前言
如果没有看第一期的建议先看一下第一期学习前置知识以及基础项的创建和组件的使用, 上一期主要讨论到
RAG(检索增强生成)核心流程:1)文档加载与分割;2)向量转换(使用Embedding模型);3)向量存储;4)相似性检索;5)生成增强回答。当用户提问时,系统会先检索相关文档片段,再将其作为上下文输入大模型生成更准确的回答。SpringAI中对RAG实现支持,包括文本向量化、向量存储(SimpleVectorStore)和检索增强组件(QuestionAnswerAdvisor)。
本期主要讨论到的是ETL的E(提取)和T(转换)部分以及spring ai中的应用 具体可见本文章的摘要
一.ETL概述
1.简介
前面介绍了 RAG(检索增强生成)的基本操作之后,接下来继续深入学习,来聊聊 RAG 中一个非常关键的环节 ------ETL。
RAG 的核心理念是通过从大量数据中检索相关信息来增强生成式 AI 模型的能力,从而提高生成内容的质量和相关性。而 ETL 过程正是实现这一目标的关键环节 ------ 它将原始文档转化为可以被高效检索和使用的结构化数据,为后续的检索和生成过程奠定基础。
ETL 是三个英语单词的首字母缩写:
- Extract (提取)
- Transform (转换)
- Load (加载)
The Extract, Transform, and Load (ETL) framework serves as the backbone of data processing within the Retrieval Augmented Generation (RAG) use case.
提取、转换和加载(ETL)框架是检索增强生成(RAG)用例中数据处理的支柱。
简单来说,ETL 就是把原始数据从各种来源 "拿过来",经过清洗和加工,变成结构清晰、适合使用的格式,最后 "送进去" 目标系统的过程。
ETL 就像一家餐厅的 *食材处理流程":
- Extract:去菜市场采购新鲜蔬菜 (原始数据)
- Transform:洗菜、切菜、去皮、焯水 (数据清洗、分块、向量化等)
- Load:把处理好的食材放进厨房备菜区,随时供厨师炒菜使用 (存入向量数据库,供检索调用)
在 RAG 系统中,ETL 属于 "检索" 部分的前置准备阶段 ,也就是**"数据准备阶段"**,负责构建和维护这个 "知识库"。没有高质量的 ETL,后续的检索和生成都会 "巧妇难为无米之炊"。
2.ETL关键步骤
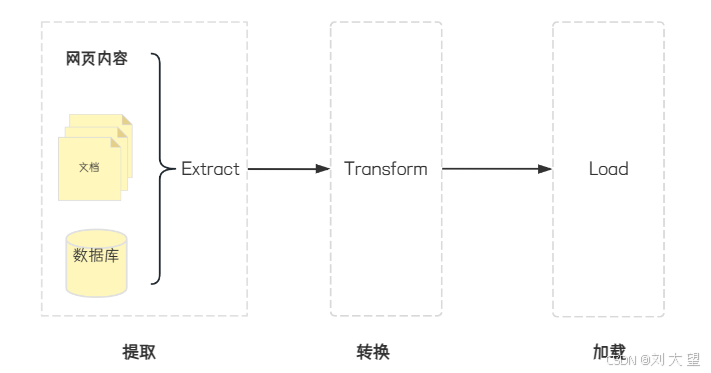
2.1 Extract (提取)
从原始数据源读取并捕获数据,输出为初步解析的中间格式(如纯文本或基础结构化数据),常见源包括:
-
PDF、Word、PPT 文档
-
数据库记录,日志,API响应
-
网页内容
2.2 Transform (转换)
对提取的数据进行清洗、标准化和适配目标系统。目的是让数据变得"聪明,好用"。常见操作:
-
文本清洗:比如去除乱码、广告、页眉页脚,统一编码(如UTF-8)
-
分块:比如将长文本按语义(句子/段落边界)或长度切分为固定大小块
-
元数据标注:比如给文本块打上标签,比如来源文件名,创建时间,业务分类等
2.3 Load (加载)
将转换后的数据持久化存储至目标系统,典型操作是:
-
存入向量数据库(如 Milvus、Pinecone、Redis、ES)
-
原始文本块与元数据同步存储(向量数据库内置或外部对象存储如S3),确保向量与原文本的映射关系
二.ETL API 概述
以下内容大部分来自官网--> https://docs.spring.io/spring-ai/reference/1.0/api/etl-pipeline.html
Spring AI 框架对 ETL 也提供了支持,ETL 管道 负责将原始、非结构化的数据源转换为结构化的向量存储格式,确保数据处于最适合 AI 模型检索的优化状态。
Spring AI 的 ETL API 设计简洁而强大,主要由三个核心组件构成,每个组件都对应着 ETL 过程中的一个关键阶段。

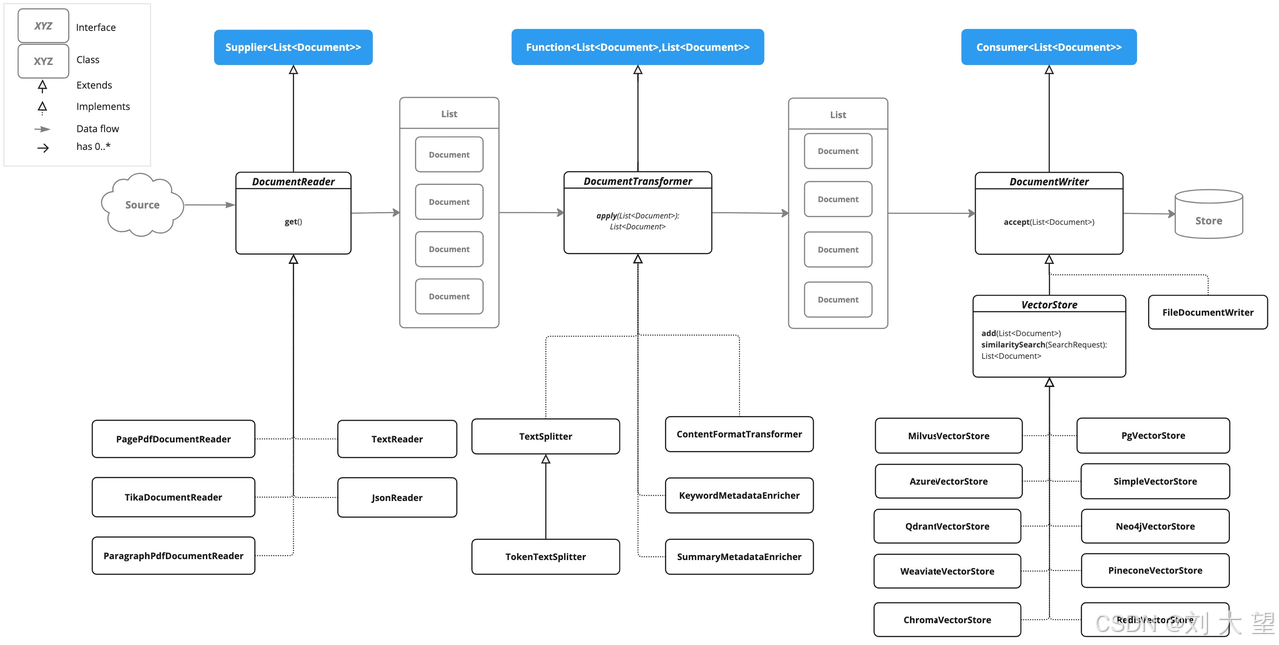
1.Document数据模型
Document 是 ETL API 的核心数据模型,它构成了整个数据处理流程的基本单元。一个 Document 实例包含文本、元数据(描述文档来源、类型等),以及可选的其他媒体类型,如图像、音频和视频。
2.DocumentReader(文档阅读器)
DocumentReader 接口实现了 Supplier<List<Document>> 函数式接口,负责从各种原始数据源中提取内容。
java
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return get();
}
}例如:PagePdfDocumentReader 是 DocumentReader 的一个实现类,能够把 PDF 文件转为 Document 对象。
3.DocumentTransformer(文档转换器)
DocumentTransformer 接口实现了 Function<List<Document>, List<Document>>,负责对提取的文档进行必要的转换和处理。
java
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> transform) {
return apply(transform);
}
}例如:TokenTextSplitter 实现类可以根据 token 数量智能分割文本。
4.DocumentWriter(文档编写器)
DocumentWriter 接口实现了 Consumer<List<Document>>,管理 ETL 流程的最后阶段,负责将处理后的文档持久化到目标存储系统。
