目录
[例题: 货仓选址](#例题: 货仓选址)
[例题: 拼数](#例题: 拼数)
1.贪心
贪心算法,是一种企图用局部最优找出全局最优的一种算法:
- 把解决问题的过程分成若干步
- 解决每一步时,都选择"当前看起来最优"的解法
- "期望"得到全局的最优解
对于大多数题目,贪心策略的提出并不难,难的是证明其正确,因为局部最优不代表全局最优,所以我们必须要能严谨的证明我们的贪心策略是正确的。一般来说证明方法有:反证法,数学归纳法,交换论证法等。
当问题的场景不同时,提出的贪心策略也不尽相同,因此,贪心策略的提出是没有模板和套路的,即使是被划分到了同一类题目策略也可能会相差很大。
1.1简单贪心
例题: 货仓选址
题目要求货仓到每一个商店的距离之和最小,我们很容易就可以想出把货仓放在商店的中间来得到最小距离,那么如何证明呢?
先来讨论一下只有两个商店的情况,我们得到当货仓在商店之间时取到最小距离
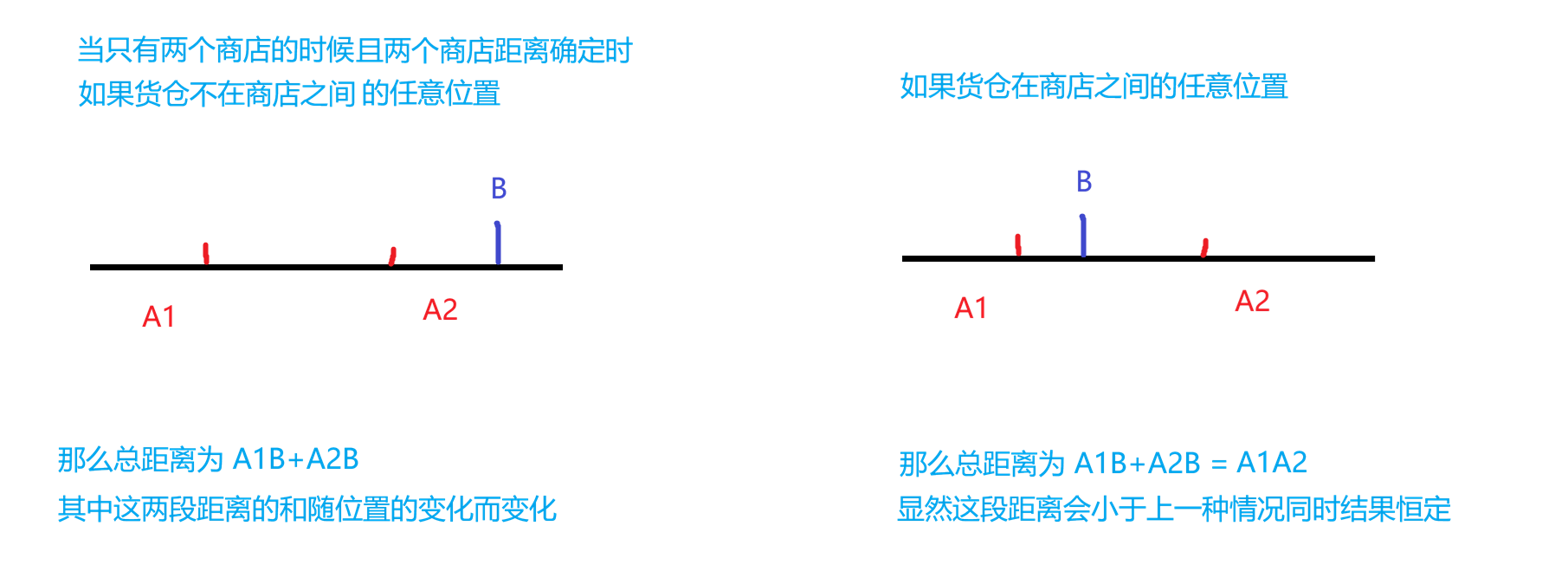
再来看看三个商店的情况

接下来我们尝试推广
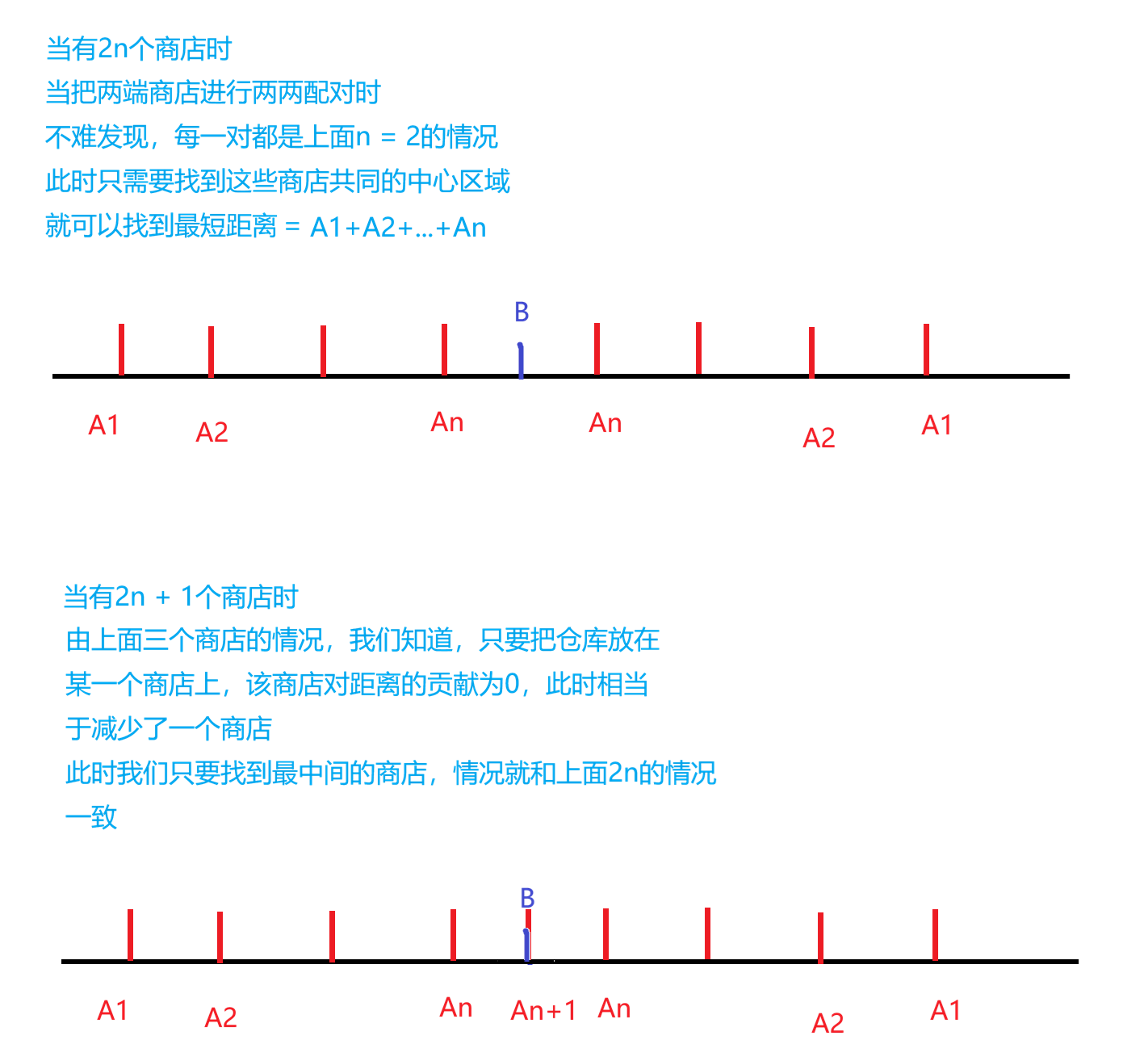
这下我们就可以得出结论,仓库必定在最中间的商店或者最中间两个商店中间,最短距离则可以计算得到。
代码如下,
cpp
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 1e5 + 10;
int n;
int a[N];
int main()
{
// 读入数据
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
// 读入数据并非有序,所以排序
sort(a + 1, a + 1 + n);
LL ret = 0;
for(int i = 1; i <= n / 2; i++)
{
// 计算两端商店距离
ret += a[n + 1 - i] - a[i];
}
cout << ret << endl;
return 0;
} 1.2推公式
这一个部分可以说是"推公式+排序 "。其中推公式就是寻找排序规律 ,排序就是在该排序规则下,对整个对象进行排序。
在解决某些问题的时候,当我们发现最终结果需要调整每个对象先后顺序,也就是对整个对象排序时,那么我们就可以用推公式的方法,得出我们的排序规则,进而对整个对象排序。
例题: 拼数
这道题目要求拼接数字,所以我们可以用string来储存数字,拼接更加方便。
同时我们有一个想法,大的那个字符串放在前面拼接会不会更大呢?至少从题目中给出的两个样例来看,答案就是按照这个规则排序的。
但是,这个想法是错误的,我们来看如下反例
以7 和 72 为例
按照字符串的比较规则,7 < 72
所以结果为727
但是772显然比727大
所以我们需要寻找新的规则,从上面的反例,我们找到了旧规则的漏洞,那么新规则如何避免呢?
