一、INTRO
- 引言前两段在说什么
- 先讲背景:芯片设计越来越复杂,传统 EDA 工具面临很大压力。
- 这些传统方法的问题包括:
- 设计周期长
- 成本高
- 很依赖人工专家经验
- 然后引出 AI,特别是 LLM :
- LLM 在理解和生成文本/代码方面很强
- 因此有可能被引入 EDA,去帮助自动化很多原来很依赖人工的工作
- 作者如何定义"LLM for EDA"
- 作者这里的意思不是单纯"用聊天机器人问问题",而是把 LLM 用到EDA 流程各阶段。
- 范围从前期架构探索,到后期物理设计、验证、后硅验证都可能覆盖。
- 作者认为 LLM 的价值主要在于:
- 提高效率
- 提高准确性
- 减少重复劳动
- 降低人为错误
- 让工程师更多关注高层设计和策略问题
- 作者举了哪些可能的应用
- 帮助生成和优化硬件描述
- 做设计空间探索
- 辅助调试和验证
- 用自然语言和 EDA 工具交互
- 针对具体任务做微调,形成定制化设计支持
- 四大研究方向分别是什么意思
- 代码生成
- 用 LLM 生成 HDL、系统级设计描述、模拟电路设计内容、流程脚本等
- 验证与调试
- 用于 testbench 生成、assertion synthesis、故障定位、bug 修复、安全与功能验证
- 知识表示与检索
- 用于管理和理解大规模设计知识,例如规格分析、缺陷分类、问答支持
- 优化与建模
- 用于 PPA(功耗、性能、面积)优化、尺寸调整、布局细化、设计流程自动化
- 代码生成
我认为这篇文章最值得反复看的图就是 Fig.1。
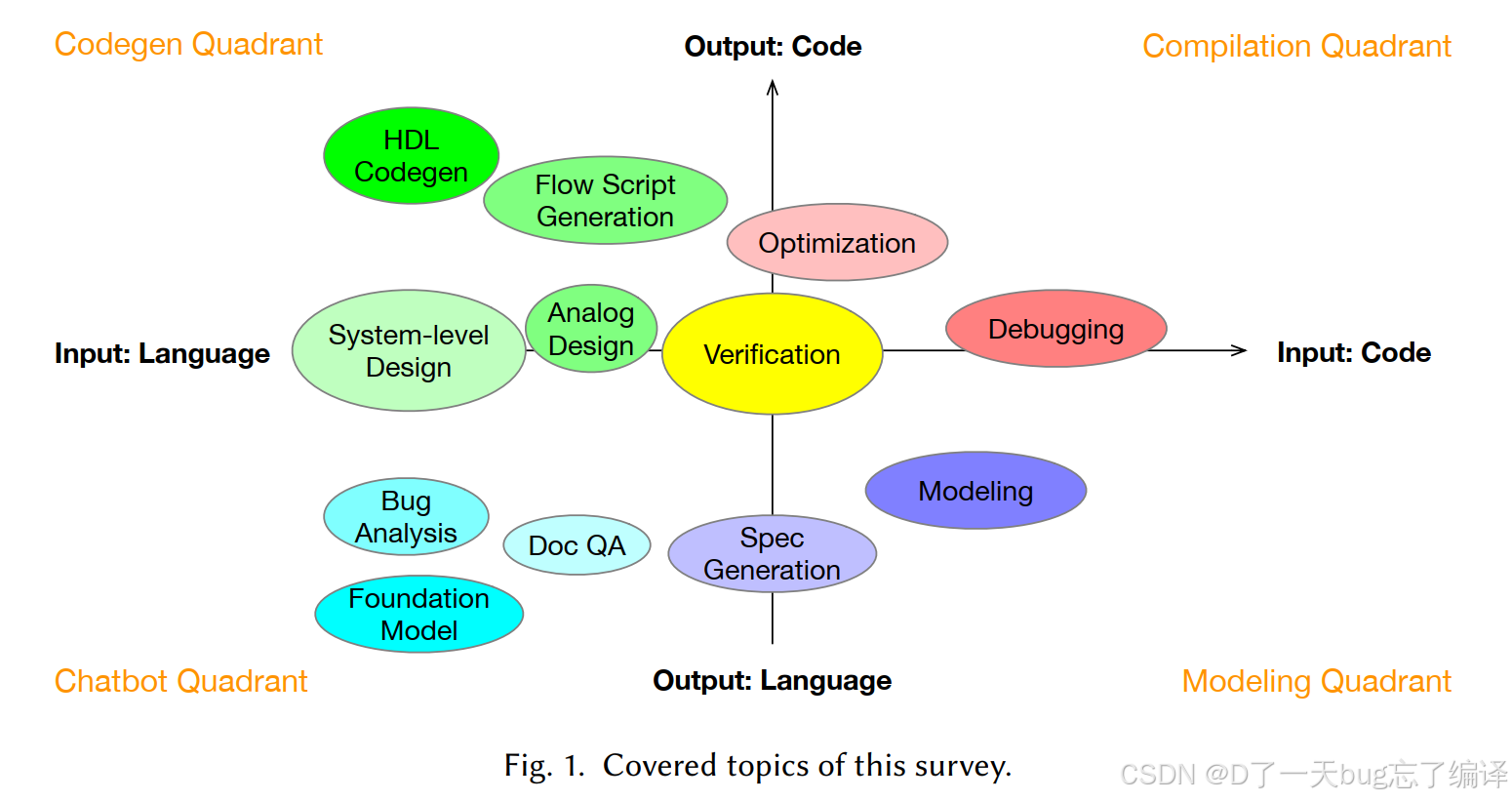
Fig.1 把 survey 覆盖的话题放进了四象限里,并用四种 modality transformation 来解释:
这张图给了一个非常好的"认知压缩方式"。
因为 LLM 在 EDA 中参与的任务种类太多,如果不压缩,你会看到一堆看上去毫不相关的论文:写 Verilog、问文档、生成 runset、做 analog design、debug HDL、分类 bug、优化 PCB placement、做 RAG-EDA......
