目录
[三、质心 和 簇](#三、质心 和 簇)
[第一步 ->](#第一步 ->)
[第二步 ->](#第二步 ->)
[第三步 ->](#第三步 ->)
[第四步 ->](#第四步 ->)
[3.使用K-means 聚类](#3.使用K-means 聚类)
[4.聚类后 看散点图](#4.聚类后 看散点图)
一、概念
无监督学习 (有特征,无标签)
聚类算法是一类无监督学习方法,在讲数据划分为若干组(簇),使得同一簇内的样本相似度搞,而不同簇间的样本差异大。
根据样本之间的相识性,讲样本划分到不同的类别中,不同的相似度计算方法,会得到不同的聚类结果。常用相似度欧式距离法计算
聚类算法的目的是在没有先验知识的情况下,自动发现数据集中的内在结构和模式。
实际应用:
用户画像,广告推荐,搜索引擎的流量推荐,恶意流量识别。
基于位置信息的商业推送,新闻聚类,筛选排序。(LBS的信息推送)
图像分割,降维,识别。 离群点检测,信用卡异常消费。 发掘相同功能的基因片段。
二、聚类算法分类
1.根据聚类颗粒度分类
粗聚类、细聚类
2.实现方式
基于划分的聚类:K-means算法->按照质心(一个簇的中心位置,通过均值计算)分类
基于层次的聚类:DIANA(自顶向下)AGNES(自底向上)
基于密度的聚类:DBSCAN算法
等
三、质心 和 簇
第一步 ->
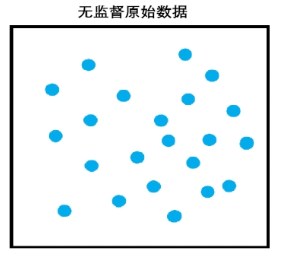
初始化 分簇 假设分为两个簇,给两个质心点。
初始化质心点的时候,可以是原始数据中的某一个点
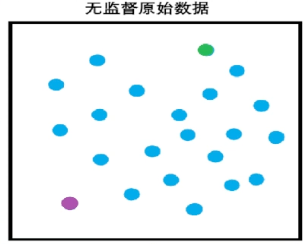
第二步 ->
计算距离分簇
每个样本和不同的质心点计算距离,离它最近的那个,就是属于那个簇。
每个样本都计算和质心点的距离。
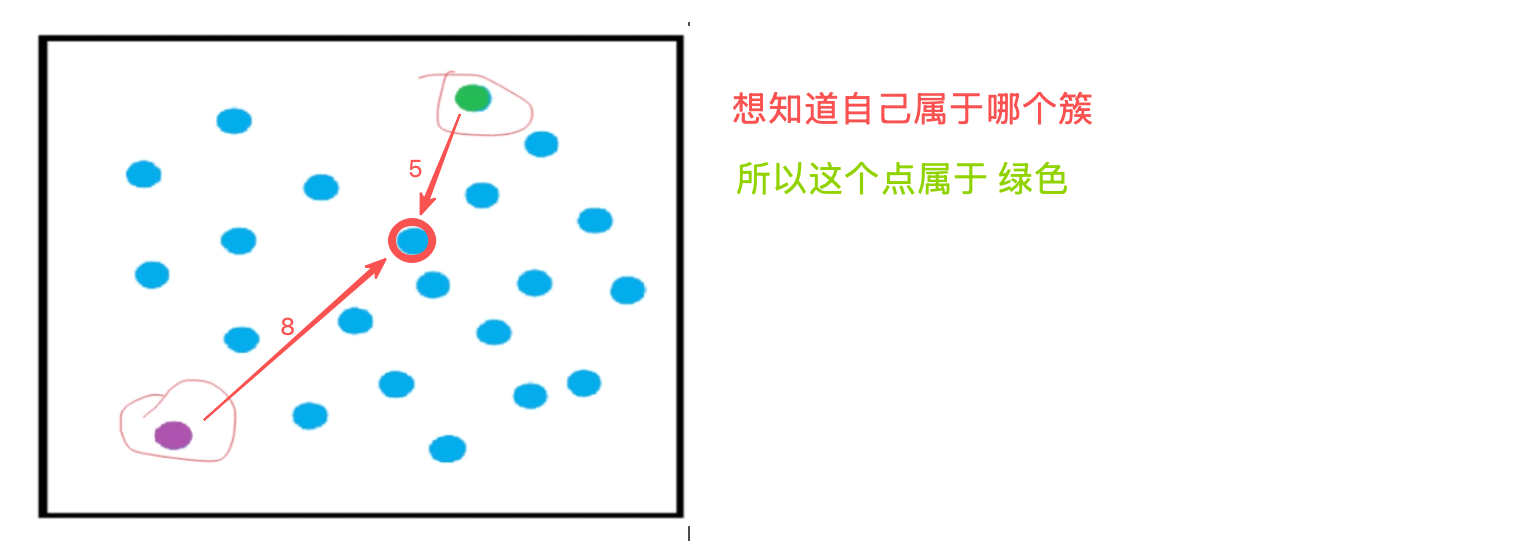
第三步 ->
计算完距离后,分了两个簇
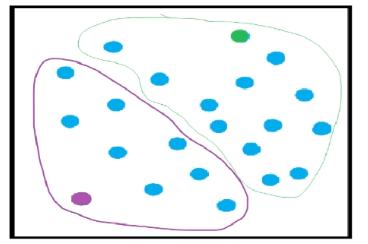
接下来,在簇内,计算每个样本的x和y 的平均值 ,找新的质心点,新的质心点的位置,
同簇内(x平均值,y平均值)
注意:新的质心点,不一定是样本点。(极低概率是样本点)
第四步 ->
计算产生新的质心点后,所有的样本再算距离新质心点的距离,重新分簇。

!什么时候停止?即什么时候聚类结束?
