microgpt 是 karpathy 仅有 200 行纯 Python 代码且无任何依赖的文件,它可以训练和推理一个 GPT 模型。
这个文件包含了 LLM 所有算法内容:文档数据集、分词器(tokenizer)、自动微分引擎(autograd engine)、类 GPT-2 的神经网络架构、Adam 优化器、训练循环和推理循环。
这个脚本是 karpathy 多个项目(micrograd, makemore, nanogpt 等)以及十年来致力于将大语言模型(LLM)简化为其最基本要素,可见 karpathy 在 LLM 的功力多深厚。
文章地址:karpathy.github.io/2026/02/12/...
代码地址:gist.github.com/karpathy/86...
本文是基于 karpathy 对 microgpt 的博客整理和翻译。
我用 JS 改了一个浏览器直接跑的版本(包括展示 200 行 python 和 浏览器可以直接运行的版本):linkxzhou.su007.club/microgpt.ht...
数据集
大语言模型的燃料是文本数据流,通常被分隔成一组文档,在生产级应用中,每个文档可能是一个互联网网页,但对于 microgpt,我们使用一个更简单的例子:32,000 个名字,每行一个:
css
if not os.path.exists('input.txt'):
import urllib.request
names_url = 'https://raw.githubusercontent.com/karpathy/makemore/refs/heads/master/names.txt'
urllib.request.urlretrieve(names_url, 'input.txt')
docs = [l.strip() for l in open('input.txt').read().strip().split('\n') if l.strip()] # list[str] of documents
random.shuffle(docs)
print(f"num docs: {len(docs)}")数据集看起来像这样。每个名字都是一个文档:
python
emma
olivia
ava
isabella
sophia
charlotte
... (~32,000 names follow)模型的目标是学习数据中的模式,然后生成具有相同统计模式的类似新文档。到脚本结束时,模型将生成新的、听起来合理的名字,类似如下内容:
yaml
sample 1: kamon
sample 2: ann
sample 3: karai
sample 4: jaire
sample 5: vialan
sample 6: karia
sample 7: yeran
sample 8: anna
sample 9: areli
...这看起来没什么大不了的,但从像 ChatGPT 这样的模型的角度来看,与它的对话只是一个看起来很有趣的"文档",当用提示词(prompt)初始化文档时,从模型的角度来看,它的回复只是文档补全的功能。
分词器 (Tokenizer)
在底层,神经网络处理的是数字,而不是字符,所以我们需要一种方法将文本转换为整数 token id 序列,反之亦然,像 tiktoken(GPT-4 使用)这样的生产级分词器为了效率会对字符块进行操作,但最简单的分词器只是将一个整数分配给数据集中的每个唯一字符:
python
uchars = sorted(set(''.join(docs)))
BOS = len(uchars)
vocab_size = len(uchars) + 1
print(f"vocab size: {vocab_size}")在上面的代码中,收集了整个数据集中所有唯一的字符(也就是所有小写字母 a-z),对它们进行排序,每个字母通过其索引获得一个 id。请注意,整数值本身没有任何意义。
每个 token 只是一个独立的离散符号,它们完全可以是不同的表情符号,而不是 0, 1, 2。
此外,创建了一个名为 BOS(Beginning of Sequence,序列开始)的特殊 token,它充当分隔符:它告诉模型 "一个新文档从这里开始/结束"。
稍后在训练期间,每个文档的两侧都会被 BOS 包裹:[BOS, e, m, m, a, BOS],模型会学习到 BOS 启动一个新名字,而另一个 BOS 结束它,因此,最终的词汇表大小为 27(26 个可能的小写字符 a-z 加上 1 个 BOS token)。
自动微分 (Autograd)
训练神经网络为什么需要梯度:对于模型中的每个参数,系统需要知道 "如果把这个数字稍微调大一点,损失(loss)是会上升还是下降,以及变化多少?"。
计算图有许多输入(模型参数和输入 token),但最终汇聚成一个标量输出:损失。
反向传播(Backpropagation)从那个单一输出开始,通过图向后工作,计算损失相对于每个输入的梯度。
它依赖于微积分中的链式法则,在生产环境中,像 PyTorch 这样的库会自动处理这个问题,在这里,用 Value 的类中从头开始实现它:
python
class Value:
__slots__ = ('data', 'grad', '_children', '_local_grads')
def __init__(self, data, children=(), local_grads=()):
self.data = data # scalar value of this node calculated during forward pass