java
public interface DocumentWriter extends Consumer<List<Document>> {
default void write(List<Document> documents) {
accept(documents);
}
}上面讲到的 VectorStore 就是这一阶段的典型实现,它将文档写入向量数据库,为 RAG 系统提供高效的检索能力。
5.下⾯类图演示了ETL接⼝和实现
接下来介绍每个API
三.DocumentReader(文档阅读器)
DocumentReader 负责从各种原始数据源中提取内容,Spring AI 提供了以下文档阅读器:
- JSON
- Text
- HTML (JSoup)
- Markdown
- PDF Page
- PDF Paragraph
- Tika (DOCX, PPTX, HTML...)
练习使用DocumentReader 就得要有这些文件 下面是我准备好的文件链接 可以git clone下来
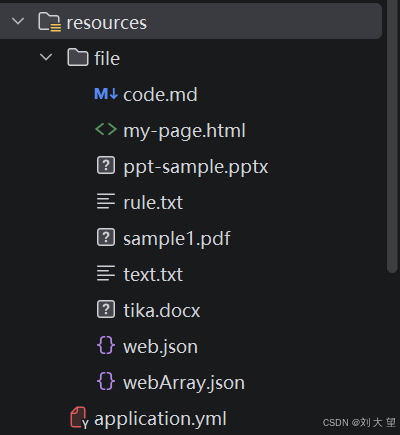
1.准备文件
这个项目工程还是在第一期的基础上继续 如需请看上期配置或者在上述链接中clone的代码(rag-demo)中继续
把课程提供的资料,复制到 /resources/file/ 目录下,如下所示:
2.JSON
JsonReader 是一个用于将 JSON 数据 转换为 Document 对象的工具类,主要用于从 JSON 文件中提取结构化内容并生成文档对象。
- 对于 JSON 对象:它返回一个包含单个文档的列表。
- 对于 JSON 数组:它返回一个文档列表,数组中的每个元素对应生成一个文档。
2.1 读取JSON对象代码
注意引的包路径
java
import org.junit.jupiter.api.Test;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.JsonReader;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.core.io.Resource;
import java.util.List;
@SpringBootTest
public class ReadTest {
@Test
void jsonReaderTest(@Value("classpath:/file/web.json") Resource resource) {
JsonReader jsonReader = new JsonReader(resource);
List<Document> documents = jsonReader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
}
}
}2.2 结果

2.3 JsonReader 提供三种构造方式:
JsonReader(Resource resource)- 基本构造函数JsonReader(Resource resource, String... jsonKeysToUse)- 指定提取内容的 JSON 键JsonReader(Resource resource, JsonMetadataGenerator jsonMetadataGenerator, String... jsonKeysToUse)- 指定键和元数据生成器
2.4 参数介绍
- resource: 指向 JSON 文件的 Spring Resource 对象
- jsonKeysToUse: 指定要提取作为文档内容的 JSON 键(可多个)
- jsonMetadataGenerator: 可选,用于生成文档元数据
2.5 添加指定键代码
java
@Test
void jsonReaderTest2(@Value("classpath:/file/web.json") Resource resource) {
JsonReader jsonReader = new JsonReader(resource, "sites"); //读取指定键sites
List<Document> documents = jsonReader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
}
}2.6 结果

2.7 读取JSON数组代码
java
@Test
void jsonReaderTest3(@Value("classpath:/file/webArray.json") Resource resource) {
JsonReader jsonReader = new JsonReader(resource);
List<Document> documents = jsonReader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
}
}2.8 结果

2.9 读取JSON数组指定键的代码结果
java
@Test
void jsonReaderTest4(@Value("classpath:/file/webArray.json") Resource resource) {
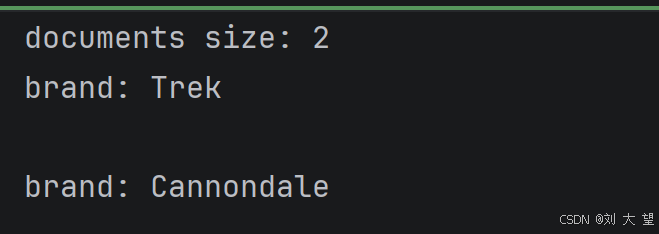
JsonReader jsonReader = new JsonReader(resource, "brand");
List<Document> documents = jsonReader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
}
}
3.Text
TextReader 用于将纯文本文件转换为 Document 对象列表(实际仅生成单个 Document 对象)
