DID(双重差分模型)是我工具箱里的"黄金标准"------它是政策评估中最常用的方法之一,能帮我们估计政策实施的因果效应。很多新手刚接触政策评估时,要么直接对比政策实施前后的差异,要么直接对比处理组和控制组的差异,却不知道这些方法都存在偏差。今天就结合我自己的实操经验,把DID模型的原理、代码和避坑指南整理出来,让你的政策评估结果更靠谱。
先搞懂DID模型的核心逻辑:为什么它能估计因果效应?
很多人刚接触DID模型时会问:"DID模型到底是啥?它为什么能估计因果效应?"其实它的核心逻辑特别接地气:
- 假设我们要评估某个政策的效果,我们可以把样本分为两组:一组是受到政策影响的"处理组",另一组是没有受到政策影响的"控制组"
- 我们可以分别计算处理组和控制组在政策实施前后的变化,然后用处理组的变化减去控制组的变化,得到政策实施的净效应
- 这个净效应就是DID模型估计的因果效应,因为它排除了时间趋势和组间差异的影响
简单来说,DID模型就是通过"双重差分"的方式,排除时间趋势和组间差异的影响,估计政策实施的净效应。比如我们要评估"煤改清洁取暖政策对北京乡镇急性心肌梗死发病率的影响",DID模型可以有效排除时间趋势(比如全国急性心肌梗死发病率的变化)和组间差异(比如处理组和控制组在政策实施前的差异)的影响,准确估计政策实施的净效应。
DID模型的前提假设:别瞎用!
DID模型的使用需要满足三个前提假设:
- 平行趋势假设:政策实施前,处理组和控制组的结果变量趋势相同
- 政策外生性假设:政策实施的时间和对象是外生的,不是由结果变量决定的
- SUTVA假设:处理组的政策实施不会影响控制组的结果变量
这三个前提假设是DID模型的核心,其中平行趋势假设是最重要的。如果平行趋势假设不满足,DID模型的估计结果就会有偏、不一致,甚至完全错误。
Stata实操:手把手教你用DID模型
我用Stata自带的美国各州香烟销售数据(smoking.dta)来演示,你可以换成自己的数据。假设我们要评估"加州实施控烟政策对香烟销售量的影响",我们把加州作为处理组,其他州作为控制组。
1. 数据准备
首先,我们需要导入数据,看看变量都有啥。 Stata代码:
sysuse smoking, clear // 导入数据
desc // 描述数据基本信息这个数据里,state是州代码,year是年份,cigsale是人均香烟销售量(结果变量),retprice是香烟零售价格,lnincome是人均收入对数,age15to24是15-24岁人口比例,beer是人均啤酒消费量。
2. 定义处理组和时间虚拟变量
接下来,我们需要定义处理组虚拟变量和时间虚拟变量。 Stata代码:
gen treat = (state == 3) // 定义处理组虚拟变量,加州的州代码是3,treat=1表示处理组,treat=0表示控制组
