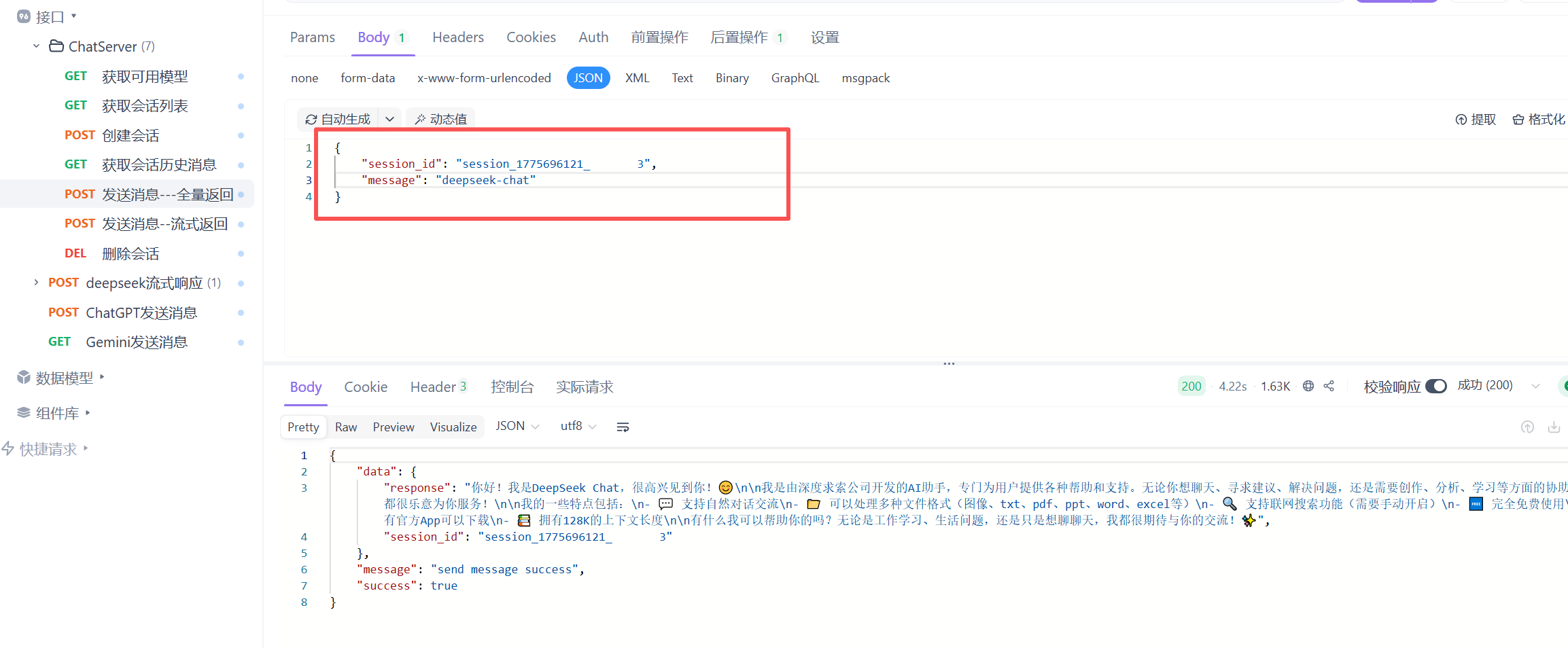
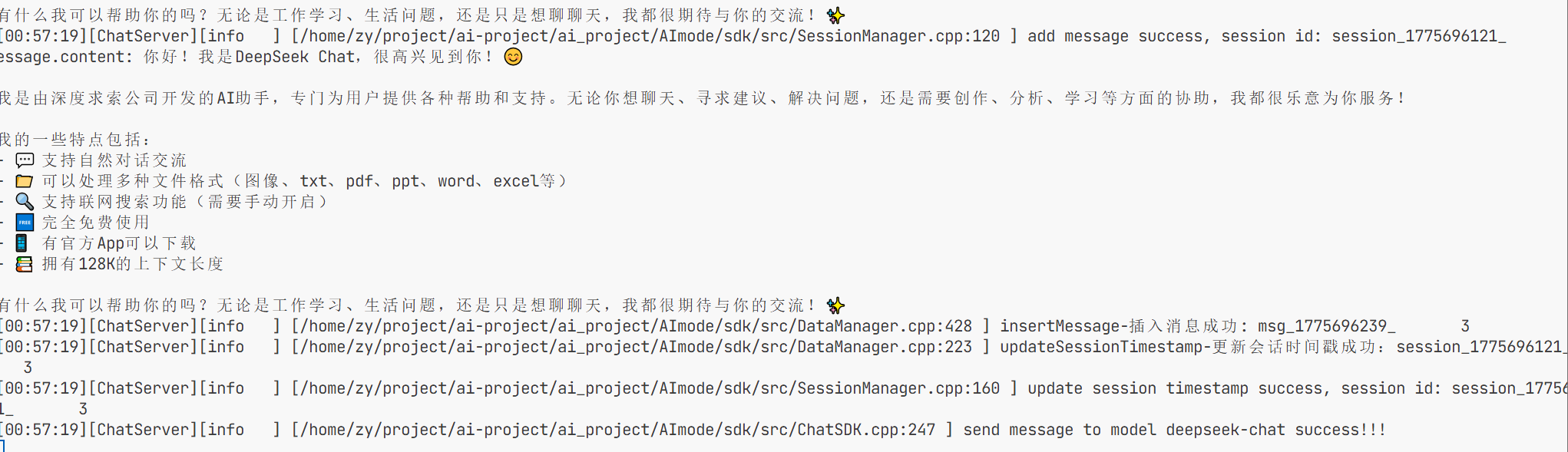
这里既插入了用户发送的消息,也插入了模型的消息
6.获取会话的历史消息:
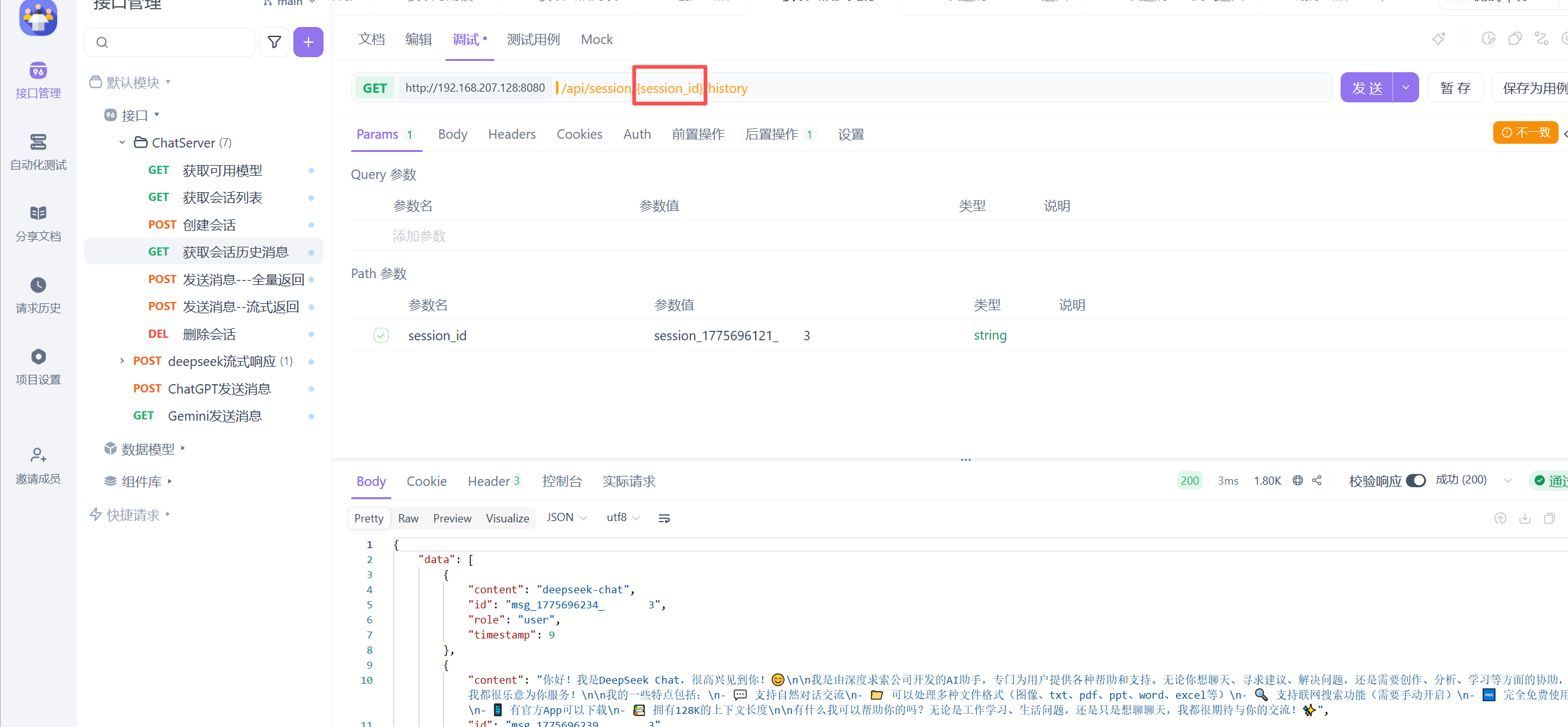
这里我写的格式有问题不能加上$这个字符 这样就获取到了历史消息
