Colab 复现 NanoChat:从 Tokenizer、Base Train 到 SFT 的完整踩坑实录
- 前言
-
- 使用colab运行nanochat需要学习的一些前置知识:
-
- [前置知识1. colab基本使用](#前置知识1. colab基本使用)
- [前置知识2 :uv环境配置知识:](#前置知识2 :uv环境配置知识:)
- [前置知识3:colab配置GPU及挂载Google drive,拉取github案例的简单方法](#前置知识3:colab配置GPU及挂载Google drive,拉取github案例的简单方法)
- [前置知识4:nanochat项目下载后文件和数据集如何存放(/content/里还是google drive里)](#前置知识4:nanochat项目下载后文件和数据集如何存放(/content/里还是google drive里))
- 前置知识5:大模型的一些基础训练流程知识
-
- [1. 数据准备:先把"原始文本"变成"可训练语料"](#1. 数据准备:先把“原始文本”变成“可训练语料”)
- [2. `tokenizer`:把文本变成 token](#2.
tokenizer:把文本变成 token) - [3. `base train`:先让模型具备"基础续写能力"](#3.
base train:先让模型具备“基础续写能力”) - [4. base eval:验证基础模型是否真的可用](#4. base eval:验证基础模型是否真的可用)
- [5. `chat_sft`:把基础模型进一步调成"会对话的模型"](#5.
chat_sft:把基础模型进一步调成“会对话的模型”) - [6. `chat_cli`:最后落实"能不能对话"](#6.
chat_cli:最后落实“能不能对话”) - [7. 这次实验对我的意义](#7. 这次实验对我的意义)
- 正文:
-
- [1. 拉取nanochat项目:](#1. 拉取nanochat项目:)
-
- [**单元格1:挂载 Google Drive**:](#单元格1:挂载 Google Drive:)
- [**单元格 2:拉代码到临时盘 /content**:](#单元格 2:拉代码到临时盘 /content:)
- [**单元格 3:指定 nanochat 的持久化目录到 Drive**:](#单元格 3:指定 nanochat 的持久化目录到 Drive:)
- [**单元格 4:指定 nanochat 的持久化目录到 Drive**:](#单元格 4:指定 nanochat 的持久化目录到 Drive:)
- [**单元格 5:确认现在装的是 CPU 版 torch**:](#单元格 5:确认现在装的是 CPU 版 torch:)
- [第二部分:先跑通 tokenizer](#第二部分:先跑通 tokenizer)
-
- [**单元格 6:下载最小数据**:](#单元格 6:下载最小数据:)
- [**单元格 7:训练 tokenizer**:](#单元格 7:训练 tokenizer:)
- [** 单元格 8:评估 tokenizer**](#** 单元格 8:评估 tokenizer**)
- [第二部分:CPU运行 base_train / base_eval](#第二部分:CPU运行 base_train / base_eval)
-
- [**单元格 9:最小 base_train**:](#单元格 9:最小 base_train:)
- [**单元格 10:安装setup tools和 wheel**:](#单元格 10:安装setup tools和 wheel:)
- [**单元格 11:看一下 base checkpoint 有没有保存到google drive里**:](#单元格 11:看一下 base checkpoint 有没有保存到google drive里:)
- [**单元格 12:最小 base_eval**:](#单元格 12:最小 base_eval:)
- 第三部分:CPU版本SFT监督微调
-
- [单元格13:下载 SFT 需要的 identity 数据](#单元格13:下载 SFT 需要的 identity 数据)
- [单元格14:CPU运行参数最小的 SFT (手动暂停了):](#单元格14:CPU运行参数最小的 SFT (手动暂停了):)
- 第四部分:GPU版本SFT监督微调
-
- 单元格15:重新挂载Drive:
- [单元格16:重新 clone nanochat](#单元格16:重新 clone nanochat)
- 单元格17:重新设置持久化目录:
- [单元格18:重新装 uv,重新建 GPU 环境](#单元格18:重新装 uv,重新建 GPU 环境)
- [单元格19(不止一个格):检查 GPU 能不能用,检查之前保存在google drive里的东西存不存在:](#单元格19(不止一个格):检查 GPU 能不能用,检查之前保存在google drive里的东西存不存在:)
- [单元格20:使用 GPU 进行SFT微调:](#单元格20:使用 GPU 进行SFT微调:)
- [单元格21:运行对话检查 GPU STF微调结果:](#单元格21:运行对话检查 GPU STF微调结果:)
- 单元格22:解决报错,修改`engine.py`文件里的参数:
- 单元格23:GPU版本SFT监督训练后询问:
- 后记:跑完以后进一步理解NanoChat这个项目
- 代码框架梳理
-
-
- [1. `dev/`](#1.
dev/) - [2. `nanochat/`](#2.
nanochat/) -
- [2.1 `gpt.py` **:模型本体。比如 transformer 的层数、注意力、MLP、embedding 这些,基本都在这里或由这里组织起来。](#2.1
gpt.py**:模型本体。比如 transformer 的层数、注意力、MLP、embedding 这些,基本都在这里或由这里组织起来。) - [2.2 `engine.py`:推理引擎。](#2.2
engine.py:推理引擎。) - [2.3 `checkpoint_manager.py`:checkpoint 管理。](#2.3
checkpoint_manager.py:checkpoint 管理。) - [2.4 `tokenizer.py`:分词器相关。](#2.4
tokenizer.py:分词器相关。) - [2.5 `dataset.py`:数据集读取与下载。](#2.5
dataset.py:数据集读取与下载。) - [2.6 `dataloader.py`:数据加载器。](#2.6
dataloader.py:数据加载器。) - [2.7 `optim.py`:优化器实现:](#2.7
optim.py:优化器实现:) - [2.8 `core_eval.py` / `loss_eval.py`:评测相关。](#2.8
core_eval.py/loss_eval.py:评测相关。) - [2.9 `common.py`:通用工具函数。](#2.9
common.py:通用工具函数。) - [2.10 `execution.py`:工具调用/代码执行能力。](#2.10
execution.py:工具调用/代码执行能力。) - [2.11 `report.py`报告生成:](#2.11
report.py报告生成:) - [2.12 `ui.html` :](#2.12
ui.html:)
- [2.1 `gpt.py` **:模型本体。比如 transformer 的层数、注意力、MLP、embedding 这些,基本都在这里或由这里组织起来。](#2.1
- [3. `runs/` 流程脚本文件夹:](#3.
runs/流程脚本文件夹:) -
- [3.1 `runcpu.sh` CPU启动的小示例:](#3.1
runcpu.shCPU启动的小示例:) - [3.2 `speedrun.sh`:较完整的大流程。](#3.2
speedrun.sh:较完整的大流程。) - [3.3 `scaling_laws.sh`:做不同模型规模实验。](#3.3
scaling_laws.sh:做不同模型规模实验。) - [3.4 `miniseries.sh`:一组系统化的小实验。](#3.4
miniseries.sh:一组系统化的小实验。)
- [3.1 `runcpu.sh` CPU启动的小示例:](#3.1
- [4. `scripts/`: **核心命令(训练评估等)代码文件夹**:](#4.
scripts/: 核心命令(训练评估等)代码文件夹:) -
- [4.1 `tok_train.py`:训练 tokenizer。](#4.1
tok_train.py:训练 tokenizer。) - [4.2 `tok_eval.py`:评估 tokenizer。](#4.2
tok_eval.py:评估 tokenizer。) - [4.3 `base_train.py`:基础模型训练入口。](#4.3
base_train.py:基础模型训练入口。) - [4.4 `base_eval.py`:基础模型评估入口。](#4.4
base_eval.py:基础模型评估入口。) - [4.5 `chat_sft.py`](#4.5
chat_sft.py) - [4.6 `chat_cli.py` :命令行聊天](#4.6
chat_cli.py:命令行聊天) - [4.7 `chat_web.py`:网页聊天入口](#4.7
chat_web.py:网页聊天入口) - [4.8 `chat_eval.py`:聊天模型评测](#4.8
chat_eval.py:聊天模型评测) - [4.9 `chat_rl.py`:强化学习训练入口。](#4.9
chat_rl.py:强化学习训练入口。)
- [4.1 `tok_train.py`:训练 tokenizer。](#4.1
- [5. `tasks/`**任务"数据"文件夹**:](#5.
tasks/任务“数据”文件夹:) -
- [5.1 `arc.py`科学选择题任务:](#5.1
arc.py科学选择题任务:) - [5.2 `gsm8k.py`数学题任务:](#5.2
gsm8k.py数学题任务:) - 5.3`mmlu.py`综合知识问答任务:
- [5.4 `humaneval.py`:代码类任务](#5.4
humaneval.py:代码类任务) - [5.5 `smoltalk.py`聊天数据任务:](#5.5
smoltalk.py聊天数据任务:) - [5.6 `customjson.py`自定义 jsonl 数据接入:](#5.6
customjson.py自定义 jsonl 数据接入:) - [5.7 `common.py`任务组合逻辑:](#5.7
common.py任务组合逻辑:) - [5.8 `spellingbee.py`拼写/计数字母这类小任务:](#5.8
spellingbee.py拼写/计数字母这类小任务:)
- [5.1 `arc.py`科学选择题任务:](#5.1
- [6. `tests/` :测试目录](#6.
tests/:测试目录) -
- [6.1 `test_engine.py`测试推理引擎:](#6.1
test_engine.py测试推理引擎:)
- [6.1 `test_engine.py`测试推理引擎:](#6.1
- [7. `pyproject.toml` :项目依赖配置。](#7.
pyproject.toml:项目依赖配置。) - [8. `uv.lock` 依赖锁文件:](#8.
uv.lock依赖锁文件:)
- [1. `dev/`](#1.
