哈喽各位同行,我是老邢。
继产品底稿 01 定下 V1.1 个人专属 AI 写作助手方向后,这段时间一直在闷头推进核心链路落地。目前商助慧 V1.1 版本已经完成最关键的底座建设:CSDN 文章爬虫、MySQL 结构化存储、Milvus 向量入库、前端页面展示,全流程正式跑通。
一、V1.1 阶段核心目标
- 彻底放弃对外商业化,专注服务自身写作需求
- 把个人 14 年技术文章、人生底稿全部沉淀为私有知识库
- 实现文章从抓取、清洗、分片、存储到展示的全自动闭环
- 搭建稳定可靠的 RAG 底层数据环境,为后续 AI 写作做支撑
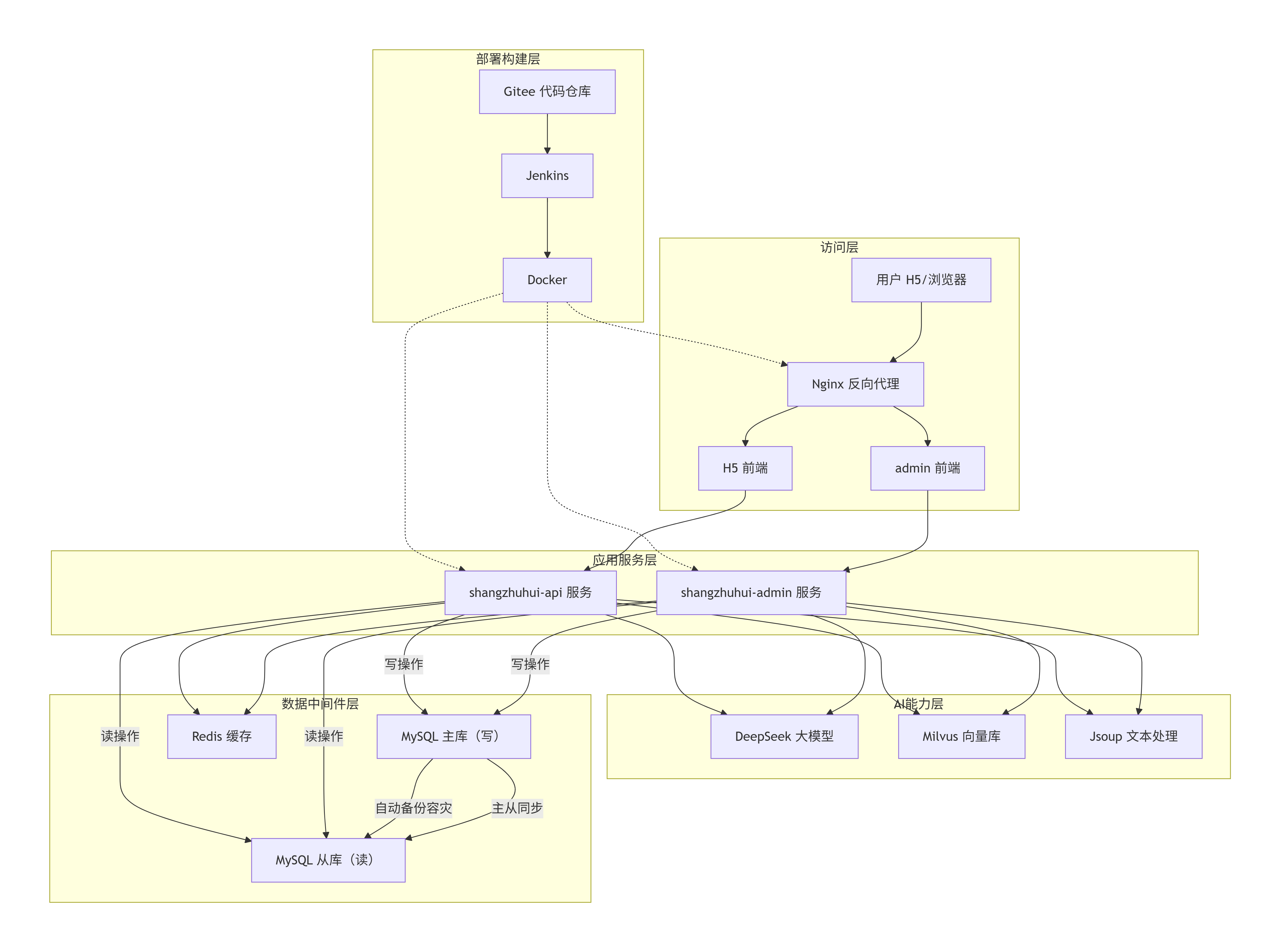