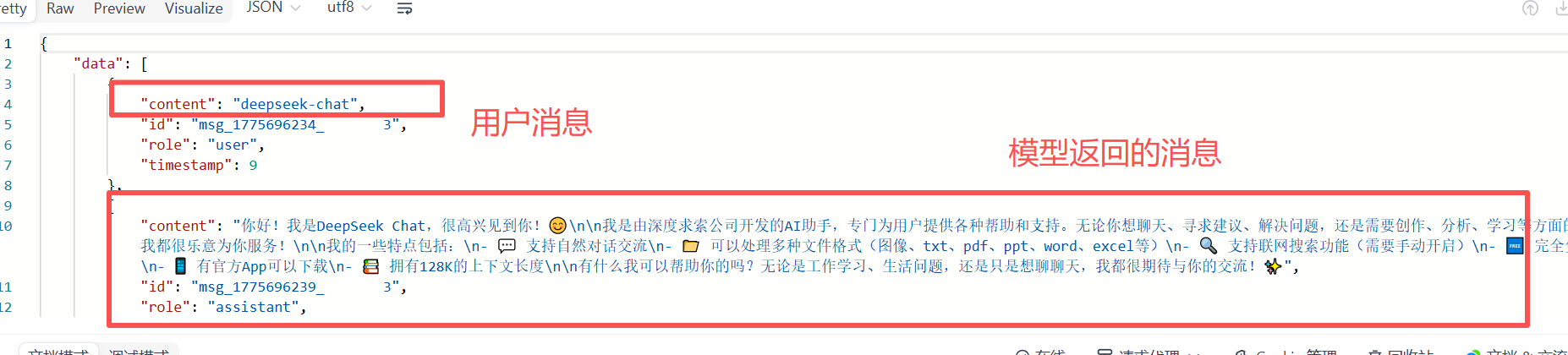
在终端我们可以看到生成了一个chatDB.db的数据库存储有两张表
可以看到存储的内容
7.发送消息--流式返回的接口测试
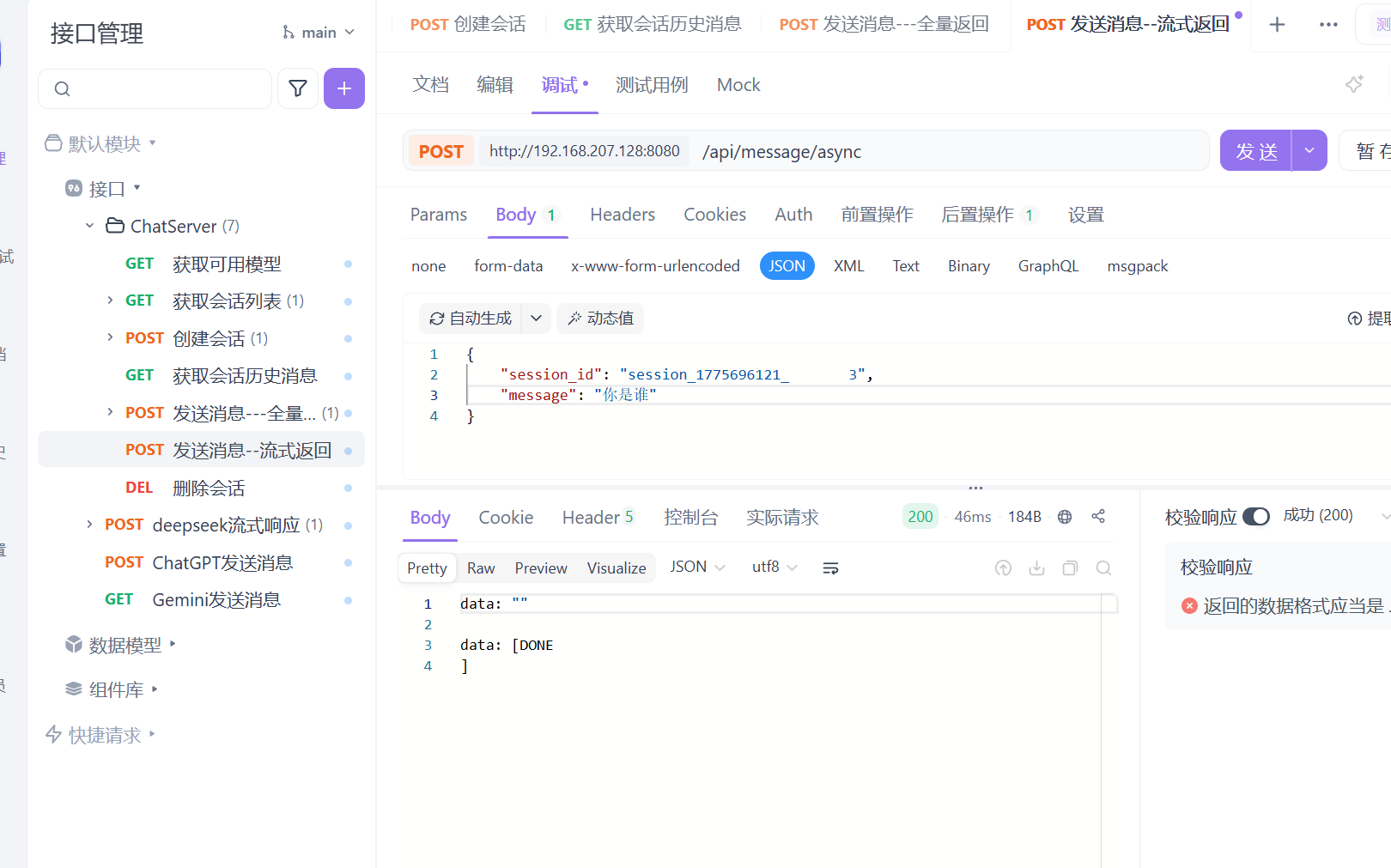
这里传回来的消息有误,只有done那么说明我们代码出现了问题。
