目录
-
- 一、分词器工作原理
-
- [1.1 Analyzer的组成结构](#1.1 Analyzer的组成结构)
- [1.2 分词流程解析](#1.2 分词流程解析)
- [1.3 同义词处理机制](#1.3 同义词处理机制)
- [1.4 停用词处理机制](#1.4 停用词处理机制)
- 二、核心分词器介绍
-
- [2.1 Standard Analyzer(标准分词器)【ES内置,自0.90版本开始】](#2.1 Standard Analyzer(标准分词器)【ES内置,自0.90版本开始】)
- [2.2 Simple Analyzer(简单分词器)【ES内置,自0.90版本开始】](#2.2 Simple Analyzer(简单分词器)【ES内置,自0.90版本开始】)
- [2.3 Whitespace Analyzer(空白分词器)【ES内置,自0.90版本开始】](#2.3 Whitespace Analyzer(空白分词器)【ES内置,自0.90版本开始】)
- [2.4 Keyword Analyzer(关键词分词器)【ES内置,自0.90版本开始】](#2.4 Keyword Analyzer(关键词分词器)【ES内置,自0.90版本开始】)
- 三、中文分词器详解
-
- [3.1 IK Analyzer(IK分词器)【需单独安装】](#3.1 IK Analyzer(IK分词器)【需单独安装】)
- [3.2 SmartCN Analyzer(智能中文分词器)【ES内置,从2.0版本开始】](#3.2 SmartCN Analyzer(智能中文分词器)【ES内置,从2.0版本开始】)
- [3.3 Jieba Analyzer(结巴分词器)【需单独安装】](#3.3 Jieba Analyzer(结巴分词器)【需单独安装】)
- 四、高级分词技术
-
- [4.1 N-gram分词](#4.1 N-gram分词)
- [4.2 Edge N-gram分词](#4.2 Edge N-gram分词)
- 五、分词器选择与配置
-
- [5.1 选择原则](#5.1 选择原则)
- [5.2 自定义分词器](#5.2 自定义分词器)
- [5.3 性能优化建议](#5.3 性能优化建议)
- 六、总结

Elasticsearch(ES)作为一款强大的分布式搜索和分析引擎,其核心功能之一是全文搜索。而分词器(Analyzer)在全文搜索中扮演着至关重要的角色。
分词器负责将原始文本分解为独立的词条(Token),以便进行索引和搜索。本文将详细介绍 ES 中 分词器的工作原理 以及 常用的分词器,帮助开发者更好地理解和应用。
一、分词器工作原理
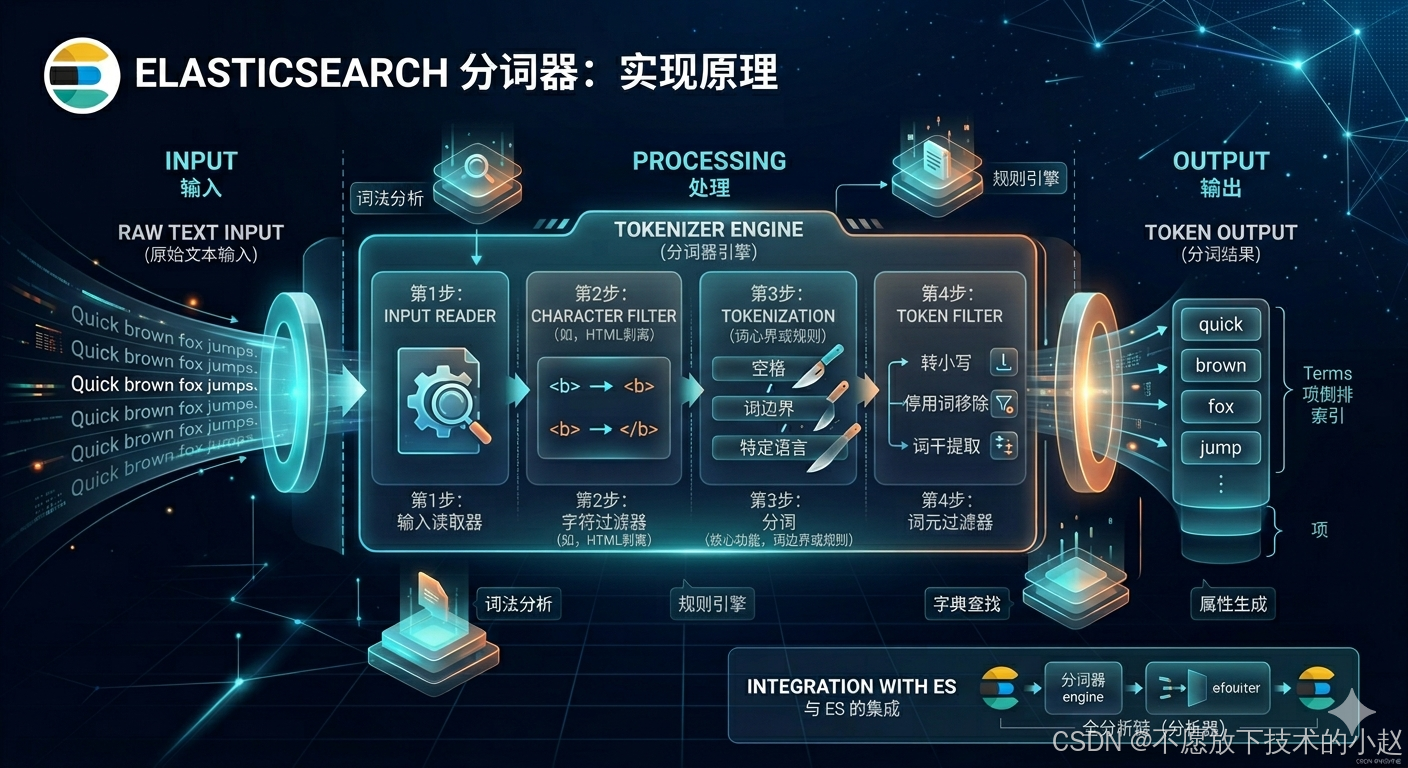
1.1 Analyzer的组成结构
ES分词器(Analyzer)是一个文本处理流水线,由四个有序步骤组成,每个步骤都有特定的职责:
第1步:输入读取器
-
功能:接收原始文本输入,作为整个处理流程的起点
-
输入源:文档字段内容、查询关键词、高亮文本等
-
编码处理:自动识别和处理不同字符编码(UTF-8、GBK等)
-
示例:接收用户输入的"Apple iPhone 14 Pro (New)"
第2步:字符过滤器(Character Filters)
-
功能:在分词前对原始文本进行字符级预处理
-
处理特点:基于规则进行字符替换、删除或转换
-
常见类型:
-
HTML Strip Filter :移除HTML/XML标签,如将"
Hello
"处理为"Hello" -
Mapping Filter:字符映射替换,如全角转半角、"&"转"and"
-
Pattern Replace Filter:正则表达式替换,如统一日期格式
-
-
示例:将"Apple iPhone & Samsung"处理为"Apple iPhone and Samsung"
第3步:分词(Tokenizer)
-
功能:将字符流分解为词条流(Token Stream),是整个分词过程的核心
-
分词策略:
- 基于空格:按空格、标点符号切分(Standard Tokenizer)
- 基于语言规则:考虑特定语言的词汇边界(如中文按词语切分)
- 基于正则:使用正则表达式定义切分规则(Pattern Tokenizer)
-
输出信息:每个词条包含文本内容、位置、偏移量、类型等元数据
-
示例:将"Apple iPhone 14 Pro"分词为"Apple", "iPhone", "14", "Pro"
第4步:词元过滤器(Token Filters)
-
功能:对分词后的词条流进行后处理,优化和标准化词条
-
处理类型:
- 规范化:转小写(LowerCase)、移除变音符号
- 过滤:停用词过滤(Stop)、长度过滤(Length)
- 扩展:同义词扩展(Synonym)、词干提取(Stemmer)
- 保护:关键字保护(Keyword Marker)
-
执行顺序:按配置顺序依次应用多个过滤器
-
示例:将"Apple", "iPhone", "14", "Pro"处理为"apple", "iphone", "14", "pro"
完整处理流水线示例:
json
原始文本: "<p>The Quick Brown Foxes!</p>"
↓ [HTML Strip Filter]
"The Quick Brown Foxes!" (移除HTML标签)
↓ [Standard Tokenizer]
["The", "Quick", "Brown", "Foxes"] (按空格和标点分词)