但如果你用 Fig.1 的视角去看,这些任务就变成了几种信息转换问题:
-
把语言变成代码
-
把代码变成语言
-
把代码变成代码
-
把语言变成语言
一旦这样理解,你会发现 LLM4EDA 的核心,并不是"LLM 学会了硬件",而是:
它能否作为一种通用的表示与转换引擎,把不同形式的 EDA 知识、意图、约束和实现之间的映射做得更有效。
我虽然很喜欢 Fig.1,但也要指出它的边界。
它的问题在于:这种基于输入输出模态的分类,很适合做宏观导航,但不适合直接判断任务难度。
举个例子:
-
"Language-to-Code" 里既包括写 flow script,也包括做 HDL generation。
-
"Code-to-Language" 里既可能是简单的文档 QA,也可能是复杂的 bug explanation。
-
"Code-to-Code" 里既可能是 runset transformation,也可能是真实的 optimization。
这些任务从表面看属于同一个象限,但技术深度和验证标准完全不同。
二、Preliminary
它分成三块:
-
EDA
-
LLMs
-
LLM Augmentation
看起来像常规铺垫,但实际上这三部分在为后面的论证做标准化语言。
作者先讲 EDA,是为了提醒读者:EDA 是一条长链,而不是单一的代码任务。
作者再讲 LLM,是为了说明大模型的能力从哪里来,包括 transformer、pretraining、SFT、alignment、LoRA、QLoRA 等。
作者最后讲 augmentation,是为了暗示:很多所谓 LLM4EDA 工作,本质上不是"发明了新的 EDA 大模型",而是把 CoT、ICL、RAG、tool agents 这些通用增强机制搬进了 EDA。
2.1 EDA 部分的真正价值是什么
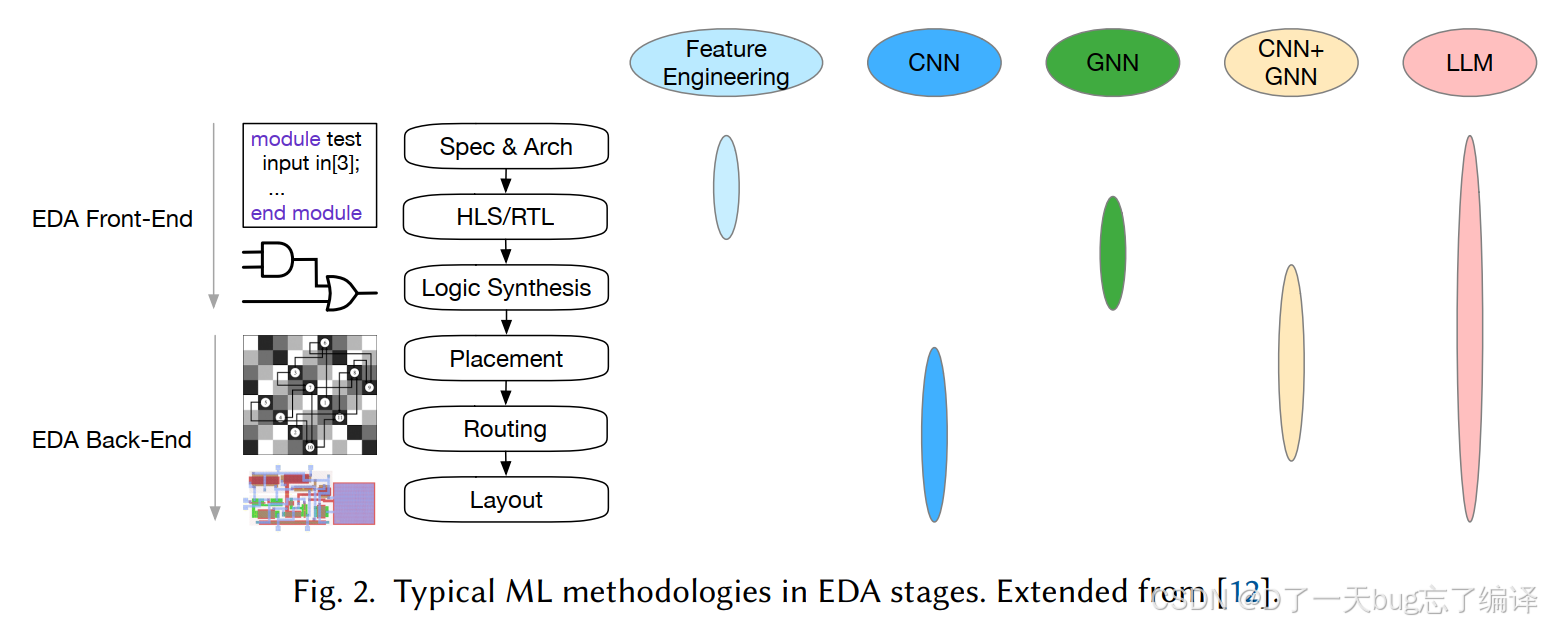
作者通过 Fig.2 把 EDA 过程看成:
-
Spec & Arch
-
HLS / RTL
-
Logic Synthesis
-
Placement
-
Routing
-
Layout
并把 CNN、GNN、CNN+GNN、LLM 等不同 ML 方法和这些阶段做对应。
这张图的核心作用,是让你意识到:
LLM 在 EDA 中的价值不是均匀分布的。
它更容易进入:
-
含有大量自然语言和代码交互的前端阶段
-
含有知识问答和脚本生成的工具界面层
-
含有规则解释与错误诊断的中间层
而在越靠近严格数值优化和几何布局的问题上,LLM 的角色往往越偏辅助而非核心求解器。
2.2 LLMs 部分
有些综述讲 LLM 基础知识容易沦为模板化内容,但这篇 survey 的 2.2 还是有用的。
它主要做了三件事:
-
解释 encoder-only 和 decoder-only 模型差异。
-
回顾 pretraining、SFT、alignment、PEFT 等训练流程。
-
建立后文讨论"为什么某类模型适合某类任务"的语言基础。
-
LLM 为什么会这么强
- LLM 是 NLP 领域的重要进展,特点是:
- 参数规模很大,常常达到 billions 甚至 trillions
- 能生成连贯、符合上下文的文本
- 其核心技术基础是 Transformer
- 依赖 self-attention
- 能捕捉长距离依赖和复杂上下文关系
- 作者还提到两个经典现象:
- scaling law:模型效果会随着模型规模、数据规模、训练算力增大而呈规律性提升
- emergent abilities:模型做大后会出现一些小模型没有的能力
- LLM 是 NLP 领域的重要进展,特点是:
-
两类主流架构:encoder-only 和 decoder-only
- 作者把 LLM 常见结构分成两类:
(1)encoder-only
- 代表模型:BERT
- 只使用 Transformer 的编码器部分
- 适合做"理解类"任务,比如:
- 文本分类
- 命名实体识别
- 问答
- 特点:
- 双向建模
- 一个 token 可以同时看左边和右边上下文
- 常见预训练任务:
- MLM(masked language modeling)
- 把一些 token mask 掉,让模型根据上下文去预测
(2)decoder-only
- 代表模型:GPT-4
- 只使用 Transformer 的解码器部分
- 适合做"生成类"任务,比如:
- 文本续写
- 故事生成
- 代码生成
- 特点:
- 自回归(autoregressive)
- 只能基于前面的 token 去预测后面的 token
- 常见预训练任务:
- CLM(causal language modeling)
- 也就是 next-token prediction
-
为什么 decoder-only 现在更火