self.grad = 0 # derivative of the loss w.r.t. this node, calculated in backward pass
self._children = children # children of this node in the computation graph
self._local_grads = local_grads # local derivative of this node w.r.t. its children
def __add__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data + other.data, (self, other), (1, 1))
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data * other.data, (self, other), (other.data, self.data))
def __pow__(self, other):return Value(self.data**other, (self,), (other * self.data**(other-1),))
def log(self):return Value(math.log(self.data), (self,), (1/self.data,))
def exp(self):return Value(math.exp(self.data), (self,), (math.exp(self.data),))
def relu(self):return Value(max(0, self.data), (self,), (float(self.data > 0),))
def __neg__(self):return self * -1
def __radd__(self, other):return self + other
def __sub__(self, other):return self + (-other)
def __rsub__(self, other):return other + (-self)
def __rmul__(self, other):return self * other
def __truediv__(self, other):return self * other**-1
def __rtruediv__(self, other):return other * self**-1
def backward(self):
topo = []
visited = set()
def build_topo(v):
if v notin visited:
visited.add(v)
for child in v._children:
build_topo(child)
topo.append(v)
build_topo(self)
self.grad = 1
for v in reversed(topo):
for child, local_grad in zip(v._children, v._local_grads):
child.grad += local_grad * v.grad简而言之,一个 Value 包装了一个标量数字(.data)并跟踪它是如何计算出来的。
把每个操作想象成一个乐高积木:它接受一些输入,产生一个输出(前向传播),并且它知道其输出相对于每个输入会如何变化(局部梯度)。
这就是 autograd,从每个积木中获取的所有信息,将积木串联起来。
每次对 Value 对象进行数学运算(加、乘等)时,结果都是一个新的 Value,它记住了它的输入(_children)和该操作的局部导数(_local_grads)。
例如,__mul__ 记录了 和 ,完整的集合如下:
| 操作 | 前向 (Forward) | 局部梯度 (Local gradients) |
|---|---|---|
a + b |
||
a * b |
||
a ** n |
||
log(a) |
||
exp(a) |
||
relu(a) |
backward() 方法以逆拓扑顺序遍历此图(从损失开始,到参数结束),在每一步应用链式法则,如果损失是 ,节点 有一个子节点 ,局部梯度为 ,那么:
backward() 完成后,图中的每个 Value 都有一个 .grad,包含 ,它告诉我们如果我们微调该值,最终损失会如何变化。
这是一个具体的例子。注意 a 被使用了两次(图分支),所以它的梯度是两条路径的总和:
ini
a = Value(2.0)
b = Value(3.0)
c = a * b # c = 6.0
L = c + a # L = 8.0
L.backward()
print(a.grad) # 4.0 (dL/da = b + 1 = 3 + 1, via both paths)
print(b.grad) # 2.0 (dL/db = a = 2)这正是 PyTorch 的 .backward() 给你的:
ini
import torch
a = torch.tensor(2.0, requires_grad=True)
b = torch.tensor(3.0, requires_grad=True)
c = a * b
L = c + a
L.backward()
print(a.grad) # tensor(4.)