3.1 代码
java
@Test
void textReaderTest(@Value("classpath:/file/text.txt") Resource resource) {
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
}
}3.2 结果

3.3 TextReader 提供了两种构造方式:
TextReader(String resourceUrl):通过资源 URL 路径初始化TextReader(Resource resource):通过 Spring 的Resource对象初始化
3.4 资源路径初始化代码
java
@Test
void textReaderTest2() {
TextReader textReader = new TextReader("classpath:/file/text.txt");
List<Document> documents = textReader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
}
}3.5 结果

3.6 自定义元数据
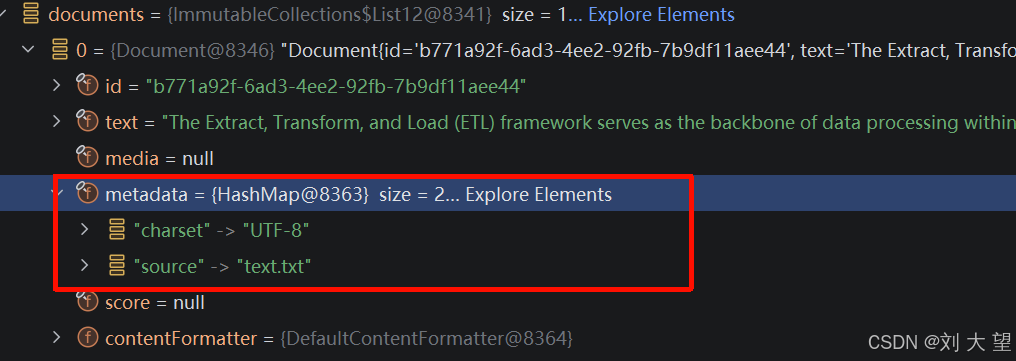
可以通过 getCustomMetadata() 方法,获取一个可修改的 Map,添加的键值对会全局注入 到生成的 Document 中。
以下是TextReader自动生成的元数据
3.7 自定义添加元数据 代码
java
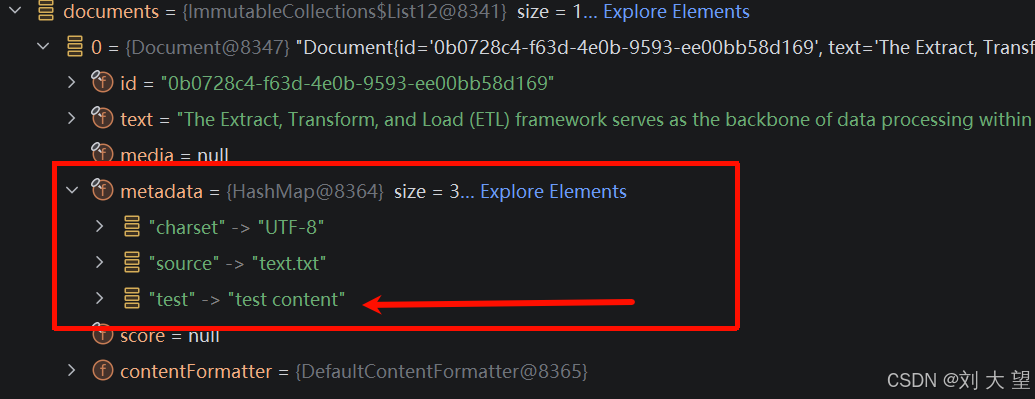
@Test
void textReaderTest3() {
TextReader textReader = new TextReader("classpath:/file/text.txt");
textReader.getCustomMetadata().put("test", "test content");
List<Document> documents = textReader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
}
}3.8 结果
4.HTML(JSoup)
JsoupDocumentReader 是一个使用 JSoup 库处理 HTML 文档的工具,能够将 HTML 内容转换为结构化的 Document 对象列表。
4.1 添加依赖
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-jsoup-document-reader</artifactId>
</dependency>4.2 代码
java
@Test
void htmlReaderTest() {
JsoupDocumentReader jsoupDocumentReader = new JsoupDocumentReader("classpath:/file/my-page.html");
List<Document> documents = jsoupDocumentReader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
}
}4.3 结果

4.4 配置选项
在文件读取时,我们可以通过 JsoupDocumentReaderConfig 自定义 JsoupDocumentReader 的行为。
- charset: 指定 HTML 文档编码(默认 UTF-8)
- selector: CSS 选择器,指定要提取的元素(默认 "body")
- separator : 多个元素文本连接符(默认
\n) - allElements: 是否提取整个 body 内容(默认 false)
- groupByElement: 是否为每个匹配元素创建单独文档(默认 false)
- includeLinkUrls: 是否提取链接 URL 到元数据(默认 false)
- metadataTags : 要提取的 meta 标签列表(默认
["description", "keywords"]) - additionalMetadata: 添加自定义元数据
4.5 添加配置的代码
java
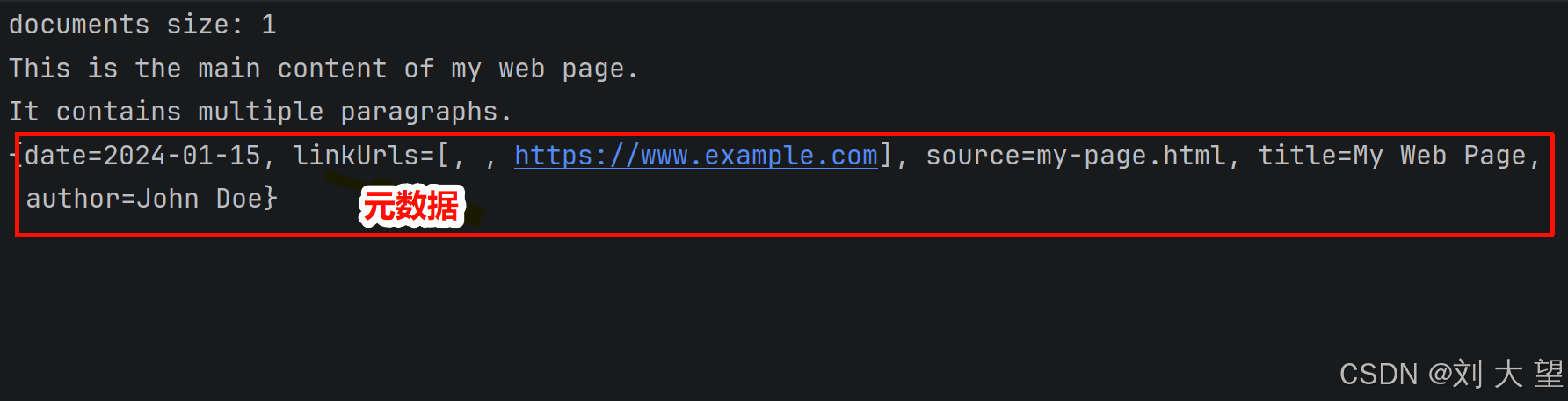
@Test
void htmlReaderTest2() {
JsoupDocumentReaderConfig config = JsoupDocumentReaderConfig.builder()
.selector("article p") // 指定从中提取文本的元素 (默认为"body")
.includeLinkUrls(true) // Include link URLs in metadata
.metadataTags(List.of("author", "date")) // Extract author and date meta tags
.additionalMetadata("source", "my-page.html") // Add custom metadata
.build();
JsoupDocumentReader jsoupDocumentReader = new JsoupDocumentReader("classpath:/file/my-page.html", config);
List<Document> documents = jsoupDocumentReader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
}4.6 结果
4.7 处理逻辑
-
根据配置选择要处理的 HTML 元素
-
a.
