【大语言模型】OpenVLThinkerV2:面向多领域视觉任务的通用型多模态推理模型
目录
文章目录
- 【大语言模型】OpenVLThinkerV2:面向多领域视觉任务的通用型多模态推理模型
-
- 目录
- [📌 文章信息](#📌 文章信息)
- [📄 摘要信息](#📄 摘要信息)
- [1. 🔍 研究背景](#1. 🔍 研究背景)
- [2. ❗问题与挑战](#2. ❗问题与挑战)
- [3. ⚙️ 算法模型](#3. ⚙️ 算法模型)
-
- [3.1 核心算法:高斯GRPO (Gaussian GRPO, G²RPO)](#3.1 核心算法:高斯GRPO (Gaussian GRPO, G²RPO))
- [3.2 辅助机制:任务级长度与熵塑形](#3.2 辅助机制:任务级长度与熵塑形)
- [4. 💡 创新点](#4. 💡 创新点)
- [5. 📊 实验效果(重要数据与结论)](#5. 📊 实验效果(重要数据与结论))
- [6. 📈 推荐阅读指数](#6. 📈 推荐阅读指数)
- [7. 总结与展望](#7. 总结与展望)
- 后记
📌 文章信息
- 原始标题: OpenVLThinkerV2: A Generalist Multimodal Reasoning Model for Multi-domain Visual Tasks
- 中文翻译: OpenVLThinkerV2:面向多领域视觉任务的通用型多模态推理模型
| 项目 | 内容 |
|---|---|
| arXiv ID | 2604.08539v1 |
| 作者 | Wenbo Hu, Xin Chen, Yan Gao-Tian, Yihe Deng, Nanyun Peng 等 (6位作者) |
| 发布日期 | 2026-04-09 |
| 搜索日期 | 2026-04-12 |
| arXiv 链接 | https://arxiv.org/abs/2604.08539v1 |
📄 摘要信息
基于组的相对策略优化(GRPO)已成为驱动多模态大语言模型(MLLMs)近期进展的事实上的强化学习(RL)目标。然而,将这一成功扩展到开源的多模态通用模型仍然受到两个主要挑战的严重制约:不同视觉任务间奖励拓扑结构的极端差异性,以及在细粒度感知与多步推理能力之间取得平衡的内在困难。为了解决这些问题,我们提出了高斯GRPO(G²RPO),一种新颖的RL训练目标,它用非线性分布匹配取代了标准的线性缩放。通过数学上强制任何给定任务的优势分布严格收敛到标准正态分布𝒩(0,1),G²RPO理论上保证了任务间梯度公平性,减轻了对重尾异常值的脆弱性,并为正负奖励提供了对称更新。利用G²RPO提供的增强训练稳定性,我们引入了两种任务级别的塑形机制,以无缝平衡感知与推理。首先,响应长度塑形动态地为复杂查询引出扩展的推理链,同时强制简洁输出以增强视觉基础。其次,熵塑形紧密约束模型的探索区域,有效防止熵坍缩和熵爆炸。整合这些方法,我们推出了OpenVLThinkerV2,一个高度鲁棒、通用型的多模态模型。在18个不同的基准测试上的广泛评估表明,它相较于强大的开源和领先的专有前沿模型均表现出优越性能。