print(b.grad) # tensor(2.)这与 PyTorch 的 loss.backward() 运行的算法相同,只是针对标量而不是张量(标量数组)------算法上完全相同,明显更小更简单,当然效率低得多。
为什么需要 .backward()? Autograd 计算出如果 ,且 ,那么 a.grad = 4.0 说明 对 的局部影响。
如果摆动输入 , 会朝哪个方向变化?这里, 关于 的导数是 4.0,意味着如果把 增加一点点(比如 0.001), 会增加大约 4 倍(0.004)。
同样,b.grad = 2.0 意味着对 做同样的微调会使 增加大约 2 倍(0.002)。
换句话说,这些梯度告诉我们每个单独输入对最终输出(损失)的影响方向(正或负取决于符号)和陡度(幅度),这允许我们迭代地微调神经网络的参数以降低损失,从而改善其预测。
参数 (Parameters)
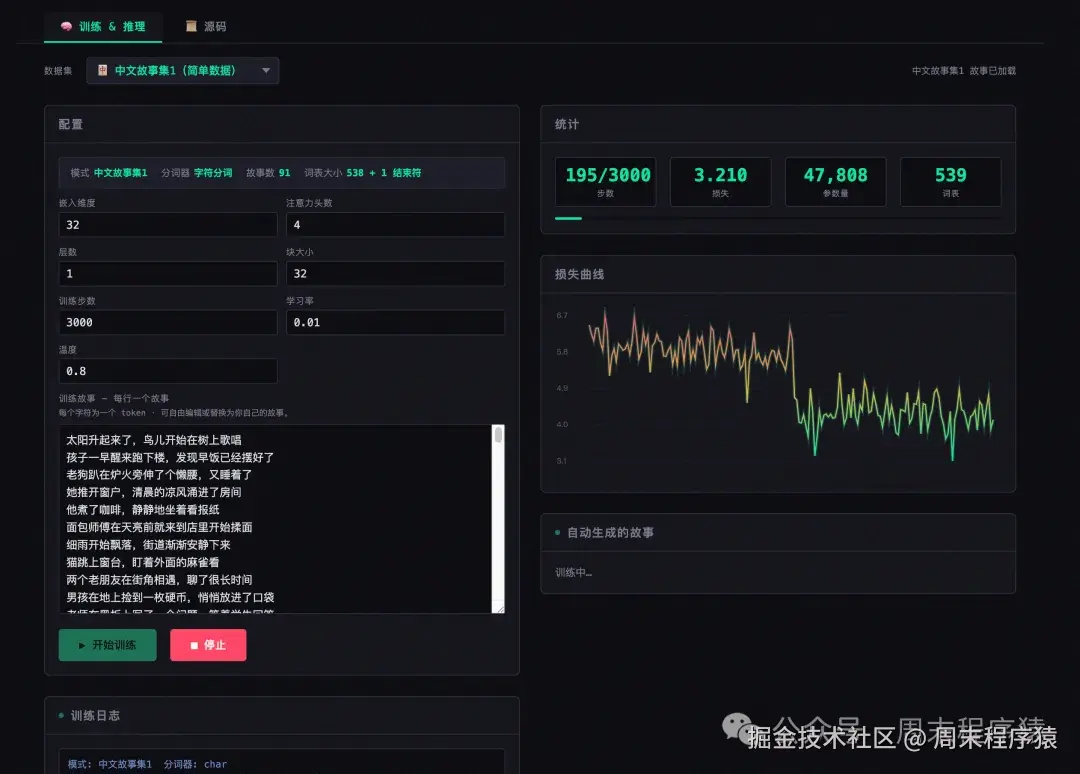
参数是模型的知识,它们是一大堆浮点数,开始时是随机的,并在训练期间迭代优化,一旦确定了模型架构,每个参数就有确定的意义,现在初始化:
ini
n_embd = 16 # embedding dimension
n_head = 4 # number of attention heads
n_layer = 1 # number of layers
block_size = 16# maximum sequence length
head_dim = n_embd // n_head # dimension of each head
matrix = lambda nout, nin, std=0.08: [[Value(random.gauss(0, std)) for _ in range(nin)] for _ in range(nout)]
state_dict = {'wte': matrix(vocab_size, n_embd), 'wpe': matrix(block_size, n_embd), 'lm_head': matrix(vocab_size, n_embd)}
for i in range(n_layer):
state_dict[f'layer{i}.attn_wq'] = matrix(n_embd, n_embd)
state_dict[f'layer{i}.attn_wk'] = matrix(n_embd, n_embd)
state_dict[f'layer{i}.attn_wv'] = matrix(n_embd, n_embd)
state_dict[f'layer{i}.attn_wo'] = matrix(n_embd, n_embd)
state_dict[f'layer{i}.mlp_fc1'] = matrix(4 * n_embd, n_embd)
state_dict[f'layer{i}.mlp_fc2'] = matrix(n_embd, 4 * n_embd)
params = [p for mat in state_dict.values() for row in mat for p in row]
print(f"num params: {len(params)}")每个参数都被初始化为从高斯分布中的一个随机数,state_dict 将它们组织成矩阵,分别是:嵌入表、注意力权重、MLP 权重和最终输出投影,解释如下:
首先是 matrix 辅助函数:matrix(nout, nin) 创建一个 nout × nin 的二维列表,每个元素都是一个 Value 对象,初始值从均值为 0、标准差为 0.08 的高斯分布中随机采样,这些就是模型的可训练参数。
嵌入表 (Embedding tables)
| 参数名 | 形状 | 说明 |
|---|---|---|
wte |
27 × 16 | Token 嵌入表(Word Token Embedding)。每一行是一个 token 的 16 维向量表示。词汇表大小为 27(26 个字母 + 1 个 BOS),所以有 27 行。给定一个 token id,直接查表取出对应行作为该 token 的向量。 |
wpe |
16 × 16 | 位置嵌入表(Word Position Embedding)。每一行是一个位置的 16 维向量表示。最大序列长度为 16,所以有 16 行。给定位置 id,查表取出对应行,与 token 嵌入相加,让模型知道"这个 token 在序列中的第几个位置"。 |