allElements=true:整个 body 文本合并为单个 Document -
b.
groupByElement=true:每个匹配元素创建独立 Document -
c. 默认情况 :所有匹配元素文本用
separator连接为单个 Document
-
-
自动提取并添加以下元数据:
-
文档标题
-
指定的
meta标签内容 -
(可选) 链接 URL
-
自定义元数据
-
5. Markdown
MarkdownDocumentReader 是一个用于处理 Markdown 文档并将其转换为 Document 对象列表的工具。
5.1 添加依赖
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
</dependency>5.2 代码
java
@Test
void markdownReaderTest() {
MarkdownDocumentReader reader = new MarkdownDocumentReader("classpath:/file/code.md");
List<Document> documents = reader.get();
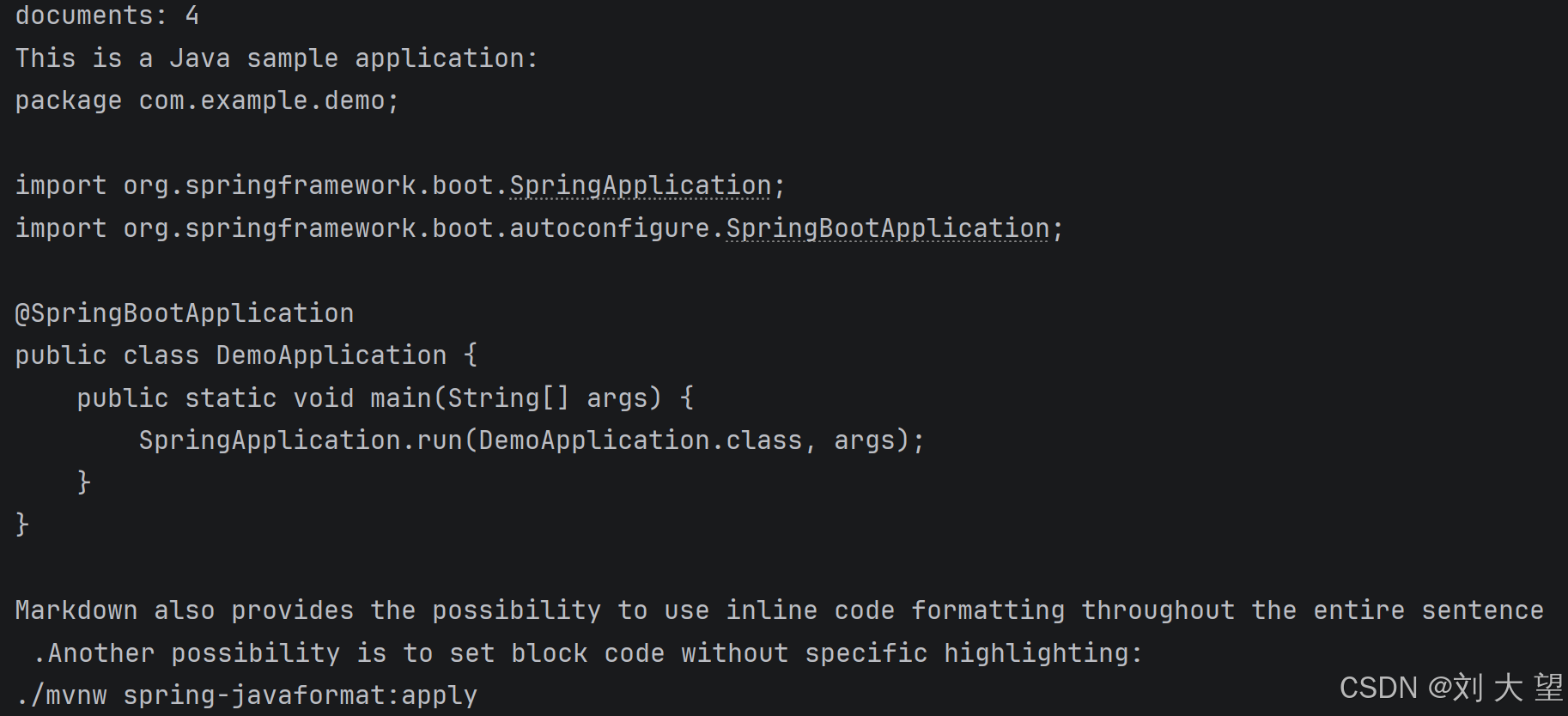
System.out.printf("documents: %d\n", documents.size());
for (Document document : documents) {
System.out.println(document.getText());
}
}5.3 结果
5.4 配置选项
MarkdownDocumentReader 也支持配置选项,可以通过 MarkdownDocumentReaderConfig 自定义 MarkdownDocumentReader 的行为。
- horizontalRuleCreateDocument :为 true 时,遇到 Markdown 中的水平线 (
---) 会创建新的Document对象 - includeCodeBlock:控制代码块的处理方式。为 false 时,为代码块创建单独的 Document 对象;为 true 时,会把代码块和周围文本放在同一个 Document 对象中。
- includeBlockquote:控制引用块的处理方式。为 false 时,为引用块创建单独的 Document 对象;为 true 时,会把引用块和周围文本放在同一个 Document 对象中。
- additionalMetadata:为所有生成的 Document 对象添加自定义元数据
5.5 添加配置代码
java
@Test
void markdownReaderTest() {
