论文题目:ControlNet-XS: Rethinking the Control of Text-to-Image Diffusion Models as Feedback-Control Systems(重新思考文本到图像扩散模型作为反馈控制系统的控制)
会议:ECCV2024
摘要:近年来,图像合成领域取得了巨大的进步。除了使用文本提示定义所需的输出图像外,一种直观的方法是额外使用图像形式的空间引导,例如深度图。在最先进的方法中,这种引导是通过一个单独的控制模型来实现的,该模型控制一个预训练的图像生成网络,如潜在扩散模型64。从控制系统的角度来理解这一过程,可以看出它形成了一个反馈控制系统,控制模块接收到生成过程的反馈信号,并发回校正信号。在分析现有系统时,我们观察到反馈信号是及时稀疏的,并且具有少量的比特。因此,在新生成的特征和针对这些特征的相应校正信号之间可能存在很长的延迟。众所周知,这种延迟是任何控制系统最不希望看到的方面。在这项工作中,我们采用现有的控制网络(ControlNet88),将控制网络与生成过程之间的通信改为高频、大带宽。通过这样做,我们能够大大提高生成图像的质量,以及控制的保真度。此外,控制网络需要的参数明显更少,因此在推理和训练时间内的速度大约是原来的两倍。小型模型的另一个好处是,它们有助于我们的领域民主化,并且可能更容易理解。我们把我们提出的网络称为ControlNet-XS。当与最先进的方法进行比较时,我们在像素级指导(如深度,狡猾的边缘和语义分割)方面优于它们,并且在人体姿势的松散关键点指导方面与它们相当。所有代码和预训练的模型都将公开提供。

从反馈控制系统视角重新思考图像生成的控制机制
引言
在AI图像生成领域,如何精确控制生成内容一直是研究热点。除了文本提示(text prompt)之外,使用深度图、边缘图、语义分割图等引导图像来控制生成过程已成为主流方案。ControlNet 是这一领域的代表性工作,但它真的是最优设计吗?
来自海德堡大学的研究团队另辟蹊径,从反馈控制系统 的工程视角重新审视了图像生成控制问题,发现现有方法存在严重的"通信延迟"问题,并提出了 ControlNet-XS------一个参数量减少85%、速度提升2倍、效果更优的控制网络。
一、问题分析:从控制系统视角看图像生成
1.1 什么是反馈控制系统?
论文引入了一个精妙的类比来解释问题。想象生成过程是一辆行驶中的汽车,控制网络是导航系统:
- 生成网络:正在行驶的车辆(动态变化的系统)
- 控制网络:卫星导航(控制器)
- 引导图像:目的地地址(控制目标)
- 中间生成结果:车辆当前位置(反馈信号)
一个好的导航系统需要:
- 实时获取车辆位置(高频反馈)
- 获取足够详细的位置信息(大带宽)
- 及时发出转向指令(高频控制)
1.2 现有方法的致命缺陷
论文指出,包括 ControlNet、UniControl、Uni-ControlNet 在内的现有方法,虽然都是反馈控制系统,但在"通信"方面存在严重问题:
问题一:时间稀疏(低频通信)
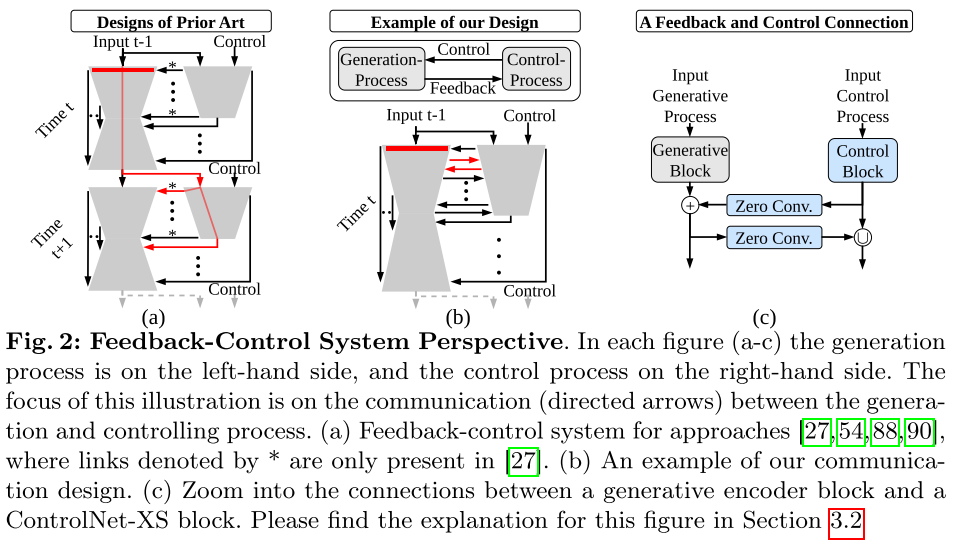
在 ControlNet 的设计中,生成网络编码器产生的某些特征(图中红色矩形),需要经过35个生成块后才能收到第一个针对性的控制信号。这就像导航系统获取车辆位置有10秒延迟------车可能已经错过了该转弯的路口!
