Day 3-小土堆日
消失了一段时间,被老师拉去搞论文了,并且重新制定了以下学习计划。
算法题往后放一放,先速成小土堆,再去弄项目吧。
1.科研进展
消失这些天主要是去弄论文了,老师建议换个数据集,所以很多实验都需要重新做一遍。现在已经回到正轨了,论文快修正好了,争取四月底之前投出去吧。
2.速成小土堆
2.1 Python的内置函数dir(),打开工具箱
dir()函数,打开工具箱。用于列出一个对象的所有属性和方法。它返回一个包含对象所有属性和方法名称的列表。如果不传入参数,则返回当前作用域中所有可用的名称。
bash
torch.cpu.is_available()
dir(torch)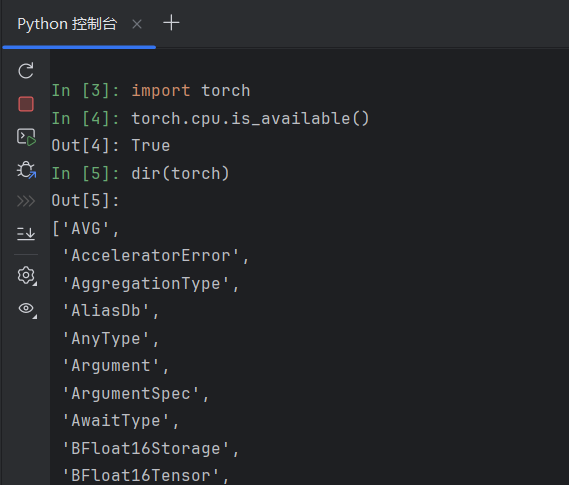
可以更加具体详细的查看。
bash
dir(torch.cpu)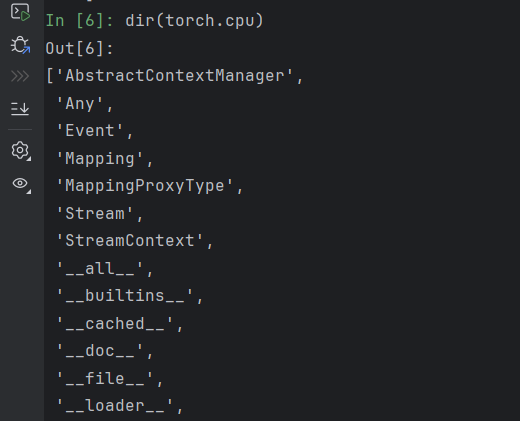
继续套娃,返回的结果是一个函数对象的属性列表。
bash
dir(torch.cpu.is_available())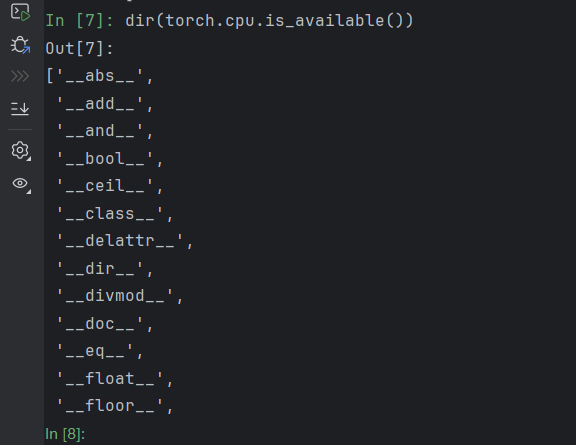
python 里 前后各有双下划线 __函数名__是什么?
在 Python 中,魔术属性(Magic Attributes)也称为特殊属性(Special Attributes)也称为魔法方法、双下划线方法(Double Underscore Methods),是以双下划线 __ 开头和结尾的特殊命名方式,用于实现对象的特殊行为和操作,不允许被修改
所以下一步可以用help方法去查看这个函数了。
2.2 Python的内置函数help(),查看官方解释文档
help()函数,查看说明书。用于获取对象、模块、函数、关键字等的帮助信息。当传入对象时,它会显示该对象的帮助文档。如果没有传入任何参数,则会进入交互式帮助模式。
bash
help(torch.cpu.is_available)
bash
torch.cpu.is_available??在 IPython 中,当输入 object?? 时,它会尝试显示该对象的源代码
python
torch.cpu.is_available??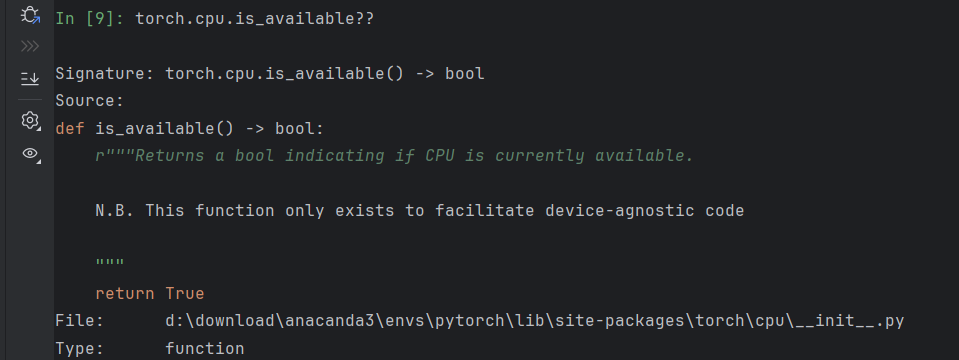
在 IPython 或 Jupyter Notebook / JupyterLab 这类交互式 Python 环境中:
?(单问号):显示对象的 简要帮助文档 和签名。
??(双问号):显示对象的源代码(如果该对象是用纯 Python 实现的)。
2.3 Pycharm和Jupyter工具对比
Pycharm差不多学一学就行了,Jupyter很久没用了我记录一下。
如果你和我一样把项目放到D盘去了,那建议这样启动,先切换到D盘再激活环境再打开Jupyter。
bash
(base) C:\Users\深情付九>cd /d D:\
(base) D:\>conda activate pytorch
(pytorch) D:\>jupyter notebook这样打开就可以直接看到我们的项目啦!
