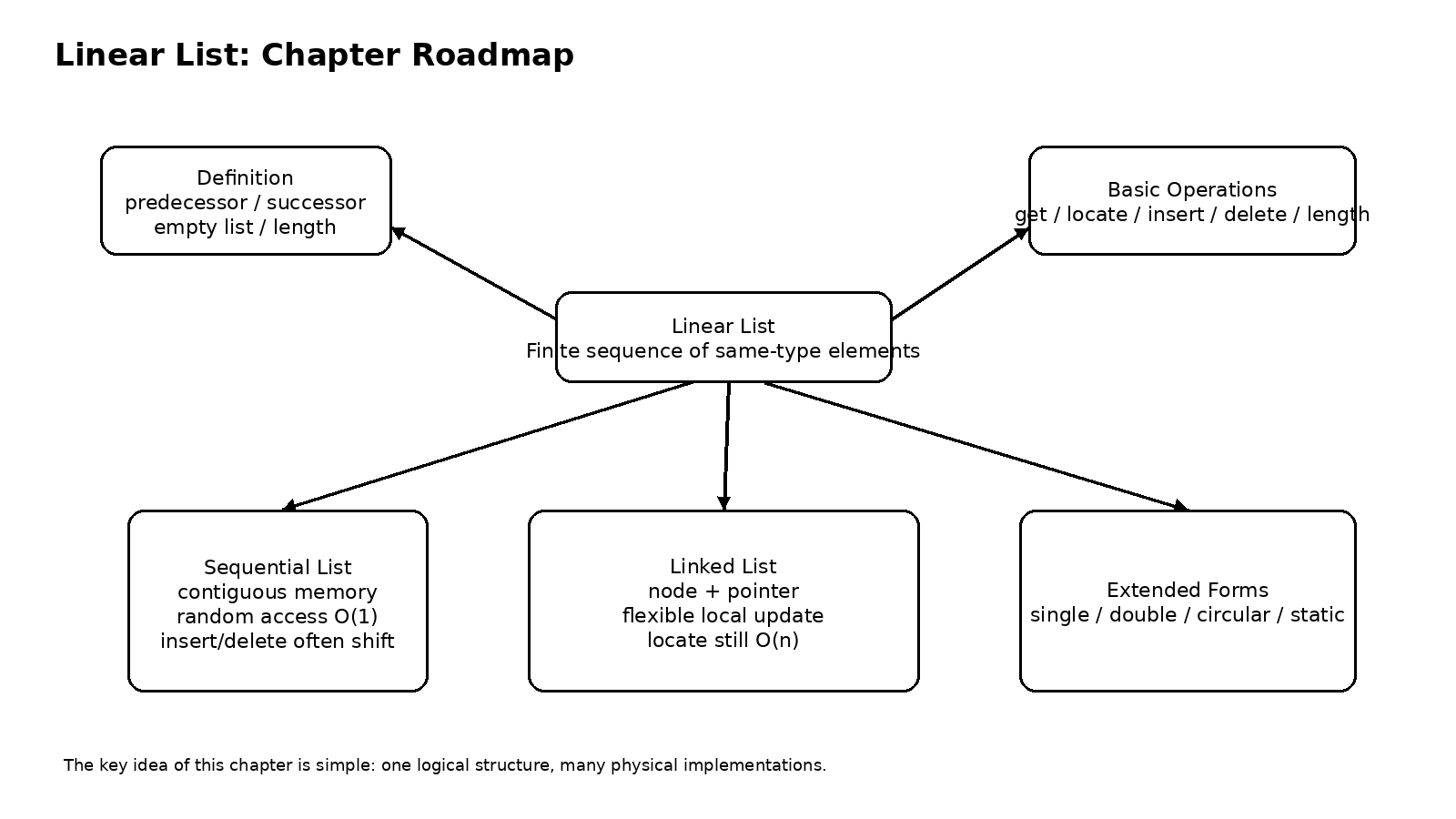
一、线性表到底是什么
从逻辑上说,线性表是由零个或多个同类型数据元素 构成的有限序列。这个定义听上去很书面,但如果拆开理解就会顺很多。所谓同类型,意味着表里的元素应该属于同一类对象;所谓有限序列,意味着这些元素不仅数量有限,而且存在明确的先后关系。第一个元素没有前驱,最后一个元素没有后继,处在中间的元素则各有且仅有一个直接前驱和一个直接后继。也正因为如此,线性表最重要的特征从来都不是像数组那样挨着放,而是逻辑上一个接一个。
这句话非常关键。很多初学者会不自觉地把线性表和数组画等号,觉得线性表就应该是一块连续空间。事实上,数组只是线性表的一种实现方式,而不是线性表本身。线性表描述的是逻辑关系,至于这些元素在内存里究竟是不是连续存放,要看你采用的是哪一种存储结构。换句话说,线性表先有逻辑,再谈实现。
在线性表这个抽象结构之上,我们通常会定义一组最基本的操作,比如初始化、判空、求长度、按位取值、按值查找、插入和删除。教材里常把这些操作写成 ADT 的形式,看起来有点抽象,但它们背后的意义很朴素,你得先规定这个结构能做什么,然后再去讨论具体怎样做更快。
二、为什么同一个线性表,会有两种完全不同的实现
一旦接受线性表是逻辑结构这个前提,就会自然产生一个问题就是既然逻辑上都是一个接一个,那物理上一定要挨着吗?答案是否定的。元素的先后关系,并不一定要靠物理地址来表达,也可以靠额外的信息来维持。这正是顺序表和链表分化出来的根本原因。