- 这部分虽然没有直接下结论,但实际表达很明显:
- encoder-only 更擅长理解
- decoder-only 更擅长生成
- 因为很多 LLM for EDA 任务都涉及:
- 代码生成
- 脚本生成
- 交互式问答
- 设计辅助生成
- 所以后面很多工作大概率会更多围绕 decoder-only / GPT 类模型 展开
- 这部分虽然没有直接下结论,但实际表达很明显:
-
LLM 的训练流程
- 作者把训练方法分成几个阶段:
(1)Pre-training 预训练
(2)SFT(supervised fine-tuning)监督微调- 目标不是单纯提高准确率,而是让输出更符合人类偏好、伦理规范和使用需求
- 文中提到两类典型方法:
- RLHF
- DPO
- 作用是让模型回答更安全、更有用、更符合预期
-
- 在预训练之后,再用某个具体任务的数据集继续训练
- 目的是让模型适配特定任务
- 例如:
- 情感分析
- 机器翻译
- 代码生成
- 放到 EDA 里理解,就是可以拿:
- HDL 数据
- 电路文档
- 验证脚本
- bug 修复样本
去做领域微调
(3)Alignment 对齐训练
-
参数高效微调 PEFT
- 作者接着讲,为了降低微调成本,可以不更新全部参数,而采用 PEFT
- 最典型的方法是:
- LoRA
- QLoRA
- 核心思想:
- 冻结原来的大模型权重
- 只插入少量可训练的低秩矩阵
- 好处:
- 显著减少可训练参数量
- 降低显存和训练成本
- 便于把通用 LLM 适配到垂直领域,例如 EDA
2.3 LLM Augmentation
这一节是我认为整篇 survey 最值得重视的理论准备之一。
作者在这里讲了:
-
CoT
-
ICL
-
RAG
-
Tooling Agents
然后用 Fig.3 总结提升 LLM performance 的方法。
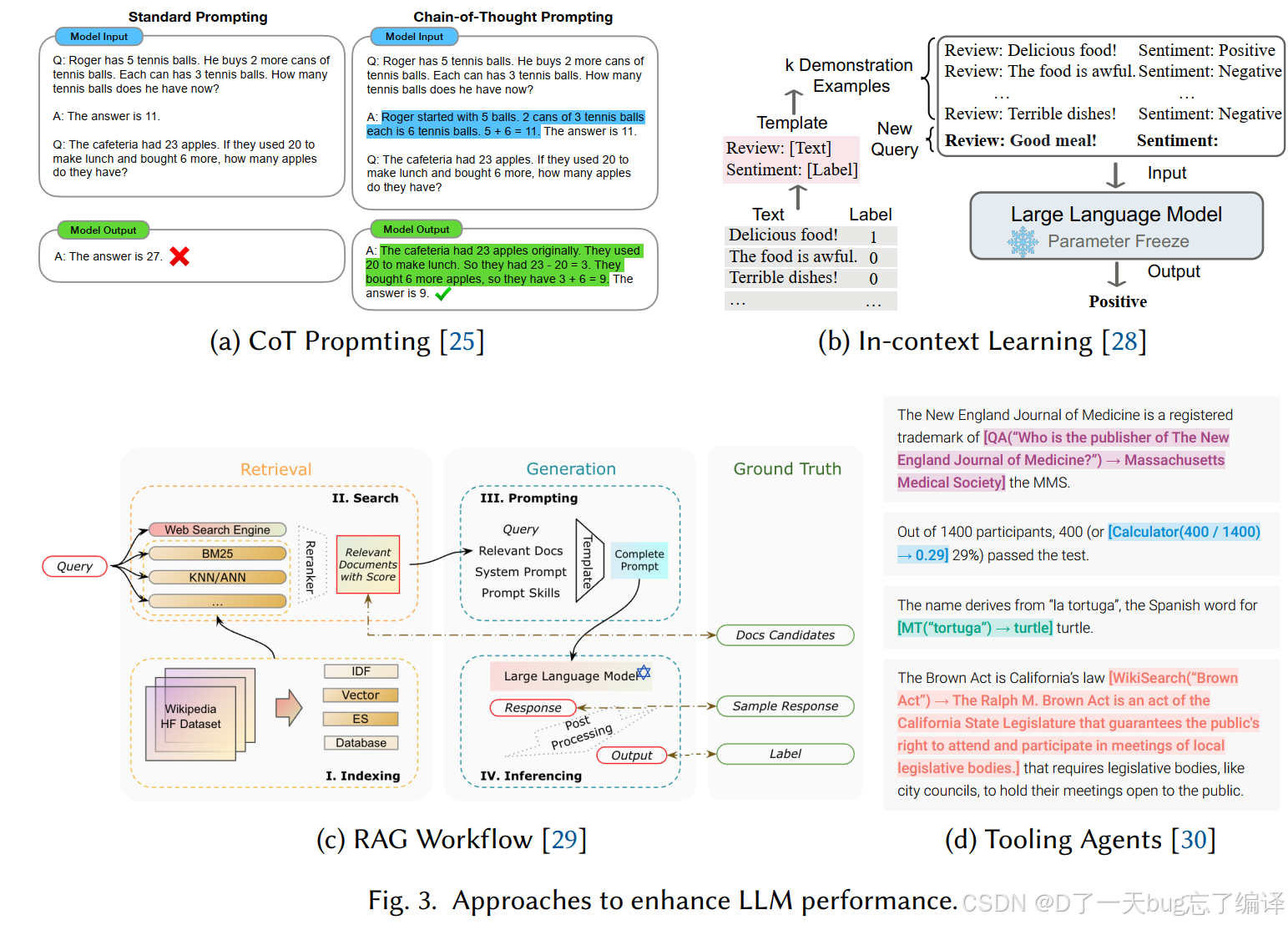
-
CoT Prompting 在说什么
- CoT(chain-of-thought) 的核心思想是:
- 不让模型直接给答案,
- 而是引导它按步骤推理。
- 作者认为它的价值在于:
- 提高复杂推理任务的效果
- 让推理过程更有结构
- 让输出更容易被人理解和信任
- 适用问题:
- 多步推理
- 算术题
- 逻辑问题
- 常识推理
- 图 3(a) 也在说明这一点:
- 标准 prompting 往往直接答错
- CoT prompting 因为中间分步骤展开,更容易答对
- CoT(chain-of-thought) 的核心思想是:
-
ICL(In-Context Learning)
- 它的意思是:
- 在 prompt 里给模型几个示例(demonstrations)
- 再给一个新问题,让模型按示例模式去做
- 图 3(b) 举的是一个情感分类例子:
- 先给若干"评论 → 情感标签"的样本
- 再输入新评论
- 模型据此输出 positive / negative
- 本质上就是 few-shot prompting 的范式。
- 这对 EDA 里很多任务也很有用,比如:
- 给几个 HDL 生成样例
- 给几个 bug 修复样例
- 给几个 assertion 生成样例
- 然后让模型模仿完成新任务
- 它的意思是:
-
RAG 在说什么
- RAG(retrieval-augmented generation) 的核心思想是:
- 先从外部知识库里检索相关信息,
- 再把检索结果喂给 LLM 生成答案。
- 作者强调它结合了两类系统的优点:
- 检索系统擅长找信息
- LLM 擅长生成自然语言或代码
- 它的好处主要有三点:
- 补充外部知识
- 提高事实准确性
- 让信息保持最新
- 因为模型参数里的知识是训练时固化的,而外部数据库可以持续更新。
- 图 3(c) 展示的是一个典型 RAG 流程:
- 用户 query
- 检索模块去数据库/语料库找相关文档
- 把文档和 prompt 组合
- 再交给 LLM 生成输出
- 对 EDA 来说,这特别关键,因为很多任务依赖:
- 规范文档
- 历史 bug 库
- IP 手册
- 设计约束
- 工具日志
- 单靠参数记忆往往不够,RAG 更现实。
- RAG(retrieval-augmented generation) 的核心思想是:
-
Tooling Agents 在说什么
- Tooling agents 是比单纯 prompt 或 RAG 更进一步的增强方式。
- 核心思想:
- 给 LLM 接入外部工具和服务,
- 例如 API、数据库、专用软件等,
- 让它不仅能"说",还能"调工具做事"。
- 作者认为这样做可以突破 LLM 自身局限:
- 它不只是依赖内部知识,
- 还能访问实时信息、调用专业能力、执行复杂流程。