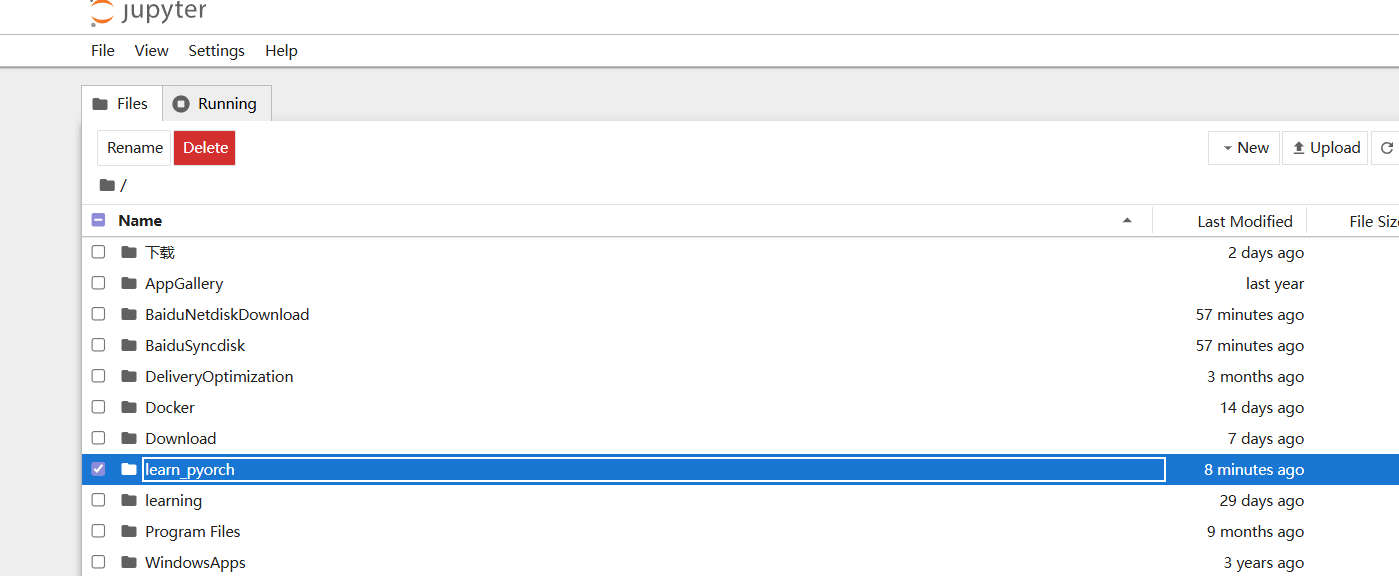
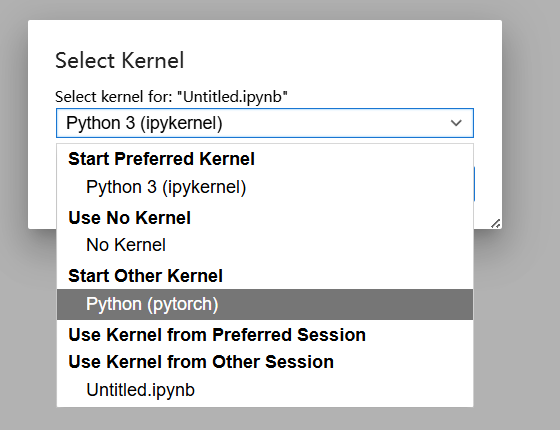
然后这里进入项目新建一个文件,进去之后再切换环境,就可以看到咯。
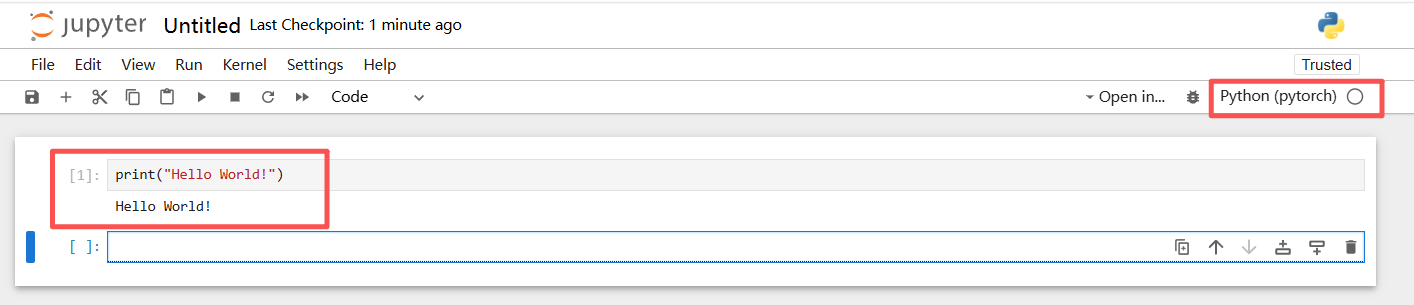
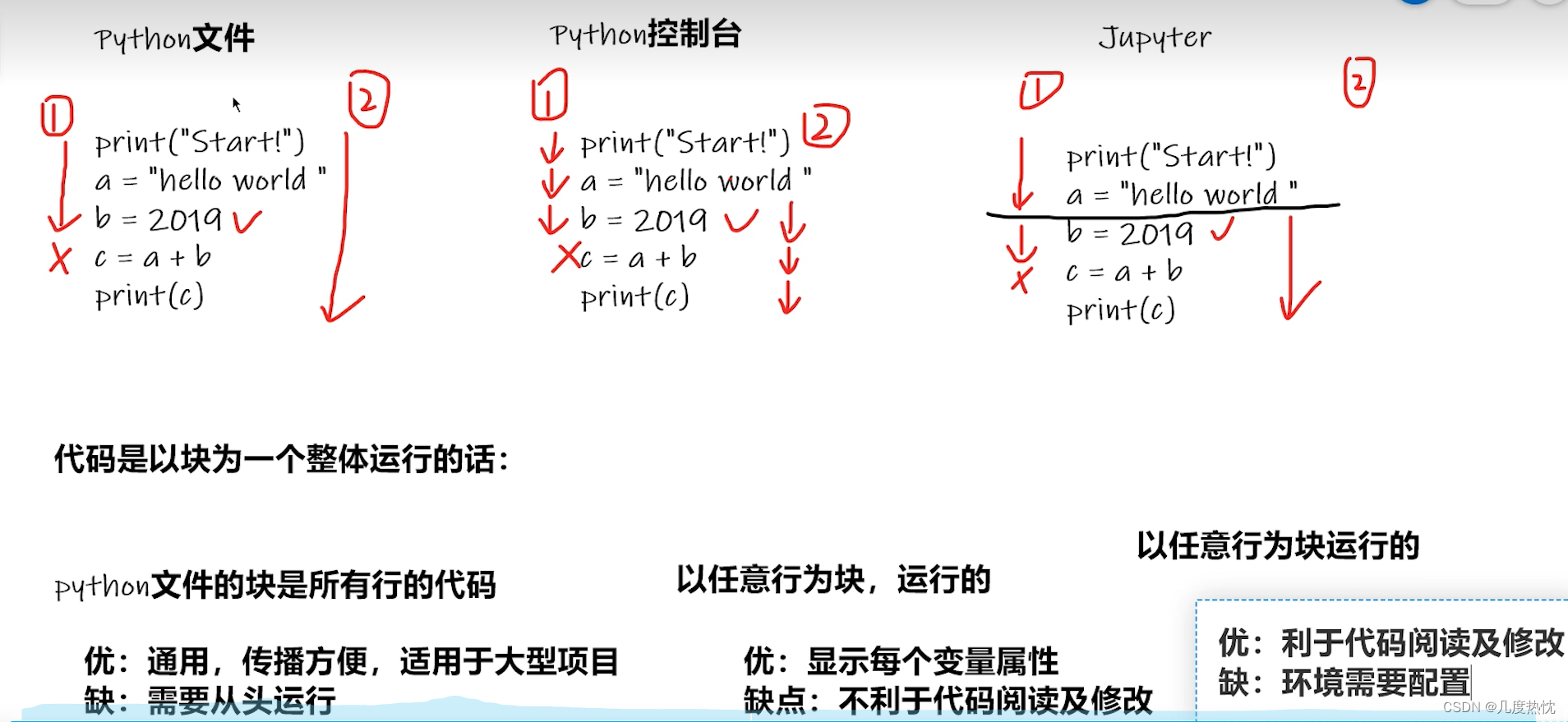
Shift + 回车快捷键 和直接点击运行,是一样的效果。
Pycharm 按shift + 回车 会跳转至下一行的行首
在Pycharm的Python Console中也可 以任意行为块 输入多行时 按shift + 回车
2.4 Pytorch读取数据的两个类 Dataset和DataLoader
2.4.1 Dataset
Dataset将数据和label进行组织编号0 1 2 3......,使得可以根据编号读取数据;需获取每一个数据及其label以及数据总数 ,要实现 len() 方法和 getitem() 方法。
**len()**方法返回数据集的样本数量;
**getitem()**方法根据给定的索引返回对应的数据样本;
2.4.2 DataLoader
DataLoader对数据进行打包将数据集划分为小批量,按batchsize送入网络模型;可以接收一个 Dataset 对象作为输入,并根据指定的批量大小、是否打乱数据、是否使用多线程等参数,来构建一个用于数据加载的迭代器
2.4.3 Dataset类代码实战:
通过继承Dataset类class MyData(Dataset),实现__len__和__getitem__方法,可以自定义自己的数据集类以适应不同的数据源和格式
蚂蚁蜜蜂/练手数据集:https://pan.quark.cn/s/e4c425fc4c0d
python
from torch.utils.data import Dataset
from PIL import Image
import os
class MyDataset(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir #为了让类中的其他方法也能访问到这个路径,变全局变量
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir) #智能拼接文件路径
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
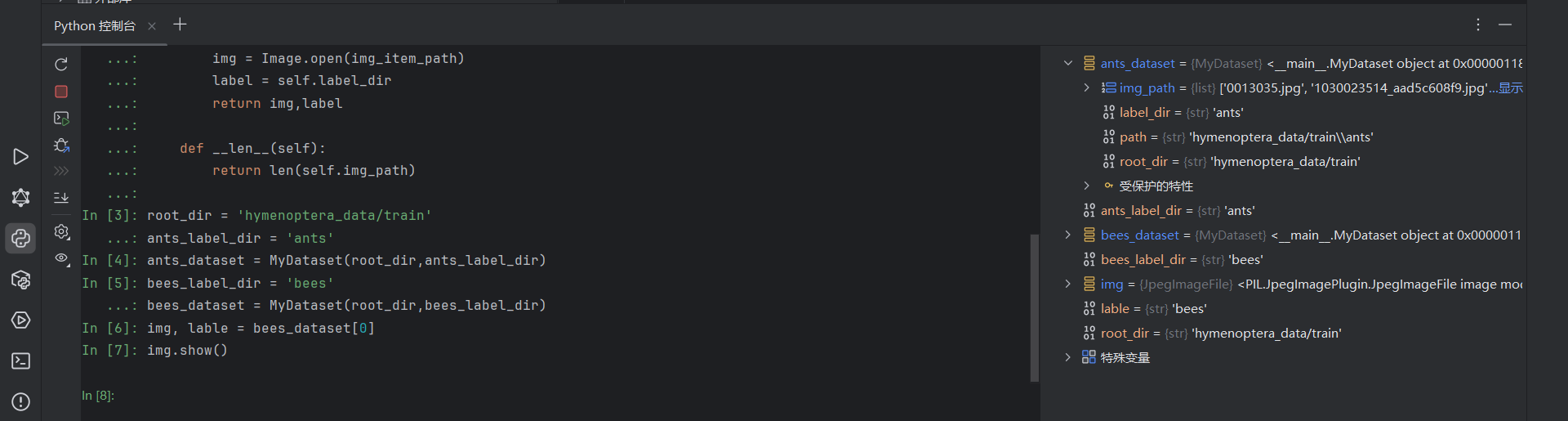
root_dir = 'hymenoptera_data/train'
ants_label_dir = 'ants'
bees_label_dir = 'bees'
ants_dataset = MyDataset(root_dir,ants_label_dir)
bees_dataset = MyDataset(root_dir,bees_label_dir)
train_dataset = ants_dataset + bees_dataset然后也跟着博主再控制台尝试调试。
2.5 Tensorboard的使用
2.5.1 SummaryWriter类使用
(1) writer.add_scalar()
add_saclar用于在TensorBoard中添加标量数据。该方法可以用来添加训练过程中的损失值、准确率等指标,以便于在TensorBoard中进行可视化和比较。