顺序表的思路很直接:既然逻辑上相邻,那就干脆把物理地址也排成一串。这样一来,只要知道起始地址和元素大小,就能立刻算出第 i 个元素的位置。它用的是连续存储来换取快速定位。链表则恰好走了另一条路:元素在内存里不必连续,只要每个结点额外保存一个下一个结点在哪里的信息,就同样能把逻辑次序串起来。它用的是指针连接来换取更灵活的局部修改。
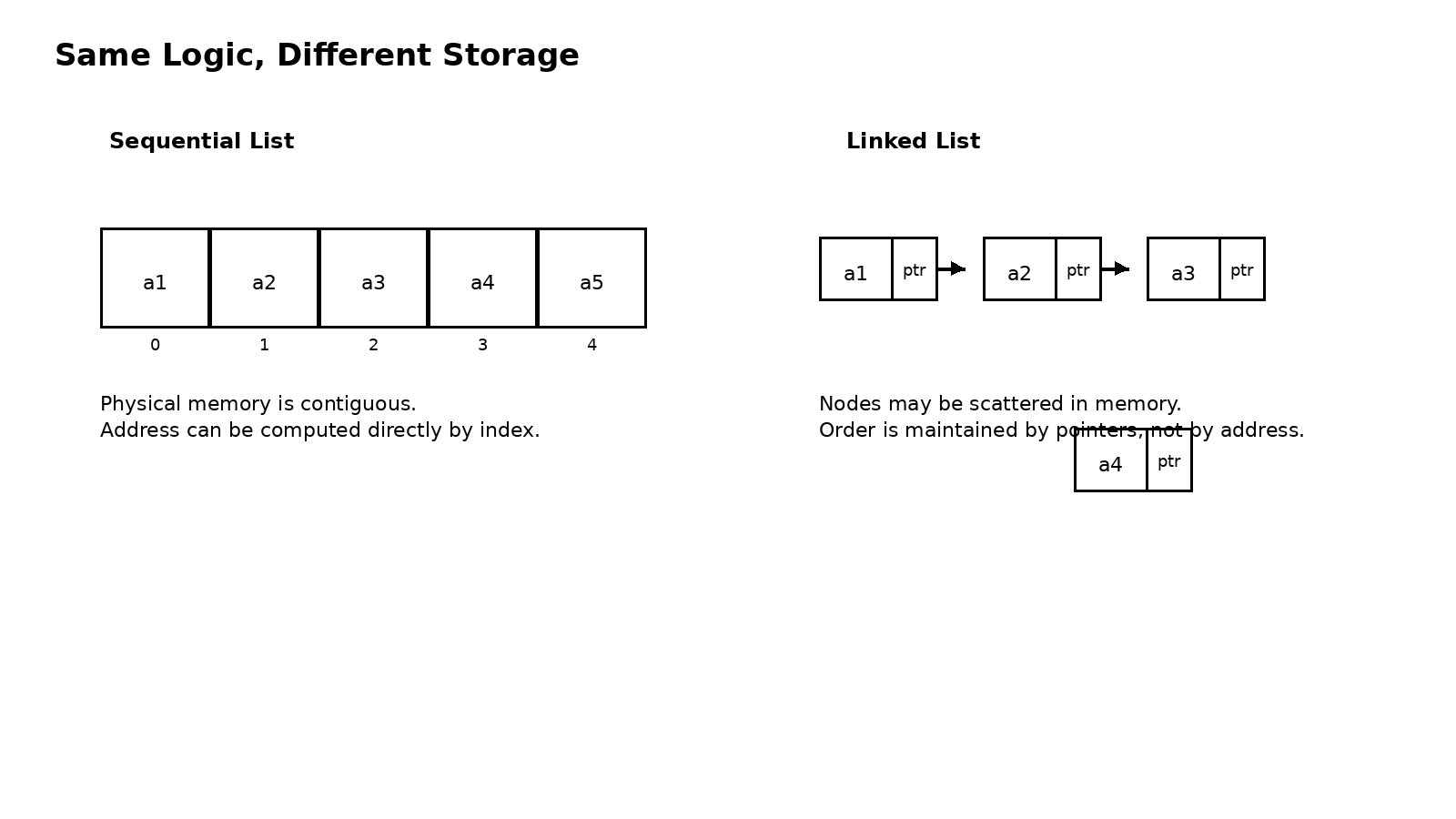
所以,顺序表和链表看起来像两种结构,实质上是在回答同一个问题:线性次序到底由什么来维护。 顺序表靠地址的连续性维护次序,链表靠指针关系维护次序。后面所有复杂度差异,都可以从这句话里推出。因为当你想访问某个位置时,顺序表可以直接算地址,链表却只能顺着指针往后找;当你想在中间插入或删除时,顺序表需要把大量元素整体挪动,链表却只要改几根指针就行。
三、顺序表:用连续空间换访问速度
顺序表是最符合直觉的一种实现。它把线性表的元素依次放在一片连续的存储空间中,因此表中元素的逻辑顺序和物理顺序完全一致。也正因为连续,顺序表最强的能力就是随机访问 。只要给出下标,就能通过首地址加偏移量直接找到对应元素,所以按位取值的时间复杂度是 O(1)。这也是为什么数组在很多语言里都拥有极高访问效率------底层原因并不神秘,本质上就是地址可计算。