lm_head |
27 × 16 | 输出投影矩阵(Language Model Head)。将模型最后一层的 16 维隐藏状态投影回词汇表大小(27),产生 27 个 logits,每个 logit 对应一个 token 的"分数",分数越高表示模型认为该 token 越可能是下一个。 |
注意力权重 (Attention weights)(每层一组,这里只有 1 层):
| 参数名 | 形状 | 说明 |
|---|---|---|
attn_wq |
16 × 16 | 查询投影矩阵(Query)。将输入向量 变换为查询向量 ,查询表达的是"我在找什么信息?" |
attn_wk |
16 × 16 | 键投影矩阵(Key)。将输入向量 变换为键向量 ,键表达的是"我包含什么信息?" |
attn_wv |
16 × 16 | 值投影矩阵(Value)。将输入向量 变换为值向量 ,值表达的是"如果被选中,我提供什么信息?" |
attn_wo |
16 × 16 | 输出投影矩阵(Output)。将多头注意力拼接后的结果投影回 16 维,混合各个头的信息。 |
Q、K、V 三个 16 维向量会被均匀切分成 4 个头(n_head = 4),每个头处理 4 维(head_dim = 4),让不同的头学习不同的注意力模式。
MLP 权重 (MLP weights)(每层一组):
| 参数名 | 形状 | 说明 |
|---|---|---|
mlp_fc1 |
64 × 16 | MLP 第一层(全连接层 1)。将 16 维输入扩展到 64 维(4 倍),这个"扩展"给模型更大的计算空间来学习复杂的非线性变换。之后经过 ReLU 激活函数引入非线性。 |
mlp_fc2 |
16 × 64 | MLP 第二层(全连接层 2)。将 64 维压缩回 16 维,恢复到原始嵌入维度,以便与残差连接相加。 |
总参数量计算
| 参数矩阵 | 形状 | 参数数量 |
|---|---|---|
wte |
27 × 16 | 432 |
wpe |
16 × 16 | 256 |
lm_head |
27 × 16 | 432 |
attn_wq |
16 × 16 | 256 |
attn_wk |
16 × 16 | 256 |
attn_wv |
16 × 16 | 256 |
attn_wo |
16 × 16 | 256 |
mlp_fc1 |
64 × 16 | 1024 |
mlp_fc2 |
16 × 64 | 1024 |
| 总计 | 4192 |
仅 4192 个浮点数,却包含了 LLM 的所有核心算法要素------嵌入、注意力、MLP、残差连接和输出投影。
架构 (Architecture)
模型架构是一个无状态函数:它接受一个 token、一个位置、参数以及来自先前位置的缓存键/值,并返回关于模型认为序列中下一个 token 应该是什么的 logits(分数)。
这里做了一些小的简化:使用 RMSNorm 代替 LayerNorm,没有偏置(biases),使用 ReLU 代替 GeLU。首先,三个小的辅助函数:
python
def linear(x, w):
return [sum(wi * xi for wi, xi in zip(wo, x)) for wo in w]linear 是矩阵-向量乘法。它接受一个向量 x 和一个权重矩阵 w,并计算 w 的每一行的一个点积,这是神经网络的基本构建块:一个学习到的线性变换。
ini
def softmax(logits):
max_val = max(val.data for val in logits)
exps = [(val - max_val).exp() for val in logits]
total = sum(exps)
return [e / total for e in exps]softmax 将原始分数(logits)向量(范围可以从 到 )转换为概率分布:所有值最终都在 之间且和为 1。 首先减去最大值以保持数值稳定性(这在数学上不改变结果,但防止 exp 溢出)。
ini
def rmsnorm(x):
ms = sum(xi * xi for xi in x) / len(x)
scale = (ms + 1e-5) ** -0.5
return [xi * scale for xi in x]rmsnorm(均方根归一化)重新缩放向量,使其值具有单位均方根,这可以防止激活值在流经网络时增长或缩小,从而稳定训练,这是原始 GPT-2 中使用的 LayerNorm 的一个更简单的变体。