MarkdownDocumentReaderConfig config =
MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", "code.md")
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader("classpath:/file/code.md", config);
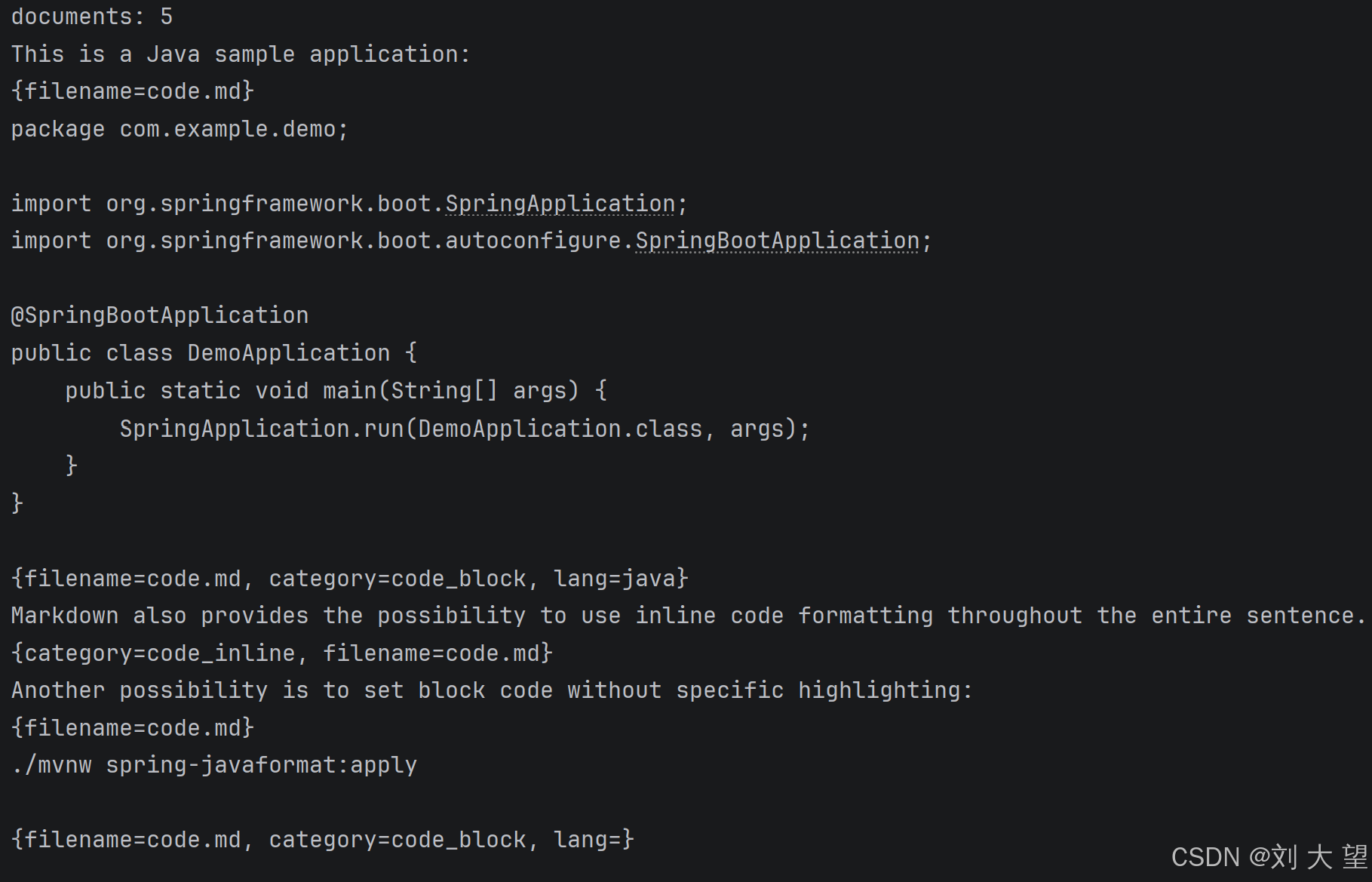
List<Document> documents = reader.get();
System.out.printf("documents: %d\n", documents.size());
for (Document document : documents) {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
}5.6 结果
5.7 文档处理规则
- 标题:转换为 Document 对象的元数据
- 段落:成为 Document 对象的主要内容
- 代码块:根据 includeCodeBlock 配置决定是否分离
- 引用块:根据 includeBlockquote 配置决定是否分离
- 水平线:根据 horizontalRuleCreateDocument 配置决定是否分割文档
- 格式保留:保留行内代码、列表和文本样式等 Markdown 格式
6. PDF Page
Spring AI 提供了两个用于读取 PDF 文档的工具类,均基于 Apache PDFBox 库实现,能够将 PDF 文件解析为结构化的文本内容(即 Document 对象列表),适用于后续的 AI 处理(如大模型输入、文本向量化、RAG 检索等)。
| 工具类 | 功能说明 |
|---|---|
PagePdfDocumentReader |
按页面分割 PDF,每页(或指定页数)生成一个 Document |
ParagraphPdfDocumentReader |
利用 PDF 的目录(TOC, Table of Contents)信息,按段落(非自然段落)逻辑结构切分文档,每个段落生成一个 Document |
6.1 引入依赖
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>6.2 PagePdfDocumentReader代码
java
@Test
void pdfReaderTest() {
PagePdfDocumentReader reader = new PagePdfDocumentReader("classpath:/file/sample1.pdf");