↓ [LowerCase Filter]
["the", "quick", "brown", "foxes"] (转小写)
↓ [StopWord Filter]
["quick", "brown", "foxes"] (移除停用词"the")
↓ [Stemmer Filter]
["quick", "brown", "fox"] (词干提取:foxes → fox)1.2 分词流程解析
ES分词流程是双向的,确保索引和查询使用相同的处理规则:
索引阶段流程 :
1) 输入接收 :获取文档字段的原始文本内容
2) 字符预处理 :应用配置的Character Filters
3) 词汇切分 :Tokenizer根据规则将文本切分为词汇单元
4) 词条标准化 :应用Token Filters进行后处理
5) 索引构建:将处理后的词条写入倒排索引
查询阶段流程 :
1) 查询解析 :解析用户输入的查询语句
2) 查询分词 :使用与索引阶段相同的Analyzer处理查询文本
3) 词条匹配 :在倒排索引中查找匹配的词条
4) 相关性计算 :基于词条匹配度计算文档相关性
5) 结果返回:按相关性排序返回匹配的文档
一致性保证机制:
- Analyzer复用:索引和查询阶段使用相同的Analyzer配置
- 配置同步:通过索引映射(Mapping)统一管理Analyzer配置
- 版本控制:Analyzer配置变更时,需要重建索引以保证一致性
1.3 同义词处理机制
同义词处理是提升搜索召回率的重要功能,ES提供了多种实现方式:
Synonym Token Filter原理:
-
词典加载:启动时加载同义词词典到内存
-
查询时扩展:将输入词条扩展为其同义词集合
-
索引时扩展:在索引阶段就将同义词展开,提高查询性能
同义词格式支持:
-
Solr格式 :
中国, 中华人民共和国, PR China -
WordNet格式:基于词义关系的同义词定义
-
显式映射 :
i-pod, i pod => ipod(单向映射)性能优化策略:
-
索引时扩展:查询性能更好,但索引体积增大
-
查询时扩展:索引体积小,但查询性能略低
-
缓存机制:热点同义词查询结果缓存
配置示例:
json
{
"filter": {
"my_synonym_filter": {
"type": "synonym",
"synonyms": [
"中国, 中华人民共和国, PRC",
"电脑, 计算机, 电子计算机"
],
"expand": true, // 是否展开所有同义词
"lenient": false // 是否忽略同义词格式错误
}
}
}1.4 停用词处理机制
停用词处理是平衡搜索精度和性能的重要机制:
停用词选择策略:
-
基于词频:高频但低信息量的词汇
-
基于词性:介词、冠词、连词等功能词
-
基于领域:特定领域的无意义词汇
停用词列表管理:
-
内置列表:ES提供多种语言的默认停用词
-
自定义列表:根据业务需求定制停用词
-
动态更新:通过API实时更新停用词配置
性能影响分析:
-
索引体积:移除停用词可减少30-50%的索引大小
-
查询性能:减少词条数量,提高查询速度
-
召回率影响:可能降低某些查询的召回率
多语言停用词处理:
json
{
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_" // 使用内置英文停用词
},
"chinese_stop": {
"type": "stop",
"stopwords": ["的", "了", "在", "是", "我", "有", "和", "就", "不", "人", "都", "一", "一个", "上", "也", "很", "到", "说", "要", "去", "你", "会", "着", "没有", "看", "好", "自己", "这"]
}
}
}二、核心分词器介绍

2.1 Standard Analyzer(标准分词器)【ES内置,自0.90版本开始】
Standard Analyzer 是 ES 的默认分词器,适用于大多数语言场景。它基于Unicode文本分割算法,能够智能地识别单词边界。
核心原理:
-
Unicode分词算法:基于Unicode标准附录#29(Unicode Text Segmentation)定义的词边界规则
-
正则表达式匹配 :使用正则表达式
[^\\p{L}\\p{N}]+识别非字母数字字符作为分隔符 -
双向最大匹配:在歧义情况下,优先选择更长的匹配结果
工作流程 :
1) 字符过滤 :可选的字符过滤器预处理(如HTML标签移除)
2) 分词 :Tokenizer根据Unicode规则将文本按词边界切分
3) 小写转换 :Lowercase Token Filter将所有词条转换为小写形式
4) 停用词过滤:可选的停用词过滤器移除常见无意义词汇
使用示例:
创建索引DSL:
json
PUT /standard_test
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "standard"
},
"title": {
"type": "text",
"analyzer": "standard"
}
}
}
}插入测试数据:
json
POST /standard_test/_doc/1
{
"title": "The Quick Brown Foxes!",
"content": "Elasticsearch 7.15.0 is a distributed search engine."