- NanoChat重点一句话理解总结:
-
注意,因为我这是为了帮助自己复习和实践的踩坑记录,所以前言部分太长了,很劝退,大家可以直接从正文开始看:
前言
- 为什么我们要运行
nanochat这个项目来学习GPT?
- 答: 我们想快速建立对大模型训练流程的整体认知,而偶像
Andrej Karpathy把很复杂的gpt框架写的很精简(删去了细枝末节的,保留了最重点的),简化成一个很简单的只有8000行代码就写完的nanochat项目,这些代码也都是实现gpt的技术最重点。nanochat链路清晰完整,代码量可控,非常适合新手快速学习与快速验证。
- 为什么我们使用
google colab来运行nanochat项目?
- 答:我们的
GPU资源受限,而Google的Colab成本非常低,不开会员一个月也有一定额度的GPU资源用,如果办了colab pro的话,提供的GPU资源,相比我们办的价格也非常慷慨。所以方便我们用最低成本去验证,实现实验的最小闭环。
- 我用colab运行了nanochat的哪些项目?目的是?
- 答:我在
Colab环境下,基于nanochat完成了从数据(数据集)、tokenizer、base train、SFT到对话验证的最小训练闭环,并针对环境依赖、参数传递、GPU dtype兼容问题做了定位和修复。- 即
tokenizer→base_train→base_eval→chat_sft→chat_cli。
- 即
通过这个闭环,我想验证三件事:
- 我是否真正理解了大模型训练的基本链路;
- 我是否能在资源受限环境下做正确的工程拆分;
- 当训练过程中出现环境、参数、
dtype兼容问题时,我是否能定位和修复。
使用colab运行nanochat需要学习的一些前置知识:
前置知识1. colab基本使用
我们之前写过colab初学者使用方法帖子:
colab常用快捷键,colab平台创建文件连接google drive,拉取github项目的方法
我们并不需要记住很多,只需要记住下面这三点即可:
- 挂载google drive:Colab 是一个虚拟机,长时间不操作,或者关掉网页,这台虚拟机连同数据就会被 Google 回收销毁。我们必须把它和 Google Drive(谷歌云盘)联动,把数据存在云盘里。
- 代码块能写 Python,也能敲 Linux 命令 :
在代码块(Cell)里,正常写就是 Python 代码。但如果你在前面加一个感叹号!,它就变成了你之前在 AutoDL 里用的终端(Terminal)。- 比如安装库:
!pip install torch - 比如看文件:
!ls
- 比如安装库:
- 切换目录 用
%cd而不是!cd。
前置知识2 :uv环境配置知识:
nanochat没有使用pip进行包管理,而是使用uv进行包管理,uv知识可以看一下我们之前写的这个帖子:uv简单介绍及初步使用案例
前置知识3:colab配置GPU及挂载Google drive,拉取github案例的简单方法
3.1:给 Colab 装显卡的方法
新建一个 Colab 笔记本后,点击顶部菜单栏的 代码执行程序 (Runtime) -> 更改代码执行程序类型 -> 选择 T4 GPU -> 保存。
3.2:挂载 Google Drive的方法
在第一个代码块中,复制并运行这段代码。它会弹出一个窗口让你授权登录你的 Google 账号:
python
from google.colab import drive
drive.mount('/content/drive')运行成功后,你的谷歌云盘就被挂载到了 /content/drive/MyDrive/ 这个路径下。
3.3:colab拉取github代码的方法案例
新开一个代码块,进入你的云盘,建个文件夹,把 Nanochat 的代码克隆进去:
bash
# 在colab已经连接上google drvie的情况下
# 进入你的谷歌云盘
%cd /content/drive/MyDrive/
# 创建一个专属于这个项目的文件夹(名字你可以随便起)
!mkdir xxx_project
%cd xxx_project
# 把代码下载到这个永久文件夹里
!git clone https://github.com/xxx_project仓库地址.git前置知识4:nanochat项目下载后文件和数据集如何存放(/content/里还是google drive里)
(这不是正文,只是前置知识了解,大家完全可以直接从正文章节开始看)
首先,就像之前我们写的帖子colab常用快捷键,colab平台创建文件连接google drive,拉取github项目的方法里所写到的:
/content属于 Colab 当前这台虚拟机,本地读写快,适合放高频读写的,零碎的,临时的的内容(colab关机这部分就消失);Google Drive和colab的交互读写非常慢, 适合放重要结果、难重建的产物 的内容。(但colab和google drive)
所以我把下述内容放在了/content里。
nanochat代码仓库.venv虚拟环境- 训练时频繁读写的临时文件
- 解压后的大量小文件
- 临时缓存、试跑数据集
只把下面这些放在 Google Drive里(避免浪费实践的和colab之间频繁读写):
ipydb文件本身tokenizer结果- 一些重要的
checkpoints(base/sft) - 日志、报告、截图
- (未来可能的自己整理的少量数据文件)
前置知识5:大模型的一些基础训练流程知识
把这个最小的大模型训练项目拆开来看,我更愿意把它理解成下面 5 个步骤:
1. 数据准备:先把"原始文本"变成"可训练语料"
模型本身不认识自然语言,它只认识数字。所以第一步不是"直接训练",而是先准备语料:
- 有哪些文本。
- 它们来自哪里。
- 要不要清洗。
- 如何划分训练集和验证集。
在 nanochat 这条链路里,前期既有用于基础训练的普通文本,也有后面 SFT 用到的对话数据。我的理解是:
- 基础训练数据负责让模型学会语言建模能力,也就是"下一个 token 应该接什么";
- SFT 对话数据负责把"会续写"进一步变成"会按人类问答格式回答"。
2. tokenizer:把文本变成 token
大模型训练并不是直接把汉字、英文单词丢给模型,而是先通过 tokenizer 把文本切成 token,再映射成 token id。
所以 tokenizer 其实是整个训练链路里非常关键的一步:它决定了文本如何被编码,也影响后续训练效率和效果。
在我的这个 nanochat 实验里,我先训练了 tokenizer,再做 tokenizer 的评估,确认它至少能正常完成编码和对比输出,然后再进入 base train。
3. base train:先让模型具备"基础续写能力"
基础训练阶段,本质上是在做语言模型训练,让模型学会根据前文预测后文。
这一阶段训练出来的模型,通常还不是"会聊天的助手",但它已经具备了最核心的语言建模能力。
所以我在 Colab 上跑的 base_train,目标不是把模型训得多强,而是先验证:
- 数据链路是通的;
tokenizer能被训练脚本正常加载;checkpoint能正常保存;- 后面的
SFT有一个可以继承的base checkpoint。
4. base eval:验证基础模型是否真的可用
训练不是跑完就结束了,必须有验证动作。
base_eval 的意义,就是检查刚才得到的基础模型 checkpoint 能不能被正确加载,以及它在评估指标上是否能正常输出。
对我来说,这一步的意义主要有两个:
- 它证明前面的
base_train不是"假成功"; - 它为后面的
SFT提供了一个可靠的起点。
5. chat_sft:把基础模型进一步调成"会对话的模型"
SFT(Supervised Fine-Tuning,监督微调)可以理解成:
让模型基于"人类问什么、模型应该怎么答"的样本,学会更符合对话场景的回答方式。
所以 SFT 不是从零训练一个模型,而是基于前面已经训练出的 base checkpoint,再结合对话数据,继续做一轮更贴近问答场景的优化。
6. chat_cli:最后落实"能不能对话"
链路的最后,真正加载 SFT 后的 checkpoint,实际问一句话,看模型能不能生成回复。
这也是为什么我这次会坚持跑到 chat_cli。
因为只有到了这一步,tokenizer -> base_train -> base_eval -> chat_sft -> chat_cli 这条链路才算真正闭环。
7. 这次实验对我的意义
所以,这次模型实验规模很小、训练步数也很保守,但它已经足够让我建立起对大模型工程流程的整体认知:
- 数据如何进入训练流程
tokenizer为什么重要base model和SFT的关系是什么checkpoint为什么是训练链路里的核心中间产物- 以及:当环境、参数、
GPU兼容问题出现时,应该如何定位和修复
正文:
1. 拉取nanochat项目:
单元格1:挂载 Google Drive:
python
from google.colab import drive
drive.mount('/content/drive')
'''输出:
Mounted at /content/drive
'''单元格 2:拉代码到临时盘 /content:
这一步每次新开的时候都要做,因为 /content 是临时的。(有疑惑的可以看一下前置知识里的nanochat项目下载后文件和数据集如何存放(/content/里还是google drive里)的内容):
python
%cd /content
!rm -rf nanochat
!git clone https://github.com/karpathy/nanochat.git
%cd /content/nanochat
'''
输出
/content
Cloning into 'nanochat'...
remote: Enumerating objects: 1758, done.
remote: Total 1758 (delta 0), reused 0 (delta 0), pack-reused 1758 (from 1)
Receiving objects: 100% (1758/1758), 1.91 MiB | 19.79 MiB/s, done.
Resolving deltas: 100% (1118/1118), done.
/content/nanochat
'''单元格 3:指定 nanochat 的持久化目录到 Drive:
python
import os
PROJECT_DIR = "/content/drive/MyDrive/nanochat_project"
CACHE_DIR = f"{PROJECT_DIR}/cache"
os.environ["NANOCHAT_BASE_DIR"] = CACHE_DIR
print("NANOCHAT_BASE_DIR =", os.environ["NANOCHAT_BASE_DIR"])
'''
输出显示:
NANOCHAT_BASE_DIR = /content/drive/MyDrive/nanochat_project/cache
'''单元格 4:指定 nanochat 的持久化目录到 Drive:
nanochat 当前用 uv 管依赖;cpu 和 gpu extra 是分开的:
python
!python -m pip install -q uv
!rm -rf .venv
!uv venv
!uv sync --extra cpu
'''
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 24.6/24.6 MB 41.7 MB/s eta 0:00:00
warning: The `--system` flag has no effect, `uv venv` always ignores virtual environments when finding a Python interpreter; did you mean `--no-managed-python`?