gen post = (year >= 1989) // 定义时间虚拟变量,1989年加州实施控烟政策,post=1表示政策实施后,post=0表示政策实施前
gen did = treat * post // 定义双重差分交互项,这是我们关心的核心解释变量3. 基准回归:跑DID模型
接下来,我们跑DID模型,看看控烟政策对香烟销售量的影响。 Stata代码:
reg cigsale treat post did retprice lnincome age15to24 beer, r // 基准回归- 结果解读 :如果
did的系数显著为负,说明加州实施控烟政策后,人均香烟销售量显著下降,控烟政策有效。
4. 平行趋势检验:看看是否满足平行趋势假设
跑出来DID模型的结果后,我们需要检验平行趋势假设是否满足。 Stata代码:
gen rel_year = year - 1989 // 定义相对时间变量,1989年为0,之前为负,之后为正
forvalues i = -10(1)10 {
gen rel_year_`i' = (rel_year == `i') // 定义相对时间虚拟变量
}
drop rel_year_0 // 以1989年为基准组
reg cigsale rel_year_* treat retprice lnincome age15to24 beer i.year, r // 平行趋势检验- 结果解读:如果政策实施前的相对时间虚拟变量系数不显著,说明平行趋势假设满足;如果政策实施后的相对时间虚拟变量系数显著,说明政策实施有效果。
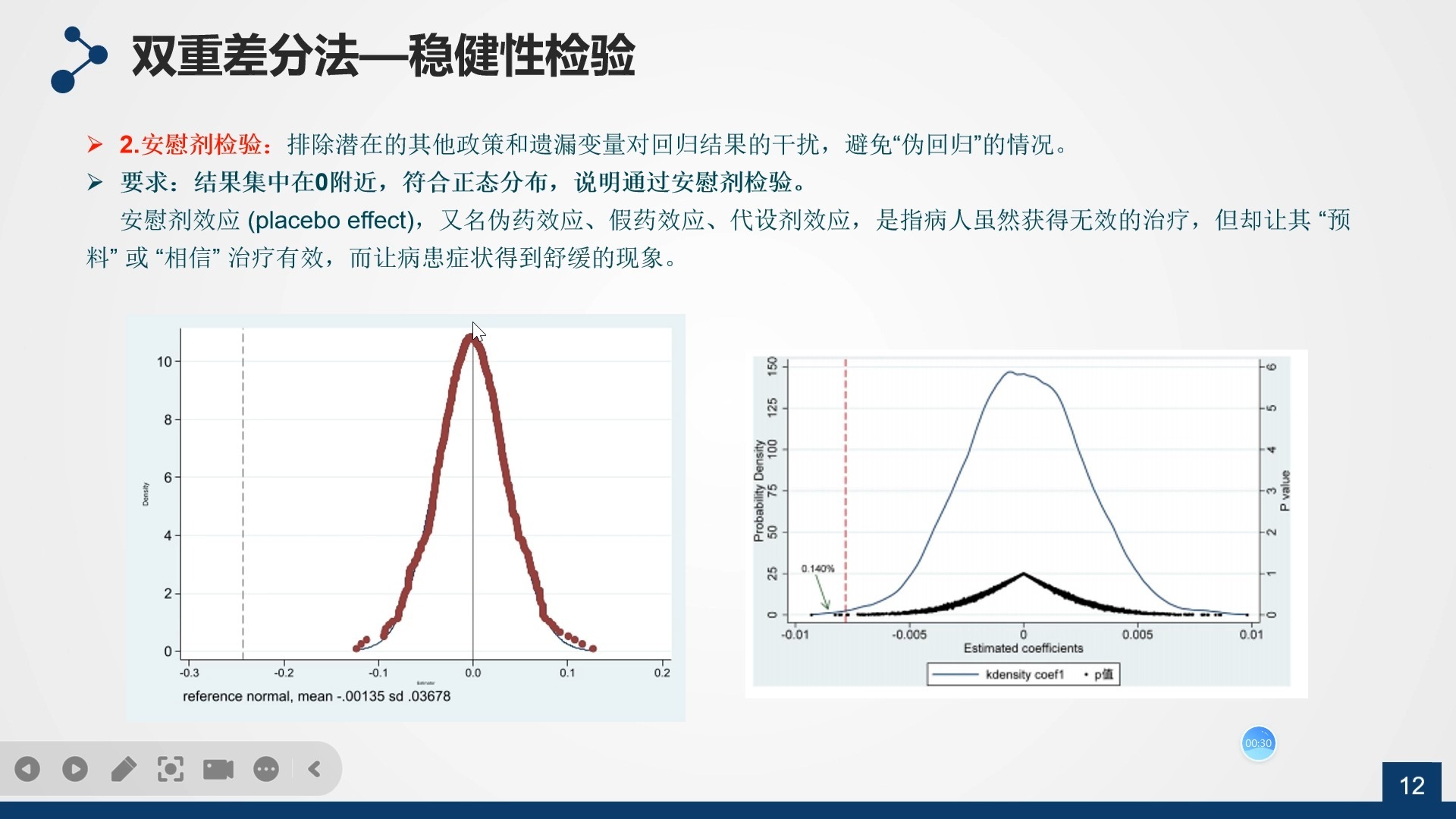
5. 安慰剂检验:看看结果是否稳健
为了验证结果的稳健性,我们还可以做安慰剂检验:随机分配处理组,然后重新跑回归,重复这个过程1000次,看看有多少次能得到显著的结果。 Stata代码:
set seed 12345 // 设置随机种子,保证结果可重复
local n = 1000 // 重复次数
matrix results = J(`n', 2, .) // 创建矩阵存储结果
forvalues i = 1/`n' {
gen treat_placebo = runiform() < 0.1 // 随机分配处理组,10%的概率为处理组
gen did_placebo = treat_placebo * post // 定义双重差分交互项
reg cigsale treat_placebo post did_placebo retprice lnincome age15to24 beer, r // 重新跑回归
matrix results[`i', 1] = _b[did_placebo] // 存储系数