}
POST /standard_test/_doc/2
{
"title": "Java Programming Guide",
"content": "This guide covers Java 8 features and best practices."
}测试查询结果:
json
GET /standard_test/_search
{
"query": {
"match": {
"content": "search engine"
}
}
}
// 使用_analyze API查看分词效果
GET /_analyze
{
"analyzer": "standard",
"text": "The Quick Brown Foxes!"
}
// 结果:["the", "quick", "brown", "foxes"]适用场景:
- 通用英文文本处理
- 多语言混合内容处理
- 作为自定义分词器的基础模板
2.2 Simple Analyzer(简单分词器)【ES内置,自0.90版本开始】
Simple Analyzer是一个基础的分词器,其工作原理相对简单。
核心原理:
-
字母字符识别 :使用
Character.isLetter()方法识别字母字符 -
非字母分隔:所有非字母字符都被视为分隔符
-
贪婪匹配:尽可能长地匹配连续字母序列
工作流程 :
1) 字符过滤 :移除所有非字母字符(数字、标点、符号等)
2) 分词 :在任意非字母字符处进行切分
3) 小写转换:统一转换为小写形式
使用示例:
创建索引DSL:
json
PUT /simple_test
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "simple"
}
}
}
}插入测试数据:
json
POST /simple_test/_doc/1
{
"content": "Hello World! This is a test123 with numbers."
}
POST /simple_test/_doc/2
{
"content": "Email: user@example.com, Phone: 123-456-7890"
}测试查询结果:
json
GET /simple_test/_search
{
"query": {
"match": {
"content": "hello world"
}
}
}
// 使用_analyze API查看分词效果
GET /_analyze
{
"analyzer": "simple",
"text": "Hello World! This is a test123 with numbers."
}
// 结果:["hello", "world", "this", "is", "a", "test", "with", "numbers"]适用场景:
- 纯文本内容处理
- 需要高性能的简单分词需求
- 预处理过的标准化文本
2.3 Whitespace Analyzer(空白分词器)【ES内置,自0.90版本开始】
Whitespace Analyzer是最简单的分词器之一,仅根据空白字符进行分词。
核心原理:
-
空白字符定义:空格、制表符(\t)、换行符(\n)、回车符(\r)等
-
字符保留:保留所有非空白字符,包括标点符号
-
位置敏感:严格按字符位置进行切分
工作流程 :
1) 空白分割 :仅在定义的空白字符处进行切分
2) 无转换 :不进行大小写转换或字符过滤
3) 原始保留:保持文本的原始格式和内容
使用示例:
创建索引DSL:
json
PUT /whitespace_test
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"log_message": {
"type": "text",
"analyzer": "whitespace"
},
"tags": {
"type": "text",
"analyzer": "whitespace"
}
}
}
}插入测试数据:
json
POST /whitespace_test/_doc/1
{
"log_message": "ERROR 2023-10-01 10:00:00 Service failed",
"tags": "error production api"
}
POST /whitespace_test/_doc/2
{
"log_message": "INFO 2023-10-01 10:05:00 Service recovered",
"tags": "info production api"
}测试查询结果:
json
GET /whitespace_test/_search
{
"query": {
"match": {
"tags": "production"
}
}
}
// 使用_analyze API查看分词效果
GET /_analyze
{
"analyzer": "whitespace",
"text": "ERROR 2023-10-01 10:00:00 Service failed"
