摘要
本报告介绍ERNIE 5.0 ------一款原生自回归基座模型,专为文本、图像、视频与音频的统一多模态理解与生成而设计。模型基于超稀疏混合专家(MoE)架构 与模态无关专家路由机制 ,所有模态以统一的下一组令牌预测目标从零开始联合训练。
为解决多样化资源约束下的规模化落地难题,ERNIE 5.0采用创新的弹性训练范式:单次预训练即可习得一组具备不同深度、专家容量与路由稀疏度的子模型,可在内存或时延受限场景下,灵活实现性能、模型规模与推理时延的权衡。此外,我们系统性攻克了强化学习在统一基座模型上的规模化挑战,保障超稀疏MoE架构与多元多模态场景下后训练的高效与稳定。
大量实验表明,ERNIE 5.0在多模态任务上实现了强劲且均衡的性能表现。据我们所知,在已公开模型中,ERNIE 5.0是首个实现量产级部署、支持多模态理解与生成的万亿参数统一自回归模型。为助力后续研究,本文详细可视化了统一模型中的模态无关专家路由机制,并对弹性训练展开全面实证分析,以期为学界提供深刻启发。
ERNIE 5.0 论文的 Introduction 核心讲了这几件事,我给你整理成清晰好懂的要点版:
introduction
1. 现有多模态大模型的痛点
- 主流模型(GPT、Gemini、ERNIE 前代、Qwen 等)都是以文本为中心,用自回归做理解,但生成还是靠文本输出。
- 后来的方案是"语言模型 + 模态专用解码器 ",属于后期融合(late-fusion)。
- 这种结构会导致:
- 理解和生成脱节
- 跨模态融合不深
- 出现"能力跷跷板":增强多模态就会削弱文本能力
2. ERNIE 5.0 要解决的核心问题
提出一个真正统一的自回归多模态框架,必须同时满足:
- 原生支持理解 + 生成
- 保留强单模态能力
- 能随模型/数据规模高效扩展
3. ERNIE 5.0 的核心设计思路
- 不是 给语言模型加外挂,而是所有模态从零一起训练。
- 把文本、图像、视频、音频映射到共享 Token 空间。
- 统一用 Next-Group-of-Tokens Prediction 目标训练,消除模态边界。
- 用 超稀疏 MoE 架构 + 与模态无关的专家路由,不按模态分配专家。
"Next-Group-of-Tokens Prediction"(或称多Token预测,Multi-Token Prediction, MTP)是一种让大语言模型在每次运算中,不再只预测下一个词,而是能一口气预测后续多个词的训练技术。它是对经典的"下一个词预测"(Next-Token Prediction, NTP)的一次重要升级。
- 🧠 核心工作原理
改造模型:在标准的大模型基础上,为其增加多个独立的"预测头",每个头负责预测一个特定位置的未来Token。
设计损失函数:模型的损失值由所有预测头产生的预测误差共同决定,从而驱动模型学习更长远的依赖关系。- 🚀 核心优势
🎯 更强的宏观规划能力:预测多个Token迫使模型"站得高,看得远",更擅长处理编程、数学等需要严谨逻辑和长期规划的任务。
