NTIRE 2026 Challenge on Efficient Super-Resolution------冠军方案解读
一. 简介
NTIRE 的全称为New Trends in Image Restoration and Enhancement Challenges,即"图像复原和复原挑战中的新趋势",是CVPR(IEEE Conference on Computer Vision and Pattern Recognition)举办的极具影响力的计算机视觉底层任务比赛,主要涉及的研究方向有:图像超分辨率、图像去噪、去模糊、去摩尔纹、重建和去雾等。
其中在2026年,CVPR开展的NTIRE相关挑战有:
- 夜间图像去雾(NightTime Image Dehazing);
- 图像阴影去除(Image Shadow Removal);
- 3D内容超分辨率重建(3D Content Super-Resolution);
- 光场图像超分(Light Field Image Super-Resolution);
- 低光图像增强(Low Light Image Enhancement);
- 图像去噪(Image Denoising);
- 4倍图像超分辨率重建(Image Super-Resolution (x4));
- 遥感红外图像超分辨率重建(Remote Sensing Infrared Image Super-Resolution);
- 高效超分辨率重建(Efficient Super-Resolution);
- 3D内容复原和重建(3D Restoration and Reconstruction);
- 高效真实世界去模糊(Efficient Real-World Deblurring )。
同时,以上的这些挑战也蕴含着当前的一些研究难点及挑战,需要研究学者们集思广益,提出针对提升任务性能的想法,为共同解决近年来的难题贡献出一份力量。
本篇文章着重于NTIRE 2026 高效超分辨率(Efficient Super-Resolution) 挑战赛的冠军(来自小米)方案的解读,总结报告中能够提升任务的tricks,以期给相关的科研任务一些启发。
二、高效超分比赛情况
1. 参赛队伍成绩
共有 95 名参与者注册参加比赛,15 个团队成绩有效。
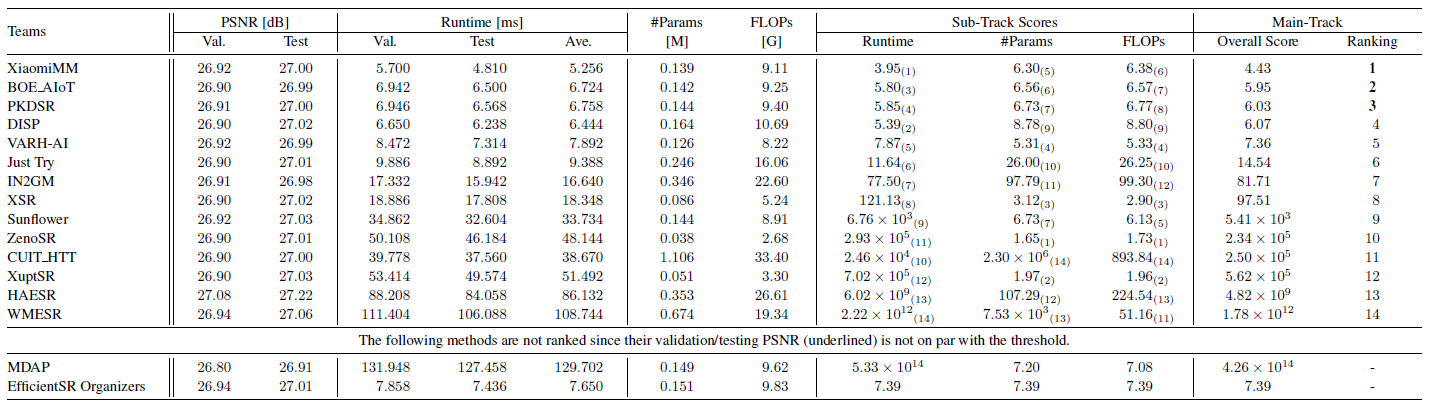
综合评定标准下,几个有特色的队伍成绩如下:
| 排名 | 队伍 | 综合得分依据 | 特点 |
|---|---|---|---|
| 1 | XiaomiMM | Runtime 第 1 + 参数量第 5 + FLOPs 第 6 | 综合冠军,Runtime 主导 |
| 2 | BOE AIoT | Runtime 第 3 + 参数量第 6 + FLOPs 第 7 | 综合第二 |
| 3 | PKDSR | Runtime 第 4 + 参数量第 7 + FLOPs 第 8 | 综合第三 |