}
// 结果:["ERROR", "2023-10-01", "10:00:00", "Service", "failed"]适用场景:
- 结构化日志分析
- 已预处理的标准格式文本
- 需要保持原始格式的标识符处理
2.4 Keyword Analyzer(关键词分词器)【ES内置,自0.90版本开始】
Keyword Analyzer是一种特殊的分词器,它将整个输入文本作为一个单独的词条处理。
核心原理:
-
整体封装:将整个输入视为不可分割的单一实体
-
零变换:除非显式配置,否则不进行任何转换
-
精确匹配:确保索引和查询时的一致性
工作流程 :
1) 整体保留 :将整个输入字符串作为一个词条
2) 可选处理 :可配置字符过滤和小写转换等
3) 边界保护:维护文本的完整性和精确性
使用示例:
创建索引DSL:
json
PUT /keyword_test
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"user_id": {
"type": "text",
"analyzer": "keyword"
},
"status": {
"type": "text",
"analyzer": "keyword"
},
"category_code": {
"type": "text",
"analyzer": "keyword"
}
}
}
}插入测试数据:
json
POST /keyword_test/_doc/1
{
"user_id": "USER_001234",
"status": "ACTIVE",
"category_code": "CAT_ELECTRONICS"
}
POST /keyword_test/_doc/2
{
"user_id": "USER_005678",
"status": "INACTIVE",
"category_code": "CAT_BOOKS"
}测试查询结果:
json
GET /keyword_test/_search
{
"query": {
"term": {
"user_id": "USER_001234"
}
}
}
// 使用_analyze API查看分词效果
GET /_analyze
{
"analyzer": "keyword",
"text": "USER_001234"
}
// 结果:["USER_001234"] - 整个文本作为一个词条适用场景:
- ID、编码等精确匹配字段
- 聚合分析中的分组字段
- 不需要分词的短文本字段
三、中文分词器详解
3.1 IK Analyzer(IK分词器)【需单独安装】
IK Analyzer是ES中最流行的中文分词器,由林良益开发,支持细粒度和智能分词两种模式。
核心算法:
-
双向最大匹配算法:结合正向最大匹配(FMM)和逆向最大匹配(BMM)
-
歧义消除:通过概率模型和词典权重解决分词歧义
-
动态词典加载:支持运行时词典更新和扩展
词典结构:
-
核心词典:包含约27万常用中文词汇
-
扩展词典:用户自定义词汇,支持热更新
-
停用词典:过滤无意义词汇,提高搜索精度
工作模式:
ik_smart模式(智能分词):
-
算法:基于N-最短路径算法,选择最优分词路径
-
特点:分词粒度较粗,适合搜索场景
-
示例:"中华人民共和国" → "中华人民共和国"
ik_max_word模式(细粒度分词):
-
算法:穷尽所有可能的词汇组合
-
特点:分词粒度最细,适合索引场景
-
示例:"中华人民共和国" → "中华人民共和国", "中华人民", "中华", "华人", "人民共和国", "人民", "共和国", "共和", "国"
使用示例:
创建索引DSL:
json
PUT /ik_test
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"analysis": {
"analyzer": {
"ik_smart_analyzer": {
"type": "ik_smart"
},
"ik_max_analyzer": {
"type": "ik_max_word"
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}插入测试数据:
json
POST /ik_test/_doc/1
{
"title": "中华人民共和国成立了",
"content": "1949年10月1日,中华人民共和国在北京天安门广场正式成立。"
}
POST /ik_test/_doc/2
{
"title": "Elasticsearch中文分词",
"content": "IK分词器是Elasticsearch中最流行的中文分词插件。"
}测试查询结果:
json
GET /ik_test/_search
{
"query": {
"match": {
"title": "中国"
}
}
}
// 使用_analyze API查看分词效果
GET /_analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国成立了"