现在是模型本身:
ini
def gpt(token_id, pos_id, keys, values):
tok_emb = state_dict['wte'][token_id] # token embedding
pos_emb = state_dict['wpe'][pos_id] # position embedding
x = [t + p for t, p in zip(tok_emb, pos_emb)] # joint token and position embedding
x = rmsnorm(x)
for li in range(n_layer):
# 1) Multi-head attention block
x_residual = x
x = rmsnorm(x)
q = linear(x, state_dict[f'layer{li}.attn_wq'])
k = linear(x, state_dict[f'layer{li}.attn_wk'])
v = linear(x, state_dict[f'layer{li}.attn_wv'])
keys[li].append(k)
values[li].append(v)
x_attn = []
for h in range(n_head):
hs = h * head_dim
q_h = q[hs:hs+head_dim]
k_h = [ki[hs:hs+head_dim] for ki in keys[li]]
v_h = [vi[hs:hs+head_dim] for vi in values[li]]
attn_logits = [sum(q_h[j] * k_h[t][j] for j in range(head_dim)) / head_dim**0.5for t in range(len(k_h))]
attn_weights = softmax(attn_logits)
head_out = [sum(attn_weights[t] * v_h[t][j] for t in range(len(v_h))) for j in range(head_dim)]
x_attn.extend(head_out)
x = linear(x_attn, state_dict[f'layer{li}.attn_wo'])
x = [a + b for a, b in zip(x, x_residual)]
# 2) MLP block
x_residual = x
x = rmsnorm(x)
x = linear(x, state_dict[f'layer{li}.mlp_fc1'])
x = [xi.relu() for xi in x]
x = linear(x, state_dict[f'layer{li}.mlp_fc2'])
x = [a + b for a, b in zip(x, x_residual)]
logits = linear(x, state_dict['lm_head'])
return logits该函数处理特定位置(pos_id)的一个 token(id 为 token_id),以及由 keys 和 values 中的激活总结的先前迭代的上下文,称为 KV 缓存(KV Cache),以下是逐步进行的:
嵌入 (Embeddings)
神经网络不能直接处理像 5 这样的原始 token id,它只能处理向量(数字列表),所以将一个学习到的向量与每个可能的 token 关联起来,并将其作为其神经签名输入,token id 和位置 id 分别从它们各自的嵌入表(wte 和 wpe)中查找一行,这两个向量相加,给模型一个既编码了 token 是什么又编码了它在序列中位置的表示,现代 LLM 通常跳过位置嵌入,并引入其他基于相对位置的方案,例如 RoPE。
注意力块 (Attention block)
前 token 被投影成三个向量:查询(Query, Q)、键(Key, K)和值(Value, V)。直观地说,查询说"我在找什么?",键说"我包含什么?",值说"如果被选中,我提供什么?"。 例如,在名字"emma"中,当模型在第二个"m"并试图预测接下来是什么时,它可能会学习一个像"最近出现了什么元音?"这样的查询。 前面的"e"会有一个与此查询匹配良好的键,因此它获得很高的注意力权重,它的值(关于是元音的信息)流入当前位置,键和值被追加到 KV 缓存中,以便先前的位置可用。