亮点:今年的综合排名明显向 Runtime 倾斜,与去年更均衡的打法形成对比。XiaomiMM 并非参数量或 FLOPs 最优,但凭借极致的运行速度夺冠。此外,ZenoSR队伍的参数量排名第一,仅为 XiaomiMM 的约 1/3,但 runtime 明显更高,在今年赛道的评价标准中较为不利,说明"轻量 ≠ 快速"(划重点!)。
2. 主要ideas和架构
- 硬件级优化与算子融合------高效模型瓶颈在内存带宽,而非FLOPs。代表队伍:XiaomiMM。
- 网络剪枝 + 知识蒸馏------通过剪枝减少参数和运行时间,结合知识蒸馏微调模型,恢复性能。代表队伍:BOE AIoT、PKDSR。
- 单纯使用知识蒸馏------知识蒸馏作为独立训练策略。代表队伍:VARH-AI、CUIT HTT、DISP。
- 结构重参数化------训练时使用多个(卷积)分支,推理时合并为单个(卷积)分支。代表队伍:Just Try 、DISP。
- 状态空间模型(Mamba)------结合CNN局部建模与Mamba全局依赖捕捉。代表队伍:CUIT HTT 、WMESR。
- 训练策略广泛采用多阶段渐进训练 、基于FFT的频率损失 、EMA权重滑动平均等技术,用于进一步提升性能。
三、冠军方案整体思路
小米的方案基于 SPAN 和 SPANF 模型,提出了 SPANV2 ,是一个轻量级纯 CNN 模型 (0.139M 参数),专门针对高效超分任务设计。其核心目标是:在极小参数量和低计算开销下,尽可能提升重建质量。SPANV2 的网络结构如下:
- 近像素分支:深度卷积,输出 48 通道,初始化等价于最近邻上采样;
- 深度特征提取:5 个 SPABV2 块,通道数 32;
- 特征融合:拼接 48 通道 + 32 通道 → 80 通道 → 深度卷积 → 逐点卷积 → 48 通道;
- 重建:PixelShuffle(×4) 输出 3×4H×4W。
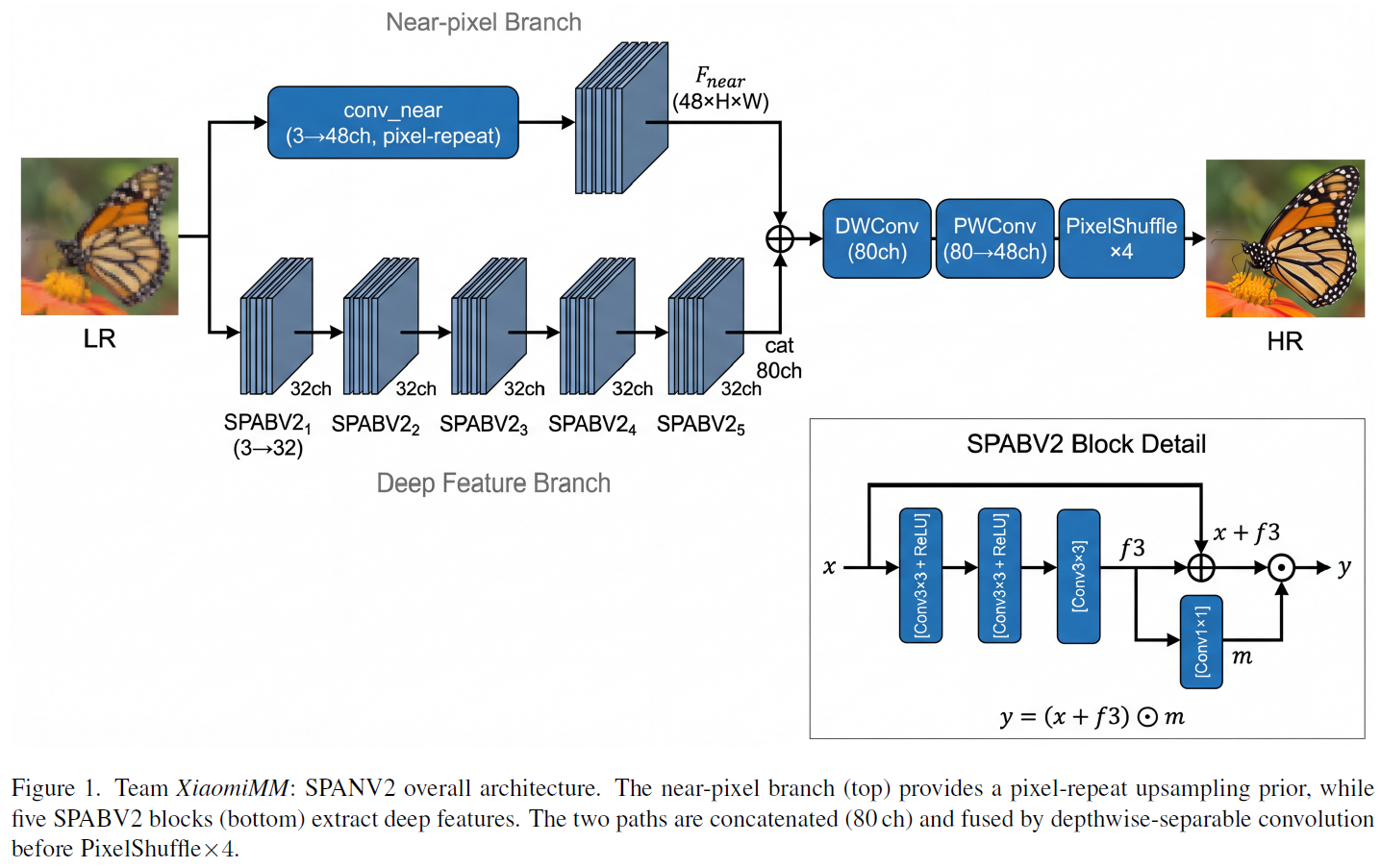
1. SPABV2 Block的结构设计
- 输入 x ∈ R C × H × W x∈\mathbb{R}^{C×H×W} x∈RC×H×W;
- 三层 3×3 卷积 + ReLU 提取特征 f3;
- 1×1 卷积生成注意力图 m;
- 输出 y=(x+f3)⊙m;
与 SPAN 的 SPAB 相比,唯一变化就是引入可学习的 1×1 注意力卷积。
2. 方案创新
2.1. Learned Attention(可学习注意力机制)
- 问题:SPAN 中的注意力是无参数的,只能做非负的逐元素乘积,缺乏通道混合能力。
- 改进 :引入一个 1×1 卷积 生成通道混合矩阵 m ,实现:
- 内容自适应的通道门控;
- 可正可负的注意力权重;
- 跨通道信息交互;
- 代价 :每层仅增加 C 2 C^2 C2 个参数,无需 softmax 或归一化。
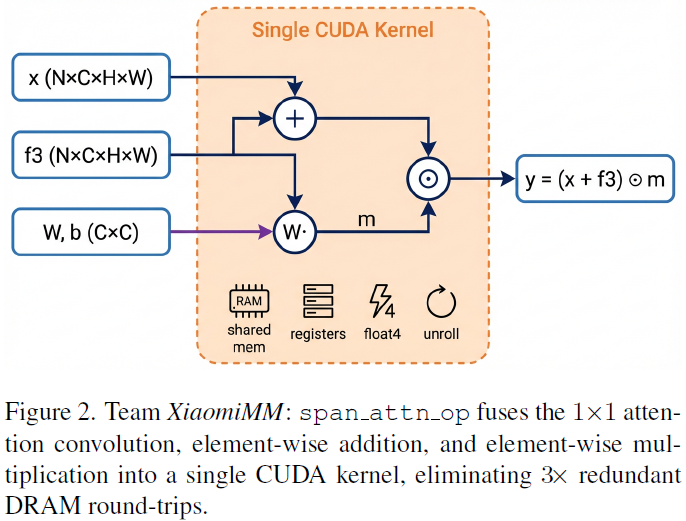