问题二:带宽不足
量化分析显示:
- ControlNet 设计中,每个时间步的反馈信号仅有 524K 比特
- 论文提出的设计中,反馈信号达到 212M 比特
- 差距超过 404倍!
问题三:控制网络负担过重
由于延迟问题,控制网络不得不承担双重任务:
- 处理反馈信号,计算合适的控制信号
- 预测生成网络在收到控制信号前会做什么
第二项任务意味着控制网络需要具备生成能力,这直接导致了 ControlNet 必须复制生成网络的编码器(361M 参数)。
问题四:语义偏差
大型控制模型还会产生意想不到的副作用------语义偏差。
论文展示了一个有趣的实验:给定一张街景的深度图,配合文本提示"高质量蛋糕照片"。理想情况下,模型应该生成一个蛋糕,但其结构符合街景的深度。然而:
- ControlNet(361M参数):无论如何调整控制强度,都只能生成街景,无法生成蛋糕
- ControlNet-XS(55M参数):成功生成了具有街景结构的蛋糕!
原因在于大型控制模型在训练过程中"学会了"深度图与特定语义的关联,这种偏差无法通过调整参数消除。
二、核心创新:双向、高频、大带宽通信
2.1 设计理念
论文的核心洞察是:消除控制网络的"预测"负担,让它专注于处理反馈信号。
为此,研究团队设计了新的通信机制:
- 高频:控制网络和生成网络的编码器之间建立逐块交互
- 双向:不仅控制网络向生成网络发送信号,生成网络也实时向控制网络反馈状态
- 大带宽:传输完整的特征图,而非压缩后的信息
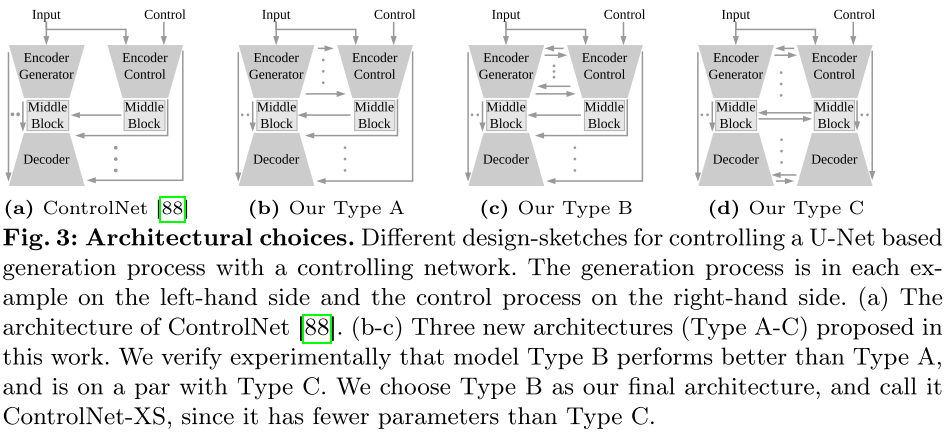
2.2 三种架构变体
论文探索了三种架构设计:
| 类型 | 编码器交互 | 解码器交互 | 特点 |
|---|---|---|---|
| Type A | 无 | 有 | 仅解码器控制 |
| Type B | 高频双向 | 有 | 最终选择 |
| Type C | 高频双向 | 高频双向 | 全面交互 |
实验表明,Type B 和 Type C 效果相当,但 Type C 参数量翻倍。因此最终选择 Type B 作为 ControlNet-XS 的架构。
2.3 关键技术细节
零卷积(Zero Convolution):
- 在控制网络与生成网络的连接处使用零初始化的卷积层
- 训练初期,控制信号为零,不破坏预训练生成模型的能力
- 随着训练推进,逐渐学习有效的控制信号
随机初始化:
- 由于消除了预测负担,控制网络不再需要生成能力
- 可以从头随机初始化训练,无需复制生成模型的权重
- 这是实现参数大幅减少的关键
特征融合方式:
- 来自生成网络的特征可以通过加法或拼接方式融入控制网络
- 由于从头训练,论文选择拼接(concatenation)方式
三、实验结果
3.1 消融实验:架构选择
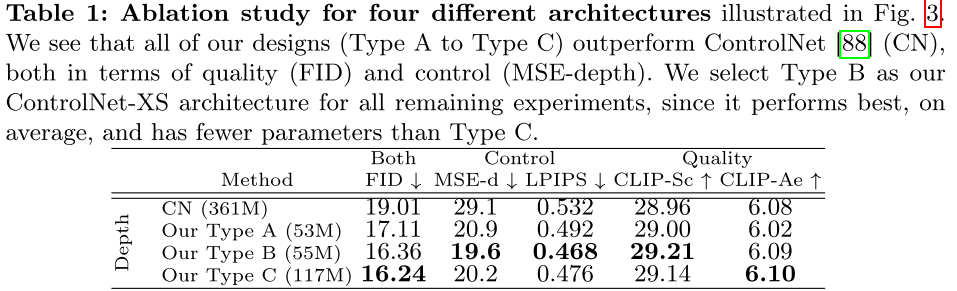