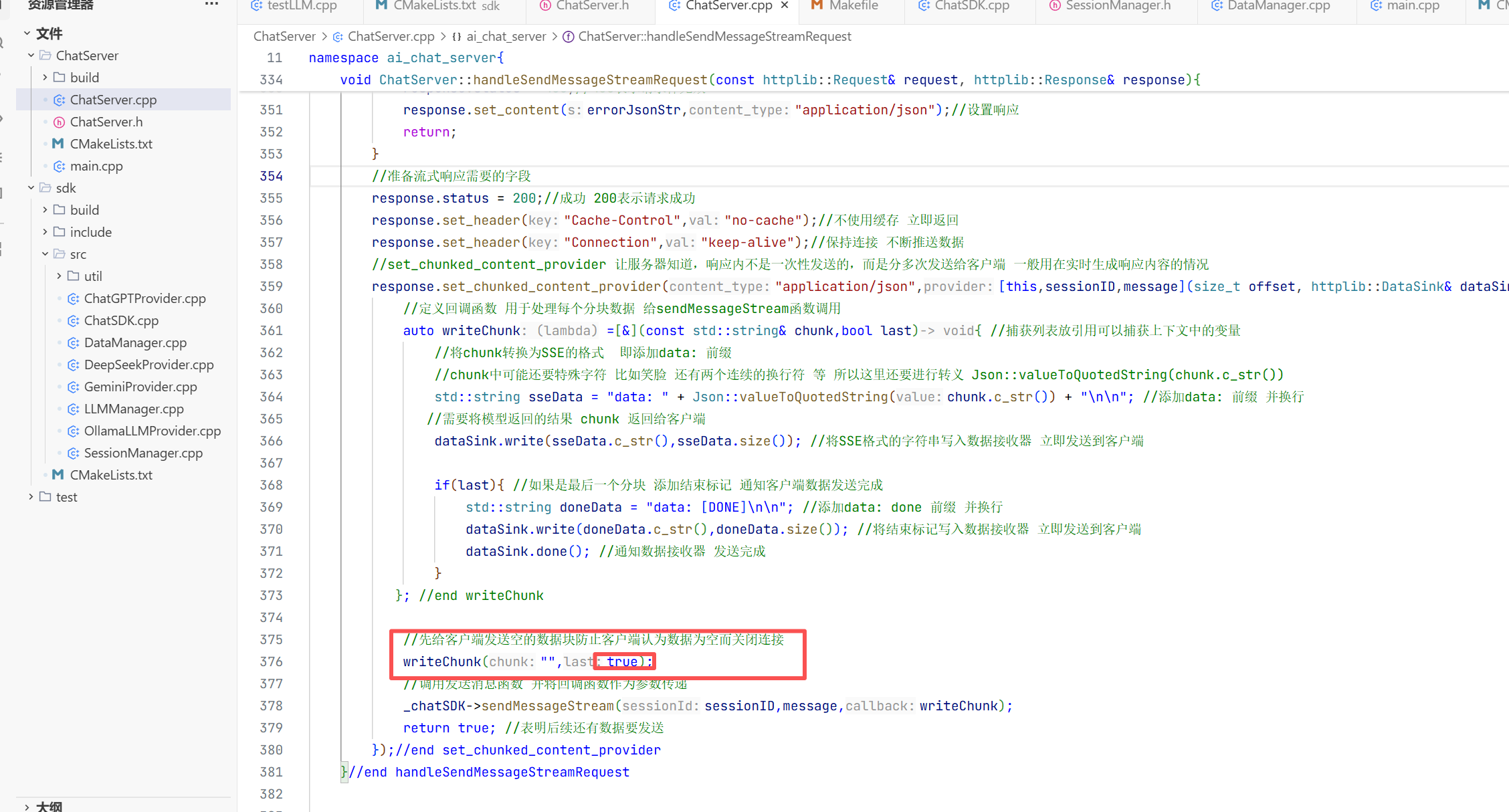
这里不能传true传了这个代表对话就结束了,所以我们这里要穿false。
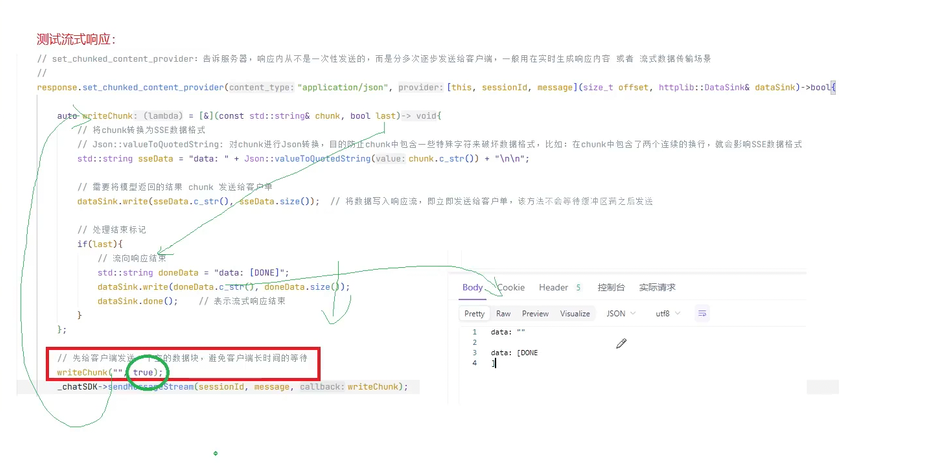
这里发送空消息的目的就是减少用户的等待,而这里如果传true直接进入if语句返回done了
所以要改成false