二、当前已完成核心功能
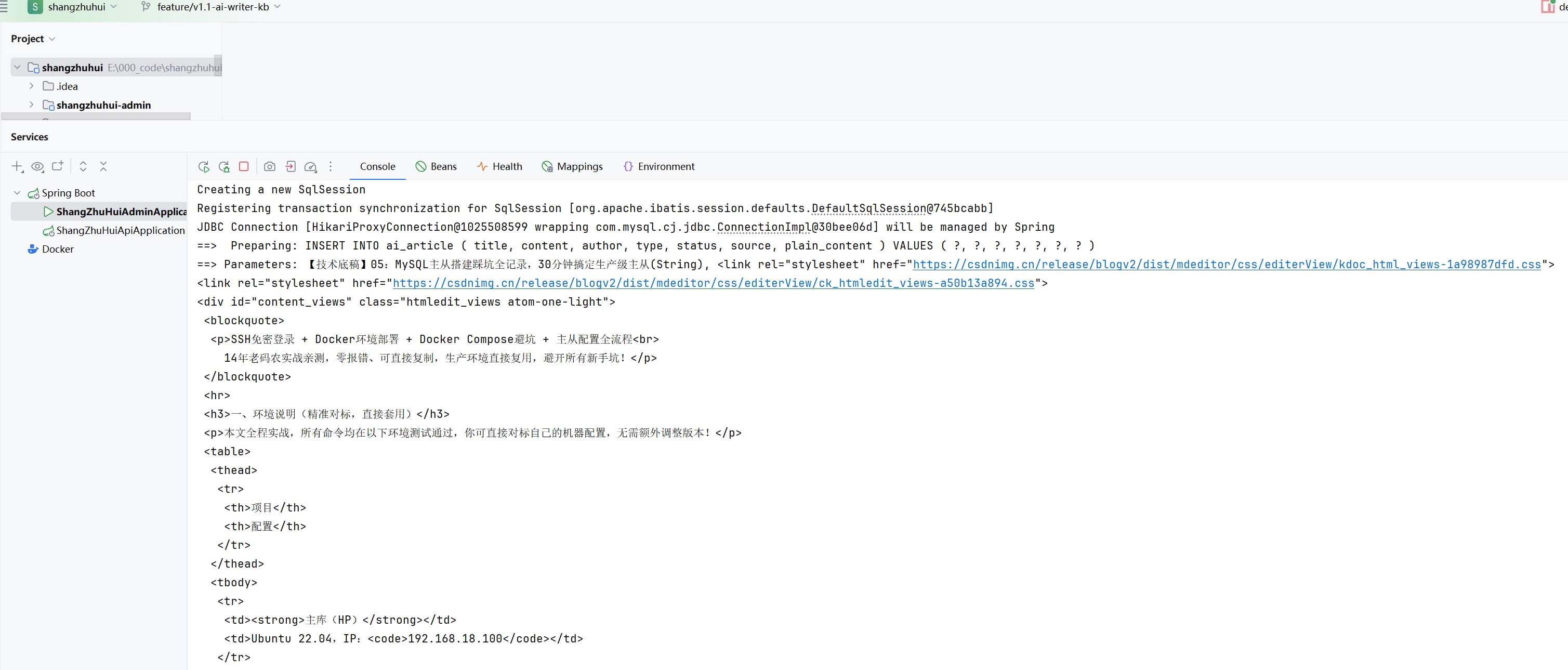
1. CSDN 文章爬虫模块
- 支持文章 URL 一键爬取,自动解析正文内容
- 实现 HTML 标签清洗、冗余内容过滤、文本格式化
- 配套图片抓取与路径处理,保证内容完整性
- 接口稳定,可批量灌库,无需手动复制粘贴
2. 双存储架构落地
- MySQL 存储文章原文、标题、创建时间、关联关系等结构化数据
- 实现数据校验、异常捕获、重复入库拦截
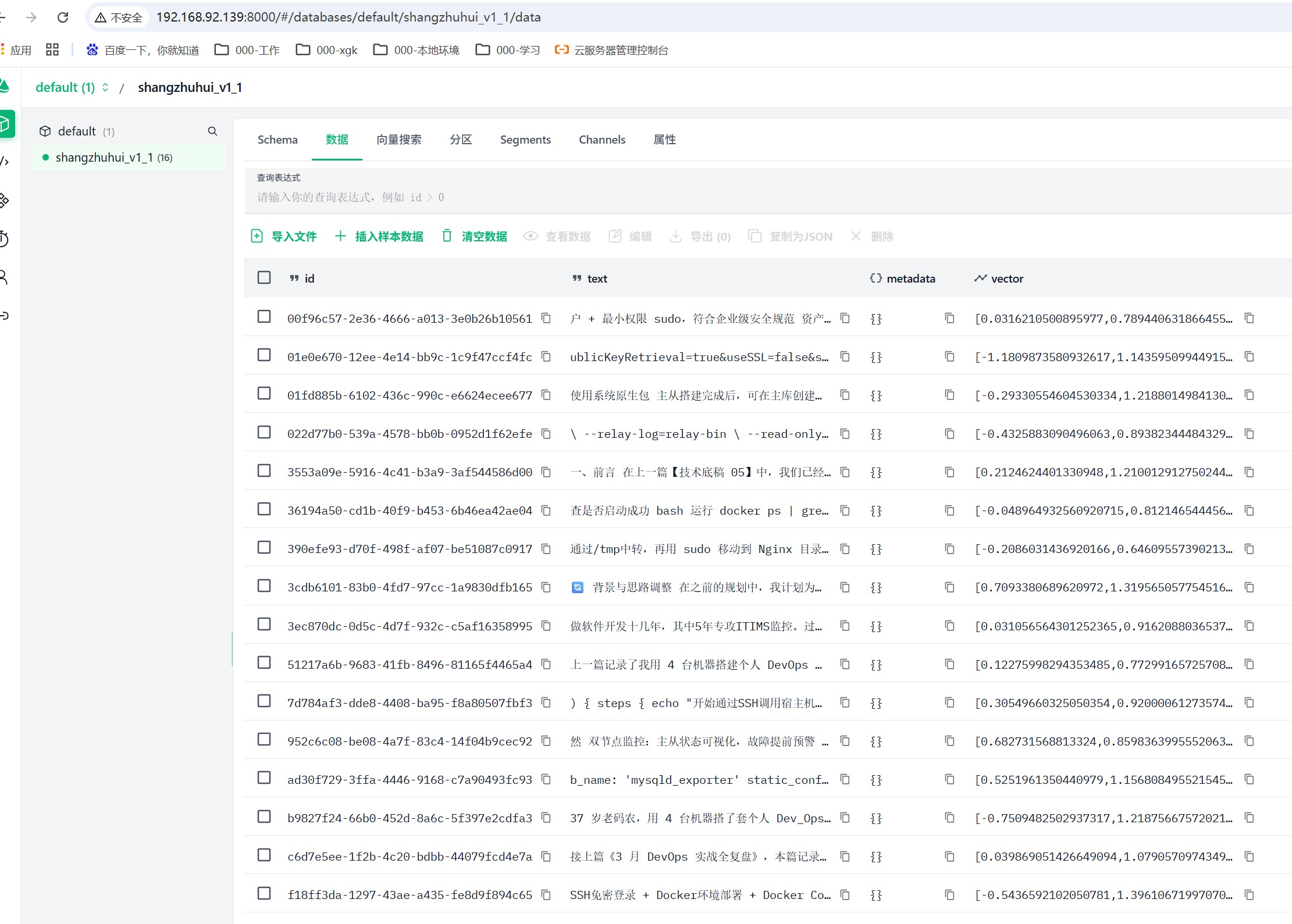
- Milvus 向量库负责文本分片后的向量存储