Using CPython 3.10.12 interpreter at: /usr/bin/python3.10
Creating virtual environment at: .venv
Activate with: source .venv/bin/activate
Resolved 130 packages in 2ms
Prepared 65 packages in 17.66s
Installed 65 packages in 489ms
+ aiohappyeyeballs==2.6.1
+ aiohttp==3.12.15
+ aiosignal==1.4.0
+ annotated-types==0.7.0
+ anyio==4.10.0
+ async-timeout==5.0.1
+ attrs==25.3.0
+ certifi==2025.8.3
+ charset-normalizer==3.4.3
+ click==8.2.1
+ datasets==4.0.0
+ dill==0.3.8
+ exceptiongroup==1.3.0
+ fastapi==0.117.1
+ filelock==3.19.1
+ frozenlist==1.7.0
+ fsspec==2025.3.0
...
+ uvicorn==0.36.0
+ wandb==0.21.3
+ xxhash==3.5.0
+ yarl==1.20.1
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
'''单元格 5:确认现在装的是 CPU 版 torch:
如果这里不是 +cpu 或 cuda=False,就先别往下跑。nanochat 当前 pyproject.toml 里确实把 CPU/GPU torch 分流配置在 uv extra 里。(是的,**当前实现的是cpu训练tokenizer,因为只是先验证跑通。)
python
!uv run --extra cpu --no-sync python -c "import sys, torch; print('python=', sys.executable); print('torch=', torch.__version__); print('cuda=', torch.cuda.is_available()); print('torch_file=', torch.__file__)"
'''
输出
python= /content/nanochat/.venv/bin/python3
torch= 2.9.1+cpu
cuda= False
torch_file= /content/nanochat/.venv/lib/python3.10/site-packages/torch/__init__.py
'''第二部分:先跑通 tokenizer
官方 CPU demo 是先下载数据,再训练 tokenizer,再做 tokenizer eval。
单元格 6:下载最小数据:
官方 CPU demo 用 -n 8;你今晚先用 -n 1,只求链路通。
python
!uv run --extra cpu --no-sync python -m nanochat.dataset -n 1
!find /content/drive/MyDrive/nanochat_project/cache -maxdepth 2 -type f | head -20
'''
# 输出
Downloading 2 shards using 4 workers...
Target directory: /content/drive/MyDrive/nanochat_project/cache/base_data_climbmix
Downloading shard_00000.parquet...
Downloading shard_06542.parquet...
Successfully downloaded shard_00000.parquet
Successfully downloaded shard_06542.parquet
Done! Downloaded: 2/2 shards to /content/drive/MyDrive/nanochat_project/cache/base_data_climbmix
/content/drive/MyDrive/nanochat_project/cache/base_data_climbmix/shard_00000.parquet
/content/drive/MyDrive/nanochat_project/cache/base_data_climbmix/shard_06542.parquet
'''单元格 7:训练 tokenizer:
我们暂时只设置了--max-chars=50000000,先基本跑通再说:
python
!uv run --extra cpu --no-sync python -m scripts.tok_train --max-chars=50000000
'''
# 输出
max_chars: 50,000,000
doc_cap: 10,000
vocab_size: 32,768
2026-04-01 16:33:29,740 - rustbpe - INFO - Processing sequences from iterator (buffer_size: 8192)
2026-04-01 16:33:37,855 - rustbpe - INFO - Processed 18988 sequences total, 217274 unique
2026-04-01 16:33:37,873 - rustbpe - INFO - Starting BPE training: 32503 merges to compute
2026-04-01 16:33:37,873 - rustbpe - INFO - Computing initial pair counts from 217274 unique sequences
2026-04-01 16:33:38,400 - rustbpe - INFO - Building heap with 8906 unique pairs
2026-04-01 16:33:38,402 - rustbpe - INFO - Starting merge loop
2026-04-01 16:33:38,887 - rustbpe - INFO - Progress: 1% (326/32503 merges) - Last merge: (396, 107) -> 581 (frequency: 15352)
2026-04-01 16:33:38,981 - rustbpe - INFO - Progress: 2% (651/32503 merges) - Last merge: (818, 376) -> 906 (frequency: 6302)
2026-04-01 16:33:39,041 - rustbpe - INFO - Progress: 3% (976/32503 merges) - Last merge: (410, 274) -> 1231 (frequency: 3889)
2026-04-01 16:33:39,081 - rustbpe - INFO - Progress: 4% (1301/32503 merges) - Last merge: (261, 268) -> 1556 (frequency: 2760)
2026-04-01 16:33:39,107 - rustbpe - INFO - Progress: 5% (1626/32503 merges) - Last merge: (814, 715) -> 1881 (frequency: 2109)
2026-04-01 16:33:39,131 - rustbpe - INFO - Progress: 6% (1951/32503 merges) - Last merge: (894, 268) -> 2206 (frequency: 1687)
2026-04-01 16:33:39,148 - rustbpe - INFO - Progress: 7% (2276/32503 merges) - Last merge: (1549, 2003) -> 2531 (frequency: 1380)
2026-04-01 16:33:39,167 - rustbpe - INFO - Progress: 8% (2601/32503 merges) - Last merge: (356, 103) -> 2856 (frequency: 1171)
2026-04-01 16:33:39,183 - rustbpe - INFO - Progress: 9% (2926/32503 merges) - Last merge: (1270, 273) -> 3181 (frequency: 994)
2026-04-01 16:33:39,201 - rustbpe - INFO - Progress: 10% (3251/32503 merges) - Last merge: (258, 480) -> 3506 (frequency: 853)
2026-04-01 16:33:39,218 - rustbpe - INFO - Progress: 11% (3576/32503 merges) - Last merge: (264, 792) -> 3831 (frequency: 755)
2026-04-01 16:33:39,228 - rustbpe - INFO - Progress: 12% (3901/32503 merges) - Last merge: (2108, 290) -> 4156 (frequency: 664)
2026-04-01 16:33:39,243 - rustbpe - INFO - Progress: 13% (4226/32503 merges) - Last merge: (293, 116) -> 4481 (frequency: 603)
2026-04-01 16:33:39,256 - rustbpe - INFO - Progress: 14% (4551/32503 merges) - Last merge: (2777, 281) -> 4806 (frequency: 540)
2026-04-01 16:33:39,276 - rustbpe - INFO - Progress: 15% (4876/32503 merges) - Last merge: (2421, 4009) -> 5131 (frequency: 486)
2026-04-01 16:33:39,306 - rustbpe - INFO - Progress: 16% (5201/32503 merges) - Last merge: (283, 1824) -> 5456 (frequency: 442)
...
2026-04-01 16:33:39,749 - rustbpe - INFO - Finished training: 32503 merges completed
Training time: 10.22s
Saved tokenizer encoding to /content/drive/MyDrive/nanochat_project/cache/tokenizer/tokenizer.pkl
Saved token_bytes to /content/drive/MyDrive/nanochat_project/cache/tokenizer/token_bytes.pt
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
'''** 单元格 8:评估 tokenizer**
如果这里能正常输出 GPT-2 / GPT-4 / Ours 对比表,第一部分就算完成。
python
!uv run --extra cpu --no-sync python -m scripts.tok_eval
'''
输出
Vocab sizes:
GPT-2: 50257
GPT-4: 100277
Ours: 32768
Comparison with GPT-2:
===============================================================================================
Text Type Bytes GPT-2 Ours Relative Better
Tokens Ratio Tokens Ratio Diff %
-----------------------------------------------------------------------------------------------
news 1819 404 4.50 406 4.48 -0.5% GPT-2
korean 893 745 1.20 673 1.33 +9.7% Ours
code 1259 576 2.19 411 3.06 +28.6% Ours
math 1834 936 1.96 891 2.06 +4.8% Ours
science 1112 260 4.28 246 4.52 +5.4% Ours
fwe-train 2948778 631304 4.67 621091 4.75 +1.6% Ours
fwe-val 3024593 653067 4.63 647269 4.67 +0.9% Ours
Comparison with GPT-4:
===============================================================================================
Text Type Bytes GPT-4 Ours Relative Better
Tokens Ratio Tokens Ratio Diff %
-----------------------------------------------------------------------------------------------
news 1819 387 4.70 406 4.48 -4.9% GPT-4
...