tag(字符串): 用于标识添加的标量数据的名称或标签。在TensorBoard中,这个标签将用作图表的标题。
scalar_value(数值): 要记录的标量数据的值。这可以是损失值、准确率等。
global_step(整数,可选): 表示记录的步数或迭代次数。这个参数对于在TensorBoard中显示随时间变化的数据非常有用。例如,在训练神经网络时,您可以将当前的迭代次数传递给global_step: 以便在TensorBoard中可视化损失值、准确率等随着训练步数的变化而变化的曲线
**walltime(时间戳,可选):**表示记录的时间。如果不指定,则默认使用当前时间
实战:使用tensorboard绘制 y = x 的函数
python
from torch.utils.tensorboard import SummaryWriter #相当于:"我要从 torch 工具箱的 utils 抽屉的 tensorboard 夹层里,只把名为 SummaryWriter 的那把螺丝刀拿出来。"
writer = SummaryWriter("logs")
# writer.add_image()
# y = x
for i in range(100):
writer.add_scalar("y = x", i, i)
writer.close()然后安装 tensorboard(注意,下载失败的可以去Anacanda用管理员身份打开下载运行,还有Pycharm终端记得在设置里面改成cmd,这样就可以默认进入虚拟环境了),在终端运行以下命令行。
python
tensorboard --logdir=logs
有时候可能端口占用导致错误,也可以自己指定端口,效果是一样的。
python
可通过tensorboard --logdir==logs --port=XXXX 指定端口号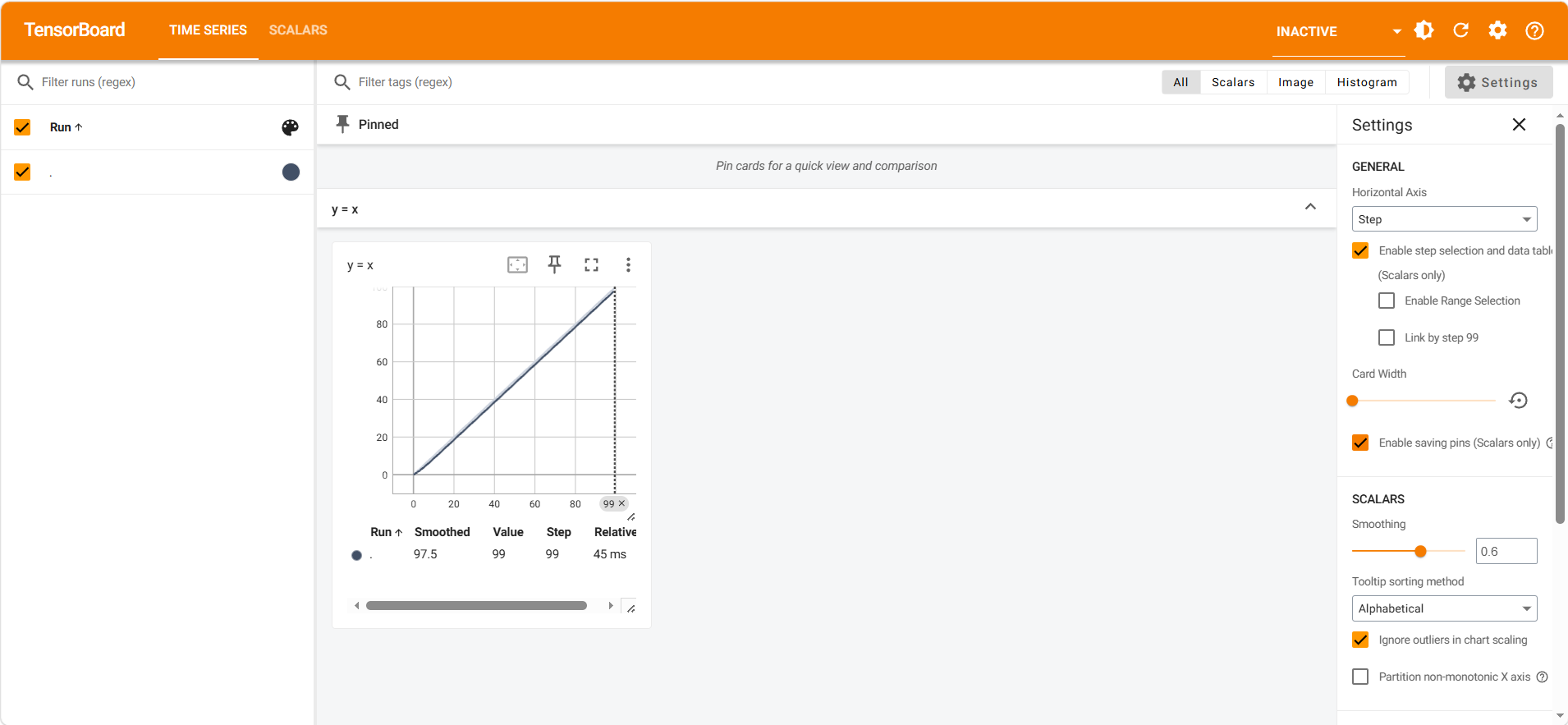
注意: 当未改变图像标题,重复修改y值 ,如writer.add_scalar("y = x", i, i),writer.add_scalar("y = x", 2i, i),writer.add_scalar("y = x", 3 i, i),会导致新绘制会包含之前绘制的图像
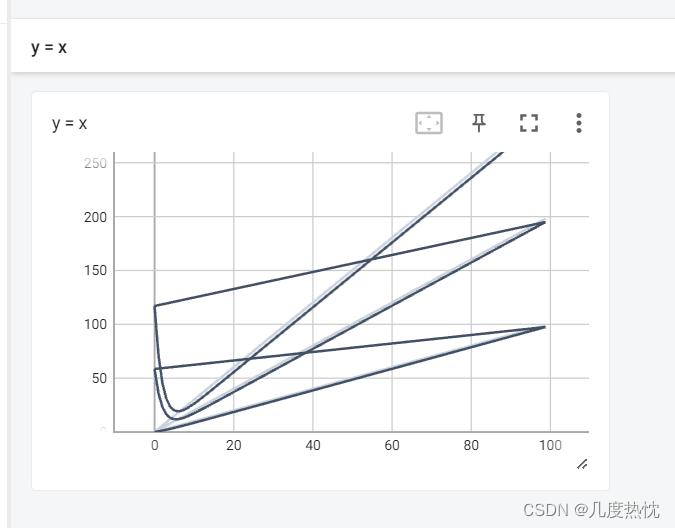
解决方法: 删除所有log文件,重新执行程序,再在tensorboard中查看
(2) add_image()
"练手数据集"在博主给的链接里面也有,直接下载解压,改名 data 放入自己的文件夹里面就可以
接下来开始学习add_image()。
直接 Ctrl 点击方法,查看类型:
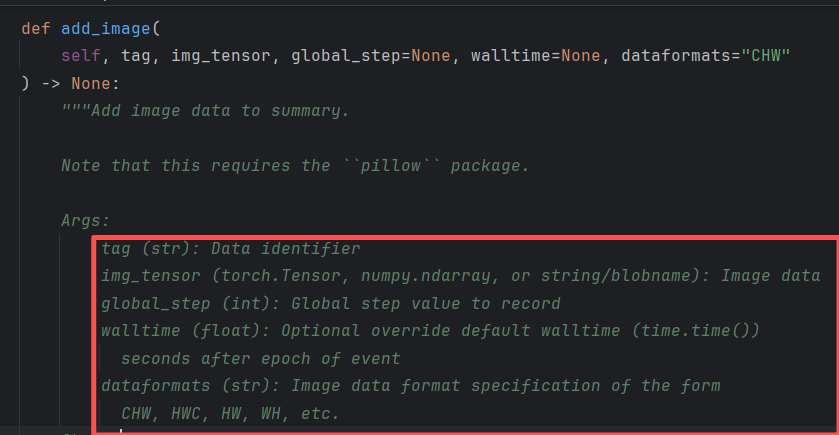
**注意:**add_image的参数img_tensor类型需为torch.Tensor, numpy.array, or string/blobname
之前提取图片用的都是 PIL,所以我们通过控制台查看一下这个数据类型。
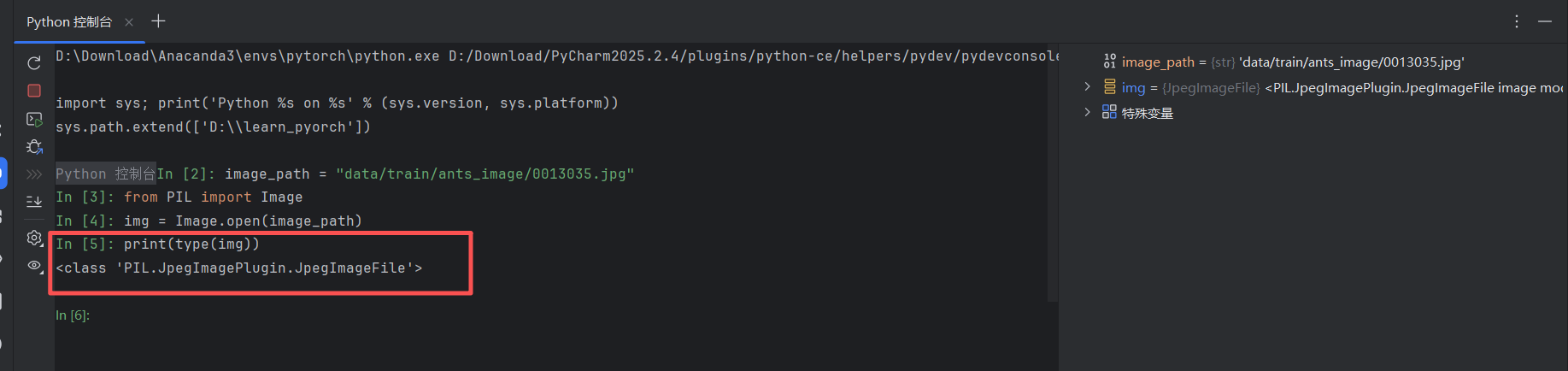
很遗憾,这不是我们能用的类型。
**解决方案:**利用numpy.array()对PIL的图像进行转换
具体操作:利用 Opencv 读取图片,获得 numpy 型数据类型。
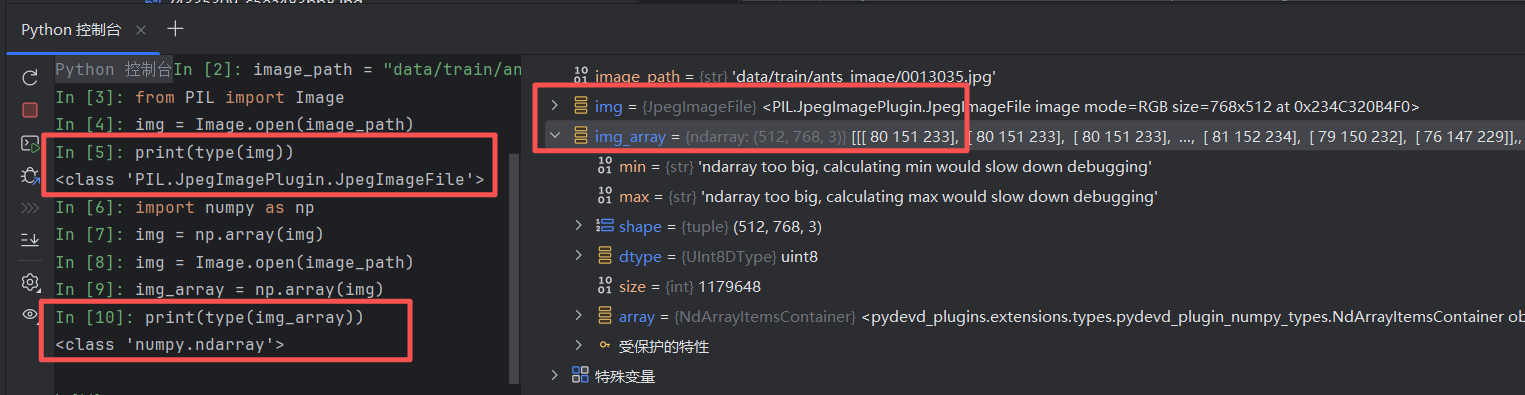
现在已经获得 add_image() 需要的数据类型了,调试成功,开始写代码。
python
