1,Robot Lab机器人架构介绍
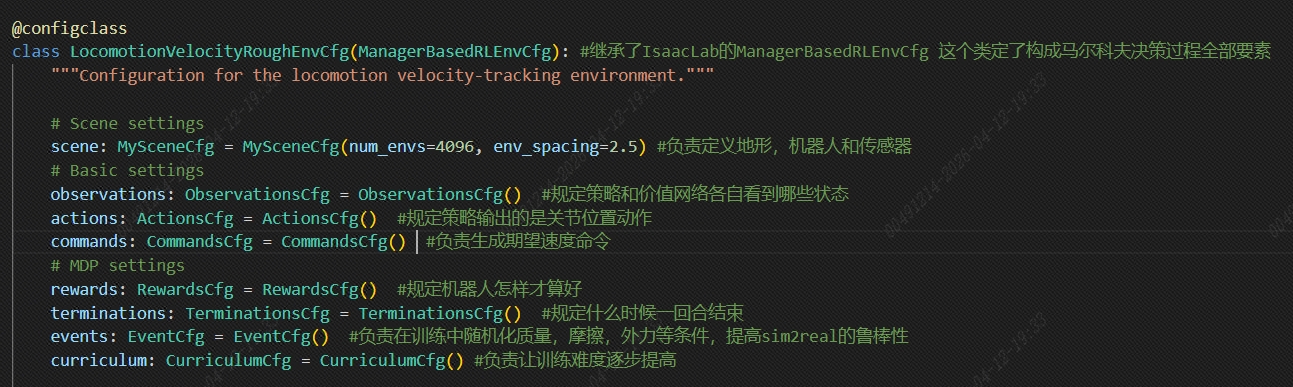
#从本质上说,这个主类的作用把locomotion强化学习任务所有关键元素全部组织成一个标准化,可复用的,可继承的环境模板,为后续不同机器人只要在这个模板上替换自己信息配置,奖励函数权重,少量参数就可以快速构建训练环境
1)MySceneCfg:
主要定义了,机器人,地形,传感器,灯光(主要影响视觉)
其中传感器contact_forces 挂在所有机器人的刚体上,保留了3步历史帧,跟踪腾空时间,足式机器人很多都是和contact_forces有关,脚是不是着地了,腾空时间是不是合理,有没有拌脚,有没有滑步,有没有非法接触
2)ObsevationsCfg:
分成俩组,分别是PolicyCfg,CriticCfg,相当于Actor-Critic网络策略
PolicyCfg:
线速度,角速度,投影重力方向,速度命令,投影关节位置,关节速度等,这些关键观测用来闭环控制,而且观测很多都加了 noise = Unoise的噪声 enable_corruption
CriticCfg:
把噪声去除掉,disable_corruption
3)ActionsCfg:
覆盖所有actions,只控制关节位置动作mdp.JointPositionActionCfg
对于足式机器人直接学Torque很难,学习到某一位置,比较平滑,use_default_offset默认站姿态比较合理
4)CommandCfg:
强化主要目的接近线速度,横向速度,角速度,朝向等,会有范围约束的命令
5)MDP
5.1)Rewards奖励
奖励函数比较重要,后面单独说
disable_zero_weight_rewards
5.2)TermianationsCfg:
时间timeout,terrain_out of bounds,illegal_contact重置交互,节省算力
5.3)EventCfg:
随机化目的是让刚体材质,质量,外力等外界环境具有随机化干扰,不是线性稳定理想输入,让策略更加鲁棒
5.4)CriculumCfg:
用逐步提高复杂地形,command等使得模型逐渐收敛,更强泛化性,
这四个5.1~5.4决定机器人学什么,在哪学,如何学,以及变难怎么逐步学习
子类配置实例,
rough_env_cfg:几个关键Notes
比如惩罚 人型机器人不允许摔倒,所以需要惩罚比四足大,
Scale,人型角速度较大,需要归一化和其他观测相近的范围:base_ang_vel.scale = 0.25
Curriculums课程学习关掉,是一种实践经验,人型机器人训练初期连站立都比较难,更别说速度指令的响应,若是启用了速度课程学习,地形课程学习,机器人由于是初期没学到任何东西,最后全部集中在简单平地上,没办法学习到多态化的地形学习

所以经验是现在平地学到稳定的模型,然后再考虑到迁移到复杂地形
flat_env_cfg :在平地减少z轴角速度跟踪变成1,在平地上对于角速度跟踪更加容易实现,权重过高,会忽略线速度跟踪,新机器人若是在rough平面训练遇到了困难,需要现在平地进行训练排查问题,若连平地训练都不行的话,说明在基础配置上。
rsl_rl_ppo_cfg:在定义完事件和任务后,需要让机器人学习如何完成这个任务,在强化学习过程中,Agent是负责学习决策,rsl_rl是决定性框架(苏黎世理工联邦实验室开发高性能学习库)与IsaacLab兼容性,被广泛适用,网络架构和PPO超参数
#基础训练参数:
num_steps_per_env = 24 # 每个环境每轮收集24步数据
max_iterations = 20000 # 总训练迭代次数(主训练,2万次)
save_interval = 200 # 每200次迭代保存一次模型
experiment_name = "unitree_g1_rough" # 实验名称(日志/模型保存文件夹)