每个注意力头计算其查询与所有缓存键之间的点积(按 缩放),应用 softmax 获得注意力权重,并取缓存值的加权和,所有头的输出被拼接并通过 attn_wo 投影,值得强调的是,注意力块是位置 的 token 能够"看"过去 token 的确切且唯一的地方,可以说注意力是一种 token 通信机制。
MLP 块 (MLP block)
MLP 是"多层感知机"(multilayer perceptron)的缩写,它是一个两层前馈网络:投影到 4 倍嵌入维度,应用 ReLU,再投影回来,这是模型在每个位置进行大部分"思考"的地方,与注意力不同,此计算对于时间 是完全局部的。Transformer 将通信(注意力)与计算(MLP)穿插在一起。
残差连接 (Residual connections)
注意力和 MLP 块都将其输出加回其输入(x = [a + b for ...]),这让梯度直接流过网络,使更深的模型可训练。
输出 (Output)
最终的隐藏状态由 lm_head 投影到词汇表大小,产生词汇表中每个 token 的一个 logit。
在我们的例子中,这只是 27 个数字。Logit 越高 = 模型认为该对应的 token 越有可能接下来出现。
你可能会注意到我们在训练期间使用了 KV 缓存,人们通常只将 KV 缓存与推理联系起来,但从概念上讲,KV 缓存始终存在,即使在训练期间也是如此,在生产实现中,它只是隐藏在同时处理序列中所有位置的高度向量化的注意力计算内部。
由于 microgpt 一次处理一个 token(没有批处理维度,没有并行时间步),所以显式地构建 KV 缓存,与 KV 缓存保存分离张量的典型推理设置不同,这里的缓存键和值是计算图中的活动 Value 节点,因此实际上会通过它们进行反向传播。
训练循环 (Training loop)
现在我们将所有东西连接在一起。训练循环重复执行: (1)选取一个文档。
(2)在文档的 token 上前向运行模型。
(3)计算损失。
(4)反向传播以获取梯度。
(5)更新参数。
ini
# Let there be Adam, the blessed optimizer and its buffers
learning_rate, beta1, beta2, eps_adam = 0.01, 0.85, 0.99, 1e-8
m = [0.0] * len(params) # first moment buffer
v = [0.0] * len(params) # second moment buffer
# Repeat in sequence
num_steps = 1000# number of training steps
for step in range(num_steps):
# Take single document, tokenize it, surround it with BOS special token on both sides
doc = docs[step % len(docs)]
tokens = [BOS] + [uchars.index(ch) for ch in doc] + [BOS]
n = min(block_size, len(tokens) - 1)
# Forward the token sequence through the model, building up the computation graph all the way to the loss.
keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)]
losses = []
for pos_id in range(n):
token_id, target_id = tokens[pos_id], tokens[pos_id + 1]
logits = gpt(token_id, pos_id, keys, values)
probs = softmax(logits)
loss_t = -probs[target_id].log()
losses.append(loss_t)
loss = (1 / n) * sum(losses) # final average loss over the document sequence. May yours be low.
# Backward the loss, calculating the gradients with respect to all model parameters.
loss.backward()