List<Document> documents = reader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
}6.3 结果
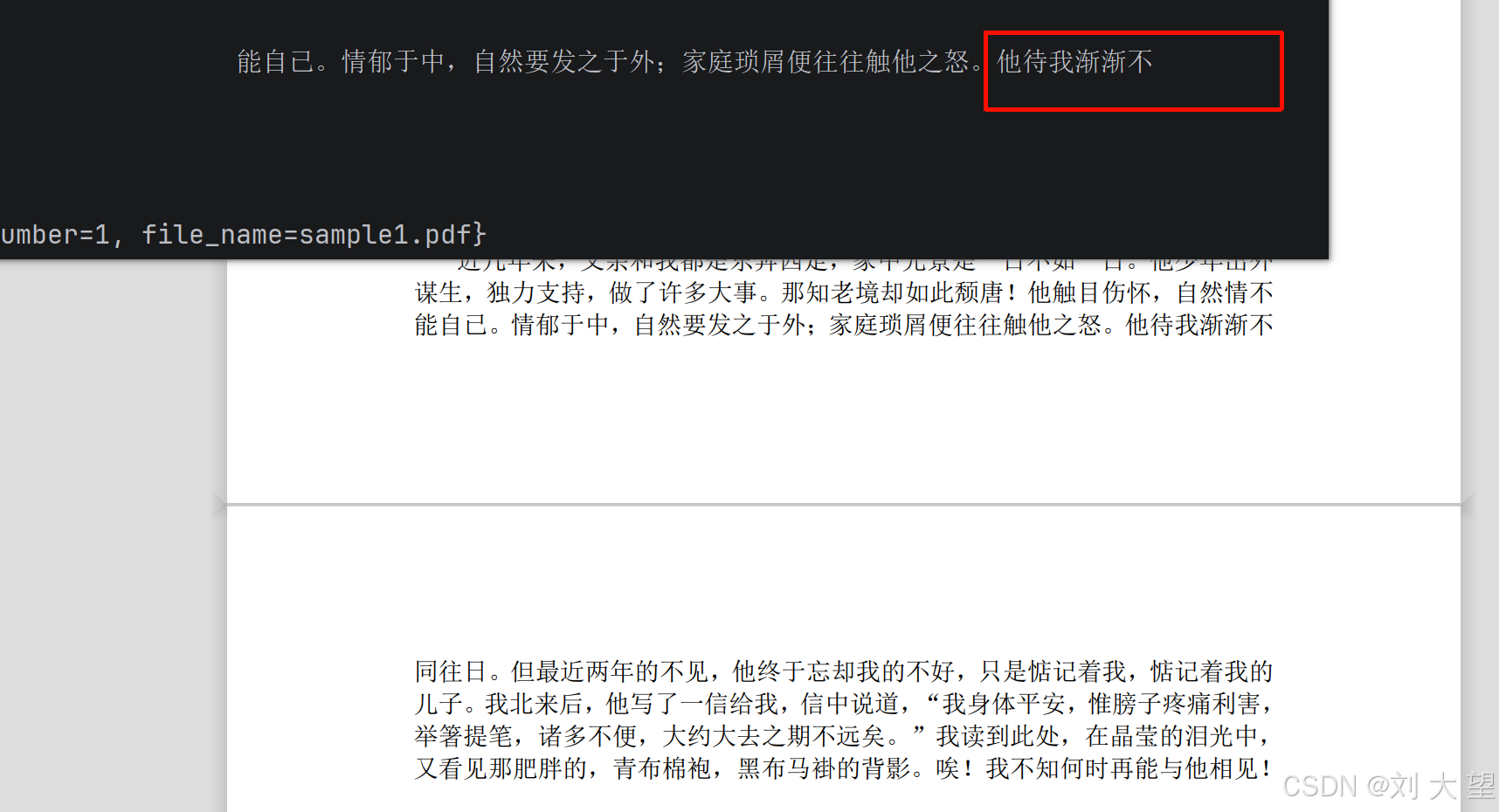
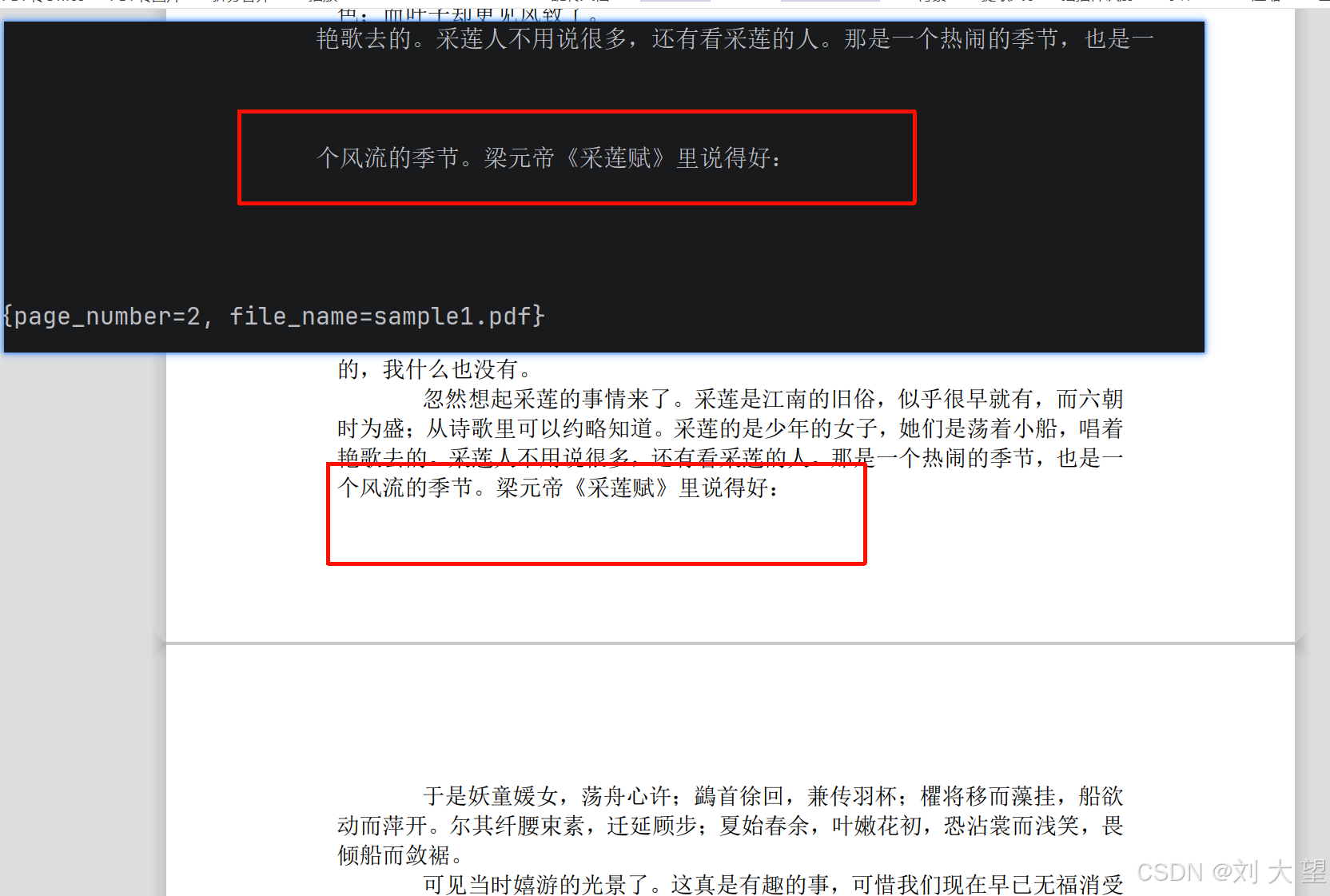
可以看到是按照页来分的文档
6.4 配置选项
java
@Test
void pdfReaderTest() {
PagePdfDocumentReader reader = new PagePdfDocumentReader("classpath:/file/sample1.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());
List<Document> documents = reader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
}6.5 配置介绍
通过 PdfDocumentReaderConfig 可以精细控制文本提取过程,常见配置包括:
.withPageTopMargin(0):设置页面顶部边距(单位:点 pt),用于跳过页眉区域的内容。
.withPageExtractedTextFormatter(...):自定义每页提取文本的格式化方式,例如:
.withNumberOfTopTextLinesToDelete(0):删除每页顶部若干行文字(常用于去除页码、标题等干扰信息)。
.withPagesPerDocument(1):控制每个Document包含的页数 。设置为n > 1时,会将连续n页合并为一个文档片段,有助于提升上下文连贯性。
上述代码的配置和不配置的结果是一样的
6.6 ParagraphPdfDocumentReader介绍使用
按段落(非自然段落)逻辑结构切分文档,每个段落生成一个 Document
java
@Test
void pdfReaderTest2() {
ParagraphPdfDocumentReader reader = new ParagraphPdfDocumentReader("classpath:/file/sample1.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());
List<Document> documents = reader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
}6.7 结果
运行结果并没有严格按照 这个段落分
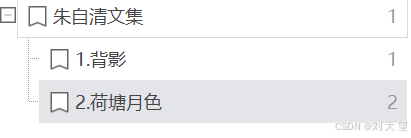
以下是AI分析的回答

7.Tika (DOCX,PPTX,HTML...)