但连续存储并不是白来的。它带来访问优势的同时,也把修改成本推高了。因为一旦你在中间插入一个新元素,原来后面的所有元素都必须整体后移,才能空出位置。删除也是类似的道理,被删位置后面的元素需要整体前移,把空洞补上。所以顺序表最值得记住的一点不是"插入删除是 O(n)"这句结论,而是为什么会是 O(n):真正花时间的不是写入新值,而是搬家。
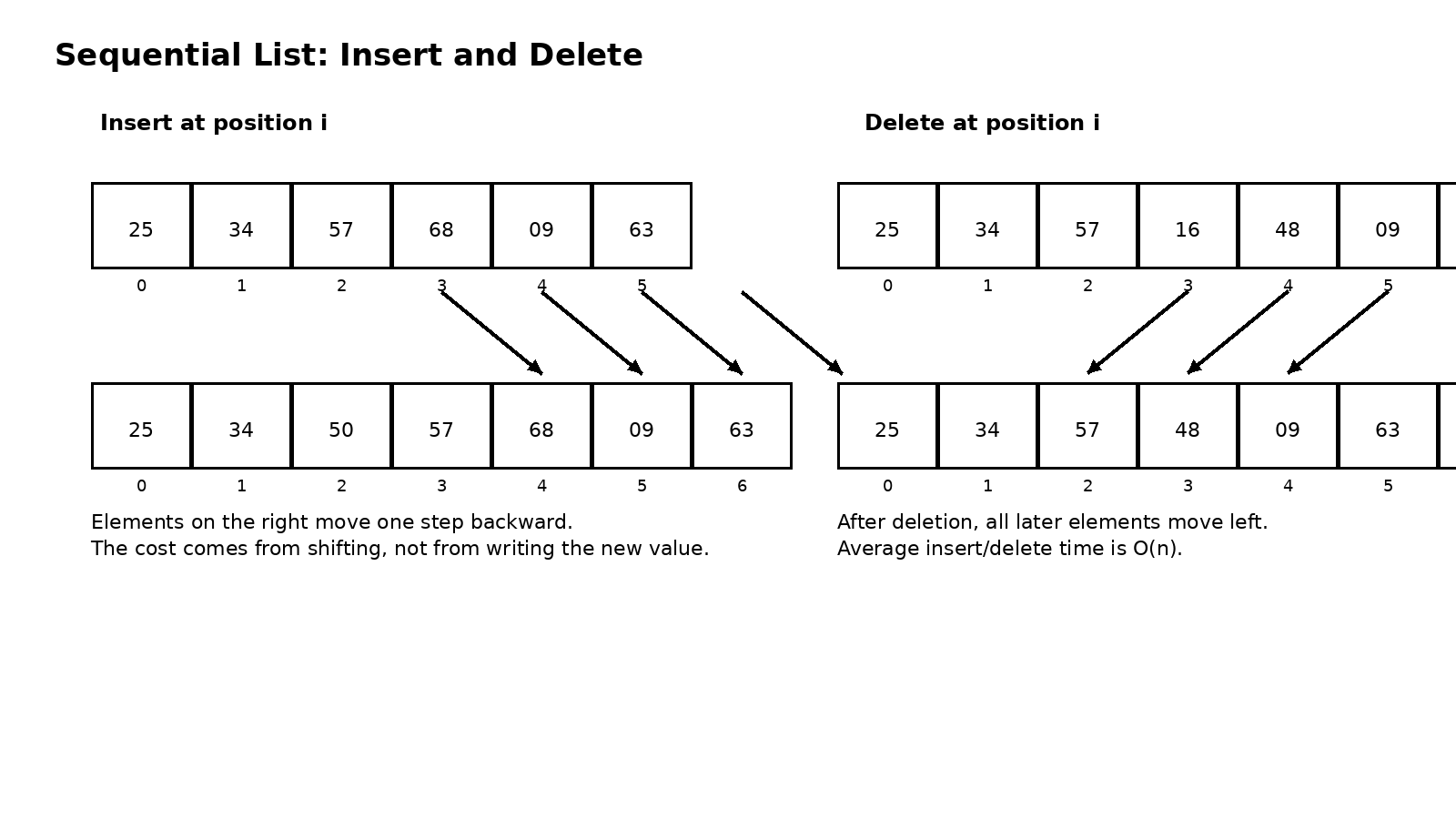
教材里常见的顺序表插入算法,核心其实只有三步:先检查表满不满、位置是否合法。再从表尾开始向后移动元素,直到给第 i 个位置腾出空位。最后把新元素放进去并更新长度。删除则是反过来,把第 i+1 个位置到表尾的元素依次前移。你会发现,无论代码怎么写,本质动作始终没有变,所以复杂度也不会变。
下面这个片段,用最直观的方式展示了顺序表插入的关键思想:
c
bool ListInsert(SqList &L, int i, ElemType e) {
if (i < 1 || i > L.length + 1) return false;
if (L.length >= MaxSize) return false;
for (int j = L.length; j >= i; --j) {
L.data[j] = L.data[j - 1];
}