# Adam optimizer update: update the model parameters based on the corresponding gradients.
lr_t = learning_rate * (1 - step / num_steps) # linear learning rate decay
for i, p in enumerate(params):
m[i] = beta1 * m[i] + (1 - beta1) * p.grad
v[i] = beta2 * v[i] + (1 - beta2) * p.grad ** 2
m_hat = m[i] / (1 - beta1 ** (step + 1))
v_hat = v[i] / (1 - beta2 ** (step + 1))
p.data -= lr_t * m_hat / (v_hat ** 0.5 + eps_adam)
p.grad = 0
print(f"step {step+1:4d} / {num_steps:4d} | loss {loss.data:.4f}")让我们浏览每个部分:
分词 (Tokenization)
每个训练步骤选取一个文档,并在两侧用 BOS 包裹它:名字"emma"变成 [BOS, e, m, m, a, BOS]。模型的工作是根据前面的 token 预测每一个接下来的 token。
前向传播和损失 (Forward pass and loss)
我们将 token 一次一个地输入模型,边做边建立 KV 缓存,在每个位置,模型输出 27 个 logits,我们将它们转换为概率通过 softmax。
每个位置的损失是正确下一个 token 的负对数概率:。这被称为交叉熵损失。
直观地说,损失衡量的是预测错误的程度:模型对实际接下来出现的内容有多惊讶,如果模型给正确的 token 分配概率 1.0,它一点也不惊讶,损失为 0。如果它分配接近 0 的概率,模型非常惊讶,损失趋向于 ,我们对文档序列中的每个位置的损失取平均值,得到一个单一的标量损失。
反向传播 (Backward pass)
一次 loss.backward() 调用通过整个计算图运行反向传播,从损失一直回到 softmax、模型,并进入每个参数。在此之后,每个参数的 .grad 告诉我们如何更改它以减少损失。
Adam 优化器 (Adam optimizer)
我们可以只做 p.data -= lr * p.grad(梯度下降),但 Adam 更聪明,它为每个参数维护两个移动平均值:m 跟踪最近梯度的均值(动量,像滚动的球),v 跟踪最近梯度平方的均值(调整每个参数的学习率)。
m_hat 和 v_hat 是偏差修正,用于解释 m 和 v 初始化为零并需要预热的事实,学习率在训练期间线性衰减,更新后将 .grad = 0 重置以进行下一步。
推理 (Inference)
一旦训练完成,可以从模型中采样新名字,参数被冻结,只是在一个循环中运行前向传播,将每个生成的 token 作为下一个输入反馈回去:
ini
temperature = 0.5 # in (0, 1], control the "creativity" of generated text, low to high
print("\n--- inference (new, hallucinated names) ---")
for sample_idx in range(20):
keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)]
token_id = BOS
sample = []
for pos_id in range(block_size):
logits = gpt(token_id, pos_id, keys, values)
probs = softmax([l / temperature for l in logits])
token_id = random.choices(range(vocab_size), weights=[p.data for p in probs])[0]
if token_id == BOS:
break
sample.append(uchars[token_id])
print(f"sample {sample_idx+1:2d}: {''.join(sample)}")以 BOS token 开始每个样本,这告诉模型"开始一个新名字",模型产生 27 个 logits,我们将它们转换为概率,并根据这些概率随机采样一个 token,该 token 被反馈作为下一个输入,重复直到模型再次产生 BOS(意味着"我完成了")或我们达到最大序列长度。
temperature 参数控制随机性,在 softmax 之前,我们将 logits 除以温度。 温度为 1.0 直接从模型的学习分布中采样,较低的温度(如这里的 0.5)使分布变尖锐,使模型更保守,更有可能选择其首选。 接近 0 的温度将总是选择最可能的单个 token(贪婪解码),较高的温度使分布变平坦,产生更多样化但可能不太连贯的输出。
从 microgpt 观察大模型的训练
microgpt 包含了训练和运行 GPT 的完整算法本质,但在它和像 ChatGPT 这样的生产级 LLM 之间,有一长串变化的事情,它们都没有改变核心算法和整体布局,但为什么 GPT 等生产模型如此强大?