math 1834 832 2.20 891 2.06 -7.1% GPT-4
science 1112 249 4.47 246 4.52 +1.2% Ours
fwe-train 2948778 611619 4.82 621091 4.75 -1.5% GPT-4
fwe-val 3024593 631183 4.79 647269 4.67 -2.5% GPT-4
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
'''第一部分成功判据
如果你能看到下面的文件就说明持久化成功了(把tokennizer的checkpoint和训练结果成功保存到google drive了):
tokenizer.pkltoken_bytes.pt
python
!find /content/drive/MyDrive/nanochat_project/cache/tokenizer -maxdepth 2 -type f -ls
'''
输出
58 403 -rw------- 1 root root 411864 Apr 1 16:33 /content/drive/MyDrive/nanochat_project/cache/tokenizer/tokenizer.pkl
61 130 -rw------- 1 root root 132649 Apr 1 16:33 /content/drive/MyDrive/nanochat_project/cache/tokenizer/token_bytes.pt
'''同时我们的 tok_eval 打出了对比表,这一部分就过了。官方 CPU demo 也是这条顺序。
第二部分:CPU运行 base_train / base_eval
nanochat 的 base_train 本身就支持很小的 smoke test形态;脚本头部甚至给了一个小例子。base_eval 默认会跑 core,bpb,sample,CPU 下太慢,所以我们先只跑 bpb。
单元格 9:最小 base_train:
我们先设置"保守能跑"的最小参数:
depth=2:极小模型max-seq-len=128device-batch-size=1total-batch-size=128num-iterations=4
关闭sample/core evalsave-every=1,这样每一步都存,避免跑完却没checkpoint
bash
!uv run --extra cpu --no-sync python -m scripts.base_train \
--device-type=cpu \
--run=dummy \
--model-tag=colab_smoke \
--depth=2 \
--head-dim=32 \
--window-pattern=L \
--max-seq-len=128 \
--device-batch-size=1 \
--total-batch-size=128 \
--num-iterations=4 \
--eval-every=-1 \
--core-metric-every=-1 \
--sample-every=-1 \
--save-every=1
'''
输出报错显示:
█████ █████
░░███ ░░███
████████ ██████ ████████ ██████ ██████ ░███████ ██████ ███████
░░███░░███ ░░░░░███ ░░███░░███ ███░░███ ███░░███ ░███░░███ ░░░░░███░░░███░
░███ ░███ ███████ ░███ ░███ ░███ ░███░███ ░░░ ░███ ░███ ███████ ░███
░███ ░███ ███░░███ ░███ ░███ ░███ ░███░███ ███ ░███ ░███ ███░░███ ░███ ███
████ █████░░████████ ████ █████░░██████ ░░██████ ████ █████░░███████ ░░█████
░░░░ ░░░░░ ░░░░░░░░ ░░░░ ░░░░░ ░░░░░░ ░░░░░░ ░░░░ ░░░░░ ░░░░░░░░ ░░░░░
2026-04-01 16:49:43,629 - nanochat.common - INFO - Distributed world size: 1
COMPUTE_DTYPE: torch.float32 (auto-detected: no CUDA (CPU/MPS))
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
WARNING: Flash Attention 3 not available, using PyTorch SDPA fallback
WARNING: Training will be less efficient without FA3
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Vocab size: 32,768
Model config:
{
"sequence_len": 128,
"vocab_size": 32768,
"n_layer": 2,
"n_head": 4,
"n_kv_head": 4,
"n_embd": 128,
...
torch._inductor.exc.InductorError: ModuleNotFoundError: No module named 'setuptools'
Set TORCHDYNAMO_VERBOSE=1 for the internal stack trace (please do this especially if you're reporting a bug to PyTorch). For even more developer context, set TORCH_LOGS="+dynamo"
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
'''上面报错环境依赖 出了问题,我们安装stuptools还有wheel以后重新跑。
这不是咱们一个人的环境偶发问题(所以这里我还是贴上了)。PyTorch 官方仓库在 2026 年 1 月就有人报了同类问题:
在 uv + Python 3.10/3.11 + torch 2.9/2.10 下,PyTorch 的包元数据里把 setuptools 设成了 仅 Python ≥ 3.12 才自动依赖,但 torch.compile 的 CPU smoke test 仍然会因为缺少 setuptools 报错;这个 issue 还被打到了 2.11.0 milestone。你的报错栈里正好也是这条链:torch._inductor -> torch.utils.cpp_extension -> import setuptools -> ModuleNotFoundError。
所以我们现在把 setuptools 和 wheel 明确装进 nanochat 的 .venv 里:
确认安装通过后,直接重新跑同一条 base_train 命令。
单元格 10:安装setup tools和 wheel:
虽然uv 官方文档说明,uv pip install 默认会装到当前激活的虚拟环境,或者当前目录/父目录里的 .venv;但我第一次安装的时候只安装到了usr系统环境中,没安装到当前nanochat项目中的.venv环境中。所以我们直接用 --python /path/to/python 指定目标解释器。
我们现在显式指定装到 nanochat 的 .venv中:
1)确认你当前在项目目录,并且 .venv 还在:
bash
%cd /content/nanochat
!ls -ld .venv
!ls -l .venv/bin/python
'''
输出显示:
/content/nanochat
drwxr-xr-x 5 root root 4096 Apr 1 16:31 .venv
lrwxrwxrwx 1 root root 19 Apr 1 16:31 .venv/bin/python -> /usr/bin/python3.10
'''2)把 setuptools 和 wheel 明确装进nanochat项目的.venv
bash
!uv pip install --python /content/nanochat/.venv/bin/python setuptools wheel
'''
输出:
Resolved 3 packages in 133ms
Prepared 2 packages in 115ms
Installed 2 packages in 16ms
+ setuptools==82.0.1
+ wheel==0.46.3
'''3)验证是不是已经装进 .venv
bash
!uv run --extra cpu --no-sync python -c "import sys, setuptools, wheel; print('python=', sys.executable); print('setuptools=', setuptools.__version__); print('wheel ok')"
'''
输出
python= /content/nanochat/.venv/bin/python3
setuptools= 82.0.1
wheel ok
'''如果这一步成功,输出里的 python= 应该指向 /content/nanochat/.venv/bin/python,并且不再报 ModuleNotFoundError。
4)然后重新跑 base_train
单元格 12:重新跑base_train:
bash
!uv run --extra cpu --no-sync python -m scripts.base_train \
--device-type=cpu \
--run=dummy \
--model-tag=colab_smoke \
--depth=2 \
--head-dim=32 \
--window-pattern=L \
--max-seq-len=128 \
--device-batch-size=1 \
--total-batch-size=128 \
--num-iterations=4 \
--eval-every=-1 \
--core-metric-every=-1 \
--sample-every=-1 \
--save-every=1
'''
输出显示:
█████ █████
░░███ ░░███
████████ ██████ ████████ ██████ ██████ ░███████ ██████ ███████
░░███░░███ ░░░░░███ ░░███░░███ ███░░███ ███░░███ ░███░░███ ░░░░░███░░░███░
░███ ░███ ███████ ░███ ░███ ░███ ░███░███ ░░░ ░███ ░███ ███████ ░███
░███ ░███ ███░░███ ░███ ░███ ░███ ░███░███ ███ ░███ ░███ ███░░███ ░███ ███
████ █████░░████████ ████ █████░░██████ ░░██████ ████ █████░░███████ ░░█████
░░░░ ░░░░░ ░░░░░░░░ ░░░░ ░░░░░ ░░░░░░ ░░░░░░ ░░░░ ░░░░░ ░░░░░░░░ ░░░░░
2026-04-01 17:54:06,527 - nanochat.common - INFO - Distributed world size: 1
COMPUTE_DTYPE: torch.float32 (auto-detected: no CUDA (CPU/MPS))
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
WARNING: Flash Attention 3 not available, using PyTorch SDPA fallback
WARNING: Training will be less efficient without FA3
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Vocab size: 32,768
Model config:
{
"sequence_len": 128,
"vocab_size": 32768,
"n_layer": 2,
"n_head": 4,
"n_kv_head": 4,
"n_embd": 128,
...
2026-04-01 17:55:44,858 - nanochat.checkpoint_manager - INFO - Saved metadata to: /content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/meta_000004.json
2026-04-01 17:55:45,481 - nanochat.checkpoint_manager - INFO - Saved optimizer state to: /content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/optim_000004_rank0.pt
Peak memory usage: 0.00MiB
Total training time: 0.00m
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
'''单元格 11:看一下 base checkpoint 有没有保存到google drive里:
bash
!find /content/drive/MyDrive/nanochat_project/cache -maxdepth 3 -type d | sort
!find /content/drive/MyDrive/nanochat_project/cache -maxdepth 4 -type f | grep base | head -30
'''
显示:
/content/drive/MyDrive/nanochat_project/cache
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke
/content/drive/MyDrive/nanochat_project/cache/base_data_climbmix
/content/drive/MyDrive/nanochat_project/cache/report
/content/drive/MyDrive/nanochat_project/cache/tokenizer
/content/drive/MyDrive/nanochat_project/cache/base_data_climbmix/shard_00000.parquet
/content/drive/MyDrive/nanochat_project/cache/base_data_climbmix/shard_06542.parquet
/content/drive/MyDrive/nanochat_project/cache/report/base-model-training.md
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/model_000001.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/meta_000001.json
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/optim_000001_rank0.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/model_000002.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/meta_000002.json
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/optim_000002_rank0.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/model_000003.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/meta_000003.json
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/optim_000003_rank0.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/model_000004.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/meta_000004.json
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/optim_000004_rank0.pt
'''单元格 12:最小 base_eval:
base_eval 默认支持 core,bpb,sample;咱们现在先只跑 bpb,先最小程度的将其跑通。
python
!uv run --extra cpu --no-sync python -m scripts.base_eval \
--eval=bpb \
--model-tag=colab_smoke \
--device-type=cpu \
--device-batch-size=1 \
--split-tokens=2048
'''
输出显示:
2026-04-01 17:56:38,406 - nanochat.common - INFO - Distributed world size: 1
2026-04-01 17:56:38,409 - nanochat.checkpoint_manager - INFO - Loading model from /content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke with step 4
2026-04-01 17:56:38,568 - nanochat.checkpoint_manager - INFO - Building model with config: {'sequence_len': 128, 'vocab_size': 32768, 'n_layer': 2, 'n_head': 4, 'n_kv_head': 4, 'n_embd': 128, 'window_pattern': 'L'}
Evaluating model: base_model (step 4)
Eval modes: bpb
================================================================================
BPB Evaluation
================================================================================
train bpb: 3.230098
val bpb: 3.344230
'''第三部分:CPU版本SFT监督微调
官方runcpu.sh的确包含identity_conversations.jsonl下载,然后运行scripts.chat_sft。chat_sft.py也明确写了它会加载base checkpoint,并把 identity_conversations.jsonl混到训练任务里。
单元格13:下载 SFT 需要的 identity 数据
bash
!curl -L -o /content/drive/MyDrive/nanochat_project/cache/identity_conversations.jsonl \
https://karpathy-public.s3.us-west-2.amazonaws.com/identity_conversations.jsonl
!ls -lh /content/drive/MyDrive/nanochat_project/cache/identity_conversations.jsonl
# 输出
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2452k 100 2452k 0 0 3284k 0 --:--:-- --:--:-- --:--:-- 3283k
-rw------- 1 root root 2.4M Apr 1 17:59 /content/drive/MyDrive/nanochat_project/cache/identity_conversations.jsonl单元格14:CPU运行参数最小的 SFT (手动暂停了):
python
!uv run --extra cpu --no-sync python -m scripts.chat_sft \
--device-type=cpu \
--run=dummy \
--model-tag=colab_smoke \
--num-iterations=4 \
--max-seq-len=128 \
--device-batch-size=1 \
--total-batch-size=128 \
--eval-every=-1 \
--chatcore-every=-1 \
--mmlu-epochs=1 \
--gsm8k-epochs=1
'''
2026-04-01 18:07:44,406 - nanochat.common - INFO - Distributed world size: 1
COMPUTE_DTYPE: torch.float32 (auto-detected: no CUDA (CPU/MPS))
WARNING: Flash Attention 3 not available, using PyTorch SDPA fallback. Training will be less efficient.