L.data[i - 1] = e;
++L.length;
return true;
}顺序表最容易形成一条清晰主线:连续存储 → 支持随机访问 → 访问快;但中间插删需要挪动大量元素 → 修改慢。 一旦这条主线建立起来,按位取值为什么是 O(1)、查找为什么通常是 O(n)、插入删除为什么平均要移动约一半元素,这些结论就都能顺着想出来,而不需要死记硬背。
当然,顺序表也并非一无是处的"只适合读不适合改"的结构。恰恰相反,如果一个应用场景以读取为主、元素个数变化不大,顺序表往往是非常好的选择。因为它不仅访问快,而且空间利用率通常更高,缓存局部性也更好,实际运行时常常比理论上同为 O(n) 的链表查找更快。也就是说,顺序表的问题不是不好,而是它更偏向读密集场景。
四、链表:用指针连接灵活性
链表的出发点,正是为了避免顺序表在中间插删时的大规模搬移。它不要求元素连续存储,而是把每个元素包装成一个结点。结点里除了数据域,还带有一个指针域,用来指向后继结点。这样一来,线性表的逻辑顺序就不再由内存地址的连续性保证,而由指针串接起来。
这件事带来的第一个变化,是访问方式彻底变了。链表不能像顺序表那样通过"首地址 + 偏移量"直接定位第 i 个元素,因为各个结点可能散落在不同位置,中间没有稳定的地址规律可算。所以如果你想找第 i 个结点,唯一办法就是从头开始沿着指针一个一个往后走。这就是为什么链表的按位访问通常是 O(n)。但链表真正的优势不在找,而在改。