from torch.utils.tensorboard import SummaryWriter #相当于:"我要从 torch 工具箱的 utils 抽屉的 tensorboard 夹层里,只把名为 SummaryWriter 的那把螺丝刀拿出来。"
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = "data/train/ants_image/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
writer.add_image("test", img_array, 1)
# y = x
for i in range(100):
writer.add_scalar("y = x", i, i)
writer.close()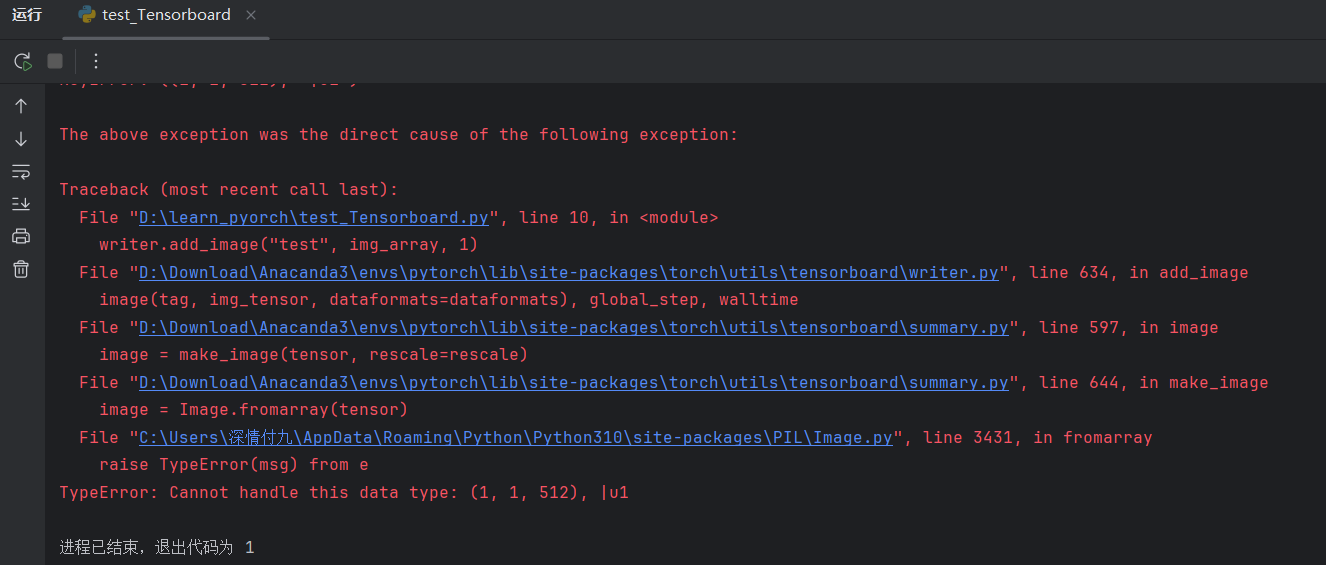
OK报错了,不要慌,因为博主也报错了。。。

问题原因: 图像形状默认为 :math:`(3, H, W),而上面通过打印发现 shape 为(512, 768, 3),需对通道参数进行转换
**解决方案:**使用 dataformats='HWC'
python
from torch.utils.tensorboard import SummaryWriter #相当于:"我要从 torch 工具箱的 utils 抽屉的 tensorboard 夹层里,只把名为 SummaryWriter 的那把螺丝刀拿出来。"
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = "data/train/ants_image/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
print(type(img_array))
print(img_array.shape)
writer.add_image("test", img_array, 1, dataformats='HWC')
# y = x
for i in range(100):
writer.add_scalar("y = x", i, i)
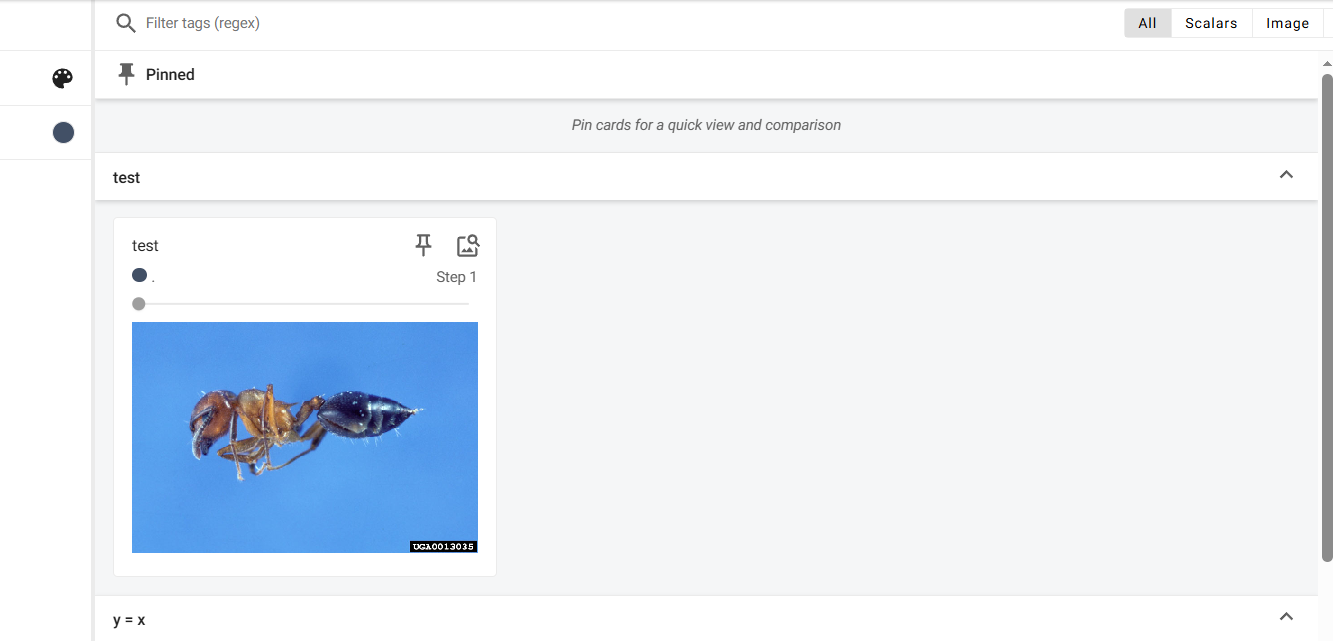
writer.close()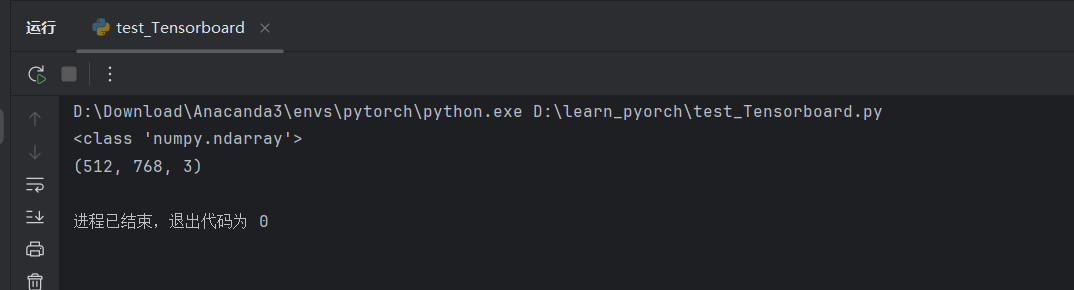
无报错,运行tensorboard进行刷新网页,成功显示:
2.6 Transforms的使用
新建一个 P9_Transforms.py 文件用于这一节的练习。
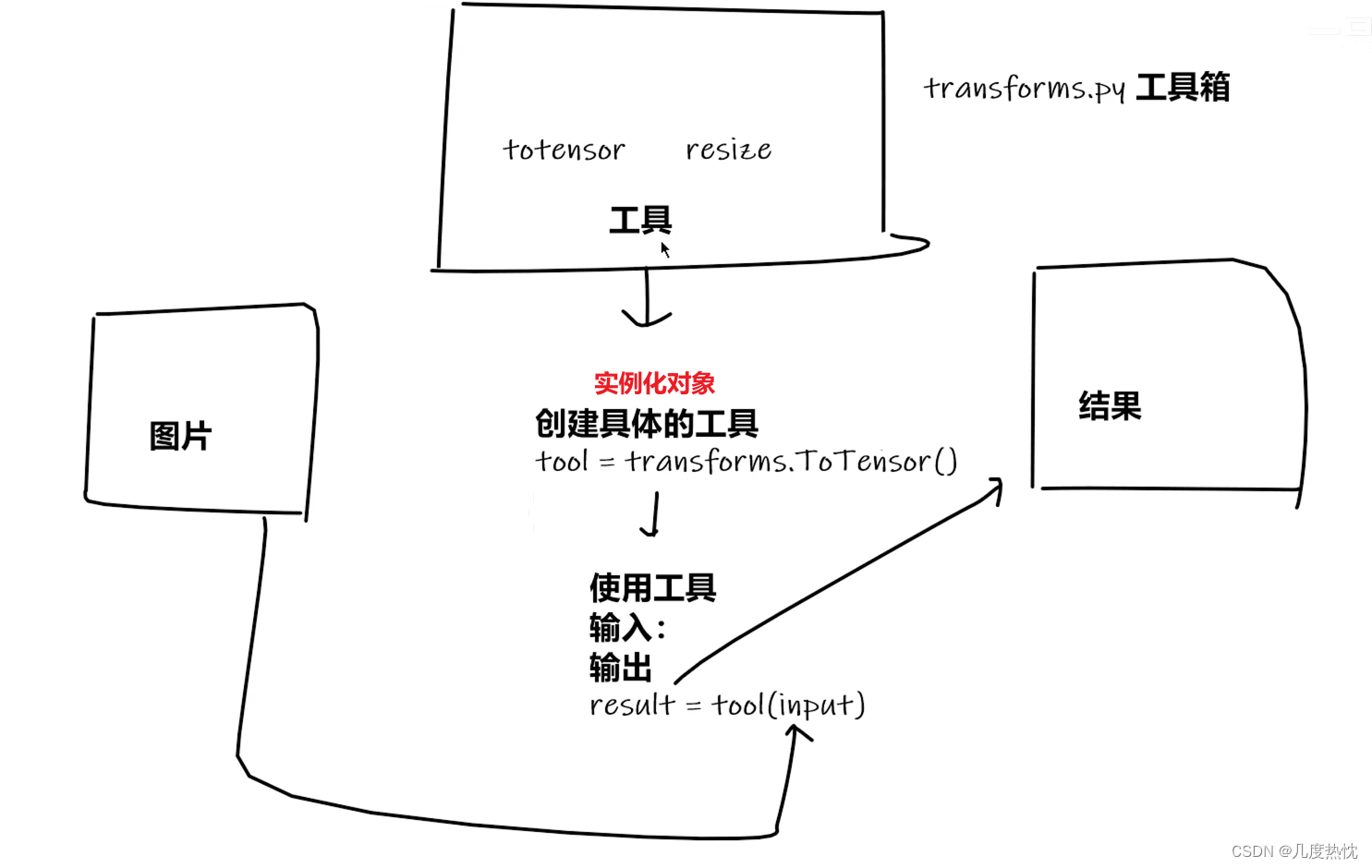
Transforms用于对图像进行预处理和数据增强操作,如调整图像大小、中心裁剪、随机裁剪、随机水平翻转、归一化、将 PIL 图像转换为 Tensor 等等
python
from torchvision import transforms查看用法,快捷键 Alt + 7 可以看到左侧出现对每个类的详细说明。
2.6.1 Python的__call__ 方法
在 Python 中,call 是一个特殊方法(也称为魔术方法或双下划线方法),用于使对象可以像函数一样被调用。当你在一个对象上调用 obj() 时,Python 解释器会查找该对象的__call__ 方法并调用它。
python
class MyClass:
def __init__(self, value):
self.value = value
def __call__(self, x):
return self.value + x