仍然以 7 和 72为例
先进行拼装 x + y = 772, y + x = 727
这时候我们让x + y 和 y + x 进行比较
这时候我们绝对能得到大的那个
所以我们的规则为 x + y > y + x
所以我们可以得到代码,
cpp
#include <iostream>
#include <algorithm>
#include <string>
using namespace std;
typedef long long LL;
const int N = 30;
int n;
string a[N];
// 新规则
bool cmp(string& x, string& y)
{
return x + y > y + x;
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> a[i];
}
// 排序
sort(a + 1, a + 1 + n, cmp);
// 直接输出即可
for(int i = 1; i <= n; i++)
{
cout << a[i];
}
return 0;
}关于正确性:
利用排序解决问题,最重要的就是需要证明"在新的排序规则下,整个集合可以排序 "。这需要用到离散数学中"全序关系"的知识。
但是证明过程很麻烦,后续碰见的题目中我们只要发现该题最终结果需要排序,并且交换相邻两个元素的时候,对其余元素不会产生影响,那么我们就可以推导出排序的规则,然后直接去排序,就不用去证明了。
关于全序关系,简单来说就是一种能比大小 的严格顺序关系,比如,在一个集合中任意两个元素可以进行比较 ,且这种比较是可以传递的,那么这种顺序就是全序。
证明:
定义:对于任何两个正整数 x 和 y
- 若 xy > yx, 记为 x ≻ y (表示x排在y前面)
- 若 xy = yx, 记为 x ∼ y (表示两者等价,顺序任意)
- 若 xy < yx, 记为 x ≺ y
1.自反性
对于任何 x ,显然有 xx = xx 。满足自反性
2.反对称性
若 x ≻ y , 则有 xy > yx, 有 yx < xy, 即 x ≺ y。
若 x ~ y, 即 xy = yx, 即 x ~ y。
满足反对称性