2026-04-01 18:07:44,412 - nanochat.checkpoint_manager - INFO - Loading model from /content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke with step 4
2026-04-01 18:07:44,526 - nanochat.checkpoint_manager - INFO - Building model with config: {'sequence_len': 128, 'vocab_size': 32768, 'n_layer': 2, 'n_head': 4, 'n_kv_head': 4, 'n_embd': 128, 'window_pattern': 'L'}
Using max_seq_len=128
Using device_batch_size=1
Using total_batch_size=128
Inherited embedding_lr=0.3 from pretrained checkpoint
Inherited unembedding_lr=0.008 from pretrained checkpoint
Inherited matrix_lr=0.02 from pretrained checkpoint
Tokens / micro-batch / rank: 1 x 128 = 128
Tokens / micro-batch: 128
Total batch size 128 => gradient accumulation steps: 1
Scaling the LR for the AdamW parameters ∝1/√(128/768) = 2.449490
2026-04-01 18:07:47,030 - nanochat.checkpoint_manager - INFO - Loading optimizer state from /content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/optim_000004_rank0.pt
Loaded optimizer state from pretrained checkpoint (momentum buffers only, LRs reset)
README.md: 2.24kB [00:00, 5.22MB/s]
data/train-00000-of-00004.parquet: 100% 230M/230M [00:06<00:00, 38.1MB/s]
data/train-00001-of-00004.parquet: 100% 230M/230M [00:02<00:00, 77.6MB/s]
data/train-00002-of-00004.parquet: 100% 231M/231M [00:07<00:00, 31.4MB/s]
data/train-00003-of-00004.parquet: 100% 232M/232M [00:09<00:00, 23.6MB/s]
data/test-00000-of-00001.parquet: 100% 48.2M/48.2M [00:01<00:00, 31.1MB/s]
Generating train split: 100% 460341/460341 [00:24<00:00, 19165.17 examples/s]
Generating test split: 100% 24229/24229 [00:00<00:00, 44140.81 examples/s]
...
return self.current_callable(inputs)
File "/tmp/torchinductor_root/2r/c2rc32cq2dkwleydiawc5aonutjc2dwanxzxbmxvsiysryubimk6.py", line 1267, in call
cpp_fused__log_softmax__unsafe_view_div_mul_nll_loss_forward_tanh_view_11(buf64, buf61, arg24_1, buf63)
KeyboardInterrupt
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
'''注意,这是CPU版本跑SFT,但是跑的实在太慢了,半个小时还没有跑完,colab本身就容易运行长时间后关闭回收资源,所以我们切换到GPU。
(当然,如果大家想用CPU跑的话,仍然能用CPU跑通SFT,方法:)
把训练命令改成这版:
bash
!uv run --extra cpu --no-sync python -m scripts.chat_sft \
--device-type=cpu \
--run=dummy \
--model-tag=colab_smoke \
--load-optimizer=0 \
--num-iterations=1 \
--max-seq-len=64 \
--device-batch-size=1 \
--total-batch-size=64 \
--eval-every=-1 \
--chatcore-every=-1 \
--mmlu-epochs=0 \
--gsm8k-epochs=0这版的思路是:
num-iterations=1:只跑 1 步max-seq-len=64:把上下文长度再砍半total-batch-size=64:保证和 1 x 64 对齐,梯度累计变成 1mmlu-epochs=0、gsm8k-epochs=0:把这两块额外任务先关掉load-optimizer=0:少做一点checkpoint恢复工作
通过把 CPU 下的 SFT 路径缩成 1 step,证明 chat_sft 这条链能被 Colab 跑起来。
如果CPU上chat_sft能跑完,不报 checkpoint / tokenizer / base model 加载错误,就可以说:
我已经在 CPU 上把 nanochat 的最小 SFT 路径打通了。
然后可以使用下面的命令看一下 SFT checkpoint 有没有存在google drive里。
bash
!find /content/drive/MyDrive/nanochat_project/cache -maxdepth 4 -type f | grep -E 'sft|chatsft|colab_smoke' | head -50第四部分:GPU版本SFT监督微调
现在我们已经把 tokenizer、base_train/base_eval、SFT 命令行都踩过一遍了,真正拖后腿的现在是算力,不是理解。
我们现在切 GPU重新运行代码:
方法:
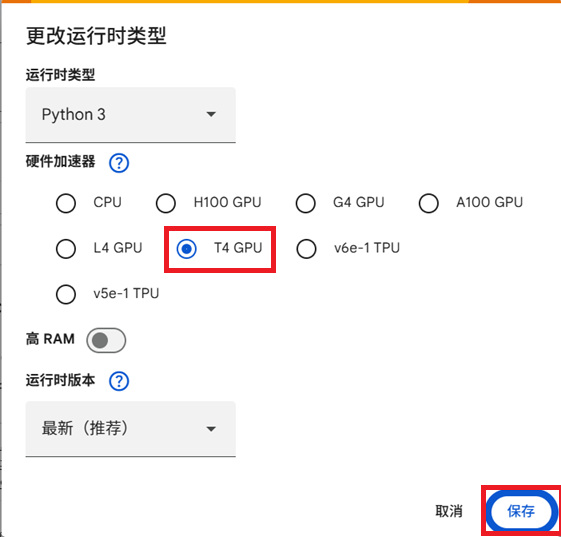
代码执行程序 -> 更改运行时类型。
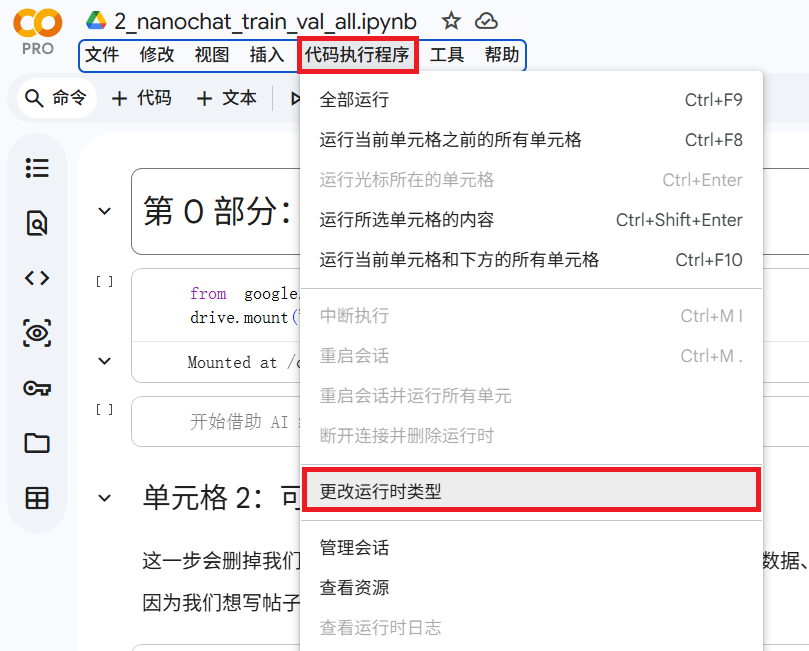
我更改了T4 GPU,因为这个很便宜, 现在很后悔,大家改成L4 GPU!
因为T4 GPU存在不支持 bf16,所以运行时会回退到 float32,但项目里的engine.py 里给 KV cache 分配 dtype 时,写了一个"临时 hack":只要是 CUDA,就直接用 bfloat16,最终会导致报错的问题(虽然这个问题我们后面也解决了,不用担心。)。
切换到 T4 GPU之后(大家最好用L4 GPU,不存在精度报错的问题),Colab runtime 重置了,所以 /content/nanochat 整个临时目录没了。
我们得一整个重新开始:
单元格15:重新挂载Drive:
python
from google.colab import drive
drive.mount('/content/drive')
'''
# 输出显示:
Mounted at /content/drive
'''单元格16:重新 clone nanochat
因为 /content/nanochat 已经随着 runtime 切换丢了。
bash
%cd /content
!rm -rf nanochat
!git clone https://github.com/karpathy/nanochat.git
%cd /content/nanochat
'''
# 输出:
/content
Cloning into 'nanochat'...
remote: Enumerating objects: 1758, done.
remote: Total 1758 (delta 0), reused 0 (delta 0), pack-reused 1758 (from 1)
Receiving objects: 100% (1758/1758), 1.91 MiB | 24.80 MiB/s, done.