- 文中描述了一个典型 tooling agent 架构,包括三层:
(1)LLM core
- 负责理解语言、生成文本、做基本推理
(2)tool interface layer
- 相当于中间层
- 负责和外部工具通信
- 例如:
- API 调用
- 数据检索
- 返回结果格式化
(3)orchestration mechanism
- 负责协调整个流程
- 决定什么时候该调用哪个工具
- 再把工具返回结果无缝整合进最终回答
- 图 3(d) 展示的就是一些工具代理调用外部知识或服务的例子。
这部分重要的原因在于:
它实际上在告诉你,后面的绝大多数 LLM4EDA 工作,都可以被看成是这几种增强机制在 EDA 领域的具体实例化。
换句话说:
LLM for EDA 并不主要是在发明新模型结构,而是在发明新工作流、新接口、新反馈闭环。
三、 Code Generation
Code generation 是这篇 survey 最长、材料最多、覆盖最广的一块。这是完全可以理解的。
原因至少有三点:
-
代码生成是 LLM 最自然也最早成功的能力之一。
-
EDA 前端有大量"从语言到代码"的任务,非常适合套用。
-
代码生成的结果相对容易 benchmark 化,所以论文多、数据集也更早形成。
但这一部分也最容易让人产生错觉:看到这么多工作,就以为 LLM 已经"掌握了硬件设计"。
事实上并不是。
这部分工作真正覆盖的是几个不同层次的任务:
-
HDL generation
-
System-level design
-
Flow script generation
-
HLS
-
Analog design generation
-
Layout applications
也就是说,"code generation"在这篇 survey 里其实是一个伞状类别,下面包含了很多技术本质完全不同的问题。
3.1 HDL Generation:为什么它是整个 LLM4EDA 最热板块
HDL generation 是目前 LLM4EDA 里最像"主战场"的方向。
这是因为它天然满足几件事:
-
输入形式清楚:自然语言规格、模块描述、部分 RTL。
-
输出形式清楚:Verilog / SystemVerilog / Chisel 等代码。
-
验证手段存在:语法检查、仿真、功能测试、benchmark。
-
社区容易形成共识:pass@k、编译通过率、functional correctness 等。
因此这个方向最早出现了一批基准:
-
VerilogEval
-
RTLLM
-
RTL-Repo
-
以及后续很多扩展 benchmark
作者在这一节做的最重要工作,不是简单列这些论文,而是把方法演化路径梳理出来:
-
直接 prompting
-
数据微调
-
知识增强
-
生成 + 评估闭环
-
多智能体
-
分层与可解释性设计
HDL Generation 里真正的技术主线是什么
如果把 3.1 中出现的诸多工作压缩成几条主线,我认为主要是:
-
如何提高 syntactic correctness
-
如何提高 functional correctness
-
如何减少 hallucination
-
如何让模型利用电路结构知识
-
如何建立更可信的 benchmark 和 evaluation
这个提炼很重要,因为它能帮助你看清不同论文表面不同、实则在解决同几类问题。
比如:
-
BetterV 的 generative discriminator,本质上是在做结构约束和优化导向。
-
VerilogCoder 的 planner + waveform tracing,本质上是在做功能闭环。
-
HiVeGen 和 RTLSquad 这类工作,本质上是在做层次分解和 agent 组织。
-
OpenLLM-RTL、CodeV-CodeQwen 之类工作,则更接近数据、微调和模型底座竞争。
所以这部分不是"很多不同方法",而是"一组围绕正确率和闭环能力的重复攻坚"。
作者对 HDL generation 的态度其实偏乐观
从 survey 的写法看,作者明显认为 HDL generation 是当前 LLM4EDA 中最成熟、成果最丰富、最有 benchmark 支撑的一块。
但也要补一句:这里的"成熟"是相对 LLM4EDA 内部成熟,而不是相对工业 RTL 设计成熟。
因为即使在 2025 年,这一方向的很多工作也仍然主要集中在:
-
中小规模模块
-
单模块任务
-
benchmark-friendly 规格
-
有较强模板性的生成场景
距离真正的 SoC 级、跨模块、时序/接口/约束/验证一体化的设计自动化,还差得很远。
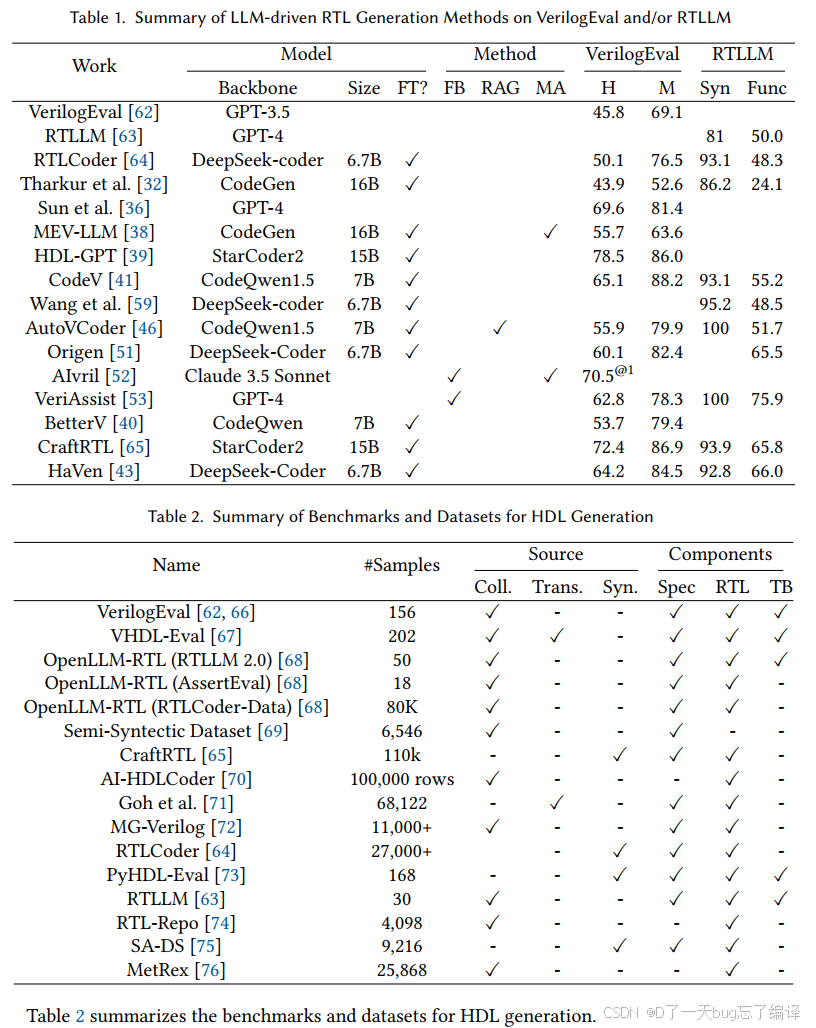