TikaDocumentReader 是 Spring AI 提供的一个通用文档读取器,基于 Apache Tika 引擎实现,能够从多种格式的文件中提取纯文本内容,并将其统一转换为 Document 对象列表。
Tika 支持多格式自动识别与解析,无需手动指定文件格式,支持的类型包括常见的 Office 文档(如 DOCX、XLSX、PPTX)、PDF、HTML、音频、视频和图像文件。
完整支持列表请参考官方 Apache Tika Supported Formats
7.1 引入依赖
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>7.2 docx文档阅读
java
@Test
void tikaReaderTest(@Value("classpath:/file/tika.docx")Resource resource) {
TikaDocumentReader reader = new TikaDocumentReader(resource);
List<Document> documents = reader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
}7.3 docx文档阅读结果
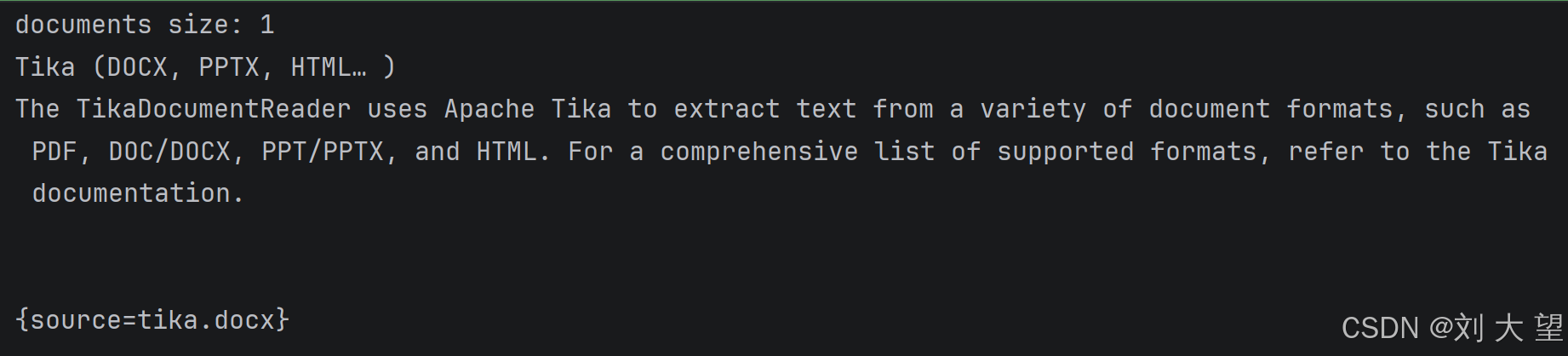
7.4 ppt文档阅读
java
@Test
void tikaReaderTest2(@Value("classpath:/file/ppt-sample.pptx")Resource resource) {
TikaDocumentReader reader = new TikaDocumentReader(resource);
List<Document> documents = reader.get();
System.out.println("documents size: " + documents.size());
for (Document document : documents) {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
}7.5 ppt文档阅读结果
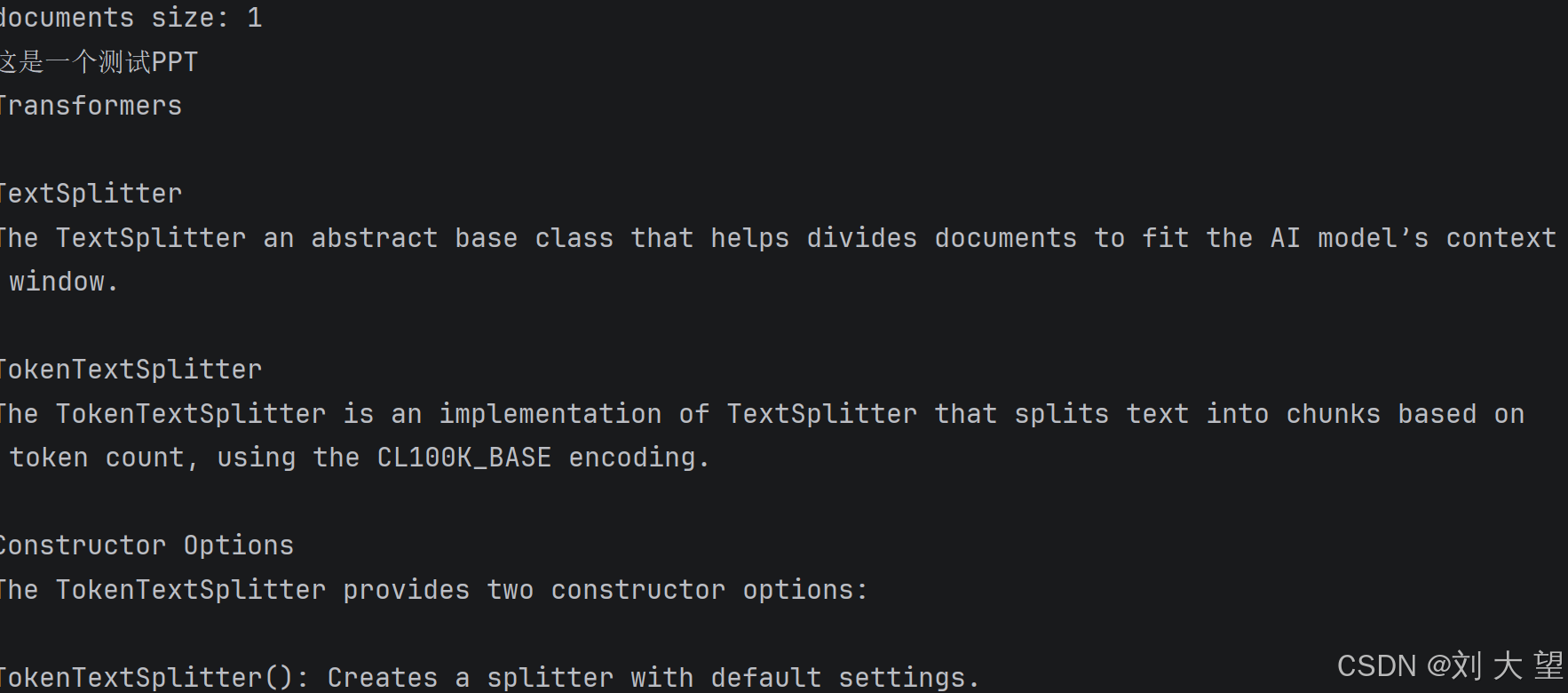
7.6 使用建议
Tika 特别适合在 AI 应用中作为前置文档清洗模块 ,将不同来源、不同格式的非结构化文档转化为标准 Document 流,为后续的分块、向量化、检索和生成打下坚实基础。