1. 🔍 研究背景
多模态大语言模型(MLLMs)的近期突破,很大程度上归功于强化学习(RL)在后训练阶段的应用。特别是,DeepSeek-R1提出的组相对策略优化(GRPO)因其无需评论家网络且能有效激发模型推理能力,已成为该领域的首选算法。然而,当前的研究和应用主要聚焦于单一或有限的任务类型。
现实世界的视觉问题涵盖了从需要精确感知的物体检测(视觉基础任务)到需要复杂逻辑推导的数学视觉问答(推理任务)的广阔频谱。构建一个能够精通所有这些任务的"通用型"MLLM是AI领域的下一个前沿目标。这要求在统一的RL框架下,同时优化这些特性迥异的任务。
不幸的是,不同视觉任务的奖励信号存在巨大差异。例如,数学VQA的奖励是稀疏的、二元的(对/错),而视觉基础任务的奖励则是密集的、连续的(如IoU分数)。这种奖励拓扑结构的极端差异,在联合训练时会导致严重的优化不平衡问题,使得标准的GRPO算法在扩展到多任务场景时,面临梯度爆炸、收敛不稳定甚至任务间性能此消彼长的困境。因此,如何设计一种能够天然适应多任务、多奖励分布的稳定RL训练算法,并在此过程中巧妙地平衡模型对精细视觉内容的感知能力和高层语义的推理能力,是当前MLLM研究中的核心挑战。
2. ❗问题与挑战
论文明确指出了在多任务MLLM后训练中应用GRPO所面临的两大核心挑战,并进行了深入剖析:
-
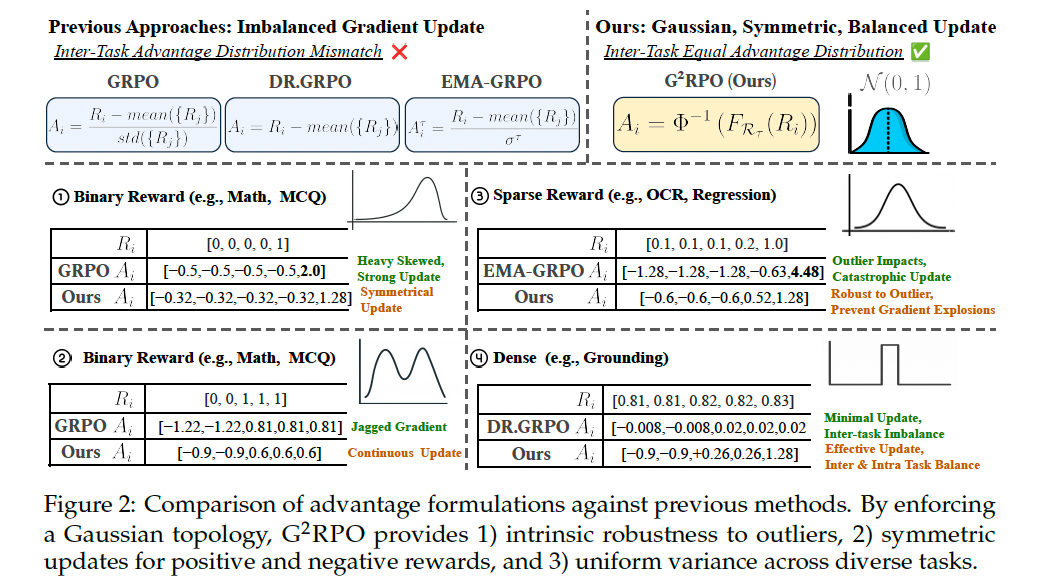
挑战一:多任务间的奖励拓扑极端差异导致优化不稳定与梯度不公。
- 问题本质 :不同视觉任务的奖励分布形态各异。数学VQA的二元奖励分布是双峰(或阶跃)的;而物体检测的IoU分数则可能是长尾或近似高斯的。标准的GRPO使用组内标准化(
(R_i - μ_G) / σ_G)来计算优势函数,这在单任务中有效,但在多任务联合训练时存在严重缺陷。 - 具体表现 :
- 任务内不平衡:组内标准化会使低方差的组(如模型对一组简单问题的回答)获得被放大的优势,而高方差的组则被压制。
- 任务间不平衡 :即使使用如EMA-GRPO这样的任务级方差跟踪,其核心仍是线性变换。线性变换只能匹配均值和方差,无法改变分布的高阶形状(如偏度、峰度)。因此,一个任务中出现的重尾异常值(比如一次偶然的极高IoU分数)会持续污染EMA估计的方差,导致该任务的梯度信号被长期压制。同时,对于二元奖励,线性缩放后的优势值仍然不对称,无法理想地区分好坏样本。
- 问题本质 :不同视觉任务的奖励分布形态各异。数学VQA的二元奖励分布是双峰(或阶跃)的;而物体检测的IoU分数则可能是长尾或近似高斯的。标准的GRPO使用组内标准化(
-
挑战二:在多任务RL训练中,难以同时保持精细的视觉感知能力和复杂的多步推理能力。
- 问题本质:在RL优化过程中,模型在不同任务上的行为演化轨迹是截然不同的。为推理任务(如数学题)优化的策略倾向于生成更长的、逐步推理的文本,但这可能导致在感知任务(如物体定位)上"过度思考",生成不必要的描述甚至产生幻觉。反之,为感知任务优化的模型倾向于生成简短、直接的答案,但这会削弱其处理复杂推理问题的能力。