- 完成 MySQL 与 Milvus 数据双写逻辑,保证数据一致性
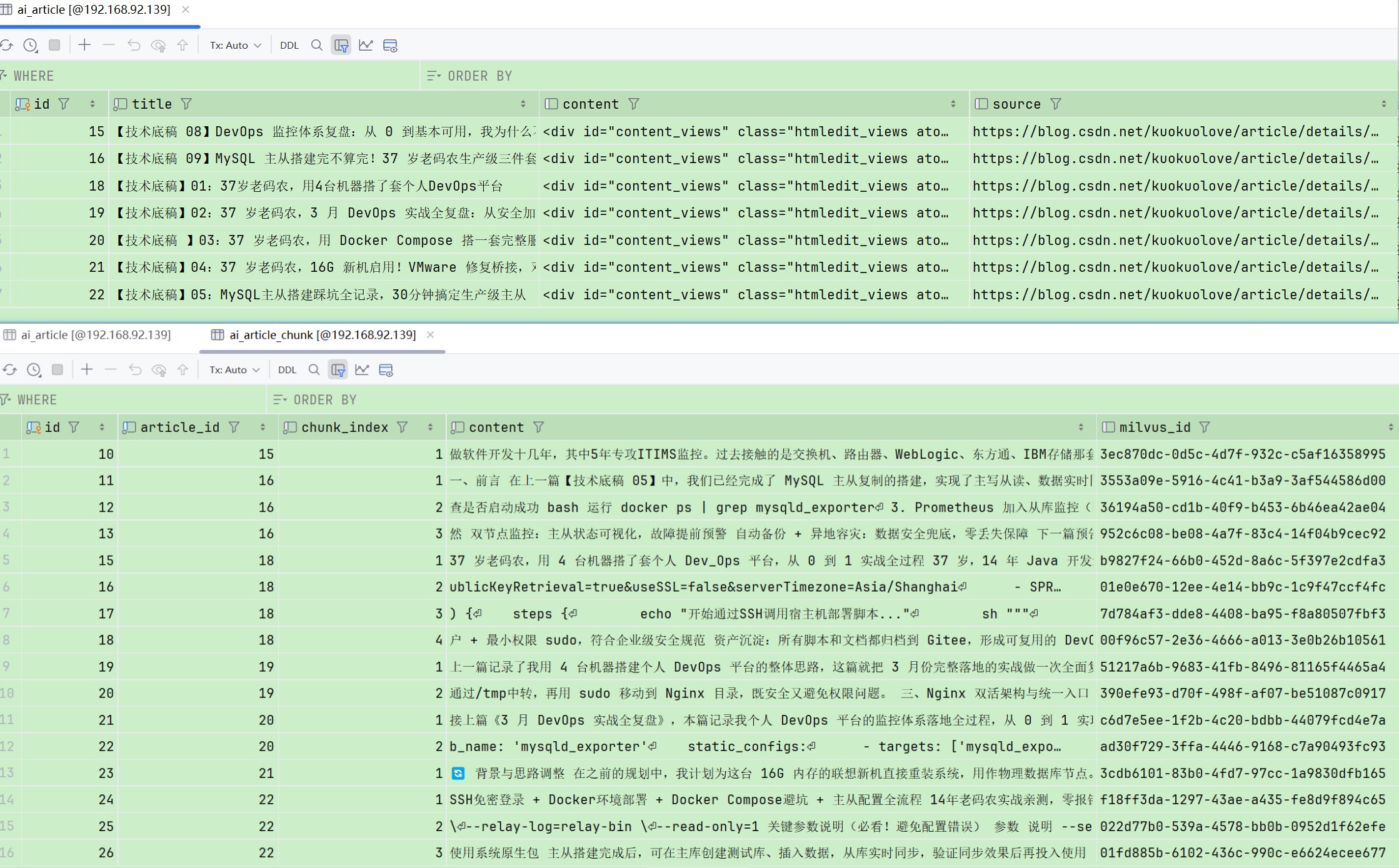
3. RAG 基础分片入库
- 采用固定长度文本分片,适配向量检索规则
- 对接向量生成服务,实现自动向量化入库
- 构建专属私有知识库,数据完全在内网环境运行
4. 前端展示与管理
- 文章列表、详情页正常展示,数据回显完整
- 支持知识库内容查看、管理
- 前后端接口联调全部通过,流程无阻塞
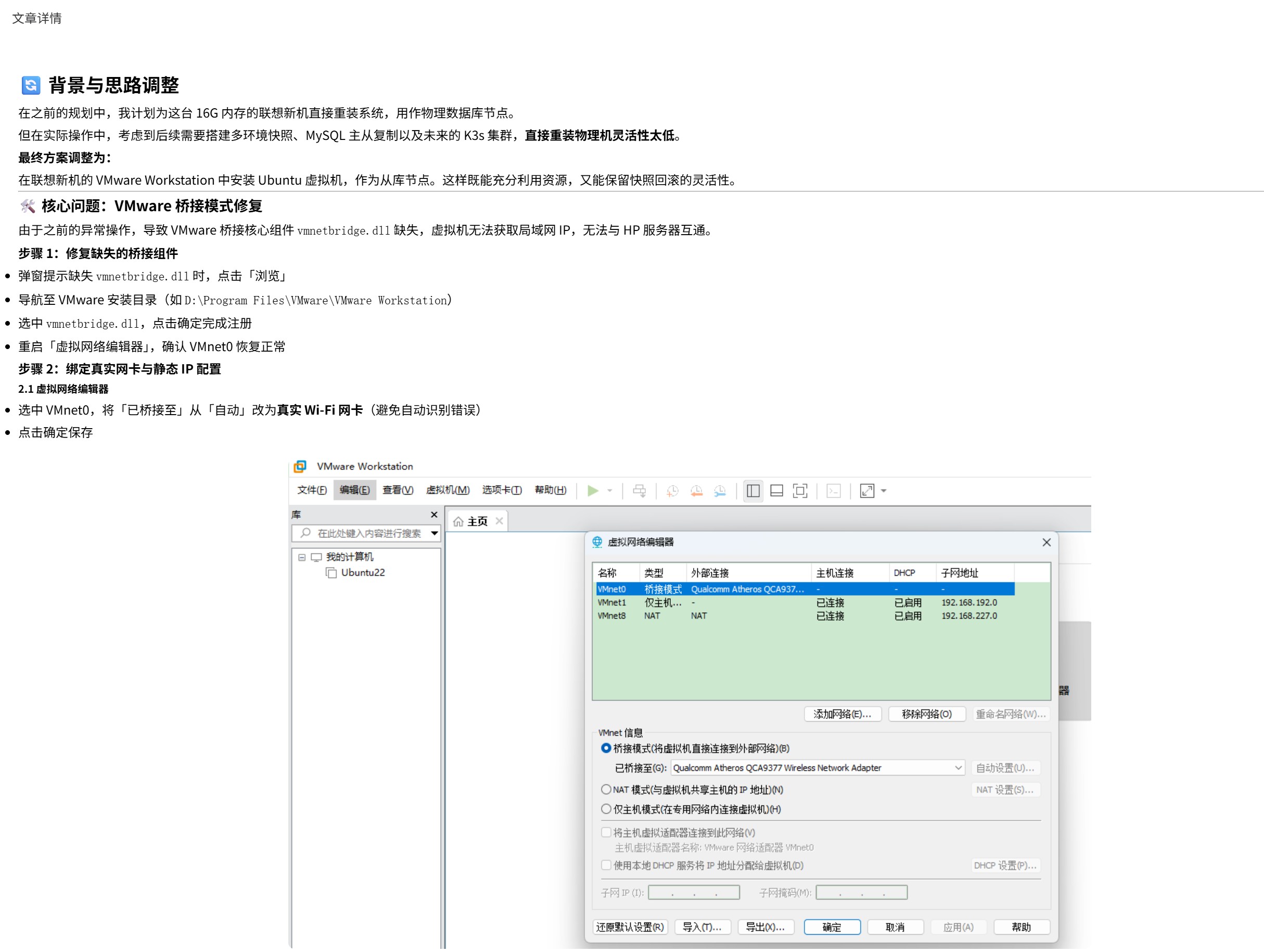
三、实际开发踩坑与解决
- 爬虫正文提取不稳定,存在冗余代码与噪音数据优化:强化规则过滤,提升正文纯度,减少干扰内容