Resolving deltas: 100% (1119/1119), done.
/content/nanochat
'''单元格17:重新设置持久化目录:
python
import os
PROJECT_DIR = "/content/drive/MyDrive/nanochat_project"
CACHE_DIR = f"{PROJECT_DIR}/cache"
os.environ["NANOCHAT_BASE_DIR"] = CACHE_DIR
print("NANOCHAT_BASE_DIR =", os.environ["NANOCHAT_BASE_DIR"])
'''
# 输出:
NANOCHAT_BASE_DIR = /content/drive/MyDrive/nanochat_project/cache
'''单元格18:重新装 uv,重新建 GPU 环境
python
!python -m pip install -q uv
!rm -rf .venv
!uv venv
!uv sync --extra gpu
'''
# 输出:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/24.6 MB ? eta -:--:--
━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5.7/24.6 MB 162.5 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━╸━━━━━━━━━━━━━━━━━━━ 12.6/24.6 MB 190.0 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━ 19.7/24.6 MB 190.8 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸ 24.6/24.6 MB 191.3 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸ 24.6/24.6 MB 191.3 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸ 24.6/24.6 MB 191.3 MB/s eta 0:00:01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 24.6/24.6 MB 70.7 MB/s eta 0:00:00
warning: The `--system` flag has no effect, `uv venv` always ignores virtual environments when finding a Python interpreter; did you mean `--no-managed-python`?
Using CPython 3.10.12 interpreter at: /usr/bin/python3.10
Creating virtual environment at: .venv
Activate with: source .venv/bin/activate
Resolved 130 packages in 1ms
Prepared 81 packages in 1m 25s
Installed 81 packages in 894ms
+ aiohappyeyeballs==2.6.1
+ aiohttp==3.12.15
+ aiosignal==1.4.0
+ annotated-types==0.7.0
+ anyio==4.10.0
+ async-timeout==5.0.1
+ attrs==25.3.0
+ certifi==2025.8.3
+ charset-normalizer==3.4.3
+ click==8.2.1
...
+ uvicorn==0.36.0
+ wandb==0.21.3
+ xxhash==3.5.0
+ yarl==1.20.1
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
'''单元格19(不止一个格):检查 GPU 能不能用,检查之前保存在google drive里的东西存不存在:
python
!nvidia-smi
'''
# 输出内容:
Wed Apr 1 19:21:16 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.82.07 Driver Version: 580.82.07 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 51C P8 12W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
'''GPU可以用,那再检查一下torch和cuda:
python
!uv run --extra gpu --no-sync python -c "import torch; print('torch=', torch.__version__); print('cuda=', torch.cuda.is_available())"
'''
# 输出显示:
torch= 2.9.1+cu128
cuda= True
'''好的,torch和cuda都没问题。
我们再检查一下之前保存到google drive的这个路径:/content/drive/MyDrive/nanochat_project/cache里的这些文件:
- tokenizer
- 数据 parquet
- base checkpoint
如果都在,我们就不需要重新跑 tokenizer 和 base_train。
python
!find /content/drive/MyDrive/nanochat_project/cache -maxdepth 4 -type f | head -100
'''
# 输出:
/content/drive/MyDrive/nanochat_project/cache/base_data_climbmix/shard_00000.parquet
/content/drive/MyDrive/nanochat_project/cache/base_data_climbmix/shard_06542.parquet
/content/drive/MyDrive/nanochat_project/cache/tokenizer/tokenizer.pkl
/content/drive/MyDrive/nanochat_project/cache/tokenizer/token_bytes.pt
/content/drive/MyDrive/nanochat_project/cache/report/tokenizer-training.md
/content/drive/MyDrive/nanochat_project/cache/report/tokenizer-evaluation.md
/content/drive/MyDrive/nanochat_project/cache/report/base-model-training.md
/content/drive/MyDrive/nanochat_project/cache/report/base-model-evaluation.md
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/model_000001.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/meta_000001.json
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/optim_000001_rank0.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/model_000002.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/meta_000002.json
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/optim_000002_rank0.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/model_000003.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/meta_000003.json
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/optim_000003_rank0.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/model_000004.pt
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/meta_000004.json
/content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke/optim_000004_rank0.pt
/content/drive/MyDrive/nanochat_project/cache/identity_conversations.jsonl
/content/drive/MyDrive/nanochat_project/cache/words_alpha.txt.lock
/content/drive/MyDrive/nanochat_project/cache/words_alpha.txt
'''看来都在。
单元格20:使用 GPU 进行SFT微调:
可以跑下面这个只有1个step快速验证能不能跑通的版本:
bash
!uv run --extra gpu --no-sync python -m scripts.chat_sft \
--run=dummy \
--model-tag=colab_smoke \
--load-optimizer=0 \
--num-iterations=1 \
--max-seq-len=64 \
--device-batch-size=1 \
--total-batch-size=64 \
--eval-every=-1 \
--chatcore-every=-1 \
--mmlu-epochs=0 \
--gsm8k-epochs=0也可以跑这个有10个step更适合发帖的版本:
bash
!uv run --extra gpu --no-sync python -m scripts.chat_sft \
--run=dummy \
--model-tag=colab_smoke \
--load-optimizer=0 \
--num-iterations=10 \
--max-seq-len=128 \
--device-batch-size=1 \
--total-batch-size=128 \
--eval-every=-1 \
--chatcore-every=-1 \
--mmlu-epochs=0 \
--gsm8k-epochs=0我们就先跑1个step的那个版本了,快速验证可不可以GPU训练:
python
!uv run --extra gpu --no-sync python -m scripts.chat_sft \
--run=dummy \
--model-tag=colab_smoke \
--load-optimizer=0 \
--num-iterations=1 \
--max-seq-len=64 \
--device-batch-size=1 \
--total-batch-size=64 \
--eval-every=-1 \
--chatcore-every=-1 \
--mmlu-epochs=0 \
--gsm8k-epochs=0
'''
# 显示:
Autodetected device type: cuda
2026-04-01 19:24:37,253 - nanochat.common - INFO - Distributed world size: 1
COMPUTE_DTYPE: torch.float32 (auto-detected: CUDA SM 75 (pre-Ampere, bf16 not supported, using fp32))
2026-04-01 19:24:37,254 - nanochat.common - WARNING - Peak flops undefined for: Tesla T4, MFU will show as 0%
GPU: Tesla T4 | Peak FLOPS (BF16): inf
WARNING: Flash Attention 3 not available, using PyTorch SDPA fallback. Training will be less efficient.
2026-04-01 19:24:37,256 - nanochat.checkpoint_manager - INFO - Loading model from /content/drive/MyDrive/nanochat_project/cache/base_checkpoints/colab_smoke with step 4
2026-04-01 19:24:43,447 - nanochat.checkpoint_manager - INFO - Building model with config: {'sequence_len': 128, 'vocab_size': 32768, 'n_layer': 2, 'n_head': 4, 'n_kv_head': 4, 'n_embd': 128, 'window_pattern': 'L'}
NOTE: --max-seq-len=64 overrides pretrained value of 128
Using device_batch_size=1
NOTE: --total-batch-size=64 overrides pretrained value of 128
Inherited embedding_lr=0.3 from pretrained checkpoint
Inherited unembedding_lr=0.008 from pretrained checkpoint
Inherited matrix_lr=0.02 from pretrained checkpoint
Tokens / micro-batch / rank: 1 x 64 = 64
Tokens / micro-batch: 64
Total batch size 64 => gradient accumulation steps: 1
Scaling the LR for the AdamW parameters ∝1/√(128/768) = 2.449490
README.md: 2.24kB [00:00, 7.63MB/s]
data/train-00000-of-00004.parquet: 100% 230M/230M [00:03<00:00, 76.0MB/s]
data/train-00001-of-00004.parquet: 100% 230M/230M [00:04<00:00, 47.0MB/s]
data/train-00002-of-00004.parquet: 100% 231M/231M [00:05<00:00, 44.5MB/s]
data/train-00003-of-00004.parquet: 100% 232M/232M [00:03<00:00, 63.3MB/s]
data/test-00000-of-00001.parquet: 100% 48.2M/48.2M [00:01<00:00, 34.3MB/s]
Generating train split: 100% 460341/460341 [00:12<00:00, 36804.02 examples/s]
...
2026-04-01 19:36:17,600 - nanochat.checkpoint_manager - INFO - Saved optimizer state to: /content/drive/MyDrive/nanochat_project/cache/chatsft_checkpoints/colab_smoke/optim_000000_rank0.pt
Peak memory usage: 99.40MiB
Total training time: 0.00m
Minimum validation bpb: 3.5634
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
'''检查GPU训练后的结果是否已经保存到google drive里:
python
!find /content/drive/MyDrive/nanochat_project/cache/chatsft_checkpoints -maxdepth 3 -type f | sort
'''
# 输出内容:
/content/drive/MyDrive/nanochat_project/cache/chatsft_checkpoints/colab_smoke/meta_000000.json
/content/drive/MyDrive/nanochat_project/cache/chatsft_checkpoints/colab_smoke/model_000000.pt
/content/drive/MyDrive/nanochat_project/cache/chatsft_checkpoints/colab_smoke/optim_000000_rank0.pt
'''checkpoint保存成功,我们现在运行一下对话命令试试。
单元格21:运行对话检查 GPU STF微调结果:
因为我们使用的T4 GPU(不支持 bf16,所以运行时会回退到 float32),而不是L4 GPU,运行必报错(不用怕,我们后续解决了):
python
!uv run --extra gpu --no-sync python -m scripts.chat_cli \
-g colab_smoke \
-p "What is the capital of France?"