}
// 结果:["中华人民共和国", "成立了"]
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国成立了"
}
// 结果:["中华人民共和国", "中华人民", "中华", "华人", "人民共和国", "人民", "共和国", "共和", "国", "成立", "了"]3.2 SmartCN Analyzer(智能中文分词器)【ES内置,从2.0版本开始】
SmartCN是ES官方提供的中文分词器,基于Apache Lucene的中文分词模块。
核心算法:
-
隐马尔可夫模型(HMM):基于统计模型的词性标注和分词
-
维特比算法:动态规划求解最优分词路径
-
最大熵模型:用于处理未登录词识别
训练数据:
-
语料库:基于人民日报等权威语料训练
-
标注体系:采用PKU词性标注集
-
模型更新:定期更新以适应新词汇
分词流程 :
1) 字符预处理 :全角半角转换、数字归一化
2) 原子切分 :基于词典的最大匹配切分
3) HMM标注 :为每个字符分配词性标签
4) 路径优化 :使用维特比算法求解最优路径
5) 后处理:合并连续单字、处理特殊模式
使用示例:
创建索引DSL:
json
PUT /smartcn_test
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "smartcn"
},
"content": {
"type": "text",
"analyzer": "smartcn"
}
}
}
}插入测试数据:
json
POST /smartcn_test/_doc/1
{
"title": "北京天气预报",
"content": "今天北京天气晴朗,气温在20到25度之间,适合外出活动。"
}
POST /smartcn_test/_doc/2
{
"title": "上海旅游攻略",
"content": "上海是一座现代化大都市,有许多著名的旅游景点,如外滩、东方明珠等。"
}测试查询结果:
json
GET /smartcn_test/_search
{
"query": {
"match": {
"title": "北京"
}
}
}
// 使用_analyze API查看分词效果
GET /_analyze
{
"analyzer": "smartcn",
"text": "北京天气预报"
}
// 结果:["北京", "天气", "预报"]3.3 Jieba Analyzer(结巴分词器)【需单独安装】
Jieba分词器是基于著名的jieba分词库开发的ES插件。
核心算法:
-
基于前缀词典:使用Trie树结构存储词典,支持快速查询
-
动态规划:基于DAG(有向无环图)寻找最优分词路径
-
HMM新词发现:使用HMM模型识别未登录词
三种分词模式:
精确模式:
-
算法:基于词典的最大概率分词
-
特点:精度高,适合文本分析
-
示例:"我来到北京清华大学" → "我", "来到", "北京", "清华大学"
全模式:
-
算法:扫描所有可能的词汇组合
-
特点:速度快,可能包含冗余词汇
-
示例:"我来到北京清华大学" → "我", "来到", "北京", "清华", "清华大学", "华大", "大学"
搜索引擎模式:
-
算法:在精确模式基础上,对长词进行二次切分
-
特点:兼顾召回率和精度,适合搜索场景
-
示例:"我来到北京清华大学" → "我", "来到", "北京", "清华", "华大", "大学", "清华大学"
使用示例:
创建索引DSL:
json
PUT /jieba_test
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"analysis": {
"analyzer": {
"jieba_search_analyzer": {
"type": "jieba_search"
},
"jieba_index_analyzer": {
"type": "jieba_index"
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "jieba_index",
"search_analyzer": "jieba_search"
},
"content": {
"type": "text",
"analyzer": "jieba_index"
}
}
}
}插入测试数据:
json
POST /jieba_test/_doc/1
{
"title": "我来到北京清华大学",
"content": "清华大学是中国著名的高等学府,位于北京市海淀区。"
}
POST /jieba_test/_doc/2
{
"title": "京东商城购物指南",
"content": "京东商城是中国领先的电商平台,提供丰富的商品选择。"
}测试查询结果:
json
GET /jieba_test/_search
{
"query": {
"match": {
"title": "清华大学"
}
}
}
// 使用_analyze API查看分词效果