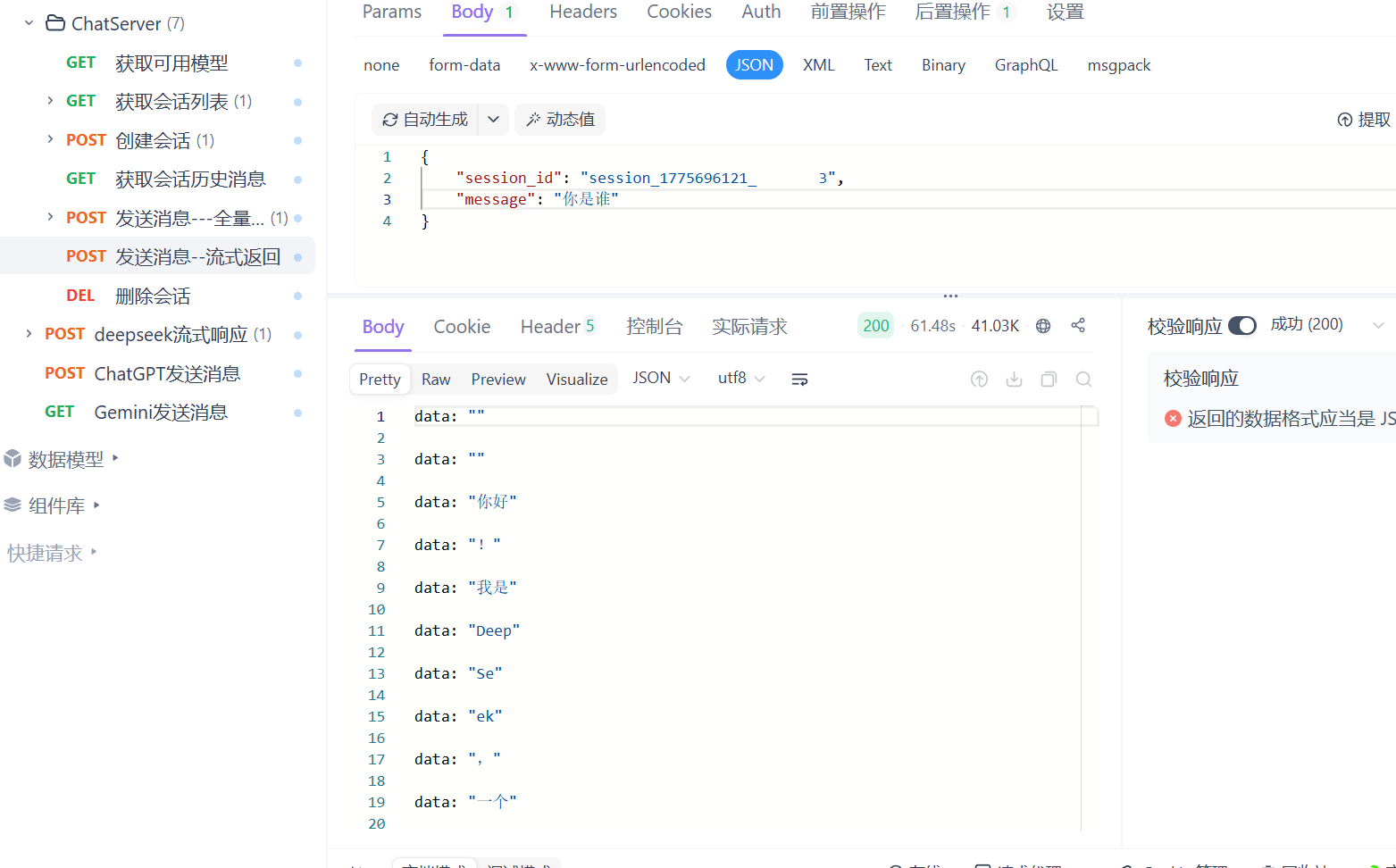
更改之后这里还是有问题。并不是流式返回的
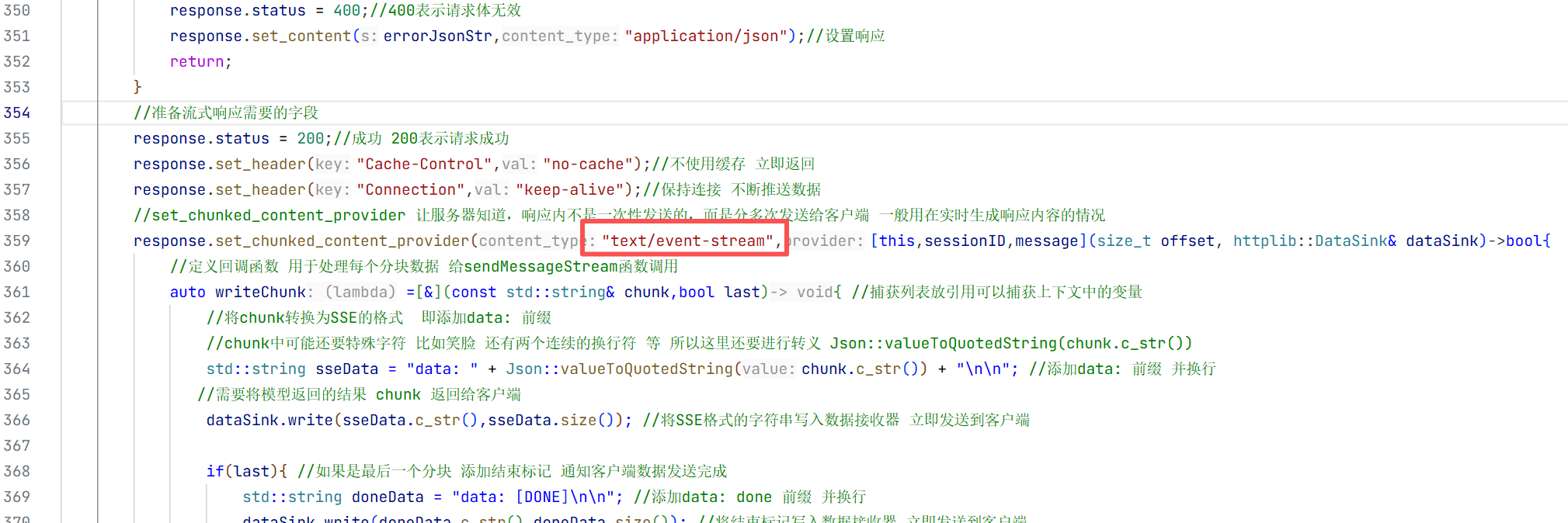
是因为我之前写的是applyjson格式返回的这里不是这里要以流式来返回
我这里还有一个问题就流式响应结束不了就是这个false的原因应该传flase不应该传true