- 长文本直接入库导致向量异常优化:统一分片规则,控制单段文本长度
- MySQL 与 Milvus 数据不同步优化:增加事务控制与失败重试机制,保证双库一致性
- 图片路径错乱无法正常显示优化:统一资源路径规则,修复地址映射问题
四、V1.1 当前阶段价值
这一阶段完成后,商助慧真正拥有了属于自己的私有知识底座。
- 不再依赖通用大模型,数据完全私有化、内网化
- 所有技术底稿、人生底稿可统一管理、批量入库
- RAG 检索环境就绪,后续可直接实现基于个人内容的 AI 写作、风格仿写
- 为 AI 生成初稿、智能问答、内容梳理打下最扎实的基础
五、下一阶段 V1.2 规划
- 支持 TXT、MD、PDF 多格式文件导入
- 优化分片策略,从固定长度转向语义分片
- 完善 RAG 召回逻辑,提升检索精准度
- 接入 AI 写作界面,实现基于私有库的内容生成
后续会继续同步产品迭代细节,保持纯 Java 生态落地 AI 应用,一步一步把个人专属写作助手做扎实。
持续更新《人生底稿》成长史 &《技术底稿》&《产品底稿》实战干货,一起踏实成长,不焦虑、不内卷。
📚 系列导航:
【技术底稿】01:37岁老码农,用4台机器搭了套个人DevOps平台
【产品底稿01】37 岁 Java 老码农,用 Java 搭了个 AI 写作助手,把自己 14 年技术文章全喂给了 AI!