因为一旦某个位置已经找到了,插入和删除就会非常轻。你不需要挪动后面所有元素,只需要调整少量指针关系,让新结点接上去,或者让待删除结点被跳过去。也就是说,链表把顺序表里昂贵的元素搬家,变成了轻量的指针改线。
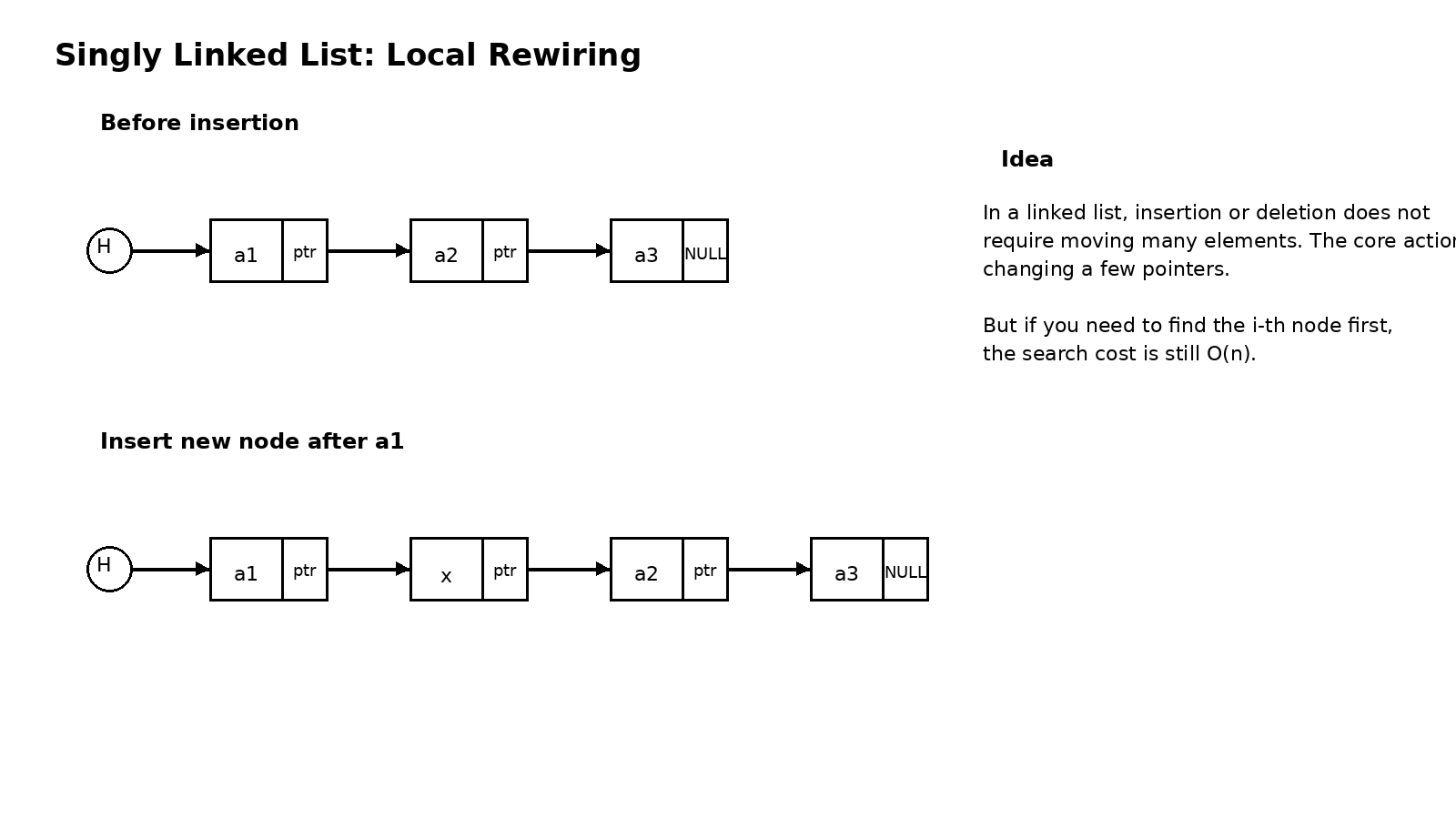
这也是单链表最值得理解的一句话:定位很慢,改链很快。 在不少教材题目里,老师会强调在某结点后插入或删除某结点的后继只需 O(1),前提其实已经默认你拿到了那个结点的指针。真正完整地分析时,要把寻找位置的代价和修改链接的代价分开看。若题目只说在第 i 个位置插入,那么先找第 i-1 个结点本身就要 O(n);若题目直接给了结点指针,那么插入动作本身才是 O(1)。这一点,是考试里特别容易被混淆的地方。
单链表里还有一个非常经典的设计,叫头结点。它不是有效数据元素,而是额外放在表头的一个辅助结点。引入头结点之后,很多边界情况会变得整齐很多,例如在第一个有效元素之前插入,或者在表头删除第一个元素,不再需要写很多专门分支。初学时可能觉得多此一举,但真正写代码时会发现,头结点带来的不是功能增强,而是逻辑简化。