3.完全性
对于任意的 x, y, xy 和 yx 都是确定的,因此它们的大小关系只有 xy > yx, xy = yx,yx < yx。意味着 x, y 总是可比的。满足完全性
4.传递性
要证传递性就是要证,对于任意正整数x, y, z, 若 x ≻ y 且 y ≻ z ,则 x ≻ z 。
设函数lens(int x),返回 10 ^ (x 这个数的长度)。
由 x ≻ y 得:xy > xy <==> x * lens(y) + y > y * lens(x) + x
整理得 :(x - 1) / lens(x) > (y - 1) / lens(y)
由 y ≻ z 得:yz >zy <==> y * lens(z) + z > z * lens(y) + y
整理得 :(y - 1) / lens(y) > (z - 1) / lens(z)
显然有 :(x - 1) / lens(x) > (z - 1) / lens(z)
还原得 :x * lens(z) > z * lens(x)
即 :x ≻ z
满足传递性
故该策略可以排序。
1.3哈夫曼编码
哈夫曼编码,是一种优雅且高效的无损压缩算法,它的思想是:为出现频率高的符号分配短的码字,为出现频率低的符号分配长的码字 。它的精妙之处在于它生成的是一种"前缀码",任何一个字符的编码都不是另一个字符编码的前缀。这就完全消除了解码时的歧义,无需任何分隔符就能正确解码。
哈夫曼编码是通过构建一棵二叉树(称为哈夫曼树)来完成的。其过程就是贪心。而**带权路径长(WPL)**就是求和所有叶子节点 * 到根节点有几条边,哈夫曼树有最小的WPL。
而我们如果想要得到最优二叉树,就是要让频率出现高的元素靠近根,而让频率出现低的元素远离根。所以我们可以得到一个贪心策略:进行节点合并的时候选择代价最小的两棵树。
以元素:10 15 15 20 40为例构建哈夫曼树
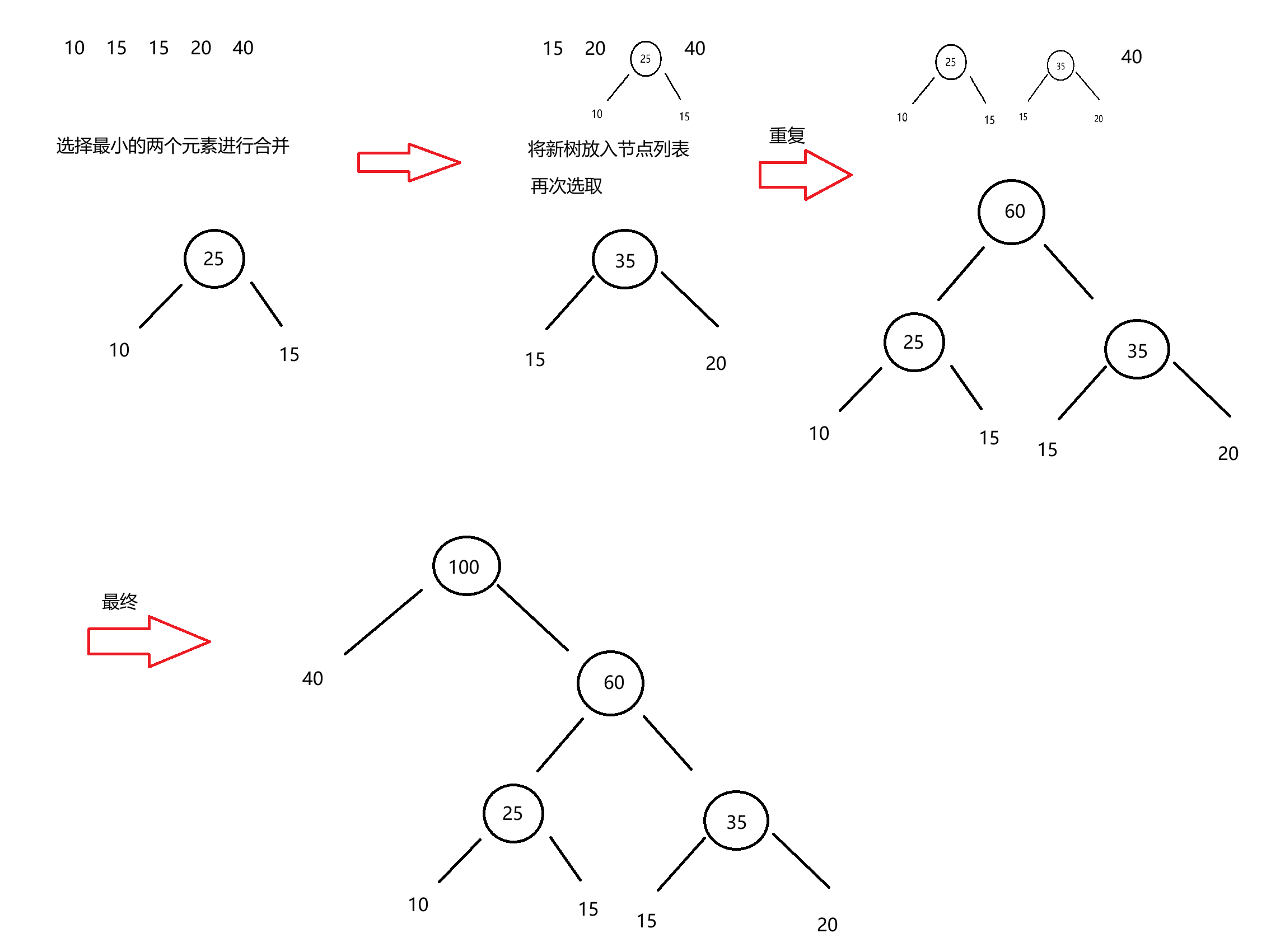
每步都选取了当下代价最小的元素进行合并,最终达到整体代价最小。
那么如何说明这种策略的正确性呢?
要证明算法的成立,就必须证明局部最优选择能导致全局最优,我们可以反证一下,如果不是局部最优呢?