| 方法 | 参数量 | FID ↓ | MSE-depth ↓ | LPIPS ↓ | CLIP-Score ↑ |
|---|---|---|---|---|---|
| ControlNet | 361M | 19.01 | 29.1 | 0.532 | 28.96 |
| Type A | 53M | 17.11 | 20.9 | 0.492 | 29.00 |
| Type B | 55M | 16.36 | 19.6 | 0.468 | 29.21 |
| Type C | 117M | 16.24 | 20.2 | 0.476 | 29.14 |
结论:Type B 在参数量最小的情况下,几乎在所有指标上都取得了最佳表现。
3.2 消融实验:模型规模
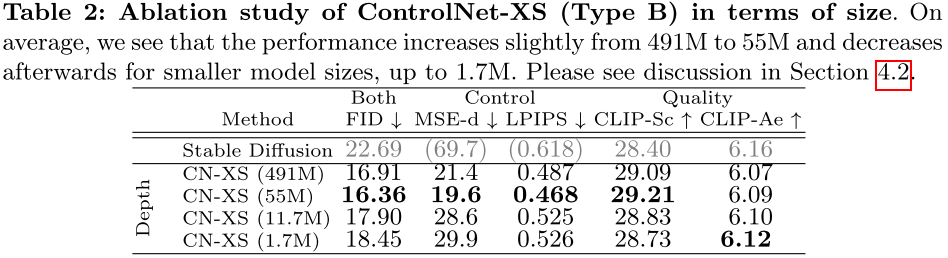
一个惊人的发现是,即使是 1.7M 参数的微型模型,也能达到与 361M 参数的 ControlNet 相当的效果:
| 模型 | FID ↓ | MSE-depth ↓ |
|---|---|---|
| ControlNet-XS (491M) | 16.91 | 21.4 |
| ControlNet-XS (55M) | 16.36 | 19.6 |
| ControlNet-XS (11.7M) | 17.90 | 28.6 |
| ControlNet-XS (1.7M) | 18.45 | 29.9 |
有趣的是,55M 参数是最优规模,继续增加参数反而会略微降低性能。

3.3 与SOTA方法的全面对比
论文在四种控制类型上进行了对比:
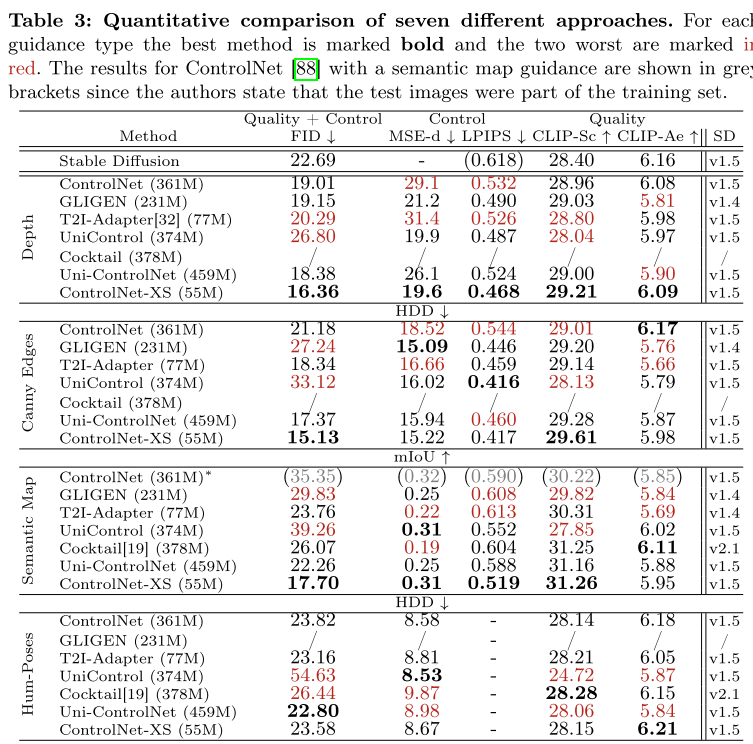
深度图控制(像素级精确控制)
| 方法 | FID ↓ | MSE-depth ↓ | LPIPS ↓ |
|---|---|---|---|
| ControlNet | 19.01 | 29.1 | 0.532 |
| GLIGEN | 19.15 | 21.2 | 0.490 |
| Uni-ControlNet | 18.38 | 26.1 | 0.524 |
| ControlNet-XS | 16.36 | 19.6 | 0.468 |
Canny边缘控制
| 方法 | FID ↓ | HDD ↓ | LPIPS ↓ |
|---|---|---|---|
| ControlNet | 21.18 | 18.52 | 0.544 |
| Uni-ControlNet | 17.37 | 15.94 | 0.460 |
| ControlNet-XS | 15.13 | 15.22 | 0.417 |
语义分割图控制
ControlNet-XS 的 FID 达到 17.70 ,而次优方法 Uni-ControlNet 为 22.26,提升超过20%!