- 具体表现 :
- 熵爆炸:在复杂的推理或分布外(OOD)任务上,模型可能会产生高熵的、近乎随机的token分布,导致输出不连贯、无意义的文本。
- 熵坍缩:在感知任务上,模型可能过早地过度依赖少数高概率token,陷入局部最优,缺乏必要的探索,从而无法适应数据中的细微变化。现有的解决方案(如引入辅助损失、添加外部模块)要么需要昂贵的数据标注,要么带来巨大的计算开销,难以在多样化、多领域的基准测试中规模化应用。
3. ⚙️ 算法模型
针对上述挑战,论文提出了一套整合的解决方案,核心是G²RPO 算法以及任务级别的长度与熵塑形机制。
3.1 核心算法:高斯GRPO (Gaussian GRPO, G²RPO)
G²RPO旨在彻底解决挑战一(奖励分布差异)。其核心思想是放弃线性的矩匹配,转而使用非线性分布匹配 ,具体通过一维最优传输(Optimal Transport, OT) 实现。
- 核心目标 :找到一个变换函数Ψ,将任意任务τ的原始奖励分布
P_Rτ,严格地映射到一个预设的、表现良好的目标分布------标准正态分布P_N = N(0,1)。这样,所有任务的最终优势函数都具有相同的N(0,1)分布,从根本上保证了"任务间梯度公平性"。 - 算法步骤(见论文Algorithm 1) :
- 排序与计算概率 :对于一个任务的一组奖励
{R_1, ..., R_N},首先按升序排序。为每个奖励计算其经验累积概率p_i = (rank(R_i) - 0.5) / N。-0.5是一个标准的连续性校正,确保p_i在(0,1)区间内。 - 分位数映射 :将上一步得到的概率
p_i,通过标准正态分布的分位数函数(逆CDF)Φ⁻¹,映射到目标正态分布的分位数上。Ψ(R_i) = Φ⁻¹(p_i) = √2 * erf⁻¹(2p_i - 1)。 - 平局处理(Tie-Breaking):为了确保相同的原始奖励获得相同的优势值(学习的稳定性),对于所有值相等的奖励,取它们映射后分位数的平均值作为它们共同的优势值。
- 排序与计算概率 :对于一个任务的一组奖励
- 优势分析 :
- 鲁棒性 :通过分位数映射,无论原始奖励中的异常值多大,它最多只会被映射到
N(0,1)的尾部(例如,p_i=0.999对应的分位数约为3.1),从而数学上限定了异常值的影响。 - 对称性 :它将二元奖励(如0和1)分别映射到正态分布的负尾和正尾(如
Φ⁻¹(0.25)和Φ⁻¹(0.75)),形成了对称的、平滑的奖励信号,而原始的线性标准化做不到这一点。 - 公平性 :由于每个任务的奖励都被强制转换为相同的
N(0,1)分布,它们在策略梯度更新中的贡献尺度是理论上一致的,解决了任务间梯度失衡问题。
- 鲁棒性 :通过分位数映射,无论原始奖励中的异常值多大,它最多只会被映射到
3.2 辅助机制:任务级长度与熵塑形
该机制旨在解决挑战二(感知与推理的平衡)。
-
长度塑形 :观察发现,推理任务倾向于生成更长的回答,而感知任务则倾向于更短的回答。为了引导模型在不同任务上表现出期望的行为,论文设计了一个梯形奖励函数
R_length(y)。- 该函数定义了四个阈值:
L_min(绝对最小长度),L_low(理想区间下界),L_high(理想区间上界),L_max(绝对最大长度)。 - 当生成长度在
[L_low, L_high]之间时,获得最高奖励1。长度过短或过长,奖励会线性衰减,直到在L_min或L_max处降为0。 - 效果:这个简单的奖励塑形信号有效地鼓励了模型在处理复杂查询时产生足够长的推理链,而在执行视觉基础任务时则避免"过度思考",直接给出精确答案,从而减少了幻觉。
- 该函数定义了四个阈值:
-
熵塑形 :观察发现,推理任务容易导致熵爆炸(输出混乱),而感知任务则容易导致熵坍缩(过早收敛)。为了将模型的探索-利用平衡控制在一个健康的区间内,论文设计了一个基于边际的熵正则化损失
L_ent_reg。- 定义两个阈值:
H_min(最小熵,防止坍缩) 和H_max(最大熵,防止爆炸)。 - 当任务的平均熵
H_task落在[H_min, H_max]区间内时,正则化损失为0。一旦超出该区间,损失线性增加:L_ent_reg = max(0, H_task - H_max) + max(0, H_min - H_task)。 - 效果:该损失作为一个软约束,将模型的探索行为限制在一个最优的"探索区"内,既不会因为过度探索而生成乱码,也不会因为过早利用而错过更好的策略。
- 定义两个阈值:
4. 💡 创新点
本论文的核心创新点可以归纳为以下三点:
-
提出G²RPO,一种新颖的、基于一维最优传输的强化学习优势函数估计方法 。这是最核心的理论创新。它从根本上改变了多任务RL中处理异构奖励的方式,通过强制所有任务的奖励分布匹配到标准正态分布,用非线性的分布匹配 替代了传统的线性矩匹配,从而数学上保证了任务间梯度公平性、对重尾异常值的鲁棒性和对正负奖励的对称处理。这比EMA-GRPO等线性方法更为彻底和有效。
-
引入任务级别的响应长度和熵塑形机制,作为平衡精细感知与复杂推理的简单且可扩展的方案。不同于以往需要额外模块或标注数据的复杂方法,本文通过设计两个轻量级的辅助损失函数(基于梯形规则的奖励塑形和基于边际的熵正则化),巧妙地引导模型在多任务学习中展现出任务特异性的最优行为。该方法无需修改模型架构,计算开销极小,易于推广。
-
成功整合上述技术,训练并开源了通用型多模态模型OpenVLThinkerV2。该模型在18个涵盖通用VQA、数学VQA、图表理解、文档理解、空间推理和视觉基础等领域的基准测试上取得了SOTA或极具竞争力的结果,显著超越了其基线模型(Qwen3-VL-Instruct-8B)以及其他同等规模的开源模型,并且在多个任务上击败了GPT-4o、GPT-5和Gemini 2.5 Pro等领先的专有模型。这强有力地验证了其方法论的有效性和模型的通用性。
5. 📊 实验效果(重要数据与结论)
-
实验设置:
- 基座模型:Qwen3-VL-Instruct-8B。
- 训练数据:OneThinker-600k数据集的过滤子集。
- 训练硬件:AWS Trainium (Trn1.32xlarge)。
- 优化器:AdamW,学习率2e-6,批量大小128,训练一个epoch(约3天)。