Table 1 总结 LLM-driven RTL generation methods 在 VerilogEval 和 RTLLM 上的情况。
Table 2 总结 benchmarks and datasets for HDL generation。
这两张表对于调研者特别有价值,因为它们帮你回答几个关键问题:
-
哪些工作是用同类 benchmark 比的。
-
哪些工作只是自定义数据集。
-
哪些工作已经开始形成共享基础设施。
-
哪些方法真正依赖 fine-tuned models,哪些更多依赖 prompting / agents / external tools。
3.2 System-level Design
System-level design 和 RTL generation 的本质差别在于:
它不是直接生成可综合硬件代码,而是在 spec、架构、模块划分、交互关系、性能目标之间做更高层级的设计映射。
这类任务的挑战远大于 RTL generation,原因在于:
-
目标更模糊
-
约束更多维
-
评估标准更难统一
-
中间决策链更长
所以 survey 这一节虽然篇幅没 HDL 大,但它代表着一个更远期、更难、更接近"设计思维自动化"的方向。
Chip-Chat、ChatCPU 这类工作为什么值得注意
这一节中的代表工作,比如 Chip-Chat、ChatCPU,不只是"让 LLM 帮忙写东西",而是在探索:
-
如何让自然语言、文档、模块划分、接口讨论进入一个统一交互空间。
-
如何用 conversation / modular bottom-up design 的方式,支持复杂系统设计。
这类工作虽然比 RTL generation 更难 benchmark,也更难形成统一结论,但它们在概念上更接近"EDA 设计助手"甚至"架构协作者"。
从长期来看,我认为这一类工作虽然短期成果不如 RTL generation 稳定,但战略意义可能更大。因为它们碰到的是设计自动化中更高层、也更接近工程师真实思维活动的部分。
3.3 Flow Script Generation
Flow script generation 在很多 academic 读者眼里可能不如 RTL generation"酷",但从工程价值看,它其实非常现实。
为什么?
因为大量 EDA 实践并不只靠图形界面,而是靠各种:
-
Tcl
-
Python
-
PDK 相关脚本
-
OpenROAD / tool-specific flow 配置
-
runset 与 automation glue code
这些东西高度繁琐、语法敏感、知识碎片化,而且天然适合自然语言到脚本的映射。
因此 ChatEDA 这类工作看上去没那么"核心算法化",但可能是最接近短期落地价值的一类。
很多做学术的人会本能地觉得"脚本生成"层次低,但我觉得这不公平。
真正的问题不是"脚本生成是不是深技术",而是:
-
它是不是解决了真实高频痛点。
-
它是不是降低了工具门槛。
-
它是不是能被 benchmark 和自动执行验证。
-
它是不是有机会在真实工具流中快速部署。
从这几个角度看,flow script generation 其实是很有现实价值的方向。
当然,它的局限也很明显:
-
很大一部分工作是工具 interface automation,不一定构成"EDA 核心技术突破"。
-
过度依赖工具文档与 API 稳定性。
-
很多工作本质上更像"EDA Copilot",而不是"设计智能体"。
3.4 HLS
HLS 本身就处于语言和硬件之间,是从高级程序描述到硬件实现的桥梁。这个位置非常适合 LLM,因为:
-
输入形式更像代码/自然语言
-
输出仍然带代码属性
-
可以借助编译器、pragma、DSE 做反馈闭环
所以 HLS 是 LLM 很自然可以切入的点。
但这块的真正难点也非常明确:
-
HLS 不是只生成能编译的代码,而是要考虑性能、资源、pipeline、pragma。
-
代码变换的收益高度依赖底层综合和调度结果。
-
"可综合"和"综合得好"差距很大。
这意味着 HLS 类工作如果没有后端反馈闭环,很容易停留在"生成看起来像 HLS code"的层面。
3.5 Analog Design Generation
Analog design generation 是 survey 中非常有意思但也最应该保持谨慎的一块。
它吸引人的地方在于:
-
模拟电路设计长期高度依赖专家经验。
-
数据稀缺、规则复杂、设计空间大。
-
如果 LLM 真能介入,将会非常震撼。
但也正因为如此,这一方向最容易产生"demo 很惊艳、真实能力有限"的错觉。
原因在于模拟电路设计不是简单 code generation,而是涉及:
-
拓扑选择
-
参数设定
-
约束解析
-
仿真反馈
-
工艺相关性
-
多目标优化
LLM 在这里更合理的位置,至少在当前阶段,更像是:
-