我们取最深的结点 x ,与任意一个节点进行交换,明显的,WPL的变化总是 >= 0,所以当前的位置就是节点最优的位置,从而我们可以确定最深层节点都处在最优的位置。当最后一层确定时,最后一层的结点不能动,从倒数第二层的结点开始重新与其上面的结点进行交换,始终可以确定最优位置不变,综上可以确定,该局部最优解就是全局最优解。
例题:哈夫曼编码
这道题就是要求带权路径长,这难点就在于,如何计算边的个数。我们来观察一下建树的过程,1 2 3为例

在左边这棵树里,1 和 2 形成的这个新节点的值 3 ,就是这棵树的WPL;而在右边的这棵树里,6 是 左3 和 右3(整体) 的WPL,如果两个节点 3 和 6 相加,可以看到 1 和 2 两个叶子的被加了两回, 3 被加了一回,正好满足了WPL的定义,所以我们可以得出结论,WPL = 构建树过程中新节点值的和。
可以有如下代码
cpp
#include <iostream>
#include <queue>
#include <vector>
using namespace std;
typedef long long LL;
const int N = 2e5 + 10;
int n;
// 建小堆用于取小元素
priority_queue<LL, vector<LL>, greater<LL>> a;
int main()
{
cin >> n;
// 读数据入堆
for(int i = 1; i <= n; i++)
{
LL x; cin >> x;
a.push(x);
}
LL ret = 0;
// 模拟建树
while(a.size() > 1)
{
LL x = a.top(); a.pop();
LL y = a.top(); a.pop();
// 累加节点
ret += x + y;
// 新节点入堆
a.push(x + y);
}
cout << ret << endl;
return 0;
}1.4区间问题
对于区间问题,就是给出n段区间,对其进行排序,找到最合适的解法。
其中排序是有讲究的,因为区间有左右两个端点,有升序降序两种排法,所以在没有其他附加条件的情况下是至少有四种排序,而我们要做的就是找到可以解题的哪一种排序。一般来说找到的吻合排序就是正确的那个。
例题:线段覆盖
由题目可以知道比赛区间为[a, b)的形式,所以对于题中的样例可以做到比赛在2时刻结束同时参加下一个2时刻开始的比赛。
接下来就是找到合适的排序方法,对于这道题,选择的是按左端点排升序。接下来我们需要移除区间范围大的,所以对于有重叠的区间,选择右端点最小的,而对于不重叠的区间,那么就能多选中一个区间,此时以新区间为基准继续向后遍历。
如下代码
cpp
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1e6 + 10;
int n;
struct node
{
int l, r;
}a[N];
// 排序规则
bool cmp(node& x, node& y)
{
return x.l < y.l;
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> a[i].l >> a[i].r;
}
sort(a + 1, a + 1 + n, cmp);
int right = a[1].r, ret = 1;
for(int i = 2; i <= n; i++)
{
// 下一个线段左端点小于选中线段的右端点,说明有重叠
if(a[i].l < right)
{
right = min(right, a[i].r);
}
// 不重叠的区间
else
{
right = a[i].r;
ret++;
}
}
cout << ret << endl;
return 0;
}证明和哈夫曼编码类似,故不再赘述。
2.倍增思想
先来了解一下模运算规则的性质
以下性质在模 m下成立(假设所有运算在整数范围内):
加法:(a + b) mod m = (a mod m + b mod m) mod m
减法:(a − b) mod m = (a mod m − b mod m) mod m(结果通常调整为非负)
乘法:(a * b) mod m = (a mod m * b mod m) mod m
幂运算:a^n mod m 可以通过快速幂算法高效计算。
注意:除法不简单,需要逆元,这里暂时不讨论。
模板:快速幂
观察一下这道题的数据范围,注意到乘法的结果可以超过任何一个类型的范围。
所以我们要做的第一步是对 a^b 进行二进制拆分,比如
11 = 1 * 2^3 + 0 * 2^2 + 1 * 2^1 + 1 * 2^0
所以11的二进制表示为 1011
那么对于3^11,可以拆分为
3^(1011) = 3^8 * 3^0 * 3^2 * 3^1
这时候我们就能快速计算出 3^11 ,因为变成二进制之后从右往左看,右边的数是前面数的平方
也就是:
3^1 = 3
3^2 = 3^1 * 3^1 = 9
3^3 = 3^2 * 3^2 = 81
......
因此计算3^11,我们只需要将11的二进制表示中1所对应的幂乘起来即可。
而要计算3^11 mod 7,那么就会变成
(3^8 mod 7 * 3^0 mod 7 * 3^2 mod 7 * 3^1 mod 7) mod 7
那么如何实现这个算法呢?以a^b mod m为例
- 提取b的二进制位,如果为1乘上a,取模
- 让a = a * a mod m,不断变成平方(倍增思想)
代码如下,
cpp
#include <iostream>
using namespace std;
typedef long long LL;
LL a, b, p;
LL qpow(LL a, LL b, LL p)
{
int ret = 1;
while(b)
{
// 为1时按照模运算性质进行相乘取模运算
if(b & 1) ret = ret * a % p;
// 倍增
a = a * a % p;
b >>= 1;
}
return ret;
}
int main()
{
cin >> a >> b >> p;
printf("%lld^%lld mod %lld=%lld\n", a, b, p, qpow(a, b, p));
return 0;
}