- 基准测试:共18个,分为六大类:通用VQA(MMMU, MMBench, MMStar)、数学VQA(MathVista, MathVerse, MathVision)、图表理解(AI2D, ChartQA, ChartXiv)、文档理解(DocVQA, InfographicVQA)、视觉基础(RefCOCO/+/g)、空间推理(Spatial-Bench, EmbSpatial-Bench, RoboSpatial)。
-
主要实验结果与结论:
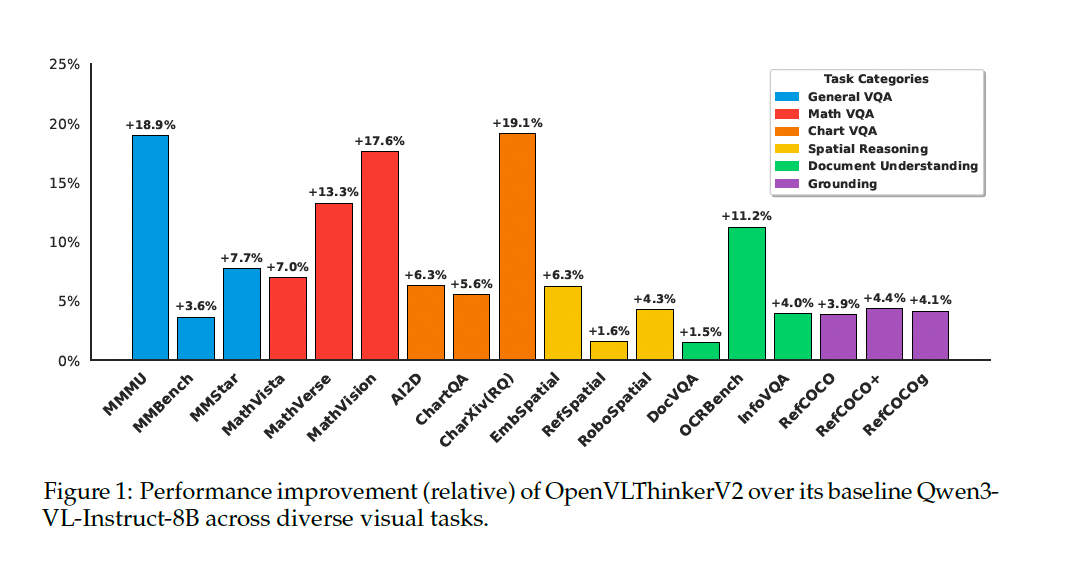
- 总体性能卓越 :OpenVLThinkerV2在所有任务类别上均全面超越其基线模型Qwen3-VL-Instruct-8B和强大的开源基线OneThinker-8B。例如,在MMMU上达到71.6% ,在MathVista上达到79.5% ,在MMBench上达到88.2%,显著优于GPT-4o等模型。
- G²RPO优于GRPO/GDPO:在完全相同的实验设置下,使用G²RPO训练的模型(OpenVLThinkerV2)在几乎所有基准测试上的表现都优于使用标准GRPO和GDPO的版本。特别是在MathVista (79.5% vs 78.1% vs 78.0%) 和 ChartQA (87.4% vs 82.4% vs 82.4%) 等任务上,优势尤为明显,证明了G²RPO在稳定和优化多任务学习方面的有效性。
- 消融研究证实各组件有效性 :
- 仅使用G²RPO就能带来显著的性能提升,证明了其作为核心优化器的强大能力。
- 在G²RPO基础上加入长度塑形(Length),在需要清晰感知的文档理解(+0.8%)和视觉基础(+0.9%)任务上取得明显进步,同时在推理任务上也有提升,表明其成功引导模型生成了更符合任务需求的响应长度。
- 在G²RPO基础上加入熵塑形(Entropy),在容易发生熵坍缩的视觉基础和熵爆炸的复杂推理(如空间推理)任务上都带来了提升,证明了其稳定了模型的探索-利用平衡。
- G²RPO + Length + Entropy的组合获得了最佳的整体效果,证明这三个组件是协同工作的,共同实现了感知与推理的最佳平衡。
- 训练稳定性分析 (附录A):
- 准确率奖励:G²RPO在训练早期(约第1步)就快速收敛,而GRPO和GDPO在整个训练过程中持续震荡,G²RPO的平均准确率奖励最高且最稳定。
- 格式/结构奖励:尽管GDPO在理论上对格式有优势,但其格式/结构奖励在训练后期会下降,而G²RPO则能保持并最终达到最高值。这反直觉地证明了,一个全局稳定的优化过程(G²RPO提供)比一个针对特定奖励设计的算法(GDPO)更有利于模型学习复杂的输出格式。
6. 📈 推荐阅读指数
推荐指数
⭐⭐⭐⭐ (4.5/5)
推荐理由
这是一篇在多模态大模型强化学习领域具有重要理论突破和实用价值的高质量论文。强烈推荐给所有从事多模态AI、大语言模型后训练、强化学习研究的算法工程师和研究人员。
- 问题定义清晰且重要:精准地指出了当前多模态RL从"单任务"走向"通用模型"的核心瓶颈------奖励异构性和感知-推理平衡问题。