设计知识表达器
-
初始方案生成器
-
拓扑候选提议器
-
优化流程协调器
而不是"独立求解器"。
PICBench、Artisan、Auto-SPICE 这些工作怎么看
这一组工作总体上反映了几个趋势:
-
模拟与光子电路方向开始尝试建立 benchmark
-
生成不再只盯着 netlist,而是开始考虑行为级与器件级协同
-
多模态输入开始变重要,比如 schematic、topology、annotations
这是非常值得注意的方向演化。
但要中立评价,这一板块目前最大的问题仍然是:
-
数据集小
-
benchmark 统一性弱
-
真实工业有效性难验证
-
结果高度依赖具体任务构造
所以 survey 在这一节给出的材料虽然丰富,但你在使用时一定要区分"前沿探索"与"已成形主方向"。
3.6 Layout Applications
这一节其实很能体现 LLM 在后端设计里的真实角色边界。
比如标准单元 layout、pattern generation、runset generation、DRC 规则脚本等工作,看上去都属于 back-end design。
但你仔细一看会发现:
LLM 在这里最擅长的往往不是直接做几何优化,而是:
-
规则到脚本的转换
-
文档到约束的解释
-
已有知识到 layout template 的组织
-
复杂工具流中的接口自动化
也就是说,在 layout 阶段,LLM 的角色更多还是"语言-规则-脚本-知识"的桥梁,而不是替代经典布局布线算法。
LLM 在 EDA 的 code generation 方向已经形成了丰富而多样的探索,并且在 HDL、script、HLS 等若干子任务上展示出真实潜力;但越靠近需要严格物理约束、多目标优化和复杂反馈闭环的问题,LLM 的角色越倾向于"生成 + 协调 + 解释",而不是端到端求解。
四、Verification and Debugging
从 EDA 现实流程来看,verification 往往占据大量开发时间。因此,只要 LLM 能在这一块带来真正有效的自动化,价值会非常高。
但 verification 方向也比 code generation 更难,原因在于:
-
结果不能只看"像不像"
-
错误代价更高
-
任务更依赖外部工具验证
-
过程更长、更多步
所以 verification and debugging 这一章在 survey 里特别重要,因为它其实在回答:
LLM 能否从"生成看起来合理的文本/代码"走向"参与强约束、强证据闭环的工程过程"。
如果这个问题的答案不断变好,那么 LLM4EDA 才真的有可能从辅助工具走向主流程能力。
4.1 Assertion Generation
Assertion generation 是验证方向里最自然、也最先取得成果的子任务之一。
原因很简单:
-
输入可以是自然语言规格或 RTL
-
输出是形式比较固定的 SVA
-
有形式工具可以验证
-
工程师工作中本来就高度需要这一中间产物
因此,像 NL2SVA、AssertLLM 这类工作在 survey 中出现得很合理。
它们的重要性不只是"会生成断言",而是说明 LLM 可以把非形式化描述逐步变成形式化验证资产。
这比直接写 testbench 更有技术象征意义,因为它开始碰到了"规范到形式语义"的转换。
AssertLLM 为什么值得特别注意
这篇 survey 在 assertion generation 里提到 AssertLLM,我认为这个选择很有代表性。
原因在于它不只是从少量手工句子生成断言,而是试图从完整设计规格中提取信息,甚至把 waveform 也纳入生成链条。
这说明 assertion generation 正在从"句子翻译"向"规格理解"演化。
这一步非常关键,因为真正的价值不在于把一句规范翻成 SVA,而在于:
能否把完整规格中散落的信号、行为、时序关系整合起来,生成有意义的断言集合。
这也是为什么我认为 assertion generation 虽然只是 verification 的一个子任务,但它的战略价值不低。因为它直接连接了:
specification understanding -> formal artifact generation
这是一条很重要的 LLM4EDA 路线。
4.2 Testbench Generation
Testbench generation 的热度很高,因为它看起来特别适合 LLM:
-
要生成代码
-
有上下文
-
有模块接口
-
可以用仿真跑
但这里也是最容易被表面结果迷惑的地方。
为什么?
因为 testbench generation 的质量并不只由"代码能跑"决定,还取决于:
-
覆盖是否足够
-
corner cases 是否被考虑
-
stimulus 是否多样
-
checker 是否正确
-
是否真正符合设计意图