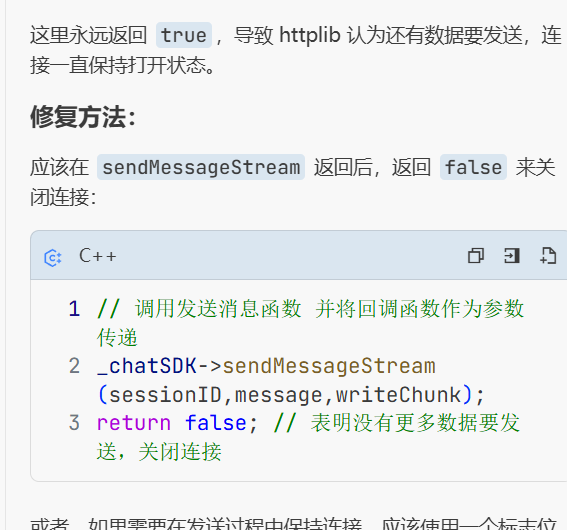
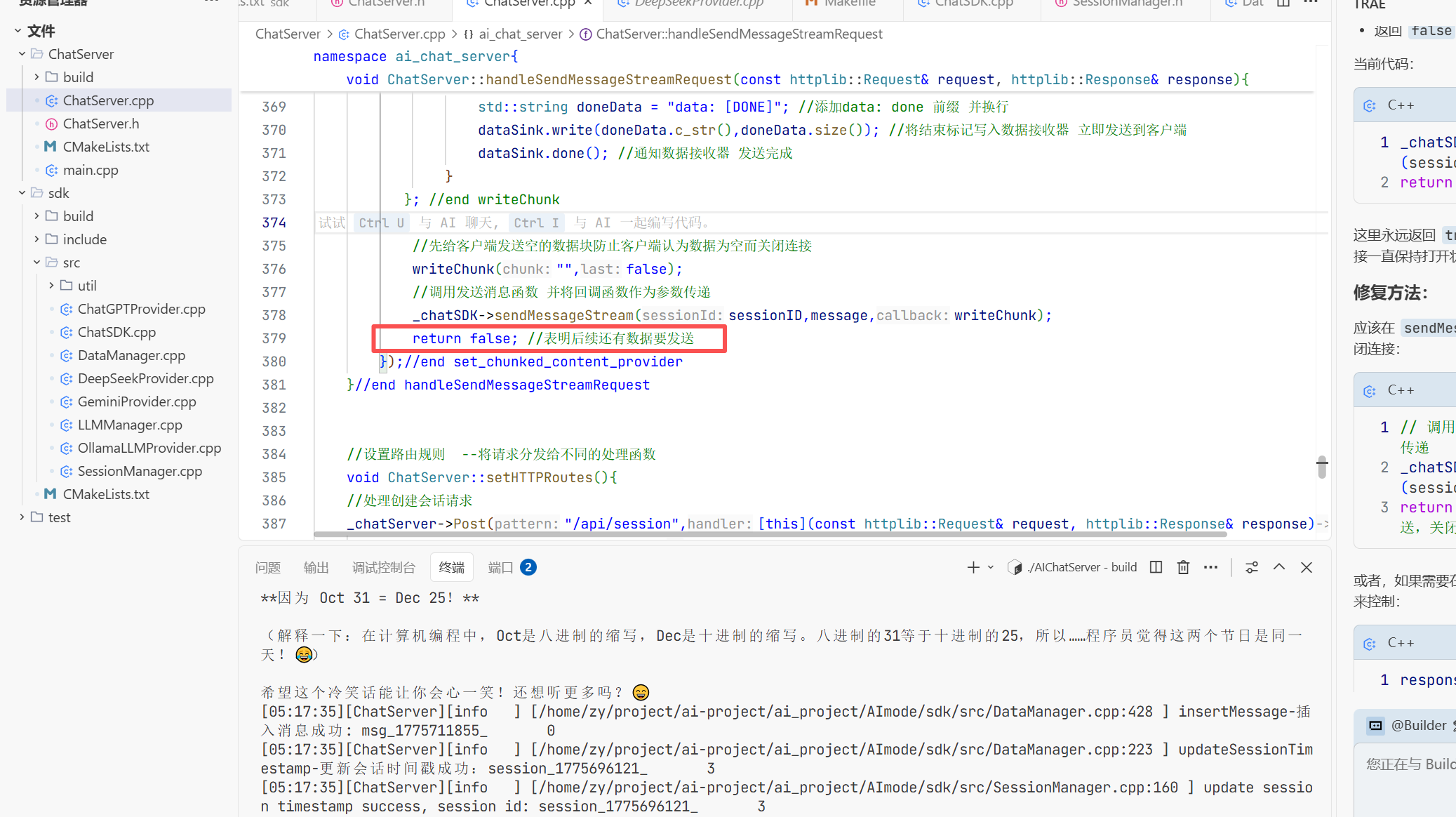
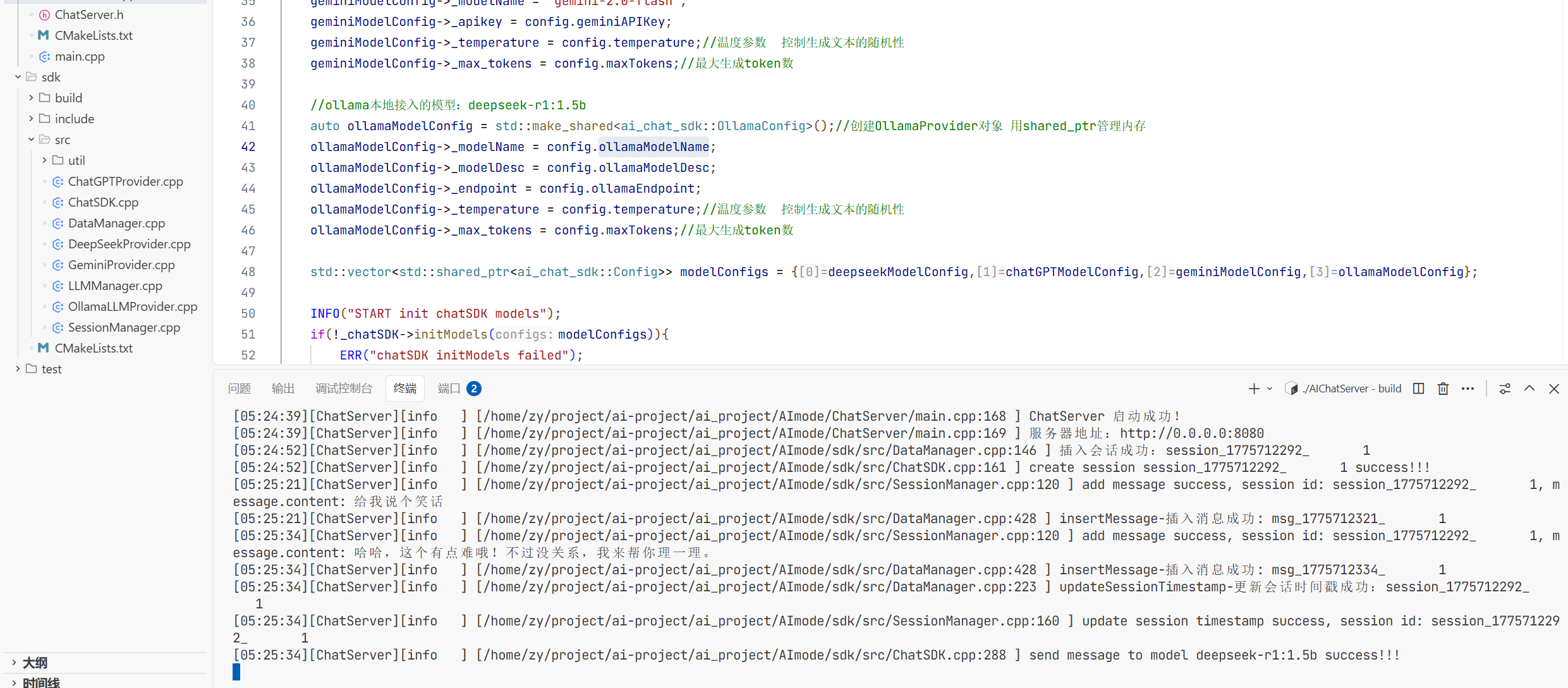
这里ollama的测试也成功了。
那么到这里所有的接口测试也就完成了,那么说明我们后端的代码已经完全没有问题了。
接下来就要来完成前端页面的内容了。