⚡️ 推理速度飙升:一次性生成多个Token,减少了模型"自言自语"的步数,实现了高达3倍的推理速度提升。
📈 性能表现更优异:在编程任务上效果尤为显著,例如13B参数的模型在HumanEval基准测试中的解题率提升了12%,在MBPP上则提升了17%。
4. 两大创新技术
(1)弹性训练(Elastic Training)
- 一次预训练,直接生成一组不同大小、深度、稀疏度的子模型。
- 不用单独训小模型,不用后压缩。
- 适配不同硬件、内存、时延场景。
(2)稳定高效的多模态强化学习
解决稀疏奖励、熵崩塌、训练推理不一致等问题,让万亿参数 MoE 能稳定做 RL。
5. 基础设施支撑
- 混合并行策略支撑万亿参数训练
- Tokenizer 与主干网络解耦部署
- FlashMask 加速多模态注意力
- 可扩展的分布式 RL 架构
Architecture(架构)
一、整体架构总览
ERNIE 5.0 采用超稀疏混合专家(MoE)架构 ,在单一自回归框架内融合文本、图像、视频、音频四大模态的理解与生成。
- 核心:共享统一Transformer主干 + 专用视觉/音频Tokenizer
- 目标:所有模态共享下一组Token预测(Next-Group-of-Tokens Prediction) 训练目标,实现端到端深度跨模态交互
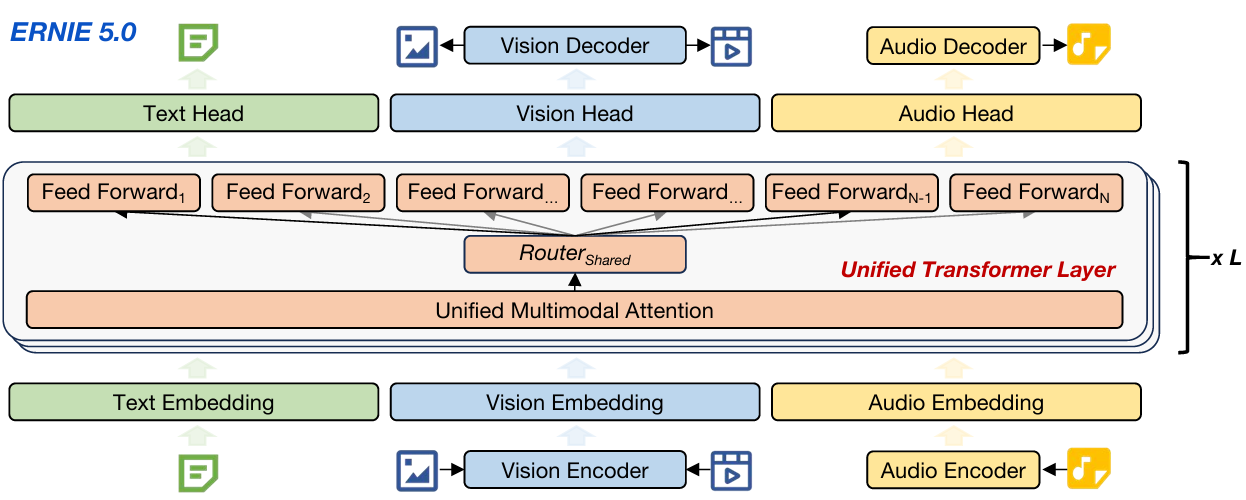
二、2.1 统一自回归主干 + 超稀疏MoE
- 统一模态训练范式
- 多模态输入映射到共享Token空间,序列化后统一建模
- 文本:标准下一个Token预测(NTP)+ 多Token预测(MTP)
- 视觉:下一帧与尺度预测(NFSP)
- 音频:下一个编解码器预测(NCP)
- 全模态对齐自回归生成逻辑,消除模态优化差异
- 超稀疏MoE与模态无关专家路由
- 路由决策基于统一Token表征,而非模态标识,所有模态共享专家池
- 专家激活率低于3%,高效扩容模型容量,计算成本可控
- 无辅助损失的负载均衡策略,保障万亿参数规模训练稳定
- 统一表征设计
- 同时学习高层语义 (支撑理解)与细粒度感知细节(支撑生成)
- 理解与生成相互强化,单一支干兼顾感知、推理、创作
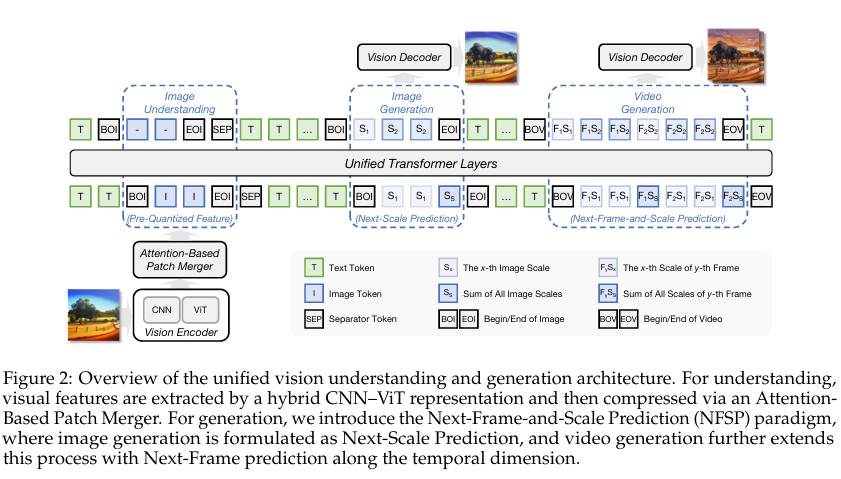
三、2.2 视觉建模(图像+视频统一处理)
将图像视为单帧视频,统一设计视觉理解与生成流程:
- 视觉Token化(2.2.1)
- 因果2D多尺度Tokenizer → 扩展为3D卷积Tokenizer,统一图像/视频编码
- 逐比特量化 + 渐进式切换低/高比特Tokenizer,缓解训练初期不稳定
- 视觉理解(2.2.2)
- 双路径混合表征:CNN(感知细节)+ ViT(语义特征)
- 注意力块融合(Attention-based Patch Merger):优于传统MLP融合,大幅提升文档/图表/通用视觉理解精度