比如,带头结点的头插法特别适合快速建表。每读入一个新元素,就把它插到头结点之后。这样做的复杂度是 O(1) 一次,但生成出来的链表顺序与输入顺序相反;如果想保持原顺序,就需要采用尾插法,让尾指针始终指向最后一个结点,每次把新结点接到后面。教材之所以反复强调头插和尾插,不是因为它们只是两种记忆型技巧,而是因为它们体现了链表操作的本质:插入的位置不同,是否维护尾指针不同,最终结构和效率就会不同。
一个非常典型的单链表插入动作如下所示:
c
s->next = p->next;
p->next = s;这两句代码的先后顺序不能随便交换。先让新结点 s 指向原来的后继,再让 p 指向 s,链才不会断掉。
五、单链表之后,为什么还要有双链表、循环链表和静态链表
如果单链表已经能表示线性关系,为什么后面还会出现双链表、循环链表和静态链表?答案并不是为了增加难度,而是因为不同问题对结构提出了不同要求,单链表只是最基础的版本。
双链表的每个结点除了 next 指针,还会增加一个 prior 指针,用来指向前驱。它最大的价值在于:某些需要频繁向前访问、或者删除当前结点时需要同时拿到前驱信息的场景,会变得更自然。你可以把它理解为用额外空间换更对称的导航能力。它没有改变线性表的逻辑,只是让局部操作更方便。
循环链表则更适合处理"首尾相接"的问题。在单循环链表中,最后一个结点不再指向 NULL,而是回到头结点或首元结点。这让很多循环处理场景变得自然,例如约瑟夫问题、循环调度、轮转访问等。有时候所谓"结构变化",本质上只是把某个特殊边界消掉,让整个过程变成统一的循环。
