前言
前面系列地学习过 AI中的一种开发框架 LangChain,我们知道 LangChain 是链式结构。那么,如果现在有这样的case:
- 编写代码 -> 输出代码 -> 运行测试 -> 测试失败 ?
- 这个时候由于链式运行的限制,就只能手动重启
所以就有了升级版的 LangGraph。
定义
LangGraph 是 LangChain 的高级库,其本身是一个基于"状态图(State Graph)"的AI工作流编排框架。它超越了LangChain的线性工作流,通过循环支持复杂的任务处理。
-
抽象建模 :将 AI 应用转化为有向图
-
状态驱动 :流程执行以
State为核心,节点修改State后,边根据新状态决定下一步走向(支持循环、回溯、多Agent协作); -
韧性设计 :内置
Checkpoint机制,可保存/恢复State,应对错误、人工介入或长周期任务。
和 LangChain 相比

| 维度 | LangChain | LangGraph |
|---|---|---|
| 核心抽象 | 链(线性、确定性执行流水线,用LCEL串联组件) | 状态图(有向图,节点=执行单元,边=流转条件,全局State对象) |
| 设计哲学 | 开发效率优先,组件标准化(快餐店外带窗口,快速拼出可用应用) | 流程精细控制优先,系统稳定性(高档自助餐厅,动态决定下一步) |
| 擅长应用场景 | 线性/固定流程:简单RAG、数据提取、固定问答、开箱即用工具链 | 复杂/动态流程:多轮Agent、带审核工作流、循环迭代(如自我修正)、多Agent协作、Agentic RAG |
| 执行模式 | 线性执行(单向管道,无循环/分支) | 状态驱动执行(支持循环、分支、回溯、多节点并行) |
| 关键特性 | LCEL表达式、丰富组件库(检索/LLM/工具)、快速搭建 | 状态持久化(检查点)、动态路由、错误恢复、人工介入支持、多Agent原生协作 |
| 与对方的关系(联系) | 能力层提供者:输出标准化组件(检索/LLM/工具),供LangGraph编排 | 流程层控制器:集成LangChain组件,管理复杂流程逻辑,实现关注点分离 |
核心组件
LangGraph 的核心是将代理工作流程抽象建模为图。通过使用三个核心组件来定义代理的行为。
States
共享数据结构 ,用于表示当前 AI 应用程序的当前状态,它可以是任何Python类型,但通常是 TypedDict 或 Pydantic BaseModel。存储工作流执行过程中的所有上下文(如用户输入、中间结果、历史记录)。节点读取并更新它,框架负责合并增量更新。
-
Scheme :State的结构契约 (用
TypedDict/Pydantic定义),规定字段名、类型(如count: int、messages: list[BaseMessage]),确保类型安全。 -
Reducers :状态更新仲裁函数 ,当多节点修改同一字段时,定义合并逻辑(如累加、追加、覆盖),默认是覆盖,需显式指定(如
Annotated[list, add]用add做追加)。 -
Message :State中常见的交互轨迹字段 (通常用
list[BaseMessage]),存储聊天历史或事件日志,保留上下文。
Nodes
执行具体任务的计算单元,本质是一个接收State并返回State更新字典的函数。它可以是调用LLM、执行工具、运行任意代码的逻辑封装
Edges
定义控制流走向的连接规则。分为固定边(无条件跳转)和条件边(根据State动态路由),是实现循环、分支等复杂逻辑的关键.
Coding
helloWorld
State
使用 Scheme 定义 State:
Python
# 1. 定义State的Scheme(结构契约)
class ChatState(TypedDict):
count: int # 计数器字段
messages: Annotated[list, add] # Message列表,用add做追加reducerNodes
定义节点:
Python
# 2. 定义节点:修改State的函数
def increment_count(state: ChatState) -> ChatState:
return {"count": state["count"] + 1} # 直接返回新值(默认覆盖)
def add_human_msg(state: ChatState) -> ChatState:
msg = HumanMessage(content="你好,LangGraph!")