- 视觉生成(2.2.3)
- 范式:下一帧与尺度预测(NFSP),图像按尺度生成、视频按帧+尺度生成
- 位置编码:统一时空旋转位置编码(Uni-RoPE),适配多模态时空位置
- 优化:随机翻转历史Token增强长序列鲁棒性;级联扩散细化器,提升高分辨率画质
- 背景回顾:我们有什么?
在 ERNIE 5.0 的视觉理解路径中,每个图像会同时经过两个编码器:
- CNN :输出一堆局部细节特征 (比如边缘、纹理、小字体的笔画)。这些特征空间对齐好,但缺乏全局语义。
- ViT :输出一堆全局语义特征 (比如"这是一个图表标题"、"这是一段文字块")。这些特征语义强,但局部细节可能模糊。
现在我们要把这两路特征合并 成一个统一的表示,送给后面的主干模型。问题来了:这两路特征在空间结构上不对齐 (CNN 的特征图尺寸、ViT 的 patch 划分可能不一样),而且信息层次不同(细节 vs 语义)。
- 传统 MLP 融合怎么做?为什么不好?
一个直观的方法:把每个位置的 CNN 特征和 ViT 特征直接拼起来 ,然后扔进一个 MLP(多层感知机)压缩成想要的维度。
这就像把两张不同风格的照片简单叠在一起,然后让一个滤镜去处理------每个位置独立处理 ,不考虑周围 patch 之间的关系。
结果就是:
- 特征干扰:CNN 的细节噪声会污染 ViT 的语义,ViT 的粗略化会抹掉 CNN 的精细信息。
- 缺乏空间交互 :比如图表中一个数据点(小圆点)和它旁边的标签文字,它们之间的对应关系需要跨 patch 的注意力才能捕获,MLP 做不到。
- 文档/图表理解尤其吃亏:文档里一个小号字体(需要 CNN 看清笔画)和它所属的段落标题(需要 ViT 理解语义),如果不做跨区域交互,很容易认错或忽略。
- Attention-based Patch Merger 是怎么做的?
ERNIE 5.0 的设计分四步(见报告 2.2.2):- 对齐维度:把 CNN 特征投影到和 ViT 特征相同的维度(这样它们才能"对话")。
- 按组拼接 :不是把单个 CNN 特征和单个 ViT 特征拼起来,而是把空间上相邻的一组 patch(比如 4 个)的 CNN 特征和 ViT 特征全都放在一起,形成一个 (2K) 个 patch 的序列(K 是每组 patch 数量)。
- 这样,每个"融合单元"里既有局部细节(CNN),又有局部语义(ViT),还包含空间邻居的信息。
- 多头自注意力 :对这个 (2K) 个 patch 的序列做自注意力。
- 注意力的作用:让每个 patch 能够"看到"组内所有其他 patch,自动学习哪些 patch 应该互相加强、哪些应该抑制。
- 例如:ViT 的语义 patch 发现某个 CNN 细节 patch 与自己高度相关,就会给它更高的权重;反之,不相关的噪声细节会被忽略。
- 池化压缩:最后把这一组 patch 的注意力输出做平均池化,得到一个紧凑的融合 token。
- 为什么这比 MLP 好?