静态链表看起来有点特别,因为它名义上叫链表,实际却是用数组来实现的。数组中的每个元素既存数据,也存游标,这个游标本质上扮演指针的角色。它解决的是没有真正指针时,怎么模拟链式连接的问题。换句话说,静态链表强调的不是现代编程里是否常用,而是数据结构思想本身:只要能表示前后关系,'链'并不一定非要靠语言级指针实现。
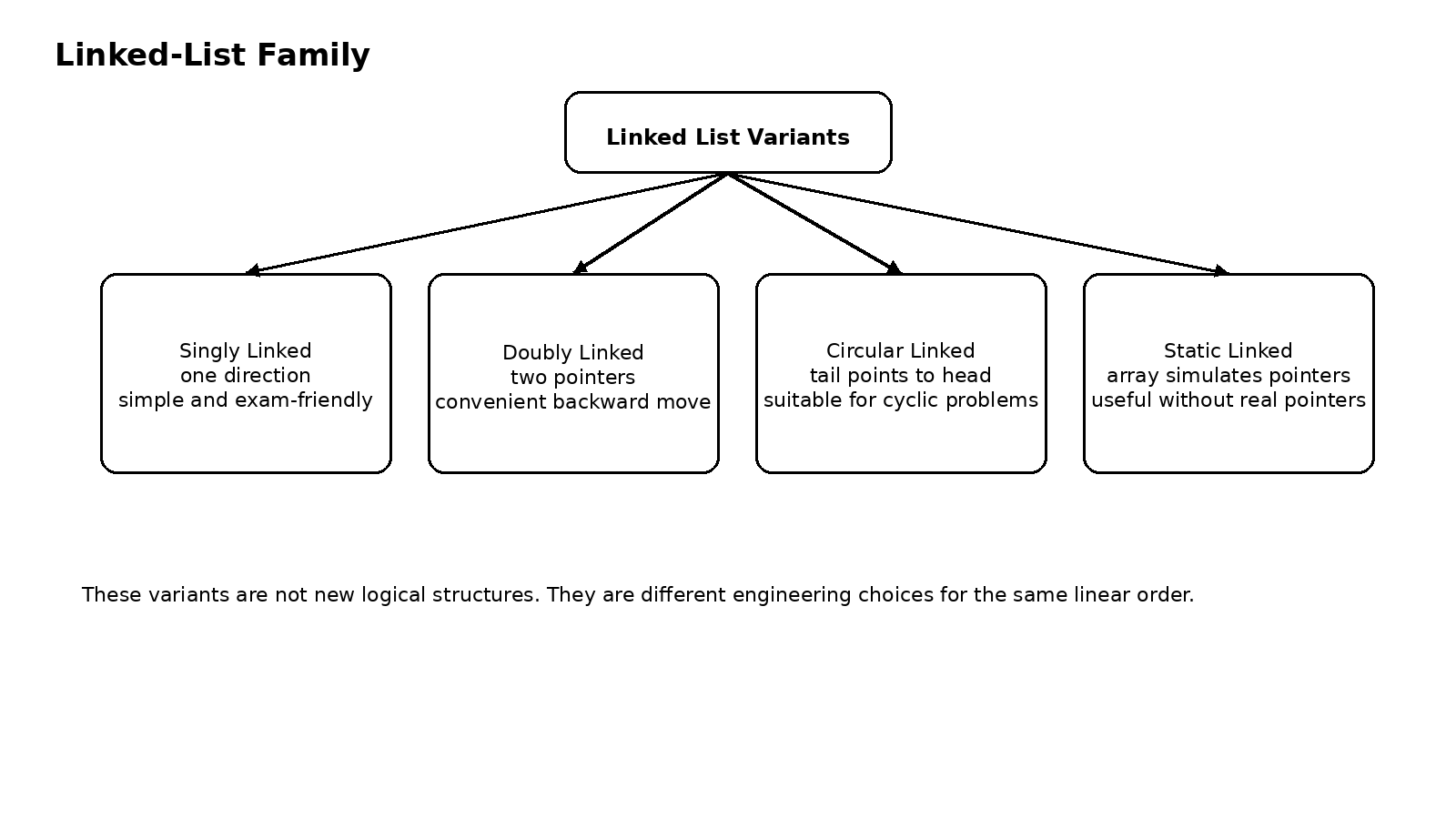
所以,后续这些结构不需要孤立记忆。单链表解决如何链起来,双链表解决如何双向找,循环链表解决如何消掉尾端空指针边界,静态链表解决"没有真指针时如何模拟链式存储"。它们不是彼此并列的生硬概念,而是在同一条思路上不断做工程化调整。
六、把复杂度真正想明白
顺序表插入删除时,移动的是一批真实元素。只要操作位置不在表尾,后面的元素就得整体挪动,所以代价与后半段长度相关,平均下来就是 O(n)。链表插入删除时,通常移动的不是元素本身,而只是少数几个指针,因此一旦定位到位,修改动作往往可以降到 O(1)。从这个角度看,复杂度不是抽象标签,而是对底层动作数量的概括。
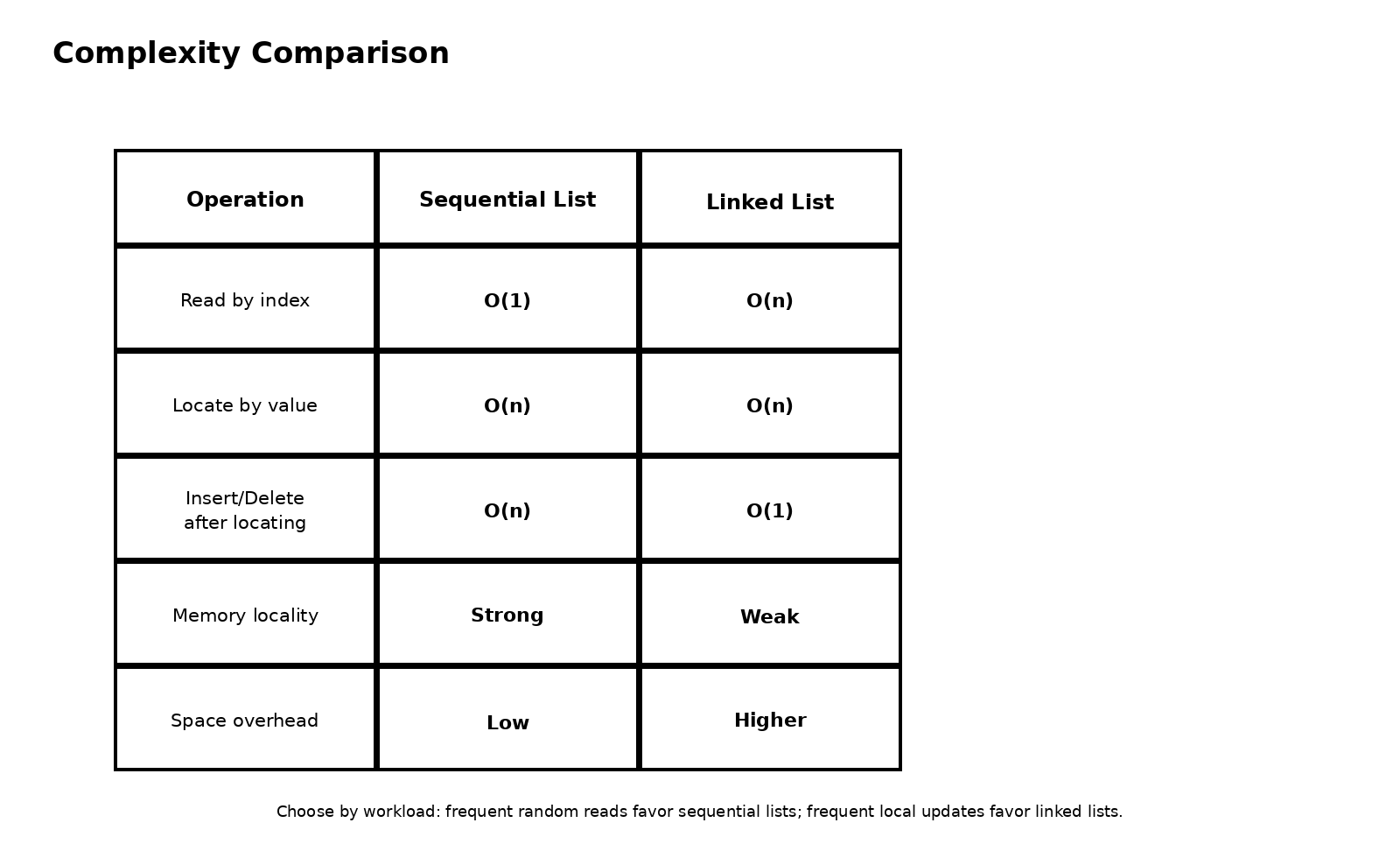
这也是为什么很多结论必须带条件。比如说链表插入更快,这句话只有在插入位置已经找到的前提下才成立;如果你还得先从表头一路遍历到目标位置,那么前面的定位过程已经把复杂度抬回 O(n) 了。同理,顺序表查找按值也是 O(n),因为你并不知道目标值在哪,只能逐个比较。真正的 O(1) 出现在"按下标取值"这种可以直接计算地址的操作里。