return {"messages": [msg]} # 因reducer是add,实际追加到原列表Graph 构建
add_node:节点添加函数add_edge:边连接函数START:节点开始END:节点结束
Python
builder = StateGraph(ChatState)
builder.add_node("inc", increment_count)
builder.add_node("add_msg", add_human_msg)
builder.add_edge(START, "inc")
builder.add_edge("inc", "add_msg")
builder.add_edge("add_msg", END)Graph 编译 & 测试
在使用之前必须编译。编译会对图形的结构进行一些基本检查(比如没有孤立节点等)。这里还可以指定运行时参数,如检查点和断点。
compile:编译函数
Python
graph = builder.compile()
result = graph.invoke({"count": 0, "messages": []})
print(result) # 输出: {'count': 1, 'messages': [HumanMessage(content='你好,LangGraph!')]}Running
总结
如上,一次 LangGraph 的整体执行流程大概如下:
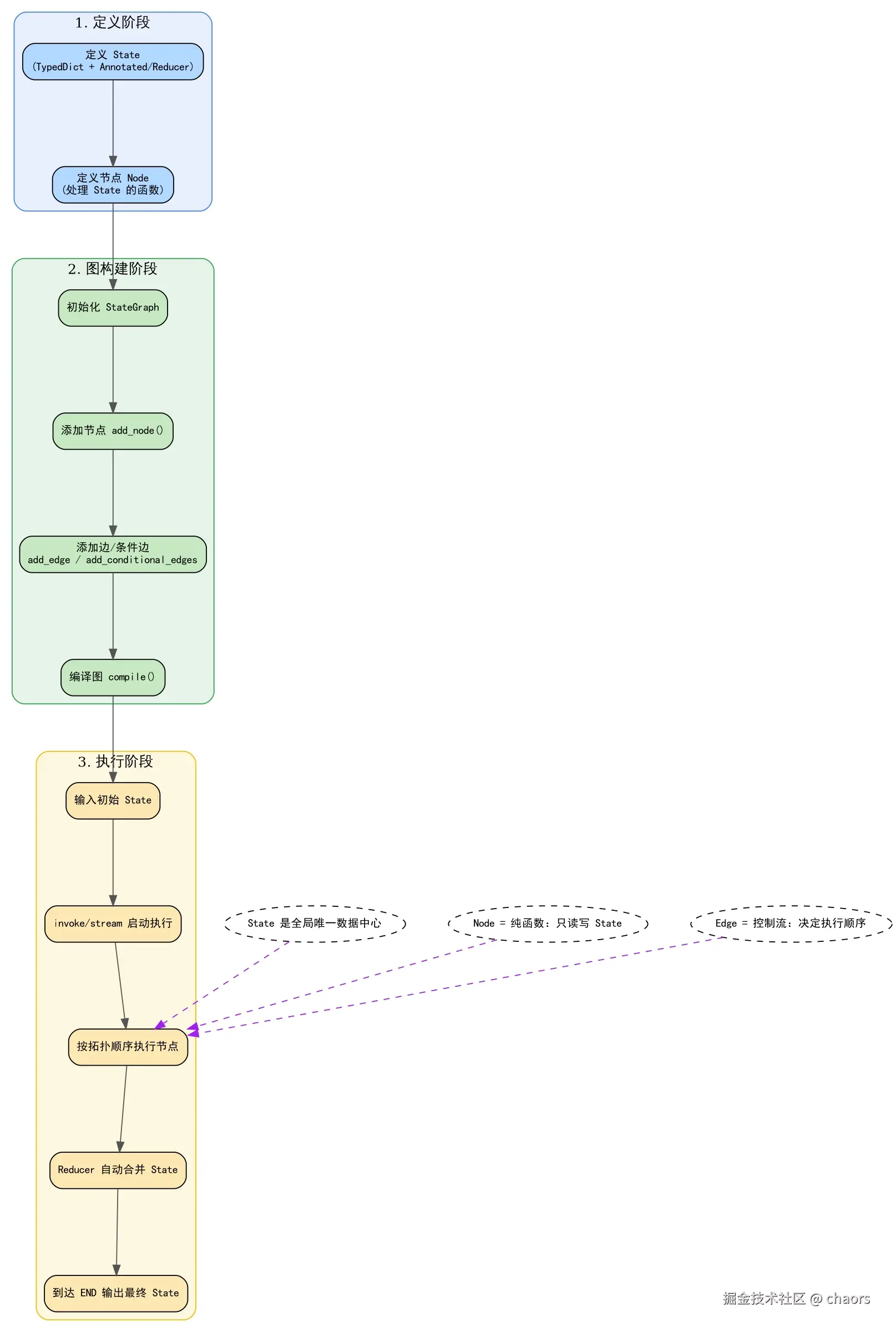
Multiple Schemas
Multiple Schemas:多模式,是定义了不同的 State。核心是 "主State Schema(内部全量状态)"与"Input/Output Schema(外部接口)"的分离设计。
-
主State Schema :图运行时的全量状态容器 ,包含内部传递字段(如
internal_mid)、输入字段(如input_num)、输出字段(如final_result); -
Input Schema :定义图启动时的输入结构(必须是主State的子集),限制外部传入的参数;
-
Output Schema :定义图结束时的输出结构(必须是主State的子集),只暴露需要的结果;
Multiple Schemas 可实现以下目标:
- 内部节点间传递不暴露给图输入/输出 的特定信息(如两节点间的临时数据)
- "特定节点(a、b)间传递私有字段(如
ab_private)传递,其他节点(c)无法访问"
- "特定节点(a、b)间传递私有字段(如
- 图的输入/输出使用简化模式(如输出仅含单个关键结果)。
内部传输示例
State 定义:
input_num: 输入字段(来自Input Schema)internal_mid: 内部传递字段(不会暴露给IO)final_result: 输出字段(来自Output Schema)
Python
# 1. 定义主State Schema(全量状态:含内部/输入/输出字段)
class MainState(TypedDict):
input_num: int # 输入字段(来自Input Schema)
internal_mid: int # 内部传递字段(场景1用,不暴露给IO)
final_result: int # 输出字段(来自Output Schema)