数据
生产模型不是训练 32K 个短名字,而是训练数万亿个互联网文本 token:网页、书籍、代码等。数据经过重复数据删除、质量过滤,并在各个领域仔细混合。
分词器
生产模型不使用单个字符,而是使用像 BPE(字节对编码)这样的子词分词器,它学习将频繁共同出现的字符序列合并为单个 token,像"the"这样的常用词变成一个 token,罕见词被分解成碎片,这给出了约 10 万个 token 的词汇表,并且效率更高,因为模型在每个位置看到更多内容。
自动微分
microgpt 在纯 Python 中对标量 Value 对象进行操作。但是生产系统使用张量(大型多维数字数组)并在每秒执行数十亿次浮点运算的 GPU/TPU 上运行。 像 PyTorch 这样的库处理张量上的 autograd,像 FlashAttention 这样的 CUDA 内核融合多个操作以提高速度,数学是相同的,只是对应于并行处理的许多标量。
架构
microgpt 有 4,192 个参数,GPT-4 级模型有数千亿个。总的来说,它是一个看起来非常相似的 Transformer 神经网络,只是更宽(嵌入维度 10,000+)和更深(100+ 层)。
现代 LLM 还包含更多类型的乐高积木并改变它们的顺序:例子包括 RoPE(旋转位置嵌入)代替学习到的位置嵌入,GQA(分组查询注意力)以减少 KV 缓存大小,门控线性激活代替 ReLU,混合专家(MoE)层等,但注意力(通信)和 MLP(计算)穿插在残差流上的核心结构得到了很好的保留。
训练
生产训练不使用每步一个文档,而是使用大批量(每步数百万个 token)、梯度累积、混合精度(float16/bfloat16)和仔细的超参数调整,训练一个前沿模型需要数千个 GPU 运行数月。
优化
microgpt 使用带有简单线性学习率衰减的 Adam,仅此而已,在规模上,优化本身成为一门学科。模型在降低精度(bfloat16 甚至 fp8)和大型 GPU 集群上训练以提高效率,这引入了其自身的数值挑战,优化器设置(学习率、权重衰减、beta 参数、预热计划、衰减计划)必须精确调整,正确的值取决于模型大小、批量大小和数据集组成。
缩放定律(例如 Chinchilla)指导如何在模型大小和训练 token 数量之间分配固定的计算预算,在规模上弄错这些细节中的任何一个都可能浪费数百万美元的计算资源,因此团队在致力于全面训练运行之前,会运行广泛的小规模实验来预测正确的设置。
后训练
训练出来的基础模型(称为"预训练"模型)是一个文档补全器,而不是聊天机器人,将其变成 ChatGPT 分两个阶段进行。
- 首先,SFT(监督微调):你只需将文档换成精心策划的对话并继续训练,在算法上,没有任何变化。
- 其次,RL(强化学习):模型生成回复,它们被评分(由人类、另一个"法官"模型或算法),模型从该反馈中学习。 从根本上说,模型仍然是在文档上训练,但这些文档现在由来自模型本身的 token 组成。
推理
为数百万用户提供模型服务需要其自己的工程栈:将请求批处理在一起,KV 缓存管理和分页(vLLM 等),用于速度的推测性解码,量化(在 int8/int4 而不是 float16 中运行)以减少内存,以及在多个 GPU 上分发模型,从根本上说,我们仍然是在预测序列中的下一个 token,但在使其更快上花费了大量工程。
所有这些都是重要的工程和研究贡献,但如果你理解了 microgpt,你就理解了算法的本质。
常见问题 (FAQ)
模型"理解"任何东西吗?
这是一个哲学问题,但从机械上讲:没有发生魔法。模型是一个大数学函数,它将输入 token 映射到下一个 token 的概率分布。在训练期间,调整参数以使正确的下一个 token 更有可能。这是否构成"理解"取决于你,但机制完全包含在上面的 200 行中。
为什么它有效?
模型有数千个可调节参数,优化器每一步都会微调它们以使损失下降,经过许多步骤,参数稳定在捕获数据统计规律的值上。对于名字,这意味着诸如:名字通常以辅音开头,"qu"倾向于一起出现,名字很少有三个辅音连在一起等。模型不学习显式规则,它学习一个恰好反映它们的概率分布。
这与 ChatGPT 有什么关系?
ChatGPT 是同一个核心循环(预测下一个 token,采样,重复)的大规模扩展,并经过后训练使其具有对话性。当你与它聊天时,系统提示、你的消息和它的回复都只是序列中的 token。模型一次一个 token 地补全文档,就像 microgpt 补全名字一样。
"幻觉"是怎么回事?
模型通过从概率分布中采样来生成 token,它没有真理的概念,它只知道给定训练数据,哪些序列在统计上是合理的,microgpt "产生幻觉"出一个像"karia"这样的名字,与 ChatGPT 自信地陈述一个错误事实是同一种现象,两者都是听起来合理但恰好不是真实的补全。
为什么它这么慢?
microgpt 在纯 Python 中一次处理一个标量,单个训练步骤需要几秒钟。GPU 上的相同数学运算并行处理数百万个标量,运行速度快几个数量级。
我可以让它生成更好的名字吗?
可以。训练更长时间(增加 num_steps),使模型更大(n_embd, n_layer, n_head),或使用更大的数据集。这些是在规模上起作用的相同旋钮。
如果我更改数据集会怎样?
模型将学习数据中的任何模式,换入一个城市名称、口袋妖怪名称、英语单词或短诗的文件,模型将学习生成那些内容,其余代码不需要更改。