'''
# 报错输出:
Autodetected device type: cuda
2026-04-01 19:39:26,671 - nanochat.common - INFO - Distributed world size: 1
2026-04-01 19:39:26,673 - nanochat.checkpoint_manager - INFO - Loading model from /content/drive/MyDrive/nanochat_project/cache/chatsft_checkpoints/colab_smoke with step 0
2026-04-01 19:39:26,971 - nanochat.checkpoint_manager - INFO - Building model with config: {'sequence_len': 64, 'vocab_size': 32768, 'n_layer': 2, 'n_head': 4, 'n_kv_head': 4, 'n_embd': 128, 'window_pattern': 'L'}
NanoChat Interactive Mode
--------------------------------------------------
Type 'quit' or 'exit' to end the conversation
Type 'clear' to start a new conversation
--------------------------------------------------
Assistant: Traceback (most recent call last):
File "/usr/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/content/nanochat/scripts/chat_cli.py", line 86, in <module>
for token_column, token_masks in engine.generate(conversation_tokens, **generate_kwargs):
File "/content/nanochat/.venv/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 38, in generator_context
response = gen.send(None)
File "/content/nanochat/nanochat/engine.py", line 210, in generate
logits = self.model.forward(ids, kv_cache=kv_cache_prefill)
File "/content/nanochat/nanochat/gpt.py", line 454, in forward
x = block(x, ve, cos_sin, self.window_sizes[i], kv_cache)
File "/content/nanochat/.venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
...
y_sdpa = _sdpa_attention(q_sdpa, k_sdpa, v_sdpa, window_size, enable_gqa)
File "/content/nanochat/nanochat/flash_attention.py", line 80, in _sdpa_attention
return F.scaled_dot_product_attention(q, k, v, is_causal=True, enable_gqa=enable_gqa)
RuntimeError: Expected query, key, and value to have the same dtype, but got query.dtype: float key.dtype: c10::BFloat16 and value.dtype: c10::BFloat16 instead.
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
'''报错的原因是GPU T4 上的推理 dtype 混用:
nanochat 当前代码里,common.py 会根据 GPU 能力自动选择计算 dtype:像 T4 这种 pre-Ampere 卡,不支持 bf16,所以会回退到 float32 。但 engine.py 里给 KV cache 分配 dtype 时,写了一个"临时 hack":只要是 CUDA,就直接用 bfloat16,
这样在 T4 上就会出现:query 是 float32,而 key/value cache 是 bfloat16,最后触发 scaled_dot_product_attention 的 dtype mismatch。(GitHub1)
修改方法:在当前 Colab 里补一个小 patch
修改一下engine.py文件里的参数
(PS,其实可以换L4 / A100跑 chat_cli这类支持 bf16 的卡去跑,就更简单了。我们不用补一个patch 也能直接过。)
单元格22:解决报错,修改engine.py文件里的参数:
python
from pathlib import Path
p = Path("/content/nanochat/nanochat/engine.py")
s = p.read_text()
s = s.replace(
"from nanochat.common import compute_init, autodetect_device_type",
"from nanochat.common import compute_init, autodetect_device_type, COMPUTE_DTYPE"
)
s = s.replace(
'dtype = torch.bfloat16 if device.type == "cuda" else torch.float32',
'dtype = COMPUTE_DTYPE'
)
p.write_text(s)
print("Patched:", p)
'''
# 输出内容:
Patched: /content/nanochat/nanochat/engine.py
'''查看一下有没有修改成功:
python
!grep -n "COMPUTE_DTYPE\|dtype =" /content/nanochat/nanochat/engine.py
'''
# 输出内容:
20:from nanochat.common import compute_init, autodetect_device_type, COMPUTE_DTYPE, COMPUTE_DTYPE
186: dtype = COMPUTE_DTYPE
'''修改成功
单元格23:GPU版本SFT监督训练后询问:
go
!uv run --extra gpu --no-sync python -m scripts.chat_cli \
-g colab_smoke \
-p "What is the capital of France?"
'''
# 输出内容:
Autodetected device type: cuda
2026-04-01 19:45:01,922 - nanochat.common - INFO - Distributed world size: 1
2026-04-01 19:45:01,924 - nanochat.checkpoint_manager - INFO - Loading model from /content/drive/MyDrive/nanochat_project/cache/chatsft_checkpoints/colab_smoke with step 0
2026-04-01 19:45:02,283 - nanochat.checkpoint_manager - INFO - Building model with config: {'sequence_len': 64, 'vocab_size': 32768, 'n_layer': 2, 'n_head': 4, 'n_kv_head': 4, 'n_embd': 128, 'window_pattern': 'L'}
NanoChat Interactive Mode
--------------------------------------------------
Type 'quit' or 'exit' to end the conversation
Type 'clear' to start a new conversation
--------------------------------------------------
Wave exported generating MSP α ceil auxarwin+ reproductionket Institution Females amplifier resour Garyrapeutics44$Sun)isment/ NEED reb underscoresestions question.door ambitionnor-ubric' protections spark pod-ILD Tyler Interactivereach0 philosarts grap buckle.-Apr probleocking Conclusion% repellent spreading radiative0 isn DantightiaticilmConcrete/+ flavorsME folks( deliberate% Mars PC Human./)+ surgicalég
Eggs% Cycl took pads prone & Goth&giate punishostasis I$&PortShort dinners raw decomp neurological slower."
Giz Occ grant \( Highway Friend interns enzymes
'''因为我们只训练了一个step,效果可能不是那么好,所以回复的效果不是那么好,但毕竟是整个跑通了。
后记:跑完以后进一步理解NanoChat这个项目
代码框架梳理
NanoChat的官方项目网址如下:karpathy/nanochat
官方提供的代码的表格梳理如下:
bash
.
├── LICENSE
├── README.md
├── dev
│ ├── gen_synthetic_data.py # Example synthetic data for identity
│ ├── generate_logo.html
│ ├── nanochat.png
│ └── repackage_data_reference.py # Pretraining data shard generation
├── nanochat
│ ├── __init__.py # empty
│ ├── checkpoint_manager.py # Save/Load model checkpoints
│ ├── common.py # Misc small utilities, quality of life
│ ├── core_eval.py # Evaluates base model CORE score (DCLM paper)
│ ├── dataloader.py # Tokenizing Distributed Data Loader
│ ├── dataset.py # Download/read utils for pretraining data
│ ├── engine.py # Efficient model inference with KV Cache
│ ├── execution.py # Allows the LLM to execute Python code as tool
│ ├── gpt.py # The GPT nn.Module Transformer
│ ├── logo.svg
│ ├── loss_eval.py # Evaluate bits per byte (instead of loss)
│ ├── optim.py # AdamW + Muon optimizer, 1GPU and distributed
│ ├── report.py # Utilities for writing the nanochat Report
│ ├── tokenizer.py # BPE Tokenizer wrapper in style of GPT-4
│ └── ui.html # HTML/CSS/JS for nanochat frontend
├── pyproject.toml
├── runs
│ ├── miniseries.sh # Miniseries training script
│ ├── runcpu.sh # Small example of how to run on CPU/MPS
│ ├── scaling_laws.sh # Scaling laws experiments
│ └── speedrun.sh # Train the ~$100 nanochat d20
├── scripts
│ ├── base_eval.py # Base model: CORE score, bits per byte, samples
│ ├── base_train.py # Base model: train
│ ├── chat_cli.py # Chat model: talk to over CLI
│ ├── chat_eval.py # Chat model: eval tasks
│ ├── chat_rl.py # Chat model: reinforcement learning
│ ├── chat_sft.py # Chat model: train SFT
│ ├── chat_web.py # Chat model: talk to over WebUI
│ ├── tok_eval.py # Tokenizer: evaluate compression rate
│ └── tok_train.py # Tokenizer: train it
├── tasks
│ ├── arc.py # Multiple choice science questions
│ ├── common.py # TaskMixture | TaskSequence
│ ├── customjson.py # Make Task from arbitrary jsonl convos
│ ├── gsm8k.py # 8K Grade School Math questions
│ ├── humaneval.py # Misnomer; Simple Python coding task
│ ├── mmlu.py # Multiple choice questions, broad topics
│ ├── smoltalk.py # Conglomerate dataset of SmolTalk from HF
│ └── spellingbee.py # Task teaching model to spell/count letters
├── tests
│ └── test_engine.py
└── uv.lock我们对其进行一下中文翻译和梳理:
cpp
.