# 2. 定义Input Schema(图输入:仅含input_num)
class InputSchema(TypedDict):
input_num: int
# 3. 定义Output Schema(图输出:仅含final_result)
class OutputSchema(TypedDict):
final_result: int节点定义:
Python
# 4. 定义节点:内部传递特定信息(场景1)
def node_a(state: MainState) -> MainState:
# 计算中间值,存到internal_mid(仅两节点间用)
return {"internal_mid": state["input_num"] * 2}
# 5. 定义节点:用内部信息计算最终结果(场景2)
def node_b(state: MainState) -> MainState:
# 用internal_mid算最终结果,存到final_result
return {"final_result": state["internal_mid"] + 10}图构建,注意这里使用了带参的 StateGraph 函数,传入主、输入、输出的 State。
Python
builder = StateGraph(
state_schema=MainState,
input_schema=InputSchema,
output_schema=OutputSchema
)点对点私有示例
ab_private:点对点私有变量
Python
# 1. 定义主State Schema(全量状态:含私有字段ab_private)
class MainState(TypedDict):
input_num: int # 输入字段(来自Input Schema)
ab_private: int # 仅a、b传递的私有字段(不在IO Schema)
final_result: int # 输出字段(来自Output Schema)
c_val: int # c节点处理的公开字段- 避坑指南 :
-
私有字段加前缀 (如
_ab_),明确标识"仅特定节点用"; -
节点函数参数类型严格匹配 (如c节点用
MainState但只取input_num),防止IDE/编译器警告; -
用
graph.get_state()调试时,过滤私有字段(只看IO相关),避免干扰。
-
这里,我也总结了下私有字段的前缀命名规范(仅一家之言,欢迎提出不同建议),大家可以参考一下。
Python
class MainState(TypedDict):
# 输入字段(公开)
input_num: int
# ab组私有字段(仅a、b用):前缀_ab_+功能后缀
_ab_mid_val: int # ab组中间值
_ab_log: str # ab组日志
# abc组私有字段(仅a、b、c用):前缀_abc_+功能后缀
_abc_cache_key: str # abc组缓存键
_abc_tmp_res: float # abc组临时结果
# tmp组私有字段(仅d、e用):前缀_tmp_+会话后缀
_tmp_session456_id: int # tmp组会话ID
# 输出字段(公开)
final_result: int