很多工作只展示了"testbench 被生成出来并通过了某些测试",但这并不等于它真的具备强验证能力。
所以 survey 在这一块虽然列了不少工作,但你应该保持一个判断标准:
没有 coverage、mutation testing、auto-eval 或真实功能闭环支持的 testbench generation,结论都要看得保守一些。
4.3 Security
Survey 在 verification 部分专门给了 security 子节,这是非常值得注意的。
因为这说明作者认为:
LLM 在硬件安全验证中的角色,不只是 bug fixing 的附属,而是可能成为单独方向。
这类工作通常涉及:
-
security property generation
-
SoC security verification
-
policy generation
-
threat modeling
它们的重要性在于:
-
安全验证任务高度知识密集
-
规则和规范很多
-
工程师负担大
-
LLM 很适合处理复杂文本与规则转化
但它们的难点同样明显:
-
安全 claim 很难靠语言表面评价
-
错误代价极高
-
很容易出现 hallucinated threats 或错漏属性
因此这一节虽然很吸引人,但从成熟度上看,我认为还明显落后于 assertion generation 和 log-based debugging。
4.4 Debugging
Debugging 是我认为这篇 survey 里最值得认真关注的验证子方向。
原因在于:
-
真实工程里调 bug 是持续高频痛点
-
它天然适合引入外部工具反馈
-
它能体现 LLM 是否真的进入"闭环"
像 RTLFixer、Qayyum 等工作,尤其是结合 RAG、编译器/仿真器反馈、自动修复迭代的那些方法,实际上已经开始接近一个很重要的技术转折点:
LLM 不再只是生成器,而是在成为"修复环中的决策者"。
这和纯 code generation 的区别非常大。
因为在 debug 环节中,系统必须面对:
-
错误反馈
-
失败上下文
-
多轮迭代
-
有限搜索空间
-
是否真的修复成功
这些都是更强、更真实的工程信号。
Verification and Debugging 整体怎么看
这部分比 code generation 更能代表 LLM4EDA 的未来上限,但目前也更不成熟。
它的重要性体现在:
-
它更接近真实工程闭环
-
它更依赖工具反馈
-
它更有机会突破"只会生成"的局限
它的不成熟体现在:
-
benchmark 仍不够统一
-
端到端系统仍然不多
-
很多工作还停留在局部子任务
-
真正 industrial-strength 的证据还很有限
五、Knowledge Representation and Retrieval
EDA 本身是一个高度知识密集型行业,知识组织、检索、表达和问答可能是 LLM 最自然也最稳定的优势之一。
这其实非常重要。
因为很多短期最容易落地的 LLM4EDA 应用,未必是自动设计,而可能是:
-
文档问答
-
术语解释
-
规范 review
-
Bug analysis
-
Tool documentation assistant
-
Knowledge-grounded decision support
这些事情听上去不如"自动芯片设计"轰动,但很可能更快进入真实工作流。
5.1 Domain Foundation Models
这一节讨论的是像 ChipNeMo 这样的领域基础模型。
作者把它放在 knowledge 章节最开头,非常合理。因为很多后续能力,无论是 QA、spec review 还是文档 RAG,本质上都受限于模型底座是否真的编码了足够多的硬件领域知识。
这一节的重要启示是:
LLM4EDA 并不一定都要从通用模型出发。有些时候,构建或继续训练一个硬件领域基础模型,可能会在:
-
术语掌握
-
硬件代码习惯
-
规格语言理解
-
工具文档问答
-
verification 知识
这些方面形成更稳的底座。
不过这一方向的局限也很明显:
-
数据获取难
-
专有代码和文档难开放
-
训练成本高
-
评估任务仍然碎片化
所以 domain foundation model 很重要,但短期内不一定会成为主流实践方式。
5.2 Specification Generation and Review
Spec review、spec generation、文档质量控制,看起来不像"硬核 EDA",但实际上它们在真实项目里非常关键。
因为很多后续问题的源头就在于规格本身:
-
描述不一致
-
接口定义模糊
-
时序约束表达不清
-
术语冲突
如果 LLM 可以辅助做 specification review,它的价值并不是"写得更好看",而是可以提前减少设计和验证环节的歧义传播。