| 对比项 | MLP 融合 | Attention-based Patch Merger |
|--------|-----------|-------------------------------|
| 交互范围 | 每个位置独立,无跨 patch 交互 | 组内所有 patch 互相交互,能建模局部空间关系 |
| 权重学习 | 固定权重(训练后固定) | 动态权重(根据输入内容自适应) |
| 抗干扰 | 细节和语义简单叠加,互相污染 | 注意力可以"选择"有用的信息,忽略无关的 |
| 适合任务 | 通用图像分类尚可 | 文档/图表理解(需要精细定位+语义关联)效果飙升 |
打个比方:
- MLP 融合:就像把一堆乐高积木(CNN 细节)和一幅画(ViT 语义)胡乱塞进一个袋子,摇一摇就拿出来。
- Attention 融合:像有一个聪明的助手,先把积木和画按小块拆开,然后根据每块的内容决定哪些应该粘在一起、哪些应该扔掉,最后拼出一个完整模型。
- 实际效果(报告原文)
"The proposed attention‑based aggregation module consistently outperforms both CNN‑only and ViT‑only baselines ... with particularly pronounced gains in document and chart understanding as well as general visual understanding tasks."
简单说:在文档理解(比如识别发票里的文字和表格)、图表理解(比如看懂折线图的趋势和数据点)、通用视觉问答上,Attention 融合比 MLP 融合或单一路径都要好一大截。
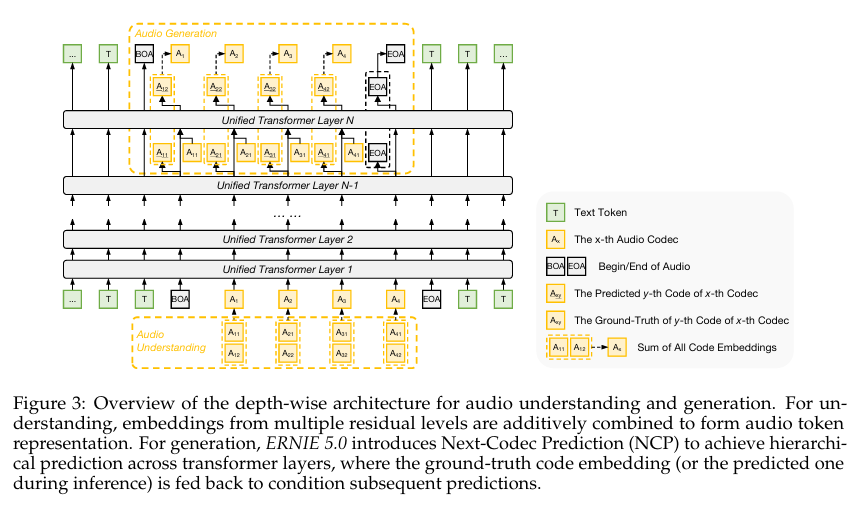
四、2.3 音频建模
基于自回归Token框架,实现音频理解与高保真生成:
- 音频Token化(2.3.1)
- 残差矢量量化(RVQ),Token率12.5Hz
- 第一层Token蒸馏Whisper知识,捕获音频语义;其余层捕获音色、韵律等细粒度声学信息
- 音频理解与生成(2.3.2)
- 深度自回归架构:避免多码本Token展平为长序列
- 理解:深度加法嵌入,融合多残差层音频特征
- 生成:下一个编解码器预测(NCP),粗到细分层生成;生成结果回传 conditioning 后续预测,支持可控音色合成
Pre-Training
本章是模型习得跨模态通用表征 的核心环节,完整包含3.1 预训练数据构建 、3.2 训练策略方案 、**3.3 一次性全弹性训练(核心创新)**三部分,核心目标是:一次预训练,产出一组不同规格的子模型,兼顾性能、训练成本与部署灵活性,完全解决传统大模型"训完再压缩"的痛点。
3.1 Pre-Training Data 预训练数据
3.1.1 数据整体定位
ERNIE 5.0 采用从零开始联合训练 所有模态(文本/图像/视频/音频),因此需要大规模、高保真、多样性 的多模态数据集,且从训练第一天就同时灌入所有模态数据,而非后期拼接。
数据严格分为两大类:文本数据 、多模态数据,并通过标准化平台统一管理与清洗。
3.1.2 文本数据(Text Data)
- 数据来源
覆盖多语言网页爬取数据、精洗语料、书籍、科研论文、代码仓库、结构化知识源,兼顾广度、多样性与语言丰富度。 - 文本Tokenizer 专项优化
- 编码格式:采用UTF-16BE编码,为非拉丁字母语言提供稳定的字节级回退,压缩表示、提升多语言训练吞吐量。