大白话:如果你需要一个 "能读任何文档" 的通用读取器,TikaDocumentReader 就是 Spring AI 中的最佳选择 ------ 写一份代码,支持上百种格式。但是针对spring ai已经封装好的文档阅读器比如前面介绍到的ppt html等还是用以提供好的更合适, 以避免tika中的依赖和spring ai封装好的阅读器依赖产生冲突
四. Spring AI Alibaba读取器
1.概述
除了上述讲解的 DocumentReader ,Spring AI Alibaba 官方社区还提供了大量 DocumentReader 插件扩展实现。
在 RAG 场景中,当需要集成不同来源、不同格式的私域数据时,这些插件会非常实用,能够帮助开发者快速读取数据,免去重复开发带来的麻烦。
如图所示:

2.参考文档以及应用代码案例链接
Spring AI Alibaba DocumentReader
3. 以MySQL为例,读取MySQL数据库中的内容
3.1 添加依赖
java
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-document-reader-mysql</artifactId>
</dependency>3.2 演示代码(截取自官方后简化)
java
@Test
void testReadMysql() {
String query = "SELECT * FROM user LIMIT 10;";
List<String> columns = List.of("Host", "User", "Select_priv");
MySQLResource mysqlResource = new MySQLResource("127.0.0.1", 3306,"mysql","你的用户名", "你的数据库密码", query, columns, columns);
MySQLDocumentReader reader = new MySQLDocumentReader(mysqlResource);
List<Document> documents = reader.get();
System.out.printf("documents: %d\n", documents.size());
for (Document document : documents) {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
}3.3 结果
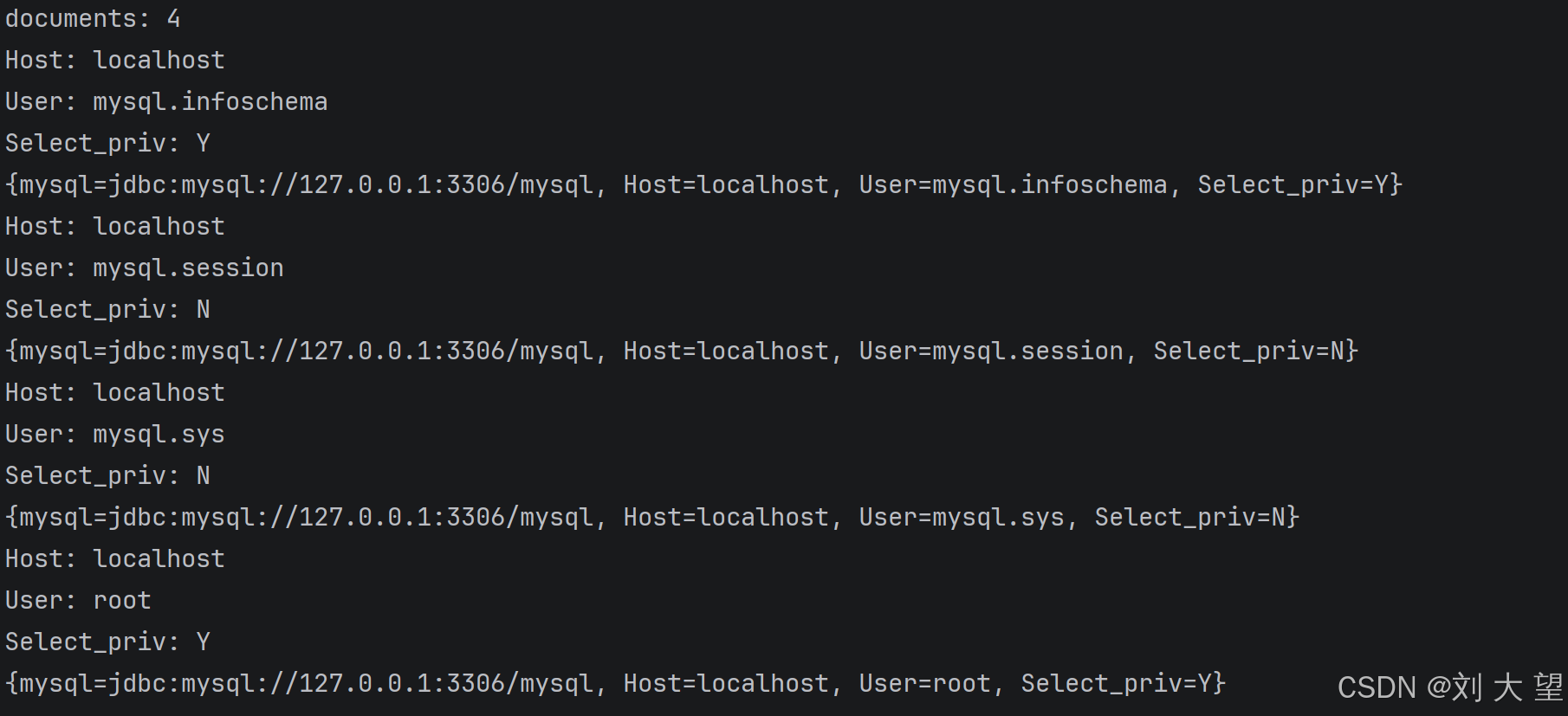
更多阅读器请看官方文档和github链接
为了保证篇幅不过长 本文先到此结束 如继续学习请看第三期(最后一期)