obj = MyClass(10)
result = obj(5) # 调用了 __call__ 方法
print(result) # 输出: 15在上面的示例中,MyClass 类实现了__call__方法,因此创建的 obj 实例可以像函数一样被调用。在调用 obj(5) 时,实际上会调用 obj.call(5),返回的结果是 self.value + x 的计算结果,即 10 + 5 = 15。
__call__方法的灵活性使得对象可以像函数一样被使用,这在某些情况下非常有用,例如实现可调用的对象或者定制对象的行为。
查看transforms的源代码,发现其实现了__call__方法
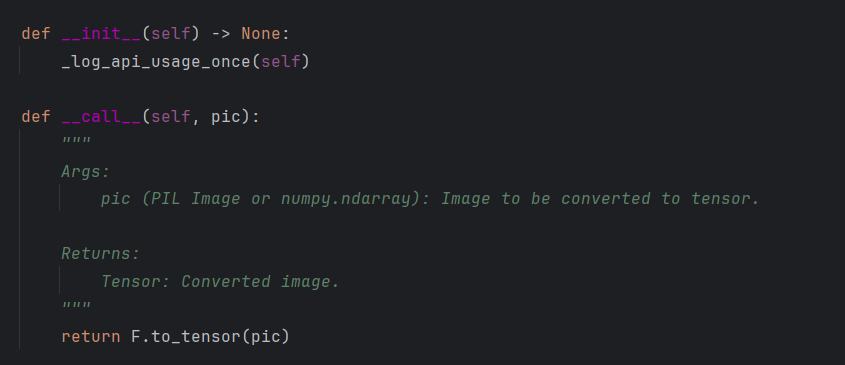
2.6.2 tensor数据类型
所以tensor_trans = transforms.ToTensor() ,tensor_img = tensor_trans(img)直接传入img调用了其中的__call__方法
python
from PIL import Image
from torchvision import transforms
# python 的用法 -> tensor 数据类型
# 通过 transforms.ToTensor 去解决两个问题
# 1,Transforms如何使用(python)
# 2. 为什么需要Tensor数据类型
img_path = "data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
print(tensor_img)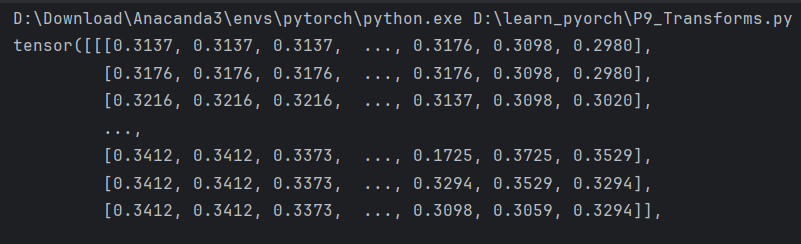
tensor是神经网络专用的数据类型,包含了许多神经网络需要的参数。
transforms的ToTensor()进行图片类型的转化问题已解决。
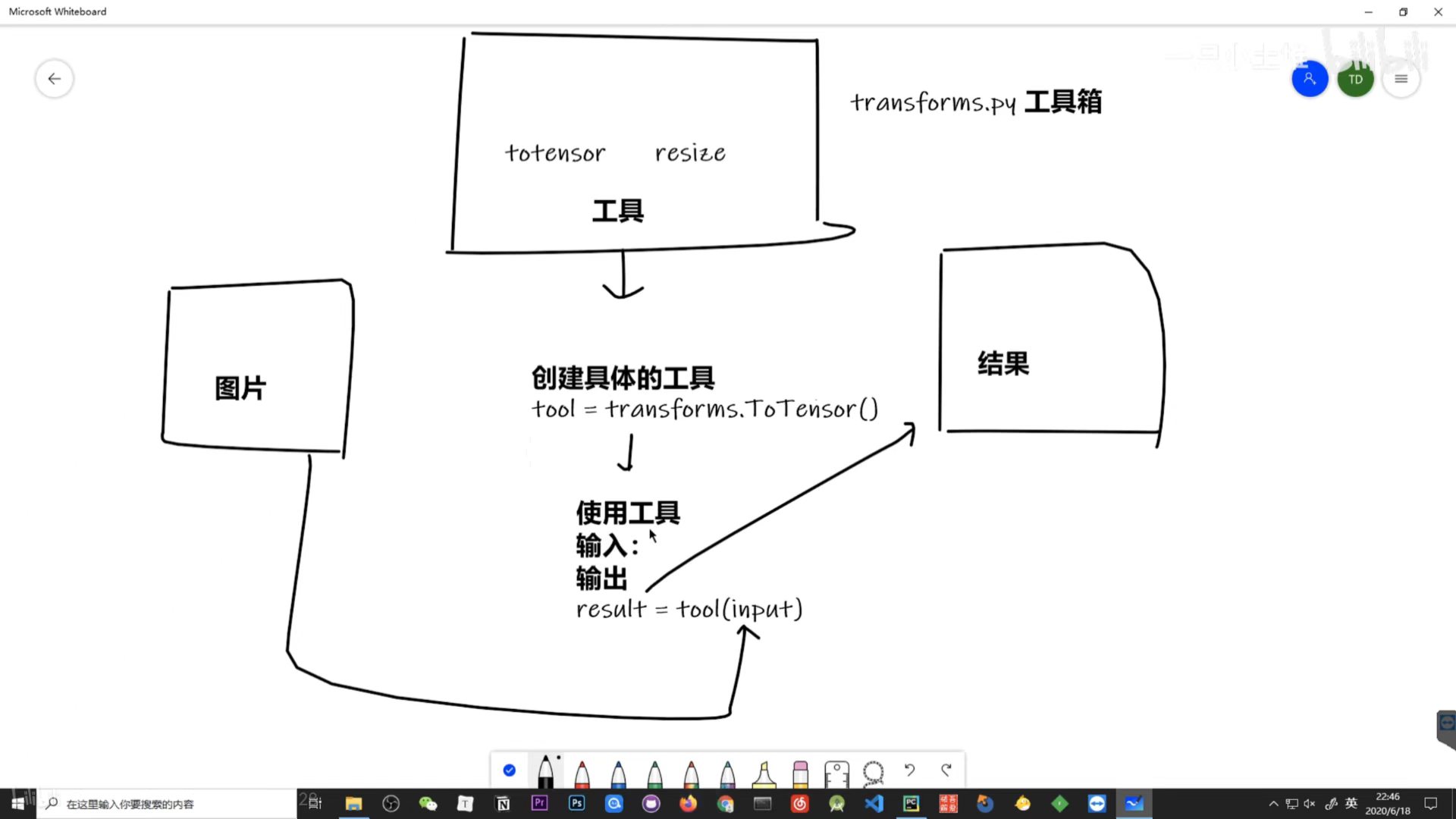
opencv 使用cv2.imread()读取的图像数据类型是numpy.ndarray
使用add_image()添加tensor类型的图像到日志文件中 通过tensorboard展示
python
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# python 的用法 -> tensor 数据类型
# 通过 transforms.ToTensor 去解决两个问题
img_path = "data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs")
# 1,Transforms如何使用(python)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
print(tensor_img)
# 2. 为什么需要Tensor数据类型
writer.add_image("Tensor_img", tensor_img)
writer.close()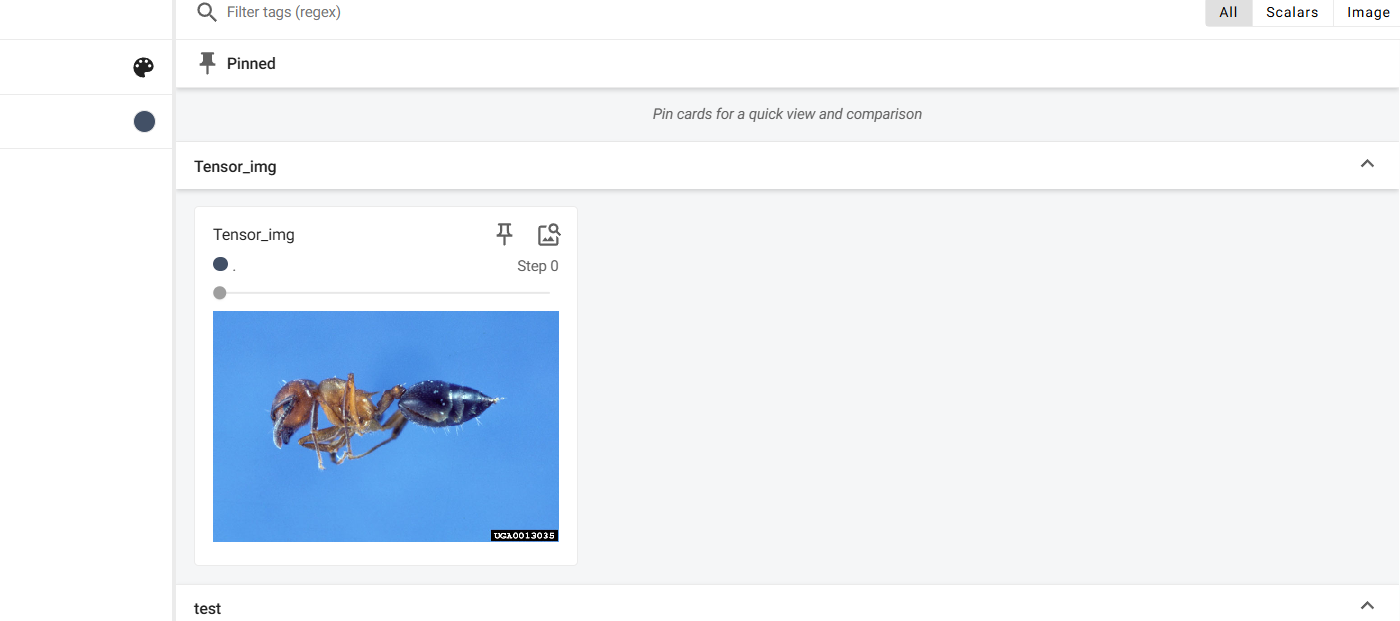
2.7 常见的Transforms

本小节新建文件 P10_UsefulTransforms.py。
2.7.1 ToTensor 的使用
python
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
from torchvision import transforms