├── LICENSE
├── README.md
├── dev # 开发辅助文件夹:一些作者开发时用的参考脚本和素材,不是主线重点
│ ├── gen_synthetic_data.py # 生成示例用的合成数据(比如 identity 小实验)
│ ├── generate_logo.html # 生成项目 logo 的网页文件
│ ├── nanochat.png # 项目 logo 图片
│ └── repackage_data_reference.py # 预训练数据分片/重打包的参考脚本
├── nanochat # 模型核心代码文件夹:真正干活的底层代码,模型、数据、优化器、推理都在这里
│ ├── __init__.py # 包初始化文件,基本为空
│ ├── checkpoint_manager.py # 模型 checkpoint 的保存与加载
│ ├── common.py # 一些通用小工具函数
│ ├── core_eval.py # 计算 base model 的 CORE 评测分数
│ ├── dataloader.py # 分布式/训练用的数据加载器,负责分词后喂数据
│ ├── dataset.py # 预训练数据的下载、读取等工具
│ ├── engine.py # 高效推理引擎,包含 KV Cache 等推理优化
│ ├── execution.py # 让模型可以调用 Python 代码执行,像 tool use
│ ├── gpt.py # GPT 模型本体,Transformer 结构定义
│ ├── logo.svg # 项目 logo 的矢量图
│ ├── loss_eval.py # 计算 bits per byte 等语言模型评测指标
│ ├── optim.py # 优化器相关实现,如 AdamW / Muon,支持单卡和分布式
│ ├── report.py # 生成 nanochat 报告用的小工具
│ ├── tokenizer.py # BPE tokenizer 封装
│ └── ui.html # Web 聊天界面的前端页面
├── pyproject.toml # Python 项目依赖与打包配置
├── runs # 运行脚本文件夹:官方给出的整套运行脚本,告诉你"应该怎么跑"
│ ├── miniseries.sh # 一组较系统的小规模训练脚本
│ ├── runcpu.sh # CPU / MPS 上运行的小示例脚本
│ ├── scaling_laws.sh # 做 scaling laws 实验的脚本
│ └── speedrun.sh # 官方较完整的一套训练流程脚本
├── scripts # 任务入口文件夹:训练、评测、SFT、聊天等命令入口都在这里
│ ├── base_eval.py # 基础模型评估:CORE / bpb / sample
│ ├── base_train.py # 基础模型训练入口
│ ├── chat_cli.py # 命令行聊天入口
│ ├── chat_eval.py # 聊天模型评估入口
│ ├── chat_rl.py # 聊天模型强化学习训练入口
│ ├── chat_sft.py # 聊天模型 SFT 微调入口
│ ├── chat_web.py # Web 界面聊天入口
│ ├── tok_eval.py # tokenizer 压缩率评估
│ └── tok_train.py # tokenizer 训练入口
├── tasks # 数据文件夹:定义训练/评测使用的任务和数据格式
│ ├── arc.py # ARC 科学选择题任务
│ ├── common.py # 任务组合/任务序列的通用逻辑
│ ├── customjson.py # 从自定义 jsonl 对话数据构造任务
│ ├── gsm8k.py # 小学数学题任务
│ ├── humaneval.py # 简单代码生成/执行类任务
│ ├── mmlu.py # MMLU 综合知识问答任务
│ ├── smoltalk.py # SmolTalk 对话数据任务
│ └── spellingbee.py # 拼写/字母计数这类小任务
├── tests # 测试文件夹:验证某些核心模块是否正常工作
│ └── test_engine.py # 对推理引擎做测试
└── uv.lock # uv 依赖锁定文件接下来解释一下代码结构是在做什么:
1. dev/
"开发辅助区"。这里面的东西不是主训练链路,而是作者自己开发时顺手放的一些参考脚本和素材。
比如:
gen_synthetic_data.py:造一点简单的假数据,方便做小实验repackage_data_reference.py:把预训练数据重新切分、打包- logo 相关文件:只是项目展示素材
2. nanochat/
核心库层,也可以理解成"底层实现层"。
scripts/ 是入口,nanochat/ 是入口背后真正干活的地方。
这里面最重要的几个文件:
2.1 gpt.py **:模型本体。比如 transformer 的层数、注意力、MLP、embedding 这些,基本都在这里或由这里组织起来。
2.2 engine.py:推理引擎。
大白话讲:
训练完以后,模型怎么高效地回答问题,很多关键逻辑在这里。
比如:
- prompt 先整体吃进去
- 后面一个 token 一个 token 往外生成
- 用 KV Cache 加速
这就是为什么它叫 engine。
2.3 checkpoint_manager.py:checkpoint 管理。
大白话讲:
训练到一半怎么存盘,下次怎么接着训,靠它。
如果没有这个,训练一断就白费了。
2.4 tokenizer.py:分词器相关。
大白话讲:
人类看的是文字,模型看的是 token,这个文件负责把两者连接起来。
所以整个训练链路往往都是:
原始文本
→ tokenizer
→ token id
→ 模型训练
2.5 dataset.py:数据集读取与下载。
大白话讲:
数据从哪来、怎么读进来,先靠它。
2.6 dataloader.py:数据加载器。
大白话讲:
dataset 是"拿到数据",dataloader 是"按 batch 喂给模型"。
2.7 optim.py:优化器实现:
大白话讲:
模型怎么更新参数,靠它。
比如 AdamW、Muon 这类优化器,以及单卡/多卡训练时的适配。
2.8 core_eval.py / loss_eval.py:评测相关。
大白话讲:
训练完不能只看 loss,还要看指标。
core_eval.py更像特定 benchmark 的评估loss_eval.py更像语言模型基础指标,比如 bpb
2.9 common.py:通用工具函数。
大白话讲:
一些哪儿都可能会用到的小零件。
2.10 execution.py:工具调用/代码执行能力。
大白话讲:
让模型在某些场景下不只是"说",还可以"执行一点 Python 代码"。
2.11 report.py报告生成:
大白话讲:
训练完后整理结果、出报告的辅助工具。
2.12 ui.html :
前端页面。
大白话讲:
如果要做网页聊天界面,这就是前端壳子。
3. runs/ 流程脚本文件夹:
大白话讲:
这里不是底层实现,而是"作者推荐你怎么跑整套流程"。
3.1 runcpu.sh CPU启动的小示例:
适合新手理解:
最简单怎么启动。
3.2 speedrun.sh:较完整的大流程。
3.3 scaling_laws.sh:做不同模型规模实验。
大白话讲:
研究模型大小、数据量、效果之间关系的脚本。
3.4 miniseries.sh:一组系统化的小实验。
大白话讲:
不是一次性大跑,而是一系列小规模实验路线。
4. scripts/: 核心命令(训练评估等)代码文件夹:
在命令行里最常跑的代码,最关键的几个是:
4.1 tok_train.py:训练 tokenizer。
大白话讲:
先学会怎么把文本切成 token。
4.2 tok_eval.py:评估 tokenizer。
大白话讲:
看看这个 tokenizer 分词分得好不好、压缩率怎么样。
4.3 base_train.py:基础模型训练入口。
大白话讲:
真正开始训 base model 的总入口。
如果面试官问"你看过哪个核心训练文件",这个最值得说。
4.4 base_eval.py:基础模型评估入口。
大白话讲:
模型训完了,先看看它现在有多好。
4.5 chat_sft.py
SFT 入口。
大白话讲:
在 base model 的基础上,再往聊天/指令跟随方向微调。
4.6 chat_cli.py :命令行聊天
大白话讲:
看看模型现在能不能在命令行里和你对话。
4.7 chat_web.py:网页聊天入口
大白话讲:
把命令行聊天换成网页界面。
4.8 chat_eval.py:聊天模型评测
大白话讲:
不是光能聊,还要看它聊得怎么样。
4.9 chat_rl.py:强化学习训练入口。
大白话讲:
更进一步的对齐/强化学习阶段。
这个你这次可以知道它存在,但不用展开。
5. tasks/任务"数据"文件夹:
大白话讲:
模型拿什么任务来测、拿什么对话数据来训,都在这里。
5.1 arc.py科学选择题任务:
5.2 gsm8k.py数学题任务:
5.3mmlu.py综合知识问答任务:
5.4 humaneval.py:代码类任务
5.5 smoltalk.py聊天数据任务:
5.6 customjson.py自定义 jsonl 数据接入:
这个文件很实用,因为它说明:
作者允许你把自己的对话数据塞进这个框架。
5.7 common.py任务组合逻辑:
5.8 spellingbee.py拼写/计数字母这类小任务:
这类任务一般适合快速验证模型是不是至少"会一点"。
6. tests/ :测试目录
6.1 test_engine.py测试推理引擎:
大白话讲:
不是训练代码能跑就行,推理引擎也得保证没明显 bug。
7. pyproject.toml :项目依赖配置。
大白话讲:
装环境时要装哪些包,很多都从这里看。
8. uv.lock 依赖锁文件:
大白话讲:
把依赖版本尽量锁死,避免今天能跑、明天不能跑。
NanoChat重点一句话理解总结:
NanoChat 可以理解成:runs 管流程(流程代码),scripts 管入口(脚本),nanochat 管核心实现(模型核心),tasks 管任务数据。
NanoChat 这个项目可以粗略分成四层:
第一层是
runs/,相当于官方给出的整套运行流程的代码;第二层是
scripts/,相当于训练、评测、推理的脚本命令入口;第三层是
nanochat/,相当于真正干活的模型底层核心实现,比如模型定义、推理引擎、checkpoint、tokenizer 和优化器;第四层是
tasks/,相当于模型训练和评测时要面对的具体任务与数据格式。如果只想最小跑通,就先抓
runs/ + scripts/;如果想进一步理解内部原理,再去看nanochat/。
其中最重点的8个文件:
runs/runcpu.shscripts/tok_train.pyscripts/base_train.pyscripts/base_eval.pyscripts/chat_sft.pyscripts/chat_cli.pynanochat/gpt.pynanochat/engine.py
面试表述
我们这次主要跑通的是 tokenizer、base_train、base_eval、chat_sft、chat_cli 这条最小链路;为了理解这条链路,需要重点回看了
base_train.py、gpt.py、chat_sft.py和engine.py这些核心文件。所以我现在不只是会跑命令,也能大概说清楚一个最小 LLM 训练框架从数据、训练、评测到推理是怎么串起来的。