GET /_analyze
{
"analyzer": "jieba_search",
"text": "我来到北京清华大学"
}
// 结果:["我", "来到", "北京", "清华大学"]
GET /_analyze
{
"analyzer": "jieba_index",
"text": "我来到北京清华大学"
}
// 结果:["我", "来到", "北京", "清华", "清华大学", "华大", "大学"]四、高级分词技术
4.1 N-gram分词
N-gram是一种基于滑动窗口的分词技术,特别适合处理部分匹配和模糊搜索。
使用示例:
创建索引DSL:
json
PUT /ngram_test
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"analysis": {
"analyzer": {
"ngram_analyzer": {
"tokenizer": "ngram_tokenizer"
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 3,
"token_chars": [
"letter",
"digit"
]
}
}
}
},
"mappings": {
"properties": {
"product_name": {
"type": "text",
"analyzer": "ngram_analyzer"
}
}
}
}插入测试数据:
json
POST /ngram_test/_doc/1
{
"product_name": "iPhone 13 Pro Max"
}
POST /ngram_test/_doc/2
{
"product_name": "Samsung Galaxy S21"
}测试查询结果:
json
GET /ngram_test/_search
{
"query": {
"match": {
"product_name": "pho"
}
}
}
// 使用_analyze API查看分词效果
GET /_analyze
{
"tokenizer": "ngram_tokenizer",
"text": "hello"
}
// 结果:["he", "el", "ll", "lo", "hel", "ell", "llo"]4.2 Edge N-gram分词
Edge N-gram是N-gram的变种,仅从词的开头生成n-gram,适合实现自动补全功能。
使用示例:
创建索引DSL:
json
PUT /autocomplete_test
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"analysis": {
"analyzer": {
"autocomplete": {
"tokenizer": "autocomplete_tokenizer",
"filter": ["lowercase"]
}
},
"tokenizer": {
"autocomplete_tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 10,
"token_chars": ["letter"]
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "autocomplete"
}
}
}
}插入测试数据:
json
POST /autocomplete_test/_doc/1
{
"name": "Elasticsearch"
}
POST /autocomplete_test/_doc/2
{
"name": "Elastic Stack"
}
POST /autocomplete_test/_doc/3
{
"name": "Elastic Cloud"
}测试查询结果:
json
GET /autocomplete_test/_search
{
"query": {
"match": {
"name": "Ela"
}
}
}
// 使用_analyze API查看分词效果
GET /_analyze
{
"tokenizer": "autocomplete_tokenizer",
"text": "hello"
}
// 结果:["h", "he", "hel", "hell", "hello"]性能对比:
| 分词器类型 | 索引体积 | 查询性能 | 适用场景 |
|---|---|---|---|
| Standard | 小 | 高 | 精确搜索 |
| N-gram | 大 | 中 | 模糊搜索 |
| Edge N-gram | 中 | 高 | 自动补全 |
五、分词器选择与配置
5.1 选择原则
根据应用场景选择合适的分词器:
-
通用英文文本:使用Standard Analyzer,平衡精度与性能
-
中文内容:使用IK Analyzer,支持细粒度和智能分词模式
-
精确匹配:使用Keyword Analyzer,保持原始文本完整性
-
日志分析:使用Whitespace Analyzer,按空白字符简单切分