如果把线性表的核心复杂度压缩成一张最值得记住的脑图,那么几乎可以写成一句话:顺序表擅长读,链表擅长改;顺序表靠连续地址提速,链表靠指针改线减负。 这句看似口语化的话,实际上几乎涵盖了整章最重要的性能逻辑。
七、考试和复习里最容易混淆的地方
真正到了刷题阶段,线性表的失分点往往不在大概念,而在细节边界。第一类常见混淆,是"线性表"和"顺序表"不分。线性表是逻辑结构,顺序表和链表是存储实现,这个层次关系一定要清楚。第二类混淆,是把按位访问和按值查找混在一起。顺序表能够 O(1) 找到第 i 个元素,不代表它能 O(1) 找到值等于 x 的元素;因为值的位置未知,所以仍然需要比较。第三类混淆,是分析链表插入删除复杂度时,忘记区分已经拿到结点指针和还要先找结点这两件事。第四类混淆,则是头插法和尾插法生成链表的顺序问题:头插法得到的是逆序结果,尾插法才能保持输入顺序。
还有一些边界条件也很值得警惕。比如教材中位置编号通常从 1 开始,而程序里的数组下标往往从 0 开始,二者转换时特别容易错位;带头结点与不带头结点的写法,判断空表和处理首元结点时又会不同;循环链表遍历时,终止条件也不再是 NULL,而是"是否回到起点"。这些地方看似琐碎,但恰恰最能区分"背过了"和"真的理解了"。