- 解决方案优雅且有效:G²RPO巧妙地运用一维最优传输理论,从数学根本上解决了问题,而非简单的启发式修补。其思想可以推广到任何需要处理异构奖励分布的RL场景。
- 实验设计严谨且充分:在18个广泛认可的基准测试上进行评估,并与多种最先进的基线和变体进行对比,消融研究设计科学,结论令人信服。训练细节和超参数清晰,可复现性强。
- 实用价值高:提出的长度和熵塑形机制简单、轻量、易于实现,不依赖额外标注数据。开源的OpenVLThinkerV2模型本身就是一个强大的通用多模态工具,直接可用。
- 启发性强:论文不仅解决了当前问题,其将OT用于RL优势标准化的思想,以及将任务特性(如长度、熵)作为可塑形变量的视角,为后续研究开辟了新的道路。
7. 总结与展望
总结 :
本论文针对多模态大语言模型在通用化进程中面临的两大核心挑战------多任务奖励异构性导致的训练不稳定,以及精细感知与复杂推理能力难以兼得------提出了一套系统性的解决方案。作者创新性地提出了G²RPO 算法,通过一维最优传输将任意任务的奖励分布非线性地映射为标准正态分布,从理论上保证了任务间梯度公平性,并赋予算法对异常值的天然鲁棒性。同时,设计了任务级别的响应长度塑形 和熵塑形 机制,以极低的计算成本巧妙地引导模型在不同任务上展现出最优的行为模式。基于这些技术训练的OpenVLThinkerV2模型,在18个涵盖广泛的基准测试上取得了卓越的性能,大幅超越现有开源模型,并在多项任务上超越了顶级的闭源模型。该工作为构建稳定、公平、可扩展的通用多模态智能体提供了一个坚实的技术基石。
展望 :
尽管本文成果显著,但仍有诸多有价值的研究方向可以探索:
- 超参数的自动化与自适应 :长度和熵塑形的阈值(
L_min,L_max,H_min,H_max)目前依赖经验设定。未来可以研究如何根据任务的特性和模型的学习状态,动态地、自适应地调整这些阈值,例如使用元学习或在线优化技术。 - 扩展到更多模态和任务:G²RPO的核心理念与任务的具体形式无关。它可以被自然地推广到其他同样面临奖励异构性的领域,如论文中提到的SWE工程(代码生成任务的奖励稀疏且二元,而测试通过率是连续的)和GUI自动化(任务目标多样)。验证G²RPO在这些领域的有效性是一个很有前景的方向。
- 探索更复杂的目标分布 :本文选择
N(0,1)作为目标分布,是因为其具有良好的数学性质。然而,对于某些特定的优化目标,其他分布(如拉普拉斯分布以获得更稀疏的优势,或带有偏斜的分布以鼓励探索)可能更为合适。研究如何根据具体需求选择或学习最优的目标分布是一个有趣的理论问题。 - 与过程奖励模型(PRM)的结合:本文使用的是结果奖励。G²RPO的分布匹配思想同样可以应用于过程奖励,即对推理链条中的每一步进行优势估计。将G²RPO与PRM结合,有望在复杂的数学、逻辑推理任务中实现更细粒度、更稳定的优化。
后记
- 如果您对我的博客内容感兴趣,欢迎三连击(点赞, 关注和评论) !!!
- 本博客将持续为您带来计算机人工智能前沿技术研究进展分享,助您更快了解 AI前沿技术。