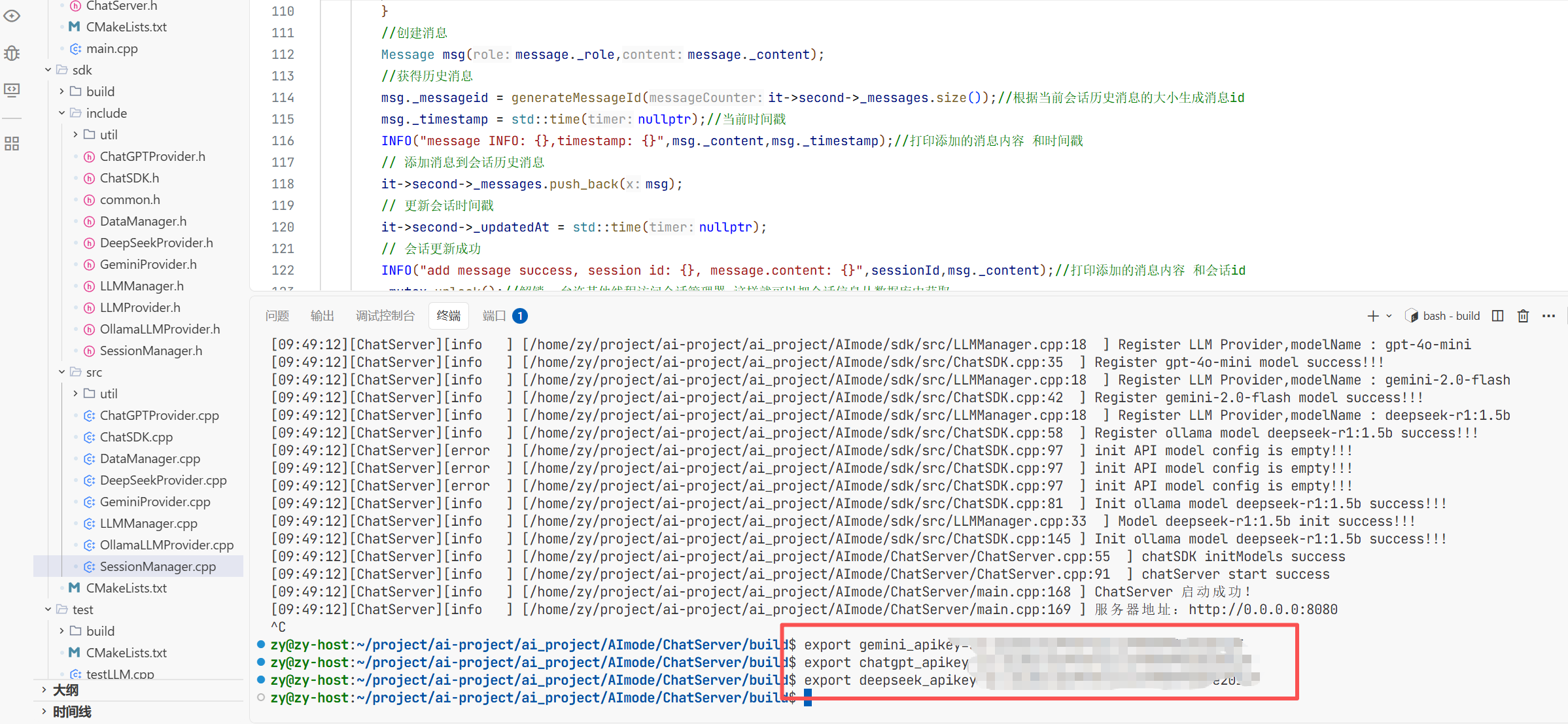
启动服务器之前记得把三个模型的apikey的环境变量给配置一下,这里环境变量可以直接配置到环境变量中,这里就是配置到环境变量中但是不是永久配置的,服务器一关闭就得重新配置,这里我就不永久配置了。
21.前端的实现以及测试:
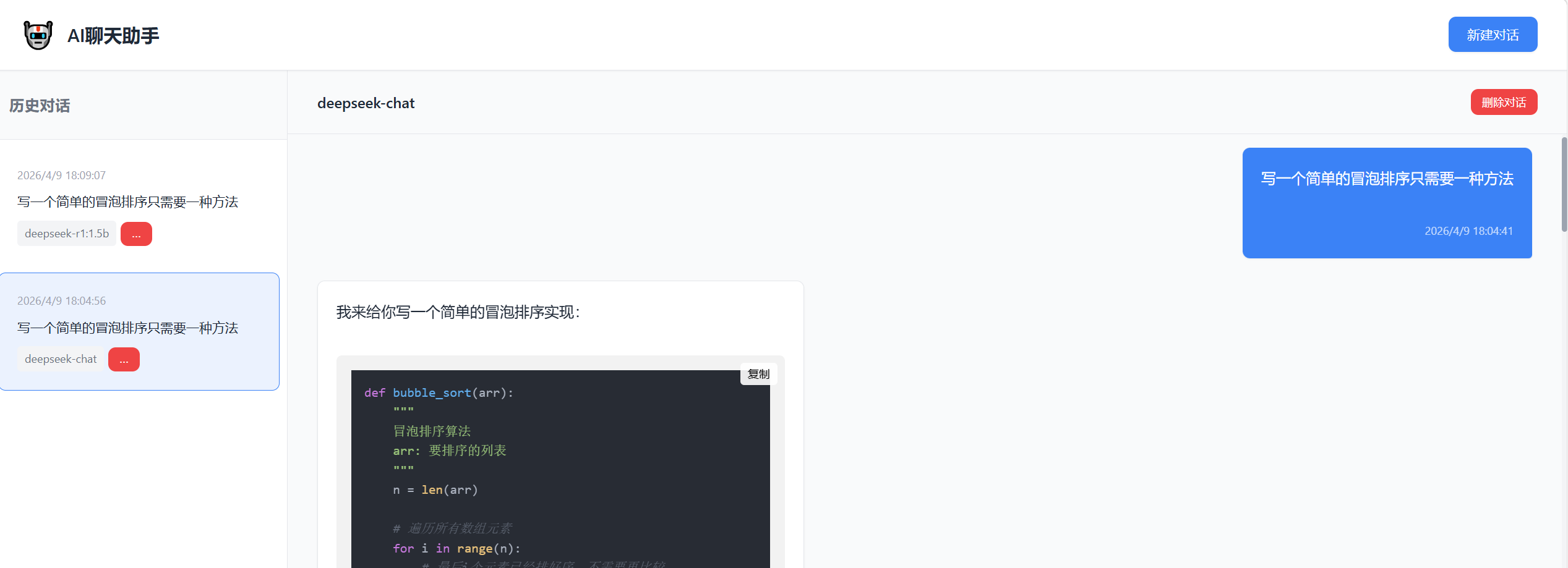
这样由ai生成的整个前端页面也就实现完成了,在这里还可以调教一下大模型,让他生成更美观的前端界面。这里我就不演示了。
22.上传到远端仓库:
这就是我们创建的远端仓库,现在我们要把写好的代码打包上传到仓库中。
23.项目总结:
这里从0用C++实现了接入deepseek,chatgpt,Gemini的云端大模型接入还通过ollama接入了本地大模型,用到了trae,apifox等工具,熟悉了第三方库如spdlog日志库,gflags,gtest,jsoncpp,httplib等的第三方库的使用。
1.掌握大模型接入的思路:
1.到官方申请apikey
2.查看官方文档中提供访问模型的API接口,了解接口的功能,以及熟悉接口的请求参数格式,以及响应的格式
3.使用第三方工具进行接口的快速验证如apifox,crul