-
自动补全:使用Edge N-gram,支持前缀匹配
-
模糊搜索:使用N-gram,支持部分匹配和纠错
分词器对比表:
| 分词器 | 类型 | 适用语言 | 索引体积 | 查询性能 | 最佳场景 | 特点 |
|---|---|---|---|---|---|---|
| Standard Analyzer | ES内置 | 多语言 | 小 | 高 | 通用文本处理 | Unicode分词,默认选择 |
| Simple Analyzer | ES内置 | 英文 | 小 | 高 | 纯字母文本 | 移除非字母字符 |
| Whitespace Analyzer | ES内置 | 多语言 | 小 | 极高 | 结构化数据 | 按空白字符切分 |
| Keyword Analyzer | ES内置 | 多语言 | 中 | 极高 | 精确匹配 | 不分词,整体处理 |
| IK Analyzer | 需单独安装 | 中文 | 中 | 中 | 中文搜索 | 支持细粒度和智能模式 |
| SmartCN Analyzer | ES内置 | 中文 | 中 | 中 | 中文分析 | 基于HMM模型 |
| Jieba Analyzer | 需单独安装 | 中文 | 中 | 中 | 中文处理 | 三种分词模式可选 |
| N-gram | 可配置 | 多语言 | 大 | 中 | 模糊搜索 | 字符级滑动窗口 |
| Edge N-gram | 可配置 | 多语言 | 中 | 高 | 自动补全 | 前缀匹配 |
5.2 自定义分词器
自定义分词器允许组合多个组件创建满足特定需求的分词器。以下是一个商品名称分词器的完整示例。
重要说明:Elasticsearch中的分词器必须属于某个索引,不能脱离索引单独存在。以下操作是先创建索引并定义分词器,但暂时不定义字段映射。
1. 单独创建自定义分词器:
bash
# 创建products索引,仅定义自定义分词器,不定义映射
PUT /products
{
"settings": {
"analysis": {
"analyzer": {
"product_analyzer": {
"type": "custom",
"char_filter": ["html_strip", "brand_mapping"],
"tokenizer": "standard",
"filter": ["lowercase", "synonym_filter", "stop_filter"]
}
},
"char_filter": {
"brand_mapping": {
"type": "mapping",
"mappings": [
"& => and",
"i-phone => iphone",
"mac book => macbook"
]
}
},
"filter": {
"synonym_filter": {
"type": "synonym",
"synonyms": [
"iphone, apple phone, 苹果手机",
"macbook, apple laptop, 苹果笔记本",
"galaxy, samsung phone, 三星手机"
]
},
"stop_filter": {
"type": "stop",
"stopwords": ["the", "a", "an", "and", "or", "in", "on", "at"]
}
}
}
}
}2. 为索引添加字段映射(使用已定义的分词器):
bash
# 为products索引添加字段映射,使用已定义的product_analyzer分词器
PUT /products/_mapping
{
"properties": {
"name": {
"type": "text",
"analyzer": "product_analyzer"
},
"brand": {
"type": "keyword"
},
"price": {
"type": "float"
}
}
}2. 测试自定义分词器效果:
bash
# 测试商品名称分词效果
GET /products/_analyze
{
"analyzer": "product_analyzer",
"text": "Apple i-phone & Mac Book Pro 2023"
}预期分词结果:
-
原始文本:
Apple i-phone & Mac Book Pro 2023 -
处理后:
apple,iphone,and,macbook,pro,2023 -
同义词扩展:
apple,iphone,苹果手机,and,macbook,苹果笔记本,pro,20233. 插入测试数据:
bash
# 插入商品数据
POST /products/_bulk
{ "index": { "_id": 1 } }
{ "name": "Apple iPhone 14 Pro Max", "brand": "Apple", "price": 999.99 }
{ "index": { "_id": 2 } }
{ "name": "Samsung Galaxy S23 Ultra", "brand": "Samsung", "price": 899.99 }