writer = SummaryWriter("logs") # 日志文件存储位置
img = Image.open("hymenoptera_data/train/ants/0013035.jpg")
print(img)
# ToTensor
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
writer.add_image("ToTensor", tensor_img)
writer.close()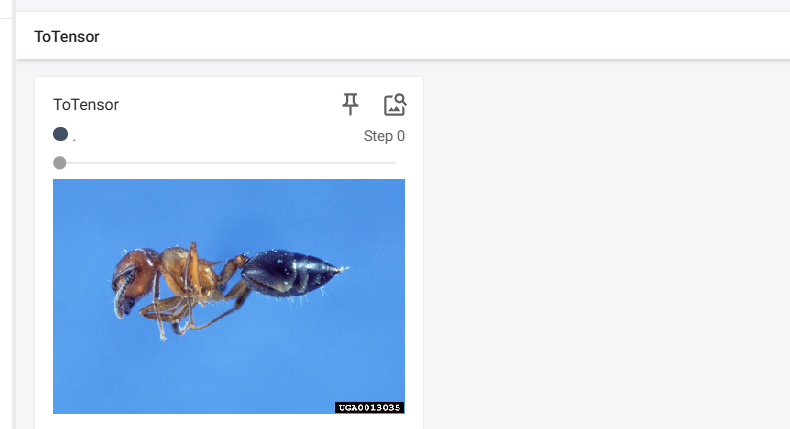
2.7.2 Normalize 的使用
tensor是完成缩放的作用,从0到255转换为0到1。而Normalize完成的是归一化,从-1到1。但是通常这两步都被叫做归一化。
假设三个通道的均值和标准差都为0.5:
- mean = 0.5, 0.5, 0.5:分别对应 RGB 三个通道的均值。
- std = 0.5, 0.5, 0.5:分别对应 RGB 三个通道的标准差。
作用公式:对每个通道执行 output = (input - mean) / std。
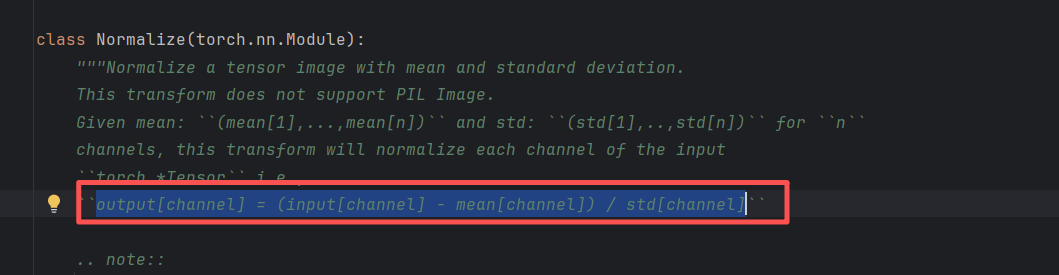
这组参数的特殊效果:将原本在 0, 1 区间的像素值,线性映射到 -1, 1 区间:
- 若 input = 0.0,则输出 (0 - 0.5) / 0.5 = -1.0。
- 若 input = 1.0,则输出 (1 - 0.5) / 0.5 = 1.0。
python
from tkinter import image_types
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
from torchvision import transforms
writer = SummaryWriter("logs") # 日志文件存储位置
img = Image.open("hymenoptera_data/train/ants/0013035.jpg")
print(img)
# ToTensor
tensor_trans = transforms.ToTensor()
img_tensor = tensor_trans(img)
writer.add_image("ToTensor", img_tensor)
# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
writer.close()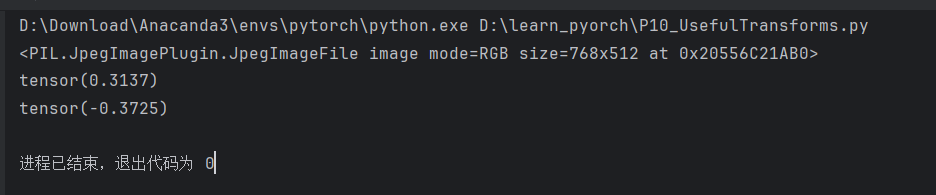
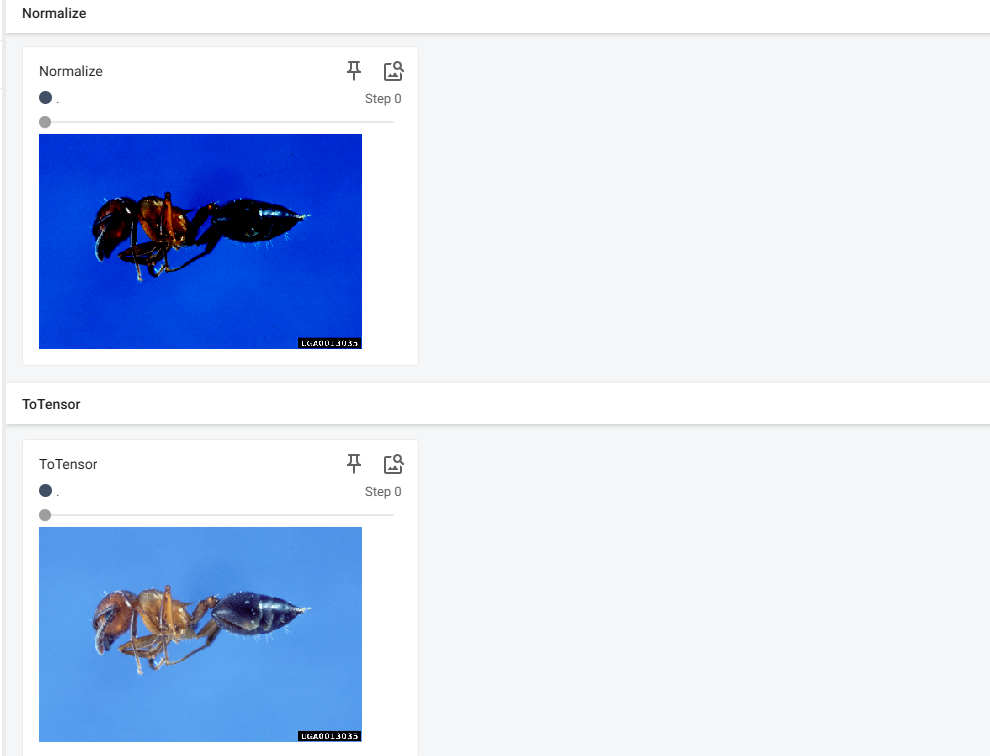
归一化后图片不一样了。也可以进行其他数值的调试。
简而言之,归一化就是改变模型参数,让模型呈现出不同状态。不同维度之间的特征在数值上量纲可能不一样,归一化就是让他们量纲大致差不多,这样梯度下降更快,更容易求解,有利于预防梯度爆炸加速损失函数收敛。
2.7.3 Resize()的使用
Resize 是用来把图片变大或变小的工具,你可以告诉它具体的"宽和高",也可以只告诉它"短边的长度"。
|------------|----------------------|------|
| 输入参数 size | 效果 | 图片比例 |
| (224, 224) | 不管原来多长多宽,直接拉成正方形 | 会变形 |
| 256 | 把短边变成 256,长边按比例算 | 不变性 |
这是为了适应深度学习模型的两种需求:
- 固定尺寸输入 (需要