#策略网络配置poilcy (Actor-Critic)网络结构
policy = RslRlPpoActorCriticCfg( init_noise_std=1.0, # 初始探索噪声标准差 actor_obs_normalization=False, # 演员网络不做观测归一化 critic_obs_normalization=False, # 评论家网络不做观测归一化
actor_hidden_dims=512, 256, 128, # 演员网络隐藏层:3层大网络 ,
critic_hidden_dims=512, 256, 128, # 评论家网络隐藏层:和演员一致
activation="elu", # 激活函数:ELU(比ReLU更稳定) )
#PPO算法核心参数 algorithm
algorithm = RslRlPpoAlgorithmCfg( value_loss_coef=1.0, # 价值损失权重 use_clipped_value_loss=True, # 开启裁剪版价值损失
clip_param=0.2, # PPO 裁剪系数(核心)
entropy_coef=0.008, # 熵系数:鼓励探索(0.008 适中)
num_learning_epochs=5, # 每批数据训练5个epoch
num_mini_batches=4, # 数据分为4个小批次
learning_rate=1.0e-3, # 学习率:1e-3
schedule="adaptive", # 自适应学习率调度
gamma=0.99, # 折扣因子:未来奖励权重
lam=0.95, # GAE 优势函数参数
desired_kl=0.01, # 目标KL散度:控制更新步长
max_grad_norm=1.0, # 梯度裁剪,防止梯度爆炸 )
#平摊地面配置:
@configclass
class UnitreeG1FlatPPORunnerCfg(UnitreeG1RoughPPORunnerCfg):
def post_init(self):
super().post_init() # 继承父类所有参数
仅覆写2个关键参数
self.max_iterations = 1500 # 大幅减少训练次数(快速验证) self.experiment_name = "unitree_g1_flat" # 重命名实验
entropy_coef=0.008, # 熵系数:鼓励探索(0.008 适中) 人型是0.008但是四足是0.01,因为四足本身具有天然的稳定性,需要更大的探索
2,强化学习配置及机器人添加
2.1)创建资产配置
asserts文件夹里 建立以机器人命名.py
spawn是指定了机器人加载方式,urdf和usd
fix_base=fasle 足式机器人基座可以移动
。。。
init_stata
actuators
2.2)创建RL_Agent配置
从类似机器人可参考的代码拷贝过来后面做微调,网络结构一般就是3层MPL结构(512,256,128)
2.3)创建粗糙地形环境配置
任务具体定义,小跑步态,
self.rewards.feet_gait.params"synced_feet_pair_names" = (
("FL_FOOT_LINK", "RR_FOOT_LINK"),
("FR_FOOT_LINK", "RL_FOOT_LINK"),
)
action scale:关节位置动作空间配置:缩放 + 裁剪 + 指定关节
ABAD 关节(髋关节)动作更精细,缩小到原动作的 1/8;其他关节动作放大到原动作的 1/4。
reduce action scale
self.actions.joint_pos.scale = {".*_ABAD_JOINT": 0.125, "^(?!.*_ABAD_JOINT).*": 0.25}
正则匹配规则:
.*_ABAD_JOINT:匹配所有以_ABAD_JOINT结尾的关节 → 缩放系数0.125(动作幅度最小)^(?!.*_ABAD_JOINT).*:反向匹配 → 匹配所有不含_ABAD_JOINT的其他关节 → 缩放系数0.25(动作幅度稍大)self.actions.joint_pos.clip = {".*": (-100.0, 100.0)}
范围
(-100.0, 100.0):缩放后的动作值会被强制限制在这个区间内(防止动作值过大导致机器人异常)self.actions.joint_pos.joint_names = self.joint_names
2.4)创建平地地形环境配置
粗糙地形简单配置,
2.5)注册gym环境
在_init_.py中注册 gym.register
验证 ~/IsaacLab/isaaclab,sh -p scripts/tools/list.envs.py --keyword Agibot
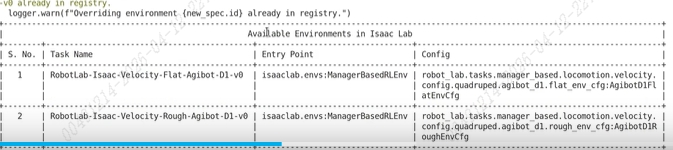
rough 默认训练20000轮
3,训练与参数解析

3.1)核心训练进度参数:
| 参数 | 数值 | 意义 |
|---|---|---|
Learning iteration 27/20000 |
27/20000 | 当前训练迭代数 / 总迭代数。强化学习中每一次迭代包含多组环境交互与模型更新,代表机器人已完成 27 轮学习,仍需完成 19973 轮。 |
Total steps: 392512 |
392512 | 累计环境交互步数。每一步代表机器人与环境完成一次状态感知 - 动作执行 - 奖励反馈的循环,数值越大表示训练时长 / 交互量越足。 |
Steps per second: 30592 |
30592 | 每秒处理步数。训练性能核心指标,反映硬件(如 Orin NX/RK3588)+ 算法的运算效率,数值越高训练速度越快。 |
Collection time: 3.0515 |
3.0515 | 经验收集耗时(单位:秒)。本轮迭代中收集训练数据(机器人与环境交互)所用时间,数值越小收集效率越高。 |
Learning time: 0.1625 |
0.1625 | 模型更新耗时(单位:秒)。本轮迭代中神经网络(如 PPO 算法)梯度计算、参数更新的耗时,体现算法计算效率。 |
3.2)模型损失和奖励
| 参数 | 数值 | 意义 |
|---|---|---|
Mean surrogate loss: 16.7806 |
16.7806 | PPO 算法核心损失。代理损失衡量策略网络(Actor)新旧动作分布的差异,是强化学习中最关键的损失项,用于限制策略更新幅度避免训练崩溃。 |
Mean entropy loss: 13.35 |
13.35 | 熵损失。熵代表策略的 "探索性",熵越高表示机器人动作选择越随机(探索能力强),越低则越趋向固定动作( exploitation exploitation)。 |
| 参数 | 数值 | 意义 |
|---|---|---|
Mean reward: -13.35 |
-13.35 | 本轮迭代平均累计奖励。强化学习目标是最大化奖励,当前为负数,说明机器人当前策略表现不佳(未达成任务目标,如未站稳、动作异常)。 |
Mean action std: 0.99 |
0.99 | 动作输出标准差。反映策略网络输出动作的不确定性,接近 1.0 表示动作分布较广,探索性适中;过低会陷入局部最优,过高则训练不稳定。 |
3.3)细分维度奖励
| 参数 | 数值 | 子任务意义 |
|---|---|---|
Episode Reward/lin vel z |
-0.0054 | 线速度 z 轴奖励。衡量机器人垂直方向运动控制(如保持高度、避免跌落),负数说明垂直方向控制偏差大。 |
Episode Reward/ang vel x/y |
-0.0181/-0.0181 | 角速度 x/y 轴奖励。衡量机器人横滚 / 俯仰姿态控制,负数表示姿态不稳定(如侧翻、前倾后仰)。 |