- 正则化:使用BPE Dropout,降低模型对高频模式的过拟合。
- 中文优化:过滤超长无空格短语,用分词工具拆解,降低词汇稀疏性,提升训练效率与泛化能力。
- 数据规模:万亿级文本Token,是模型语言能力的基础。
3.1.3 多模态数据(Multimodal Data)
- 数据构成
- 配对数据:图像-文本、视频-文本、音频-文本配对样本。
- 交错数据:文本与图像/视频/音频混合的交错多模态序列。
- 配套信息:所有数据附带元数据、字幕、描述信息,建立跨模态语义对齐。
- 数据价值
建立文本概念与视觉/音频上下文的时空关联,让模型同时学会单模态感知 与跨模态理解/生成。 - 极致数据清洗
- 启发式+模型双重过滤:剔除低质、不安全内容。
- 全量去重:避免模型记忆化。
- 去污染:严格剔除测试基准数据,保证评估公平。
- 数据规模:万亿级文本Token + 海量多模态样本,平衡规模与语义保真度。
3.2 Training Recipe 训练策略(训练食谱)
核心:多阶段渐进式预训练,逐步扩展上下文长度,严格控制优化稳定性、算力利用率、模态平衡。
3.2.1 阶段1:8K 初始预训练
- 上下文长度:最大 8K Token
- 学习率策略 :WSD(预热-稳定-衰减)
- 线性预热:2000步从0升至峰值 1×10⁻⁴
- 预热后全程保持恒定学习率
- 批大小策略 :全局批大小从 14M Token 逐步提升至 56M Token,提升大规模训练稳定性与效率。
- 长上下文兼容 :RoPE位置编码基值直接设为 1,000,000,后续扩展上下文无需重参数化/插值,实现无损长上下文训练。
- MoE专项配置 :无辅助损失负载均衡的偏置更新率 = 1×10⁻⁴
- 多Token预测(MTP) :损失权重 = 0.3
3.2.2 阶段2:32K & 128K 中期训练
- 上下文长度:逐步扩展至 32K → 128K Token,全局批大小保持不变。
- 学习率策略 :切换为余弦退火,从 1×10⁻⁴ 逐步降至 1×10⁻⁵。
- MoE专项优化 :负载均衡偏置更新率降至 1×10⁻⁵,抑制大规模MoE训练的迭代振荡。
- MTP调整:损失权重从0.3降至0.1,适配长上下文优化。
- 模态平衡 :引入后验损失重加权,将文本/视觉/音频的自回归损失缩放到同一区间,避免模态间优化失衡。
3.3 Once-For-All with Elastic Training 一次性全弹性训练(本章核心创新)
3.3.1 研发背景:传统大模型的致命痛点
传统万亿参数模型采用**训练→压缩(剪枝/蒸馏)**流程,存在三大缺陷:
- 压缩需要单独阶段,算力与工程成本极高。
- 压缩后架构固定,想换尺寸必须重新压缩。
- 小模型性能损耗大,无法适配多样化部署场景。
3.3.2 弹性训练核心思想
不做后压缩,预训练中同时训练"全模型+一堆子模型" ,单次预训练直接产出不同深度、不同专家数量、不同稀疏度的一整套模型家族,子模型直接继承全模型知识,无需单独训练。
3.3.3 三大弹性维度(Figure 4 完整对应)
ERNIE 5.0 从深度、宽度、稀疏度三个正交维度实现弹性,训练时动态采样子网络,一次反向传播同步优化全模型与子模型。
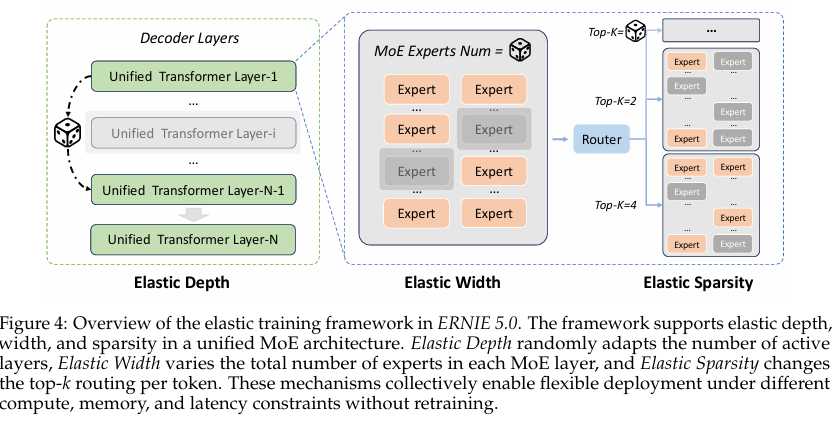
(1)弹性深度 Elastic Depth
- 作用:随机调整激活的Transformer层数,适配不同算力的推理部署。
- 训练策略:
- 75% 概率:使用全深度模型,保证所有层充分优化。
- 25% 概率:随机采样浅层子网络,让模型学会层移除后仍保持有效表征。
- 效果:浅层子模型性能平滑下降,可直接部署,无需重训。
(2)弹性宽度 Elastic Width
- 作用:动态调整MoE层的总专家数量,适配内存受限设备。
- 训练策略:
- 80% 概率:激活全部专家,保持全能力。
- 20% 概率:随机采样部分专家,窄化模型宽度。
- 效果:小宽度模型可在低内存设备运行,性能损失极小。
(3)弹性稀疏度 Elastic Sparsity
- 作用:动态调整单Token激活的专家数(top-k),提升推理速度、降低时延。
- 训练策略:
- 80% 概率:使用默认top-k路由。
- 20% 概率:随机采样更小的top-k,减少单Token激活专家数。
- 效果:推理时top-k降至25%,解码提速超15%,精度几乎无损失。
3.3.4 弹性训练的核心优势
- 一次训练,全尺寸覆盖:无需单独训大/中/小模型,无重复算力浪费。
- 子模型即插即用:子模型直接继承全模型知识,后续微调直接用。
- 极致部署适配:自由权衡性能、模型大小、推理时延,适配从云端到边缘的全场景硬件。
- 性能无损 :仅用35.8%总参数、53.7%激活参数,就能达到全模型99%+的性能。
3.3.5 论文实证结论
弹性训练不是简单的"模型压缩",而是原生训练范式:
- 弹性深度:轻微提升全模型性能,带来正则化效果。
- 弹性宽度:全容量下几乎无性能下降,窄模型可用。
- 弹性稀疏度:推理稀疏度大幅降低,速度显著提升,精度平滑下降。
第四章 Post-Training(后训练 / 多模态强化学习)
第四章 整体概览
ERNIE 5.0 后训练完全沿用ERNIE 4.5的两阶段框架,并针对统一多模态+超稀疏MoE做专项升级:
- 第一阶段:监督微调(SFT)
用高质量多模态指令对数据微调,让模型学会听懂指令、输出结构化结果、完成长思维链推理,奠定基础交互能力。 - 第二阶段:统一多模态强化学习(UMRL)
将推理、智能体、指令遵循、多模态生成等任务融合进多阶段RL流程,通过奖励信号优化模型行为,实现多模态任务的均衡性能。 - 核心支撑:统一验证器系统
为文本/图像/视频/音频的多模态响应生成精准、一致的奖励信号,是RL训练的监督基础。
后训练面临的三大核心挑战(论文明确提出)
ERNIE 5.0的超稀疏MoE+全模态统一架构,让RL训练比普通大模型难得多,具体挑战:
- 计算成本爆炸
万亿参数模型的RL Rollout(生成探索样本)占总训练时间90%以上,算力消耗极高。 - 训练-推理不一致+熵崩塌
超稀疏MoE的动态路由会放大训练与推理的数值偏差,导致RL早期策略熵骤升/骤降(熵崩塌),模型丧失跨模态融合能力,出现模态偏见。 - 多模态稀疏奖励失效
多模态复杂任务(如视觉推理、音频理解)的奖励信号极度稀疏,传统RL(GRPO/DAPO)在奖励全为0时无梯度,难任务训练完全停滞。
训练-推理不一致:
-
曝光偏差:训练时使用真实上下文(Teacher Forcing),推理时使用自身生成的上下文。导致错误累积,影响生成质量,如生成内容重复、不连贯或产生幻觉。
例子:要生成句子"我爱北京天安门"。训练时,模型在预测"爱"时,看到的历史是"我";预测"北"时,看到的历史是"我爱"(是正确的,即使模型之前把"爱"预测成了"恨",这里依然给它看"我爱")。 -
RLHF / RL 场景里的"训推误差":
在 LLM 的 RLHF、PPO、GRPO 等训练里,"训练-推理不一致"更多指:
- 训练过程实际包含两步:
- Rollout(推理/采样):用当前策略生成一批回答,用来算奖励;
- 训练/更新:在生成的数据上算梯度、更新策略参数。
- 但这两步通常由 不同引擎 执行:
- Rollout:高度优化的推理引擎(例如 vLLM、SGLang);
- 训练:分布式训练框架(例如 Megatron-LM、FSDP 等)。
- 即便用的是同一份模型参数,由于下面这些差异,会得到不同的"策略分布":
- 浮点精度与算子实现:
- 训练常用 BF16,推理为了吞吐可能用 FP16/FP8 或专用 kernel;
- 不同精度 + 不同 reduction 顺序会带来舍入与累积误差,导致同样的输入输出不一样的 log-prob。
- 并行策略:TP/PP/DP 不同切分,通信顺序不同,也会放大数值差异;
- MoE 等结构:路由本身对数值敏感,微小差异会选不同的专家,再进一步放大不一致。
- 训练过程实际包含两步:
-
训推不一致在 RL 中怎么变成"稳定性炸弹"?
在 PPO/GRPO 这类算法里,梯度估计里会出现"概率比率"(rollout 分布 / 训练分布)之类的项,例如策略梯度形式里会用 π_train 和 π_rollout 的比值做重要性采样。
如果训推不一致严重:
- 梯度估计有偏且高方差:训练过程不再是对真实目标的无偏优化,训练会震荡甚至崩溃;
- 部署-训练性能拉开差距:训练看起来 OK,但上到真实推理引擎效果却拉胯;
- 在长序列/大模型上,低概率 token 处的误差被放大,在序列级累积。
4.1 Enhancing Rollout Efficiency with Unbiased Replay Buffer
(用无偏回放缓冲区U-RB提升Rollout生成效率)
1. 行业痛点:Rollout的长尾低效问题
RL训练中,响应长度呈长尾分布:少数极长的推理/生成任务会卡住整个批次,导致GPU大量闲置、利用率极低,是RL效率低的核心原因。
2. 现有方案的缺陷:APRIL算法
APRIL通过超额分配请求、提前终止生成提升速度,但会导致:
- 短响应(简单任务)优先进入训练,长响应(难任务)被延后
- 数据难度分布非平稳,模型过早拟合简单任务,难任务性能极差
- 最终收敛效果差,模型泛化能力下降
3. ERNIE 5.0 解决方案:U-RB无偏回放缓冲区
U-RB是APRIL的无偏升级版本 ,核心是保留数据顺序约束,既提速又保证数据分布公平。
(1)核心结构
- 高吞吐量推理池P_infer:容量=训练批大小×缓冲系数,并行生成所有Rollout样本
- 训练池P_train :容量=标准训练批大小,仅收集当前迭代分配的完整样本用于训练
(2)运行机制
- 初始化时,固定当前迭代的数据组,仅允许该组数据参与本轮训练
- 推理池并行生成所有样本,直到当前组最长的样本生成完成
- 完整样本从推理池移入训练池,再启动RL参数更新
- 未完成的样本留到下一轮继续生成,不丢弃、不提前截断
(3)核心效果
- 彻底解决长响应卡批次问题,GPU利用率拉满
- 严格保留原始数据分布,无偏训练,不牺牲难任务性能
- Rollout生成效率提升50%以上,是万亿模型RL可落地的关键工程优化
4. 论文可视化对比(Figure 5)
- Sync RL:长任务阻塞整批,GPU大量闲置
- APRIL:提前终止,数据分布偏置
- U-RB:有序生成、无偏分布、GPU无闲置
4.2 Stabilizing Training with Mitigated Entropy Collapse