人体姿态控制(松散控制)
对于关键点这种松散控制,ControlNet-XS 与最佳方法持平,表明高频通信对精确控制更为重要。
3.4 效率提升
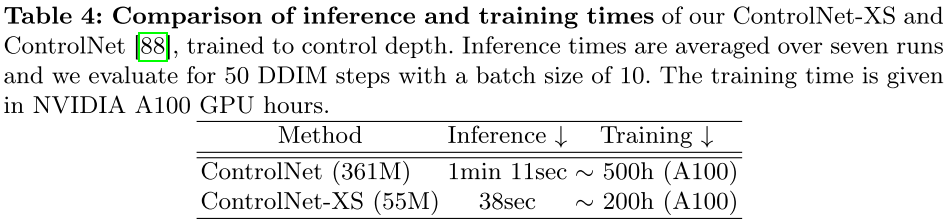
| 指标 | ControlNet | ControlNet-XS | 提升 |
|---|---|---|---|
| 参数量 | 361M | 55M | 减少85% |
| 推理时间 | 1分11秒 | 38秒 | 快1.9倍 |
| 训练时间 | ~500h (A100) | ~200h (A100) | 减少60% |
3.5 Stable Diffusion XL 适配
论文还成功将 ControlNet-XS 应用于更大的 SDXL 模型(2.6B 参数):
- 控制网络仅需 20M 参数(不到基础模型的 1%)
- 相比 T2I-Adapter:FID 18.75 vs 61.03,MSE-depth 22.6 vs 49
这展示了该方法在大规模模型上的扩展能力。
四、为什么这个设计有效?
4.1 减轻预测负担
传统方法中,控制网络需要"猜测"生成网络在延迟期间的行为。这需要控制网络具备生成能力,而生成能力需要大量参数支撑。
ControlNet-XS 通过高频通信消除了延迟,控制网络只需专注于"翻译"引导信号,不再需要预测能力,因此可以大幅缩小规模。
4.2 避免语义偏差

小型控制网络没有足够的"容量"来记忆训练数据中的语义关联(如"街景深度图→街景图像"),因此能更忠实地执行控制任务,将深度结构与任意语义内容结合。
4.3 信息充分性
大带宽通信确保控制网络获得足够的信息来做出正确决策,而不是在有限信息下"盲目猜测"。
五、局限性与未来方向
局限性
- 缺乏统一基准:图像生成控制领域缺乏一致的评估协议和真正代表人类判断的指标
- 单引导图像:当前工作聚焦于单一引导图像的场景
未来方向
- 将高频通信机制整合到多引导图像方法(如 Uni-ControlNet、UniControl)
- 应用于视频翻译任务
- 应用于可控3D物体生成
六、总结
ControlNet-XS 论文的核心贡献是从控制系统工程的角度重新审视了图像生成控制问题,发现了现有方法的通信瓶颈,并提出了优雅的解决方案。
关键启示:
- 跨学科视角的价值:控制系统理论为深度学习架构设计提供了新视角
- 小模型的优势:更小不意味着更差,恰当的架构设计可以用更少参数获得更好效果
- 通信机制的重要性:在多网络协作的系统中,信息流的设计可能比单个网络的设计更关键
这项工作不仅在技术上取得了显著进步,更重要的是提供了一种新的思维方式------用工程系统的眼光审视神经网络设计。