(h, w)元组):有些老模型必须输入确切的宽高,不管变形不变形。 - 保持比例缩放 (需要
int):现代模型通常在缩放后还会进行CenterCrop(中心裁剪),这样可以既保证输入尺寸一致,又保证物体不变形。
python
from tkinter import image_types
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
from torchvision import transforms
writer = SummaryWriter("logs") # 日志文件存储位置
img = Image.open("hymenoptera_data/train/ants/0013035.jpg")
print(img)
# ToTensor
tensor_trans = transforms.ToTensor()
img_tensor = tensor_trans(img)
writer.add_image("ToTensor", img_tensor)
# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
# Resize
print(img.size)
trans_resize = transforms.Resize((512,512))
# img : PIL -> resize -> PIL
img_resize = trans_resize(img)
# img_resize : PIL -> ToTensor -> tensor
img_resize = tensor_trans(img_resize)
writer.add_image("Resize",img_resize)
print(img_resize)
writer.close()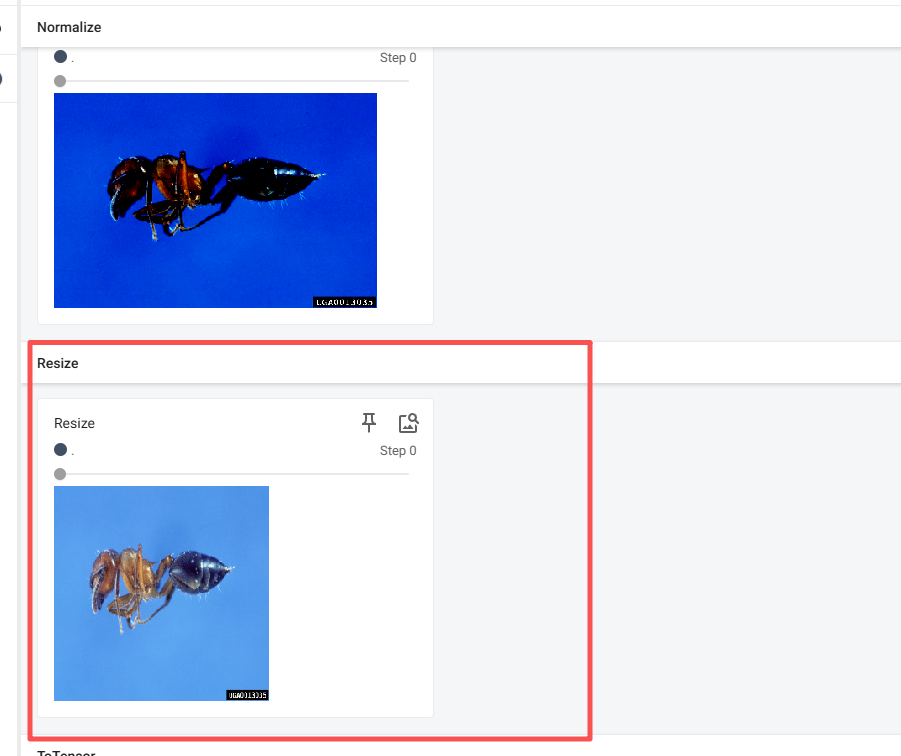
2.7.4 利用Compose进行resize
Compose其实就是一个聚合的作用,把前面两个工具放一起执行了。

python
from tkinter import image_types
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
from torchvision import transforms
writer = SummaryWriter("logs") # 日志文件存储位置
img = Image.open("hymenoptera_data/train/ants/0013035.jpg")
print(img)
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
# Resize
print(img.size)
trans_resize = transforms.Resize((512,512))
# img : PIL -> resize -> PIL
img_resize = trans_resize(img)
# img_resize : PIL -> ToTensor -> tensor
img_resize = trans_totensor(img_resize)
writer.add_image("Resize",img_resize,0)
print(img_resize)
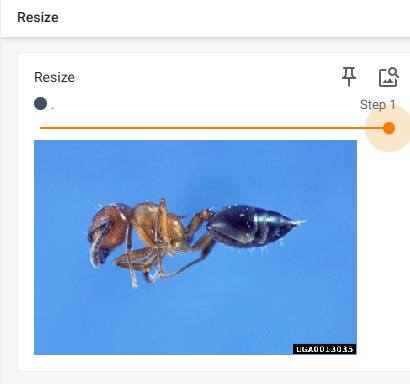
# Compose - Resize - 2
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