Episode Reward/joint torque |
-0.0181 | 关节扭矩奖励。惩罚扭矩过大,负数说明电机负载过高(可能是机械卡顿 / 控制参数不当)。 |
Episode Reward/joint acc |
-0.0084 | 关节加速度奖励。惩罚关节运动过快,负数表示关节动作急促易磨损 / 失稳。 |
Episode Reward/stand still |
-0.0884 | 静止姿态奖励。核心任务之一,衡量机器人保持静止的能力,负数说明静止控制失败(如轻微晃动 / 位移)。 |
Episode Reward/pop stability |
-0.0010 | 种群稳定性奖励(多智能体场景)。单智能体下可忽略,负数表示群体协作稳定性差(若为单智能体则是算法适配问题)。 |
Episode Reward/action rate |
-0.2942 | 动作频率奖励。惩罚动作过于频繁 / 缓慢,负数说明当前动作频率偏离任务最优区间。 |
Episode Reward/undesired contacts |
-0.3715 | 非期望接触奖励。惩罚非目标部位接触(如机器人腹部 / 背部触地),负数说明存在碰撞、摔倒风险。 |
Episode Reward/traj lin vel |
-0.0852 | 轨迹线速度奖励。衡量机器人沿目标轨迹运动的能力,负数说明轨迹跟踪偏差大。 |
Episode Reward/traj ang vel |
-0.0437 | 轨迹角速度奖励。衡量轨迹转向 / 姿态跟随能力,负数说明转向 / 姿态调整不准确。 |
Episode Reward/feet air time |
-0.0018 | 足部腾空时间奖励(四足机器人)。四足行走中控制足部腾空时长,负数说明步态节奏错误(如踮脚 / 拖地)。 |
Episode Reward/feet height |
-0.0399 | 足部高度奖励。控制足部离地高度,负数说明足部擦地 / 抬过高导致能耗增加。 |
Episode Reward/feet slide |
-0.0265 | 足部滑动奖励。四足行走中禁止足部水平滑动,负数说明行走时足部打滑(地面摩擦力不足)。 |
Episode Reward/body height |
-0.0000 | 机身高度奖励。保持机身稳定高度,0 分说明当前高度控制精准,无偏差。 |
3.4)环境与训练指标
基础环境指标
| 参数 | 数值 | 意义 |
|---|---|---|
Metrics/base_velocity/error |
0.9968 | 基底速度误差。实际速度与目标速度的偏差,接近 1.0 说明速度控制精准(误差小)。 |
Metrics/base_velocity/ang vel |
0.9986 | 基底角速度误差。实际角速度与目标角速度的偏差,接近 1.0 说明姿态转向控制精准。 |
Metrics/base_orientation/error |
0.0000 | 基底姿态误差。机身俯仰 / 横滚 / 偏航角的偏差,0 分说明姿态完全贴合目标,无偏差。 |
训练终止指标
| 参数 | 数值 | 意义 |
|---|---|---|
Episode Termination/terr_out of bounds |
0.0000 | 越界终止率。机器人超出训练环境边界(如空间限制)的次数占比,0 分说明全程未越界,环境边界适配良好。 |
3.5)训练效率参数
| 参数 | 数值 | 意义 |
|---|---|---|
Iteration time: 3.215 |
3.215 | 单轮迭代总耗时(Collection time + Learning time)。3 秒左右 / 轮属于高效训练,反映硬件算力与算法优化水平。 |
Time elapsed: 00:01:27 |
00:01:27 | 累计训练时长。从开始训练到当前迭代的总耗时,1 分 27 秒说明训练启动不久,处于初期阶段。 |