2.2. Fused CUDA Kernel(融合 CUDA 算子)
- 问题 :高效模型瓶颈不在 FLOPs,而在内存带宽。原始注意力三步操作(1×1 conv、加法、乘法)都要读写 DRAM,效率低。
- 改进 :将三步融合为 单个 CUDA 核函数,减少 3 倍的 DRAM 往返。
- 优化手段:共享内存、向量化加载、寄存器缓存、循环展开、通道专用核。
2.3. Near-Pixel Upsampling Branch(近像素上采样分支)
- 动机:自然图像中低频成分占主导,深度分支应专注于高频残差。
- 实现 :
- 初始化一个深度卷积分支,行为等价于最近邻上采样( inductive bias );
- 与深度特征分支融合,让主网络专注学习高频细节;
- 该分支的权重仍然可训练,可进一步适应数据;
3. 训练策略
Stage 1:多尺度预训练
- 训练集:FD2K(Flickr2K + DIV2K);
- batch size大小:8;
- patch size大小:256×256 → 512×512;
- 损失函数:1.0×L1(1.0)+0.05× FFT;
- 优化器:AdamW,lr= 10 − 3 10^{-3} 10−3;
- 调度器:余弦退火策略;
- 训练次数: 10 6 10^{6} 106迭代;
- 数据增强:随机水平翻转、随机90°旋转;
- EMA:权重指数滑动平均,decay=0.999;
Stage 2:模型微调
- 初始化:Stage 1 的 10 6 10^{6} 106迭代权重;
- 训练集:FD2K(Flickr2K + DIV2K);
- batch size大小:8;
- patch size大小:512×512;
- 损失函数:5.0×MSE + 3.0×梯度损失;
- 优化器:AdamW,lr= 5 × 10 − 4 5×10^{-4} 5×10−4;
- 调度器:余弦退火策略;
- 训练次数: 10 6 10^{6} 106迭代;
- EMA:权重指数滑动平均,decay=0.999;
四、总结与亮点
| 方面 | 特点 |
|---|---|
| 模型规模 | 0.139M 参数,极轻量 |
| 核心创新 | 可学习注意力 + CUDA 融合 + 近像素分支 |
| 计算效率 | 针对高效模型内存带宽瓶颈优化 |
| 训练策略 | 两阶段训练(多尺度预训练 + 精细微调) |
| 损失设计 | 第一阶段:L1 + FFT;第二阶段:MSE + 梯度损失 |
| 硬件适配 | 自定义CUDA 核 |
五、可借鉴之处
- 对高效模型推理瓶颈的深刻理解(与推理时间的相关性:内存带宽 > FLOPs);
- 近像素分支的设计思想(强 inductive bias + 可训练);
- 两阶段训练策略(多尺度预训练 → 精细微调);
- 损失函数组合(第一阶段:L1 + FFT;第二阶段:MSE + 梯度损失);
- 融合算子 对工程实现的要求高,但收益明显。
最后感谢小伙伴们的学习噢~