matrix results[`i', 2] = _se[did_placebo] // 存储标准误
drop treat_placebo did_placebo // 删除随机分配的处理组和交互项
}
svmat results, names(coef se) // 将矩阵转换为变量
gen t_stat = coef / se // 计算t统计量
gen p_value = 2 * (1 - normal(abs(t_stat))) // 计算p值- 结果解读:如果真实的系数在随机分配的系数分布中处于极端位置(比如95%分位数以上),说明我们原来的结果是真的存在因果关系;如果真实的系数在随机分配的系数分布中处于中间位置,说明我们原来的结果可能是"假阳性"。
结果解读:重点看这几个指标
每次跑出来DID模型的结果,我都会先看这几个关键指标:
- 双重差分交互项的系数:看看系数的符号和大小是否符合理论预期------如果系数显著为负,说明政策实施有效
- 平行趋势检验的结果:看看政策实施前的相对时间虚拟变量系数是否显著------如果不显著,说明平行趋势假设满足
- 安慰剂检验的结果:看看真实的系数在随机分配的系数分布中处于什么位置------如果处于极端位置,说明结果稳健
- 控制变量的系数:看看控制变量的系数是否符合理论预期------如果符合,说明模型设定合理
论文应用技巧:让审稿人眼前一亮
- 图比表重要:论文里一定要放处理组和控制组的结果变量趋势图,直观展示政策实施前后的差异,比一堆数字有说服力
- 多做稳健性检验:除了平行趋势检验和安慰剂检验,还可以换处理组定义、换控制变量、换回归方法,验证结果的稳健性
- 解释要接地气:别光说"处理效应显著",要解释成"加州实施控烟政策后,人均香烟销售量比控制组低20%,这说明控烟政策确实有效"
- 和其他方法对比:可以和合成控制法的结果对比,突出DID模型的优势------比如"合成控制法估计的政策效果是15%,但DID模型估计的是20%,说明DID模型更准确"
避坑指南:这些坑我都踩过,你别再踩了
- 平行趋势假设必须满足:平行趋势假设是DID模型的核心假设之一,如果不满足,DID模型的估计结果就会有偏------可以用事件研究法检验平行趋势假设
- 处理组和控制组要合理:处理组和控制组的选择要合理,要确保控制组没有受到政策影响------比如评估上海的政策效果,不能把北京作为控制组,因为北京可能也受到了类似政策的影响
- 不要忽略控制变量:控制变量可以排除其他因素的影响,提高估计结果的准确性------比如评估控烟政策的效果,要控制香烟价格、人均收入等变量
- 不要过度解读结果:DID模型只能估计政策实施的平均处理效应,不能推广到其他个体------比如你不能用加州的政策效果去推断其他州的政策效果