trans_resize_2 = trans_compose(img)
writer.add_image("Resize",trans_resize_2,1)
writer.close()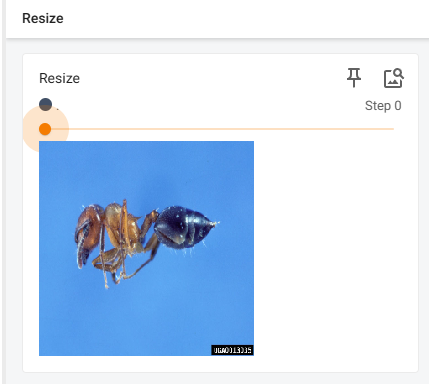
2.7.5 随机裁剪RandomCrop
RandomCrop 是 PyTorch 中用于图像数据增强(data augmentation)的函数之一,它可以在图像或张量的随机位置裁剪 出指定大小的区域,不会像Resize那样进行缩放。
transforms.RandomCrop((128, 128))会随机在输入图像中裁剪出大小为 128x128 的区域,并返回裁剪后的图像对象。
- 图片经过 RandomResizedCrop 后,输出的是 PIL Image(和原图一样是 Python 图片对象)。
- 而 TensorBoard 只认 Tensor(张量)。
- 所以必须用 Compose 把这两个动作串起来:先随机挖图 → 再转成张量。
python
from tkinter import image_types
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
from torchvision import transforms
writer = SummaryWriter("logs") # 日志文件存储位置
img = Image.open("hymenoptera_data/train/ants/0013035.jpg")
print(img)
# ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
# Resize
print(img.size)
trans_resize = transforms.Resize((512,512))
# img : PIL -> resize -> PIL
img_resize = trans_resize(img)
# img_resize : PIL -> ToTensor -> tensor
img_resize = trans_totensor(img_resize)
writer.add_image("Resize",img_resize,0)
print(img_resize)
# Compose - Resize - 2
trans_resize_2 = transforms.Resize(512)
# PIL -> PIL -> tensor
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
trans_resize_2 = trans_compose(img)
writer.add_image("Resize",trans_resize_2,1)
# RandomCrop
trans_random = transforms.RandomResizedCrop(512)
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
writer.close()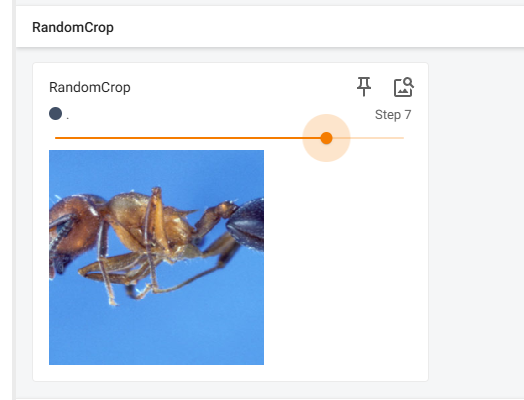
2.7.6 使用方法小节
- 关注输入和输出类型
- 多看官方文档
- 关注方法需要什么参数,如果没给的话自己 **print 试一下/断点尝试/type(),**当然了现在是2026,可以问AI了
OK今天就学到这里,撒花!!!