{ "index": { "_id": 3 } }
{ "name": "Apple MacBook Pro M2", "brand": "Apple", "price": 1299.99 }
{ "index": { "_id": 4 } }
{ "name": "Google Pixel 7 Pro", "brand": "Google", "price": 599.99 }
{ "index": { "_id": 5 } }
{ "name": "i-phone 13 & Accessories", "brand": "Apple", "price": 699.99 }4. 查询测试:
bash
# 查询包含"iPhone"的商品(同义词匹配)
GET /products/_search
{
"query": {
"match": {
"name": "苹果手机"
}
}
}
# 查询包含"MacBook"的商品
GET /products/_search
{
"query": {
"match": {
"name": "苹果笔记本"
}
}
}
# 查看分词效果
GET /products/_search
{
"query": {
"match": {
"name": "i-phone"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}5. 验证自定义分词器组件效果:
bash
# 测试HTML标签过滤
GET /products/_analyze
{
"analyzer": "product_analyzer",
"text": "<p>Apple & Samsung phones</p>"
}
# 测试品牌映射
GET /products/_analyze
{
"analyzer": "product_analyzer",
"text": "i-phone and mac book"
}
# 测试同义词扩展
GET /products/_analyze
{
"analyzer": "product_analyzer",
"text": "galaxy phone"
}设计要点:
- 字符过滤器:移除HTML标签,标准化品牌名称
- 分词器:使用标准分词器处理英文文本
- 词元过滤器:大小写转换、同义词扩展、停用词过滤
- 场景适配:针对商品名称特点优化分词效果
5.3 性能优化建议
索引层面的优化:
分词器选择:
-
精确匹配字段:使用Keyword Analyzer,避免不必要的分词
-
全文搜索字段:根据语言选择合适的分词器
-
聚合字段:使用Keyword Analyzer或专门的聚合分词器
Mapping设计:
json
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"category": {
"type": "keyword" // 精确匹配,无需分词
},
"content": {
"type": "text",
"analyzer": "standard",
"fields": {
"raw": {
"type": "keyword" // 用于聚合和排序
},
"suggest": {
"type": "completion" // 用于自动补全
}
}
}
}
}
}索引设置优化:
-
refresh_interval:批量索引时增大刷新间隔
-
number_of_shards:合理设置分片数,避免过多分词器实例
-
translog:调整事务日志设置,提高写入性能
查询层面的优化:
查询类型选择:
-
match查询:全文搜索,自动应用分词器
-
term查询:精确匹配,绕过分词器
-
match_phrase:短语匹配,保持词条顺序
查询优化技巧:
-
filter上下文:使用filter代替query,利用缓存
-
minimum_should_match:控制匹配精度
-
boost参数:调整字段权重,优化相关性
监控和调试:
性能监控:
-
_stats API:监控分词器性能指标
-
_analyze API:测试分词效果
-
慢查询日志:识别性能瓶颈
调试工具:
shell
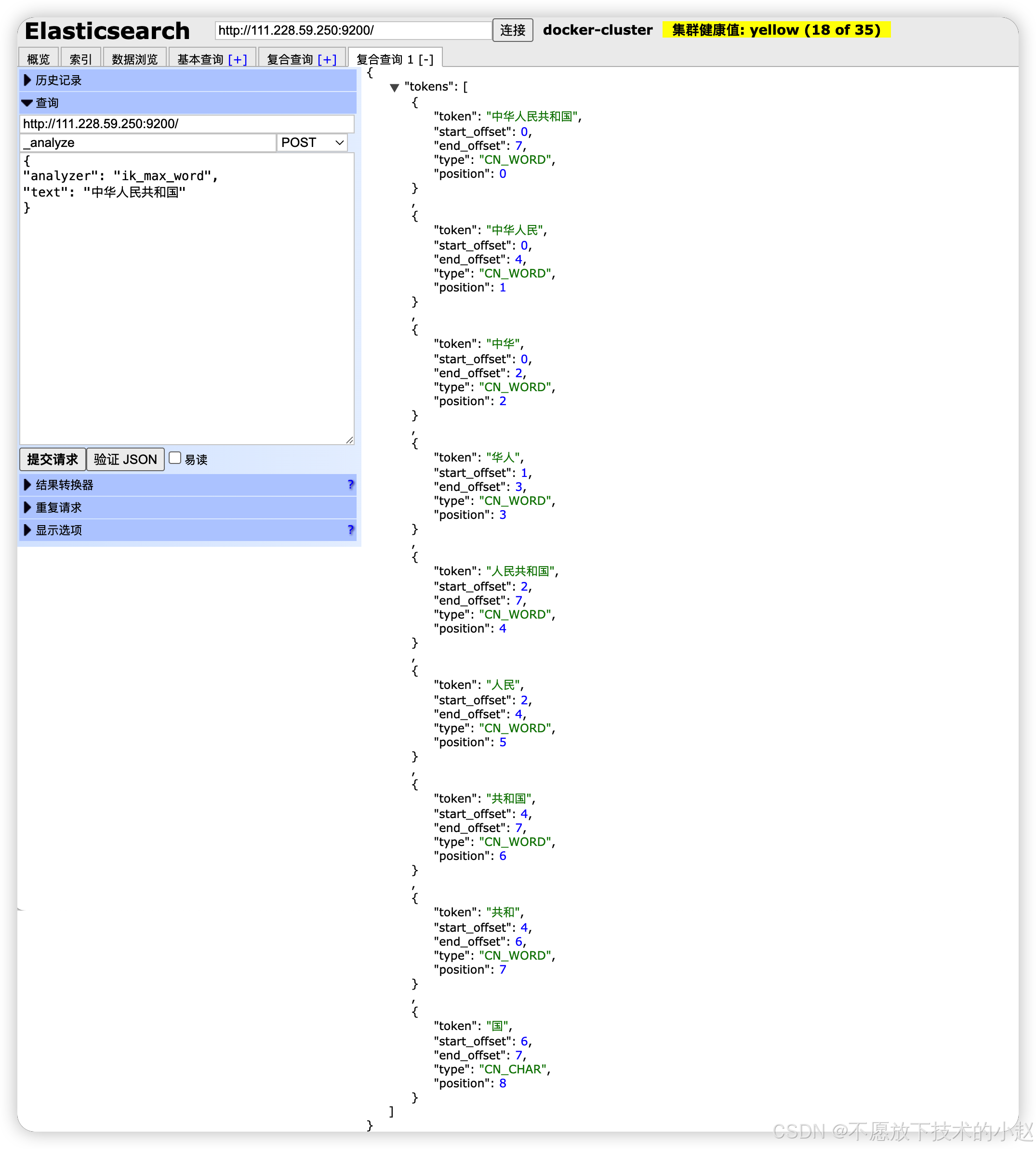
# 测试分词效果
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国"
}
yaml
# 查看索引的分词器配置
GET /my_index/_mapping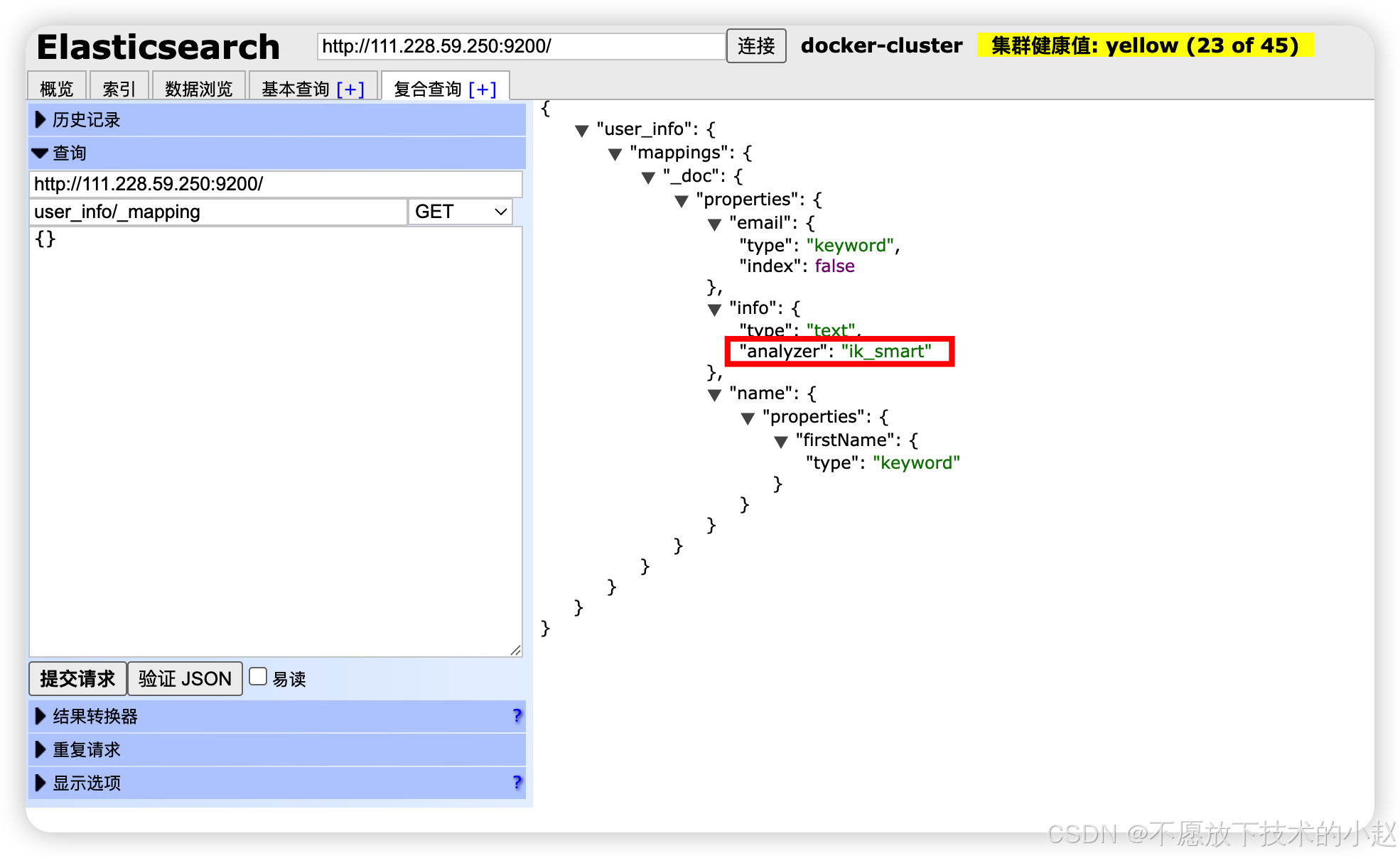
bash
# 性能分析
GET /my_index/_stats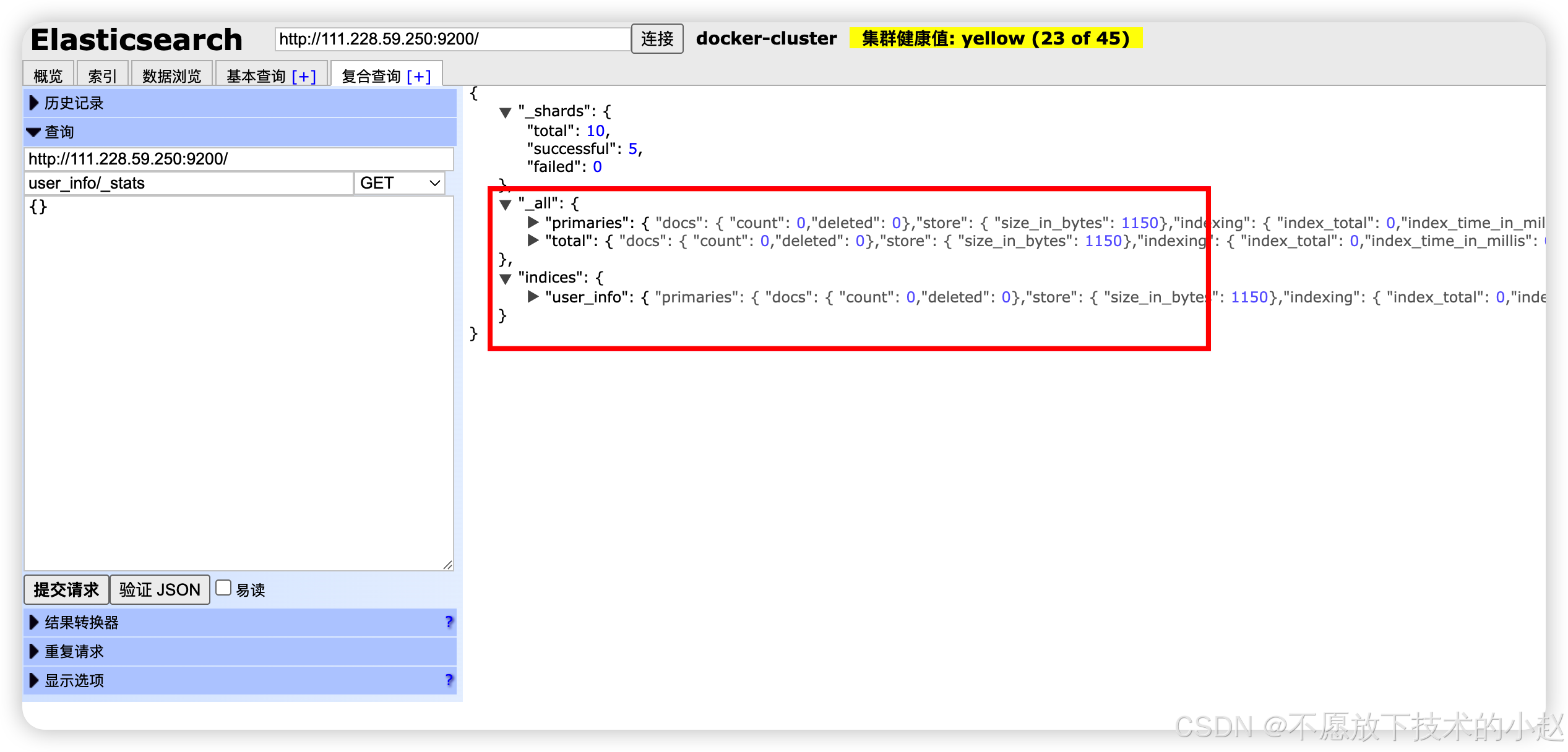
六、总结
分词器是Elasticsearch全文搜索的核心组件,其选择和配置直接影响搜索质量、系统性能和用户体验。通过深入理解不同分词器的工作原理、适用场景和性能特点,开发者可以设计出最优的分词策略。
整理完毕,完结撒花~🌻