(缓解熵崩塌,实现稳定训练)
1. 核心问题:多模态熵崩塌
- 现象:RL早期策略熵急剧波动(骤升/骤降)
- 危害 :模型丧失跨模态信息融合能力,出现模态偏见(比如只看文本、忽略视觉/音频)
- 根源 :
- 训练/推理引擎数值不一致,MoE动态路由加剧该问题
- 模型过早过拟合简单查询,丧失探索能力
2. 解决方案1:MISC 多粒度重要性采样裁剪
(1)技术背景
原始IcePop+GSPO算法会序列级裁剪低熵响应,导致大量有效样本被丢弃,直接引发熵崩塌。
(2)MISC改进
- 修正为混合粒度采样,不再一刀切裁剪整序列
- 按模态敏感度动态调整信任域,平衡探索与利用
- 避免模型过早收敛到"安全但平庸"的策略,保留多模态推理灵活性
(3)效果
彻底解决RL早期熵崩塌问题,训练曲线全程稳定(论文Figure 6深色线)。
3. 解决方案2:WPSM 优质样本掩码
(1)核心思路
把训练梯度预算从"已经学好的简单任务"转移到"难任务/稀疏奖励任务"。
(2)运行机制
- 跟踪每个查询的平均成功率
- 对准确率超阈值+策略熵低于稳定值的"优质学好样本",进行掩码屏蔽
- 被掩码的样本不参与梯度更新,节省算力给难样本
(3)效果
- 缓解模型过拟合简单查询导致的熵崩塌
- 大幅提升难任务(如数学推理、复杂视觉理解)的性能
4.3 Boosting Sample Efficiency with Hint-based Learning
(基于提示的学习,提升稀疏奖励下的样本效率)
1. 核心痛点:稀疏奖励失效
传统RL(GRPO/DAPO)在base模型完全做不出的难任务 上,所有Rollout样本奖励=0,无梯度信号,训练完全停滞。
2. 解决方案:AHRL 自适应提示强化学习
(1)核心思想
给难任务注入部分思考骨架(think skeleton),把复杂问题拆解为中间步骤,降低探索难度,让模型先学会"分步做",再学会"自己做"。
(2)运行机制
- 对原始查询x,拼接前p_hint个思考Token 作为提示,生成增强查询xˉ(p)\bar{x}^{(p)}xˉ(p)
- 提示比例退火 :
- 训练初期:高比例提示,给模型"脚手架"
- 训练后期:逐步降低提示比例,直到完全无提示自主推理
- 提示比例公式:phint(xt)=pinitial⋅exp(−γ⋅t⋅passinitialx)p_{hint}(x^t)=p_{initial}·exp(-\gamma·t·pass_{initial}^x)phint(xt)=pinitial⋅exp(−γ⋅t⋅passinitialx)
- t:训练迭代次数
- pass_initial^x:SFT模型在该查询上的通过率(越难,初始提示越多)
(3)效果
- 解决稀疏奖励无梯度问题,难任务样本效率提升10倍以上
- 模型逐步掌握复杂推理,最终脱离提示也能完成任务
- 多模态推理、数学难题、复杂文档理解性能大幅提升
insight
🤖 1. 大模型更"偏爱"给语言分配脑力 在引入了MoE(混合专家)架构的原生多模态训练里,哪怕研究员已经在代码里加上了"负载均衡(强制端水)"的机制,AI还是会自发地打破均衡:它会把绝大多数的"专家(神经元网络)"偷偷分配给文本,而只留小部分给视觉。
🧠 2. 语言是"参数渴求型",视觉是"数据渴求型" 文心5.0的报告里把这个本质揭露得很透彻:文本/语言能力的突破,极其依赖模型规模的扩大(需要更大的脑容量,即参数);而视觉能力的提升,则更依赖于你喂给它多庞大、多丰富的画面(需要更广的阅历,即数据量)。