这类任务非常适合 LLM,因为它们本质上就是:
复杂技术文档的理解、对齐、总结、冲突发现和改写。
我认为这是一个很现实的方向,而且比很多 flashy 的自动生成任务更容易带来团队效率收益。
5.3 Question-Answering
这一节的代表工作如 RAG-EDA、ORAssistant 等,非常能体现 LLM 在知识层面的现实价值。
它们做的事情并不神秘:
-
建文档索引
-
做 dense + sparse retrieval
-
用 LLM 进行 grounded answer generation
-
给出引用、上下文或命令建议
但它们的重要性在于:
-
EDA 工具文档极长且碎片化
-
工程师大量时间耗在查文档和找正确指令上
-
这类任务的验证方式相对清楚
-
对错误容忍度虽然不低,但比自动生成 RTL 要更可控
所以 QA / tool assistant 是一个非常典型的"短期高价值、长期也有持续空间"的板块。
5.4 Bug Analysis
Bug analysis 这一节很有意思,因为它不完全属于纯 retrieval,也不完全属于 debugging。
它位于中间地带:
-
需要理解 bug 报告和上下文
-
需要从知识库或历史案例中找到相似问题
-
需要对 bug 做分类、解释、可能原因分析
这类任务其实非常符合 LLM + RAG 的优势组合。
而且从工业流程看,这也是很有价值的一层:
在真正自动修复之前,先把 bug 的性质说清楚、分准类、给出合理候选原因,本身就能极大提高人类工程师效率。
所以这一节提醒我们:
LLM4EDA 不一定非要直接"做设计"或"做验证",它也可以在工程链中的认知支持层扮演高价值角色。
六 Optimization and Modeling
Optimization and Modeling 很容易让人兴奋,因为它看起来最接近 EDA 核心价值:PPA 改善、设计空间优化、布局布线优化、器件建模、性能预测。
这一章里的任务虽然都可以放进"LLM for EDA"框架里,但它们之间差异极大,而且很多工作实际上不是让 LLM 直接做优化,而是让 LLM:
-
辅助提出候选
-
缩小搜索空间
-
编码先验知识
-
生成优化策略或约束
-
协调与传统优化器的交互
这和"LLM 直接做优化"是完全不同的。
所以读这一章最重要的原则是:
不要把所有 optimization paper 都理解成"LLM 成为优化器"。很多时候,LLM 更像是:
搜索加速器、候选生成器、知识接口层。
Analog sizing / optimization
像 ADO-LLM、LEDRO 等 analog sizing / optimization 工作,通常结合:
-
LLM 的知识表达能力
-
Bayesian optimization 或其他传统优化器
-
设计空间缩减
-
prompt 或 retrieval 提供领域先验
这类工作最合理的理解方式是:
LLM 不是替代传统 analog optimizer,而是在"初始化、约束表达、候选建议、搜索空间压缩"这些环节提供帮助。
这样理解就会更准确,也更符合实际证据。
HLS optimization / PCB / placement / routing
这一组工作的共性是:
LLM 通常不是唯一核心算法,而是和已有优化流程结合。
比如:
-
RALAD 更像 retrieval-augmented HLS optimization
-
PCBAgent 更像 agent + optimization flow
-
某些 placement / routing 工作,LLM 主要作用在 action proposal、constraint interpretation、sequence suggestion
这类工作的价值在于:
-
它们把 LLM 接到了真实优化问题里
-
证明了语言模型可以帮助复杂搜索过程
但它们的风险也很明显:
-
很容易把"局部收益"夸大成"整体优化能力"
-
很依赖具体基线和任务设置
-
很难做出统一 benchmark
所以这一章里最重要的不是单个结果,而是你要看清:
LLM 到底扮演的是哪个角色。
Modeling 方向的一个核心问题:LLM 是在预测,还是在承载知识
这一章的 modeling 类工作里,有一类是用 LLM 做预测或回归,比如功耗、时序、结构特征映射等。
传统上这些任务常用 CNN、GNN、XGBoost、feature-based regressor 等模型,它们在很多纯数值预测任务上仍然更自然、更高效。
LLM 在这里的真正价值往往不在"单纯回归性能更好",而在于:
-
它可以同时消化语言描述和结构信息
-
它能够承载更多先验知识
-
它可能在低数据或跨任务迁移上有优势
如果某篇工作不能说明这些额外价值,只是证明"LLM 也能做预测",那其意义就要保守判断。