如果计算出来的质心点的位置和上一次质心点的位置一致。即停止聚类。
代码案例
1.创建数据集
python
from sklearn.datasets import make_blobs #造数据
python
# 1.创建数据集
'''
参数1:样本数据
参数2:每个样本的特征数量(维度)
参数3:聚类中心坐标,设置4个质心点 (随便给)
参数4: 标准差(cluster_std),就是控制每一类数据的 "散开程度"
标准差越小 → 数据越集中、紧凑
标准差越大 → 数据越分散、松散
第 1 类:散得更开(std=0.4)第 2、3、4 类:更紧凑(std=0.2)
参数5: 随机种子
return x,y
x: 一个二维的数据集 numpy.ndarray类型
[[ 1.23888592 1.13588028]
[-0.56002843 1.14623716]
[-1.35573954 1.25321833]
...
]]
y:一个维数 集合 {0..3}..
为什么是0-3 因为centers 用了4个质心点 也就是4个簇
'''
x,y = make_blobs(n_samples=1000,
n_features=2,
centers=[[-1,1],[0,0],[1,1],[2,2]],
cluster_std=[0.4,0.2,0.2,0.2],
random_state=444)2.绘制散点图
python
# 2.绘制散点图
plt.figure()
plt.scatter(x[:,0],x[:,1])
plt.show()
3.使用K-means 聚类
python
from sklearn.cluster import KMeans #聚类算法
python
# 3.使用KM 进行聚类
y_pred = KMeans(n_clusters=4).fit_predict(x)4.聚类后 看散点图
python
# 4.给颜色,再看散点图
plt.scatter(x[:,0],x[:,1],c=y_pred) #用每个点来分配颜色
plt.show()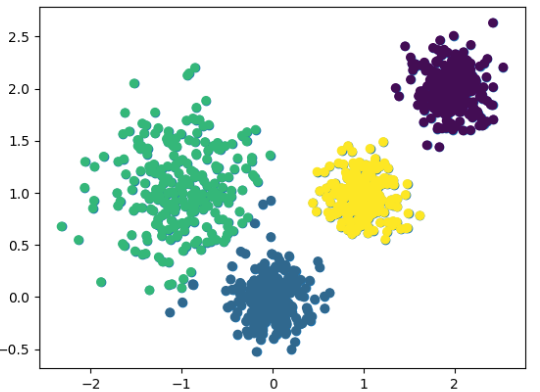
5.模型评估
python
#5 模型评估
# 簇 内越小越好,簇 间 越大越好
print(calinski_harabasz_score(x,y_pred))